

La génération augmentée par la récupération (RAG) et le réglage fin sont deux concepts très différents dans le domaine de l’IA et ils servent deux objectifs très différents. La RAG permet à un LLM d’accéder à des informations externes pendant l’exécution. Le réglage fin permet au LLM d’ajuster ses connaissances internes pour un apprentissage plus approfondi et permanent.
À la fin de ce guide, vous serez en mesure de répondre aux questions suivantes.
- Qu’est-ce que le réglage fin ?
- Qu’est-ce que le RAG ?
- Quand faut-il utiliser le réglage fin ?
- Quand faut-il utiliser le RAG ?
- Comment le RAG et le réglage fin se complètent-ils ?
Qu’est-ce que le réglage fin ?
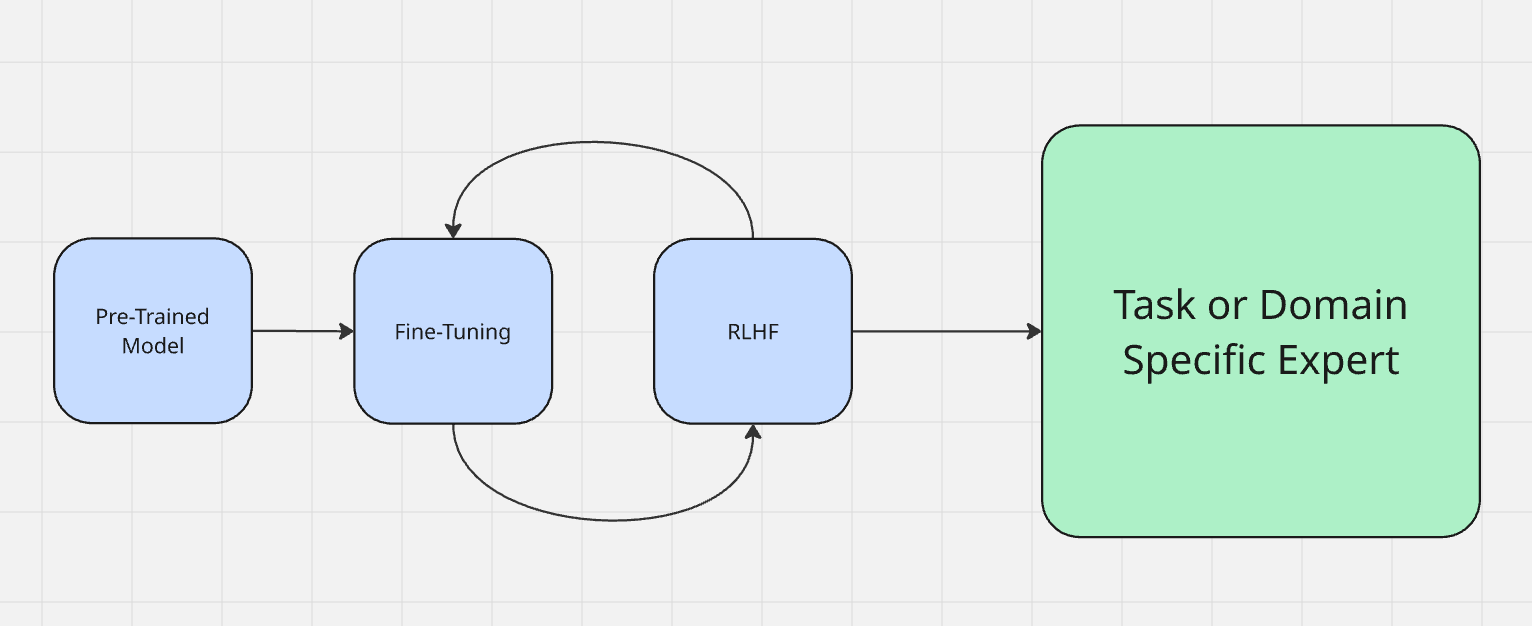
Le réglage fin est souvent considéré comme faisant partie du processus de formation du modèle proprement dit. Vous pouvez en savoir plus sur la façon dont les modèles sont formés ici. Les modèles passent d’abord par une période appelée « pré-formation ». En termes simples, c’est à ce moment-là qu’ils apprennent à ingérer des données et à générer des résultats. Une fois la pré-formation terminée, le modèle contient une grande quantité de connaissances, mais n’est pas encore tout à fait optimisé pour les appliquer.
