

Dans ce guide, vous verrez :
- Ce qu’est le réglage fin.
- Comment affiner GPT-4o avec une API de scraper web via n8n.
- Une comparaison entre les approches de réglage fin.
- Pourquoi des données de haute qualité sont au cœur de tout processus de mise au point.
Plongeons dans l’aventure !
Qu’est-ce que le réglage fin ?
Le réglage fin – également connu sous le nom de réglage fin supervisé (SFT)– est une procédure visant à améliorer des connaissances ou des capacités spécifiques dans un LLM pré-entraîné. Dans le contexte des LLM, le pré-entraînement fait référence à la formation d’un modèle d’IA à partir de zéro.
Le réglage fin est important car les modèles imitent les données d’apprentissage. Cela signifie que lorsque vous testez un LLM après la formation, sa sortie suivra en quelque sorte les données de formation. Les LLM étant des modèles généralistes, si vous souhaitez qu’ils acquièrent des connaissances spécifiques, vous devez les adapter à des données spécifiques.
Si vous souhaitez en savoir plus sur le SFT, lisez notre guide sur le réglage fin supervisé dans les LLM.
Comment affiner GPT-4o avec l’intégration de Bright Data n8n
Comme nous l’avons vu dans un récent tutoriel, vous savez maintenant comment affiner Llama 4 en utilisant le nuage avec des données récupérées à l’aide des API Web Scraper. Dans cette section guidée, vous obtiendrez le même résultat en affinant GPT-4o à l’aide de n8n, une plateforme populaire d’automatisation des flux de travail.
Dans le détail, nous nous référerons à la même page web cible, à savoir la page des produits de bureau les plus vendus sur Amazon :
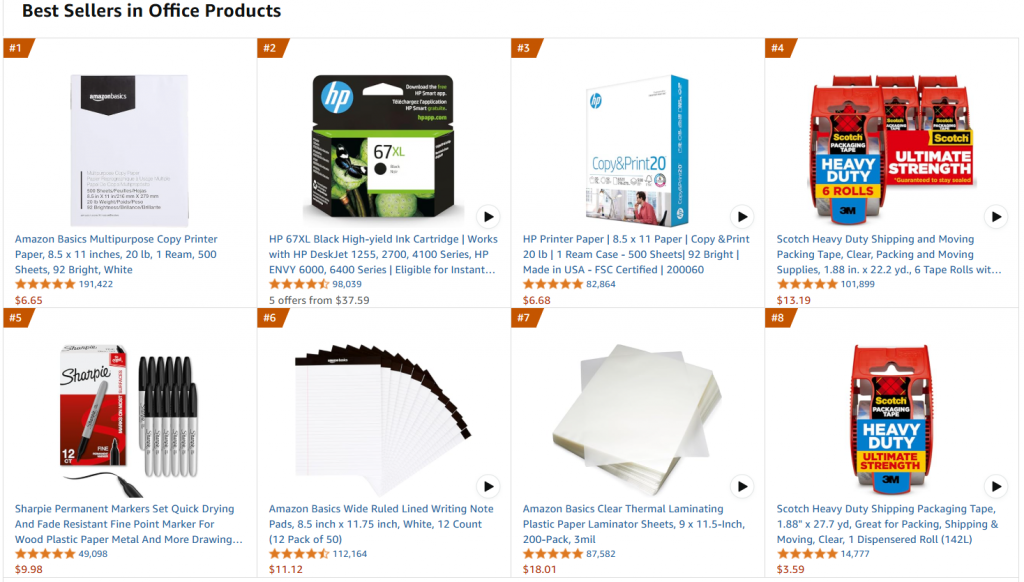
L’objectif de ce projet est d’affiner GPT-4o-mini pour créer des descriptions de produits de type bureautique à partir de certaines caractéristiques saisies dans une invite.
Suivez les étapes ci-dessous pour apprendre à affiner GPT-4o-mini à l’aide de n8n avec un ensemble de données d’entraînement récupérées via les solutions de Bright Data !
Exigences
Pour reproduire ce processus de mise au point, vous avez besoin des éléments suivants :
- Une clé API Bright Data active.
- Un compte n8n actif.
- Un jeton API OpenAI.
C’est parfait ! Vous êtes prêt à peaufiner le GPT-4o.
Étape 1 : créer un nouveau flux de travail n8n et installer le nœud de données Bright
Après s’être connecté à n8n, le tableau de bord ressemble à l’image suivante :
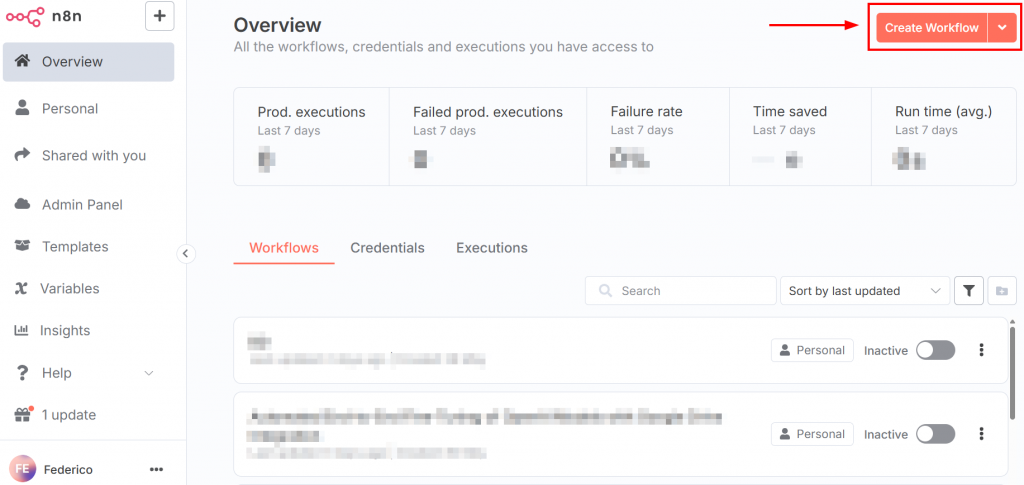
Pour créer un nouveau flux de travail, cliquez sur le bouton “Créer un flux de travail”. Cliquez ensuite sur “Ouvrir le panneau des nœuds” :
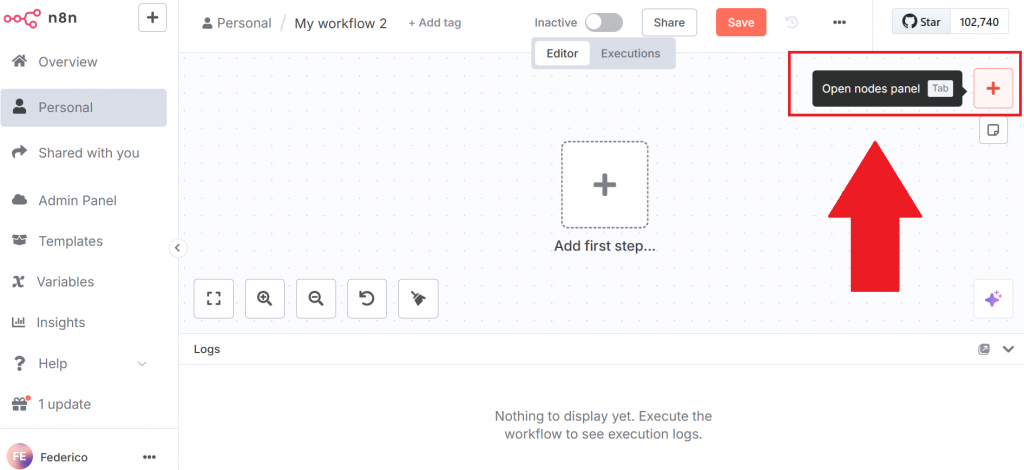
Dans le panneau des nœuds, recherchez le nœud de Bright Data. Dans n8n, un “nœud” est un élément constitutif d’un flux de travail automatisé, représentant une étape ou une action distincte dans le pipeline de traitement des données.
Cliquez sur le nœud Bright Data n8n pour l’installer :

