

Dans ce guide, vous apprendrez :
- Qu’est-ce que Pipedream et pourquoi l’utiliser ?
- C’est la raison pour laquelle vous devriez l’intégrer à un plugin de scraping intégré.
- Avantages de l’intégration de Pipedream à l’architecture de scraping de Bright Data.
- Un tutoriel étape par étape pour créer un workflow de web scraping avec Pipedream.
Plongeons-y !
Pipedream en un coup d’œil : Automatiser et intégrer en toute simplicité
Pipedream est une plateforme permettant de créer et d’exécuter des flux de travail qui relient diverses applications et fournisseurs tiers. Plus précisément, elle offre des fonctionnalités “no-code” et “low-code”. Grâce à ces capacités, vous pouvez automatiser des processus et intégrer des systèmes par le biais de composants préconstruits ou de code personnalisé.
Vous trouverez ci-dessous une analyse de ses principales caractéristiques :
- Constructeur visuel de flux de travail: Définissez des flux de travail à l’aide d’une interface visuelle, en connectant des composants préconstruits pour les applications les plus courantes. Actuellement, il propose des intégrations pour plus de 2700 applications.
- Pas de code/faible code: Il ne nécessite pas de connaissances techniques. Toutefois, pour les besoins complexes, les applications Pipedream peuvent intégrer des nœuds de code personnalisés. Les langages de programmation pris en charge sont Node.js, Python, Go et Bash.
- Architecture axée sur les événements: Les flux de travail sont déclenchés par des événements tels que HTTP/webhooks, heure programmée, courriels entrants, etc. Ainsi, le flux de travail reste inactif et ne consomme aucune ressource jusqu’à ce qu’un événement déclencheur spécifique se produise.
- Exécution sans serveur : La fonctionnalité principale de Pipedream s’articule autour de son exécution sans serveur. Cela signifie que vous n’avez pas besoin de provisionner ou de gérer des serveurs. Pipedream exécute les flux de travail dans un environnement évolutif et à la demande.
- L‘IA construit des flux de travail: Deal with String, une IA dédiée à la rédaction d’agents personnalisés qui ne nécessitent que l’insertion d’invites. Vous pouvez également l’utiliser si vous n’êtes pas particulièrement familiarisé avec Pipedream. Vous pouvez écrire une invite et laisser l’IA construire un flux de travail pour vous.
Pourquoi ne pas le coder ? Les avantages d’une intégration de scraping prête à l’emploi
Pipedream prend en charge les actions de code. Celles-ci vous permettent d’écrire des scripts complets à partir de zéro dans votre langue préférée (parmi celles qui sont prises en charge). Techniquement, cela signifie que vous pourriez construire un robot de scraping entièrement dans Pipedream en utilisant ces nœuds.
D’un autre côté, cela ne simplifie pas nécessairement le processus d’élaboration d’un flux de travail pour le scraping. Vous serez toujours confronté aux défis et obstacles habituels liés aux protections anti-scraping.
Il est donc plus pratique, plus efficace et plus rapide de s’appuyer sur un plugin de scraping intégré qui gère ces complexités pour vous. C’est précisément l’expérience offerte par l’intégration de Bright Data dans Pipedream.
Vous trouverez ci-dessous une liste des principales raisons de faire confiance au plugin de scraping prêt à l’emploi de Bright Data :
- Authentification facile: Pipedream stocke en toute sécurité votre clé d’API Bright Data (requise pour l’authentification) et vous offre une grande facilité d’utilisation. Vous n’avez pas besoin d’écrire de code personnalisé pour l’authentification, et vous êtes sûr de ne pas exposer votre clé.
- Surmonter les systèmes anti-bots: Sous le capot, les API de Bright Data gèrent tous les défis liés au scraping web, de la rotation du proxy et de la gestion de l’IP à la résolution des CAPTCHA et à l’analyse des données. Ainsi, votre flux de travail Pipedream est assuré de recevoir des données web cohérentes et de haute qualité.
- Données structurées: Après le scraping, vous obtenez des données structurées et organisées sans avoir à écrire la moindre ligne de code. Le plugin s’occupe de la structuration des données pour vous.
Principaux avantages de la combinaison de Pipedream et de Bright Data Plugin
Lorsque vous connectez les capacités d’automatisation de Pipedream à Bright Data, vous pouvez.. :
- Accédez à des données fraîches: L’objectif du web scraping est d’extraire des données du web, et Bright Data vous aide à le faire. Cependant, les données changent avec le temps. Par conséquent, si vous ne voulez pas que vos analyses soient obsolètes, vous devez continuer à extraire des données fraîches. C’est là que la puissance de Pipedream s’avère utile (par exemple, par le biais de déclencheurs de planification).
- Intégrez l’IA dans vos flux de travail de scraping: Pipedream s’intègre à plusieurs LLM, comme ChatGPT et Gemini. Cela vous permet d’automatiser plusieurs tâches qui nécessiteraient des heures de travail manuel. Par exemple, vous pouvez créer un flux de travail RAG pour surveiller une liste de produits concurrents sur un site de commerce électronique.
- Simplifier les aspects techniques: Les sites Web utilisent des techniques sophistiquées de blocage anti-scraping qui sont mises à jour presque chaque semaine. L’intégration de Bright Data contourne les blocages pour vous, car elle prend en charge toutes les solutions anti-bots.
Il est temps de voir l’intégration de Bright Data en action dans un flux de travail de scraping Pipedream !
Créez un flux de travail de scraping alimenté par l’IA avec Pipedream et Bright Data : Tutoriel étape par étape
Dans cette section guidée, vous apprendrez à construire un flux de travail Pipedream qui utilise Bright Data pour récupérer les données d’un produit Amazon. En particulier, la page cible sera :
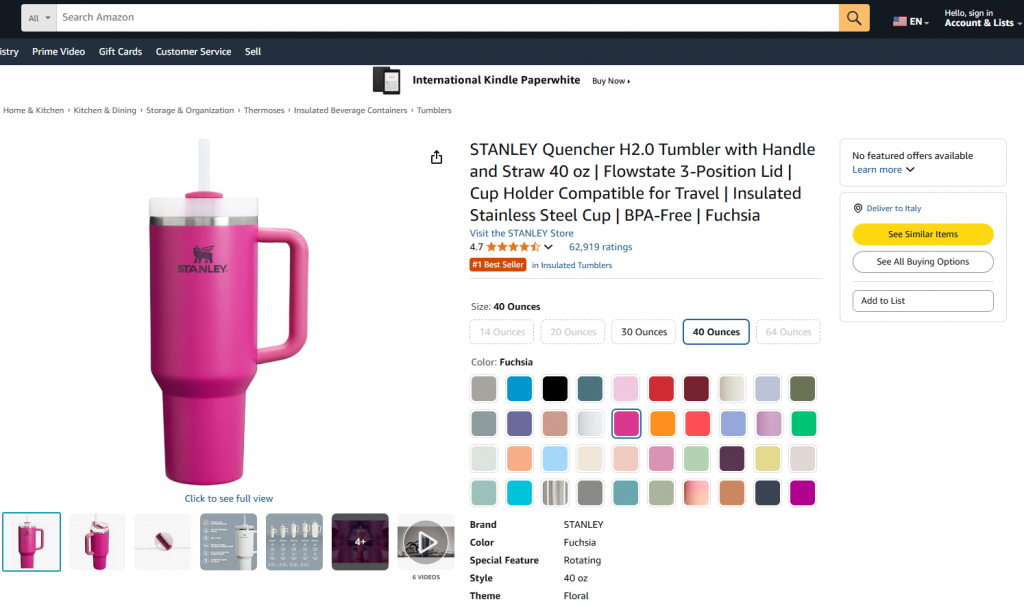
L’objectif est de vous montrer comment créer un flux de travail Pipedream qui effectue les opérations suivantes :
- Récupère les données de la page web cible à l’aide de l’intégration Bright Data.
