
Dans cet article de blog, vous apprendrez :
- Ce qu’est OpenFang et ce qu’il apporte en tant que système d’exploitation d’agents.
- Les principales raisons de l’équiper des outils de Scraping web, de recherche, de découverte et d’interaction de Bright Data.
- Un guide étape par étape pour connecter OpenFang au Bright Data Web MCP.
- Comment donner rapidement à OpenFang une connaissance des solutions Bright Data grâce à des Agent Skills.
Plongeons dans le vif du sujet !
Qu’est-ce qu’OpenFang ?
OpenFang est un système d’exploitation d’agents open-source et complet, développé en Rust. Plutôt que de proposer des flux de travail basés sur le chat, un OS d’agents exécute et coordonne des agents IA autonomes en fournissant le contexte nécessaire, les normes de codage et les règles architecturales.
Ainsi, plutôt que d’attendre des invites, les agents OpenFang fonctionnent en continu. En détail, ils effectuent des recherches, surveillent, génèrent des prospects et rapportent les résultats pour vous.
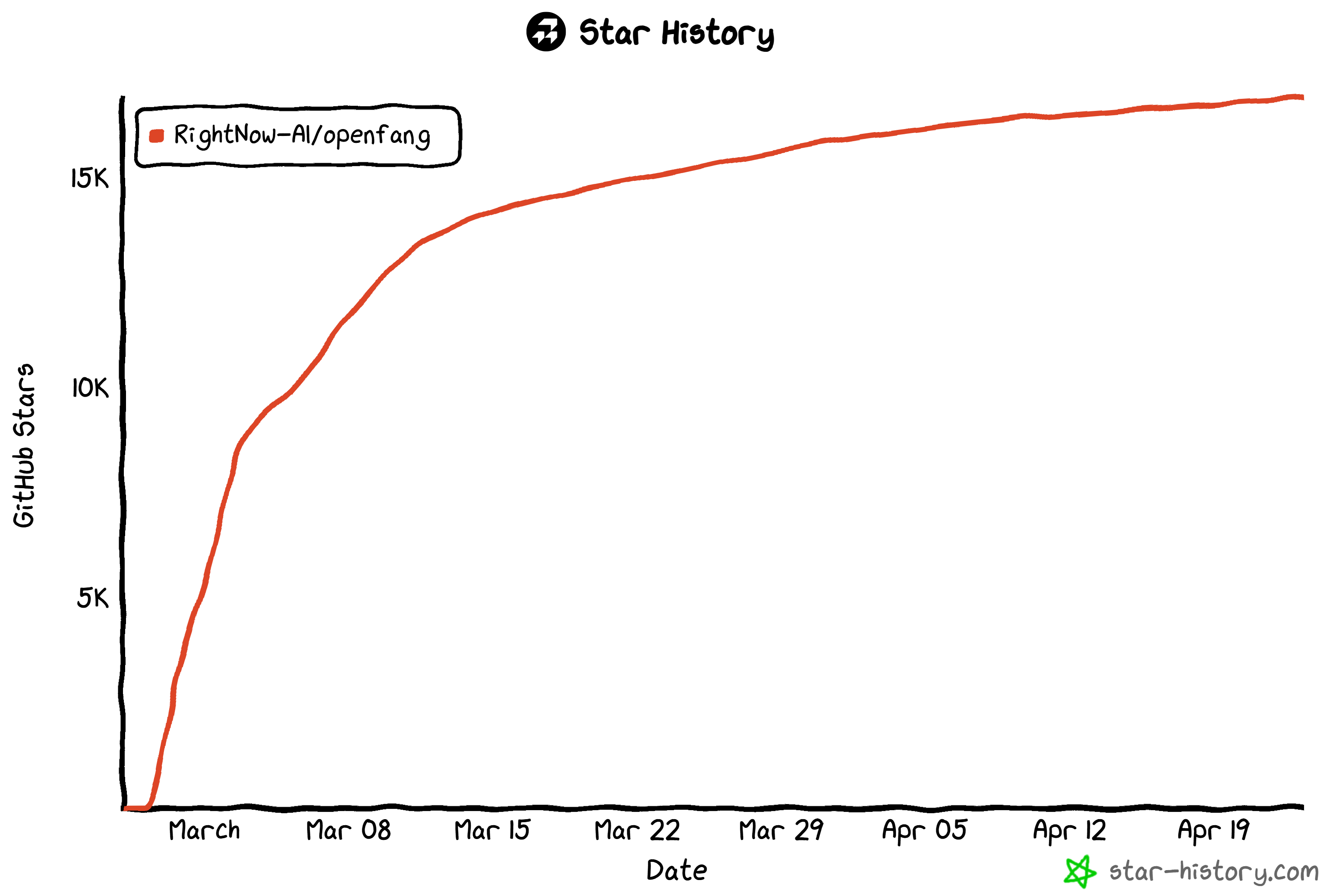
Comparé à certains concurrents comme OpenClaw et ZeroClaw, OpenFang privilégie la performance, la sécurité et l’automatisation dans le monde réel. Il a connu une adoption rapide dans la communauté, comme en témoigne sa forte popularité sur GitHub avec plus de 16 000 étoiles.
Fonctionnalités principales, aspects et capacités
Les principales fonctionnalités offertes par la solution OS d’agents OpenFang sont :
- « Mains » autonomes : Des agents préconfigurés qui s’exécutent indépendamment selon des planifications, effectuant des flux de travail complexes sans invites utilisateur et livrant les résultats directement aux tableaux de bord ou aux canaux.
- Architecture binaire unique : L’ensemble du système se compile en un seul exécutable léger (~32 Mo), simplifiant l’installation et le déploiement.
- Noyau Rust haute performance : Construit de zéro en Rust pour la vitesse, une faible utilisation de la mémoire et des temps de démarrage rapides par rapport aux frameworks Python traditionnels.
- Modèle de sécurité approfondi : Inclut le sandboxing, la signature cryptographique, les pistes d’audit et la protection contre les injections pour garantir une exécution sûre des agents autonomes.
- Runtime multi-agents + outils : Prend en charge des dizaines d’agents et plus de 50 outils intégrés, ainsi que des intégrations externes via MCP et la communication agent à agent.
- Système de mémoire persistante : Combine le stockage SQLite avec des embeddings vectoriels, permettant une rétention de contexte à long terme et une intelligence inter-sessions.
- Plus de 40 intégrations de canaux : Connecteurs natifs pour des plateformes comme Slack, WhatsApp et Telegram.
- Large support de l’écosystème LLM : S’intègre avec plus de 25 fournisseurs et plus de 100 modèles, avec un routage intelligent, des solutions de repli et une optimisation des coûts.
- Couche desktop et API intégrée : Offre une application desktop native et plus de 140 endpoints API pour un contrôle total, une observabilité et une intégration dans les systèmes existants.
En savoir plus dans la documentation officielle.
Pourquoi donner à OpenFang accès au Web
OpenFang est une excellente solution pour l’orchestration et la gestion sécurisée des agents. Pourtant, les agents IA peuvent facilement dériver ou produire des résultats de faible qualité lorsqu’ils opèrent sur des informations obsolètes.
C’est une limitation fondamentale des LLMs, qui sont entraînés sur des jeux de données statiques représentant le passé. Par conséquent, ils peuvent halluciner ou prendre des décisions basées sur un contexte incomplet ou obsolète, réduisant la fiabilité et l’efficacité.
Pour y remédier, OpenFang inclut des outils de recherche et de navigation web de base. Cependant, ces outils ne sont pas prêts pour la production et peuvent facilement être bloqués par les sites web modernes utilisant des restrictions anti-bot et anti-scraping.
La solution est de connecter OpenFang au Bright Data Web MCP. Grâce à cette intégration, les agents OpenFang accèdent à des outils web de qualité production, fiables et évolutifs pour le Scraping web, la recherche, la découverte et l’interaction automatisée avec les navigateurs.
Ce qui distingue Bright Data, c’est son énorme infrastructure mondiale de plus de 400 millions d’IPs résidentielles dans 195 pays. Cela prend en charge une concurrence et une évolutivité illimitées, tout en atteignant 99,99 % de disponibilité et un taux de succès de 99,95 %.
Au total, Web MCP fournit plus de 70 outils prêts pour l’IA. Même dans le niveau gratuit (5 000 requêtes gratuites par mois), il inclut des outils essentiels (ainsi que des versions par lots pour l’exécution parallèle) :
| Outil | Description |
|---|---|
search_engine + search_engine_batch |
Récupère les résultats Google, Bing ou Yandex au format JSON ou Markdown |
scrape_as_markdown + scrape_batch |
Extrait le contenu propre des pages web en Markdown tout en contournant les protections anti-bot |
discover |
Recherche pilotée par l’IA qui classe les résultats en fonction de l’intention de l’utilisateur |
Mais c’est en mode Pro que Web MCP brille vraiment. Il vous donne des outils premium pour l’extraction structurée depuis des plateformes comme LinkedIn, Yahoo Finance, YouTube, TikTok, Zillow, Google Maps et plus de 40 autres. De plus, il équipe vos agents d’outils pour l’interaction web automatisée.
Découvrez comment intégrer Bright Data Web MCP dans OpenFang !
Comment connecter OpenFang à Bright Data Web MCP
Dans cette section guidée, vous verrez comment configurer une instance locale de Bright Data Web MCP dans OpenFang.
Suivez les instructions ci-dessous !
Prérequis
Pour suivre ce tutoriel, assurez-vous d’avoir :
- Rust installé localement.
- Python installé localement.
- Node.js installé localement.
- Un compte Bright Data, idéalement avec une clé API déjà configurée (vous serez guidé à travers cela dans une étape dédiée).
- Une clé API d’un fournisseur pris en charge (dans ce guide, nous utiliserons OpenAI).
Étape n°1 : Installer OpenFang
Sur Linux ou macOS, lancez le script d’installation OpenFang avec :
curl -fsSL https://openfang.sh/install | shDe manière équivalente, sur Windows, exécutez :
irm https://openfang.sh/install.ps1 | iexVoici la sortie que vous devriez voir :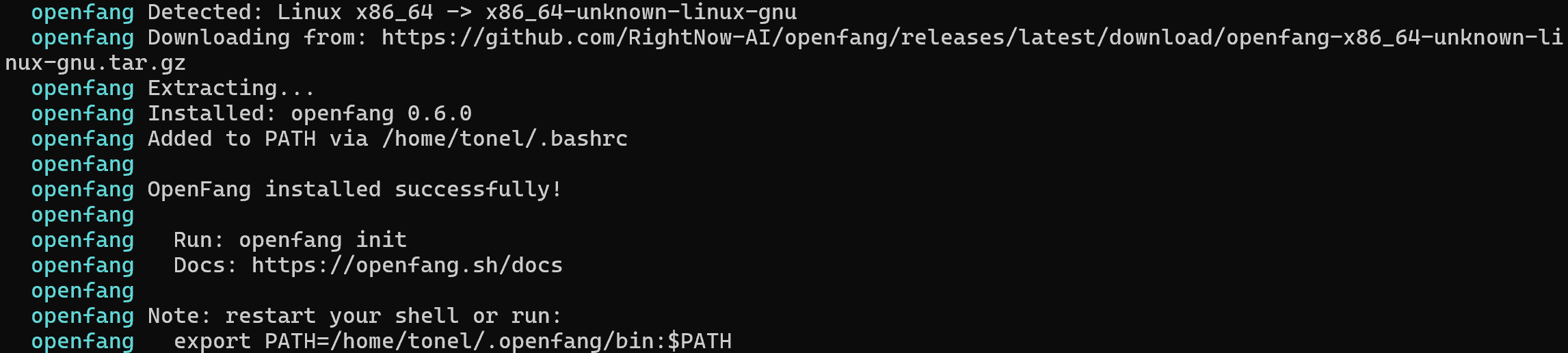
Maintenant, redémarrez votre shell. Vérifiez ensuite l’installation avec :
openfang --versionVous devriez obtenir une sortie comme suit :
openfang 0.6.0Bravo ! OpenFang est maintenant installé localement.
