
Dans ce tutoriel, vous apprendrez
- Ce qu’est Cursor et pourquoi il est devenu si populaire.
- Les principales raisons d’ajouter à Cursor un serveur MCP qui change la donne, comme celui de Bright Data.
- Comment connecter Cursor au MCP Web de Bright Data.
- Comment obtenir les mêmes résultats dans Visual Studio Code.
Plongeons dans l’aventure !
Qu’est-ce que Cursor ?
Cursor est un éditeur de code alimenté par l’IA, conçu comme une fourche de Visual Studio Code. Sa fonctionnalité principale, comme tout éditeur de texte, est de fournir une interface pour écrire du code. Cependant, ce qui le rend spécial, c’est son intégration profonde de l’IA.
Au lieu d’une simple autocomplétion, Cursor utilise LLms pour comprendre l’ensemble de votre base de code et votre contexte. Cela lui permet d’offrir des fonctionnalités intelligentes telles que
- Des invites conversationnelles: Décrivez ce que vous voulez en langage clair et Cursor écrira ou modifiera le code pour vous.
- L’autocomplétion multiligne: Il suggère et complète des blocs entiers de code, et pas seulement des lignes individuelles.
- Refactorisation pilotée par l’IA: Il peut optimiser, nettoyer et corriger votre code de manière intelligente en fonction du contexte de l’ensemble du projet.
- Aide au débogage: Demandez à l’IA de trouver et d’expliquer les bogues dans votre code.
Cursor transforme un éditeur de code standard en un programmeur en binôme proactif et hautement intelligent. Il prend en charge plusieurs LLM de différents fournisseurs et inclut une prise en charge intégrée des outils via MCP.
Pourquoi ajouter le Web MCP de Bright Data à Cursor ?
En coulisses, Cursor s’appuie sur des modèles LLM connus. Bien que son intégration soit plus profonde et plus soignée que celle de la plupart des outils, il est toujours confronté à la même limitation fondamentale que tout LLM : la connaissance de l’IA est statique !
Après tout, les données d’entraînement de l’IA reflètent un instantané dans le temps. Ces données deviennent rapidement obsolètes, en particulier dans des domaines qui évoluent rapidement comme le développement de logiciels. Imaginez maintenant que vous donniez à l’agent IA de Cursor la capacité de :
- d’extraire les derniers tutoriels et la documentation pour les flux de travail RAG,
- de consulter des guides en direct pendant qu’il écrit du code, et
- de parcourir des sites web en temps réel aussi facilement qu’il peut naviguer dans vos fichiers locaux.
C’est précisément ce que vous débloquez en connectant Cursor au Web MCP de Bright Data!
Web MCP offre un accès à plus de 60 outils prêts pour l’IA, conçus pour l’interaction web en temps réel et la collecte de données. Ces outils sont tous alimentés par la riche infrastructure de Données pour l’IA de Bright Data.
Même avec la version gratuite, votre agent Cursor peut déjà accéder à deux outils puissants :
| Outil | Description de l’outil |
|---|---|
moteur_de_recherche |
Récupère les résultats de recherche de Google, Bing ou Yandex en JSON ou Markdown. |
scrape_as_markdown |
Récupère n’importe quelle page web dans un format Markdown propre, en contournant la détection des robots et les CAPTCHA. |
En outre, Web MCP comprend des outils pour l’automatisation des navigateurs en nuage et l’extraction de données structurées à partir de plateformes comme Amazon, YouTube, LinkedIn, TikTok, Google Maps et bien d’autres.
Voici quelques exemples de ce qui devient possible lorsque l’on étend Cursor avec le Web MCP de Bright Data :
- Récupérer les dernières références d’API ou les tutoriels de framework, puis générer automatiquement du code de travail ou des échafaudages de projet.
- Récupérer instantanément les résultats des moteurs de recherche les plus récents et les intégrer à votre documentation ou aux commentaires de votre code.
- Recueillez des données web en direct pour créer des simulacres de test réalistes, des tableaux de bord analytiques ou des pipelines de contenu automatisés.
Pour découvrir l’ensemble des fonctionnalités, consultez la documentation Bright Data MCP.
Comment intégrer Web MCP à Cursor pour une expérience de codage IA améliorée ?
Dans cette section étape par étape, vous verrez comment connecter une instance de serveur local Bright Data Web MCP à Cursor. Cette configuration offre une expérience d’IA suralimentée avec plus de 60 outils disponibles directement dans votre IDE.
En détail, nous utiliserons les outils Web MCP pour créer un backend Express avec une API simulée qui renvoie des données réelles d’Amazon. Ceci n’est qu’un exemple des nombreux cas d’utilisation supportés par cette intégration.
Suivez les instructions ci-dessous !
Conditions préalables
Pour suivre ce tutoriel, assurez-vous d’avoir :
- Un compte Cursor (un plan gratuit suffit).
