

Dans ce guide, vous découvrirez :
- Ce que propose le framework NVIDIA NeMo, en particulier pour la création d’agents IA à l’aide du kit d’outils NVIDIA NeMo Agent.
- Comment intégrer Bright Data dans un agent IA NAT à l’aide d’outils personnalisés via LangChain.
- Comment connecter un workflow NVIDIA NeMo Agent Toolkit à Bright Data Web MCP.
C’est parti !
Présentation du framework NVIDIA NeMo
Le framework NVIDIA NeMo est une plateforme de développement IA complète et native du cloud, conçue pour créer, personnaliser et déployer des modèles IA génératifs, notamment des LLM et des modèles multimodaux.
Il offre des outils de bout en bout pour l’ensemble du cycle de vie de l’IA, de la formation et du réglage fin à l’évaluation et au déploiement. NeMo tire également parti d’une formation distribuée à grande échelle et comprend des composants pour des tâches telles que la curation des données, l’évaluation des modèles et la mise en œuvre de garde-fous de sécurité.
Il est pris en charge par une bibliothèque Python open source avec plus de 16 000 étoiles GitHub et des images Docker dédiées.
NVIDIA NeMo Agent Toolkit
Faisant partie du framework NVIDIA NeMo, le NVIDIA NeMo Agent Toolkit (abrégé en « NAT ») est un framework open source permettant de créer, d’optimiser et de gérer des systèmes d’agents IA complexes.
Il vous aide à connecter divers agents et outils dans des flux de travail unifiés avec une observabilité, un profilage et une analyse des coûts approfondis, agissant comme un « chef d’orchestre » pour les opérations multi-agents et aidant à faire évoluer les applications d’IA.
NAT met l’accent sur la composabilité, traitant les agents et les outils comme des appels de fonction modulaires. Il fournit également des fonctionnalités permettant d’identifier les goulots d’étranglement, d’automatiser les évaluations et de gérer les systèmes d’IA agentielle de niveau entreprise.
Pour plus d’informations, consultez :
Relier les LLM et les données en temps réel avec les outils Bright Data
La boîte à outils NVIDIA NeMo Agent Toolkit offre la flexibilité, la personnalisation, l’observabilité et l’évolutivité nécessaires pour créer et gérer des projets d’IA à l’échelle de l’entreprise. Elle permet aux organisations d’orchestrer des flux de travail d’IA complexes, de connecter plusieurs agents et de surveiller les performances et les coûts.
Cependant, même les applications NAT les plus sophistiquées sont confrontées aux limites inhérentes aux LLM. Il s’agit notamment de connaissances obsolètes dues à des données d’entraînement statiques et à un manque d’accès aux informations web en temps réel.
La solution consiste à intégrer votre workflow NVIDIA NeMo Agent Toolkit à un fournisseur de données web pour l’IA, tel que Bright Data.
Bright Data propose des outils pour le Scraping web, la recherche, l’automatisation des navigateurs, et bien plus encore. Ces solutions permettent à votre système IA de récupérer des données exploitables en temps réel et de libérer tout son potentiel pour les applications d’entreprise!
Comment connecter Bright Data à un agent NVIDIA NeMo IA
