

Dans ce tutoriel, vous allez explorer :
- Un workflow complet étape par étape pour l’identification de clients.
- Comment générer un jeu de données Crunchbase spécifiquement adapté à vos besoins grâce à l’API de filtrage de Bright Data.
- Comment traiter ce jeu de données pour la prospection de clients, en tirant parti des API Bright Data et de l’IA pour l’enrichissement et l’analyse des données.
Plongeons dans le vif du sujet !
Présentation du workflow d’identification de nouveaux clients
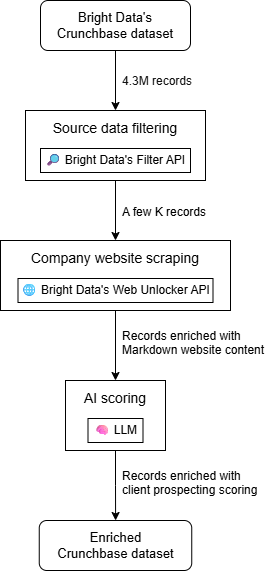
À un niveau général, vous pouvez construire un workflow de prospection de clients optimisé par l’IA en trois étapes principales :
- Filtrage des données sources : Commencez avec un jeu de données Crunchbase et filtrez-le selon vos besoins spécifiques.
- Scraping web des sites d’entreprises : Récupérez le contenu de la page d’accueil de chaque entreprise dans le jeu de données.
- Scoring par IA : Utilisez l’IA pour évaluer chaque entreprise sur la base du contenu de son site web (et potentiellement d’autres champs dans la fiche entreprise) afin de générer un score de prospection client adapté à vos produits ou services.
Le résultat sera un jeu de données enrichi, où chaque fiche d’entreprise Crunchbase inclut des colonnes supplémentaires contenant des scores de prospection client et d’autres informations additionnelles. Vous pouvez ensuite filtrer le jeu de données résultant ou trier par score pour déterminer quelles entreprises contacter en premier.
Découvrez chaque étape et comment les mettre en œuvre !
1. Filtrage des données sources
La source idéale pour ce workflow est un jeu de données contenant des informations sur les entreprises. Bright Data est le meilleur fournisseur de données d’entreprises, proposant des jeux de données riches couvrant des plateformes comme LinkedIn, Crunchbase, Indeed, et bien d’autres.
Pour la prospection de clients, Crunchbase est particulièrement précieux grâce à ses champs spécialisés tels que le CB Rank, le Heat Score, et d’autres métriques qui vous permettent d’évaluer rapidement l’impact d’une entreprise dans le secteur.
Bright Data fournit un jeu de données Crunchbase avec plus de 4,3 millions d’enregistrements. Travailler directement avec un jeu de données aussi volumineux serait difficile, c’est pourquoi vous pouvez utiliser l’API de filtrage pour le réduire aux entreprises répondant à vos critères spécifiques. Par exemple, vous pouvez obtenir uniquement les entreprises dans une plage d’effectifs spécifique, actuellement actives, et répondant à d’autres aspects pertinents.
2. Scraping web des sites d’entreprises
Les champs de données dans le jeu de données Crunchbase filtré sont certainement intéressants. Cependant, à eux seuls, ils ne sont généralement pas suffisants pour une identification précise des clients. Pour véritablement évaluer une entreprise, l’analyse de son site web est l’une des meilleures approches. Cela vous donne un aperçu de ce que fait l’entreprise et si elle pourrait bénéficier de vos services.
