

Faire fonctionner un pipeline de données de produits Amazon sur votre ordinateur portable est une chose. Le maintenir en production, avec des Proxies, des CAPTCHA, des changements de mise en page et des blocages d’IP, en est une autre. Même si vous résolvez le problème du scraping lui-même, vous avez encore besoin d’une planification, de nouvelles tentatives, d’une gestion des erreurs et d’un moyen de voir réellement ce que vous avez collecté.
Nous allons mettre tout cela en place ici. Nous utiliserons l’API de Scraping web de Bright Data et Mage IA pour créer un pipeline qui collecte les produits et les avis Amazon, exécute l’analyse des sentiments Gemini et transfère tout vers PostgreSQL et un tableau de bord Streamlit. Le pipeline complet fonctionne avec Docker et une seule clé API (plus une clé Gemini optionnelle pour l’analyse IA).
TL;DR: des informations sur les produits Amazon sans avoir à créer d’infrastructure de scraping.
- Ce que vous obtenez: un pipeline qui découvre des produits par mot-clé, analyse les avis avec IA Gemini et fournit un tableau de bord Streamlit en direct.
- Coût: paiement à l’utilisation, facturé par enregistrement (page de tarification), 5 à 8 minutes de bout en bout.
- Fonctionnement: Bright Data gère les Proxy, les CAPTCHA et l’analyse ; Mage IA gère la planification, les réessais et les branchements.
- Comment commencer:
docker compose up– tout le code sur le dépôt GitHub
Ce que nous construisons : un pipeline d’intégration Bright Data + IA
L’API de Scraping web de Bright Data gère la couche de scraping. Vous envoyez un mot-clé ou l’URL d’un produit, et vous obtenez en retour un JSON structuré (titres, prix, évaluations, avis, informations sur le vendeur), déjà analysé. Pas d’infrastructure Proxy à gérer, pas de HTML à analyser. Lorsque Amazon modifie son site, Bright Data met généralement à jour ses analyseurs. Votre code reste le même.
Si vous n’avez jamais utilisé Mage IA auparavant, il s’agit d’un outil de pipeline de données gratuit et open source, similaire à Airflow, mais sans le boilerplate. Vous écrivez du code Python dans un éditeur de type notebook où chaque bloc est une unité réutilisable avec son propre test et son aperçu de sortie. Ce qui importe ici : Mage IA prend en charge les pipelines ramifiés, essentiellement un DAG (graphe acyclique dirigé) avec des chemins parallèles. Il dispose également d’une logique de réessai intégrée par bloc et de variables de pipeline que vous pouvez modifier à partir de l’interface utilisateur, sans avoir à modifier le code.
Le pipeline comporte 6 blocs répartis sur deux branches parallèles :
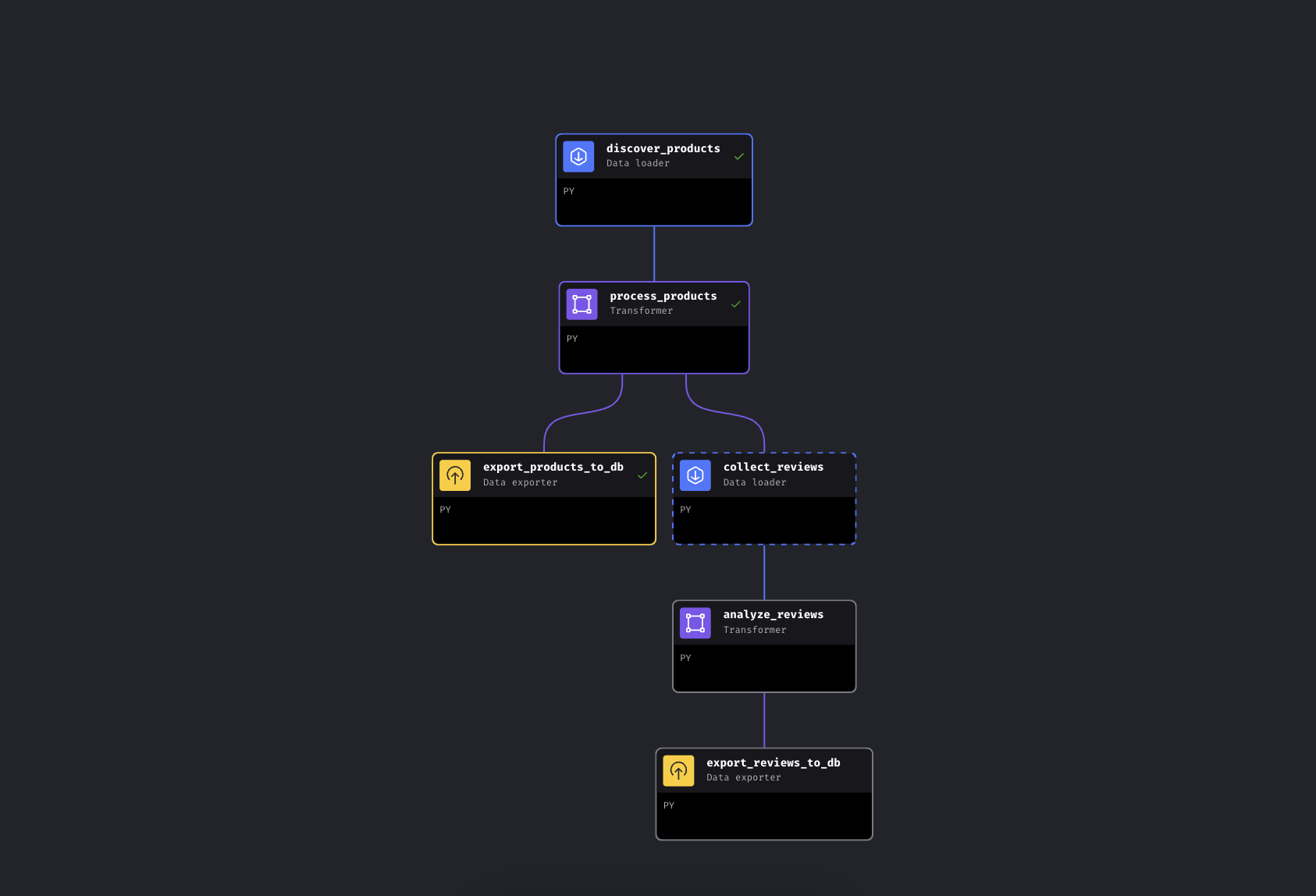
Le pipeline ramifié dans Mage IA. La branche gauche exporte immédiatement les produits, tandis que la branche droite collecte et analyse les avis.