- Intègre les données dans un LLM.
- Demande au MLD d’analyser les données et de créer un résumé du produit à partir de celles-ci.
Suivez les étapes ci-dessous pour apprendre à créer, tester et déployer un tel flux de travail dans Pipedream.
Exigences
Pour reproduire ce tutoriel, vous avez besoin de :
- Un compte Pipedream (un compte gratuit suffit).
- Une clé d’API de Bright Data.
- Une clé API OpenAI.
Si vous ne les avez pas encore, utilisez les liens ci-dessus et suivez les instructions pour tout mettre en place.
Il est également utile d’avoir ces connaissances pour suivre le tutoriel :
- Familiarité avec l’infrastructure et les produits de Bright Data (en particulier l’API Web Scraper).
- Une compréhension de base du traitement de l’IA (par exemple, les LLM).
- Connaissance du fonctionnement des déclencheurs et des appels API via les webhooks.
Étape 1 : Créer un nouveau flux de travail Pipedream
Connectez-vous à votre compte Pipedream et accédez à votre tableau de bord. Créez ensuite un nouveau flux de travail en cliquant sur le bouton “Nouveau flux de travail” :
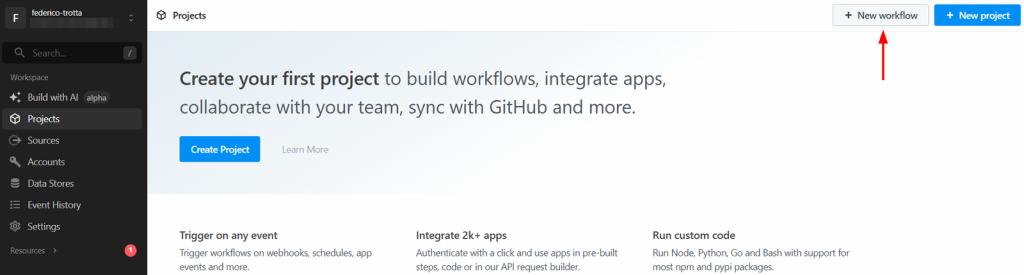
Le système vous demandera de créer un nouveau projet. Donnez-lui un nom et cliquez sur le bouton “Créer un projet” lorsque vous avez terminé :
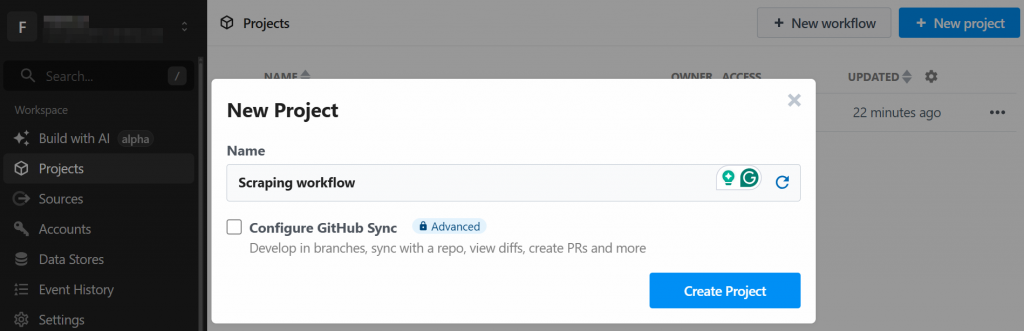
L’outil vous demandera d’attribuer un nom au flux de travail et de définir ses paramètres. Vous pouvez laisser les paramètres tels quels et appuyer sur le bouton “Créer un flux de travail” à la fin :
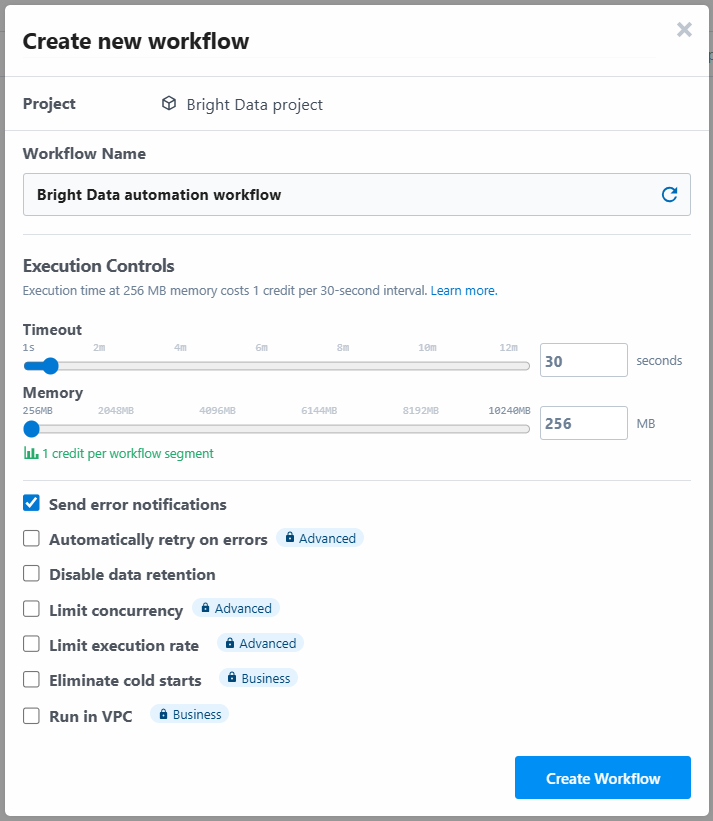
Vous trouverez ci-dessous l’interface utilisateur de votre nouveau flux de travail :
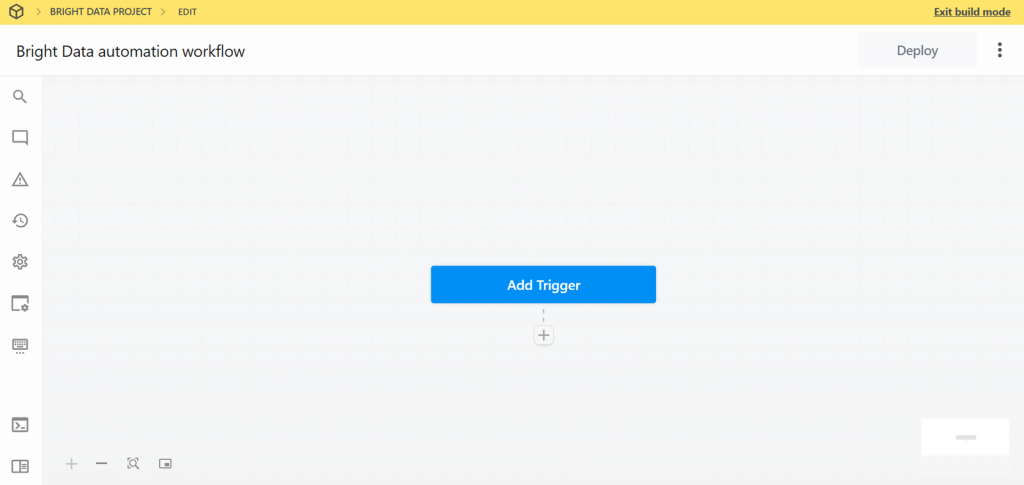
Très bien ! Vous avez créé un nouveau flux de travail dans Pipedream. Vous êtes maintenant prêt à y ajouter des intégrations de plugins.