La récupération programmatique du contenu du site de chaque entreprise est un défi. En effet, chaque site a une structure différente et peut être protégé par des mesures anti-bot, telles que les blocages d’IP, les restrictions géographiques, les CAPTCHAs, etc. Certains sites nécessitent également le rendu JavaScript.
Pour gérer ces défis de manière cohérente et obtenir le contenu des sites web dans un format optimisé pour l’analyse par LLM, la meilleure solution est de s’appuyer sur l’API Web Unlocker de Bright Data. Cet endpoint vous permet de scraper n’importe quel site web, quelle que soit sa protection.
3. Scoring par IA
Enfin, une fois que vous disposez du jeu de données Crunchbase filtré enrichi avec le contenu du site web de chaque entreprise, alimentez chaque enregistrement vers l’IA. Fournissez une description de vos services/produits et demandez à l’IA d’évaluer si chaque entreprise correspond bien à vos offres.
Récupérer un jeu de données Crunchbase spécifiquement adapté à vos besoins via l’API de filtrage de Bright Data
Commençons le workflow de prospection client optimisé par l’IA en récupérant les données sources. Il s’agira d’un jeu de données Crunchbase filtré contenant les entreprises correspondant aux critères pertinents pour votre hypothèse de prospection.
Cette étape initiale garantit que vous ne travaillez qu’avec les données qui comptent, économisant ainsi du temps et des coûts par rapport au traitement d’un jeu de données beaucoup plus volumineux. Comme vous allez le voir, c’est là que Bright Data excelle grâce à ses capacités de filtrage avancées, notamment via son API de filtrage.
Suivez les instructions ci-dessous pour récupérer votre jeu de données Crunchbase personnalisé !
Prérequis
Pour suivre cette section, vous devez disposer de :
- Un compte Bright Data avec une clé API configurée.
- Un environnement Python local avec
requestsinstallé. - Une compréhension de base du fonctionnement des jeux de données Bright Data et de la génération de snapshots.
Pour configurer une clé API Bright Data, consultez le guide officiel.
Étape n°1 : Filtrer le jeu de données Crunchbase
Commencez par vous connecter à votre compte Bright Data. Dans le panneau de contrôle, accédez à la page « Web Datasets » et sélectionnez l’onglet « Dataset Marketplace ». Sur la page « Dataset Marketplace », recherchez « crunchbase » et sélectionnez le jeu de données « Crunchbase companies information » :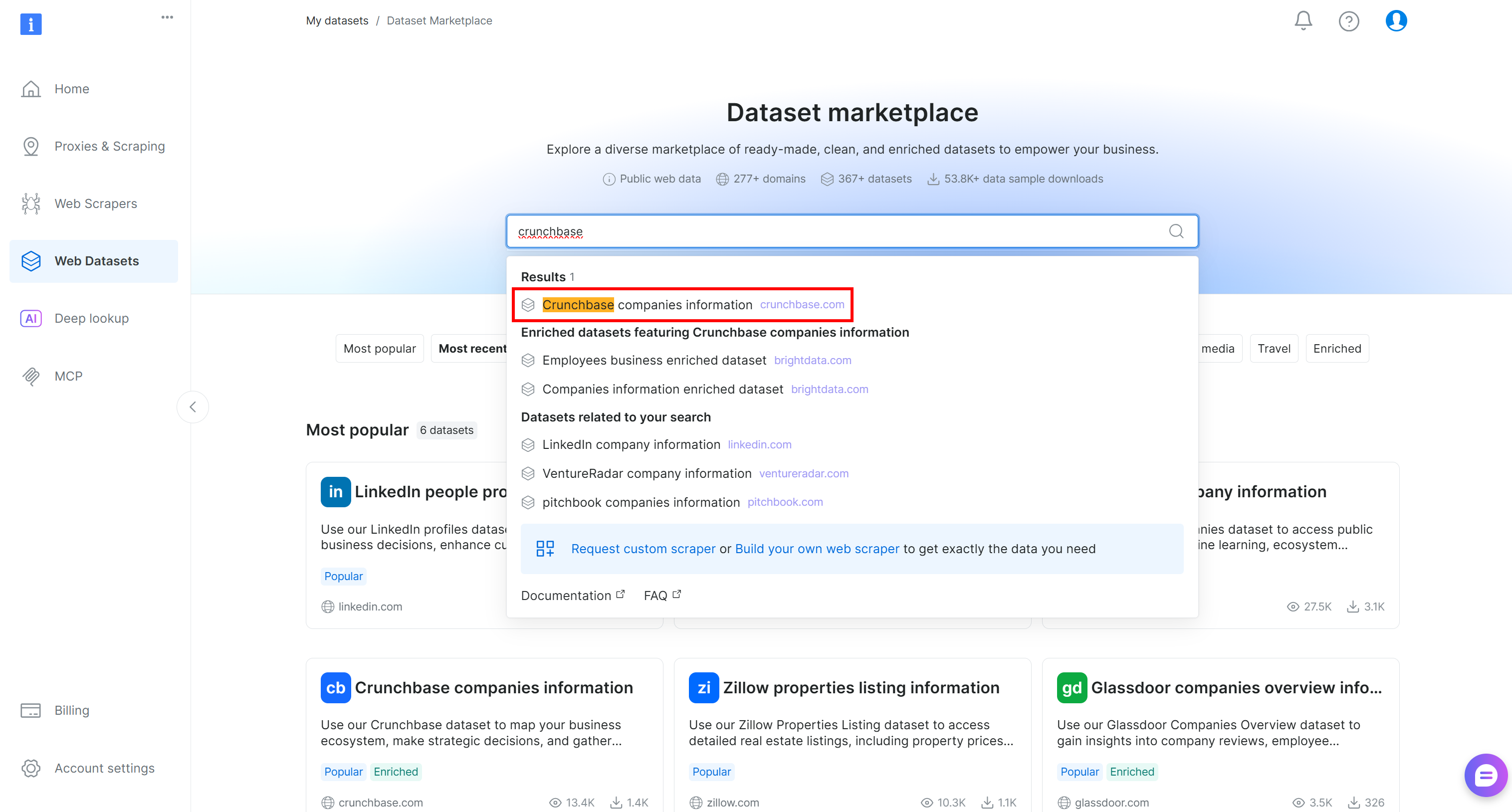
Vous serez redirigé vers la page du jeu de données « Crunchbase companies information ». Là, vous pouvez appliquer des filtres de données directement dans le panneau de contrôle en appuyant sur le bouton « Filters » à gauche :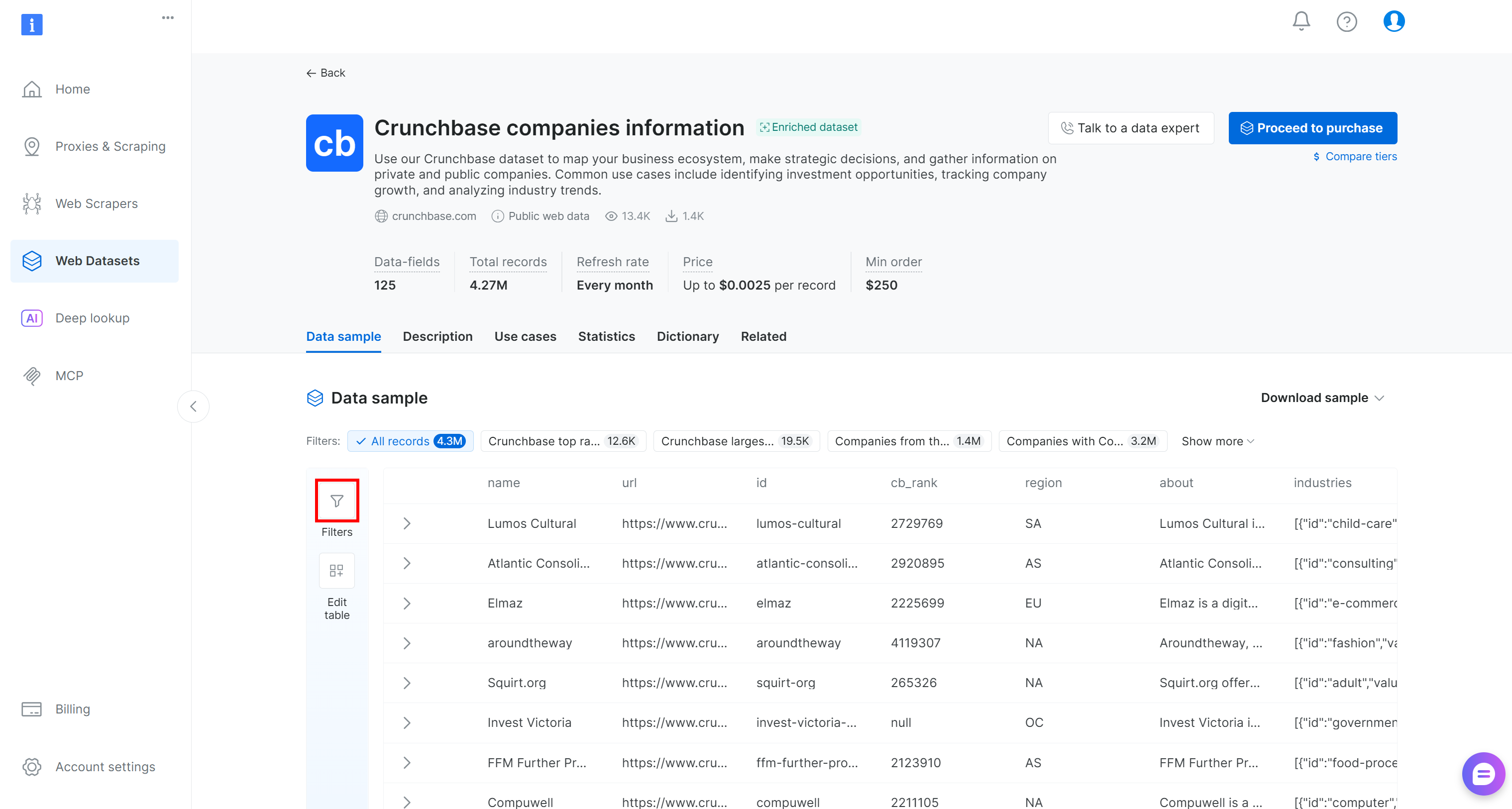
En détail, vous avez la possibilité d’ajouter un ou plusieurs filtres pour chacun des 125+ champs de données. Appliquez des filtres pour identifier plus facilement les clients potentiellement intéressants à partir de la liste complète de 4,3 millions d’entrées d’entreprises.
Par exemple, supposons que vous souhaitiez trouver des entreprises qui :
- Sont situées en Amérique du Nord ou en Europe.
- Sont en activité.
- Opèrent dans le secteur de l’IA.
- Ont un CB Rank inférieur ou égal à 10 000.
- Ont moins de 250 employés.
- Ont le champ
websiterenseigné. - Ont un heat score inférieur ou égal à 60.