- Un compte Bright Data avec une clé API active.
Ne vous préoccupez pas de la configuration de Bright Data pour l’instant. Vous serez guidé à travers le processus au fur et à mesure que vous lirez l’article !
Une compréhension de base du fonctionnement de MCP, de Cursor et des outils fournis par Web MCP sera également utile.
Étape 1 : Démarrer avec Cursor
Installez la version de Cursor correspondant à votre système d’exploitation, ouvrez-la et connectez-vous avec votre compte.
Si vous lancez l’application pour la première fois, complétez l’assistant d’installation.
Vous devriez alors voir quelque chose comme ceci :
Génial ! Ouvrez maintenant votre dossier de projet et préparez-vous à utiliser l’agent de codage IA intégré, étendu à Web MCP.
Étape 2 : Configurer votre LLM
A ce jour, Cursor utilise le modèle Claude 4.5 par défaut (en mode “Auto”). Si cela vous convient, n’hésitez pas à passer à la section suivante. N’oubliez pas que Claude peut également être intégré à Web MCP.
Si vous souhaitez modifier le modèle par défaut, recherchez “paramètres du curseur” et sélectionnez l’option équivalente :
Dans l’onglet qui s’ouvre, allez dans l’onglet “Modèles” :

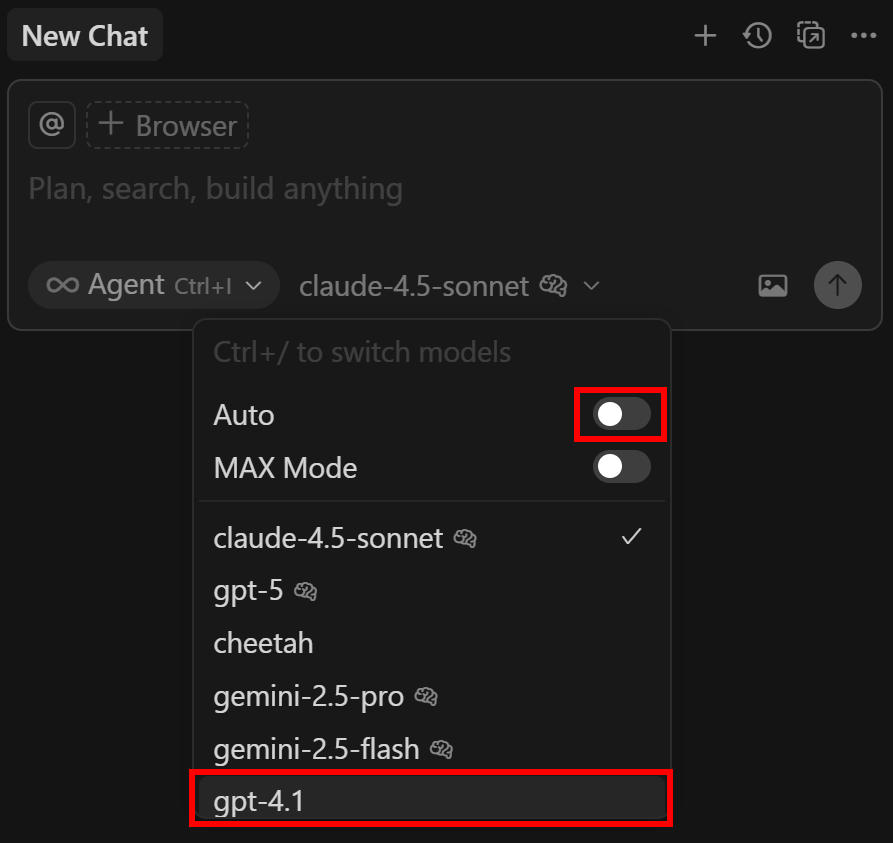
Ici, vous pouvez configurer quel agent IA du curseur LLM doit utiliser. Gardez à l’esprit que les utilisateurs gratuits ne peuvent choisir que GPT-4.1 et “Auto” comme modèles premium.
Pour changer le modèle en GTP 4.1, recherchez “gpt”, trouvez le modèle “gpt-4.1” et activez-le :

Si vous disposez d’un abonnement Pro ou Business, vous pouvez activer tous les autres LLM pris en charge. En outre, vous pouvez même fournir votre propre clé API pour le fournisseur choisi.
Ensuite, ouvrez le panneau “Nouveau chat” sur la droite. Cliquez sur la liste déroulante “Auto”, désactivez-la et sélectionnez l’option “gpt-4.1” :
Voilà qui est fait ! Le curseur fonctionne maintenant par le biais de votre LLM configuré.
