

Dans ce guide, vous apprendrez :
- Qu’est-ce que le LlamaIndex et pourquoi est-il si largement utilisé ?
- Ce qui le rend unique pour le développement d’agents d’IA, c’est surtout sa prise en charge intégrée des intégrations de données.
- Comment utiliser LlamaIndex pour construire un agent d’intelligence artificielle capable d’extraire des données de sites généraux et de moteurs de recherche spécifiques.
Plongeons dans l’aventure !
Qu’est-ce que LlamaIndex ?
LlamaIndex est un cadre de données Python open-source pour la construction d’applications alimentées par LLM.
Il vous aide à créer des flux de travail et des agents d’IA prêts pour la production, capables de trouver et d’extraire des informations pertinentes, de synthétiser des idées, de générer des rapports détaillés, de prendre des mesures automatisées, etc.
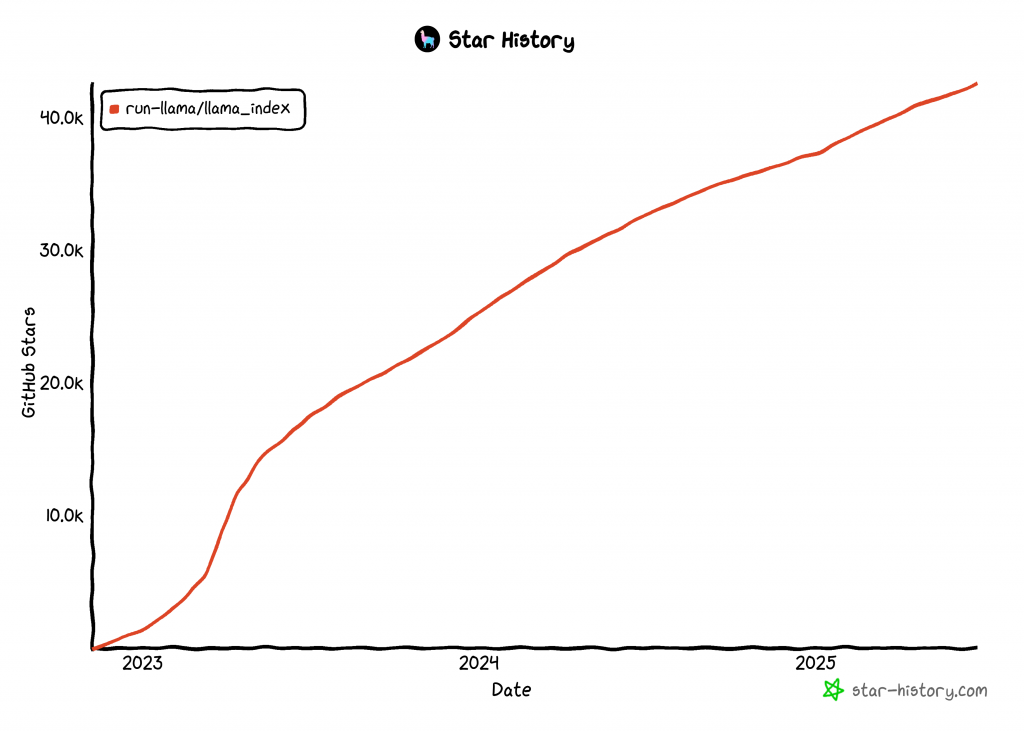
LlamaIndex est l’une des bibliothèques à la croissance la plus rapide pour la construction d’agents d’intelligence artificielle, avec plus de 42k étoiles GitHub:
Intégrer des données dans votre agent d’IA LlamaIndex
Comparé à d’autres technologies de construction d’agents d’IA, LlamaIndex se concentre sur les données. C’est pourquoi le dépôt GitHub du projet définit LlamaIndex comme un “cadre de données”.
Plus précisément, LlamaIndex s’attaque à l’une des plus grandes limites des LLM. Il s’agit de leur manque de connaissances sur les événements actuels ou en temps réel. Cette limitation est due au fait que les LLM sont formés sur des ensembles de données statiques et n’ont pas d’accès intégré à des informations actualisées.
Pour résoudre ce problème, LlamaIndex prend en charge les outils qui :
- Fournir des connecteurs de données pour ingérer des données provenant d’API, de PDF, de documents Word, de bases de données SQL, de pages web, etc.
- Structurez vos données à l’aide d’indices, de graphiques et d’autres formats optimisés pour la consommation de LLM.
