

Ce système trouve de nouveaux prospects à l’aide d’une intelligence web en temps réel, détecte automatiquement les signaux d’achat et génère des communications personnalisées basées sur des événements commerciaux réels. Passez directement à l’action sur GitHub.
Vous apprendrez :
- Comment créer des systèmes multi-agents à l’aide de CrewAI pour des tâches de prospection spécialisées
- Comment tirer parti de Bright Data MCP pour obtenir des informations en temps réel sur les entreprises et les contacts
- Comment détecter automatiquement les événements déclencheurs tels que les embauches, les financements et les changements de direction
- Comment générer des communications personnalisées basées sur des informations commerciales en temps réel
- Comment créer un pipeline automatisé, de la découverte de prospects à l’intégration CRM
C’est parti !
Le défi du développement commercial moderne
Le développement commercial traditionnel repose sur des recherches manuelles, qui consistent notamment à passer d’un profil LinkedIn à un autre, à consulter les sites web des entreprises et à lire des articles d’actualité pour identifier des prospects. Cette approche est chronophage, source d’erreurs et conduit souvent à des listes de contacts obsolètes et à des communications mal ciblées.
L’intégration de CrewAI à Bright Data automatise l’ensemble du processus de prospection, réduisant ainsi les heures de travail manuel à quelques minutes seulement.
Ce que nous construisons : un système intelligent de développement commercial
Vous allez créer un système d’IA multi-agents qui trouve les entreprises correspondant à votre profil client idéal. Il suivra les événements déclencheurs qui indiquent une intention d’achat, recueillera des informations vérifiées sur les décideurs et créera des messages de communication personnalisés à l’aide de données commerciales réelles. Le système se connecte directement à votre CRM pour maintenir un pipeline qualifié.
Prérequis
Configurez votre environnement de développement avec les exigences suivantes :
- Installation dePython 3.11+
- Compte Bright Data avec accès MCP
- Clé API OpenAI pour la génération d’IA
- Identifiants HubSpot CRM pour l’intégration du pipeline
Configuration de l’environnement
Créez votre répertoire de projet et installez les dépendances. Commencez par configurer un environnement virtuel propre afin d’éviter tout conflit avec d’autres projets Python.
python -m venv ai_bdr_env
source ai_bdr_env/bin/activate # Windows : ai_bdr_envScriptsactivate
pip install crewai « crewai-tools[mcp] » openai pandas python-dotenv streamlit requestsCréer la configuration de l’environnement :
BRIGHT_DATA_API_TOKEN="votre_token_bright_data_api"
OPENAI_API_KEY="votre_clé_openai_api"
HUBSPOT_API_KEY="votre_clé_hubspot_api"Création du système BDR IA
Commençons maintenant à créer les agents IA pour notre système IA BDR.
Étape 1 : Configuration de Bright Data MCP
Créez les bases d’une infrastructure de scraping web qui collecte des données en temps réel à partir de plusieurs sources. Le client MCP gère toutes les communications avec le réseau de scraping de Bright Data.
Créez un fichier mcp_client.py dans le répertoire racine de votre projet et ajoutez le code suivant :
from crewai import Agent, Task
from crewai.tools import BaseTool
from typing import Any
from pydantic import BaseModel, Field
from .utils import validate_companies_input, safe_mcp_call, deduplicate_by_key, extract_domain_from_url
class CompanyDiscoveryInput(BaseModel):
industry: str = Field(description="Secteur cible pour la recherche d'entreprises")
size_range: str = Field(description="Taille de l'entreprise (start-up, petite, moyenne, grande)")
location: str = Field(default="", description="Localisation géographique ou région")
class CompanyDiscoveryTool(BaseTool):
name: str = "discover_companies"
description: str = "Rechercher des entreprises correspondant aux critères ICP à l'aide du Scraping web"
args_schema: type[BaseModel] = CompanyDiscoveryInput
mcp: Any = None
def __init__(self, mcp_client):
super().__init__()
self.mcp = mcp_client
def _run(self, industry: str, size_range: str, location: str = "") -> list:
companies = []
search_terms = [
f"{industry} companies {size_range}",
f"{industry} startups {location}",
f"{industry} technology companies"
]
for term in search_terms:
results = self._search_companies(term)
for company in results:
enriched = self._enrich_company_data(company)
if self._matches_icp(enriched, industry, size_range):
companies.append(enriched)
return deduplicate_by_key(companies, lambda c: c.get('domain') or c['name'].lower())
def _search_companies(self, term):
"""Rechercher des entreprises à l'aide d'une recherche Web réelle via Bright Data."""
try:
companies = []
search_queries = [
f"{term} directory",
f"{term} list",
f"{term} news"
]
for query in search_queries:
try:
results = self._perform_company_search(query)
companies.extend(results)
if len(companies) >= 10:
break
except Exception as e:
print(f"Erreur dans la requête de recherche '{query}': {str(e)}")
continue
return self._filter_unique_companies(companies)
except Exception as e:
print(f"Erreur lors de la recherche d'entreprises pour '{term}': {str(e)}")
return []
def _enrich_company_data(self, company) :
linkedin_data = safe_mcp_call(self.mcp, 'scrape_company_linkedin', company['name'])
website_data = safe_mcp_call(self.mcp, 'scrape_company_website', company.get('domain', ''))
employee_count = linkedin_data.get('employee_count') or 150
return {
**company,
'linkedin_intelligence': linkedin_data,
'website_intelligence': website_data,
'employee_count': employee_count,
'icp_score': 0
}
def _matches_icp(self, company, industry, size_range):
score = 0
if industry.lower() in company.get('industry', '').lower():
score += 30
if self._check_size_range(company.get('employee_count', 0), size_range):
score += 25
if company.get('name') and company.get('domain'):
score += 20
company['icp_score'] = score
return score >= 20
def _check_size_range(self, count, size_range):
ranges = {'startup': (1, 50), 'small': (51, 200), 'medium': (201, 1000)}
min_size, max_size = ranges.get(size_range, (0, 999999))
return min_size <= count <= max_size
def _perform_company_search(self, query):
"""Effectuer une recherche d'entreprise à l'aide de Bright Data MCP."""
search_result = safe_mcp_call(self.mcp, 'search_company_news', query)
if search_result and search_result.get('results'):
return self._extract_companies_from_mcp_results(search_result['results'], query)
else:
print(f"No MCP results for: {query}")
return []
def _filter_unique_companies(self, companies):
"""Filtrer les entreprises en double."""
seen_names = set()
unique_companies = []
for company in companies:
name_key = company.get('name', '').lower()
if name_key and name_key not in seen_names:
seen_names.add(name_key)
unique_companies.append(company)
return unique_companies
def _extract_companies_from_mcp_results(self, mcp_results, original_query):
"""Extraire les informations sur les entreprises à partir des résultats de recherche MCP."""
companies = []
for result in mcp_results[:10]:
try:
title = result.get('title', '')
url = result.get('url', '')
snippet = result.get('snippet', '')
company_name = self._extract_company_name_from_result(title, url)
if company_name and len(company_name) > 2:
domain = self._extract_domain_from_url(url)
industry = self._extract_industry_from_query(original_query)
companies.append({
'name': company_name,
'domain': domain,
'industry': industry
})
except Exception as e:
print(f"Erreur lors de l'extraction de la société à partir du résultat MCP : {str(e)}")
continue
return companies
def _extract_company_name_from_result(self, title, url):
"""Extraire le nom de la société à partir du titre ou de l'URL du résultat de recherche."""
