

Dans ce guide, vous apprendrez :
- Ce qu’est
llm-scraper - Comment l’utiliser, étape par étape
- Comment l’utiliser pour la génération de code
- Quelles sont les principales alternatives au scraping basé sur le LLM ?
- Ses principales limites et la manière de les surmonter
Plongeons dans l’aventure !
Qu’est-ce qu’llm-scraper ?
llm-scraper est une bibliothèque TypeScript qui utilise des LLM pour extraire des données structurées de n’importe quelle page web.
Au lieu d’écrire une logique d’analyse personnalisée pour chaque site, vous définissez simplement un schéma, et le paquet emploie un LLM pour le remplir intelligemment en analysant le contenu de la page.
La bibliothèque a été publiée pour la première fois au milieu de l’année 2024, elle est donc encore assez récente. Cependant, elle a déjà obtenu plus de 4 000 étoiles sur GitHub, ce qui montre à quel point elle devient rapidement populaire :

Il est idéal pour les sites web dynamiques ou incohérents (comme le commerce électronique) où les scrapers traditionnels se cassent souvent la figure. Dans ces scénarios, le scraping LLM brille.
En détail, les principales fonctionnalités prises en charge par llm-scraper sont les suivantes :
- Intégration avec plusieurs fournisseurs de LLM: Fonctionne avec des modèles locaux (comme Ollama ou GGUF) et des fournisseurs de cloud (comme OpenAI et Vercel AI SDK).
- Extraction de données basée sur des schémas: Définissez ce que vous voulez extraire en utilisant les schémas Zod pour une structure et une validation solides.
- Sécurité totale des types: Conçu pour TypeScript, vous bénéficiez d’une vérification complète des types au moment de la compilation.
- Construit sur Playwright: Utilise Playwright sous le capot pour contrôler le navigateur et récupérer le contenu des pages.
- Prise en charge du streaming: Possibilité de diffuser des objets en continu pendant l’extraction au lieu d’attendre la fin de l’extraction complète.
- Génération de code: Peut générer dynamiquement du code de scraping en fonction de votre schéma et de votre cible.
- Plusieurs options de formatage du contenu des pages: Vous pouvez choisir comment envoyer le contenu de la page au LLM
Comment utiliser llm-scraper pour le Web Scraping ?
Dans cette section du tutoriel, vous apprendrez à utiliser la bibliothèque llm-scraper pour construire un scraper alimenté par l’IA. Le site cible sera une page de produit de commerce électronique du site web ToScrape:

Il s’agit d’un excellent exemple, car il n’est pas toujours facile de récupérer des sites de commerce électronique. La structure de leurs pages change souvent, et les produits peuvent avoir des mises en page et des informations différentes. Pour cette raison, il est difficile et peu efficace d’écrire une logique d’analyse statique. L’IA peut donc être d’une aide précieuse.
Suivez les étapes ci-dessous pour construire un Scraper alimenté par LLM !
Conditions préalables
Pour suivre ce tutoriel, vous aurez besoin de :
- Node.js installé sur votre machine
- Une clé API OpenAI (ou une clé d’un fournisseur similaire comme Groq)
- Compréhension de base de TypeScript et de la programmation asynchrone.
Étape 1 : Configuration du projet
Avant de commencer, assurez-vous que la dernière version LTS de Node.js est installée localement. Si ce n’est pas le cas, téléchargez-la depuis le site officiel et installez-la.
Maintenant, créez un projet pour votre scraper et naviguez jusqu’à lui dans le terminal :
mkdir llm-scraper-project
cd llm-scraper-projectDans votre projet, exécutez la commande suivante pour initialiser un projet Node.js vierge :
npm init -yOuvrez le fichier package.json créé par la commande ci-dessus et assurez-vous qu’il contient :
"type": "module"Chargez le dossier du projet llm-scraper-project dans votre IDE TypeScript préféré, tel que Visual Studio Code.