Le pipeline découvre les produits par mot-clé via Bright Data, les enrichit avec des niveaux de prix et des notes, puis se ramifie. Un chemin exporte immédiatement les produits vers PostgreSQL, tandis que l’autre collecte les avis sur les meilleurs produits, les analyse à l’aide de Gemini pour évaluer le sentiment et les exporte également.
Nous utilisons Mage IA ici parce que le pipeline se ramifie (il s’agit d’un DAG, et non d’un script linéaire : si la collecte des avis échoue, vos données produit sont déjà en sécurité), mais les appels à l’API Bright Data ne sont que des requêtes HTTP. Ils fonctionnent de la même manière dans Airflow, Prefect, Dagster ou un simple script Python.
Démarrage rapide
Clonez le dépôt, ajoutez vos clés API et lancez-le. Tout fonctionne dans Docker, vous n’avez donc pas besoin d’installer Python localement.
Prérequis
Vous aurez besoin de :
- Docker et Docker Compose (obtenir Docker)
- Un compte Bright Data avec un jeton API
- Une clé API Google Gemini (offre gratuite disponible avec des limites ; voir la section Gemini ci-dessous)
- Une connaissance de base de Python et Docker. Aucune expérience en scraping n’est requise ; c’est justement le but
Étape 1 : cloner et configurer
Clonez le dépôt et créez votre fichier de configuration :
git clone https://github.com/triposat/mage-brightdata-demo.git
cd mage-brightdata-demo
cp .env.example .envAjoutez maintenant vos clés API à .env:
BRIGHT_DATA_API_TOKEN=votre_clé_api_ici
GEMINI_API_KEY=votre_clé_api_gemini_iciObtenir votre jeton API Bright Data: inscrivez-vous sur [Bright Data]() (essai gratuit, aucune carte de crédit requise), puis accédez aux paramètres du compte et créez une clé API. Le pipeline utilise deux Scrapers API de Scraping web (un pour la découverte de produits, un pour les avis), facturés par enregistrement, selon le principe du Paiement à l’utilisation. Consultez la page des tarifs pour connaître les tarifs actuels.
Obtenir votre clé API Gemini: rendez-vous sur Google AI Studio, connectez-vous, puis cliquez sur Créer une clé API. Niveau gratuit, aucune carte de crédit requise. Le pipeline fonctionne également sans cette clé ; il se rabat alors sur les sentiments basés sur les notes.
Étape 2 : démarrer les services
docker compose up -dSi vous souhaitez vérifier que vos clés sont bien chargées :
docker compose exec mage python -c « import os; t=os.getenv('BRIGHT_DATA_API_TOKEN',''); assert t and t!='your_api_token_here', 'Token not set'; print('OK') »Cela lance trois conteneurs :
| Service | URL | Objectif |
|---|---|---|
| Mage IA | http://localhost:6789 |
Éditeur et planificateur de pipeline |
| Tableau de bord Streamlit | http://localhost:8501 |
Visualisation des données en direct + chat |
| PostgreSQL | localhost:5432 |
Stockage des données |
La première exécution extrait les images et installe les dépendances, ce qui prend environ 3 à 5 minutes selon votre connexion. Les redémarrages avec docker compose stop/start prennent quelques secondes ; docker compose down/up réinstalle les paquets pip et prend environ une minute.
Les trois services sont en cours d’exécution
Étape 3 : exécuter le pipeline
Ouvrez http://localhost:6789, accédez à Pipelines, cliquez sur amazon_product_intelligence, puis cliquez sur Triggers dans la barre latérale gauche et appuyez sur Run@once.
Le tableau de bord Mage IA
Le pipeline prend environ 5 à 8 minutes de bout en bout. La majeure partie de ce temps est consacrée à la collecte de données par les API Bright Data auprès d’Amazon ; l’enrichissement et les exportations de la base de données ne prennent que quelques secondes, et l’analyse Gemini dépend de la taille des lots et des limites de débit. Lorsque les 6 blocs sont verts, ouvrez http://localhost:8501 pour voir le tableau de bord.