Étape 3 : tester le MCP Web de Bright Data sur votre machine
Avant de connecter Cursor au MCP Web de Bright Data, vérifiez que vous pouvez exécuter le serveur localement. Cela est nécessaire car le serveur MCP sera configuré via STDIO.
Commencez par vous inscrire à Bright Data. Sinon, si vous avez déjà un compte, il vous suffit de vous connecter. Pour une installation rapide, suivez les instructions de la section “MCP” du tableau de bord :
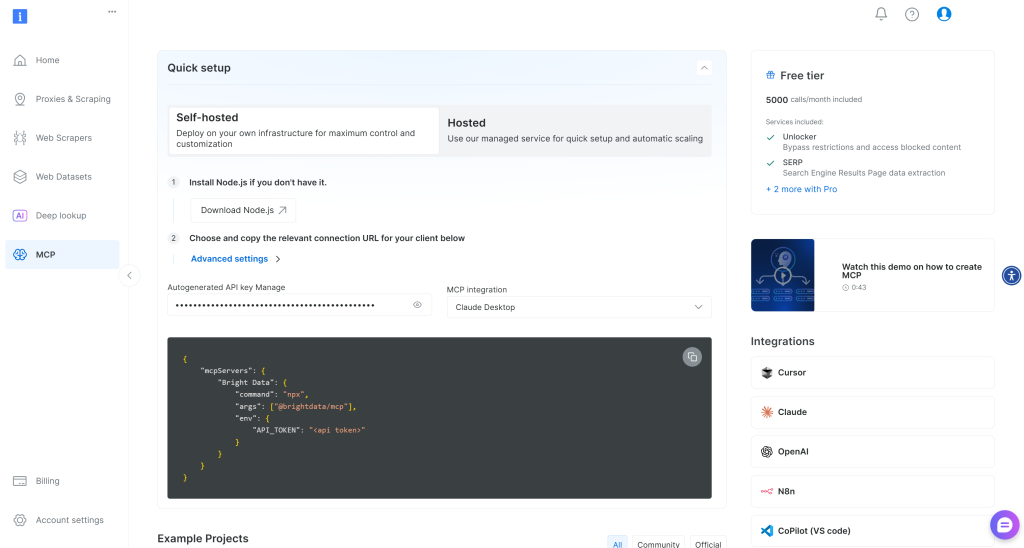
Pour plus d’informations, reportez-vous aux instructions ci-dessous.
Tout d’abord, générez votre clé API Bright Data et conservez-la dans un endroit sûr. Vous en aurez besoin à l’étape suivante. Nous supposerons que votre clé API dispose d’autorisations d’administrateur, car cela simplifie l’intégration du MCP Web.
Maintenant, installez le Web MCP globalement sur votre machine via cette commande npm :
npm install -g @brightdata/mcpVérifiez que le serveur MCP fonctionne en le lançant :
API_TOKEN="<Votre_clé_API_BRIGHT_DATA>" npx -y @brightdata/mcpOu, de manière équivalente, en PowerShell :
$Env:API_TOKEN="<Votre_BRIGHT_DATA_API_KEY>" ; npx -y @brightdata/mcpRemplacez le caractère générique <Votre_BRIGHT_DATA_API> par votre clé d’API Bright Data. Ces commandes définissent la variable d’environnement API_TOKEN requise et lancent le Web MCP localement via le paquet @brightdata/mcp.
En cas de succès, vous devriez obtenir un résultat comme celui-ci :

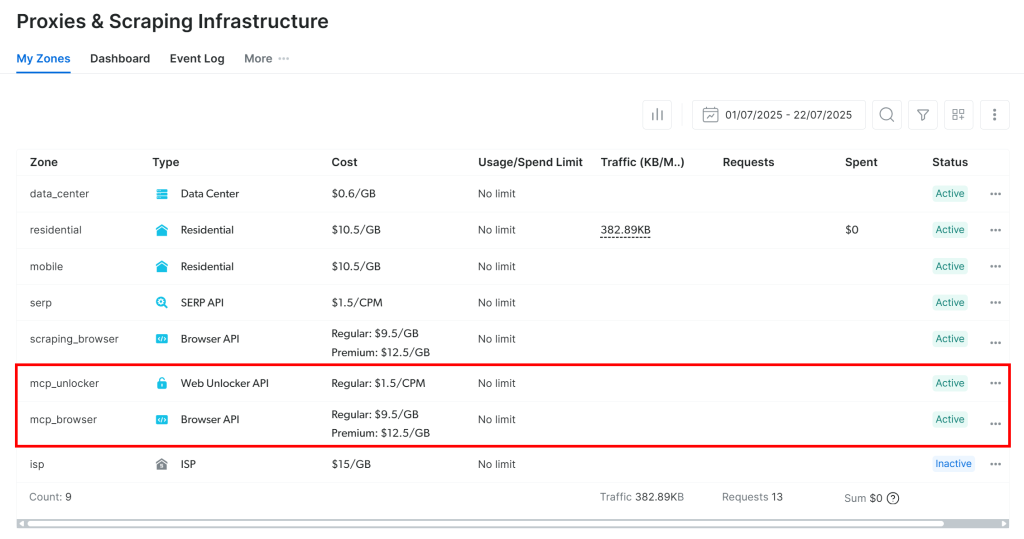
Lors du premier lancement, le MCP Web crée deux zones par défaut dans votre compte Bright Data :
mcp_unlocker: Une zone pour Web Unlocker.mcp_browser: Une zone pour Browser API.
