

Google a supprimé le paramètre num en septembre 2025 sans avertissement. Le rendu JavaScript est devenu obligatoire et les aperçus IA ont été déployés dans 200 pays et territoires. Si vous effectuez du scraping sur Google, vos requêtes HTTP brutes renvoient désormais des réponses vides ou dégradées, la pagination basée sur num est interrompue et le contenu généré par l’IA repousse les résultats organiques sous le pli.
Chaque URL de recherche Google contient des paramètres après le ? (comme q pour votre requête, gl pour le pays, hl pour la langue, tbs pour les filtres temporels, et des dizaines d’autres). Si vous vous trompez, votre Scraper renvoie des données provenant du mauvais pays ou des résultats vides difficiles à déboguer.
Vous trouverez ci-dessous tous les paramètres importants, avec du code testé et des exemples pratiques. Tout le code a été exécuté sur l’API SERP de Bright Data en direct.
TL;DR : Ce que vous devez savoir pour 2026 :
- Suivi du classement :
q=...&gl=us&hl=en&pws=0&udm=14&brd_json=1(non personnalisé, pas d’aperçus IA)- Pagination :
start=10,start=20, etc. (10 résultats par page).numne fonctionne plus- Filtres temporels :
tbs=qdr:d(jour précédent),tbs=sbd:1(tri par date),tbs=li:1(mot pour mot)- Nouveau :
udmétendtbmavec des modes tels queudm=14(web uniquement, sans IA). Les deux fonctionnent aujourd’hui. Prise en charge des deux.- Requis : rendu JavaScript. Les appels bruts
requests.get()renvoient des résultats vides depuis janvier 2025
Exemple minimal fonctionnel :
curl -X POST "https://api.brightdata.com/request"
-H "Content-Type: application/json"
-H "Authorization: Bearer <API_TOKEN>"
-d '{"zone":"<ZONE_NAME>","url":"https://www.google.com/search?q=tools+for+scraping+web+content&gl=us&hl=en&brd_json=1","format":"raw"}'(brd_json=1 dans l’URL indique à Bright Data d’analyser le code HTML de Google en JSON structuré. format: raw dans le corps de la requête renvoie la réponse telle quelle depuis l’infrastructure de Bright Data, qui dans ce cas est le JSON analysé produit par brd_json=1.)
Référence rapide : aide-mémoire des paramètres de recherche Google
| Paramètre | Fonction | Statut |
|---|---|---|
q |
Requête de recherche | Actif |
hl |
Langue de l’interface (en, fr, de) |
Actif |
gl |
Géolocalisation / pays (us, gb, in) |
Actif |
lr |
Limiter les résultats à des langues spécifiques | Actif |
cr |
Limiter les résultats aux pages hébergées dans des pays spécifiques | Actif |
num |
Résultats par page | Inactif (septembre 2025) |
début |
Décalage de pagination | Actif |
tbm |
Type de recherche (isch, nws, shop, vid) |
Actif |
udm |
Filtre de mode de contenu (14, 2, 39, 50) |
Actif (Nouveau) |
tbs |
Filtres temporels et avancés (qdr:d, qdr:w) |
Actif |
sécurisé |
Filtrage SafeSearch | Actif |
filtre |
Filtrage des résultats en double | Actif |
nfpr |
Désactiver la correction automatique | Actif |
pws |
Désactiver les résultats personnalisés (pws=0) |
Actif |
uule |
Emplacement codé (ciblage au niveau de la ville) | Actif |
sclient |
Identifiant du client de recherche | Actif (interne) |
kgmid |
ID d’entité du graphe de connaissances | Actif |
si |
Onglets du Knowledge Graph (chaîne codée opaque ; non constructible par l’utilisateur) | Actif (interne) |
ibp |
Contrôle du rendu (emplois, listes d’entreprises) | Actif |
ei, ved, sxsrf |
Suivi interne / jetons de session | Actif (interne) |
Les opérateurs de recherche Google (site:, filetype:, intitle:, etc.) sont décrits dans la section consacrée aux opérateurs plus bas.
Essayez les recherches de base dans l’API SERP – aucune connexion requise. Pour obtenir l’ensemble complet des paramètres, utilisez directement l’API.
Que sont les paramètres de recherche Google ?
Les paramètres de recherche Google contrôlent la requête, l’emplacement, la langue et le filtrage des résultats. Ils sont importants pour le suivi du classement SEO, l’analyse de la concurrence, la surveillance des publicités et l’alimentation des résultats de recherche dans les applications LLM.
Un changement intervenu en 2025 : Google a annoncé en avril 2025 que les ccTLD (domaines de premier niveau nationaux tels que google.co.uk, google.de, google.ca) redirigeraient vers google.com. Le déploiement est progressif et certains ccTLD continuent de fournir directement des résultats. Dans tous les cas, utilisez gl et hl pour la localisation, et non le domaine.
Paramètres de recherche de base
Ce sont ceux que vous définirez pour presque toutes les requêtes : requête, langue, pays et pagination.
q – requête de recherche
Votre requête de recherche va dans q.
https://www.google.com/search?q=bright+data+Scraping webLes espaces dans la requête sont encodés sous la forme + ou %20. Le paramètre q prend également en charge les opérateurs de recherche Google, par exemple :
https://www.google.com/search?q=filetype:pdf+Scraping web+guide
https://www.google.com/search?q=site:github.com+API SERP
https://www.google.com/search?q=intitle:Proxy rotatif+tutorialEncodez correctement votre chaîne de requête, en particulier les caractères non latins (chinois, arabe, japonais, coréen, etc.) – le fait de ne pas les encoder est une cause fréquente de résultats inattendus ou vides. Si vous utilisez l’API SERP de Bright Data, placez toujours le paramètre q en premier dans votre URL. La documentation de Bright Data l’exige. Placer d’autres paramètres avant q peut ralentir les réponses et réduire les taux de réussite.
Via la méthode Proxy de l’API SERP de Bright Data:
curl --proxy brd.superproxy.io:33335
--proxy-user brd-customer-<CUSTOMER_ID>-zone-<ZONE_NAME>:<PASSWORD> -k
"https://www.google.com/search?q=Scraping web tools&brd_json=1"Si vous avez besoin que le code HTML brut soit conservé dans le JSON, utilisez brd_json=html à la place de brd_json=1. L’API Direct prend en charge des formats de sortie supplémentaires, notamment Markdown, les captures d’écran et la sortie analysée allégée.
La réponse JSON se présente comme suit (raccourcie) :
{
"general": {
"search_engine": "google",
"results_cnt": 33500000,
"search_time": 0.21,
"language": "en",
"mobile": false,
"search_type": "text"
},
"input": {
"original_url": "https://www.google.com/search?q=Scraping web tools&brd_json=1"
},
"organic": [
{
« link » : « https://www.reddit.com/r/automation/comments/1ncuv8k/best_web_scraping_tools_ive_tried_and_what_i/ »,
« title » : « Les meilleurs outils de Scraping web que j'ai essayés (et ce que j'ai appris de ... »,
« description » : « Playwright : excellent pour l'automatisation et les tests structurés, mais un peu trop lourd en code pour un scraping léger. »,
« rank » : 1,
« global_rank » : 5
}
]
}Le JSON regroupe tout par section SERP. Les résultats organiques sont séparés des top_ads et bottom_ads, les panneaux de connaissances sont séparés des people_also_ask, les résultats locaux sont dans snack_pack, et les nouvelles fonctionnalités comme ai_overview sont chacune dans leur propre champ. Il y a plus d’une douzaine de sections au total, selon la requête.
hl – langue hôte
Abréviation de « host language » (langue hôte), hl contrôle la langue de l’interface Google et la manière dont Google interprète votre requête.
https://www.google.com/search?q=coffee&hl=en
https://www.google.com/search?q=coffee&hl=es
https://www.google.com/search?q=coffee&hl=jaLes valeurs sont des codes ISO 639-1 tels que hl=en (anglais), hl=fr (français), hl=de (allemand) ou des balises de langue BCP 47 telles que hl=en-gb (anglais britannique), hl=pt-br (portugais brésilien), hl=es-419 (espagnol latino-américain).
Grâce à l’API SERP, la même recherche se présente comme suit :
curl --proxy brd.superproxy.io:33335
--proxy-user brd-customer-<CUSTOMER_ID>-zone-<ZONE_NAME>:<PASSWORD> -k
"https://www.google.com/search?q=meilleurs+outils+de+scraping&hl=fr&gl=fr&brd_json=1"Cela permet d’obtenir des résultats en français pour une requête en français, comme si vous effectuiez votre recherche depuis la France.
gl – géolocalisation
Votre emplacement de recherche influe sur les résultats. Le paramètre gl simule votre géolocalisation (le pays d’où semble provenir la recherche). Il utilise les codes pays à deux lettres ISO 3166-1 alpha-2.
