
Dans ce guide, vous apprendrez :
- Qu’est-ce que la génération assistée par récupération (RAG) et pourquoi l’ajout de capacités agentiques est-il important ?
- Comment Bright Data permet la récupération autonome et en direct de données web pour les systèmes RAG
- Comment traiter et nettoyer les données extraites d’un site web pour les intégrer à la génération de données ?
- Mise en œuvre d’un contrôleur d’agent pour orchestrer la recherche vectorielle et la génération de texte LLM
- Conception d’une boucle de rétroaction permettant de recueillir les commentaires de l’utilisateur et d’optimiser la recherche et la génération de manière dynamique.
Plongeons dans l’aventure !
L’essor de l’intelligence artificielle (IA) a introduit de nouveaux concepts, dont la GCR agentique. En termes simples, la RAG agentique est une génération augmentée de recherche (RAG) qui intègre des agents d’intelligence artificielle. Comme son nom l’indique, la RAG est un système de recherche d’informations qui suit un processus linéaire : il reçoit une requête, recherche les informations pertinentes et génère une réponse.
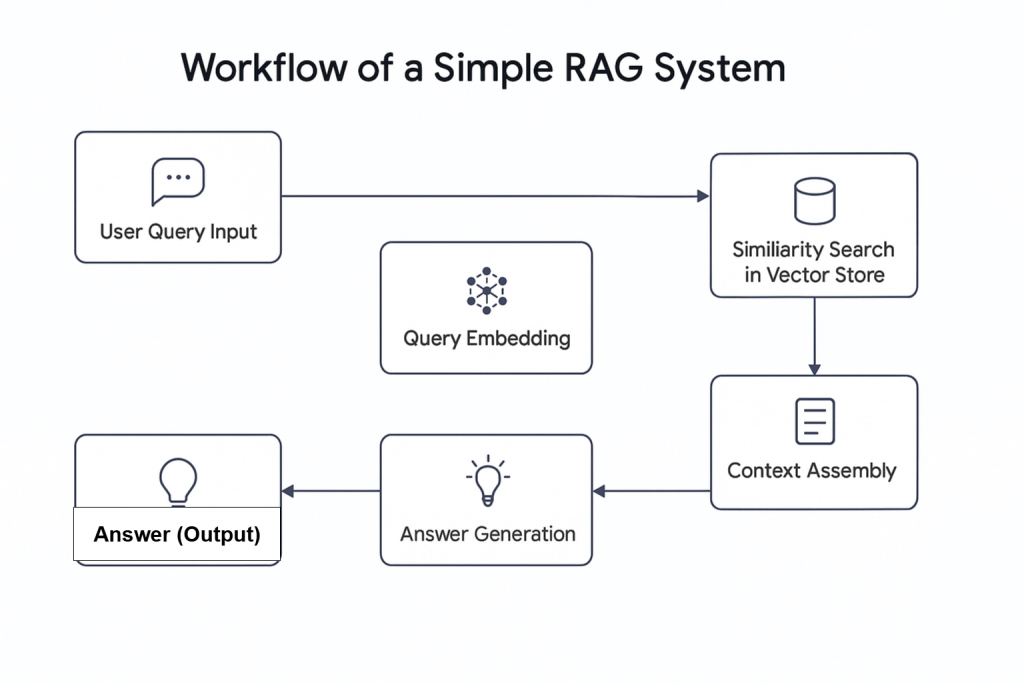
Pourquoi combiner les agents d’intelligence artificielle avec RAG ?
Une enquête récente montre que près de deux tiers des flux de travail utilisant des agents d’intelligence artificielle font état d’une augmentation de la productivité. En outre, près de 60 % d’entre eux font état d’économies. La combinaison d’agents d’intelligence artificielle et de RAG pourrait donc changer la donne pour les flux de recherche modernes.
Le système Agentic RAG offre des capacités avancées. Contrairement aux systèmes RAG traditionnels, il peut non seulement récupérer des données, mais aussi décider d’aller chercher des informations dans des sources externes, telles que des données Web en direct intégrées dans une base de données.
Cet article montre comment construire un système Agentic RAG qui récupère des informations d’actualité en utilisant Bright Data pour la collecte de données web, Pinecone comme base de données vectorielle, OpenAI pour la génération de texte, et Agno comme contrôleur d’agent.
Vue d’ensemble de Bright Data
Qu’il s’agisse d’un flux de données en direct ou de données préparées à partir de votre base de données, la qualité des résultats de votre système Agentic RAG dépend de la qualité des données qu’il reçoit. C’est là que Bright Data devient essentiel.
Bright Data fournit des données web fiables, structurées et actualisées pour un large éventail de cas d’utilisation. Grâce à l’API Web Scraper de Bright Data, qui a accès à plus de 120 domaines, le scraping web est plus efficace que jamais. Elle gère les défis courants liés au scraping, tels que les interdictions d’IP, les CAPTCHA, les cookies et d’autres formes de détection des robots.