- Activer la recherche avancée afin que vous puissiez saisir une invite LLM et recevoir une réponse enrichie de connaissances, ancrée dans un contexte pertinent.
- Prise en charge de l’intégration transparente avec des cadres externes tels que LangChain, Flask, Docker et ChatGPT.
En d’autres termes, construire avec LlamaIndex signifie généralement combiner la bibliothèque de base avec un ensemble de plugins/intégrations adaptés à votre cas d’utilisation. Par exemple, explorons un scénario de web scraping LlamaIndex.
Aujourd’hui, le web est la source de données la plus vaste et la plus complète de la planète. Un agent d’IA devrait donc idéalement y avoir accès afin de fonder ses réponses et d’effectuer des tâches plus efficacement. C’est là que les outils Bright Data de LlamaIndex entrent en jeu !
Avec les outils Bright Data, votre agent LlamaIndex AI gagne en efficacité :
- Fonctionnalité de scraping web en temps réel à partir de n’importe quelle page web.
- Données structurées sur les produits et les plateformes provenant de sites tels qu’Amazon, LinkedIn, Zillow, Facebook et bien d’autres.
- La possibilité de récupérer les résultats des moteurs de recherche pour n’importe quelle requête.
- Capture visuelle des données via des captures d’écran pleine page, utile pour la synthèse ou l’analyse visuelle.
Vous verrez comment fonctionne cette intégration dans le prochain chapitre !
Construire un agent LlamaIndex capable de rechercher des informations sur le Web à l’aide des outils Bright Data
Dans cette section étape par étape, vous apprendrez à utiliser LlamaIndex pour construire un agent d’intelligence artificielle Python qui se connecte aux outils de Bright Data.
Cette intégration donnera à votre agent de puissantes fonctions d’accès aux données web. En particulier, l’agent d’intelligence artificielle pourra extraire le contenu de n’importe quelle page web, obtenir des résultats de moteurs de recherche en temps réel, etc. Pour plus d’informations, consultez notre documentation officielle.
Suivez les étapes ci-dessous pour créer votre agent d’IA alimenté par Bright Data en utilisant LlamaIndex !
Conditions préalables
Pour suivre ce tutoriel, vous aurez besoin des éléments suivants :
- Python 3.9 ou supérieur installé sur votre machine (la dernière version est recommandée).
- Une clé API Bright Data pour l’intégration avec
BrightDataToolSpec. - Une clé API d’un fournisseur LLM supporté (dans ce guide, nous utiliserons Gemini, dont l’utilisation via l’API est gratuite. N’hésitez pas à utiliser n’importe quel fournisseur supporté par LlamaIndex).
Ne vous inquiétez pas si vous n’avez pas encore de clé API Gemini ou Bright Data. Nous vous expliquerons comment les créer dans les prochaines étapes.
Étape 1 : Créer votre projet Python
Commencez par ouvrir un terminal et créez un nouveau dossier pour votre projet d’agent d’intelligence artificielle LlamaIndex :
mkdir llamaindex-bright-data-agentllamaindex-bright-data-agent/ contiendra le code de votre agent d’intelligence artificielle avec des capacités de récupération de données web alimentées par Bright Data.
Ensuite, allez dans le répertoire du projet et créez un environnement virtuel à l’intérieur de celui-ci :
cd llamaindex-bright-data-agent
python -m venv venvMaintenant, ouvrez le dossier du projet dans votre IDE Python préféré. Nous recommandons Visual Studio Code (avec l’extension Python) ou PyCharm Community Edition.
Créez un nouveau fichier appelé agent.py à la racine du dossier. La structure de votre projet devrait maintenant ressembler à ceci :
llamaindex-bright-data-agent/
├── venv/
└── agent.pyDans votre terminal, activez l’environnement virtuel. Sous Linux ou macOS, exécutez cette commande :
source venv/bin/activateDe manière équivalente, sous Windows, exécutez :
venv/Scripts/activateDans les prochaines étapes, nous vous guiderons dans l’installation des paquets nécessaires. Cependant, si vous préférez les installer maintenant, exécutez :
pip install python-dotenv llama-index-tools-brightdata llama-index-llms-gemini llama-indexNote: Nous installons llama-index-llms-gemini parce que ce tutoriel utilise Gemini comme fournisseur LLM. Si vous prévoyez d’utiliser un fournisseur différent, assurez-vous d’installer l’intégration LlamaIndex correspondante.