Pour plus d’informations, consultez la page de documentation officielle sur la configuration de Bright Data dans n8n.
Très bien ! Vous avez initialisé votre premier flux de travail n8n.
Étape 2 : Configurer le nœud de données Bright et extraire les données
Cliquez sur “Ajouter une première étape” dans l’interface utilisateur et sélectionnez “Déclencher manuellement” :
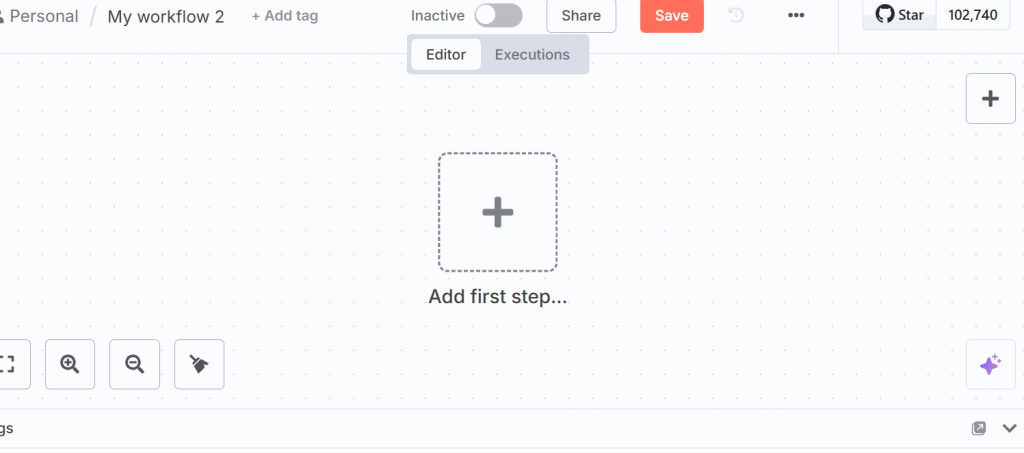
Ce nœud vous permet de déclencher manuellement l’ensemble du flux de travail.
Cliquez sur le “+” à droite du nœud de déclenchement manuel et recherchez Bright Data. Dans la section “web scraper actions”, cliquez sur “scrape data synchronously by URL” :
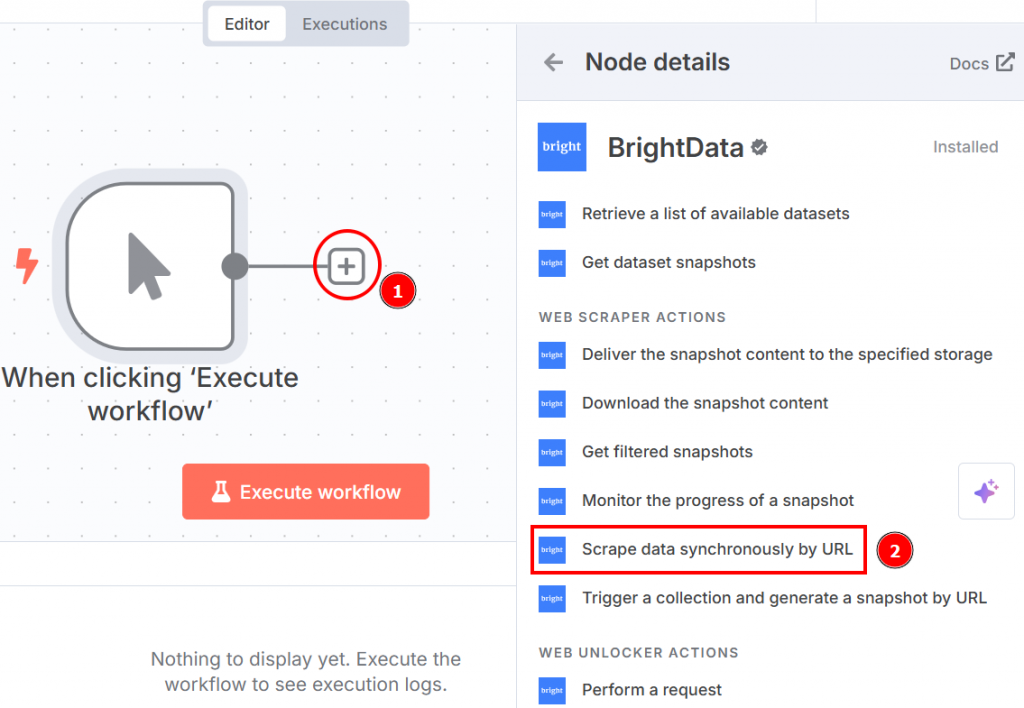
Voici comment les paramètres du nœud apparaissent lorsque vous cliquez dessus :