Pour commencer, inscrivez-vous à un essai gratuit, puis obtenez votre clé API et votre dataset_id pour le domaine que vous souhaitez récupérer. Une fois que vous les avez, vous êtes prêt à commencer.
Voici les étapes à suivre pour récupérer des données fraîches d’un domaine populaire comme BBC News :
- Créez un compte Bright Data si vous ne l’avez pas encore fait. Un essai gratuit est disponible.
- Accédez à la page Web Scrapers. Sous la rubrique Bibliothèque de scripteurs Web, explorez les modèles de scripteurs disponibles.
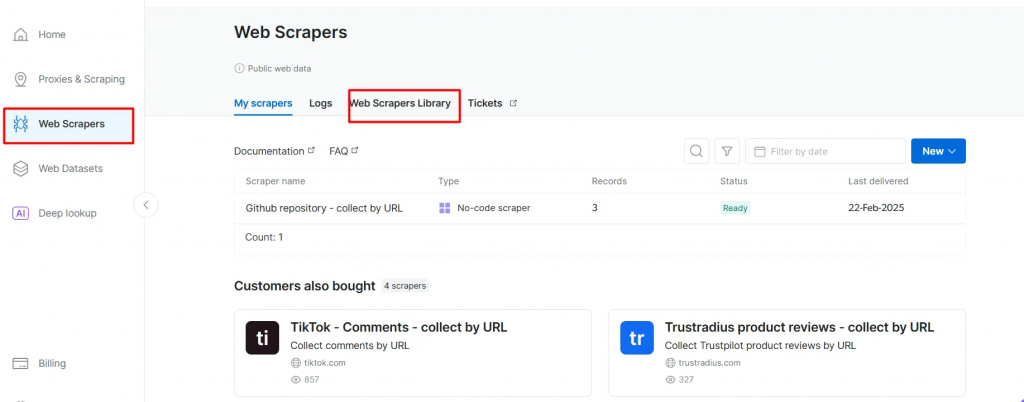
- Recherchez votre domaine cible, par exemple BBC News, et sélectionnez-le.
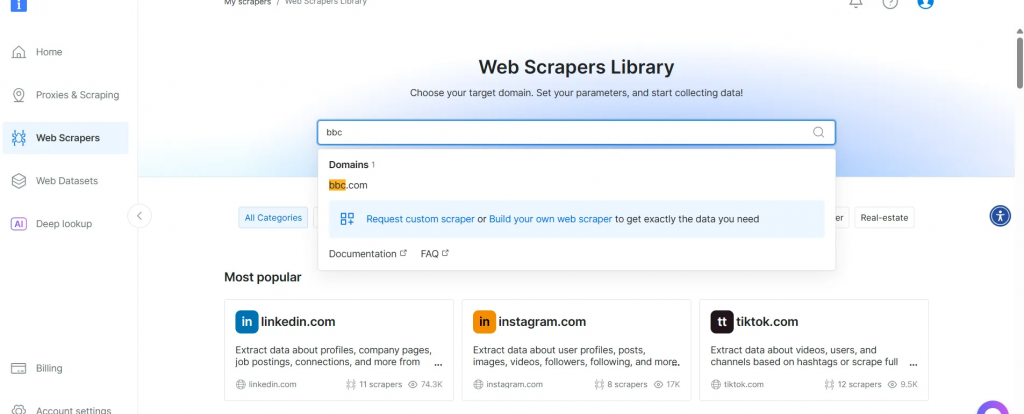
- Dans la liste des scrapeurs de BBC News, sélectionnez BBC News – collect by URL. Ce scraper vous permet de récupérer des données sans vous connecter au domaine.
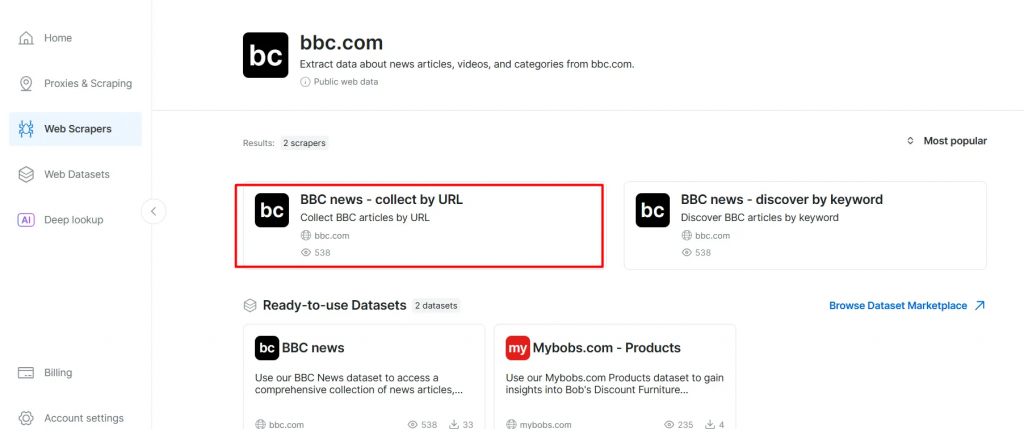
- Choisissez l’option Scraper API. Le No-Code Scraper permet d’extraire des ensembles de données sans code.