import re
if title:
title_clean = re.sub(r'[|-—–].*$', '', title).strip()
title_clean = re.sub(r's+(Inc|Corp|LLC|Ltd|Solutions|Systems|Technologies|Software|Platform|Company)$', '', title_clean, flags=re.IGNORECASE)
if len(title_clean) > 2 and len(title_clean) < 50:
return title_clean
if url:
domain_parts = url.split('/')[2].split('.')
if len(domain_parts) > 1:
return domain_parts[0].title()
return None
def _extract_domain_from_url(self, url) :
"""Extraire le domaine de l'URL."""
return extract_domain_from_url(url)
def _extract_industry_from_query(self, query) :
"""Extraire le secteur d'activité de la requête de recherche."""
query_lower = query.lower()
industry_mappings = {
'saas': 'SaaS',
'fintech': 'FinTech',
'ecommerce': 'E-commerce',
'healthcare': 'Healthcare',
'ai': 'IA/ML',
'machine learning': 'IA/ML',
'artificial intelligence': 'IA/ML'
}
for keyword, industry in industry_mappings.items():
if keyword in query_lower:
return industry
return 'Technology'
def create_company_discovery_agent(mcp_client) :
return Agent(
role='Company Discovery Specialist',
goal='Find high-quality prospects matching ICP criteria',
backstory='Expert at identifying potential customers using real-time web intelligence.',
tools=[CompanyDiscoveryTool(mcp_client)],
verbose=True
)Ce client MCP gère toutes les tâches de Scraping web à l’aide de l’infrastructure IA de Bright Data. Il offre un accès fiable aux pages d’entreprise LinkedIn, aux sites web d’entreprise, aux bases de données de financement et aux sources d’information. Le client se charge de la mise en commun des connexions et traite automatiquement les protections anti-bot.
Étape 2 : Agent de découverte d’entreprises
Transformez vos critères de profil client idéal en un système de découverte intelligent qui trouve les entreprises correspondant à vos exigences spécifiques. L’agent recherche plusieurs sources et améliore les données des entreprises grâce à l’intelligence économique.
Commencez par créer un dossier agents à la racine de votre projet. Créez ensuite un fichier agents/company_discovery.py et ajoutez-y le code suivant :
from crewai import Agent, Task
from crewai.tools import BaseTool
from typing import Any
from pydantic import BaseModel, Field
from .utils import validate_companies_input, safe_mcp_call, deduplicate_by_key, extract_domain_from_url
class CompanyDiscoveryInput(BaseModel):
industry: str = Field(description="Secteur cible pour la découverte d'entreprises")
size_range: str = Field(description="Taille de l'entreprise (start-up, petite, moyenne, grande)")
location: str = Field(default="", description="Localisation géographique ou région")
class CompanyDiscoveryTool(BaseTool):
name: str = "discover_companies"
description: str = "Rechercher des entreprises correspondant aux critères ICP à l'aide du Scraping web"
args_schema: type[BaseModel] = CompanyDiscoveryInput
mcp: Any = None
def __init__(self, mcp_client):
super().__init__()
self.mcp = mcp_client
def _run(self, industry: str, size_range: str, location: str = "") -> list:
companies = []
search_terms = [
f"{industry} companies {size_range}",
f"{industry} startups {location}",
f"{industry} technology companies"
]
for term in search_terms:
results = self._search_companies(term)
for company in results:
enriched = self._enrich_company_data(company)
if self._matches_icp(enriched, industry, size_range):
companies.append(enriched)
return deduplicate_by_key(companies, lambda c: c.get('domain') or c['name'].lower())
def _search_companies(self, term):
"""Rechercher des entreprises à l'aide d'une recherche Web réelle via Bright Data."""
try:
companies = []
search_queries = [
f"{term} directory",
f"{term} list",
f"{term} news"
]
for query in search_queries:
try:
results = self._perform_company_search(query)
companies.extend(results)
if len(companies) >= 10:
break
except Exception as e:
print(f"Erreur dans la requête de recherche '{query}': {str(e)}")
continue
return self._filter_unique_companies(companies)
except Exception as e:
print(f"Erreur lors de la recherche d'entreprises pour '{term}': {str(e)}")
return []
def _enrich_company_data(self, company) :
linkedin_data = safe_mcp_call(self.mcp, 'scrape_company_linkedin', company['name'])
website_data = safe_mcp_call(self.mcp, 'scrape_company_website', company.get('domain', ''))
employee_count = linkedin_data.get('employee_count') or 150
return {
**company,
'linkedin_intelligence': linkedin_data,
'website_intelligence': website_data,
'employee_count': employee_count,
'icp_score': 0
}
def _matches_icp(self, company, industry, size_range):
score = 0
if industry.lower() in company.get('industry', '').lower():
score += 30
if self._check_size_range(company.get('employee_count', 0), size_range):
score += 25
if company.get('name') and company.get('domain'):
score += 20
company['icp_score'] = score
return score >= 20
def _check_size_range(self, count, size_range):
ranges = {'startup': (1, 50), 'small': (51, 200), 'medium': (201, 1000)}
min_size, max_size = ranges.get(size_range, (0, 999999))
return min_size <= count <= max_size
def create_company_discovery_agent(mcp_client) :
return Agent(
role='Company Discovery Specialist',
goal='Find high-quality prospects matching ICP criteria',
backstory='Expert at identifying potential customers using real-time web intelligence.',
tools=[CompanyDiscoveryTool(mcp_client)],
verbose=True
)L’agent de découverte recherche plusieurs sources de données afin de trouver les entreprises qui correspondent à votre profil client idéal. Il ajoute des informations commerciales provenant de LinkedIn et des sites Web d’entreprise pour chaque entreprise. Il filtre ensuite les résultats en fonction des critères de notation que vous pouvez définir. Le processus de déduplication permet de garder les listes de prospects propres, en évitant les doublons.
Étape 3 : Agent de détection des déclencheurs
Surveillez les événements commerciaux qui indiquent une intention d’achat et le meilleur moment pour prendre contact. L’agent examine les tendances en matière de recrutement, les annonces de financement, les changements de direction et les signes d’expansion afin de classer les prospects par ordre de priorité.