Étape 2 : Ajouter un déclencheur
Dans Pipedream, chaque flux de travail commence par un déclencheur. En cliquant sur “Ajouter un déclencheur”, vous verrez apparaître les déclencheurs que vous pouvez choisir :
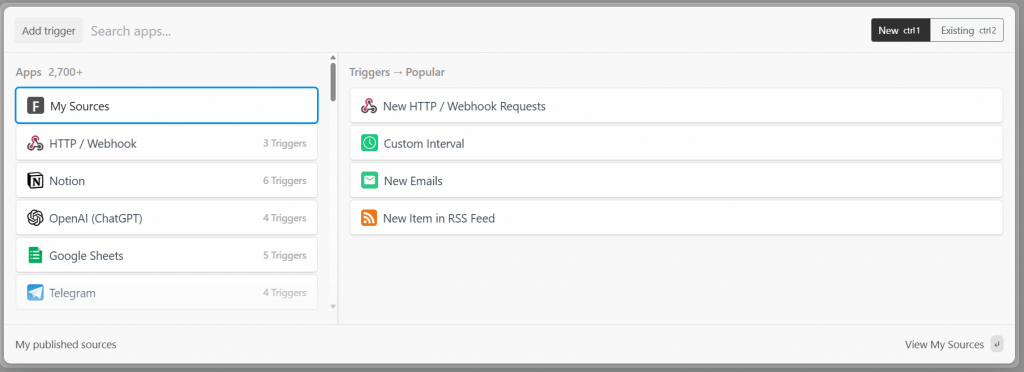
Dans ce cas, sélectionnez le déclencheur “New HTTP/Webhook Requests”, qui est nécessaire pour se connecter à Bright Data. Laissez les données de remplacement telles quelles et cliquez sur le bouton “Enregistrer et continuer” :
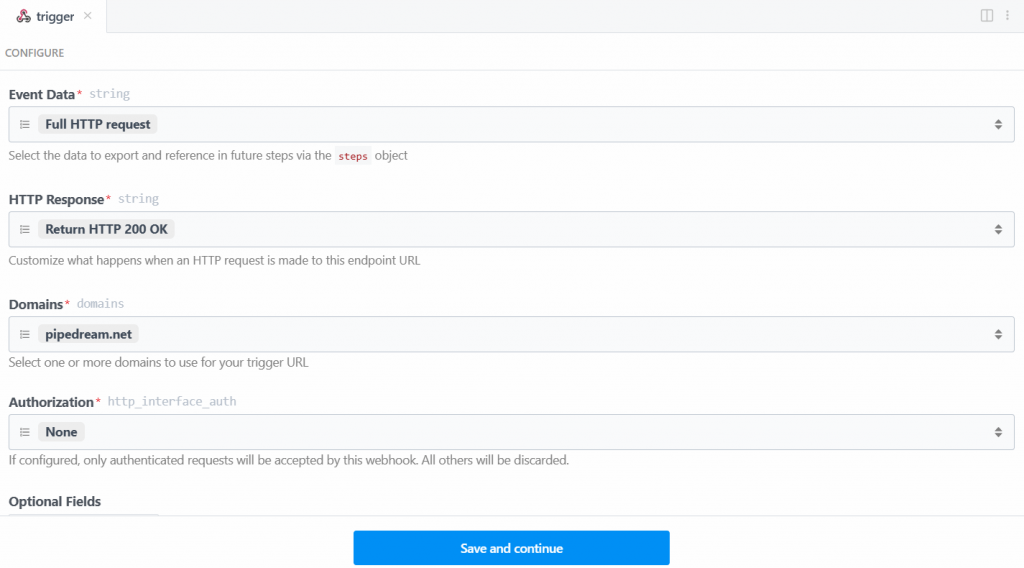
Pour que le déclencheur fonctionne, vous devez générer un événement. Cliquez donc sur “Générer un événement de test” :
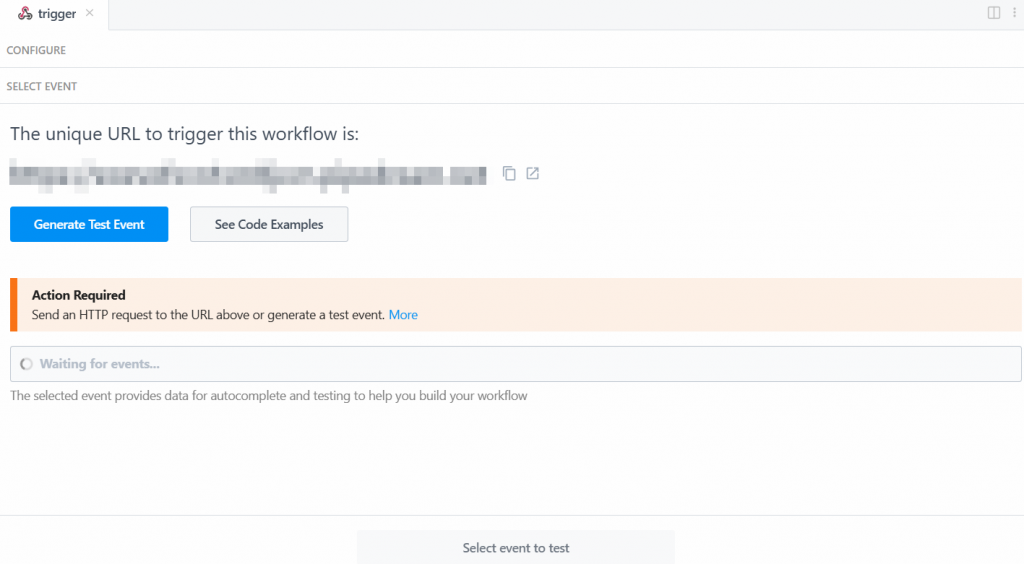
Le système vous fournit une valeur prédéfinie d’un événement de test comme suit :
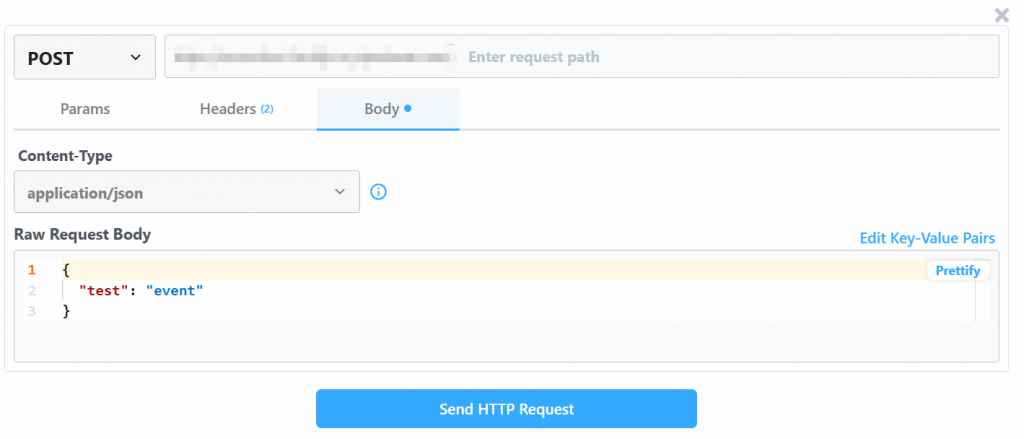
Modifier la valeur “Raw Request Body” avec :
{
"url": "https://www.amazon.com/Quencher-FlowState-Stainless-Insulated-Smoothie/dp/B0CRMZHDG8",
"zipcode": "94107",
"language": ""
}La raison en est que le déclencheur généré par Pipedream lancera l’appel à l’API Amazon Scraper de Bright Data. Le point de terminaison (qui sera configuré ultérieurement) nécessite des données d’entrée dans ce format de charge utile spécifique. Vous pouvez le vérifier en consultant la section “API Request Builder” du scraper “Collect by URL” dans Aamzon Web Scrapers de Bright Data :
