

La plupart des équipes de données n’échouent pas parce qu’elles ne peuvent pas collecter des données. Elles échouent parce que les données brutes arrivent désordonnées, dupliquées et incohérentes, sans méthode rigoureuse pour les transformer en quelque chose en quoi les analystes et les modèles peuvent avoir confiance. L’architecture médaillon est le modèle que la plupart des plateformes de données modernes utilisent pour résoudre exactement ce problème, en faisant passer les données par trois couches progressivement plus propres : bronze, argent et or.
Ce guide explique le modèle tel qu’un ingénieur de données doit le comprendre : le comportement de chaque couche, la façon dont les données se déplacent physiquement entre elles, et où les données web provenant de sources externes entrent en jeu comme entrée brute bronze.
Dans cet article :
- Ce qu’est l’architecture médaillon et pourquoi Databricks l’a popularisée
- Ce que font les couches bronze, argent et or, et qui les consomme
- Comment les données se déplacent entre les couches avec les formats de tables, les transactions ACID et la capture de données modifiées
- Où les données externes et web entrent dans le modèle comme source bronze
- Bonnes pratiques, pièges courants et cas d’usage où le modèle est rentable
What is the medallion architecture?
L’architecture médaillon est un modèle de conception pour organiser les données dans un lakehouse afin que leur structure et leur qualité s’améliorent à chaque étape, au fur et à mesure qu’elles passent du bronze à l’argent, puis à l’or. Le nom emprunte la métaphore des médailles : les données entrent sous forme de bronze brut de faible valeur et sont affinées en argent plus précieux, puis en or. Vous verrez également ce modèle appelé architecture multi-sauts, car chaque enregistrement effectue plusieurs sauts avant d’être prêt à être consommé.
Le modèle a été popularisé par Databricks avec son paradigme lakehouse et le format de table Delta Lake, dont le code source a été ouvert en 2019. Un lakehouse combine le faible coût de stockage d’un data lake avec les fonctionnalités de fiabilité d’un entrepôt de données, comme les transactions ACID et l’application de schémas. L’architecture médaillon est le principe organisateur qui donne à ce lakehouse un flux de confiance clair. Il s’agit désormais d’une convention multi-plateforme : le même langage bronze, argent et or apparaît dans la documentation de Databricks, Microsoft Fabric et Snowflake.
L’idée centrale est simple. Au lieu de nettoyer les données en une seule étape opaque, vous conservez une copie brute permanente, puis vous les affinez par étapes où chaque étape a un contrat clair. C’est cette séparation qui rend le modèle si durable, et c’est le fondement de tout ce qui suit.
Why data teams adopt it
L’architecture médaillon mérite sa place car elle résout plusieurs problèmes à la fois.
Qualité des données incrémentale et inspectable. La qualité est améliorée par étapes plutôt qu’en une seule transformation difficile à analyser. Chaque saut a un rôle défini, donc quand quelque chose semble incorrect, vous savez quelle couche inspecter.
Retraitement à partir des données brutes. Comme la couche bronze est une archive historique permanente, vous pouvez reconstruire les tables argent et or à tout moment sans retourner au système source. Si une transformation contient un bug ou si la logique métier change, vous rejouez depuis bronze au lieu de recollecte des données qui pourraient ne plus être disponibles.
Lignage et auditabilité. Bronze conserve la charge utile originale, ce qui vous fournit un enregistrement forensique. Les équipes de conformité et d’audit peuvent retracer n’importe quel chiffre d’un tableau de bord jusqu’à l’enregistrement brut exact dont il provient.
Séparation des responsabilités entre consommateurs. Différentes couches servent différents publics. Les ingénieurs de données et les équipes opérationnelles travaillent au niveau bronze et argent. Les analystes et les data scientists travaillent au niveau argent. Les analystes métier, les dirigeants et les applications consomment l’or.
Service multi-consommateurs. Une seule entité argent propre peut alimenter de nombreuses tables or, afin que les équipes finance, opérations et marketing puissent chacune construire leurs propres vues prêtes à la consommation à partir de la même source fiable.
C’est également pourquoi le modèle s’associe naturellement à une approche ELT. Vous chargez d’abord les données brutes, puis vous les transformez à l’intérieur de la plateforme, plutôt que de tout transformer avant qu’elles n’arrivent. Pour un rappel sur le flux d’ingestion global, l’explication sur les pipelines ETL et l’aperçu de l’architecture de pipeline de données s’alignent tous deux parfaitement sur le modèle médaillon.
The three layers in detail
Le flux est linéaire dans le concept : les données brutes atterrissent dans bronze, sont affinées dans argent, et sont façonnées pour la consommation dans or.
flowchart LR
S["External and web sources"] --> B["Bronze: raw, as-is, append-only"]
B --> SI["Silver: cleaned, conformed, deduplicated"]
SI --> G["Gold: aggregated, business-level"]
G --> C["BI, dashboards, ML, applications"]Les données sont progressivement affinées au fur et à mesure qu’elles passent du bronze à l’argent, puis à l’or.
Bronze layer: raw and immutable
Bronze est la zone d’atterrissage pour tout ce qui arrive des systèmes sources externes. Ses tables reflètent la forme de la source telle quelle, avec quelques colonnes de métadonnées supplémentaires enregistrant des détails comme l’horodatage de chargement et le processus qui a écrit la ligne. Les priorités ici sont la rapidité de capture, une archive historique durable de la source, un lignage propre et la possibilité de retraiter ultérieurement sans jamais relire le système d’origine.
Bronze possède quelques propriétés définissantes. Il contient l’état brut des données dans leur format original. Il est ajouté de façon incrémentale et croît avec le temps. Il sert de source unique de vérité, préservant la fidélité des données exactement telles qu’elles sont arrivées. Il est destiné au traitement en aval plutôt qu’à l’accès direct des analystes.