Vous êtes prêt ! Vous avez maintenant un environnement de développement Python prêt à construire un agent d’intelligence artificielle en utilisant LlamaIndex et les outils de Bright Data.
Étape 2 : Configurer les variables d’environnement Lecture
Votre agent LlamaIndex se connectera à des services externes tels que Gemini et Bright Data via des clés API. Pour des raisons de sécurité, ne codifiez jamais les clés API directement dans votre code Python. Utilisez plutôt des variables d’environnement pour les garder privées.
Pour faciliter le travail avec les variables d’environnement, installez la bibliothèque python-dotenv. Dans votre environnement virtuel activé, exécutez :
pip install python-dotenvEnsuite, ouvrez votre fichier agent.py et ajoutez les lignes suivantes en haut pour charger des variables à partir d’un fichier .env :
from dotenv import load_dotenv
load_dotenv()La fonction load_dotenv() recherche un fichier .env dans le répertoire racine du projet et charge automatiquement ses valeurs dans l’environnement.
Maintenant, créez un fichier .env à côté de votre fichier agent.py, comme ceci :
llamaindex-bright-data-agent/
├── venv/
├── .env # <-------------
└── agent.pyC’est parfait ! Vous avez maintenant mis en place un moyen sécurisé de gérer les identifiants API sensibles pour les services tiers. Tim pour continuer la configuration initiale en remplissant le fichier .env avec les envs nécessaires.