Les mettre en place comme suit :
- “Credential to connect with” : Cliquez dessus et ajoutez votre clé API Bright Data. Les informations d’identification seront enregistrées.
- “Opération” : Sélectionnez l’option “Scrape by URL”. Cela vous permet de transmettre une liste d’URL que l’API Web Scraper utilisera comme pages cibles pour extraire les données.
- “Dataset” : Choisissez l’option “Amazon best seller products”. Cette option est optimisée pour extraire les données des produits les plus vendus sur Amazon.
- “URL” : Allez sur la page des produits de bureau les plus vendus sur Amazon pour copier et coller une liste d’au moins 10 URL. Vous avez besoin d’au moins 10 URL parce que le nœud OpenAI Chat en a besoin d’au moins 10. Si vous donnez moins de 10, le nœud OpenAI renverra une erreur lors de l’ajustement du LLM cible.
- “Format” : Sélectionnez le format de données “JSON”, car l’API Web Scraper prend en charge plusieurs formats de sortie.
Voici comment se présente votre flux de travail jusqu’à présent :

Si vous appuyez sur le bouton “Exécuter le flux de travail”, les données scannées seront disponibles dans le nœud de Bright Data dans la section de sortie :
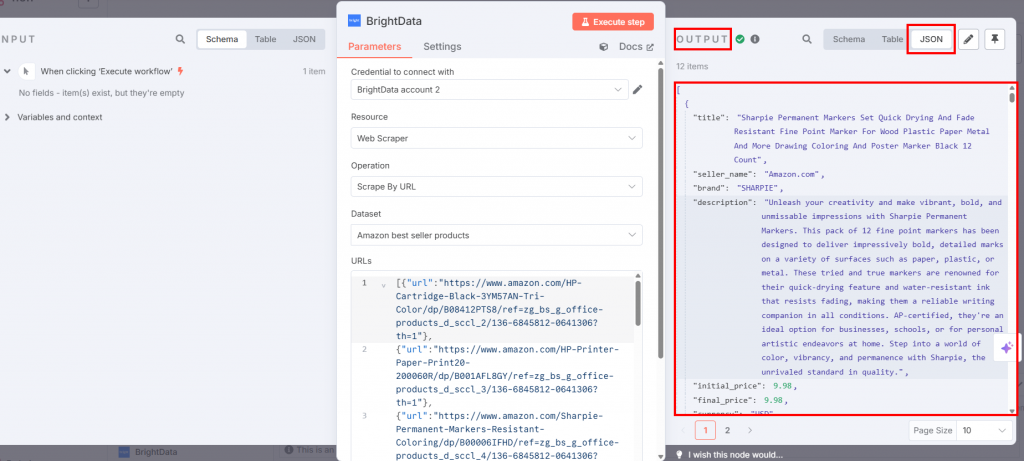
Fantastique ! Vous avez récupéré les données ciblées dont vous aviez besoin avec l’API Web Scraper de Bright Data sans même écrire une ligne de code.
Étape 3 : Configurer le nœud de code
Connectez le nœud Code du nœud Bright Data et sélectionnez JavaScript dans la case “Language” :