- Cliquez sur API Request Builder, puis copiez votre
clé API, l’URL de l'ensemble de données BBCet l’identifiant de l'ensemble de données. Vous les utiliserez dans la section suivante lors de la création du flux de travail Agentic RAG.
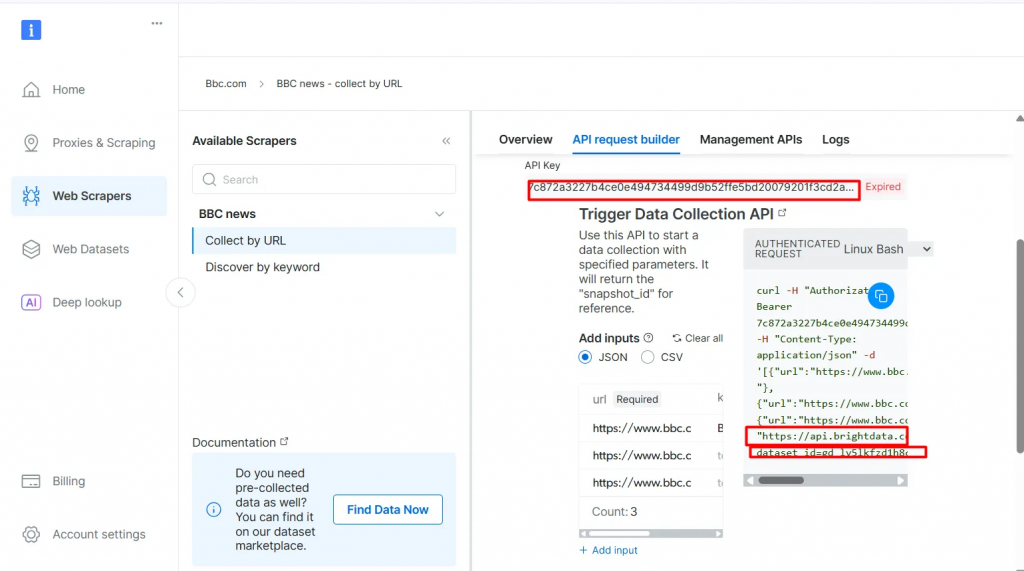
La clé API et l’identifiant du jeu de données sont nécessaires pour activer les capacités agentiques dans votre flux de travail. Elles vous permettent d’intégrer des données en direct dans votre base de données vectorielle et de prendre en charge les requêtes en temps réel, même lorsque la requête de recherche ne correspond pas directement au contenu pré-indexé.
Conditions préalables
Avant de commencer, assurez-vous que vous disposez des éléments suivants :
- Un compte Bright Data
- Une clé API OpenAI Inscrivez-vous sur OpenAI pour obtenir votre clé API :
- Une clé API Pinecone Reportez-vous à la documentation Pinecone et suivez les instructions de la section Obtenir une clé API.
- Une connaissance de base de Python Vous pouvez installer Python à partir du site officiel.
- Une compréhension de base des concepts de RAG et d’agent
Structure du RAG agentique
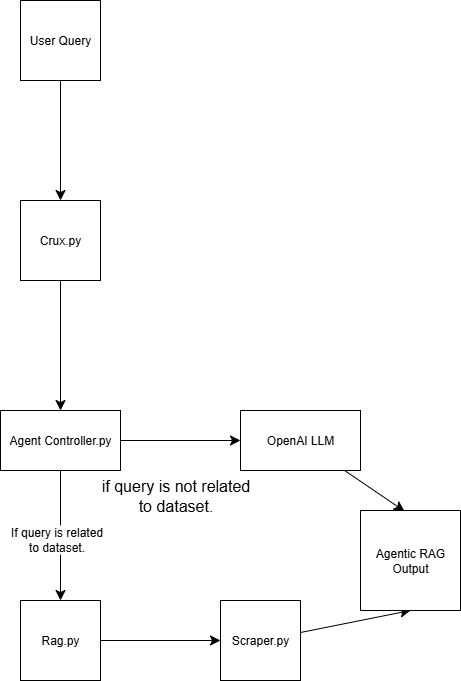
Ce système Agentic RAG est construit à l’aide de quatre scripts :
scraper.py Récupère des données web via Bright Data
rag.py Incorpore des données dans la base de données vectorielle (Pinecone) Remarque : une base de données vectorielle (incorporation numérique) est utilisée parce qu’elle stocke des données non structurées typiquement générées par un modèle d’apprentissage automatique. Ce format est idéal pour la recherche de similarités dans les tâches d’extraction.