Web MCP s’appuie sur ces deux services Bright Data pour alimenter ses plus de 60 outils.
Si vous souhaitez vérifier que les zones ont été configurées, accédez à la page “Proxy & Scraping Infrastructure” dans votre compte Bright Data. Vous devriez repérer les deux zones dans le tableau :
Remarque: si votre jeton API ne dispose pas des autorisations Admin, les deux zones ne seront pas créées automatiquement. Dans ce cas, définissez-les manuellement et définissez-les via des variables d’environnement comme expliqué sur GitHub.
Rappelez-vous que, dans la version gratuite, Web MCP n’expose que les outils search_engine et scrape_as_markdown (et leurs versions batch). Pour débloquer tous les autres outils, activez le mode Pro **en définissant la variable d’environnement PRO_MODE="true":
API_TOKEN="<Votre_API_BRIGHT_DATA>" PRO_MODE="true" npx -y @brightdata/mcpOu, sous Windows :
$Env:API_TOKEN="<Votre_BRIGHT_DATA_API>" ; $Env:PRO_MODE="true" ; npx -y @brightdata/mcpLe mode Pro débloque les 60+ outils, mais il n’est pas inclus dans le niveau gratuit, ce qui signifie qu’il entraînera des frais supplémentaires.
Formidable ! Vous venez de vous assurer que le serveur Web MCP fonctionne localement. Arrêtez le processus MCP, car vous êtes sur le point de configurer Cursor pour qu’il le démarre pour vous et s’y connecte.
Étape 4 : Configurer Web MCP dans Cursor
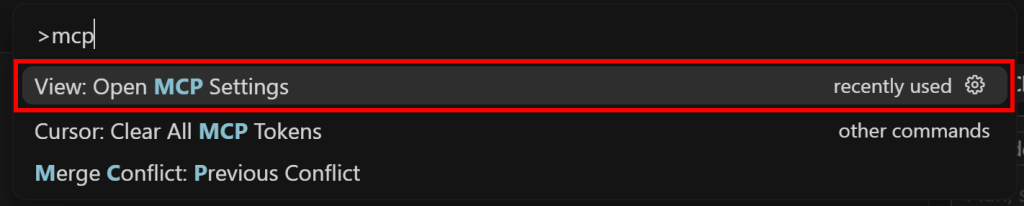
Commencez par rechercher “>mcp” et sélectionnez l’option “View : Open MCP Settings” :
Dans la section “Tools & MCP”, cliquez sur le bouton “Add Custom MCP” :

Cela ouvrira le fichier de configuration mcp.json suivant :

Comme vous pouvez le voir, il est vide par défaut. Pour l’intégration Web MCP de Bright Data, remplissez-le comme suit :
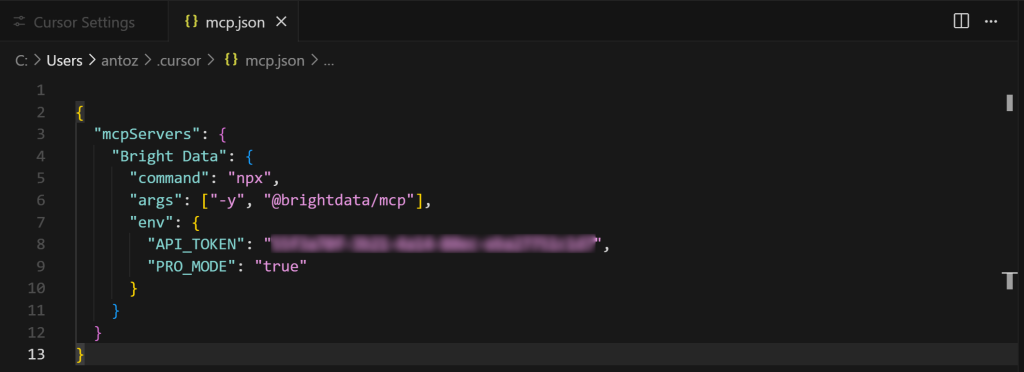
{
"mcpServers" : {
"Bright Data" : {
"command" : "npx",
"args" : ["-y", "@brightdata/mcp"],
"env" : {
"API_TOKEN" : "<VOTRE_CLÉ_API_DATA_BRIGHT>",
"PRO_MODE" : "true"
}
}
}
}Ensuite, enregistrez le fichier en utilisant Ctrl + S (ou Cmd + S sur macOS) :
La configuration ci-dessus reproduit la commande npx que nous avons testée précédemment, en utilisant des variables d’environnement pour transmettre les informations d’identification et les paramètres :
API_TOKENest nécessaire. Définissez-la sur la clé API de Bright Data que vous avez générée précédemment.PRO_MODEest facultatif. Supprimez-la si vous n’avez pas l’intention d’activer le mode Pro.