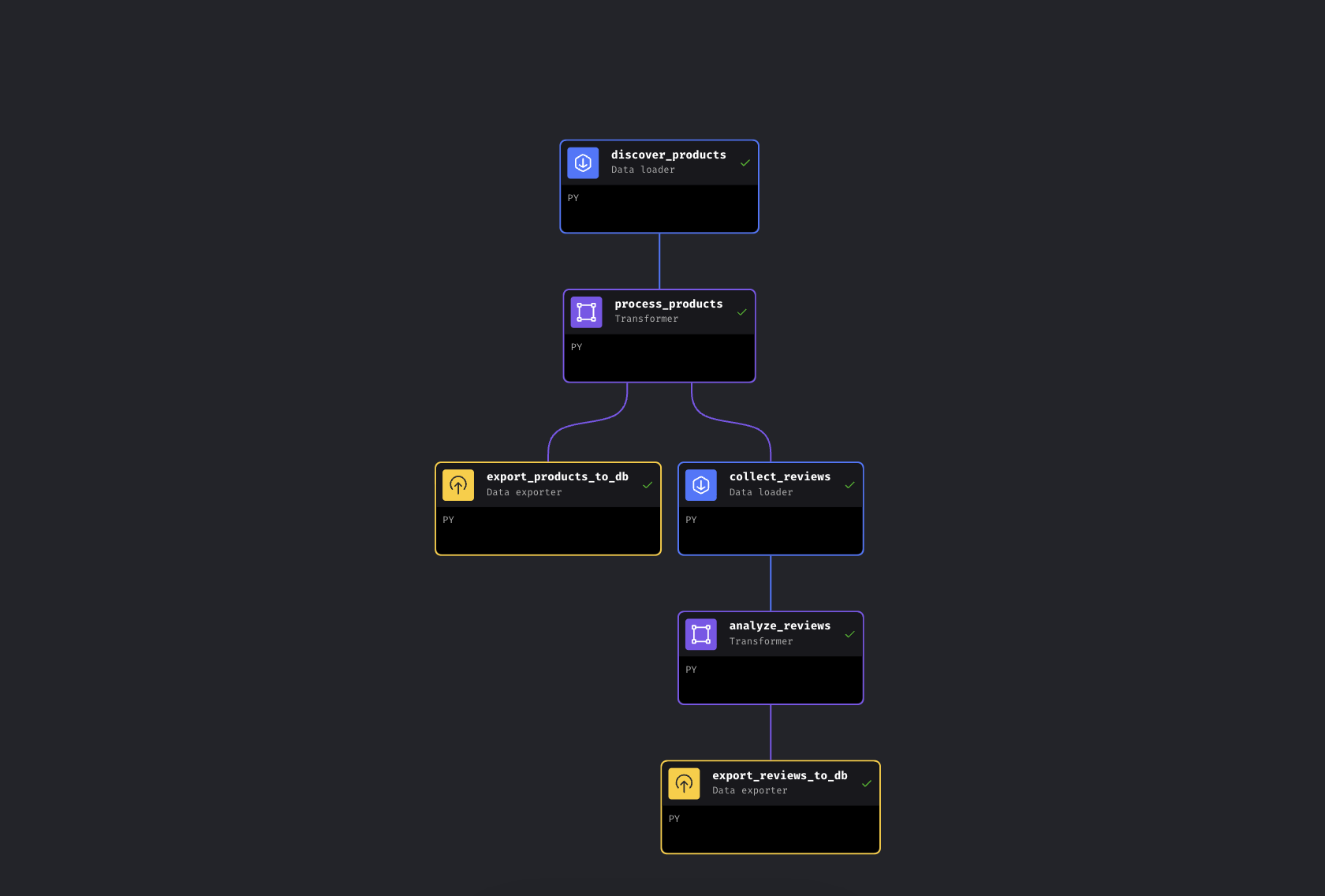
Les 6 blocs sont verts. Pipeline terminé
Fonctionnement du pipeline de données Mage IA
Passons en revue le code. Nous nous concentrerons sur les intégrations Bright Data et l’analyse Gemini.
Connexion de l’API de Scraping web de Bright Data à Mage IA
Nous envoyons des mots-clés à l’API Amazon Products et obtenons en retour des données structurées. Bright Data appelle cela un Scraper « Discovery » : il trouve des produits par mot-clé ou par catégorie. Le bloc des avis utilise ensuite un Scraper distinct, Reviews, qui prend en entrée les URL des produits. L’API utilise un modèle asynchrone : déclencher la collecte, obtenir un identifiant de snapshot, interroger jusqu’à ce que les résultats soient prêts.
DATASET_ID = « gd_l7q7dkf244hwjntr0 » # Amazon Products (vérifiez le dépôt pour les ID actuels)
API_BASE = « https://api.brightdata.com/datasets/v3 »
# Déclencher la collecte (utilise /scrape – passe automatiquement en mode asynchrone si >1 min ; pour la production, envisager /trigger)
response = requests.post(
f"{API_BASE}/scrape",
headers={"Authorization": f"Bearer {api_token}",
"Content-Type": "application/json"},
params={"dataset_id": DATASET_ID,
"type": "discover_new",
"discover_by": "keyword",
"limit_per_input": kwargs.get('limit_per_keyword', 5)},
json={"input": [{"keyword": kw} for kw in keywords]})
snapshot_id = response.json()["snapshot_id"]
# Interroger jusqu'à ce que les résultats soient prêts
data = requests.get(
f"{API_BASE}/snapshot/{snapshot_id}",
headers={"Authorization": f"Bearer {api_token}"},
params={"format": "json"}
).json()Voici ce que Bright Data renvoie :
{
"title": "BESIGN LS03 Aluminum Laptop Stand",
"asin": "B07YFY5MM8", // Identifiant unique du produit Amazon
"url": "https://www.amazon.com/dp/B07YFY5MM8",
"initial_price": 19.99,
"final_price": 16.99,
"currency": "USD",
"rating": 4.8,
« reviews_count » : 22776,
« seller_name » : « BESIGN »,
« categories » : [« Office Products », « Office & School Supplies »],
« image_url » : « https://m.media-amazon.com/images/I/... »
}La variable kwargs.get('limit_per_keyword', 5) est extraite des variables du pipeline IA, vous pouvez donc l’ajuster depuis l’interface utilisateur.
