

Dans ce guide sur le réglage fin de Llama 4 avec des données web, vous apprendrez :
- Qu’est-ce que le réglage fin ?
- Comment récupérer les jeux de données prêts pour le réglage fin à l’aide de certaines API de scraping
- Comment configurer l’infrastructure cloud pour le processus de réglage fin
- Comment affiner Llama 4 grâce à un tutoriel étape par étape
C’est parti !
Qu’est-ce que le réglage fin ?
Le réglage fin, également appelé réglage fin supervisé (SFT), est un processus utilisé pour améliorer des connaissances ou des capacités spécifiques dans un LLM pré-entraîné. Dans le contexte des LLM, le pré-entraînement fait référence à l’entraînement d’un modèle d’IA à partir de zéro.
Le SFT est utilisé parce qu’un modèle imite ses données d’entraînement. Cependant, à l’heure actuelle, les LLM sont principalement des modèles généralistes. Cela signifie que si vous voulez qu’un modèle apprenne des connaissances spécifiques, vous devez l’ajuster.
Si vous souhaitez en savoir plus sur le SFT, consultez notre guide sur le réglage fin supervisé dans les LLM.
Récupération des données pour affiner LLama 4
Pour affiner un LLM, vous avez d’abord besoin d’un ensemble de données d’affinage. Cette section vous explique comment extraire des données d’un site web à l’aide des API Web Scraperde Bright Data, des points de terminaison dédiés à plus de 100 domaines qui extraient pour vous des données récentes et les récupèrent dans le format souhaité.
La page web cible sera la page des produits de bureau les plus vendus sur Amazon:
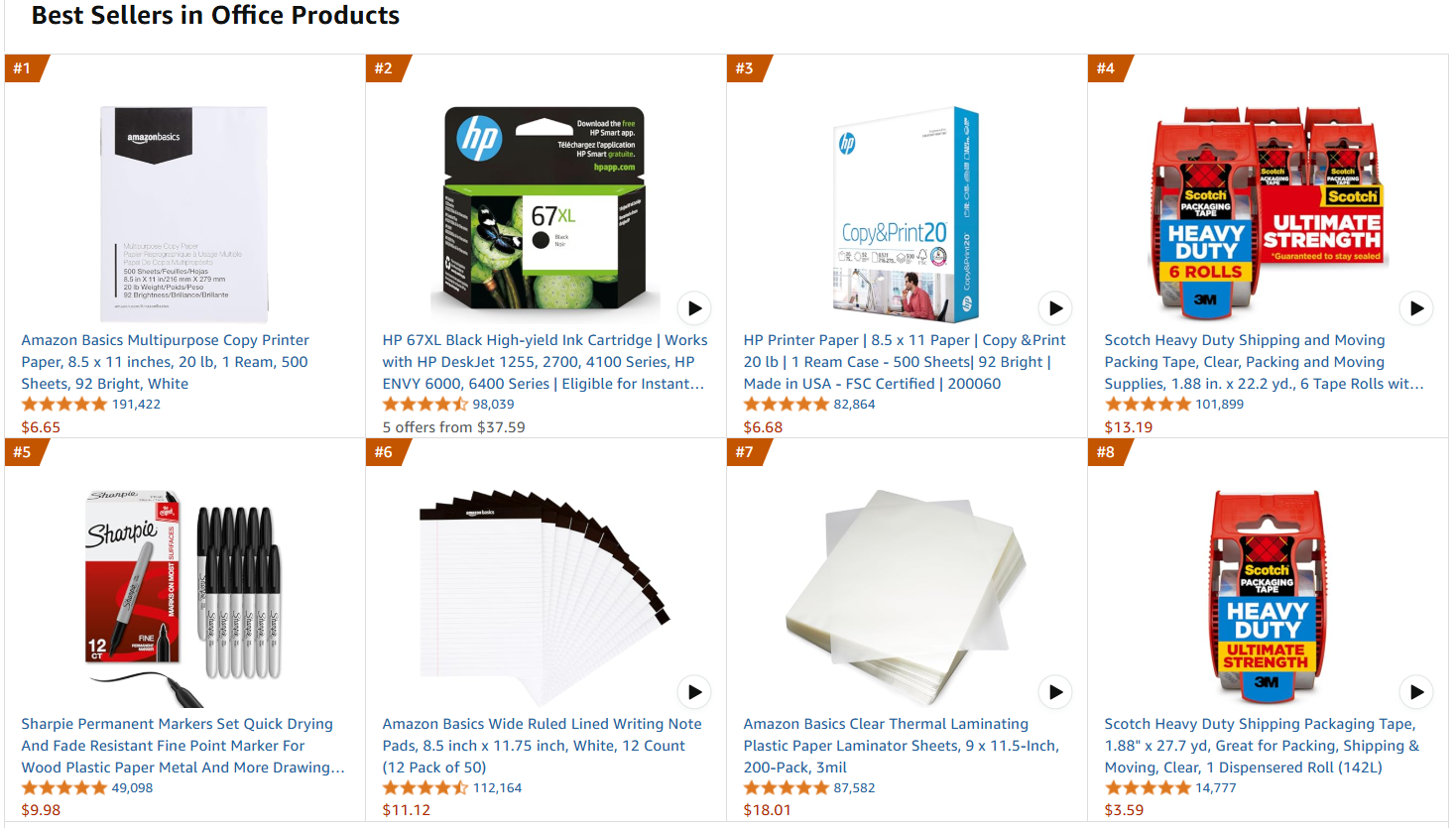
Suivez les étapes ci-dessous pour récupérer les données de réglage fin !
Exigences
Pour utiliser le code permettant de récupérer les données d’Amazon, vous devez disposer des éléments suivants :
- Python 3.10+ installé sur votre machine.
- Une clé API Bright Data Scraper valide.
Suivez la documentation Bright Data pour récupérer votre clé API.
Structure du projet et dépendances
Supposons que vous appeliez le dossier principal de votre projet amazon_scraper/. À la fin de cette étape, le dossier aura la structure suivante :
amazon_scraper/
├── scraper.py
└── venv/Où :
scraper.pyest le fichier Python qui contient la logique de codage.venv/contient l’environnement virtuel.
Vous pouvez créer le répertoire d’environnement virtuel venv/ comme suit :
python -m venv venvPour l’activer, sous Windows, exécutez :
venvScriptsactivateDe manière équivalente, sous macOS et Linux, exécutez :
source venv/bin/activateDans l’environnement virtuel activé, installez les dépendances avec :
pip install requestsOù requests est une bibliothèque permettant d’effectuer des requêtes web HTTP.
Parfait ! Vous êtes désormais prêt à obtenir les données qui vous intéressent à l’aide des API Scraper de Bright Data.
Étape n° 1 : définir la logique de scraping
L’extrait de code suivant définit l’ensemble de la logique de scraping :
import requests
import json
import time
def trigger_amazon_products_scraping(api_key, urls):
# Point de terminaison pour déclencher la tâche de l'API Web Scraper
url = "https://api.brightdata.com/datasets/v3/trigger"
params = {
"dataset_id": "gd_l7q7dkf244hwjntr0",
"include_errors": "true",
"type": "discover_new",
"discover_by": "best_sellers_url",
}
# Convertir les données d'entrée au format souhaité pour appeler l'API
data = [{"category_url": url} for url in urls]
headers = {
"Authorization": f"Bearer {api_key}",
"Content-Type": "application/json",
}
response = requests.post(url, headers=headers, params=params, json=data)
if response.status_code == 200:
snapshot_id = response.json()["snapshot_id"]
print(f"Demande réussie ! Réponse : {snapshot_id}")
return response.json()["snapshot_id"]
else:
print(f"Demande échouée ! Erreur : {response.status_code}")
print(response.text)
def poll_and_retrieve_snapshot(api_key, snapshot_id, output_file, polling_timeout=20):
snapshot_url = f"https://api.brightdata.com/datasets/v3/snapshot/{snapshot_id}?format=json"
headers = {
"Authorization": f"Bearer {api_key}"
}
print(f"Interrogation du snapshot pour l'ID : {snapshot_id}...")