En d’autres termes, Cursor utilisera la configuration dans mcp.json pour exécuter la commande npx vue précédemment. Il lancera un processus Web MCP localement, s’y connectera et aura accès aux outils exposés.
Fermez l’onglet mcp.json, l’intégration Cursor + Bright Data Web MCP est terminée !
Remarque: si vous préférez ne pas utiliser STDIO et utiliser SSE ou HTTP en continu, n’oubliez pas que le Web MCP de Bright Data offre également une option de serveur distant.
Étape 5 : vérification de la disponibilité de l’outil à partir de l’intégration MCP
Il est temps de vérifier si Cursor s’est connecté avec succès au serveur Web MCP et s’il peut accéder à tous ses outils.
Pour ce faire, retournez à la section “Tools & MCP” dans l’onglet “Cursor Settings”. Vous devriez maintenant voir l’option configurée “Bright Data”, qui répertorie tous les outils disponibles :
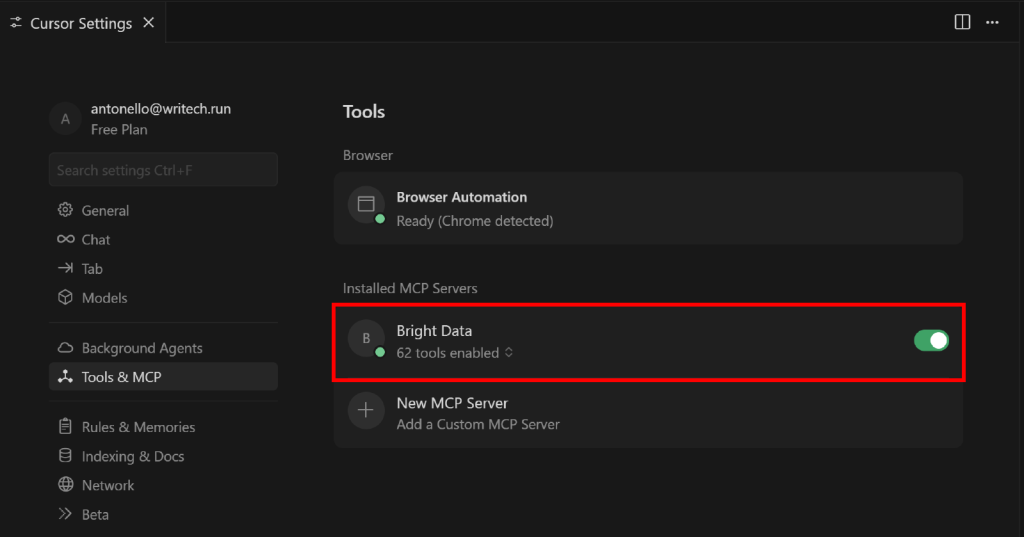
Développez le menu déroulant “N outils activés” (où N est le nombre d’outils activés) pour inspecter tous les outils disponibles :
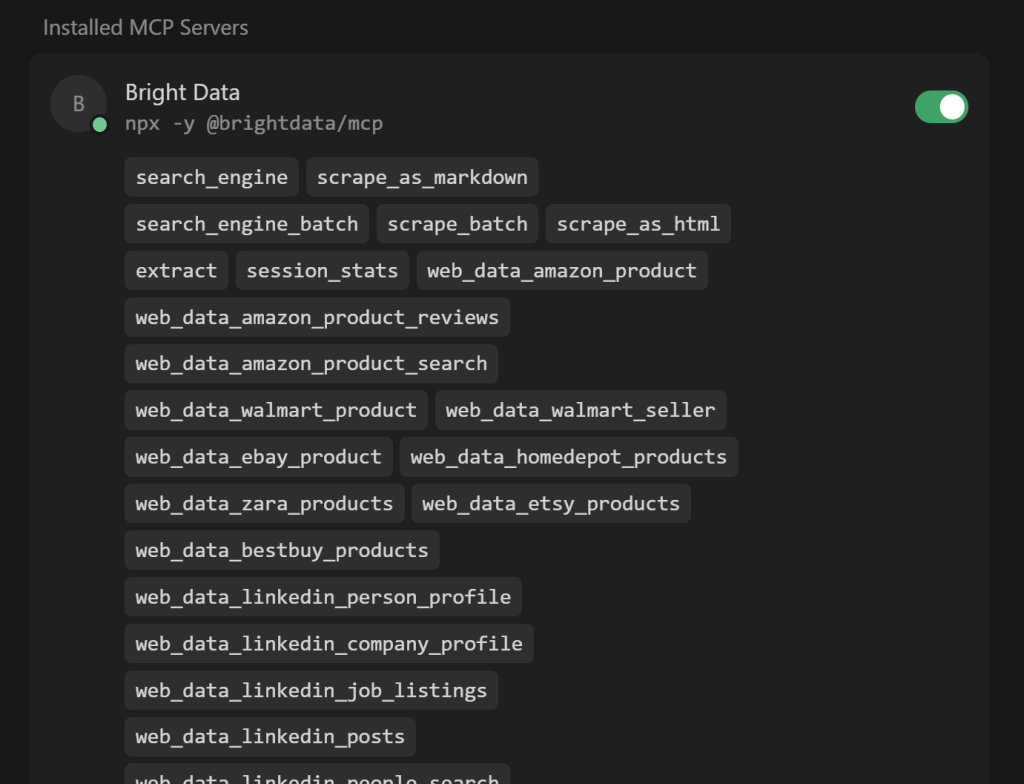
Notez que Cursor se connecte automatiquement au serveur et récupère ses plus de 60 outils.