Ajout d’un deuxième appel API : collecte des avis Amazon
Le collecteur d’avis prend les produits traités à partir du bloc en amont et les trie par nombre d’avis. Il sélectionne les N meilleurs et transmet leurs URL Amazon à une deuxième API Bright Data :
REVIEWS_DATASET_ID = "gd_le8e811kzy4ggddlq" # Avis Amazon
# Produits les plus populaires en amont (transmis automatiquement par Mage IA)
top_products = data.sort_values('reviews_count', ascending=False).head(top_n)
product_urls = top_products['url'].dropna().tolist()
# Entrer les URL dans l'API Reviews (même modèle /scrape)
response = requests.post(
f"{API_BASE}/scrape",
headers={"Authorization": f"Bearer {api_token}",
"Content-Type": "application/json"},
params={"dataset_id": REVIEWS_DATASET_ID},
json={"input": [{"url": url} for url in product_urls]})
# Même modèle de sondage asynchrone que pour les produits...Les deux blocs API ont une configuration de réessai dans le fichier metadata.yaml de la démo : si un appel échoue, le pipeline réessaie 3 fois avec un délai de 30 secondes. Chaque bloc de cette démo dispose également d’une fonction @test qui s’exécute après l’exécution. En cas d’échec, les blocs en aval ne s’exécutent pas, ce qui évite que des données erronées ne se retrouvent dans votre base de données.
Ajout d’une analyse IA : bloc de pipeline Gemini Sentiment
Au lieu de la correspondance de mots-clés (qui signalerait « pas cher, excellente qualité ! » comme négatif à cause du mot « pas cher »), nous utilisons Gemini pour comprendre le contexte. Le bloc traite les avis par lots avec une rotation de 3 modèles afin de rester dans les limites du niveau gratuit :
GEMINI_MODELS = ["gemini-2.5-flash-lite", "gemini-2.5-flash", "gemini-2.5-pro"] # vérifier le dépôt pour les modèles actuels
prompt = f"""Analyser ces avis. Pour CHAQUE avis, renvoyer un JSON avec :
- « sentiment » : « Positif », « Neutre » ou « Négatif »
- « problèmes » : problèmes spécifiques mentionnés concernant le produit
- « thèmes » : 1 à 3 balises thématiques
- « résumé » : résumé en une phrase
Renvoyer UNIQUEMENT JSON.nn{reviews_text}"""
for model in models:
try:
response = client.models.generate_content(model=model, contents=prompt)
return json.loads(response.text.strip())
except Exception as e:
if '429' in str(e):
continue # Taux limité -- passer au modèle suivantLa rotation commence par flash-lite (le moins cher et le plus rapide), puis passe à flash, puis à pro. Si les trois sont épuisés, l’avis obtient à la place un sentiment basé sur la note. Les quotas gratuits changent périodiquement, mais la rotation des trois modèles gère automatiquement la plupart des limites de débit. Gemini renvoie le sentiment, les problèmes spécifiques (tels que « vacille sur les surfaces inégales » ou « la charnière se desserre avec le temps ») et 1 à 3 balises thématiques par avis. Chaque avis est également accompagné d’un résumé d’une phrase.
Les blocs restants (un transformateur pour les niveaux de prix et les calculs de remise, et deux exportateurs de base de données avec logique upsert) sont simples. Ils se trouvent dans le dépôt GitHub si vous souhaitez les examiner.
Résultats du pipeline : résultats et tableau de bord Streamlit
Voici ce que le pipeline a produit en un seul passage avec les mots-clés par défaut : « support pour ordinateur portable » et « écouteurs sans fil ». Vos résultats varieront en fonction des listes actuelles d’Amazon.
Dans cette exécution : 10 produits découverts, 20 avis analysés par Gemini. Les avis sur les écouteurs ont fait ressortir des plaintes qui n’apparaissent pas dans la moyenne de 4,3 étoiles, notamment sur des thèmes tels que la « qualité sonore », l’« autonomie de la batterie » et la « connectivité », accompagnés de problèmes spécifiques.