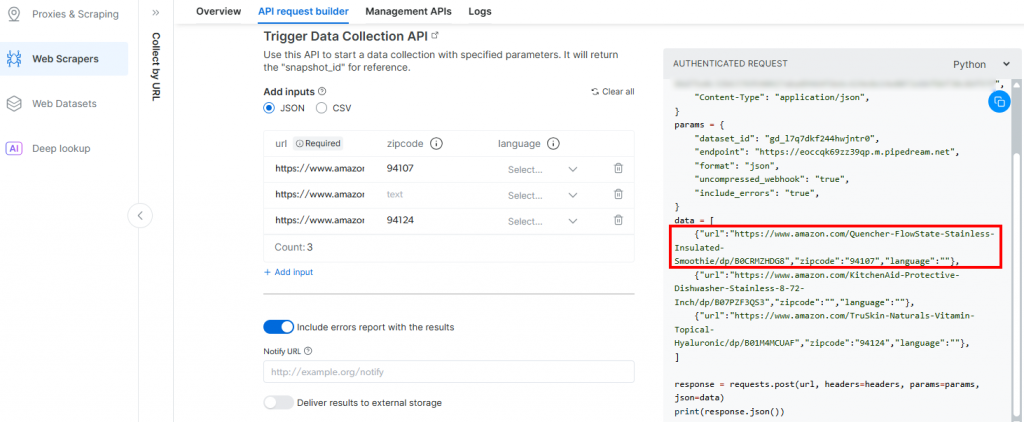
De retour à la fenêtre Pipedream, cliquez sur le bouton “Send HTTP Request”. Si tout se passe comme prévu, vous verrez un message de succès dans la section des résultats. Le déclencheur sera également coloré en vert :
C’est parfait ! Le déclencheur du démarrage de l’intégration de Bright Data dans le flux de travail de scraping Pipedream a été correctement configuré. Vous êtes maintenant prêt à ajouter une action.
Étape 3 : Ajouter l’étape d’action Bright Data
Après le déclencheur, vous pouvez ajouter une étape d’action dans le flux de travail Pipedream. Il s’agit maintenant de relier l’étape Bright Data au déclencheur. Pour ce faire, cliquez sur le “+” sous le déclencheur et recherchez “bright data” :
Pipedream vous propose plusieurs actions du plugin Bright Data. Sélectionnez-le pour les voir toutes :
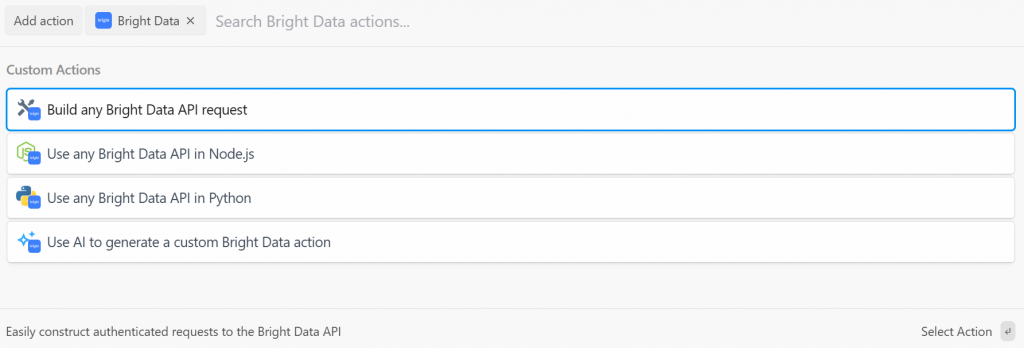
Les options disponibles sont les suivantes :
- Créez n’importe quelle demande d’API Bright Data: Créez des requêtes authentifiées auprès des API de Bright Data.
- Utilisez n’importe quelle API Bright Data dans Node.js/Python: Connectez votre compte Bright Data à Pipedream et personnalisez les requêtes dans Node.js/Python.
- Utiliser l’IA pour générer une action Bright Data personnalisée: Demander à l’IA de générer un code personnalisé pour Bright Data.
