

Crawl4AI et Firecrawl sont deux des produits d’IA les plus en vogue dans l’industrie de la collecte de données. Dans ce guide, nous aborderons l’utilisation de base et les statistiques de ces deux produits.
À la fin de votre lecture, vous serez en mesure de répondre aux questions suivantes.
- Qu’est-ce que Crawl4AI ?
- Qu’est-ce que Firecrawl ?
- Où chacun d’entre eux brille-t-il ?
- Où se situent les lacunes ?
- Pourquoi Bright Data est-il une excellente alternative à ces deux solutions ?
La comparaison de ces nouveaux outils permet de mettre en évidence les solutions complètes et évolutives de Bright Data. Que vous ayez besoin de capacités générales de scraping ou d’une suite complète de collecte de données, Bright Data vous propose une technologie éprouvée.
Vue d’ensemble et objectif
Avant d’entrer dans les détails, examinons de plus près ce que sont ces produits et à qui ils s’adressent. Étant donné qu’ils sont conçus pour des objectifs différents, il ne s’agit pas d’une comparaison entre des pommes et des pommes. Il s’agit plutôt d’une comparaison entre une boîte à outils et un couteau suisse.
Crawl4AI

Crawl4AI est une bibliothèque Python open source qui facilite et rend plus accessible le scraping web piloté par l’IA. Elle s’adresse davantage aux développeurs désireux d’étendre leurs pipelines d’extraction. Elle est entièrement open source. Le code est disponible gratuitement sur leur page GitHub. Crawl4AI s’aligne davantage sur les outils de scraping traditionnels de Bright Data.
Firecrawl
Firecrawl est l’un des leaders de l’entreprise dans le domaine du web scraping alimenté par l’IA. L’entreprise propose un cadre de travail qui ne dépend pas de la langue et de nombreuses options d’intégration. Firecrawl suscite surtout l’intérêt de personnes qui ne s’occuperaient pas traditionnellement de la collecte de données ou même du développement. Avec Firecrawl, le scraping devient accessible aux personnes qui n’ont pas toujours des compétences en codage.
Caractéristiques uniques
Crawl4AI
Crawl4AI se distingue par le fait qu’il est entièrement open source et qu’il utilise des licences permissives. Jetez un coup d’œil aux caractéristiques qui font de Crawl4AI une option très attrayante pour les développeurs. Cet outil offre des options configurables et la confiance grâce à la transparence du code.
- Open Source: Tout le monde peut consulter le code. Les bogues sont souvent repérés et corrigés rapidement par la communauté. La transparence du code signifie qu’il n’y a pas de surprises – si vous savez lire le code.
- Extraction avec ou sans LLM: Avec Crawl4AI, vous avez le choix d’utiliser un petit modèle local pour l’extraction ou de vous connecter à un modèle externe tel que Deepseek.
- Licence permissive: La licence de Crawl4AI est très flexible et permissive. Cela suscite l’intérêt des amateurs comme des développeurs d’entreprise.
- Bibliothèque Python: Crawl4AI n’est pas un service d’abonnement. C’est une bibliothèque Python. Vous pouvez l’intégrer à d’autres choses et si vous le souhaitez, vous pouvez créer votre propre scraper en utilisant Crawl4AI comme backend.
Firecrawl
Firecrawl est l’un des outils d’entreprise les plus populaires pour le web scraping. Il offre un cadre agnostique en termes de langage – vous pouvez utiliser Python, JavaScript ou leur site web GUI pour effectuer votre extraction. Ils offrent une variété de plans adaptés aux amateurs et aux clients d’entreprise.
- Entreprise: Firecrawl est un produit destiné aux entreprises. Il propose une option open source. Cependant, sa ligne de produits principale est destinée aux personnes qui souhaitent une collecte de données évolutive dès aujourd’hui.
- Agnostique au niveau du langage: Firecrawl offre un support GUI à travers son application web. Ils proposent également un SDK pour Python et JavaScript. Il existe également des SDK en Go et en Rust, gérés par la communauté. Avec Firecrawl, vous n’êtes pas limité à Python. Vous n’êtes même pas limité à un environnement de programmation.
- Traitement du langage naturel (NLP): Firecrawl est axé sur le développement et la collecte de données en langage naturel. Vous dites au modèle ce qu’il doit faire. Ensuite, le modèle exécute la tâche de collecte.
Facilité d’utilisation
Crawl4AI
Démarrer avec Crawl4AI est relativement simple. Vous pouvez l’installer via pip et l’appeler depuis votre environnement Python. Les extraits ci-dessous montrent comment l’installer et vérifier votre installation.
Installez Crawl4AI avec la commande ci-dessous.
pip install crawl4aiExécutez le programme d’installation des navigateurs et de l’outillage.
crawl4ai-setupUtilisez la commande doctor pour vérifier votre installation et identifier les problèmes éventuels.
crawl4ai-doctorLe code ci-dessous est très simple. Il provient directement de la documentation de Crawl4AI ici. Collez-le dans n’importe quel fichier Python et exécutez-le avec python nom-du-fichier.py. En pratique, Crawl4AI fonctionne mieux en tant que commande shell. L’exécution directe à partir de VSCode ou d’autres IDE a tendance à causer des problèmes d’asynchronisme.
import asyncio
from crawl4ai import AsyncWebCrawler, BrowserConfig, CrawlerRunConfig
async def main():
async with AsyncWebCrawler() as crawler:
result = await crawler.arun(
url="https://www.example.com",
)
print(result.markdown[:300]) # Show the first 300 characters of extracted text
if __name__ == "__main__":
asyncio.run(main())Firecrawl
Lorsque vous commencez à utiliser Firecrawl, il vous suffit de vous rendre sur leur terrain de jeu et d’entrer votre URL cible. Cette interface est très conviviale pour les non-développeurs.