Étape n°2 : Compléter la configuration d’OpenFang
Pour compléter la configuration d’OpenFang, exécutez la commande suivante :
openfang initVoici ce que vous devriez voir :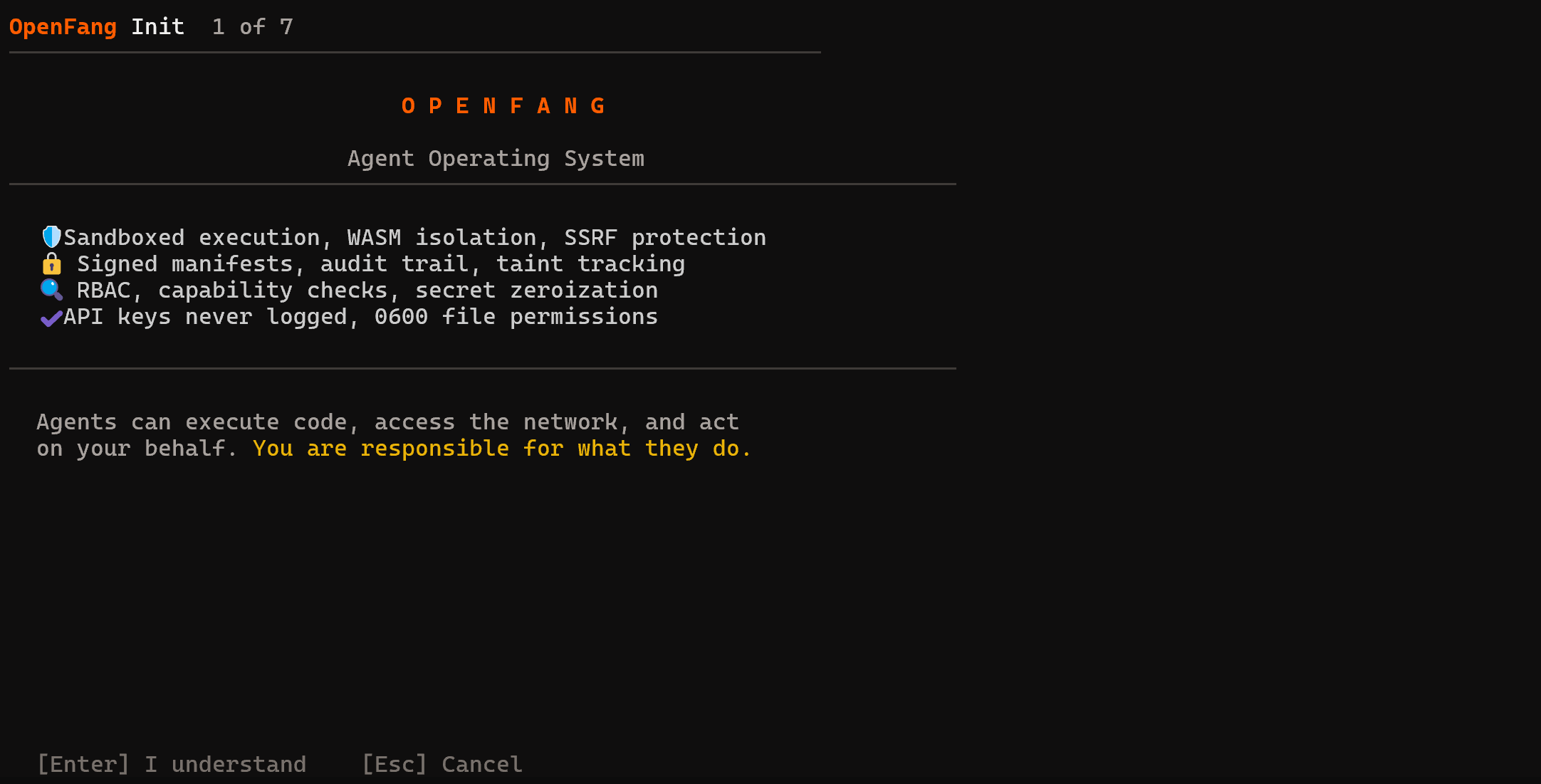
Appuyez sur Entrée pour continuer. Il est temps de passer à travers l’assistant de configuration en 7 étapes !
Tout d’abord, choisissez si vous souhaitez migrer votre configuration depuis OpenClaw (si vous l’avez installé) ou repartir de zéro. Dans ce guide, nous procéderons à une nouvelle configuration. Si vous souhaitez plutôt connecter OpenClaw au Web MCP, référez-vous à la vidéo dédiée.
Ensuite, choisissez votre fournisseur LLM :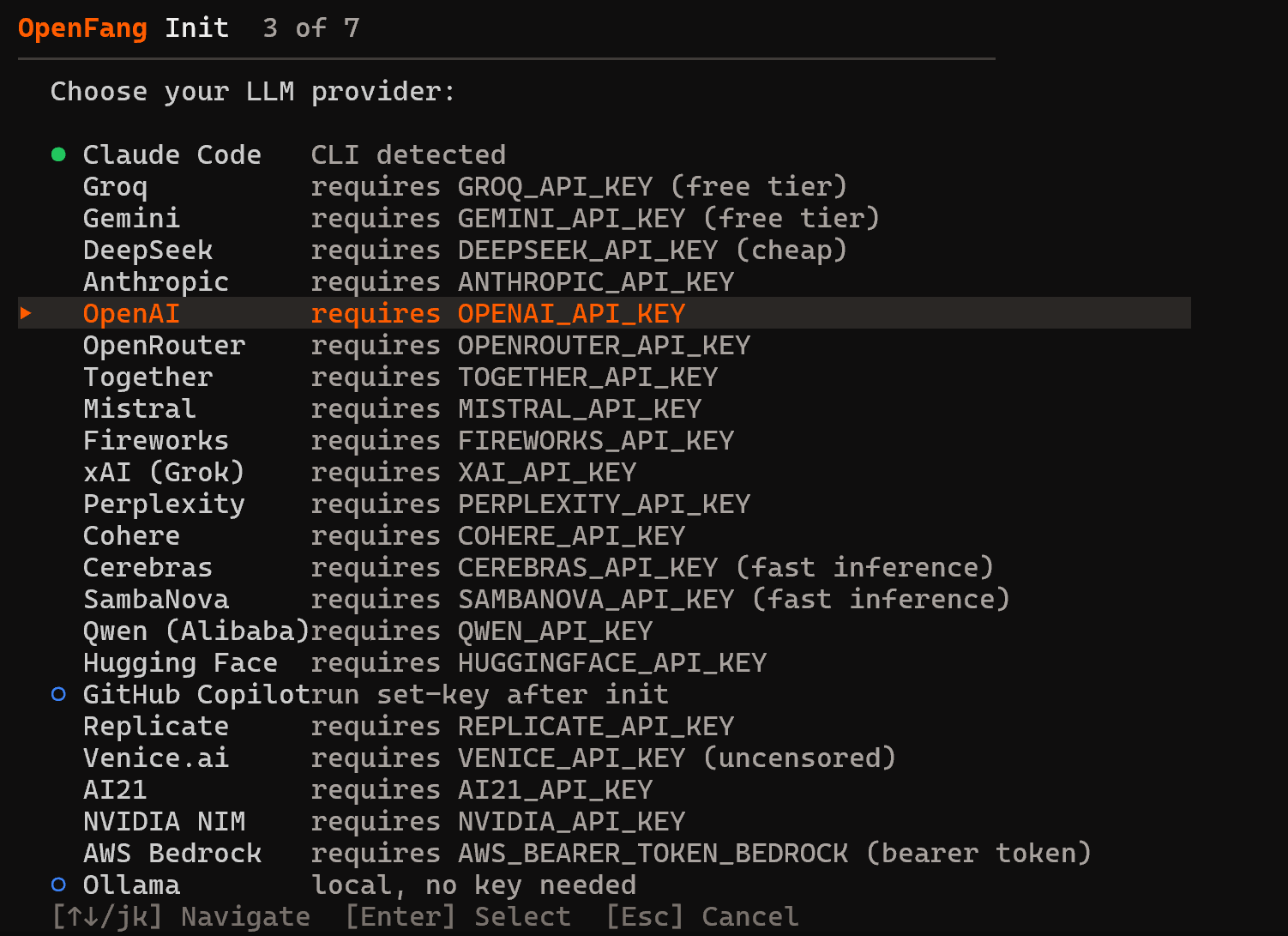
Dans cet exemple, nous avons sélectionné OpenAI, mais vous pouvez choisir le fournisseur qui correspond le mieux à vos besoins. Entrez votre clé API et continuez avec la sélection du modèle par défaut :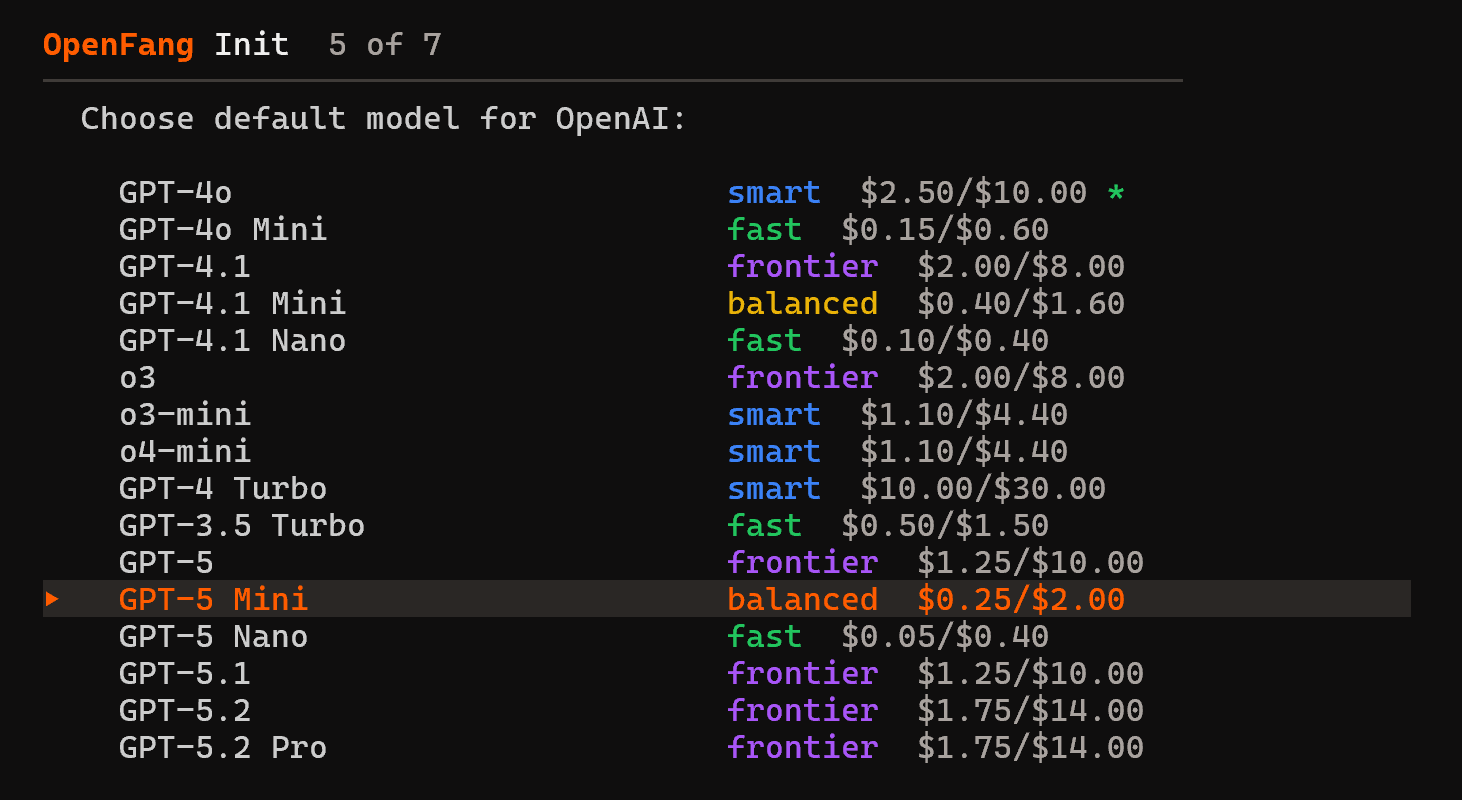
Le modèle GPT-5 Mini est plus que suffisant comme modèle OpenFang par défaut.
