
Dans cet article de blog, vous verrez :
- Ce qu’est Ctush et pourquoi il s’agit d’une application CLI très appréciée pour l’assistance au codage de l’IA.
- Comment l’extension de l’interaction web et de l’extraction de données la rend beaucoup plus efficace.
- Comment connecter le CLI Crush au serveur Bright Data Web MCP pour créer un agent de codage IA amélioré.
Plongeons dans l’aventure !
Qu’est-ce que Crush ?
Crush est un agent de codage IA open-source pour votre terminal. En particulier, le CLI Crush est une application CLI basée sur Go qui apporte l’assistance de l’IA directement dans votre environnement terminal. Il offre une TUI(Terminal User Interface) pour interagir avec plusieurs LLMs pour aider au codage, au débogage et à d’autres tâches de développement.
C’est précisément ce qui fait la particularité de Crush :
- Multiplateforme: Fonctionne dans tous les principaux terminaux sur macOS, Linux, Windows (PowerShell et WSL), FreeBSD, OpenBSD et NetBSD.
- Prise en charge de plusieurs modèles: Choisissez parmi une large gamme de LLM, intégrez le vôtre via des API compatibles avec OpenAI ou Anthropic, ou connectez-vous à des modèles locaux.
- Expérience basée sur les sessions: Maintenez plusieurs sessions de travail et contextes par projet.
- Très flexible: Possibilité de passer d’un LLM à l’autre en cours de session tout en préservant le contexte.
- Prêt pour LSP: Crush supporte les LSP(Language Server Protocols) pour plus de contexte et d’intelligence, tout comme un IDE moderne.
- Extensible: Prise en charge de l’intégration de fonctionnalités tierces via des MCP(HTTP, stdio et SSE).
Le projet a déjà obtenu plus de 10 000 étoiles sur GitHub et est activement maintenu par une communauté de développeurs dynamique, avec plus de 35 contributeurs.
Surmonter le manque de connaissances des LLM dans Crush CLI avec le Web MCP
Un défi commun à tous les LLM est d’avoir un seuil de connaissances. Le LLM que vous configurez dans Crush CLI n’est pas différent. Comme ces modèles sont formés sur un ensemble de données fixe, leur connaissance est un instantané statique du passé. Cela signifie qu’ils ne connaissent pas les événements ou les développements récents.
Il s’agit d’un inconvénient important dans le monde technologique en constante évolution. Sans une base de connaissances actualisée, un LLM pourrait suggérer des bibliothèques obsolètes, des pratiques de programmation dépassées, ou simplement ne pas être au courant des nouvelles fonctionnalités et des nouveaux outils.
Et si votre assistant de codage Crush AI pouvait faire plus que rappeler de vieilles informations ? Imaginez qu’il soit capable de rechercher sur le web la documentation, les articles et les guides les plus récents, puis d’utiliser ces données en temps réel pour fournir une assistance de meilleure qualité et plus précise.
Vous pouvez y parvenir en connectant Crush à une solution qui donne aux LLM la puissance de l’accès au web et de la recherche de données. C’est précisément ce que vous obtenez avec le serveur Web MCP de Bright Data. Ce serveur open-source(désormais avec un niveau gratuit !) vous équipe de plus de 60 outils prêts pour l’IA pour l’interaction web et la collecte de données.
Intégration de Bright Data Web MCP
Voici deux des principaux outils que vous pouvez trouver sur ce serveur MCP :
search_engine: Se connecte à l’API SERP pour effectuer des recherches sur Google, Bing ou Yandex et renvoie les données de la page de résultats du moteur de recherche au format HTML ou Markdown.scrape_as_markdown: Utilise Web Unlocker pour extraire le contenu d’une seule page web. Il prend en charge des options d’extraction avancées, contourne les systèmes de détection des robots et résout les CAPTCHA pour vous.
En outre, il existe plus de 55 outils spécialisés pour interagir avec les pages web (comme scraping_browser_click) et collecter des flux de données structurées à partir d’une variété de domaines, y compris Amazon, LinkedIn et TikTok. Par exemple, l’outil web_data_amazon_product permet d’obtenir des informations détaillées et structurées sur un produit directement à partir d’Amazon en utilisant l’URL du produit.
Compte tenu de ces outils, voici comment vous pouvez exploiter Bright Data Web MCP avec Crush :
- Récupérez des informations de dernière minute pour vos projets, comme les cours de bourse de Yahoo Finance ou les détails des produits des sites de commerce électronique. Stockez ces données dans des fichiers locaux à des fins d’analyse, de test, de simulation, etc.
- Laissez l’IA chercher la dernière documentation d’une bibliothèque ou d’un cadre que vous utilisez, en vous assurant que le code qu’elle suggère est à jour et qu’il n’est pas obsolète.