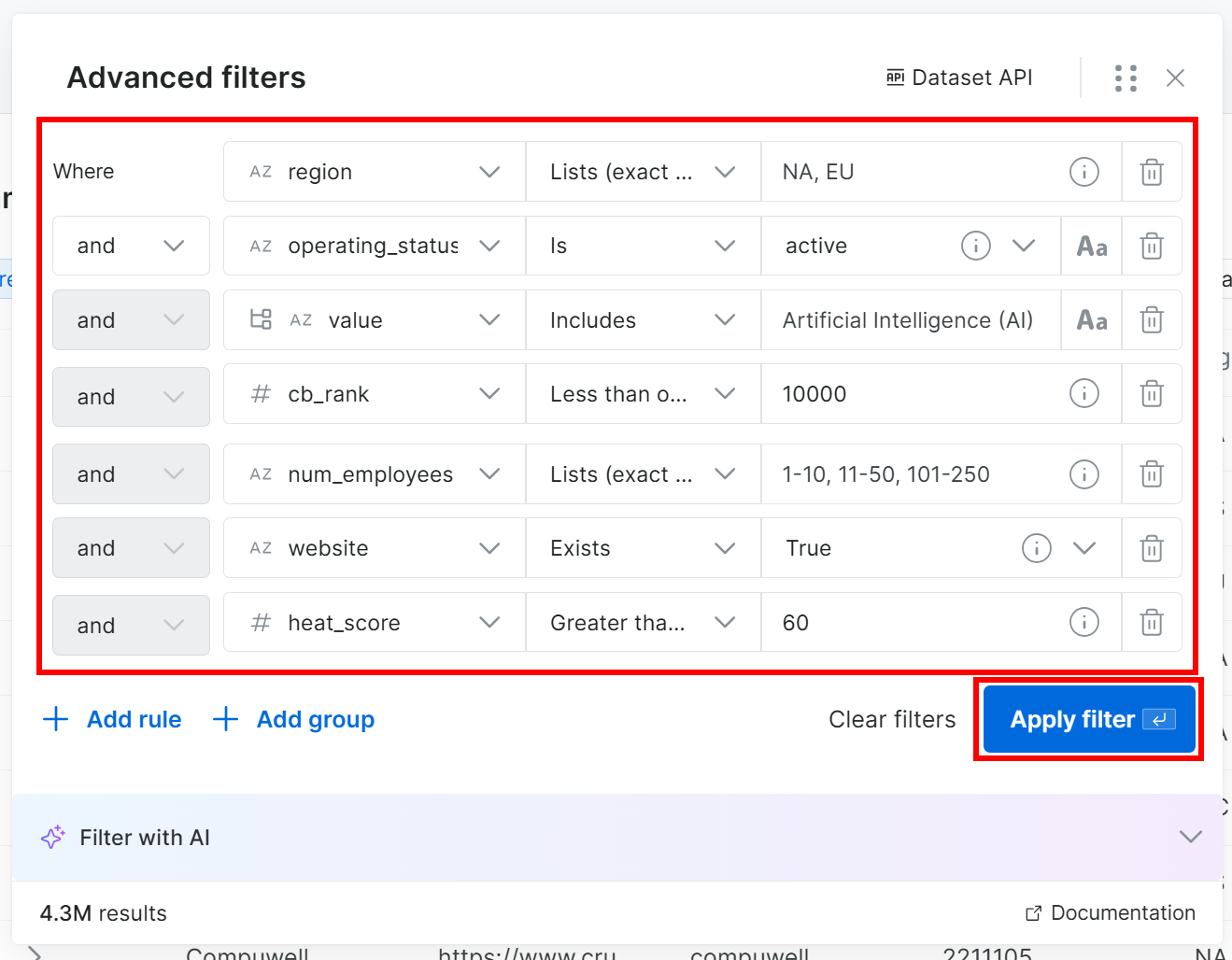
Remarque : Si vous ne souhaitez pas ajouter des filtres manuellement, cliquez sur le bouton « Filter with AI » et décrivez les données souhaitées à l’aide d’une invite en anglais courant.
Appuyez sur le bouton « Apply Filter » et soyez patient, car le filtrage peut prendre un certain temps. Bright Data affichera un aperçu des 30 premiers enregistrements afin que vous puissiez vérifier que les filtres correspondent à vos attentes.
Vous verrez également le nombre total d’enregistrements dans le jeu de données filtré :
Dans cet exemple, à partir de 4,3 millions d’enregistrements, vous avez obtenu 1 300 clients potentiels pour la prospection. C’est la puissance des capacités de filtrage de Bright Data, qui vous aide à extraire précisément les données dont vous avez besoin à partir d’un large jeu de données initial. Impressionnant !
Étape n°2 : Appeler l’API de filtrage
Vous avez maintenant deux options : cliquer sur « Proceed to purchase » pour télécharger directement le jeu de données, ou utiliser l’API de filtrage pour le générer de manière programmatique. L’appel à l’API de filtrage (qui fait partie de l’API Dataset de Bright Data) offre une répétabilité et un meilleur contrôle, c’est donc cette approche que nous allons adopter.
Dans la fenêtre des filtres, cliquez sur le bouton « Dataset API ». Cela affichera le code nécessaire pour appeler l’API de filtrage sur le jeu de données donné avec vos filtres sélectionnés appliqués. Choisissez l’option « Python » pour obtenir un extrait Python :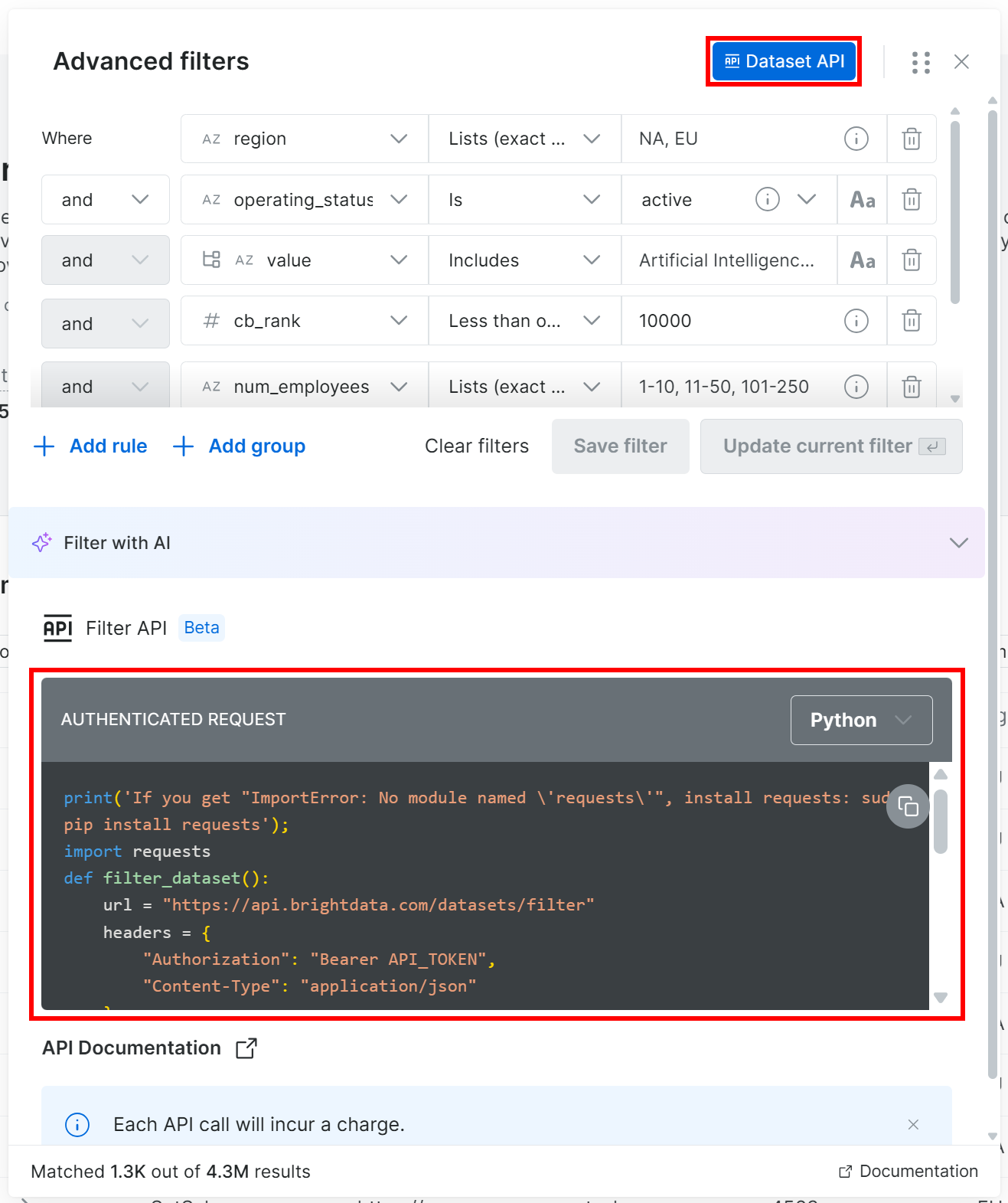
Cette fois, vous obtiendrez un extrait Python comme :
print('If you get "ImportError: No module named 'requests'", install requests: sudo pip install requests');
import requests
def filter_dataset():
url = "https://api.brightdata.com/datasets/filter"
headers = {
"Authorization": "Bearer API_TOKEN",
"Content-Type": "application/json"
}
payload = {
"dataset_id": "gd_l1vijqt9jfj7olije",
"filter": {"operator":"and","filters":[{"name":"region","value":["NA","EU"],"operator":"in"},{"name":"operating_status","value":"active","operator":"="},{"name":"industries:value","value":"Artificial Intelligence (AI)","operator":"includes"},{"name":"cb_rank","value":10000,"operator":"<="},{"name":"num_employees","value":["1-10","11-50","101-250"],"operator":"in"},{"name":"website","operator":"is_not_null"},{"name":"heat_score","value":60,"operator":">="}]}
}
response = requests.post(url, headers=headers, json=payload)
if response.ok:
print("Request succeeded:", response.json())
else:
print("Request failed:", response.text)
filter_dataset()Remplacez l’espace réservé API_TOKEN par votre clé API Bright Data, enregistrez le script localement et exécutez-le dans votre environnement Python.