Ce que le pipeline ajoute à vos données brutes:
| Champ | Exemple | Ajouté par |
|---|---|---|
best_price |
16,99 | Transformateur (calculé) |
discount_percent |
15 | Transformateur (calculé) |
price_tier |
Budget (<25 $) | Transformateur (enrichi) |
catégorie |
Excellent (4,5-5) | Transformateur (enrichi) |
sentiment |
Négatif | Gemini IA |
Problèmes |
[« Le Bluetooth perd souvent la connexion »] | Gemini IA |
Thèmes |
[« connectivité », « autonomie de la batterie »] | Gemini IA |
ai_summary |
« La batterie ne dure que 2 heures malgré les 8 heures annoncées » | Gemini IA |
Voici à quoi cela ressemble en pratique : les 10 produits avec les champs enrichis visibles :
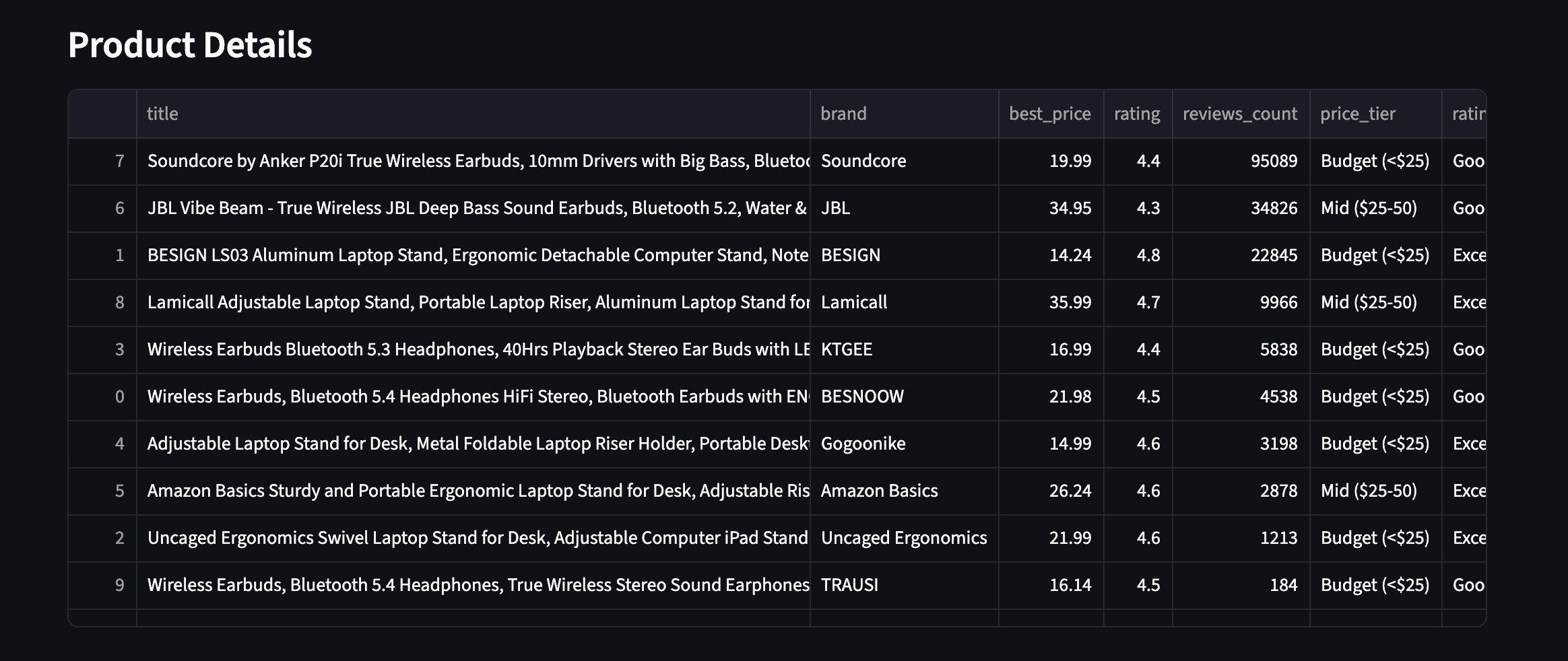
Les 10 produits avec champs enrichis. Niveaux de prix, notes et nombre d’avis pour deux catégories de produits différentes
Le tableau de bord
Ouvrez http://localhost:8501 pour accéder au tableau de bord Streamlit. Cliquez sur « Refresh Data » (Actualiser les données) dans la barre latérale pour extraire les derniers résultats de PostgreSQL.
