
TL;DR: Ce tutoriel montre comment extraire des données d’un site web en C++ et pourquoi c’est l’un des langages les plus efficaces pour le scraping.
Ce guide couvre les points suivants :
- Le C++ est-il un langage adapté au web scraping ?
- Les meilleures bibliothèques C++ pour le web scraping
- Comment construire un scraper web en C++ ?
Le C++ est-il un langage adapté au web scraping ?
Le C++ est un langage de programmation à typage statique largement utilisé pour le développement d’applications performantes. Il est en effet réputé pour sa rapidité, son efficacité et ses capacités de gestion de la mémoire. Le C++ est un langage polyvalent qui s’avère utile dans un grand nombre d’applications, y compris le web scraping.
Le C++ est un langage compilé et il est intrinsèquement plus rapide que les langages interprétés, tels que Python. Il s’agit donc d’un excellent choix pour créer des scrapers rapides. Cependant, le C++ n’est pas conçu pour le développement web et il existe peu de bibliothèques disponibles pour le web scraping. Bien qu’il existe des paquets tiers, les options ne sont pas aussi nombreuses qu’en Python, Ruby ou Java.
En résumé, il est possible d’utiliser le C++ pour le web scraping et c’est d’ailleurs un langage efficace, mais cela nécessite davantage de programmation de bas niveau que dans d’autres langages. Découvrons les outils qui peuvent faciliter ce processus !
Les meilleures bibliothèques de web scraping en C++
Voici quelques bibliothèques de web scraping populaires en C++ :
- CPR : une bibliothèque client HTTP moderne en C++ inspirée par le projet Python Requests. C’est un wrapper de libcurl qui fournit une interface facile à comprendre, des capacités d’authentification intégrées et un support pour les appels asynchrones.
- libxml2 : une bibliothèque puissante et complète pour l’analyse des documents XML et HTML, développée à l’origine pour Gnome. Elle prend en charge la manipulation du DOM via des sélecteurs XPath.
- Lexbor : une bibliothèque d’analyse HTML rapide et légère, entièrement écrite en C, qui prend en charge les sélecteurs CSS. Elle n’est disponible que pour Linux.
Pendant des années, l’analyseur HTML le plus utilisé en C++ était Gumbo. Il n’est plus maintenu depuis 2016 et même le README officiel déconseille désormais son utilisation.
Prérequis
Avant de plonger dans le codage, vous devez :
Suivez le guide ci-dessous pour votre système d’exploitation pour apprendre à remplir ces conditions préalables.
Configurer C++ sur macOS
Sur macOS, le compilateur C, C++ et Objective-C le plus populaire est Clang. Gardez à l’esprit que Clang est préinstallé sur de nombreux Mac. Pour vérifier si c’est le cas sur le vôtre, ouvrez un terminal et lancez la commande ci-dessous :
clang --version
Si vous obtenez une erreur de type « command not found : clang », cela signifie que Clang n’est pas installé ou mal configuré. Dans ce cas, vous pouvez l’installer via les outils en ligne de commande de Xcode :
xcode-select --install
Cela peut prendre un certain temps, soyez patient.
Pour installer vcpkg, vous aurez d’abord besoin des macOS Developer Tools. Ajoutez-les à votre Mac avec :
xcode-select --install
Ensuite, vous devrez installer vcpkg globalement. Créez un dossier /dev ouvrez-le dans le terminal et exécutez :
git clone https://github.com/microsoft/vcpkg
Le répertoire contient à présent le code source. Construisez le gestionnaire de paquets avec :
./vcpkg/bootstrap-vcpkg.sh
Pour exécuter cette commande, il se peut que vous ayez besoin de privilèges élevés.
Enfin, ajoutez /dev/vcpkg à votre $PATH en suivant ce guide.
Pour installer CMake, téléchargez le programme d’installation depuis le site officiel, lancez-le et suivez l’assistant d’installation.
Installation de C++ sur Windows
Téléchargez le programme d’installation MinGW-x64 depuis MSYS2, lancez-le et suivez les instructions. Ce paquetage fournit des versions natives à jour de GCC, Mingw-w64 et d’autres outils et bibliothèques C++ utiles.
Dans le terminal MSYS2 ouvert à la fin du processus d’installation, exécutez la commande ci-dessous pour installer la chaîne d’outils Mingw-w64 :
pacman -S --needed base-devel mingw-w64-x86_64-toolchain
Attendez la fin du processus, puis ajoutez MinGW aux variables d’environnement PATH, comme expliqué ici.
Ensuite, vous devez installer vcpkg globalement. Créez un dossier C: /dev ouvrez-le dans PowerShell et exécutez :
git clone https://github.com/microsoft/vcpkg
Construisez le code source du gestionnaire de paquets contenu dans le sous-dossier vcpkg avec :
./vcpkg/bootstrap-vcpkg.bat
Ajoutez maintenant C: /dev/vcpkg à votre PATH comme vous l’avez fait précédemment.