Étape 3 : Démarrer avec Bright Data
À l’heure actuelle, BrightDataToolSpec expose les outils suivants au sein de LlamaIndex :
scrape_as_markdown: Récupère le contenu brut de n’importe quelle page web et le renvoie au format Markdown.get_screenshot: Effectue une capture d’écran pleine page d’une page web et l’enregistre localement.search_engine: Effectue une recherche sur des moteurs de recherche tels que Google, Bing, Yandex, etc. Il renvoie l’ensemble des SERP ou une version structurée en JSON de ces données.web_data_feed: Récupère des données JSON structurées provenant de plateformes bien connues.
Les trois premiers outils -crape_as_markdown, get_screenshot et search_engine - utilisent l ‘API Web Unlocker de Bright Data. Cette solution permet d’effectuer du scraping et des captures d’écran à partir de n’importe quel site, même ceux qui disposent d’une protection anti-bot stricte. De plus, elle prend en charge l’accès aux données web SERP de tous les principaux moteurs de recherche.
En revanche, web_data_feed exploite l’API Web Scraper de Bright Data. Ce point d’accès renvoie des données pré-structurées à partir d’une liste prédéfinie de plateformes prises en charge, telles qu’Amazon, Instagram, LinkedIn, ZoomInfo, etc.
Pour intégrer ces outils, vous devrez :
- Activez la solution Web Unlocker dans votre tableau de bord Bright Data.