Pour ce tutoriel, sélectionnez l’option “Use any Bright Data API in Python” (Utiliser n’importe quelle API de données Bright en Python). Voici ce que vous verrez :
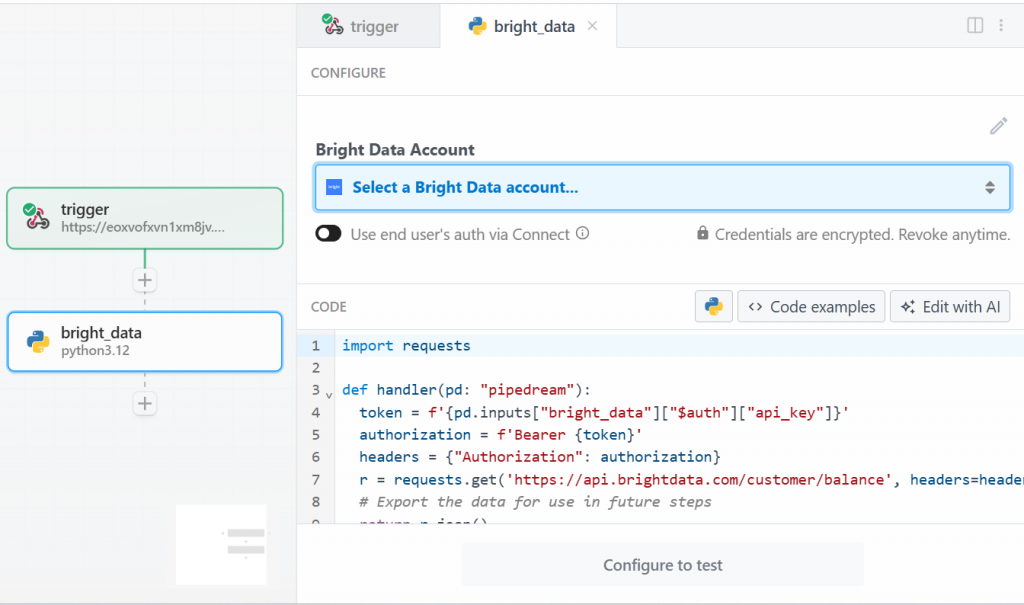
Tout d’abord, cliquez sur ” Sélectionner un compte Bright Data ” sous ” Compte Bright Data ” et ajoutez votre clé d’API Bright Data. Si vous ne l’avez pas encore fait, assurez-vous de suivre le guide officiel pour configurer une clé d’API Bright Data.
Ensuite, supprimez le code dans la section “CODE” et écrivez ce qui suit :
import requests
import json
import time
def handler(pd: "pipedream"):
# Retrieve the Bright Data API key from Pipedream's authenticated accounts
api_key = pd.inputs["bright_data"]["$auth"]["api_key"]
# Get the target Amazon product URL from the trigger data
amazon_product_url = pd.steps["trigger"]["event"]["body"]["url"]
# Configure the Bright Data API request
brightdata_api_endpoint = "https://api.brightdata.com/datasets/v3/trigger"
params = { "dataset_id": "gd_l7q7dkf244hwjntr0", "include_errors": "true" }
payload_data = [{"url": amazon_product_url}]
headers = { "Authorization": f"Bearer {api_key}", "Content-Type": "application/json" }
# Initiate the data collection job
print(f"Triggering Bright Data dataset with URL: {amazon_product_url}")
trigger_response = requests.post(brightdata_api_endpoint, headers=headers, params=params, json=payload_data)
# Check if the trigger request was successful
if trigger_response.status_code == 200:
response_json = trigger_response.json()
# Extract the snapshot ID, which is needed to poll for results.
snapshot_id = response_json.get("snapshot_id")
# Handle cases where the trigger is successful but no snapshot ID is provided
if not snapshot_id:
print("Trigger successful, but no snapshot_id was returned.")
return {"error": "Trigger successful, but no snapshot_id was returned.", "response": response_json}
# Begin polling for the completed snapshot using its ID
print(f"Successfully triggered. Snapshot ID is {snapshot_id}. Now starting to poll for results.")
final_scraped_data = poll_and_retrieve_snapshot(api_key, snapshot_id)
# Return the final scraped data from the workflow
return final_scraped_data
else:
# If the trigger failed, log the error and exit the Pipedream workflow
print(f"Failed to trigger. Error: {trigger_response.status_code} - {trigger_response.text}")
pd.flow.exit(f"Error: Failed to trigger Bright Data scrape. Status: {trigger_response.status_code}")
def poll_and_retrieve_snapshot(api_key, snapshot_id, polling_timeout=20):
# Construct the URL for the specific snapshot
snapshot_url = f"https://api.brightdata.com/datasets/v3/snapshot/{snapshot_id}?format=json"
# Set the authorization header for the API request
headers = { "Authorization": f"Bearer {api_key}" }
print(f"Polling snapshot for ID: {snapshot_id}...")
# Loop until the snapshot is ready
while True:
response = requests.get(snapshot_url, headers=headers)
# If status is 200, the data is ready
if response.status_code == 200:
print("Snapshot is ready. Returning data...")
return response.json()
# If status is 202, the data is not ready yet. Wait and retry
elif response.status_code == 202:
print(f"Snapshot is not ready yet. Retrying in {polling_timeout} seconds...")
time.sleep(polling_timeout)
# If any other status code is received, an error occurred.
else:
print(f"Polling failed! Error: {response.status_code}")
print(response.text)
return {"error": "Polling failed", "status_code": response.status_code, "details": response.text}Ce code effectue les opérations suivantes :
- La fonction
handler()gère le flux de travail au niveau de Pipedream. Il s’agit d’une fonction de gestion du flux de travail au niveau de Pipedream :- Récupère la clé de l’API Bright Data, après l’avoir stockée dans Pipedream.
- Configure la requête Bright Data API en fonction de l’URL cible, de l’ID de l’ensemble de données et de toutes les données spécifiques nécessaires.
- Gère la réponse. En cas de problème, vous verrez les erreurs dans les journaux de Pipedream.
- La fonction
poll_and_retrieve_snapshot()interroge l’API Bright Data pour obtenir un instantané jusqu’à ce qu’elle soit prête. Lorsqu’elle est prête, elle renvoie les données demandées. En cas de problème, elle gère les erreurs et les affiche dans les journaux.