https://www.google.com/search?q=pizza+delivery&gl=us
https://www.google.com/search?q=pizza+delivery&gl=gb
https://www.google.com/search?q=pizza+delivery&gl=inComparez la même requête dans deux pays :
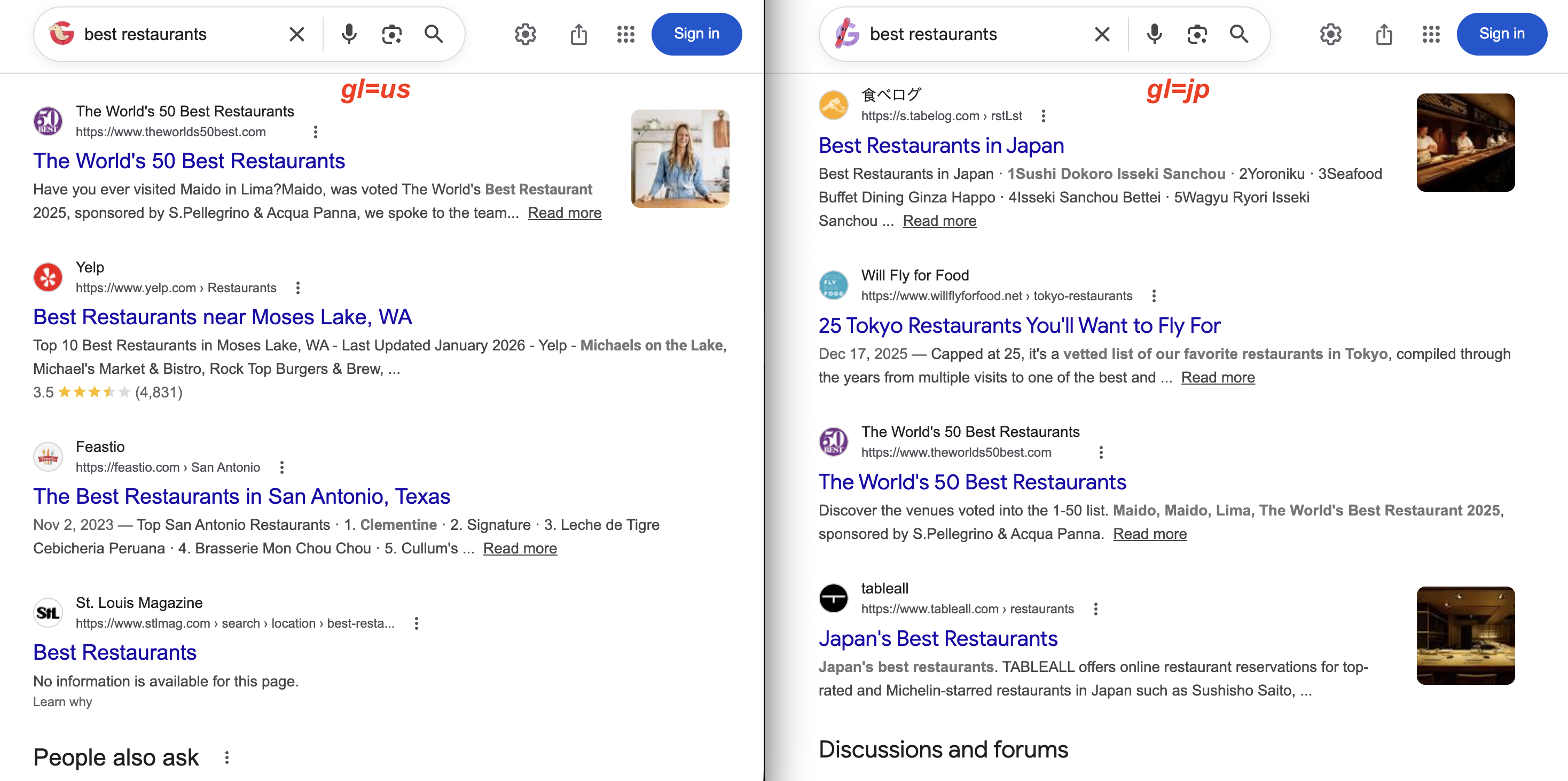
gl=us renvoie Yelp et des magazines locaux américains. Avec gl=jp, les résultats affichent plutôt 食べログ (Tabelog) et des guides de restaurants à Tokyo. Même requête, résultats très différents.
lr – restriction linguistique
Une recherche sur le machine learning avec hl=en renvoie toujours des articles en chinois, japonais ou allemand si Google les juge pertinents. Le paramètre lr résout ce problème. Il limite les résultats aux pages réellement rédigées dans des langues spécifiques, et pas seulement à l’interface.
https://www.google.com/search?q=machine+learning&lr=lang_en
https://www.google.com/search?q=machine+learning&lr=lang_en|lang_frAjoutez le préfixe lang_ au code de la langue (ainsi, l’anglais est lang_en et le français est lang_fr). Utilisez la barre verticale | pour combiner plusieurs langues.
cr – restriction par pays
Similaire à lr, mais filtre par pays d’hébergement plutôt que par langue du contenu. Utilisez cr=countryUS pour un seul pays, cr=countryUS|countryGB pour plusieurs pays. La principale différence avec gl: gl géolocalise votre recherche comme si vous vous trouviez dans ce pays, cr filtre les pages réellement hébergées dans ce pays. Utilisez les deux ensemble si vous avez besoin d’un filtrage précis.
num – nombre de résultats
Le paramètre num permettait de contrôler le nombre de résultats de recherche affichés par page (par exemple, num=20, num=50, num=100).
Si votre Scraper n’affiche plus que 10 résultats depuis septembre 2025, c’est à cause de cette modification du paramètre. En septembre 2025, Google a discrètement désactivé le paramètre num. Il est désormais complètement ignoré. Google affiche 10 résultats par page, quelle que soit la valeur num que vous transmettez, sans erreur ni redirection. Cela a perturbé le fonctionnement des outils SEO et des workflows de scraping SERP qui s’appuyaient sur ce paramètre. Un porte-parole de Google a confirmé : « L’utilisation de ce paramètre d’URL n’est pas quelque chose que nous soutenons officiellement ». La section consacrée aux changements de 2025-2026 traite de la solution de contournement utilisant le point de terminaison Top 100 Results de Bright Data.
Vous pouvez le vérifier. num=100 figure dans l’URL, mais seuls 10 résultats sont renvoyés :
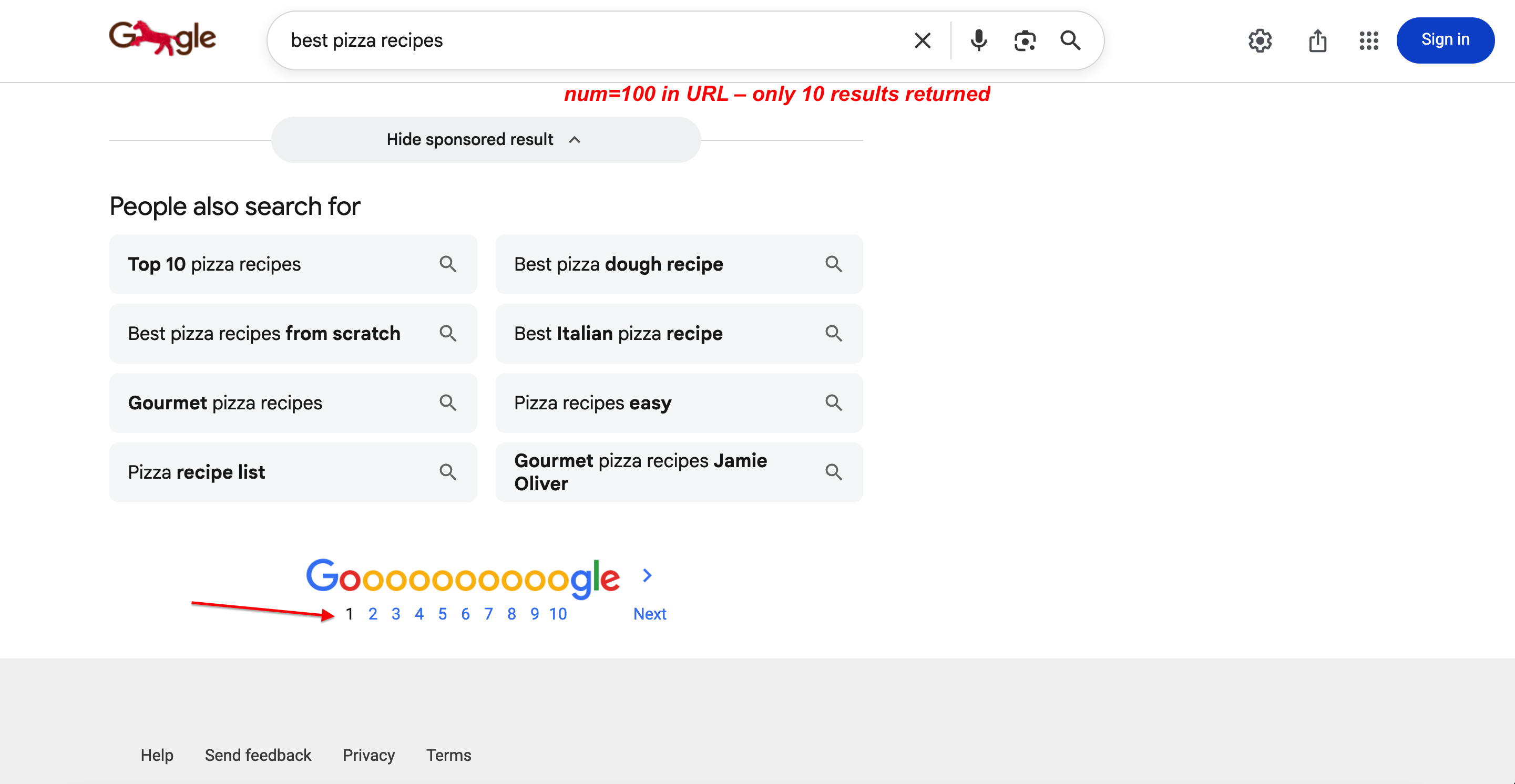
Recherche avec num=100 dans l’URL. Google ne renvoie toujours que 10 résultats par page avec une pagination complète. Le paramètre est complètement ignoré.
start – décalage des résultats (pagination)
Depuis que Google a supprimé num, start est votre seule option de pagination native. Il définit le décalage des résultats, contrôlant la position à partir de laquelle commencer.
https://www.google.com/search?q=Scraping web&start=0
https://www.google.com/search?q=Scraping web&start=10
https://www.google.com/search?q=Scraping web&start=20start=0 correspond à la page 1 (par défaut), start=10 à la page 2 et start=20 à la page 3.
Comme Google renvoie 10 résultats par page, start=20 vous donne les résultats 21 à 30, start=30 vous donne les résultats 31 à 40, et ainsi de suite. Lors de la pagination sur plusieurs pages, Google peut renvoyer des résultats qui se chevauchent ou qui sont légèrement réorganisés entre les pages. Dédupliquez par URL avant le traitement.