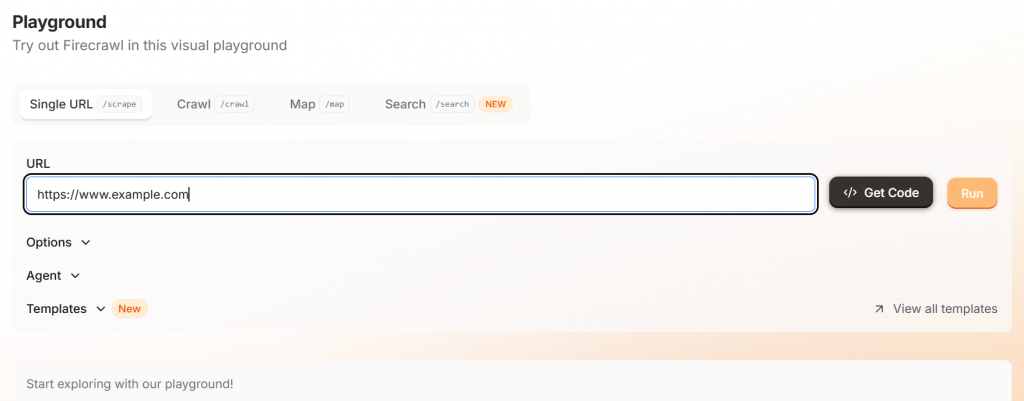
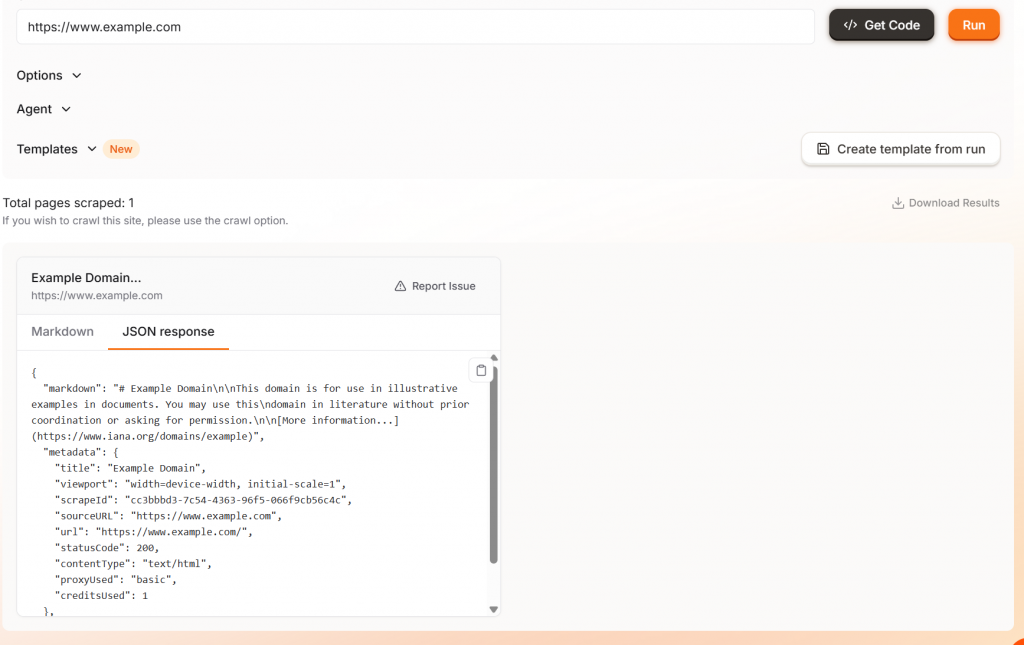
Si vous cliquez sur le bouton “Exécuter”, vous verrez un exemple de sortie avec votre choix de markdown ou de JSON.
Performance et évolutivité
Crawl4AI
L’extrait ci-dessous provient de l’exemple de code que vous avez vu plus tôt. En tout et pour tout, il a fallu un peu moins de deux secondes pour analyser le domaine de l’exemple. Sans LLM, Crawl4AI est exceptionnellement rapide. Il rivalise avec le scraping manuel avec Requests et BeautifulSoup en termes de performance.

Cependant, le scraping markdown et le HTML brut sont à peu près aussi propres que possible. Crawl4AI liste le support pour l’extraction JSON sans LLM mais le support est limité et bogué. Pour extraire des structures de données complètes, vous devez ajouter un support LLM à votre code. C’est le coût caché de Crawl4AI, vous devez héberger ou payer pour un LLM externe afin de réaliser de vrais travaux d’analyse.
Dans le code ci-dessous, nous utilisons un modèle OpenAI pour analyser la page de Books to Scrape. Si vous décidez de l’exécuter vous-même, assurez-vous de remplacer la clé API par la vôtre.