Lorsque vous êtes prêt, cliquez sur le bouton “Test”. Vous verrez un message de réussite dans la section “RESULTATS”, et l’étape d’action “Données brillantes” sera colorée en vert :
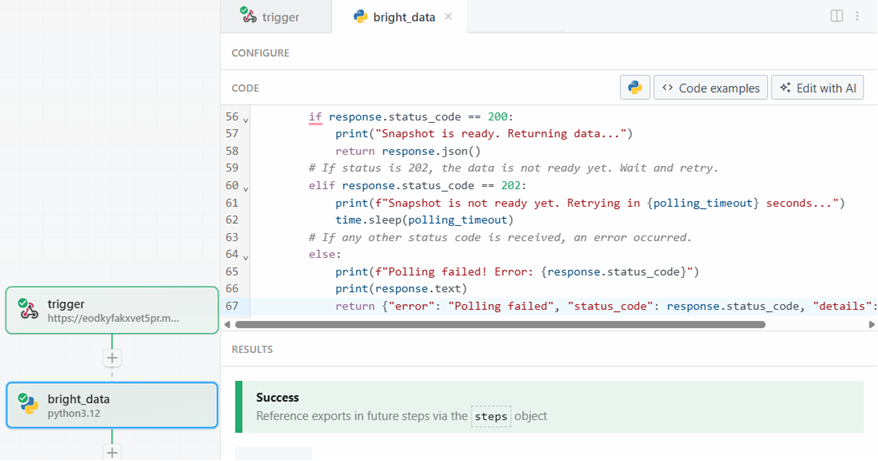
Dans la section “Exportations” sous “RÉSULTATS”, vous pouvez voir les données extraites :
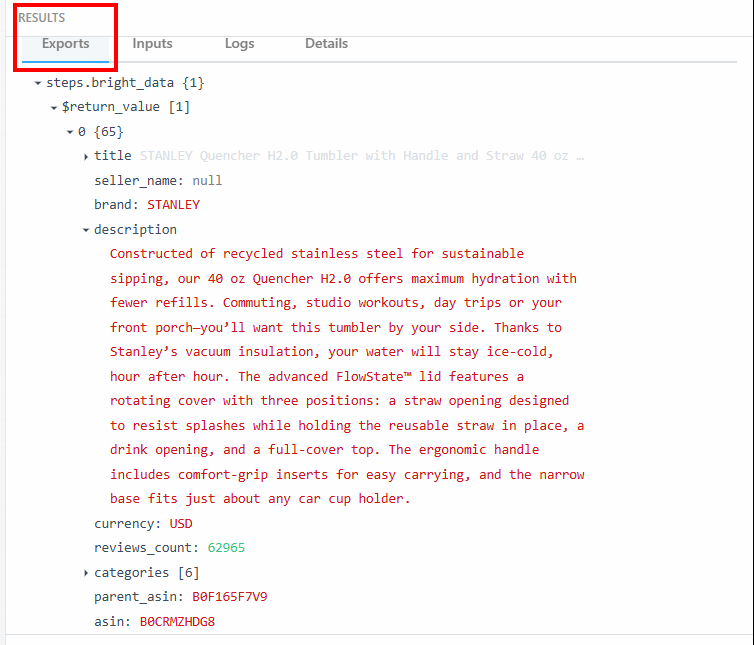
Vous trouverez ci-dessous les données extraites sous forme de texte :
steps.bright_data{
$return_value{
0{
"title":"STANLEY Quencher H2.0 Tumbler with Handle and Straw 40 oz | Flowstate 3-Position Lid | Cup Holder Compatible for Travel | Insulated Stainless Steel Cup | BPA-Free | Fuchsia",
"seller_name":"null",
"brand":"STANLEY",
"description":"Constructed of recycled stainless steel for sustainable sipping, our 40 oz Quencher H2.0 offers maximum hydration with fewer refills. Commuting, studio workouts, day trips or your front porch—you’ll want this tumbler by your side. Thanks to Stanley’s vacuum insulation, your water will stay ice-cold, hour after hour. The advanced FlowState™ lid features a rotating cover with three positions: a straw opening designed to resist splashes while holding the reusable straw in place, a drink opening, and a full-cover top. The ergonomic handle includes comfort-grip inserts for easy carrying, and the narrow base fits just about any car cup holder.",
"currency":"USD",
"reviews_count":"62965",
..OMITTED FOR BREVITY...
}
}
}Vous utiliserez ces données et leur structure dans l’étape suivante du flux de travail.
C’est super ! Vous avez correctement récupéré les données cibles grâce à l’action Bright Data dans Pipedream.
Étape 4 : Ajouter l’étape d’action OpenAI
Les données des produits Amazon ont été récupérées avec succès par l’intégration Beight Data. Vous pouvez maintenant les transmettre à un LLM. Pour ce faire, ajoutez une nouvelle action en cliquant sur le bouton “+” et recherchez “openai”. Ici, vous pouvez choisir parmi différentes options :

Sélectionnez l’option “Build any OpenAI (ChatGPT) API request”, puis sélectionnez l’option “Chat” :
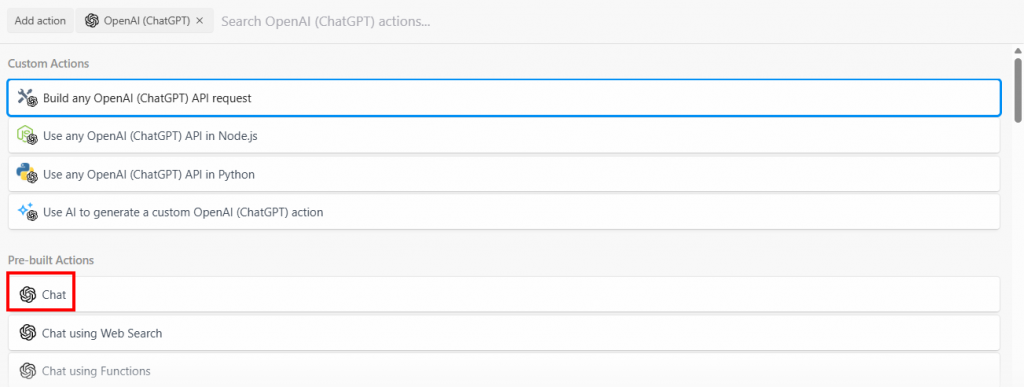
Vous trouverez ci-dessous la section de configuration de cette action :
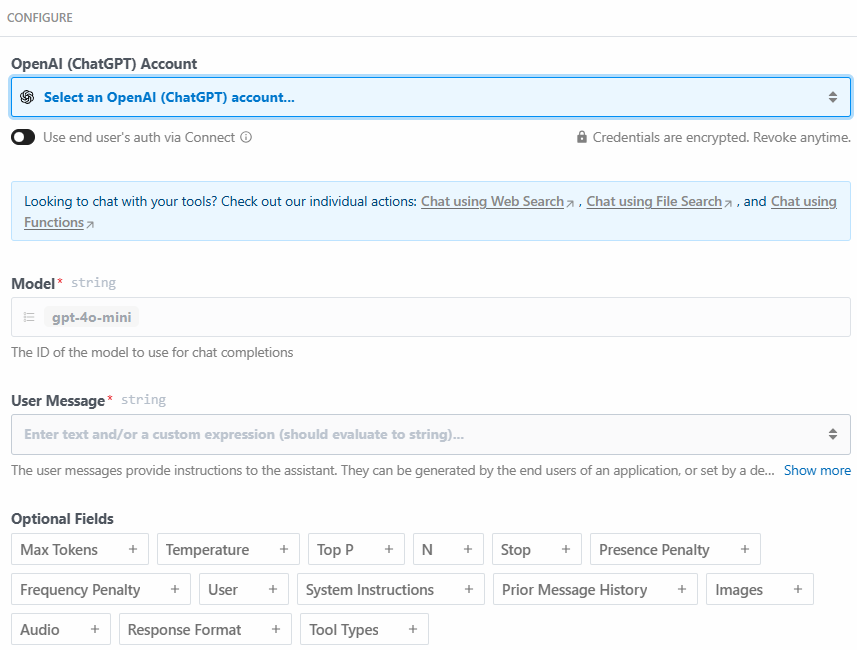
Cliquez sur “Select an OpenAI (ChatGPT) account…” pour ajouter la clé API de votre plateforme OpenAI. Ensuite, écrivez l’invite suivante dans la section “Message de l’utilisateur” :
Act as an expert product analyst. Consider the following data from an Amazon product page:
PRODUCT TITLE:
{{steps.bright_data.$return_value[0].title}}
BRAND:
{{steps.bright_data.$return_value[0].brand}}
DESCRIPTION:
{{steps.bright_data.$return_value[0].description}}
REVIEWS COUNT
{{steps.bright_data.$return_value[0].reviews_count}}
Based on this data, provide a concise summary of the product that should entice potential customers to buy it. The summary should include what the product is, and its most important features.L’invite demande au MLD de.. :
- Agir comme un analyste produit expert. Ce point est important car, avec cette instruction, le MLD se comportera comme le ferait un analyste produit expert. Cela contribue à rendre sa réponse spécifique à l’industrie.