Pagination via l’API SERP :
# Récupérer la page 3 des résultats
curl --proxy brd.superproxy.io:33335
--Proxy-user brd-customer-<CUSTOMER_ID>-zone-<ZONE_NAME>:<PASSWORD> -k
"https://www.google.com/search?q=serp+scraping&start=20&brd_json=1"Paramètres de type de recherche
Google dispose de deux paramètres pour basculer entre les différents types de recherche (images, actualités, achats, vidéos) : tbm et udm.
tbm – type de contenu recherché
Le paramètre tbm (généralement interprété comme « to be matched », bien que Google n’ait jamais confirmé cet acronyme) indique à Google le type de résultats de recherche que vous souhaitez obtenir. Sans lui, Google effectue par défaut une recherche Web classique.
| Valeur | Type de recherche | Exemple |
|---|---|---|
| (vide) | Recherche Web | q=café |
isch |
Recherche d’images | tbm=isch&q=café |
vid |
Recherche vidéo | tbm=vid&q=café |
nws |
Recherche d’actualités | tbm=nws&q=café |
shop |
Recherche de magasins | tbm=shop&q=café |
bks |
Recherche de livres | tbm=bks&q=café |
Même requête pour trois types de recherche :
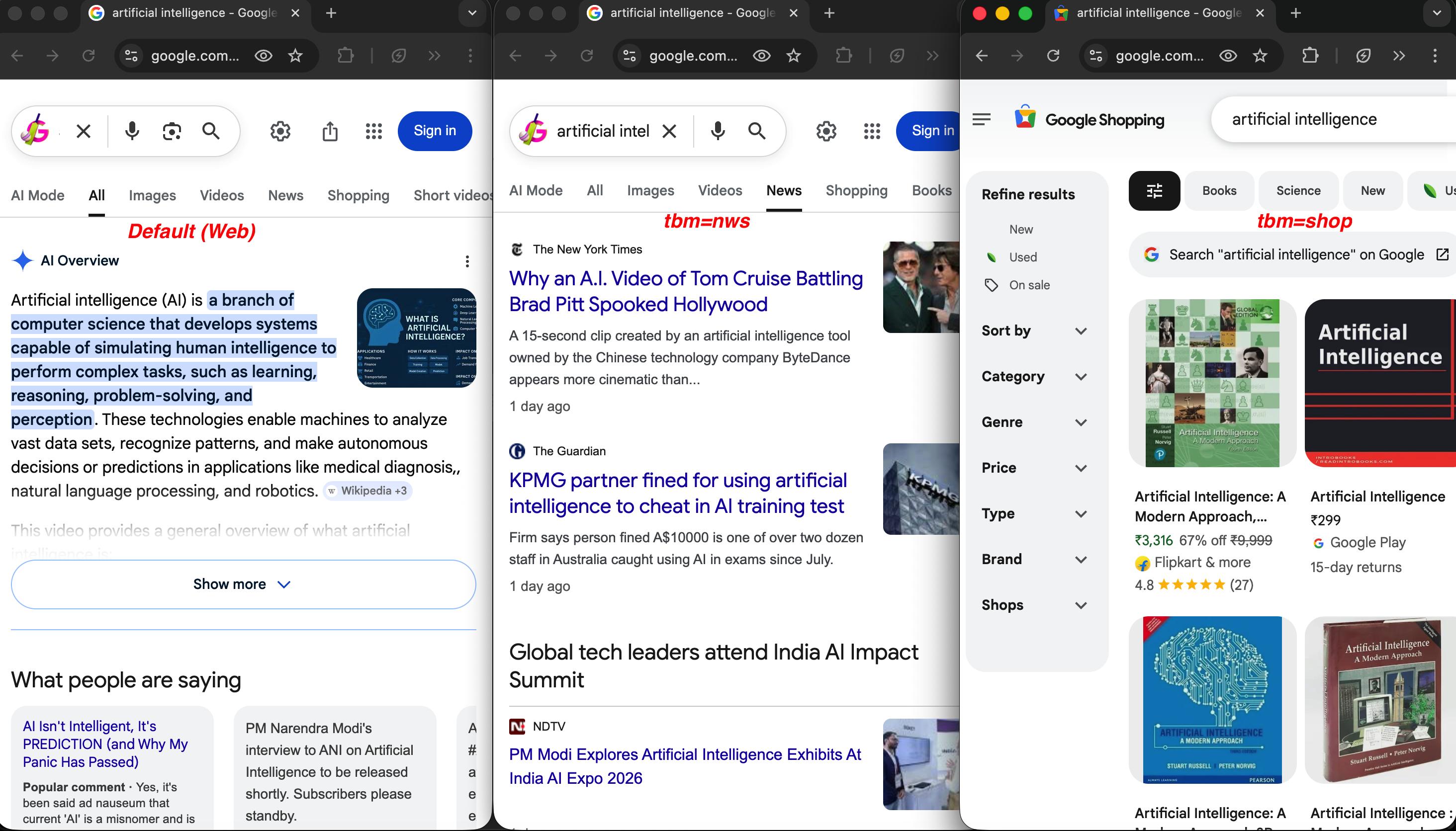
Même requête, valeurs tbm différentes : la recherche Web par défaut (à gauche) affiche une présentation de l’IA, tbm=nws (au centre) renvoie des articles d’actualité du NYT et du Guardian, et tbm=shop (à droite) affiche des listes de produits avec leurs prix et leurs notes.
Recherche d’actualités sur l’intelligence artificielle :
https://www.google.com/search?q=artificial+intelligence&tbm=nws&hl=en&gl=usRecherche d’achat pour les claviers mécaniques :
https://www.google.com/search?q=mechanical+keyboard&tbm=shop&gl=usTous ces types de recherche fonctionnent de manière native. Lors de l’analyse de la réponse JSON, les publicités sont séparées dans les champs top_ads et bottom_ads, et les listes de produits apparaissent sous popular_products, tous distincts des résultats organiques. Pour la surveillance dédiée des annonces, consultez le Scraper Google Ads. Les paramètres de voyage et d’hôtel (hotel_occupancy, hotel_dates, brd_dates, brd_occupancy, brd_currency, etc.) sont spécifiques à Bright Data et documentés dans la référence des paramètres de l’API SERP.
udm – mode d’affichage utilisateur
Le nouveau filtre de mode de contenu de Google est udm, qui étend tbm avec des types de résultats supplémentaires. Il contrôle le « mode » des résultats de recherche que vous voyez. Aucune des valeurs udm ne figure dans la documentation officielle de Google. Elles ont toutes été rétro-conçues par la communauté des développeurs à travers des tests. Les valeurs ci-dessous sont stables et largement utilisées, mais Google pourrait les modifier sans préavis.
| Valeur | Mode de résultat | Description |
|---|---|---|
udm=2 |
Images | Résultats de recherche d’images |
udm=7 |
Vidéos | Résultats vidéo ; équivalent plus récent de tbm=vid |
udm=12 |
Actualités | Résultats d’actualités ; équivalent plus récent de tbm=nws |
udm=14 |
Web | Résultats Web classiques sans fonctionnalités IA |
udm=18 |
Forums | Résultats de discussion et de forum |
udm=28 |
Achats | Résultats des achats/produits |
udm=36 |
Livres | Résultats de recherche de livres ; équivalent plus récent de tbm=bks |
udm=39 |
Vidéos courtes | Contenu vidéo court |
udm=50 |
Mode IA | Recherche conversationnelle alimentée par l’IA de Google |
La valeur la plus notable est udm=14. Elle oblige Google à afficher les résultats Web traditionnels sans aperçus IA ni autre contenu généré par l’IA:
https://www.google.com/search?q=Scraping web tools&udm=14La différence entre le mode par défaut et udm=14 est immédiatement visible :
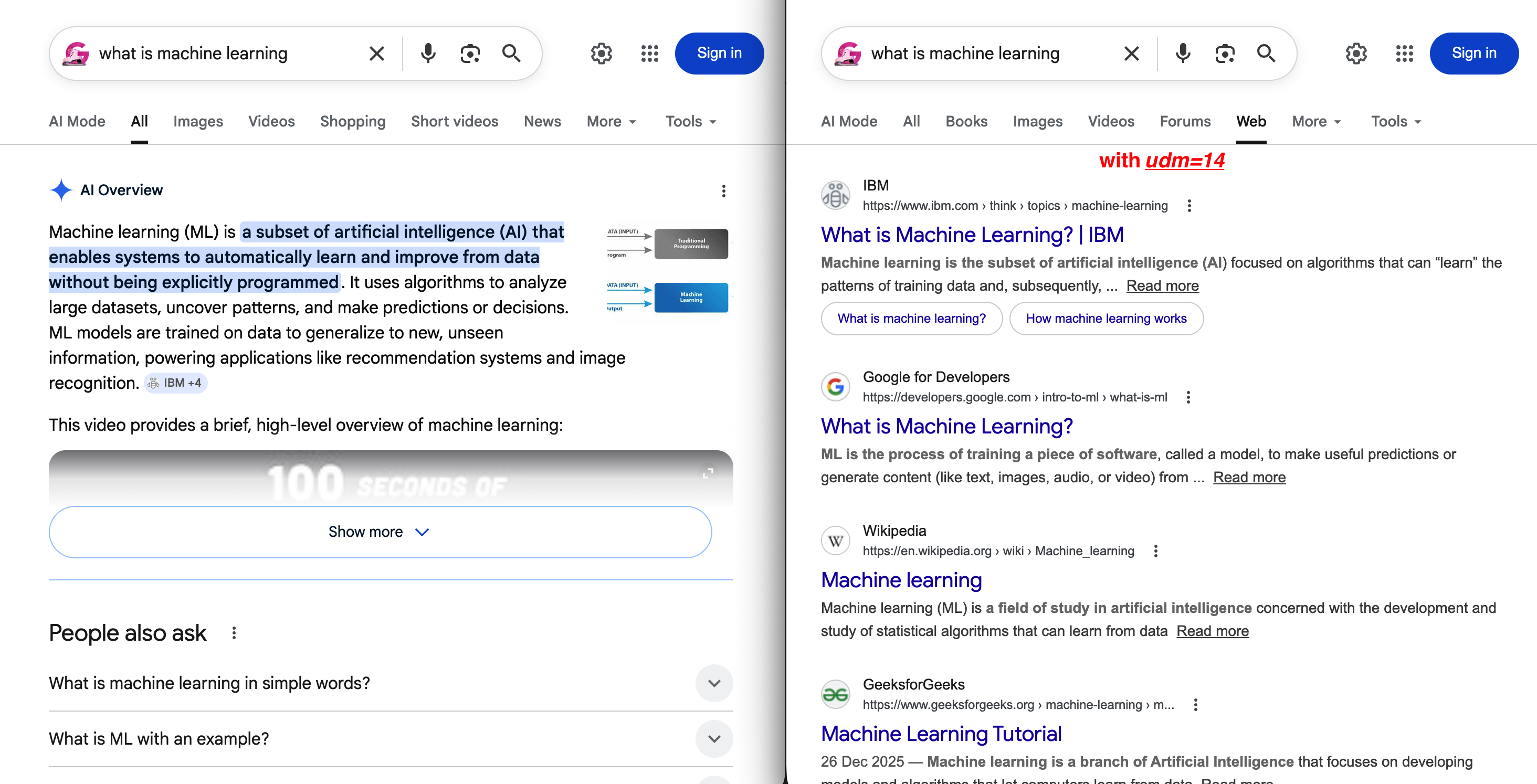
À gauche : le SERP par défaut avec un aperçu IA qui repousse les résultats organiques sous le pli. À droite : udm=14 supprime tout cela et affiche un onglet « Web » propre avec des liens bleus traditionnels.