- Collectez des liens contextuels et intégrez ces ressources dans des fichiers Markdown, de la documentation ou d’autres sorties, le tout sans quitter votre éditeur de code.
Préparez-vous à voir comment le Web MCP peut améliorer votre agent Crush CLI !
Comment connecter Crush au Web MCP de Bright Data ?
Dans ce tutoriel guidé, vous apprendrez à installer et à configurer Crush localement et à l’intégrer au MCP Web de Bright Data. Le résultat sera un agent de codage IA amélioré capable de :
- Récupérer une page de produit Amazon à la volée.
- Stocker les données dans un fichier JSON local.
- Créer un script Node.js pour charger et traiter ces données.
Suivez les instructions ci-dessous !
Conditions préalables
Avant de commencer, assurez-vous que vous disposez des éléments suivants :
- Node.js est installé localement (la dernière version LTS est recommandée).
- Une clé API de l’un des fournisseurs LLM pris en charge (dans ce guide, nous utiliserons Google Gemini).
- Un compte Bright Data avec une clé API prête (ne vous inquiétez pas, vous serez guidé dans la création d’un compte si vous ne l’avez pas encore).
En outre, les connaissances de base suivantes sont facultatives mais utiles :
- Une compréhension générale du fonctionnement de MCP.
- Une certaine familiarité avec le serveur MCP de Bright Data Web et ses outils.
- Connaissance du fonctionnement des agents de codage CLI et de la manière dont ils peuvent interagir avec votre système de fichiers.
Étape 1 : installation et configuration de Crush
Installez l’interface de programmation Crush globalement sur votre système via le paquetage npm @charmland/crush:
npm install -g @charmland/crushSi vous ne souhaitez pas installer le CLI via npm, découvrez les autres options d’installation.
Vous pouvez maintenant lancer Crush avec :
crushCe que vous devriez voir est l’écran de sélection LLM ci-dessous :
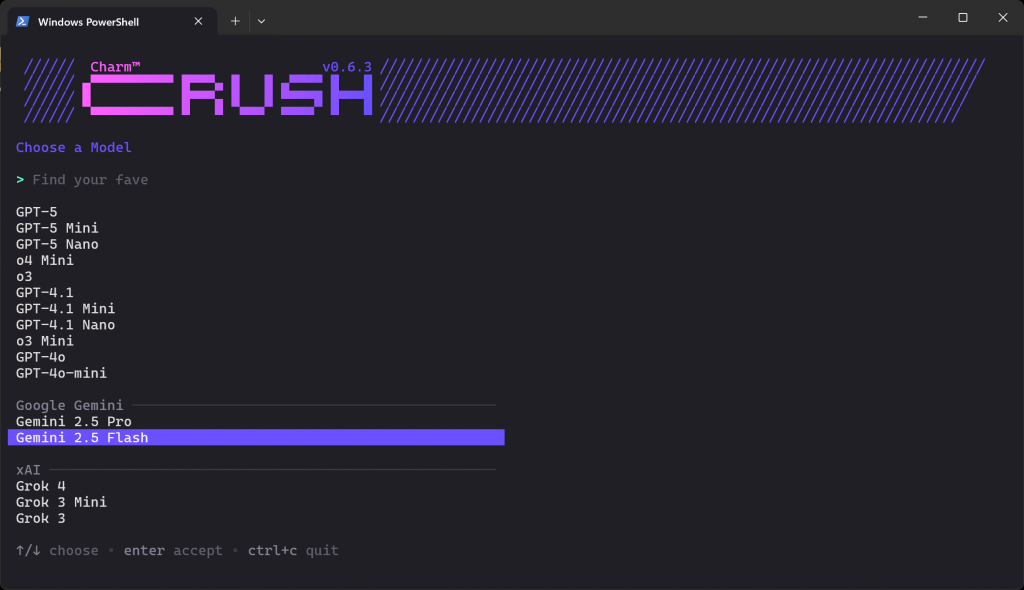
Il existe des dizaines de fournisseurs et des centaines de modèles parmi lesquels choisir. Utilisez les touches fléchées pour naviguer jusqu’à ce que vous trouviez le modèle que vous voulez chez le fournisseur pour lequel vous avez une clé API. Dans cet exemple, nous sélectionnerons “Gemini 2.5 Flash” (dont l’utilisation est essentiellement gratuite via l’API).