Une façon de tirer parti des capacités de Bright Data dans un agent NVIDIA NeMo IA consiste à créer des outils personnalisés via le NeMo Agent Toolkit.
Ces outils se connecteront aux produits Bright Data via des fonctions personnalisées alimentées par LangChain (ou toute autre intégration prise en charge avec les bibliothèques de création d’agents IA).
Suivez les instructions ci-dessous !
Prérequis
Pour suivre ce tutoriel, vous devez disposer des éléments suivants :
- Python 3.11, 3.12 ou 3.13 installé localement.
- Un compte Bright Data configuré pour l’intégration avec les outils officiels LangChain.
- Un compte NVIDIA NIM avec une clé API configurée.
Ne vous inquiétez pas pour la configuration des comptes Bright Data et NVIDIA NIM pour le moment, car vous serez guidé à travers cette procédure dans des chapitres dédiés.
Remarque: en cas de problème lors de l’installation ou de l’exécution de la boîte à outils, assurez-vous d’utiliser l’une des plateformes prises en charge.
Étape n° 1 : récupérez votre clé API NVIDIA NIM
La plupart des workflows NVIDIA NeMo Agent nécessitent une variable d’environnement NVIDIA_API_KEY. Celle-ci est nécessaire pour authentifier la connexion aux LLM NVIDIA NIM derrière le workflow.
Pour récupérer votre clé API, commencez par créer un compte NVIDIA NIM (si vous n’en avez pas déjà un). Connectez-vous et cliquez sur l’image de votre compte dans le coin supérieur droit. Sélectionnez l’option « API Keys » (Clés API) :
Vous accéderez à la page API Keys. Cliquez sur le bouton « Generate API Key » pour créer une nouvelle clé :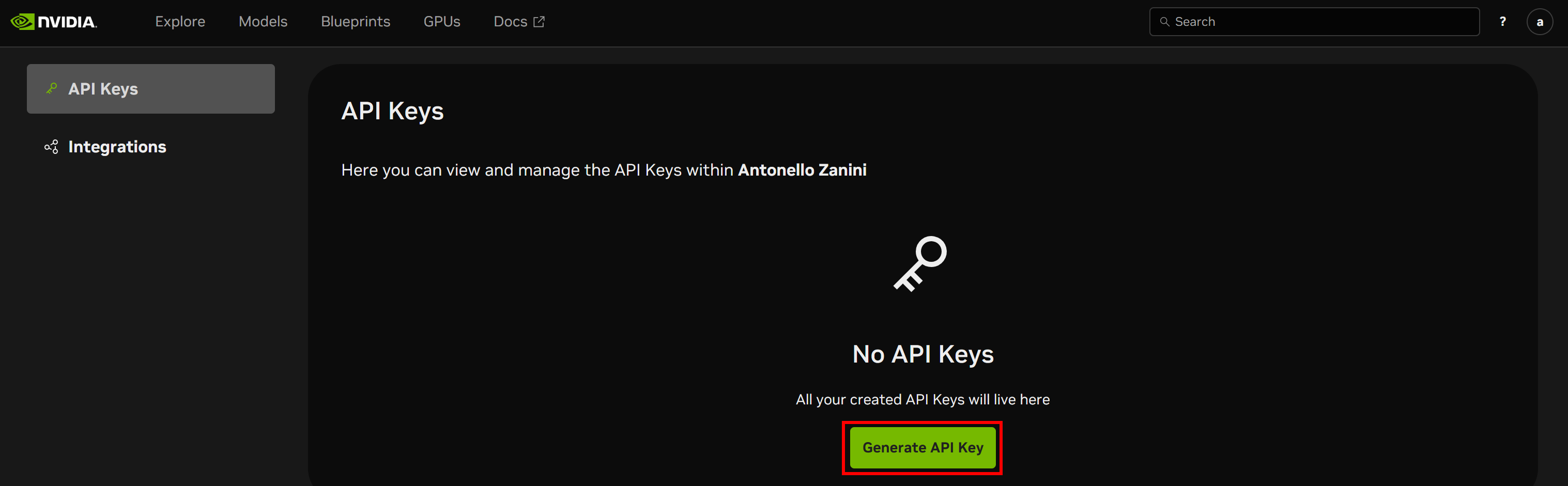
Donnez un nom à votre clé API et cliquez sur « Générer une clé » :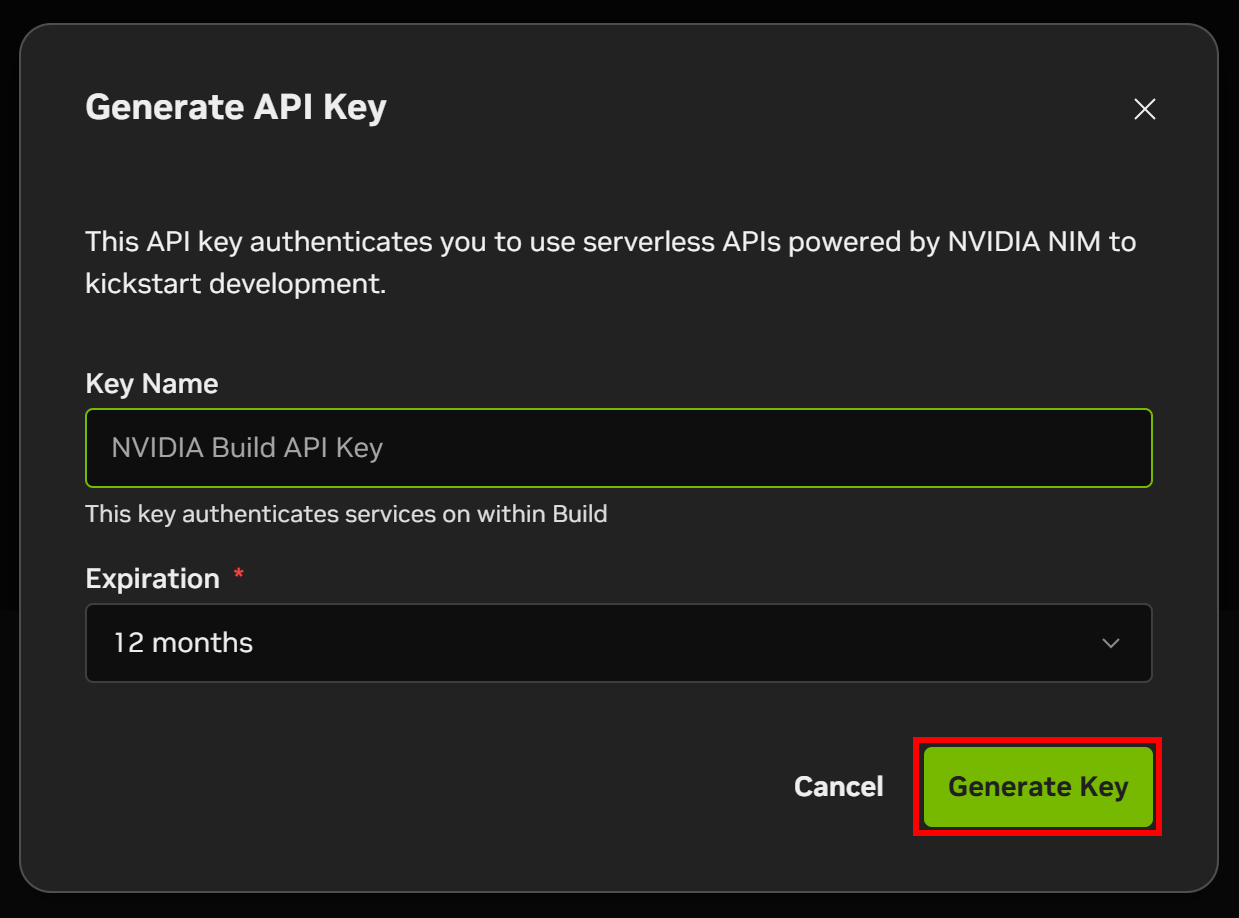
Une fenêtre modale affichera votre clé API. Cliquez sur le bouton « Copier la clé API » et conservez la clé en lieu sûr, car vous en aurez besoin sous peu.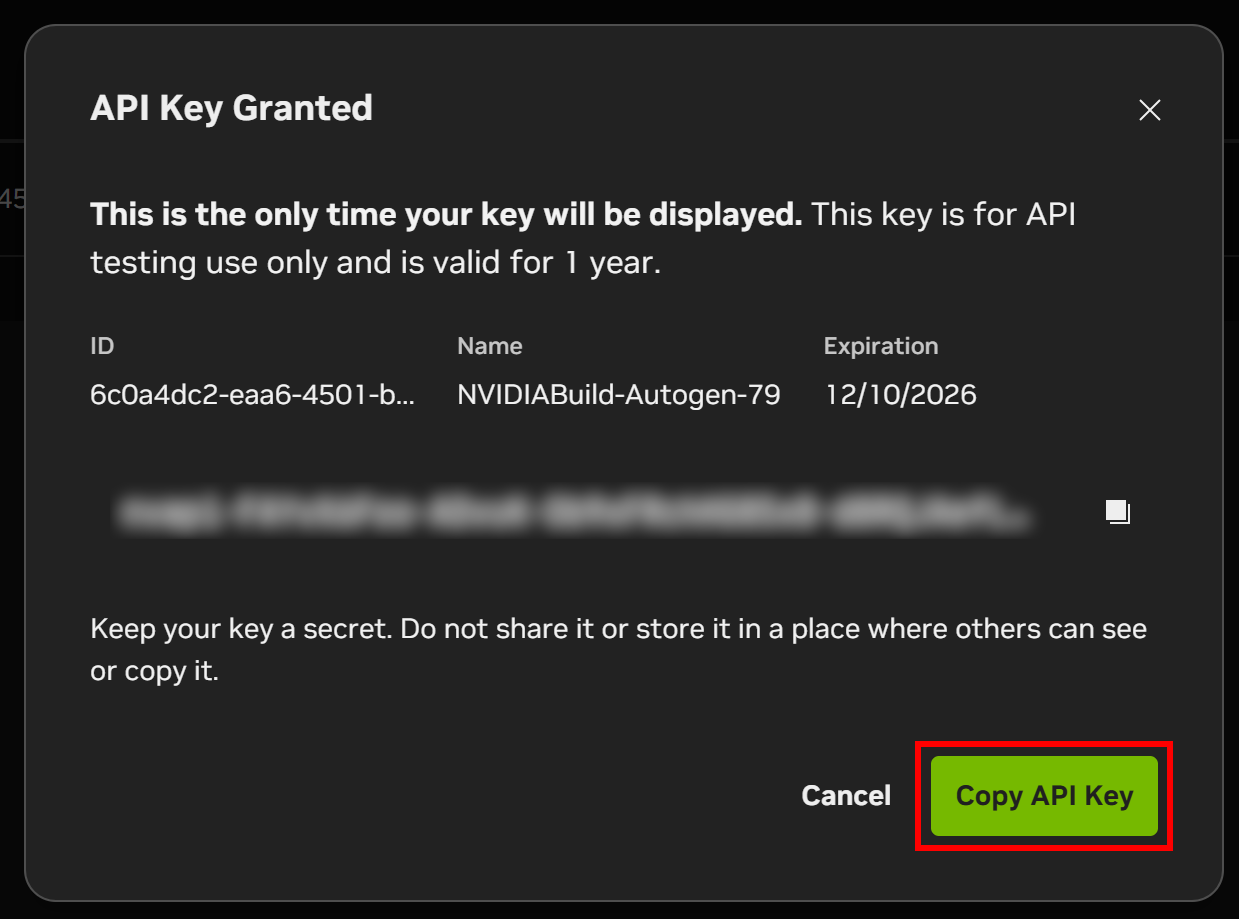
Bravo ! Vous êtes prêt à installer le kit d’outils NVIDIA NeMo Agent et à commencer.
Étape n° 2 : configurer un projet NVIDIA NeMo
Pour installer la dernière version stable de NeMo Agent Toolkit, exécutez :
pip install nvidia-natNeMo Agent Toolkit comporte de nombreuses dépendances facultatives qui peuvent être installées avec le package principal. Ces dépendances facultatives sont regroupées par framework.
Une fois installé, vous devriez avoir accès à la commande nat. Vérifiez qu’elle fonctionne en exécutant :
nat --versionVous devriez obtenir un résultat similaire à celui-ci :
nat, version 1.3.1Ensuite, créez un dossier racine pour votre application NVIDIA NeMo. Par exemple, nommez-le « bright_data_nvidia_nemo » :
mkdir bright_data_nvidia_nemoDans ce dossier, créez un workflow NeMo Agent appelé « web_data_workflow » à l’aide de la commande suivante :
nat workflow create --workflow-dir bright_data_nvidia_nemo web_data_workflow Remarque: si vous rencontrez l’erreur « A required privilege is not held by the client » (Le client ne dispose pas des privilèges requis), exécutez la commande en tant qu’administrateur.
Si l’opération réussit, vous devriez voir des journaux tels que :
Installation du workflow « web_data_workflow »...
Workflow « web_data_workflow » installé avec succès.