Pour les résultats vidéo courts, utilisez udm=39 (non documenté par Google ; le comportement peut varier selon les régions) :
https://www.google.com/search?q=coffee+recipes&udm=39Le mode IA (udm=50) est un type de recherche très différent :
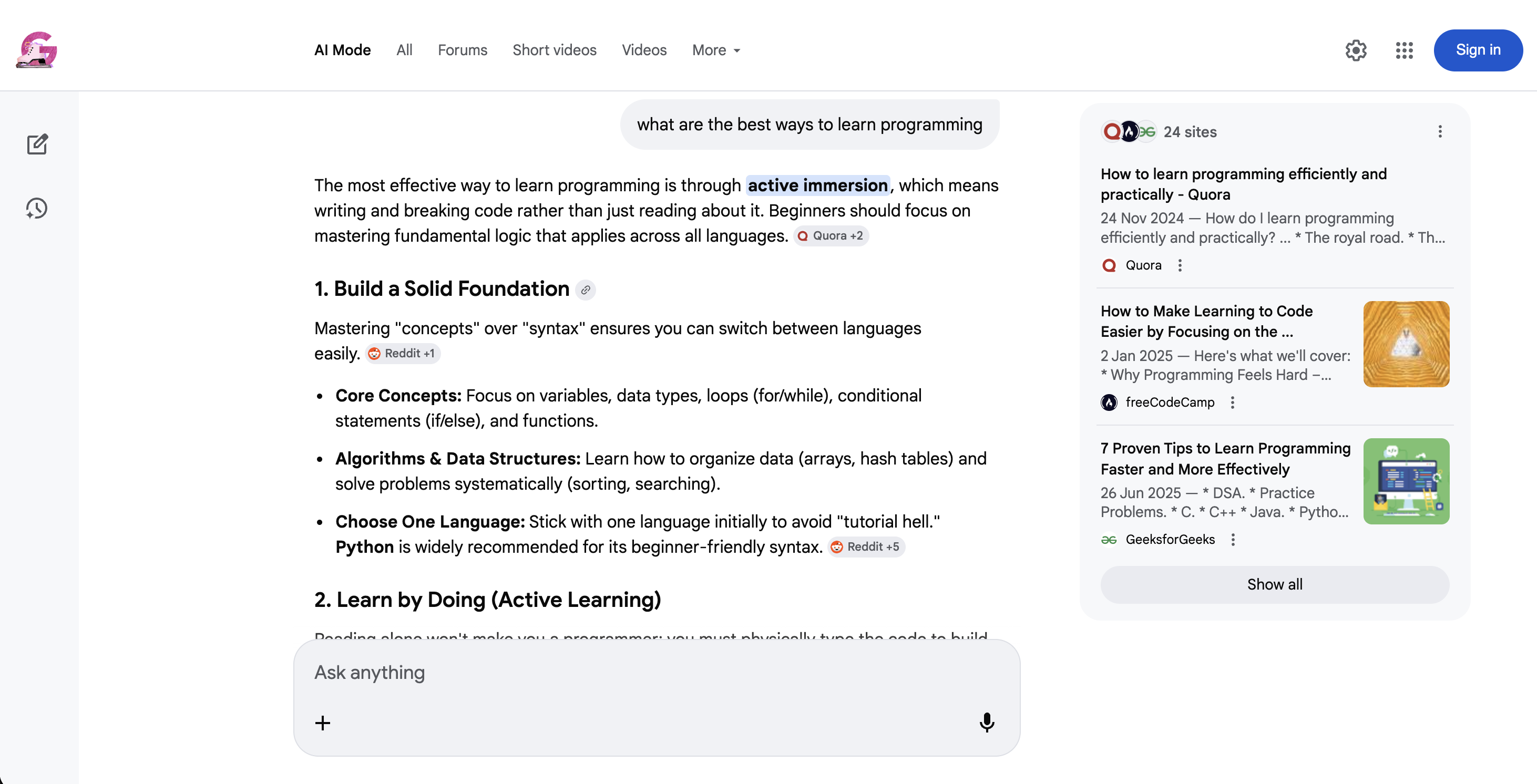
Mode IA Google (udm=50) : au lieu des résultats traditionnels, Google renvoie une réponse IA conversationnelle avec des citations de sources en ligne et des questions complémentaires suggérées.
tbm et udm se recoupent pour les images, les actualités et les achats, mais udm couvre également des modes que tbm ne couvre pas (forums, vidéos courtes, mode IA, web uniquement). Les deux fonctionnent aujourd’hui. Si vous créez de nouveaux flux de travail de scraping, prenez en charge les deux paramètres pour une compatibilité maximale.
Paramètres de filtrage et de tri
tbs – filtres temporels et avancés
Le paramètre tbs (généralement interprété comme « à rechercher », bien qu’aucune source officielle ne le confirme) contrôle le filtrage temporel, le tri par date et la correspondance mot à mot.
L’utilisation la plus courante est le filtrage temporel avec qdr (query date range, plage de dates de requête) :
| Valeur | Plage horaire |
|---|---|
tbs=qdr:h |
Dernière heure |
tbs=qdr:d |
24 dernières heures |
tbs=qdr:w |
Semaine écoulée |
tbs=qdr:m |
Mois écoulé |
tbs=qdr:y |
Année écoulée |
Vous pouvez également définir une plage de dates personnalisée avec tbs=cdr:1,cd_min:01/01/2025,cd_max:12/31/2025. Cela est utile pour suivre l’évolution des résultats de recherche sur une période donnée.
Au-delà du filtrage temporel, tbs dispose de deux autres modes utiles. tbs=sbd:1 force Google à trier les résultats par date (les plus récents en premier) plutôt que par pertinence, ce qui est utile pour surveiller les mentions récentes. Et tbs=li:1 active la recherche littérale. Google recherche exactement ce que vous avez tapé, sans corrections automatiques, synonymes ou termes associés.
Pour surveiller les actualités récentes sur un sujet :
curl --proxy brd.superproxy.io:33335
--proxy-user brd-customer-<CUSTOMER_ID>-Zone-<ZONE_NAME>:<PASSWORD> -k
"https://www.google.com/search?q=Scraping web regulations&tbs=qdr:w&brd_json=1"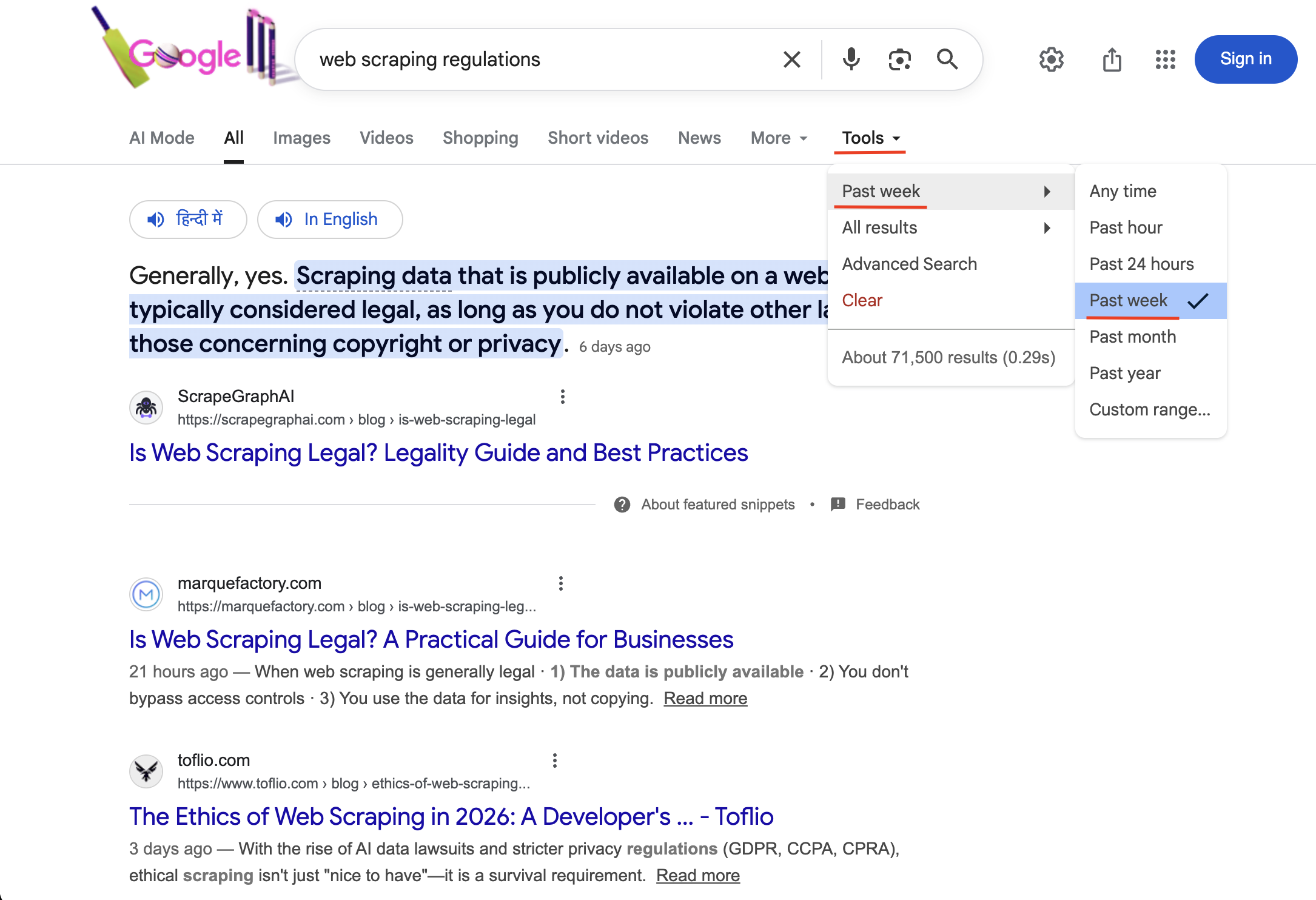
La recherche avec tbs=qdr:w active le filtre temporel « Semaine passée » (visible sous Outils avec une coche). Seuls les résultats publiés au cours des 7 derniers jours sont renvoyés.