Enfin, décidez si vous souhaitez activer la fonctionnalité Smart Model Routing. Lorsqu’elle est activée, les tâches simples utilisent des modèles plus rapides et moins coûteux, tandis que les tâches plus complexes sont acheminées vers des modèles avancés. Cela aide à réduire les coûts sans sacrifier la qualité.
Ensuite, sélectionnez comment vous souhaitez utiliser OpenFang. Dans ce guide, nous utiliserons l’option « Tableau de bord Web » :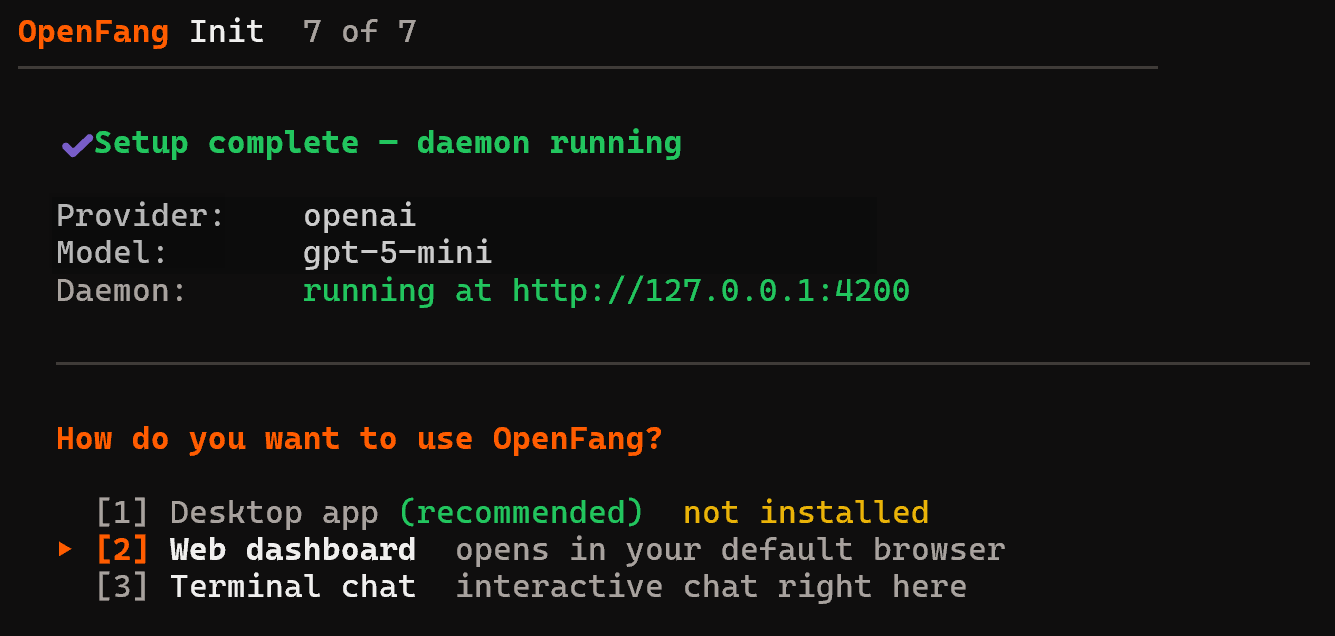
Si vous utilisez un serveur sans interface graphique, l’option « Terminal chat » est le choix par défaut.
Remarque : Tous les fichiers de configuration et les ressources nécessaires (comme la base de données SQLite et les agents) sont stockés dans le répertoire ~/.openfang/.
Parfait ! OpenFang est maintenant entièrement configuré.
Étape n°3 : Lancer OpenFang
Par défaut, après l’initialisation, le démon OpenFang devrait déjà être en cours d’exécution. Vérifiez-le avec :
openfang statusVoici le résultat que vous devriez recevoir :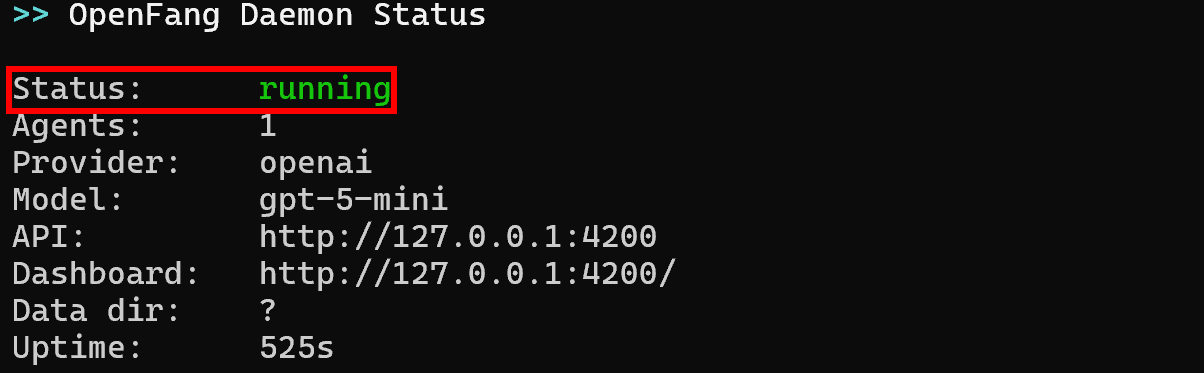
Recherchez le statut « running ». S’il ne fonctionne pas, démarrez le démon OpenFang avec :
openfang startSi vous avez sélectionné l’option « Tableau de bord Web » lors de la configuration, vous pouvez accéder au tableau de bord OpenFang à : http://127.0.0.1:4200.
Ouvrez cette URL dans votre navigateur, et voici ce que vous observerez :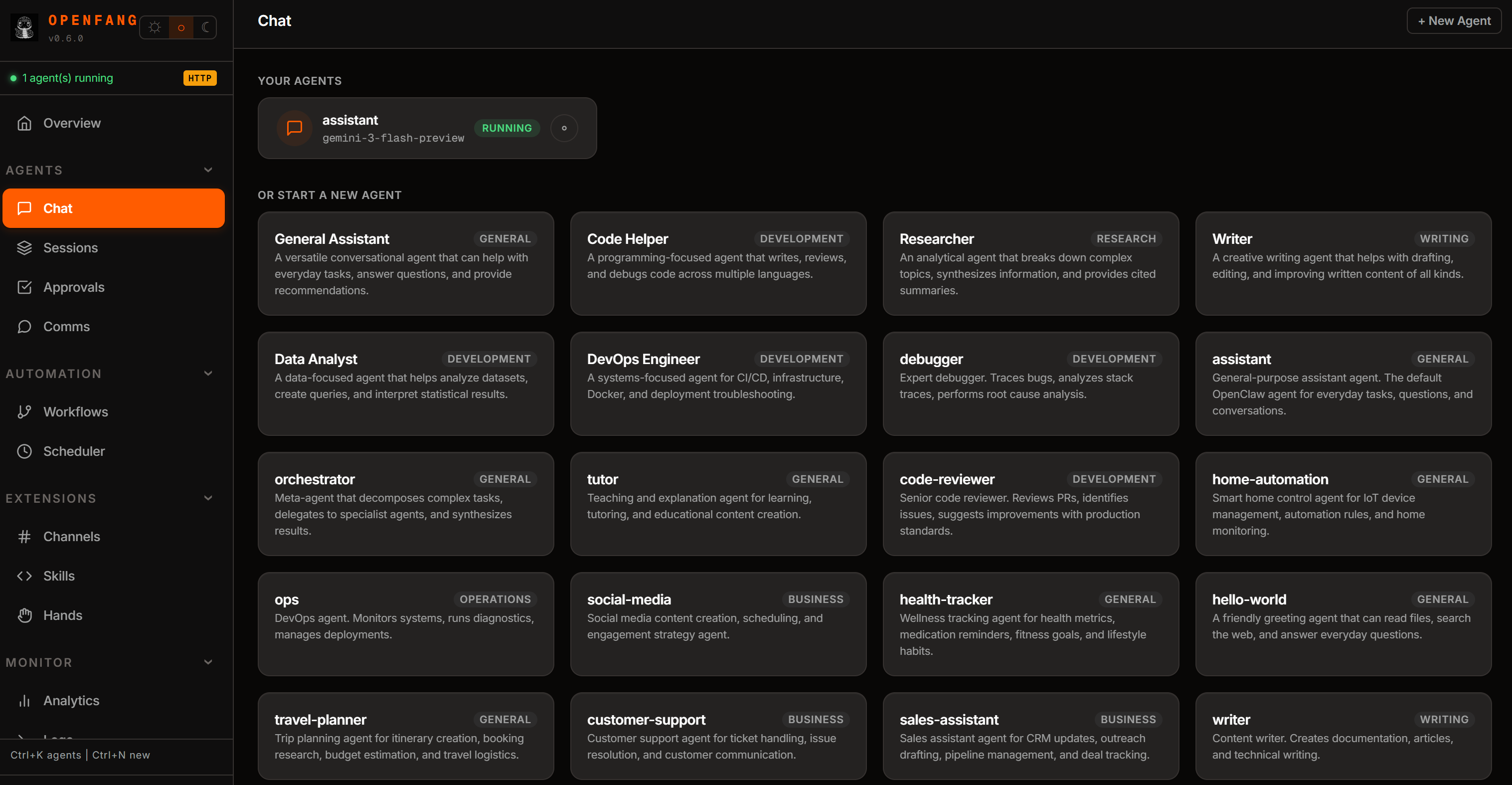
Prenez le temps d’explorer les options disponibles et de vous familiariser avec le tableau de bord OpenFang. Excellent !