import asyncio
import json
from pydantic import BaseModel
from crawl4ai import AsyncWebCrawler, BrowserConfig, CrawlerRunConfig, CacheMode, LLMConfig
from crawl4ai.extraction_strategy import LLMExtractionStrategy
openai_api_key = "your-openai-api-key"
class Product(BaseModel):
name: str
price: str
async def main():
#tell the llm what to scrape and set config
llm_strategy = LLMExtractionStrategy(
llm_config = LLMConfig(provider="openai/gpt-4o-mini", api_token=openai_api_key),
schema=Product.model_json_schema(),
extraction_type="schema",
instruction="Extract all product objects with 'name' and 'price' from the content.",
chunk_token_threshold=1000,
overlap_rate=0.0,
apply_chunking=True,
input_format="markdown",
extra_args={"temperature": 0.0, "max_tokens": 800}
)
#build the crawler config
crawl_config = CrawlerRunConfig(
extraction_strategy=llm_strategy,
cache_mode=CacheMode.BYPASS
)
#create a browser config if needed
browser_cfg = BrowserConfig(headless=True)
async with AsyncWebCrawler(config=browser_cfg) as crawler:
#crawl a single page
result = await crawler.arun(
url="https://books.toscrape.com",
config=crawl_config
)
if result.success:
#assume the extracted content is json
data = json.loads(result.extracted_content)
print("Extracted items:", data)
#show usage stats
llm_strategy.show_usage()
else:
print("Error:", result.error_message)
if __name__ == "__main__":
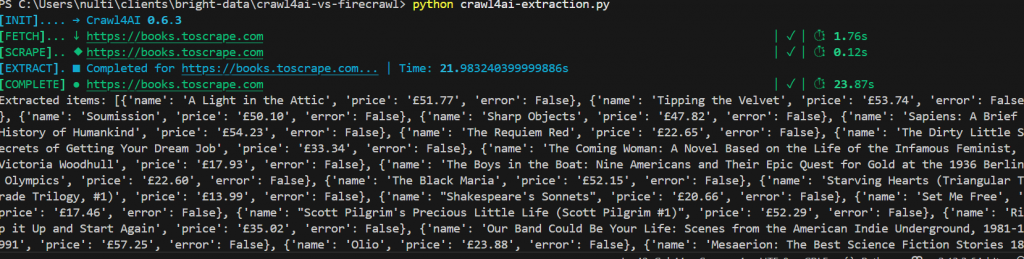
asyncio.run(main())Voici notre résultat. Au total, cela a pris un peu moins de 25 secondes. Vous pouvez également voir chaque livre listé avec son prix sous la forme d’un objet JSON proprement structuré.
Firecrawl
Firecrawl vous permet simplement d’entrer une URL et il scrape la page. Lorsque vous utilisez la version par défaut de Firecrawl, votre page est restituée sous la forme d’un markdown brut déposé dans un objet JSON.
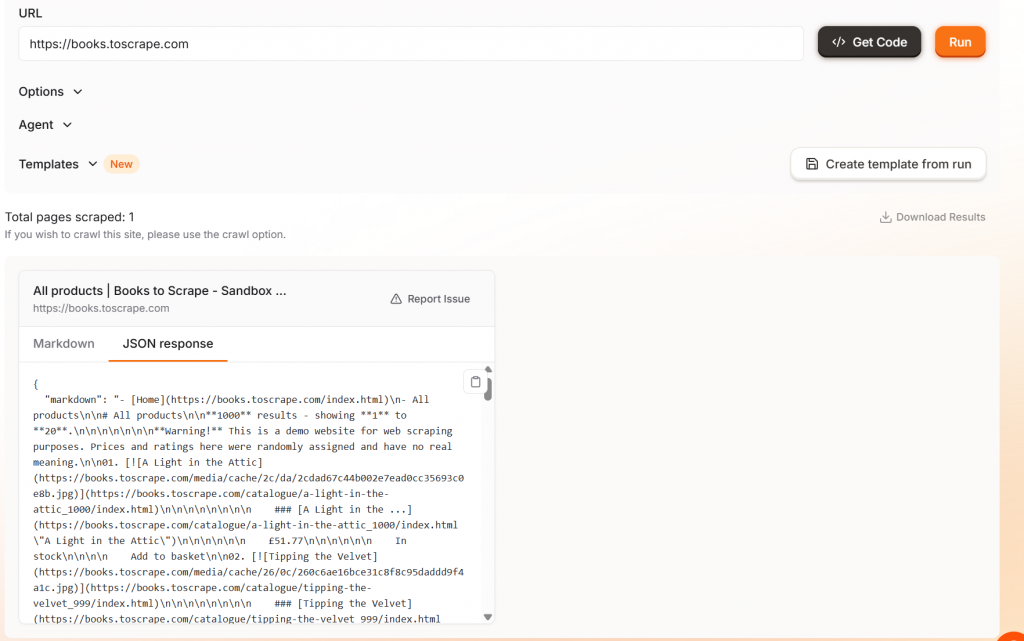
Firecrawl dispose d’une fonctionnalité intéressante lorsque vous exécutez votre code. Lorsque votre scraper s’exécute, vous pouvez observer le navigateur pendant qu’il rend la page.
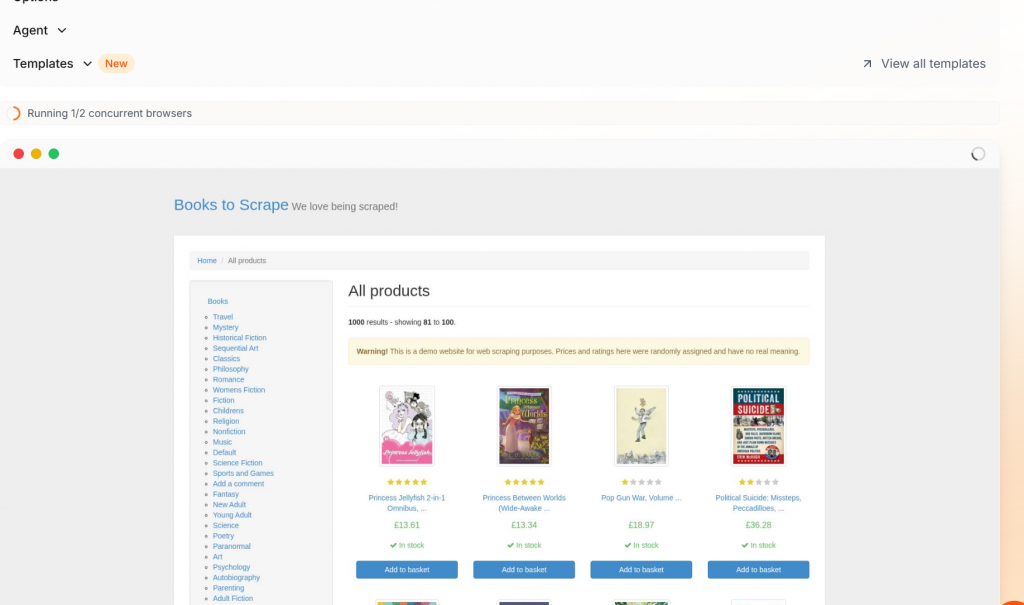
Qualité et précision des données
Crawl4AI
Lorsqu’il est connecté à GPT-4o, Crawl4AI fonctionne avec une précision de 100 %. Pour vérifier le nombre d’articles, nous avons ajouté la ligne suivante à notre code.