Astuce : associez filter=0 à n’importe quel filtre temporel tbs pour obtenir tous les résultats. Sans cela, Google regroupe les pages similaires et vous risquez de passer à côté d’informations pertinentes.
safe – Filtrage SafeSearch
safe=active filtre le contenu explicite, safe=off désactive le filtrage.
https://www.google.com/search?q=photography&safe=active
https://www.google.com/search?q=photography&safe=offfilter – filtrage des doublons
Le paramètre filter contrôle la manière dont Google regroupe les résultats similaires ou en double.
https://www.google.com/search?q=Scraping web&filter=0
https://www.google.com/search?q=Scraping web&filter=1filter=0 affiche tous les résultats, y compris les doublons. filter=1 (valeur par défaut) regroupe les pages similaires. Particulièrement utile lorsqu’il est combiné avec des filtres temporels (voir l’astuce tbs ci-dessus).
nfpr – pas de correction automatique
Définissez nfpr=1 pour empêcher Google de corriger automatiquement votre requête.
https://www.google.com/search?q=scraping+brwser&nfpr=1Lorsque cette option est définie sur 1, Google recherche exactement ce que vous avez saisi sans suggérer « vouliez-vous dire : Navigateur de scraping ». Utile lorsque vous recherchez intentionnellement des termes mal orthographiés, des noms de marque que Google considère comme des fautes d’orthographe ou des termes techniques que Google pourrait essayer de corriger. Remarque : nfpr=1 supprime uniquement la correction automatique. tbs=li:1 (mode verbatim) va plus loin en désactivant également les synonymes, les racines et les termes associés. Utilisez les deux ensemble pour obtenir la correspondance la plus stricte.
pws – recherche web personnalisée
Google personnalise les résultats de recherche par défaut. pws contrôle si cette personnalisation est active.
https://www.google.com/search?q=Scraping web tools&pws=0Il est important de désactiver la personnalisation (pws=0) car les résultats personnalisés varient selon les utilisateurs, ce qui rend les données en vrac incohérentes. Pour toute collecte sérieuse de données SERP, incluez toujours pws=0 afin d’obtenir les classements de base, non personnalisés.
Paramètres de localisation
La plupart des suivis de classement ne nécessitent qu’un ciblage au niveau national avec gl. Cependant, pour le référencement local, vous avez besoin d’un ciblage plus précis.
uule – emplacement codé
uule vous offre une précision au niveau de la ville lorsque gl n’est pas assez granulaire.
La valeur uule est une chaîne codée basée sur les cibles géographiques de l’API Google Ads. Elle utilise soit un codage de nom canonique (provenant de la base de données de géolocalisation de Google), soit un codage de coordonnées GPS (latitude/longitude).
https://www.google.com/search?q=best+restaurants&uule=w+CAIQICIGUGFyaXMLa génération manuelle de valeurs uule est compliquée. Vous devez rechercher le nom canonique du lieu dans la documentation Geo Targets de Google, puis l’encoder dans le format spécifique attendu par Google.
Avec l’API SERP de Bright Data, vous pouvez ignorer complètement l’encodage et simplement transmettre le nom du lieu sous forme de chaîne lisible :
https://www.google.com/search?q=best+restaurants&uule=New+York,New+York,United+StatesL’API gère automatiquement la recherche et l’encodage.
Utilisez gl pour le ciblage au niveau national et uule lorsque vous avez besoin d’une précision au niveau de la ville. Pour la plupart des suivis de classement, gl suffit. Réservez uule pour les audits SEO locaux où les résultats diffèrent entre les villes d’un même pays.
Paramètres de l’appareil et du client
Google renvoie des résultats différents pour les mobiles et les ordinateurs de bureau. Ces paramètres contrôlent l’émulation des appareils et l’identification des navigateurs.
sclient – client de recherche
Vous verrez sclient dans presque toutes les URL de recherche Google. Il identifie le client de recherche qui a lancé la recherche. Valeurs courantes : gws-wiz (recherche web), gws-wiz-serp (lancée par SERP), img (recherche d’images), psy-ab (associée à la recherche instantanée/prédictive de Google). Il est utilisé pour les analyses internes de Google et n’affecte pas vos résultats.
brd_mobile / brd_browser – émulation d’appareil et de navigateur
L’API SERP propose brd_mobile pour simuler des recherches à partir d’appareils spécifiques :
| Valeur | Appareil | Type d’agent utilisateur |
|---|---|---|
0 ou omettre |
Ordinateur | Ordinateur |
1 |
Mobile | Mobile |
iOS ou iPhone |
iPhone | iOS |
iPad ou tablette iOS |
iPad | Tablette iOS |
Android |
Android | Android |
Tablette Android |
Tablette Android | Tablette Android |
curl --proxy brd.superproxy.io:33335
--proxy-user brd-customer-<CUSTOMER_ID>-zone-<ZONE_NAME>:<PASSWORD> -k
"https://www.google.com/search?q=best+apps&brd_mobile=ios&brd_json=1"Si vous rencontrez des erreurs
expect_bodylorsque vous utilisezbrd_mobileavec la méthode Proxy, essayez plutôt la méthode Direct API. Elle est généralement plus fiable pour l’émulation d’appareils. L’intégration LangChain fonctionne également bien ici, car elle transmet automatiquementdevice_typevia Direct API.
Vous pouvez également contrôler le type de navigateur avec brd_browser:
brd_browser=chrome(Google Chrome)brd_browser=safari(Safari)brd_browser=firefox(Mozilla Firefox, non compatible avecbrd_mobile=1)
Si aucun paramètre n’est spécifié, l’API choisit un navigateur au hasard. Combinez les deux paramètres pour définir la combinaison exacte appareil + navigateur :
curl --proxy brd.superproxy.io:33335
--proxy-user brd-customer-<CUSTOMER_ID>-Zone-<ZONE_NAME>:<PASSWORD> -k
"https://www.google.com/search?q=best+smartphones&brd_browser=safari&brd_mobile=ios&brd_json=1"Paramètres avancés et internes
Vous n’avez pas besoin de les définir. Il s’agit de paramètres internes à Google. Cependant, si vous souhaitez savoir ce que signifient ei, ved et sxsrf lorsque vous les voyez dans une URL Google, cette section vous les explique.
kgmid – Identifiant machine du Knowledge Graph
Le paramètre kgmid fournit des résultats provenant du Knowledge Graph de Google et peut remplacer entièrement le paramètre q.
https://www.google.com/search?kgmid=/m/07gyp7Cela charge directement le panneau Knowledge Graph pour McDonald’s. Chaque entité possède un identifiant machine unique, et le transmettre via kgmid permet de récupérer le panneau de cette entité.
Le panneau renvoyé par Google pour cet identifiant :
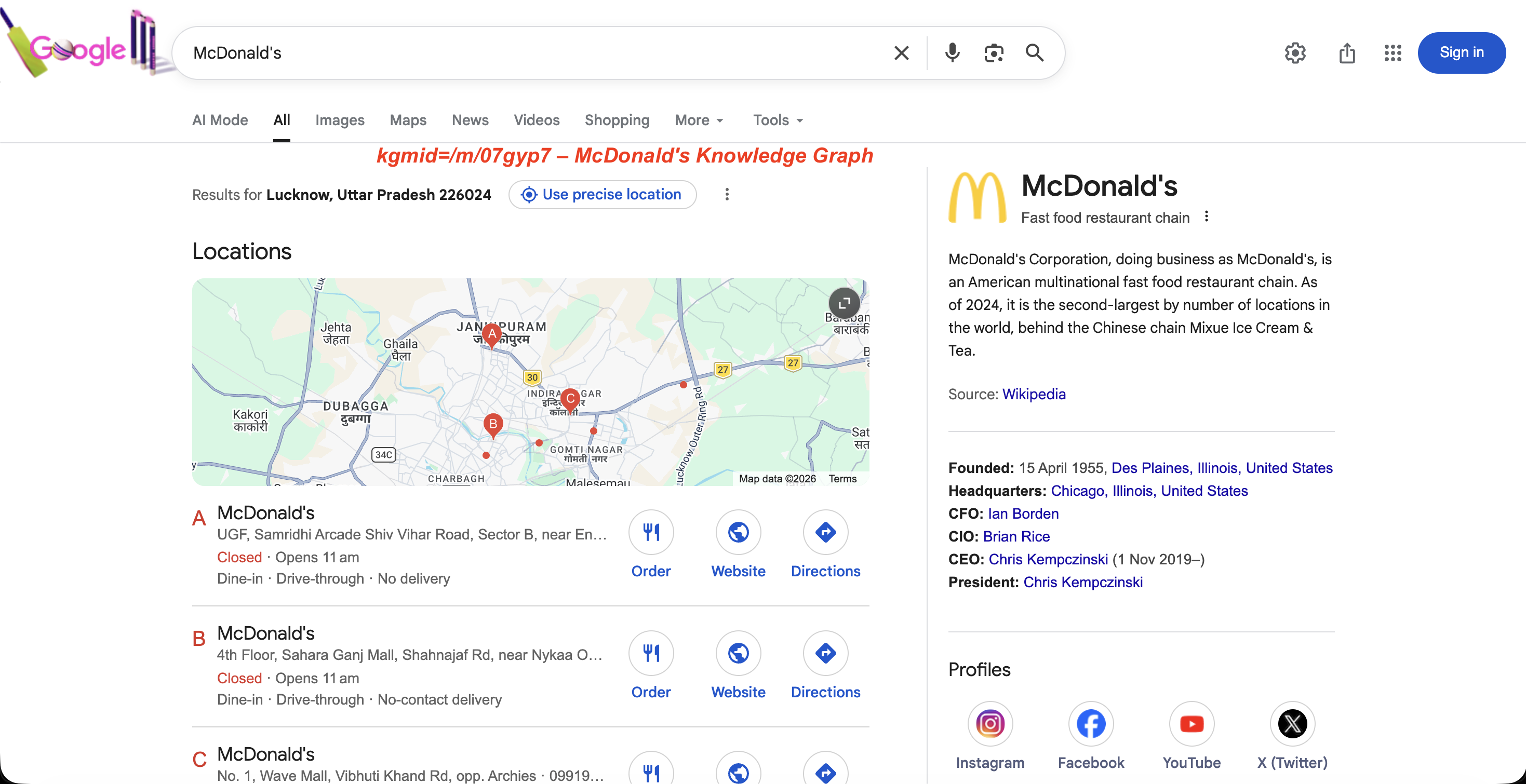
Le panneau Knowledge Graph pour kgmid=/m/07gyp7: description de l’entité, date de création, direction et profils sociaux.
