

Si vous êtes vendeur ou effectuez une étude de marché, connaître l’ASIN d’un produit peut vous aider à trouver rapidement des produits correspondants, à analyser les listes de vos concurrents et à rester en tête sur le marché. Cet article vous présente des méthodes simples et efficaces pour extraire les ASIN Amazon à grande échelle. Vous découvrirez également la solution de Bright Data, qui peut considérablement accélérer ce processus.
Qu’est-ce qu’un ASIN sur Amazon ?
Un ASIN est un code à 10 caractères combinant des lettres et des chiffres (par exemple, B07PZF3QK9). Amazon attribue ce code unique à chaque produit de son catalogue, des livres aux appareils électroniques en passant par les vêtements.
Il existe deux méthodes simples pour trouver l’ASIN d’un produit :
1. Regardez l’URL du produit : l’ASIN apparaît juste après « /dp/ » dans la barre d’adresse.
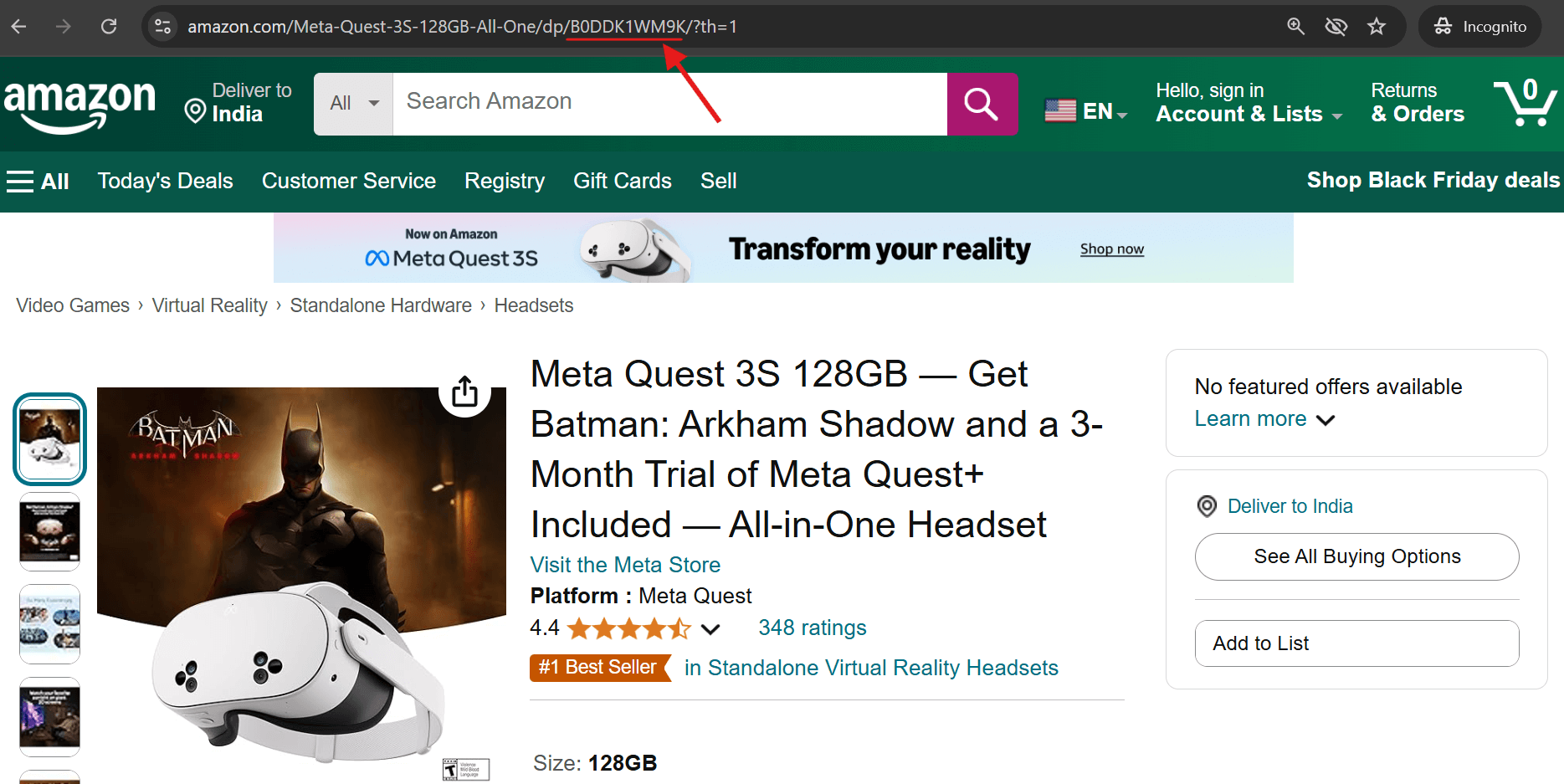
2. Faites défiler vers le bas jusqu’à la section « Informations sur le produit » de n’importe quelle fiche produit Amazon : vous y trouverez l’ASIN.