agent_controller.py Contient la logique de contrôle. Il détermine s’il faut utiliser les données prétraitées de la base de données vectorielle ou s’appuyer sur les connaissances générales de GPT, en fonction de la nature de la requête.
crux.py Joue le rôle de noyau du système Agentic RAG. Il stocke les clés API et initialise le flux de travail.
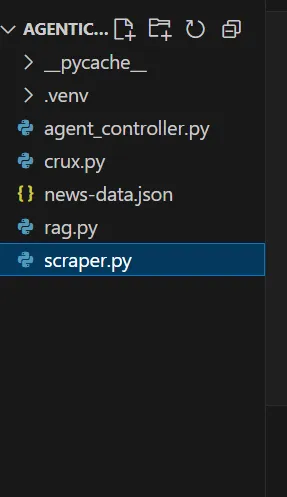
La structure de votre chiffon agentique ressemblera à ceci à la fin de la démo :
Construire un RAG agentique avec Bright Data
Étape 1 : Mise en place du projet
1.1 Créer un nouveau répertoire de projet
Créez un dossier pour votre projet et naviguez-y :
mkdir agentic-rag
cd agentic-rag
1.2 Ouvrir le projet dans Visual Studio Code
Lancez Visual Studio Code et ouvrez le répertoire nouvellement créé :
.../Desktop/agentic-rag> code .
1.3 Mise en place et activation d’un environnement virtuel
Pour configurer un environnement virtuel, exécutez la commande suivante
python -m venv venv
Sinon, dans Visual Studio Code, suivez les instructions du guide des environnements Python pour créer un environnement virtuel.
Pour activer l’environnement :
- Sous Windows :
.venv\Scripts\activate - Sous macOS ou Linux :
source venv/bin/activate
Étape 2 : Mise en œuvre du Bright Data Retriever
2.1 Installer la bibliothèque requests dans votre fichier scraper.py
pip install requests
2.2 Importer les modules suivants
import requests
import json
import time
2.3 Configurer vos informations d’identification
Utilisez la clé API Bright Data, l’URL du jeu de données et l’identifiant du jeu de données que vous avez copiés précédemment.
def trigger_bbc_news_articles_scraping(api_key, urls):
# Endpoint to trigger the Web Scraper API task
url = "<https://api.brightdata.com/datasets/v3/trigger>"
params = {
"dataset_id": "gd_ly5lkfzd1h8c85feyh", # ID of the BBC web scraper
"include_errors": "true",
}
# Convert the input data in the desired format to call the API
data = [{"url": url} for url in urls]
headers = {
"Authorization": f"Bearer {api_key}",
"Content-Type": "application/json",
}
2.4 Mise en place de la logique de réponse
Remplissez votre demande avec les URL des pages que vous souhaitez récupérer. Dans ce cas, concentrez-vous sur les articles liés au sport.
response = requests.post(url, headers=headers, params=params, json=data)
if response.status_code == 200:
snapshot_id = response.json()["snapshot_id"]
print(f"Request successful! Response: {snapshot_id}")
return response.json()["snapshot_id"]
else:
print(f"Request failed! Error: {response.status_code}")
print(response.text)
def poll_and_retrieve_snapshot(api_key, snapshot_id, output_file, polling_timeout=20):
snapshot_url = f"<https://api.brightdata.com/datasets/v3/snapshot/{snapshot_id}?format=json>"
headers = {
"Authorization": f"Bearer {api_key}"
}
print(f"Polling snapshot for ID: {snapshot_id}...")
while True:
response = requests.get(snapshot_url, headers=headers)
if response.status_code == 200:
print("Snapshot is ready. Downloading...")
snapshot_data = response.json()
# Write the snapshot to an output json file
with open(output_file, "w", encoding="utf-8") as file:
json.dump(snapshot_data, file, indent=4)
print(f"Snapshot saved to {output_file}")
return
elif response.status_code == 202:
print(F"Snapshot is not ready yet. Retrying in {polling_timeout} seconds...")