Il ne reste plus qu’à installer CMake. Téléchargez l’installeur, double-cliquez dessus, et cochez l’option ci-dessous lors de l’installation.

Configurer C++ sous Linux
Sur les distributions basées sur Debian, installez GCC (GNU Compiler Collection), CMake et d’autres paquets utiles pour le développement avec :
sudo apt install build-essential cmake
Cela peut prendre un certain temps, soyez donc patient.
Ensuite, vous devez installer globalement vcpkg. Créez un répertoire /dev, ouvrez-le dans le terminal et écrivez :
git clone https://github.com/microsoft/vcpkg
Le sous-répertoire vcpkg contient désormais le code source du gestionnaire de paquets. Construisez l’outil avec :
./vcpkg/bootstrap-vcpkg.sh
Notez que cette commande peut nécessiter des privilèges d’administrateur.
Ensuite, ajoutez /dev/vcpkg à vos variables d’environnement $PATH en suivant ce guide.
Parfait ! Vous avez maintenant tout ce qu’il vous faut pour commencer à faire du web scraping en C++ !
Comment construire un scraper web en C++
Dans ce chapitre, vous allez apprendre à coder un robot de web scraping en C++. Le site cible sera la page d’accueil de Bright Data et le script se chargera des tâches suivantes :
- Connexion à la page web
- Sélection des éléments HTML intéressants dans le DOM
- Récupération des données de ces éléments
- Exportation des données récupérées au format CSV
Pour l’instant, voici ce que voient les visiteurs lorsqu’ils affichent la page cible :

N’oubliez pas que la page d’accueil de BrightData change fréquemment. Il se peut donc qu’elle ait changé au moment où vous lirez cet article.
Les informations sectorielles contenues dans ces cartes constituent des données intéressantes à extraire de la page :
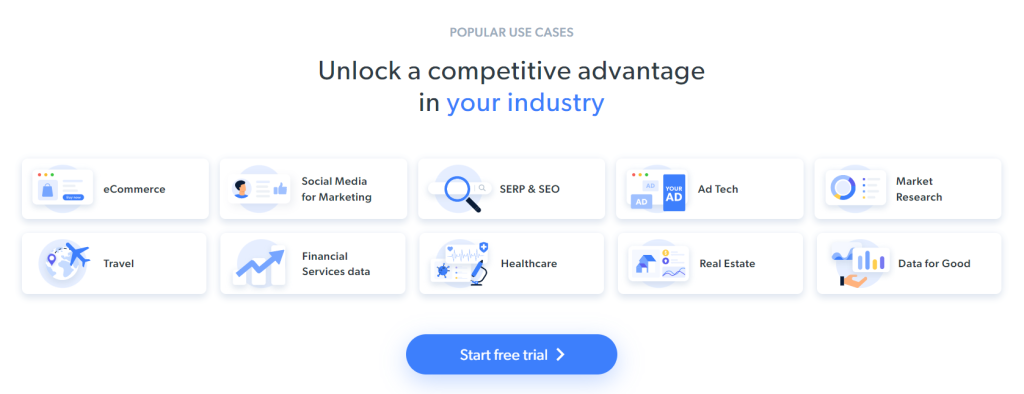
L’objectif du scraping pour ce tutoriel étape par étape a été défini. Voyons comment faire du web scraping avec C++ !
Étape 1 : initialisation d’un projet de scraping en C++
Tout d’abord, vous avez besoin d’un dossier dans lequel placer votre projet C++. Ouvrez le terminal et créez le répertoire du projet avec :
mkdir c++-web-scraper
Celui-ci contiendra votre script de web scraping.
Lorsque vous construisez un logiciel en C++, vous devriez opter pour l’IDE Visual Studio. Nous allons vous montrer en détail comment configurer Visual Studio Code (VS Code) pour le développement C++ avec vcpkg comme gestionnaire de paquets. Notez que des procédures similaires peuvent être appliquées à d’autres IDE C++.
VS Code n’offre pas de support intégré pour C++, vous devez donc d’abord ajouter le plugin C/C++. Lancez Visual Studio Code, cliquez sur l’icône « Extensions » dans la barre de gauche et écrivez « C++ » dans le champ de recherche en haut.