while True:
response = requests.get(snapshot_url, headers=headers)
if response.status_code == 200:
print("L'instantané est prêt. Téléchargement en cours...")
snapshot_data = response.json()
# Écriture de l'instantané dans un fichier json de sortie
with open(output_file, "w", encoding="utf-8") as file:
json.dump(snapshot_data, file, indent=4)
print(f"Instantané enregistré dans {output_file}")
return
elif response.status_code == 202:
print(F"L'instantané n'est pas encore prêt. Réessayer dans {polling_timeout} secondes...")
time.sleep(polling_timeout)
else:
print(f"Échec de la requête ! Erreur : {response.status_code}")
print(response.text)
break
if __name__ == "__main__":
BRIGHT_DATA_API_KEY = "<VOTRE clé API>" # Remplacez-la par votre clé API Web Scraper de Bright Data ou lisez-la à partir des envs
# URL des produits les plus vendus à partir desquels récupérer les données
urls = [
"https://www.amazon.com/gp/bestsellers/office-products/ref=pd_zg_ts_office-products"
]
snapshot_id = trigger_amazon_products_scraping(BRIGHT_DATA_API_KEY, urls)
poll_and_retrieve_snapshot(BRIGHT_DATA_API_KEY, snapshot_id, "amazon-data.json")Ce code :
- Crée la fonction
trigger_amazon_products_scraping()qui lance la tâche de Scraping web par :- Définissant le point de terminaison de l’API Scraper à déclencher.
- Configurant les paramètres de l’activité de scraping.
- Formatant les
URLd’entrée dans une structure JSON attendue par l’API. - Envoyant une requête
POSTà l’API Bright Data Scraper avec le point de terminaison, les en-têtes, les paramètres et les données spécifiés. - Gestion du statut de la réponse.
- Création d’une fonction
poll_and_retrieve_snapshot()qui vérifie le statut de la tâche de scraping (identifiée parsnapshot_id) et récupère les données une fois qu’elles sont prêtes.
Notez que l’API de scraping a été appelée en utilisant une seule URL. Ainsi, le code ci-dessus récupère les données d’une seule page Amazon cible. Cela suffit pour le cadre de ce tutoriel, mais vous pouvez ajouter autant d’URL Amazon que vous le souhaitez dans la liste.
Sachez que plus vous ajoutez d’URL, plus la taille des Jeux de données augmente. Un ensemble de données plus important, s’il est bien organisé, permet un meilleur réglage. D’un autre côté, plus l’ensemble de données est important, plus le temps de calcul nécessaire est long.
Parfait ! Votre logique de scraping est bien définie et vous êtes maintenant prêt à exécuter le script.
Étape n° 2 : exécuter le script
Pour scraper la page web cible, exécutez le script avec :
python Scraper.pyVous obtiendrez le résultat suivant :
Demande réussie ! Réponse : s_m9in0ojm4tu1v8h78
Instantané de sondage pour l'ID : s_m9in0ojm4tu1v8h78...
L'instantané n'est pas encore prêt. Nouvelle tentative dans 20 secondes...
# ...
L'instantané n'est pas encore prêt. Nouvelle tentative dans 20 secondes...
L'instantané est prêt. Téléchargement en cours...
Instantané enregistré dans amazon-data.jsonÀ la fin du processus, le dossier du projet contiendra :
amazon_scraper/
├── scraper.py
├── amazon-data.json # <-- Notez l'ensemble de données de réglage fin
└── venv/Le processus a automatiquement créé le fichier amazon-data.json qui contient les données récupérées. Vous trouverez ci-dessous la structure attendue du fichier JSON :
[
{
"title": "Papier d'impression polyvalent Amazon Basics, 8,5 x 11 pouces, 20 lb, 1 rame, 500 feuilles, 92 brillant, blanc",
"seller_name": "Amazon.com",
"brand": "Amazon Basics",
"description": « Description du produit Papier polyvalent pour imprimante et photocopieuse Amazon Basics, 8,5 x 11 pouces, 20 lb - 1 rame (500 feuilles), 92 GE Bright White Du fabricant AmazonBasics »,
« initial_price » : 6,65,
« currency » : « USD »,
« availability » : « En stock »,
« nombre_d'avis » : 190989,
« catégories » : [
« Fournitures de bureau »,
« Fournitures scolaires et de bureau »,
« Papier »,
« Papier pour photocopies et impressions »,
« Papier polyvalent et pour photocopies »
],
...
// omis pour plus de concision...
}Très bien ! Vous avez réussi à extraire les données d’Amazon et à les enregistrer dans un fichier JSON. Ce fichier JSON est l’ensemble de données de réglage fin que vous utiliserez plus tard dans le processus de réglage fin.
Configuration de Hugging Face pour utiliser Llama 4
Le modèle que vous utiliserez est Llama-4-Scout-17B-16E-Instruct de Hugging Face.
Si vous n’avez jamais utilisé Hugging Face auparavant, lorsque vous cliquerez sur le lien pour la première fois, vous serez invité à créer un compte :
Après avoir créé le compte, si vous n’avez jamais utilisé de modèle Llama 4, vous devez remplir le formulaire d’accord. Cliquez sur « Développer pour consulter et accéder » pour lire et remplir le formulaire :
Une fois le formulaire rempli, votre demande sera examinée :
Vérifiez le statut de votre demande dans la section «Gated Repositories »:
Une fois votre demande acceptée, vous pouvez créer un nouveau jeton. Accédez à «Access Tokens » (Jetons d’accès) et créez un jeton avec des autorisations d'écriture. Ensuite, copiez-le et enregistrez-le dans un endroit sûr pour pouvoir l’utiliser plus tard :
Bravo ! Vous avez terminé toutes les étapes nécessaires pour utiliser un modèle Llama 4 avec Hugging Face.
Configuration de l’infrastructure cloud pour affiner Llama 4
Les modèles Llama 4 sont très volumineux, et leur nom vous aide à comprendre leur taille. Par exemple, Llama-4-Scout-17B-16E-Instruct signifie qu’il comporte 17 milliards de paramètres avec 128 experts.
Le processus de réglage fin nécessite de former le modèle à l’aide de l’ensemble de données de réglage fin que vous avez récupéré précédemment. Comme le modèle comporte 17 milliards de paramètres, vous avez besoin de beaucoup de matériel pour le faire. Plus précisément, vous avez besoin de plusieurs GPU. C’est pourquoi vous utiliserez un service cloud pour effectuer le processus de réglage fin.
Pour ce tutoriel, vous utiliserez RunPod comme service cloud. Rendez-vous sur «RunPod »et créez un compte. Ensuite, allez dans le menu « Facturation » et ajoutez 25 $ à l’aide de votre carte de crédit :
Remarque: vous paierez immédiatement 25 $ et RunPod ajoutera l’équivalent de 25 $ en crédits à votre compte. Vous consommerez des crédits toutes les heures, en fonction du nombre d’heures pendant lesquelles votre pod sera actif une fois déployé. Ne le déployez donc que lorsque vous êtes sûr de pouvoir l’utiliser. Sinon, vous consommerez des crédits sans les utiliser réellement. La consommation horaire réelle dépend du type et du nombre de GPU que vous choisirez dans les étapes suivantes.