Créez un fichier agents/trigger_detection.py et ajoutez le code suivant :
from crewai import Agent, Task
from crewai.tools import BaseTool
from datetime import datetime, timedelta
from typing import Any, List
from pydantic import BaseModel, Field
from .utils import validate_companies_input, safe_mcp_call
class TriggerDetectionInput(BaseModel):
companies: List[dict] = Field(description="Liste des entreprises à analyser pour les événements déclencheurs")
class TriggerDetectionTool(BaseTool):
name: str = "detect_triggers"
description: str = "Rechercher des signaux d'embauche, des actualités sur le financement, des changements de direction"
args_schema: type[BaseModel] = TriggerDetectionInput
mcp : Any = None
def __init__(self, mcp_client) :
super().__init__()
self.mcp = mcp_client
def _run(self, companies) -> list :
companies = validate_companies_input(companies)
if not companies :
return []
for company in companies:
triggers = []
hiring_signals = self._detect_hiring_triggers(company)
triggers.extend(hiring_signals)
funding_signals = self._detect_funding_triggers(company)
triggers.extend(funding_signals)
signaux_leadership = self._detect_leadership_triggers(entreprise)
déclencheurs.étendre(signaux_leadership)
signaux_expansion = self._detect_expansion_triggers(entreprise)
déclencheurs.étendre(signaux_expansion)
company['trigger_events'] = triggers
company['trigger_score'] = self._calculate_trigger_score(triggers)
return sorted(companies, key=lambda x: x.get('trigger_score', 0), reverse=True)
def _detect_hiring_triggers(self, company) :
"""Détecter les déclencheurs d'embauche à l'aide des données LinkedIn."""
linkedin_data = safe_mcp_call(self.mcp, 'scrape_company_linkedin', company['name'])
triggers = []
if linkedin_data:
hiring_posts = linkedin_data.get('hiring_posts', [])
recent_activity = linkedin_data.get('recent_activity', [])
if hiring_posts:
triggers.append({
'type': 'hiring_spike',
'severity': 'high',
'description': f"Recrutement actif détecté chez {company['name']} - {len(hiring_posts)} postes à pourvoir",
'date_detected': datetime.now().isoformat(),
'source': 'linkedin_api'
})
if recent_activity:
triggers.append({
'type': 'company_activity',
'severity': 'medium',
'description': f"Augmentation de l'activité LinkedIn chez {company['name']}",
'date_detected': datetime.now().isoformat(),
'source': 'linkedin_api'
})
return triggers
def _detect_funding_triggers(self, company) :
"""Détecter les déclencheurs de financement à l'aide de la recherche d'actualités."""
funding_data = safe_mcp_call(self.mcp, 'search_funding_news', company['name'])
triggers = []
if funding_data and funding_data.get('results') :
triggers.append({
'type': 'funding_round',
'severity': 'high',
'description': f"Recent funding activity detected at {company['name']}",
'date_detected': datetime.now().isoformat(),
'source': 'news_search'
})
return triggers
def _detect_leadership_triggers(self, company):
"""Détecter les changements de direction à l'aide de la recherche d'actualités."""
return self._detect_keyword_triggers(
company, 'leadership_change', 'medium',
['ceo', 'cto', 'vp', 'hired', 'joins', 'appointed'],
f"Changements de direction détectés chez {company['name']}"
)
def _detect_expansion_triggers(self, company) :
"""Détecter l'expansion commerciale à l'aide d'une recherche d'actualités."""
return self._detect_keyword_triggers(
company, 'expansion', 'medium',
['expansion', 'new office', 'opening', 'market'],
f"Expansion commerciale détectée chez {company['name']}"
)
def _detect_keyword_triggers(self, company, trigger_type, severity, keywords, description) :
"""Méthode générique pour détecter les déclencheurs basés sur des mots-clés dans l'actualité."""
news_data = safe_mcp_call(self.mcp, 'search_company_news', company['name'])
triggers = []
if news_data and news_data.get('results'):
for result in news_data['results']:
if any(keyword in str(result).lower() for keyword in keywords):
triggers.append({
'type': trigger_type,
'severity': severity,
'description': description,
'date_detected': datetime.now().isoformat(),
'source': 'news_search'
})
break
return triggers
def _calculate_trigger_score(self, triggers) :
severity_weights = {'high': 15, 'medium': 10, 'low': 5}
return sum(severity_weights.get(t.get('severity', 'low'), 5) for t in triggers)
def create_trigger_detection_agent(mcp_client) :
return Agent(
role='Trigger Event Analyst',
goal='Identify buying signals and optimal timing for outreach',
backstory='Expert at detecting business events that indicate readiness to buy.',
tools=[TriggerDetectionTool(mcp_client)],
verbose=True
)Le système de détection des déclencheurs surveille divers signaux commerciaux qui indiquent une intention d’achat et les meilleurs moments pour entrer en contact. Il examine les tendances en matière de recrutement à partir des offres d’emploi publiées sur LinkedIn, suit les annonces de financement dans les sources d’information, surveille les changements de direction et identifie les activités d’expansion. Chaque déclencheur reçoit une note de gravité qui aide à hiérarchiser les prospects en fonction de l’urgence et de l’importance de l’opportunité.
Étape 4 : Agent de recherche de contacts
Recherchez et vérifiez les coordonnées des décideurs tout en tenant compte des scores de confiance provenant de diverses sources de données. L’agent hiérarchise les contacts en fonction de leur rôle et de la qualité des données.
Créez un fichier agents/contact_research.py et ajoutez le code suivant :
from crewai import Agent, Task
from crewai.tools import BaseTool
from typing import Any, List
from pydantic import BaseModel, Field
import re
from .utils import validate_companies_input, safe_mcp_call, validate_email, deduplicate_by_key
class ContactResearchInput(BaseModel):
companies: List[dict] = Field(description="Liste des entreprises pour lesquelles rechercher des contacts")
target_roles: List[str] = Field(description="Liste des rôles cibles pour lesquels trouver des contacts")
class ContactResearchTool(BaseTool):
name: str = "research_contacts"
description : str = « Rechercher et vérifier les coordonnées des décideurs à l'aide de MCP »
args_schema : type[BaseModel] = ContactResearchInput
mcp : Any = None
def __init__(self, mcp_client) :
super().__init__()
self.mcp = mcp_client
def _run(self, companies, target_roles) -> list:
companies = validate_companies_input(companies)
if not companies:
return []
if not isinstance(target_roles, list):
target_roles = [target_roles] if target_roles else []
for company in companies:
contacts = []
for role in target_roles:
role_contacts = self._search_contacts_by_role(company, role)
for contact in role_contacts:
enriched = self._enrich_contact_data(contact, company)
if self._validate_contact(enriched):
contacts.append(enriched)
entreprise['contacts'] = self._deduplicate_contacts(contacts)
entreprise['contact_score'] = self._calculate_contact_quality(contacts)
return entreprises
def _search_contacts_by_role(self, entreprise, rôle):
"""Rechercher des contacts par rôle à l'aide de MCP."""
contacts = []
search_query = f"{company['name']} {role} LinkedIn contact"
search_result = safe_mcp_call(self.mcp, 'search_company_news', search_query)
if search_result and search_result.get('results'):
contacts.extend(self._extract_contacts_from_mcp_results(search_result['results'], role))
if not contacts:
contact_query = f"{company['name']} {role} email contact"
contact_result = safe_mcp_call(self.mcp, 'search_company_news', contact_query)
if contact_result and contact_result.get('results'):
contacts.extend(self._extract_contacts_from_mcp_results(contact_result['results'], role))
return contacts[:3]
def _extract_contacts_from_mcp_results(self, results, role):
"""Extraire les coordonnées des résultats de recherche MCP."""
contacts = []
for result in results:
try:
title = result.get('title', '')
snippet = result.get('snippet', '')
url = result.get('url', '')
names = self._extract_names_from_text(title + ' ' + snippet)
for name_parts in names:
if len(name_parts) >= 2:
first_name, last_name = name_parts[0], ' '.join(name_parts[1:])
contacts.append({
'first_name': first_name,
'last_name': last_name,
'title': role,
'linkedin_url': url if 'linkedin' in url else '',
'data_sources': 1,
'source': 'mcp_search'
})
if len(contacts) >= 2:
break
except Exception as e:
print(f"Erreur lors de l'extraction du contact du résultat : {str(e)}")
continue
return contacts
def _extract_names_from_text(self, text):
"""Extraire les noms probables du texte."""
