

Dans ce guide, vous apprendrez :
- Qu’est-ce que le protocole MCP (Model Context Protocol) et pourquoi est-il important pour les agents IA ?
- Comment configurer le serveur MCP de Bright Data avec Augment Code
- Comment utiliser les outils de recherche Web, de scraping Markdown et d’API SERP
- Comment naviguer sur des sites web dynamiques à l’aide du Navigateur de scraping
- Comment combiner le codage IA avec les données web en direct pour des flux de travail pratiques
Avant de vous lancer dans la configuration, il est utile de comprendre les deux technologies que vous allez connecter.
Qu’est-ce que le protocole MCP (Model Context Protocol) ?
Le MCP est un moyen standardisé permettant aux modèles d’IA de se connecter à des outils et des sources de données externes. Considérez le MCP comme le port USB-C des LLM. Tout comme l’USB-C vous permet de connecter n’importe quel périphérique à n’importe quel appareil grâce à une norme unique, le MCP permet aux modèles d’IA de se connecter à n’importe quelle source de données ou outil via un protocole unifié.
Avant le MCP, connecter un LLM à des outils externes impliquait de créer des intégrations personnalisées pour chaque combinaison. Vous souhaitez que votre agent alimenté par Claude effectue des recherches sur le Web ? Créez une intégration. Vous passez à GPT ? Recréez-la. Vous ajoutez une nouvelle source de données ? Encore plus de code personnalisé.
Le MCP élimine cette complexité. Il définit une méthode standard permettant aux modèles IA de découvrir, d’invoquer et de recevoir des résultats provenant d’outils externes. Créez un serveur MCP une seule fois, et tout client compatible MCP pourra l’utiliser.
Pour approfondir vos connaissances techniques, consultez notre guide sur les serveurs MCP pour le Scraping web.
Maintenant que vous comprenez comment MCP standardise les connexions entre les outils, examinons l’assistant de codage IA que vous allez améliorer grâce à l’accès au Web.
Qu’est-ce que Augment Code ?
Augment Code est un assistant de codage IA conçu pour les bases de code volumineuses et complexes. Contrairement aux outils qui se concentrent sur la saisie automatique ligne par ligne, Augment Code indexe l’ensemble de votre projet et comprend les dépendances entre les fichiers.
Son principal facteur de différenciation est ce qu’ils appellent le « Context Engine ». Plutôt que de simplement offrir une grande fenêtre contextuelle (plus de 200 000 jetons), il indexe activement votre base de code et garde en mémoire l’architecture de votre projet. Demandez-lui de refactoriser une fonction, et il identifie les autres fichiers qui importent cette fonction et doivent être mis à jour.
Principales fonctionnalités
- Indexation complète de la base de code. Augment indexe l’ensemble de votre projet, y compris les dépendances entre plusieurs référentiels. Les questions extraient le contexte pertinent de n’importe quel endroit de votre base de code.
- Mode agent. Au-delà du chat et de la saisie automatique, Augment peut exécuter de manière autonome des tâches en plusieurs étapes. Vous pouvez lui demander d’ajouter la gestion des erreurs à tous les appels API, et il l’applique à votre base de code fichier par fichier.
- Flexibilité IDE. Fonctionne avec VS Code, tous les IDE JetBrains (IntelliJ, PyCharm, WebStorm), Vim/Neovim, et propose un outil CLI appelé Auggie pour les workflows terminaux.
- Certifications de sécurité. Certifié SOC 2 Type II et conforme à la norme ISO/IEC 42001.
Augment Code excelle dans la compréhension de votre base de code, mais il présente une limitation importante : il ne peut pas voir ce qui se passe sur le web en direct. C’est là que Bright Data entre en jeu.
Pourquoi combiner Bright Data MCP avec Augment Code ?

La fenêtre contextuelle et les capacités d’agent d’Augment Code le rendent efficace pour les tâches complexes en plusieurs étapes. Mais il ne peut pas accéder seul au web en direct. Il ne peut pas vérifier si un point de terminaison API a changé la semaine dernière, vérifier les versions actuelles des bibliothèques ou recueillir de l’Intelligence compétitive.
Le serveur MCP de Bright Data comble cette lacune. Le serveur MCP fournit plus de 60 outils pour accéder au web. Selon la documentation de Bright Data, cela inclut l’accès à plus de 150 millions d’IPs résidentielles dans 195 pays.