Nous affinons généralement un modèle à l’aide de l’apprentissage par renforcement à partir du retour d’information humain (RLHF). Lors de l’affinage, vous communiquez avec le modèle pour tester ses sorties. Par exemple, si un modèle dit « le ciel est vert », il doit être corrigé pour dire « le ciel est bleu ». Lors du réglage fin, vous évaluez les résultats de la machine et renforcez le comportement souhaité, un peu comme lorsque vous dites « bon chien ! » à votre chien pour le féliciter de son bon comportement ou que vous roulez un journal pour le punir de son mauvais comportement.
Lorsque vous affinez un LLM, vous le préparez à sa tâche réelle dans le monde réel. Il existe deux principaux types d’affinage.
- Adaptation au domaine: imaginez que vous souhaitiez créer un expert en programmation à partir d’un modèle de base tel que DeepSeek. Vous disposez d’un modèle solide avec des bases solides, mais il n’est encore expert en rien. Bien sûr, il comprend les commandes shell et la plupart des codes Python, mais il a besoin d’expertise. C’est là que vous lui enseignez les subtilités de l’informatique et du codage avec des outils tels que StackOverflow et LeetCode. Une fois le réglage fin terminé, vous disposez d’un modèle capable d’écrire du code plus rapidement et mieux que n’importe quel humain.
- Adaptation à la tâche: l’adaptation à la tâche consiste à s’adapter à la tâche à accomplir. Dans les LLM actuels, on observe cela le plus souvent dans les chats réels. Au début de l’année 2026, ChatGPT-4o a fait l’objet d’un réglage très poussé afin de s’adapter au sentiment de la personne qui lui parle. Dans ce cas, le RLHF a été utilisé pour inciter le bot à refléter le sentiment de l’utilisateur. Si l’utilisateur s’exprime de manière technique, GPT fait de même. Si l’utilisateur parle de droit, GPT s’exprime en jargon juridique. Si l’utilisateur semble religieux, GPT devient religieux (oui, vraiment).
Le réglage fin est utilisé pour influencer la prise de décision et les déductions réelles du modèle.
Qu’est-ce que le RAG ?
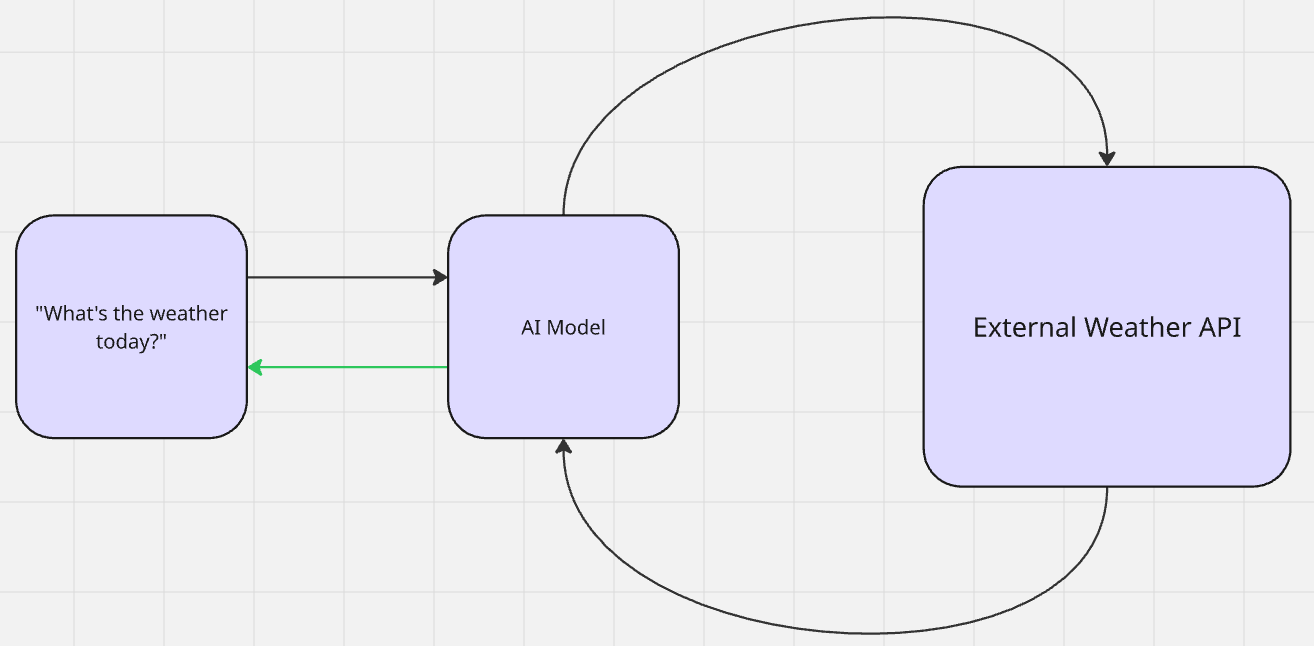
Avec le RAG, aucun apprentissage réel n’a lieu. Une IA récupère des données supplémentaires pour la pertinence contextuelle et génère un résultat. Une fois le résultat créé, le modèle revient à son état antérieur à la récupération. Il s’agit d’une forme d’apprentissage sans apprentissage préalable. Le modèle référence les informations sans contexte préalable. Ensuite, il utilise son pré-entraînement pour faire des déductions et générer un résultat.