import re
name_patterns = [
r'b([A-Z][a-z]+)s+([A-Z][a-z]+)b',
r'b([A-Z][a-z]+)s+([A-Z].?s*[A-Z][a-z]+)b',
r'b([A-Z][a-z]+)s+([A-Z][a-z]+)s+([A-Z][a-z]+)b'
]
names = []
for pattern in name_patterns:
matches = re.findall(pattern, text)
for match in matches:
if isinstance(match, tuple):
names.append(list(match))
return names[:3]
def _enrich_contact_data(self, contact, company):
if not contact.get('email'):
contact['email'] = self._generate_email(
contact['first_name'],
contact['last_name'],
company.get('domain', '')
)
contact['email_valid'] = validate_email(contact.get('email', ''))
contact['confidence_score'] = self._calculate_confidence(contact)
return contact
def _generate_email(self, first, last, domain):
if not all([first, last, domain]):
return ""
return f"{first.lower()}.{last.lower()}@{domain}"
def _calculate_confidence(self, contact) :
score = 0
si contact.get('linkedin_url') : score += 30
si contact.get('email_valid') : score += 25
si contact.get('data_sources', 0) > 1 : score += 20
si all(contact.get(f) pour f dans ['prénom', 'nom', 'titre']) : score += 25
retourne score
def _validate_contact(self, contact) :
required = ['first_name', 'last_name', 'title']
return (all(contact.get(f) for f in required) and
contact.get('confidence_score', 0) >= 50)
def _deduplicate_contacts(self, contacts) :
unique = deduplicate_by_key(
contacts,
lambda c: c.get('email', '') or f"{c.get('first_name', '')}_{c.get('last_name', '')}"
)
return sorted(unique, key=lambda x: x.get('confidence_score', 0), reverse=True)
def _calculate_contact_quality(self, contacts):
if not contacts:
return 0
avg_confidence = sum(c.get('confidence_score', 0) for c in contacts) / len(contacts)
high_quality = sum(1 for c in contacts if c.get('confidence_score', 0) >= 75)
return min(avg_confidence + (high_quality * 5), 100)
def create_contact_research_agent(mcp_client) :
return Agent(
role='Contact Intelligence Specialist',
goal='Find accurate contact information for decision-makers using MCP',
backstory='Expert at finding and verifying contact information using advanced MCP search tools.',
tools=[ContactResearchTool(mcp_client)],
verbose=True
)Le système de recherche de contacts identifie les décideurs en recherchant leurs rôles sur LinkedIn et les sites web des entreprises. Il génère des adresses e-mail à partir des modèles types utilisés par les entreprises et vérifie les coordonnées à l’aide de diverses méthodes de vérification. Le système attribue des scores de confiance en fonction de la qualité des sources de données. Le processus de déduplication permet de maintenir la propreté des listes de contacts, en les classant par ordre de priorité en fonction du niveau de confiance de la vérification.
Étape 5 : Génération intelligente de messages
Transformez les informations commerciales en messages personnalisés qui mentionnent des événements déclencheurs spécifiques et présentent les résultats de la recherche. Le générateur crée plusieurs formats de messages pour différents canaux.
Créez un fichier agents/message_generation.py et ajoutez le code suivant :
from crewai import Agent, Task
from crewai.tools import BaseTool
from typing import Any, List
from pydantic import BaseModel, Field
import openai
import os
class MessageGenerationInput(BaseModel):
companies: List[dict] = Field(description="Liste des entreprises avec lesquelles générer des messages")
message_type: str = Field(default="cold_email", description="Type de message à générer (cold_email, linkedin_message, follow_up)")
class MessageGenerationTool(BaseTool):
name: str = "generate_messages"
description : str = « Créer une communication personnalisée basée sur les informations sur l'entreprise »
args_schema : type[BaseModel] = MessageGenerationInput
client : Any = None
def __init__(self) :
super().__init__()
self.client = openai.OpenAI(api_key=os.getenv("OPENAI_API_KEY"))
def _run(self, companies, message_type="cold_email") -> list:
# S'assurer que companies est une liste
if not isinstance(companies, list):
print(f"Avertissement : liste d'entreprises attendue, obtenu {type(companies)}")
return []
if not companies:
print("Aucune entreprise fournie pour la génération de messages")
return []
for company in companies:
if not isinstance(company, dict):
print(f"Avertissement : dict de sociétés attendu, obtenu {type(company)}")
continue
for contact in company.get('contacts', []):
if not isinstance(contact, dict):
continue
message = self._generate_personalized_message(contact, company, message_type)
contact['generated_message'] = message
contact['message_quality_score'] = self._calculate_message_quality(message, company)
return companies
def _generate_personalized_message(self, contact, company, message_type):
context = self._build_message_context(contact, company)
if message_type == "cold_email":
return self._generate_cold_email(context)
elif message_type == "linkedin_message":
return self._generate_linkedin_message(context)
else:
return self._generate_cold_email(context)
def _build_message_context(self, contact, company):
triggers = company.get('trigger_events', [])
primary_trigger = triggers[0] if triggers else None
return {
'contact_name': contact.get('first_name', ''),
'contact_title': contact.get('title', ''),
'company_name': company.get('name', ''),
'industry': company.get('industry', ''),
'primary_trigger': primary_trigger,
'trigger_count': len(triggers)
}
def _generate_cold_email(self, context):
trigger_text = ""
if context['primary_trigger']:
trigger_text = f"J'ai remarqué que {context['company_name']} {context['primary_trigger']['description'].lower()}."
prompt = f"""Rédigez un e-mail de prospection personnalisé :
Contact : {context['contact_name']}, {context['contact_title']} chez {context['company_name']}
Secteur d'activité : {context['industry']}
Contexte : {trigger_text}
Exigences :
- Objet faisant référence à l'événement déclencheur
- Salutation personnalisée avec le prénom
- Introduction démontrant que vous avez fait des recherches
- Brève proposition de valeur
- Appel à l'action clair
- 120 mots maximum
Format :
OBJET : [objet]
CORPS : [corps de l'e-mail]"""
response = self.client.chat.completions.create(
model="gpt-4",
messages=[{"role": "user", "content": prompt}],
temperature=0.7,
max_tokens=300
)
return self._parse_email_response(response.choices[0].message.content)
def _generate_linkedin_message(self, context):
prompt = f"""Rédigez une demande de connexion LinkedIn (300 caractères maximum) :
Contact : {context['contact_name']} chez {context['company_name']}
Contexte : {context.get('primary_trigger', {}).get('description', '')}
Soyez professionnel, faites référence à l'activité de leur entreprise, pas de discours commercial direct."""
response = self.client.chat.completions.create(
model="gpt-4",
messages=[{"role": "user", "content": prompt}],
temperature=0.7,
max_tokens=100
)
return {
'subject': 'Demande de connexion LinkedIn',
'body': response.choices[0].message.content.strip()
}
def _parse_email_response(self, response):
lines = response.strip().split('n')
subject = ""
body_lines = []
for line in lines:
if line.startswith('SUBJECT:'):
subject = line.replace('SUBJECT:', '').strip()
elif line.startswith('BODY:'):
body_lines.append(line.replace('BODY:', '').strip())
elif body_lines:
body_lines.append(line)
return {
'subject': subject,
'body': 'n'.join(body_lines).strip()
}
def _calculate_message_quality(self, message, company):
score = 0
body = message.get('body', '').lower()
if company.get('name', '').lower() in message.get('subject', '').lower():
score += 25
if company.get('trigger_events') and any(t.get('type', '') in body for t in company['trigger_events']):
score += 30
si len(corps.split()) <= 120 :
score += 20
si n'importe quel mot dans le corps pour n'importe quel mot dans ['appel', 'réunion', 'discuter', 'connecter'] :
score += 25
return score
def create_message_generation_agent():
return Agent(
role='Personalization Specialist',
goal='Create compelling personalized outreach that gets responses',
backstory='Expert at crafting messages that demonstrate research and provide value.',
tools=[MessageGenerationTool()],
verbose=True
)Le système de génération de messages transforme l’intelligence économique en communication personnalisée. Il fait référence à des événements déclencheurs spécifiques et présente des recherches détaillées. Il crée des objets adaptés au contexte, des salutations personnalisées et des propositions de valeur qui correspondent à la situation de chaque prospect. Le système génère différents formats de messages qui fonctionnent bien pour différents canaux. Il maintient une qualité de personnalisation constante.