Lorsque vous vous connectez, vous bénéficiez des avantages suivants :
| Catégorie | Ce qu’il fait | Exemples d’outils |
|---|---|---|
| Recherche sur le Web | Interroger les moteurs de recherche de manière programmatique | search_engine, search_engine_batch |
| Extraction de pages | Extraire le contenu de n’importe quelle URL | scrape_as_markdown, scrape_as_html |
| Automatisation du navigateur | Naviguer, cliquer, taper, faire défiler | scraping_browser_navigate, scraping_browser_click_ref |
| Extraction structurée | Obtenez un JSON propre à partir de plus de 60 plateformes | web_data_amazon_product, web_data_linkedin_profile |
Les outils du Navigateur de scraping méritent votre attention. Contrairement aux simples requêtes de récupération, ces outils contrôlent un véritable navigateur qui gère le rendu JavaScript, les flux de connexion, le défilement infini et la navigation en plusieurs étapes. Cela est important pour les systèmes agentifs qui doivent interagir avec des applications web modernes.
Lorsque j’ai testé cette configuration pour la première fois, j’ai demandé à Augment de vérifier si l’API OpenAI avait récemment modifié ses limites de débit. En huit secondes environ, il a extrait la documentation actuelle, l’a comparée à celle que j’avais mise en cache localement et a signalé que les limites de jetons par minute avaient changé pour le point de terminaison GPT-4 Turbo. Cette seule requête m’a évité de déployer un code qui aurait atteint les limites de débit en production.
Les avantages étant clairs, passons en revue le processus de configuration proprement dit.
Connexion de Bright Data à Augment Code
Prérequis
Avant de commencer, assurez-vous de disposer des éléments suivants :
- Node.js 18+ installé
- l’extension Augment Code installée dans VS Code (ou votre IDE préféré)
- Un compte Bright Data (configuration décrite ci-dessous)
Ne vous inquiétez pas si vous ne disposez pas encore d’un jeton API Bright Data. Nous vous guiderons dans sa création dans la section suivante.
Étape 1 : Créez votre compte Bright Data et obtenez un jeton API
Pour commencer, vous aurez besoin d’un compte Bright Data et d’un jeton API pour l’authentification auprès du serveur MCP, ce qui prend environ deux minutes.
- Rendez-vous sur brightdata.com et cliquez sur « Essai gratuit » pour créer votre compte.
- Une fois connecté au tableau de bord, accédez aux paramètres (icône en forme d’engrenage) dans la barre latérale gauche, puis cliquez sur « API tokens » (Jetons API).
- Cliquez sur « Créer un jeton » et donnez-lui un nom descriptif, tel que « Augment Code MCP ».
- Copiez votre nouveau jeton et conservez-le en lieu sûr. Vous en aurez besoin pour l’étape suivante.
Étape 2 : Configurer Bright Data MCP dans Augment Code
Ce tutoriel utilise l’extension Augment Code pour Visual Studio Code.
Augment prend en charge trois méthodes pour ajouter des serveurs MCP : Easy MCP (configuration en un clic), l’interface graphique du panneau Paramètres et l’importation JSON. Nous utiliserons l’importation JSON, car elle offre un contrôle total sur les options de configuration.
- Ouvrez VS Code et cliquez sur l’icône Augment Code dans votre barre d’activité (barre latérale gauche).
- Dans le panneau Augment, cliquez sur l’icône en forme d’engrenage (Paramètres) dans le coin supérieur droit. La page des paramètres d’Augment s’ouvre dans un nouvel onglet.
- Cliquez sur la section Serveurs MCP.
- Cliquez sur « Importer depuis JSON ».