Lorsque vous demandez à Gemini « Quel temps fait-il aujourd’hui ? », il recherche (récupère) la météo (augmente ses connaissances), puis vous donne (génère) la réponse.
Il existe deux principaux types de RAG : passif et actif. Cela est particulièrement bien illustré dans la dernière génération de modèles de chat avec mémoires stockées.
- RAG passif: les « souvenirs » sont stockés dans une base de données vectorielle et référencés ultérieurement pour le contexte. Lorsqu’un LLM connaît votre nom ou vos préférences, il s’agit d’un RAG passif. Les informations référencées sont censées être statiques et permanentes. La seule façon de supprimer les « souvenirs » est de les effacer manuellement.
- RAG actif: repensez à notre exemple météo précédent. Le temps change tous les jours. Le modèle effectue une recherche active (probablement via une API) sur la météo. Une fois qu’il est sûr de bien comprendre la météo, il vous la restitue selon sa propre « personnalité » personnalisée.
Les pipelines RAG suivent exactement ce flux de travail : récupération des données -> augmentation de l’inférence -> génération du résultat.
Quand faut-il procéder à un réglage fin ?
Le réglage fin est particulièrement utile lorsque vous souhaitez définir la manière dont votre modèle pense réellement. Si vous souhaitez que les connaissances et les inférences soient permanentes, vous devez procéder à un réglage fin. Si votre LLM doit vraiment comprendre les données, vous devez le régler finement.
Si la sortie produite par votre modèle n’est pas tout à fait correcte, si son processus de réflexion semble même légèrement décalé, vous devez procéder à un réglage fin.
- Ton et personnalité: si vous avez une attitude ou une intonation spécifique en tête pour votre modèle, procédez à un ajustement. Cela est particulièrement utile dans les chatbots personnalisés. Lorsque Grok 3 a surpris le monde entier avec ses personnalités définies par l’utilisateur, cela était en grande partie dû à l’ajustement.
- Cas limites et précision: lorsque votre modèle rencontre des problèmes avec des cas limites ou ne parvient pas à représenter correctement ses données d’entraînement, un ajustement est nécessaire. Cela est particulièrement vrai pour les modèles utilisés dans le diagnostic médical. Un modèle hallucinant la loi pourrait entraîner des poursuites judiciaires. Un modèle hallucinant une condition médicale est dangereux pour le patient.
- Taille du modèle et réduction des coûts: le réglage fin peut réduire considérablement la taille et le coût opérationnel de votre modèle. Par exemple, l’équipe Llama a pu distiller les résultats de GPT-4 dans GPT-3.5. Vous pouvez en savoir plus à ce sujet dans leur documentation sur le réglage fin ici.
- Nouvelles tâches et capacités: si vous souhaitez ajouter une capacité réelle qui n’existe pas encore dans un modèle pré-entraîné, vous devez l’ajuster. Imaginez que vous disposiez d’un modèle entraîné à n’utiliser que l’anglais, mais que vous ayez besoin d’une sortie en espagnol. Aucune quantité d’ingénierie de prompt ou de RAG ne permettra de résoudre ce problème, vous devez procéder à un ajustement.
Quand utiliser le RAG ?
Le RAG est particulièrement adapté aux modèles qui fonctionnent déjà correctement. Si votre modèle produit des résultats corrects après ajustement, il est probablement temps d’ajouter le RAG pour accéder à des données externes. Sans contexte approprié, les modèles sont souvent inutiles pour de nombreuses tâches, quelle que soit leur intelligence.