Ensuite, il vous sera demandé d’entrer votre clé API. Collez-la et appuyez sur Entrée:
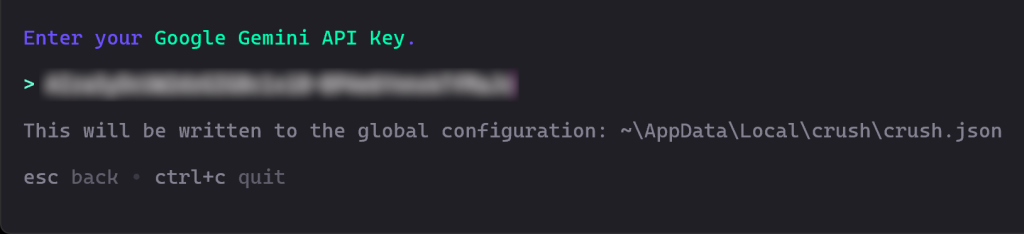
Dans ce cas, saisissez votre clé d’API Google Gemini, que vous pouvez récupérer gratuitement auprès de Google Studio AI.
Crush validera alors votre clé API pour confirmer qu’elle fonctionne.
Une fois la validation terminée, vous devriez voir quelque chose comme ceci :
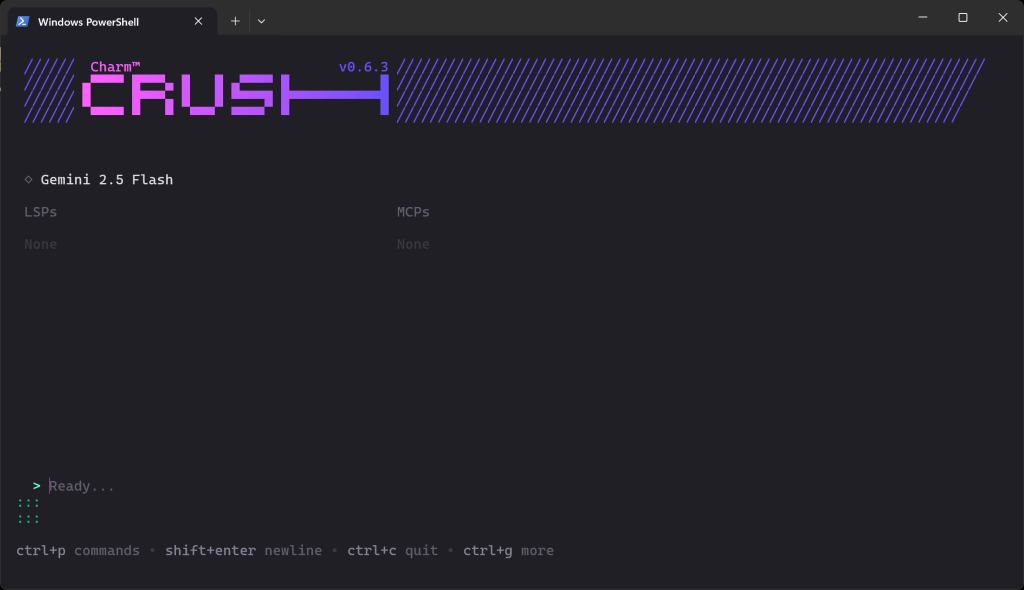
Dans la section “Ready…”, vous pouvez maintenant saisir votre invite.
Remarque: Si vous lancez à nouveau le CLI de Crush, il ne vous sera pas demandé de configurer une connexion LLM une seconde fois. C’est parce que votre clé LLM configurée est automatiquement sauvegardée dans la configuration globale $HOME/.config/crush/crush.json (ou sous Windows, %USERPROFILE%AppDataLocalcrushcrush.json).