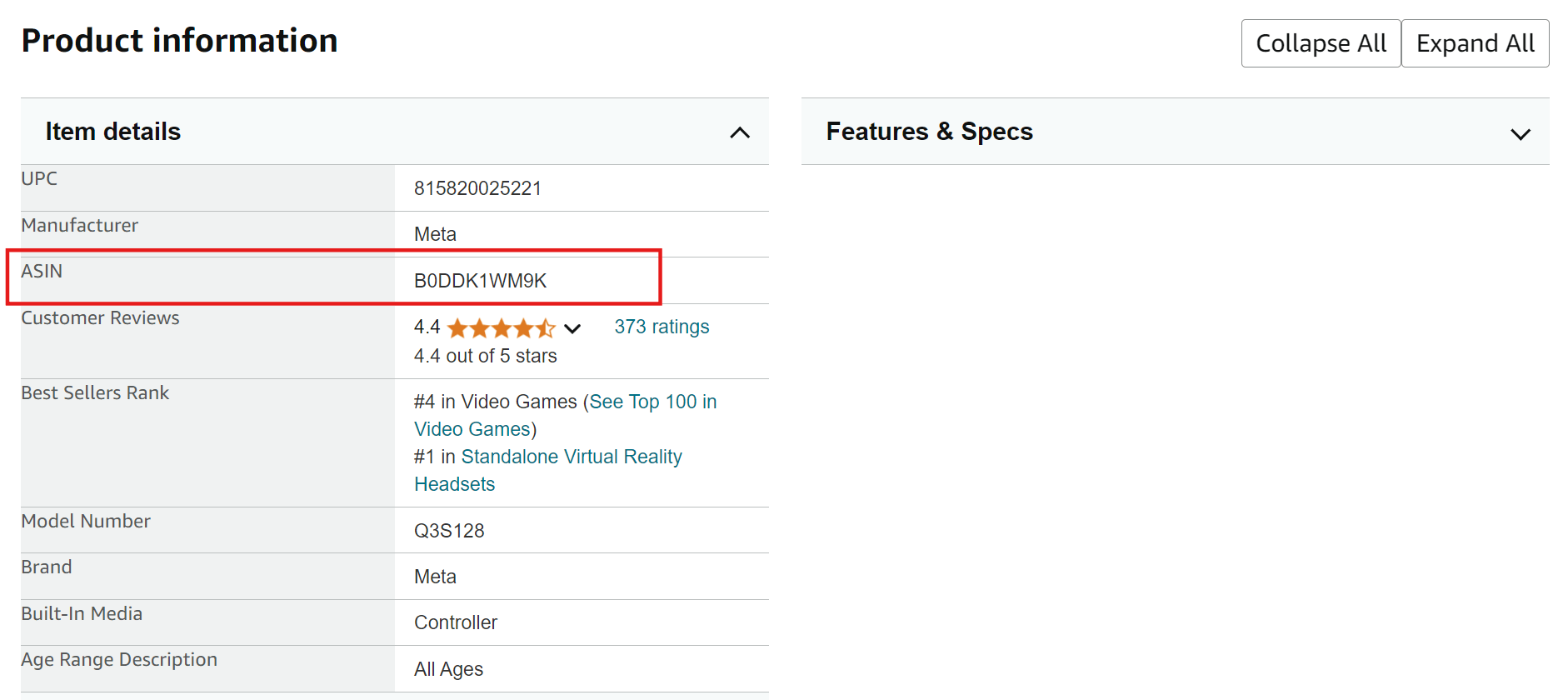
Comment extraire les ASIN d’Amazon
Extraire des données d’Amazon peut sembler simple à première vue, mais cela s’avère assez difficile en raison des mesures anti-scraping robustes mises en place par le site. Amazon se protège activement contre la collecte automatisée de données à l’aide de plusieurs méthodes sophistiquées :
- Défis CAPTCHA
- Erreurs HTTP 503 qui bloquent l’accès aux pages demandées
- Modifications fréquentes de la mise en page du site web qui perturbent la logique d’analyse
Voici une capture d’écran d’une erreur HTTP 503 typique déclenchée par Amazon :

Vous pouvez essayer ce script simple pour extraire les ASIN d’Amazon :
import asyncio import os from curl_cffi import requests from bs4 import BeautifulSoup from tenacity import retry, stop_after_attempt, wait_random class AsinScraper: def __init__(self): self.session = requests.Session() self.asins = set() def create_url(self, keyword: str, page: int) -> str: return f"https://www.amazon.com/s?k={keyword.replace(' ', '+')}&page={page}" @retry(stop=stop_after_attempt(3), wait=wait_random(min=2, max=5)) async def fetch_page(self, url: str) -> str | None: try: print(f"Récupération de l'URL : {url}") response = self.session.get( url, impersonate="chrome120", timeout=30) print(f"Code d'état HTTP : {response.status_code}") if response.status_code == 200: # Vérifier s'il y a des indicateurs de blocage dans la réponse if "Sorry" not in response.text: return response.text else: print("Désolé, demande bloquée !") else: print(f"Code d'état HTTP inattendu : {response.status_code}") except Exception as e: print(f"Exception survenue pendant la récupération : {e}") return None def extract_asins(self, html: str) -> set[str]: soup = BeautifulSoup(html, "lxml") containers = soup.find_all( "div", {"data-component-type": "s-search-result"}) new_asins = set() for container in containers: asin = container.get("data-asin") if asin and asin.strip(): new_asins.add(asin) return new_asins def save_to_csv(self, keyword: str): if not self.asins: print("Aucun ASIN à enregistrer") return # Créer le répertoire des résultats s'il n'existe pas os.makedirs("results", exist_ok=True) # Générer le nom du fichier csv_path = f"results/amazon_asins_{keyword.replace(' ', '_')}.csv" # Enregistrer au format CSV with open(csv_path, 'w') as f: f.write("asinn") for asin in sorted(self.asins): f.write(f"{asin}n") print(f"ASIN enregistrés dans : {csv_path}") async def main(): scraper = AsinScraper() keyword = "laptop" max_pages = 5 for page in range(1, max_pages + 1): print(f"Scraping page {page}...") html = await scraper.fetch_page(scraper.create_url(keyword, page)) if not html: print(f"Échec de récupération de la page {page}") break new_asins = scraper.extract_asins(html) if new_asins: scraper.asins.update(new_asins) print(f"{len(new_asins)} ASIN trouvés sur la page { page}. Total ASIN : {len(Scraper.asins)}") else: print("Plus aucun ASIN trouvé. Fin du scraping.") break # Enregistrer les résultats au format CSV Scraper.save_to_csv(mot-clé) if __name__ == "__main__": asyncio.run(main())
Alors, quelle est la solution pour scraper les ASIN Amazon ? L’approche la plus fiable consiste à utiliser des Proxys résidentiels provenant des meilleurs fournisseurs de proxys, ainsi que des en-têtes HTTP appropriés.
