

Dans ce guide sur le réglage fin de GPT-OSS avec des données web, vous apprendrez :
- Ce qu’est Unsloth et pourquoi il accélère la mise au point
- Comment collecter des données de formation de qualité à l’aide des API de scraping de Bright Data.
- Comment configurer votre environnement pour un réglage fin efficace
- Comment affiner le réglage de GPT-OSS avec un tutoriel complet étape par étape
C’est parti !
Qu’est-ce qu’Unsloth et pourquoi l’utiliser pour le réglage fin ?
Unsloth est une bibliothèque légère qui rend le réglage fin LLM significativement plus rapide tout en étant entièrement compatible avec l’écosystème Hugging Face (Hub, transformers, PEFT, TRL). La bibliothèque prend en charge la plupart des GPU NVIDIA, de la GTX 1070 à la H100, et fonctionne de manière transparente avec l’ensemble de la suite de formateurs de la bibliothèque TRL.

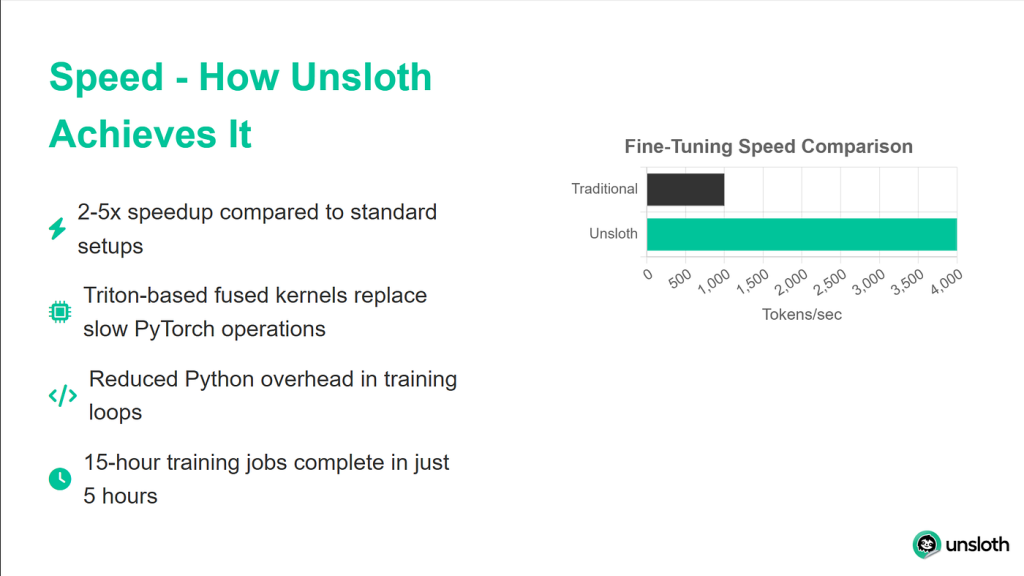
Les améliorations de performances apportées par Unsloth sont impressionnantes. Dans les benchmarks, il atteint des vitesses d’entraînement deux fois plus rapides que les implémentations de transformateurs standard, tout en utilisant 40 % de mémoire en moins. Cela signifie que vous pouvez entraîner de plus grands modèles ou utiliser des lots plus importants sur le même matériel. Plus important encore, la dégradation de la précision est nulle, ce qui vous permet de bénéficier de tous ces avantages sans sacrifier la qualité du modèle.
Comprendre les modèles GPT-OSS
La sortie de GPT-OSS par OpenAI marque un changement important dans son approche du développement de l’IA. Pour la première fois, nous avons accès à de véritables modèles GPT sans limitations d’API, sans facturation basée sur l’utilisation ou sans limites de taux.
GPT-OSS se décline en deux variantes principales :
- GPT-OSS-120B: ce modèle plus grand correspond à la qualité de GPT-4 mais nécessite au moins 80 Go de mémoire GPU.
- GPT-OSS-20B: comparable aux performances de GPT-3.5, ce modèle fonctionne efficacement sur des GPU de 16 Go (parfait pour notre tutoriel).
Une caractéristique unique qui distingue GPT-OSS des autres modèles ouverts est son contrôle de l’effort de raisonnement. Vous pouvez ajuster la profondeur de réflexion du modèle en réglant le niveau de raisonnement sur “faible”, “moyen” ou “élevé”. Cela vous permet d’équilibrer la vitesse et la précision en fonction de votre cas d’utilisation spécifique.
Pourquoi les données de qualité sont-elles importantes pour le réglage fin ?
La qualité duréglage fin dépend des données que vous lui fournissez. Nous pourrions avoir la configuration d’entraînement la plus sophistiquée, mais si nos données sont bruyantes, incohérentes ou mal formatées, votre modèle apprendra ces mêmes problèmes. C’est pourquoi nous utiliserons les API Web Scraper de Bright Data pour obtenir des données propres, bien formatées et précises.
Bright Data gère les parties complexes du Scraping web qui font souvent échouer les solutions personnalisées. Il gère la rotation des adresses IP pour éviter la limitation du débit, résout automatiquement les CAPTCHA, gère le contenu dynamique rendu par JavaScript et maintient une qualité de données cohérente sur des millions de requêtes.
Pour notre tutoriel, nous utiliserons l’API de Bright Data pour collecter de la documentation Python, que nous transformerons ensuite en données d’entraînement pour notre modèle.
Conditions préalables et configuration de l’environnement
Avant de commencer, assurez-vous que vous disposez de tout ce qui est nécessaire à la réussite de l’ajustement. Nous utiliserons Google Colab car il offre un accès gratuit au GPU, mais le même processus fonctionne sur n’importe quelle machine disposant d’au moins 16 Go de VRAM.
Matériel requis
Pour ce tutoriel, vous aurez besoin de :
- Un GPU avec au moins 16 Go de VRAM (T4, V100, ou mieux)
- 25 Go d’espace disque libre pour les poids des modèles et les points de contrôle
- Une connexion internet stable pour télécharger les modèles et les dépendances.
Dans Google Colab, vous pouvez accéder gratuitement à un GPU T4 :
- Ouvrir un nouveau notebook
- Aller dans Runtime → Change runtime type (changer le type de runtime)
- Sélectionnez GPU comme accélérateur matériel
- Cliquez sur Enregistrer pour appliquer les changements.
Installation d’Unsloth et des dépendances
Une fois que votre runtime GPU est prêt, nous allons installer Unsloth et toutes les dépendances nécessaires. Le processus d’installation est optimisé pour éviter les conflits entre les différentes versions des paquets :
%%capture
# Installer Unsloth et ses dépendances
!pip install --upgrade -qqq uv
try : import numpy ; get_numpy = f "numpy=={numpy.__version__}"
except : get_numpy = "numpy"
!uv pip install -qqq N
"torch>=2.8.0" "triton>=3.4.0" {get_numpy} torchvision bitsandbytes "transformers>=4.55.3" N- "unsloth_zoo[1]" (en anglais)
"unsloth_zoo[base] @ git+https://github.com/unslothai/unsloth-zoo" N- "unsloth_zoo[base]" @ git+https://github.com/unslothai/unsloth-zoo
"unsloth[base] @ git+https://github.com/unslothai/unsloth" N- "unsloth_zoo[base]" @ git+https://github.com/unslothai/unsloth
git+https://github.com/triton-lang/triton.git@05b2c186c1b6c9a08375389d5efe9cb4c401c075#sous-répertoire=python/triton_kernels
!uv pip install --upgrade --no-deps transformers==4.56.2 tokenizers
!uv pip install --no-deps trl==0.22.2
!pip install -q brightdata-sdkCe script d’installation gère plusieurs détails importants. Tout d’abord, il utilise uv pour une résolution plus rapide des paquets. Il épingle également des versions spécifiques pour éviter les problèmes de compatibilité, installe les noyaux Triton personnalisés d’Unsloth pour des performances optimales, et inclut le SDK Bright Data pour notre étape de collecte de données.
