
Dans ce tutoriel, vous verrez :
- Ce qu’est opencode, les fonctionnalités qu’il offre et pourquoi il ne faut pas le confondre avec Crush.
- Comment l’étendre avec des capacités d’interaction web et d’extraction de données peut le rendre encore plus utile.
- Comment connecter opencode au serveur MCP de Bright Data dans le CLI pour créer un agent de codage IA puissant.
Plongeons dans le vif du sujet !
Qu’est-ce qu’opencode ?
opencode est un agent de codage IA open-source conçu pour le terminal. En particulier, il fonctionne comme
- Une TUI(Terminal User Interface) dans votre CLI.
- Une intégration IDE dans Visual Studio Code, Cursor, etc.
- Une extension GitHub.
Plus en détail, opencode vous permet de :
- Configurer une interface de terminal réactive et thématisable.
- Charger le bon LSP(Language Server Protocols) pour votre LLM.
- Exécuter plusieurs agents en parallèle sur le même projet.
- Partager des liens vers n’importe quelle session à des fins de référence ou de débogage.
- Connectez-vous avec Anthropic pour utiliser votre compte Claude Pro ou Max, ainsi que l’intégration avec d’autres 75+ fournisseurs LLM via Models.dev (y compris les modèles locaux).
Comme vous pouvez le voir, le CLI est agnostique au LLM. Il est principalement développé en Go et TypeScript et a déjà accumulé plus de 20k étoiles sur GitHub, ce qui témoigne de sa popularité dans la communauté.
Note: Cette technologie ne doit pas être confondue avec Crush, un projet différent dont le nom original était “opencode”. En savoir plus sur le conflit de noms sur X. Si vous recherchez plutôt Crush, consultez notre guide sur l’intégration de Crush avec le MCP Web de Bright Data.
Pourquoi l’intégration du MCP Web de Bright Data dans l’interface utilisateur d’opencode est-elle importante ?
Quel que soit le LLM que vous finissez par configurer dans opencode, ils partagent tous la même limitation : leurs connaissances sont statiques. Les données sur lesquelles ils ont été formés représentent un instantané dans le temps, qui devient rapidement obsolète. C’est particulièrement vrai dans des domaines qui évoluent rapidement comme le développement de logiciels.
Imaginez maintenant que vous donniez à votre assistant CLI d’opencode la possibilité de :
- Tirer profit des nouveaux tutoriels et de la nouvelle documentation.
- Consulter des guides en direct pendant qu’il écrit du code.
- Parcourir des sites web dynamiques aussi facilement qu’il peut naviguer dans vos fichiers locaux.
Ce sont précisément les capacités que vous débloquez en le connectant au MCP Web de Bright Data.
Le MCP Web de Bright Data donne accès à plus de 60 outils prêts pour l’IA, conçus pour l’interaction Web en temps réel et la collecte de données, tous alimentés par l’infrastructure d’IA de Bright Data.
Les deux outils les plus utilisés(même dans la version gratuite) sur le MCP Web de Bright Data sont les suivants :
| Outil | Description de l’outil |
|---|---|
scrape_as_markdown |
Récupère le contenu d’une page Web unique avec des options d’extraction avancées, en renvoyant les données résultantes en Markdown. Peut contourner la détection des robots et le CAPTCHA. |
search_engine |
Extrait les résultats de recherche de Google, Bing ou Yandex. Renvoie les données SERP au format JSON ou Markdown. |
En plus de ces deux outils, il existe plus de 55 outils spécialisés pour interagir avec les pages web (par exemple, scraping_browser_click) et collecter des données structurées à partir de plusieurs domaines, tels que LinkedIn, Amazon, Yahoo Finance, TikTok, et d’autres. ool récupère des informations de profil structurées à partir d’une page LinkedIn publique lorsqu’on lui donne l’URL d’un professionnel.
Il est temps de voir comment Web MCP fonctionne dans opencode !
Comment connecter opencode au Web MCP de Bright Data
Apprenez à installer et à configurer opencode localement et à l’intégrer au serveur Web MCP de Bright Data. Le résultat sera un agent de codage étendu avec un accès à plus de 60 outils Web. Cet agent CLI sera ensuite utilisé dans un exemple de tâche pour :
- Scraper à la volée une page de produit LinkedIn pour collecter des données de profil du monde réel.
- Stocker les données localement dans un fichier JSON.
- Créer un script Node.js pour charger et traiter les données.
Suivez les étapes ci-dessous !
Remarque: cette section du tutoriel se concentre sur l’utilisation d’opencode via l’interface de programmation. Cependant, vous pouvez utiliser une configuration similaire pour l’intégrer directement dans votre IDE, comme mentionné dans la documentation.
Conditions préalables
Avant de commencer, vérifiez que vous disposez des éléments suivants :
- Un environnement macOS ou Linux (les utilisateurs de Windows doivent utiliser le WSL).
- Un abonnement Claude Pro ou Max ou un compte Anthropic avec des fonds et une clé API (dans ce tutoriel, nous utiliserons une clé API Anthropic, mais vous pouvez configurer n’importe quel autre LLM supporté).
- Node.js installé localement (nous recommandons la dernière version LTS).
- Un compte Bright Data avec une clé API prête.
Ne vous préoccupez pas de la configuration de Bright Data pour l’instant, car vous serez guidé à travers les étapes suivantes.
Ensuite, voici quelques connaissances de base facultatives mais utiles à avoir :
- Une compréhension générale du fonctionnement de MCP.
- Une certaine familiarité avec le Web MCP de Bright Data et ses outils.
Étape 1 : Installer opencode
Installez opencode sur votre système Unix à l’aide de la commande suivante :
curl -fsSL https://opencode.ai/install | bashCette commande téléchargera le programme d’installation à partir de https://opencode.ai/install et l’exécutera pour installer opencode sur votre machine. Explorez les autres options d’installation possibles.
Vérifiez qu’opencode fonctionne avec :
opencodeSi vous rencontrez une erreur de type “missing executable” ou “unrecognized command”, redémarrez votre machine et réessayez.
Si tout fonctionne comme prévu, vous devriez voir quelque chose comme ceci :