Dans le champ “JavaScript”, collez le code suivant :
// get all incoming items
const allInputItems = $input.all();
let jsonlString = "";
// define the training prompt
const systemMessage = "You are an expert marketing assistant specializing in writing compelling and informative product descriptions.";
// loop through each item retrieved from the input
for (const item of allInputItems) {
const product = item.json;
// validate if the product data exists and is an object
if (!product || typeof product !== 'object') {
console.warn('Skipping an item because product data is missing or not an object:', item);
continue;
}
// extract product data
const title = product.title || "N/A";
const brand = product.brand || "N/A";
let featuresString = "Not specified";
if (product.features && Array.isArray(product.features) && product.features.length > 0) {
featuresString = product.features.slice(0, 5).join(', ');
}
// create a snippet of the original product description for training
const originalDescSnippet = (product.description || "No original description available.").substring(0, 250) + "...";
// create prompt with specific details about the product
const userPrompt = `Generate a product description for the following item. Title: ${title}. Brand: ${brand}. Key Features: ${featuresString}. Original Description Snippet: ${originalDescSnippet}.`;
// create template for the kind of description the AI should generate
let idealDescription = `Discover the ${title} from ${brand}, a top-choice for discerning customers. `;
idealDescription += `Key highlights include: ${featuresString}. `;
if (product.rating) {
idealDescription += `Boasting an impressive customer rating of ${product.rating} out of 5 stars! `;
}
idealDescription += `This product, originally described as "${originalDescSnippet}", is perfect for anyone seeking quality and reliability. `;
idealDescription += `Don't miss out on the ${product.availability === "In Stock" ? "readily available" : "upcoming"} ${title} – enhance your collection today!`;
// create a training example object in the format expected by OpenAI
const trainingExample = {
messages: [
{ role: "system", content: systemMessage },
{ role: "user", content: userPrompt },
{ role: "assistant", content: idealDescription }
]
};
jsonlString += JSON.stringify(trainingExample) + "n";
}
// remove any leading or trailing whitespace
const fileContentString = jsonlString.trim();
// check if any product data was actually processed
if (fileContentString.length === 0) {
console.warn("No product data was processed, outputting empty file content.");
return [{
json: { error: "No products processed", fileNameToUse: "data.jsonl" },
binary: {}
}];
}
// convert the final JSONL string into a Buffer (raw binary data)
const buffer = Buffer.from(fileContentString, 'utf-8');
// define the filename that will be used when this data is sent to OpenAI
const actualFileNameForOpenAI = "data.jsonl";
// define the MIME type for the file
const mimeType = 'application/jsonl';
// prepare the binary data for output
const binaryData = await this.helpers.prepareBinaryData(buffer, actualFileNameForOpenAI, mimeType);
// return the processed data
return [{
json: {
processedFileName: actualFileNameForOpenAI
},
binary: {
// the "Input Data Field Name" in the OpenAI node
"data.jsonl": binaryData
}
}];L’entrée de ce nœud est le fichier JSON contenant les données extraites de Bright Data. Cependant, le nœud OpenAI a besoin d’un fichier JSONL. Ce code JavaScript transforme le JSON en JSONL comme suit :
- Il récupère toutes les données provenant du nœud précédent avec la méthode
$input.all(). - Il itère et traite les produits. En particulier, pour chaque produit, il.. :
- Extrait les détails du produit tels que
le titre, lamarque, lescaractéristiques, ladescription, l’évaluationet ladisponibilité. Il inclut des valeurs de repli si certaines données sont manquantes. - Construit une
userPrompten formatant ces détails dans une requête pour que le LLM génère la description du produit. - Génère une
idealDescriptionà l’aide d’un modèle qui incorpore les attributs du produit. Il s’agit de la réponse souhaitée de l'”assistant” dans les données de formation. - Combine un message système, le
userPromptet leidealDescriptionen un seul objettrainingExample, formaté pour la formation LLM conversationnelle. - Sérialise cet
exemple de formationen une chaîne JSON et l’ajoute à une chaîne croissante, avec chaque objet JSON sur une nouvelle ligne (format JSONL).
- Extrait les détails du produit tels que
- Après avoir traité tous les éléments, il convertit la chaîne JSONL accumulée en un
tampon dedonnées binaires. - Il renvoie le fichier
data.jsonl.
Si vous cliquez sur “Execute step” dans le nœud Code, le JSONL sera disponible dans la section output :
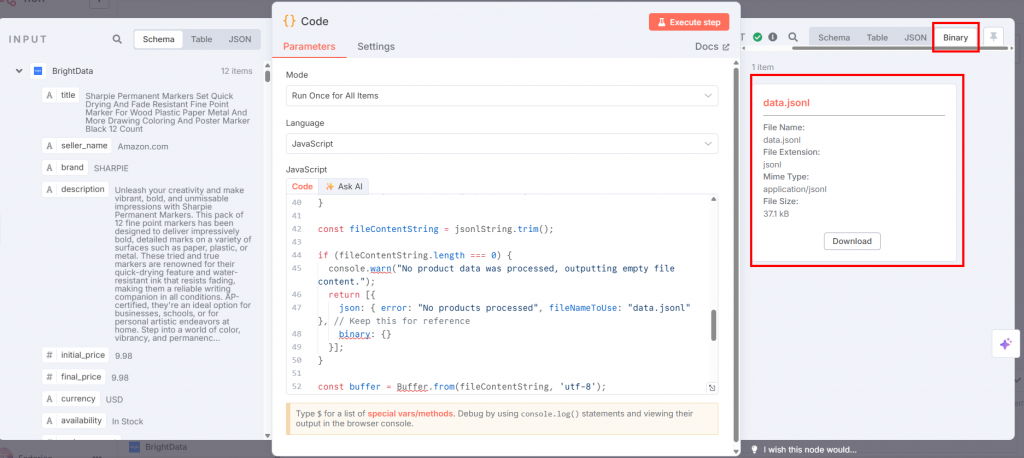
Voici comment se présente votre flux de travail jusqu’à présent :
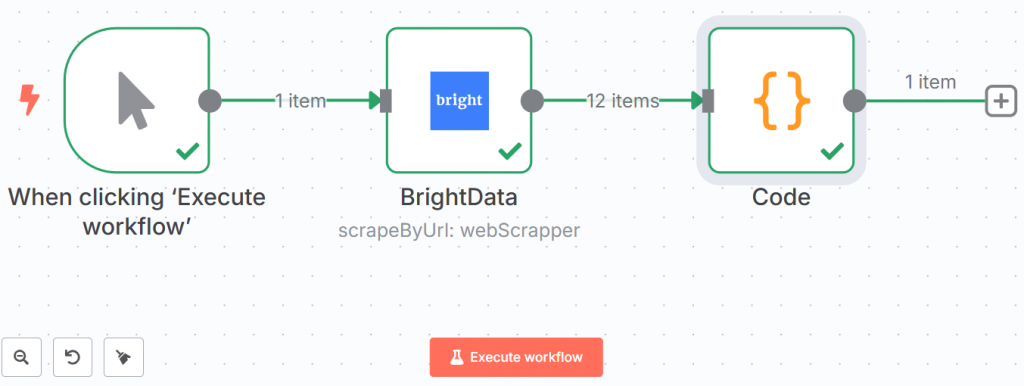
Les lignes vertes et les coches indiquent que chaque étape a été franchie avec succès.
Hourra ! Vous avez récupéré les données à l’aide de Bright Data et les avez enregistrées au format JSONL. Vous êtes maintenant prêt à les intégrer dans le LLM.
Étape #4 : Introduire les données de réglage dans le nœud de chat OpenAI
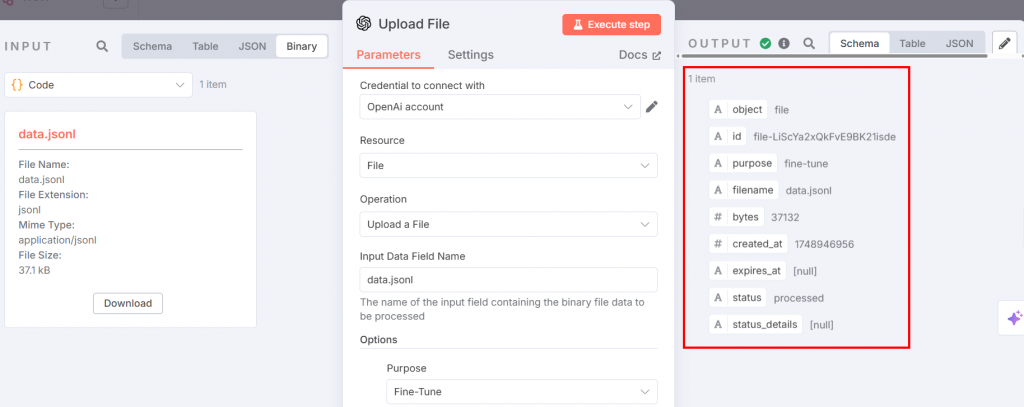
Le fichier JSONL de réglage fin est prêt à être téléchargé sur la plateforme OpenAI pour le réglage fin. Pour ce faire, ajoutez un nœud OpenAI. Choisissez l’option “Upload a file” dans la section “File actions” :