Vérification de la configuration de votre GPU
Après l’installation, vérifions que votre GPU est correctement détecté et qu’il dispose de suffisamment de mémoire :
import torch
# Obtenir des informations sur le GPU
gpu_stats = torch.cuda.get_device_properties(0)
max_memory = round(gpu_stats.total_memory / 1024 / 1024 / 1024, 3)
print(f "GPU = {gpu_stats.name}")
print(f "Mémoire maximale = {max_mémoire} Go")
print(f "Version CUDA = {torch.version.cuda}")
print(f "PyTorch version = {torch.__version__}")
# Vérifier les exigences minimales
if max_memory < 15 :
print("⚠️ Warning : Your GPU may not have enough memory for GPT-OSS-20B")
else :
print("✅ Votre GPU a suffisamment de mémoire pour le réglage fin")Vous devriez voir au moins 15 Go de mémoire GPU disponible. Le GPU T4 de free Colab dispose de 16 Go, ce qui est parfait pour nos besoins avec les optimisations d’Unsloth.
Chargement de GPT-OSS avec Unsloth
Nous allons maintenant charger le modèle GPT-OSS en utilisant le chargeur optimisé d’Unsloth. Le processus est remarquablement simple comparé aux transformateurs standards, car Unsloth gère tous les détails d’optimisation automatiquement.
Chargement du modèle de base
from unsloth import FastLanguageModel
import torch
# Configuration
max_seq_length = 1024 # Ajuster en fonction de vos données
dtype = None # Auto-détection du meilleur dtype pour votre GPU
# Unsloth fournit des modèles pré-quantifiés pour un chargement plus rapide
fourbit_models = [
"unsloth/gpt-oss-20b-unsloth-bnb-4bit", # BitsAndBytes 4bit
"unsloth/gpt-oss-120b-unsloth-bnb-4bit",
"unsloth/gpt-oss-20b", # Format MXFP4
"unsloth/gpt-oss-120b",
]
# Charger le modèle
model, tokenizer = FastLanguageModel.from_pretrained(
nom_du_modèle = "unsloth/gpt-oss-20b",
dtype = dtype,
max_seq_length = max_seq_length,
load_in_4bit = True, # Essentiel pour l'ajustement dans 16GB
full_finetuning = False, # Utilise LoRA pour l'efficacité
)
print(f"✅ Modèle chargé avec succès !")
print(f "Taille du modèle : {model.num_parameters() :,} paramètres")
print(f "Utilisation de l'appareil : {model.device}")La méthode FastLanguageModel.from_pretrained() effectue plusieurs opérations en coulisse. Elle détecte automatiquement les capacités de votre GPU et les optimise en conséquence, applique une quantification sur 4 bits pour réduire l’utilisation de la mémoire de 75 %, configure le modèle pour l’entraînement LoRA au lieu d’un réglage fin complet, et configure des mécanismes d’attention efficaces sur le plan de la mémoire.
Configuration des adaptateurs LoRA
LoRA (Low-Rank Adaptation) est ce qui rend le réglage fin possible sur du matériel grand public. Au lieu de mettre à jour tous les paramètres du modèle, nous n’entraînons que de petites matrices d’adaptation qui sont insérées dans les couches clés :
model = FastLanguageModel.get_peft_model(
modèle,
r = 8, # rang LoRA - plus élevé = plus de capacité mais plus lent
target_modules = ["q_proj", "k_proj", "v_proj", "o_proj",
"gate_proj", "up_proj", "down_proj"],
lora_alpha = 16, # facteur d'échelle LoRA
lora_dropout = 0, # Dropout désactivé pour un entraînement plus rapide
bias = "none", # Ne pas entraîner les termes de biais
use_gradient_checkpointing = "unsloth", # Critique pour les économies de mémoire
random_state = 3407,
use_rslora = False, # La LoRA standard fonctionne mieux dans la plupart des cas
loftq_config = None,
)
# Afficher les statistiques d'entraînement
trainable_params = sum(p.numel() for p in model.parameters() if p.requires_grad)
all_params = sum(p.numel() for p in model.parameters())
trainable_percent = 100 * trainable_params / all_params
print(f "Entraînement de {paramètres entraînables :,} paramètres sur {tous_paramètres :,}")
print(f "C'est seulement {trainable_percent :.2f}% de tous les paramètres !")
print(f "Mémoire sauvegardée : ~{(1 - pourcentage_formable/100) * 40 :.1f}GB")Cette configuration permet de trouver un équilibre entre l’efficacité de l’apprentissage et la capacité du modèle. Avec r=8, nous formons moins de 1% des paramètres totaux tout en obtenant d’excellents résultats de réglage fin. Le point de contrôle du gradient permet à lui seul d’économiser environ 30 % de mémoire, ce qui peut faire la différence entre l’ajustement de votre modèle en mémoire et l’obtention d’erreurs OOM (Out of Memory).
Test du contrôle de l’effort de raisonnement GPT-OSS
Avant de commencer le réglage fin, explorons la fonction unique d’effort de raisonnement de GPT-OSS. Celle-ci vous permet de contrôler la quantité de “réflexion” que le modèle effectue avant de répondre :
from transformers import TextStreamer
# Problème de test nécessitant un raisonnement mathématique
messages = [
{"role" : "user", "content" : "Résolvez x^5 + 3x^4 - 10 = 3. Expliquez votre approche."},
]
# Test avec un faible effort de raisonnement
print("="*60)
print("LOW REASONING (Rapide mais moins approfondi)")
print("="*60)
inputs = tokenizer.apply_chat_template(
messages,
add_generation_prompt = True,
return_tensors = "pt",
return_dict = True,
reasoning_effort = "low",
).to("cuda")
text_streamer = TextStreamer(tokenizer, skip_prompt=True, skip_special_tokens=True)
_ = model.generate(**inputs, max_new_tokens = 128, streamer = text_streamer)
# Test avec effort de raisonnement HAUT
print("n" + "="*60)
print("RAISONNEMENT HAUT (plus lent mais plus précis)")
print("="*60)
inputs = tokenizer.apply_chat_template(
messages,
add_generation_prompt = True,
return_tensors = "pt",
return_dict = True,
reasoning_effort = "high",
).to("cuda")
_ = model.generate(**inputs, max_new_tokens = 512, streamer = text_streamer)Lorsque nous exécutons ce code, nous constatons qu’avec un raisonnement “faible”, le modèle donne une réponse rapide et approximative, tandis que le raisonnement “élevé” produit une solution plus détaillée avec un travail étape par étape. Cette fonctionnalité est inestimable pour équilibrer la vitesse et la précision dans les déploiements de production.