Si tout fonctionne correctement, vous devriez voir :
Request succeeded: {'snapshot_id': 'snap_XXXXXXXXXXXXXXXXXXX'}Cela signifie que la tâche de génération d’un nouveau snapshot du jeu de données a démarré.
À ce stade, vous pouvez soit :
- Vérifier le statut et le télécharger via l’API Dataset, ou
- Le télécharger manuellement depuis le panneau de contrôle (ce que nous ferons à l’étape suivante !)
Étape n°3 : Récupérer les données filtrées
Une fois la tâche de génération du snapshot terminée, vous recevrez un e-mail vous informant que votre snapshot est prêt :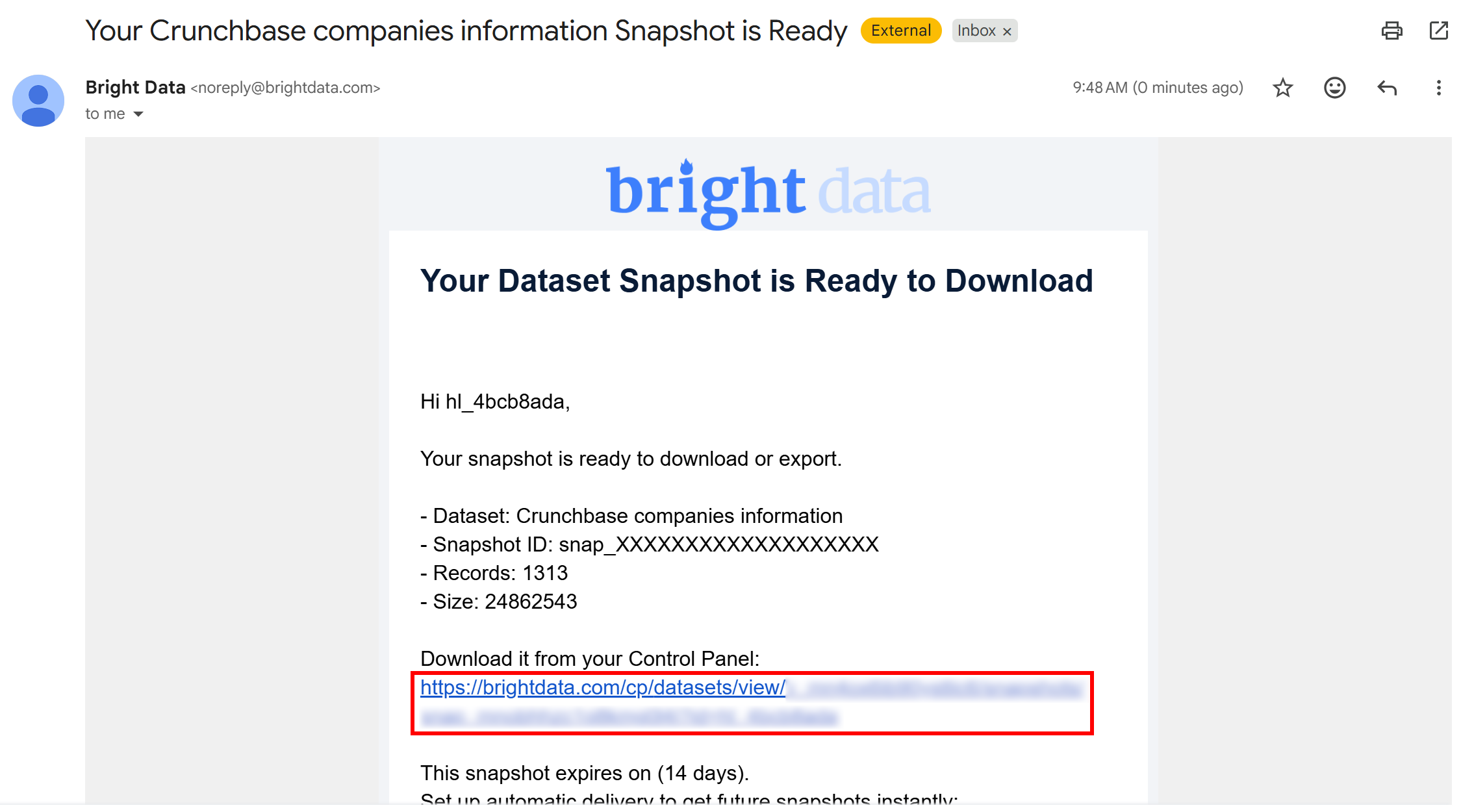
Cliquez sur l’URL dans l’e-mail et vous accéderez à la page du snapshot dans le panneau de contrôle Bright Data :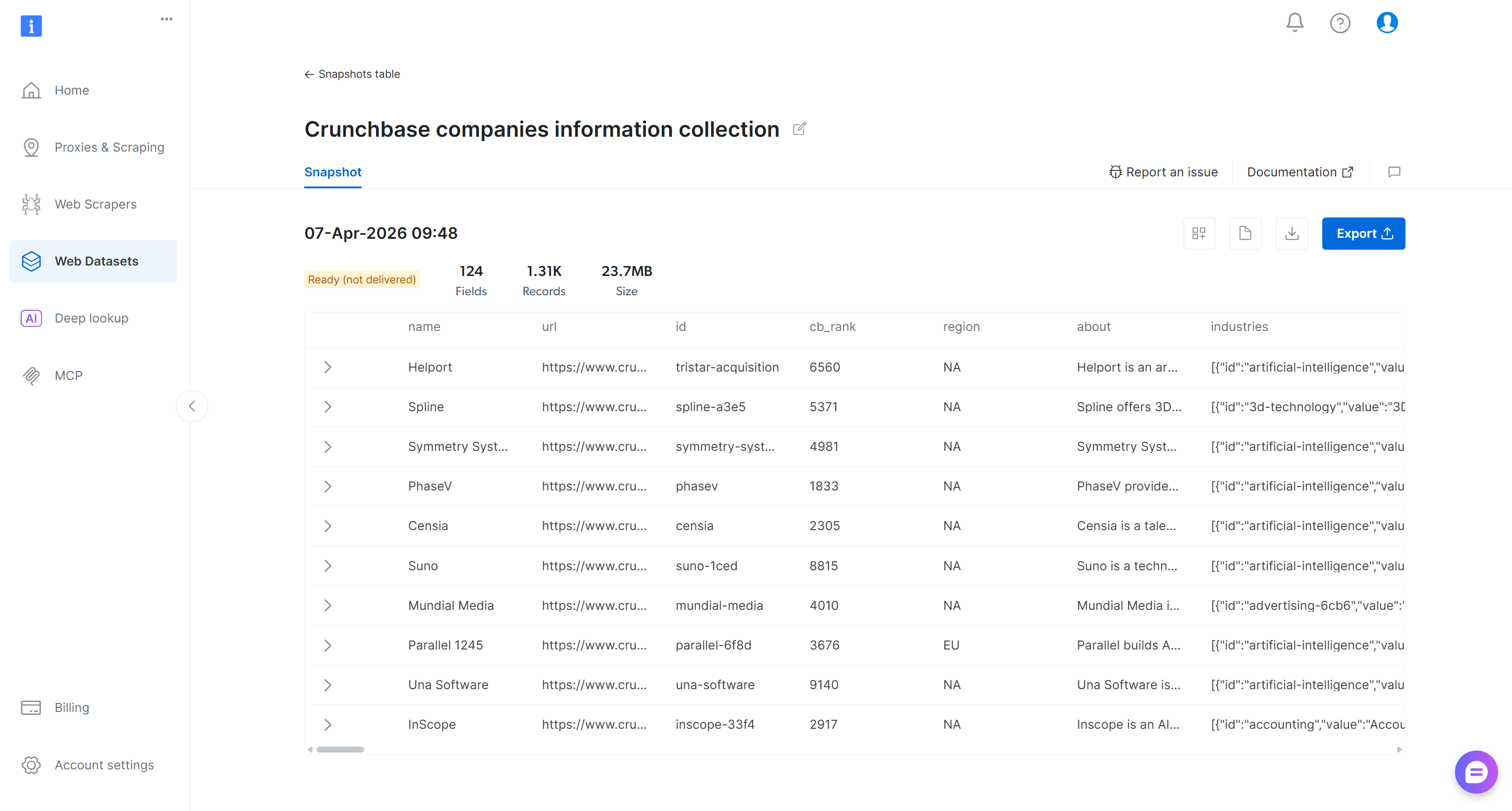
Ici, vous avez la possibilité d’explorer le jeu de données filtré, de le télécharger et d’accéder à des détails supplémentaires. Par exemple, vous pouvez télécharger un rapport contenant des informations telles que le nombre d’enregistrements et le coût total. Dans ce cas, le rapport indique que vous avez dépensé 3,29 $ et récupéré 1 313 enregistrements (Rappel : La tarification est de 2,50 $ pour 1 000 enregistrements) :

Pour récupérer le snapshot, cliquez sur l’icône « Download » et sélectionnez l’option « CSV » :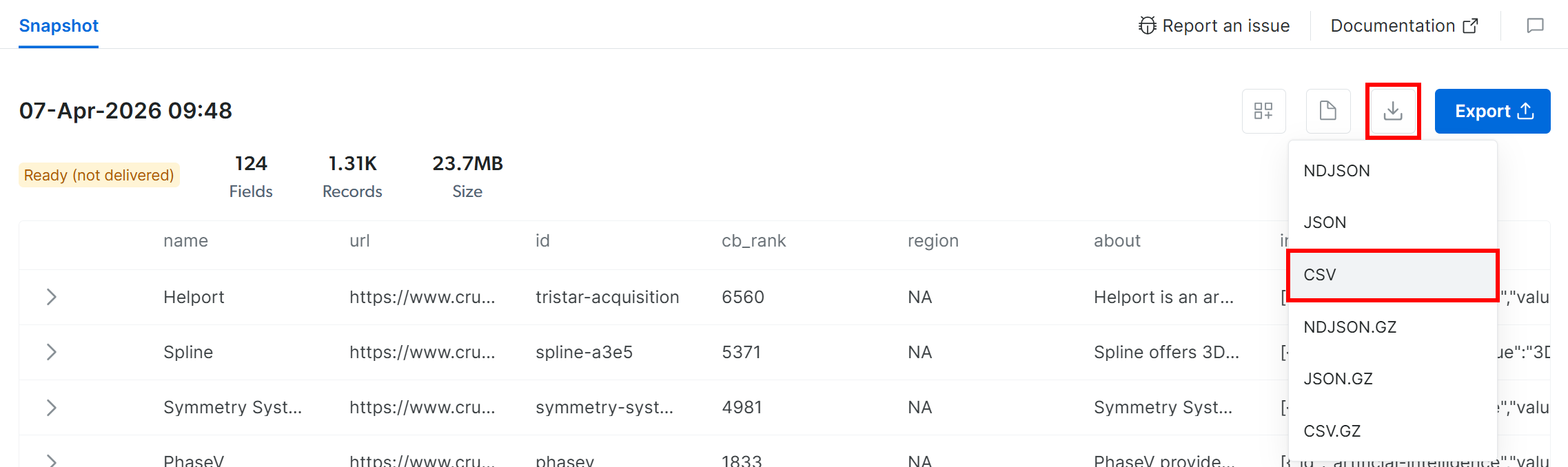
Votre navigateur téléchargera un fichier nommé snap_XXXXXXXXXXXXXXXXXXX.csv contenant les données Crunchbase filtrées. Parfait !
Étape n°4 : Explorer le jeu de données filtré
Ouvrez le fichier snap_XXXXXXXXXXXXXXXXXXX.csv, et voici ce que vous devriez voir :
Remarquez comment le jeu de données téléchargé contient les 1 313 entrées d’entreprises Crunchbase (chacune avec 133 colonnes) correspondant aux filtres spécifiés.
Mission accomplie ! Vous disposez maintenant des données sources pour effectuer la prospection de clients via une transformation et un enrichissement des données optimisés par l’IA.
Remarque : Avant de continuer, examinez le jeu de données et envisagez d’appliquer des étapes de filtrage supplémentaires pour affiner encore davantage le contenu, comme démontré dans le notebook Kaggle « Crunchbase Data Analysis for Client Prospecting » qui accompagne cet article.
Comment prospecter de nouveaux clients avec l’IA à partir d’un jeu de données Crunchbase personnalisé
Le jeu de données Crunchbase filtré servira de source pour le workflow de traitement et d’enrichissement des données. Pour chaque ligne, ce processus va :