- Tenez compte des données extraites par l’étape Bright Data, telles que le titre et la description du produit. Cela permet au LLM de se concentrer sur les données spécifiques dont vous avez besoin.
- Fournissez un résumé du produit, basé sur les données récupérées. L’invite est également précise quant au contenu du résumé. C’est ici que vous verrez la puissance de l’IA-automation pour le résumé de produit. Le LLM créera un résumé du produit, sur la base des données récupérées, en agissant comme un spécialiste du produit.
Vous pouvez récupérer le titre du produit avec {{steps.bright_data.$return_value[0].title}} car, comme spécifié dans l’étape précédente, la structure des données de sortie de l’étape d’action Bright Data est la suivante :
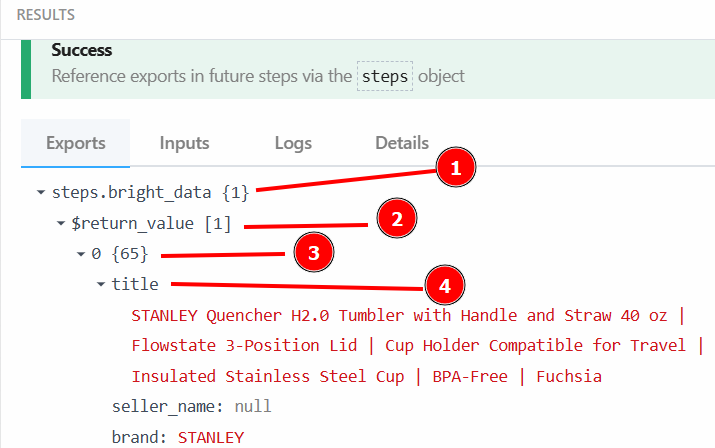
Après avoir cliqué sur “Test”, vous trouverez le résultat du LLM dans la section “RESULTS” de l’étape d’action OpenAI Chat sous “Generated message” > “content” :
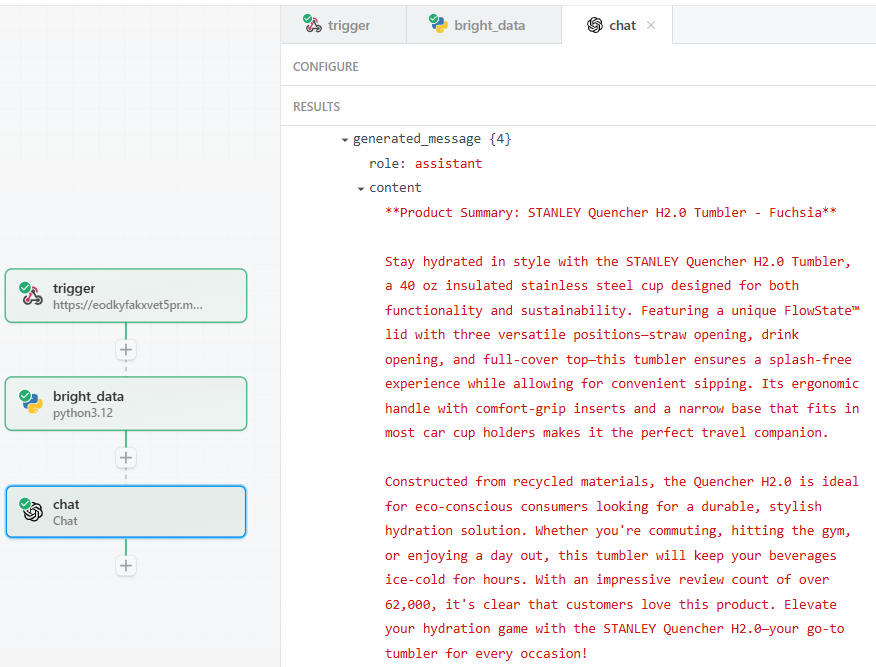
Voici un résultat textuel possible :
**Product Summary: STANLEY Quencher H2.0 Tumbler - Fuchsia**
Stay hydrated in style with the STANLEY Quencher H2.0 Tumbler, a 40 oz insulated stainless steel cup designed for both functionality and sustainability. Featuring a unique FlowState™ lid with three versatile positions—straw opening, drink opening, and full-cover top—this tumbler ensures a splash-free experience while allowing for convenient sipping. Its ergonomic handle with comfort-grip inserts and a narrow base that fits in most car cup holders makes it the perfect travel companion.
Constructed from recycled materials, the Quencher H2.0 is ideal for eco-conscious consumers looking for a durable, stylish hydration solution. Whether you're commuting, hitting the gym, or enjoying a day out, this tumbler will keep your beverages ice-cold for hours. With an impressive review count of over 62,000, it's clear that customers love this product. Elevate your hydration game with the STANLEY Quencher H2.0—your go-to tumbler for every occasion!Comme vous pouvez le voir, le LLM a fourni le résumé du produit, agissant en tant que spécialiste du produit. Le résumé répond exactement à la question posée dans l’invite :
- Ce qu’est le produit.
- Quelques-unes de ses caractéristiques importantes.
La raison pour laquelle vous voulez extraire des données exactes – comme le nombre d’évaluations – est de vous assurer que le LLM n’est pas en train d’halluciner. Le résumé indique que le nombre d’évaluations est supérieur à 62 000. Si vous voulez voir le nombre exact, vous pouvez le vérifier dans le champ “contenu” des résultats :
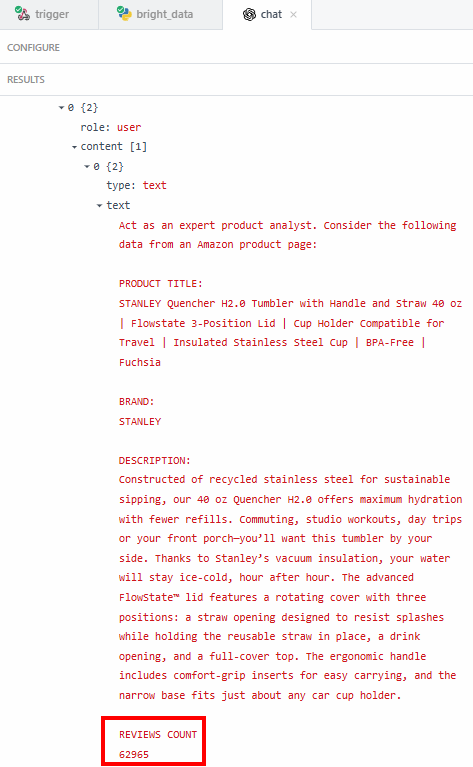
Vous devez ensuite vérifier si ce numéro correspond à celui qui figure sur la page du produit Amazon.
