

Dans ce guide, vous découvrirez :
- Comment automatiser le scraping de LinkedIn en utilisant n8n, Bright Data, et OpenAI
- Comment créer un flux de travail sans code qui envoie les profils des candidats directement dans votre boîte de réception ?
- Pourquoi la combinaison de Web Unlocker, ChatGPT et SMTP crée-t-elle un puissant outil de recrutement ?
C’est parti !
Pour commencer
Vous pouvez visualiser ce flux de travail sur n8n ici. Cependant, pour une installation plus facile, il y a plusieurs choses à faire d’abord.
Auto-hébergement n8n
Ce flux de travail s’appuie sur les nœuds communautaires de n8n. Les nœuds communautaires sont des outils tiers fournis par de bons samaritains de la communauté n8n. La meilleure façon de gérer toutes ces parties mobiles est de les intégrer dans un conteneur Docker.
Installation de Docker
En utilisant Ubuntu natif ou Ubuntu via WSL sur Windows, exécutez la commande suivante pour installer Docker. Pour en savoir plus sur l’installation de Docker sur d’autres plateformes , cliquez ici.
sudo snap install dockerUne fois Docker installé, créez un volume de stockage et lancez votre conteneur.
Création d’un conteneur n8n
sudo docker volume create n8n_data
sudo docker run -it --rm --name n8n -p 5678:5678 -v n8n_data:/home/node/.n8n docker.n8n.io/n8nio/n8nInstallation des nœuds communautaires
Ouvrez http://localhost:5678/ dans votre navigateur. Vous aurez une version complètement auto-hébergée de l’application web n8n fonctionnant localement.
Dans la barre latérale, cliquez sur les trois points situés à côté de votre profil et sélectionnez “paramètres”.

Une fois que vous êtes dans le menu des paramètres, sélectionnez “Community Nodes”. Cela vous permet d’accéder aux outils tiers que j’ai mentionnés précédemment.
Cliquez sur “Install” et vous verrez un popup pour le nœud que vous voulez installer. Dans la section npm package, collez le package suivant.
n8n-nodes-brightdataLorsque vous êtes prêt, cliquez sur “Installer”.

Répétez cette opération pour le générateur de documents.
n8n-nodes-document-generator
Redémarrage du conteneur
Une fois que vos nœuds communautaires sont installés, fermez le conteneur avec ctrl+c. Exécutez la commande ci-dessous pour redémarrer n8n.
sudo docker run -it --rm --name n8n -p 5678:5678 -v n8n_data:/home/node/.n8n docker.n8n.io/n8nio/n8nImportation du flux de travail
Après l’installation, nous sommes enfin prêts à importer le flux de travail dont j’ai parlé plus haut. Rendez-vous sur la page n8n et cliquez sur le bouton “Use for free”.

Vous devriez voir une fenêtre popup avec plusieurs options différentes. Le plus simple est de sélectionner “Importer le modèle dans l’instance auto-hébergée localhost:5678”.

Saisissez ou importez vos données d’identification
Vous serez alors automatiquement invité à saisir vos informations d’identification pour Bright Data, OpenAI et SMTP.

Obtention des clés API
Bright Data
Ce flux de travail utilise Web Unlocker pour effectuer notre recherche. Après vous être inscrit à Web Unlocker, rendez-vous sur le tableau de bord Web Unlocker et obtenez votre clé API. n8n utilisera cette clé pour extraire les résultats avec Bright Data.

OpenAI
Rendez-vous sur la plateforme de développement d’ OpenAI et créez un compte si vous ne l’avez pas encore fait. Cliquez ensuite sur “API keys” pour générer une clé.

SMTP
Ce processus est compatible avec n’importe quel client SMTP. Actuellement, j’utilise Elastic Email. Leur plan gratuit est excellent pour des projets locaux comme celui-ci. Enregistrez votre nom d’utilisateur, votre mot de passe, votre serveur et votre port. Nous les utiliserons avec n8n pour automatiser votre processus de courrier électronique.

Étapes du flux de travail

Lorsque l’utilisateur remplit un formulaire
Lorsqu’un utilisateur remplit un formulaire web, cela déclenche notre flux de travail. N’hésitez pas à ouvrir ce nœud et à examiner les paramètres et les réglages. Cependant, tout ce qui se trouve dans cette étape devrait être préconfiguré – il n’est pas nécessaire de l’éditer.

Création de l’URL LinkedIn et de la recherche d’entreprise
Lorsque le formulaire est rempli, nous lançons deux flux de travail distincts.
L’un d’eux crée une URL Google pour rechercher le profil LinkedIn de cette personne.

L’autre crée une url Google distincte pour effectuer une recherche sur LinkedIn pour son entreprise.
Ces deux URL sont transmises à Web Unlocker pour éviter qu’elles ne soient bloquées.