Génial ! opencode est maintenant prêt à être utilisé.
Etape #2 : Configurer le LLM
opencode peut se connecter à de nombreux LLMs, mais les modèles recommandés sont ceux d’Anthropic. Assurez-vous d’avoir un abonnement Claude Max ou Pro, ou un compte Anthropic avec des fonds et une clé API.
Les étapes suivantes vous montreront comment connecter opencode à votre compte Anthropic via une clé API, mais toute autre intégration LLM prise en charge fonctionnera également.
Fermez votre fenêtre opencode avec la commande /exit, puis lancez l’authentification avec un fournisseur LLM en utilisant :
opencode auth login Il vous sera demandé de sélectionner un fournisseur de modèle d’IA :

Choisissez “Anthropic” en appuyant sur Entrée, puis sélectionnez l’option “Manually enter API key” :

Collez votre clé API Anthropic et appuyez sur Entrée :

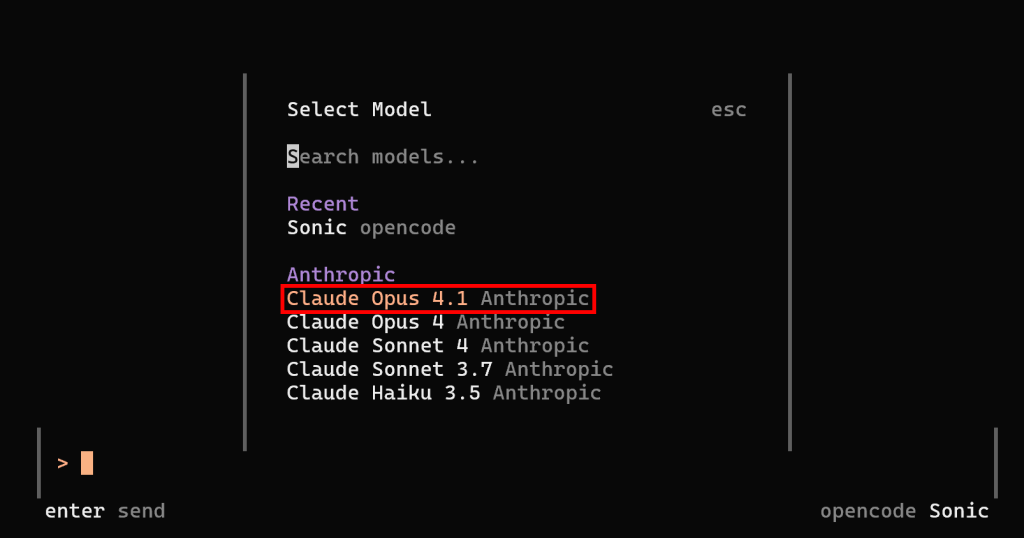
La configuration du LLM est maintenant terminée. Redémarrez opencode, lancez la commande /models, et vous pourrez sélectionner un modèle Anthropic. Par exemple, choisissez “Claude Opus 4.1” :
Appuyez sur Entrée, et vous devriez maintenant voir :