Ouvrez le fichier de configuration global crush.json dans Visual Studio Code (ou votre IDE préféré) pour l’inspecter :
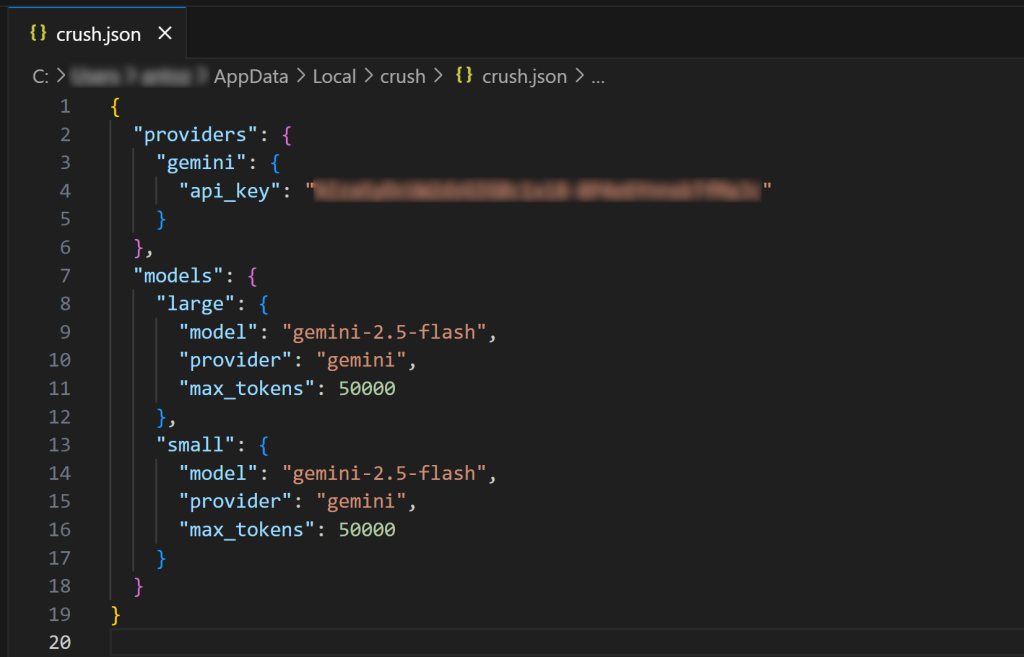
Comme vous pouvez le voir, le fichier crush.json contient votre clé API ainsi que la configuration du modèle choisi. Ce fichier a été rempli par le CLI de Crush lorsque vous avez sélectionné un LLM. Vous pouvez également éditer ce fichier pour configurer d’autres modèles d’IA(même des modèles locaux).
De même, vous pouvez créer des fichiers crush.json ou .crush.json locaux dans le répertoire de votre projet pour remplacer la configuration globale. Pour plus de détails, voir la documentation officielle.
Incroyable ! L’interface de commande Crush est maintenant installée et fonctionne sur votre système.
Étape 2 : tester le MCP Web de Bright Data
Si vous n’en avez pas encore, créez un compte Bright Data. Sinon, connectez-vous à votre compte existant.
Ensuite, suivez les instructions officielles pour générer votre clé API Bright Data. Conservez-la en lieu sûr, car vous en aurez bientôt besoin. Pour plus de simplicité, nous supposerons que vous utilisez une clé API avec des autorisations d’administrateur.
Installez le Web MCP globalement en utilisant le paquetage @brightdata/mcp avec :
npm install -g @brightdata/mcpEnsuite, vérifiez que le serveur fonctionne avec cette commande Bash :
API_TOKEN="<Votre_BRIGHT_DATA_API>" npx -y @brightdata/mcpOu, de manière équivalente, avec Windows PowerShell :
$Env:API_TOKEN="<Votre_BRIGHT_DATA_API>" ; npx -y @brightdata/mcpRemplacez le caractère générique <YOUR_BRIGHT_DATA_API> par la clé d’API Bright Data que vous avez générée précédemment. Les commandes ci-dessus définissent la variable d’environnement API_TOKEN requise et lancent le serveur MCP via le paquetage npm @brightdata/mcp.
Si tout fonctionne correctement, vous devriez voir des journaux comme celui-ci :

Lors du premier lancement, le serveur MCP crée automatiquement deux zones dans votre compte Bright Data :
mcp_unlocker: Une zone pour Web Unlocker.mcp_browser: Une zone pour Browser API.
Ces zones sont nécessaires pour utiliser l’ensemble des outils du serveur MCP.
Pour confirmer leur création, connectez-vous à votre tableau de bord Bright Data et accédez à la page “Proxies & Scraping Infrastructure“. Vous devriez voir les deux zones répertoriées :
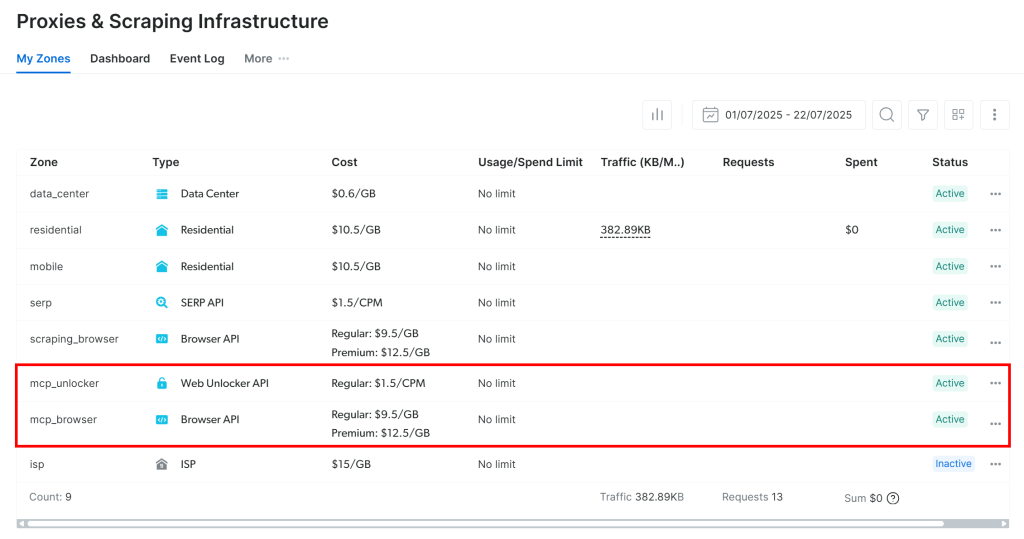
Remarque: si votre jeton API ne dispose pas d’autorisations d’administration, il se peut que ces zones ne soient pas créées pour vous. Dans ce cas, vous pouvez les configurer manuellement et spécifier leurs noms à l’aide de variables d’environnement, comme illustré dans la documentation officielle.