Utilisation des proxies Bright Data pour scraper les ASIN Amazon
Bright Data est l’un des principaux fournisseurs de proxys, disposant d’un réseau mondial de proxys. Il propose différents types de proxys sur des serveurs partagés et privés, répondant à un large éventail de cas d’utilisation. Ces serveurs peuvent acheminer le trafic à l’aide des protocoles HTTP, HTTPS et SOCKS.
Pourquoi choisir Bright Data pour le scraping Amazon ?
- Vaste réseau IP: accès à 400M+ monthly adresses IP dans 195 pays
- Ciblage géographique précis: ciblez des villes, des codes postaux ou même des opérateurs spécifiques
- Plusieurs types de proxys: choisissez parmi des proxys résidentiels, de centre de données, mobiles ou ISP.
- Haute fiabilité: taux de réussite de 99,9 % avec une disponibilité optionnelle de 100
- Évolutivité flexible : options de paiement à l’utilisation disponibles pour les entreprises de toutes tailles
Configuration de Bright Data pour le scraping Amazon
Si vous souhaitez utiliser les Proxy Bright Data pour le scraping d’ASIN Amazon, suivez ces étapes simples :
Étape 1 : Inscrivez-vous à Bright Data
Rendez-vous sur le site web de Bright Data et créez un compte. Si vous avez déjà un compte, passez à l’étape suivante.
Étape 2 : créez une nouvelle zone Proxy
Connectez-vous, accédez à la section Proxy & Infrastructure de scraping (Infrastructure proxy et scraping) et cliquez sur Add (Ajouter ) pour créer une nouvelle zone proxy. Sélectionnez Proxys résidentiels, qui constituent la meilleure option pour contourner les restrictions anti-scraping, car ils utilisent les adresses IP réelles des appareils.
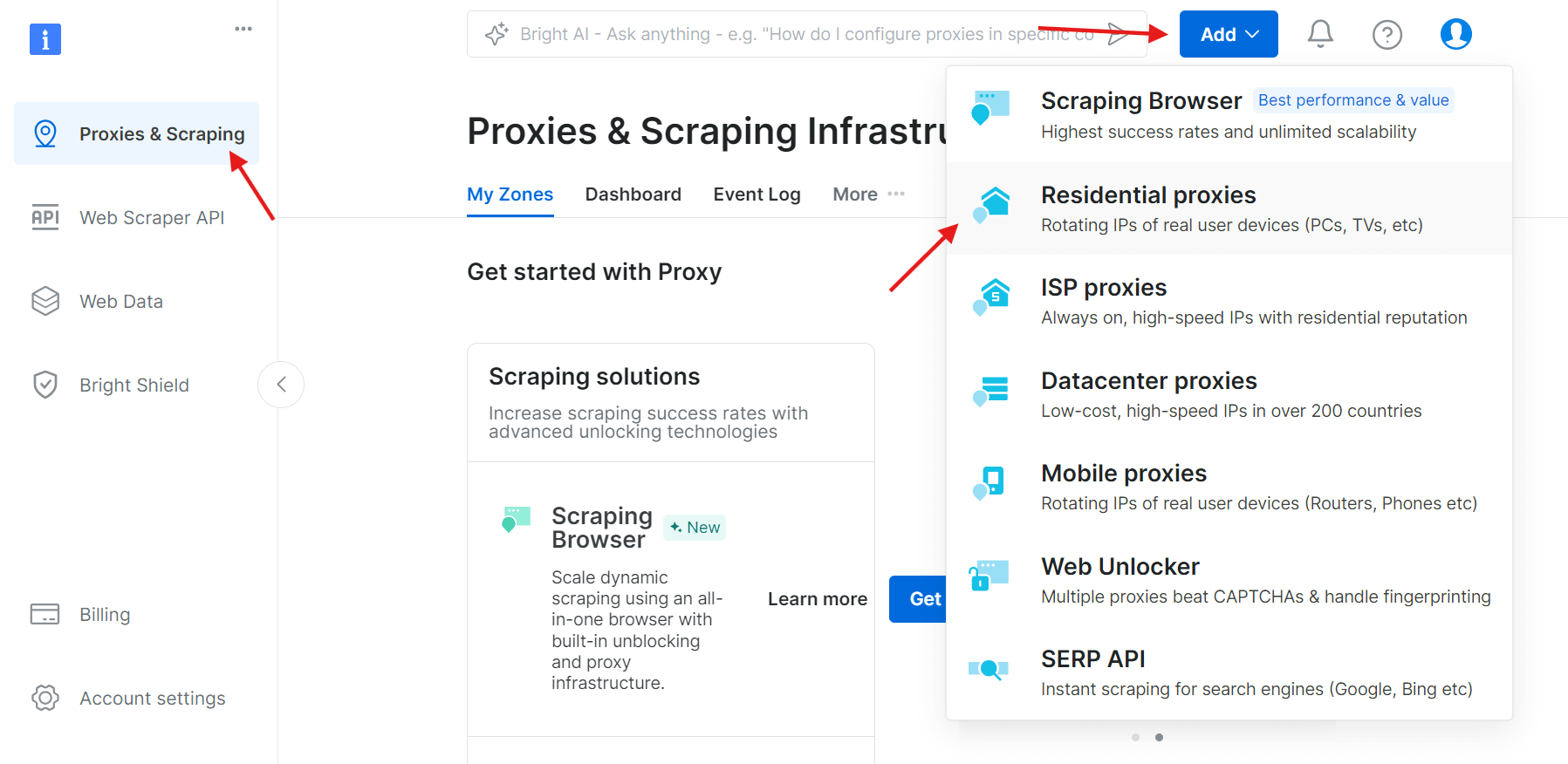
Étape 3 : Configurez les paramètres du Proxy
Choisissez les régions ou les pays pour la navigation. Donnez un nom approprié à votre Zone (par exemple, « asin_scraping »).