Les équipes de surveillance des marques utilisent cet outil pour suivre l’évolution du panneau Knowledge Graph de Google au fil du temps pour leur entreprise ou leurs concurrents.
ibp – contrôle du rendu
Google n’utilise pas ibp pour les résultats de recherche classiques. Il contrôle la manière dont certains éléments s’affichent sur la SERP, en particulier les fiches Google Business et Google Jobs.
https://www.google.com/search?ibp=gwp%3B0,7&ludocid=1663467585083384531Lorsqu’il est utilisé avec le paramètre ludocid (qui est l’identifiant unique d’une fiche Google Business), ibp peut déclencher l’affichage en pleine page de la fiche d’entreprise.
Pour les recherches d’emploi, ibp=htl;jobs (encodé en URL sous la forme ibp=htl%3Bjobs) déclenche l’affichage du panneau Google Jobs avec la liste complète des offres d’emploi :
curl --proxy brd.superproxy.io:33335
--Proxy-user brd-customer-<CUSTOMER_ID>-zone-<ZONE_NAME>:<PASSWORD> -k
"https://www.google.com/search?q=technical+copywriter&ibp=htl%3Bjobs&brd_json=1"Le panneau Emplois déclenché par ibp=htl%3Bjobs:
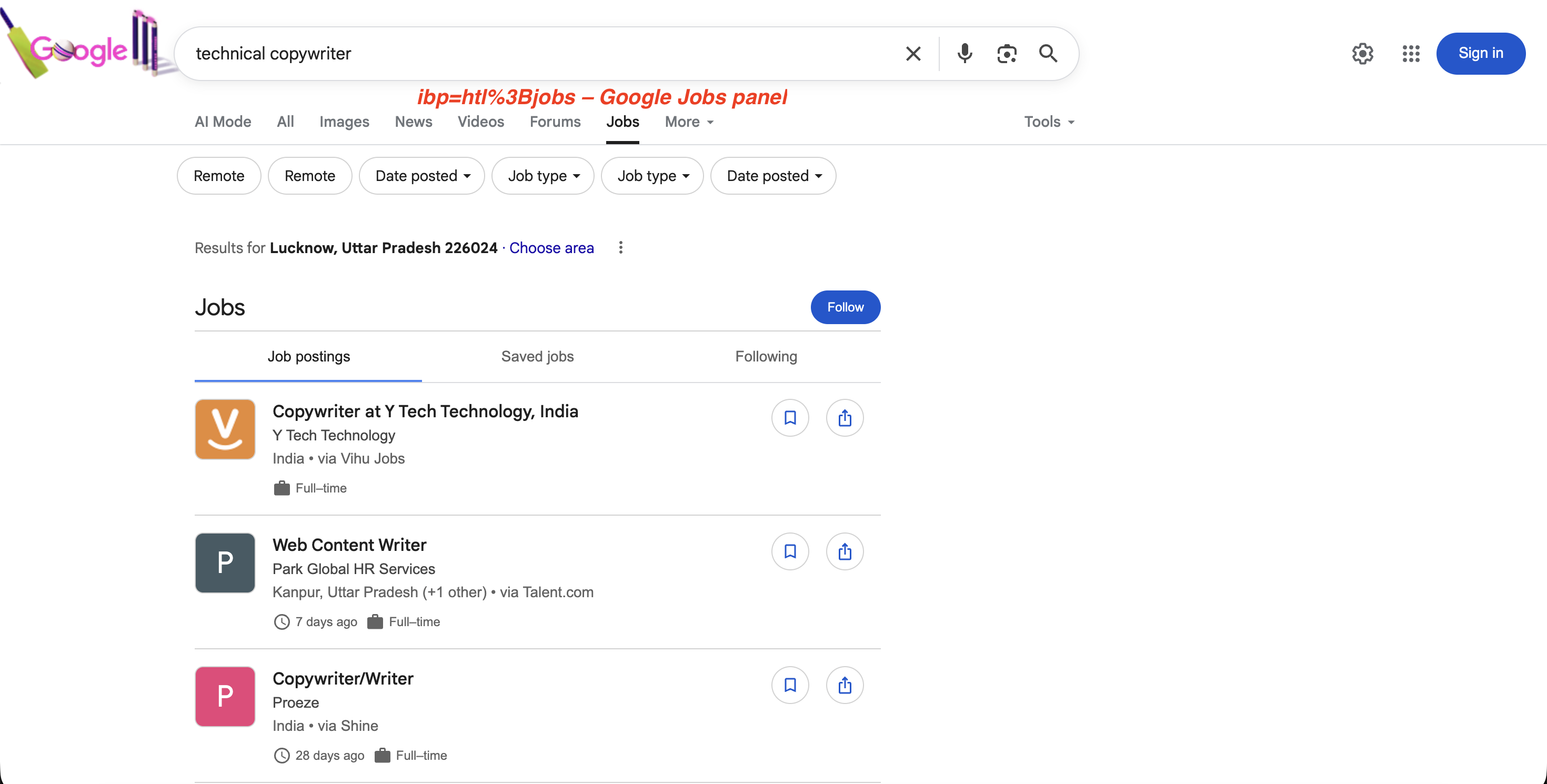
Le paramètre ibp=htl%3Bjobs déclenche le panneau Emplois dédié de Google avec des offres d’emploi, des filtres et une option « Suivre », tous extractibles via l’API SERP.
Le point-virgule dans
htl;jobsdoit être encodé en URL sous la forme%3B(c’est-à-direibp=htl%3Bjobs) lorsqu’il est utilisé dans curl ou tout autre client HTTP. Sans encodage approprié, la requête peut renvoyer des résultats vides.
ei, ved, sxsrf, oq, gs_lp – paramètres de suivi internes
Aucun de ces paramètres n’affecte les résultats renvoyés. Vous pouvez les supprimer de vos URL en toute sécurité. Voici ce que chacun d’entre eux fait :
| Paramètre | Objectif |
|---|---|
ei |
Identifiant de session contenant un horodatage Unix et des valeurs opaques |
ved |
Suivi des clics : encode l’élément SERP sur lequel l’utilisateur a cliqué, son index et son type |
sxsrf |
Jeton CSRF avec un horodatage Unix encodé |
oq |
Requête originale telle qu’elle a été saisie avant que la saisie semi-automatique ne la modifie (par exemple, oq=web+scrap lorsque q=web+Scraping web+API) |
gs_lp |
Données de session internes liées à l’état du client de recherche |
ie / oe |
Codage des caractères d’entrée/sortie (presque toujours UTF-8; peut être ignoré sans risque) |
client |
Type de client de recherche (par exemple, firefox-b-d, safari) ; identifie le navigateur ou l’application |
source |
Identifiant de la source de recherche (par exemple, hp pour la page d’accueil, lnms pour le commutateur de mode) |
biw / bih |
Largeur/hauteur interne du navigateur en pixels ; peut influencer la variante de mise en page SERP proposée par Google |
Opérateurs de recherche Google
Les opérateurs de recherche sont des commandes spéciales dans le paramètre q qui filtrent les résultats par domaine, type de fichier, titre, URL ou expression exacte. Google en documente certains dans sa page d’aide sur l’affinement de la recherche.
Ils se distinguent des paramètres d’URL : les opérateurs sont intégrés à la valeur q, tandis que les paramètres sont des paires clé-valeur distinctes dans l’URL. Voici les plus utiles pour le scraping et la collecte de données :
| Opérateur | Fonction | Exemple |
|---|---|---|
site: |
Limiter à un domaine spécifique | site:github.com python Scraper |
filetype: |
Limiter au type de fichier | filetype:pdf guide de Scraping web |
intitle: |
Rechercher dans les titres des pages | intitle:API SERP comparison |
inurl: |
Rechercher dans les URL | inurl:documentation API |
intext: |
Recherche dans le corps de la page | intext:rotation des proxys |
allintitle: |
Tous les mots dans le titre | allintitle:Scraping web python |
allinurl: |
Tous les mots dans l’URL | allinurl:API docs scraping |
related: |
Trouver des sites similaires | related:brightdata.com |
OU |
Correspondre à l’un ou l’autre terme | Scraping web OU web crawling |
« expression exacte » |
Correspondance exacte | « API SERP pour python » |
- |
Exclure le terme | Scraping web -selenium |
avant : / après : |
Période | Aperçu de l'IA après : 2025-01-01 |
AROUND(n) |
Recherche de proximité | scraping AROUND(3) python |
définir : |
Définition du dictionnaire | définir : Scraping web |
* |
Caractère générique | « meilleur * pour le Scraping web » |
Toutes ces options fonctionnent également dans les requêtes API. Par exemple :
curl --proxy brd.superproxy.io:33335
--proxy-user brd-customer-<CUSTOMER_ID>-zone-<ZONE_NAME>:<PASSWORD> -k
« https://www.google.com/search?q=site:reddit.com+Scraping web+tools+2026&brd_json=1 »Recherche spécifiquement sur Reddit les discussions concernant les outils de Scraping web en 2026, avec une sortie JSON structurée.
