
Si vous développez une application de génération augmentée par la recherche (RAG), vous avez besoin de données récentes sur votre sujet, et non d’un PDF statique issu d’un tutoriel. Mais le scraping d’articles réels implique des barrières anti-bot et des requêtes bloquées. Même avec des données, vous devez encore les segmenter, les intégrer, les indexer et mettre en place la recherche.
Ce tutoriel fait tout cela. Bright Data trouve et extrait des articles sur n’importe quel sujet, Weaviate les stocke et les recherche, et vous obtenez des réponses avec des citations dans un seul script Python.
TL;DR
Transformez n’importe quel sujet en une base de connaissances consultable et capable de répondre à des questions, alimentée par des données Web en temps réel plutôt que par des données d’entraînement obsolètes.
- L’API SERP de Bright Data trouve les URL d’articles réels pour votre sujet ; Web Unlocker les extrait (même sur les sites protégés contre les bots).
- Weaviate vectorise automatiquement des segments via Cohere, les indexe avec une recherche hybride et génère des réponses référencées en un seul appel API
- Exécutez
python3 pipeline.py, saisissez un sujet et obtenez des réponses RAG référencées en quelques minutes. - Code source complet sur GitHub – clonez et exécutez
Obtenez vos clés API et essayez-le avec votre propre sujet.
Voici à quoi ressemble le résultat final :

Exécutez le pipeline en 3 à 5 minutes
Si vous disposez déjà de clés API, exécutez le pipeline dès maintenant :
# 1. Clonez le dépôt (nécessite Python 3.10+)
git clone https://github.com/triposat/weaviate-bright-data-rag.git
cd weaviate-bright-data-rag
# 2. Installez les dépendances
pip3 install -r requirements.txt
# 3. Créez votre fichier .env
cp .env.example .env
# Modifiez .env et saisissez vos clés API (voir « Obtenir vos clés API » ci-dessous)
# 4. Exécutez-le
python3 pipeline.pyLe pipeline vous demande un sujet et détecte automatiquement vos zones Bright Data. Il trouve et extrait des articles réels. Il les découpe en morceaux et les stocke dans Weaviate (vectorisation automatique via Cohere), exécute des requêtes de démonstration et passe en mode interactif pour que vous puissiez poser vos propres questions.
Obtenez vos clés API (gratuit pour commencer)
Vous avez besoin de 3 clés API – 1 pour chaque service. Cohere et Weaviate ne nécessitent pas de carte de crédit ; Bright Data vous offre un crédit d’essai gratuit lors de votre inscription.
1. Clé API Bright Data
Créez une clé API et 2 zones :
- Inscrivez-vous sur brightdata.com
- Allez dans Paramètres du compte → Utilisateurs et clés API
- Créez une nouvelle clé API → copiez-la → collez-la en tant que valeur
BRIGHT_DATA_API_TOKENdans votre fichier.env
Le pipeline a également besoin de 2 zones : API SERP et Web Unlocker. Vérifiez si vous les avez déjà dans Proxies & Scraping → Mes zones. Si vous ne les voyez pas, créez-les :
- Allez dans Proxies & Scraping → sélectionnez Mes zones
- Sélectionnez Ajouter → choisissez le type de zone API SERP → donnez-lui un nom (par exemple,
serp) → enregistrez - Sélectionnez à nouveau Ajouter → choisissez le type de zone Unlocker API → donnez-lui un nom (par exemple,
unlocker) → enregistrez
Vous n’avez pas besoin de copier les noms de zone ou les mots de passe. Le pipeline utilise votre clé API pour les détecter automatiquement.
2. Clé API Cohere (gratuite)
Cohere gère à la fois l’intégration et la génération dans ce pipeline :
- Rendez-vous sur dashboard.cohere.com
- Inscrivez-vous avec Google, GitHub ou par e-mail – aucune carte de crédit requise
- Votre clé API d’essai s’affiche sur le tableau de bord – copiez-la
- Le forfait d’essai est limité en termes de débit, mais généreux (l’exécution automatisée utilise moins de 20 appels ; chaque question interactive en ajoute 2 de plus)
3. Identifiants Weaviate Cloud (gratuit)
Créez un cluster sandbox gratuit pour stocker et interroger vos vecteurs :
- Rendez-vous sur console.weaviate.cloud
- Inscrivez-vous avec Google ou GitHub
- Sélectionnez « Créer un cluster » → choisissez « Sandbox (gratuit) » → sélectionnez une région → créez
- Patientez environ 30 secondes, puis sélectionnez votre cluster → onglet « Détails »
- Copiez le point de terminaison REST (l’URL de votre cluster) et la clé API
Remarque : les clusters Sandbox expirent au bout de 14 jours. Si votre cluster expire, créez-en un nouveau et mettez à jour l’URL et la clé dans votre fichier .env. Relancez pipeline.py pour réimporter vos données.
Une fois que vous disposez des 3 clés, revenez à la section « Exécuter le pipeline en 3 à 5 minutes » et suivez les étapes de clonage/installation.