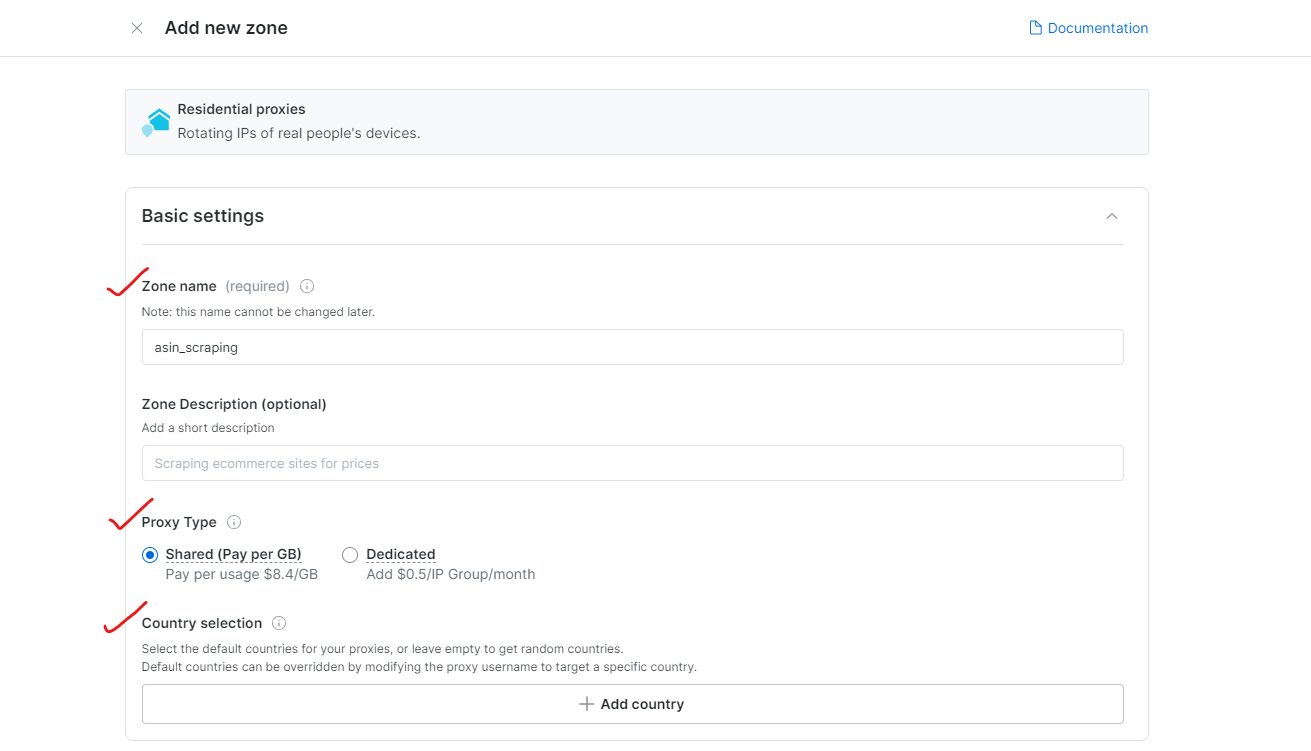
Bright Data permet un ciblage géolocalisé précis, jusqu’à la ville ou au code postal.
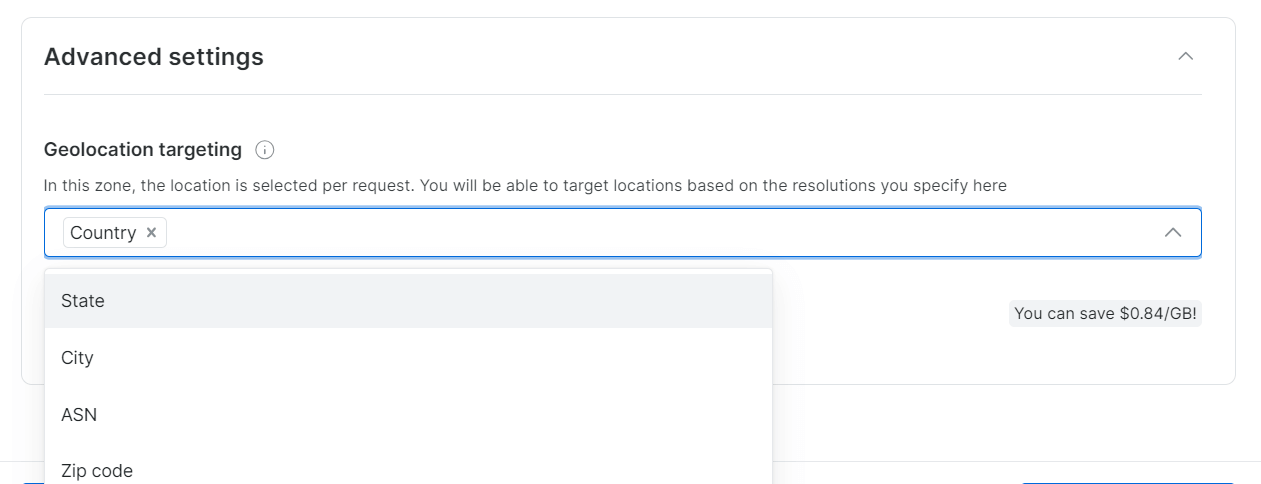
Étape 4 : Effectuez la vérification KYC
Pour bénéficier d’un accès complet aux Proxys résidentiels de Bright Data, effectuez la vérification KYC.
Étape 5 : Commencez à utiliser les Proxy
Une fois la zone Proxy créée, vous verrez apparaître les identifiants (hôte, port, nom d’utilisateur, mot de passe) pour commencer le scraping.