time.sleep(polling_timeout)
else:
print(f"Request failed! Error: {response.status_code}")
print(response.text)
break
if __name__ == "__main__":
BRIGHT_DATA_API_KEY = "BRIGHT DATA KEY" # Replace it with your Bright Data's Web Scraper API key
# URLs of BBC articles to retrieve data from
urls = [
"<https://www.bbc.com/sport/formula1/articles/c9dj0elnexyo>",
"<https://www.bbc.com/sport/formula1/articles/cgenqvv9309o>",
"<https://www.bbc.com/sport/formula1/articles/c78jng0q2dxo>",
"<https://www.bbc.com/sport/formula1/articles/cdrgdm4ye53o>",
"<https://www.bbc.com/sport/formula1/articles/czed4jk7eeeo>",
"<https://www.bbc.com/sport/football/articles/c807p94r41do>",
"<https://www.bbc.com/sport/football/articles/crgglxwge10o>",
"<https://www.bbc.com/sport/tennis/articles/cy700xne614o>",
"<https://www.bbc.com/sport/tennis/articles/c787dk9923ro>",
"<https://www.bbc.com/sport/golf/articles/ce3vjjq4dqzo>"
]
snapshot_id = trigger_bbc_news_articles_scraping(BRIGHT_DATA_API_KEY, urls)
poll_and_retrieve_snapshot(BRIGHT_DATA_API_KEY, snapshot_id, "news-data.json")
2.5 Exécuter le code
Après l’exécution du script, un fichier nommé news-data.json apparaîtra dans le dossier de votre projet. Il contient les données des articles scannés au format JSON structuré.
Voici un exemple du contenu du fichier JSON :
[
{
"id": "c9dj0elnexyo",
"url": "<https://www.bbc.com/sport/formula1/articles/c9dj0elnexyo>",
"author": "BBC",
"headline": "Max Verstappen: Red Bull adviser Helmut Marko has 'great concern' about world champion's future with team",
"topics": [
"Formula 1"
],
"publication_date": "2026-04-14T13:42:08.154Z",
"content": "Saudi Arabian Grand PrixVenue: Jeddah Dates: 18-20 April Race start: 18:00 BST on SundayCoverage: Live radio commentary of practice, qualifying and race online and BBC 5 Sports Extra; live text updates on the BBC Sport website and app; Red Bull motorsport adviser Helmut Marko says he has \\"great concern\\" about Max Verstappen's future with the team in the context of their current struggles.AdvertisementThe four-time champion finished sixth in the Bahrain Grand Prix on Sunday, while Oscar Piastri scored McLaren's third win in four races so far this year.Dutchman Verstappen is third in the drivers' championship, eight points behind leader Lando Norris of McLaren.Marko told Sky Germany: \\"The concern is great. Improvements have to come in the near future so that he has a car with which he can win again.\\"We have to create a basis with a car so that he can fight for the world championship.\\"Verstappen has a contract with Red Bull until 2028. But Marko told BBC Sport this month that it contains a performance clause that could allow him to leave the team.; The wording of this clause is not known publicly but it effectively says that Red Bull have to provide Verstappen with a winning car.Verstappen won the Japanese Grand Prix a week before Bahrain but that victory was founded on a pole position lap that many F1 observers regarded as one of the greatest of all time.Because overtaking was next to impossible at Suzuka, Verstappen was able to hold back the McLarens of Norris and Piastri and take his first win of the year.Verstappen has qualified third, fourth and seventh for the other three races in Australia, China and Bahrain.The Red Bull is on average over all qualifying sessions this year the second fastest car but 0.214 seconds a lap slower than the McLaren.Verstappen has complained all year about balance problems with the Red Bull, which is unpredictable on corner entry and has mid-corner understeer.Red Bull team principal Christian Horner admitted after the race in Bahrain that the car's balance problems were fundamentally similar to the ones that made the second half of last year a struggle for Verstappen.He won just twice in the final 13 races of last season, but managed to win his fourth world title because of the huge lead he built up when Red Bull were in dominant form in the first five races of the season.Horner also said the team were having difficulties with correlation between their wind tunnel and on-track performance. Essentially, the car performs differently on track than the team's simulation tools say it should.; Verstappen had a difficult race in Bahrain including delays at both pit stops, one with the pit-lane traffic light system and one with fitting a front wheel.At one stage he was running last, and he managed to snatch sixth place from Alpine's Pierre Gasly only on the last lap.Verstappen said that the hot weather and rough track surface had accentuated Red Bull's problems.He said: \\"Here you just get punished a bit harder when you have big balance issues because the Tarmac is so aggressive.\\"The wind is also quite high and the track has quite low grip, so everything is highlighted more.\\"Just the whole weekend struggling a bit with brake feeling and stopping power, and besides that also very poor grip. We tried a lot on the set-up and basically all of it didn't work, didn't give us a clear direction to work in.\\"Verstappen has said this year that he is \\"relaxed\\" about his future.Any decision about moving teams for 2026 is complicated by the fact that F1 is introducing new chassis and engine rules that amount to the biggest regulation change in the sport's history, and it is impossible to know which team will be in the best shape.But it is widely accepted in the paddock that Mercedes are looking the best in terms of engine performance for 2026.Mercedes F1 boss Toto Wolff has made no secret of his desire to sign Verstappen.The two parties had talks last season but have yet to have any discussions this season about the future.",
"videos": [],
"images": [
{
"image_url": "<https://ichef.bbci.co.uk/ace/branded_sport/1200/cpsprodpb/bfc4/live/d3cc7850-1931-11f0-869a-33b652e8958c.jpg>",
"image_description": "Main image"
},
Maintenant que vous disposez des données, l’étape suivante consiste à les intégrer.