Accédez au menu « Pods » pour commencer à configurer votre pod. Le pod sert de serveur virtuel qui vous fournit les CPU, GPU, mémoire et stockage nécessaires à vos tâches. Cliquez sur le bouton « Déployer » :
Vous pouvez choisir parmi différentes configurations :
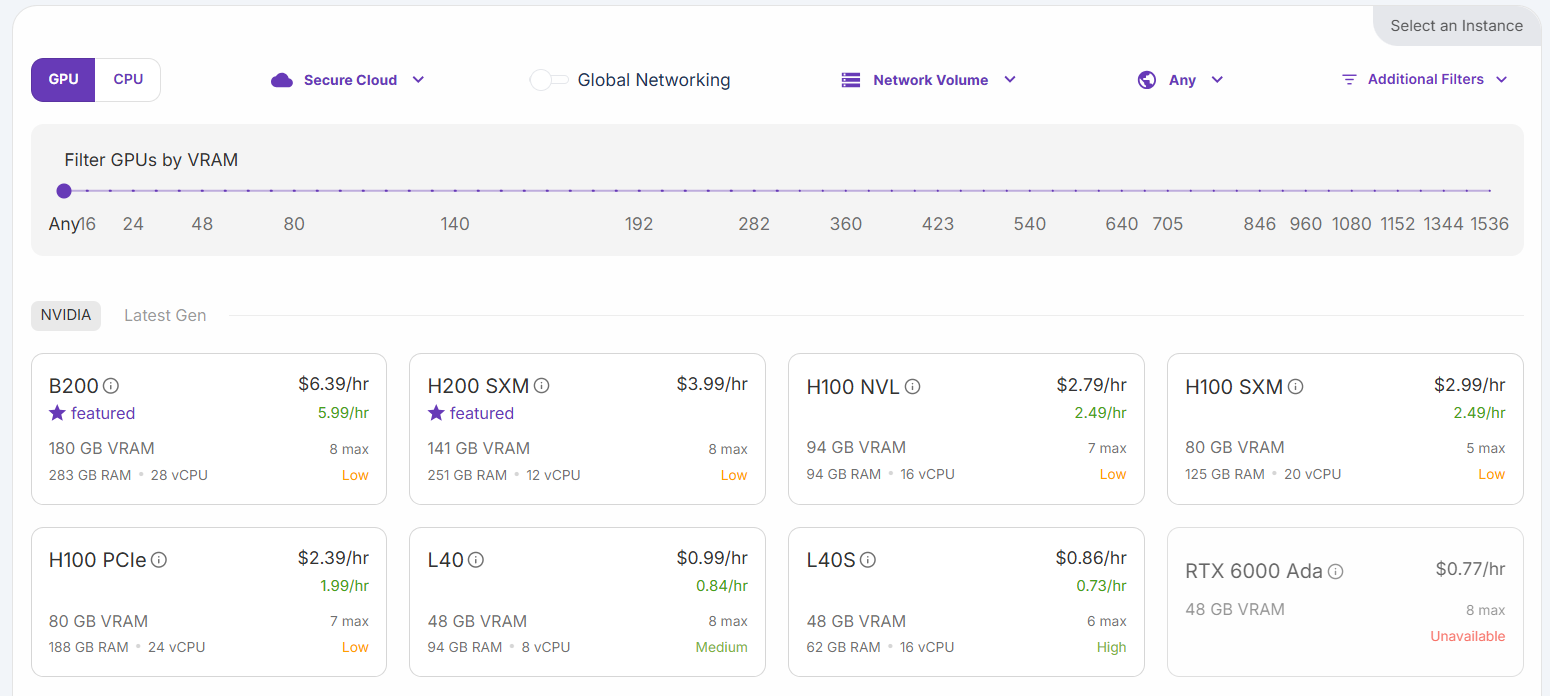
Sélectionnez l’option « H200 SXM GPU ». Donnez un nom au pod et sélectionnez le nombre de GPU. 3 GPU suffisent pour ce tutoriel :
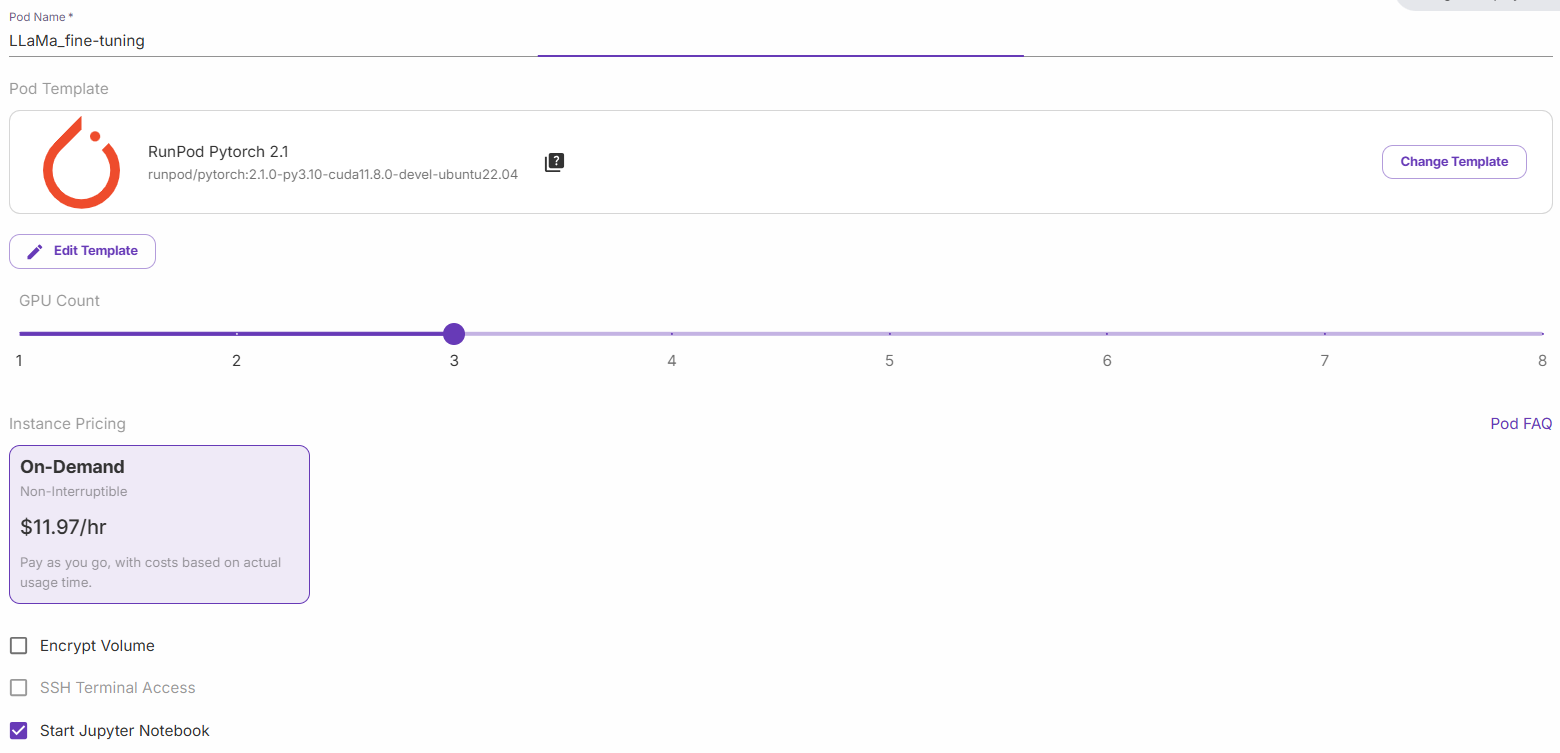
Sélectionnez « Démarrer un notebook Jupyter » et cliquez sur « Déployer à la demande ». Maintenant, allez dans la section « Pods » et modifiez votre pod :
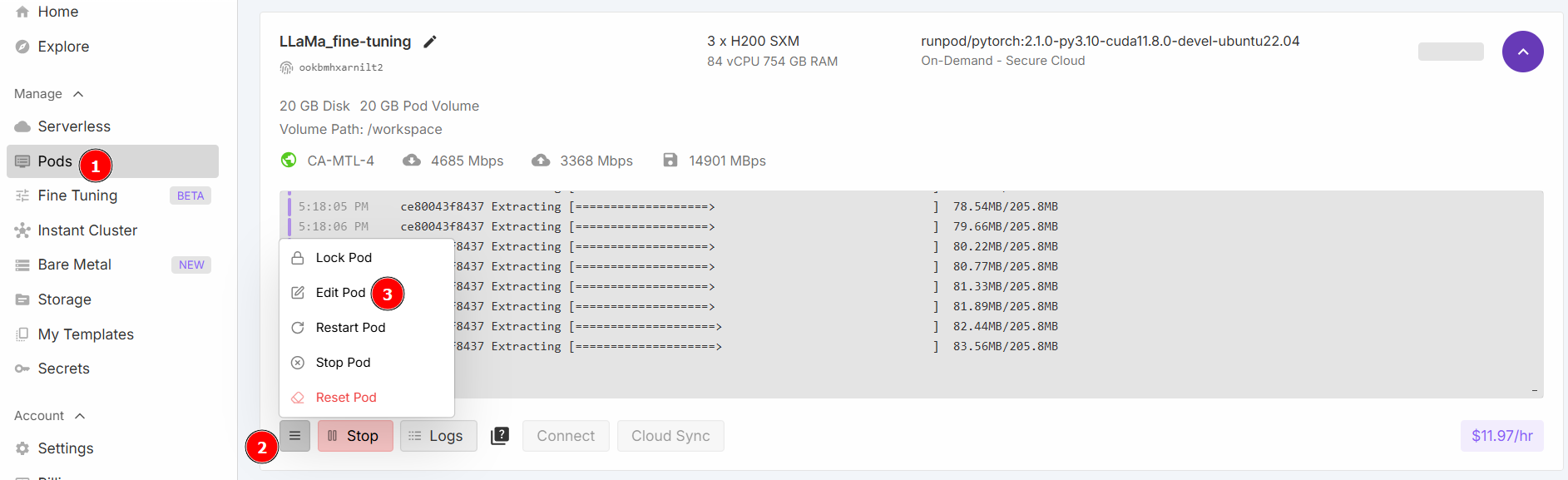
Modifiez les valeurs « Contained Disk » (Disque contenu) et « Volume Disk » (Disque de volume) comme indiqué ci-dessous, puis enregistrez :
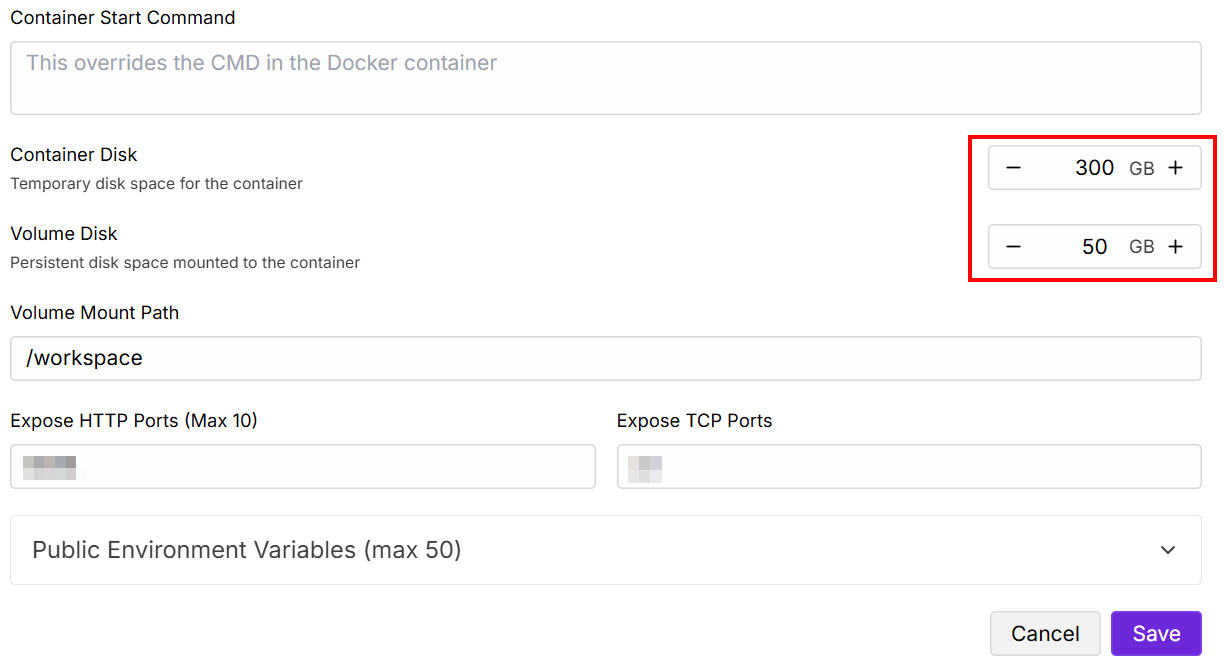
Une fois la configuration terminée, cliquez sur le bouton « Connect » :
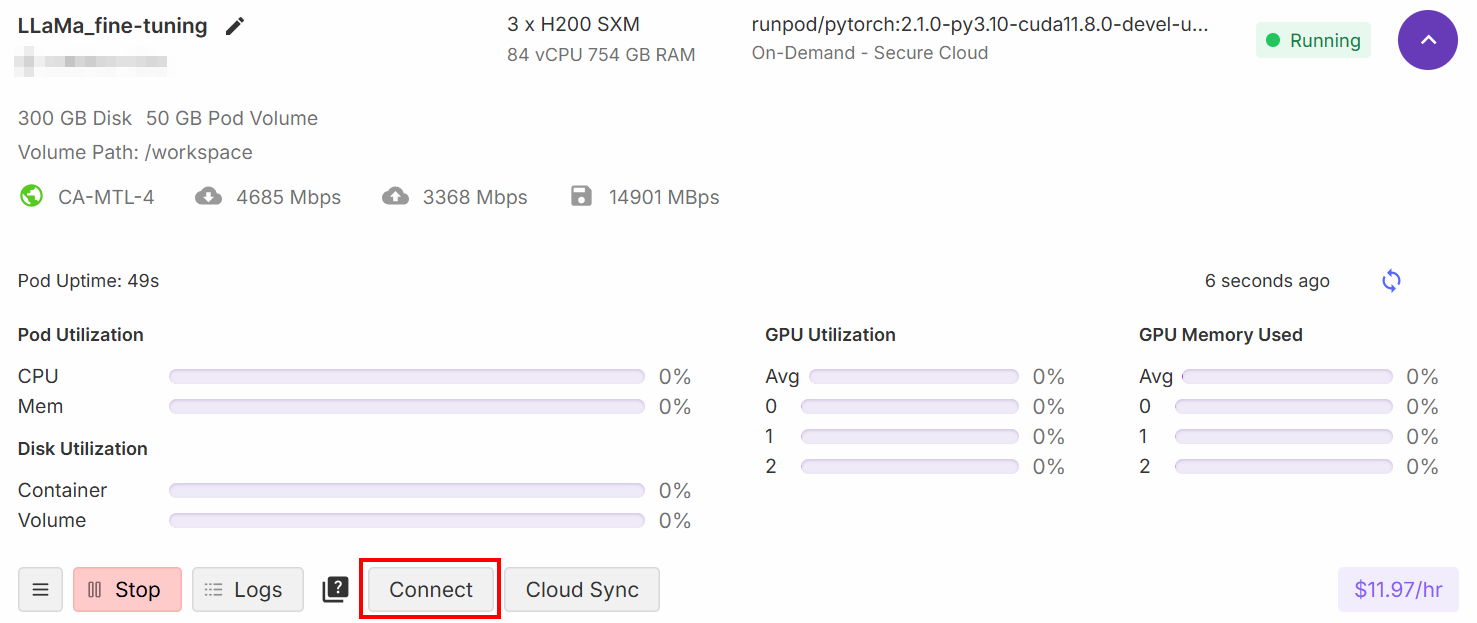
Cela vous permet de connecter le pod à un notebook Jupiter Lab:
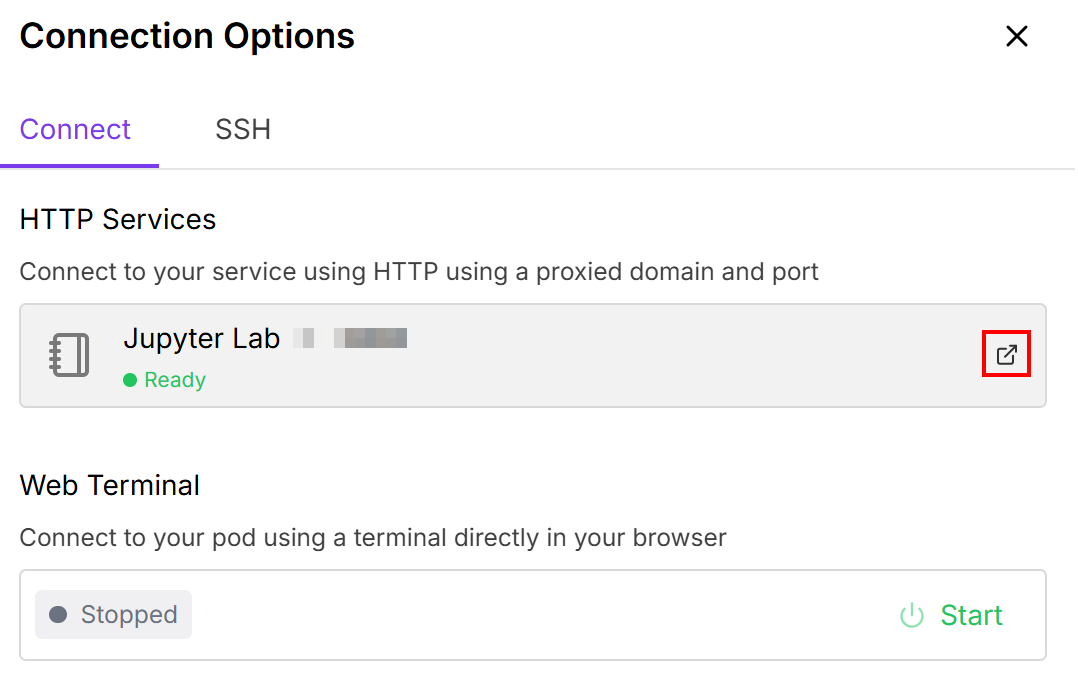
Sélectionnez le notebook avec la carte « Python 3 (ipykernel) » :
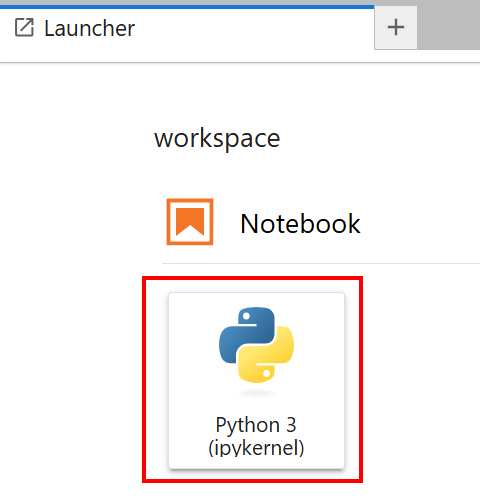
Très bien ! Vous disposez désormais de l’infrastructure adéquate pour entraîner le modèle Llama 4.
Affiner Llama 4 avec les données récupérées