Si le mode Pro est désactivé, vous ne verrez que les 4/5 outils gratuits disponibles. Ici, vous pouvez également activer ou désactiver les outils selon vos préférences. Par défaut, ils sont tous activés.
Une fois l’activation confirmée, fermez l’onglet “Paramètres du curseur”. Préparez-vous à tirer parti de ces outils pour une expérience de codage étendue et alimentée par l’IA !
Étape n° 6 : Exécuter une tâche avec l’agent de codage IA amélioré
Pour tester les capacités de votre agent de codage Cursor, vous avez besoin d’une invite qui exerce les fonctions de récupération de données Web nouvellement configurées.
Par exemple, supposons que vous construisiez un backend dans Express.js pour votre application de commerce électronique. Vous souhaitez simuler une API qui renvoie des données de produits Amazon réels.
Réalisez cela avec une invite comme celle-ci :
Récupérez les données des produits Amazon suivants :
1. https://www.amazon.com/Clean-Skin-Club-Disposable-Sensitive/dp/B07PBXXNCY/
2. https://www.amazon.com/Neutrogena-Cleansing-Towelettes-Waterproof-Alcohol-Free/dp/B00U2VQZDS/
3. https://www.amazon.com/Medicube-Zero-Pore-Pads-Dual-Textured/dp/B09V7Z4TJG/
Enregistrez ensuite les données extraites dans un fichier JSON local. Ensuite, créez un projet Express.js simple avec un point de terminaison qui accepte un ASIN (représentant un produit Amazon) et renvoie les données correspondantes lues dans le fichier JSON.Supposons que vous travaillez en mode Pro. Exécutez l’invite ci-dessus dans le curseur.
Voici ce qui se passe ensuite, étape par étape :
- Le LLM configuré dans Cursor identifie
web_data_amazon_productcomme l’outil permettant de récupérer les données des produits Amazon. - Pour chacun des trois produits Amazon figurant dans l’invite, on vous demande l’autorisation d’exécuter
web_data_amazon_productpour récupérer les données. - Vous accordez l’autorisation pour chaque outil, ce qui déclenche des tâches de collecte de données asynchrones (qui, sous le capot, appellent le Bright Data Amazon Scraper).
- Les données récupérées pour chaque produit sont affichées au format JSON.
- GPT-4.1 traite les données récupérées et remplit un fichier
products.json. - Cursor crée la structure du projet npm, en définissant le
fichier package.jsonet le fichierindex.jsavec la logique du serveur Express. - On vous demande l’autorisation d’installer les dépendances du projet via
npm install. Il en résultera un fichierpackage.jsondans le dossiernode_modules/. - On vous demande l’autorisation de lancer le serveur avec
npm start.
Note: Même si ce n’était pas explicitement spécifié dans l’invite, GPT-4.1 a également décidé de demander l’installation des dépendances du projet et la configuration du serveur. C’est un ajout intéressant !
Dans cet exemple, la sortie finale produira une structure de projet comme suit :
votre-projet/
├── node_modules/
├── index.js
├── package.json
├── package-lock.json
└── products.jsonParfait ! Inspectons le résultat pour voir s’il atteint l’objectif visé.
Étape 7 : Explorer le projet de sortie
Au fur et à mesure que l’agent de codage IA générait les fichiers, ceux-ci apparaissaient dans la colonne de gauche dans Cursor.