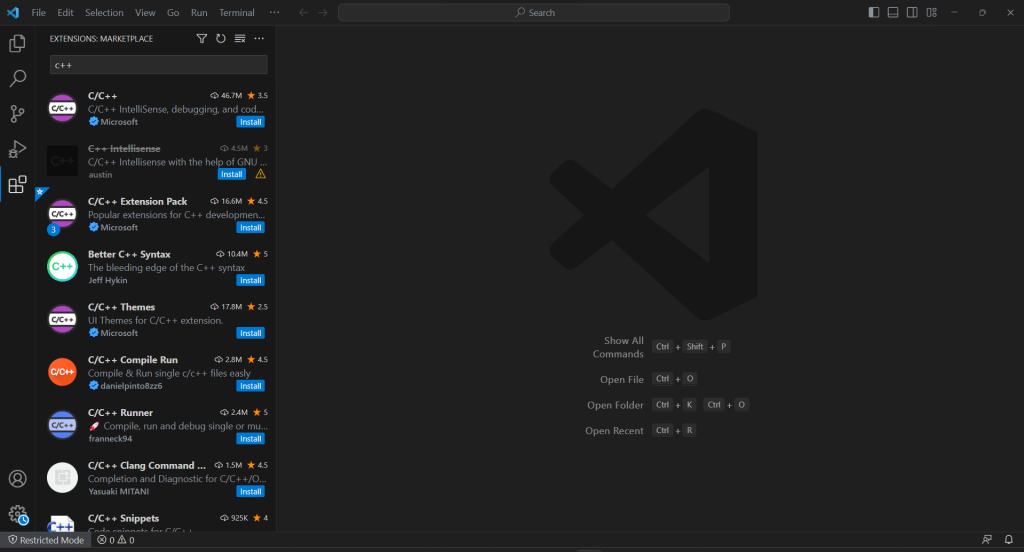
Cliquez sur le bouton « Installer » du premier élément pour ajouter la fonctionnalité de développement C++ à VS Code. Attendez que l’extension soit installée, puis ouvrez le dossier c++-web-scraper avec Fichier > Ouvrir le dossier....
Faites un clic droit dans la section « EXPLORER », sélectionnez « Nouveau fichier… » et créez un fichier scraper.cpp comme suit :
#include <iostream>
int main()
{
std::cout << "Hello World" << std::endl;
}
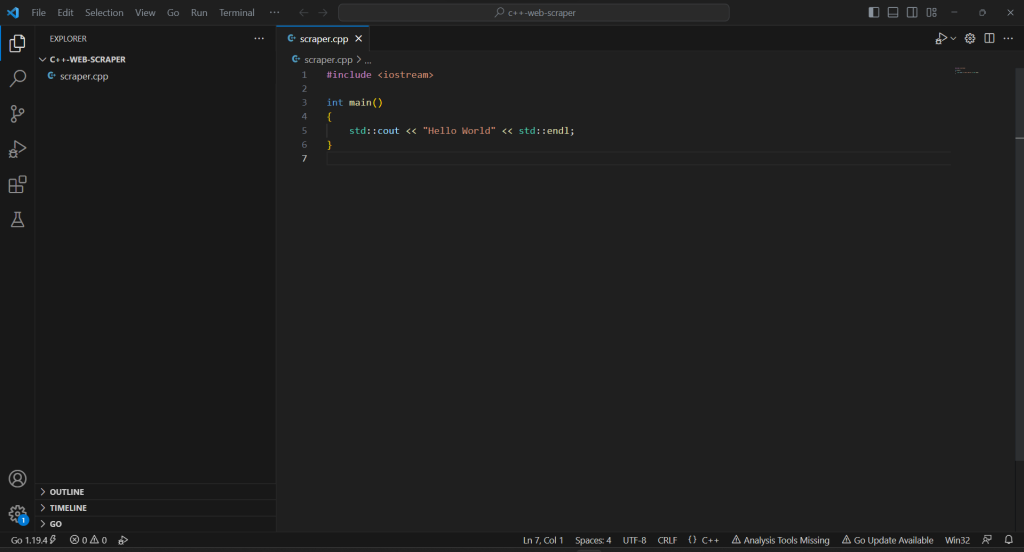
Vous avez maintenant un projet C++ !
Étape 2 : installation des bibliothèques de scraping
La syntaxe encombrante du C++ et ses capacités web limitées peuvent représenter un obstacle lors de la création d’un scraper web. Pour simplifier ce processus, vous pouvez utiliser des bibliothèques C++ de web scraping. Comme nous l’avons déjà mentionné, le choix est assez limité. Vous pouvez opter pour les plus populaires : cpr et libxml2.
Installez-les sous Windows via vcpkg avec :
vcpkg install cpr libxml2 --triplet=x64-windows
Sur macOS, remplacez l’option triplet par x64-osx. Sous Linux, utilisez x64-linux.
Sur le terminal Visual Studio Code, vous devez également exécuter la commande suivante dans le répertoire racine de votre projet :
vcpkg integrate install
Cela permettra de lier les paquets vcpkg au projet.
Redémarrez VS Code et vous pouvez maintenant importer n’importe quelle bibliothèque installée avec #include. Ainsi, ajoutez les trois lignes suivantes en haut de votre fichier scraper.cpp :
#include "cpr/cpr.h"
#include "libxml/HTMLparser.h"
#include "libxml/xpath.h"
Vérifiez que l’IDE ne signale aucune erreur.