Rappel: Par défaut, le serveur MCP n’expose que les outils search_engine et scrape_as_markdown.
Pour débloquer les outils avancés pour l’automatisation du navigateur et les flux de données structurées, vous devez activer le mode Pro. Pour ce faire, définissez la variable d’environnement PRO_MODE=true avant de lancer le serveur MCP :
API_TOKEN="<Votre_BRIGHT_DATA_API>" PRO_MODE="true" npx -y @brightdata/mcpOu, sous Windows :
$Env:API_TOKEN="<Votre_BRIGHT_DATA_API>" ; $Env:PRO_MODE="true" ; npx -y @brightdata/mcpImportant: avec le mode Pro, vous aurez accès à l’ensemble des 60+ outils. Cependant, les outils supplémentaires du mode Pro ne sont pas inclus dans le niveau gratuit, et vous devrez payer des frais.
Pour en savoir plus sur le serveur Web MCP de Bright Data , consultez la documentation officielle.
C’est parfait ! Vous avez vérifié que le serveur Web MCP fonctionne correctement sur votre machine. Arrêtez le serveur, car la prochaine étape consistera à configurer Crush pour qu’il le lance et s’y connecte au démarrage.
Etape #3 : Configurer le Web MCP dans Crush
Crush supporte l’intégration MCP à travers l’entrée mcp dans le fichier de configuration local ou global crush.json.
Dans cet exemple, supposons que vous souhaitiez configurer globalement le MCP Web de Bright Data dans votre environnement CLI Crush. Ouvrez donc le fichier de configuration global :
- Sous Linux/macOS :
$HOME/.config/crush/crush.json. - Sous Windows :
%USERPROFILE%AppDataLocalcrushcrush.json.
Assurez-vous qu’il contient les éléments suivants :
"mcp" : {
"brightData" : {
"type" : "stdio",
"command" : "npx",
"args" : [
"-y",
"@brightdata/mcp"
],
"env" : {
"API_TOKEN" : "<VOTRE_CLÉ_D'API_BRIGHT_DATA>",
"PRO_MODE" : "true"
}
}
}Dans cette configuration, l’entrée mcp indique à Crush comment lancer des serveurs MCP externes :
- L’entrée
mcpindique à Crush comment lancer des serveurs MCP externes. - L’entrée
brightDatadéfinit la commande et les variables d’environnement nécessaires à l’exécution du MCP Web. (N’oubliez pas : La définition dePRO_MODEest facultative mais recommandée. Remplacez également<YOUR_BRIGHT_DATA_API_KEY>par votre clé d’API Bright Data).
En d’autres termes, cette configuration ajoute un serveur MCP personnalisé appelé brightData. Crush utilise les variables d’environnement que vous avez définies dans le fichier et démarre le serveur via la commande npx spécifiée (qui correspond à la commande indiquée à l’étape précédente). En termes plus simples, Crush peut maintenant démarrer un processus Web MCP local et s’y connecter au démarrage.
Génial ! Il est temps de tester l’intégration de MCP dans le CLI de Crush.