print("Total products scraped:", len(data))Comme vous le voyez dans le résultat ci-dessous, Crawl4AI et GPT-4o ont trouvé les 20 éléments de la page.

Associé à un LLM, Crawl4AI devient un outil étonnamment puissant et d’une précision remarquable.
Firecrawl
Firecrawl propose en fait deux produits différents en matière de raclage. Vous pouvez utiliser le bon vieux Firecrawl pour des options de scraping simples et sales. Firecrawl Extract vous permet d’extraire des objets JSON structurés.
Course à l’incendie régulière
Voici le résultat de Books To Scrape en utilisant Firecrawl normal. Comme vous pouvez le voir, c’est mauvais, vraiment mauvais. Firecrawl a converti la page en markdown. Ensuite, il a découpé le markdown brut en champs JSON apparemment aléatoires. Ces données doivent être nettoyées manuellement à l’aide de code ou transmises à un LLM.
{
"markdown": "All products \| Books to Scrape - Sandboxnn[Books to Scrape](index.html) We love being scraped!nn- [Home](index.html)n- All productsnn- [Books](catalogue/category/books_1/index.html) - [Travel](catalogue/category/books/travel_2/index.html)n - [Mystery](catalogue/category/books/mystery_3/index.html)n - [Historical Fiction](catalogue/category/books/historical-fiction_4/index.html)n - [Sequential Art](catalogue/category/books/sequential-art_5/index.html)n - [Classics](catalogue/category/books/classics_6/index.html)n - [Philosophy](catalogue/category/books/philosophy_7/index.html)n - [Romance](catalogue/category/books/romance_8/index.html)n - [Womens Fiction](catalogue/category/books/womens-fiction_9/index.html)n - [Fiction](catalogue/category/books/fiction_10/index.html)n - [Childrens](catalogue/category/books/childrens_11/index.html)n - [Religion](catalogue/category/books/religion_12/index.html)n - [Nonfiction](catalogue/category/books/nonfiction_13/index.html)n - [Music](catalogue/category/books/music_14/index.html)n - [Default](catalogue/category/books/default_15/index.html)n - [Science Fiction](catalogue/category/books/science-fiction_16/index.html)n - [Sports and Games](catalogue/category/books/sports-and-games_17/index.html)n - [Add a comment](catalogue/category/books/add-a-comment_18/index.html)n - [Fantasy](catalogue/category/books/fantasy_19/index.html)n - [New Adult](catalogue/category/books/new-adult_20/index.html)n - [Young Adult](catalogue/category/books/young-adult_21/index.html)n - [Science](catalogue/category/books/science_22/index.html)n - [Poetry](catalogue/category/books/poetry_23/index.html)n - [Paranormal](catalogue/category/books/paranormal_24/index.html)n - [Art](catalogue/category/books/art_25/index.html)n - [Psychology](catalogue/category/books/psychology_26/index.html)n - [Autobiography](catalogue/category/books/autobiography_27/index.html)n - [Parenting](catalogue/category/books/parenting_28/index.html)n - [Adult Fiction](catalogue/category/books/adult-fiction_29/index.html)n - [Humor](catalogue/category/books/humor_30/index.html)n - [Horror](catalogue/category/books/horror_31/index.html)n - [History](catalogue/category/books/history_32/index.html)n - [Food and Drink](catalogue/category/books/food-and-drink_33/index.html)n - [Christian Fiction](catalogue/category/books/christian-fiction_34/index.html)n - [Business](catalogue/category/books/business_35/index.html)n - [Biography](catalogue/category/books/biography_36/index.html)n - [Thriller](catalogue/category/books/thriller_37/index.html)n - [Contemporary](catalogue/category/books/contemporary_38/index.html)n - [Spirituality](catalogue/category/books/spirituality_39/index.html)n - [Academic](catalogue/category/books/academic_40/index.html)n - [Self Help](catalogue/category/books/self-help_41/index.html)n - [Historical](catalogue/category/books/historical_42/index.html)n - [Christian](catalogue/category/books/christian_43/index.html)n - [Suspense](catalogue/category/books/suspense_44/index.html)n - [Short Stories](catalogue/category/books/short-stories_45/index.html)n - [Novels](catalogue/category/books/novels_46/index.html)n - [Health](catalogue/category/books/health_47/index.html)n - [Politics](catalogue/category/books/politics_48/index.html)n - [Cultural](catalogue/category/books/cultural_49/index.html)n - [Erotica](catalogue/category/books/erotica_50/index.html)n - [Crime](catalogue/category/books/crime_51/index.html)nn# All productsnn**1000** results - showing **1** to **20**.nnnnnnn**Warning!** This is a demo website for web scraping purposes. Prices and ratings here were randomly assigned and have no real meaning.nn01. [](catalogue/a-light-in-the-attic_1000/index.html)nnnnnnnn ### [A Light in the ...](catalogue/a-light-in-the-attic_1000/index.html "A Light in the Attic")nnnnnn £51.77nnnnnn In stocknnnn Add to basketnn02. [](catalogue/tipping-the-velvet_999/index.html)nnnnnnnn ### [Tipping the Velvet](catalogue/tipping-the-velvet_999/index.html "Tipping the Velvet")nnnnnn £53.74nnnnnn In stocknnnn Add to basketnn03. [](catalogue/soumission_998/index.html)nnnnnnnn ### [Soumission](catalogue/soumission_998/index.html "Soumission")nnnnnn £50.10nnnnnn In stocknnnn Add to basketnn04. [](catalogue/sharp-objects_997/index.html)nnnnnnnn ### [Sharp Objects](catalogue/sharp-objects_997/index.html "Sharp Objects")nnnnnn £47.82nnnnnn In stocknnnn Add to basketnn05. [](catalogue/sapiens-a-brief-history-of-humankind_996/index.html)nnnnnnnn ### [Sapiens: A Brief History ...](catalogue/sapiens-a-brief-history-of-humankind_996/index.html "Sapiens: A Brief History of Humankind")nnnnnn £54.23nnnnnn In stocknnnn Add to basketnn06. [](catalogue/the-requiem-red_995/index.html)nnnnnnnn ### [The Requiem Red](catalogue/the-requiem-red_995/index.html "The Requiem Red")nnnnnn £22.65nnnnnn In stocknnnn Add to basketnn07. [](catalogue/the-dirty-little-secrets-of-getting-your-dream-job_994/index.html)nnnnnnnn ### [The Dirty Little Secrets ...](catalogue/the-dirty-little-secrets-of-getting-your-dream-job_994/index.html "The Dirty Little Secrets of Getting Your Dream Job")nnnnnn £33.34nnnnnn In stocknnnn Add to basketnn08. [](catalogue/the-coming-woman-a-novel-based-on-the-life-of-the-infamous-feminist-victoria-woodhull_993/index.html)nnnnnnnn ### [The Coming Woman: A ...](catalogue/the-coming-woman-a-novel-based-on-the-life-of-the-infamous-feminist-victoria-woodhull_993/index.html "The Coming Woman: A Novel Based on the Life of the Infamous Feminist, Victoria Woodhull")nnnnnn £17.93nnnnnn In stocknnnn Add to basketnn09. [](catalogue/the-boys-in-the-boat-nine-americans-and-their-epic-quest-for-gold-at-the-1936-berlin-olympics_992/index.html)nnnnnnnn ### [The Boys in the ...](catalogue/the-boys-in-the-boat-nine-americans-and-their-epic-quest-for-gold-at-the-1936-berlin-olympics_992/index.html "The Boys in the Boat: Nine Americans and Their Epic Quest for Gold at the 1936 Berlin Olympics")nnnnnn £22.60nnnnnn In stocknnnn Add to basketnn10. [](catalogue/the-black-maria_991/index.html)nnnnnnnn ### [The Black Maria](catalogue/the-black-maria_991/index.html "The Black Maria")nnnnnn £52.15nnnnnn In stocknnnn Add to basketnn11. [](catalogue/starving-hearts-triangular-trade-trilogy-1_990/index.html)nnnnnnnn ### [Starving Hearts (Triangular Trade ...](catalogue/starving-hearts-triangular-trade-trilogy-1_990/index.html "Starving Hearts (Triangular Trade Trilogy, \#1)")nnnnnn £13.99nnnnnn In stocknnnn Add to basketnn12. [](catalogue/shakespeares-sonnets_989/index.html)nnnnnnnn ### [Shakespeare's Sonnets](catalogue/shakespeares-sonnets_989/index.html "Shakespeare's Sonnets")nnnnnn £20.66nnnnnn In stocknnnn Add to basketnn13. [](catalogue/set-me-free_988/index.html)nnnnnnnn ### [Set Me Free](catalogue/set-me-free_988/index.html "Set Me Free")nnnnnn £17.46nnnnnn In stocknnnn Add to basketnn14. [](catalogue/scott-pilgrims-precious-little-life-scott-pilgrim-1_987/index.html)nnnnnnnn ### [Scott Pilgrim's Precious Little ...](catalogue/scott-pilgrims-precious-little-life-scott-pilgrim-1_987/index.html "Scott Pilgrim's Precious Little Life (Scott Pilgrim \#1)")nnnnnn £52.29nnnnnn In stocknnnn Add to basketnn15. [](catalogue/rip-it-up-and-start-again_986/index.html)nnnnnnnn ### [Rip it Up and ...](catalogue/rip-it-up-and-start-again_986/index.html "Rip it Up and Start Again")nnnnnn £35.02nnnnnn In stocknnnn Add to basketnn16. [](catalogue/our-band-could-be-your-life-scenes-from-the-american-indie-underground-1981-1991_985/index.html)nnnnnnnn ### [Our Band Could Be ...](catalogue/our-band-could-be-your-life-scenes-from-the-american-indie-underground-1981-1991_985/index.html "Our Band Could Be Your Life: Scenes from the American Indie Underground, 1981-1991")nnnnnn £57.25nnnnnn In stocknnnn Add to basketnn17. [](catalogue/olio_984/index.html)nnnnnnnn ### [Olio](catalogue/olio_984/index.html "Olio")nnnnnn £23.88nnnnnn In stocknnnn Add to basketnn18. [](catalogue/mesaerion-the-best-science-fiction-stories-1800-1849_983/index.html)nnnnnnnn ### [Mesaerion: The Best Science ...](catalogue/mesaerion-the-best-science-fiction-stories-1800-1849_983/index.html "Mesaerion: The Best Science Fiction Stories 1800-1849")nnnnnn £37.59nnnnnn In stocknnnn Add to basketnn19. [](catalogue/libertarianism-for-beginners_982/index.html)nnnnnnnn ### [Libertarianism for Beginners](catalogue/libertarianism-for-beginners_982/index.html "Libertarianism for Beginners")nnnnnn £51.33nnnnnn In stocknnnn Add to basketnn20. [](catalogue/its-only-the-himalayas_981/index.html)nnnnnnnn ### [It's Only the Himalayas](catalogue/its-only-the-himalayas_981/index.html "It's Only the Himalayas")nnnnnn £45.17nnnnnn In stocknnnn Add to basketnnn-nPage 1 of 50nnn- [next](catalogue/page-2.html)",
"metadata": {
"language": "en-us",
"description": "",
"created": "24th Jun 2016 09:29",
"viewport": "width=device-width",
"title": "n All products | Books to Scrape - Sandboxn",
"robots": "NOARCHIVE,NOCACHE",
"favicon": "https://books.toscrape.com/static/oscar/favicon.ico",
"scrapeId": "aa3667ec-647b-42ab-adb2-9c35e042896d",
"sourceURL": "https://books.toscrape.com",
"url": "https://books.toscrape.com/",
"statusCode": 200,
"contentType": "text/html",
"proxyUsed": "basic",
"creditsUsed": 80
},
"scrape_id": "aa3667ec-647b-42ab-adb2-9c35e042896d"
}Firecrawl normal récupère la page, mais ne fait pas grand-chose de plus. Vous obtenez une page markdown découpée en tranches et écrasée dans un gros objet JSON. Vous pouvez récupérer la page, mais il faut beaucoup de travail pour transformer votre page web en données utilisables.