Étape n°4 : Démarrer avec Bright Data Web MCP
Avant de connecter OpenFang au Bright Data Web MCP, vérifiez que le serveur MCP fonctionne sur votre machine.
Tout d’abord, créez un compte Bright Data. Si vous en avez déjà un, connectez-vous simplement. Pour une configuration rapide, suivez l’assistant dans la section « MCP » de votre tableau de bord :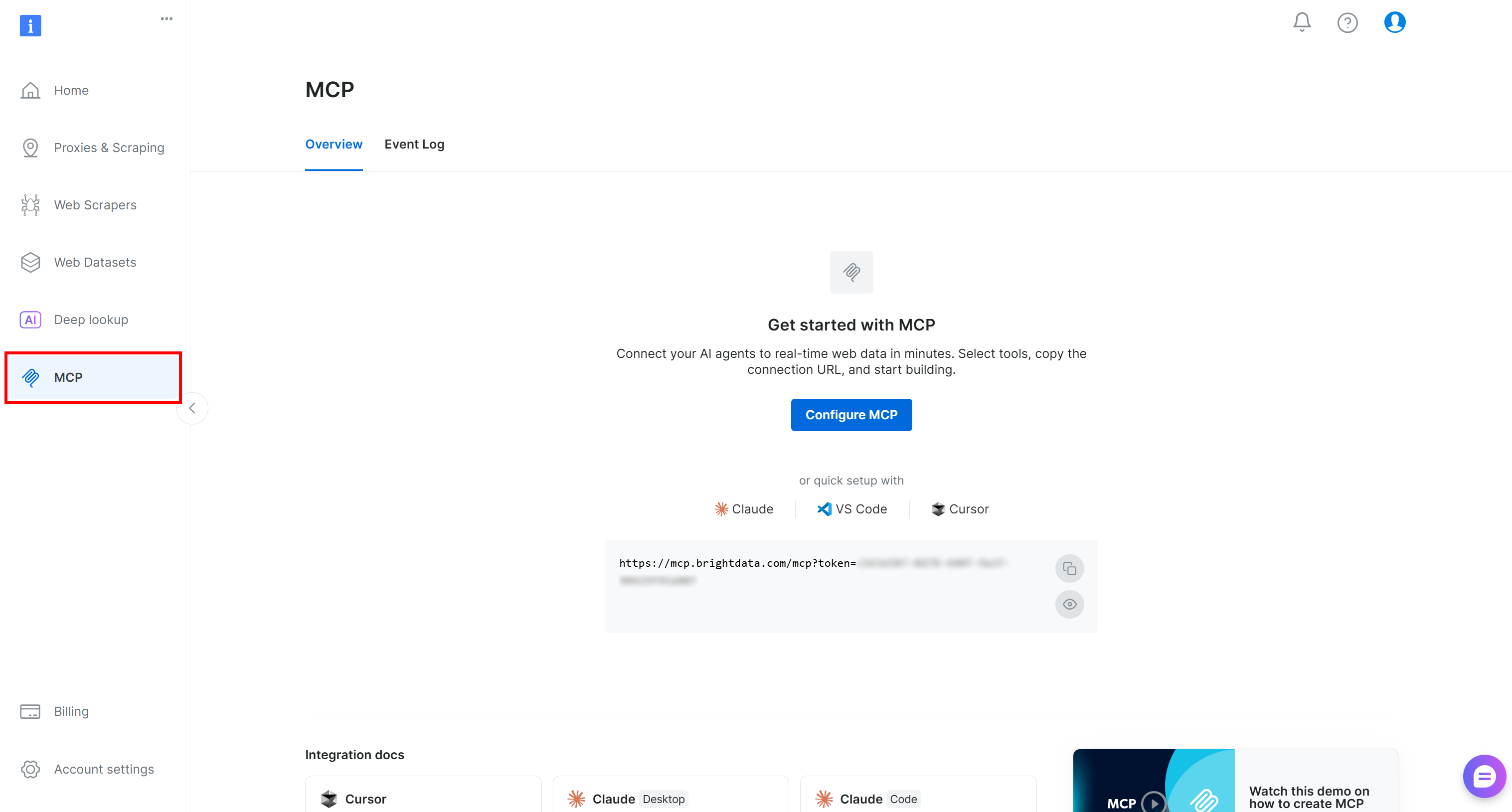
Pour des conseils plus détaillés, référez-vous aux instructions ci-dessous.
Commencez par générer votre clé API Bright Data. Conservez-la en lieu sûr, car vous en aurez besoin sous peu pour authentifier votre instance locale de Web MCP avec votre compte Bright Data.
Ensuite, installez le Web MCP globalement via le package @brightdata/mcp :
npm install -g @brightdata/mcpVérifiez que le serveur MCP démarre avec :
API_TOKEN="<YOUR_BRIGHT_DATA_API>" npx -y @brightdata/mcpOu, de manière équivalente, dans PowerShell :
$Env:API_TOKEN="<YOUR_BRIGHT_DATA_API>"; npx -y @brightdata/mcpRemplacez <YOUR_BRIGHT_DATA_API> par votre jeton API Bright Data réel. La commande ci-dessus définit la variable d’environnement API_TOKEN requise et lance le serveur Web MCP localement.
En cas de succès, vous devriez voir une sortie similaire à :
Au premier lancement, @brightdata/mcp crée automatiquement deux zones dans votre compte Bright Data :
mcp_unlocker: Une Zone pour Web Unlocker.mcp_browser: Une Zone pour Browser API.
Ces deux zones alimentent les plus de 70 outils disponibles dans Web MCP. Notez que vous pouvez également les configurer avec d’autres zones, comme expliqué dans la documentation.
Pour vérifier qu’elles ont été créées, accédez à la page « Proxies & Infrastructure de scraping » dans votre tableau de bord Bright Data. Vous devriez voir les deux zones répertoriées dans le tableau « Mes Zones » :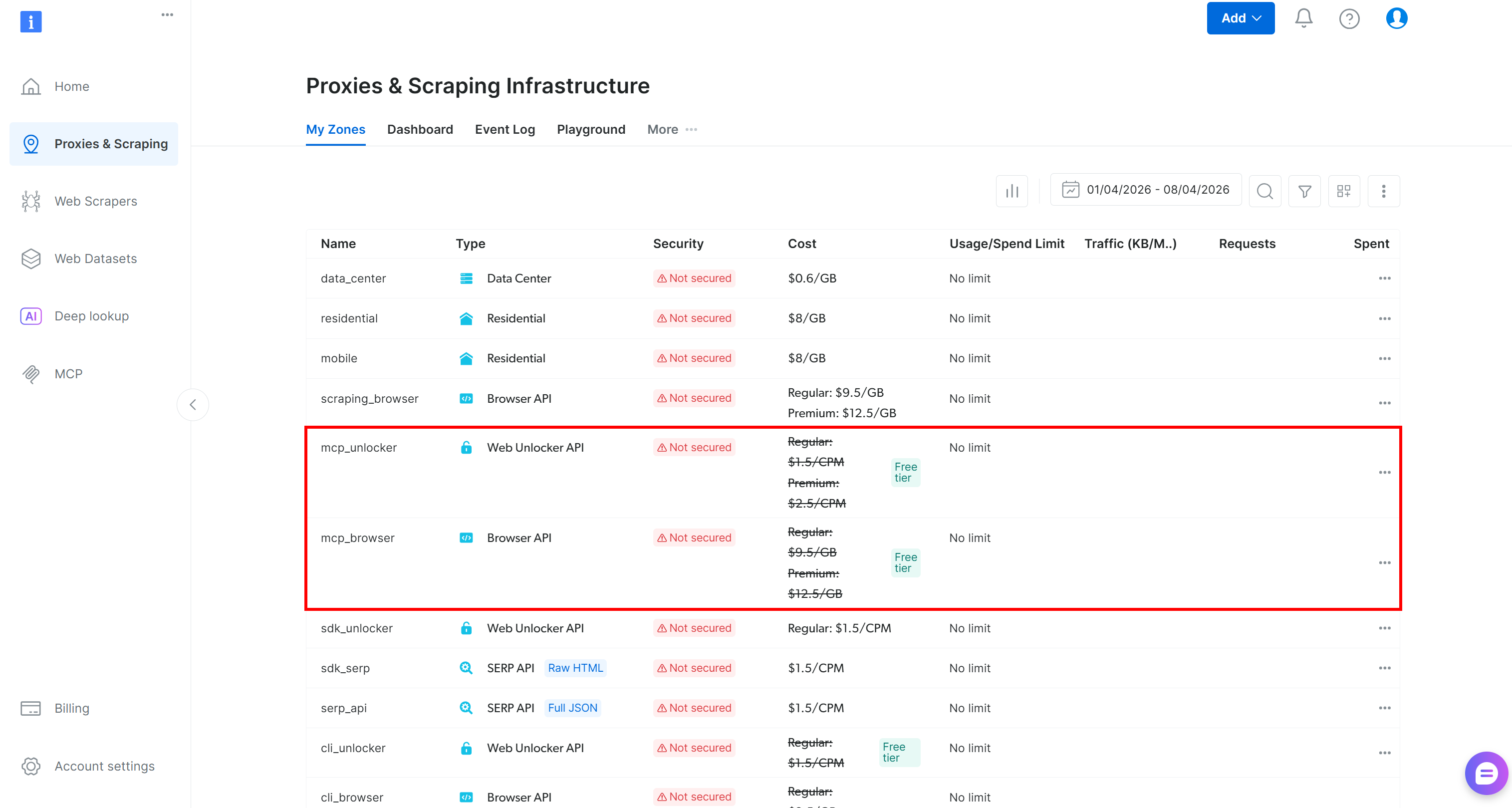
Maintenant, rappelez-vous que sur le niveau gratuit de Web MCP, vous n’avez accès qu’à quelques outils.