Workflow « web_data_workflow » créé avec succès dans <votre_chemin>Votre dossier de projet bright_data_nvidia_nemo/web_data_workflow contiendra désormais la structure suivante :
bright_data_nvidia_nemo/web_data_workflow/
├── configs -> src/web_data_workflow/configs
├── data -> src/text_file_ingest/data
├── pyproject.toml
└── src/
├── web_data_workflow.egg-info/
└── web_data_workflow/
├── __init__.py
├── configs/
│ └── config.yml
├── data/
├── __init__.py
├── register.py
└── web_data_workflow.pyVoici ce que représentent chaque fichier et chaque dossier :
configs/→src/web_data_workflow/configs: lien symbolique pour faciliter l’accès à la configuration du flux de travail.data/→src/text_file_ingest/data: lien symbolique pour stocker des exemples de données ou des fichiers d’entrée.pyproject.toml: fichier contenant les métadonnées et les dépendances du projet.src/: répertoire du code source.web_data_workflow.egg-info/: dossier de métadonnées créé par les outils de packaging Python.web_data_workflow/: Module principal du workflow.__init__.py: initialise le module.configs/config.yml: fichier de configuration du workflow dans lequel vous définissez le comportement d’exécution (configuration LLM, définitions des fonctions/outils, type et paramètres de l’agent, orchestration du workflow, etc.).
data/: répertoire permettant de stocker les données spécifiques au workflow, les exemples d’entrées ou les fichiers de test.register.py: module d’enregistrement permettant de connecter vos fonctions personnalisées à NAT.web_data_workflow.py: fichier d’exemple définissant des outils personnalisés.
Ouvrez le projet dans votre IDE Python préféré et prenez le temps de vous familiariser avec les fichiers générés.
Vous verrez que la définition du flux de travail se trouve dans le fichier ci-dessous :
bright_data_nvidia_nemo/web_data_workflow/web_data_workflow/configs/config.ymlOuvrez-le et vous remarquerez la configuration YAML suivante :
functions:
current_datetime:
_type: current_datetime
web_data_workflow:
_type: web_data_workflow
prefix: "Hello:"
llms:
nim_llm:
_type: nim
model_name: meta/llama-3.1-70b-instruct
temperature: 0.0
workflow:
_type: react_agent
llm_name: nim_llm
tool_names: [current_datetime, web_data_workflow]Cela définit un workflow d’agent ReAct alimenté par le modèle meta/llama-3.1-70b-instruct de NVIDIA NIM, avec accès à :
- L’outil intégré
current_datetime. - L’outil
web_data_workflowpersonnalisé.
En particulier, l’outil web_data_workflow lui-même est défini dans :
bright_data_nvidia_nemo/web_data_workflow/web_data_workflow/web_data_workflow.pyCet outil exemple prend une entrée texte et la renvoie préfixée par une chaîne prédéfinie (par exemple, « Hello: »).
Super ! Vous disposez désormais d’un workflow prêt à l’emploi avec le NAT.
Étape n° 3 : tester le workflow actuel
Avant de personnaliser le workflow généré, il est conseillé de prendre le temps de vous familiariser avec celui-ci et de comprendre son fonctionnement. Cela facilitera l’adaptation du workflow pour l’intégrer à Bright Data.
Commencez par accéder au dossier du workflow dans votre terminal :
cd ./bright_data_nvidia_nemo/web_data_workflowAvant d’exécuter le workflow, vous devez définir la variable d’environnement NVIDIA_API_KEY. Sous Linux/macOS, exécutez :
export NVIDIA_API_KEY="<VOTRE_NVIDIA_API_KEY>"De manière équivalente, sous Windows PowerShell, exécutez :
$Env:NVIDIA_API_KEY="<VOTRE_CLÉ_API_NVIDIA>"Remplacez l’espace réservé <VOTRE_CLÉ_API_NVIDIA> par la clé API NVIDIA NIM que vous avez récupérée précédemment.
Testez maintenant le workflow avec la commande nat run comme suit :
nat run --config_file configs/config.yml --input "Hey! How's it going?"Cela charge le fichier config.yml (via le lien symbolique configs/ ) et envoie l’invite « Hey! How's it going? ».
Vous devriez obtenir un résultat similaire à celui-ci :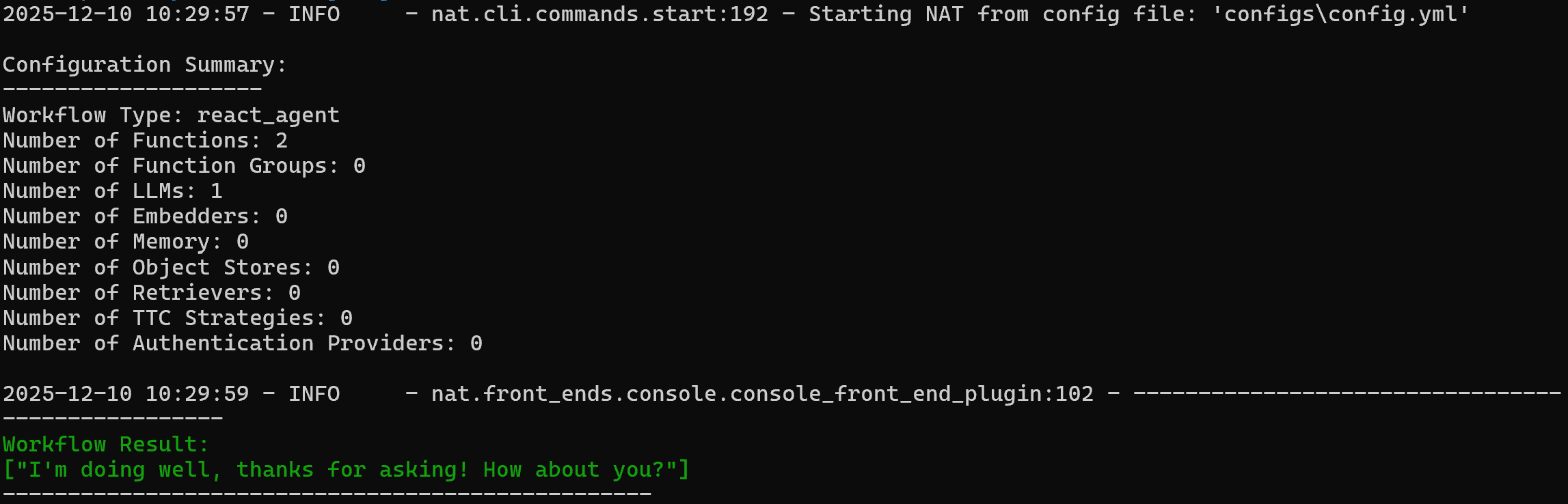
Notez que l’agent a répondu :
Je vais bien, merci de demander ! Et toi ?Pour vérifier que l’outil web_data_workflow personnalisé fonctionne, essayez une invite telle que :
nat run --config_file configs/config.yml --input « Utilisez l'outil web_data_workflow sur « World ! » »Étant donné que l’outil web_data_workflow est configuré avec le préfixe « Hello: », le résultat attendu est le suivant :
Résultat du workflow :
['Hello: World!']Remarquez comment le résultat correspond au comportement attendu :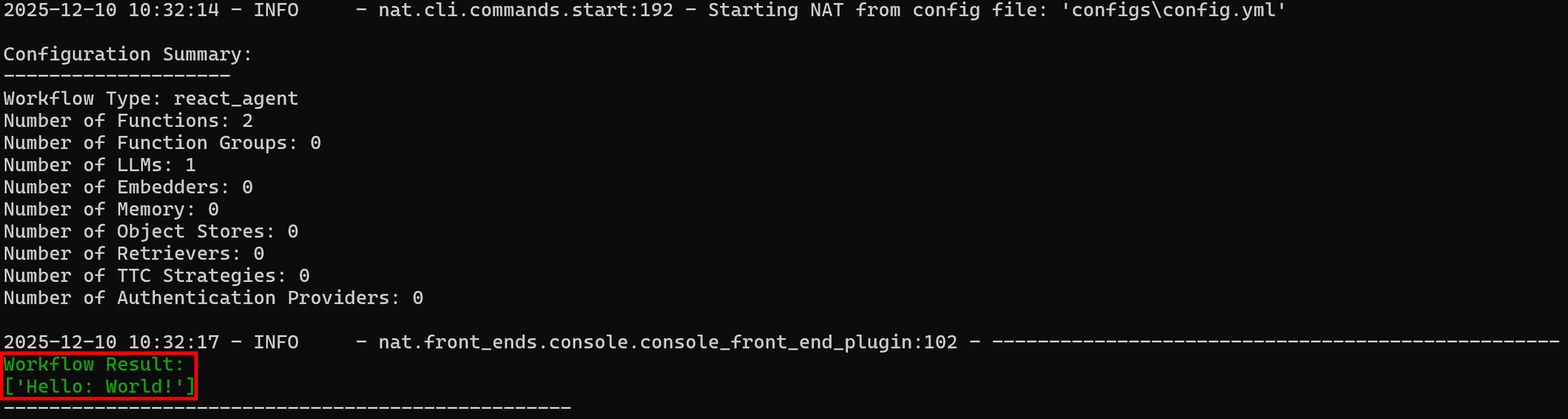
Incroyable ! Votre workflow NAT fonctionne parfaitement. Vous êtes maintenant prêt à l’intégrer à Bright Data.