Étape 6 : Évaluation des prospects et gestion du pipeline
Évaluez les prospects à l’aide de divers facteurs d’intelligence, puis exportez automatiquement les prospects qualifiés vers votre système CRM. Le gestionnaire hiérarchise les prospects en fonction de leur adéquation, du timing et de la qualité des données.
Créez un fichier agents/pipeline_manager.py et ajoutez le code suivant :
from crewai import Agent, Task
from crewai.tools import BaseTool
from datetime import datetime
from typing import List
from pydantic import BaseModel, Field
import requests
import os
from .utils import validate_companies_input
class LeadScoringInput(BaseModel):
companies: List[dict] = Field(description="Liste des entreprises à noter")
class LeadScoringTool(BaseTool):
name: str = "score_leads"
description: str = "Évaluer les prospects en fonction de plusieurs facteurs d'intelligence"
args_schema: type[BaseModel] = LeadScoringInput
def _run(self, companies) -> list:
companies = validate_companies_input(companies)
if not companies:
return []
for company in companies:
score_breakdown = self._calculate_lead_score(company)
company['lead_score'] = score_breakdown['total_score']
company['score_breakdown'] = score_breakdown
company['lead_grade'] = self._assign_grade(score_breakdown['total_score'])
return sorted(companies, key=lambda x: x.get('lead_score', 0), reverse=True)
def _calculate_lead_score(self, company) :
breakdown = {
'icp_score' : min(company.get('icp_score', 0) * 0.3, 25),
'trigger_score' : min(company.get('trigger_score', 0) * 2, 30),
'contact_score': min(company.get('contact_score', 0) * 0.2, 20),
'timing_score': self._assess_timing(company),
'company_health': self._assess_health(entreprise)
}
breakdown['total_score'] = sum(breakdown.values())
return breakdown
def _assess_timing(self, entreprise):
triggers = entreprise.get('trigger_events', [])
if not triggers:
return 0
recent_triggers = sum(1 for t in triggers if 'high' in t.get('severity', ''))
return min(recent_triggers * 8, 15)
def _assess_health(self, company):
score = 0
if company.get('trigger_events'):
score += 5
if company.get('employee_count', 0) > 50:
score += 5
return score
def _assign_grade(self, score):
if score >= 80: return 'A'
elif score >= 65: return 'B'
elif score >= 50: return 'C'
else: return 'D'
class CRMIntegrationInput(BaseModel) :
companies : List[dict] = Field(description="Liste des entreprises à exporter vers le CRM")
min_grade : str = Field(default="B", description="Note minimale des prospects à exporter (A, B, C, D)")
class CRMIntegrationTool(BaseTool) :
name : str = « crm_integration »
description : str = « Exporter les prospects qualifiés vers HubSpot CRM »
args_schema : type[BaseModel] = CRMIntegrationInput
def _run(self, companies, min_grade='B') -> dict :
companies = validate_companies_input(entreprises)
si pas d'entreprises :
renvoyer {"message" : "Aucune entreprise fournie pour l'exportation CRM", "success" : 0, "errors" : 0}
qualifiées = [c pour c dans entreprises si isinstance(c, dict) et c.get('lead_grade', 'D') dans ['A', 'B']]
if not os.getenv("HUBSPOT_API_KEY"):
return {"error": "Clé API HubSpot non configurée", "success": 0, "errors": 0}
results = {"success": 0, "errors": 0, "details": []}
for company in qualified:
for contact in company.get('contacts', []):
if not isinstance(contact, dict):
continue
result = self._create_hubspot_contact(contact, company)
if result.get('success'):
results['success'] += 1
else:
results['errors'] += 1
results['details'].append(result)
return results
def _create_hubspot_contact(self, contact, company):
api_key = os.getenv("HUBSPOT_API_KEY")
if not api_key:
return {"success": False, "error": "HubSpot API key not configured"}
url = "https://api.hubapi.com/crm/v3/objects/contacts"
headers = {
"Authorization": f"Bearer {api_key}",
"Content-Type": "application/json"
}
trigger_summary = "; ".join([
f"{t.get('type', '')}: {t.get('description', '')}"
for t in company.get('trigger_events', [])
])
email = contact.get('email', '').strip()
if not email:
return {"success": False, "error": "L'adresse e-mail du contact est obligatoire", "contact": contact.get('first_name', 'Inconnu')}
properties = {
"email": email,
"firstname": contact.get('first_name', ''),
"lastname": contact.get('last_name', ''),
"jobtitle": contact.get('title', ''),
« company » : company.get('name', ''),
« website » : f"https://{company.get('domain', '')}" si company.get('domain') sinon "",
« hs_lead_status » : "NEW",
"lifecyclestage" : "lead"
}
if company.get('lead_score'):
properties["lead_score"] = str(company.get('lead_score', 0))
if company.get('lead_grade'):
properties["lead_grade"] = company.get('lead_grade', 'D')
if trigger_summary:
properties["trigger_events"] = trigger_summary[:1000]
if contact.get('confidence_score'):
properties["contact_confidence"] = str(contact.get('confidence_score', 0))
properties["ai_discovery_date"] = datetime.now().isoformat()
try:
response = requests.post(url, json={"properties": properties}, headers=headers, timeout=30)
if response.status_code == 201:
return {
"success": True,
"contact": contact.get('first_name', ''),
"company": company.get('name', ''),
"hubspot_id": response.json().get('id')
}
elif response.status_code == 409:
existing_contact = response.json()
return {
"success": True,
"contact": contact.get('first_name', ''),
"company": company.get('name', ''),
"hubspot_id": existing_contact.get('id'),
"note": "Contact already exists"
}
else :
error_detail = response.text if response.text else f"HTTP {response.status_code}"
return {
"success": False,
"contact": contact.get('first_name', ''),
"company": company.get('name', ''),
"error": f"API Error: {error_detail}"
}
except requests.exceptions.RequestException as e:
return {
"success": False,
"contact": contact.get('first_name', ''),
"company": company.get('name', ''),
"error": f"Network error: {str(e)}"
}
except Exception as e:
return {
"success": False,
"contact": contact.get('first_name', ''),
"company": company.get('name', ''),
"error": f"Erreur inattendue : {str(e)}"
}
def create_pipeline_manager_agent():
return Agent(
role='Pipeline Manager',
goal='Score leads and manage CRM integration for qualified prospects',
backstory='Expert at evaluating prospect quality and managing sales pipeline.',
tools=[LeadScoringTool(), CRMIntegrationTool()],
verbose=True
)Le système de notation des prospects évalue ces derniers dans plusieurs domaines, notamment leur adéquation avec le profil client idéal, l’urgence des événements déclencheurs, la qualité des données de contact et les facteurs temporels. Il fournit des ventilations détaillées des notes qui permettent une hiérarchisation basée sur les données et attribue automatiquement des notes alphabétiques pour une qualification rapide. L’outil d’intégration CRM exporte les prospects qualifiés directement vers HubSpot, garantissant ainsi que toutes les données de renseignement sont correctement formatées pour que l’équipe commerciale puisse assurer le suivi.