Enfin, si vous avez déjà essayé de récupérer des données sur de grands sites de commerce électronique comme Amazon, vous savez à quel point il est difficile de le faire par soi-même. Par exemple, vous pouvez rencontrer le fameux CAPTCHA d’Amazon, qui peut bloquer la plupart des scrapeurs :
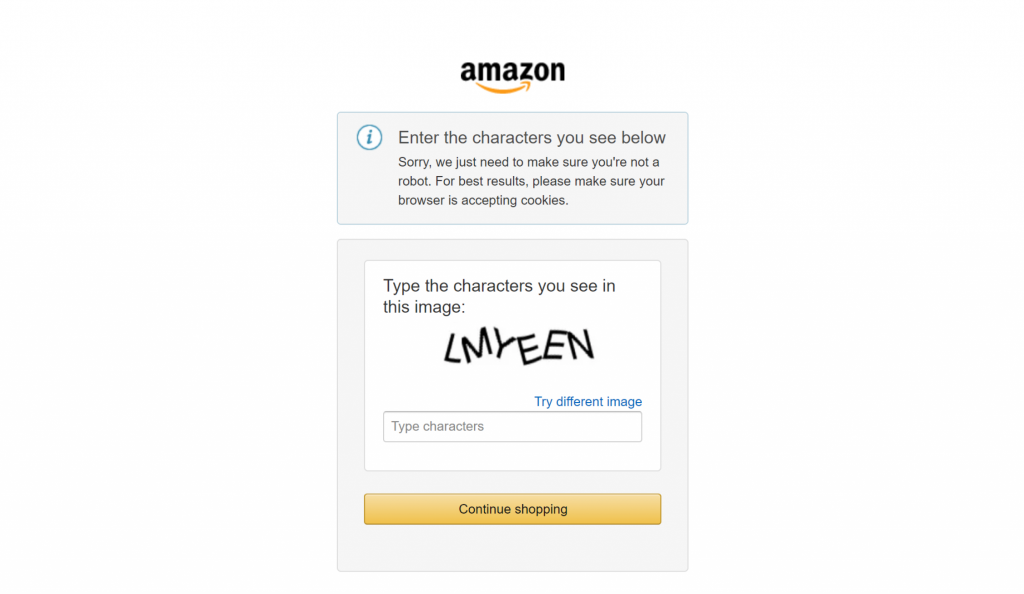
C’est là que l’intégration de Bright Data fait toute la différence dans vos flux de travail de scraping. Elle prend en charge toutes les mesures anti-scraping en coulisses et veille à ce que le processus de récupération des données se déroule sans heurts.
C’est formidable ! Vous avez testé avec succès l’étape LLM. Vous êtes maintenant prêt à déployer le flux de travail.
Étape 5 : Déployer le flux de travail
Pour déployer votre flux de travail, cliquez sur l’un des boutons “Déployer” :
Voici ce que vous verrez après le déploiement :
Pour exécuter l’ensemble du flux de travail, cliquez sur “Générer un événement” :
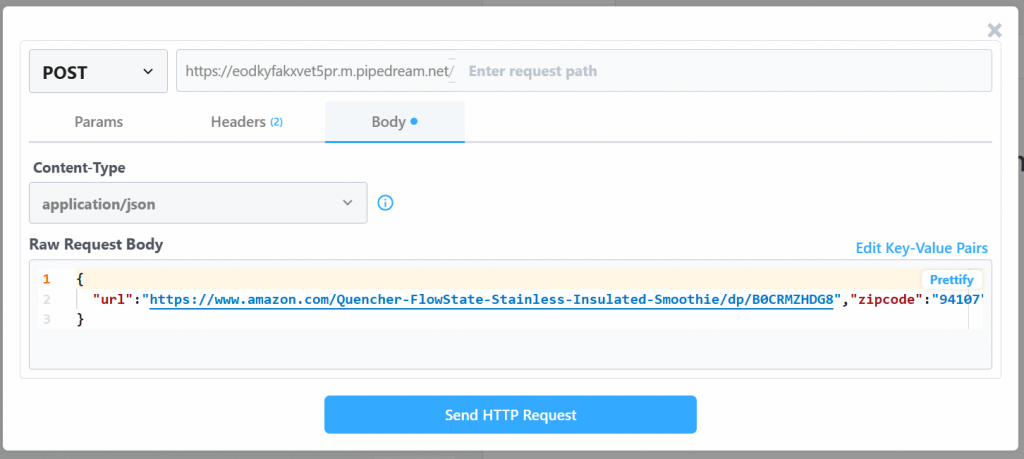
Cliquez sur “Send HTTP Request” pour déclencher le flux de travail, qui s’exécutera entièrement. Pour voir les résultats des flux de travail déployés, allez dans “Historique des événements” sur la page d’accueil. Sélectionnez le flux de travail qui vous intéresse et consultez les résultats sous “Exportations” :
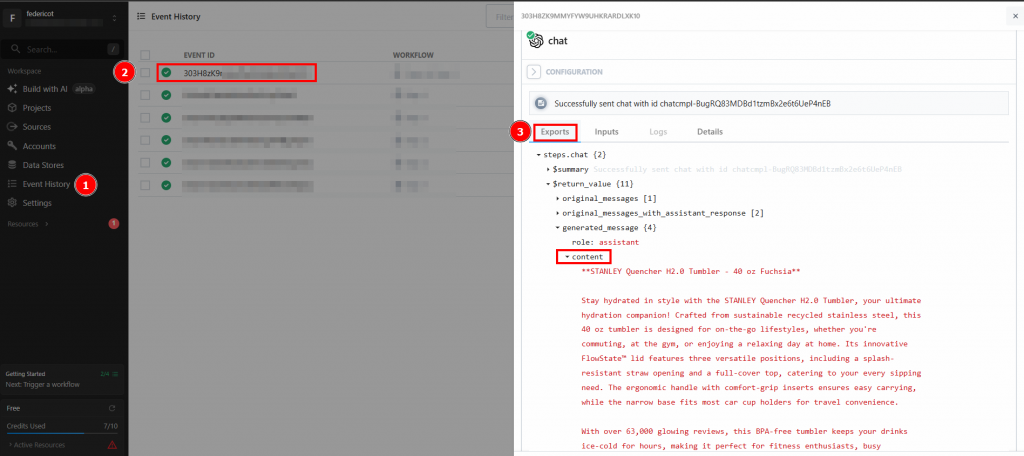
Et voilà ! Vous avez créé et déployé votre premier workflow de scraping dans Pipedream à l’aide de Bright Data.
Conclusion
Dans ce guide, vous avez appris à créer un flux de travail automatisé pour le scraping Web à l’aide de Pipedream. Vous avez pu constater que l’interface intuitive de la plateforme, combinée à l’intégration du scraping de Bright Data, permet de créer des pipelines de scraping sophistiqués en quelques minutes.
Le principal défi de toute automatisation axée sur les données est d’assurer un flux constant de données propres et fiables. Pipedream fournit le moteur d’automatisation et de planification, tandis que l ‘infrastructure d’IA de Bright Data gère les complexités du web scraping et fournit des données prêtes à l’emploi. Cette synergie vous permet de vous concentrer sur la création de valeur à partir des données, plutôt que sur les obstacles techniques liés à leur acquisition.
Créez un compte Bright Data gratuit et commencez à expérimenter nos outils de données prêts pour l’IA dès aujourd’hui !