Étape n° 4 : Installer les outils LangChain Bright Data
L’une des particularités du kit d’outils NVIDIA NeMo Agent est qu’il fonctionne avec d’autres bibliothèques d’IA, notamment LangChain, LlamaIndex, CrewAI, Agno, Microsoft Semantic Kernel, Google ADK et bien d’autres.
Pour simplifier l’intégration avec Bright Data, plutôt que de réinventer la roue, nous utiliserons les outils officiels Bright Data pour LangChain.
Pour plus d’informations sur ces outils, consultez la documentation officielle ou ces articles de blog :
- Scraping web avec LangChain et Bright Data
- Utilisation de LangChain et Bright Data pour la recherche sur le Web
Préparez-vous à utiliser LangChain dans le kit d’outils NVIDIA NeMo Agent en installant les bibliothèques suivantes :
pip install « nvidia-nat[langchain] » langchain-brightdataLes paquets requis sont les suivants :
« nvidia-nat[langchain] »: un sous-paquetage permettant d’intégrer LangChain (ou LangGraph) au NeMo Agent Toolkit.langchain-brightdata: fournit des intégrations LangChain pour la suite d’outils de collecte de données Web de Bright Data. Il permet aux agents IA de collecter les résultats des moteurs de recherche, d’accéder à des sites Web géo-restreints ou protégés contre les bots, et d’extraire des données structurées à partir de plateformes populaires telles qu’Amazon, LinkedIn et bien d’autres.
Pour éviter tout problème lors du déploiement, assurez-vous que le fichier pyproject.toml de votre projet comprend :
dependencies = [
"nvidia-nat[langchain]~=1.3",
"langchain-brightdata~=0.1.3",
]Remarque: ajustez les versions de ces paquets en fonction des besoins de votre projet.
Parfait ! Votre workflow NVIDIA NeMo Agent peut désormais s’intégrer aux outils LangChain pour simplifier les connexions Bright Data.
Étape n° 5 : préparer l’intégration Bright Data
Les outils LangChain Bright Data fonctionnent en se connectant aux services Bright Data configurés dans votre compte. Les deux outils présentés dans cet article sont les suivants :
BrightDataSERP: récupère les résultats des moteurs de recherche pour localiser les pages web réglementaires pertinentes. Il se connecte à l’API SERP de Bright Data.BrightDataUnblocker: accède à n’importe quel site web public, même s’il est soumis à des restrictions géographiques ou protégé par des mesures anti-bot. Cela aide l’agent à extraire le contenu de pages web individuelles et à en tirer des enseignements. Il se connecte à l’API Web Unblocker de Bright Data.
Pour utiliser ces outils, vous devez disposer d’un compte Bright Data avec une zone API SERP et une zone API Web Unblocker configurées. Configurons-les !
Si vous n’avez pas encore de compte Bright Data, créez-en un. Sinon, connectez-vous et accédez à votre tableau de bord. Ensuite, naviguez vers la page « Proxies & Scraping » et consultez le tableau « My Zones » :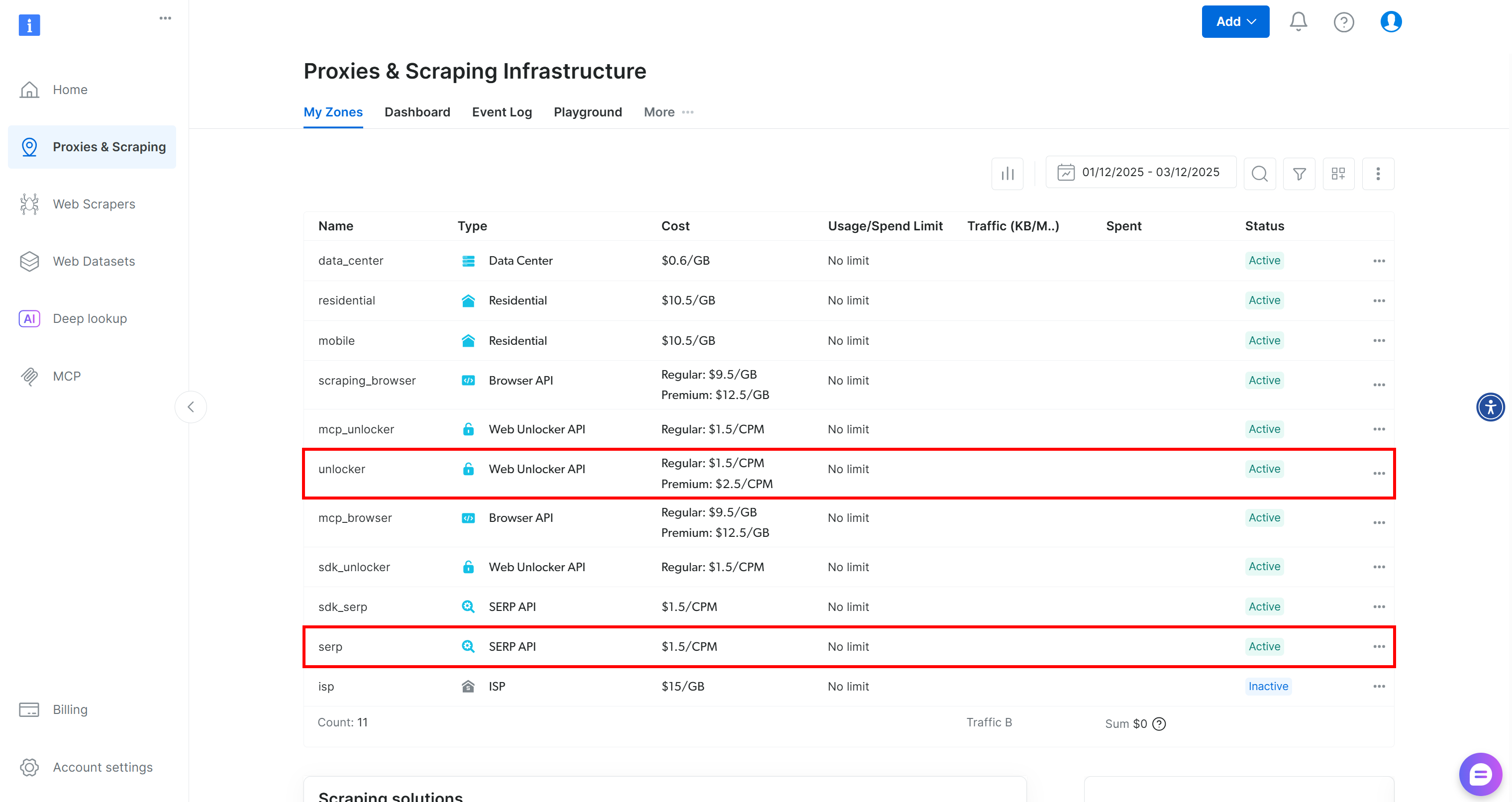
Si le tableau contient déjà une zone API Web Unlocker appelée unlocker et une zone API SERP appelée serp, vous êtes prêt. En effet :
- L’outil
BrightDataSERPLangChain se connecte automatiquement à une zone API SERP appeléeserp. - L’outil
BrightDataUnblockerLangChain se connecte automatiquement à une zone Web Unblocker API appeléeweb_unlocker.