Avertissement: vos fichiers peuvent différer de ceux présentés ci-dessous, car les résultats de l’IA peuvent varier d’une exécution à l’autre.
Commencez par examiner le fichier products.json:
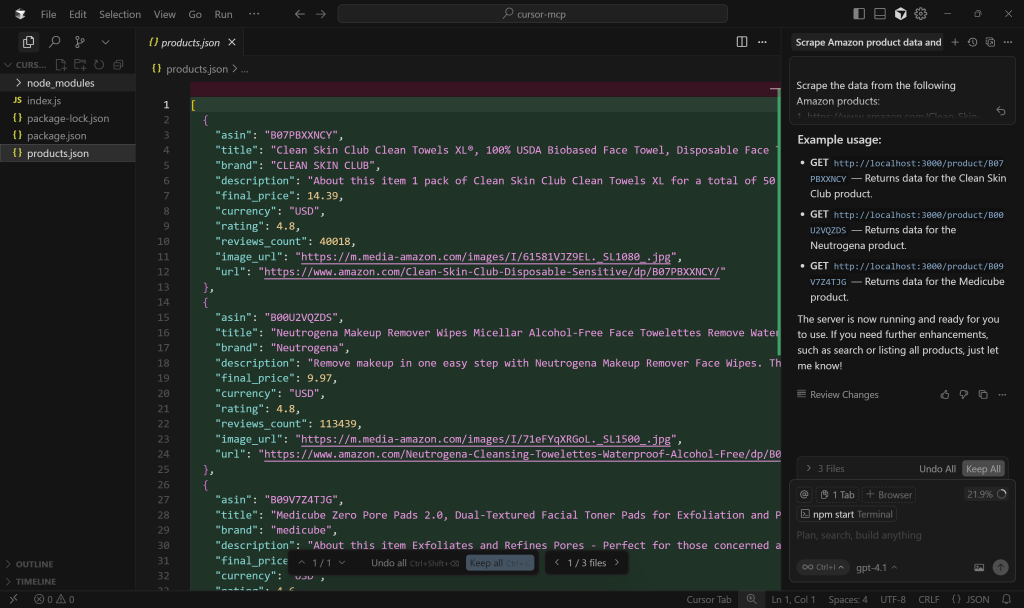
Comme vous pouvez le constater, il contient une version simplifiée des données extraites par l’outil web_data_amazon_product:
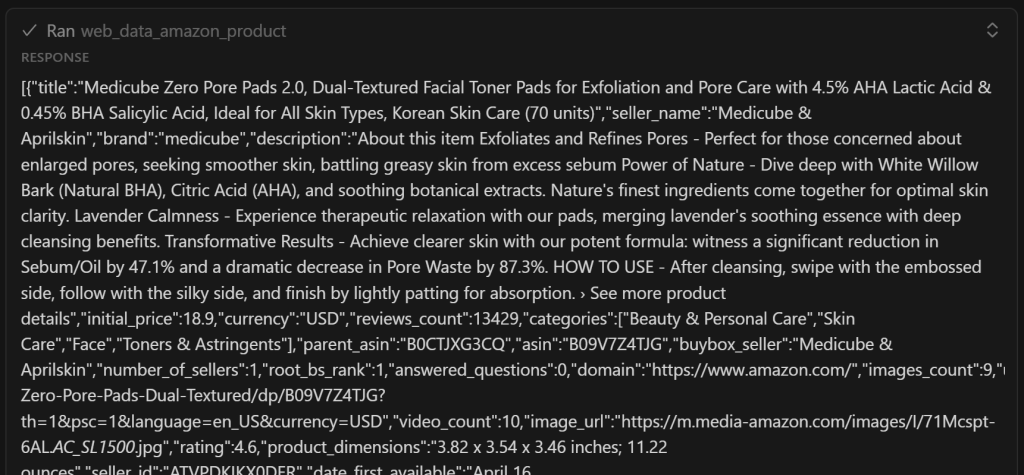
Important: web_data_amazon_product renvoie en fait toutes les données produit de la page Amazon, et pas seulement quelques champs. L’IA a tout de même décidé de n’inclure que les champs les plus pertinents. Avec un peu d’optimisation de l’invite, vous pouvez demander à l’IA d’inclure tous les champs si vous le souhaitez.