Étape 6.1 : Utilitaires partagés
Avant de créer l’application principale, créez un fichier agents/utils.py contenant les fonctions utilitaires partagées utilisées par tous les agents :
"""
Fonctions utilitaires partagées pour tous les modules d'agent.
"""
from typing import List, Dict, Any
import re
def validate_companies_input(companies: Any) -> List[Dict]:
"""Valider et normaliser les entrées des entreprises pour tous les agents."""
if isinstance(companies, dict) and 'companies' in companies:
companies = companies['companies']
if not isinstance(companies, list):
print(f"Avertissement : liste d'entreprises attendue, obtenu {type(companies)}")
return []
if not companies:
print("Aucune entreprise fournie")
return []
valid_companies = []
for company in companies:
if isinstance(company, dict):
valid_companies.append(company)
else:
print(f"Avertissement : dictionnaire d'entreprises attendu, obtenu {type(company)}")
return valid_companies
def safe_mcp_call(mcp_client, method_name: str, *args, **kwargs) -> Dict:
"""Appeler les méthodes MCP en toute sécurité avec une gestion cohérente des erreurs."""
try:
method = getattr(mcp_client, method_name)
result = method(*args, **kwargs)
return result if result and not result.get('error') else {}
except Exception as e:
print(f"Erreur lors de l'appel de MCP {method_name}: {str(e)}")
return {}
def validate_email(email: str) -> bool:
"""Valider le format de l'adresse e-mail."""
pattern = r'^[a-zA-Z0-9._%+-]+@[a-zA-Z0-9.-]+.[a-zA-Z]{2,}$'
return bool(re.match(pattern, email))
def deduplicate_by_key(items: List[Dict], key_func) -> List[Dict]:
"""Supprimer les doublons de la liste des dictionnaires à l'aide d'une fonction clé."""
seen = set()
unique_items = []
for item in items:
key = key_func(item)
if key and key not in seen:
seen.add(key)
unique_items.append(item)
return unique_items
def extract_domain_from_url(url: str) -> str:
"""Extrait le domaine de l'URL avec analyse de secours."""
if not url:
return ""
try:
from urllib.parse import urlparse
parsed = urlparse(url)
return parsed.netloc
except:
if '//' in url:
return url.split('//')[1].split('/')[0]
return ""Vous devrez également créer un fichier agents/__init__.py vide pour faire du dossier agents un package Python.
Étape 7 : Orchestration du système
Créez l’application Streamlit principale qui coordonne tous les agents dans un flux de travail intelligent. L’interface fournit des commentaires en temps réel et permet aux utilisateurs de personnaliser les paramètres pour différents scénarios de prospection.
Créez un fichier ai_bdr_system.py dans le répertoire racine de votre projet et ajoutez le code suivant :
import streamlit as st
import os
from dotenv import load_dotenv
from crewai import Crew, Process, Task
import pandas as pd
from datetime import datetime
import json
from mcp_client import Bright DataMCP
from agents.company_discovery import create_company_discovery_agent
from agents.trigger_detection import create_trigger_detection_agent
from agents.contact_research import create_contact_research_agent
from agents.message_generation import create_message_generation_agent
from agents.pipeline_manager import create_pipeline_manager_agent
load_dotenv()
st.set_page_config(
page_title="Système IA BDR/SDR",
page_icon="🤖",
layout="wide")
st.title("🤖 Système d'agent IA BDR/SDR")
st.markdown("**Prospection en temps réel grâce à l'intelligence multi-agents et à la personnalisation basée sur des déclencheurs**")
if 'workflow_results' not in st.session_state:
st.session_state.workflow_results = None
with st.sidebar:
try:
st.image("bright-data-logo.png", width=200)
st.markdown("---")
except:
st.markdown("**🌐 Propulsé par Bright Data**")
st.markdown("---")
st.header("⚙️ Configuration")
st.subheader("Profil du client idéal")
industry = st.selectbox("Secteur d'activité", ["SaaS", "FinTech", "E-commerce", "Santé", "IA/ML"])
size_range = st.selectbox("Taille de l'entreprise", ["startup", "petite", "moyenne", "grande"])
location = st.text_input("Localisation (facultatif)", placeholder="San Francisco, New York, etc.")
max_companies = st.slider("Nombre maximal d'entreprises", 5, 50, 20)
st.subheader(« Décideurs cibles »)
all_roles = [« PDG », « Directeur technique », « Vice-président ingénierie », « Responsable produit », « Vice-président ventes », « Directeur marketing », « Directeur financier »]
target_roles = st.multiselect(« Rôles », all_roles, default=[« PDG », « Directeur technique », « VP Engineering »])
st.subheader(« Configuration de la prise de contact »)
message_types = st.multiselect(
« Types de messages »,
[« cold_email », « linkedin_message », « follow_up »],
default=[« cold_email »])
avec st.expander(« Intelligence avancée ») :
enable_competitive = st.checkbox("Intelligence compétitive", value=True)
enable_validation = st.checkbox("Validation multisource", value=True)
min_lead_grade = st.selectbox("Note minimale d'exportation CRM", ["A", "B", "C"], index=1)
st.divider()
st.subheader("🔗 Statut de l'API")
apis = [
("Bright Data", "BRIGHT_DATA_API_TOKEN", "🌐"),
("OpenAI", "OPENAI_API_KEY", "🧠"),
("HubSpot CRM", "HUBSPOT_API_KEY", "📊")
]
for name, env_var, icon in api://
if os.getenv(env_var):
st.success(f"{icon} {name} Connected")
else:
if name == "HubSpot CRM":
st.warning(f"⚠️ {name} Requis pour l'exportation CRM")
elif name == "Bright Data" :
st.error(f"❌ {name} Manquant")
if st.button("🔧 Aide à la configuration", key="bright_data_help") :
st.info("""
**Configuration Bright Data requise :**
1. Obtenir les identifiants depuis le tableau de bord Bright Data
2. Mettre à jour le fichier .env avec :
```
BRIGHT_DATA_API_TOKEN=votre_mot_de_passe
WEB_UNLOCKER_ZONE=lum-customer-username-zone-zonename
```
3. Consultez BRIGHT_DATA_SETUP.md pour obtenir un guide détaillé
**Erreur actuelle** : 407 Authentification non valide = identifiants incorrects
""")
else:
st.error(f"❌ {name} Manquant")
col1, col2 = st.columns([3, 1])
avec col1 :
st.subheader("🚀 Workflow de prospection IA")
si st.button("Démarrer la prospection multi-agents", type="primary", use_container_width=True) :
required_keys = ["BRIGHT_DATA_API_TOKEN", "OPENAI_API_KEY"]
missing_keys = [key for key in required_keys if not os.getenv(key)]
if missing_keys:
st.error(f"Clés API requises manquantes : {', '.join(missing_keys)}")
st.stop()
progress_bar = st.progress(0)
status_text = st.empty()
try:
mcp_client = Bright DataMCP()
discovery_agent = create_company_discovery_agent(mcp_client)
trigger_agent = create_trigger_detection_agent(mcp_client)
contact_agent = create_contact_research_agent(mcp_client)
message_agent = create_message_generation_agent()
pipeline_agent = create_pipeline_manager_agent()
status_text.text("🔍 Recherche des entreprises correspondant à l'ICP...")