Un détail d’implémentation clé : au niveau bronze, vous n’appliquez généralement pas de types. Databricks recommande de stocker la plupart des champs sous forme de chaîne, VARIANT ou binaire pour se protéger contre les changements de schéma inattendus en amont. En pratique, bronze est un schéma à la lecture. Vous capturez d’abord et interprétez ensuite, ce qui est exactement ce que vous voulez lorsque le schéma source est hors de votre contrôle. Les sources bronze peuvent être n’importe quel mélange d’entrées en streaming et par lots, notamment le stockage d’objets cloud comme Amazon S3, Google Cloud Storage et Azure Data Lake Storage, les bus de messages comme Kafka et Kinesis, et les systèmes fédérés.
Silver layer: cleaned and conformed
Argent est l’endroit où les enregistrements bronze sont mis en correspondance, fusionnés, conformés et nettoyés, suffisamment pour donner à l’entreprise une vue cohérente unique de ses entités, concepts et transactions principaux. Imaginez des enregistrements clients maîtres, des transactions dédupliquées et des tables de référence croisée. En réconciliant les données de nombreuses sources en une forme cohérente unique, argent devient la couche qui alimente l’analytique en libre-service, les rapports ad hoc, l’analytique avancée et l’apprentissage automatique.
Les opérations qui se produisent généralement ici sont concrètes : application de schémas, gestion des valeurs nulles et manquantes, déduplication, résolution des enregistrements en désordre et arrivant en retard, contrôles de qualité des données, évolution de schéma, conversion de types et jointures. C’est également là que commence la véritable modélisation des données, souvent en utilisant des structures plus normalisées et performantes en écriture. Le suivi des métriques de qualité des données à ce stade est ce qui distingue une couche argent fiable d’une simple copie de bronze.
Une bonne pratique ferme : n’écrivez pas directement dans argent depuis l’ingestion. Si vous sautez bronze et écrivez directement dans argent, vous introduisez des échecs dus aux changements de schéma et aux enregistrements sources corrompus, et vous perdez la capacité de rejouer. Argent doit toujours inclure au moins une représentation validée et non agrégée de chaque enregistrement, afin que l’analyse détaillée soit encore possible sans descendre au niveau du bronze brut.
Gold layer: business-ready
Or contient des données prêtes à la consommation et spécifiques au projet. Les modèles ici sont plus dénormalisés et optimisés pour des lectures rapides avec moins de jointures, et c’est là que les transformations finales et les règles métier atterrissent. C’est le foyer du travail de la couche de présentation : analytique client et d’inventaire, segmentation, rapports de ventes, et ainsi de suite. En pratique, vous trouverez souvent des schémas en étoile de style Kimball ou des data marts de style Inmon dans cette couche.
Or représente des vues hautement affinées qui alimentent les tableaux de bord, l’apprentissage automatique et les applications. Les données sont souvent fortement agrégées et filtrées sur des périodes ou régions spécifiques. Parce qu’un seul domaine métier s’adapte rarement à une seule forme, de nombreuses équipes construisent plusieurs tables or, par exemple des vues séparées pour la finance, les opérations et les ressources humaines, toutes dérivées de la même fondation argent.
Le tableau ci-dessous résume les différences entre les trois couches.
| Couche | État des données | Opérations typiques | Consommateurs principaux |
|---|---|---|---|
| Bronze | Brut, tel quel, ajout uniquement | Ingestion, capture de métadonnées, préservation de l’historique | Ingénieurs de données, équipes d’audit et de conformité |
| Argent | Nettoyé, conformé, dédupliqué | Validation, déduplication, application de schéma, jointures | Ingénieurs de données, analystes, data scientists |
| Or | Agrégé, niveau métier | Agrégats finaux, règles métier, schémas en étoile | Développeurs BI, dirigeants, applications, ML |
How data moves through the layers
L’architecture médaillon est un modèle logique, mais elle repose sur un ensemble spécifique de mécanismes physiques. L’image complète ressemble à ceci : de nombreuses sources alimentent bronze, les données s’affinent à travers argent et or à l’intérieur du lakehouse, et de nombreux consommateurs lisent depuis or.
flowchart LR
subgraph SRC["Sources"]
WEB["Web data via Bright Data"]
DB["Databases and apps"]
MB["Message buses: Kafka, Kinesis"]
end
subgraph LH["Lakehouse: Delta, Iceberg, or Hudi on Parquet"]
BRONZE["Bronze: raw, append-only"] --> SILVER["Silver: cleaned, conformed"] --> GOLD["Gold: business aggregates"]
end
subgraph CON["Consumers"]
BI["BI and dashboards"]
ML["ML and AI"]
APP["Applications"]
end
WEB --> BRONZE
DB --> BRONZE
MB --> BRONZE
GOLD --> BI
GOLD --> ML
GOLD --> APPUne pile médaillon de référence : de nombreuses sources atterrissent dans bronze, s’affinent à travers argent et or, et servent de nombreux consommateurs.