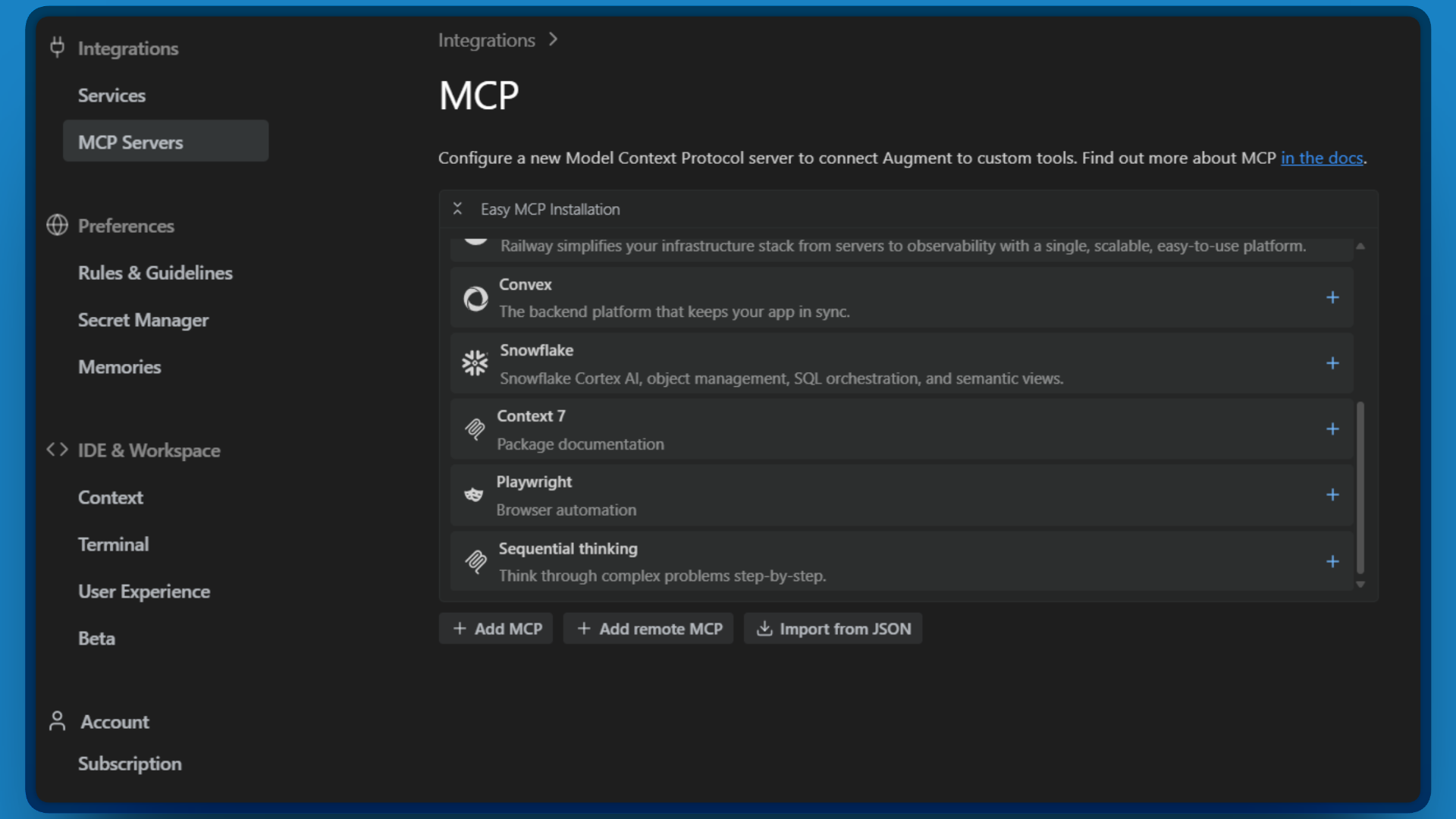
Il est maintenant temps de coller votre configuration. Copiez le JSON ci-dessous, en remplaçant<YOUR_API_TOKEN>par le jeton Bright Data que vous avez créé à l’étape 1 :
{
"mcpServers": {
"Bright Data": {
"command": "npx",
"args": ["@brightdata/mcp"],
"env": {
"API_TOKEN": ""
}
}
}
}Redémarrez VS Code pour vous assurer que le serveur MCP s’initialise correctement, puis votre Augment aura un accès complet à l’Infrastructure de scraping web de Bright Data.
Alternative : configuration du serveur distant
Si vous préférez ne rien exécuter localement, vous pouvez vous connecter directement au serveur hébergé de Bright Data à l’aide de SSE (Server-Sent Events) :
{
"mcpServers": {
"Bright Data": {
"url": "https://mcp.brightdata.com/sse?token=&pro=1",
"type": "sse"
}
}
}Cette approche à distance ne nécessite aucune configuration locale. Le serveur MCP fonctionne entièrement sur l’infrastructure de Bright Data, ce qui peut être utile si vous travaillez sur une machine sur laquelle vous ne pouvez pas installer de paquets npm ou si vous préférez minimiser les dépendances locales.