- Visiter le site web de l’entreprise et récupérer son contenu au format Markdown à l’aide de l’API Web Unlocker.
- Transmettre le contenu de l’entreprise à un modèle d’IA, en lui demandant de comprendre ce que fait l’entreprise et de fournir un score indiquant dans quelle mesure elle est un client potentiel pour votre activité.
Voyez comment mettre cela en œuvre !
Prérequis
Pour suivre cette section, assurez-vous de satisfaire aux prérequis précédents, ainsi que :
- Une zone API Web Unlocker (par ex.,
web_unlocker) configurée dans votre compte Bright Data. - Une connaissance du fonctionnement de l’API Web Unlocker et des fonctionnalités qu’elle prend en charge.
- Une clé API OpenAI.
Pour créer une zone Web Unlocker, lisez le guide « Create Your First Unlocker API » dans la documentation Bright Data. Ci-dessous, nous supposerons que votre zone Web Unlocker est nommée web_unlocker.
Par souci de simplicité et pour garder ce tutoriel concis, nous supposerons que vous disposez déjà d’un environnement Jupyter Notebook local prêt à l’emploi.
Étape n°1 : Téléverser le jeu de données filtré source dans votre notebook
Lancez Jupyter Notebook et créez un nouveau notebook (par ex., nommez-le client_prospecting.ipynb). Ensuite, téléversez le fichier snap_XXXXXXXXXXXXXXXXXXX.csv :
Ce fichier sera utilisé comme données sources pour votre workflow de prospection de clients optimisé par l’IA. Bien joué !
Étape n°2 : Installer les bibliothèques requises
Avant de plonger dans la logique d’enrichissement des données, installez les dépendances requises par ce workflow. Pour ce faire, ajoutez une cellule contenant :
!pip install pandas requests pydantic openaiCela installera les bibliothèques suivantes :
pandas: Pour charger le CSV source avec les données Crunchbase et l’utiliser comme DataFrame.requests: Pour se connecter à l’API Web Unlocker de Bright Data afin de télécharger les pages d’accueil des entreprises.pydantic: Pour définir une sortie structurée pour les tâches OpenAI.openai: Pour interagir avec un modèle OpenAI afin de classer les pages d’accueil données pour la prospection de clients.
Exécutez la cellule en appuyant sur le bouton « ▶ » pour installer ces bibliothèques. Votre notebook contient maintenant toutes les dépendances requises pour la prospection de clients optimisée par l’IA, à partir d’un jeu de données Crunchbase filtré.