Fonctionnement de bout en bout du pipeline RAG
Le pipeline comporte 4 étapes : collecte des données, traitement, stockage des vecteurs et génération :
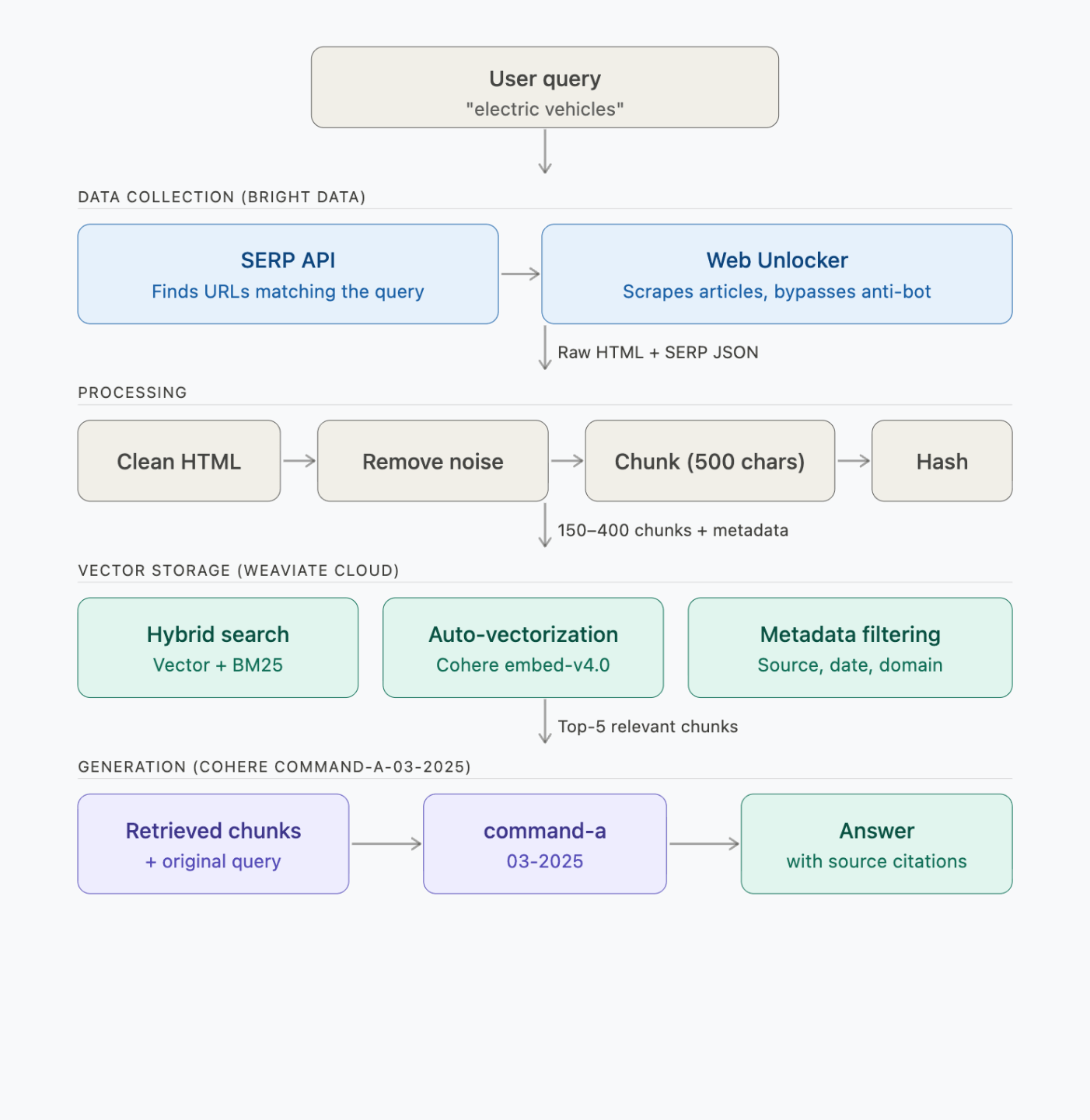
Chaque étape effectue les appels API suivants :
| Étape | Ce qui s’exécute | Durée | Appels API |
|---|---|---|---|
| 1. Recherche + extraction | Bright Data SERP + Web Unlocker | ~2–3 min | 2 requêtes SERP + 6 requêtes de scraping |
| 2. Traiter + segmenter | Local (BeautifulSoup + chunker) | <1 s | 0 |
| 3. Intégration + stockage | Weaviate → Cohere embed-v4.0 | ~30–60 s | ~150–400 intégrations (par lots) |
| 4. Requête (3 démos) | Weaviate → Cohere command-a-03-2025 | ~5 s/requête | 1 recherche + 1 génération par requête |
Rôle de Bright Data dans le pipeline
Bright Data est une plateforme de données Web. Dans ce pipeline, elle joue deux rôles :
| Produit | Ce qu’elle fait dans ce pipeline |
|---|---|
| API SERP | Vous saisissez un sujet, l’API SERP effectue une recherche sur Google et renvoie les URL réelles des articles – aucune URL codée en dur n’est nécessaire |
| Web Unlocker | Récupère 6 articles par sujet, y compris sur les sites dotés d’une protection anti-bot – de 200 000 à 1,8 million de caractères chacun |
Ce pipeline utilise l’API SERP et Web Unlocker. Pour d’autres approches de collecte de données, consultez la liste complète des produits de Bright Data.
Pourquoi utiliser Bright Data pour le RAG
Voici quelques points importants à prendre en compte lorsque vous effectuez du scraping pour le RAG :
- Un scraping fiable. Web Unlocker gère automatiquement les tentatives de reconnexion, la rotation des adresses IP et l’empreinte digitale du navigateur, afin que le pipeline ne se bloque pas sur des pages anti-bot en cours d’exécution.
- Sortie compatible LLM. L’API Crawl renvoie du Markdown propre au lieu de HTML brut, ce qui réduit le prétraitement pour les pipelines d’intégration (ce tutoriel utilise Web Unlocker + BeautifulSoup, mais l’API Crawl est une solution plus rapide si vous n’avez pas besoin de HTML brut).
- Évolutivité. Ce tutoriel extrait 6 articles. En production, vous pourriez en avoir besoin de 6 000. L’infrastructure IA de Bright Data prend en charge le scraping simultané à cette échelle sans modification de code de votre part.
- Conformité. Bright Data est conforme au RGPD et au CCPA et exige une vérification d’identité avant d’accorder un accès complet au réseau.
Ce que fait Weaviate dans le pipeline
Weaviate est une base de données vectorielle open source. Elle effectue la récupération et la génération en un seul appel API, vous n’avez donc pas besoin d’appeler le LLM séparément.
Ici, Weaviate stocke les segments extraits et les vectorise via Cohere. Lorsque vous effectuez une requête, il exécute une recherche hybride et génère une réponse via son API de recherche générative.
| Fonctionnalité | Fonctionnement dans ce pipeline |
|---|---|
| Recherche hybride | Combine des vecteurs sémantiques (70 %) avec la correspondance de mots-clés BM25 (30 %) via un paramètre alpha réglable |
| Recherche générative intégrée | Récupère les 5 meilleurs segments et génère les réponses citées en un seul appel à generate.hybrid() |
| Vectorisation automatique | Weaviate appelle automatiquement l’API d’intégration Cohere lors de l’importation – vous n’avez pas à écrire de code d’intégration |
| Filtrage des métadonnées | Stocke l’URL source, le domaine, l’horodatage de l’extraction et le type de contenu à côté de chaque fragment |
Weaviate à grande échelle
Weaviate dispose également de fonctionnalités que ce pipeline n’utilise pas, mais qui sont importantes à grande échelle :
- Licence BSD à 3 clauses – vous pouvez l’héberger vous-même ou créer un fork si nécessaire
- Plusieurs options de déploiement: Weaviate Cloud (sandbox gratuite), Dedicated Cloud, Kubernetes auto-hébergé
- Multi-tenancy – plus de 50 000 locataires par nœud pour les applications SaaS
- Quantification par rotation – compression vectorielle 4x avec un taux de rappel de 98 à 99 %
Construire le pipeline RAG étape par étape
Chaque étape ci-dessous présente la logique principale issue du fichier pipeline.py. Le code source complet est disponible sur GitHub.
