

Apollo.io est l’une des plateformes de prospection B2B les plus utilisées sur le marché : plus de 275 millions de contacts, séquençage d’e-mails intégré et un niveau gratuit avec plus d’un million d’utilisateurs. Pour les petites équipes SDR axées uniquement sur l’e-mail sortant, elle regroupe la recherche, la prospection et le suivi dans une seule interface.
Bright Data adopte une approche différente. Au lieu de maintenir une base de contacts statique, il vous offre un accès API pour collecter des données B2B à la demande depuis plus de 10 sources premium (LinkedIn, Crunchbase, ZoomInfo, 6sense, PitchBook, et plus encore). Chaque enregistrement est scrapé au moment où vous le demandez.
Nous avons comparé les deux plateformes en termes de qualité des données, de fraîcheur, de capacités API, de couverture et de tarification. Voici ce que nous avons trouvé.
Comparaison rapide
| Fonctionnalité | Bright Data | Apollo.io |
|---|---|---|
| Architecture des données | Scraping en temps réel + jeux de données multi-sources pré-agrégés | Base de données statique propriétaire avec actualisation périodique |
| Sources de données | 10+ (LinkedIn, Crunchbase, ZoomInfo, 6sense, PitchBook, etc.) | Réseau de contributeurs + exploration web publique + fournisseurs tiers |
| Total des enregistrements | Plus de 500 millions de profils d’entreprises dans les jeux de données de l’API Company Data ; scraping LinkedIn à la demande | 275M+ contacts, 35M+ entreprises |
| Fraîcheur des données | Temps réel (collecté au moment de la demande) | Cycle d’actualisation périodique (varie selon la priorité de l’enregistrement) |
| Accès API | API REST complètes sur tous les comptes | Enrichissement de données via API sur les plans payants (Basic+) ; le plan gratuit a retourné une erreur 403 sur les endpoints de recherche/enrichissement lors de nos tests |
| Livraison des données | JSON, CSV, Parquet via API, S3, Snowflake, Azure, Webhook | Export CSV/JSON ; réponses API sur les endpoints pris en charge |
| Modèle de tarification | Paiement à l’utilisation par enregistrement (1,5 $/1K en PAYG) ou plan Scale (499 $/mois pour 384K enregistrements) | Siège par utilisateur + système de crédits (0 à 119 $/utilisateur/mois) |
| Outils de prospection | Aucun (infrastructure de données uniquement) | Séquences e-mail, numéroteur, planificateur de réunions, CRM |
| Idéal pour | Équipes data, pipelines IA, enrichissement à grande échelle, intelligence multi-sources | Équipes SDR PME gérant des campagnes sortantes autonomes |
Le problème de fraîcheur des bases de données B2B statiques
Les données de contact B2B se dégradent à un rythme d’environ 22 à 30 % par an. Les personnes changent d’emploi, les entreprises se rebrandent, les numéros de téléphone sont réattribués. Le Bureau of Labor Statistics américain a signalé un taux total de séparations de 3,3 % en 2024 et 2025, ce qui signifie qu’une part significative de toute base de contacts devient obsolète chaque année, rien que par les changements d’emploi.
Apollo maintient sa base de données via trois canaux : un réseau de contributeurs de plus de 2 millions d’utilisateurs qui synchronisent leurs données d’e-mail et de calendrier, l’exploration web publique, et des fournisseurs de données tiers. Le système traite environ 270 millions d’enregistrements par mois dans son cycle d’actualisation. « Traité » ne signifie pas « vérifié par enregistrement » : les contacts à fort trafic sont actualisés plus fréquemment, et les enregistrements à faible trafic peuvent rester intacts pendant des mois.