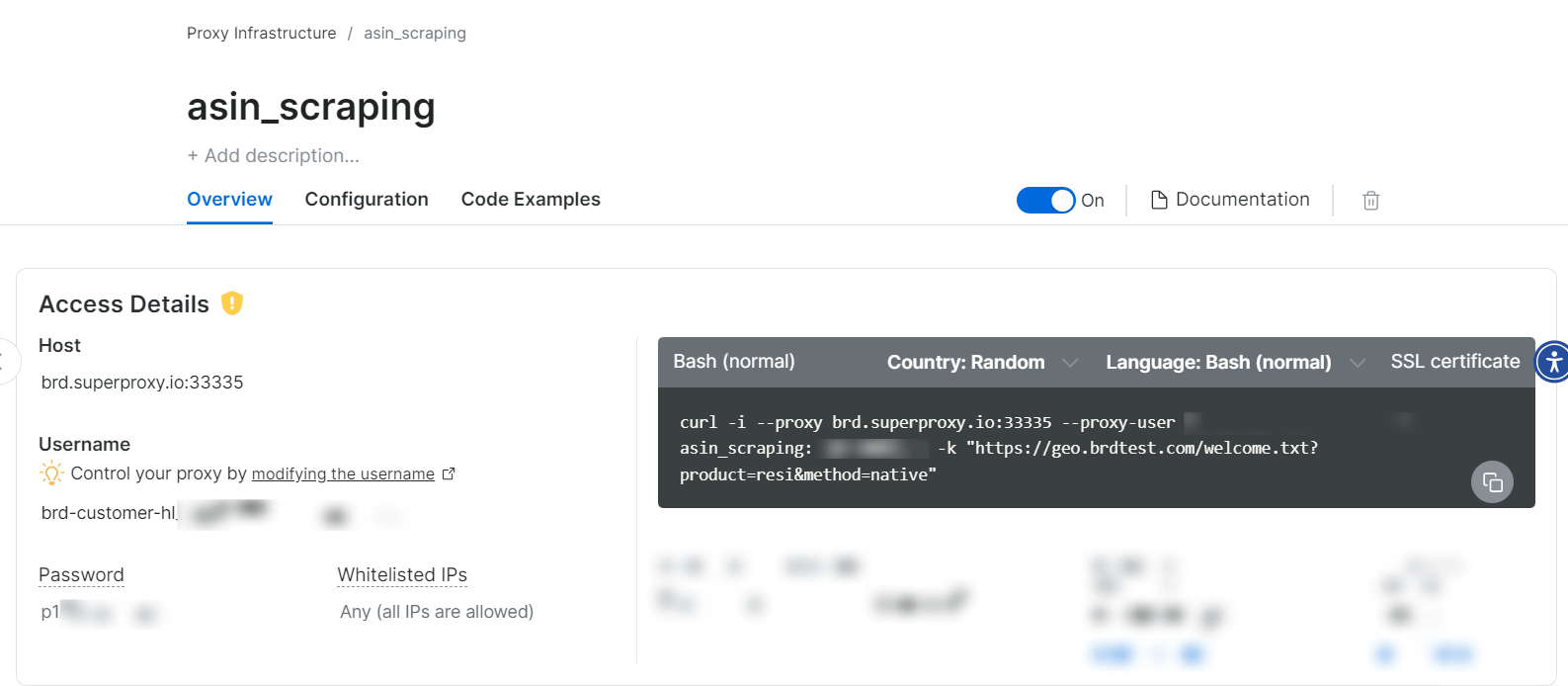
Oui, c’est aussi simple que cela !
Mise en œuvre du Scraper
Étape 1 : configuration des en-têtes du navigateur
headers = {
"accept": "text/html,application/xhtml+xml,application/xml;q=0.9,image/avif,image/webp,image/apng,*/*;q=0.8",
"accept-language": "en-US,en;q=0.9",
"sec-ch-ua": '"Chromium";v="119", "Not?A_Brand";v="24"',
"sec-ch-ua-mobile": "?0",
« sec-ch-ua-platform » : « Windows »,
« sec-fetch-dest » : « document »,
« sec-fetch-mode » : « navigate »,
« sec-fetch-site » : « none »,
« sec-fetch-user » : « ?1 »,
« upgrade-insecure-requests » : « 1 »,
« user-agent » : « Mozilla/5.0 (Windows NT 10.0 ; Win64 ; x64) AppleWebKit/537.36 (KHTML, comme Gecko) Chrome/119.0.0.0 Safari/537.36 »,
}
Étape 2 : Configuration des paramètres du Proxy
proxy_config = {
« username » : « VOTRE_NOM_D'UTILISATEUR »,
« password » : « VOTRE_MOT_DE_PASSE »,
« server » : « brd.superproxy.io:33335 »,
}
proxy_url = f"http://{proxy_config['username']}:{proxy_config['password']}@{proxy_config['server']}"
Étape 3 : Envoi de requêtes
Effectuez une requête à l’aide d’en-têtes et de Proxies avec la bibliothèque curl_cffi:
response = session.get(
url,
headers=headers,
impersonate="chrome120",
proxies={"http": proxy_url, "https": proxy_url},
timeout=30,
verify=False,
)
Remarque : la bibliothèque curl_cffi est un excellent choix pour le Scraping web, car elle offre des capacités avancées d’usurpation d’identité de navigateur qui surpassent celles de la bibliothèque standard requests.
Étape 4 : Exécution de votre Scraper
Pour exécuter votre Scraper, vous devez configurer vos mots-clés cibles. Voici un exemple :
keywords = [
"coffee maker",
"office desk",
"cctv camera"
]
max_pages = None # Définir sur None pour toutes les pages
Vous trouverez le code complet ici.