Avant de commencer à affiner votre modèle, téléchargez le fichier amazon-data.json dans votre notebook Jupyter Lab. Pour ce faire, cliquez sur le bouton « Upload files » (Télécharger les fichiers) :
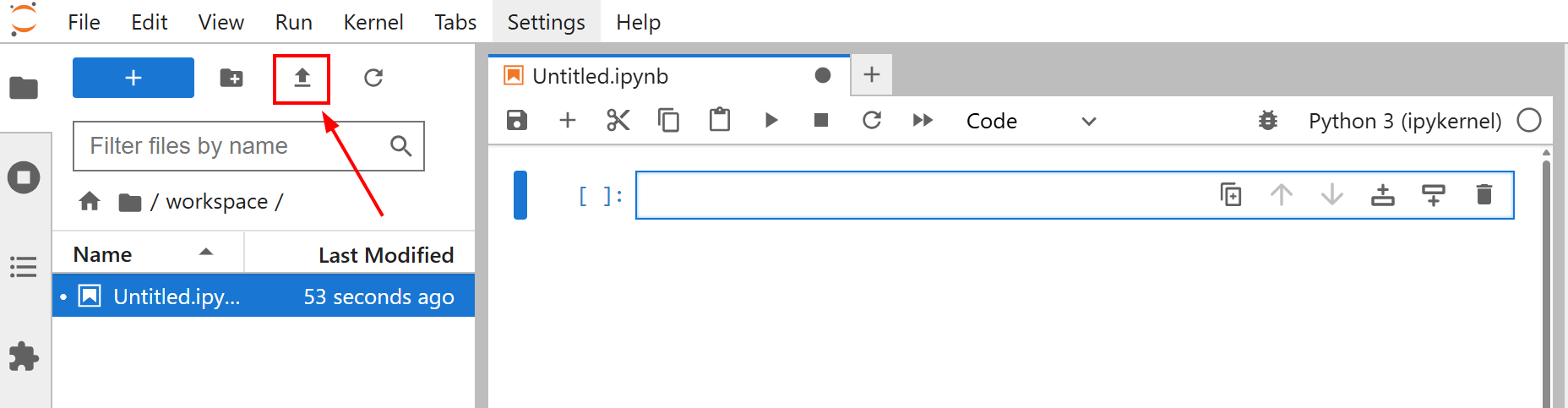
L’objectif du réglage fin de ce tutoriel est de former Llama 4 à l’aide de l’ensemble de données amazon-data.json. De cette façon, vous apprenez à Llama 4 à créer des descriptions d’objets de bureau à partir de certaines caractéristiques telles que le nom de l’objet et certaines fonctionnalités.
Vous êtes maintenant prêt à commencer l’entraînement du modèle. Suivez les étapes ci-dessous pour affiner Llama 4 avec de nouvelles données web !
Étape n° 1 : Installez les bibliothèques
Dans la première cellule de votre bloc-notes, installez les bibliothèques nécessaires :
%%capture
!pip install transformers==4.51.0
%pip install -U Jeux de données
%pip install -U accelerate
%pip install -U peft
%pip install -U trl
%pip install -U bitsandbytes
%pip install huggingface_hub[hf_xet]Ces bibliothèques sont les suivantes :
transformers: fournit des milliers de modèles pré-entraînés.Jeux de données: offre un accès à une vaste collection de jeux de données et à des outils efficaces de traitement des données.accelerate: simplifie l’exécution des scripts de formation PyTorch sur diverses