Collecte de données de formation avec Bright Data
Nous allons maintenant collecter des données de formation de haute qualité à l’aide de l’API Web Scraper de Bright Data. Cette approche est beaucoup plus fiable que la création de votre propre Scraper, car Bright Data gère toute l’infrastructure complexe nécessaire au Scraping web à grande échelle.
Configuration du collecteur de données
from brightdata import bdclient
from typing import List, Dict
import re
import json
classe DataCollector :
def __init__(self, api_token : str) :
"""
Initialise le client Bright Data pour le Scraping web.
Args :
api_token : Votre clé d'API Bright Data
"""
self.client = bdclient(api_token=api_token)
self.collected_data = []
print("✅ Client Bright Data initialisé")
def collect_documentation(self, urls : List[str]) -> List[Dict] :
"""
Récupère les pages de documentation et les convertit en données d'entraînement.
Cette méthode gère à la fois le scraping d'URLs par lot et individuel,
automatiquement les requêtes individuelles si le lot échoue.
"""
print(f "Démarrage du scrape de {len(urls)} URLs...")
try :
# Tentative de scraping par lot pour plus d'efficacité
results = self.client.scrape(urls, data_format="markdown")
if isinstance(results, str) :
# Un seul résultat est retourné
print("Traitement d'un seul résultat...")
training_data = self.process_single_result(results)
elif isinstance(results, list) :
# Retour de plusieurs résultats
print(f "Traitement de {len(résultats)} résultats...")
training_data = []
for i, content in enumerate(results, 1) :
if content :
print(f" Traitement du résultat {i}/{len(résultats)}")
exemples = self.process_single_result(content)
training_data.extend(examples)
else :
print(f "Type de résultat inattendu : {type(résultats)}")
training_data = []
except Exception as e :
print(f "L'analyse par lots a échoué : {e}")
print("Retour au scraping d'URL individuel...")
# Fallback : scraper les URL une par une
training_data = []
for url in urls :
try :
print(f" Scraping : {url}")
content = self.client.scrape(url, data_format="markdown")
if content :
examples = self.process_single_result(content)
training_data.extend(examples)
print(f" ✓ Extracted {len(examples)} examples")
except Exception as url_error :
print(f" ✗ Échec : {url_error}")
self.collected_data = training_data
print(f"n✅ Collection complete : {len(self.collected_data)} exemples de formation")
return self.collected_dataCe que fait ce code :
- Stratégie de repli intelligente: Le collecteur essaie d’abord le scraping par lots pour des raisons d’efficacité. En cas d’échec (en raison de problèmes de réseau ou de limites de l’API), il revient automatiquement au scraping d’URL individuelles.
- Suivi de la progression: Des mises à jour en temps réel nous montrent exactement ce qui se passe pendant le processus de scraping, ce qui facilite le débogage.
- Résistance aux erreurs: Chaque URL est enveloppée dans son propre bloc try-catch, de sorte qu’une URL défaillante n’interrompt pas l’ensemble du processus de collecte.
- Format Markdown: Nous demandons des données au format Markdown parce qu’il est plus propre que le HTML et plus facile à traiter dans les données de formation.
Le client Bright Data gère plusieurs tâches complexes pour nous :
- Rotation des adresses IP pour éviter la limitation du débit
- Résolution de CAPTCHAs automatiquement
- Rendu des pages à forte teneur en JavaScript
- Réessayer les requêtes échouées avec un backoff exponentiel
Traitement du contenu récupéré en données de formation
La clé d’un bon réglage fin réside dans des données propres et bien formatées. Voici comment nous traitons le contenu brut en paires question-réponse :
def process_single_result(self, content : str) -> List[Dict] :
"""
Traiter le contenu scrapé en paires d'entraînement Q&A propres.
Cette méthode effectue un nettoyage agressif pour supprimer tous les
artefacts de formatage et créer des exemples à la sonorité naturelle.
"""
exemples = []
# Étape 1 : Supprimer tous les formats HTML et Markdown
content = re.sub(r'<[^>]+>', '', content) # Balises HTML
content = re.sub(r'!N-[.*?N]N(.*?N)', '', content) # Images
content = re.sub(r'N-[([^N]]+)N-([^N]]+N)', r'N1', content) # Liens
content = re.sub(r'``[^`]*```', '', content) # Blocs de code
content = re.sub(r'`[^`]+`', '', content) # Code Inline
content = re.sub(r'[#*_~>`|-]+', ' ', content) # Symboles Markdown
content = re.sub(r'\N(.)', r'N', content) # Séquences d'échappement
content = re.sub(r'https?://[^s]+', '', content) # URLs
content = re.sub(r'S+.w+', '', content) # Chemins d'accès aux fichiers
content = re.sub(r's+', ' ', content) # Normaliser les espaces blancs
# Etape 2 : Diviser en phrases
sentences = re.split(r'(?<=[. !?])s+', content)
# Etape 3 : Filtrer la navigation et le contenu de type "boilerplate
clean_sentences = []
skip_patterns = ['navigation', 'copyright', 'index',
'table des matières', 'précédent', 'suivant',
'cliquer ici', 'télécharger', 'partager']
pour sent dans sentences :
sent = sent.strip()
# Ne garder que les phrases substantielles
if (len(sent) > 30 and
not any(skip in sent.lower() for skip in skip_patterns)) :
clean_sentences.append(sent)
# Étape 4 : Créer des paires Q&A à partir de phrases consécutives
for i in range(0, len(clean_sentences) - 1) :
instruction = clean_sentences[i][:200].strip()
réponse = clean_sentences[i + 1][:300].strip()
# S'assurer que les deux parties sont substantielles
if len(instruction) > 20 and len(response) > 30 :
exemples.append({
"instruction" : instruction,
"response" : response
})
Retourner les exemplesFonctionnement du traitement :
La méthode process_single_result transforme le contenu web brut en données de formation propres en quatre étapes critiques :
- Étape 1 – Nettoyage agressif: Nous supprimons tous les artefacts de formatage susceptibles de perturber le modèle :
- les balises HTML qui ont pu survivre à la conversion Markdown
- les références d’images et les liens qui n’ajoutent aucune valeur à la compréhension du texte
- Blocs de code et code en ligne (nous voulons de la prose, pas des échantillons de code)
- Les caractères spéciaux et les séquences d’échappement qui créent du bruit
- Étape 2 – Segmentation des phrases: Nous divisons le contenu en phrases individuelles à l’aide de marqueurs de ponctuation. Nous obtenons ainsi des unités de texte logiques sur lesquelles nous pouvons travailler.
- Étape 3 – Filtrage de la qualité: Nous supprimons :
- les phrases courtes (moins de 30 caractères) qui manquent de substance
- Les éléments de navigation tels que “cliquez ici” ou “page suivante”.
- Le contenu de base comme les avis de droits d’auteur
- Toute phrase contenant des schémas de navigation courants sur le web
- Étape 4 – Création de paires: Nous créons des paires de formation en traitant les phrases consécutives comme des paires question-réponse. Cette méthode fonctionne car la documentation suit souvent un modèle qui consiste à énoncer un concept puis à l’expliquer.
Il en résulte des données de formation propres et contextuelles qui enseignent au modèle des flux naturels et des schémas de réponse.