Pour débloquer tous les 70+ outils, activez le mode Pro en définissant la variable d’environnement PRO_MODE="true" :
API_TOKEN="<YOUR_BRIGHT_DATA_API>" PRO_MODE="true" npx -y @brightdata/mcpOu, sur Windows :
$Env:API_TOKEN="<YOUR_BRIGHT_DATA_API>"; $Env:PRO_MODE="true"; npx -y @brightdata/mcpRemarque : Le mode Pro n’est pas inclus dans le niveau gratuit et entraîne des frais supplémentaires.
Fantastique ! Vous avez maintenant vérifié que le serveur Web MCP fonctionne sur votre machine. Ensuite, vous configurerez OpenFang pour démarrer le serveur et s’y connecter.
Étape n°5 : Configurer la connexion Web MCP dans OpenFang
OpenFang prend en charge l’intégration MCP via une section dédiée dans son fichier de configuration global. Modifiez-le avec :
openfang config editAlternativement, localisez le fichier à ~/.openfang/config.toml et ouvrez-le avec votre éditeur préféré.
Pour activer la connexion Bright Data Web MCP, assurez-vous que votre configuration inclut :
[[mcp_servers]]
name = "bright-data-web-mcp"
env = ["API_TOKEN", "PRO_MODE"]
[mcp_servers.transport]
type = "stdio"
command = "npx"
args = ["@brightdata/mcp"]Cette configuration reproduit la commande npx utilisée précédemment. Comme indiqué auparavant, elle nécessite deux variables d’environnement. Pour des raisons de sécurité, OpenFang vous permet uniquement de stocker leurs noms, pas leurs valeurs. Vous devez donc les définir dans votre système avec :
export API_TOKEN="<YOUR_BRIGHT_DATA_API_KEY>" PRO_MODE="true"Ou, de manière équivalente, dans PowerShell :
$Env:API_TOKEN="<YOUR_BRIGHT_DATA_API_KEY>"; $Env:PRO_MODE="true"Voici ce que représentent ces variables :
API_TOKEN: Requis. Votre clé API Bright Data.PRO_MODE: Facultatif. Définissez sur"true"pour activer le mode Pro, ou supprimez/définissez sur"false"pour le désactiver.
Une fois configuré, OpenFang démarrera automatiquement le serveur MCP en utilisant la commande npx spécifiée et s’y connectera au démarrage.
Arrêtez OpenFang pour appliquer les modifications :
openfang stopEt relancez-le avec :
openfang startExcellent ! OpenFang devrait maintenant être connecté à une instance locale du Bright Data Web MCP.
Étape n°6 : Vérifier la connexion MCP
Retournez au tableau de bord OpenFang et ouvrez la page « Skills ». Naviguez jusqu’à la section « MCP Servers ». Vous devriez voir l’entrée bright-data-web-mcp exposant plus de 70 outils disponibles :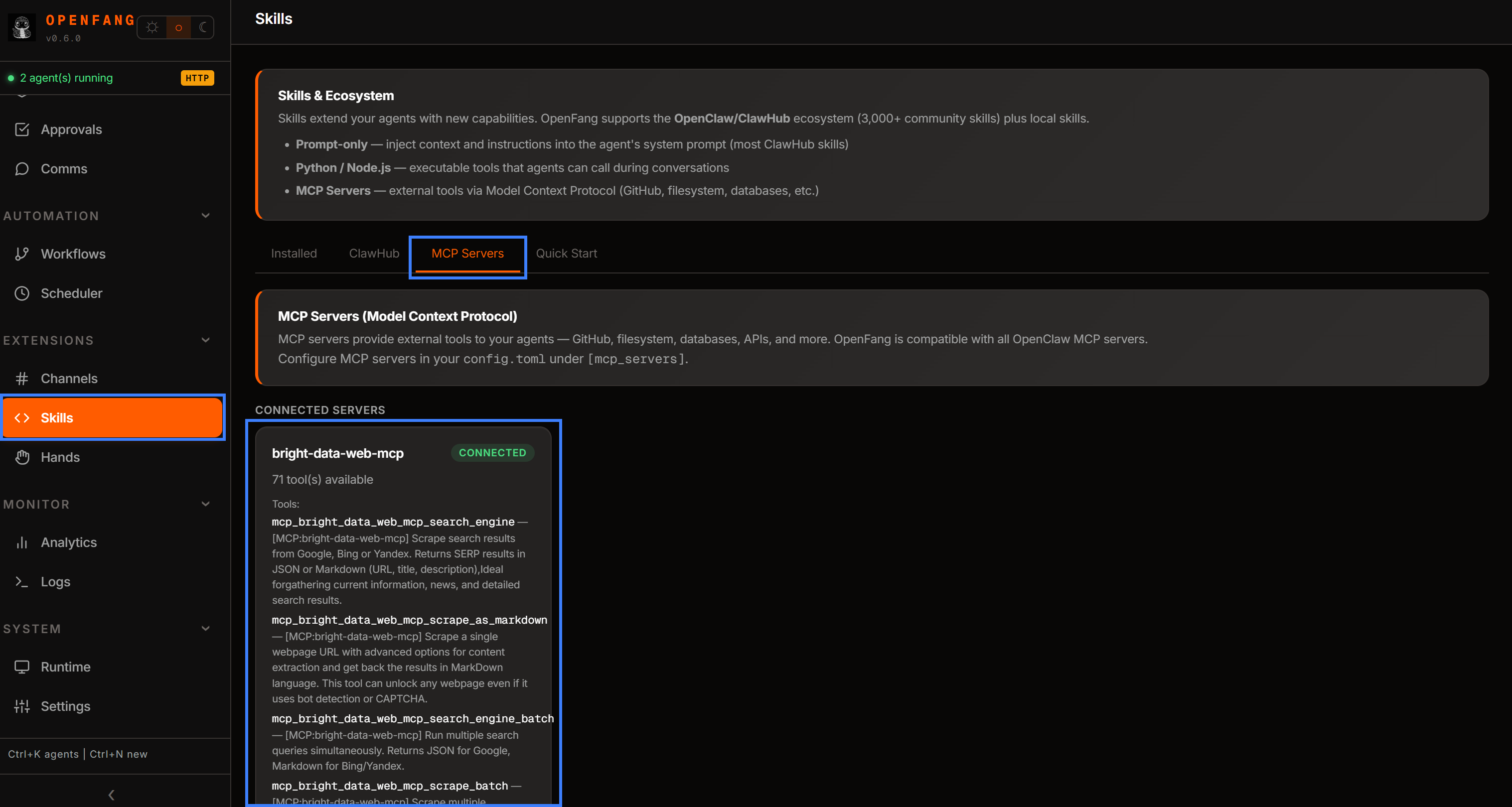
Si vous l’avez configuré sans mode Pro, vous ne verrez qu’un sous-ensemble limité d’outils. Cela confirme que le système fonctionne comme prévu.
À ce stade, vous avez vérifié avec succès que le Web MCP est actif dans OpenFang. La dernière étape consiste à créer un nouvel agent et à explorer à quel point il devient précieux lorsqu’il est équipé de ces outils nouvellement disponibles.
Étape n°7 : Créer un nouvel agent IA
Supposons que vous souhaitiez créer un agent IA autonome pour le recrutement. Cet agent se connectera aux outils Bright Data Web MCP pour récupérer des informations sur les candidats et les entreprises depuis LinkedIn, les profils GitHub et d’autres sources publiques.
OpenFang est livré avec 30 modèles d’agents préconfigurés. Chaque modèle est un manifeste agent.toml prêt à être instancié, situé dans le répertoire ~/.openfang/agents/. Dans ce cas, nous partirons de l’agent recruiter par défaut. Tout d’abord, copiez son répertoire dans un nouveau appelé web-recruiter :
cp -r ~/.openfang/agents/recruiter ~/.openfang/agents/web-recruiterCela crée un nouvel agent web-recruiter.
Ensuite, modifiez le fichier ~/.openfang/agents/web-recruiter/agent.toml et assurez-vous qu’il contient :
Notez que l’agent a maintenant accès à plusieurs outils Bright Data Web MCP. Pour lui donner accès à tous les outils disponibles, ajoutez le motif générique mcp_bright_data_web_* dans le tableau tools à l’intérieur de [capabilities].
Après avoir redémarré OpenFang et ouvert le tableau de bord, vous verrez le nouvel agent « web-recruiter » disponible dans la section « Chat » :
Parfait ! Il ne reste plus qu’à tester l’agent.
Étape n°8 : Tester l’agent propulsé par Web MCP
Lancez l’agent en sélectionnant « web-recruiter » dans la page Chat. Alternativement, pour une interaction basée sur la CLI, exécutez :
openfang chat web-recruiterTout d’abord, initialisez l’agent en envoyant un message de salutation :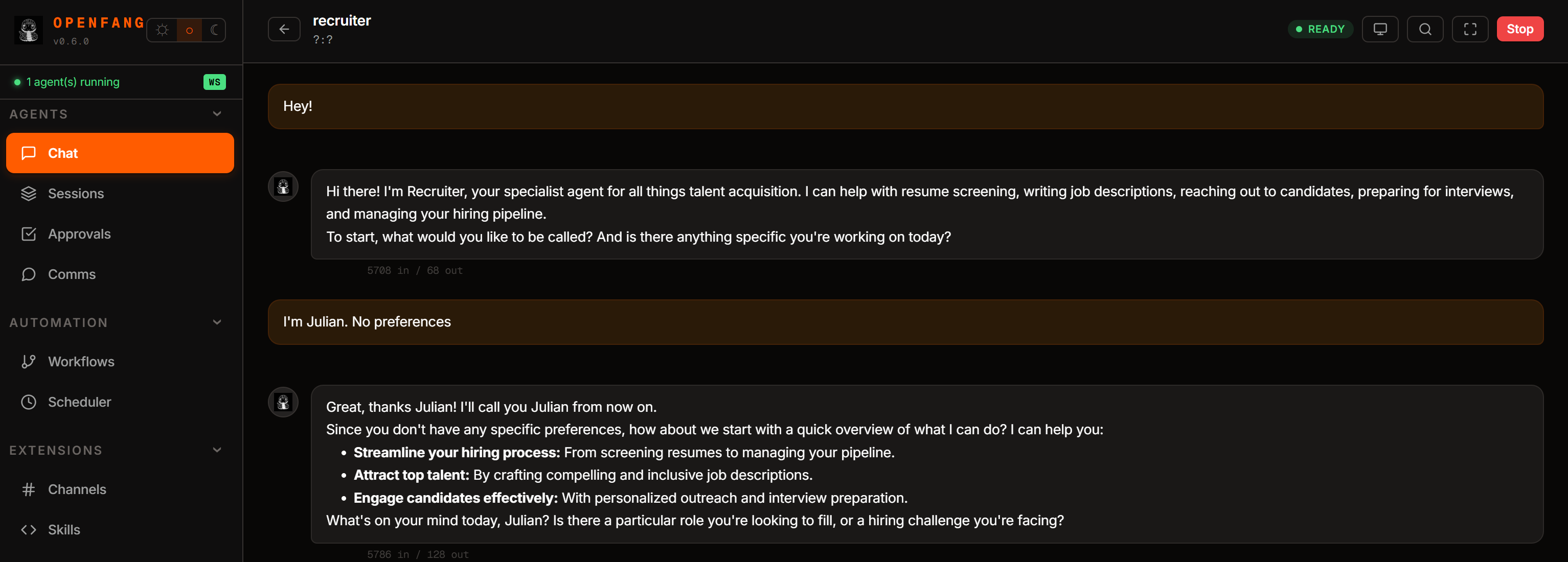
Maintenant, supposons que vous évaluez un poste de spécialiste en intégration IA. Vous souhaitez que l’agent IA évalue trois candidats, alors rédigez une invite comme celle-ci :
Suppose you are looking for a strong candidate for the following position:
POSITION:
AI Integration Specialist
Description:
We are seeking an AI Integration Specialist to design, implement, and optimize the integration between AI systems and enterprise software environments. In this role, you will be responsible for integrating large language models, agent-based systems, APIs, and external data services into scalable and reliable workflows that support real-world business use cases. You will work closely with engineering, product, and data teams to ensure seamless interoperability between AI components and existing infrastructure.