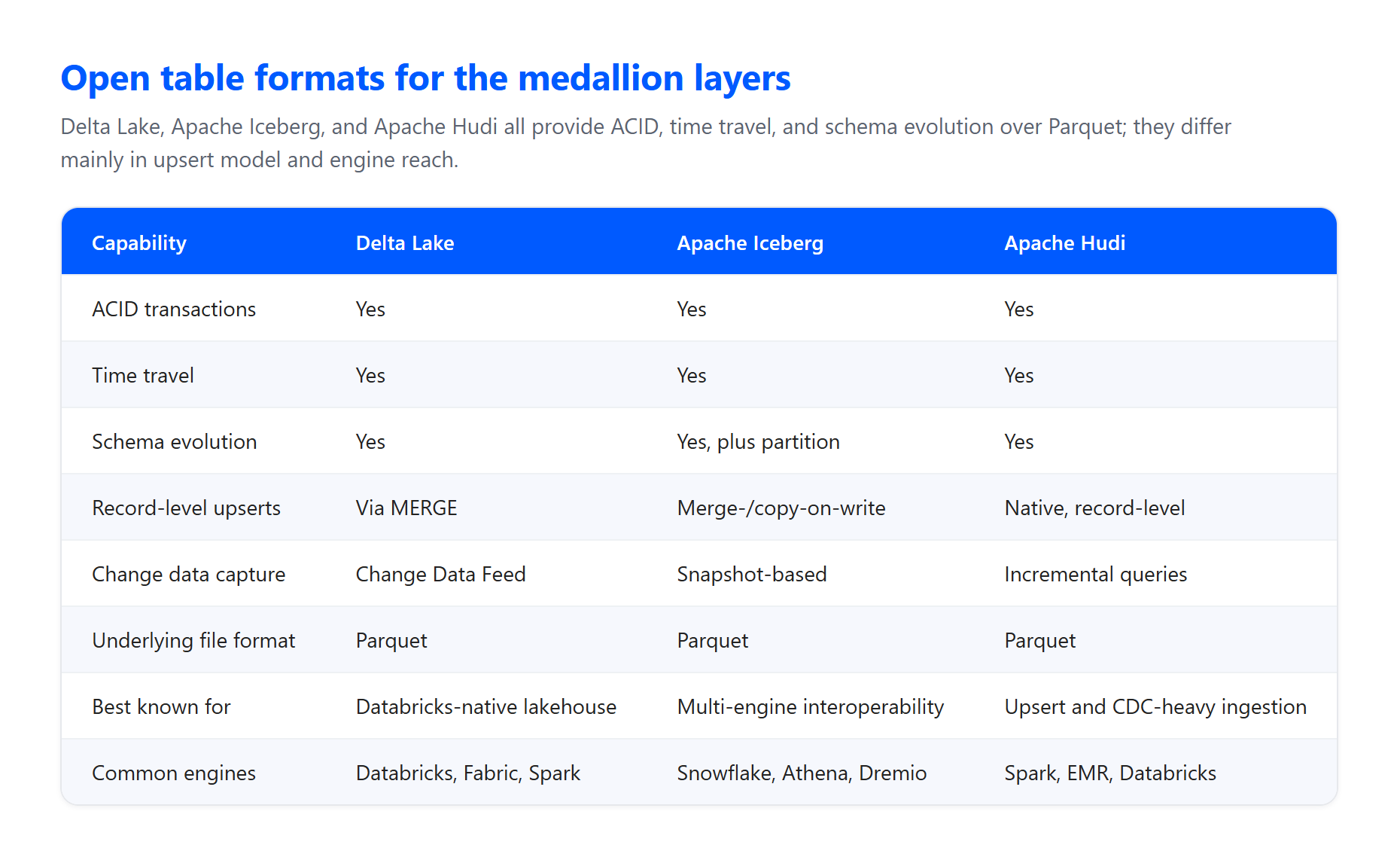
Formats de tables et de fichiers. Les couches sont généralement construites sur un format de table ouvert reposant sur des fichiers Parquet dans le stockage d’objets cloud. Delta Lake est le format natif sur Databricks et Microsoft Fabric : en interne, il stocke les données sous forme de Parquet, mais il ajoute un journal de transactions et des statistiques qui offrent fiabilité et performance au-delà du Parquet simple. Apache Iceberg est une alternative tout aussi capable lorsque l’interopérabilité multi-moteur est importante, et Apache Hudi convient parfaitement à l’ingestion par capture de données modifiées avec de nombreuses mises à jour. Ces trois formats vous offrent les garanties ACID dont le modèle dépend.
Transactions ACID. L’architecture garantit l’atomicité, la cohérence, l’isolation et la durabilité au fur et à mesure que les données passent par les validations et les transformations. C’est ce qui empêche un travail échoué de laisser une table à moitié écrite et corrompue, ce qui est extrêmement important lorsque de nombreux pipelines lisent et écrivent simultanément.
Chargements incrémentiels et capture de données modifiées. Vous retraitez rarement tout à chaque exécution. Le flux de données modifiées de Delta Lake permet aux couches en aval de ne consommer que ce qui a changé. Par exemple, vous pouvez activer le flux sur une table argent et l’utiliser pour mettre à jour de façon incrémentale les agrégats or sans une actualisation complète à chaque exécution. L’ingestion incrémentale au niveau bronze est un compromis entre coût et latence : le streaming continu a la latence la plus faible et le coût le plus élevé, les chargements incrémentiels déclenchés coûtent moins mais ajoutent de la latence, et les chargements par lots complets ont la latence la plus élevée.
Idempotence. L’ingestion bronze doit être idempotente, afin que la réexécution d’un chargement ne crée pas de doublons ou ne perde pas de données. La conception en ajout uniquement plus la déduplication au niveau argent est ce qui rend la relecture sécurisée possible.
Orchestration, lots et streaming. Des outils comme Apache Spark gèrent les transformations bronze-vers-argent et argent-vers-or, en modes batch et streaming structuré. Des frameworks déclaratifs tels que Spark Declarative Pipelines, les vues de lac matérialisées de Microsoft Fabric et les tâches Snowflake réduisent le code standard pour déplacer les données entre les couches. Des orchestrateurs comme Apache Airflow coordonnent les exécutions. Un exemple concret de ce modèle d’orchestration, utilisant Airflow pour la planification et Spark pour la transformation, est présenté dans cette présentation du pipeline Airflow et Spark, et une variante streaming dans ce guide sur le Spark Structured Streaming.
Il convient de noter que le vocabulaire médaillon n’est pas universel. Le framework de transformation populaire dbt structure les projets en couches staging, intermediate et marts. Les préoccupations s’alignent étroitement sur bronze, argent et or, mais les noms sont distincts, alors ne supposez pas que les deux vocabulaires sont interchangeables lorsque vous lisez la documentation.
Where web data enters: the bronze layer
Voici la partie que la plupart des diagrammes d’architecture survolent : d’où viennent réellement les données externes, et comment atterrissent-elles dans bronze dans un état utilisable ?