Étape 3 : Vérifier la connexion
Pour vérifier la connexion, confirmons que tout fonctionne avant de nous plonger dans les fonctionnalités avancées.
- Ouvrez le panneau Augment Code dans VS Code en cliquant sur l’icône Augment dans la barre d’activité.
- Lancez une nouvelle conversation et tapez une requête simple qui nécessite un accès au web, par exemple :
« Recherchez sur le Web les nouvelles fonctionnalités de Python 3.13 et résumez les principaux résultats. »
- Observez comment Augment Code invoque l’outil
search_engineet renvoie les résultats de recherche actuels.
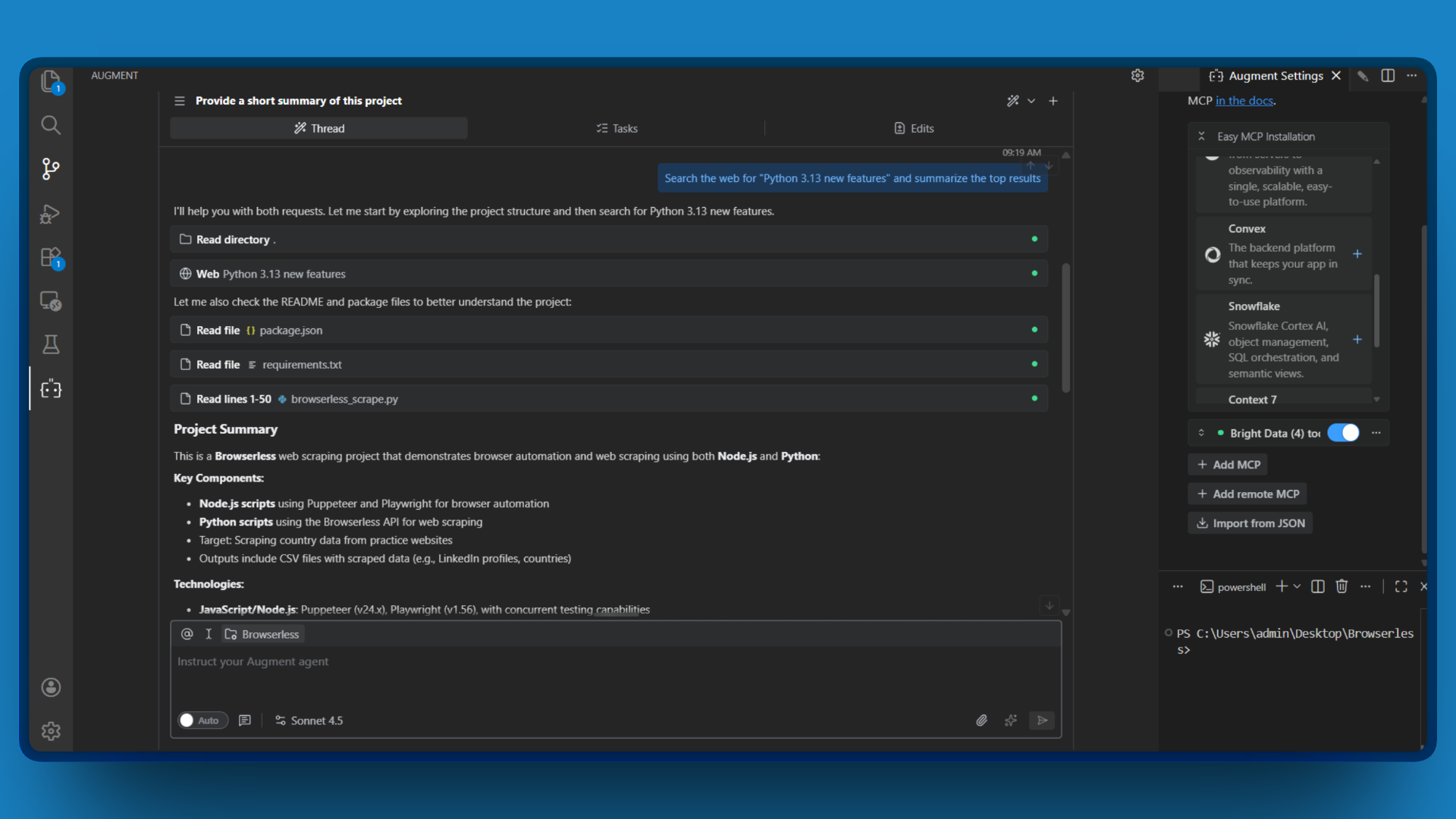
Si vous voyez les résultats de recherche provenant du Web en direct, félicitations ! Votre connexion Bright Data MCP fonctionne.