Vous trouverez ci-dessous les paramètres que vous devez configurer :

Le nœud ci-dessus fournit l’entrée pour le processus de réglage fin. Réglez les paramètres comme suit :
- “Credential to connect with” : Ajoutez votre jeton API OpenAI. Une fois que vous l’aurez défini, les informations d’identification seront sauvegardées.
- “Ressource” : Choisissez “File”. En effet, vous allez télécharger un fichier JSONL sur la plateforme.
- “Opération” : Sélectionnez “Télécharger un fichier”.
- “Nom du champ des données d’entrée” : Le nom du fichier de réglage fin est
data.jsonl. - Dans la section “Options”, ajoutez “Objet” et choisissez “Affiner”.
Après l’exécution de l’étape, la sortie se présente comme suit :
Votre flux de travail se présente désormais comme suit :
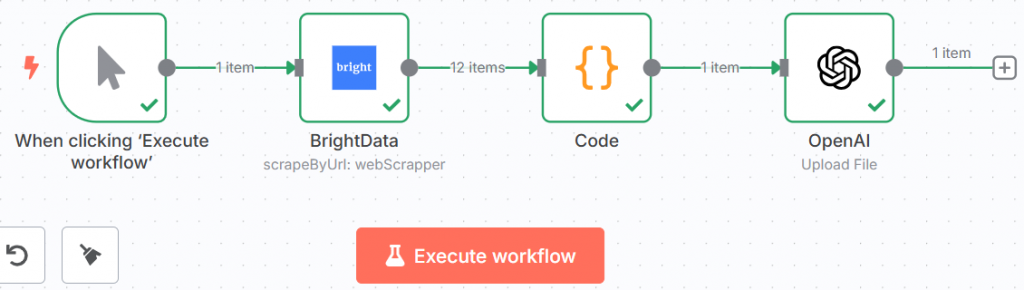
C’est incroyable ! Vous avez tout préparé pour le processus de mise au point. Il est temps de passer au processus proprement dit.
Étape n° 5 : Affiner le programme d’éducation et de formation tout au long de la vie
Pour effectuer la mise au point proprement dite, connectez un nœud de requête HTTP à celui de l’OpenAI :

Les réglages doivent être les suivants :
- La “méthode” doit être “POST” car vous téléchargez le fichier de données de formation.
- Le champ “URL” doit être
https://api.openai.com/v1/fine_tuning/jobsendpoint. Il s’agit de l’URL standard pour les travaux de mise au point sur la plateforme OpenAI. - Pour le champ “Authentification”, choisissez “Predefined Credential Type” afin d’utiliser votre jeton API OpenAI.
- Pour le “Credential Type”, sélectionnez “OpenAi” pour que le nœud se connecte à OpenAI.
- Dans la case “OpenAI”, choisissez votre nom de compte OpenAI.
- L’option “Send Body” doit être activée. Sélectionnez “JSON” et “Using JSON” respectivement pour les champs “Body Content Type” et “Specify Body”.
Le champ JSON doit contenir les éléments suivants :
{
"training_file": "{{ $json.id }}",
"model": "gpt-4o-mini-2024-07-18"
} Ce JSON :
- Spécifie le nom des données d’apprentissage avec
$json.id. - Définit le modèle à utiliser pour le réglage fin. Dans ce cas, vous utiliserez GPT-4o-mini selon la version publiée le 2024-07-18.
Vous trouverez ci-dessous le résultat que vous recevrez :
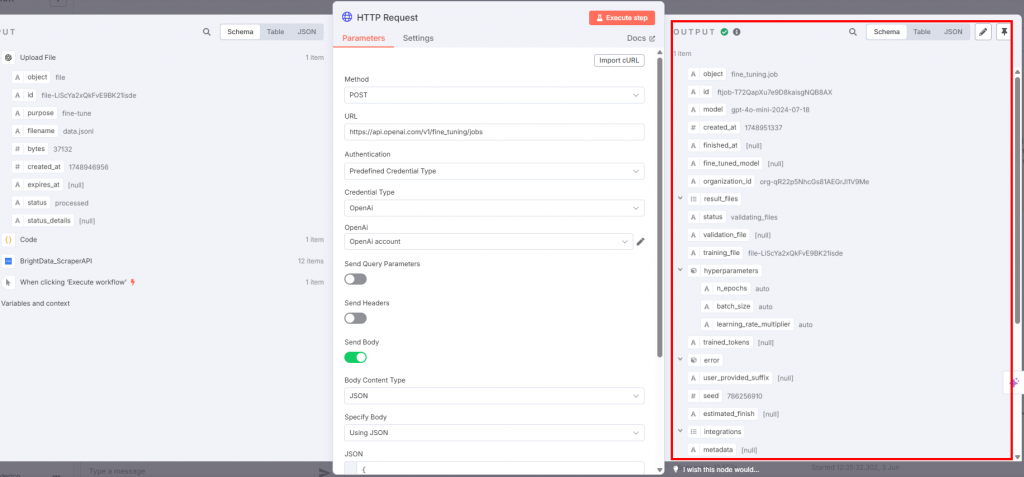
Lorsque le nœud HTTP Request est déclenché, le processus de réglage fin commence. Vous pouvez voir ses progrès dans la section “fine-tuning” de la plateforme OpenAI. Lorsque le processus de mise au point est terminé avec succès, OpenAI vous fournit le modèle mis au point que vous utiliserez à l’étape 7 :