Étape 3 : Mise en place de l’intégration et de l’entrepôt de vecteurs
3.1 Installer les bibliothèques nécessaires dans votre fichier rag.py
pip install openai pinecone pandas
3.2 Importer les bibliothèques nécessaires
import json
import time
import re
import openai
import pandas as pd
from pinecone import Pinecone, ServerlessSpec
3.3 Configurer votre clé OpenAI
Utiliser OpenAI pour générer des embeddings à partir du champ text_for_embedding.
# Configure your OpenAI API key here or pass to functions
OPENAI_API_KEY = "OPENAI_API_KEY" # Replace with your OpenAI API key
3.4 Configurer votre clé API Pinecone et les paramètres de l’index
Mettez en place l’environnement Pinecone et définissez la configuration de votre index.
pinecone_api_key = "PINECONE_API_KEY" # Replace with your Pinecone API key
index_name = "news-articles"
dimension = 1536 # OpenAI embedding dimension for text-embedding-ada-002 (adjust if needed)
namespace = "default"
3.5 Initialisation du client et de l’index Pinecone
S’assurer que le client et l’index sont correctement initialisés pour le stockage et l’extraction des données.
# Initialize Pinecone client and index
pc = Pinecone(api_key=pinecone_api_key)
# Check if index exists
if index_name not in pc.list_indexes().names():
pc.create_index(
name=index_name,
dimension=dimension,
metric="cosine",
spec=ServerlessSpec(cloud="aws", region="us-east-1")
)
while not pc.describe_index(index_name).status["ready"]:
time.sleep(1)
pinecone_index = pc.Index(index_name)
print(pinecone_index)
3.6 Nettoyer, charger et prétraiter les données
# Text cleaning helper
def clean_text(text):
text = re.sub(r"\\s+", " ", text)
return text.strip()
# Load and preprocess `news-data.json`
def load_and_prepare_data(json_path="news-data.json"):
with open(json_path, "r", encoding="utf-8") as f:
news_data = json.load(f)
df = pd.DataFrame(news_data)
df["text_for_embedding"] = df["headline"].map(clean_text) + ". " + df["content"].map(clean_text)
df["id"] = df["id"].astype(str)
return df
Remarque : vous pouvez réexécuter
scraper.pypour vous assurer que vos données sont à jour.
3.7 Générer des embeddings à l’aide d’OpenAI
Créez des embeddings à partir de votre texte prétraité en utilisant le modèle d’embedding d’OpenAI.
# New embedding generation via OpenAI API
def openai_generate_embeddings(texts, model="text-embedding-ada-002"):
openai.api_key = OPENAI_API_KEY
# OpenAI endpoint accepts a list of strings and returns list of embeddings
response = openai.embeddings.create(
input=texts,
model=model
)
embeddings = [datum.embedding for datum in response.data]
return embeddings
3.8 Mise à jour de Pinecone avec les embeddings
Envoyer les embeddings générés à Pinecone pour maintenir la base de données vectorielle à jour.
# Embed and upsert to Pinecone
def embed_and_upsert(json_path="news-data.json", namespace=namespace):
df = load_and_prepare_data(json_path)
texts = df["text_for_embedding"].tolist()
print(f"Generating embeddings for {len(texts)} texts using OpenAI...")
embeddings = openai_generate_embeddings(texts)
df["embedding"] = embeddings
records = []
for row in df.itertuples():
records.append((
row.id,
row.embedding,
{
"url": getattr(row, "url", ""), # safe get url if present
"text": row.text_for_embedding
}
))
pinecone_index.upsert(vectors=records, namespace=namespace)
print(f"Upserted {len(records)} records to Pinecone index '{index_name}'.")
Remarque : vous ne devez exécuter cette étape qu’une seule fois pour alimenter la base de données. Par la suite, vous pouvez commenter cette partie du code.