Le Scraper affichera les résultats dans un fichier CSV contenant :
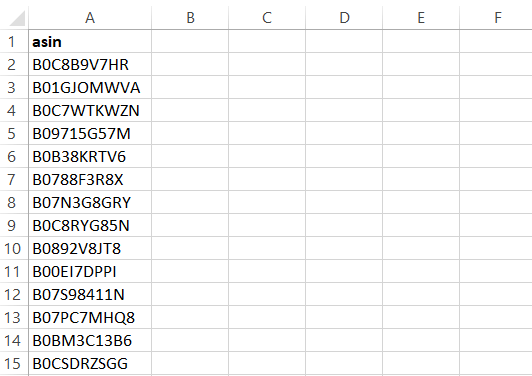
Utilisation de l’API Bright Data Amazon Scraper pour extraire les ASIN
Bien que le scraping basé sur des proxys fonctionne, l’utilisation de l’API Bright Data Amazon Scraper offre des avantages significatifs :
- Aucune gestion d’infrastructure: pas besoin de se soucier des Proxys, des rotations d’IP ou des captchas
- Scraping géolocalisé: scrapez depuis n’importe quelle région géographique
- Intégration simple: mise en œuvre en quelques minutes avec n’importe quel langage de programmation
- Plusieurs options de livraison des données:
- Exportation vers Amazon S3, Google Cloud, Azure, Snowflake ou SFTP
- Obtenez les données aux formats JSON, NDJSON, CSV ou .gz
- Conforme au RGPD et au CCPA: garantit la conformité en matière de confidentialité pour un Scraping web éthique
- 20 appels API gratuits: testez le service avant de vous engager
- Assistance 24 h/24, 7 j/7: assistance dédiée pour répondre à toutes vos questions ou résoudre tous vos problèmes liés à l’API
Configuration de l’API Amazon Scraper
La configuration de l’API est simple et peut être effectuée en quelques étapes.
Étape 1 : accédez à l’API
Accédez à l’API Web Scraper et recherchez « amazon products search » parmi les API disponibles :
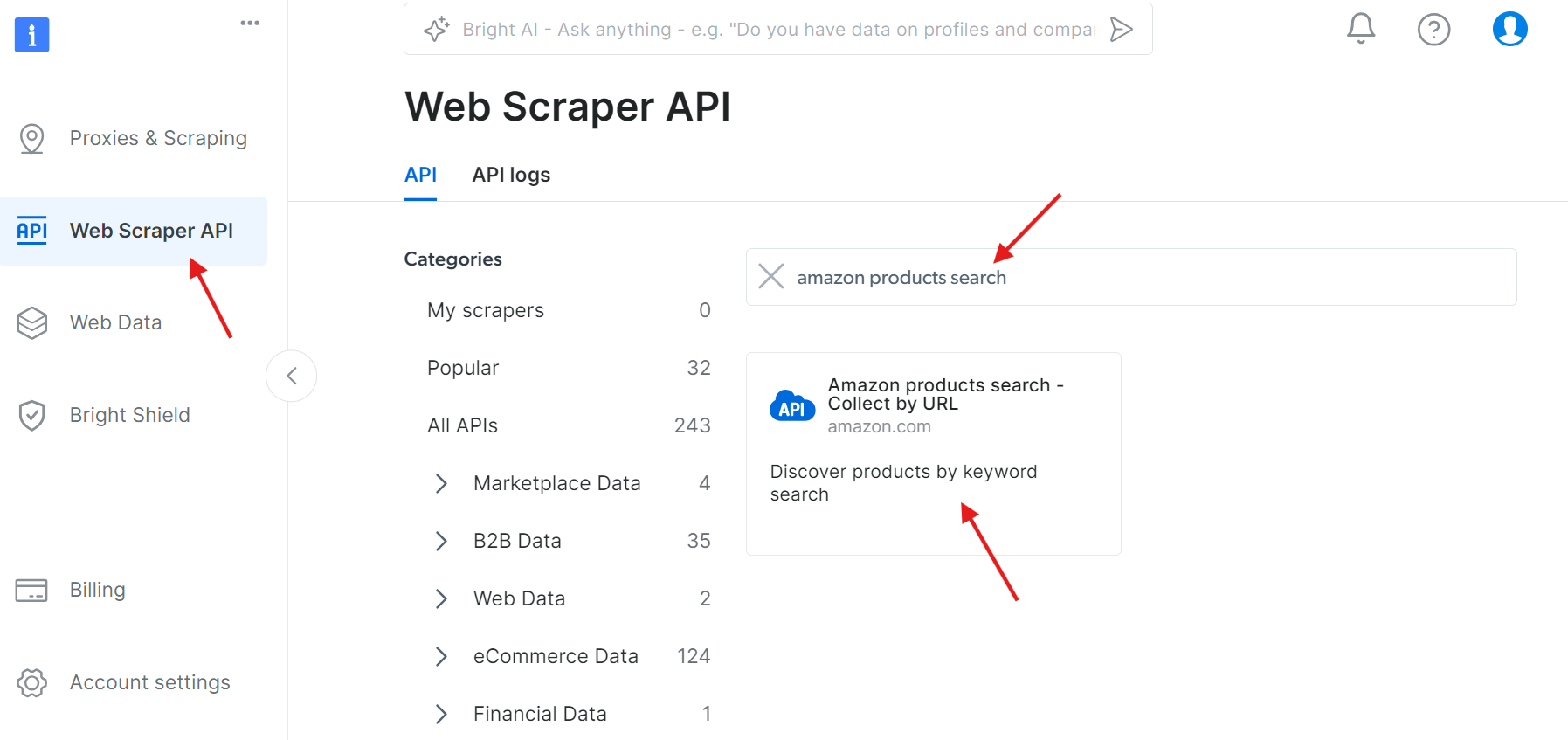
Cliquez sur « Commencer à configurer un appel API » :
Étape 2 : Obtenir votre jeton API
Cliquez sur « Obtenir le jeton API » :
Sélectionnez « Ajouter un jeton » :
Enregistrez votre nouveau jeton API en toute sécurité :
Étape 3 : Configurer la collecte de données
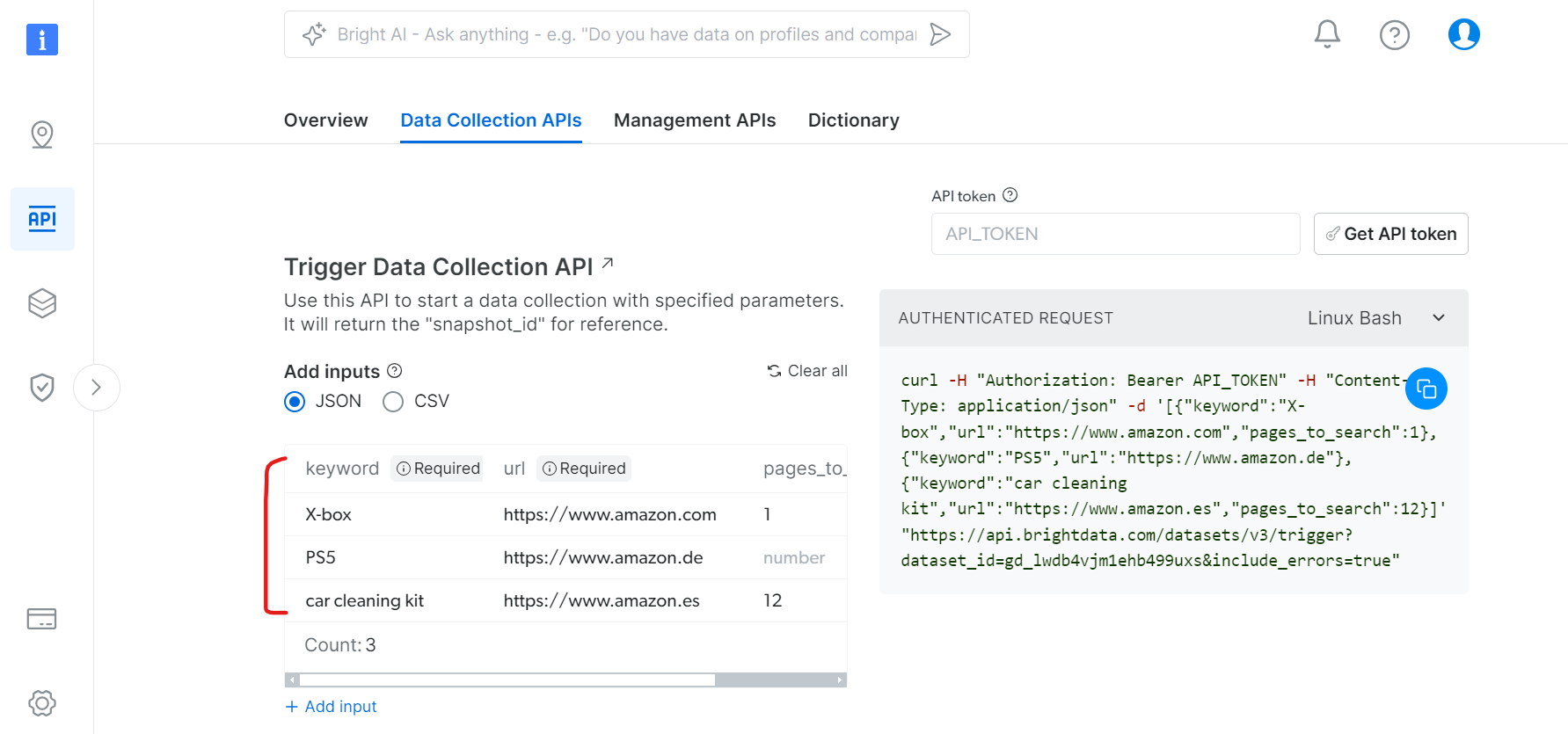
Dans l’onglet API de collecte de données :
- Spécifiez les mots-clés pour la recherche de produits
- Définissez les domaines Amazon cibles
- Définissez le nombre de pages à explorer
- Filtres supplémentaires (facultatif)
Utilisation de l’API avec Python
Voici un exemple de script Python pour déclencher la collecte de données et récupérer les résultats :