configurations distribuées avec un minimum de modifications du code.peft: permet d’affiner plus efficacement les grands modèles pré-entraînés en ne mettant à jour qu’un petit sous-ensemble de paramètres.trl: conçue pour former des modèles linguistiques de transformateurs à l’aide de techniques d’apprentissage par renforcement.scipy: bibliothèque pour le calcul scientifique et technique en Python.huggingface_hub: fournit une interface Python pour interagir avec le Hugging Face Hub. Cela vous permet de télécharger et de charger des modèles, des Jeux de données et des espaces.bitsandbytes: offre des optimiseurs 8 bits et des fonctions de quantification faciles à utiliser, réduisant l’empreinte mémoire pour l’entraînement et l’inférence de grands modèles d’apprentissage profond.
Parfait ! Vous avez installé les bibliothèques nécessaires au processus de réglage fin.
Étape n° 2 : se connecter à Hugging Face
Dans la deuxième cellule de votre notebook, écrivez :
from huggingface_hub import notebook_login, login
# Connexion interactive
notebook_login()
print("Cellule de connexion exécutée. Si elle réussit, vous pouvez continuer.")Lorsque vous l’exécutez, l’affichage suivant apparaît :
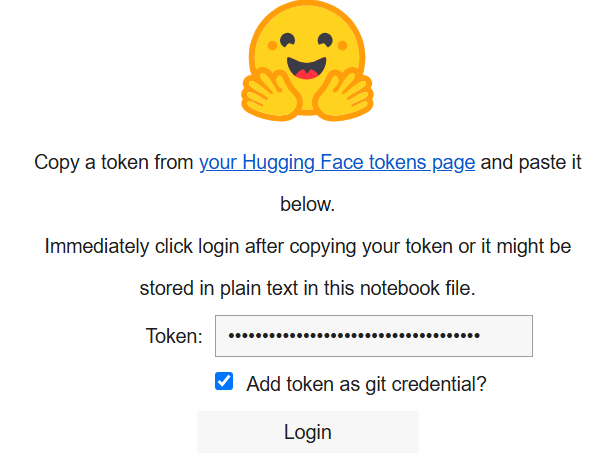
Dans la case « Token », collez le jeton que vous avez créé sur votre compte Hugging Face.