Si ces deux zones sont manquantes, vous devez les créer. Faites défiler les cartes « Unblocker API » et « API SERP », puis cliquez sur les boutons « Create zone » (Créer une zone). Suivez l’assistant pour ajouter les deux zones avec les noms requis :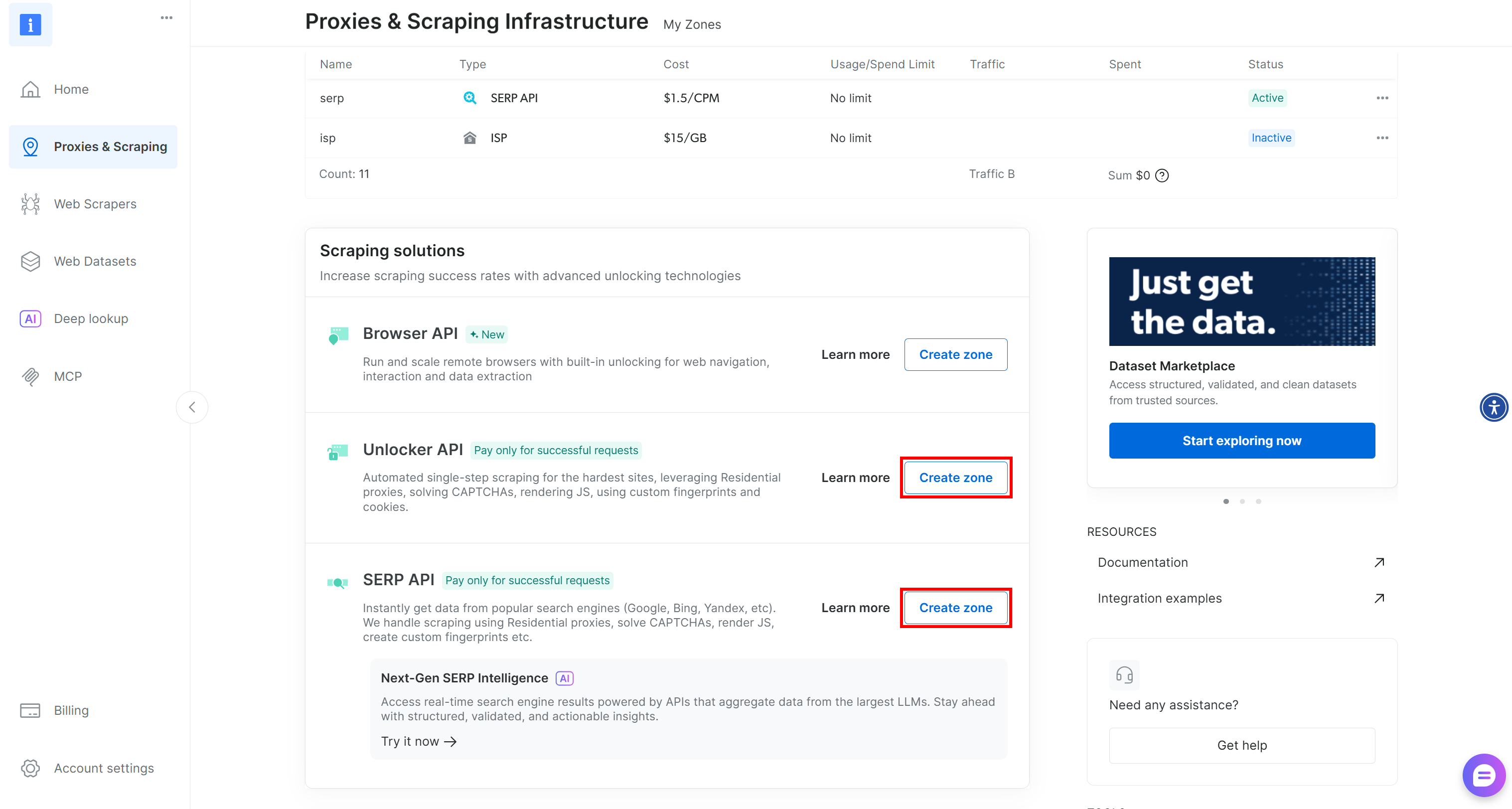
Pour obtenir des instructions étape par étape, consultez ces pages de documentation :
Enfin, vous devez indiquer aux outils LangChain Bright Data comment s’authentifier avec votre compte. Générez votre clé API Bright Data et enregistrez-la en tant que variable d’environnement :
export BRIGHT_DATA_API_KEY="<VOTRE_CLÉ_API_BRIGHT_DATA>"Ou, dans PowerShell :
$Env:BRIGHT_DATA_API_KEY="<VOTRE_CLÉ_API_BRIGHT_DATA>"Parfait ! Vous disposez désormais de tous les prérequis pour connecter votre agent NVIDIA NeMo à Bright Data via les outils LangChain.
Étape n° 6 : définir les outils Bright Data personnalisés
Vous disposez désormais de tous les éléments nécessaires pour créer de nouveaux outils dans votre workflow NVIDIA NeMo Agent Toolkit. Ces outils permettront à l’agent d’interagir avec l’API SERP et l’API Web Unblocker de Bright Data, lui permettant ainsi d’effectuer des recherches sur le Web et d’extraire des données de n’importe quelle page Web publique.
Commencez par ajouter un fichier bright_data.py au dossier src/ de votre projet :
Définissez un outil personnalisé pour interagir avec l’API SERP comme suit :
# bright_data_nvidia_nemo/web_data_workflow/src/web_data_workflow/bright_data.py
from pydantic import Field
from typing import Optional
from nat.builder.builder import Builder
from nat.builder.function_info import FunctionInfo
from nat.cli.register_workflow import register_function
from nat.data_models.function import FunctionBaseConfig
import json
class BrightDataSERPAPIToolConfig(FunctionBaseConfig, name="bright_data_serp_api"):
"""
Configuration pour l'outil API SERP Bright Data.
Nécessite BRIGHT_DATA_API_KEY.
"""
api_key: str = Field(
default="",
description="Votre clé API Bright Data utilisée pour les requêtes SERP."
)
# Paramètres SERP par défaut (remplacements facultatifs)
search_engine: str = Field(
default="google",
description="Moteur de recherche à interroger (par défaut : google)."
)
country : str = Field(
default="us",
description="Code pays à deux lettres pour les résultats localisés (par défaut : us)."
)
language : str = Field(
default="en",
description="Code langue à deux lettres (par défaut : en)."
)
search_type : Facultatif[str] = Champ(
par défaut=None,
description="Type de recherche : None, 'shop', 'isch', 'nws', 'jobs'."
)
device_type : Facultatif[str] = Champ(
par défaut=None,
description="Type d'appareil : None, 'mobile', 'ios', 'android'."
)
parse_results : Facultatif[bool] = Field(
par défaut=None,
description="Indique s'il faut renvoyer un JSON structuré au lieu d'un HTML brut."
)
@register_function(config_type=BrightDataSERPAPIToolConfig)
async def bright_data_serp_api_function(tool_config: BrightDataSERPAPIToolConfig, builder: Builder):
import os
from langchain_brightdata import BrightDataSERP
# Définir la clé API si elle est manquante
if not os.environ.get("BRIGHT_DATA_API_KEY"):
if tool_config.api_key:
os.environ["BRIGHT_DATA_API_KEY"] = tool_config.api_key
async def _bright_data_serp_api(
query: str,
search_engine: Optional[str] = None,
country: Optional[str] = None,
language: Optional[str] = None,
search_type: Optional[str] = None,
device_type: Optional[str] = None,
parse_results: Optional[bool] = None,
) -> str:
"""
Effectue une requête de recherche en temps réel à l'aide de l'API SERP de Bright Data.
Arguments :
query (str) : texte de la requête de recherche.
search_engine (str, facultatif) : moteur de recherche à utiliser (par défaut : google).
country (str, facultatif) : code pays pour des résultats localisés.
language (str, facultatif) : code de langue pour des résultats localisés.
search_type (str, facultatif) : type de recherche (par exemple, None, 'isch', 'shop', 'nws').
device_type (str, facultatif) : type d'appareil (par exemple, None, 'mobile', 'ios').
parse_results (bool, facultatif) : indique s'il faut renvoyer un JSON structuré.
Retourne :
str : résultats de recherche au format JSON.