- Récupérez votre clé API Bright Data, qui vous donne accès aux API Web Unlocker et Web Scraper.
Suivez les étapes ci-dessous pour terminer l’installation !
Tout d’abord, si vous n’avez pas encore de compte Bright Data, allez-y et [créez-en un](). Si vous avez déjà un compte, connectez-vous et ouvrez votre tableau de bord. Cliquez sur le bouton “Obtenir des produits proxy” :
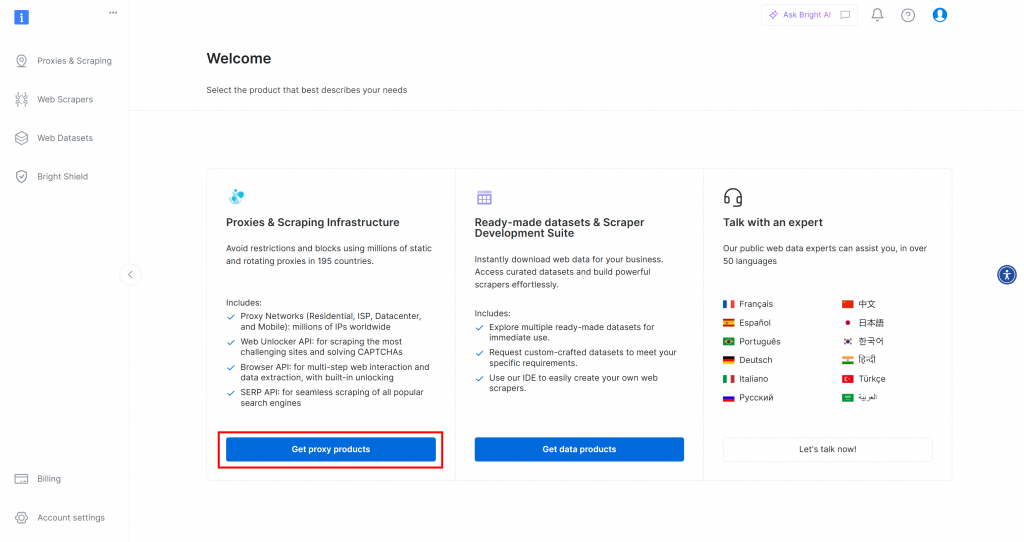
Vous serez redirigé vers la page “Proxies & Scraping Infrastructure” :
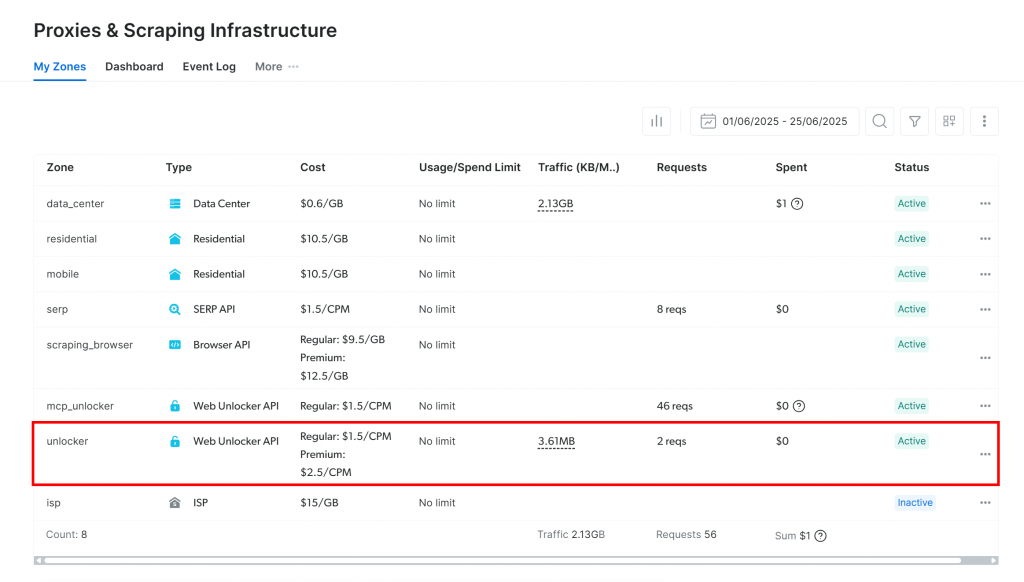
Si vous voyez déjà une zone API Web Unlocker active (comme ci-dessus), vous pouvez commencer. Le nom de la zone(unlocker, dans ce cas) est important, car vous en aurez besoin plus tard dans votre code.
Si vous n’en avez pas encore, descendez jusqu’à la section “Web Unlocker API” et cliquez sur “Créer une zone” :
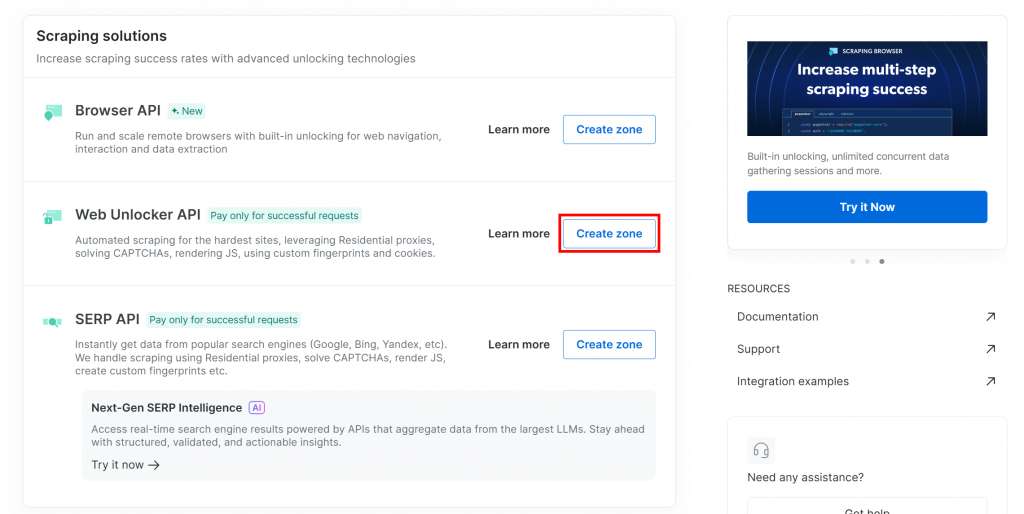
Donnez un nom à votre nouvelle zone, par exemple débloqueur, activez les fonctions avancées pour de meilleures performances, et cliquez sur “Ajouter” :
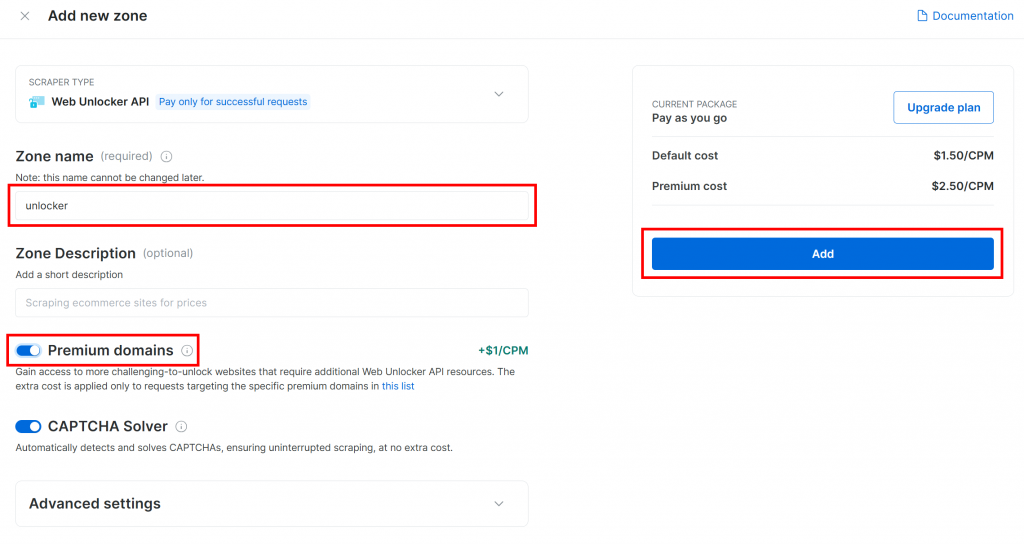
Une fois la zone créée, vous serez redirigé vers la page de configuration de la zone :
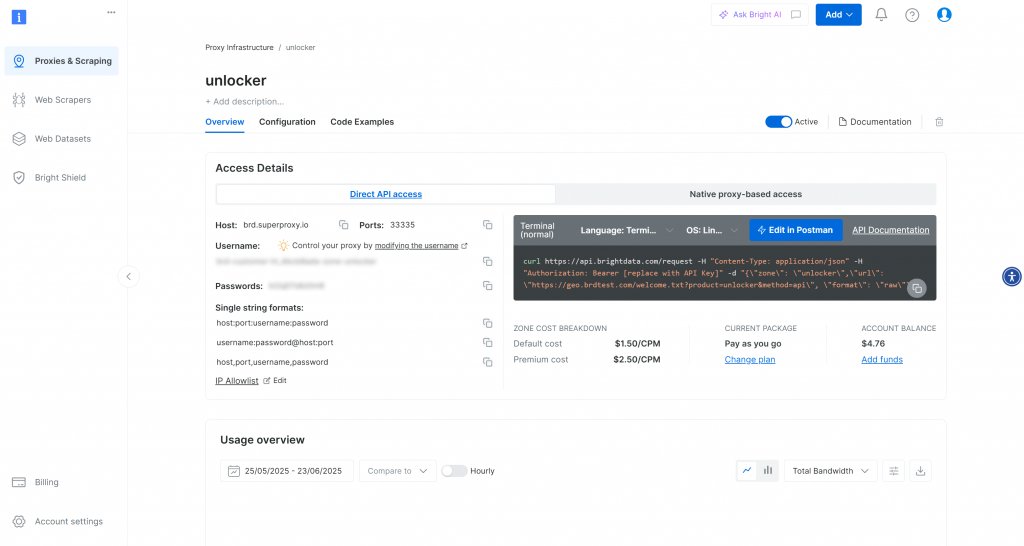
Assurez-vous que la bascule d’activation est réglée sur “Actif”. Cela confirme que la zone est correctement configurée et prête à être utilisée.