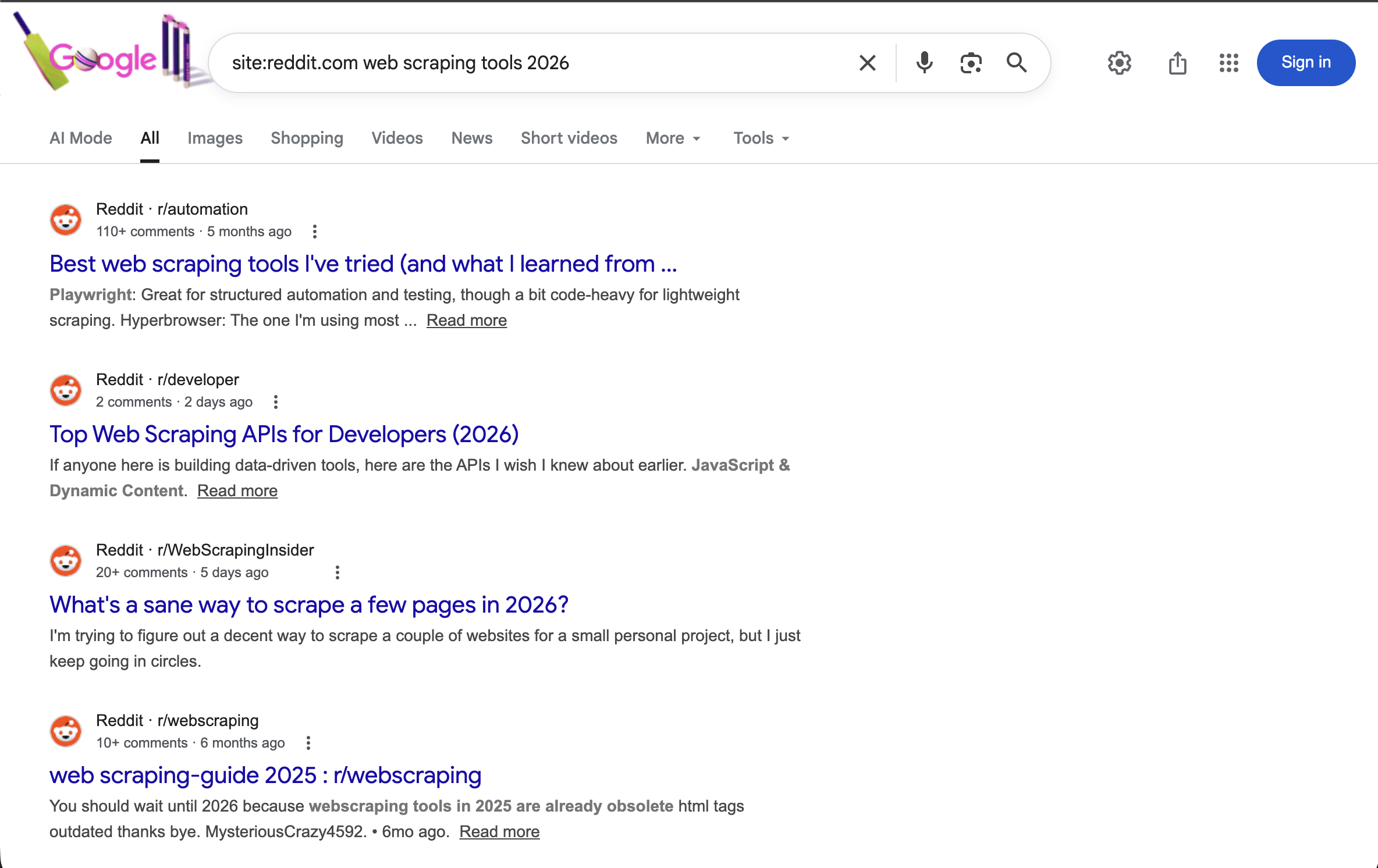
L’opérateur site:reddit.com limite tous les résultats à Reddit. Associé à un terme annuel, il affiche les discussions récentes de la communauté sur les outils de Scraping web.
Les opérateurs peuvent être combinés :
site:github.com filetype:pdf machine learningrenvoie uniquement les fichiers PDF hébergés sur GitHub qui correspondent à « machine learning ».
as_* – paramètres de recherche avancée
Le formulaire de recherche avancée de Google génère des paramètres préfixés par as_ (as_q, as_epq, as_sitesearch, as_filetype, etc.) qui correspondent aux opérateurs ci-dessus. La plupart des ingénieurs utilisent plutôt les opérateurs directement dans q. Ceux-ci sont principalement utiles si vous créez une interface utilisateur de formulaire de recherche et que vous souhaitez mapper les champs du formulaire aux paramètres URL sans concaténer les chaînes d’opérateurs.
Changements à connaître pour 2025-2026
Google a apporté trois changements en 2025-2026 qui ont perturbé les configurations de scraping existantes : rendu JavaScript obligatoire (janvier 2025), suppression du paramètre num (septembre 2025) et extension des aperçus IA à plus de 200 pays.
Google exige désormais le rendu JavaScript
À partir de janvier 2025, Google ne fournira plus de résultats de recherche sans rendu JavaScript. Si vous utilisez un Scraper requests + BeautifulSoup, ce changement en est la raison. Chaque requête requests.get('https://google.com/search?q=...') renvoie désormais une réponse vide ou dégradée. Vous avez besoin d’un rendu complet du navigateur ou d’une API SERP qui s’en charge pour vous.
Le rendu JavaScript est automatique avec l’API SERP, vos appels API restent donc inchangés.
Le paramètre num ne fonctionne plus
Entre le 12 et le 14 septembre 2025, Google a discrètement désactivé num. L’impact a été considérable : selon une étude portant sur 319 propriétés, 87,7 % des sites suivis ont vu leurs impressions baisser dans Google Search Console.
Pour récupérer plus de 10 résultats, l’API SERP de Bright Data dispose d’un point de terminaison Top 100 Results qui renvoie les positions 1 à 100 en une seule requête. Elle utilise une surface API différente (/datasets/v3/trigger avec l’ID de l’ensemble de données gd_mfz5x93lmsjjjylob) et vous fournit les paramètres start_page et end_page pour contrôler la profondeur de pagination :
curl -X POST "https://api.brightdata.com/Jeux de données/v3/trigger?dataset_id=gd_mfz5x93lmsjjjylob&include_errors=true"
-H "Authorization: Bearer <API_TOKEN>"
-H "Content-Type: application/json"
-d '[{
"url": "https://www.google.com/",
« keyword » : « Scraping web tools »,
« language » : « en »,
« country » : « US »,
« start_page » : 1,
« end_page » : 10
}]'Plages de pages : 1..2 = top 20, 1..5 = top 50, 1..10 = top 100 (10 résultats par page). La réponse inclut le texte IA Overview (dans le champ aio_text ) lorsque Google en affiche un, et vous pouvez ajouter « include_paginated_html » : true pour capturer le HTML brut en plus des données analysées. Le traitement par lots est également pris en charge. Transmettez un tableau d’objets de requête pour rechercher plusieurs mots-clés dans une seule requête.
Aperçus IA dans les résultats de recherche
Les aperçus IA de Google (les résumés générés par l’IA en haut des résultats de recherche) sont désormais disponibles dans plus de 200 pays et 40 langues. En janvier 2026, Google a mis à niveau les aperçus IA vers Gemini 3. Google a également ajouté des transitions entre les aperçus IA et les conversations en mode IA (udm=50). La capture de ce contenu nécessite un rendu JavaScript et une logique d’extraction spécifique. Un aperçu IA sur une SERP en direct :
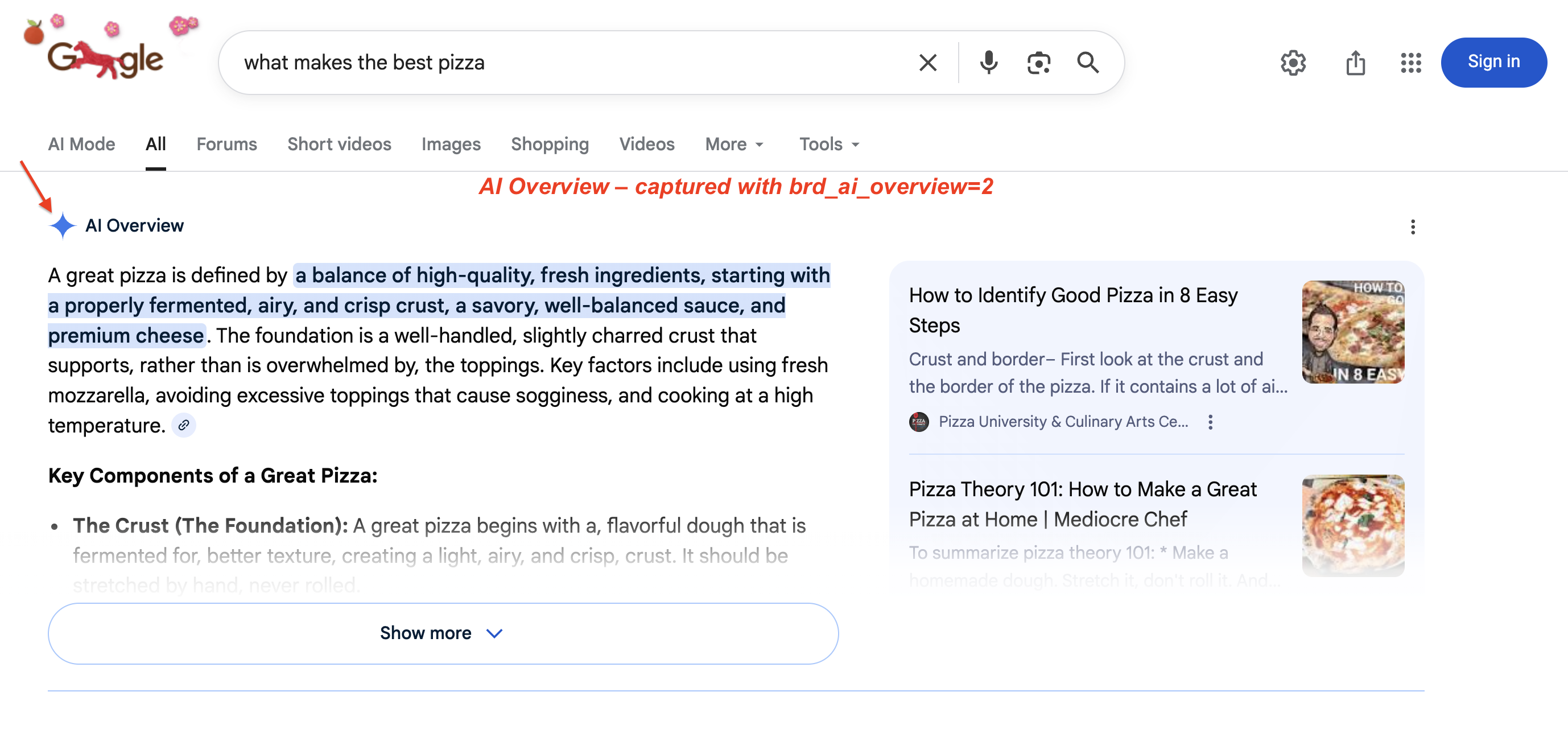
Un aperçu IA typique : Google génère un résumé de plusieurs paragraphes avec des phrases clés mises en évidence et des cartes sources à droite. Ce bloc repousse les résultats organiques sous le pli. Utilisez brd_ai_overview=2 pour le capturer via l’API SERP.
Le Scraper AI Overview fonctionne grâce au paramètre brd_ai_overview. Définissez brd_ai_overview=2 pour augmenter la probabilité de recevoir des aperçus générés par l’IA dans vos résultats :
curl --proxy brd.superproxy.io:33335
--proxy-user brd-customer-<CUSTOMER_ID>-zone-<ZONE_NAME>:<PASSWORD> -k
"https://www.google.com/search?q=what+makes+the+best+pizza&brd_ai_overview=2&brd_json=1"Lors de nos tests (requêtes aux États-Unis), l’activation de la capture IA Overview a ajouté 5 à 10 secondes au temps de réponse. Ce temps d’attente supplémentaire est dû au rendu du contenu IA chargé dynamiquement par Google dans un navigateur sans interface graphique.