progress_bar.progress(15)
discovery_task = Task(
description=f"Trouver {max_companies} entreprises dans {industry} (taille {size_range}) à {location}",
expected_output="Liste des entreprises avec scores ICP et informations",
agent=discovery_agent
)
discovery_crew = Crew(
agents=[discovery_agent],
tasks=[discovery_task],
process=Process.sequential
)
companies = discovery_agent.tools[0]._run(industry, size_range, location)
st.success(f"✅ Découverte de {len(companies)} entreprises")
status_text.text("🎯 Analyse des événements déclencheurs et des signaux d'achat...")
progress_bar.progress(30)
trigger_task = Task(
description="Détecter les pics d'embauche, les cycles de financement, les changements de direction et les signaux d'expansion",
expected_output="Entreprises présentant des événements déclencheurs et des scores",
agent=trigger_agent
)
trigger_crew = Crew(
agents=[trigger_agent],
tasks=[trigger_task],
process=Process.sequential
)
companies_with_triggers = trigger_agent.tools[0]._run(companies)
total_triggers = sum(len(c.get('trigger_events', [])) for c in companies_with_triggers)
st.success(f"✅ Détection de {total_triggers} événements déclencheurs")
progress_bar.progress(45)
status_text.text("👥 Recherche des contacts des décideurs...")
contact_task = Task(
description=f"Trouver des contacts vérifiés pour les rôles : {', '.join(target_roles)}",
expected_output="Entreprises avec les coordonnées des décideurs",
agent=contact_agent
)
contact_crew = Crew(
agents=[contact_agent],
tasks=[contact_task],
process=Process.sequential
)
companies_with_contacts = contact_agent.tools[0]._run(companies_with_triggers, target_roles)
total_contacts = sum(len(c.get('contacts', [])) for c in companies_with_contacts)
st.success(f"✅ Found {total_contacts} verified contacts")
progress_bar.progress(60)
status_text.text("✍️ Generating personalized outreach messages...")
message_task = Task(
description=f"Générer {', '.join(message_types)} pour chaque contact à l'aide de l'intelligence déclencheur",
expected_output="Entreprises avec messages personnalisés",
agent=message_agent
)
message_crew = Crew(
agents=[message_agent],
tasks=[message_task],
process=Process.sequential
)
companies_with_messages = message_agent.tools[0]._run(companies_with_contacts, message_types[0])
total_messages = sum(len(c.get('contacts', [])) for c in companies_with_messages)
st.success(f"✅ Génération de {total_messages} messages personnalisés")
progress_bar.progress(75)
status_text.text("📊 Évaluation des prospects et mise à jour du CRM...")
pipeline_task = Task(
description=f"Évaluer les prospects et exporter ceux ayant obtenu une note {min_lead_grade}+ vers HubSpot CRM",
expected_output="Prospects évalués avec résultats d'intégration CRM",
agent=pipeline_agent
)
pipeline_crew = Crew(
agents=[pipeline_agent],
tasks=[pipeline_task],
process=Process.sequential
)
final_companies = pipeline_agent.tools[0]._run(companies_with_messages)
qualified_leads = [c for c in final_companies if c.get('lead_grade', 'D') in ['A', 'B']]
crm_results = {"success": 0, "errors": 0}
if os.getenv("HUBSPOT_API_KEY"):
crm_results = pipeline_agent.tools[1]._run(final_companies, min_lead_grade)
progress_bar.progress(100)
status_text.text("✅ Workflow completed successfully!")
st.session_state.workflow_results = {
'companies': final_companies,
'total_companies': len(final_companies),
'total_triggers': total_triggers,
'total_contacts': total_contacts,
'qualified_leads': len(qualified_leads),
'crm_results': crm_results,
'timestamp': datetime.now()
}
except Exception as e:
st.error(f"❌ Échec du workflow : {str(e)}")
st.write("Veuillez vérifier vos configurations API et réessayer.")
if st.session_state.workflow_results:
results = st.session_state.workflow_results
st.markdown("---")
st.subheader("📊 Résultats du workflow")
col1, col2, col3, col4 = st.columns(4)
with col1:
st.metric("Entreprises analysées", results['total_companies'])
with col2:
st.metric("Événements déclencheurs", results['total_triggers'])
with col3:
st.metric("Contacts trouvés", results['total_contacts'])
with col4:
st.metric("Prospects qualifiés", results['qualified_leads'])
if results['crm_results']['success'] > 0 or results['crm_results']['errors'] > 0:
st.subheader("🔄 Intégration HubSpot CRM")
col1, col2 = st.columns(2)
avec col1 :
st.metric("Exporté vers CRM", résultats['crm_results']['success'], delta="contacts")
avec col2 :
si résultats['crm_results']['errors'] > 0 :
st.metric("Erreurs d'exportation", résultats['crm_results']['errors'], delta_color="inverse")
st.subheader("🏢 Renseignements sur l'entreprise")
for company in results['companies'][:10]:
with st.expander(f"📋 {company.get('name', 'Unknown')} - Grade {company.get('lead_grade', 'D')} (Score: {company.get('lead_score', 0):.0f})"):
col1, col2 = st.columns(2)
with col1:
st.write(f"**Secteur d'activité :** {company.get('industry', 'Unknown')}")