Ensuite, suivez le guide officiel de Bright Data pour générer votre clé API. Une fois que vous l’avez obtenue, stockez-la en toute sécurité dans votre fichier .env comme suit :
BRIGHT_DATA_API_KEY="<YOUR_BRIGHT_DATA_API_KEY>"Remplacez le par la valeur réelle de votre clé API.
Incroyable ! Il est temps d’intégrer les outils de Bright Data dans votre script d’agent LlamaIndex.
Étape 4 : Installer et configurer les outils de données LlamaIndex Bright
Dans agent.py, commencez par charger votre clé d’API Bright Data dans l’environnement :
BRIGHT_DATA_API_KEY = os.getenv("BRIGHT_DATA_API_KEY")N’oubliez pas d’importer os de la bibliothèque standard de Python:
import osUne fois votre environnement virtuel activé, installez le paquet d’outils LlamaIndex Bright Data:
pip install llama-index-tools-brightdataDans votre fichier agent.py, importez la classe BrightDataToolSpec:
from llama_index.tools.brightdata import BrightDataToolSpecEnsuite, créez une instance de BrightDataToolSpec à l’aide de votre clé API et du nom de la zone :
brightdata_tool_spec = BrightDataToolSpec(
api_key=BRIGHT_DATA_API_KEY,
zone="<BRIGHT_DATA_WEB_UNLOCKER_API_ZONE_NAME>", # Replace with the actual value
verbose=True, # Useful while developing
)Remplacez le par le nom de la zone de l’API Web Unlocker que vous avez configurée précédemment. Dans ce cas, il s’agit de unlocker:
brightdata_tool_spec = BrightDataToolSpec(
api_key=BRIGHT_DATA_API_KEY,
zone="unlocker",
verbose=True,
)Notez que l’option verbose a été réglée sur True. C’est utile lors du développement, car cela permet d’afficher des informations utiles sur ce qui se passe lorsque l’agent LlamaIndex effectue des requêtes via Bright Data.
Ensuite, convertissez la spécification de l’outil en une liste d’outils utilisables par votre agent :
brightdata_tools = brightdata_tool_spec.to_tool_list()Fantastique ! Les outils Bright Data sont maintenant intégrés et prêts à alimenter votre agent LlamaIndex. La prochaine étape consiste à connecter votre LLM.
Étape n° 5 : Préparer le modèle LLM
Pour utiliser Gemini (le fournisseur LLM choisi), commencez par installer le paquet d’intégration requis :
pip install llama-index-llms-google-genaiEnsuite, importez la classe GoogleGenAI du paquet installé :
from llama_index.llms.google_genai import GoogleGenAIMaintenant, initialisez le Gemini LLM comme suit :
llm = GoogleGenAI(
model="models/gemini-2.5-flash",
)Dans cet exemple, nous utilisons le modèle gemini-2.5-flash. Vous pouvez remplacer ce modèle par n’importe quel autre modèle Gemini pris en charge.
Dans les coulisses, GoogleGenAI recherche automatiquement une variable d’environnement nommée GEMINI_API_KEY. Pour la définir, ouvrez votre fichier .env et ajoutez la ligne suivante :
GEMINI_API_KEY="<YOUR_GEMINI_API_KEY>"Remplacez le par votre clé API Gemini. Si vous n’en avez pas, récupérez-la gratuitement en suivant le guide officiel.
Note: Si vous préférez utiliser un autre fournisseur LLM, LlamaIndex supporte de nombreuses options. Référez-vous à la documentation officielle de LlamaIndex pour les instructions d’installation.
Bon travail ! Vous avez maintenant tous les composants de base pour construire un agent LlamaIndex avec des capacités de récupération de données web.
Étape 6 : Créer l’agent LlamaIndex
Tout d’abord, installez le paquetage principal de LlamaIndex:
pip install llama-indexEnsuite, dans votre fichier agent.py, importez la classe FunctionCallingAgent:
from llama_index.core.agent import FunctionCallingAgentFunctionCallingAgent est un type spécial d’agent LlamaIndex AI qui peut interagir avec des outils externes, tels que les outils Bright Data que vous avez configurés précédemment.