Extrait de Firecrawl
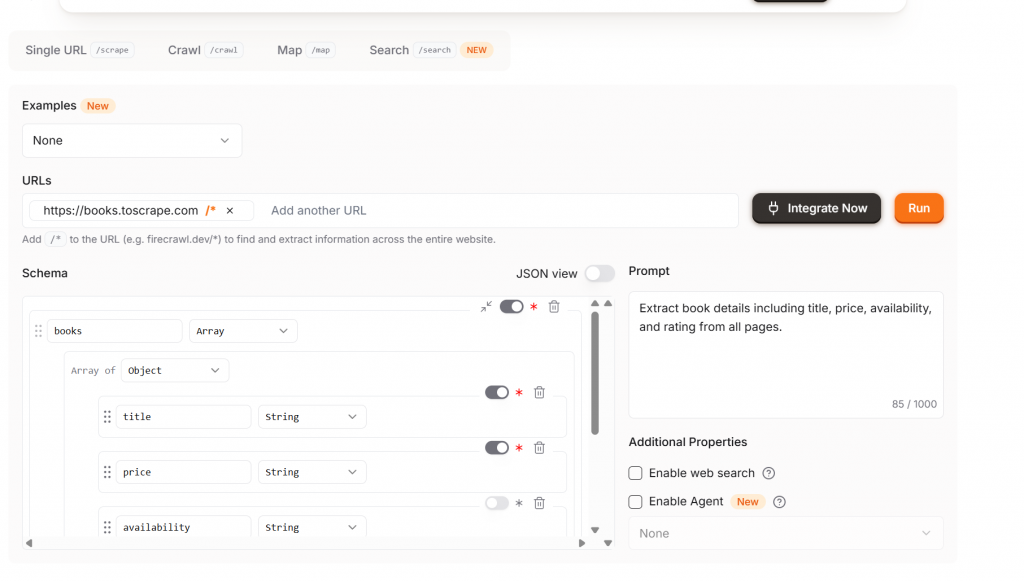
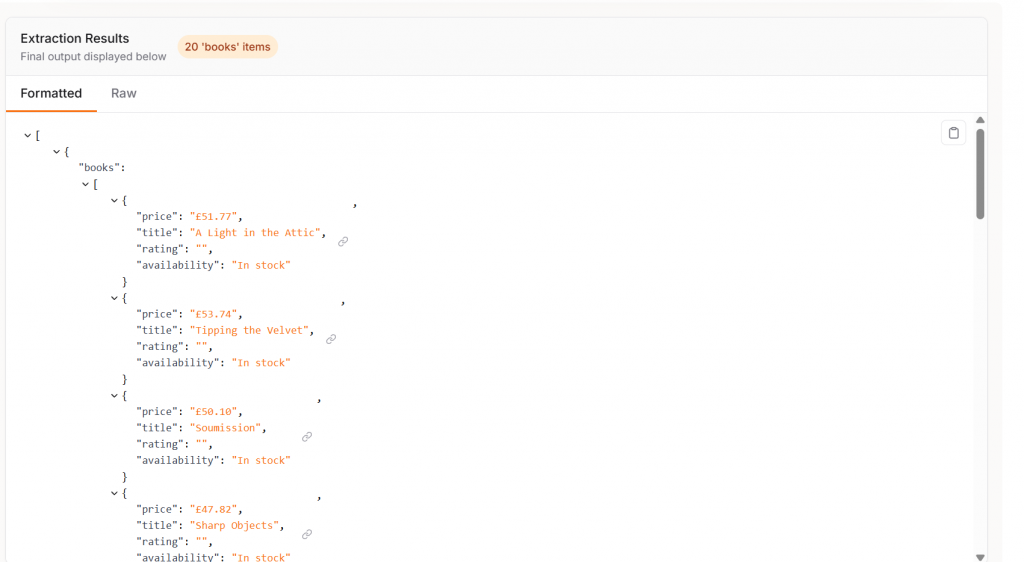
Extract est le niveau supérieur. Avec Extract, vous bénéficiez d’une prise en charge complète du scraping via le NLP. Indiquez au modèle les données à obtenir et il les extrait de la page. Comme vous pouvez le voir dans l’image ci-dessous, nous obtenons même un schéma recommandé contenant les champs titre, prix et disponibilité. Si vous êtes satisfait de votre schéma, cliquez sur le bouton “Exécuter”.