Lorsque vous demandez à Augment Code d’effectuer une recherche sur le Web, voici le déroulement :
- Augment Code analyse votre demande et détermine qu’il a besoin de données Web
- Le client MCP (intégré à Augment) interroge le serveur Bright Data MCP pour connaître les outils disponibles
- Le serveur MCP renvoie la liste des outils, y compris search_engine
- Augment Code invoque search_engine avec votre requête
- Bright Data exécute la recherche à l’aide de son API SERP, en gérant automatiquement le ciblage géographique et les mesures anti-bot
- Les résultats sont renvoyés via MCP à Augment Code, qui les formate pour vous
L’ensemble du processus se déroule en quelques secondes. Vous ne quittez jamais votre IDE.
Une fois la connexion vérifiée, vous êtes prêt à explorer ce que ces outils peuvent réellement faire.
Utilisation des outils MCP classiques de Bright Data
Maintenant que la connexion est établie, explorons les outils de base qui fonctionnent à la fois en mode rapide (gratuit) et en mode pro.
Recherche Web avec search_engine
L’outil search_engine interroge Google, Bing ou Yandex et renvoie des résultats structurés. Il est parfait pour :
- Rechercher la documentation API actuelle lorsque vous avez besoin des derniers points de terminaison
- Trouver des tutoriels récents ou des réponses Stack Overflow pour des bibliothèques inconnues
- Vérifier les versions actuelles des paquets avant d’ajouter des dépendances
- Recueillir de l’intelligence compétitive sur des produits ou services similaires
Par exemple, si vous demandez à Augment de :