The ideal candidate has strong experience with API design, system architecture, and modern AI frameworks, as well as a practical understanding of how to deploy and maintain production-grade AI systems. You will also play a key role in evaluating new AI tools, defining integration standards, and ensuring security, performance, and maintainability across all AI-driven services.
Requirements:
- 3+ years of experience in software engineering, backend development, or system integration
- Strong knowledge of REST APIs, webhooks, and distributed systems
- Experience working with AI/ML models, LLMs, or agent-based frameworks
- Familiarity with cloud platforms (AWS, GCP, or Azure)
- Understanding of data pipelines, authentication systems, and secure API design
- Ability to write clean, maintainable code in at least one modern programming language (Python, Rust, or JavaScript preferred)
- Strong problem-solving skills and ability to translate business needs into technical solutions
- Excellent communication skills and ability to collaborate across teams
---
Using the Bright Data Web MCP tools, retrieve the structured JSON profiles of the following three candidates from LinkedIn and evaluate each for the position. Produce a report with the main information from each candidate, assign a score from 1 to 10, include a ~50-word comment, and conclude with a dedicated section outlining pros and cons for each candidate:
- https://www.linkedin.com/in/antonello-zanini/
- https://www.linkedin.com/in/federico-trotta/
- https://www.linkedin.com/in/hello-agents
Note: If the information available on the public LinkedIn profiles is not sufficient for a proper evaluation, search the web for their GitHub profiles via Bright Data Web MCP, identify the correct ones for each candidate, and extract additional relevant information.Lancez l’invite, et vous devriez voir quelque chose comme ci-dessous :
Important : L’agent peut demander la permission d’utiliser les outils Web MCP. Si c’est le cas, accordez-la.
Dans l’exécution ci-dessus, l’agent :
- A utilisé