Les preuves apparaissent de manière constante dans les avis publics :
- Les avis sur G2 et Capterra font état d’une précision des données d’environ 65 à 70 % globalement, en dessous des taux annoncés par Apollo
- Les taux de rebond des e-mails sur les listes exportées depuis Apollo atteignent régulièrement 15 à 35 % dans des tests indépendants, selon la géographie et le secteur
- Les intitulés de poste et les associations d’entreprises pour les contacts ayant changé de rôle il y a 6 à 12 mois restent souvent obsolètes
- Les contacts tech et SaaS basés aux États-Unis constituent le segment le plus fiable, avec une précision de 80 à 88 % ; les données internationales descendent à 60-73 %
- Les numéros de téléphone coûtent 8 crédits chacun et ont une précision inférieure à celle des e-mails — la plainte spécifique la plus fréquente sur toutes les plateformes d’avis
Un test détaillé partagé sur r/coldemail a montré des taux de rebond de 32 à 38 % sur 500 à 1 000 leads exportés depuis Apollo, même sur des contacts étiquetés « vérifiés ».
La recherche de personnes d’Apollo fournit une base de données consultable de plus de 275 millions de contacts avec plus de 65 attributs de filtrage.
Bright Data élimine entièrement le problème d’actualisation. Lorsque vous appelez l’API LinkedIn Profiles Scraper, les données sont collectées depuis la page LinkedIn en direct au moment de la demande. Il n’y a pas de couche de cache ni de cycle d’actualisation. Si un prospect a mis à jour son profil LinkedIn ce matin, l’API retourne la version mise à jour cet après-midi.
Nous avons testé cela directement. Le scraping du profil LinkedIn de Satya Nadella via l’API Profiles a retourné une réponse en 7,2 secondes avec un horodatage de collecte de 2026-05-27T10:22:15.544Z, confirmant que les données ont été extraites en direct et non depuis un cache.
La stack de données B2B de Bright Data : présentation pratique
L’API Dataset Filter : recherche d’entreprises à grande échelle
L’API Filter est l’équivalent le plus direct de la recherche d’entreprises d’Apollo. Vous définissez des filtres structurés et interrogez des jeux de données d’entreprises pré-agrégés. L’API Company Data de Bright Data annonce plus de 500 millions d’enregistrements d’entreprises dans toutes ses sources agrégées (LinkedIn, Crunchbase, ZoomInfo, 6sense, PitchBook, et d’autres). Les résultats arrivent en quelques minutes, et vous ne payez que pour les enregistrements du résultat final.