Rechercher les dernières modifications importantes de Next.js 15 et les répertorier
Augment Code invoque search_engine, traite les résultats et vous fournit un résumé des modifications majeures avec leurs sources. Aucun changement d’onglet n’est nécessaire.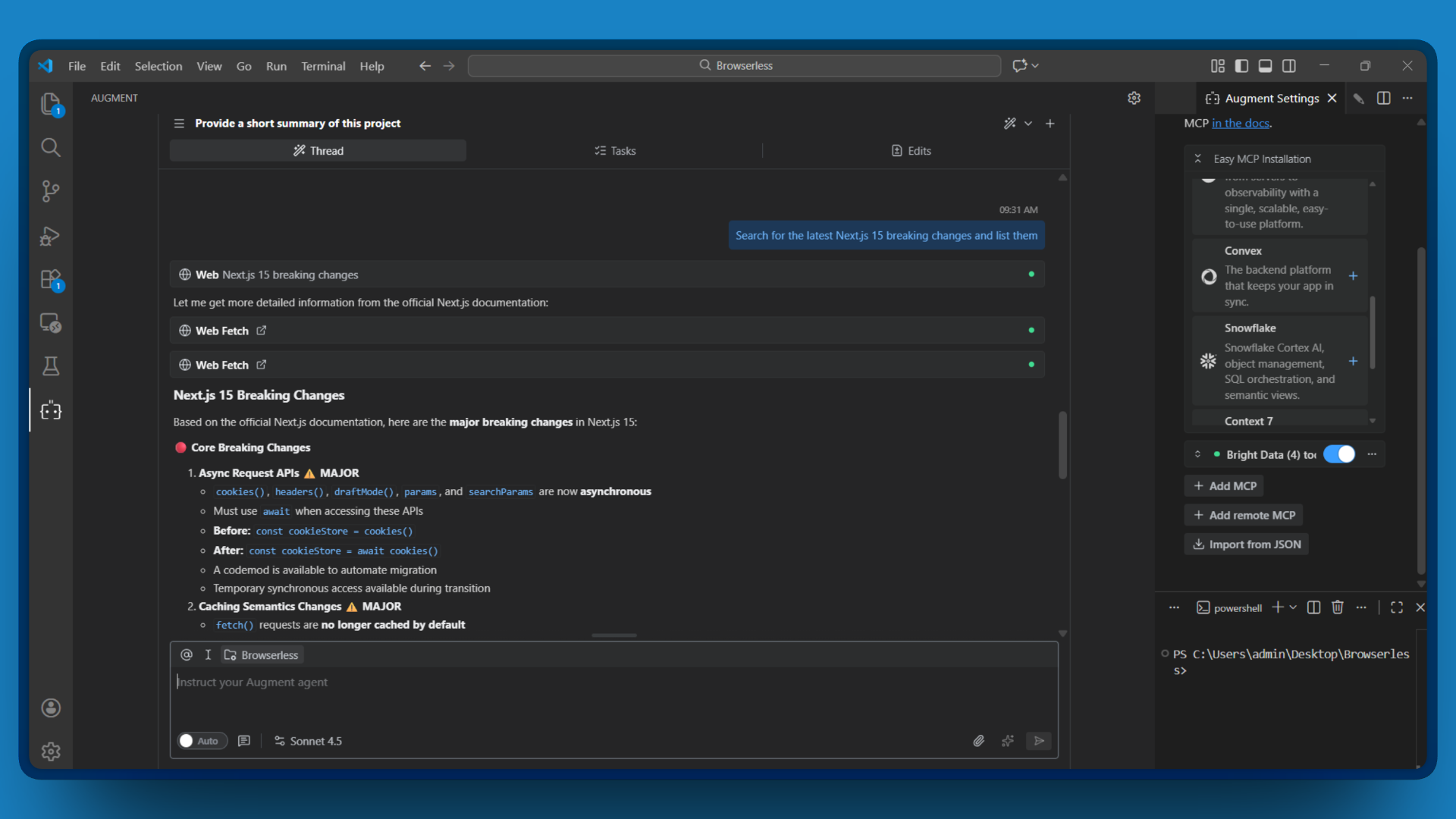
Pour les recherches par lots (jusqu’à 10 requêtes à la fois), le mode Pro débloque search_engine_batch.
Extraction de page avec scrape_as_markdown
Lorsque vous avez besoin du contenu complet d’une page spécifique, scrape_as_markdown le récupère et convertit le HTML en Markdown propre. Cet outil utilise la technologie Web Unlocker pour contourner automatiquement les CAPTCHA et les mesures anti-bot.
Exemple d’invite :
Récupérez la documentation de l’API Stripe à l’adresse https://stripe.com/docs/api et expliquez leurs méthodes d’authentification
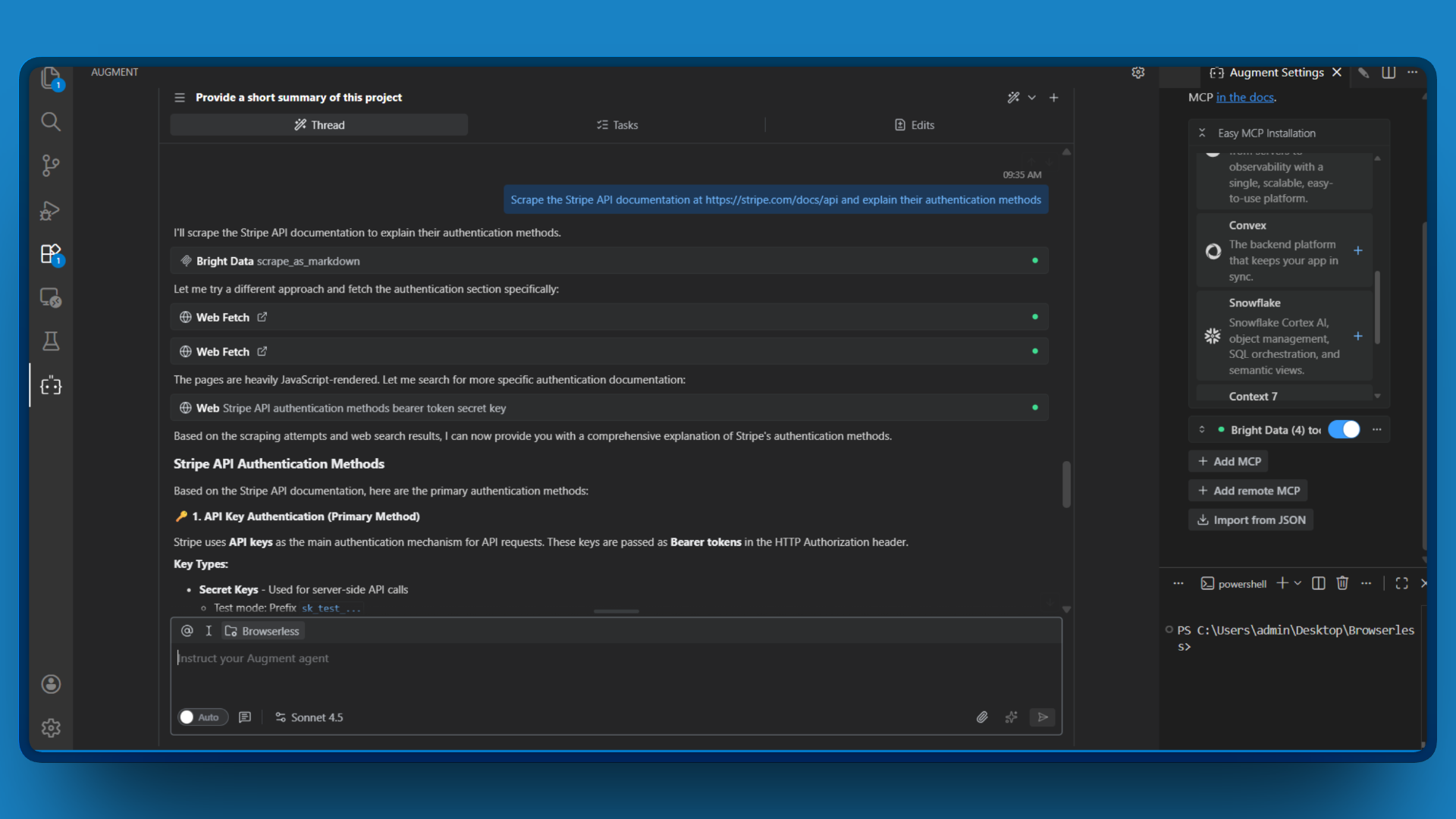
L’outil renvoie le contenu de la page au format Markdown, qu’Augment Code analyse et résume. Vous obtenez les informations dont vous avez besoin sans avoir à lire manuellement une documentation dense.
Données structurées avec les API de données Web
Pour les plateformes populaires, il n’est pas nécessaire d’analyser manuellement le code HTML. Le mode Pro comprend des extracteurs pré-intégrés qui renvoient un JSON propre et structuré.
Exemple de requête :
Obtenir les détails du produit pour cette liste Amazon : https://www.amazon.com/dp/B0CHX3QBCH
L’outil web_data_amazon_product renvoie des données structurées, notamment le titre, le prix, les notes, les avis et les spécifications. Aucun code d’analyse n’est nécessaire.