Le flux de travail du n8n devrait maintenant se présenter comme suit :

Félicitations ! Vous avez formé votre premier modèle GPT en utilisant des données récupérées avec l’API Scraper de Bright Data via n8n.
Il s’agit du nœud final de la première moitié de l’ensemble du flux de travail.
Étape 6 : Ajouter le nœud de discussion
La seconde moitié de l’ensemble du flux de travail doit commencer par un nœud de déclenchement de discussion. C’est là que vous insérerez l’invite pour tester le LLM affiné :

Vous trouverez ci-dessous l’invite que vous pouvez insérer dans le chat :
You are an expert marketing assistant specializing in writing compelling and informative product descriptions. Generate a product description for the following office item:
Title: ErgoComfort Pro Executive Chair.
Brand: OfficeSolutions.
Key Features: Adjustable lumbar support, Breathable mesh back, Memory foam seat cushion, 360-degree swivel, Smooth-rolling casters.Comme vous pouvez le constater, cette invite :
- Rapporte la même phrase sur l’expertise de l’assistant marketing que celle utilisée dans la phase de formation.
- Demande de générer une description de produit à partir des informations sur l’article de bureau nécessaire défini par :
- Le titre.
- La marque.
- Caractéristiques principales du produit de bureau.
Il est important que la structure de l’invite soit ainsi. En effet, le modèle, dans cette phase, imite les données d’entraînement. Vous devez donc lui donner une invite et des données similaires à celles que vous avez utilisées dans la phase de formation. Ensuite, le LLM affiné écrira la description du produit sur la base de ces facteurs.
Vous pouvez insérer l’invite dans la section de discussion au bas de l’interface utilisateur :
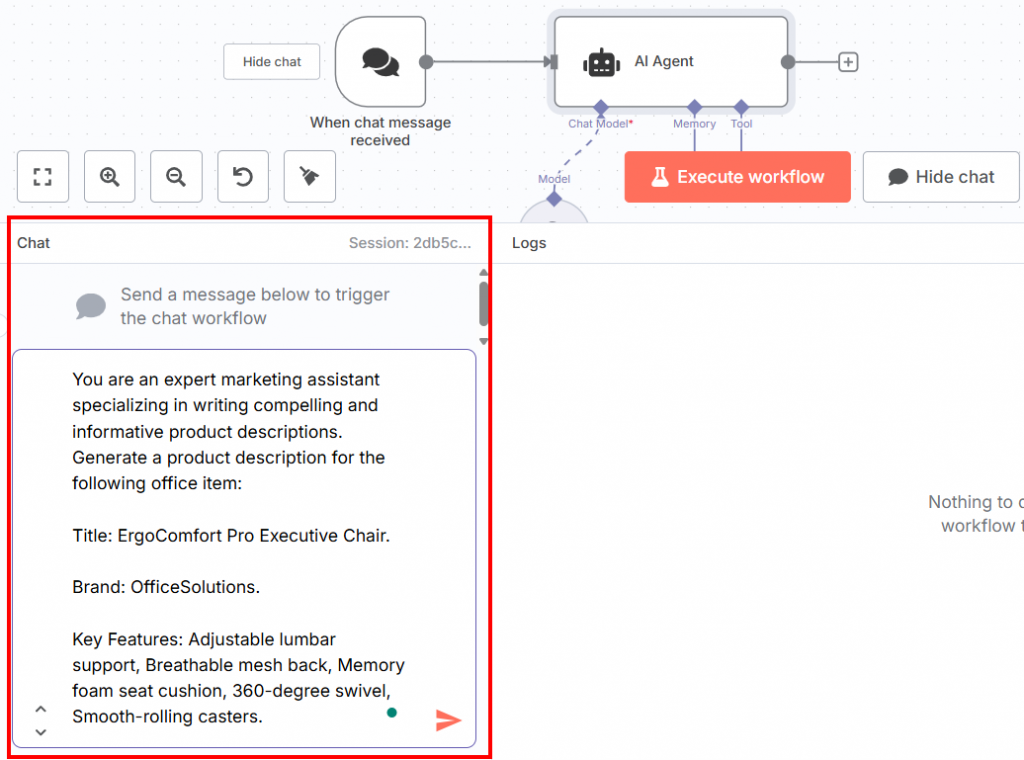
Il s’agit de votre flux de travail n8n actuel :
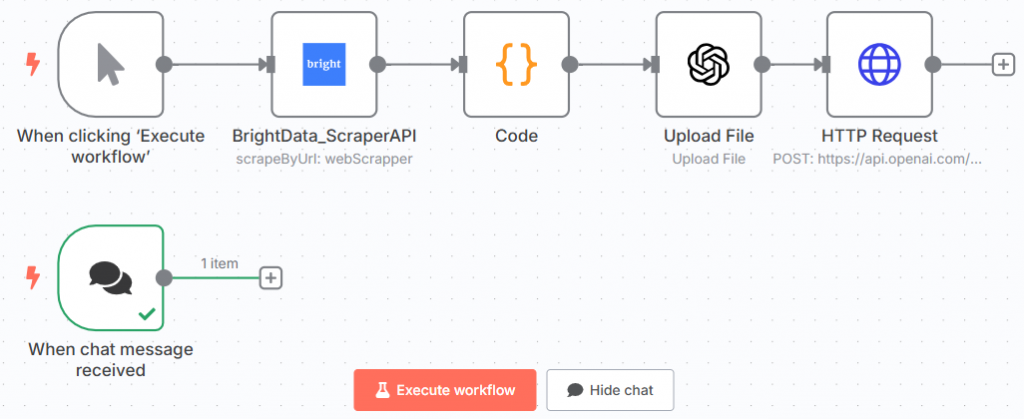
Formidable ! Vous avez défini l’invitation à tester le modèle affiné.
Étape 7 : Ajouter l’agent d’IA et les nœuds de chat OpenAI
Vous devez maintenant connecter un nœud d’agent d’intelligence artificielle au déclencheur de conversation :