Configuration du projet et importations
Commencez par importer les dépendances et charger les informations d’identification depuis votre fichier .env:
import os
import sys
import time
import hashlib
import requests
import urllib3
from urllib.parse import quote
from datetime import datetime, timezone
from dotenv import load_dotenv
from bs4 import BeautifulSoup
import weaviate
from weaviate.classes.init import Auth
from weaviate.classes.config import Configure, Property, DataType
urllib3.disable_warnings()
load_dotenv()
# Chargement des informations d'identification à partir du fichier .env
COHERE_API_KEY = os.getenv("COHERE_API_KEY")
WEAVIATE_URL = os.getenv("WEAVIATE_URL")
WEAVIATE_API_KEY = os.getenv("WEAVIATE_API_KEY")
BD_API_TOKEN = os.getenv("BRIGHT_DATA_API_TOKEN")
COLLECTION_NAME = "WebResearch"
def clean_url(url):
"""Corrige les artefacts nbsp dans les URL (provenant de problèmes d'encodage sur certains sites)."""
cleaned = url.replace("nbsp", "-")
while "--" in cleaned:
cleaned = cleaned.replace("--", "-")
return cleaned
def clean_generated_text(text):
"""Nettoie le texte généré par le LLM pour l'affichage en terminal."""
text = text.replace("**", "")
text = text.replace("nbsp", "-")
while "--" in text:
text = text.replace("--", "-")
return textAvant toute chose, le pipeline vérifie que toutes les informations d’identification requises sont définies dans votre fichier .env:
def validate_env():
"""Vérifie que toutes les variables d'environnement requises sont définies."""
missing = []
if not BD_API_TOKEN:
missing.append("BRIGHT_DATA_API_TOKEN")
if not COHERE_API_KEY:
missing.append("COHERE_API_KEY")
if not WEAVIATE_URL:
missing.append("WEAVIATE_URL")
if not WEAVIATE_API_KEY:
missing.append("WEAVIATE_API_KEY")
if missing:
print("ERREUR : Variables d'environnement manquantes dans le fichier .env :")
for var in missing:
print(f" - {var}")
# ... affiche un exemple de format .env ...
print("nConsultez l'article de blog pour savoir comment obtenir chaque clé (tout est gratuit pour commencer).")
sys.exit(1)Vous n’avez pas besoin de configurer les noms de zone ou les mots de passe : le pipeline les détecte automatiquement à partir de votre clé API :
def discover_bright_data_credentials():
"""
Détecte automatiquement les identifiants du Proxy Bright Data à partir de la clé API.
Fonctionne pour tout compte Bright Data. Aucune valeur codée en dur n'est nécessaire.
"""
headers = {"Authorization": f"Bearer {BD_API_TOKEN}"}
# 1. Récupérer les zones actives
zones = requests.get(
"https://api.brightdata.com/zone/get_active_zones", headers=headers
).json()
# Sélectionner la première zone de chaque type (si vous en avez plusieurs, définissez le nom explicitement)
zone_names = {}
for z in zones:
if z["type"] not in zone_names:
zone_names[z["type"]] = z["name"]
# « unblocker » est le nom de l'API du produit Web Unlocker
unlocker_zone = zone_names.get("unblocker")
serp_zone = zone_names.get("serp")
# 2. Récupérer les mots de passe des zones
unlocker_pwd = requests.get(
f"https://api.brightdata.com/zone/passwords?zone={unlocker_zone}",
headers=headers,
).json()["passwords"][0]
serp_pwd = requests.get(
f"https://api.brightdata.com/zone/passwords?zone={serp_zone}",
headers=headers,
).json()["passwords"][0]
# 3. Récupérer l'ID client (l'API cost renvoie {customer_id: cost_data})
cost = requests.get(
f"https://api.brightdata.com/Zone/cost?Zone={unlocker_zone}",
headers=headers,
).json()
customer_id = list(cost.keys())[0]
return customer_id, unlocker_zone, unlocker_pwd, serp_zone, serp_pwdClonez le dépôt, ajoutez votre clé API, et le pipeline s’occupe du reste.
Étape 1 : Rechercher et extraire des articles avec Bright Data
Le pipeline utilise l’API SERP pour trouver les URL d’articles correspondant à votre sujet, puis extrait le contenu de chacun d’entre eux via Web Unlocker :
def get_bd_proxy(customer_id, zone, password):
"""Construire l'URL du Proxy Bright Data."""
proxy = f"http://brd-customer-{customer_id}-zone-{zone}:{password}@brd.superproxy.io:33335"
return {"http": Proxy, "https": Proxy}
def search_serp(query, customer_id, zone, password, num=10):
"""Effectuer une recherche sur Google via l'API SERP de Bright Data et renvoyer les résultats naturels."""
proxies = get_bd_proxy(customer_id, zone, password)
# brd_json=1 indique à Bright Data de renvoyer du JSON structuré au lieu de HTML brut
search_url = f"https://www.google.com/search?q={quote(query)}&brd_json=1&num={num}"
try:
# verify=False contourne la vérification SSL pour le Proxy BD.
# Pour la production, installez plutôt le certificat CA de Bright Data :
# https://docs.brightdata.com/general/account/ssl-certificate
response = requests.get(search_url, proxies=proxies, timeout=30, verify=False)
if response.status_code == 200:
data = response.json()
return [
{
"title": item.get("title", ""),
"url": item.get("link", ""),
"description": item.get("description", ""),
}
for item in data.get("organic", [])
]
except Exception as e:
print(f"Erreur SERP : {str(e)[:60]}", end=" ", flush=True)
return []search_serp() envoie la requête via le Proxy SERP de Bright Data et renvoie un JSON structuré (titres, URL, descriptions). Le paramètre brd_json=1 indique à Bright Data de réaliser l’analyse du code HTML de Google en JSON propre pour vous.
Ensuite, find_articles_for_topic() exécute 2 requêtes SERP par sujet et filtre les résultats, tandis que scrape_url() récupère chaque article via Web Unlocker :
def find_articles_for_topic(topic, customer_id, serp_zone, serp_pwd):
"""Utilise l'API SERP de Bright Data pour trouver les URL d'articles réels sur un sujet."""
search_queries = [
f"{topic} dernières actualités et tendances",
f"{topic} guide d'analyse approfondie",
]
# Ignorer les domaines qui renvoient du contenu autre que des articles (vidéos, flux, réseaux sociaux)
skip_domains = {
"youtube.com", "twitter.com", "x.com", "facebook.com", "instagram.com",
"reddit.com", "linkedin.com", "wikipedia.org", "amazon.com", "tiktok.com",
}
skip_extensions = (".pdf", ".doc", ".ppt", ".xls", ".zip", ".mp4", ".mp3")
all_urls = []
seen_domains = set()
serp_docs = []
for query in search_queries:
results = search_serp(query, customer_id, serp_zone, serp_pwd, num=10)
if results:
# Enregistrer les titres et descriptions SERP dans un document afin que le LLM puisse
# se référer aux résumés d'articles même en cas d'échec de l'extraction complète
serp_text = f"Résultats de recherche Google pour : {query}nn"
for r in results:
serp_text += f"Titre : {r['title']}nURL : {r['url']}n"
serp_text += f"Résumé : {r['description']}nn"
serp_docs.append({
"url": f"https://google.com/search?q={quote(query)}",
"html": serp_text,
"scraped_at": datetime.now(timezone.utc).isoformat(),
"is_serp": True,
})
# Extraire les URL des articles (1 par domaine pour plus de diversité)
for r in results:
url = r.get("url", "")
if not url:
continue
domain = url.split("/")[2] if "://" in url else ""
base_domain = ".".join(domain.split(".")[-2:])
if base_domain in skip_domains:
continue
if any(url.lower().endswith(ext) for ext in skip_extensions):
continue
if base_domain in seen_domains:
continue # Un article par domaine pour plus de diversité
seen_domains.add(base_domain)
all_urls.append(url)
return all_urls[:6], serp_docs # Les 6 premières URL
def scrape_url(url, customer_id, zone, password, retries=2):
"""Extraire une URL à l'aide de Bright Data Web Unlocker avec réessai automatique."""