Etape #4 : Vérifier la connexion MCP
Fermez toutes les instances de Crush en cours d’exécution et lancez-les à nouveau :
Crush Si la connexion MCP fonctionne comme prévu, vous devriez voir l’entrée brightData listée dans la section “MCPs” :
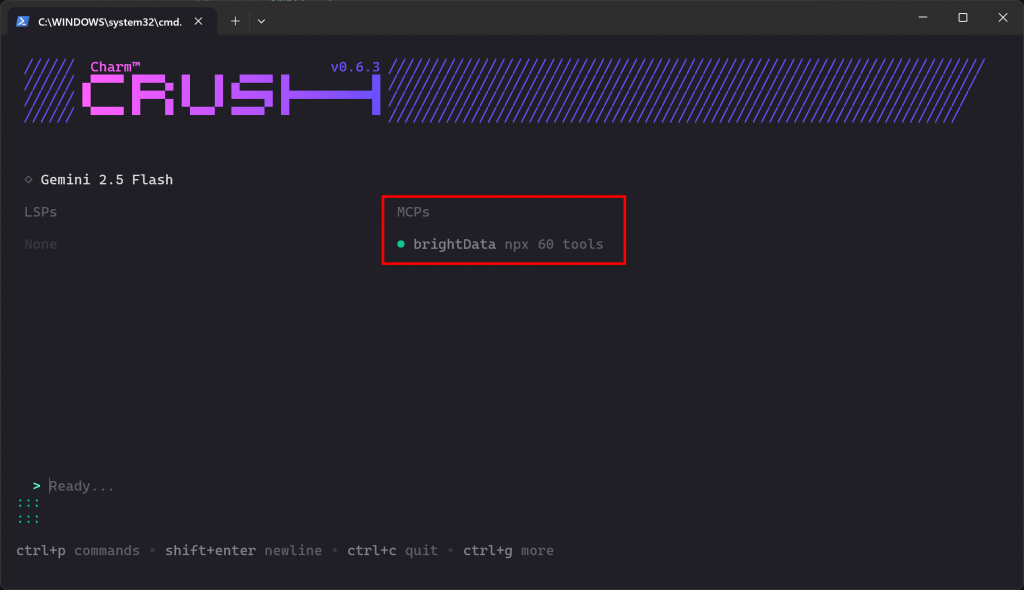
Le CLI indique que 60 outils sont disponibles. C’est parce que nous l’avons configuré pour fonctionner en mode Pro. Sinon, vous n’auriez accès qu’à 2 outils(scrape_as_markdown et search_engine). Voilà qui est bien fait !
Étape 5 : Exécuter une tâche dans Crush
Pour vérifier les nouvelles capacités de votre configuration CLI Crush, essayez de lancer une invite comme celle-ci :
Scraper les données de "https://www.amazon.com/Microfiber-Cleaning-Cloth-Performance-Washes/dp/B08BRJHJF9/", les sauvegarder dans un fichier local "product.json", et définir un script Node.js "script.js" pour charger le fichier et imprimer son contenu dans le terminal.Il s’agit d’un excellent cas de test car il demande la récupération de données de produits fraîches, ce qui devrait être réalisé à l’aide des outils exposés par le MCP Web de Bright Data. De plus, il démontre un flux de travail réaliste que vous pourriez utiliser lors de la simulation ou de la mise en place d’un projet d’analyse de données.
Collez l’invite dans Crush et appuyez sur Entrée pour l’exécuter. Vous devriez voir quelque chose comme ceci :
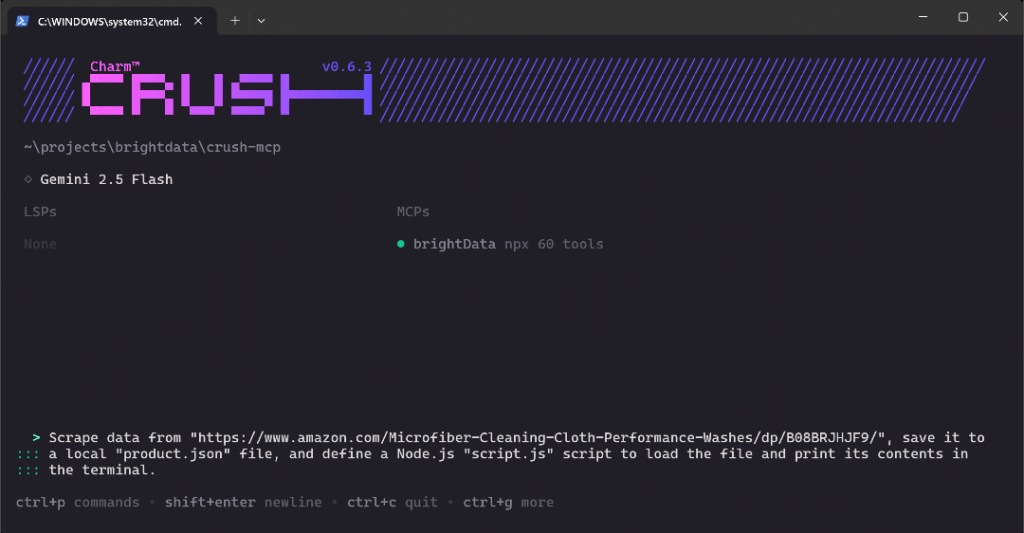
Le GIF ci-dessus a été accéléré, mais voici ce qui se passe étape par étape :
- Crush identifie l’outil
web_data_amazon_product(référencé commemcp_brightData_web_data_amazon_productpar le CLI) comme étant le bon pour la tâche et vous demande la permission de l’exécuter. - Une fois approuvée, la tâche de scraping s’exécute via l’intégration MCP.