Remarquez que l’opencode fonctionne maintenant avec le modèle Anthropic Claude Opus 4.1 configuré. C’est très bien !
Etape #3 : Initialiser votre projet opencode
Déplacez-vous dans le répertoire de votre projet en utilisant la commande cd et lancez opencode à cet endroit :
cd <chemin_vers_votre_répertoire_de_projet>
opencodeExécutez la commande /init pour initialiser un projet opencode. La sortie devrait ressembler à ceci :

Plus précisément, la commande /init créera un fichier AGENTS.md. Similaire à CLAUDE.md ou aux règles de Cursor, il fournit des instructions personnalisées à opencode. Ces instructions sont incluses dans le contexte du LLM afin de personnaliser son comportement pour votre projet spécifique.
Ouvrez le fichier AGENTS.md dans votre IDE (par exemple, Visual Studio Code), et vous devriez voir :

Personnalisez-le en fonction de vos besoins pour indiquer à l’agent de codage AI comment opérer dans le répertoire de votre projet.
Conseil: le fichier AGENTS.md doit être transféré dans le dépôt Git de votre dossier de projet.
Étape 4 : Tester le MCP Web de Bright Data
Avant d’essayer d’intégrer votre agent opencode au serveur Web MCP de Bright Data, il est important de comprendre comment ce serveur fonctionne et si votre machine peut l’exécuter.
Si vous ne l’avez pas encore fait, commencez par créer un compte Bright Data. Si vous en avez déjà un, il vous suffit de vous connecter. Pour une installation rapide, consultez la page “MCP” de votre compte:

Sinon, suivez les instructions ci-dessous.
Maintenant, générez votre clé API Bright Data. Veillez à la conserver en lieu sûr, car vous en aurez bientôt besoin. Nous supposerons ici que vous utilisez une clé API avec des autorisations d’administrateur, car cela facilite l’intégration.
Dans le terminal, installez le Web MCP globalement via le paquet @brightdata/mcp:
npm install -g @brightdata/mcpVérifiez que le serveur MCP local fonctionne avec cette commande Bash :
API_TOKEN="<Votre_BRIGHT_DATA_API>" npx -y @brightdata/mcpRemplacez le caractère générique <Votre_BRIGHT_DATA_API> par le jeton d’API Bright Data. La commande définit la variable d’environnement API_TOKEN requise, puis lance le MCP Web via le paquet @brightdata/mcp.
En cas de succès, vous devriez voir des journaux similaires à celui-ci :

Au premier lancement, le paquet configure automatiquement deux zones par défaut dans votre compte Bright Data :
mcp_unlocker: Une zone pour Web Unlocker.mcp_browser: Une zone pour Browser API.
Ces deux zones sont nécessaires au MCP Web pour alimenter tous les outils qu’il expose.
Pour confirmer que les deux zones ci-dessus ont été créées, connectez-vous à votre compte Bright Data. Dans le tableau de bord, accédez à la page“Proxies & Scraping Infrastructure“. Vous devriez y voir les deux zones dans le tableau :