proxies = get_bd_proxy(customer_id, Zone, password)
# Aucun en-tête personnalisé n'est nécessaire : Web Unlocker gère automatiquement l'User-Agent,
# les cookies et les empreintes digitales.
for attempt in range(retries + 1):
try:
# verify=False contourne la vérification SSL pour le Proxy BD.
# Pour la production, installez plutôt le certificat CA de Bright Data :
# https://docs.brightdata.com/general/account/ssl-certificate
response = requests.get(
url, proxies=proxies, timeout=60, verify=False
)
if response.status_code == 200:
return {
"url": url,
"html": response.text,
"scraped_at": datetime.now(timezone.utc).isoformat(),
}
else:
print(f"HTTP {response.status_code}", end=" → ", flush=True)
except Exception as e:
print(f"Error: {str(e)[:60]}", end=" → ", flush=True)
if attempt < retries:
time.sleep(2)
return Nonecollect_data() combine les deux étapes : SERP trouve les URL, Web Unlocker les extrait :
def collect_data(topic, customer_id, unlocker_zone, unlocker_pwd, serp_zone, serp_pwd):
"""Rechercher des articles sur le sujet via SERP, puis les extraire avec Web Unlocker."""
documents = []
# 1. Utiliser l'API SERP pour trouver les URL des articles
urls_to_scrape, serp_docs = find_articles_for_topic(
topic, customer_id, serp_zone, serp_pwd
)
if not urls_to_scrape:
return []
# 2. Extraire les articles trouvés avec Web Unlocker
for i, url in enumerate(urls_to_scrape):
domain = url.split("/")[2] if "://" in url else url
print(f" ({i+1}/{len(urls_to_scrape)}) {domain}... ", end="", flush=True)
result = scrape_url(url, customer_id, unlocker_zone, unlocker_pwd)
if result:
documents.append(result)
print(f"OK ({len(result['html']):,} caractères)")
else:
print("ÉCHEC (ignoration)")
# 3. Ajouter les résultats SERP en tant que documents supplémentaires
documents.extend(serp_docs)
return documentsL’exécution avec « OpenAI vs Google vs Anthropic IA race » produit le résultat suivant :
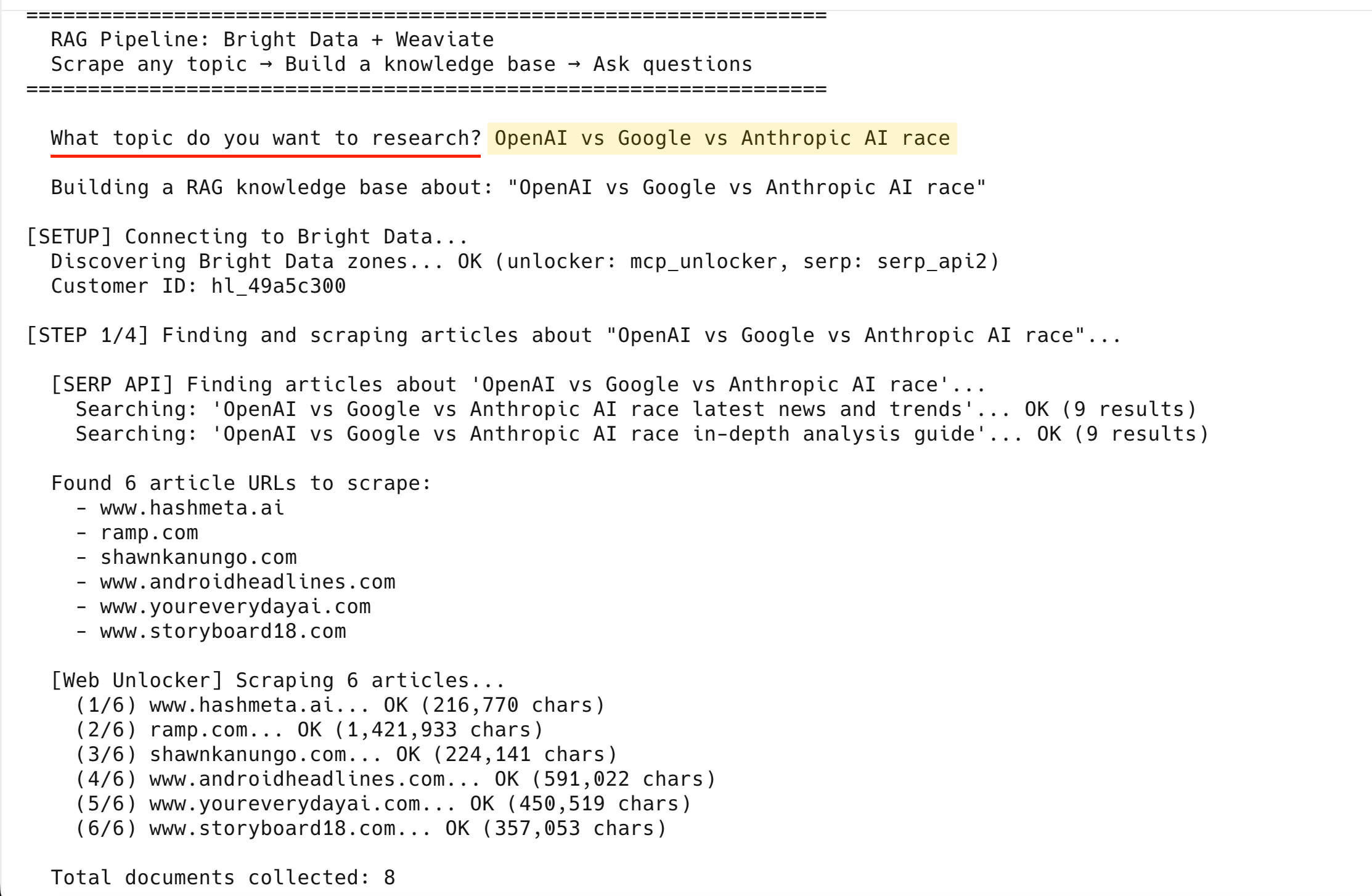
[API SERP] Recherche d'articles sur « OpenAI vs Google vs Anthropic IA race »...
Recherche : « OpenAI vs Google vs Anthropic IA race dernières actualités et tendances »... OK (9 résultats)
Recherche : « OpenAI vs Google vs Anthropic IA race guide d'analyse approfondie »... OK (9 résultats)
6 URL d'articles à extraire trouvées :
- www.hashmeta.ia
- ramp.com
- shawnkanungo.com
- www.androidheadlines.com
- www.youreverydayai.com
- www.storyboard18.com
[Web Unlocker] Extraction de 6 articles...