La couche bronze est définie comme la zone d’atterrissage pour tous les systèmes sources externes, et Databricks liste explicitement le stockage d’objets cloud comme S3, GCS et ADLS parmi les sources bronze valides. C’est la jointure où les données web collectées de l’extérieur s’insèrent. Les prix des concurrents, les catalogues de produits, les enregistrements publics d’entreprises, les résultats de recherche et les données d’avis sont tous des entrées brutes qui appartiennent à bronze dans leur forme originale, avec leurs particularités et incohérences préservées pour que la couche argent les résolve.
C’est exactement là qu’opère Bright Data. Bright Data est une plateforme de données web qui collecte des données web publiques à grande échelle et les livre sous forme de fichiers bruts et structurés, ce qui en fait une source naturelle pour la couche bronze. L’alignement est direct : les destinations vers lesquelles Bright Data livre sont les mêmes magasins d’objets cloud que les plateformes lakehouse traitent comme des entrées bronze.
flowchart LR
W["Public web: sites, SERPs, marketplaces"] --> BD["Bright Data ingestion: Web Scraper API, Datasets, Data Firehose"]
BD -->|"JSON, NDJSON, CSV, Parquet"| L["Cloud storage: S3, GCS, Azure, or Snowflake"]
L --> BR["Bronze layer: raw, preserved as source of truth"]
BR --> SV["Silver: clean and conform"]
SV --> GD["Gold: serve analytics and ML"]Les données web externes livrées par Bright Data atterrissent dans le stockage cloud comme couche bronze, puis remontent à travers argent et or.
Il existe plusieurs façons d’alimenter bronze, selon que vous avez besoin d’un flux de données par lots, à la demande ou continu :
- L’API Web Scraper transforme n’importe quel site en un point de terminaison de données structurées avec plus de 437 scrapers préconstruits, renvoyant des données en JSON, NDJSON ou CSV. C’est le déclencheur à la demande pour des enregistrements bronze frais.
- Les jeux de données prêts à l’emploi fournissent des données pré-collectées provenant de centaines de domaines populaires, téléchargeables immédiatement ou actualisées selon un calendrier. C’est le chemin par lots vers bronze.
- Le Data Firehose livre un flux continu et en temps réel d’enregistrements web directement vers Amazon S3, un webhook ou un flux, ce qui convient à un modèle d’ingestion bronze en streaming.
- L’API SERP fournit des résultats de moteurs de recherche structurés, une entrée bronze courante pour les pipelines d’intelligence compétitive et de surveillance des moteurs génératifs.
- Le Navigateur de scraping gère les sites à forte charge JavaScript, fournissant des données de page rendues que la collecte statique manquerait.
- Pour les flux sur mesure, l’API de données d’entreprise et les jeux de données IA et LLM curés livrent des données verticales prêtes à intégrer dans un pipeline, tandis que l’API Web Archive fournit des instantanés historiques pour les tables bronze de séries temporelles.
L’histoire de livraison est ce qui rend tout cela propre. Les jeux de données Bright Data s’exportent en JSON, NDJSON, CSV, XLSX et, surtout, Parquet, le format en colonnes que les tables lakehouse utilisent nativement. Les destinations de livraison incluent Amazon S3, Google Cloud Storage, Microsoft Azure Blob Storage, Snowflake, Google Cloud Pub/Sub, SFTP, webhook et téléchargement direct via API. En pratique, cela signifie qu’un jeu de données planifié peut atterrir dans votre bucket S3 bronze en tant que Parquet selon une cadence récurrente, sans code de liaison à écrire. Le Scraper Studio sans code étend encore cela, vous permettant de construire un scraper visuellement et de charger la sortie directement dans S3, GCS, Azure, BigQuery ou Snowflake.
Deux principes maintiennent cela fidèle au modèle médaillon. Premièrement, préservez la charge utile brute. Faites atterrir la sortie du fournisseur dans bronze exactement telle que livrée, y compris les champs que vous n’utilisez pas encore, afin de conserver l’enregistrement forensique complet. Deuxièmement, normalisez dans argent, pas dans bronze. Les formats de dates, les devises, le mappage des champs et la déduplication inter-sources appartiennent tous au saut argent, quelle que soit la façon dont le fournisseur externe a structuré ses données. Si vous décidez entre les chemins par lots et à la demande, la comparaison des jeux de données versus les API de scraping web est un bon point de départ, ainsi que l’introduction sur les données structurées versus non structurées.
La fiabilité est plus importante ici qu’ailleurs, car une source bronze qui échoue silencieusement empoisonne chaque couche au-dessus d’elle. Bright Data rapporte un taux de succès moyen de 98,44 % dans un benchmark indépendant de onze fournisseurs, soutenu par un réseau de proxys résidentiels de plus de 400 millions d’IPs éthiquement sourcées et un objectif de disponibilité de 99,99 %. Pour les équipes ayant des exigences de gouvernance, Bright Data maintient la conformité RGPD, CCPA, SOC 2 Type II et ISO 27001 et ne collecte que des données publiquement disponibles, ce qui est le type de provenance qu’une piste d’audit au niveau de la couche bronze est censée capturer.
A worked example: from raw scrape to gold table
La théorie est plus facile à faire confiance quand on peut l’exécuter. Voici un pipeline médaillon minimal sur un petit échantillon réel de données de produits web : douze annonces collectées à partir de résultats de recherche Amazon US et UK en direct dans trois catégories. Le code est délibérément simple, afin que le modèle, et non les outils, soit ce qui ressort.