- Les données produit JSON résultantes sont affichées dans le terminal.
- Crush demande s’il peut enregistrer ces données dans un fichier local nommé
product.json. - Après approbation, le fichier est créé et rempli avec les données scannées.
- Crush CLI génère ensuite la logique JavaScript pour
script.js, qui charge et imprime le contenu JSON. - Une fois que vous avez donné votre accord, le fichier
script.jsest créé. - Un message vous demande l’autorisation d’exécuter le script Node.js.
- Une fois l’autorisation accordée, le
script.jsest exécuté et les données du produit sont imprimées dans le terminal.
Notez que l’interface de programmation a demandé l’exécution du script Node.js produit, même si vous ne l’avez pas explicitement demandé. Ce comportement était intentionnel, car il facilite les tests (et donc la correction en cas d’erreurs) et ajoute de la valeur au flux de travail.
À la fin, votre répertoire de travail devrait contenir ces deux fichiers :
├── prodcut.json
└── script.jsOuvrez product.json dans VS Code, et vous devriez voir :
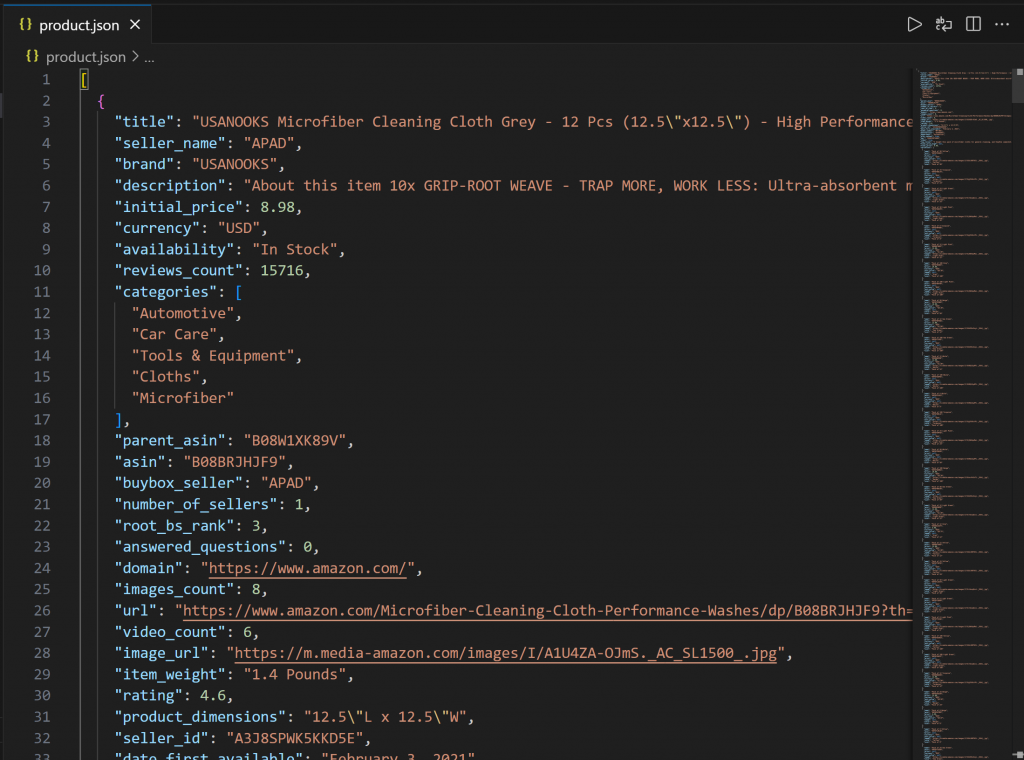
Ce fichier contient de vraies données de produits récupérées sur Amazon via le MCP Web de Bright Data.