Ensuite, installez TypeScript en tant que dépendance de développement :
npm install typescript --save-devUne fois TypeScript installé, initialisez votre projet TypeScript en exécutant :
npx tsc --initUn fichier tsconfig.json apparaîtra dans le dossier de votre projet. Ouvrez-le et remplacez-le par :
{
"compilerOptions": {
"module": "ESNext",
"target": "ESNext",
"moduleResolution": "node",
"esModuleInterop": true,
"allowSyntheticDefaultImports": true,
"strict": true,
"skipLibCheck": true
}
}Maintenant, ajoutez un fichier scraper.ts à votre projet :

Ce fichier contiendra bientôt la logique d’extraction des données de llm-scraper. Comme le script utilisera une logique TypeScript asynchrone, initialisez une fonction asynchrone à l’intérieur du fichier :
async function llmScraping() {
// your LLM scraping logic...
}
llmScraping()Merveilleux ! Vous êtes entièrement configuré et prêt à commencer à construire votre scraper alimenté par l’IA.
Étape 2 : Installer les bibliothèques récupérées
Pour fonctionner, llm-scraper s ‘appuie sur les deux bibliothèques supplémentaires suivantes :
- Zod: Une bibliothèque de déclaration et de validation de schémas TypeScript.
- Playwright: Une bibliothèque pour automatiser les navigateurs Chromium, Firefox et WebKit avec une API unique.
Installez-les en même temps que llm-scraper à l’aide de la commande suivante :
npm install zod playwright llm-scraperPlaywright nécessite quelques dépendances supplémentaires (comme les binaires du navigateur). Installez-les avec :
npx playwright installMaintenant, importez Zod et Playwright dans scraper.ts :
import { z } from "zod"
import { chromium } from "playwright"
import LLMScraper from "llm-scraper"Génial ! Vous disposez maintenant de toutes les bibliothèques nécessaires pour démarrer le web scraping LLM en TypeScript.
Étape 3 : Configurer OpenAI
llm-scraper prend en charge plusieurs fournisseurs LLM, notamment OpenAI, Groq, Ollama et GGUF. Dans ce cas, nous allons utiliser OpenAI. Si vous ne l’avez pas encore fait, assurez-vous d’obtenir votre clé d’API OpenAI.
Tout d’abord, installez le client JavaScript OpenAI :
npm install @ai-sdk/openaiEnsuite, importez-la dans votre code et utilisez-la pour initialiser votre modèle LLM dans la fonction llmScraping() :
// other imports...
import { openai } from "@ai-sdk/openai"
// ...
const llm = openai.chat("gpt-4o")Pour une intégration différente, consultez la documentation officielle de llm-scraper`.
Pour éviter de coder en dur la clé OpenAI dans votre code, installez dotenv:
npm install dotenvImportez dotenv dans votre fichier scraper.ts et appelez dotenv.config() pour charger les variables d’environnement :
// other imports...
import * as dotenv from "dotenv"
// ...
dotenv.config()Cela vous permet de charger des variables d’environnement, comme votre clé API OpenAI, à partir d’un fichier .env. Ajoutez donc un fichier .env à votre projet :

Ouvrez-le et ajoutez votre clé API OpenAI comme suit :
OPENAI_API_KEY="<YOUR_OPENAI_KEY>"Remplacer par la valeur de votre clé Open AI
Notez qu’il n’est pas nécessaire de lire manuellement la variable dans votre code. En effet, @ai-sdk/openai tente automatiquement de lire la variable d’environnement OPENAI_KEY.
Incroyable ! Intégration du LLM achevée.
Étape 4 : Connexion à la page cible
llm-scraper s’appuie sur Playwright en tant que moteur d’automatisation du navigateur pour extraire le contenu HTML des pages web. Pour commencer, ajoutez les lignes de code suivantes à l’intérieur de llmScraping():
- Initialiser un navigateur Chromium
- Ouvrir une nouvelle page
- Demander au dramaturge de visiter la page cible
Pour ce faire, il convient d’utiliser :
const browser = await chromium.launch()
const page = await browser.newPage()
await page.goto("https://books.toscrape.com/catalogue/a-light-in-the-attic_1000/index.html")À la fin, n’oubliez pas de fermer le navigateur et de libérer ses ressources :
await page.close()
await browser.close()Si vous n’êtes pas familier avec ce processus, lisez notre guide sur le scraping web Playwright.