(1/6) www.hashmeta.ai... OK (216 770 caractères)
(2/6) ramp.com... OK (1 421 933 caractères)
(3/6) shawnkanungo.com... OK (224 141 caractères)
(4/6) www.androidheadlines.com... OK (591 022 caractères)
(5/6) www.youreverydayai.com... OK (450 519 caractères)
(6/6) www.storyboard18.com... OK (357 053 caractères)
Nombre total de documents collectés : 8Les 6 ont été récupérés avec succès – les 2 pages de résultats SERP portent le total à 8 documents.
Si Web Unlocker échoue sur une URL après 3 tentatives, le pipeline l’ignore et passe aux articles restants.
À ce stade, vous disposez de 8 documents bruts (6 articles + 2 pages de résultats SERP). Il faut maintenant les nettoyer et les découper en morceaux pour les intégrer.
Étape 2 : Nettoyer et découper les données
Le code HTML brut contient environ 90 % de bruit. L’étape de traitement le réduit à du texte propre et le divise en segments de 500 caractères (environ 125 tokens) qui se terminent, dans la mesure du possible, à la fin d’une phrase.
La taille des segments détermine un compromis essentiel du RAG : des segments plus petits (200 à 500 caractères) permettent une récupération précise par fait, tandis que des segments plus grands (1 000 à 2 000 caractères) fournissent au LLM davantage de contexte, au prix de résultats de recherche plus bruyants. La valeur par défaut de 500 caractères fonctionne bien pour les questions factuelles (« Quel est le taux de réussite d’Anthropic face à OpenAI dans le secteur des entreprises ? »). Augmentez la taille des segments (chunk_size) à 1 500–2 000 pour les requêtes nécessitant un contexte plus large, comme les résumés ou les comparaisons.
Le chevauchement de 50 caractères empêche la perte d’informations aux limites ; sans cela, une phrase s’étendant sur deux segments serait coupée et aucun des deux segments ne contiendrait la pensée complète.
def clean_html(html, is_serp=False):
"""Dépouille le code HTML pour obtenir du texte propre, en supprimant la navigation, les publicités et les éléments standard."""
if is_serp:
return html # Les résultats SERP sont déjà du texte propre
soup = BeautifulSoup(html, "html.parser")
# Supprimer les éléments parasites
for tag in soup(["nav", "footer", "header", "script", "style",
"aside", "iframe", "noscript", "svg", "form", "button"]):
tag.decompose()
# Supprimer les conteneurs courants de publicités, cookies et fenêtres contextuelles
for selector in [".ad", ".ads", ".cookie", ".popup", ".modal", ".sidebar",
"#cookie-banner", "#ad-container", "[role='banner']",
"[role='navigation']", "[role='complementary']"]:
for el in soup.select(selector):
el.decompose()
text = soup.get_text(separator="n", strip=True)
lines = [line.strip() for line in text.splitlines() if line.strip()]
return "n".join(lines)
def chunk_text(text, chunk_size=500, chunk_overlap=50):
"""Divise le texte en morceaux qui se chevauchent, en coupant aux limites des phrases.
Le chevauchement garantit que les phrases situées aux limites des segments ne sont pas perdues entre les segments."""
if len(text) <= chunk_size:
return [text]
chunks = []
start = 0
while start < len(text):
end = start + chunk_size
# Essayer de couper à la limite d'une phrase
if end < len(text):
for sep in [". ", ".n", "nn", "n", " "]:
last_sep = text[max(start, end - 100):end].rfind(sep)
if last_sep != -1:
end = max(start, end - 100) + last_sep + len(sep)
break
chunk = text[start:end].strip()
if chunk and len(chunk) > 50:
chunks.append(chunk)
start = end - chunk_overlap
return chunks
def process_documents(documents):
"""Nettoyer, segmenter et ajouter des métadonnées à tous les documents."""
all_chunks = []
for doc in documents:
is_serp = doc.get("is_serp", False)
clean_text = clean_html(doc["html"], is_serp=is_serp)
if len(clean_text) < 100:
continue
chunks = chunk_text(clean_text)
domain = doc["url"].split("/")[2] if "://" in doc["url"] else "unknown"
for i, chunk in enumerate(chunks):
all_chunks.append({
"text": chunk,
"source_url": doc["url"],
"source_domain": domain,
"scraped_at": doc["scraped_at"],
"chunk_index": i,
"total_chunks": len(chunks),
"content_hash": hashlib.md5(chunk.encode()).hexdigest(),
"content_type": "serp_result" if is_serp else "article",
})
return all_chunksAprès traitement, 8 documents sont transformés en environ 150 à 400 segments de texte épurés (selon la longueur de l’article), chacun accompagné de métadonnées (URL source, domaine, horodatage, hachage du contenu).
Étape 3 : Intégrer et stocker dans Weaviate
Connectez-vous à Weaviate Cloud, créez une collection avec la vectorisation Cohere, puis importez tous les chunks par lots.
def connect_weaviate():
"""Se connecter à Weaviate Cloud avec des délais d'expiration prolongés."""
client = weaviate.connect_to_weaviate_cloud(
cluster_url=WEAVIATE_URL,
auth_credentials=Auth.api_key(WEAVIATE_API_KEY),
headers={"X-Cohere-Api-Key": COHERE_API_KEY},
additional_config=weaviate.classes.init.AdditionalConfig(
timeout=weaviate.classes.init.Timeout(init=30, query=60, insert=120),
),
skip_init_checks=True, # Empêche le délai d'expiration gRPC sur les sandbox inactives
)
if not client.is_ready():
print(" ERREUR : le cluster Weaviate n'est pas prêt.")
print(" Vérifiez vos variables WEAVIATE_URL et WEAVIATE_API_KEY dans .env")
print(" Assurez-vous que votre cluster de sandbox est en cours d'exécution sur console.weaviate.cloud")
sys.exit(1)
return client
def setup_collection(client):
"""Créer la collection avec la recherche hybride + la configuration générative."""