Ensuite, ouvrez index.js pour voir la logique du serveur Express.js :
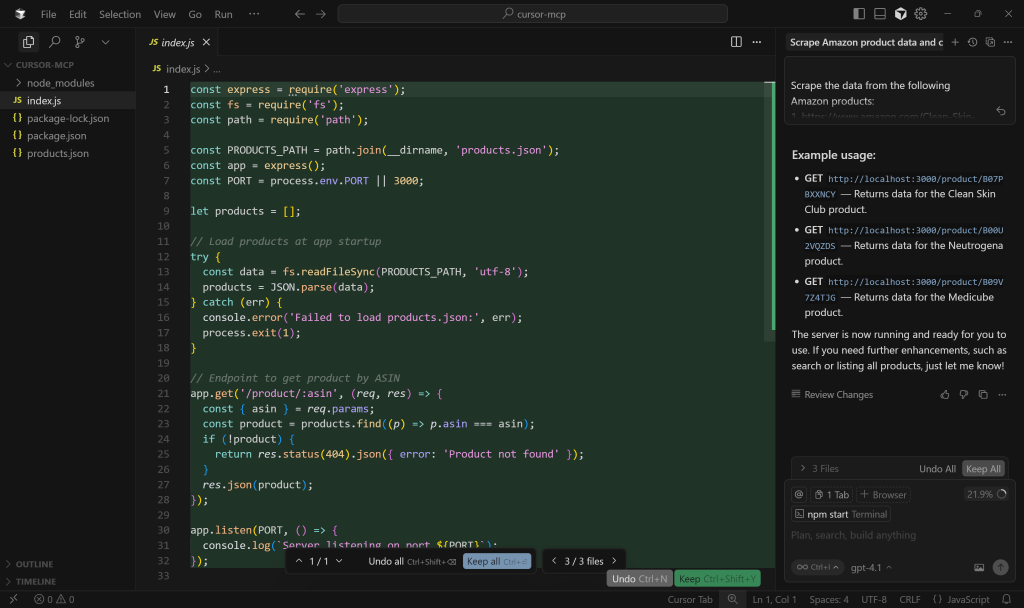
Plus précisément, le point de terminaison simulé pour la récupération des données sur les produits utilise le chemin /product/:asin.
Continuez en inspectant les autres fichiers, mais ils devraient tous être corrects. Appuyez donc sur le bouton “Garder tout” pour confirmer la sortie générée par l’IA et préparez-vous à tester votre projet !
Étape 8 : Tester le projet produit
Votre application Express.js devrait déjà être en cours d’exécution, car GPT-4.1 a demandé la permission d’exécuter npm start. Si ce n’est pas le cas, vous pouvez la démarrer manuellement avec :
npm startVotre backend Express.js devrait maintenant être en cours d’exécution à l’adresse http://localhost.
Ensuite, exécutez la commande cURL suivante pour tester le point de terminaison GET /product/:asin:
curl "http://localhost/ produit/B07PBXXNCYOù B07PBXXNCY est l’ASIN de l’un des produits Amazon mentionnés dans l’invite.
Vous devriez voir quelque chose comme ceci :

Merveilleux ! Ces données ont été récupérées correctement dans le fichier products.json généré. Le résultat correspond (à une version simplifiée) aux données de la page Amazon d’origine.
Si vous avez déjà essayé de récupérer des données de produits sur Amazon, vous savez à quel point cela peut être difficile en raison du fameux CAPTCHA d’Amazon et d’autres mesures anti-bots. Il est certain que la version vanille de GPT-4.1 ne peut à elle seule extraire des données d’Amazon à la volée.
Ceci démontre la puissance de la combinaison de Web MCP avec Cursor. Il ne s’agit là que d’un exemple très simple. Cependant, avec les 60+ outils disponibles et les bonnes invites, vous pouvez gérer des scénarios plus avancés directement dans votre IDE !
Et voilà ! Un backend Express avec un point d’extrémité API simulé a été créé avec succès, grâce à l’intégration Cursor + Bright Data Web MCP.
[Approches alternatives dans Visual Studio Code
Si vous souhaitez obtenir une expérience similaire à celle de Cursor dans Visual Studio Code, utilisez des extensions telles que Cline ou Roo Code.
En particulier, pour l’intégration de Web MCP dans VS Code, reportez-vous à ces guides :
- Ajouter Web MCP de Bright Data à Roo Code dans Visual Studio Code
- Scraping web dans Cline avec le serveur MCP de Bright Data
Conclusion
Dans cet article de blog, vous avez appris à tirer pleinement parti de l’intégration de MCP dans Cursor. L’agent de codage IA intégré à l’IDE est déjà utile, mais il devient beaucoup plus performant et plein de ressources une fois connecté au Web MCP de Bright Data.
Cette intégration permet à Cursor d’effectuer des recherches en direct sur le Web, d’extraire des données structurées, de consommer des flux de données dynamiques et même d’automatiser les interactions avec le navigateur. Tout cela, directement à partir de votre environnement de codage.
Pour créer des flux de travail encore plus avancés alimentés par l’IA, explorez la gamme complète de services et de solutions de données disponibles dans l’écosystème IA de Bright Data.
Créez un compte Bright Data gratuit dès aujourd’hui et commencez à expérimenter avec nos outils de données web prêts pour l’IA !