3.9 Initialisation de la fonction de recherche Pinecone
def pinecone_search(index, query, namespace=namespace, top_k=3, score_threshold=0.8, embedding_model=None):
# OpenAI embedding here
query_embedding = openai_generate_embeddings([query])[0]
results = index.query(
vector=query_embedding,
top_k=top_k,
namespace=namespace,
include_metadata=True,
)
filtered = []
for match in results.matches:
if match.score >= score_threshold:
filtered.append({
"score": match.score,
"url": match.metadata.get("url", ""),
"text": match.metadata.get("text", ""),
})
return filtered
Remarque :
Le seuil de score définit le score de similarité minimum pour qu’un résultat soit considéré comme pertinent. Vous pouvez ajuster cette valeur en fonction de vos besoins. Plus le score est élevé, plus le résultat est précis.
3.10 Générer des réponses à l’aide d’OpenAI
Utiliser OpenAI pour générer des réponses à partir du contexte récupéré via Pinecone.
# OpenAI answer generation
def openai_generate_answer(openai_api_key, query, context=None):
import openai
openai.api_key = openai_api_key
prompt_context = ""
if context:
prompt_context = "\\n\\nContext:\\n" + "\\n\\n".join(context)
prompt = f"Answer the following question: {query}" + prompt_context
response = openai.chat.completions.create(
model="gpt-4",
messages=[{"role": "user", "content": prompt}],
max_tokens=256,
temperature=0.7,
)
answer = response.choices[0].message.content.strip()
return answer
3.11 (Facultatif) Exécuter un test simple pour interroger et imprimer les résultats
Inclure un code facile à utiliser qui vous permet d’exécuter un test de base. Ce test permet de vérifier que votre implémentation fonctionne et donne un aperçu des données stockées dans la base de données.
def search_news_and_answer(openai_api_key, query):
results = pinecone_search(pinecone_index, query)
if results:
print(f"Found {len(results)} relevant documents.")
print("Top documents:")
for doc in results:
print(f"Score: {doc['score']:.4f}")
print(f"URL: {doc['url']}")
print(f"Text (excerpt): {doc['text'][:250]}...\\n")
answer = openai_generate_answer(openai_api_key, query, [r["text"] for r in results])
print("\\nGenerated answer:\\n", answer)
if __name__ == "__main__":
OPENAI_API_KEY = "OPENAI_API_KEY" # Replace with your OpenAI key here or pass via arguments/env var
test_query = "What is wrong with Man City?"
search_news_and_answer(OPENAI_API_KEY, test_query)
Conseil : vous pouvez contrôler la quantité de texte affichée en découpant le résultat, par exemple :
[:250].
Vos données sont maintenant stockées dans la base de données vectorielle. Vous avez donc deux possibilités d’interrogation :
- Extraire de la base de données
- Utiliser une réponse générique générée par OpenAI
Étape 4 : Construire le contrôleur d’agent
4.1 Dans agent_controller.py
Importer les fonctionnalités nécessaires à partir de rag.py.
from rag import openai_generate_answer, pinecone_search
4.2 Mise en œuvre de la récupération des pommes de pin
Ajouter une logique pour récupérer les données pertinentes dans le magasin de vecteurs de Pinecone.
def agent_controller_decide_and_act(
pinecone_api_key,
openai_api_key,
pinecone_index,
query,
namespace="default"
):
print(f"Agent received query: {query}")
try:
print("Trying Pinecone retrieval...")
results = pinecone_search(pinecone_index, query, namespace=namespace)
if results:
print(f"Found {len(results)} matching documents in Pinecone.")
context_texts = [r["text"] for r in results]
answer = openai_generate_answer(openai_api_key, query, context_texts)
return answer
else:
print("No good matches found in Pinecone. Falling back to OpenAI generator.")
except Exception as e:
print(f"Pinecone retrieval failed: {e}")
4.3 Mise en œuvre d’une réponse OpenAI de repli
Créer une logique pour générer une réponse à l’aide d’OpenAI lorsqu’aucun contexte pertinent n’est trouvé.
try:
print("Generating answer from OpenAI without retrieval context...")
answer = openai_generate_answer(openai_api_key, query)
return answer
except Exception as e:
print(f"OpenAI generation failed: {e}")
return "Sorry, I am currently unable to answer your query."
Étape 5 : Assembler le tout
5.1 Dans crux.py
Importez toutes les fonctions nécessaires depuis le fichier agent_controller.py.
from rag import pinecone_index # Import Pinecone index & embedding model
from rag import openai_generate_answer, pinecone_search # Import helper functions if needed
from agent_controller import agent_controller_decide_and_act # Your orchestration function
5.2 Fournissez vos clés API
Assurez-vous que vos clés d’API OpenAI et Pinecone sont correctement configurées.