# Supprime toute collection existante portant ce nom – relancer l'opération avec un
# nouveau sujet remplace la base de connaissances précédente, et ne l'enrichit pas.
if client.collections.exists(COLLECTION_NAME):
client.collections.delete(COLLECTION_NAME)
print(f" Collection '{COLLECTION_NAME}' existante supprimée")
client.collections.create(
name=COLLECTION_NAME,
description="Articles Web extraits via Bright Data pour RAG",
# Cohere embed-v4.0 : vectorise automatiquement le texte au moment de l'importation
vector_config=Configure.Vectors.text2vec_cohere(
model="embed-v4.0",
),
# Cohere command-a-03-2025 : génère des réponses RAG au moment de la requête
generative_config=Configure.Generative.cohere(
model="command-a-03-2025",
),
properties=[
Property(name="text", data_type=DataType.TEXT,
description="Contenu textuel du chunk"),
Property(name="source_url", data_type=DataType.TEXT,
skip_vectorization=True),
Property(name="source_domain", data_type=DataType.TEXT,
skip_vectorization=True),
Property(name="scraped_at", data_type=DataType.TEXT,
skip_vectorization=True),
Propriété(nom="chunk_index", type_données=DataType.INT,
skip_vectorization=True),
Propriété(nom="total_chunks", type_données=DataType.INT,
skip_vectorization=True),
Propriété(nom="content_hash", type_données=DataType.TEXT,
skip_vectorization=True),
Property(name="content_type", data_type=DataType.TEXT,
skip_vectorization=True),
],
)
print(f" Création de la collection '{COLLECTION_NAME}'")Quelques points à noter :
skip_vectorization=Truesur les champs de métadonnées – seul le champtexteest intégré, ce qui permet d’économiser des appels API et de produire des vecteurs plus proprescontent_hashstocké par bloc – utilisez-le pour éviter de réintégrer du contenu inchangé lorsque vous ajoutez une logique de réextraction incrémentielle (le pipeline actuel réimporte les données à chaque exécution)
Comportement lors de la réexécution : le pipeline supprime et recrée la collection à chaque exécution. Une exécution avec « AI race » puis « quantum computing » remplace les données de la course à l’IA. Pour conserver plusieurs sujets, remplacez
COLLECTION_NAMEpar un nom unique par sujet (par exemple,WebResearch_ai_race,WebResearch_quantum).
Pour en savoir plus sur la préparation de jeux de données vectorielles prêtes pour l’IA, consultez le guide Bright Data.
La fonction store_chunks() insère par lots tous les chunks dans la collection :
def store_chunks(client, chunks):
"""Importe par lots les chunks dans Weaviate (auto-vectorisés via Cohere)."""
collection = client.collections.use(COLLECTION_NAME)
with collection.batch.fixed_size(batch_size=50) as batch:
for chunk in chunks:
batch.add_object(properties=chunk)
failed = len(collection.batch.failed_objects) if collection.batch.failed_objects else 0
if failed > 0:
print(f" Première erreur : {collection.batch.failed_objects[0].message[:120]}")
return failedbatch.fixed_size(50) regroupe les importations par lots pour améliorer le débit au lieu d’effectuer des insertions une par une. Lors du test, tous les chunks ont été importés sans aucune erreur. Weaviate appelle Cohere pour intégrer chaque chunk au moment de l’importation.
Étape 4 : Requête avec recherche et génération hybrides
Une fois tous les chunks intégrés et indexés, interrogez-les à l’aide de la fonction rag_query(). Celle-ci appelle generate.hybrid() pour effectuer la récupération et la génération en une seule requête :
def rag_query(client, question, alpha=0.7, limit=5):
"""Exécute une requête RAG à l'aide de la recherche hybride Weaviate + IA générative."""
collection = client.collections.use(COLLECTION_NAME)
response = collection.generate.hybrid(
query=question,
alpha=alpha, # 0.7 = 70 % sémantique, 30 % mots-clés
limit=limit,
grouped_task=f"""À partir des documents récupérés ci-dessous, répondez à cette question :
"{question}"
Instructions :
- Fournissez une réponse claire et complète
- Citez l'URL source pour chaque affirmation clé
- Si les informations semblent obsolètes ou contradictoires, signalez-le
- Restez concis tout en fournissant des informations pertinentes (2 à 4 paragraphes)""",
)
print(f"n Q: {question}")
print(f" {'─' * 60}")
if response.generated:
print(f" R: {clean_generated_text(response.generated)}")
else:
print(" R: (Aucune réponse générée — vérifiez votre clé API Cohere)")
# Séparer les sources des articles des extraits du résumé SERP
article_sources = []
serp_sources = []
seen_urls = set()
for obj in response.objects:
url = obj.properties.get("source_url", "unknown")
if url in seen_urls:
continue
seen_urls.add(url)
content_type = obj.properties.get("content_type", "")
domain = obj.properties.get("source_domain", "")
if content_type == "serp_result":
serp_sources.append((domain, url))
else:
article_sources.append((domain, clean_url(url)))
print(f"n Sources ({len(response.objects)} extraits récupérés) :")
for domain, url in article_sources:
print(f" - [{domain}] {url}")
if not article_sources and serp_sources:
print(" (D'après les résumés SERP — aucun extrait d'article n'a été trouvé)")
return responseUne recherche vectorielle pure peut passer à côté de termes exacts tels que « GPT-5 » ou « Claude Code ». Une recherche par mots-clés pure ne permet pas de trouver le contenu sémantiquement lié. Le mélange alpha=0,7 vous offre les deux. L’algorithme BlockMax WAND de Weaviate maintient la rapidité de la composante mots-clés BM25 à grande échelle.
Avec limit=5, la requête récupère les 5 meilleurs extraits — suffisamment de contexte pour une réponse détaillée sans surcharger le LLM de bruit. Augmentez à 10 pour les questions générales couvrant plusieurs sous-thèmes ; réduisez à 3 pour les recherches factuelles précises. Le paramètre grouped_task envoie tous les segments récupérés à Cohere en une seule invite afin qu’il puisse rédiger une réponse unique. L’alternative, single_prompt, génère une réponse par segment – utile pour les résumés par document, mais pas pour les réponses inter-sources.
Consultez le tour d’horizon de Bright Data sur les API de recherche sémantique pour découvrir d’autres options.
Assemblez les 4 étapes
La fonction main() exécute l’ensemble du pipeline. Vous choisissez un sujet et elle s’occupe du reste :
def main():
print("=" * 65)
print(" Pipeline RAG : Bright Data + Weaviate")
print(" Extraire n'importe quel sujet → Construire une base de connaissances → Poser des questions")
print("=" * 65)
# ── Valider l'environnement ──
validate_env()
# ── Demander un sujet à l'utilisateur ──
print()
try:
topic = input(" Quel sujet souhaitez-vous rechercher ? ").strip()
except (EOFError, KeyboardInterrupt):
print("n Au revoir !")
return
if not topic:
print(" Aucun sujet saisi. Sortie.")
return
print(f'n Création d'une base de connaissances RAG sur : "{topic}"')
# ── Détection automatique des identifiants Bright Data ──
print("n[CONFIGURATION] Connexion à Bright Data...")
cust_id, unlocker_zone, unlocker_pwd, serp_zone, serp_pwd = (
discover_bright_data_credentials()
)
# ── Étape 1 : Rechercher et extraire des articles sur le sujet ──
print(f'n[ÉTAPE 1/4] Recherche et extraction d'articles sur "{topic}"...')
documents = collect_data(
topic, cust_id, unlocker_zone, unlocker_pwd, serp_zone, serp_pwd
)
print(f"n Nombre total de documents collectés : {len(documents)}")
if not documents:
print(" ERREUR : Aucun document collecté. Essayez un autre sujet.")
return
# ── Étape 2 : Traitement et découpage en morceaux ──
print("n[ÉTAPE 2/4] Traitement et découpage des documents en morceaux...")
chunks = process_documents(documents)
print(f" {len(chunks)} segments créés à partir de {len(documents)} documents")
if not chunks:
print(" ERREUR : Aucun segment créé. Les documents sont peut-être trop courts.")