"""
serp_client = BrightDataSERP(
bright_data_api_key=os.environ["BRIGHT_DATA_API_KEY"]
)
payload = {
"query": query,
"search_engine": search_engine ou tool_config.search_engine,
"country": country ou tool_config.country,
"language": language ou tool_config.language,
"search_type": search_type ou tool_config.search_type,
« device_type » : device_type ou tool_config.device_type,
« parse_results » : (
parse_results
si parse_results n'est pas None
sinon tool_config.parse_results),
}
# Supprimer les paramètres explicitement définis sur None
payload = {k: v pour k, v dans payload.items() si v n'est pas None}
results = serp_client.invoke(payload)
return json.dumps(results)
yield FunctionInfo.from_fn(
_bright_data_serp_api,
description=_bright_data_serp_api.__doc__,
)
Cet extrait définit un outil NVIDIA NeMo Agent personnalisé appelé bright_data_serp_api. Vous devez d’abord définir une classe BrightDataSERPAPIToolConfig, qui spécifie les arguments requis et les paramètres configurables pris en charge par l’API SERP pour Google (par exemple, la clé API, le moteur de recherche, le pays, la langue, le type d’appareil, le type de recherche, si les résultats doivent être analysés en JSON, etc.).
Ensuite, une fonction personnalisée bright_data_serp_api_function() est enregistrée en tant que fonction de workflow NeMo. La fonction vérifie que la clé API Bright Data est définie dans l’environnement, puis définit une fonction asynchrone _bright_data_serp_api().
_bright_data_serp_api() construit une requête de recherche à l’aide du client BrightDataSERP de LangChain, l’appelle et renvoie les résultats au format JSON. Enfin, elle expose la fonction au framework NeMo Agent via FunctionInfo, qui contient toutes les métadonnées nécessaires à l’agent pour appeler la fonction.
Remarque: le renvoi des résultats au format JSON fournit une sortie de chaîne standardisée. Il s’agit d’une astuce utile, étant donné que les réponses de l’API SERP peuvent varier (JSON analysé, HTML brut, etc.) en fonction des arguments configurés.
De même, vous pouvez définir un outil bright_data_web_unlocker_api dans le même fichier avec :
class BrightDataWebUnlockerAPIToolConfig(FunctionBaseConfig, name="bright_data_web_unlocker_api"):
"""
Configuration pour l'outil Bright Data Web Unlocker.
Permet d'accéder à des pages géo-restreintes ou protégées contre les bots à l'aide de
Bright Data Web Unlocker.
Nécessite BRIGHT_DATA_API_KEY.
"""
api_key: str = Field(
default="",
description="Clé API Bright Data pour le Web Unlocker."
)
country: str = Field(
default="us",
description="Code pays à deux lettres simulé pour la requête (par défaut : us)."
)
data_format : str = Field(
default="html",
description="Format du contenu de sortie : 'html', 'markdown' ou 'screenshot'."
)
zone : str = Field(
default="unblocker",
description='Zone Bright Data à utiliser (par défaut : "unblocker").'
)
@register_function(config_type=BrightDataWebUnlockerAPIToolConfig)
async def bright_data_web_unlocker_api_function(tool_config: BrightDataWebUnlockerAPIToolConfig, builder: Builder):
import os
import json
from typing import Optional
from langchain_brightdata import BrightDataUnlocker
# Définir la variable d'environnement si nécessaire
if not os.environ.get("BRIGHT_DATA_API_KEY") and tool_config.api_key:
os.environ["BRIGHT_DATA_API_KEY"] = tool_config.api_key
async def _bright_data_web_unlocker_api(
url: str,
country: Optional[str] = None,
data_format: Optional[str] = None,
) -> str:
"""
Accédez à une URL géo-restreinte ou protégée contre les robots à l'aide de Bright Data Web Unlocker.
Arguments :
url (str) : URL cible à récupérer.
country (str, facultatif) : Remplace le pays simulé.
data_format (str, facultatif) : Format de contenu de sortie (« html », « markdown », « screenshot »).
Renvoie :
str : Contenu récupéré à partir du site Web cible.
"""
unlocker = BrightDataUnlocker()
result = unlocker.invoke({
"url": url,
"country": country ou tool_config.country,
"data_format": data_format ou tool_config.data_format,
"zone": tool_config.zone,
})
return json.dumps(result)
yield FunctionInfo.from_fn(
_bright_data_web_unlocker_api,
description=_bright_data_web_unlocker_api.__doc__,
)
Ajustez les valeurs par défaut des arguments pour les deux outils en fonction de vos besoins.
N’oubliez pas que BrightDataSERP et BrightDataUnlocker tentent de lire la clé API à partir de la variable d’environnement BRIGHT_DATA_API_KEY (que vous avez configurée précédemment, vous êtes donc prêt).
Ensuite, importez ces deux outils en ajoutant la ligne suivante à register.py:
# bright_data_nvidia_nemo/web_data_workflow/src/web_data_workflow/register.py
# ...
from .bright_data import bright_data_serp_api_function, bright_data_web_unlocker_api_functionCes deux outils ne sont pas disponibles dans le fichier config.yml. La raison en est que le fichier pyproject.toml généré automatiquement contient :
[project.entry-points.'nat.components']
web_data_workflow = "web_data_workflow.register"Cela indique à la commande nat: « Lors du chargement du workflow web_data_workflow, recherchez les composants dans le module web_data_workflow.register. »
Remarque: de la même manière, vous pouvez créer un outil pour BrightDataWebScraperAPI afin de l’intégrer aux API de Scraping web de Bright Data. Cela permet à l’agent de récupérer des flux de données structurés à partir de sites Web populaires tels qu’Amazon, Instagram, LinkedIn, Yahoo Finance et bien d’autres.
Et voilà ! Il ne reste plus qu’à mettre à jour le fichier config.yml en conséquence pour permettre à l’agent de se connecter à ces deux nouveaux outils.
Étape n° 7 : configurer les outils Bright Data
Dans config.yml, importez les outils Bright Data et transmettez-les à l’agent avec :
# bright_data_nvidia_nemo/web_data_workflow/src/web_data_workflow/configs/config.yml
functions:
# Définir et personnaliser les outils Bright Data personnalisés
bright_data_serp_api:
_type: bright_data_serp_api
bright_data_web_unlocker_api:
_type: bright_data_web_unlocker_api
data_format: markdown
llms:
nim_llm:
_type: nim
model_name: meta/llama-3.1-70b-instruct # Remplacez-le par un modèle d'IA prêt à l'emploi pour les entreprises.
temperature: 0.0
workflow :
_type : react_agent
llm_name : nim_llm
tool_names : [bright_data_serp_api, bright_data_web_unlocker_api] # Configurez les outils Bright Data
Pour utiliser les outils définis précédemment :
- Ajoutez-les dans la section
functionsdu fichierconfig.yml. Notez que vous pouvez les personnaliser à l’aide des arguments exposés par leurs classesFunctionBaseConfig. Par exemple, l’outilbright_data_web_unlocker_apia été configuré pour renvoyer des données au format Markdown, qui est un excellentformat pour le traitement par les agents IA. - Répertoriez les outils dans le champ
tool_namesdu blocworkflowafin que l’agent puisse les appeler.
Fantastique ! Votre agent React, alimenté par meta/llama-3.1-70b-instruct, a désormais accès aux deux outils personnalisés basés sur LangChain :
bright_data_serp_apibright_data_web_unlocker_api
Remarque: dans cet exemple, le LLM est configuré comme un modèle NVIDIA NIM. Envisagez de passer à un modèle plus orienté entreprise en fonction de vos besoins de déploiement.
Étape n° 8 : Tester le workflow NVIDIA Nemo Agent Toolkit
Pour vérifier que votre workflow NVIDIA NeMo Agent Toolkit peut désormais interagir avec les outils Bright Data, vous avez besoin d’une tâche qui déclenche à la fois la recherche sur le Web et l’extraction de données Web.