Étape 5 : Définir le schéma des données
llm-scraper fonctionne en alimentant le modèle LLM sous-jacent avec une invite – opérant sur le contenu extrait de la page via Playwright – pour extraire des données structurées telles que définies dans un modèle de données spécifique.
C’est là que Zod intervient, en vous aidant à spécifier ce modèle de données en TypeScript. Pour comprendre à quoi doit ressembler le schéma de vos données scrappées, ouvrez le site cible dans votre navigateur et commencez par analyser le niveau supérieur de la page :

À partir de là, vous devez vous concentrer sur l’extraction des données suivantes :
- Titre
- Prix
- État des stocks
- Quantité
- Description
Passez ensuite à la dernière section de la page :

Ici, vous serez intéressé par :
- UPC (code universel des produits)
- Type de produit
- Impôts
- Nombre d’examens
Mettez tout cela ensemble et vous obtiendrez le schéma de produit suivant :
const productSchema = z.object({
title: z.string().describe("The name of the product"),
price: z.string().describe("The price of the product, typically formatted as a string like '£19.99'"),
stock: z.string().describe("The availability status of the product, such as 'In Stock' or 'Out of Stock'"),
quantity: z.string().describe("The specific quantity of products available in stock"),
description: z.string().describe("A detailed description of the product, including features and specifications"),
upc: z.string().describe("The Universal Product Code (UPC) to uniquely identify the product"),
productType: z.string().describe("The category or type of the product, such as 'Books', 'Clothing', etc."),
tax: z.string().describe("Information about the applicable tax amount for the product"),
reviews: z.number().describe("The number of reviews the product has received"),
})Conseil: N’oubliez pas de décrire votre schéma, car cela aide le modèle LLM à comprendre ce qu’il doit faire avec les données.
Fantastique ! Vous êtes prêt à lancer la tâche de scraping alimentée par l’IA dans llm-scraper.
Étape 6 : Exécuter la tâche de récupération
Utilisez l’intégration LLM définie à l’étape 3 pour créer un objet LLMScraper:
const scraper = new LLMScraper(llm)Il s’agit de l’objet principal exposé par la bibliothèque llm-scraper, et il est responsable de l’exécution des tâches de scraping assistées par l’IA.
Ensuite, lancez le grattoir comme suit :
const { data } = await scraper.run(page, productSchema, {
format: "markdown",
})Le paramètre de format définit la manière dont le contenu de la page est transmis au LLM. Les valeurs possibles sont les suivantes :
"html": Le code HTML brut de la page."texte": Tout le contenu textuel extrait de la page."markdown": Le contenu HTML converti en Markdown."cleanup": Une version nettoyée du texte extrait de la page.- “
image": Une capture d’écran de la page.
Note: Vous pouvez également fournir une fonction personnalisée pour contrôler le formatage du contenu si nécessaire.
Comme indiqué dans le guide “Pourquoi les nouveaux agents d’IA choisissent-ils Markdown plutôt que HTML ?“, l’utilisation du format Markdown est un choix judicieux car il permet d’économiser des tokens et d’accélérer le processus de scraping.
Enfin, la fonction scraper.run() renvoie un objet qui correspond au schéma Zod attendu.
C’est parfait ! Votre tâche de raclage assistée par l’IA est terminée.