Voici l’appel API que nous avons utilisé pour trouver des entreprises logicielles aux États-Unis avec 51 à 200 employés :
import requests
import time
# Step 1: Trigger a filtered snapshot
# Field names vary by dataset; use API Request Builder for your selected dataset.
response = requests.post(
"https://api.brightdata.com/datasets/filter",
headers={
"Authorization": "Bearer YOUR_API_TOKEN",
"Content-Type": "application/json"
},
json={
"dataset_id": "gd_l1vikfnt1wgvvqz95w",
"filter": {
"operator": "and",
"filters": [
{"name": "industries", "operator": "includes",
"value": "Software Development"},
{"name": "country_code", "operator": "=", "value": "US"},
{"name": "company_size", "operator": "=",
"value": "51-200 employees"}
]
},
"records_limit": 100
}
)
snapshot_id = response.json().get("snapshot_id")
# Step 2: Poll until ready, then download
download_url = (
f"https://api.brightdata.com/datasets/snapshots"
f"/{snapshot_id}/download?format=json"
)
# Poll download_url until HTTP 200, then parse the JSON response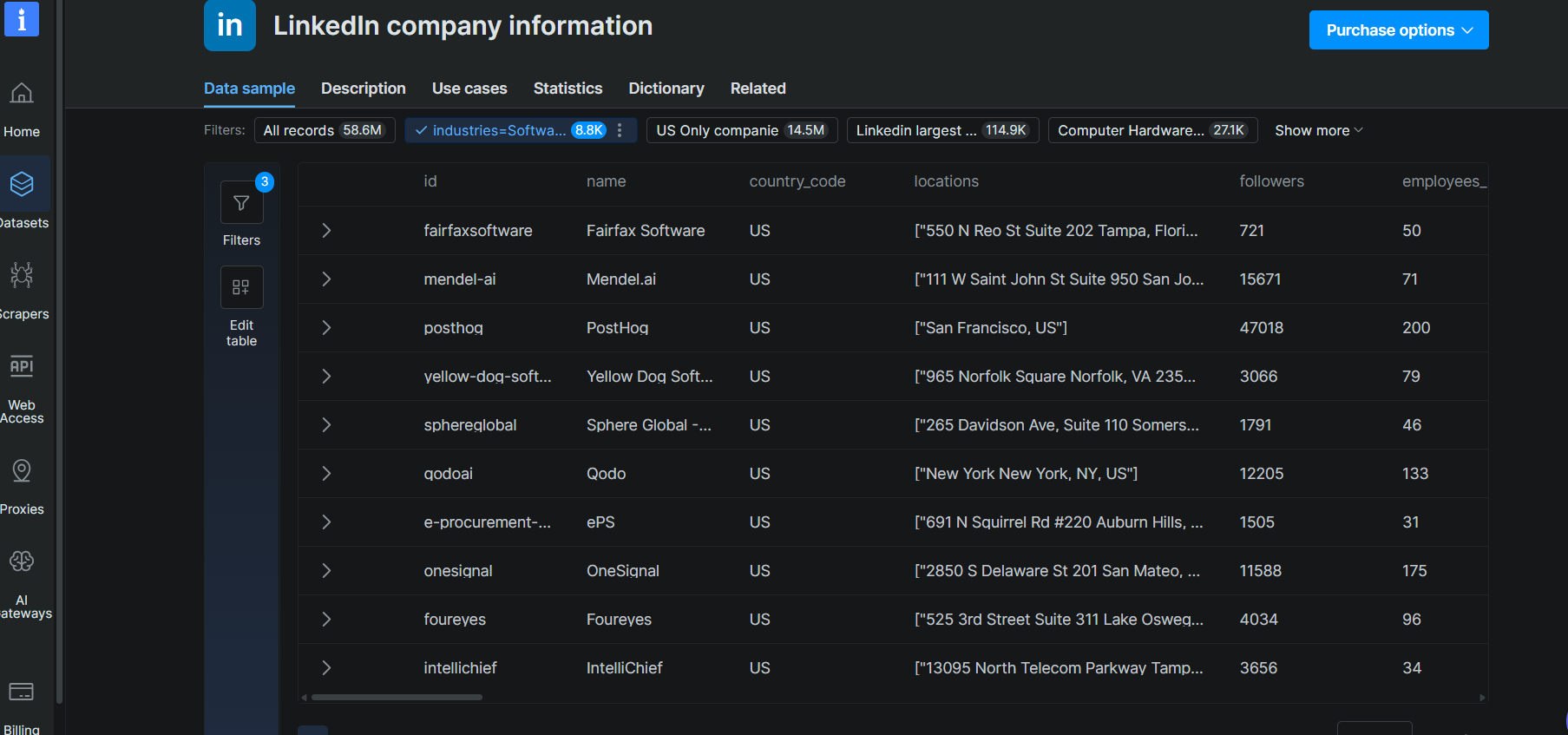
La réponse a retourné 100 entreprises correspondantes en 46,5 secondes. Chaque enregistrement comprenait le nom de l’entreprise, le domaine, la classification sectorielle, le nombre d’employés, le siège social, l’année de fondation, l’URL LinkedIn et l’URL Crunchbase. Les enregistrements peuvent également inclure des champs de financement lorsqu’ils sont disponibles depuis les sources sous-jacentes.
Exemple d’enregistrement (Leanpath) :
{
"about": "Leanpath, a Certified B-Corp, is on a mission to make food waste prevention and measurement everyday practice in the world's kitchens...",
"company_id": "400488",
"company_size": "51-200 employees",
"country_code": "US",
"crunchbase_url": "https://www.crunchbase.com/organization/leanpath-inc",
"employees_in_linkedin": 78,
"followers": 6199,
"founded": 2004,
"funding": {
"last_round_date": "2025-03-04T00:00:00.000Z",
"last_round_raised": "US$ 750.0K",
"last_round_type": "Debt financing",
"rounds": 3
}
}C’est là que l’architecture multi-sources prend tout son sens. Les données LinkedIn d’une entreprise peuvent indiquer le nombre d’employés et le secteur. Crunchbase ajoute les tours de financement, les investisseurs et les données de valorisation. ZoomInfo contribue aux technographies et aux estimations de revenus. L’API Filter fusionne ces données en un seul enregistrement, validé de manière croisée entre les fournisseurs. La recherche d’entreprises d’Apollo interroge une seule base de données propriétaire.