Collecte et validation des données
Maintenant, mettons tout cela ensemble et collectons nos données de formation :
# Initialiser le collecteur avec votre jeton API
# Obtenez votre jeton à partir de : /cp/api_tokens
BRIGHTDATA_API_TOKEN = "your_brightdata_api_token_here"
collector = DataCollector(api_token=BRIGHTDATA_API_TOKEN)
# URLs à gratter - la documentation Python fait d'excellentes données d'entraînement
urls = [
"https://docs.python.org/3/tutorial/introduction.html",
"https://docs.python.org/3/tutorial/controlflow.html",
"https://docs.python.org/3/tutorial/datastructures.html",
"https://docs.python.org/3/tutorial/modules.html",
"https://docs.python.org/3/tutorial/classes.html",
]
print("="*60)
print("COMMENCER LA COLLECTE DE DONNÉES")
print("="*60)
training_data = collector.collect_documentation(urls)
# Valider que nous avons des données
if len(training_data) == 0 :
print("⚠️ ERREUR : Aucune donnée de formation n'a été collectée !")
print("Étapes de dépannage :")
print("1. vérifiez que votre clé API Bright Data est correcte")
print("2. vérifiez que votre compte dispose de suffisamment de crédits")
print("3. Essayez d'abord avec une seule URL pour tester la connectivité")
raise ValueError("Aucune donnée de formation collectée")Comprendre la configuration de la collecte de données :
- Jeton API: Vous devez ouvrir un compte Bright Data pour obtenir votre clé API. Bright Data propose un essai gratuit avec des crédits pour vous aider à démarrer.
- Sélection de l’URL: Nous utilisons la documentation Python pour les raisons suivantes :
- Elle est bien structurée et cohérente
- Elle contient un contenu technique parfait pour la formation d’un assistant de codage.
- Le style explicatif se traduit bien par des questions-réponses.
- Elle est accessible au public et d’origine éthique.
- Gestion des erreurs: Le contrôle de validation permet de s’assurer que vous ne procédez pas avec un jeu de données vide, ce qui ferait échouer la formation par la suite. Les étapes de dépannage permettent de diagnostiquer les problèmes courants.
Validation finale des données et nettoyage
Avant d’utiliser les données pour la formation, nous effectuons un dernier nettoyage :
# Validation et nettoyage finaux
def final_validation(examples : List[Dict]) -> List[Dict] :
"""
Effectuer la validation finale et le dédoublonnage des exemples d'entraînement.
"""
clean_data = []
seen_instructions = set()
pour ex dans exemples :
instruction = ex.get('instruction', '').strip()
response = ex.get('response', '').strip()
# Dernière passe de nettoyage
instruction = re.sub(r'[^a-zA-Z0-9s.,? !]', '', instruction)
response = re.sub(r'[^a-zA-Z0-9s.N,N?N !]', '', response)
# Supprimer les doublons et assurer la qualité
if (len(instruction) > 10 and
len(response) > 20 et
instruction pas dans seen_instructions) :
seen_instructions.add(instruction)
clean_data.append({
"instruction" : instruction,
"response" : réponse
})
return clean_data
training_data = final_validation(training_data)
print(f"n✅ Jeux de données final : {len(training_data)} exemples uniques")
print("nExemples de formation :")
print("="*60)
for i, example in enumerate(training_data[:3], 1) :
print(f"nExemple {i} :")
print(f "Q : {exemple['instruction']}")
print(f "A : {exemple['réponse']}")Ce que la validation accomplit :
- Ladéduplication: L’ensemble
seen_instructionspermet de s’assurer qu’il n’y a pas de questions en double, ce qui pourrait entraîner un surajustement lors de la formation. - Nettoyage final des caractères: Nous supprimons tous les caractères spéciaux restants, à l’exception de la ponctuation de base, afin de garantir la propreté et la cohérence du texte.
- Validation de la longueur: Nous appliquons des longueurs minimales pour nous assurer que les exemples ont de la substance :
- Les instructions doivent comporter au moins 10 caractères.
- Les réponses doivent comporter au moins 20 caractères.
- Assurance qualité: En imprimant des exemples, vous pouvez vérifier visuellement la qualité des données avant de procéder à la formation.
La sortie finale doit présenter des paires de questions-réponses propres et lisibles qui ont un sens en tant que données de formation. Si les exemples semblent absurdes ou mal formatés, vous devrez peut-être ajuster les paramètres de traitement ou choisir d’autres URL sources.
Conseil de pro : pour les cas d’utilisation en production, pensez à utiliser la place de marché de Bright Data pour les jeux de données pré-collectés. Elle propose des Jeux de données curatées pour divers domaines qui peuvent vous faire gagner un temps considérable et garantir une qualité constante.
Formatage des données pour la formation GPT-OSS
GPT-OSS attend des données dans un format de chat spécifique. Nous utiliserons les utilitaires d’Unsloth pour nous assurer que nos données sont correctement formatées pour des résultats de formation optimaux :
from unsloth.chat_templates import standardize_sharegpt
from Jeux de données import Dataset
def prepare_dataset(raw_data : List[Dict]) :
"""
Convertit les paires de questions-réponses brutes en jeux de données d'entraînement correctement formatés.
Cette fonction gère :
1. Conversion au format message
2. Application du modèle de chat GPT-OSS
3. Correction des problèmes de formatage
"""
print("Préparation des Jeux de données pour l'entraînement...")
# Étape 1 : Conversion au format du message de chat
données_formatées = []
pour item dans raw_data :
formatted_data.append({
"messages" : [
{"role" : "user", "content" : item["instruction"]},
{"rôle" : "assistant", "content" : item["response"]}
]
})
# Étape 2 : Création du jeu de données HuggingFace
dataset = Dataset.from_list(formatted_data)
print(f "Jeu de données créé avec {len(jeu de données)} exemples")
# Étape 3 : Normalisation au format ShareGPT
dataset = standardize_sharegpt(dataset)Ce qui se passe dans cette première partie :
- Conversion du format des messages: Nous transformons nos paires de questions-réponses simples en un format de conversation auquel les modèles GPT s’attendent. Chaque exemple d’entraînement devient une conversation à deux tours avec une question de l’utilisateur et une réponse de l’assistant.
- Création de données: La classe Jeux de données de HuggingFace permet une gestion efficace des données, notamment :
- Accès en mémoire pour les Jeux de données de grande taille.
- Mise en lot et mélange intégrés
- Compatibilité avec l’ensemble de l’écosystème HuggingFace
- Standardisation de ShareGPT: La fonction
standardize_sharegptgarantit que nos données correspondent au format ShareGPT, qui est devenu la norme de facto pour l’entraînement des modèles de chat. Cela permet de gérer les cas particuliers et d’assurer la cohérence.