Maintenant, ouvrez script.js:
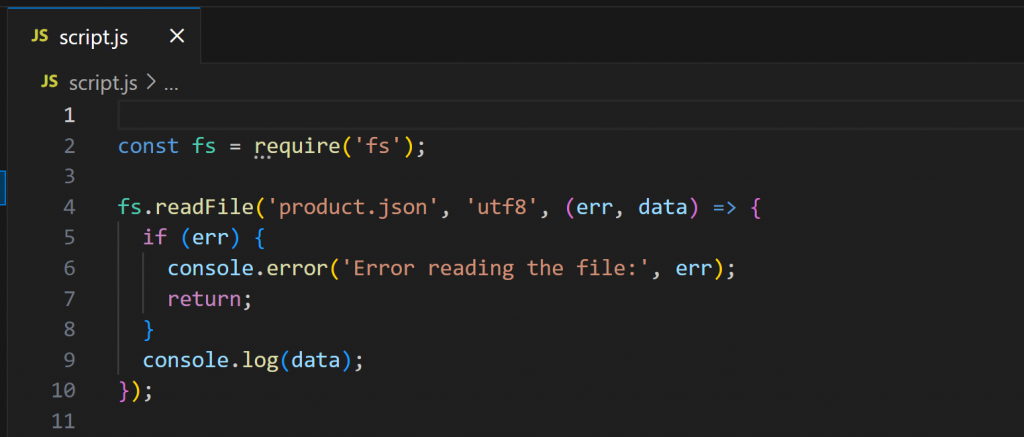
Ce script utilise Node.js pour charger et afficher le contenu de product.json. Exécutez-le avec :
node script.jsLa sortie devrait être :
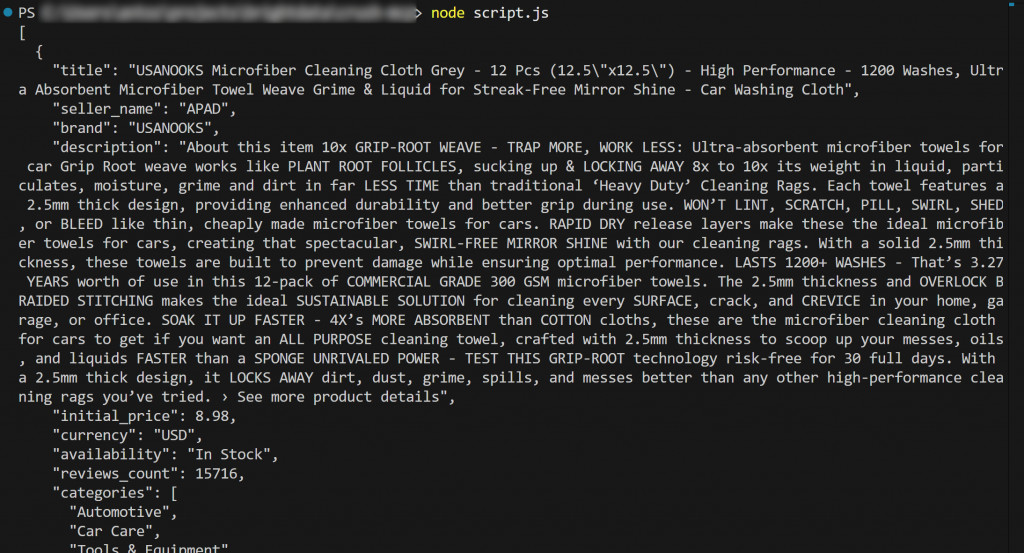
Et voilà ! Le flux de travail a réussi.
En détail, le contenu chargé à partir de product.json et imprimé dans le terminal correspond aux données réelles que vous pouvez trouver sur la page originale du produit Amazon.
Important: le fichier product.json contient de véritables données récupérées, et non un contenu halluciné ou inventé par l’IA. Il est essentiel de le souligner, car le scraping d’Amazon est notoirement difficile en raison de ses protections anti-bots avancées (par exemple, à cause du CAPTCHA d’Amazon). Ainsi, un LLM ordinaire ne pourrait pas atteindre cet objectif à lui seul !
Cet exemple montre la véritable puissance de la combinaison de Crush avec le serveur MCP de Bright Data. Essayez maintenant d’expérimenter de nouvelles invites et d’explorer des flux de données plus avancés, pilotés par LLM, directement dans le CLI !
Conclusion
Dans ce tutoriel, vous avez vu comment connecter Crush avec le Web MCP de Bright Data(qui offre maintenant un niveau gratuit !). Le résultat est un puissant agent de codage CLI capable d’accéder et d’interagir avec le web. Cette intégration est possible grâce au support intégré de Crush CLI pour les serveurs MCP.
L’exemple de tâche présenté dans ce guide est volontairement simple. Cependant, n’oubliez pas qu’avec cette intégration, vous pouvez vous attaquer à des cas d’utilisation beaucoup plus complexes. Après tout, les outils MCP de Bright Data Web prennent en charge une grande variété de scénarios agentiques.
Pour créer des agents plus avancés, explorez la gamme complète de services disponibles dans l’infrastructure d’IA de Bright Data.
Ouvrez un compte Bright Data gratuit et commencez à expérimenter les outils Web prêts pour l’IA dès aujourd’hui !