Étape n°3 : Configurer la cellule initiale
Pour éviter de disperser vos imports, secrets et constantes dans votre code, placez-les tous dans la première cellule de votre notebook, comme ceci :
import os
import pandas as pd
import requests
import datetime
import concurrent.futures
from typing import Optional
from pydantic import BaseModel, Field
from openai import OpenAI
# Secrets to connect to third-party services (replace them with the actual values)
BRIGHT_DATA_API_KEY="<YOUR_BRIGHT_DATA_API_KEY>"
OPENAI_API_KEY="<YOUR_OPENAI_API_KEY>"
# Define the required constants
SOURCE_CSV_PATH = "snap_XXXXXXXXXXXXXXXXXXX.csv"
ENRICHED_CSV_PATH = "crunchbase_analyzed_companies.csv"
# Initialize the OpenAI client
openai_client = OpenAI(api_key=OPENAI_API_KEY)Assurez-vous de :
- Remplacer
<YOUR_BRIGHT_DATA_API_KEY>par votre clé API Bright Data. - Remplacer
<YOUR_OPENAI_API_KEY>par votre clé API OpenAI. - Mettre à jour les noms du fichier source (
SOURCE_CSV_PATH) et du chemin du fichier enrichi (ENRICHED_CSV_PATH) selon vos besoins.
Gardez à l’esprit que ENRICHED_CSV_PATH définit le chemin du fichier de sortie où vos données enrichies seront sauvegardées.
Parfait ! Avec cette configuration, vous disposez maintenant de tous les éléments nécessaires pour commencer.
Étape n°4 : Charger le jeu de données
Dans une nouvelle cellule, ajoutez la logique pour charger le jeu de données source dans un DataFrame et afficher ses informations principales :
# Load the CSV file containing the filtered Crunchbase dataset
df = pd.read_csv(SOURCE_CSV_PATH, keep_default_na=False)
# Print the basic info about the dataset
df.info()
# Print the first rows
df.head()Remarque : L’option keep_default_na=False est requise. Sinon, les colonnes region contenant "NA" seraient interprétées comme NaN par pandas par défaut.
Exécutez la cellule, et vous devriez voir une sortie comme celle-ci :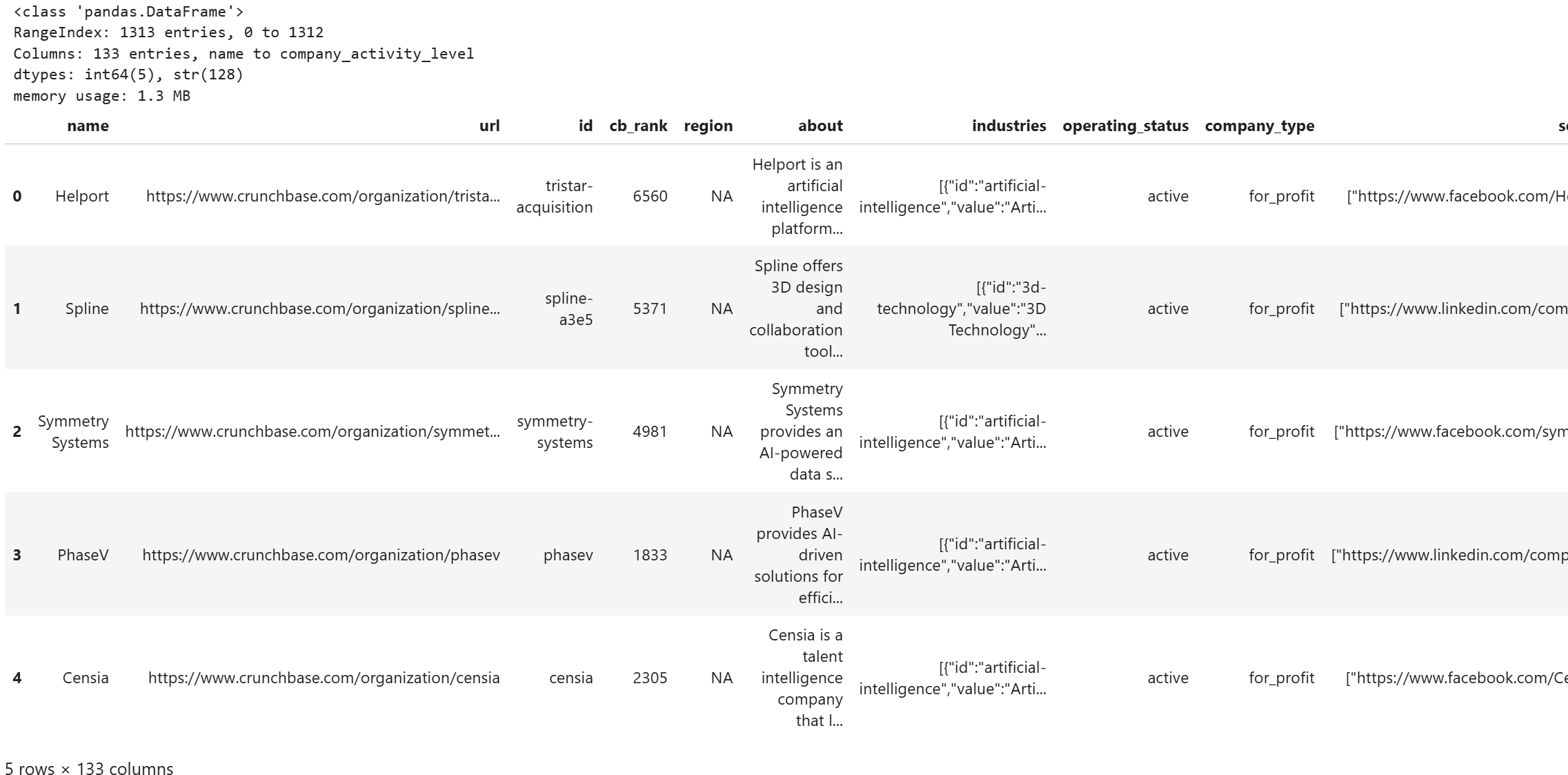
Remarquez comment le DataFrame stocke les 1 313 entrées, chacune avec 133 colonnes du jeu de données Crunchbase filtré. Excellent !
Étape n°5 : Définir la fonction pour le scraping web des sites
Maintenant, définissez une fonction pour appeler l’API Web Unlocker et scraper le site web d’une entreprise :
def fetch_website(url, zone = "web_unlocker"):
headers = {
"Authorization": f"Bearer {BRIGHT_DATA_API_KEY}",
"Content-Type": "application/json"
}
data = {
"zone": zone,
"url": url,
"format": "raw", # Get the response directly in the body
"data_format": "markdown" # Get the webpage in Markdown format (ideal for LLM ingestion)
}
api_url = "https://api.brightdata.com/request"
try:
response = requests.post(api_url, json=data, headers=headers)
# Raise an error if the response is 4xx/5xx
response.raise_for_status()
return response.text
except requests.RequestException as e:
print(f"Error fetching '{url}' via Web Unlocker API: {e}")
return NoneSi vous n’êtes pas familier avec le fonctionnement de l’API Web Unlocker, consultez la documentation officielle.
La fonction fetch_website() appelle votre zone API Web Unlocker Bright Data (remplacez "web_unlocker" par le nom de votre propre zone) sur l’URL fournie. Grâce au paramètre data_format: "markdown", la réponse sera une version Markdown du site web, prête pour l’IA. Ce format de données est parfait pour l’ingestion par LLM, ce que vous ferez très prochainement.
Cette fonction sera appliquée à chaque entrée d’entreprise pour l’enrichir avec la version Markdown de sa page d’accueil. Voyez comment procéder à l’étape suivante !
Étape n°6 : Récupérer toutes les pages d’accueil des entreprises en parallèle
L’API Web Unlocker, comme tout autre produit basé sur une API de Bright Data, est soutenue par une infrastructure de niveau entreprise avec plus de 400 millions d’IPs résidentielles. Grâce à cela, vous pouvez appeler l’API avec une simultanéité illimitée sans vous soucier des limites de débit ou des problèmes de mise à l’échelle.