Super ! Vous pouvez désormais récupérer le modèle Llama 4 depuis Hugging Face.
Étape n° 3 : charger le modèle Llama 4
Dans la troisième cellule de votre notebook, écrivez le code suivant :
import os
import torch
import json
from transformers import AutoTokenizer, AutoModelForCausalLM, pipeline, Llama4ForConditionalGeneration, BitsAndBytesConfig
from trl import SFTTrainer
# Charger le modèle
base_model_name = "meta-llama/Llama-4-Scout-17B-16E-Instruct"
# Configuration pour la quantification BitsAndBytes
bnb_config = BitsAndBytesConfig(
load_in_4bit=True,
bnb_4bit_use_double_quant=False,
bnb_4bit_quant_type="nf4",
bnb_4bit_compute_dtype=torch.bfloat16,
)
# Chargement du modèle Llama4 avec les configurations spécifiées
model = Llama4ForConditionalGeneration.from_pre-trained(
base_model_name,
device_map="auto",
torch_dtype=torch.bfloat16,
quantization_config=bnb_config,
trust_remote_code=True,
)
# Désactiver la mise en cache pour le modèle
model.config.use_cache = False
# Définir le parallélisme du tenseur de pré-entraînement sur 1
model.config.pre-training_tp = 1
# Chemin d'accès au fichier de données JSON de réglage fin.
fine_tuning_data_file_path = "amazon-data.json"
# Chemin d'accès aux résultats
output_model_dir = "results_llama_office_items_finetuned/"
final_model_adapter_path = os.path.join(output_model_dir, "final_adapter")
max_seq_length_for_tokenization = 1024
# Créer un répertoire de sortie
os.makedirs(output_model_dir)L’extrait ci-dessus :
- Définit le nom du modèle à charger avec
base_model_name. - Configure les poids du modèle avec
bnb_configà l’aide de la méthodeBitsAndBytesConfig(). - Charge le modèle avec la méthode
from_pre-trained()pour l’entraîner. - Charge l’ensemble de données de réglage fin avec
fine_tuning_data_file_path. - Définit le chemin du répertoire de sortie pour les résultats et le crée avec la méthode
makedirs().
Une fois la cellule exécutée, vous devriez obtenir un résultat similaire à celui-ci :

Fantastique ! Votre modèle Llama 4 est configuré et chargé dans le notebook.
Étape n° 4 : préparer l’ensemble de données de réglage fin pour le processus d’entraînement
Écrivez le code suivant dans la quatrième cellule de votre notebook pour préparer le jeu de données de réglage fin pour le processus d’entraînement :
from jeux de données import Dataset
# Ouvrir l'ensemble de données de réglage fin
with open(fine_tuning_data_file_path, "r") as f:
data_list = json.load(f)
# Convertir la liste des éléments de données en un objet Hugging Face Dataset
raw_fine_tuning_dataset = Dataset.from_list(data_list)
print(f"Données JSON converties en ensemble de données Hugging Face. Nombre d'exemples : {len(raw_fine_tuning_dataset)}")
def format_fine_tuning_entry(data_item):
system_message = "Vous êtes un rédacteur expert. Générez une description concise et attrayante du produit à partir des informations fournies."
# ADAPTEZ LES LIGNES SUIVANTES à votre fichier de réglage fin
item_title = data_item.get("title")
item_brand = data_item.get("brand")
item_category = data_item.get("categories")
item_name = data_item.get("name")
item_features_list = data_item.get("features")
item_features_str = ", ".join(item_features_list) if isinstance(item_features_list, list) else str(item_features_list)
target_description = data_item.get("description")
# Invite d'entraînement
user_prompt = (
f"Générer une description de produit pour l'élément suivant :n"
f"Titre : {item_title}nMarque : {item_brand}nCatégorie : {item_category}n"
f"Nom : {item_name}nCaractéristiques : {item_features_str}nDescription :"
)
# Format de chat Llama
formatted_string = (
f"<|start_header_id|>system<|end_header_id|>nn{system_message}<|eot_id|>"
f"<|start_header_id|>user<|end_header_id|>nn{user_prompt}<|eot_id|>"
f"<|start_header_id|>assistant<|end_header_id|>nn{target_description}<|eot_id|>"
)
return {"text": formatted_string}
# Appliquez la fonction de formatage à chaque entrée du jeu de données brut afin de le structurer pour le réglage fin.
text_formatted_dataset = raw_fine_tuning_dataset.map(format_fine_tuning_entry)
# Configuration du tokenizer
tokenizer = AutoTokenizer.from_pre-trained(base_model_name, trust_remote_code=True)
tokenizer.pad_token = tokenizer.eos_token
# Pré-tokeniser l'ensemble de données
def tokenize_function_for_sft(examples):
# Tokeniser le champ « text » qui contient la chaîne complète au format chat
tokenized_output = tokenizer(
examples["text"],
truncation=True,
padding="max_length",
max_length=max_seq_length_for_tokenization,
)
return tokenized_output
# Appliquer la fonction de tokenisation à l'ensemble de données formaté
tokenized_train_dataset = text_formatted_dataset.map(
tokenize_function_for_sft,
batched=True,
remove_columns=["text"]
)Cette cellule du notebook :
- Ouvre l’ensemble de données de réglage fin et le convertit en un objet Hugging Face
Datasetà l’aide de la méthodeDataset.from_list(). - Définit une fonction
format_fine_tuning_entry(). Son objectif est de prendre un seul élément de données (les détails d’un produit) et de le transformer en un format de texte structuré adapté au réglage fin des instructions d’un modèle de chat comme Llama. Notez que cela doit être adapté à la structure de votre ensemble de données de réglage fin. - Tokenise le jeu de données et applique la tokenisation à l’aide de la méthode
map(). Cela est nécessaire car les modèles linguistiques ne comprennent pas le texte brut. Ils fonctionnent sur des représentations numériques appelées tokens.
Une fois la cellule exécutée, le résultat attendu est le suivant :

Notez que la valeur de « Num exemples » dépend de votre jeu de données de réglage fin.
Incroyable ! Votre jeu de données de réglage fin est prêt pour le processus de réglage fin.
Étape n° 5 : Configurer l’environnement et les paramètres pour le réglage fin efficace en termes de paramètres (PEFT)
Dans une nouvelle cellule de votre notebook, écrivez le code suivant pour définir l’environnement et les paramètres du PEFT :
from transformers import BitsAndBytesConfig
from peft import LoraConfig
# Configuration QLoRA
bnb_config = BitsAndBytesConfig(
load_in_4bit=True,
bnb_4bit_quant_type="nf4",
bnb_4bit_compute_dtype=torch.bfloat16,
bnb_4bit_use_double_quant=True,)
# Configuration LoRA
lora_config = LoraConfig(
r=16,
lora_alpha=32,
lora_dropout=0.05,
bias="none",
task_type="CAUSAL_LM",
target_modules=["q_proj", "k_proj", "v_proj", "o_proj", "gate_proj", "up_proj", "down_proj"],
)Ce code :
- Définit la configuration QLoRA pour la quantification à l’aide de la méthode
BitsAndBytesConfig()afin de spécifier comment un modèle linguistique pré-entraîné doit être quantifié lors de son chargement. La quantification est une technique permettant de réduire les coûts de calcul et de mémoire. - Définit la configuration LoRA pour configurer le modèle pour un réglage fin efficace des paramètres avec la méthode LoraConfig().
Très bien ! L’environnement est prêt pour un réglage fin efficace.