Application du modèle de conversation
Nous appliquons maintenant les exigences de formatage spécifiques de GPT-OSS :
# Étape 4 : Appliquer le modèle de conversation spécifique à GPT-OSS
def formatting_prompts_func(examples) :
"""Appliquer le modèle de discussion GPT-OSS à chaque exemple."""
convos = exemples["messages"]
textes = []
for convo in convos :
# Appliquer le modèle sans invite de génération (nous sommes en train de nous entraîner)
text = tokenizer.apply_chat_template(
convo,
tokenize = False,
add_generation_prompt = False
)
texts.append(text)
return {"text" : texts}
dataset = dataset.map(
formatting_prompts_func,
batched = True,
desc = "Applying chat template"
)Comprendre l’application du modèle :
- Chat Template Objectif: Chaque famille de modèles a ses propres balises et formatages. GPT-OSS utilise des balises telles que
<|start|>,<|message|>et<|channel|>pour délimiter les différentes parties de la conversation. - Pas d’invite de génération: Nous avons défini
add_generation_prompt = Falseparce que nous sommes en train de nous entraîner, pas de générer. Pendant l’entraînement, nous voulons que le modèle voie des conversations complètes, et non des invites qui attendent d’être complétées. - Traitement par lots: Le paramètre
batched = Truetraite plusieurs exemples à la fois, ce qui accélère considérablement le processus de formatage pour les jeux de données volumineux. - Sortie texte: À ce stade, nous conservons la sortie sous forme de texte (non symbolisé), car le formateur gérera la symbolisation avec ses propres paramètres.
Vérification et résolution des problèmes de format
GPT-OSS a une exigence spécifique pour l’étiquette de canal que nous devons vérifier :
# Étape 5 : Vérifier et corriger la balise de canal si nécessaire
sample_text = Jeux de données[0]['text']
print("nVérification du format...")
print(f "Échantillon (200 premiers caractères) : {sample_text[:200]}")
si "<|channel|>" n'est pas dans sample_text :
print("⚠️ Balise de canal manquante, correction du format...")
def fix_formatting(examples) :
"""Ajouter la balise channel pour la compatibilité GPT-OSS."""
textes_fixés = []
pour texte dans exemples["texte"] :
# GPT-OSS attend une balise de canal entre le rôle et le message
text = text.replace(
"<|start|>assistant<|message|>",
"<|start|>assistant<|canal|>final<|message|>"
)
fixed_texts.append(text)
return {"text" : fixed_texts}
jeux de données = jeux de données.map(
fix_formatting,
batched = True,
desc = "Adding channel tags"
)
print("✅ Format fixé")
print(f"n✅ Jeux de données prêt : {len(dataset)} exemples formatés")
return jeux de données
# Préparer le jeu de données
dataset = prepare_dataset(training_data)Pourquoi l’étiquette de canal est-elle importante ?
- Fonction de la balise de canal: La balise
<|channel|>finalindique à GPT-OSS qu’il s’agit de la réponse finale, et non d’une étape de raisonnement intermédiaire. Cela fait partie du système unique de contrôle de l’effort de raisonnement de GPT-OSS. - Vérification du format: Nous vérifions si la balise existe et l’ajoutons si elle est manquante. Cela permet d’éviter les échecs de formation dus à des erreurs de format.
- Correction automatique: L’opération de remplacement assure la compatibilité sans nécessiter d’intervention manuelle. Ceci est particulièrement important lors de l’utilisation de différentes versions de tokenizer qui peuvent avoir des comportements par défaut différents.
Statistiques et validation de l’ensemble de données
Enfin, vérifions notre jeu de données préparé :
# Afficher les statistiques
print("NStatistiques du jeu de données :")
print(f "Nombre d'exemples : {len(jeux de données)}")
print(f "Longueur moyenne du texte : {sum(len(x['text']) for x in dataset) / len(dataset) :.0f} chars")
# Afficher un exemple formaté complet
print("nExemple formaté :")
print("="*60)
print(Jeux de données[0]['text'][:500])
print("="*60)
# Vérifier que tous les exemples ont le bon format
format_checks = {
"has_user_tag" : all("<|start|>user" in ex['text'] for ex in dataset),
"has_assistant_tag" : all("<|start|>assistant" in ex['text'] for ex in dataset),
"has_channel_tag" : all("<|channel|>" in ex['text'] for ex in dataset),
"has_message_tags" : all("<|message|>" in ex['text'] for ex in dataset),
}
print("nValidation du format :")
pour check, passé dans format_checks.items() :
status = "✅" if passed else "❌"
print(f"{status} {check} : {passed}")Ce qu’il faut rechercher dans la validation :
- Statistiques de longueur: La longueur moyenne du texte vous aide à définir les longueurs de séquence appropriées pour la formation. S’il est trop long, il peut être nécessaire de le tronquer ou d’utiliser une longueur max_seq_length plus importante.
- Complétude du format: Les quatre contrôles doivent être réussis :
- Les balises utilisateur indiquent où commence la saisie de l’utilisateur
- Les balises Assistant marquent les réponses du modèle
- Les balises de canal spécifient le type de réponse
- Les balises de message contiennent le contenu réel
- Inspection visuelle: L’exemple imprimé vous permet de voir exactement ce sur quoi le modèle va s’entraîner. Il devrait ressembler à ceci :
<|start|>utilisateur<|message|>Votre question ici<|end|>
<|start|>assistant<|canal|>final<|message|>La réponse ici<|end|>Si une validation échoue, la formation peut ne pas fonctionner correctement ou le modèle peut apprendre des modèles incorrects. La correction automatique devrait résoudre la plupart des problèmes, mais l’inspection manuelle permet d’identifier les cas particuliers.
Configuration de l’apprentissage avec Unsloth et TRL
Nous allons maintenant mettre en place la configuration de l’apprentissage. Unsloth s’intègre parfaitement à la bibliothèque TRL de Hugging Face, nous donnant le meilleur des deux mondes : les optimisations de vitesse d’Unsloth et les algorithmes d’apprentissage éprouvés de TRL.
from trl import SFTConfig, SFTTrainer
from unsloth.chat_templates import train_on_responses_only
# Créer la configuration d'entraînement
training_config = SFTConfig(
# Paramètres de base
per_device_train_batch_size = 2, # Ajuster en fonction de la mémoire de votre GPU
gradient_accumulation_steps = 4, # Taille effective du lot = 2 * 4 = 8
warmup_steps = 5,
max_steps = 60, # Pour les tests rapides ; augmenter pour la production
# Paramètres du taux d'apprentissage
learning_rate = 2e-4,
lr_scheduler_type = "linear",
# Paramètres d'optimisation
optim = "adamw_8bit", # L'optimiseur 8 bits économise de la mémoire
weight_decay = 0.01,
# Enregistrement et sauvegarde
logging_steps = 1,
save_steps = 20,
output_dir = "outputs",
# Paramètres avancés
seed = 3407, # Pour la reproductibilité
fp16 = True, # Entraînement de précision mixte
report_to = "none", # Fixé à "wandb" pour le suivi de l'expérience
)
print("Configuration de l'entraînement :")
print(f" Taille effective du lot : {training_config.per_device_train_batch_size * training_config.gradient_accumulation_steps}")
print(f" Nombre total d'étapes d'apprentissage : {training_config.max_steps}")
print(f" Taux d'apprentissage : {training_config.learning_rate}")Configuration du formateur
Le SFTTrainer (Supervised Fine-Tuning Trainer) gère toute la complexité de l’apprentissage :
# Initialiser le formateur
trainer = SFTTrainer(
modèle = modèle,
tokenizer = tokenizer,
jeux_de données = jeux_de données,
args = training_config,
)
print("✅ Formation initialisée")
# Configurer la formation uniquement sur les réponses de l'assistant
# Ceci est crucial - nous ne voulons pas que l'apprentissage du modèle génère des questions de l'utilisateur
gpt_oss_kwargs = dict(
instruction_part = "<|start|>user<|message|>",
response_part = "<|start|>assistant<|channel|>final<|message|>"
)
trainer = train_on_responses_only(
trainer,
**gpt_oss_kwargs,
)
print("✅ Configuré pour la formation en réponse seule")Comprendre la configuration du formateur :
- SFTTrainer Intégration: Le formateur combine plusieurs composants :
- Votre modèle configuré par LoRA
- Le tokenizer pour le traitement du texte
- Votre jeu de données préparé
- les paramètres de configuration de l’entraînement.