Puisque notre jeu de données contient des milliers d’entreprises, il est judicieux de scraper plusieurs sites simultanément. La cellule suivante fait exactement cela :
batch_size = 5
total = len(df)
defprocess_row_for_scraping(idx):
url = df.at[idx, "website"]
# Skip the row if the "website" field is missing
if pd.isna(url):
return None
# Retrieve the website homepage in Markdown
markdown = fetch_website(url)
timestamp = datetime.datetime.now(datetime.UTC)
return idx, markdown, timestamp
for start in range(0, total, batch_size):
# Get the current batch
end = min(start + batch_size, total)
batch_indices = df.index[start:end]
print(f"Processing Crunchbase records {start} to {end-1}")
# Fetching website homepages in parallel for the batch
with concurrent.futures.ThreadPoolExecutor(max_workers=batch_size) as executor:
results = list(executor.map(process_row_for_scraping, batch_indices))
# Update the DataFrame with the results
for r in results:
# Skip
if r is None:
continue
idx, markdown, timestamp = r
df.at[idx, "website_markdown"] = markdown
df.at[idx, "website_markdown_fetching_timestamp"] = timestamp
# Save the updated CSV after each batch
df.to_csv(ENRICHED_CSV_PATH, index=False)
print(f"Batch {start}-{end-1} saved to disk.")Cet extrait traite un jeu de données Crunchbase pour enrichir chaque entrée d’entreprise avec la version Markdown de son site web, prête pour une analyse optimisée par l’IA. Il fonctionne par lots de 5 lignes à la fois, récupérant les sites web en parallèle pour accélérer les opérations liées aux E/S.
La fonction process_row() gère chaque entreprise : elle récupère la page d’accueil via l’API Web Unlocker et enregistre un horodatage. Ignorer les URLs manquantes garantit l’efficacité et évite les appels API inutiles. De plus, garder une trace de l’horodatage est important car le site web d’une entreprise peut changer fréquemment. Il est donc utile de savoir quand il a été scrapé pour la dernière fois.
Les lots sont traités avec un pool de threads, permettant à plusieurs requêtes de s’exécuter simultanément. Après chaque lot, le DataFrame est mis à jour et sauvegardé sur le disque. La sauvegarde incrémentale est fondamentale, car elle prévient la perte de données si le processus est interrompu et vous permet de reprendre sans recommencer depuis le début.
Conseil pro : Lors de votre premier essai, limitez le nombre de lignes à 5 ou 10 pour confirmer que le workflow fonctionne comme prévu avant de traiter le jeu de données complet.
Après l’exécution, vous obtiendrez des messages de sortie comme dans l’image ci-dessous :
Un fichier crunchbase_analyzed_companies.csv apparaîtra dans le répertoire du notebook. Il contiendra toutes les données Crunchbase originales, plus deux nouvelles colonnes :
website_markdown: La version Markdown prête pour l’IA de la page d’accueil de chaque entreprise.website_markdown_fetching_timestamp: L’heure exacte à laquelle chaque page a été récupérée.
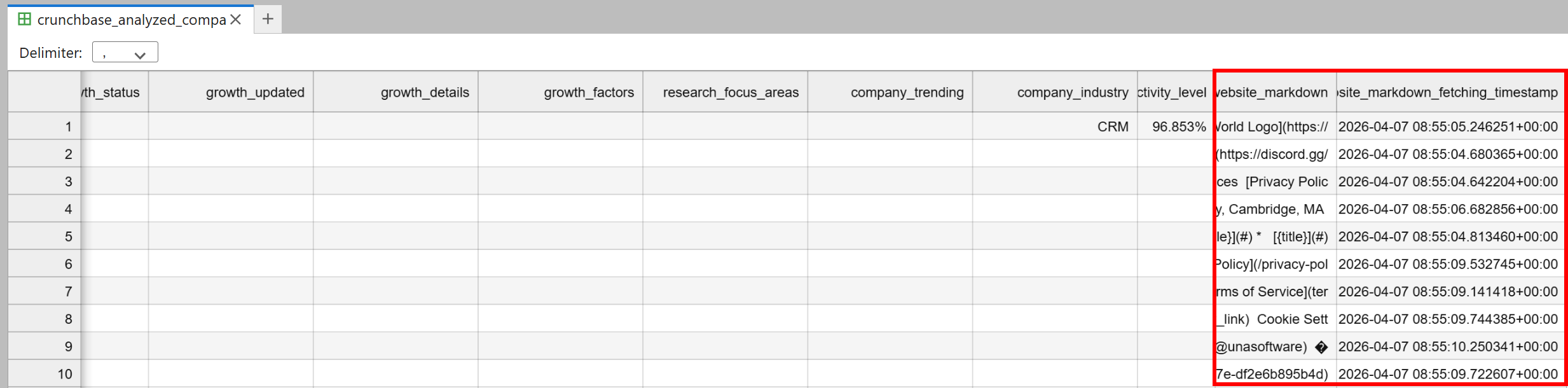
Fantastique ! Ce jeu de données est maintenant prêt pour l’analyse optimisée par l’IA et la prospection de clients.
Étape n°7 : Spécifier la fonction pour la prospection de clients par IA
L’étape suivante consiste à ajouter une fonction qui demande à l’IA d’effectuer la prospection de clients. L’idée est de décrire ce que fait votre entreprise et de laisser l’IA évaluer chaque entrée d’entreprise Crunchbase pour produire :
- Un score indiquant dans quelle mesure cette entreprise pourrait être un client potentiel solide.
- Un court commentaire expliquant le raisonnement derrière le score (utile, car le chiffre seul ne donne pas toujours une image complète).
- Une courte description de l’activité principale de l’entreprise basée sur le contenu du site web (utile pour comprendre si elle est un bon candidat).
Remarque : L’invite suivante utilise le site web de l’entreprise comme seule entrée, mais vous pourriez transmettre l’enregistrement entier pour une analyse plus avancée et nuancée.
Implémentez le processus avec cette cellule :
# Define the structured output schema
class AIProspectingResult(BaseModel):
ai_client_prospecting_score: float
ai_client_prospecting_comment: str
ai_core_business: str
def analyze_website(markdown):
# Ask the AI to perform the client prospecting task
system_prompt = (
"You are a business intelligence analyst specialized in identifying potential clients "
"for a cybersecurity firm. We are a specialized cybersecurity firm providing adversarial testing "
"for AI-powered ecosystems. Our mission is to proactively identify vulnerabilities by attempting to 'break' "
"AI models through sophisticated attack simulations. Following our assessment, we deliver a comprehensive "
"Vulnerability & Patch Report, detailing specific weaknesses discovered and providing actionable technical "
"strategies to remediate these risks and fortify the system's integrity.nn"
"Analyze the provided website content and produce a structured JSON with:n"
"- `ai_client_prospecting_score`: 0-10 float indicating how good a potential client this company could be.n"
"- `ai_client_prospecting_comment`: short comment (<=30 words) explaining the score.n"
"- `ai_core_business`: short description (<= 50 words) of what the company does based on the website.n"
)
user_prompt = f"WEBSITE CONTENT:n{markdown}"
try:
response = openai_client.responses.parse(
model="gpt-5.4-mini",
input=[
{"role": "system", "content": system_prompt},
{"role": "user", "content": user_prompt},
],
text_format=AIProspectingResult,
)
# Return the parsed result
return response.output_parsed
except Exception as e:
print("Error analyzing website with AI:", e)
return NonePour garantir que le modèle OpenAI choisi (GPT-5.4 Mini, dans ce cas) réponde avec une sortie structurée, appelez la méthode responses.parse(). Celle-ci accepte un modèle de données Pydantic et garantit que la réponse générée suit ce format. Pour plus d’informations, consultez notre guide sur le scraping web avec ChatGPT.