return
# ── Étape 3 : Stockage dans Weaviate ──
print("n[ÉTAPE 3/4] Stockage dans Weaviate (intégration + indexation)...")
print(" Connexion à Weaviate Cloud...", end=" ", flush=True)
client = connect_weaviate()
print("OK")
print(" Configuration de la collection...")
setup_collection(client)
print(f" Importation de {len(chunks)} chunks (vectorisation automatique via Cohere)...")
failed = store_chunks(client, chunks)
print(f" Importés : {len(chunks) - failed} réussis, {failed} échoués")
# Vérification du nombre
collection = client.collections.use(COLLECTION_NAME)
count = collection.aggregate.over_all(total_count=True).total_count
print(f" Nombre total d'objets dans Weaviate : {count}")
# ── Étape 4 : Requêtes de démonstration + Mode interactif ──
print(f'n[ÉTAPE 4/4] Requêtes RAG sur "{topic}"...')
print("=" * 65)
demo_queries = [
f"Quelles sont les dernières évolutions et tendances concernant {topic}?",
f"Quels sont les principaux défis et risques liés à {topic}?",
f"Quelles sont les perspectives d'avenir pour {topic}?",
]
for question in demo_queries:
rag_query(client, question)
print()
# ── Résumé ──
print("=" * 65)
print(" Pipeline terminé !")
print(f' Sujet : "{topic}"')
print(f" - {len(documents)} sources extraites via Bright Data")
print(f" - {count} segments stockés dans Weaviate")
print(f" - {len(demo_queries)} requêtes RAG de démonstration exécutées")
print("=" * 65)
# ── Mode interactif ──
print(f'n Votre base de connaissances sur "{topic}" est prête !')
print(" Posez n'importe quelle question. Tapez 'quit' pour quitter.n")
while True:
try:
user_question = input(" Votre question : ").strip()
except (EOFError, KeyboardInterrupt):
print("n Au revoir !")
break
if not user_question:
continue
if user_question.lower() in ("quit", "exit", "q"):
print(" Au revoir !")
break
rag_query(client, user_question)
print()
client.close()
if __name__ == "__main__":
main()Exécutez-le :
python3 pipeline.pyRéponses RAG issues du test de la course à l’IA
Le pipeline a été exécuté avec le sujet « Course à l’IA : OpenAI vs Google vs Anthropic ». Voici des exemples de réponses RAG issues d’un test – vos résultats refléteront les articles disponibles au moment de l’exécution.
Requête 1 : « Quelles sont les dernières évolutions et tendances dans la course à l’IA entre OpenAI, Google et Anthropic ? »
La course à l’IA entre OpenAI, Google et Anthropic continue d’évoluer rapidement, chaque entreprise tirant parti de ses atouts propres. OpenAI conserve une avance en termes de chiffre d’affaires et d’adoption par les consommateurs, bénéficiant de son avantage de précurseur. Anthropic comble son retard en matière d’adoption par les entreprises, grâce à des outils spécialisés tels que Claude Code et à un taux de réussite de 70 % dans les confrontations directes entre entreprises achetant des services d’IA. Google apporte des ressources informatiques inégalées et une intégration transparente à travers son écosystème.
Sources : shawnkanungo[.]com, hashmeta[.]ia, ramp[.]com
Question 2 : « Quels sont les principaux défis et risques dans la course à l’IA entre OpenAI, Google et Anthropic ? »
OpenAI doit relever le défi de maintenir son rythme d’innovation tout en conservant son indépendance, d’autant plus qu’elle dépend de partenariats pour ses ressources de calcul. Google est confronté à l’inertie bureaucratique et risque de cannibaliser son activité principale de publicité sur les moteurs de recherche, car l’IA conversationnelle réduit le nombre de clics publicitaires. Anthropic, qui se positionne comme une entreprise privilégiant la sécurité, doit transformer son accent mis sur l’interprétabilité en parts de marché dans un marché axé sur les capacités.
Sources : hashmeta[.]ia, shawnkanungo[.]com
Question 3 : « Quelles sont les perspectives d’avenir de la course entre OpenAI, Google et Anthropic IA ? »
OpenAI est en tête en termes de chiffre d’affaires et d’adoption par les consommateurs, avec une feuille de route comprenant GPT-5 et des investissements visant à réduire les coûts d’inférence. Le succès futur d’Anthropic dépendra de l’émergence ou non d’exigences réglementaires en matière d’explicabilité — ses investissements précoces dans la sécurité et l’interprétabilité pourraient lui conférer un avantage significatif. Google reste un concurrent de taille, notamment dans l’adaptation d’outils tels que Gemini à des cas d’utilisation spécifiques et l’intégration de l’IA dans les flux de travail quotidiens.
Sources : hashmeta[.]ia, shawnkanungo[.]com
Chaque réponse est basée sur des articles extraits lors de cette même exécution du pipeline. Chaque citation renvoie à une source extraite à l’étape 1 — vous pouvez vérifier toute affirmation en ouvrant l’URL. Si vous posez une question sur un sujet que les articles extraits ne couvrent pas, le modèle vous le signale ou donne une réponse moins détaillée.
Après les requêtes de démonstration, le pipeline passe en mode interactif où vous pouvez poser vos propres questions :

Passage en production
Si vous avez besoin de cette solution en production, vous aurez besoin de fonctionnalités de multi-location, de conformité et de contrôle des coûts. (Pour une vue d’ensemble, découvrez comment RAG s’intègre dans une pile technologique d’agent IA en production.)
La multi-location pour l’isolation des données
Si vous développez RAG pour plusieurs clients, la multi-location de Weaviate attribue à chaque locataire un shard dédié avec des index vectoriels isolés :
from weaviate.classes.config import Configure
from weaviate.classes.tenants import Tenant
# Activer la multi-location sur la collection
collection = client.collections.create(
name="WebContent",
multi_tenancy_config=Configure.multi_tenancy(enabled=True),
# ... vectorizer + configuration générative
)
# Chaque client dispose de son propre tenant isolé
collection.tenants.create([
Tenant(name="customer_a"),
Tenant(name="customer_b"),
Tenant(name="customer_c"),
])
# Récupérer et stocker les données par tenant
tenant_collection = collection.with_tenant("customer_a")
with tenant_collection.batch.dynamic() as batch:
for chunk in customer_a_chunks:
batch.add_object(properties=chunk)Un seul nœud prend en charge plus de 50 000 locataires actifs – un cluster de 20 nœuds en gère un million.
Optimisation des coûts
4 techniques permettent de réduire les coûts à mesure que vos données augmentent :
- Quantification par rotation Weaviate: compression vectorielle 4x avec un taux de rappel de 98 à 99 %.
- Hachage du contenu: le champ
content_hashpermet des mises à jour incrémentielles qui évitent de réintégrer les chunks inchangés (voir l’étape 3 ci-dessus) skip_vectorization=Truesur les champs de métadonnées : n’intégrez que ce qui compte.- Bright Data Dataset Marketplace – utilisez des Jeux de données pré-collectés plutôt que de procéder à un scraping pour les domaines courants.