Les paramètres doivent être :
- “Agent” : Choisissez “Agent conversationnel”. Cela vous permet de modifier ce que vous voulez à l’aide du nœud Chat Trigger, comme vous le feriez avec n’importe quel autre agent conversationnel.
- Définissez la “Source of Prompt (User Message)” comme “Connected Chat Trigger Node” afin qu’il puisse ingérer l’invite directement à partir du chat.
Connecter un nœud du modèle de chat OpenAI à celui de l’agent d’IA par l’intermédiaire de son option de connexion “Modèle de chat” :

L’image ci-dessous montre les paramètres du nœud OpenAI Chat Model :

Configurez le nœud comme suit :
- “Credential to connect with” : Sélectionnez les informations d’identification OpenAI que vous avez enregistrées.
- “Model” : Collez le modèle de sortie affiné à partir de la section d’affinage de la plateforme OpenAI.
Retournez au nœud de l’agent AI et cliquez sur le bouton “Exécuter l’étape”. Vous verrez la description du produit qui en résulte :
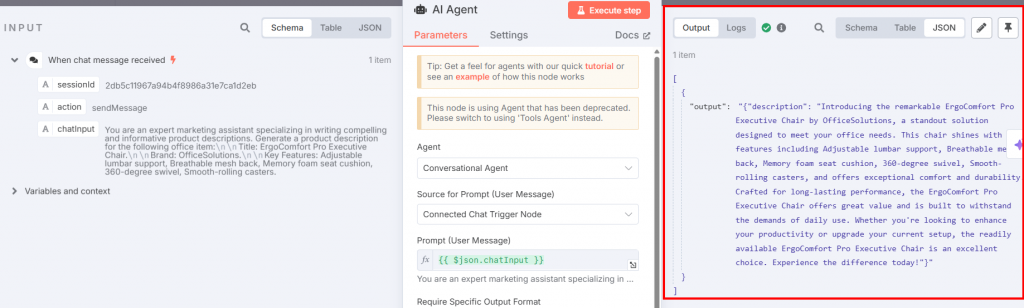
Vous trouverez ci-dessous la description en texte clair qui en résulte :
Introducing the remarkable ErgoComfort Pro Executive Chair by OfficeSolutions, a standout solution designed to meet your office needs. This chair shines with key features including Adjustable lumbar support, Breathable mesh back, Memory foam seat cushion, 360-degree swivel, Smooth-rolling casters, and offers exceptional comfort and durability. Crafted for long-lasting performance, the ErgoComfort Pro Executive Chair offers great value and is built to withstand the demands of daily use. Whether you're looking to enhance your productivity or upgrade your current setup, the readily available ErgoComfort Pro Executive Chair is an excellent choice. Experience the difference today!Comme vous pouvez le constater, la description s’appuie sur le nom de l’objet (“ErgoComfort Pro Executive Chair”), sa marque (“OfficeSolutions”) et toutes ses caractéristiques pour générer la description du produit. En particulier, la description ne se contente pas d’énumérer les données d’entrée ; elle les exploite pour créer une description attrayante. Les dernières phrases sont essentielles :
- “Fabriqué pour une performance durable, le fauteuil de direction ErgoComfort Pro offre un excellent rapport qualité-prix et est conçu pour résister aux exigences d’une utilisation quotidienne.
- “Que vous cherchiez à améliorer votre productivité ou à moderniser votre installation actuelle, le fauteuil de direction ErgoComfort Pro est un excellent choix. Faites l’expérience de la différence dès aujourd’hui !”
Et voilà ! Vous avez testé votre modèle GPT-4o-mini, qui a généré une description de produit pour répondre à l’invite donnée (définie à l’étape 6).
Étape n° 8 : Assembler le tout
Le processus final de mise au point du GTP-4o n8n se présente désormais comme suit :