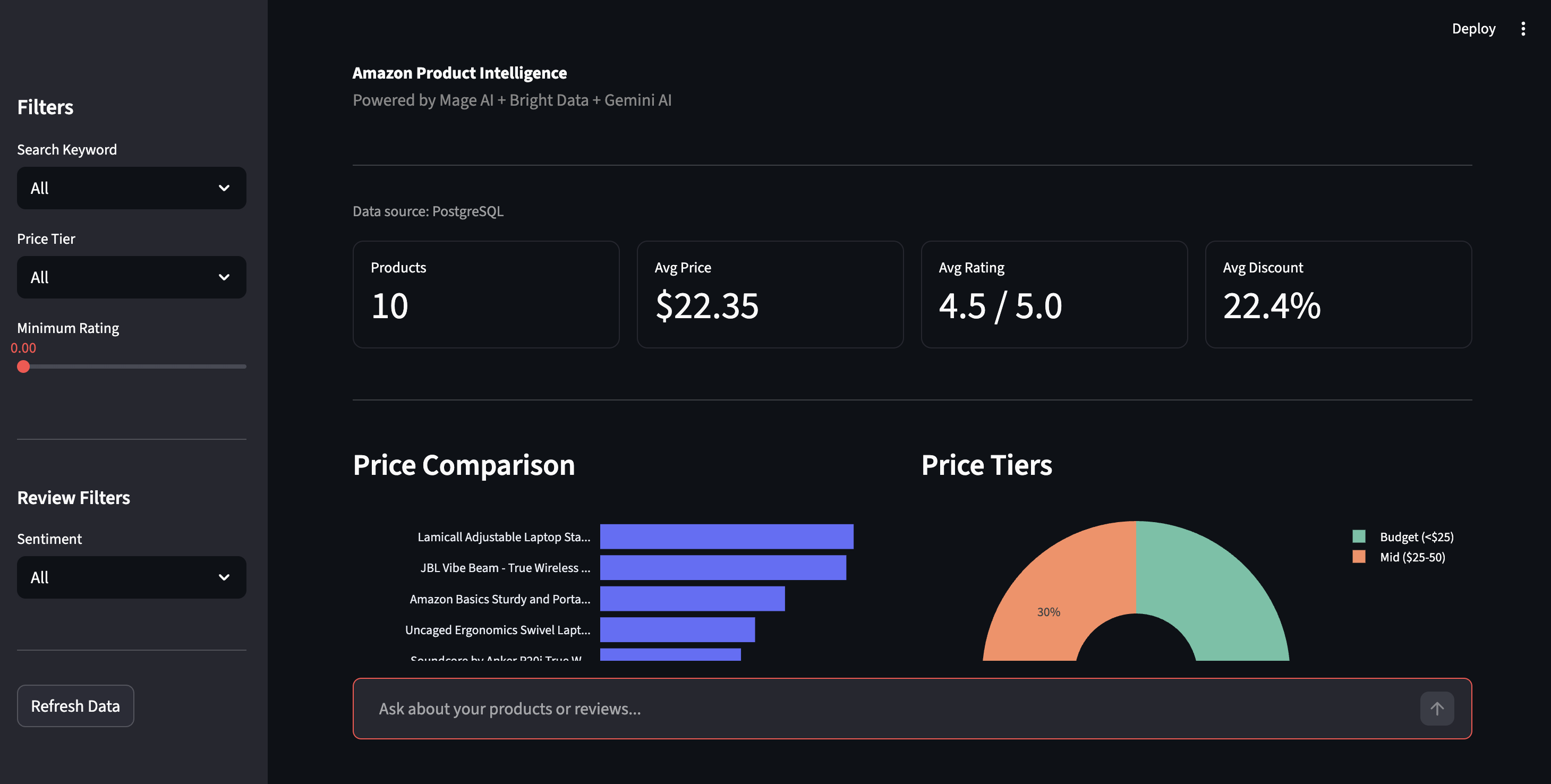
Tableau de bord d’informations sur les produits : comparaison des prix, niveaux de prix et commandes de filtrage
La barre latérale vous permet de filtrer par niveau de prix, note ou sentiment. La vue « Sentiment » affiche la répartition positive/négative de tous les avis, avec les problèmes spécifiques relevés par Gemini : « La connexion Bluetooth se coupe », « La charnière se desserre avec le temps », le genre de détails que les notes par étoiles ne révèlent pas.

Répartition des sentiments et problèmes liés aux produits détectés par l’IA. Réclamations réelles extraites par Gemini, et non par correspondance de mots-clés
Le tableau de bord dispose également d’une fonctionnalité « Chat with Your Data » (Discutez avec vos données). Posez des questions en anglais courant et Gemini vous répond en utilisant vos données réelles comme contexte. Voici un exemple tiré d’une autre exécution avec davantage de produits :
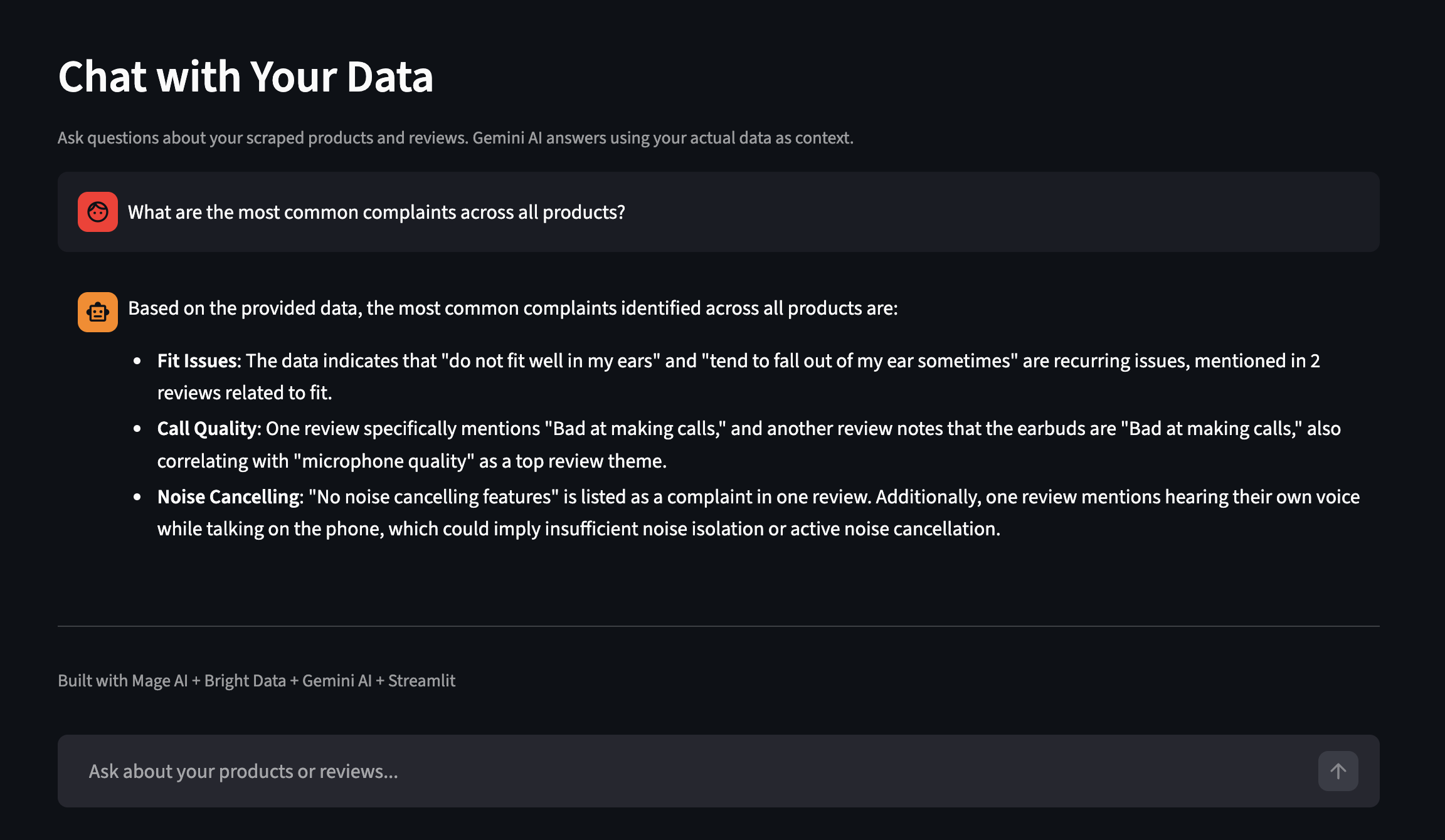
Posez des questions sur vos données collectées en anglais courant
Mise à l’échelle du pipeline
La démo fonctionne avec deux mots-clés et 10 produits.
Variables du pipeline
Toutes configurables à partir de l’interface utilisateur IA ou metadata.yaml:
| Variable | Ce qu’elle contrôle | Par défaut |
|---|---|---|
Mots-clés |
Termes de recherche Amazon | [« support pour ordinateur portable », « écouteurs sans fil »] |
limite_par_mot_clé |
Produits par mot-clé provenant de Bright Data | 5 |
top_n_products |
Combien de produits phares font l’objet d’avis collectés | 2 |
reviews_per_product |
Nombre maximal d’avis par produit | 10 |
sort_by |
Comment classer les produits pour la sélection des avis | nombre_d'avis |
Remplacez les mots-clés par « étui de téléphone » et « hub USB-C » pour obtenir un jeu de données complètement différent. Aucune modification du code n’est nécessaire.
Variables de pipeline dans l’interface utilisateur Mage IA
Planification
Pour exécuter cette opération selon un calendrier, accédez à Triggers (Déclencheurs) dans la barre latérale de Mage IA, cliquez sur + New trigger(Nouveau déclencheur), sélectionnez Schedule (Calendrier) et choisissez une fréquence (une fois, toutes les heures, tous les jours, toutes les semaines, tous les mois ou cron personnalisé).