Initialisez l’agent avec vos outils LLM et Bright Data comme suit :
agent = FunctionCallingAgent.from_tools(
tools=brightdata_tools,
llm=llm,
verbose=True, # Useful while developing
)Cela permet de mettre en place un agent d’intelligence artificielle qui traite les entrées de l’utilisateur à l’aide de votre LLM et qui peut appeler les outils de Bright Data pour récupérer des informations si nécessaire. L’option verbose=True est pratique pendant le développement, car elle permet de savoir quels outils l’agent utilise pour chaque requête.
C’est fait ! L’intégration LlamaIndex + Bright Data est terminée. La prochaine étape est de construire le REPL pour une utilisation interactive.
Étape n° 7 : Mise en œuvre de la bibliothèque virtuelle (REPL)
REPL signifie “Read-Eval-Print Loop” (boucle de lecture, d’évaluation et d’impression). Il s’agit d’un modèle de programmation interactive qui permet d’entrer des commandes, de les faire évaluer et de voir les résultats immédiatement. Dans ce contexte, vous :
- Saisir une commande ou une tâche.
- Laissez l’agent d’intelligence artificielle l’évaluer et le traiter.
- Voir la réponse.
Cette boucle se poursuit indéfiniment, jusqu’à ce que vous tapiez "exit".
Lorsqu’il s’agit d’agents d’intelligence artificielle, la REPL est généralement plus pratique que l’envoi d’invites isolées. La raison en est qu’elle permet à votre agent LlamaIndex de maintenir le contexte de la session et d’améliorer ses réponses en apprenant des interactions précédentes.
Maintenant, implémentez la logique REPL dans agent.py comme ci-dessous :
# Implement the REPL interaction loop
print("Gemini-powered Agent with Bright Data tools for web data retrieval. Type 'exit' to quit.n")
while True:
# Read the user request for the AI agent from the CLI
request = input("Request -> ")
# Terminate the execution if the user type "exit"
if request.strip().lower() == "exit":
print("nAgent terminated")
break
try:
# Execute the request
response = agent.chat(request)
print(f"nResponse ->:n{response}n")
except Exception as e:
print(f"nError: {str(e)}n")Ce REPL :
- Lit l’entrée de l’utilisateur à partir de la ligne de commande avec
input(). - L’évalue en utilisant l’agent LlamaIndex alimenté par Gemini et Bright Data avec
agent.chat(). - Imprime la réponse sur la console.
Génial ! L’agent IA LlamaIndex est prêt.
Étape n° 8 : Rassembler tous les éléments et exécuter l’agent
Voici ce que devrait contenir votre fichier agent.py :
from dotenv import load_dotenv
import os
from llama_index.tools.brightdata import BrightDataToolSpec
from llama_index.llms.google_genai import GoogleGenAI
from llama_index.core.agent import FunctionCallingAgent
# Load environment variables from the .env file
load_dotenv()
# Read the Bright Data API key from the envs
BRIGHT_DATA_API_KEY = os.getenv("BRIGHT_DATA_API_KEY")
# Set up the Bright Data Tools
brightdata_tool_spec = BrightDataToolSpec(
api_key=BRIGHT_DATA_API_KEY,
zone="unlocker",
verbose=True, # Useful while developing
)
brightdata_tools = brightdata_tool_spec.to_tool_list()
# Configure the connection to Gemini
llm = GoogleGenAI(
model="models/gemini-2.5-flash",
)
# Create the LlamaIndex agent powered by Gemini and connected to Bright Data tools
agent = FunctionCallingAgent.from_tools(
tools=brightdata_tools,
llm=llm,
verbose=True, # Useful while developing
)
# Implement the REPL interaction loop
print("Gemini-powered Agent with Bright Data tools for web data retrieval. Type 'exit' to quit.n")
while True:
# Read the user request for the AI agent from the CLI
request = input("Request -> ")
# Terminate the execution if the user type "exit"
if request.strip().lower() == "exit":
print("nAgent terminated")
break
try:
# Execute the request
response = agent.chat(request)
print(f"nResponse ->:n{response}n")
except Exception as e:
print(f"nError: {str(e)}n")Exécutez le script de l’agent à l’aide de la commande suivante :
python agent.pyLorsque le script démarre, vous verrez quelque chose comme ceci :

Entrez l’invite suivante dans le terminal :
Generate a report summarizing the most important information about the product "Death Stranding 2" using data from its Amazon page: "https://www.amazon.com/Death-Stranding-2-Beach-PlayStation-5/dp/B0F19GPDW3/"Le résultat sera le suivant :
C’est allé très vite, alors voyons ce qui s’est passé :
- L’agent identifie que la tâche nécessite des données sur les produits Amazon, il appelle donc l’outil
web_data_feedavec cette entrée :{"source_type" : "amazon_product", "url" : "https://www.amazon.com/Death-Stranding-2-Beach-PlayStation-5/dp/B0F19GPDW3/"} - Cet outil interroge de manière asynchrone l ‘API Amazon Web Scraper de Bright Data pour récupérer des données structurées sur les produits.