Étape 3 : finalisation de l’initialisation du projet C++
Pour créer le script de scraping C++ et terminer le processus d’initialisation du projet, vous devez ajouter l’extension CMake Tools à VS Code :
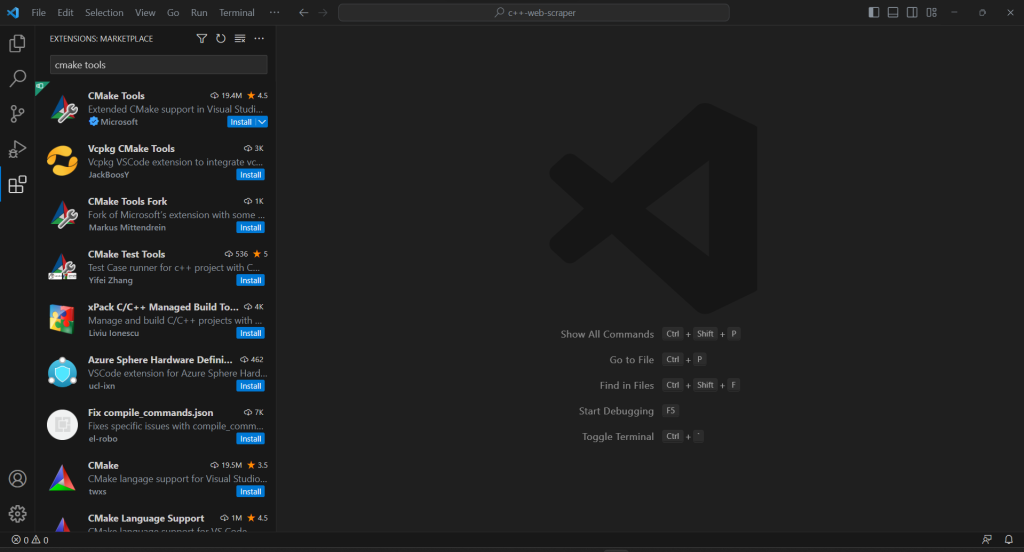
Si votre projet n’a pas de dossier .vscode, créez-le. C’est là que VS Code recherche les configurations relatives au projet en cours.
Configurez CMake Tools pour utiliser vcpkg comme chaîne d’outils en créant un fichier settings.jsondans le dossier .vscode comme suit :
{
"cmake.configureSettings": {
"CMAKE_TOOLCHAIN_FILE": "c:/dev/vcpkg/scripts/buildsystems/vcpkg.cmake"
}
}
Sur macOS et Linux, corrigez le champ CMAKE_TOOLCHAIN_FILE en fonction du chemin dans lequel vous avez installé vcpkg. Si vous avez suivi le guide d’installation ci-dessus, ce devrait être /dev/vcpkg/scripts/buildsystems/vcpkg.cmake.
Dans la barre de recherche principale de VS Code, écrivez « >cmake » et sélectionnez l’option « CMake : Configure » :

Cela vous permettra de sélectionner la plateforme de compilation cible. Sous Windows, optez pour « Visual Studio Build Tools 2019 Release – x86_amd64 » :

Ajoutez le fichier CMakeLists.txt dans le dossier racine de votre projet pour configurer CMake :
cmake_minimum_required(VERSION 3.0.0)
project(main VERSION 0.1.0)
INCLUDE_DIRECTORIES(
C:/dev/vcpkg/installed/x86-windows/include
)
LINK_DIRECTORIES(
C:/dev/vcpkg/installed/x86-windows/lib
)
add_executable(main scraper.cpp)
target_compile_features(main PRIVATE cxx_std_20)
find_package(cpr CONFIG REQUIRED)
target_link_libraries(main PRIVATE cpr::cpr)
find_package(LibXml2 REQUIRED)
target_link_libraries(main PRIVATE LibXml2::LibXml2)
Notez que cela implique les deux paquets installés précédemment. Veillez à mettre à jour INCLUDE_DIRECTORIES et LINK_DIRECTORIES en fonction de votre dossier d’installation vcpkg
Pour permettre à Visual Studio Code d’exécuter le programme C++, vous avez besoin d’un fichier de configuration de lancement. Dans le dossier .vscode, initialisez launch.jsoncomme suit :
{
"configurations": [
{
"name": "C++ Launch (Windows)",
"type": "cppvsdbg",
"request": "launch",
"program": "${workspaceFolder}/build/Debug/main.exe",
"args": [],
"stopAtEntry": false,
"cwd": "${workspaceFolder}",
"environment": []
}
]
}
Lors du lancement de la commande d’exécution ou de débogage, VS Code exécutera désormais le fichier dans le chemin du programme produit par CMake. Notez que sur macOS et Linux, il ne s’agira pas d’un fichier .exe.
La configuration est prête !
Chaque fois que vous voulez déboguer ou construire votre application, écrivez « >cmake : Build » dans le champ de saisie supérieur et sélectionnez l’option « CMake : Build ».

Attendez la fin du processus de compilation, puis exécutez le programme compilé dans la section « Run & Debug » ou en appuyant sur F5. Vous verrez le résultat de votre application sur la console de débogage de VSC.