Remarque: si votre jeton API ne dispose pas d’autorisations d’administration, il se peut que ces zones ne soient pas créées automatiquement. Dans ce cas, vous pouvez les configurer manuellement dans le tableau de bord et spécifier leurs noms via des variables d’environnement, comme expliqué sur la page GitHub du paquet.
Par défaut, le serveur MCP n’expose que les outils search_engine et scrape_as_markdown(qui peuvent être utilisés gratuitement!).
Pour débloquer des fonctionnalités avancées comme l’automatisation du navigateur et la récupération de flux de données structurées, vous devez activer le mode Pro. Pour ce faire, définissez la variable d’environnement PRO_MODE=true avant de lancer le serveur MCP :
API_TOKEN="<Votre_BRIGHT_DATA_API>" PRO_MODE="true" npx -y @brightdata/mcpImportant: Une fois le mode Pro activé, vous aurez accès à l’ensemble des 60+ outils. En revanche, le mode Pro n’est pas inclus dans la version gratuite et entraînera des frais supplémentaires.
C’est parfait ! Vous venez de vérifier que le serveur Web MCP fonctionne sur votre machine. Arrêtez le processus du serveur, car vous allez maintenant configurer opencode pour qu’il le lance pour vous et s’y connecte.
Etape #5 : Intégrer le Web MCP dans opencode
opencode supporte l’intégration du MCP via l’entréemcp dans le fichier de configuration. Gardez à l’esprit qu’il y a deux approches de configuration possibles :
- Globalement: Via le fichier
~/.config/opencode/opencode.json. La configuration globale est utile pour les paramètres tels que les thèmes, les fournisseurs, ou les raccourcis clavier. - Par projet: Via un fichier local
opencode.jsondans le répertoire de votre projet.
Supposons que vous souhaitiez configurer l’intégration MCP localement. Commencez par ajouter un fichier opencode.json dans votre répertoire de travail.
Ensuite, ouvrez le fichier et assurez-vous qu’il contient les lignes suivantes :
{
"$schema" : "https://opencode.ai/config.json",
"mcp" : {
"brightData" : {
"type" : "local",
"enabled" : vrai,
"command" : [
"npx",
"-y",
"@brightdata/mcp"
],
"environnement" : {
"API_TOKEN" : "<VOTRE_CLÉ_D'API_BRIGHT_DATA>",
"PRO_MODE" : "true"
}
}
}
}Remplacez <YOUR_BRIGHT_DATA_API_KEY> par la clé d’API Bright Data que vous avez générée et testée précédemment.
Dans cette configuration :
- L’objet
mcpindique à opencode comment démarrer les serveurs MCP externes. - L’entrée
brightDataspécifie la commande(npx) et les variables d’environnement nécessaires pour lancer le MCP Web.(PRO_MODEest facultatif, mais son activation permet de débloquer l’ensemble des outils disponibles).
En d’autres termes, la configuration opencode.json ci-dessus demande au CLI d’exécuter la même commande npx avec les variables d’environnement définies précédemment. Cela permet à opencode de lancer le serveur MCP de Bright Data Web et de s’y connecter.
À ce jour, il n’existe pas de commande dédiée à la vérification des connexions au serveur MCP ni d’outils disponibles. Passons donc directement aux tests !
Étape 6 : Exécution d’une tâche dans opencode
Pour vérifier les capacités web de votre agent de codage amélioré opencode, lancez une invite comme la suivante :
Scraper "https://it.linkedin.com/in/antonello-zanini" et stocker les données résultantes dans un fichier local "profile.json". Ensuite, configurez un script Node.js de base qui lit le fichier JSON et renvoie son contenuIl s’agit d’un cas d’utilisation réel, puisqu’il recueille des données réelles et les utilise ensuite dans un script Node.js.
Lancez opencode, tapez l’invite et appuyez sur Entrée pour l’exécuter. Vous devriez voir un comportement similaire à celui-ci :

Le GIF a été accéléré, mais voici ce qui se passe étape par étape :
- Le modèle Claude Opus définit un plan.
- La première étape du plan consiste à récupérer les données de LinkedIn. Pour ce faire, le LLM sélectionne l’outil MCP approprié
(web_data_linkedin_person_profile, référencé commeBrightdata_web_data_linkedin_person_profiledans le CLI) avec les arguments corrects extraits de l’invite(https://it.linkedin.com/in/antonello-zanini). - Le LLM recueille les données cibles via l’outil de scraping LinkedIn et met à jour le plan.
- Les données sont stockées dans un fichier local
profile.json. - Un script Node.js (appelé
readProfile.js) est créé pour lire les données dufichier profile.jsonet les imprimer. - Un résumé des étapes exécutées vous est présenté, avec des instructions pour exécuter le script Node.js produit.
Dans cet exemple, la sortie finale produite par la tâche ressemble à ceci :

À la fin de l’interaction, votre répertoire de travail devrait contenir ces fichiers :
├── AGENTS.md
├── opencode.json
├── profile.json # <-- créé par le CLI
└── readProfile.js # <-- créé par la CLIMerveilleux ! Vérifions maintenant si les fichiers générés contiennent les données et la logique prévues.
Étape 7 : Explorer et tester la sortie
Ouvrez le répertoire du projet dans Visual Studio Code et commencez par inspecter le fichier profile.json:

Important: Les données dans profile.json sont des données LinkedIn réelles collectées par le Bright Data LinkedIn Scraper via l’outil web_data_linkedin_person_profile MCP dédié. Il ne s’agit pas d’un contenu halluciné ou inventé généré par le modèle Claude !
Les données LinkedIn ont été récupérées avec succès, comme vous pouvez le vérifier en inspectant la page de profil LinkedIn publique mentionnée dans l’invite :

Note: Le scraping de LinkedIn est notoirement difficile en raison de ses protections anti-bots sophistiquées. Un LLM ordinaire ne peut pas effectuer cette tâche de manière fiable, ce qui démontre à quel point votre agent de codage est devenu puissant grâce à l’intégration de Bright Data Web MCP.
Examinez ensuite le fichier readProfile.js:
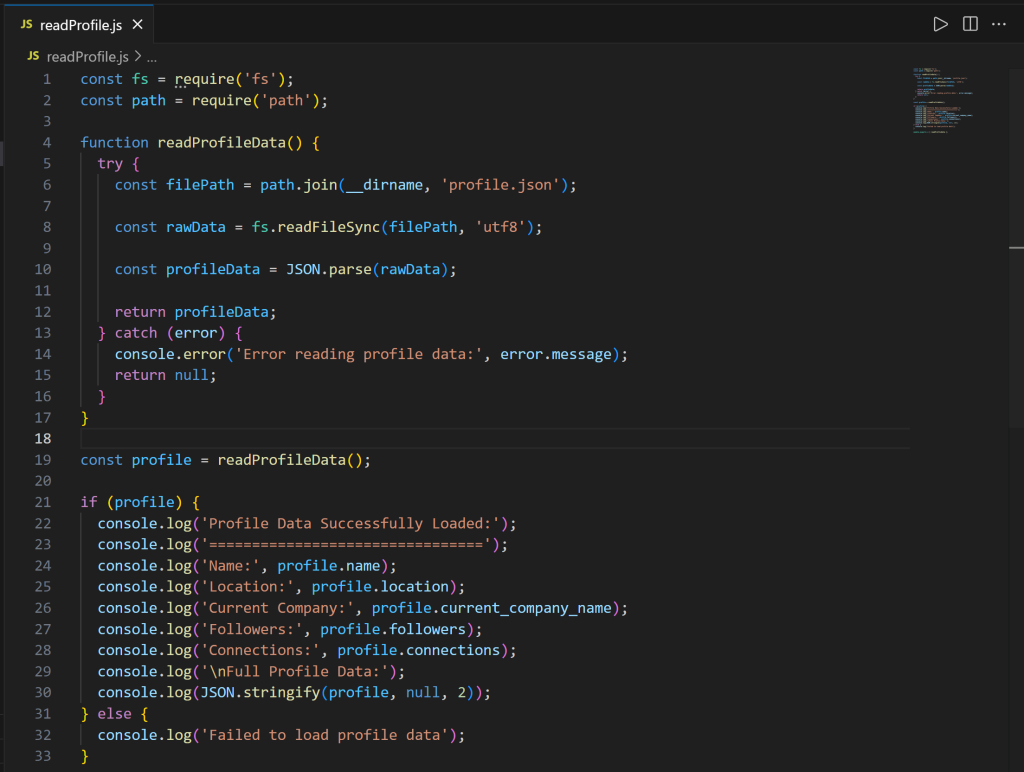
Remarquez que le code définit une fonction readProfileData() pour lire les données du profil LinkedIn à partir de profile.json. Cette fonction est ensuite appelée pour imprimer les données du profil avec tous les détails.
Testez le script avec :
node readProfile.jsLa sortie devrait être :

Voyez comment le script produit imprime les données récupérées de LinkedIn comme prévu.
La mission est terminée ! Essayez différentes invites et testez des flux de données avancés pilotés par LLM directement dans le CLI.
Conclusion
Dans cet article, vous avez vu comment connecter opencode avec le Web MCP de Bright Data(qui offre maintenant un niveau gratuit !). Le résultat est un agent de codage IA riche en outils, capable d’extraire des données du web et d’interagir avec elles.
Pour créer des agents d’IA plus complexes, explorez la gamme complète de services et de produits disponibles dans l’infrastructure d’IA de Bright Data. Ces solutions prennent en charge une grande variété de scénarios d’agents, y compris plusieurs intégrations CLI.
Inscrivez-vous gratuitement à Bright Data et commencez à expérimenter avec nos outils web prêts pour l’IA !