Maintenant que le flux de travail est entièrement configuré, si vous cliquez sur “Exécuter le flux de travail”, il sera exécuté à nouveau depuis le début. Notez toutefois que les résultats sont enregistrés à chaque étape. Cela signifie que si vous souhaitez essayer différentes invites pour tester le modèle affiné, il vous suffit de les écrire dans le nœud Déclencheur de conversation et d’exécuter ce nœud et le nœud Agent d’intelligence artificielle.
Comparaison des approches de réglage fin : Infrastructure en nuage et automatisation des flux de travail
Ce guide a été conçu pour deux raisons :
- Vous apprendre à peaufiner un LLM à l’aide d’un outil d’automatisation des flux de travail tel que n8n
- Si l’on compare cette façon d’affiner les LLM avec celle utilisée dans notre article “Fine-Tuning Llama 4 with Fresh Web Data for Better Results” (Affiner le réglage du Llama 4 avec des données Web fraîches pour obtenir de meilleurs résultats)
Il est temps de comparer les deux approches !
Comparaison des méthodes de réglage fin
L’approche que nous avons suivie dans notre article précédent pour peaufiner le Llama 4 nécessite :
- L’utilisation d’une infrastructure en nuage, qui prend du temps à mettre en place et engendre des coûts.
- Écrire le code pour récupérer les données en utilisant les API Scraper de Bright Data.
- Mise en place d’un visage étreignant.
- La nécessité de développer un carnet de notes avec le code Python pour la mise au point, ce qui demande du temps et des compétences techniques.
Il n’est pas possible d’estimer les compétences techniques nécessaires. En revanche, vous pouvez estimer le temps nécessaire à la mise en place de l’ensemble de l’infrastructure, ainsi que l’argent dépensé :
- Durée: environ une journée de travail.
- Argent: 25 $. Après avoir dépensé 25 $ pour le service en nuage, la consommation se fera par heure. En même temps, vous devez payer 25 $ avant de commencer. Il s’agit donc du prix minimum pour utiliser le nuage.
L’approche que vous avez apprise dans ce guide nécessite :
- n8n, dont l’utilisation est gratuite et ne nécessite pas de grandes compétences techniques.
- Un jeton API OpenAI pour accéder à GPT-4o ou à d’autres modèles.
- Compétences de base en codage, notamment pour écrire un extrait JavaScript pour le nœud Code.
Dans ce cas, les compétences techniques sont bien moindres. L’extrait de code JavaScript peut être facilement créé par n’importe quel LLM – si vous ne pouvez pas l’écrire vous-même. Par ailleurs, vous n’avez pas besoin d’écrire d’autres extraits de code dans l’ensemble du flux de travail.
Dans ce cas, vous pouvez estimer comme suit le temps nécessaire à la mise en place de l’infrastructure et l’argent nécessaire :
- Durée: environ une demi-journée de travail.
- Argent: 10 $ pour un jeton API OpenAI. Même dans ce cas, vous devrez payer pour chaque demande d’API. Néanmoins, vous pouvez commencer avec seulement 10 $. Une licence n8n coûte actuellement 25 $/mois pour le plan de base, ou est totalement gratuite si vous choisissez d’utiliser la version auto-hébergée. Pour commencer, vous avez donc besoin d’environ 10 $.
Quelle approche choisir ?
| Aspect | Approche de l’infrastructure en nuage | Approche de l’automatisation des flux de travail |
|---|---|---|
| Compétences techniques | Élevé (nécessite des compétences en codage Python, Cloud et en extraction de données) | Faible (JavaScript de base) |
| Temps d’installation | Environ une journée de travail complète | Environ une demi-journée de travail |
| Coût initial | ~25 $ minimum pour le service en nuage + frais horaires | ~10$ pour le jeton API OpenAI + 24$/mois pour la licence n8n ou gratuit en auto-hébergement |
| Flexibilité | Élevé (adapté à une personnalisation avancée et à divers cas d’utilisation) | Modéré (bon pour l’automatisation des flux de travail et la personnalisation à faible code) |
| Meilleur pour | Équipes ayant des compétences techniques élevées et ayant besoin d’une infrastructure puissante et flexible | Équipes à la recherche d’une installation rapide ou disposant d’une expertise limitée en matière de codage |
| Avantages supplémentaires | Contrôle total de l’environnement et du processus de réglage fin | Modèles prédéfinis, faible barrière à l’entrée, intégration à d’autres flux de travail |
Les deux approches nécessitent un investissement initial similaire, tant en termes de temps que d’argent. Alors, comment choisir entre l’une et l’autre ? Voici quelques conseils :
- n8n: Choisissez n8n – ou tout autre outil similaire d’automatisation des flux de travail – pour affiner les MLD si vous avez besoin d’automatiser d’autres flux de travail et si votre équipe n’est pas très compétente sur le plan technique. Cette approche “low-code” vous aidera à automatiser d’autres flux de travail. Elle ne nécessite d’écrire du code que si vous avez besoin d’une personnalisation. Il fournit également des modèles préconstruits que vous pouvez utiliser gratuitement, ce qui réduit la barrière d’entrée à l’utilisation de l’outil.
- Services en nuage: Choisissez un service en nuage pour affiner les LLM si vous en avez besoin pour plusieurs raisons et si vous disposez d’une équipe hautement qualifiée. La mise en place de l’environnement en nuage et le développement du carnet de réglage fin nécessitent une expertise technique avancée.
Le cœur du processus de mise au point : Des données de haute qualité
Quelle que soit l’approche choisie, Bright Data reste l’intermédiaire clé dans les deux cas. La raison en est simple : des données de haute qualité constituent la base du processus de mise au point !
Bright Data vous couvre avec une infrastructure d’IA pour les données, offrant une gamme de services et de solutions pour soutenir vos applications d’IA :
- Serveur MCP: Un serveur MCP Node.js open-source qui expose plus de 20 outils pour la recherche de données dans les agents d’IA.
- Web Scraper APIs: API préconfigurées pour l’extraction de données structurées à partir de plus de 100 domaines majeurs.
- Web Unlocker: Une API tout-en-un qui gère le déverrouillage des sites dotés de protections anti-bots.
- SERP API: Une API spécialisée qui déverrouille les résultats des moteurs de recherche et extrait des données SERP complètes.
- Modèles de base: Accédez à des ensembles de données conformes, à l’échelle du web, afin d’alimenter le pré-entraînement, l’évaluation et le réglage fin de LLM.
- Fournisseurs de données: Connectez-vous avec des fournisseurs de confiance pour obtenir des ensembles de données de haute qualité, prêts pour l’IA, à grande échelle.
- Paquets de données: Obtenez des ensembles de données curatifs et prêts à l’emploi, structurés, enrichis et annotés.
Bien que ce guide vous ait appris à affiner GPT-4o-mini en scrappant les données à l’aide des API Web Scraper, vous pouvez choisir une approche différente en utilisant l’un de nos services.
Conclusion
Dans cet article, vous avez appris à affiner GPT-4o-mini avec des données récupérées sur Amazon en utilisant n8n pour automatiser l’ensemble du flux de travail. Vous avez parcouru l’ensemble du processus, qui se compose de deux branches :
- Effectue le réglage fin après avoir récupéré les données.
- Tester le modèle affiné en insérant l’invite par l’intermédiaire d’un déclencheur de chat.
Vous avez également comparé cette approche, qui utilise un outil d’automatisation des flux de travail, à une autre qui utilise un service en nuage.
Quelle que soit l’approche la mieux adaptée à vos besoins et à votre équipe, n’oubliez pas que des données de haute qualité restent au cœur du processus. À cet égard, Bright Data vous propose plusieurs services de données pour l’IA.
Créez gratuitement un compte Bright Data et testez notre infrastructure de données prête pour l’IA !