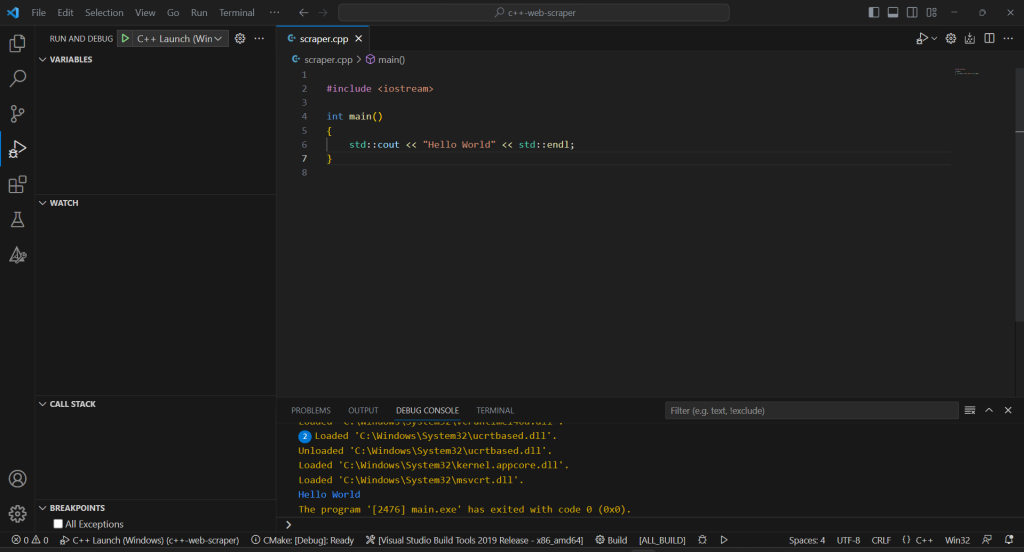
C’est fini ! Il est temps de commencer à scraper des données en C++ !
Étape 4 : téléchargement de la page cible avec CPR
Si vous voulez extraire des données d’une page, vous devez d’abord le fichier HTML par le biais d’une requête HTTP GET.
Utilisez CPR pour télécharger la page cible :
cpr::Response response = cpr::Get(cpr::Url{"https://brightdata.com/"});
En coulisse, la méthode Get() effectue une requête GET à l’URL passée en paramètre. response.text contiendra la représentation sous forme de chaîne du code HTML renvoyé par le serveur.
Notez que l’exécution de requêtes HTTP automatisées peut déclencher des technologies anti-bots. Celles-ci peuvent intercepter vos requêtes et empêcher votre script d’accéder au site cible. En particulier, les solutions anti-scraping les plus basiques bloquent les requêtes entrantes n’ayant pas d’en-tête HTTP User-Agent valide. Pour en savoir plus, consultez notre guide sur l’en-tête User-Agent pour le web scraping.
Comme tout autre client HTTP, CPR utilise une valeur de remplacement pour User-Agent. Comme cette valeur est très différente des agents utilisés par les navigateurs courants, les systèmes anti-bots peuvent facilement vous repérer. Pour éviter d’être bloqué pour cette raison, vous pouvez définir un User-Agent valide dans CPR avec :
cpr::Header headers = {{"User-Agent", "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/113.0.0.0 Safari/537.36"}};
cpr::Response response = cpr::Get(cpr::Url{"https://brightdata.com/121.21.21.da/31/3das/32/1"}, headers);
La requête HTTP faite par ce Get() apparaîtra maintenant comme provenant de Google Chrome 113.
Voici ce que contient actuellement scraper.cpp :
#include <iostream>
#include "cpr/cpr.h"
#include "libxml/HTMLparser.h"
#include "libxml/xpath.h"
int main()
{
// define the user agent for the GET request
cpr::Header headers = {{"User-Agent", "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/113.0.0.0 Safari/537.36"}};
// make the HTTP request to retrieve the target page
cpr::Response response = cpr::Get(cpr::Url{"https://brightdata.com/"}, headers);
// scraping logic...
}
Étape 5 : analyse du contenu HTML avec libxml2
Pour rendre le document HTML retourné par le serveur facilement explorable, vous devez d’abord l’analyser.
Pour cela, passez sa représentation en chaîne C++ à la fonction libxml2 HtmlReadMemory () :
htmlDocPtr doc = htmlReadMemory(response.text.c_str(), response.text.length(), nullptr, nullptr, HTML_PARSE_NOWARNING | HTML_PARSE_NOERROR);
La variable doc contient maintenant l’API d’exploration du DOM fournie par libxml2. En détail, vous pouvez récupérer des éléments HTML sur la page par le biais de sélecteurs XPath. Au moment de la rédaction de ce document, libxml2 ne prend pas en charge les sélecteurs CSS.