API LinkedIn Profiles Scraper : données de contact en direct en 7 secondes
Pour les données au niveau des contacts, nous avons testé l’API LinkedIn Profiles Scraper de Bright Data. Cette API accepte une URL de profil LinkedIn, scrape la page en direct (gérant les CAPTCHAs, les murs de connexion et le rendu JS), et retourne un JSON structuré.
import requests
response = requests.post(
"https://api.brightdata.com/datasets/v3/scrape",
params={
"dataset_id": "gd_l1viktl72bvl7bjuj0",
"format": "json"
},
headers={
"Authorization": "Bearer YOUR_API_TOKEN",
"Content-Type": "application/json"
},
json=[{"url": "https://www.linkedin.com/in/fimber-elemuwa/"}]
)
profile = response.json()Cette fois, nous avons scrapé le profil de Fimber Elemuwa à titre de test. La réponse est revenue en 7,2 secondes et comprenait : nom, titre actuel, entreprise actuelle, localisation, historique complet du travail, formation, compétences et données d’engagement. Le champ horodatage indiquait 2026-05-27T10:22:15.544Z, confirmant que les données ont été collectées en direct.
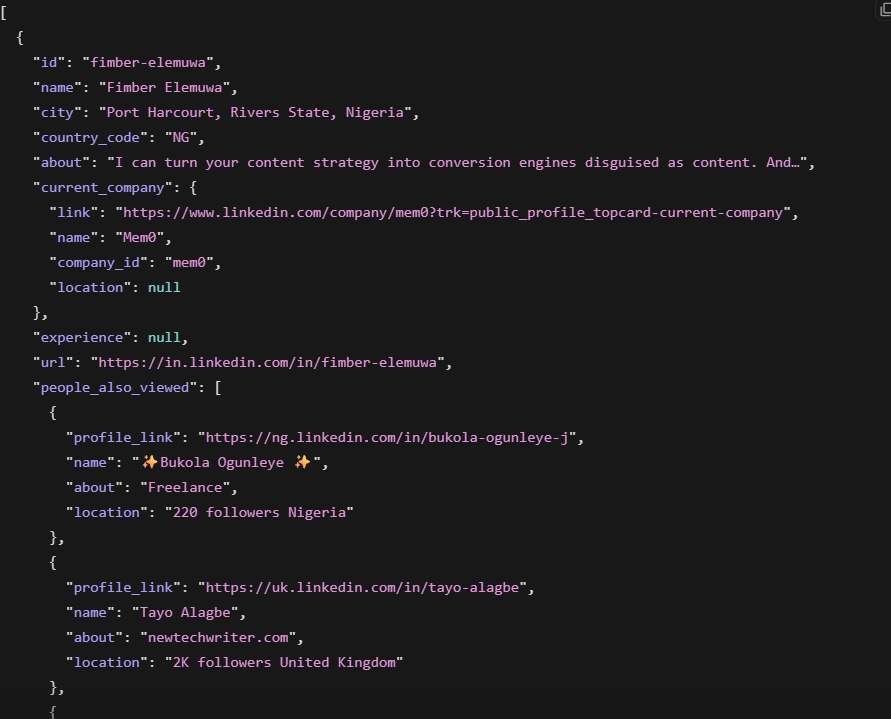
Apollo stocke un instantané de ce profil actualisé selon son propre calendrier. Bright Data collecte les données depuis LinkedIn au moment de la demande. Pour un PDG bien connu, les deux sources s’accorderont probablement. L’écart apparaît pour les contacts de niveau intermédiaire dans les petites entreprises, où le cycle d’actualisation d’Apollo est moins fréquent et les données obsolètes plus probables.