Extraction de HTML à partir des résultats
Maintenant, nous extrayons le HTML de nos résultats. Nous avons deux nœuds appelés “Extraire le corps et le titre du site Web”. Ces deux nœuds extraient le titre et le corps de la réponse JSON de Bright Data.

Dans le flux de travail, les deux étapes mises en évidence se déroulent en même temps.

Analyse des résultats avec ChatGPT
Maintenant que nous avons extrait le titre et le corps de chaque recherche, nous transmettons nos résultats HTML à ChatGPT pour traitement. Chacun de ces nœuds contient un processus comme celui que vous voyez ci-dessous. Nous définissons notre modèle (GPT-4o mini) et lui donnons l’ordre d’extraire nos données.

Comme vous pouvez le voir ci-dessous, cela se produit simultanément sur nos deux processus.
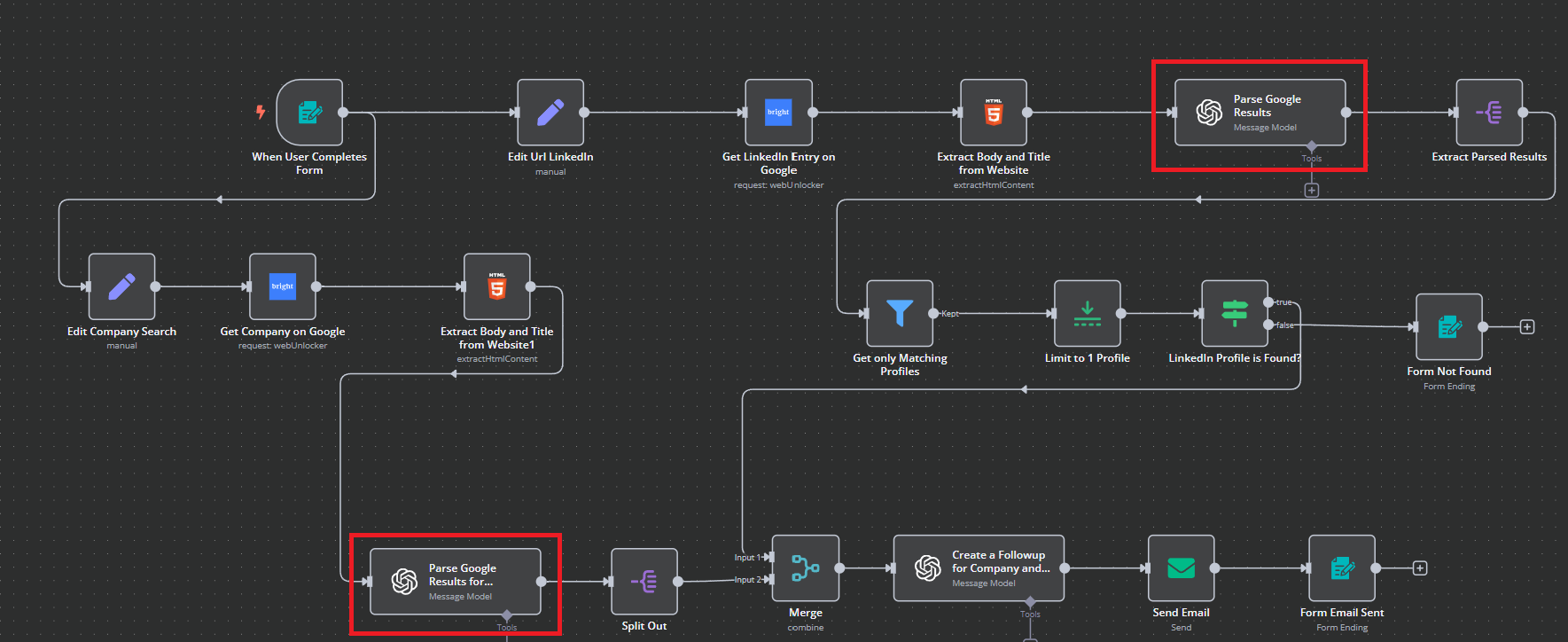
Extraire les résultats analysés et diviser pour terminer la recherche d’entreprise
Au cours de cette étape, l’un de nos flux de travail distincts se termine par un “Split Out”. Lorsque le flux de travail “Entreprise” se termine, nous extrayons les résultats analysés de notre flux de travail “Personne”.
Voici les instructions pour l’extraction. Comme vous pouvez le voir, nous ne faisons qu’extraire de petits morceaux du corps JSON.