Étape 6 : définition des sélecteurs XPath pour obtenir les éléments HTML souhaités
Pour définir une stratégie de sélection XPath efficace pour les nœuds HTML d’intérêt, vous devez analyser le DOM de la page cible. Ouvrez la page d’accueil de Bright Data dans le navigateur, cliquez avec le bouton droit de la souris sur l’une des cartes industrielles et choisissez « Inspecter ». La section DevTools apparaît alors :
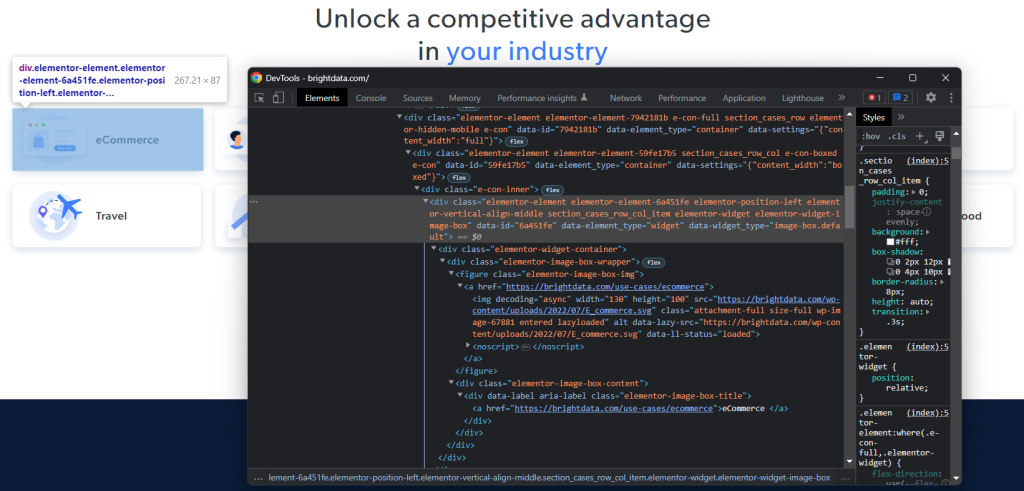
Parcourez le code HTML et vous remarquerez que chaque fiche industrielle est un élément <div> qui contient :
- Un élément
<figure>avec un élément<img>représentant l’image de l’industrie et un élément<a>contenant l’URL de la page de l’industrie. - Un élément HTML
<div>stockant le nom de l’industrie dans un<a>.
Pour chaque carte, l’objectif du scraper C++ est d’extraire :
- L’URL de l’image de l’industrie
- L’URL de la page de l’industrie
- Le nom de l’industrie
Pour définir les sélecteurs XPath appropriés, portez votre attention sur la structure DOM des éléments qui vous intéressent. Vous remarquerez que vous pouvez obtenir toutes les cartes de l’industrie avec le sélecteur XPath ci-dessous :
//div[contains(@class, 'section_cases_row_col_item')]
Si vous avez des doutes, testez les instructions XPath sur la console du navigateur avec $x() :
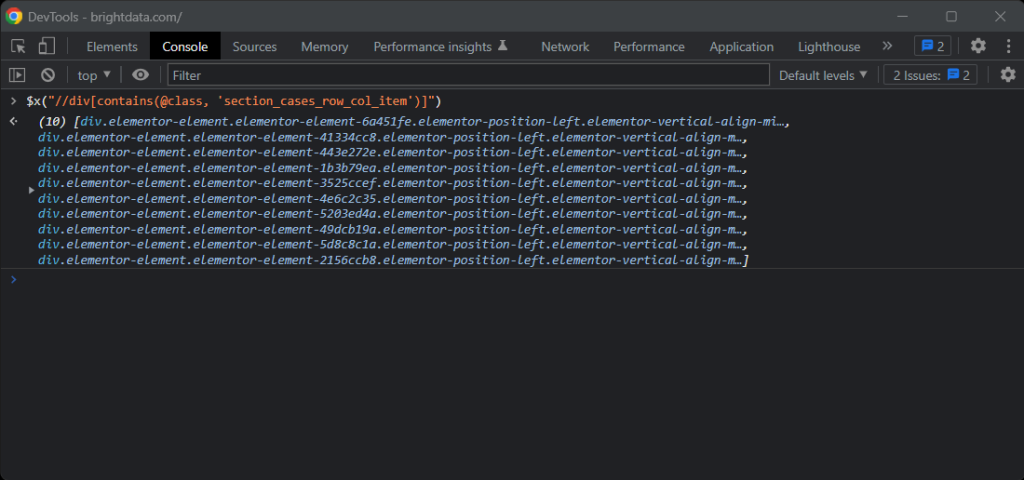
Étant donné une carte, vous pouvez obtenir les nœuds souhaités avec :
.//figure/a/img.//figure/a.//div[contains(@class, 'elementor-image-box-title')]/a
Étape 7 : récupération des données d’une page web avec libxml2
Vous pouvez maintenant utiliser libxml2 pour appliquer les sélecteurs XPath définis précédemment et obtenir les données souhaitées à partir de la page web HTML cible.
Tout d’abord, vous avez besoin d’une structure de données dont les instances stockeront les données extraites :
struct IndustryCard
{
std::string image;
std::string url;
std::string name;
};
En C++, un élément struct permet de regrouper plusieurs attributs de données sous le même nom dans un bloc de mémoire.