Veuillez noter que votre site web est accompagné de /* – ce qui indique à Extract d’explorer automatiquement l’ensemble du site. Pour économiser des crédits, supprimez le /*.
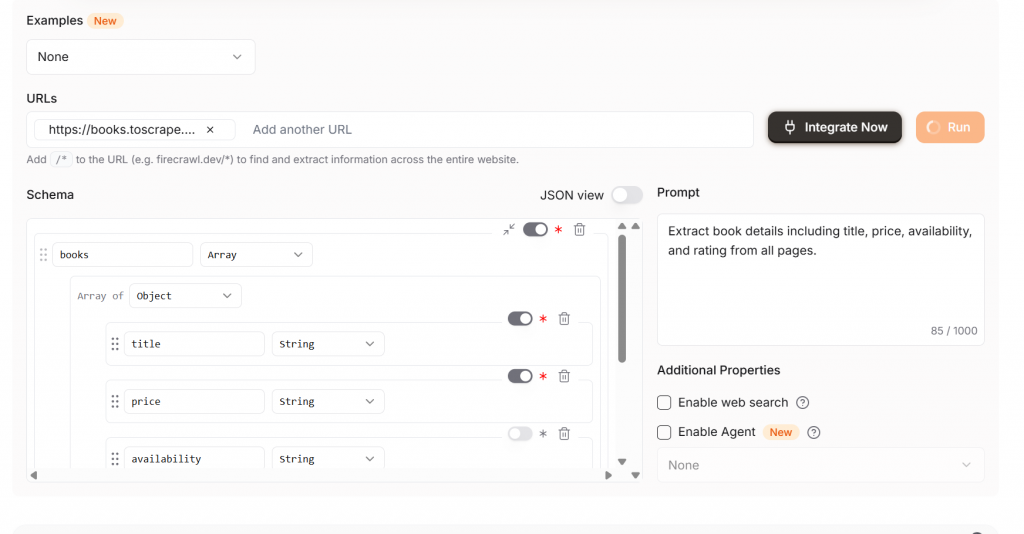
Si vous souhaitez un crawl d’une seule page, assurez-vous de modifier Extract par rapport à la configuration par défaut. L’image ci-dessous montre notre configuration pour le crawl d’une seule page. L’opérateur /* est très facile à négliger, économisez de l’argent et ne l’utilisez que lorsque c’est nécessaire.
Avec Firecrawl Extract, notre résultat est propre et prêt à l’emploi. Comme vous pouvez le voir, nous obtenons des objets JSON structurés avec les caractéristiques suivantes.
titreprixnotedisponibilité
Sécurité et conformité
Crawl4AI
Crawl4AI n’offre pas de garanties de conformité intégrées au logiciel. Il offre certaines configurations qui peuvent vous aider à respecter des éléments tels que le fichier robots.txt.
Lorsque vous utilisez Crawl4AI, vous êtes responsable de votre propre conformité aux lois telles que GDPR et CCPA. Crawl4AI n’offre pratiquement aucune aide en matière de conformité juridique et de sécurité. Cela signifie que lorsque vous menez un projet à grande échelle, vous devrez probablement engager une aide supplémentaire pour vous assurer que vous suivez les bonnes pratiques.
Firecrawl
D’après leur documentation, Firecrawl transmet vos informations à Google pour traitement. Ils indiquent explicitement dans leurs conditions qu’ils respectent le GDPR et le CCPA, mais que vous êtes tenu de respecter ces politiques vous-même. Toute violation de ces lois relève de votre responsabilité et Firecrawl n’est pas responsable de l’utilisation abusive de ses outils.
Firecrawl offre une meilleure protection de la responsabilité que Crawl4AI. Toutefois, ce n’est pas grand-chose. Leurs produits ne sont pas accompagnés de garde-fous. On attend de vous que vous suiviez les règles et si vous ne le faites pas, vous êtes responsable de toute mauvaise utilisation. Pour plus d’informations, consultez les conditions d’utilisation de Firecrawl.
Prix et licences
Crawl4AI
L’utilisation de Crawl4AI est gratuite pour tous. Nous utilisons ici le terme “gratuit” de manière assez vague. Comme vous l’avez probablement remarqué en nous suivant, tout véritable travail d’extraction nécessite l’intégration du LLM. Vous pouvez soit héberger le LLM vous-même, soit vous connecter à un service tel que l’API OpenAI. Lorsque vous utilisez Crawl4AI, vous devez toujours payer pour des services externes ou des coûts d’infrastructure si vous vous hébergez vous-même. Ces coûts s’additionnent. Crawl4AI ne réduira pas vos coûts d’exploitation à zéro.
Crawl4AI est distribué sous la licence Apache. Vous êtes autorisé à modifier, distribuer et même vendre commercialement des dérivés de Crawl4AI. Si vous disposez d’une aide à la conformité, la licence permissive de Crawl4AI en fait une option très attrayante pour les développeurs et les équipes chargées des données.
Firecrawl
Course à l’incendie régulière
Vanilla Firecrawl se décline en plusieurs niveaux de prix. Vous pouvez essayer leur plan gratuit. Les plans payants vont de 16 $/mois pour 3 000 pages à 333 $/mois pour 500 000 pages.

Extrait de Firecrawl
En ce qui concerne Extract, les plans payants vont de 89 $/mois pour 18 000 000 jetons par an à 719 $/mois pour 192 000 000 jetons API par an.

Licences Firecrawl
Firecrawl utilise différentes licences pour une variété de ses produits. Vous pouvez consulter toutes les licences ici. Veuillez noter que Firecrawl est un produit de niveau entreprise et que vous ne pourrez pas reconditionner leur code comme étant le vôtre. Même leur code open source est distribué sous la licence AGPL-3.0. Tout comme les autres accords de logiciels GNU, cette licence est très restrictive en ce qui concerne l’utilisation en entreprise.