Étape n° 6 : initialiser le processus d’entraînement
Dans une nouvelle cellule, écrivez le code suivant pour initialiser le processus d’entraînement :
from peft import get_peft_model, prepare_model_for_kbit_training
from transformers import TrainingArguments
# Préparer le modèle pour l'entraînement k-bit
model = prepare_model_for_kbit_training(
model,
gradient_checkpointing_kwargs={"use_reentrant": False}
)
# Appliquer la configuration PEFT (LoRA) au modèle.
model = get_peft_model(model, lora_config)
# Désactiver la mise en cache dans la configuration du modèle.
model.config.use_cache = False
# Imprimer le nombre de paramètres entraînables dans le modèle.
model.print_trainable_parameters()
# Définir les arguments d'entraînement.
training_args = TrainingArguments(
output_dir=output_model_dir,
num_train_epochs=3,
per_device_train_batch_size=1,
gradient_accumulation_steps=4,
learning_rate=2e-4,
logging_steps=25,
save_steps=50,
fp16=True,
optim="paged_adamw_8bit",
lr_scheduler_type="cosine",
warmup_ratio=0.03,
report_to="none",
max_grad_norm=0.3,
save_total_limit=2,)
# Initialiser SFTTrainer
trainer = SFTTrainer(
model=model,
args=training_args,
train_dataset=tokenized_train_dataset,
peft_config=lora_config,
)Le code dans cette cellule :
- La méthode
prepare_model_for_kbit_training()prépare lemodèlepréchargé pour l’entraînement avec quantification. - La méthode
get_peft_model()prend lemodèlede base quantifié et préparé et applique lelora_config. - Définit les arguments d’entraînement en appelant la classe
TrainingArguments(). - Initialise le formateur avec
SFTTrainer().
Voici le résultat attendu :

Étape n° 7 : entraîner le modèle
Le processus est enfin prêt à entraîner le modèle Llama 4 à l’aide de la méthode train():
# Entraîner le modèle
trainer.train()
# Enregistrer le modèle ajusté
trainer.save_model(final_model_adapter_path) # Enregistrer l'adaptateur LoRA
tokenizer.save_pre-trained(final_model_adapter_path) # Enregistrer le tokenizer avec l'adaptateurLe résultat est le suivant :

Notez que vous pouvez obtenir des chiffres différents en raison de la nature stochastique de l’IA.
Étape n° 8 : préparer le modèle pour l’inférence
Pour préparer le modèle pour l’inférence, écrivez le code suivant dans une nouvelle cellule :
# Charger le modèle avec quantification pour l'inférence
base_model_for_inference = AutoModelForCausalLM.from_pre-trained(
base_model_name,
quantization_config=bnb_config,
device_map="auto",
trust_remote_code=True
)
# Charger l'adaptateur LoRA affiné et l'attacher au modèle
fine_tuned_model_for_testing = PeftModel.from_pre-trained(
base_model_for_inference,
final_model_adapter_path
)
# Fusionner l'adaptateur LoRA dans le modèle de base
fine_tuned_model_for_testing = fine_tuned_model_for_testing.merge_and_unload()
# Charger le tokenizer
fine_tuned_tokenizer_for_testing = AutoTokenizer.from_pre-trained(
final_model_adapter_path,
trust_remote_code=True)
# Configurer le tokenizer pour l'inférence
fine_tuned_tokenizer_for_testing.pad_token = fine_tuned_tokenizer_for_testing.eos_token
fine_tuned_tokenizer_for_testing.padding_side = "left"
# Définir le modèle affiné en mode évaluation
fine_tuned_model_for_testing.eval()Le code dans cette cellule :
- Charge le modèle avec la méthode
from_pre-trained()pour l’inférence. - Charge, applique et fusionne l’adaptateur LoRA au modèle de base pour l’inférence.
- Charge le tokenizer affiné et le configure pour l’inférence.
- Met le modèle en mode évaluation avec la méthode
eval(). Cela désactive les comportements spécifiques à l’entraînement, garantissant des résultats cohérents et déterministes pendant l’inférence.
Et voilà ! Tout est prêt pour l’inférence.
Étape n° 9 : Inférence du modèle
Dans cette dernière étape, vous allez effectuer l’inférence. Auparavant, vous avez entraîné Llama 4 sur des produits récupérés sur Amazon. Maintenant, à partir de données comprenant le nom et les caractéristiques d’articles de bureau, vous voulez voir si le modèle est capable de générer leur description.
Le code suivant vous permet de gérer le processus d’inférence :
# Définir une liste d'éléments de données de produits synthétiques pour tester le modèle affiné
synthetic_test_items = [
{
"title": "Chaise de bureau ergonomique Executive", "brand": "ComfortLuxe", "category": "Chaises de bureau", "name": "ErgoPro-EL100",
« features » : [« Conception à dossier haut », « Soutien lombaire réglable », « Tissu en maille respirante », « Mécanisme d'inclinaison synchronisé », « Accoudoirs rembourrés », « Base en nylon robuste »]
},
{
« titre » : « Convertisseur de bureau debout réglable », « marque » : « FlexiDesk », « catégorie » : « Bureaux et postes de travail », « nom » : « HeightRise-FD20 »,
« caractéristiques » : [« Surface spacieuse à deux niveaux », « Levage à ressort à gaz fluide », « Plage de hauteur réglable de 15 à 43 cm », « Supporte jusqu'à 16 kg », « Plateau pour clavier inclus », « Pieds en caoutchouc antidérapants »]
},
{
« titre » : « Ensemble clavier et souris sans fil », « marque » : « TechGear », « catégorie » : « Périphériques informatiques », « nom » : « SilentType-KM850 »,
« features » : [« Clavier pleine taille avec pavé numérique », « Touches silencieuses », « Souris ergonomique avec DPI réglable », « Connectivité sans fil 2,4 GHz », « Longue durée de vie de la batterie », « Récepteur USB plug-and-play »]
},
{
« titre » : « Organiseur de bureau avec tiroirs », « marque » : « NeatOffice », « catégorie » : « Accessoires de bureau », « nom » : « SpaceSaver-DO3 »,
« caractéristiques » : [« Conception à plusieurs compartiments », « Deux tiroirs coulissants », « Construction en bois durable », « Encombrement réduit », « Idéal pour les stylos, les notes et les petits fournitures »]
},
{
« title » : « Lampe de bureau LED avec port de chargement USB », « brand » : « BrightSpark », « category » : « Éclairage de bureau », « name » : « LumiCharge-LS50 »,
« caractéristiques » : [« Niveaux de luminosité réglables (5) », « Modes de température de couleur (3) », « Conception flexible à col de cygne », « Port de chargement USB intégré », « Lumière sans scintillement, respectueuse des yeux », « LED à faible consommation d'énergie »]
},
]
# Message système et structure d'invite pour l'inférence
system_message_inference = « Vous êtes un rédacteur publicitaire expert. Générez une description concise et attrayante du produit à partir des informations fournies. »
print("n--- Génération de descriptions avec un modèle affiné à l'aide de données de test synthétiques ---")
# Itérer à travers chaque élément de la liste synthetic_test_items
for item_data in synthetic_test_items:
# Construire la partie invite utilisateur en fonction de la structure de l'élément synthétique
user_prompt_inference = (
f"Générer une description de produit pour l'article de bureau suivant :n"
f"Titre : {item_data["title"]}n"
f"Marque : {item_data["brand"]}n"
f"Catégorie : {item_data["category"]}n"
f"Nom : {item_data["name"]}n"
f"Caractéristiques : {", ".join(item_data["features"])}n"
f"Description :" # Le modèle générera du texte après cela.