Initialisez ensuite un tableau de IndustryCards dans la fonction main() :
std::vector<IndustryCard> industry_cards;
Ce tableau stockera tous les objets de données de scraping.
Remplissez ce vecteur avec la logique de scraping web C++ suivante :
// define an array to store all retrieved data
std::vector<IndustryCard> industry_cards;
// set the libxml2 context to the current document
xmlXPathContextPtr context = xmlXPathNewContext(doc);
// select all industry card HTML elements
// with an XPath selector
xmlXPathObjectPtr industry_card_html_elements = xmlXPathEvalExpression((xmlChar *)"//div[contains(@class, 'section_cases_row_col_item')]", context);
// iterate over the list of industry card elements
for (int i = 0; i < industry_card_html_elements->nodesetval->nodeNr; ++i)
{
// get the current element of the loop
xmlNodePtr industry_card_html_element = industry_card_html_elements->nodesetval->nodeTab[i];
// set the libxml2 context to the current element
// to limit the XPath selectors to its children
xmlXPathSetContextNode(industry_card_html_element, context);
xmlNodePtr image_html_element = xmlXPathEvalExpression((xmlChar *)".//figure/a/img", context)->nodesetval->nodeTab[0];
std::string image = std::string(reinterpret_cast<char *>(xmlGetProp(image_html_element, (xmlChar *)"data-lazy-src")));
xmlNodePtr url_html_element = xmlXPathEvalExpression((xmlChar *)".//figure/a", context)->nodesetval->nodeTab[0];
std::string url = std::string(reinterpret_cast<char *>(xmlGetProp(url_html_element, (xmlChar *)"href")));
xmlNodePtr name_html_element = xmlXPathEvalExpression((xmlChar *)".//div[contains(@class, 'elementor-image-box-title')]/a", context)->nodesetval->nodeTab[0];
std::string name = std::string(reinterpret_cast<char *>(xmlNodeGetContent(name_html_element)));
// instantiate an IndustryCard struct with the collected data
IndustryCard industry_card = {image, url, name};
// add the object with the scraped data to the vector
industry_cards.push_back(industry_card);
}
// free up the resource allocated by libxml2
xmlXPathFreeObject(industry_card_html_elements);
xmlXPathFreeContext(context);
xmlFreeDoc(doc);
L’extrait ci-dessus sélectionne les cartes industrielles en appliquant le sélecteur XPath défini précédemment avec xmlXPathEvalExpression(). Ensuite, il les parcourt et implémente une approche similaire pour obtenir les éléments enfants intéressants de chaque carte. Ensuite, il récupère l’URL de l’image de l’industrie, l’URL de la page et le nom. Enfin, il libère les ressources allouées par libxml2.
Comme vous pouvez le voir, ce n’est pas si complexe de faire du web scraping en C++ avec libxml2. Grâce aux fonctions xmlGetProp() et xmlNodeGetContent(), vous pouvez obtenir la valeur d’un attribut HTML et le contenu d’un nœud, respectivement.
Maintenant que vous savez comment fonctionne le scraping de données en C++, vous disposez des outils nécessaires pour aller plus loin et scraper également les pages de l’industrie. Il vous suffit de suivre les liens découverts ici et de concevoir une nouvelle logique de scraping. Voilà ce que sont le web crawling et le web scraping !
Excellent, n’est-ce pas ? Vous venez d’atteindre vos objectifs. Mais le tutoriel n’est pas encore terminé.
Étape 7 : exportation des données scannées au format CSV
À la fin de la boucle for(), industry_cards stocke les données collectées dans des instances struct. Comme vous pouvez l’imaginer, ce n’est pas un format idéal pour transmettre les données récupérées à une autre équipe. Voici pourquoi vous devriez convertir les données récupérées au format CSV.
Vous pouvez exporter un vecteur vers un fichier CSV à l’aide de fonctions C++ intégrées, comme suit :
// initialize the CSV output file
std::ofstream csv_file("output.csv");
// write the CSV header
csv_file << "url,image,name" << std::endl;
// poupulate the CSV output file
for (IndustryCard industry_card : industry_cards)
{
// transfrom each industry card record to a CSV record
csv_file << industry_card.url << "," << industry_card.image << "," << industry_card.name << std::endl;
}
// free up the file resources
csv_file.close();
Le code ci-dessus crée un fichier output.csv et l’initialise avec l’enregistrement d’en-tête. Il parcourt ensuite le tableau industry_cards, convertit chaque élément en une chaîne au format CSV et l’ajoute au fichier de sortie.
Créez votre script de scraping C++, exécutez-le et vous verrez le fichier output.csv suivant dans le répertoire racine de votre projet :
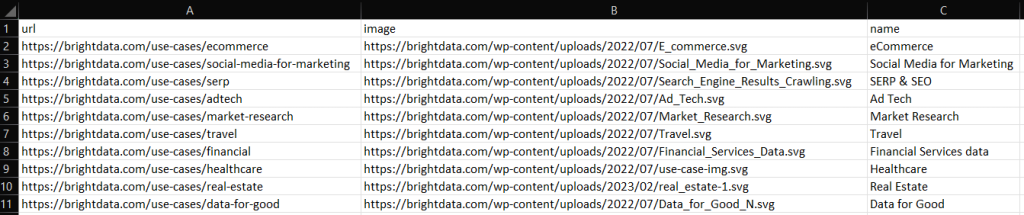
Bravo ! Vous savez maintenant comment exporter des données scrapées au format CSV en C++ !