scrape_batchpour récupérer les profils LinkedIn en parallèle (ou alternativement, il peut appelerweb_data_linkedin_person_profile, qui se connecte aux API Scraper de profils LinkedIn de Bright Data). - A utilisé l’outil
search_engine_batchpour effectuer plusieurs recherches Google en parallèle (via l’API SERP) et localiser les profils GitHub. - Une fois identifiés, il a scrapé les dépôts GitHub en utilisant
scrape_batch(ouweb_data_github_repository_file, qui s’intègre avec le Scraper GitHub de Bright Data). - A traité toutes les informations collectées et généré un rapport structuré avec des scores et des commentaires pour chaque candidat.
Les outils Bright Data Web MCP permettent à l’agent de récupérer des données au format Markdown (ou JSON) optimisé pour l’IA depuis LinkedIn, Google et GitHub. Markdown et JSON sont idéaux pour le traitement par LLM.
Cela ne serait pas possible de manière fiable avec les outils intégrés de récupération et de recherche web, qui sont susceptibles de déclencher des solutions anti-bot. De plus, ils ne récupèrent pas les sorties dans des formats de données optimisés pour l’IA, ce qui amène l’agent à consommer beaucoup plus de tokens.
Examinez le résultat final. Vous remarquerez un rapport de recrutement détaillé, basé sur des données web :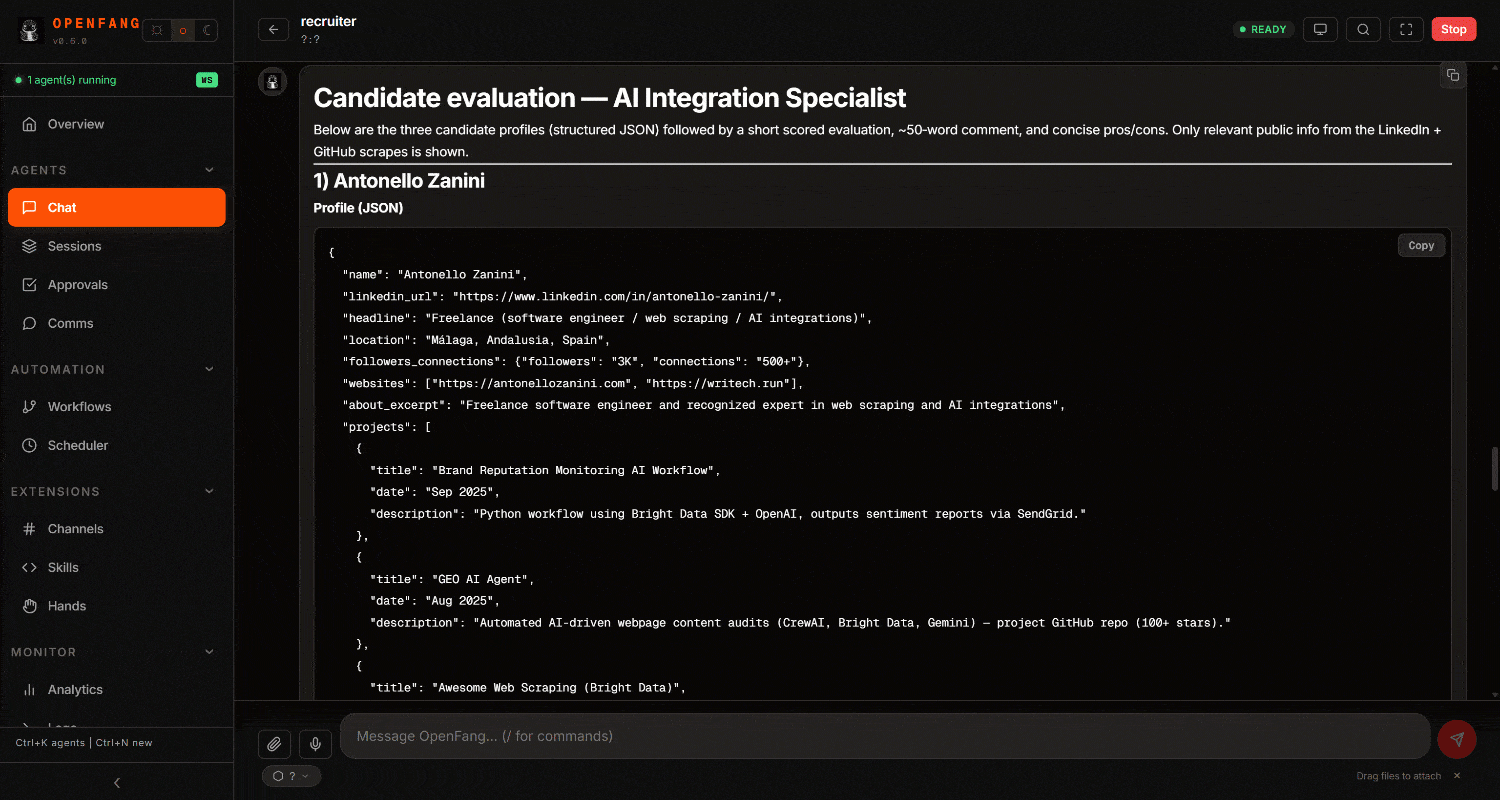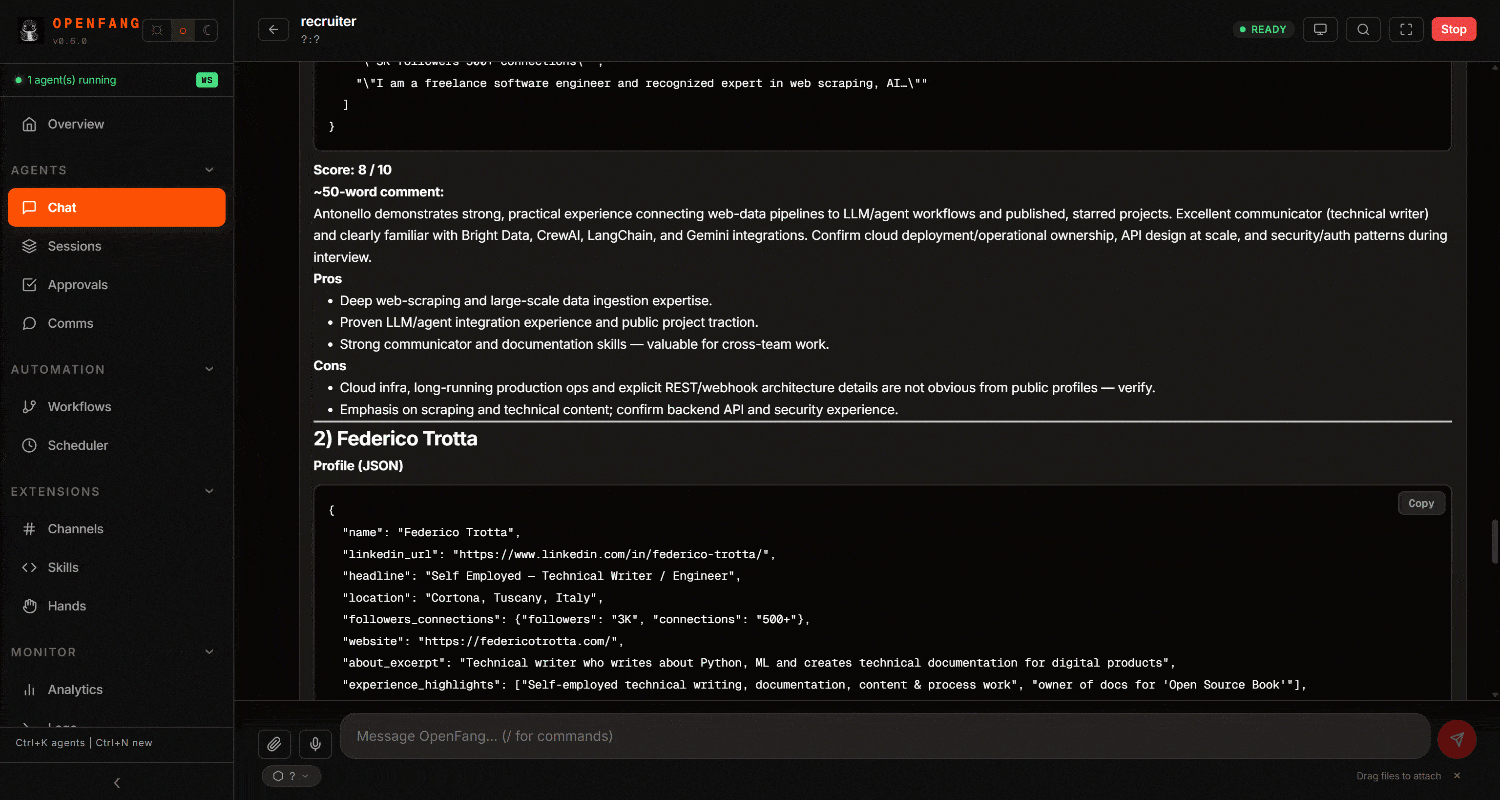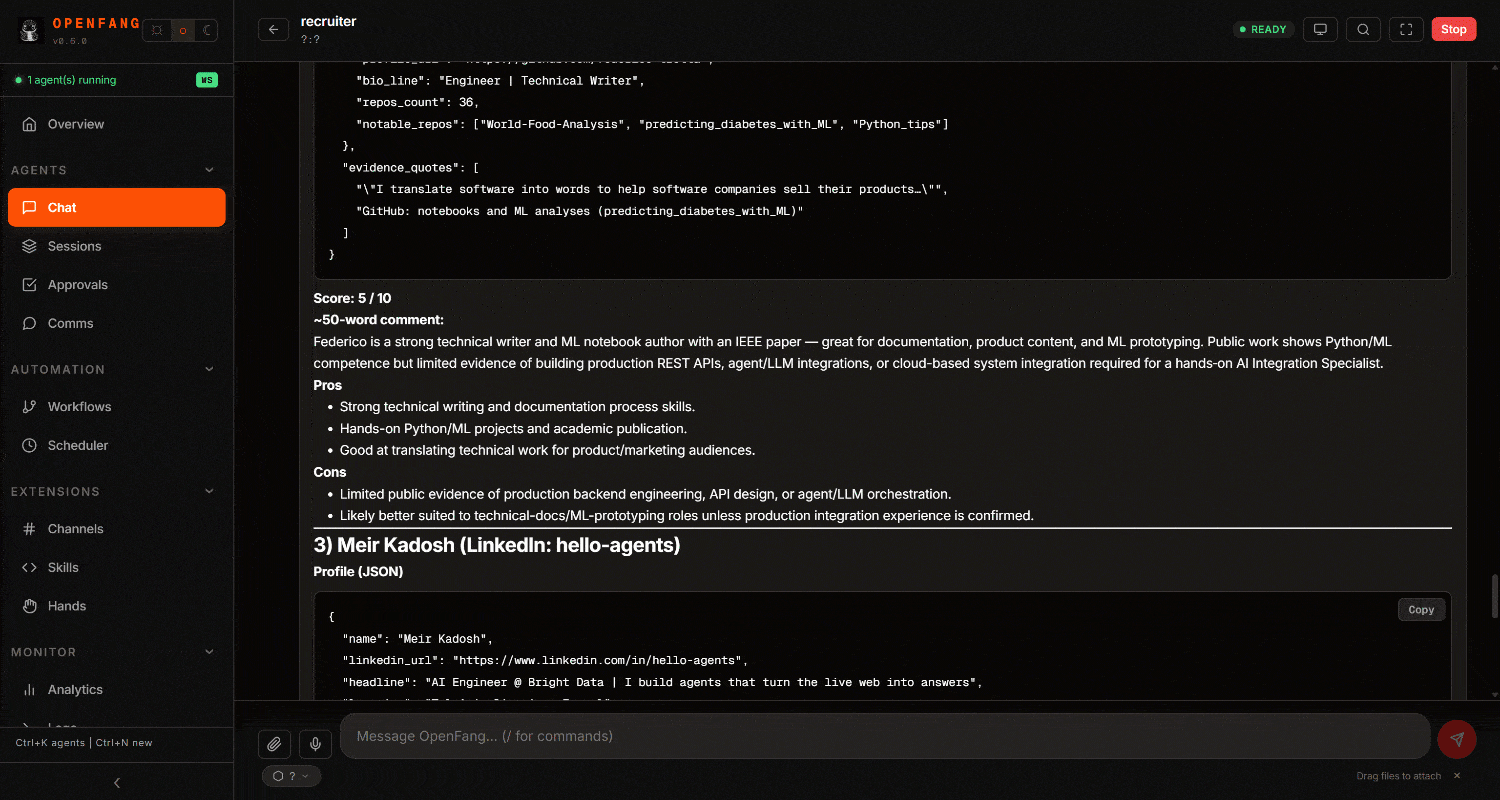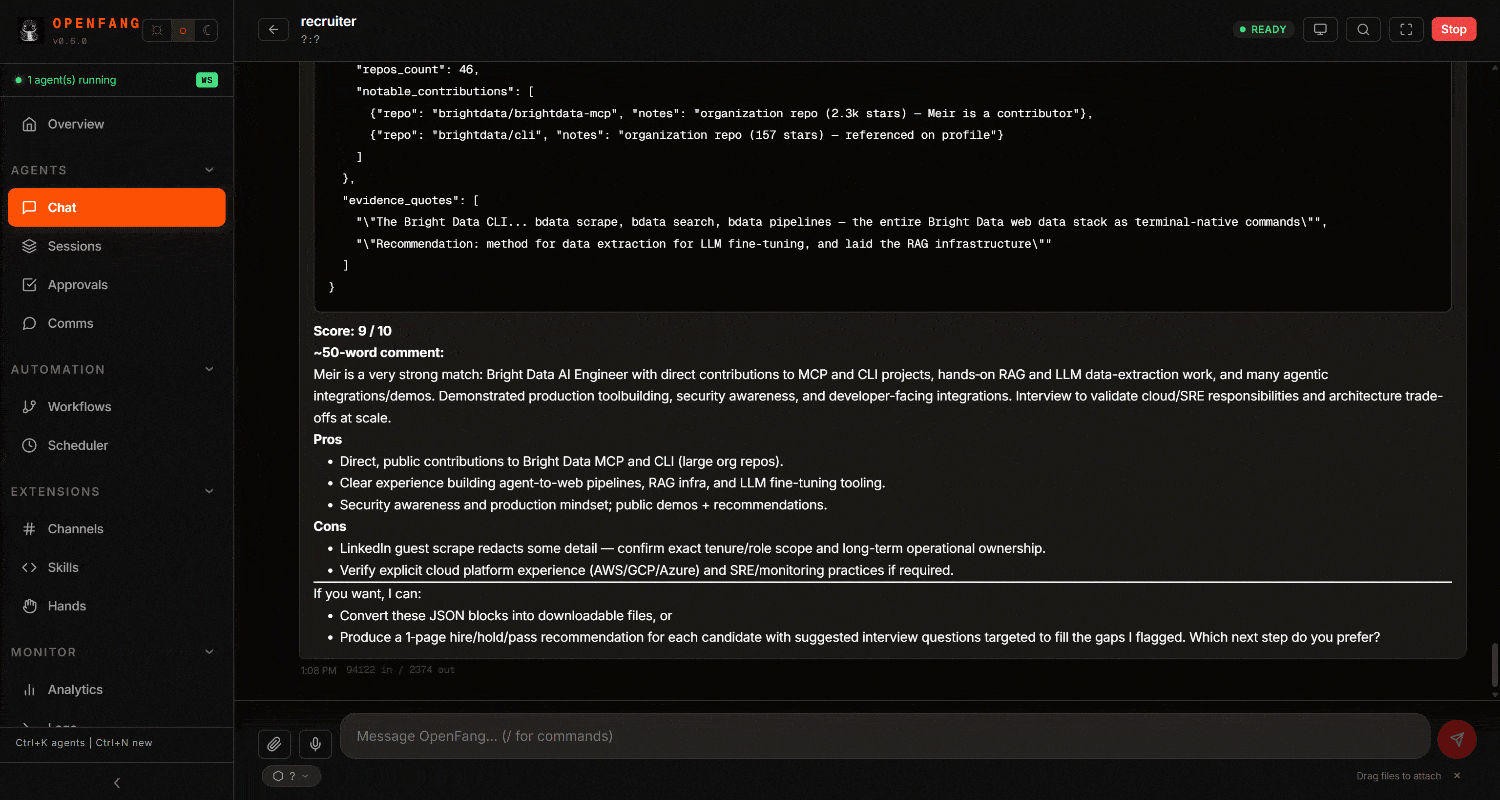
Et voilà ! Vous venez de voir la puissance d’un agent OpenFang étendu avec Bright Data Web MCP.
Il ne s’agit que d’un exemple simple utilisant un sous-ensemble limité des capacités d’OpenFang et de Web MCP. En combinant des flux de travail et en activant les Hands d’OpenFang, vous pouvez construire des systèmes autonomes nettement plus avancés pour des cas d’utilisation complexes.
[Extra] Étendre OpenFang avec les Bright Data Skills
OpenFang prend également en charge l’intégration avec Agent Skills. En particulier, il prend en charge toutes les compétences provenant de ClawHub, y compris celles de Bright Data (voir comment ces compétences fonctionnent et comment les intégrer dans OpenClaw).