Bronze. Faites atterrir les lignes exactement telles que collectées. Les prix sont encore des chaînes, les devises sont mélangées, et rien n’est nettoyé ou supprimé.
import pandas as pd
# Bronze: raw scraped rows, landed as-is with ingestion metadata
bronze = pd.DataFrame(scraped_rows)
bronze["_ingested_at"] = "2026-06-23T00:00:00Z"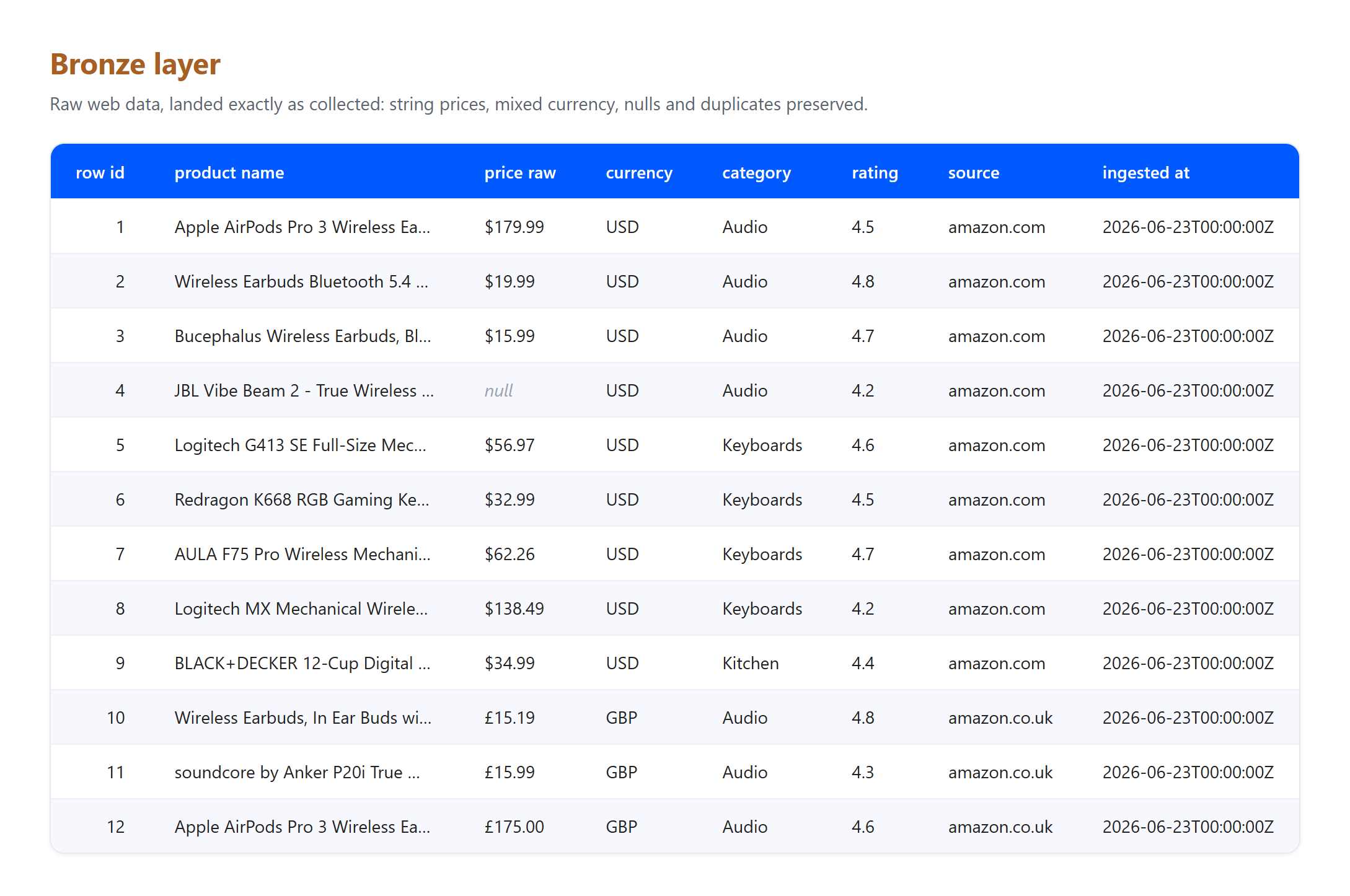
Argent. Analysez les prix en nombres, normalisez tout en USD, décodez les entités HTML dans les titres, supprimez les lignes sans prix utilisable, et dédupliquez le même produit capturé plus d’une fois.
import html, re
def to_usd(price_raw, gbp_rate=1.27): # 1.27 is an illustrative fixed rate
if not price_raw:
return None # no price, the row cannot be trusted
is_gbp = "£" in price_raw
value = float(re.sub(r"[^0-9.]", "", price_raw.replace(",", "")))
return round(value * gbp_rate, 2) if is_gbp else round(value, 2)
silver = bronze.copy()
silver["price_usd"] = silver["price_raw"].map(to_usd)
silver["rating"] = silver["rating"].astype(float) # text rating to number
silver["product_name"] = silver["product_name"].map(html.unescape) # & becomes &
silver = silver[silver["price_usd"].notna()] # drop unpriced rows