st.write(f"**Domaine :** {company.get('domain', 'Unknown')}")
st.write(f"**Score ICP :** {company.get('icp_score', 0)}")
triggers = company.get('trigger_events', [])
if triggers:
st.write("**🎯 Événements déclencheurs :**")
for trigger in triggers:
severity_emoji = {"high": "🔥", "medium": "⚡", "low": "💡"}.get(trigger.get('severity', 'low'), '💡')
st.write(f"{severity_emoji} {trigger.get('description', 'Déclencheur inconnu')}")
avec col2 :
contacts = company.get('contacts', [])
si contacts :
st.write("**👥 Décideurs :**")
for contact in contacts:
confidence = contact.get('confidence_score', 0)
confidence_color = "🟢" if confidence >= 75 else "🟡" if confidence >= 50 else "🔴"
st.write(f"{confidence_color} **{contact.get('first_name', '')} {contact.get('last_name', '')}**")
st.write(f" {contact.get('title', 'Unknown title')}")
st.write(f" 📧 {contact.get('email', 'No email')}")
st.write(f" Confidence: {confidence}%")
message = contact.get('message_généré', {})
if message.get('objet') :
st.write(f" **Objet :** {message['objet']}")
if message.get('body'):
preview = message['body'][:100] + "..." if len(message['body']) > 100 else message['body']
st.write(f" **Aperçu :** {preview}")
st.write("---")
st.subheader("📥 Exportation et actions")
col1, col2, col3 = st.columns(3)
with col1:
export_data = []
for company in results['companies']:
for contact in company.get('contacts', []):
export_data.append({
'Entreprise' : company.get('name', ''),
'Secteur d'activité' : company.get('industry', ''),
'Niveau de prospect' : company.get('lead_grade', ''),
'Score de prospect' : company.get('lead_score', 0),
'Nombre de déclencheurs' : len(company.get('trigger_events', [])),
'Nom du contact' : f"{contact.get('first_name', '')} {contact.get('last_name', '')}",
'Titre' : contact.get('title', ''),
'E-mail' : contact.get('email', ''),
« Confidence » : contact.get('confidence_score', 0),
« Subject Line » : contact.get('generated_message', {}).get('subject', ''),
« Message » : contact.get('generated_message', {}).get('body', '')
})
if export_data:
df = pd.DataFrame(export_data)
csv = df.to_csv(index=False)
st.download_button(
label="📄 Télécharger le rapport complet (CSV)",
data=csv,
file_name=f"ai_bdr_prospects_{datetime.now().strftime('%Y%m%d_%H%M')}.csv",
mime="text/csv",
use_container_width=True
)
avec col2 :
si st.button("🔄 Synchroniser avec HubSpot CRM", use_container_width=True) :
si os.getenv("HUBSPOT_API_KEY") n'existe pas :
st.warning("Clé API HubSpot requise pour l'exportation CRM")
sinon :
avec st.spinner("Synchronisation avec HubSpot..."):
pipeline_agent = create_pipeline_manager_agent()
new_crm_results = pipeline_agent.tools[1]._run(results['companies'], min_lead_grade)
st.session_state.workflow_results['crm_results'] = new_crm_results
st.rerun()
avec col3 :
si st.button("🗑️ Effacer les résultats", use_container_width=True) :
st.session_state.workflow_results = None
st.rerun()
si __name__ == "__main__" :
passLe système d’orchestration Streamlit coordonne tous les agents dans un flux de travail efficace avec un suivi en temps réel de la progression et des paramètres personnalisables. Il offre un affichage clair des résultats avec des métriques, des informations détaillées sur l’entreprise et des options d’exportation. L’interface facilite la gestion des opérations multi-agents complexes grâce à un tableau de bord intuitif que les équipes commerciales peuvent utiliser sans compétences techniques.
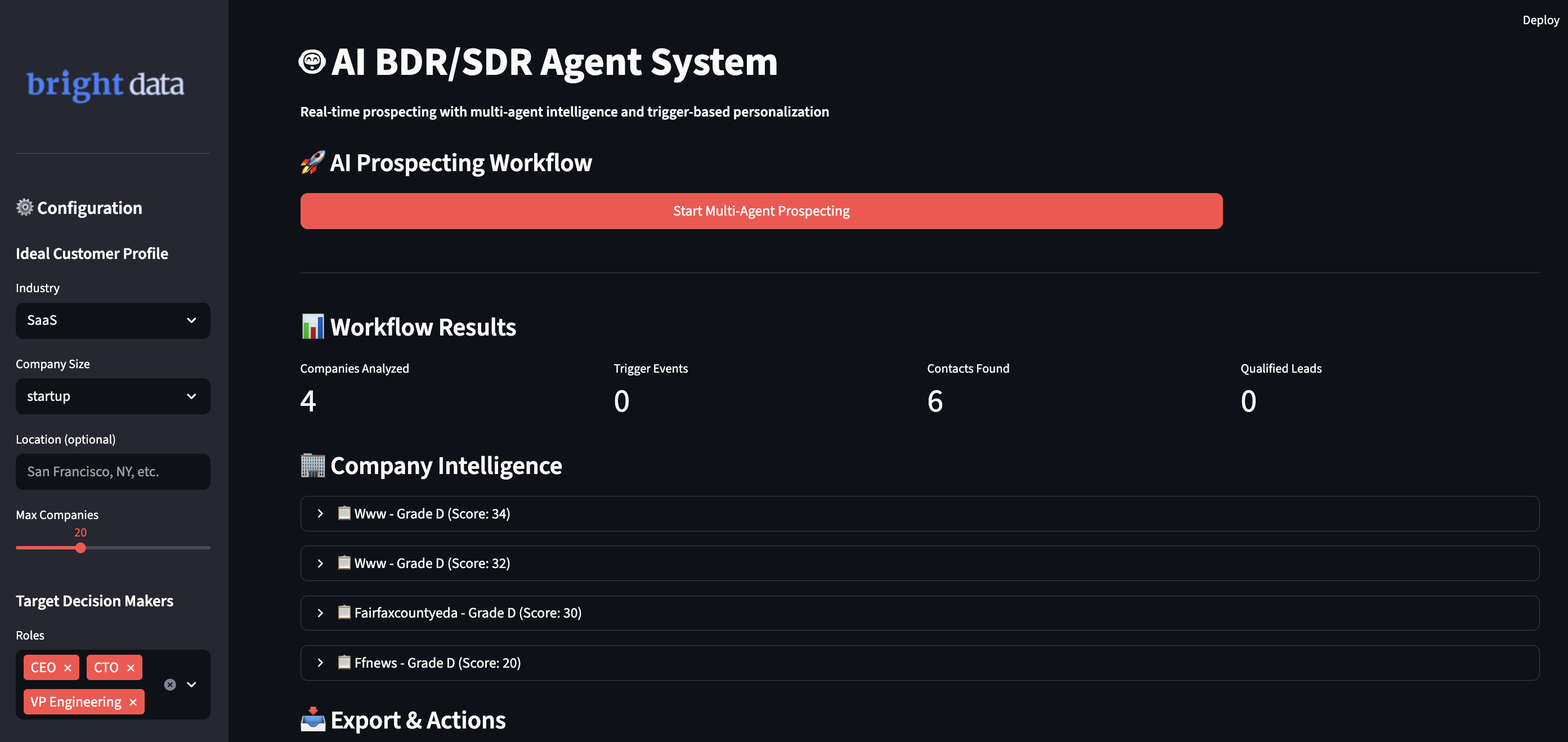
Exécution de votre système BDR IA
Exécutez l’application pour lancer des flux de travail de prospection intelligents. Ouvrez votre terminal et accédez au répertoire de votre projet.
streamlit run ai_bdr_system.py
Vous verrez le flux de travail intelligent du système répondre à vos besoins :
- Il trouve les entreprises qui correspondent à votre profil client idéal à l’aide de vérifications de données en temps réel.
- Il suit les événements déclencheurs provenant de diverses sources afin de trouver le meilleur moment.
- Il recherche les contacts des décideurs à l’aide de plusieurs sources et les note en fonction de leur fiabilité.
- Il crée des messages personnalisés qui mentionnent des informations commerciales spécifiques.
- Il note automatiquement les prospects et ajoute les prospects qualifiés à votre pipeline CRM.
Conclusion
Ce système BDR basé sur l’IA montre comment l’automatisation peut rationaliser la prospection et la qualification des prospects. Pour améliorer encore votre pipeline de ventes, pensez aux produits Bright Data tels que notre ensemble de données LinkedIn pour obtenir des coordonnées et des informations précises sur les entreprises, ainsi que d’autres jeux de données et outils d’automatisation conçus pour les équipes BDR et commerciales.
Découvrez d’autres solutions dans la documentation Bright Data.
Créez un compte Bright Data gratuit pour commencer à créer vos workflows BDR automatisés.