Étape 8 : assembler le tout
Voici le scraper C++ complet :
// scraper.cpp
#include <iostream>
#include "cpr/cpr.h"
#include "libxml/HTMLparser.h"
#include "libxml/xpath.h"
#include <vector>
// define a struct where to store the scraped data
struct IndustryCard
{
std::string image;
std::string url;
std::string name;
};
int main()
{
// define the user agent for the GET request
cpr::Header headers = {{"User-Agent", "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/113.0.0.0 Safari/537.36"}};
// make an HTTP GET request to retrieve the target page
cpr::Response response = cpr::Get(cpr::Url{"https://brightdata.com/"}, headers);
// parse the HTML document returned by the server
htmlDocPtr doc = htmlReadMemory(response.text.c_str(), response.text.length(), nullptr, nullptr, HTML_PARSE_NOWARNING | HTML_PARSE_NOERROR);
// define an array to store all retrieved data
std::vector<IndustryCard> industry_cards;
// set the libxml2 context to the current document
xmlXPathContextPtr context = xmlXPathNewContext(doc);
// select all industry card HTML elements
// with an XPath selector
xmlXPathObjectPtr industry_card_html_elements = xmlXPathEvalExpression((xmlChar *)"//div[contains(@class, 'section_cases_row_col_item')]", context);
// iterate over the list of industry card elements
for (int i = 0; i < industry_card_html_elements->nodesetval->nodeNr; ++i)
{
// get the current element of the loop
xmlNodePtr industry_card_html_element = industry_card_html_elements->nodesetval->nodeTab[i];
// set the libxml2 context to the current element
// to limit the XPath selectors to its children
xmlXPathSetContextNode(industry_card_html_element, context);
xmlNodePtr image_html_element = xmlXPathEvalExpression((xmlChar *)".//figure/a/img", context)->nodesetval->nodeTab[0];
std::string image = std::string(reinterpret_cast<char *>(xmlGetProp(image_html_element, (xmlChar *)"data-lazy-src")));
xmlNodePtr url_html_element = xmlXPathEvalExpression((xmlChar *)".//figure/a", context)->nodesetval->nodeTab[0];
std::string url = std::string(reinterpret_cast<char *>(xmlGetProp(url_html_element, (xmlChar *)"href")));
xmlNodePtr name_html_element = xmlXPathEvalExpression((xmlChar *)".//div[contains(@class, 'elementor-image-box-title')]/a", context)->nodesetval->nodeTab[0];
std::string name = std::string(reinterpret_cast<char *>(xmlNodeGetContent(name_html_element)));
// instantiate an IndustryCard struct with the collected data
IndustryCard industry_card = {image, url, name};
// add the object with the scraped data to the vector
industry_cards.push_back(industry_card);
}
// free up the resource allocated by libxml2
xmlXPathFreeObject(industry_card_html_elements);
xmlXPathFreeContext(context);
xmlFreeDoc(doc);
// initialize the CSV output file
std::ofstream csv_file("output.csv");
// write the CSV header
csv_file << "url,image,name" << std::endl;
// poupulate the CSV output file
for (IndustryCard industry_card : industry_cards)
{
// transfrom each industry card record to a CSV record
csv_file << industry_card.url << "," << industry_card.image << "," << industry_card.name << std::endl;
}
// free up the file resources
csv_file.close();
return 0;
}
Et voilà ! En environ 80 lignes de code, vous pouvez créer un script de scraping de données en C++ !
Conclusion
Dans ce tutoriel, nous avons appris pourquoi le C++ est un langage efficace pour le web scraping. Bien qu’il n’y ait pas autant de bibliothèques de scraping que dans d’autres langages, il en existe tout de même quelques-unes. Et vous avez eu l’occasion de voir quelles sont les plus populaires. Ensuite, vous avez vu comment utiliser CPR et libxml2 pour construire un scraper en C++ qui peut collecter des données à partir d’une cible réelle.
Cependant, le web scraping rencontre de nombreux obstacles. En fait, un nombre croissant de sites ont mis en place des technologies anti-bot et anti-scraping pour protéger leurs données. Ces outils sont capables de détecter les requêtes automatisées effectuées par votre script C++ de scraping et de les interdire. Heureusement, il existe de nombreuses solutions automatisées pour vos besoins de collecte de données. Contactez-nous pour savoir quelle est la meilleure solution pour votre cas d’utilisation.
Vous ne voulez pas vous occuper du web scraping mais vous avez besoin de données web ? Découvrez nos ensembles de données prêts à l’emploi.