silver = silver.sort_values("price_usd").drop_duplicates("product_name") # dedup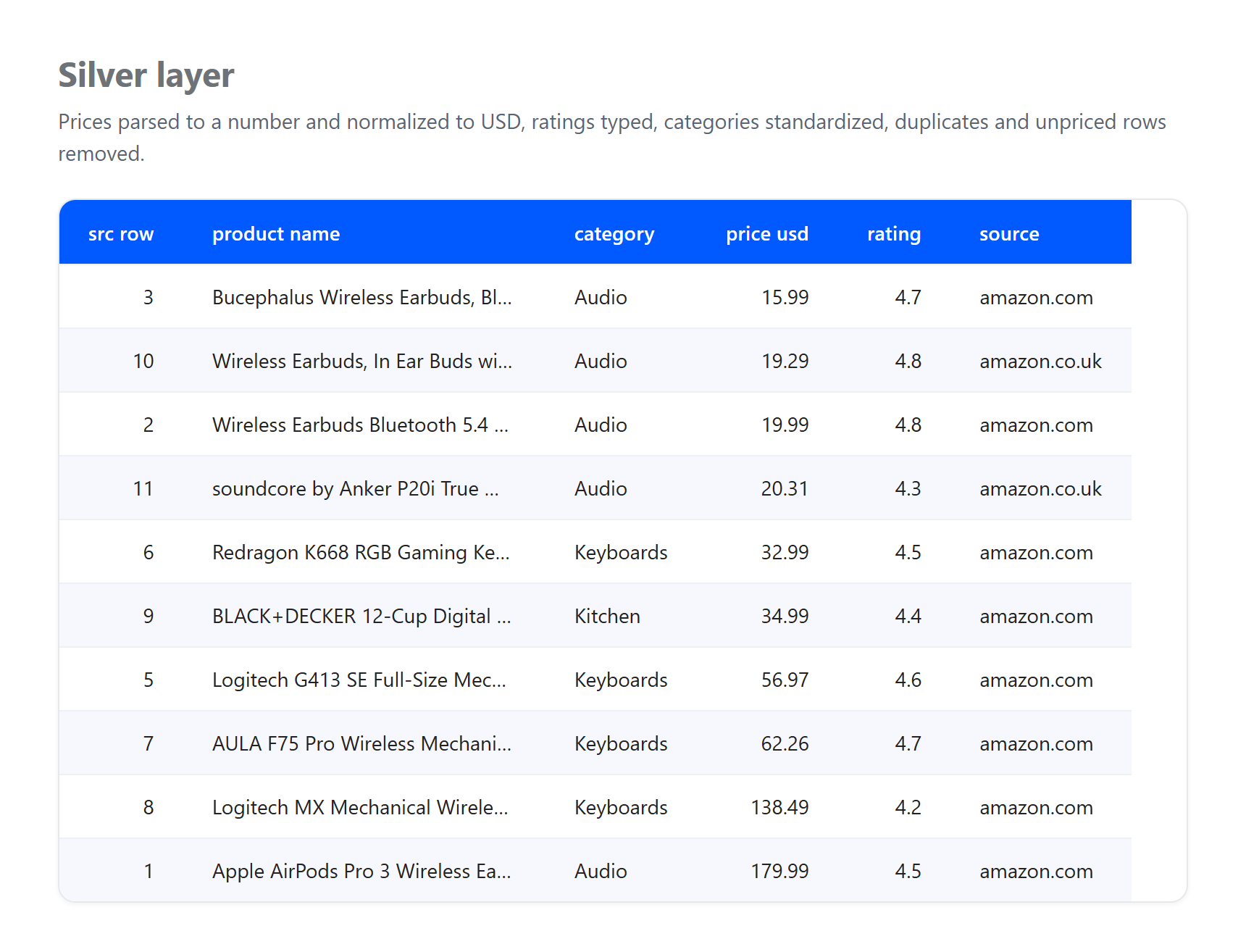
Or. Agrégez les enregistrements propres dans la vue métier qu’un tableau de bord ou un modèle interroge réellement.
gold = (
silver.groupby("category")
.agg(
products=("product_name", "count"),
avg_price_usd=("price_usd", "mean"),
min_price_usd=("price_usd", "min"),
max_price_usd=("price_usd", "max"),
avg_rating=("rating", "mean"),
)
.round(2)
.reset_index()
)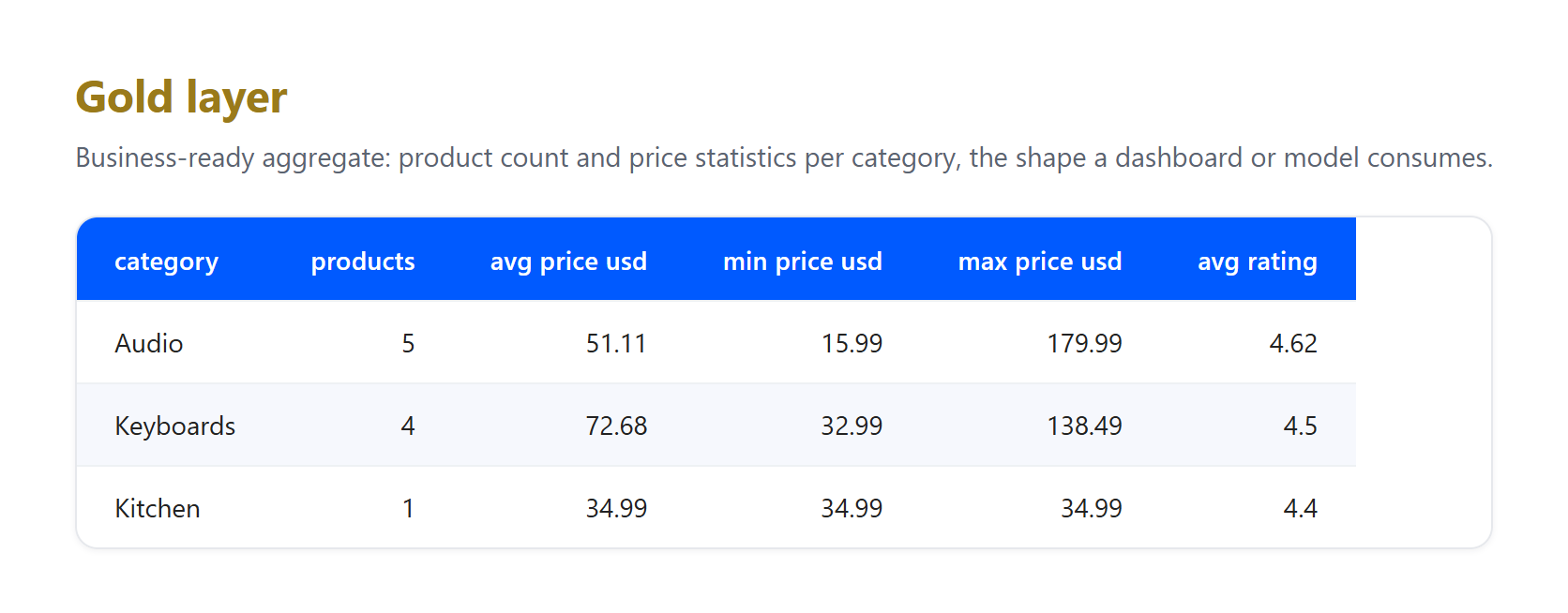
Remarquez ce que les couches ont absorbé, car c’est exactement ce qu’un vrai pipeline doit affronter. Il s’agit d’un petit échantillon réel collecté le 23 juin 2026, et le taux GBP vers USD est un taux fixe illustratif, pas une conversion en direct. Trois artefacts authentiques sont arrivés au bronze et ont été résolus dans argent : une annonce est arrivée sans prix et a été supprimée, le même produit Apple AirPods Pro 3 a été capturé depuis les pages US et UK et dédupliqué en un seul enregistrement, et les titres portant des entités HTML brutes comme & ont été décodés en texte brut. Aucun de ce nettoyage n’appartient à bronze, dont le seul rôle est de préserver ce qui est arrivé. Cette séparation des responsabilités est tout l’intérêt du modèle.