# Your actual API keys here - replace with your real keys
PINECONE_API_KEY = "PINECONE_API_KEY"
OPENAI_API_KEY = "OPENAI_API_KEY"
5.3 Entrez votre invite dans la fonction main()
Définissez l’entrée de l’invite dans la fonction main().
def main():
query = "What is the problem with Man City?"
answer = agent_controller_decide_and_act(
pinecone_api_key=PINECONE_API_KEY,
openai_api_key=OPENAI_API_KEY,
pinecone_index=pinecone_index,
query=query,
namespace="default"
)
print("\\nAgent's answer:\\n", answer)
if __name__ == "__main__":
main()
5.4 Appeler le RAG agentique
Exécutez la logique Agentic RAG. Vous verrez comment elle traite une requête en vérifiant d’abord sa pertinence avant d’interroger la base de données vectorielle.

Agent received query: What exactly is the problem with Man City Women Team?
Trying Pinecone retrieval...
Found 1 matching documents in Pinecone.
Agent's answer:
The problems with the Man City Women Team this season include a significant injury crisis, managerial upheaval, and poor performances in key games. Key players such as Vivianne Miedema, Khadija Shaw, Lauren Hemp, and Alex Greenwood have been sidelined due to injuries, which has severely impacted the team's performance and highlighted a lack of squad depth. Interim manager Nick Cushing suggests that the number of injuries is not solely down to bad luck or bad practice and calls for an examination of the situation.
Essayez de le tester avec une requête qui ne correspond pas à votre base de données, par exemple :
def main():
query = "Why Sleep?"
L’agent détermine qu’aucune bonne correspondance n’a été trouvée dans Pinecone et se rabat sur la génération d’une réponse générique à l’aide d’OpenAI.

Agent received query: Why Sleep?
Trying Pinecone retrieval...
No good matches found in Pinecone. Falling back to OpenAI generator.
as a car crash), or it can harm you over time.
For example, ongoing sleep deficiency can raise your risk for some chronic health problems. It also can affect how well you think, react, work, learn, and get along with as a car crash), or it can harm you over time.
Conseil : vous pouvez imprimer le score de pertinence (score_threshold) pour chaque invite afin de comprendre le niveau de confiance de l’agent.
Voilà, c’est fait ! Vous avez réussi à construire votre RAG Agentic.
Étape 6 (facultative) : Boucle de rétroaction et optimisation
Vous pouvez améliorer votre système en mettant en place une boucle de rétroaction pour améliorer la formation et l’indexation au fil du temps.
6.1 Ajouter une fonction de retour d’information
Dans agent_controller.py, créez une fonction qui demande à l’utilisateur de réagir après l’affichage d’une réponse. Vous pouvez appeler cette fonction à la fin du runner principal dans crux.py.
def collect_user_feedback():
feedback = input("Was the answer helpful? (yes/no): ").strip().lower()
comments = input("Any comments or corrections? (optional): ").strip()
return feedback, comments
6.2 Mise en œuvre de la logique de rétroaction
Créez une nouvelle fonction dans agent_controller.py qui réinitialise le processus de récupération si le feedback est négatif. Appelez ensuite cette fonction dans crux.py :
def agent_controller_handle_feedback(
feedback,
comments,
openai_api_key,
pinecone_index,
query,
namespace="default"
):
if feedback == "no":
print("Feedback: answer not helpful. Retrying with relaxed retrieval parameters...")
# Relaxed retrieval - increase number of docs and lower score threshold
results = pinecone_search(
pinecone_index,
query,
namespace=namespace,
top_k=5,
score_threshold=0.3
)
if results:
print(f"Found {len(results)} documents after retry.")
context_texts = [r["text"] for r in results]
answer = openai_generate_answer(openai_api_key, query, context_texts)
print("\\nNew answer based on feedback:\\n", answer)
return answer
else:
print("No documents found even after retry. Generating answer without retrieval context...")
answer = openai_generate_answer(openai_api_key, query)
print("\\nAnswer generated without retrieval:\\n", answer)
return answer
else:
print("Thank you for your positive feedback!")
return None
Conclusion et prochaines étapes
Dans cet article, vous avez construit un système autonome Agentic RAG qui combine Bright Data pour le web scraping, Pinecone comme base de données vectorielle, et OpenAI pour la génération de texte. Ce système fournit une base qui peut être étendue pour prendre en charge une variété de fonctionnalités supplémentaires, telles que :
- Intégration de bases de données vectorielles dans des bases de données relationnelles ou non relationnelles
- Créer une interface utilisateur avec Streamlit
- Automatiser la recherche de données sur le web pour maintenir les données de formation à jour
- Améliorer la logique de recherche et le raisonnement des agents
Comme nous l’avons démontré, la qualité des résultats du système Agentic RAG dépend fortement de la qualité des données d’entrée. Bright Data a joué un rôle clé en fournissant des données web fiables et fraîches, ce qui est essentiel pour une recherche et une génération efficaces.
Envisagez d’améliorer encore ce flux de travail et d’utiliser Bright Data dans vos futurs projets afin de conserver des données d’entrée cohérentes et de haute qualité.