Ces éléments sont importants dès que vous dépassez le stade du prototype à utilisateur unique.
Erreurs courantes et comment les résoudre
Si vous rencontrez un problème, consultez d’abord ce tableau :
| Problème | Cause | Solution |
|---|---|---|
Weaviate gRPC DEADLINE_EXCEEDED |
Le cluster Sandbox est resté inactif pendant le scraping | Relancez pipeline.py – le script se reconnecte automatiquement. Si le problème persiste, vérifiez votre cluster dans la console Weaviate |
Limite de débit de l'API Cohere (429) |
Le forfait d’essai est soumis à une limite de débit | Attendez une minute et réessayez, ou vérifiez l’utilisation sur le tableau de bord Cohere. L’exécution automatisée utilise moins de 20 appels ; chaque question interactive en ajoute 2 de plus |
Aucune zone Web Unlocker trouvée |
Votre compte Bright Data ne dispose pas d’une zone Web Unlocker | Accédez à Bright Data → Proxies & Scraping → Mes zones → créez une zone Web Unlocker |
Aucune zone API SERP trouvée |
Votre compte Bright Data ne dispose pas d’une zone SERP | Accédez à Bright Data → Proxys et scraping → Mes zones → créez une zone API SERP |
ErreurHTTP 403 sur toutes les URL |
Les tentatives de Web Unlocker sont épuisées | Essayez un autre sujet – certains sites de niche utilisent un blocage anti-bot strict. Découvrez comment contourner les CAPTCHA pour accéder aux options avancées |
Le cluster Weaviate n'est pas prêt |
Sandbox expirée (limite de 14 jours) | Créez un nouveau bac à sable dans la console Weaviate et mettez à jour le fichier .env |
| Modèle Cohere indisponible | command-a-03-2025 ou embed-v4.0 retirés |
Vérifiez les modèles disponibles sur docs.cohere.com/docs/models et mettez à jour le paramètre model= dans setup_collection() |
ModuleNotFoundError : Aucun module nommé « weaviate » |
Dépendances non installées | Exécutez pip3 install -r requirements.txt depuis le répertoire du projet |
Si votre erreur ne figure pas dans la liste, vérifiez la sortie complète : le pipeline consigne chaque étape avec des détails.
Cas d’utilisation
La même architecture fonctionne pour n’importe quel sujet. Quelques idées :
- Intelligence compétitive – sujet : « stratégie tarifaire du concurrent X ». Le pipeline explore les sites web des concurrents, les pages de tarifs et les rapports d’analystes. Demandez ensuite : « Comment les tarifs entreprise du concurrent X se comparent-ils aux nôtres ? »
- Étude de marché – sujet : « tendances fintech en Asie du Sud-Est ». Récupère les actualités régionales et les publications du secteur, vous permettant de poser des questions telles que « Quelles sont les principales tendances fintech émergentes en Asie du Sud-Est ? »
- E-commerce – sujet : « marché de la mode durable ». Il explore les rapports de marché et les études de marché. « Quelles marques de mode durable gagnent des parts de marché ? »
- Recherche technique – sujet : « Meilleures pratiques de sécurité Kubernetes ». Récupère les blogs techniques et les avis de sécurité pour vous permettre de poser des questions sur des CVE spécifiques ou des erreurs de configuration.
Prochaines étapes
Il s’agit d’un prototype fonctionnel présentant des contraintes connues :
- Remplace l’intégralité de la collection à chaque exécution (pas de mises à jour incrémentielles) – utilisez
content_hashpour ajouter des différences - Traite uniquement le texte ; les tableaux, images et PDF des pages extraites sont ignorés
- Recherche le contenu via Google – pour des URL spécifiques, transmettez-les directement à
scrape_url() - Fonctionne comme une interface CLI mono-utilisateur
À partir de là, vous pouvez :
- Planification – exécuter le pipeline via une tâche cron pour maintenir votre base de connaissances à jour
- Multi-tenancy – attribuer à chaque client son propre shard isolé (voir la section « Mise en production » ci-dessus)
- Différentes sources de données – utilisez l’API Bright Data Web Scraper pour les données structurées d’Amazon ou de LinkedIn, ou l’API Crawl pour le Markdown de sites complets
- Frontend – encapsulez
rag_query()dans un point de terminaison Flask ou FastAPI et connectez une interface utilisateur de chat - RAG agentique – créer un système RAG agentique qui décide de lui-même quand et quoi scraper
- LangChain – portez le pipeline vers LangChain avec Bright Data pour bénéficier d’une orchestration de chaînes et d’une mémoire intégrées
Foire aux questions
Quels sujets fonctionnent avec ce pipeline ?
Tout sujet pour lequel il existe des articles sur le Web ouvert. Le pipeline utilise l’API SERP de Bright Data pour rechercher votre sujet sur Google, puis extraire les premiers résultats. Les sujets de niche comportant moins de pages indexées renvoient moins d’articles, mais le pipeline fonctionne tout de même : il utilise simplement ce qu’il trouve.
Combien coûte son utilisation ?
Les trois services proposent des formules gratuites pour commencer. Le plan d’essai de Cohere est gratuit et ne nécessite pas de carte de crédit. Weaviate Cloud propose un cluster sandbox gratuit, et Bright Data offre un essai gratuit pour l’API SERP et Web Unlocker.
Puis-je utiliser un autre modèle d’embedding ou un autre LLM ?
Oui. Modifiez le paramètre du modèle dans setup_collection() pour les encodages et la génération. Weaviate prend en charge les vectoriseurs Cohere, OpenAI, Google et Hugging Face dès l’installation. Pour changer, remplacez text2vec_cohere par text2vec_openai, mettez à jour l’en-tête de la clé API dans connect_weaviate(), puis relancez le pipeline.
Comment maintenir la base de connaissances à jour ?
Relancez pipeline.py avec le même sujet. Le pipeline supprime l’ancienne collection et en crée une nouvelle avec les données fraîchement extraites. Pour une utilisation en production, ajoutez une vérification content_hash afin d’ignorer la ré-intégration des segments qui n’ont pas changé. Planifiez le pipeline via une tâche cron pour actualiser automatiquement les données à n’importe quel intervalle.
Que faire si je dispose déjà d’URL à extraire ?
Ignorez l’étape de découverte des SERP. Dans collect_data(), remplacez l’appel find_articles_for_topic() par votre propre liste d’URL, puis transmettez chaque URL à scrape_url(). Le reste du pipeline (segmentation, intégration, requête) fonctionne de la même manière.
Comment extraire plus de 6 articles ?
Remplacez la tranche [:6] à la fin de find_articles_for_topic() par un nombre plus élevé (par exemple, [:12]). Vous pouvez également ajouter davantage de requêtes de recherche à la liste search_queries pour obtenir un éventail de résultats plus large. Un plus grand nombre d’articles implique un temps de scraping plus long et davantage de chunks, mais le reste du pipeline gère cela automatiquement.