import json
import requests
import time
from typing import Dict, List, Optional, Union, Tuple
from datetime import datetime, timedelta
import logging
from requests.adapters import HTTPAdapter
from urllib3.util.retry import Retry
from enum import Enum
class SnapshotStatus(Enum):
SUCCESS = "success"
PROCESSING = « processing »
FAILED = « failed »
TIMEOUT = « timeout »
class BrightDataAmazonScraper :
def __init__(self, api_token: str, dataset_id: str) :
self.api_token = api_token
self.dataset_id = dataset_id
self.base_url = "https://api.brightdata.com/datasets/v3"
self.headers = {
"Authorization": f"Bearer {api_token}",
"Content-Type": "application/json",
}
# Configuration de la journalisation avec un format personnalisé
logging.basicConfig(
level=logging.INFO,
format='%(message)s' # Format simplifié pour n'afficher que les messages
)
self.logger = logging.getLogger(__name__)
# Configurer la session avec une stratégie de réessai
self.session = self._create_session()
# Suivre la progression
self.last_progress_update = 0
def _create_session(self) -> requests.Session:
"""Créer une session avec stratégie de réessai"""
session = requests.Session()
retry_strategy = Retry(
total=3,
backoff_factor=0.5,
status_forcelist=[500, 502, 503, 504]
)
adapter = HTTPAdapter(max_retries=retry_strategy)
session.mount("https://", adapter)
session.mount("http://", adapter)
return session
def trigger_collection(self, datasets: List[Dict]) -> Optional[str]:
"""Déclencher la collecte de données pour les Jeux de données spécifiés"""
trigger_url = f"{self.base_url}/trigger?dataset_id={self.dataset_id}"
try:
response = self.session.post(
trigger_url,
headers=self.headers,
json=Jeux de données
)
response.raise_for_status()
snapshot_id = response.json().get("snapshot_id")
if snapshot_id:
self.logger.info("Initialisation de la collecte de données Amazon...")
return snapshot_id
else:
self.logger.error("Impossible d'initialiser la collecte de données.")