Étape 7 : Exporter les données extraites
Actuellement, les données extraites sont stockées dans un objet JavaScript. Pour faciliter l’accès aux données, leur analyse et leur partage, exportez-les dans un fichier JSON, comme indiqué ci-dessous :
const jsonData = JSON.stringify(data, null, 4)
await fs.writeFile("product.json", jsonData, "utf8")Notez que vous n’avez pas besoin de bibliothèques externes pour cela. Assurez-vous simplement d’ajouter l’importation suivante au début de votre fichier scraper.ts :
import { promises as fs } from "fs"Étape n° 8 : Assembler le tout
scraper.ts devrait maintenant contenir :
import { z } from "zod"
import { chromium } from "playwright"
import LLMScraper from "llm-scraper"
import { openai } from "@ai-sdk/openai"
import * as dotenv from "dotenv"
import { promises as fs } from "fs"
// load the environment variables from the local .env file
dotenv.config()
async function llmScraping() {
// initialize the LLM engine
const llm = openai.chat("gpt-4o")
// launch a browser instance and open a new page
const browser = await chromium.launch()
const page = await browser.newPage()
// navigate to the target e-commerce product page
await page.goto("https://books.toscrape.com/catalogue/a-light-in-the-attic_1000/index.html")
// define the product schema
const productSchema = z.object({
title: z.string().describe("The name of the product"),
price: z.string().describe("The price of the product, typically formatted as a string like '£19.99'"),
stock: z.string().describe("The availability status of the product, such as 'In Stock' or 'Out of Stock'"),
quantity: z.string().describe("The specific quantity of products available in stock"),
description: z.string().describe("A detailed description of the product, including features and specifications"),
upc: z.string().describe("The Universal Product Code (UPC) to uniquely identify the product"),
productType: z.string().describe("The category or type of the product, such as 'Books', 'Clothing', etc."),
tax: z.string().describe("Information about the applicable tax amount for the product"),
reviews: z.number().describe("The number of reviews the product has received"),
})
// create a new LLMScraper instance
const scraper = new LLMScraper(llm)
// run the LLM scraper
const { data } = await scraper.run(page, productSchema, {
format: "markdown", // or "html", "text", etc.
})
// conver the scraped data to a JSON string
const jsonData = JSON.stringify(data, null, 4)
// populate an output file with the JSON string
await fs.writeFile("product.json", jsonData, "utf8")
// close the page and the browser and release their resources
await page.close()
await browser.close()
}
llmScraping()Comme vous pouvez le constater, llm-scraper vous permet de définir un script de scraping basé sur JavaScript en quelques lignes de code.
Compilez votre script TypeScript en JavaScript à l’aide de cette commande :
npx tscUn fichier scraper.js apparaîtra dans le dossier de votre projet. Exécutez-le avec :
node scraper.jsLorsque le script s’exécute, un fichier appelé product.json apparaît dans le dossier de votre projet.
Ouvrez-le, et vous verrez quelque chose comme ceci :
{
"title": "A Light in the Attic",
"price": "£51.77",
"stock": "In Stock",
"quantity": "22",
"description": "It's hard to imagine a world without A Light in the Attic. This now-classic collection of poetry and drawings from Shel Silverstein celebrates its 20th anniversary with this special edition. Silverstein's humorous and creative verse can amuse the dowdiest of readers. Lemon-faced adults and fidgety kids sit still and read these rhythmic words and laugh and smile and love that Silverstein. Need proof of his genius? Rockabye Rockabye baby, in the treetop Don't you know a treetop Is no safe place to rock? And who put you up there, And your cradle, too? Baby, I think someone down here's Got it in for you. Shel, you never sounded so good.",
"upc": "a897fe39b1053632",
"productType": "Books",
"tax": "£0.00",
"reviews": 0
}Ce fichier contient exactement les informations affichées sur la page du produit que vous avez ciblé. Comme vous pouvez le constater, les données ont été extraites sans nécessiter de logique d’analyse personnalisée, grâce à la puissance des LLM. C’est très bien !
Extra : Génération de code avec llm-scraper
llm-scraper a également la capacité de générer la logique d’analyse des données Playwright sous-jacente, en fonction du schéma. Cela est possible grâce à la fonction generate().