API LinkedIn Companies Scraper : données firmographiques à la demande
Nous avons également testé l’API Companies Scraper en extrayant la page entreprise LinkedIn de Microsoft.
response = requests.post(
"https://api.brightdata.com/datasets/v3/scrape",
params={
"dataset_id": "gd_l1vikfnt1wgvvqz95w",
"format": "json"
},
headers={
"Authorization": "Bearer YOUR_API_TOKEN",
"Content-Type": "application/json"
},
json=[{"url": "https://www.linkedin.com/company/microsoft/"}]
)
company = response.json()La réponse est revenue en 12,3 secondes et comprenait : nom de l’entreprise, nombre d’employés (231 622 employés sur LinkedIn), siège social, secteurs d’activité, URL Crunchbase et publications récentes de l’entreprise. Des champs de financement étaient également présents dans ce cas, bien que leur disponibilité varie selon l’entreprise.
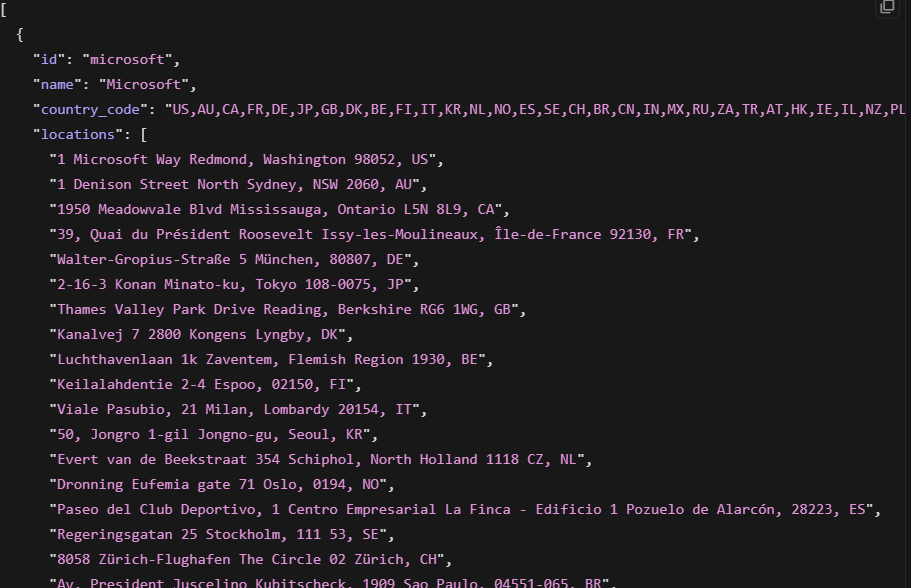
Pour des données firmographiques plus approfondies — historique complet des tours de financement avec montants et investisseurs, estimations de revenus, profils technographiques — la couche d’agrégation multi-sources de l’API Company Data offre une image plus complète qu’un scraping LinkedIn seul. Le scraper d’entreprises convient aux recherches ponctuelles à source unique ; l’API Filter convient aux enregistrements enrichis multi-sources à grande échelle.
La suite complète d’API Scraper
Au-delà des deux API testées, la suite de scrapers LinkedIn de Bright Data comprend également :
| API | Entrée | Sortie principale |
|---|---|---|
| API Jobs | URL d’offre d’emploi LinkedIn | Titre, entreprise, localisation, salaire, description, exigences, date de publication |
| API Posts | URL de publication LinkedIn | Auteur, contenu, métriques d’engagement, date, médias |
Elles sont utiles pour la détection de signaux de recrutement (quelles entreprises développent quelles équipes) et l’intelligence compétitive (suivi des publications des entreprises). Soumettez une URL, recevez un JSON structuré issu d’un scraping en direct.
Construire des pipelines automatisés de génération de leads
La véritable puissance de ces API se manifeste lorsque vous les enchaînez dans des workflows automatisés. Bright Data maintient un générateur de leads IA open source basé sur Streamlit qui :
- Accepte une requête en langage naturel (« Trouver des responsables marketing dans des entreprises fintech au Kenya »)
- Utilise OpenAI pour extraire des filtres structurés de la requête
- Appelle l’API de Bright Data pour collecter les leads correspondants depuis LinkedIn
- Score et enrichit chaque lead avec l’IA
- Retourne des suggestions de prospection par lead
Apollo dispose de fonctionnalités IA (rédaction d’e-mails, suggestions de scoring de leads), mais elles fonctionnent dans l’interface d’Apollo — et non comme des blocs de construction composables pour des pipelines personnalisés. Pour les équipes qui construisent des workflows basés sur des agents avec LangChain, LlamaIndex ou CrewAI, les API de Bright Data s’intègrent directement comme outils de récupération de données.