Les extracteurs disponibles couvrent plus de 60 plateformes, notamment :
- Commerce électronique : Amazon, Walmart, eBay, Etsy, Best Buy, Google Shopping
- Réseaux sociaux : LinkedIn, Instagram, Facebook, TikTok, X/Twitter, YouTube, Reddit
- Entreprises : Crunchbase, ZoomInfo, Zillow, Google Maps
- Finance : Yahoo Finance, Reuters
Consultez la liste complète dans la documentation des outils MCP.
Avec plusieurs outils à votre disposition, savoir lequel utiliser dans différentes situations vous aidera à travailler plus efficacement.
Choisir le bon outil
Différents outils conviennent à différentes situations. Utilisez ce tableau pour choisir le bon :
| Situation | Outil recommandé | Pourquoi |
|---|---|---|
| Recherche rapide d’informations factuelles | Moteur de recherche |
Rapide, renvoie des résultats structurés, faible coût |
| Besoin du contenu complet de la page | scrape_as_markdown |
Gère les mesures anti-bot, renvoie un texte propre |
| La page nécessite JavaScript | scraping_browser_navigate |
Rend JS, attend le contenu dynamique |
| Connexion ou flux en plusieurs étapes | Navigateur de scraping | Peut cliquer, taper, gérer l’authentification |
| Amazon, LinkedIn, etc. | APIweb_data_* |
Renvoie un JSON structuré, aucune analyse syntaxique nécessaire |
| Recherches multiples simultanées | search_engine_batch |
Jusqu’à 10 requêtes, plus efficace |
Règle générale : commencez par l’outil le plus simple susceptible de fonctionner. Ne passez à l’automatisation du navigateur que lorsque les méthodes plus simples échouent.