Pour les installer, allez sur la page « Skills », ouvrez l’onglet « ClawHub » et recherchez « bright-data ». Installez les compétences « Bright Data » fournies par @meirkad.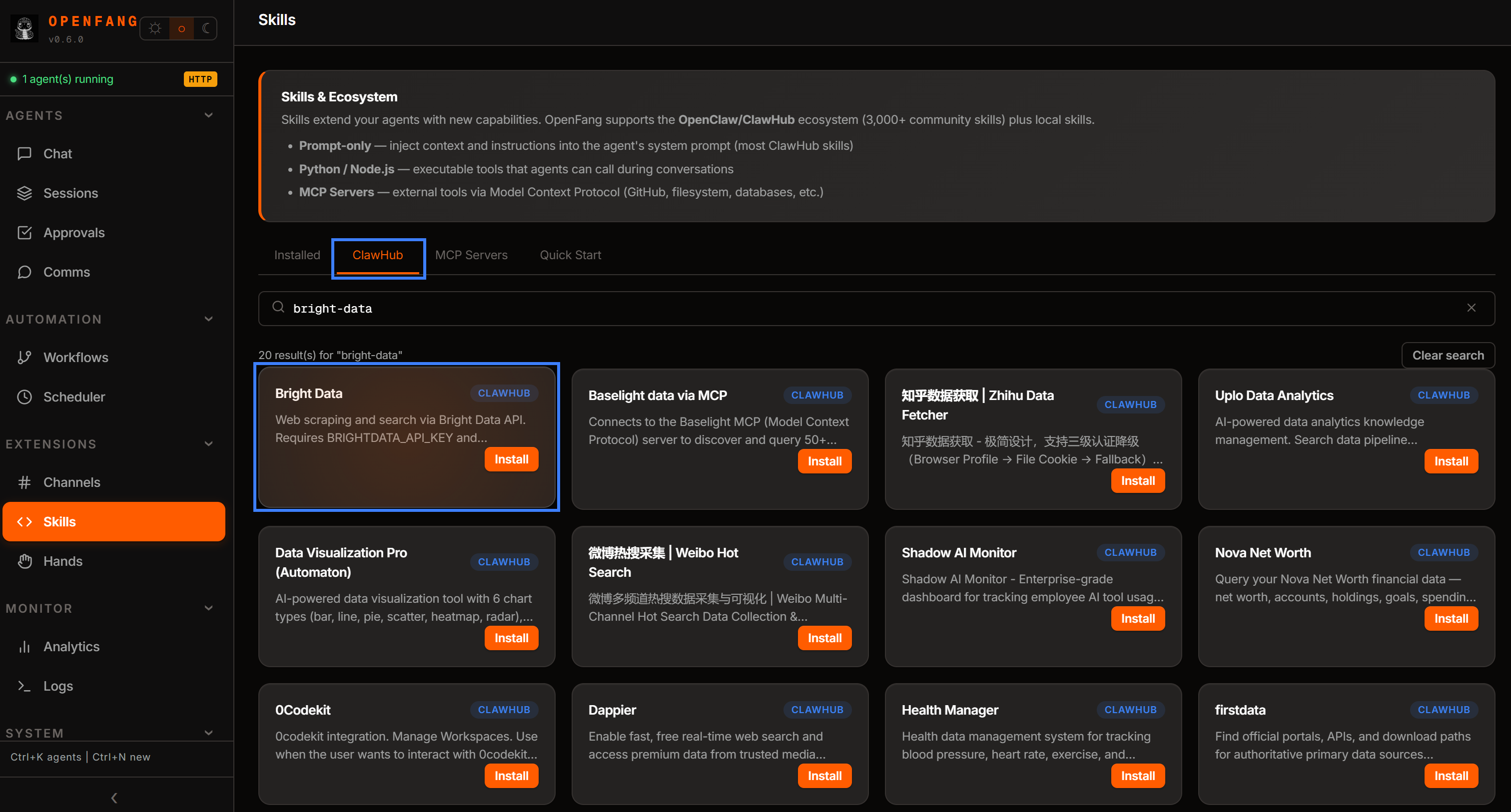
Pour plus d’informations sur les prérequis, référez-vous à la documentation officielle. Cela ajoutera la connectivité à l’API Web Unlocker de Bright Data et à l’API SERP, permettant des capacités de Scraping web et de recherche web.
Pour donner à votre agent une compréhension plus approfondie de l’infrastructure Bright Data, vous devriez également installer les compétences officielles Bright Data. Avant de les ajouter, suivez la documentation officielle pour vous assurer que tous les prérequis sont remplis.
Ensuite, ajoutez les compétences Bright Data à OpenFang avec :
git clone https://github.com/brightdata/skills
mkdir ~/.openfang/skills
cp -r skills/skills/* ~/.openfang/skills/Cela clone le dépôt de compétences Bright Data. Ensuite, il crée le répertoire OpenFang ~/.openfang/skills — l’emplacement où les Agent Skills doivent être placés pour qu’OpenFang les détecte. Enfin, il copie toutes les définitions de compétences dans ce répertoire afin qu’OpenFang puisse charger et utiliser les capacités Bright Data dans son système d’agents.
Redémarrez OpenFang, et vous les verrez disponibles dans l’onglet « Installed » de la section « Skills » :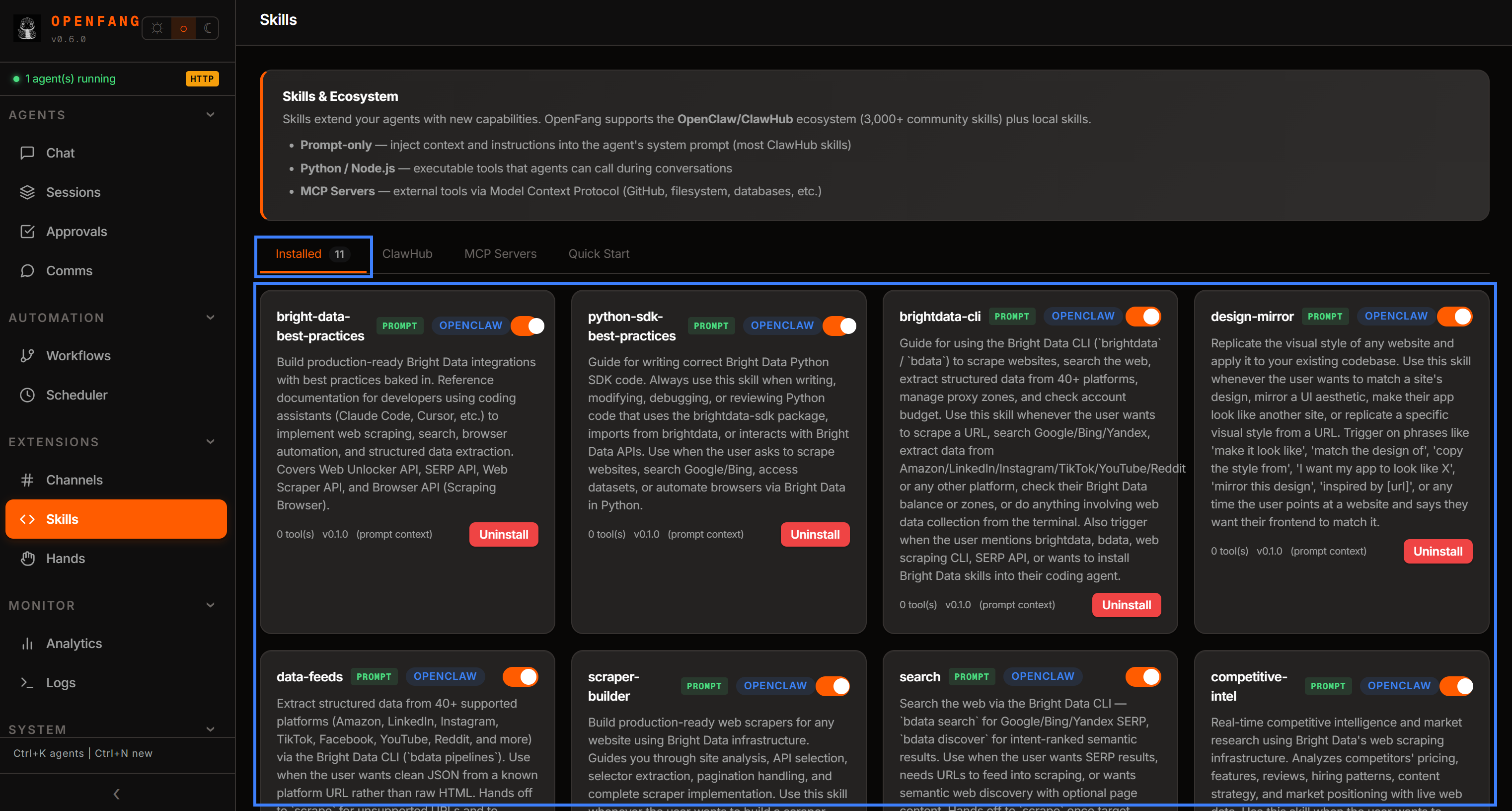
Merveilleux ! Vos agents IA OpenFang sont maintenant entièrement enrichis des connaissances Bright Data.
Conclusion
Dans cet article de blog, vous avez compris ce qu’est OpenFang et quelles fonctionnalités il offre en tant que solution OS d’agents. Plus précisément, vous avez vu comment et pourquoi l’étendre en le connectant à Bright Data via Web MCP et les Agent Skills officiels.
Cette intégration amène les agents OpenFang à un tout nouveau niveau. Les agents IA peuvent désormais effectuer des recherches web, de la découverte web, de l’extraction de données structurées et des interactions automatisées avec des sites web réels.
Pour des flux de travail plus avancés, explorez la gamme complète des services prêts pour l’IA dans l’écosystème Bright Data.
Créez un compte Bright Data gratuit aujourd’hui et commencez à intégrer nos outils de données web !
FAQ
Dois-je étendre OpenFang avec Bright Data Web MCP ou les compétences ?
Étendre Bright Data via Web MCP et les compétences d’agents ne sont pas des approches alternatives. Bien au contraire, elles sont complémentaires et fonctionnent mieux ensemble ! En pratique, les compétences Bright Data fournissent à l’agent OpenFang les connaissances nécessaires pour utiliser et tirer le meilleur parti des solutions Bright Data, y compris Web MCP. En d’autres termes, ces compétences guident la façon dont l’agent devrait utiliser les outils Web MCP plus efficacement.
OpenClaw vs OpenFang : Quelle est la différence ?
OpenFang est un système d’exploitation d’agents autonomes haute performance, basé sur Rust, conçu pour la vitesse et la sécurité. En revanche, OpenClaw est une plateforme d’agents IA conversationnelle plus large. OpenFang se concentre sur l’automatisation sécurisée, planifiée et persistante, tandis qu’OpenClaw privilégie l’orchestration de tâches conversationnelles multi-tours. N’oubliez pas que Bright Data prend également en charge OpenClaw.
ZeroClaw vs OpenFang : Quelle est la différence ?
ZeroClaw et OpenFang sont tous deux des frameworks d’agents IA haute performance basés sur Rust. Pourtant, ils privilégient des aspects différents. ZeroClaw met l’accent sur une efficacité légère extrême (binaire de 3,4 Mo, <5 Mo de RAM) pour les appareils edge, tandis qu’OpenFang offre un « OS d’agents » plus complet avec des outils intégrés plus larges (53 outils, 40 adaptateurs) et des couches de sécurité spécialisées.
Quelles capacités OpenFang acquiert-il grâce à la connexion Bright Data Web MCP ?
Grâce à Bright Data Web MCP, OpenFang acquiert des capacités fiables de Scraping web, de recherche et d’extraction de données à grande échelle, notamment l’accès à des données structurées depuis des plateformes comme LinkedIn, GitHub, Amazon et plus de 40 autres. Il peut contourner les protections anti-bot, exécuter des requêtes de recherche en parallèle et récupérer des données prêtes pour l’IA dans des formats propres comme Markdown ou JSON.