Chaque exécution effectue une mise à jour par ASIN : elle remplace les données pour les mêmes produits tout en conservant les résultats des autres mots-clés. Une sauvegarde CSV horodatée est également enregistrée à des fins de comparaison historique.
Une fois que vous disposez de quelques exécutions de données, vous pouvez interroger directement PostgreSQL pour faire apparaître les plaintes que les notes par étoiles ne prennent pas en compte :
-- Trouver les produits ayant un sentiment négatif élevé
SELECT asin, product_name,
AVG(CASE WHEN sentiment = 'Negative' THEN 1 ELSE 0 END) as negative_rate
FROM amazon_reviews
GROUP BY asin, product_name
HAVING AVG(CASE WHEN sentiment = 'Negative' THEN 1 ELSE 0 END) > 0.2;Pour surveiller vos propres produits plutôt que des mots-clés de recherche, supprimez les paramètres type, discover_by et limit_per_input et transmettez directement les URL de vos produits sous la forme [{"url": "https://www.amazon.com/dp/YOUR_ASIN"}].
Si vous avez besoin de tableaux de bord et d’alertes sans avoir à les créer vous-même, Bright Insights le fait sans configuration supplémentaire pour les données de vente au détail.
Mise à l’échelle. Cette démo fonctionne dans Docker sur une seule machine, mais Mage IA prend en charge un exécuteur Kubernetes pour la production, et les API de Bright Data gèrent la concurrence de leur côté (avec des limites de débit pour les requêtes par lots). La mise à l’échelle consiste à ajouter de la capacité Mage IA, et non à modifier votre code de collecte de données.
Intégration d’autres Scrapers Bright Data
Le même modèle de pipeline fonctionne avec tous les Scrapers prêts à l’emploi de Bright Data pour plus de 100 sites web. Par exemple, consultez les dépôts Google Maps Scraper, LinkedIn Scraper et Crunchbase Scraper. Pour passer d’Amazon à une autre plateforme, remplacez le DATASET_ID dans les blocs du chargeur de données et ajustez les paramètres d’entrée pour qu’ils correspondent au schéma du nouveau Scraper.