The lakehouse tooling ecosystem
Le modèle médaillon est implémenté dans un ensemble d’outils familiers. Aucun d’entre eux n’est interchangeable avec les autres, mais une architecture fonctionnelle en combine généralement plusieurs.
- Databricks est la plateforme lakehouse commerciale qui a inventé à la fois le paradigme lakehouse et l’architecture médaillon, avec un support natif de Delta Lake et des outils de pipeline déclaratifs.
- Delta Lake est le format de table open source qui ajoute des transactions ACID, l’application de schémas, le voyage dans le temps et la capture de données modifiées au-dessus de Parquet.
- Apache Spark est le moteur de calcul distribué qui exécute les transformations bronze-vers-argent et argent-vers-or en mode batch ou streaming.
- Apache Iceberg est un format de table ouvert préféré lorsque plusieurs moteurs doivent lire les mêmes tables.
- Apache Hudi est un format de table ouvert avec un fort support de mise à jour au niveau des enregistrements et d’extraction incrémentale, courant dans les couches bronze à fort taux de changement.
- Snowflake prend en charge le modèle nativement, y compris les tables Iceberg gérées pour la couche or.
- dbt est le framework de transformation SQL-first que de nombreuses équipes utilisent pour construire les couches argent et or.
- Microsoft Fabric implémente l’architecture médaillon nativement sur OneLake, en standardisant sur Delta Lake.
Si votre plateforme est Snowflake ou Google Cloud, les guides d’intégration pour Bright Data avec Snowflake Cortex et le workflow Vertex AI plus API SERP montrent le transfert bronze en contexte.
Best practices
Quelques conventions séparent une implémentation propre d’une implémentation fragile.
- N’écrivez pas dans argent depuis l’ingestion. Faites toujours atterrir les données brutes dans bronze en premier, afin que les changements de schéma et les enregistrements corrompus ne puissent pas casser vos tables affinées.
- Gardez bronze avec des types lâches. Stockez la plupart des champs sous forme de chaîne, VARIANT ou binaire pour que la dérive de schéma en amont ne supprime pas de données.
- Lisez bronze comme un flux quand vous le pouvez. Pour les sources en ajout uniquement, les lectures en streaming maintiennent une faible latence ; réservez les lectures par lots aux petits jeux de données.
- Conservez toujours un enregistrement non agrégé dans argent. L’agrégation appartient à or, afin qu’argent reste réutilisable pour de nombreux consommateurs.
- Ne forcez pas or à être en temps réel. Or est optimisé pour des agrégats fréquemment interrogés et actualisés par lots. Le rétrofit pour des charges de travail à faible latence tend à créer des pipelines fragiles et coûteux.
- Nommez les tables par couche. Un espace de noms comme catalog.bronze.table, catalog.silver.table, catalog.gold.table communique le niveau de confiance de n’importe quelle table d’un coup d’œil.
Common pitfalls and critiques
Le modèle est robuste, mais il est suffisamment mal utilisé pour que les modes d’échec soient bien documentés.
Sauter bronze. C’est tentant lorsque les données externes semblent déjà propres, mais sauter bronze supprime la piste d’audit et la capacité de retraiter. La sémantique de votre couche argent change silencieusement quand il n’y a pas d’enregistrement brut derrière elle.
Traiter argent comme or. Lorsque les équipes construisent des KPI métier et des agrégations lourdes directement dans argent, différentes équipes définissent les métriques différemment et il n’y a pas de version unique faisant autorité. Gardez les agrégats dans or.
Lire le bronze brut comme s’il s’agissait de données de production. Bronze n’est pas vérifié et souvent désordonné. Pointer un tableau de bord dessus conduit à des comptages en double et des résultats incohérents. Bronze est un enregistrement historique, pas une source de vérité pour l’analytique.
Enchevêtrement entre couches. Lorsque les pipelines laissent fuir les responsabilités entre les couches, par exemple en ingérant des événements bruts directement dans or, un seul changement de schéma peut se propager à travers toute la pile.
Il existe également une critique légitime de l’application rigide du modèle. Comme une analyse l’a formulé, appliquer une structure rigide à trois couches à toutes les sources conduit à des inefficacités lorsque certains jeux de données ne nécessitent pas de nettoyage extensif, et le découpage séquentiel ajoute une latence que les cas d’usage en temps réel peuvent ne pas tolérer. La communauté des praticiens a répondu en proposant des couches supplémentaires dans certaines conceptions, comme une zone d’atterrissage pré-bronze ou une couche platine au-dessus de or pour le service opérationnel et d’apprentissage automatique.
La façon saine de lire tout cela est que l’architecture médaillon est un cadre flexible, pas un mandat. Databricks lui-même déclare que suivre l’architecture médaillon est une meilleure pratique recommandée mais pas une exigence, et le projet Delta Lake la décrit comme un cadre optionnel et flexible. Utilisez le nombre de couches et la dénomination qui correspondent à vos modèles de requêtes et à vos consommateurs.
Common use cases
Le modèle est le plus rentable là où les entrées brutes sont désordonnées et où de nombreux consommateurs ont besoin de sorties fiables.