- Entraînement par réponse uniquement: Ce paramètre est essentiel pour les modèles de chat. En utilisant
train_on_responses_only, nous nous assurons que :- Le modèle ne calcule la perte que sur les réponses de l’assistant
- Il n’apprend pas à générer des questions d’utilisateurs
- La formation est plus efficace (moins de tokens à optimiser)
- Le modèle conserve sa capacité à comprendre les diverses entrées de l’utilisateur.
- Tags spécifiques GPT-OSS: Les parties instruction et réponse doivent correspondre exactement à ce que contiennent vos données formatées. Ces balises indiquent au formateur la répartition entre ce qu’il doit ignorer (données de l’utilisateur) et ce sur quoi il doit s’entraîner (réponse de l’assistant).
Vérification du masque de formation
Il est important de vérifier que nous nous entraînons uniquement sur les réponses de l’assistant, et non sur les questions de l’utilisateur :
# Vérifier que le masque d'entraînement est correct
print("nVérification du masque de formation...")
sample = trainer.train_dataset[0]
# Décoder les étiquettes pour voir sur quoi nous nous entraînons
# -100 indique les tokens sur lesquels nous ne nous entraînons pas (masqués)
visible_tokens = []
for token_id, label_id in zip(sample["input_ids"], sample["labels"]) :
if label_id != -100 :
visible_tokens.append(token_id)
si visible_tokens :
decoded = tokenizer.decode(visible_tokens)
print(f "Formation sur : {decoded[:200]}...")
print("✅ Masque vérifié - formation uniquement sur les réponses")
else :
print("⚠️ Warning : No visible training tokens detected")Ce que la vérification du masque vous apprend :
- L’étiquette -100: Dans PyTorch, -100 est une valeur spéciale qui indique à la fonction de perte d’ignorer ces jetons. C’est ainsi que nous mettons en œuvre l’apprentissage par réponse seule :
- Les jetons d’entrée de l’utilisateur sont étiquetés comme -100 (ignorés).
- Les jetons de réponse de l’assistant conservent leurs identifiants réels (formés).
- Vérification des jetons visibles: En extrayant uniquement les jetons non masqués, nous pouvons voir exactement ce que le modèle va apprendre. Vous ne devriez voir que le texte de réponse de l’assistant, et non la question de l’utilisateur.
- Pourquoi c’est important: Sans un masquage approprié :
- Le modèle pourrait apprendre à générer des questions au lieu de réponses.
- La formation serait moins efficace (optimisation des jetons inutiles).
- Le modèle pourrait développer des comportements indésirables tels que l’écho de l’entrée de l’utilisateur.
- Conseils de débogage: Si vous voyez une entrée utilisateur dans le texte décodé, vérifiez :
- Les chaînes
instruction_partetresponse_partcorrespondent exactement. - Le formatage de l’ensemble des données comprend toutes les balises requises.
- Le tokenizer applique correctement le modèle de chat.
- Les chaînes
Démarrage du processus de formation
Une fois que tout est configuré, nous sommes prêts à commencer la formation. Surveillons l’utilisation de la mémoire du GPU et suivons la progression de la formation :
import time
import torch
# Vider le cache du GPU avant l'entraînement
torch.cuda.empty_cache()
# Enregistrer l'état initial du GPU
start_gpu_memory = torch.cuda.max_memory_reserved() / 1024**3
start_time = time.time()
print("="*60)
print("DÉMARRAGE DE L'ENTRAÎNEMENT")
print("="*60)
print(f "Mémoire GPU initiale réservée : {start_gpu_memory :.2f} GB")
print(f "Entraînement pour {training_config.max_steps} pas...")
print("nProgression de l'entraînement :")
# Démarrer la formation
trainer_stats = trainer.train()
# Calculer les statistiques de l'entraînement
training_time = time.time() - start_time
final_gpu_memory = torch.cuda.max_memory_reserved() / 1024**3
memory_used = final_gpu_memory - start_gpu_memory
print("n" + "="*60)
print("FORMATION COMPLETE")
print("="*60)
print(f "Temps nécessaire : {training_time/60 :.1f} minutes")
print(f "Perte finale : {trainer_stats.metrics['train_loss'] :.4f}")
print(f "Mémoire GPU utilisée pour l'entraînement : {memory_used :.2f} GB")
print(f "Mémoire GPU maximale : {final_gpu_memory :.2f} GB")
print(f "Vitesse d'entraînement : {trainer_stats.metrics.get('train_steps_per_second', 0) :.2f} pas/seconde")Comprendre les métriques d’entraînement :
- Gestion de la mémoire du GPU:
- L’effacement du cache avant l’entraînement permet de libérer la mémoire inutilisée.
- Le suivi de l’utilisation de la mémoire permet d’optimiser la taille des lots pour les prochaines exécutions.
- La différence entre le début et la fin indique la surcharge réelle de l’entraînement.
- Le pic de mémoire vous indique à quel point vous êtes proche des erreurs OOM.
- Indicateurs de progression de la formation:
- Perte: elle doit diminuer avec le temps. Si elle plafonne rapidement, il se peut que votre taux d’apprentissage soit trop faible.
- Pas/seconde: vous aide à estimer la durée de la formation pour des jeux de données plus importants.
- Temps nécessaire: Sur un GPU T4, comptez environ 10 à 15 minutes pour 60 étapes.
- Ce qu’il faut surveiller pendant l’entraînement:
- Perte diminuant régulièrement (bon)
- La perte augmente de façon irrégulière (taux d’apprentissage trop élevé)
- Perte inchangée (taux d’apprentissage trop faible ou problèmes de données)
- Erreurs de mémoire (réduire la taille du lot ou la longueur de la séquence)
- Attentes en matière de performances:
- GPU T4 : 0,5-1,0 pas/seconde
- V100 : 1,5-2,5 pas/seconde
- A100 : 3-5 pas/seconde
L’entraînement devrait se dérouler sans erreur et vous devriez voir la perte passer d’environ 2-3 au départ à moins de 1,0 à la fin.
Test de votre modèle affiné
Voici maintenant la partie la plus excitante : tester si notre réglage fin a réellement fonctionné ! Nous allons créer une fonction de test complète et évaluer le modèle sur diverses questions liées à Python :
from transformers import TextStreamer
def test_model(prompt : str, reasoning_effort : str = "medium", max_length : int = 256) :
"""
Teste le modèle affiné avec une invite donnée.