Merveilleux ! L’étape suivante consiste à appeler cette fonction en parallèle pour chaque enregistrement d’entreprise.
Étape n°8 : Prospecter toutes les entreprises en parallèle
Comme précédemment, ajoutez une cellule pour permettre à l’IA de traiter plusieurs entrées en parallèle :
batch_size = 5
total = len(df)
def process_row(idx):
markdown = df.at[idx, "website_markdown"]
# Skip rows with missing markdown
if pd.isna(markdown):
return None
# Call the AI prospecting function
result = analyze_website(markdown)
if result is None:
return None
return idx, result.ai_client_prospecting_score, result.ai_client_prospecting_comment, result.ai_core_business
for start in range(0, total, batch_size):
end = min(start + batch_size, total)
batch_indices = df.index[start:end]
print(f"Processing AI prospecting for records {start} to {end-1}")
# Run AI analysis in parallel
with concurrent.futures.ThreadPoolExecutor(max_workers=batch_size) as executor:
results = list(executor.map(process_row, batch_indices))
# Update the DataFrame with the results (if the array is not full of None values)
for r in results:
if r is None:
continue # Skip
idx, score, comment, core_business = r
df.at[idx, "ai_client_prospecting_score"] = score
df.at[idx, "ai_client_prospecting_comment"] = comment
df.at[idx, "ai_core_business"] = core_business
# Save CSV after each batch
df.to_csv(ENRICHED_CSV_PATH, index=False)
print(f"Batch {start}-{end-1} saved to disk.")Exécutez-le, et il imprimera des messages comme ceux-ci :
Bien ! Le jeu de données Crunchbase a maintenant été enrichi avec l’extraction Bright Data et l’analyse optimisée par l’IA pour la prospection de clients.
Il est temps d’explorer les résultats !
Étape n°9 : Analyser les données enrichies
Dans la cellule finale, ajoutez la logique pour présenter les données enrichies :
relevant_columns = [
"name",
"cb_rank",
"region",
"ai_client_prospecting_score",
"ai_client_prospecting_comment",
"ai_core_business"
]
pd.set_option("display.max_columns", None) # Show all columns
pd.set_option("display.max_colwidth", None) # Do not truncate text
# Print only the relevant fields
df[relevant_columns].head(10)Le jeu de données résultant contiendra :
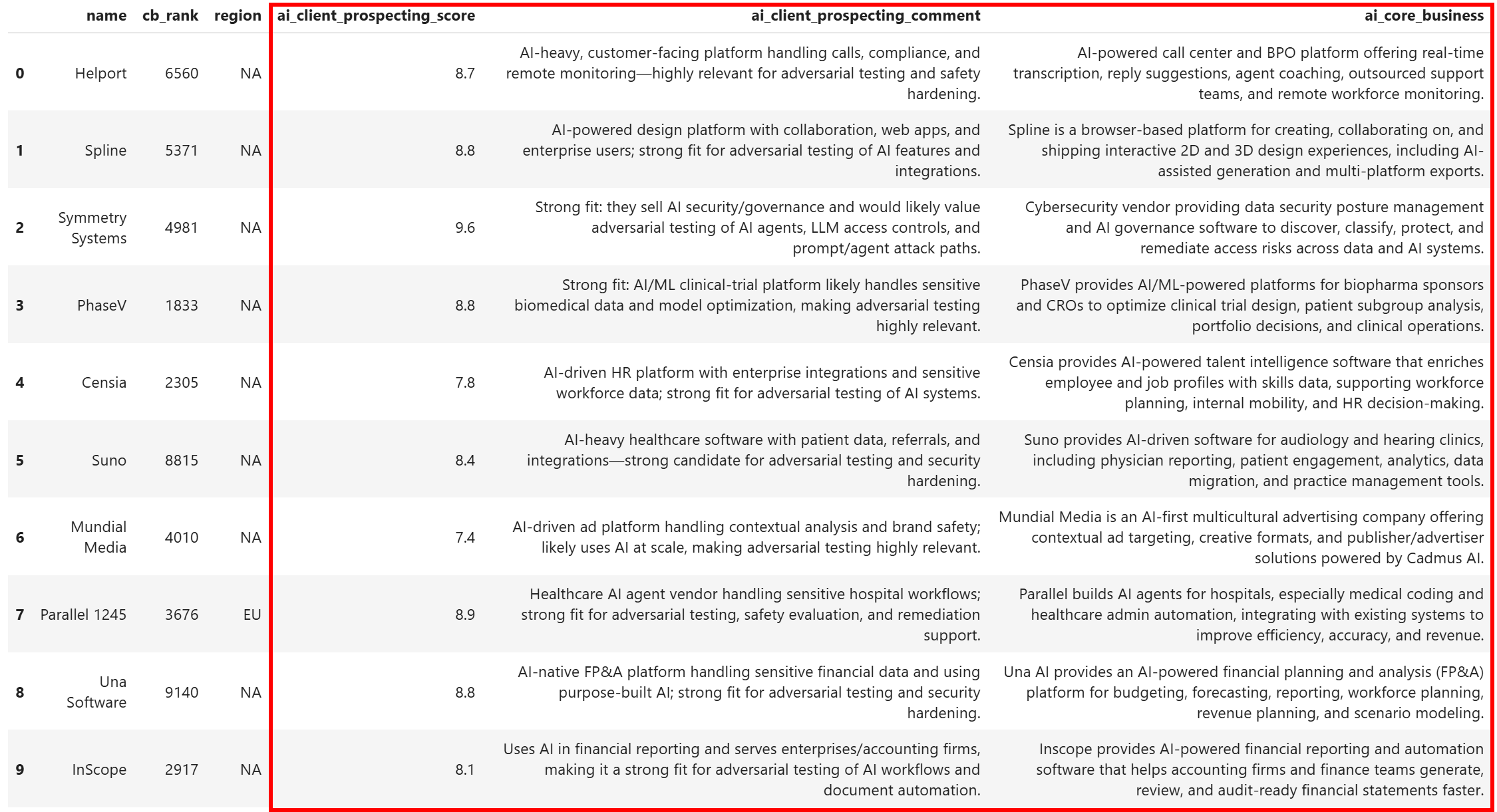
Remarquez comment chaque entreprise a été enrichie avec un score de prospection clair, un court commentaire expliquant ce score, et une description concise de ce que fait l’entreprise. Cela n’aurait pas été possible sans :
- L’API de filtrage de Bright Data : Pour récupérer un jeu de données Crunchbase ciblé et filtré.
- L’API Web Unlocker : Pour scraper de manière fiable n’importe quel site web d’entreprise, sans blocages.
Et voilà ! Vous pouvez maintenant appliquer une analyse de données supplémentaire et un traitement pour sélectionner uniquement les meilleurs candidats à contacter.
Conclusion
Dans cet article, vous avez appris à tirer parti des jeux de données de Bright Data, ainsi que des API Bright Data et de l’IA, pour construire un workflow de prospection de clients automatisé, complet et prêt pour la production. Ce workflow :
- Commence avec un jeu de données Crunchbase contenant plus de 4,3 millions d’enregistrements.
- Le filtre de manière programmatique en utilisant l’API de filtrage de Bright Data pour n’inclure que les entreprises répondant à vos critères spécifiques.
- Utilise l’API Web Unlocker pour récupérer le contenu du site web de chaque entreprise.
- Transmet ce contenu à l’IA pour un scoring programmatique, évaluant dans quelle mesure chaque entreprise est un client potentiel.
Le résultat est un jeu de données enrichi, où chaque entreprise dispose d’un score et d’un bref commentaire indiquant s’il est judicieux de la contacter pour vos produits ou services. Grâce aux données de haute qualité du marketplace de Bright Data, aux capacités de filtrage avancées et à l’enrichissement par IA, trouver de nouveaux clients n’a jamais été aussi facile !
Créez un compte Bright Data gratuit dès aujourd’hui et commencez à expérimenter avec nos outils web prêts pour l’IA !