)
full_prompt_for_inference = (
f"<|start_header_id|>system<|end_header_id|>nn{system_message_inference}<|eot_id|>"
f"<|start_header_id|>user<|end_header_id|>nn{user_prompt_inference}<|eot_id|>"
f"<|start_header_id|>assistant<|end_header_id|>nn"
)
print(f"nPROMPT for item: {item_data["name"]}")
# Tokeniser la chaîne de prompt complète à l'aide du tokenizer finement ajusté.
inputs = fine_tuned_tokenizer_for_testing(
full_prompt_for_inference,
return_tensors="pt",
padding=False,
truncation=True,
max_length=max_seq_length_for_tokenization - 150
).to(fine_tuned_model_for_testing.device)
# Effectuer l'inférence
with torch.no_grad():
outputs = fine_tuned_model_for_testing.generate(
**inputs,
max_new_tokens=150,
num_return_sequences=1,
do_sample=True,
temperature=0.6,
top_k=50,
top_p=0.9,
pad_token_id=fine_tuned_tokenizer_for_testing.eos_token_id,
eos_token_id=[
fine_tuned_tokenizer_for_testing.eos_token_id,
fine_tuned_tokenizer_for_testing.convert_tokens_to_ids("<|eot_id|>")
]
)
# Décoder les identifiants de jetons générés en une chaîne de texte lisible par l'utilisateur
generated_text_full = fine_tuned_tokenizer_for_testing.decode(outputs[0], skip_special_tokens=False)
# Définir le marqueur qui indique le début de la réponse de l'assistant dans le format de chat Llama.
assistant_marker = "<|start_header_id|>assistant<|end_header_id|>nn"
# Trouver la dernière occurrence du marqueur assistant dans le texte généré
assistant_response_start_index = generated_text_full.rfind(assistant_marker)
# Extraire la description réelle générée à partir de la sortie complète du modèle
if assistant_response_start_index != -1:
# Si le marqueur assistant est trouvé, extraire le texte qui le suit
description_générée = texte_généré_complet[assistant_response_start_index + len(assistant_marker):]
# Définir le jeton de fin de tour pour Llama
eot_token = "<|eot_id|>"
# Vérifier si la description extraite se termine par le jeton de fin de tour Llama et le supprimer.
if generated_description.endswith(eot_token):
generated_description = generated_description[:-len(eot_token)]
# Vérifier également s'il se termine par le jeton de fin de séquence standard du tokenizer et le supprimer.
if generated_description.endswith(fine_tuned_tokenizer_for_testing.eos_token):
description_générée = description_générée[:-len(jeton_eos_du_tokenizer_affiné_pour_les_tests)]
# Supprimez tous les espaces blancs en début ou en fin de la description nettoyée.
description_générée = description_générée.strip()
else:
# Solution de secours : Si le marqueur assistant n'est pas trouvé, essayez d'extraire la partie générée en supposant qu'il s'agit de tout ce qui se trouve après l'invite d'entrée d'origine.
input_prompt_decoded_len = len(fine_tuned_tokenizer_for_testing.decode(inputs["input_ids"][0], skip_special_tokens=False))
# Décodez les jetons de l'invite d'entrée pour obtenir sa longueur sous forme de chaîne.
description_générée = texte_généré_complet[longueur_décodée_de_l'invite_de_saisie:].strip()
# Nettoyer tout jeton de fin de tour Llama résiduel de cette extraction de secours.
si description_générée.endswith("<|eot_id|>"):
description_générée = description_générée[:-len("<|eot_id|>")]
description_générée = description_générée.strip()
# Imprimer la description générée extraite et nettoyée.
print(f"GÉNÉRÉ (ajusté) :n{description_générée}")
# Imprimer une ligne de séparation pour une meilleure lisibilité entre les éléments.
print("-" * 50)Cette dernière cellule du notebook Jupyter gère le processus d’inférence. Ce processus est utile pour évaluer la qualité de l’entraînement pendant le processus de réglage fin.
En particulier, le code ci-dessus :
- Définit les données de test comme une liste appelée
synthetic_test_items. Chaque élément de cette liste est un dictionnaire représentant un produit, contenant des détails tels que son titre, sa marque, sa catégorie, son nom et une liste de caractéristiques. Ces données servent d’entrée pour le modèle et leur structure doit correspondre à celle de l’ensemble de données de réglage fin. - Configure la structure de l’invite de référence avec
system_message_inference. Celle-ci doit correspondre à l’invite utilisée pendant le processus d’entraînement. - La boucle
for item_data in synthetic_test_itemscrée une invite utilisateur pour chaqueitem_data. La structure de chaqueitem_datadoit correspondre à celle utilisée dans le processus d’entraînement. - Tokenise et contrôle la manière dont le modèle produit le texte de sortie. L’inférence réelle est effectuée sous l’instruction
with. En particulier, grâce à la méthodegenerate()qui est l’étape d’inférence principale. - Décode la sortie brute du modèle (qui est une séquence d’identifiants de jetons) en une chaîne lisible par l’homme (
generated_text_full) à l’aide du tokenizer. - Utilise un bloc
if-elsepour nettoyer la sortie brute du modèle linguistique afin d’extraire uniquement la description du produit générée par l’assistant. La sortie brute (generated_text_full) comprend généralement l’intégralité de l’invite d’entrée suivie de la réponse du modèle, le tout formaté avec les jetons de chat spéciaux de Llama. - Affiche les résultats.
Vous pouvez vous attendre au résultat suivant :
--- Génération de descriptions avec un modèle affiné à l'aide de données de test synthétiques ---
INVITATION pour l'article : ErgoPro-EL100
GÉNÉRÉ (affiné) :
**Présentation de l'ErgoPro-EL100 : le fauteuil de bureau ergonomique ultime pour cadres**
Découvrez le summum du confort et du soutien avec le ComfortLuxe ErgoPro-EL100, conçu pour améliorer votre expérience de travail. Ce fauteuil de bureau haut de gamme est doté d'un dossier haut qui enveloppe le haut de votre corps, offrant un soutien lombaire inégalé et favorisant une posture saine.
Le tissu en maille respirante garantit une assise fraîche et confortable, tandis que le mécanisme d'inclinaison synchronisé permet de régler en douceur votre position de travail préférée. Les accoudoirs rembourrés offrent un soutien et un confort supplémentaires, réduisant la tension sur vos épaules et vos poignets.
Conçue pour durer, la ErgoPro-EL100 est dotée d'une base en nylon robuste qui garantit stabilité et durabilité. Que vous travailliez de longues heures ou simplement
--------------------------------------------------
PROMPT pour l'article : HeightRise-FD20
GÉNÉRÉ (affiné) :
**Augmentez votre productivité avec le convertisseur de bureau debout réglable HeightRise-FD20 de FlexiDesk**
Donnez une nouvelle dimension à votre travail avec le HeightRise-FD20 de FlexiDesk, le convertisseur de bureau debout réglable ultime. Conçu pour révolutionner votre espace de travail, ce convertisseur innovant transforme n'importe quel bureau en un poste de travail debout confortable et ergonomique.
**Découvrez les avantages du travail debout**
Le HeightRise-FD20 dispose d'une surface spacieuse à deux niveaux, parfaite pour accueillir votre ordinateur portable, votre écran et d'autres outils de travail essentiels. Le vérin à gaz fluide permet un réglage en hauteur sans effort, de 15 à 43 cm, garantissant une position debout confortable qui répond à vos besoins.
**Durable et fiable**
Avec une construction robuste et des pieds en caoutchouc antidérapants
--------------------------------------------------Et voilà ! Vous avez affiné Llama 4 grâce à un nouvel ensemble de données récupérées à l’aide des API Bright Data Scraper.
Conclusion
Dans cet article, vous avez appris à affiner Llama 4 à l’aide d’un ensemble de données extraites d’Amazon à l’aide des API Bright Data Scraper. Vous avez suivi tout le processus qui consiste à :
- Récupérer les données sur le web.
- Créer un compte Hugging Face avec un jeton.
- Configurer l’infrastructure cloud nécessaire.
- La formation et le test (inférence) de Llama 4.
Le cœur du processus de réglage fin repose sur la disponibilité de jeux de données de haute qualité. Heureusement, Bright Data vous propose de nombreux services prêts à l’emploi pour l’acquisition ou la création de jeux de données :
- Navigateur de scraping: un navigateur compatible avec Playwright, Selenium et Puppeter, doté de capacités de déverrouillage intégrées.
- API Web Scraper: API préconfigurées pour extraire des données structurées de plus de 100 domaines majeurs.
- Web Unlocker: une API tout-en-un qui gère le déverrouillage des sites dotés de protections anti-bot.
- API SERP: une API spécialisée qui déverrouille les résultats des moteurs de recherche et extrait les données SERP complètes.
- Modèles de base: accédez à des jeux de données conformes et à l’échelle du Web pour alimenter la préformation, l’évaluation et le réglage fin.
- Fournisseurs de données: connectez-vous à des fournisseurs de confiance pour obtenir des jeux de données de haute qualité, prêts pour l’IA, à grande échelle.
- Packages de données: obtenez des jeux de données sélectionnés, prêts à l’emploi, structurés, enrichis et annotés.
Créez gratuitement un compte Bright Data pour tester notre infrastructure de données prête pour l’IA !