- Prix compétitifs et intelligence e-commerce. Les données de produits et de prix collectées auprès de nombreux détaillants atterrissent dans bronze telles quelles, sont normalisées et dédupliquées dans argent, et alimentent les tableaux de bord or de suivi des prix et d’assortiment.
- Données d’entraînement pour l’IA et l’apprentissage automatique. Les textes et données structurées à l’échelle du web atterrissent bruts dans bronze, sont nettoyés et dédupliqués dans argent, et sont façonnés en caractéristiques prêtes pour les modèles dans or. Les étapes pratiques sont couvertes dans ce guide sur le scraping web pour l’apprentissage automatique, et la stratégie plus large dans l’article sur le volant de données IA.
- Recherche de marché et données alternatives. Les signaux externes de nombreuses sources sont conformés dans argent en une seule vue de recherche, puis agrégés en indicateurs or.
- Surveillance des recherches et des SERP. Un flux continu de résultats de recherche s’écoule dans bronze, est structuré dans argent, et s’accumule en métriques de visibilité or et de part de voix.
- Enrichissement firmographique et client. Les flux de données d’entreprise enrichissent les enregistrements internes au niveau de la couche argent, produisant des tables or pour les ventes et le marketing.
Pour la plomberie d’ingénierie derrière tout cela, les guides pratiques sur AWS Glue ETL, AWS Step Functions, les pipelines Kubeflow, le pipeline Mage AI, et la connexion de données web en direct à Tableau montrent chacun un vrai chemin bronze-vers-service. Les fondamentaux de l’étape d’extraction elle-même sont couverts dans cette introduction à l’extraction de données.
Conclusion
L’architecture médaillon perdure parce qu’elle donne aux équipes un langage commun pour transformer des données brutes en données fiables, un saut discipliné à la fois. Bronze préserve la vérité, argent la rend cohérente, et or la rend utile. Le modèle ne fonctionne qu’aussi bien que les données brutes qui l’alimentent, c’est pourquoi une source bronze fiable et bien structurée n’est pas un détail mais un fondement.
Pour les données externes et web, c’est là que Bright Data s’insère : une collecte de qualité production livrée en JSON, CSV ou Parquet directement dans le stockage cloud que votre lakehouse traite déjà comme bronze. Prêt à alimenter votre couche bronze avec des données web fiables ? Commencez un essai gratuit et voyez à quelle vitesse les données web brutes peuvent s’écouler dans votre pipeline.
Frequently Asked Questions
Q : Qu’est-ce que l’architecture médaillon en termes simples ?
C’est une façon d’organiser les données dans un lakehouse pour qu’elles deviennent plus propres et plus utiles au fur et à mesure qu’elles traversent trois couches. Les données brutes atterrissent dans la couche bronze, sont nettoyées et standardisées dans la couche argent, et sont agrégées en tables prêtes pour les métiers dans la couche or. Chaque couche a un rôle clair, ce qui facilite la gestion et l’audit de la qualité des données.
Q : Quelle est la différence entre les couches bronze, argent et or ?
Bronze contient les données brutes exactement telles qu’elles sont arrivées, en ajout uniquement et non transformées, comme source permanente de vérité. Argent contient des données nettoyées et conformées, avec déduplication, application de schéma et jointures appliquées pour que les données soient fiables et cohérentes. Or contient des données agrégées au niveau métier modélisées pour des rapports spécifiques, des tableaux de bord, l’apprentissage automatique et les applications.
Q : L’architecture médaillon est-elle la même chose que l’ETL ?
Non, mais elles sont liées. L’ETL décrit l’extraction, la transformation et le chargement des données. L’architecture médaillon est un modèle de couches qui organise où ces transformations se produisent. Dans un lakehouse, elle suit généralement un style ELT, où les données brutes sont chargées dans bronze en premier et transformées par étapes dans argent et or à l’intérieur de la plateforme.
Q : Ai-je toujours besoin des trois couches ?
Non. Databricks décrit l’architecture médaillon comme une meilleure pratique recommandée, pas une exigence. Certains jeux de données qui arrivent propres peuvent ne pas nécessiter une étape argent extensive, et certains cas d’usage en temps réel contournent délibérément certaines parties du flux. Le nombre de couches et la dénomination doivent correspondre à vos modèles de requêtes et à vos consommateurs. La principale mise en garde est que sauter bronze supprime votre piste d’audit brute et votre capacité de retraitement.
Q : Quel format de fichier dois-je utiliser pour les tables médaillon ?
La plupart des implémentations utilisent un format de table ouvert comme Delta Lake, Apache Iceberg ou Apache Hudi, tous reposant sur des fichiers Parquet dans le stockage d’objets cloud. Ces formats ajoutent des transactions ACID, l’application de schémas et le voyage dans le temps, dont le modèle dépend. Delta Lake est le format natif sur Databricks et Microsoft Fabric, tandis qu’Iceberg est courant lorsque plusieurs moteurs lisent les mêmes tables.
Q : Comment les données externes ou web s’intègrent-elles dans une architecture médaillon ?
Les données externes et web sont une entrée de la couche bronze. Vous faites atterrir les données collectées brutes, par exemple des données de produits, de prix, de recherche ou d’entreprise, dans leur forme originale dans bronze, puis vous les normalisez et dédupliquez dans argent. Comme les plateformes lakehouse traitent le stockage d’objets cloud comme S3, GCS et Azure comme des sources bronze valides, un fournisseur comme Bright Data peut livrer des données web en JSON, CSV ou Parquet directement dans ces magasins, où elles deviennent la couche bronze.
Q : L’architecture médaillon est-elle liée à Databricks ?
Databricks a popularisé le terme avec le paradigme lakehouse et Delta Lake, mais le modèle ne lui est pas exclusif. Le même langage bronze, argent et or est utilisé dans la documentation de Microsoft Fabric et Snowflake, et les formats de tables ouverts sous-jacents fonctionnent sur de nombreux moteurs. Le modèle est une convention générale, pas le produit d’un seul fournisseur.