Pour trouver les champs d’identification et de saisie appropriés, parcourez la bibliothèque de Scrapers dans votre tableau de bord ou appelez le point de terminaison /datasets/list. Le générateur de requêtes API du tableau de bord vous indique exactement ce que chaque Scraper attend. L’analyse Gemini et la structure du pipeline sont reprises telles quelles ; les blocs d’enrichissement et d’exportation peuvent nécessiter des ajustements des noms de colonnes si les champs de réponse du nouveau Scraper diffèrent de ceux d’Amazon.
Dépannage
Si un problème survient pendant la configuration ou l’exécution, voici les solutions les plus courantes :
- Le port 6789 ou 8501 est déjà utilisé. Un autre service occupe le port. Arrêtez ce service ou modifiez
le fichier docker-compose.ymlpour remapper les ports (par exemple, remplacez6789:6789par6790:6789). - L’API Bright Data renvoie 401 Non autorisé. Votre jeton API est manquant ou mal formé. Accédez aux paramètres du compte, copiez le jeton complet et assurez-vous qu’il n’y a pas d’espaces à la fin de votre fichier
.env. Le jeton est une longue chaîne hexadécimale (64 caractères). Si ce que vous avez copié est court ou comporte des tirets comme un UUID, vous avez peut-être copié le mauvais champ. - Gemini renvoie 429 (limite de débit) sur tous les modèles. Le niveau gratuit a des limites par minute qui changent périodiquement. Le pipeline gère cela en alternant entre trois modèles, mais si les trois sont épuisés, les avis reviennent à une évaluation basée sur les sentiments. Pour éviter cela : réduisez
reviews_per_productdans les variables du pipeline, ajoutez untime.sleep(60)entre les lots dans le bloc Gemini, ou activez la facturation sur votre projet IA pour obtenir des quotas plus élevés. Consultez la page des limites de débit de Google pour connaître les quotas actuels. - Un bloc du pipeline s’affiche en rouge (échec). Accédez à la page Logs (Journaux ) de votre pipeline (accessible depuis la barre latérale gauche) pour voir l’erreur. Vous pouvez filtrer par nom de bloc et niveau de journalisation. Causes courantes : jeton API expiré, délai d’attente réseau sur l’API Bright Data (augmentez
max_wait_secondsdans le bloc) ou réponse Gemini qui n’est pas un JSON valide (la fonction@testdu bloc détecte cela). - Docker Compose est lent ou échoue sur Apple Silicon. L’image Mage IA est multi-architecture et fonctionne sur ARM, mais le téléchargement initial peut prendre plus de temps. Si la compilation échoue avec une erreur de mémoire, augmentez l’allocation de mémoire de Docker Desktop à au moins 4 Go dans Paramètres → Ressources.
Prochaines étapes
Vous disposez désormais d’un pipeline fonctionnel qui collecte les données sur les produits Amazon, effectue une analyse des avis à l’aide de l’IA et stocke le tout dans PostgreSQL, sans Proxy, sans analyseur syntaxique et sans tâche cron que vous craignez de toucher.
Si vous avez suivi ces étapes, personnalisez-le. Remplacez la liste de mots-clés dans metadata.yaml par une autre catégorie de produits, sans avoir à modifier le code. Pour une personnalisation plus poussée, pointez-le vers des ASIN spécifiques ou passez à un autre Scraper Bright Data.
Vous êtes nouveau ici ? [Commencez par un essai gratuit de Bright Data]() (aucune carte de crédit requise), clonez le dépôt de démonstration et exécutez docker compose up.
FAQ
Questions fréquentes sur cette configuration :
Comment extraire les données des produits Amazon avec Python ?
Vous pouvez créer votre propre Scraper avec requests et BeautifulSoup (qui ne fonctionne plus lorsque Amazon modifie ses mises en page), ou utiliser le Scraper Amazon de Bright Data qui renvoie un JSON structuré à partir d’un seul appel API. Pour un exemple Python autonome, consultez le dépôt Amazon Scraper. Pour plus de détails, consultez le guide complet de scraping Amazon de Bright Data
Combien coûte le scraping d’Amazon avec Bright Data ?
L’API de Scraping web utilise une tarification à l’utilisation, facturée par tranche de 1 000 enregistrements collectés. L’offre gratuite de Gemini couvre l’analyse IA. Les nouveaux comptes bénéficient d’un essai gratuit. Consultez la page des tarifs pour connaître les tarifs actuels.
Puis-je scraper Walmart, eBay ou d’autres sites de commerce électronique avec ce pipeline ?
Remplacez le DATASET_ID dans les blocs du chargeur de données et ajustez les paramètres d’entrée pour qu’ils correspondent au nouveau schéma du Scraper. L’analyse Gemini et la structure du pipeline sont conservées ; les blocs d’enrichissement et d’exportation peuvent nécessiter des modifications des noms de colonnes.
Que se passe-t-il lorsque Amazon modifie la mise en page de ses pages ?
Rien de votre côté. Bright Data gère les analyseurs syntaxiques, donc lorsque Amazon met à jour son HTML, vos appels API et le format de réponse restent généralement les mêmes.
Ai-je besoin de Gemini ou puis-je utiliser un autre LLM ?
Le pipeline fonctionne sans Gemini ; il se rabat sur le sentiment basé sur les notes. Pour passer à un autre LLM (OpenAI, Claude, Llama), modifiez la fonction analyze_reviews dans le bloc Gemini. Le format de l’invite reste le même ; il vous suffit de modifier l’appel API.