Args :
prompt : La question ou l'instruction
effort_de_raisonnement : "faible", "moyen" ou "élevé"
max_length : Nombre maximal de jetons à générer
Returns :
La réponse générée
"""
# Créer le format du message
messages = [
{"role" : "system", "content" : "Vous êtes un assistant expert Python."},
{"rôle" : "user", "content" : prompt}
]
# Appliquer le modèle de chat
inputs = tokenizer.apply_chat_template(
messages,
add_generation_prompt = True,
return_tensors = "pt",
return_dict = True,
reasoning_effort = reasoning_effort,
).to("cuda")
# Configurer le streaming pour une sortie en temps réel
streamer = TextStreamer(
tokenizer,
skip_prompt=True,
skip_special_tokens=True
)
# Générer la réponse
outputs = model.generate(
**entrées,
max_new_tokens = max_length,
streamer = streamer,
température = 0,7,
top_p = 0,9,
do_sample = True,
)
# Décoder et renvoyer la réponse
response = tokenizer.decode(outputs[0], skip_special_tokens=True)
Retourner la réponse
# Test sur différents sujets Python
test_questions = [
"Qu'est-ce qu'un générateur Python et quand dois-je l'utiliser ?
"Comment lire un fichier CSV en Python ?",
"Expliquer async/await en Python avec un exemple simple",
"Quelle est la différence entre une liste et un tuple en Python ?
"Comment gérer correctement les exceptions en Python ?",
]
print("="*60)
print("TESTING FINE-TUNED MODEL")
print("="*60)
for i, question in enumerate(test_questions, 1) :
print(f"n{'='*60}")
print(f "Question {i} : {question}")
print(f"{'='*60}")
print("Réponse :")
_ = test_model(question, reasoning_effort="medium")
print()
Vous devriez remarquer que le modèle fournit maintenant des réponses plus détaillées, spécifiques à Python, par rapport à ce qu’il était avant la mise au point. Les réponses doivent refléter le style de documentation et la profondeur technique de vos données de formation.
Test de différents niveaux de raisonnement
Testons également l’impact de l’effort de raisonnement sur les réponses :
complex_question = "Write a Python function that finds all prime numbers up to n using the Sieve of Eratosthenes" (Écrire une fonction Python qui trouve tous les nombres premiers jusqu'à n en utilisant le tamis d'Eratosthène)
print("="*60)
print("TESTING REASONING EFFORT LEVELS")
print("="*60)
pour effort dans ["faible", "moyen", "élevé"] :
print(f"n{'='*40}")
print(f "Effort de raisonnement : {effort.upper()}")
print(f"{'='*40}")
_ = test_model(complex_question, reasoning_effort=effort, max_length=300)
print()Lorsque vous exécuterez le code, vous verrez que “low” donne une implémentation de base, “medium” fournit un bon équilibre entre les explications et le code, tandis que “high” inclut des explications détaillées et des optimisations.
Sauvegarde et déploiement de votre modèle
Après une mise au point réussie, vous voudrez sauvegarder votre modèle pour une utilisation ultérieure. Nous vous proposons plusieurs options en fonction de vos besoins de déploiement :
Sauvegarde locale
import os
# Créer un répertoire pour la sauvegarde
save_dir = "gpt-oss-python-expert"
os.makedirs(save_dir, exist_ok=True)
print("Sauvegarde locale du modèle...")
# Option 1 : Sauvegarde des adaptateurs LoRA uniquement (petit, ~200MB)
lora_save_dir = f"{save_dir}-lora"
model.save_pretrained(lora_save_dir)
tokenizer.save_pretrained(lora_save_dir)
print(f"✅ Adaptateurs LoRA sauvegardés dans {lora_save_dir}")
# Vérifier la taille
lora_size = sum(
os.path.getsize(os.path.join(lora_save_dir, f))
for f in os.listdir(lora_save_dir)
) / (1024**2)
print(f" Taille : {lora_size :.1f} MB")
# Option 2 : Sauvegarder le modèle fusionné (pleine taille, ~20GB)
merged_save_dir = f "{save_dir}-merged"
model.save_pretrained_merged(
répertoire_save_fusionné,
tokenizer,
save_method = "merged_16bit" # Options : "merged_16bit", "mxfp4"
)
print(f"✅ Modèle fusionné sauvegardé dans {merged_save_dir}")Pousser vers Hugging Face Hub
Pour faciliter le partage et le déploiement, poussez votre modèle sur Hugging Face :
from huggingface_hub import login
# Se connecter à Hugging Face (vous aurez besoin de votre jeton)
# Obtenir le jeton à partir de : https://huggingface.co/settings/tokens
login(token="hf_...") # Remplacer par votre token
# Pousser les adaptateurs LoRA (recommandé pour le partage)
model_name = "votre-nom-d'utilisateur/gpt-oss-python-expert-lora"
print(f "Pushing LoRA adapters to {model_name}...")
model.push_to_hub(
nom_du_modèle,
use_auth_token=True,
commit_message="Mise au point de GPT-OSS sur la documentation Python"
)
tokenizer.push_to_hub(
nom_du_modèle,
use_auth_token=True
)
print(f"✅ Modèle disponible à : https://huggingface.co/{nom_du_modèle}")
# Optionnellement, pousser le modèle fusionné (prend plus de temps)
if False : # Mettre à True si vous voulez pousser le modèle complet
merged_model_name = "votre-nom-d'utilisateur/gpt-oss-python-expert"
model.push_to_hub_merged(
nom_du_modèle_fusionné,
tokenizer,
save_method = "mxfp4", # 4-bit pour une taille plus petite
use_auth_token=True
)Chargement de votre modèle affiné
Voici comment charger votre modèle plus tard pour l’inférence :
from unsloth import FastLanguageModel
# Chargement à partir du répertoire local
model, tokenizer = FastLanguageModel.from_pretrained(
nom_du_modèle = "gpt-oss-python-expert-lora",
max_seq_length = 1024,
dtype = None,
load_in_4bit = True,
)
# Ou charger à partir de Hugging Face Hub
modèle, tokenizer = FastLanguageModel.from_pretrained(
model_name = "your-username/gpt-oss-python-expert-lora",
max_seq_length = 1024,
dtype = None,
load_in_4bit = True,
)
print("✅ Modèle chargé et prêt pour l'inférence !")Stratégies d’optimisation pour de meilleurs résultats
Voici quelques-unes des stratégies que j’ai trouvées utiles pour optimiser la mise au point du modèle :
Techniques d’optimisation de la mémoire
Lorsque l’on travaille avec une mémoire GPU limitée, ces techniques peuvent faire la différence entre le succès et les erreurs OOM :
# 1. Vérification du gradient - échange le calcul contre la mémoire
model.gradient_checkpointing_enable()
# 2. Réduire la longueur des séquences si vos données le permettent
max_seq_length = 512 # Au lieu de 1024
# 3. Utiliser des lots plus petits avec plus d'accumulation
taille_du_lot_de_formation_par_appareil = 1
gradient_accumulation_steps = 16 # Toujours une taille de lot efficace de 16
# 4. Activer l'attention efficace en mémoire (si supporté)
model.config.use_flash_attention_2 = True
# 5. Vider le cache régulièrement pendant l'entraînement
import gc
gc.collect()
torch.cuda.empty_cache()Meilleures pratiques d’entraînement
D’après notre expérience, les pratiques suivantes permettent d’obtenir de meilleurs résultats en matière de réglage fin :
- Commencez petit: Testez d’abord avec 100 exemples. Si cela fonctionne, augmentez progressivement.
- Surveillez les mesures: Surveillez le surajustement : si la perte d’entraînement diminue mais que la perte de validation augmente, arrêtez-vous rapidement.