Notre flux de travail “Entreprise” est maintenant terminé et notre flux de travail “Personne” doit encore effectuer quelques étapes. Le flux de travail “Entreprise” restera en pause jusqu’à ce que ces processus soient prêts à être fusionnés. C’est là que la beauté de n8n commence vraiment à briller… une programmation asynchrone sans codage !

Se limiter à un profil et valider son existence
Notre flux de travail “Personne” filtre les résultats pour n’utiliser que les profils correspondants. Ensuite, nous le limitons à un seul profil et nous nous assurons que ce profil existe. S’il n’existe pas, nous le gérons en mettant à jour le formulaire et en indiquant à l’utilisateur que le profil n’a pas été trouvé.

Tant que le profil existe, nous sommes prêts à le fusionner en un flux de travail unique et cohérent.

Fusionner les flux de travail
Comme vous pouvez le voir ci-dessous, les données des deux flux de travail sont utilisées en entrée. Elles sont fusionnées en une seule sortie que nous transmettons une dernière fois à ChatGPT.

Tout se met enfin en place. Une fois que nous avons obtenu un flux de travail unique, nous sommes prêts à exécuter les dernières étapes.

Élaborer des mesures de sensibilisation et de suivi
Maintenant, nous renvoyons cette sortie unique dans ChatGPT pour finaliser notre email. Il écrit même du HTML personnalisé, de sorte que nous n’avons pas besoin de nous préoccuper du code de balisage.

Une fois le code HTML renvoyé, nous sommes prêts à envoyer les résultats par courrier électronique.

Envoi de l’e-mail
Ouvrez le nœud “Send Email” pour vous assurer que vos informations d’identification et de connexion sont correctes. Comme vous pouvez le voir, nous passons json.message.content.content pour créer l’email. Cela prend littéralement le HTML de ChatGPT et le colle directement dans le corps de l’email.

Remplacez le champ “From Email” par l’adresse SMTP que vous utilisez. L’e-mail est ensuite envoyé à l’adresse “To Email” – remplacez-la par votre adresse personnelle pour recevoir les résultats dans votre boîte de réception personnelle.

Mise à jour du formulaire pour indiquer l’achèvement
Enfin, nous mettons à jour le formulaire pour indiquer à l’utilisateur que l’opération a réussi. Si vous ouvrez “Form Email Sent”, vous verrez les différents paramètres de la mise à jour du formulaire. Comme vous pouvez le voir, nous affichons une “tuile d’achèvement” qui dit “Merci !” et un message disant “Nous vous avons envoyé un courriel”.

Nous avons maintenant terminé la dernière étape du flux de travail ! N’hésitez pas à cliquer sur le bouton “Tester le flux de travail” pour voir comment l’ensemble fonctionne.

Les résultats
Si vous décidez d’exécuter le flux de travail, vous verrez d’abord une fenêtre contextuelle vous demandant de remplir votre formulaire de recherche. Remplissez le formulaire et cliquez sur “Obtenir des références”.

Une fois le processus terminé, votre formulaire devrait ressembler à celui ci-dessous. Comme vous pouvez le voir, il dit “Merci !” et affiche notre message d’achèvement.
Si vous ouvrez votre boîte de réception, vous trouverez un nouvel e-mail contenant un aperçu détaillé de votre candidat avec des liens vers son site web et son profil LinkedIn. En dessous, vous trouverez des recommandations de ChatGPT en matière d’approche et de suivi.

Conclusion
Avec n8n, Bright Data, OpenAI et SMTP, vous avez construit un flux de travail entièrement automatisé de raclage et d’approche de LinkedIn, sans avoir à écrire de code complexe. Cette puissante configuration rationalise votre processus de recrutement, en fournissant des profils de candidats enrichis et des contacts personnalisés directement dans votre boîte de réception.
Qu’il s’agisse de développer un pipeline d’embauche ou d’améliorer la génération de leads, ce flux de travail n’est qu’un début. Bright Data propose une suite complète d’outils pour faire passer votre automatisation au niveau supérieur :
- Web Unlocker: contourner les CAPTCHA, les blocages et la détection des robots pour récupérer des données sur LinkedIn et d’autres sites en toute fiabilité.
- Proxies résidentiels: Accédez à des IP d’utilisateurs réels du monde entier pour garantir des taux de réussite élevés et un ciblage géographique.
- Navigateur de capture: Un navigateur sans tête avec prise en charge intégrée du proxy, idéal pour les pages contenant beaucoup de JavaScript.
- API d’extraction: Utilisez des modèles de scraping prédéfinis pour extraire des données structurées sans effort.
- Jeux de données: Exploitez des ensembles de données prêtes à l’emploi pour les offres d’emploi, les données d’entreprise, etc. afin d’enrichir votre travail de sensibilisation.
Inscrivez-vous pour un essai gratuit et commencez à automatiser plus intelligemment dès aujourd’hui !