Repensez à notre exemple météo précédent. Vous pourriez disposer du modèle le plus intelligent de la planète, mais sans accès aux données en temps réel, votre modèle ne peut pas vous donner la météo, ni aucune information en temps réel d’ailleurs. Le RAG est utile pour les besoins en données suivants.
- Données en temps réel: nous avons déjà abordé ce sujet avec la météo. Cela inclut les actualités, les projections financières, la surveillance des systèmes et d’autres flux de données à évolution rapide.
- Assistants de recherche ou bibliothécaires: parfois, les gens ont simplement besoin d’être orientés vers la bonne ressource. Lorsque vous posez une question à Gemini ou Brave Search, vous obtenez une réponse directe. Le modèle parcourt la documentation et vous oriente vers les ressources pertinentes.
- Assistance à la clientèle: lorsque vous avez besoin d’un LLM pour gérer le service d’assistance et répondre à des questions générales, le RAG est rapide et efficace. Les modèles d’IA savent déjà comment répondre aux questions et lire la documentation, ils ont juste besoin d’accéder au bon contenu.
- Sortie personnalisée: vous vous souvenez que nous avons mentionné plus tôt le ton reflétant l’utilisateur de GPT ? Il ne s’agit pas de sorcellerie médiévale. Le modèle fait référence à des faits stockés dans une base de données. Si OpenAI devait réentraîner les modèles pour chaque utilisateur, il n’existerait pas.
Comment choisir entre les deux
Si votre modèle doit mieux réfléchir, vous devez l’affiner. Si votre modèle a besoin d’informations externes, utilisez RAG. En réalité, nous nous dirigeons vers des systèmes hybrides. Une fois que vous l’avez mis en service, votre modèle doit réfléchir clairement et accéder aux bonnes données. Le tableau ci-dessous vous aidera à décider quand utiliser chacun d’entre eux pour votre projet.
| Situation | Meilleur choix | Pourquoi |
|---|---|---|
| Le résultat semble incorrect ou incohérent | Ajustement | Vous corrigez le raisonnement, le ton ou le comportement |
| Le résultat est correct, mais manque de détails | RAG | Il vous manque des informations externes ou spécifiques au domaine |
| Vous avez besoin de faits actualisés ou de données en temps réel | RAG | Les modèles statiques ne peuvent pas apprendre après la formation |
| Vous souhaitez obtenir des performances élevées dans un nouveau domaine | Ajustement | Vous ajoutez une expertise approfondie et internalisée |
| Vous avez besoin à la fois de précision et de fraîcheur | Les deux | Réglage fin pour la logique, RAG pour les connaissances externes |
Outils Bright Data pour RAG et réglage fin
Chez Bright Data, nous proposons des outils robustes pour répondre à vos besoins en matière de réglage fin et de RAG. Que vous ayez besoin de Jeux de données d’entraînement ou de pipelines en temps réel, nos systèmes sont là pour vous aider.
Ajustement
- Jeux de données: obtenez des données historiques provenant de partout sur Internet, mises à jour quotidiennement. Que vous recherchiez des données issues des réseaux sociaux, des listes de produits ou même Wikipédia, nous avons ce qu’il vous faut, prêt à être utilisé pour la formation.
- API d’archivage: entraînez-vous sur des sources multimodales et autres avec des pétaoctets de données ajoutés quotidiennement.
- Annotation: accélérez votre formation grâce à un service d’annotation flexible avec votre choix d’étiquetage assisté par l’IA et supervisé par des humains.
RAG
- API de recherche: effectuez des recherches sur le Web en temps réel à l’aide de n’importe quel moteur de recherche majeur avec des paramètres personnalisés tels que les images ou les achats.
- API Unlocker: utilisez nos services de Proxy gérés pour explorer presque tous les sites web.
- Navigateur d’agent: automatisation complète du navigateur pour votre agent IA.
- Serveur MCP: connectez votre agent IA à nos outils grâce à une intégration transparente.
Conclusion
Le réglage fin apprend à votre modèle à réfléchir. Le RAG permet à votre modèle d’accéder à des données externes sans avoir à le réentraîner ou à le surcharger. En réalité, vous devriez utiliser les deux, mais à des stades différents du développement.
En comprenant quand et pourquoi utiliser le réglage fin et le RAG, vous pouvez prendre des décisions éclairées avec vos propres modèles d’IA. Que vous créiez un expert spécialisé dans un domaine spécifique ou que vous lui donniez accès à des données en temps réel, nos outils sont là pour vous, tout comme nous.
Inscrivez-vous pour un essai gratuit et commencez dès aujourd’hui !