- Mélangez vos données: Combinez des données spécifiques au domaine avec des données d’instruction générales pour éviter les oublis catastrophiques.
- Calendrier du taux d’apprentissage: Commencez par la valeur par défaut 2e-4, mais n’hésitez pas à expérimenter. J’ai obtenu de bons résultats avec 5e-5 pour des Jeux de données plus petits.
- Stratégie de vérification: Sauvegarder tous les N pas afin de pouvoir récupérer le meilleur point de contrôle :
training_config = SFTConfig(
save_steps = 50,
save_total_limit = 3, # Ne conserver que les 3 meilleurs points de contrôle
load_best_model_at_end = True,
metric_for_best_model = "loss",
)Optimisation de la vitesse
Pour maximiser la vitesse d’entraînement :
# Utiliser la compilation PyTorch 2.0 pour un entraînement plus rapide
if hasattr(torch, 'compile') :
model = torch.compile(model)
print("✅ Modèle compilé pour un entraînement plus rapide")
# Activer TF32 sur les GPU Ampere (A100, RTX 30xx)
torch.backends.cuda.matmul.allow_tf32 = True
torch.backends.cudnn.allow_tf32 = True
# Utiliser des lots plus importants si la mémoire le permet
# Les lots plus importants s'entraînent généralement plus rapidement
optimal_batch_size = find_optimal_batch_size(model, max_memory=0.9)Options de déploiement pour la production
Une fois votre modèle affiné, plusieurs options de déploiement s’offrent à vous :
API locale rapide avec FastAPI
Pour un prototypage rapide, créez une API simple:
# save as : api.py
from fastapi import FastAPI, HTTPException
from pydantic import BaseModel
import uvicorn
from unsloth import FastLanguageModel
app = FastAPI()
# Charge le modèle une fois au démarrage
modèle, tokenizer = None, None
@app.on_event("startup")
async def load_model() :
global model, tokenizer
modèle, tokenizer = FastLanguageModel.from_pretrained(
"gpt-oss-python-expert-lora",
max_seq_length = 1024,
load_in_4bit = True,
)
classe GenerateRequest(BaseModel) :
prompt : str
reasoning_effort : str = "medium" (effort de raisonnement)
max_tokens : int = 256
@app.post("/generate")
async def generate(request : GenerateRequest) :
if not model :
raise HTTPException(status_code=503, detail="Modèle non chargé")
messages = [{"role" : "user", "content" : request.prompt}]
inputs = tokenizer.apply_chat_template(
messages,
add_generation_prompt = True,
return_tensors = "pt",
reasoning_effort = request.reasoning_effort,
).to("cuda")
outputs = model.generate(
**entrées,
max_new_tokens = request.max_tokens,
température = 0.7,
)
response = tokenizer.decode(outputs[0], skip_special_tokens=True)
return {"response" : response}
# Exécuter avec : uvicorn api:app --host 0.0.0.0 --port 8000Déploiement en production avec vLLM
Pour les services de production à haut débit, vLLM offre d’excellentes performances:
# Installer vLLM
pip install vllm
# Servez votre modèle
python -m vllm.entrypoints.openai.api_server N- --modèle gpt-oss-python-expert-fusionné N
--model gpt-oss-python-expert-merged N --tensor-parallel-size 1 N
--tensor-parallel-size 1 N --max-model-len-len N
--max-model-len 1024 N- --densor-parallel-size 1 N
--dtype float16Options de déploiement dans le nuage
Chaque plateforme en nuage a ses avantages :
Points d’extrémité pour l’inférence des visages
- Installation la plus simple – il suffit de pousser et de déployer
- Idéal pour les tests et la production à petite échelle
- Mise à l’échelle automatique disponible
- Parfait pour le déploiement sans serveur
- Payez uniquement pour l’utilisation réelle
- Idéal pour les charges de travail en rafale
- Le plus rentable pour un service 24/7
- Contrôle total de l’environnement
- Idéal pour les applications à haut débit
- Niveau entreprise avec intégration complète d’AWS
- Surveillance et journalisation avancées
- Idéal pour les déploiements de production à grande échelle
Résolution des problèmes courants
Même avec les optimisations d’Unsloth, vous pouvez rencontrer des problèmes. Voici comment résoudre les problèmes les plus courants :
Erreurs CUDA de mémoire insuffisante
Il s’agit du problème le plus courant lors de l’ajustement de grands modèles :
# Solution 1 : Réduire la taille du lot
training_config = SFTConfig(
per_device_train_batch_size = 1, # Taille minimale du lot
gradient_accumulation_steps = 8, # Compenser avec l'accumulation
)
# Solution 2 : Réduire la longueur des séquences
max_seq_length = 512 # Au lieu de 1024
# Solution 3 : Utiliser une quantification plus agressive
model = FastLanguageModel.from_pretrained(
nom_du_modèle = "unsloth/gpt-oss-20b",
load_in_4bit = True,
use_double_quant = True, # Encore plus d'économies de mémoire
)
# Solution 4 : Activer toutes les optimisations de la mémoire
use_gradient_checkpointing = "unsloth"
use_flash_attention = TrueRalentir la vitesse d’entraînement
Si l’entraînement prend trop de temps :
# Utiliser la suite d'optimisation complète d'Unsloth
model = FastLanguageModel.get_peft_model(
modèle,
use_gradient_checkpointing = "unsloth", # Critique
lora_dropout = 0, # 0 est plus rapide que dropout
bias = "none", # "none" est plus rapide que les biais d'entraînement
use_rslora = False, # LoRA standard est plus rapide
)
# Vérifier que vous utilisez le bon dtype
torch.set_float32_matmul_precision('medium') # Ou 'high'Le modèle n’apprend pas
Si votre perte ne diminue pas :
- Vérifiez le format des données: Assurez-vous que vos données correspondent exactement au format GPT-OSS
- Vérifiez le masquage des réponses: Confirmez que vous ne vous entraînez que sur les réponses
- Ajustez le taux d’apprentissage: Essayez 5e-4 ou 1e-4 au lieu de 2e-4
- Améliorer la qualité des données: Supprimez les exemples de mauvaise qualité
- Ajoutez plus de données: Plus de 500 exemples donnent généralement de meilleurs résultats que 100
Résultats incohérents
Si le modèle génère des résultats incohérents ou de mauvaise qualité :
# Utiliser une température plus basse pour des sorties plus cohérentes
outputs = model.generate(
temperature = 0.3, # Plus basse = plus cohérente
top_p = 0.9,
repetition_penalty = 1.1, # Réduire les répétitions
)
# Ajustement fin pour plus de pas
max_steps = 200 # Au lieu de 60
# Utiliser un filtrage de données de meilleure qualité
min_response_length = 50 # Au lieu de 30Conclusion
Conclusion
Le réglage fin de GPT-OSS est plus rapide et plus facile lorsque vous combinez la vitesse d’Unsloth avec des données d’entraînement structurées et de haute qualité fournies par l’une des meilleures entreprises de données d’entraînement pour l’IA. L’utilisation des solutions de Bright Data pour l’IA vous garantit l’accès aux données fiables nécessaires à un réglage fin efficace, afin que vous puissiez construire des modèles d’IA sur mesure pour n’importe quel cas d’utilisation.
Pour une exploration plus approfondie des stratégies d’extraction de données pour l’IA, pensez à ces ressources supplémentaires :