Communauté et soutien
Crawl4AI
En tant que projet open source, Crawl4AI offre le support limité qu’il peut avec les ressources dont il dispose. Il n’y a pas de service d’assistance ou de SLA. Cependant, vous êtes libre de contacter les développeurs via leur canal Discord. Les temps d’attente peuvent varier. Ne vous attendez pas à ce qu’une équipe dédiée suive les problèmes et résolve vos besoins rapidement.
Firecrawl
Depuis son tableau de bord, Firecrawl vous offre des options d’assistance telles que de la documentation, des pages FAQ et des mises à jour de statut. Vous pouvez contacter leur équipe d’assistance via le bouton “Contacter l’assistance” – bien que votre priorité varie en fonction de votre niveau de plan. Vous êtes toujours libre de rejoindre leur canal Discord pour le soutien de la communauté.

Cas d’utilisation dans le monde réel
Crawl4AI
Crawl4AI a une variété de cas d’utilisation dans le monde réel pour les développeurs modernes. Vous n’êtes limité que par ce que vous pouvez construire.
- Support backend: Si vous décidez de créer vos propres produits de données, vous pouvez intégrer Crawl4AI à votre propre LLM et vendre vos produits.
- Agents d’IA: Comme nous l’avons fait plus haut dans cet article, vous pouvez brancher des LLM externes directement dans Crawl4AI pour des opérations d’extraction puissantes avec une sortie de structure de données personnalisée – CSV, JSON XML – tout format que votre LLM a vu est un format viable.
- Projets amateurs et startups: Les outils open source tels que Crawl4AI offrent un accès rapide aux expériences, aux preuves de concept et aux prototypes de pipeline.
Firecrawl
Firecrawl est conçu pour les équipes qui ont besoin d’un grand volume de scraping avec très peu de développement en interne. Si vous souhaitez passer d’une idée à un produit tangible sans trop de travail, Firecrawl peut vous aider.
- La navigation à l’échelle de la production: Firecrawl est conçu pour le crawling à grande échelle. Les outils de Firecrawl permettent même d’explorer des sites web complets par défaut.
- Surveillance du contenu: Effectuez des recherches de routine sur les concurrents pour surveiller leurs prix et leur contenu.
- Des données propres et prêtes: Avec Extract, vous pouvez transmettre vos données directement à l’équipe chargée des données, sans qu’aucun nettoyage ne soit nécessaire.
Avantages et inconvénients
| Crawl4AI | Firecrawl | |
|---|---|---|
| Pour | – Entièrement open source et transparent. – Licence Apache permissive – construire, modifier, revendre. – Flexible : Options avec ou sans LLM. – Bibliothèque Python prête à l’emploi pour les pipelines personnalisés. |
– Très simple pour les non-développeurs : Interface graphique, aire de jeu, invite NLP. – Fonctionne dans plusieurs langages (Python, JS, Go, Rust). – Rapide à déployer pour un scraping ponctuel ou de routine. – Prix d’entreprise et niveaux de support disponibles. |
| Cons | – Nécessite un LLM séparé pour l’extraction structurée réelle – ajoute des coûts cachés. – Support de conformité intégré limité – l’utilisateur doit gérer GDPR/CCPA. – Les bizarreries de l’asynchronisme – le shell fonctionne mieux, les IDE peuvent l’interrompre. |
– La sortie de la base est souvent désordonnée sans extrait – le markdown brut nécessite plus de travail. – Pas de véritables garde-fous pour la conformité – l’utilisateur reste responsable. – Le noyau fermé, les restrictions AGPL limitent les constructions personnalisées. – Les coûts d’utilisation peuvent augmenter rapidement avec l’échelle ou l’exploration sauvage. |
Pourquoi vous devriez considérer Bright Data
Crawl4AI et Firecrawl présentent tous deux des inconvénients. Crawl4AI s’accompagne de besoins en matière de développement et de coûts LLM cachés. Avec Firecrawl, vous êtes lié à des niveaux d’utilisation et à l’écosystème Firecrawl.
Bright Data offre une variété de produits qui peuvent aider à remplir les mêmes niches que ces deux outils mentionnés ci-dessus.
Top Bright Data Tools
- API de scraper: exécutez des scrappers préconstruits avec des données propres et prêtes à l’emploi, quand vous le souhaitez.
- API Web Unlocker: Contournez les blocages de sites et résolvez les CAPTCHA, scrapez en tant que markdown et contrôlez même votre géolocalisation.
- API navigateur: Contrôlez un navigateur distant avec des proxies intégrés et la résolution des CAPTCHA à partir de votre environnement de programmation.
- Jeux de données: Accédez à une vaste bibliothèque d’ensembles de données historiques provenant de plus de 100 domaines et remontant à plusieurs années.
Notre serveur MCP vous permet d’accéder à tous les meilleurs produits Bright Data dans un package LLM convivial. Branchez-le sur votre LLM, écrivez vos invites et laissez votre système faire son travail.
Options d’intégration des données Bright
Nous offrons même une intégration avec certains des meilleurs outils dans les industries de l’IA et du développement aujourd’hui. Nous ajoutons de nouvelles intégrations en permanence. Consultez notre documentation pour obtenir la liste la plus récente.
Conclusion
Chez Bright Data, nous ne nous contentons pas de résoudre un problème de scraping, nous offrons un écosystème complet pour votre pile d’IA. De la récolte de données en direct à l’exploitation d’archives historiques pour la formation, nous veillons à ce que vous consacriez votre temps à la connaissance, et non à l’infrastructure.
Commencez votre essai gratuit aujourd’hui et voyez la différence.