- Une fois la réponse JSON renvoyée, l’agent la transmet au LLM Gemini.
- Les Gémeaux traitent les nouvelles données et génèrent un résumé clair et précis.
En d’autres termes, compte tenu de l’invite, l’agent sélectionne intelligemment le meilleur outil. Dans le cas présent, il s’agit de web_data_feed. Il récupère les données produit en temps réel à partir de la page Amazon donnée avec une approche asynchrone. Ensuite, le LLM utilise ces données pour générer un résumé significatif.
Dans ce cas, l’agent IA est revenu :
Here's a summary report for "Death Stranding 2: On The Beach - PS5" based on its Amazon product page:
**Product Report: Death Stranding 2: On The Beach - PS5**
* **Title:** Death Stranding 2: On The Beach - PS5
* **Brand/Manufacturer:** Sony Interactive Entertainment
* **Price:** $69.99 USD
* **Release Date:** June 26, 2026
* **Availability:** Available for pre-order.
**Description:**
"Death Stranding 2: On The Beach" is an upcoming PlayStation 5 title from legendary game creator Hideo Kojima. Players will embark on a new journey with Sam and his companions to save humanity from extinction, traversing a world filled with otherworldly enemies and obstacles. The game explores the question of human connection and promises to once again change the world through its unique narrative and gameplay.
**Key Features:**
* **Pre-order Bonus:** Includes Quokka Hologram, Battle Skeleton Silver (LV1,LV2,LV3), Boost Skeleton Silver (LV1,LV2,LV3), and Bokka Silver (LV1,LV2,LV3).
* **Open World:** Features large, varied open-world environments with unique challenges.
* **Gameplay Choices:** Offers multiple approaches to combat and stealth, allowing players to choose between aggressive tactics, sneaking, or avoiding danger.
* **New Story:** Continues the narrative from the original Death Stranding, following Sam on a fresh journey with unexpected twists.
* **Player Interaction:** Player actions can influence how other players interact with the game's world.
**Category & Ranking:**
* **Categories:** Video Games, PlayStation 5, Games
* **Best Sellers Rank:** #10 in Video Games, #1 in PlayStation 5 Games
**Sales Performance:**
* **Bought in past month:** 7,000 unitsRemarquez que l’agent d’IA ne serait pas en mesure d’obtenir un tel résultat sans les outils de Bright Data. Cela s’explique par le fait que :
- Le produit Amazon choisi est un nouveau produit et les LLM ne sont pas formés sur des données aussi récentes.
- Les LLM peuvent ne pas être en mesure de récupérer ou d’accéder à des pages web en temps réel par leurs propres moyens.
- Lescraping des produits Amazon est notoirement difficile en raison des systèmes anti-bots stricts comme le fameux CAPTCHA d’Amazon.
Important: si vous essayez d’autres invites, vous verrez que l’agent sélectionne et utilise automatiquement les outils configurés appropriés pour récupérer les données dont il a besoin pour générer des réponses fondées.
Et voilà ! Vous disposez désormais d’un agent LlamaIndex AI doté de fonctions d’accès aux données Web de premier ordre, grâce à l’intégration avec Bright Data.
Conclusion
Dans cet article, vous avez appris à utiliser LlamaIndex pour construire un agent d’intelligence artificielle avec un accès en temps réel aux données web, grâce aux outils de Bright Data.
Cette intégration permet à votre agent de récupérer du contenu web public au format Markdown, au format JSON structuré et même sous forme de captures d’écran. Cela vaut aussi bien pour les sites web que pour les moteurs de recherche.
N’oubliez pas que l’intégration présentée ici n’est qu’un exemple de base. Si vous souhaitez créer des agents plus avancés, vous aurez besoin d’outils fiables pour récupérer, valider et transformer les données Web en direct. C’est exactement ce pour quoi l’infrastructure d’IA de Bright Data est conçue.
Créez un compte Bright Data gratuit et commencez à explorer nos outils de données prêts pour l’IA dès aujourd’hui !