Un exemple est donné dans l’extrait ci-dessous :
const { code } = await scraper.generate(page, productSchema)Comme vous pouvez le voir, il prend l’objet de page Playwright et le schéma Zod, puis renvoie une chaîne contenant le code Playwright généré. Dans ce cas, le résultat est le suivant :
(function() {
function extractData() {
const title = document.querySelector('h1').innerText;
const price = document.querySelector('.price_color').innerText;
const stockText = document.querySelector('.instock.availability').innerText.trim();
const stock = stockText.includes('In stock') ? 'In Stock' : 'Out of Stock';
const quantityMatch = stockText.match(/d+/);
const quantity = quantityMatch ? quantityMatch[0] : '0';
const description = document.querySelector('#product_description ~ p').innerText;
const upc = document.querySelector('th:contains("UPC") + td').innerText;
const productType = document.querySelector('th:contains("Product Type") + td').innerText;
const tax = document.querySelector('th:contains("Tax") + td').innerText;
const reviews = parseInt(document.querySelector('th:contains("Number of reviews") + td').innerText, 10);
return {
title,
price,
stock,
quantity,
description,
upc,
productType,
tax,
reviews
};
}
const data = extractData();
console.log(data);
})()Vous pouvez ensuite exécuter ce code JavaScript généré de manière programmatique et analyser le résultat avec :
const result = await page.evaluate(code)
const data = schema.parse(result)L’objet de données contiendra le même résultat que les données produites à l’étape 6 du chapitre précédent.
llm-scraper Alternatives pour LLM Scraping
llm-scraper n’est pas la seule bibliothèque disponible pour le scraping alimenté par LLM. Il existe d’autres alternatives intéressantes :
- Crawl4AI: Une bibliothèque Python pour construire des agents de crawling web et des pipelines de données ultra-rapides et prêts pour l’IA. Elle est très flexible et optimisée pour que les développeurs puissent la déployer avec rapidité et précision. Vous pouvez la voir en action dans notre tutoriel sur le scraping avec Crawl4AI.
- ScrapeGraphAI: Une bibliothèque Python de scraping web qui combine LLMs et logique graphique directe pour construire des pipelines de scraping pour les sites web et les documents locaux (comme XML, HTML, JSON, et Markdown). Consultez notre guide sur le scraping avec ScrapeGraphAI.
Limites de cette approche du Web Scraping
ToScrape, le site cible que nous avons utilisé dans cet article, n’est, comme son nom l’indique, qu’un bac à sable accueillant des scripts de scraping. Malheureusement, lorsqu’on utilise llm-scraper contre des sites Web réels, les choses risquent d’être beaucoup plus difficiles…
Pourquoi ? Parce que les sociétés de commerce électronique et les entreprises en ligne savent à quel point leurs données sont précieuses et se donnent beaucoup de mal pour les protéger. Cela est vrai même si ces données sont accessibles au public sur les pages de leurs produits.
Par conséquent, la plupart des plateformes de commerce électronique mettent en œuvre des mesures anti-bots et anti-scraping pour bloquer les crawlers automatisés. Ces techniques peuvent même arrêter les scrapers basés sur des outils d’automatisation de navigateur tels que Playwright – tout comme llm-scraper.