Tarification : ce que vous payez réellement
Apollo
Apollo utilise un système de crédits unifié. Les plans payants accordent des crédits à l’avance pour l’année complète ; le plan gratuit les accorde mensuellement. Voici ce que la page de tarification indique :
| Plan | Facturation annuelle | Crédits | Calendrier d’attribution |
|---|---|---|---|
| Gratuit | 0 $ | 900/an | Mensuel (75/mois) |
| Basic | 49 $/siège/mois | 30 000/an | À l’avance |
| Professional | 79 $/siège/mois | 48 000/an | À l’avance |
| Organization | 119 $/siège/mois (min. 3 sièges) | 72 000/an | À l’avance |
Les trois plans payants incluent l’export CSV, CRM et l’enrichissement de données via API. Le plan gratuit ne les inclut pas. Lors de nos tests, les endpoints API de recherche de personnes et d’enrichissement (mixed_people/api_search, people/match, people/bulk_match) ont tous retourné des erreurs 403 sur un compte en plan gratuit — ce qui est cohérent avec l’absence d’« enrichissement de données via API » dans le niveau gratuit.
Les crédits sont consommés par action : révéler un e-mail coûte 1 crédit, révéler un numéro de mobile coûte plus (rapporté à 8 crédits selon la configuration du compte), et l’enrichissement via API varie selon les champs demandés. Les crédits ne sont pas reportés au-delà de la période du contrat annuel. Les équipes actives en prospection sortante dépassent régulièrement le prix de leur plan de base en recharges de crédits dès que l’enrichissement et les révélations de numéros de téléphone augmentent.
Fonctionnalités notables par niveau : Basic ajoute les intégrations CRM, les filtres avancés, l’enrichissement en cascade et un numéroteur américain. Professional ajoute les tests A/Z sur les séquences, les workflows automatisés, les enregistrements d’appels (4 000 minutes) et les analyses. Organization ajoute des rapports personnalisables, SSO, une sécurité avancée et la possibilité d’utiliser votre propre clé API LLM.
Bright Data
| Produit | Tarification |
|---|---|
| API LinkedIn Scraper (PAYG) | 1,5 $/1K enregistrements (paiement uniquement en cas de succès) |
| API LinkedIn Scraper (Scale) | 499 $/mois (384 000 enregistrements inclus ; 1,3 $/1K supplémentaire) |
| API Company Data (Filter) | À partir de 2,50 $/1K enregistrements |
| Jeux de données préconstruits | À partir de 250 $/100K enregistrements |
| Essai gratuit | 1K requêtes (usage unique), disponible pendant une semaine, sans carte bancaire requise |
Aucun frais par siège. Aucun système de crédits. Aucune restriction de fonctionnalités par niveau de plan. Accès API complet sur chaque compte, y compris l’essai gratuit. La livraison des données vers S3, Snowflake, Azure, Google Cloud ou Webhook est incluse.
Comparaison des coûts pour un workflow réel
Extraction de 10 000 profils d’entreprises LinkedIn par mois :
Bright Data : 10 000 enregistrements sur le plan PAYG à 1,5 $/1K = 15 $/mois. Ajoutez l’API Filter pour le ciblage au niveau des comptes à 2,50 $/1K = 25 $ pour 10K enregistrements filtrés. Total : environ 40 $/mois. À des volumes plus élevés (100K+ enregistrements/mois), le plan Scale à 499 $/mois avec 384 000 enregistrements inclus ramène le taux effectif à 1,3 $/1K.
Apollo : Le plan le moins cher avec accès API est Basic à 49 $/siège/mois (588 $/an), avec 30 000 crédits par an accordés à l’avance. À 1 crédit par révélation d’e-mail, 30 000 crédits couvrent 30 000 exports d’e-mails uniquement — mais les numéros de téléphone à 8 crédits chacun épuisent le pool beaucoup plus rapidement. Une équipe de 3 personnes sur Basic paie 1 764 $/an en coûts de sièges seuls, partageant 90 000 crédits au total sur l’année.