Imaginons, par exemple, que votre entreprise souhaite surveiller les nouveaux produits et les prix de ses concurrents afin d’étayer ses analyses commerciales. Si votre concurrent est Nike, vous pourriez rédiger une invite telle que :
Recherchez sur le Web les dernières chaussures Nike. À partir des résultats de recherche obtenus, sélectionnez jusqu'à trois des pages Web les plus pertinentes, en donnant la priorité aux pages officielles du site Web de Nike. Accédez à ces pages et récupérez leur contenu au format Markdown. Pour le modèle de chaussure découvert, indiquez le nom, le statut de commercialisation, le prix, les informations clés et un lien vers la page officielle de Nike (si disponible).Assurez-vous que les variables d’environnement NVIDIA_API_KEY et BRIGHT_DATA_API_KEY sont définies, puis exécutez votre agent avec :
nat run --config_file configs/config.yml --input « Recherchez sur le Web les dernières chaussures Nike. À partir des résultats de recherche obtenus, sélectionnez jusqu'à trois des pages Web les plus pertinentes, en donnant la priorité aux pages du site Web officiel de Nike. Accédez à ces pages et récupérez leur contenu au format Markdown. Pour les modèles de chaussures trouvés, indiquez le nom, le statut de sortie, le prix, les informations clés et un lien vers la page officielle de Nike (si disponible). »Le résultat initial sera similaire à celui-ci :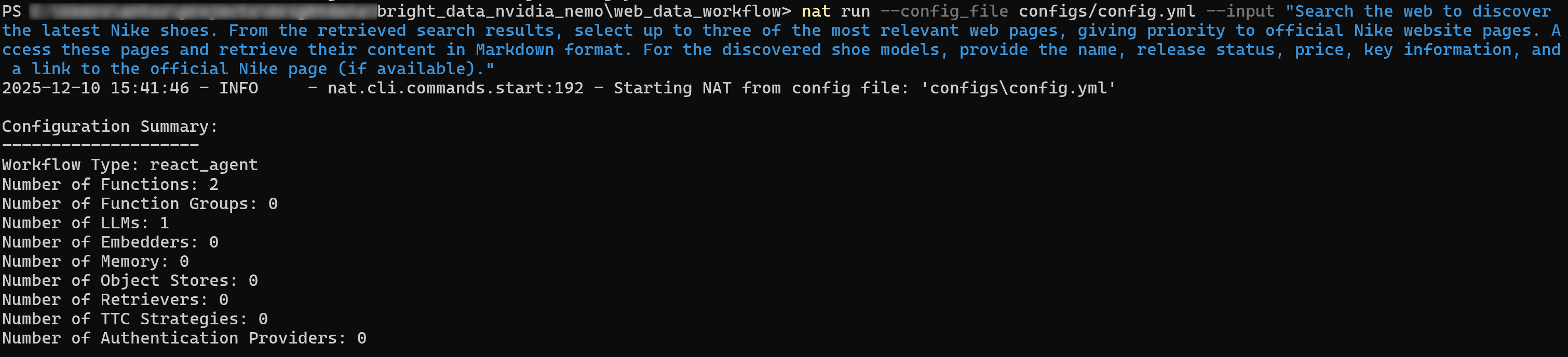
Si vous activez le mode verbose (définissez verbose: true dans le bloc workflow ), vous verrez l’agent effectuer les étapes suivantes :
- Appeler l’API SERP avec des requêtes telles que « dernières chaussures Nike » et « nouvelles chaussures Nike ».
- Sélectionner les pages les plus pertinentes, en donnant la priorité à la page officielle «Nouvelles chaussures »de Nike.
- Utiliser l’outil API Web Unlocker pour accéder à la page sélectionnée et extraire son contenu au format Markdown.
- Traiter les données extraites et produire une liste structurée de résultats :
[Air Jordan 11 Retro « Gamma » - Chaussures pour hommes](https://www.nike.com/t/air-jordan-11-retro-gamma-mens-shoes-DYkD1oXL/CT8012-047)
Statut de sortie : bientôt disponible
Couleurs : 1
Prix : 235 $
[Air Jordan 11 Retro « Gamma » - Chaussures pour grands enfants](https://www.nike.com/t/air-jordan-11-retro-gamma-big-kids-shoes-LJyljnZt/378038-047)
Statut de sortie : bientôt disponible
Couleurs : 1
Prix : 190 $
# Omis pour plus de concision...Ces résultats correspondent exactement à ce que vous trouveriez sur la page « Nouvelles chaussures » de Nike :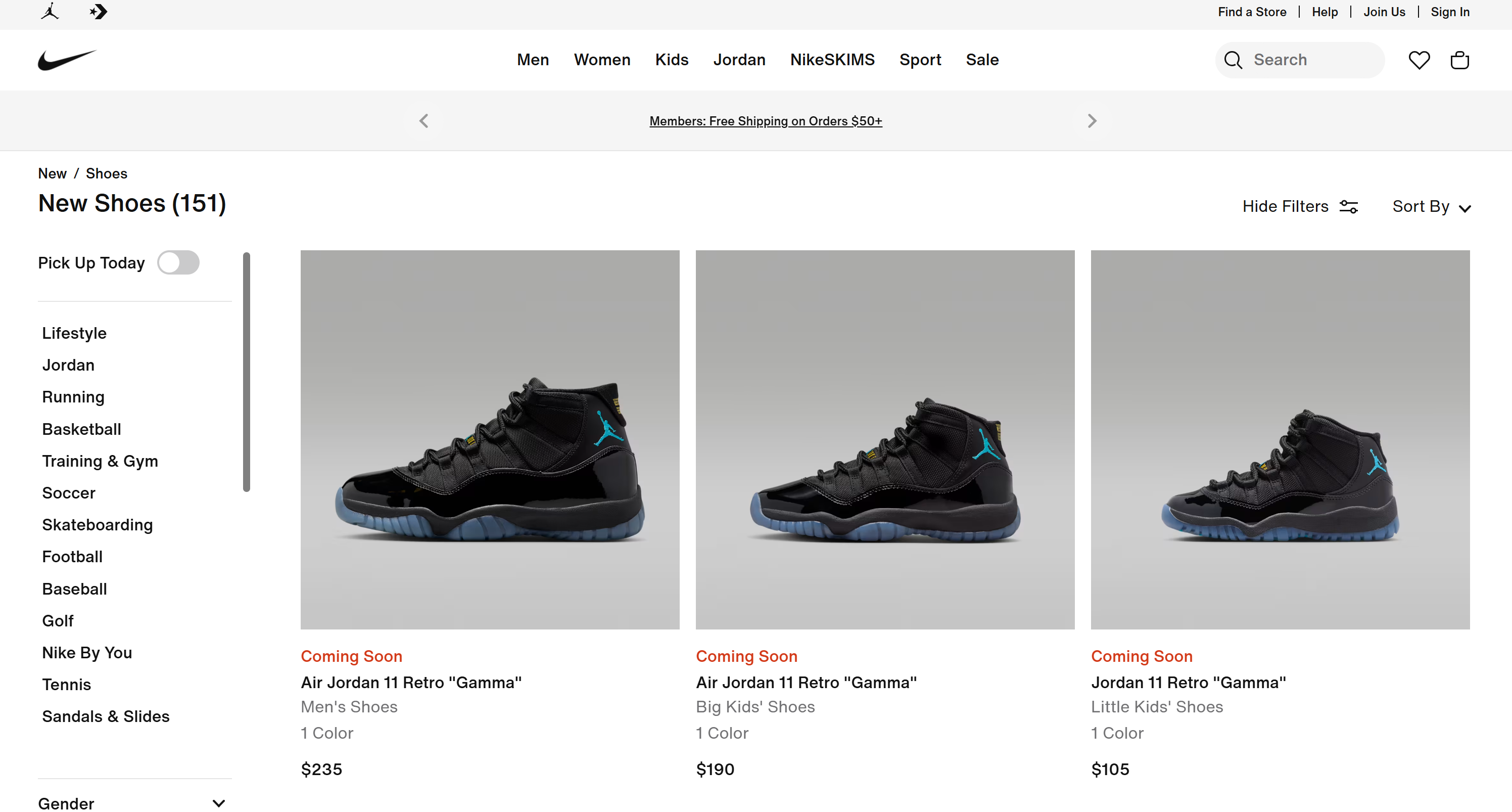
Mission accomplie ! L’agent IA a recherché de manière autonome sur le Web, sélectionné les bonnes pages, les a scrapées et en a extrait des informations structurées sur les produits. Rien de tout cela n’aurait été possible sans l’intégration des outils Bright Data dans votre workflow NAT !
N’oubliez pas que l’intelligence économique agentielle n’est qu’un des nombreux cas d’utilisation rendus possibles par les solutions Bright Data lorsqu’elles sont combinées avec NVIDIA NeMo Agent Toolkit. Essayez d’ajuster la configuration de l’outil, d’intégrer des outils supplémentaires ou de modifier l’invite de saisie pour explorer d’autres scénarios !