Nous parlons ici de défenses telles que le fameux CAPTCHA d’Amazon, qui suffit à arrêter la plupart des robots :
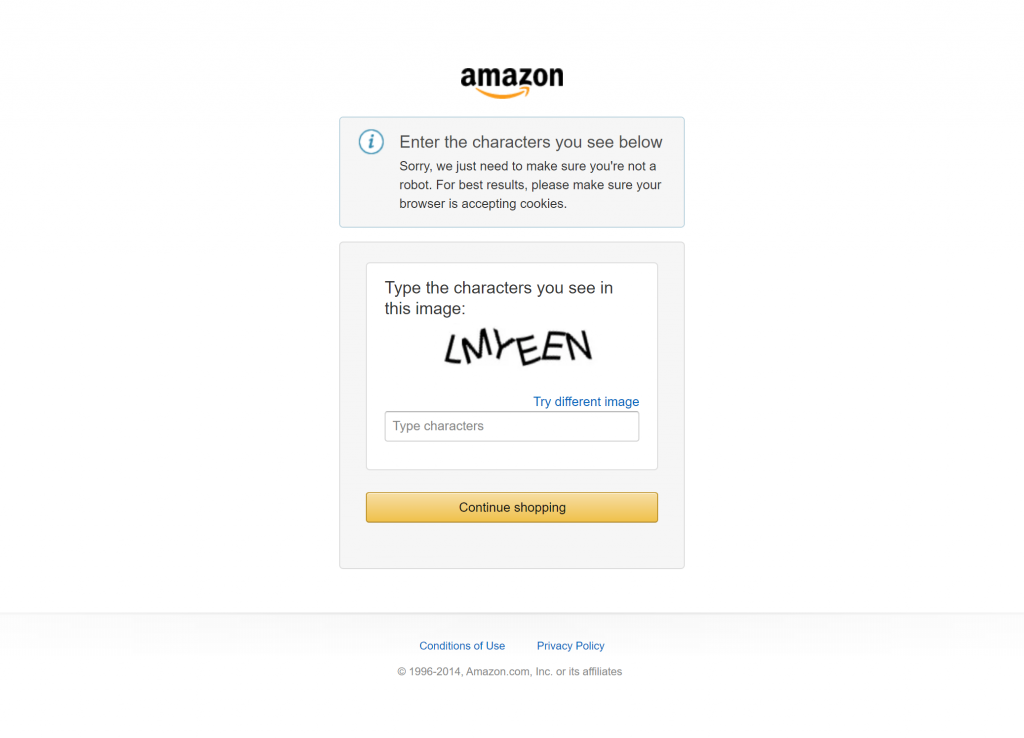
Aujourd’hui, même si vous parvenez à contourner les CAPTCHA avec Playwright, d’autres problèmes tels que les interdictions d’IP causées par un trop grand nombre de requêtes automatisées peuvent mettre un terme à votre opération de scraping.
À ce stade, la solution ne consiste pas à peaufiner sans cesse votre script pour le rendre plus complexe. L’idée est d’utiliser les bons outils.
En intégrant Playwright à un navigateur spécialement conçu pour le grattage Web, comme Scraping Browser, toutdevient beaucoup plus facile. Cette solution est un navigateur basé sur le cloud optimisé pour le scraping. Elle gère la rotation des IP, les tentatives automatiques, les mécanismes avancés de contournement des robots, et même la résolution intégrée des CAPTCHA, le tout sans qu’il soit nécessaire de gérer soi-même l’infrastructure.
Intégrer le navigateur de scraping avec Playwright dans llm-scraper comme n’importe quel autre navigateur, comme expliqué dans notre documentation.
Conclusion
Dans cet article de blog, vous avez appris ce que llm-scraper a à offrir et comment l’utiliser pour construire un script de scraping alimenté par l’IA en TypeScript. Grâce à son intégration avec les LLM, vous pouvez scraper des sites avec des structures de pages complexes ou dynamiques.
Comme nous l’avons vu, le moyen le plus efficace d’éviter d’être bloqué est de l’utiliser avec le Scraping Browser de Bright Data, qui est doté d’un résolveur CAPTCHA intégré et de nombreuses autres capacités de contournement des robots.
Si vous souhaitez créer un agent d’intelligence artificielle directement basé sur cette solution, jetez un coup d’œil à Agent Browser. Cette solution exécute des flux de travail pilotés par des agents sur des navigateurs distants qui ne sont jamais bloqués. Elle est extensible à l’infini et s’appuie sur le réseau de serveurs mandataires le plus fiable au monde.
Créez un compte Bright Data gratuit dès aujourd’hui et explorez nos solutions de données et de scraping pour alimenter votre parcours d’IA !