return None
except requests.exceptions.RequestException as e:
self.logger.error(f"Échec de l'initialisation de la collecte : {str(e)}")
return None
def check_snapshot_status(self, snapshot_id: str) -> Tuple[SnapshotStatus, Optional[Dict]]:
"""Vérifier l'état actuel d'un instantané"""
snapshot_url = f"{self.base_url}/snapshot/{snapshot_id}?format=json"
try:
response = self.session.get(snapshot_url, headers=self.headers)
if response.status_code == 200:
return SnapshotStatus.SUCCESS, response.json()
elif response.status_code == 202:
return SnapshotStatus.PROCESSING, None
else:
return SnapshotStatus.FAILED, None
except requests.exceptions.RequestException:
return SnapshotStatus.FAILED, None
def wait_for_snapshot_data(
self,
snapshot_id: str,
timeout: Optional[int] = None,
check_interval: int = 10,
max_interval: int = 300,
callback=None
) -> Optional[Dict] :
"""Attendre les données de l'instantané avec un minimum de sortie console"""
start_time = datetime.now()
current_interval = check_interval
attempts = 0
progress_shown = False
while True :
attempts += 1
if timeout is not None:
elapsed_time = (datetime.now() - start_time).total_seconds()
if elapsed_time >= timeout:
self.logger.error("Data collection exceeded time limit.")
return None
status, data = self.check_snapshot_status(snapshot_id)
if status == SnapshotStatus.SUCCESS:
self.logger.info(
"Collecte des données Amazon terminée avec succès !")
return data
elif status == SnapshotStatus.FAILED:
self.logger.error("Une erreur s'est produite lors de la collecte des données.")
return None
elif status == SnapshotStatus.PROCESSING:
# Afficher l'indicateur de progression toutes les 30 secondes seulement
current_time = time.time()
if not progress_shown:
self.logger.info("Collecte des données depuis Amazon...")
progress_shown = True
elif current_time - self.last_progress_update >= 30:
self.logger.info("Collecte de données en cours...")
self.last_progress_update = current_time
if callback:
callback(attempts, (datetime.now() -
start_time).total_seconds())
time.sleep(current_interval)
current_interval = min(current_interval * 1.5, max_interval)
def store_data(self, data: Dict, filename: str = "amazon_data.json") -> None:
"""Stocker les données collectées dans un fichier JSON"""
if data:
try:
with open(filename, "w", encoding='utf-8') as file:
json.dump(data, file, indent=4, ensure_ascii=False)
self.logger.info(f"Données enregistrées avec succès dans {filename}")
except IOError as e:
self.logger.error(f"Erreur lors de l'enregistrement des données : {str(e)}")
else:
self.logger.warning("Aucune donnée disponible à enregistrer.")
def progress_callback(attempts: int, elapsed_time: float):
"""Fonction de rappel minimale - peut être personnalisée en fonction des besoins"""
pass # Silencieux par défaut
def main():
# Configuration
API_TOKEN = "YOUR_API_TOKEN"
DATASET_ID = "gd_lwdb4vjm1ehb499uxs"
# Initialisation du Scraper
scraper = BrightDataAmazonScraper(API_TOKEN, DATASET_ID)
# Définition des paramètres de recherche
datasets = [
{"keyword": "X-box", "url": "https://www.amazon.com", "pages_to_search": 1},
{"keyword": "PS5", "url": "https://www.amazon.de"},
{"keyword": "car cleaning kit",
"url": "https://www.amazon.es", "pages_to_search": 4},
]
# Exécuter le processus de scraping
snapshot_id = scraper.trigger_collection(Jeux de données)
if snapshot_id:
data = scraper.wait_for_snapshot_data(
snapshot_id,
timeout=None,
check_interval=10,
max_interval=300,
callback=progress_callback
)
if data:
Scraper.store_data(data)
print("nProcessus de scraping terminé avec succès !n")
if __name__ == "__main__":
main()
Pour exécuter ce code, veillez à remplacer les valeurs suivantes :
API_TOKENpar votre jeton API réel.- Modifiez la liste
des Jeux de donnéespour inclure les produits ou les mots-clés que vous souhaitez rechercher.
Voici un exemple de structure JSON des données récupérées :
{
"asin": "B0CJ3XWXP8",
"url": "https://www.amazon.com/Xbox-X-Console-Renewed/dp/B0CJ3XWXP8/ref=sr_1_1",
"name": "Console Xbox Series X (reconditionnée) Console Xbox Series X (reconditionnée) 15 septembre 2023",
"sponsored": "false",
"initial_price": 449.99,
"final_price": 449.99,
"currency": "USD",
"sold": 2000,
"rating": 4.1,
« num_ratings » : 1529,
« variations » : null,
« badge » : null,
« business_type » : null,
« brand » : null,
« delivery » : [« Livraison GRATUITE le dimanche 1er décembre », « Ou livraison rapide le vendredi 29 novembre »],
« keyword » : « X-box »,
« image » : « https://m.media-amazon.com/images/I/51ojzJk77qL._AC_UY218_.jpg »,
« domain » : « https://www.amazon.com/ »,
« acheté_le_mois_dernier » : 2000,
« numéro_de_page » : 1,
« rang_sur_la_page » : 1,
« horodatage » : « 2024-11-26T05:15:24.590Z »,
« input » : {
« keyword » : « X-box »,
« url » : « https://www.amazon.com »,
« pages_to_search » : 1,
},
}
Vous pouvez consulter le résultat complet en téléchargeantcet exemple de fichier JSON.
Conclusion
Nous avons discuté du processus de collecte des ASIN Amazon à l’aide de Python, mais nous avons également rencontré plusieurs difficultés en cours de route. Des problèmes tels que les CAPTCHA et les limites de débit peuvent considérablement entraver nos efforts de collecte de données. Pour y remédier, nous pouvons utiliser des outils tels que les Proxies de Bright Data ou l’API Amazon Scraper. Ces options peuvent aider à accélérer le processus et à contourner les obstacles courants. Si vous préférez éviter les tracas liés à la configuration de vos outils de scraping, Bright Data propose également des Jeux de données Amazon prêts à l’emploi que vous pouvez utiliser immédiatement.
Inscrivez-vous dès maintenant et commencez votre essai gratuit !