Connectez NVIDIA NeMo Agent Toolkit à Bright Data via Web MCP
Une autre façon d’intégrer NVIDIA NeMo Agent Toolkit aux produits Bright Data consiste à le connecter à Web MCP. Pour plus de détails, consultez la documentation officielle.
Web MCP donne accès à plus de 60 outils basés sur la plateforme d’automatisation web et de collecte de données de Bright Data. Même avec la version gratuite, vous pouvez déjà accéder à deux outils puissants :
| Outil | Description |
|---|---|
search_engine |
Récupérez les résultats de Google, Bing ou Yandex au format JSON ou Markdown. |
scrape_as_markdown |
Récupérez n’importe quelle page web au format Markdown propre tout en contournant les mesures anti-bot. |
Mais c’est en mode Pro que Web MCP révèle tout son potentiel. Ce niveau premium n’est pas gratuit, mais il permet d’extraire des données structurées pour les principales plateformes telles qu’Amazon, Zillow, LinkedIn, YouTube, TikTok, Google Maps, etc. Il offre également des outils supplémentaires pour automatiser les actions du navigateur.
Remarque: pour la configuration du projet et les prérequis, reportez-vous au chapitre précédent.
Voyons maintenant comment utiliser Web MCP de Bright Data dans la boîte à outils NVIDIA NeMo Agent !
Étape n° 1 : installer le package NVIDIA NAT MCP
Comme mentionné précédemment, le kit d’outils NVIDIA NeMo Agent est modulaire. Le package de base fournit les fondements, et des fonctionnalités supplémentaires sont ajoutées via des extensions optionnelles.
Pour la prise en charge du MCP, le package requis est nvidia-nat[mcp]. Installez-le à l’aide de la commande suivante :
pip install nvidia-nat[mcp]Votre agent NVIDIA NeMo Agent Toolkit peut désormais se connecter aux serveurs MCP. En particulier, pour garantir des performances et une fiabilité de niveau entreprise, vous vous connecterez au Web MCP de Bright Data à l’aide d’une communication HTTP streamable à distance via le serveur distant géré.
Étape n° 2 : configurer la connexion Web MCP à distance
Dans votre fichier config.yml, configurez la connexion au serveur Web MCP distant de Bright Data à l’aide du protocole HTTP Streamable :
# bright_data_nvidia_nemo/web_data_workflow/src/web_data_workflow/configs/config.yml
function_groups:
bright_data_web_mcp:
_type: mcp_client
server:
transport: streamable-http
url: "https://mcp.brightdata.com/mcp?token=<YOUR_BRIGHT_DATA_API_KEY>&pro=1" tool_call_timeout: 600
auth_flow_timeout: 300
reconnect_enabled: true
reconnect_max_attempts: 3
llms :
nim_llm :
_type : nim
model_name : meta/llama-3.1-70b-instruct # Remplacez-le par un modèle d'IA prêt à l'emploi pour les entreprises.
temperature : 0.0
workflow :
_type : react_agent
llm_name : nim_llm
tool_names : [bright_data_web_mcp]
Cette fois-ci, au lieu de définir les outils dans le bloc functions, vous utilisez function_groups. Cela permet de configurer la connexion Web MCP et de récupérer l’ensemble des outils MCP à partir du serveur distant. Le groupe est ensuite transmis à l’agent via le champ tool_names, tout comme les outils individuels.
L’URL Web MCP inclut le paramètre de requête &pro=1. Cela active le mode Pro, qui est facultatif mais fortement recommandé pour une utilisation en entreprise, car il débloque la suite complète d’outils d’extraction de données structurées, et pas seulement les outils de base.
Étape n° 3 : vérifier la connexion Web MCP
Exécutez votre agent NVIDIA NeMo avec une nouvelle invite. Dans les journaux initiaux, vous devriez voir l’agent charger tous les outils exposés par Web MCP :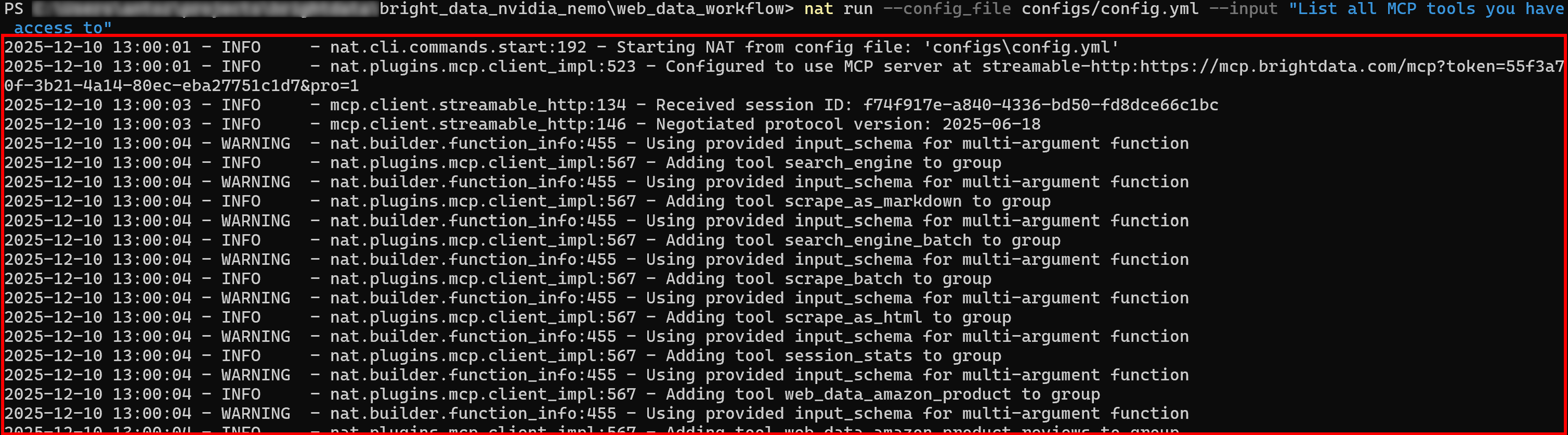
Si le mode Pro est activé, les plus de 60 outils seront chargés initialement.
Ensuite, les journaux de configuration afficheront un seul groupe de fonctions, comme prévu :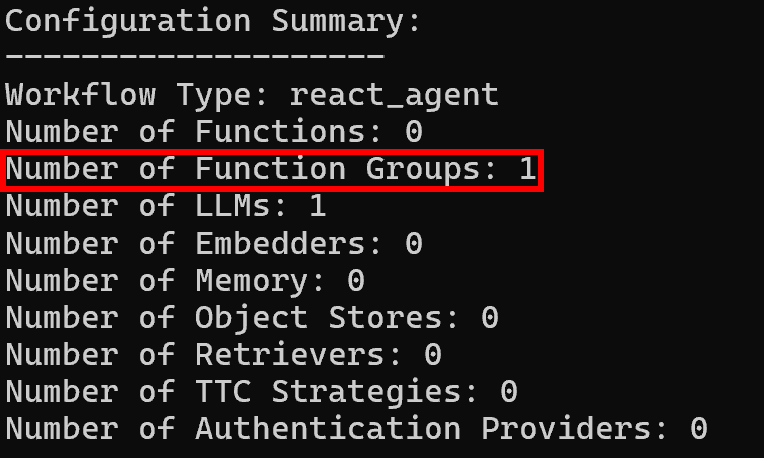
Et voilà ! Votre workflow NVIDIA NeMo Agent Toolkit a désormais un accès complet à toutes les fonctionnalités fournies par Bright Data Web MCP.
Conclusion
Dans cet article, vous avez appris à intégrer Bright Data à NVIDIA NeMo Agent Toolkit, soit via des outils personnalisés optimisés par LangChain, soit via Web MCP.
Ces configurations ouvrent la voie à des recherches Web en temps réel, à l’extraction de données structurées, à l’accès à des flux Web en direct et à des interactions Web automatisées dans les workflows NAT. Elles exploitent la gamme complète des services Bright Data pour l’IA, libérant ainsi tout le potentiel de vos agents IA !
Inscrivez-vous dès aujourd’hui à Bright Data et commencez à intégrer nos outils de données web prêts pour l’IA !