Même avec l’outil approprié, vous pouvez parfois rencontrer des problèmes. Voici comment diagnostiquer et résoudre les problèmes les plus courants.
Dépannage des problèmes courants
Vous rencontrez des problèmes ? Voici les solutions aux problèmes les plus courants :
Erreur « Outil introuvable »
Si Augment Code ne parvient pas à trouver les outils Bright Data, commencez par vérifier que votre jeton API est correct et n’a pas expiré. Ensuite, vérifiez que la configuration MCP a été correctement enregistrée et essayez de redémarrer complètement Augment Code plutôt que de simplement le recharger. Si le problème persiste, vérifiez les journaux Augment pour voir s’il y a des erreurs de connexion.
Réponses lentes
L’automatisation du navigateur prend naturellement plus de temps que le simple scraping. Si les réponses semblent lentes, voici quelques points à garder à l’esprit. Le rendu JavaScript prend du temps, car le Navigateur de scraping doit rendre entièrement les pages avant d’interagir avec elles. Les pages complexes comportant de nombreux éléments interactifs nécessitent des instantanés plus volumineux, ce qui augmente également le temps de traitement.
Pour les pages plus simples qui ne nécessitent pas d’interaction, envisagez d’utiliser scrape_as_markdown comme alternative plus rapide.
Limitation du débit
Si vous atteignez les limites de débit, commencez par vérifier votre utilisation dans le tableau de bord Bright Data. Vous pouvez également ajuster la variable d’environnement RATE_LIMIT dans votre configuration afin de mieux gérer la fréquence des requêtes. Pour les projets exigeants qui nécessitent des limites plus élevées, envisagez de passer à un forfait supérieur.
Au-delà des questions techniques, la connexion d’agents IA au web soulève des considérations de sécurité qu’il convient de garder à l’esprit.
Meilleures pratiques en matière de sécurité
Lorsque vous connectez des agents IA au Web, la sécurité est importante. Gardez ces principes à l’esprit :
- Considérez le contenu récupéré comme non fiable. N’exécutez jamais de code provenant de pages récupérées et ne transmettez jamais de contenu brut à eval().
- Utilisez l’extraction structurée lorsqu’elle est disponible. Les outils web_data_* renvoient du JSON validé, ce qui réduit les risques d’injection par rapport à l’analyse HTML brut.
- Stockez les jetons API de manière sécurisée. Utilisez des variables d’environnement, et non des valeurs codées en dur dans votre base de code.
- Vérifiez les actions de l’agent. Surveillez ce que fait votre agent, en particulier dans les environnements de production.
Une fois ces pratiques mises en place, vous êtes prêt à commencer à développer.
Conclusion
Le serveur MCP de Bright Data transforme Augment Code d’un assistant axé sur le code en un agent sensible au Web capable de recueillir des informations en temps réel. Avec plus de 60 outils pour la recherche, le scraping, l’automatisation des navigateurs de scraping et l’extraction structurée (soutenus par plus de 150 millions d’IPs résidentielles et un taux de réussite de 99,95 %), votre assistant de codage IA peut désormais :
- Rechercher la documentation actuelle et les API en direct
- Recueillir automatiquement de l’intelligence compétitive
- Automatiser les workflows complexes de collecte de données
- Naviguer sur des sites web dynamiques avec des interactions en plusieurs étapes
Les outils du Navigateur de scraping sont particulièrement puissants pour les systèmes agentifs. À l’aide d’instantanés ARIA et de références d’éléments stables, votre agent gère les flux de connexion, les formulaires en plusieurs étapes et le contenu dynamique qui mettraient à mal des approches de scraping plus simples.
Prêt à donner à votre assistant de codage IA un accès web en temps réel ?
Pour des techniques plus avancées, consultez nos guides sur la création d’agents IA avec LlamaIndex et l’intégration de MCP avec CrewAI.