L’écart se creuse à 100 000 enregistrements/mois. Le tarif PAYG de Bright Data s’élève à 150 $/mois, ou le plan Scale à 499 $/mois couvre 384 000 enregistrements avec une marge confortable.
La tarification Apollo ci-dessus est tirée directement de la page de tarification d’Apollo en date de mai 2026. Les coûts en crédits par action (révélations d’e-mails, de téléphones, enrichissement) ne sont pas indiqués sur la page de tarification et peuvent varier. La tarification Bright Data reflète les tarifs publiés actuels.
Quand utiliser lequel
Utilisez Apollo si vous êtes une petite équipe SDR (1 à 5 représentants) qui souhaite recherche, séquençage et suivi dans une seule plateforme. Votre ICP est concentré dans la tech/SaaS américaine (où les données d’Apollo sont les plus fiables), et votre volume mensuel de prospection reste dans les limites de crédits de votre plan.
Utilisez Bright Data si vous avez besoin de données fraîches à grande échelle (10K+ enregistrements/mois), si votre ICP inclut des marchés internationaux ou de petites entreprises où les bases de données statiques présentent des lacunes connues, si vous construisez des pipelines d’enrichissement automatisés ou de génération de leads alimentés par l’IA, ou si votre cas d’usage s’étend au-delà de la prospection commerciale vers l’intelligence compétitive, la recherche d’investissement ou la cartographie de marché.
Utilisez les deux ensemble pour la stack la plus performante. C’est l’approche recommandée pour les équipes de croissance qui veulent qualité des données et efficacité d’exécution :
- L’API Company Data de Bright Data pour construire une liste de comptes qualifiés depuis 10+ sources, filtrée par firmographiques, stade de financement, technographies ou signaux de croissance
- L’API LinkedIn Profiles Scraper de Bright Data pour extraire des données de contact fraîches pour les décideurs de ces comptes cibles
- Un outil de vérification (NeverBounce, ZeroBounce ou Prospeo) pour valider les adresses e-mail avant l’envoi
- Apollo (ou tout outil de séquençage) pour charger ces contacts vérifiés et exécuter des campagnes de prospection
Cette configuration utilise chaque plateforme là où elle est la plus performante : Bright Data gère la couche données, un outil de vérification gère la précision des e-mails, et Apollo gère la couche d’exécution.
!bright-data-apollo-combined-stack
Réflexions finales
Apollo est une plateforme sortante efficace pour les équipes commerciales PME qui ont besoin d’un workflow abordable et autonome. Le niveau gratuit, le séquençage intégré et le faible temps de configuration en font le chemin le plus rapide de zéro à la première campagne.
La limitation réside dans la fraîcheur des données. Les avis publics rapportent systématiquement une précision globale de 65 à 70 %, avec des taux de rebond de 15 à 35 % sur les listes exportées. Les intitulés de poste des contacts ayant changé de rôle il y a plusieurs mois restent souvent obsolètes. Pour une prospection e-mail à faible volume axée sur les États-Unis, cela peut être tolérable. À grande échelle, le coût cumulatif des données obsolètes devient significatif : crédits gaspillés, réputation d’expéditeur endommagée et pipeline manqué auprès de prospects qui sont passés à autre chose.
L’API Dataset Filter et les API LinkedIn Scraper de Bright Data extraient les données depuis la source au moment de la demande, sur des produits de données d’entreprises agrégées, avec une tarification par enregistrement qui ne pénalise pas la croissance de l’équipe. Nous avons extrait un profil LinkedIn en direct en 7,2 secondes, une page d’entreprise en 12,3 secondes, et filtré 100 entreprises depuis le jeu de données LinkedIn Companies en moins d’une minute.
Si vos résultats de prospection sont limités par la qualité des données, ou si vous avez besoin de données B2B pour autre chose que la prospection e-mail basique, Bright Data vous donne l’infrastructure pour construire exactement ce que le cas d’usage exige.