Comment utiliser les paramètres de recherche Google avec une API SERP
Si vous effectuez un scraping à un volume réel, vous serez confronté à des CAPTCHA, des blocages d’IP, un rendu JavaScript obligatoire et des modifications de l’infrastructure Google qui perturbent silencieusement les analyseurs syntaxiques. Nous avons testé toutes les méthodes ci-dessous avec l’API en direct afin de confirmer qu’elles fonctionnent comme indiqué.
Quatre façons d’utiliser ces paramètres avec l’API SERP de Bright Data, de la plus simple à la plus avancée. Si vous êtes simplement en phase d’exploration, commencez par la méthode 1 (API directe). Si vous intégrez une base de code existante avec des en-têtes personnalisés, optez pour la méthode 2 (Proxy). Pour les workflows d’agents IA, passez à la méthode 4 (LangChain). Le guide de démarrage vous accompagne tout au long de la configuration.
| Méthode | Idéale pour | Réponse | Complexité |
|---|---|---|---|
| API directe | Pour commencer, requêtes uniques | Synchrone | Faible |
| Routage Proxy | Workflows HTTP existants, en-têtes de requête personnalisés | Synchrone | Faible |
| Asynchrone par lots | Volume élevé (plus de 1 000 requêtes), balayages de pagination | En file d’attente | Moyen |
| LangChain | Agents IA, pipelines RAG, workflows multi-outils | Synchrone | Faible |
Méthode 1 : requête API directe
La méthode la plus simple. Effectuez une requête POST avec votre URL de recherche et récupérez des données structurées :
import requests
import json
from urllib.parse import urlencode
# Créez l'URL de recherche Google avec un encodage approprié (prend en charge les caractères non latins et les caractères spéciaux)
params = urlencode({"q": "API de scraping web", "gl": "us", "hl": "en", "brd_json": "1"})
search_url = f"https://www.google.com/search?{params}"
url = "https://api.brightdata.com/request"
headers = {
"Content-Type": "application/json",
"Authorization": "Bearer <API_TOKEN>"
}
payload = {
"Zone": "<ZONE_NAME>",
"url": search_url,
"format": "raw"
}
response = requests.post(url, headers=headers, json=payload, timeout=30)
response.raise_for_status()
data = response.json()
# Valider la réponse avant traitement
if "organic" not in data or len(data.get("organic", [])) == 0:
print("Avertissement : aucun résultat organique renvoyé (blocage temporaire ou SERP vide possible)")
print(json.dumps(data, indent=2))Le nom de zone par défaut est généralement « serp ». La réponse analysée se présente comme suit :
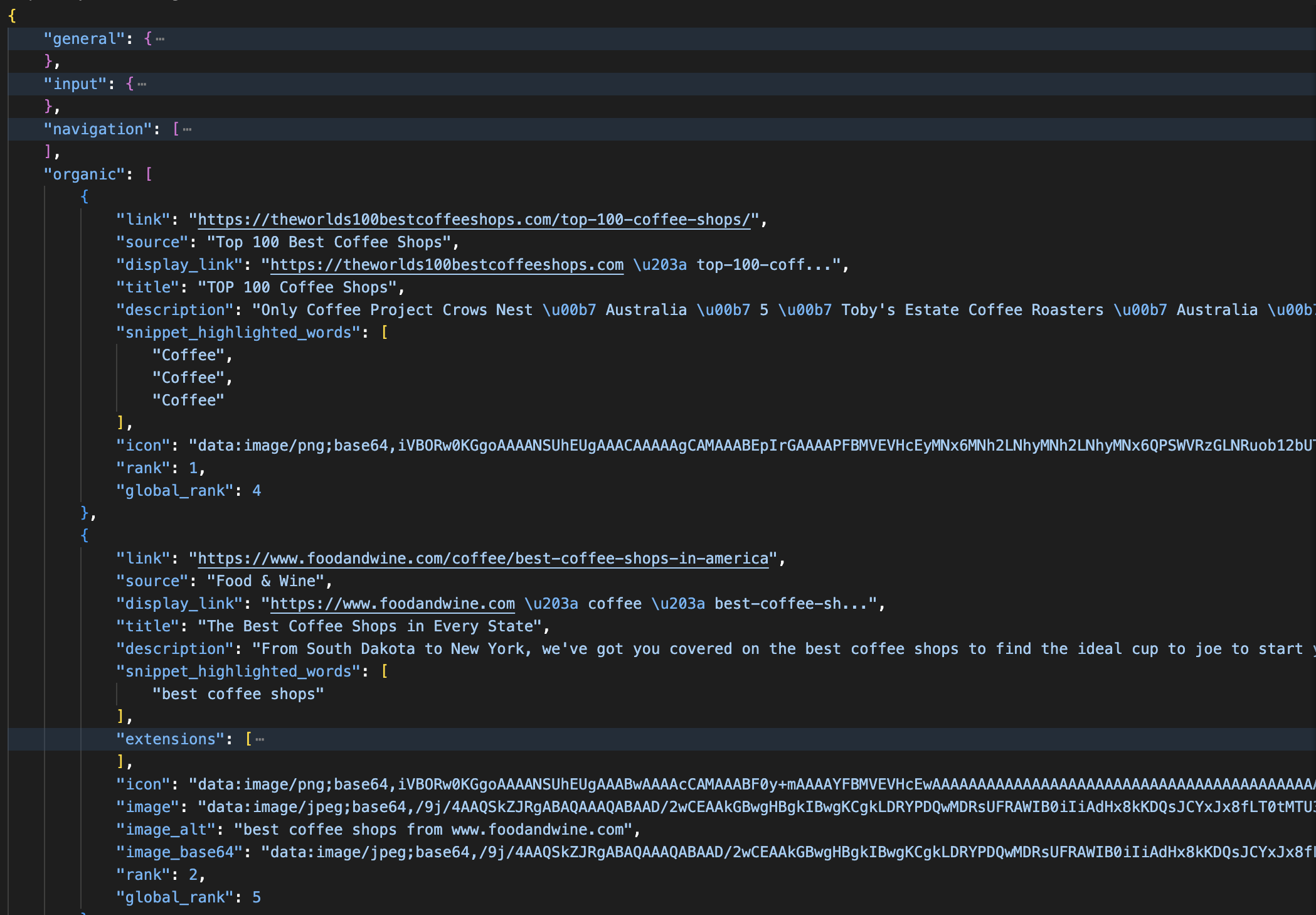
Réponse JSON analysée provenant de l’API SERP : chaque résultat organique comprend les champs title, link, description, rank et global_rank. La réponse sépare également les publicités, les panneaux de connaissances et les aperçus IA en sections nommées.
L’API Direct accepte également un champ « data_format » (distinct de « format ») : « markdown » pour les pipelines LLM/RAG (Retrieval-Augmented Generation), « screenshot » pour une capture PNG ou « parsed_light » pour les 10 premiers résultats organiques uniquement. Utilisez brd_json=html dans l’URL si vous souhaitez conserver le HTML brut dans le JSON.
countrydans le corps n’est pas identique àgldans l’URL.« country » : « us »contrôle le nœud de sortie du Proxy (l’emplacement IP de la requête).gl=usindique à Google les résultats du pays à afficher. Pour obtenir des résultats géolocalisés précis, définissez les deux.
Méthode 2 : routage Proxy
Acheminez vos requêtes via l’infrastructure Proxy de Bright Data. Le Proxy gère le rendu JavaScript de son côté, donc même si votre code effectue une requête HTTP standard, il renvoie des résultats entièrement rendus. Cela fonctionne avec n’importe quel client HTTP et vous permet de définir des en-têtes personnalisés, des cookies et des options au niveau de la requête que l’API Direct n’expose pas. Avec l’approche Proxy, vous contrôlez le format de sortie via les paramètres URL : ajoutez brd_json=1 pour obtenir un JSON analysé au lieu d’un HTML brut :
import requests
# Utilisez une session pour le pool de connexions (réutilise les connexions TCP entre les requêtes)
session = requests.Session()
session.proxies = {
"http": "http://brd-customer-<CUSTOMER_ID>-zone-<ZONE_NAME>:<PASSWORD>@brd.superproxy.io:33335",
"https": "http://brd-customer-<CUSTOMER_ID>-zone-<ZONE_NAME>:<PASSWORD>@brd.superproxy.io:33335"
}
session.verify = False # pour les tests ; charger le certificat TLS/SSL de Bright Data en production
url = "https://www.google.com/search?q=API SERP comparison&gl=us&hl=en&tbs=qdr:m&brd_json=1"
response = session.get(url, timeout=30)
response.raise_for_status()
print(response.json())Les informations d’identification se trouvent dans l’onglet « Détails d’accès » de la Zone API SERP de votre tableau de bord. Vérifiez toujours la réponse avant de la traiter. Un blocage temporaire de Google peut renvoyer un JSON valide avec des ensembles de résultats vides ou réduits. Si general.results_cnt affiche des millions de résultats estimés, mais que le tableau organique est vide ou ne contient que 1 ou 2 entrées, cela indique généralement un blocage temporaire plutôt qu’un SERP véritablement vide.
Le drapeau
verify=False(ou-kdans curl) ignore la vérification TLS/SSL, ce qui convient pour les tests. Pour la production, chargez plutôt le certificat SSL de Bright Data.
Méthode 3 : traitement asynchrone par lots
Pour les opérations à volume élevé (plus de 1 000 requêtes), utilisez le mode asynchrone. Le mode asynchrone est utile lorsque vous paginez des centaines de combinaisons de mots-clés et d’emplacements à l’aide des paramètres start, gl et hl (par exemple, pour suivre 500 mots-clés dans 10 pays). Vous n’êtes facturé que lorsque vous envoyez la requête ; la collecte de la réponse est gratuite. Les délais de rappel varient en fonction du volume et de la charge maximale.
Commencez par activer l’option « Requêtes asynchrones » dans les paramètres avancés de votre zone. Utilisez ensuite le point de terminaison /unblocker/req:
import requests
import json
import time
url = "https://api.brightdata.com/unblocker/req"
params = {"customer": "<CUSTOMER_ID>", "Zone": "<ZONE_NAME>"}
headers = {
"Content-Type": "application/json",
"Authorization": "Bearer <API_TOKEN>"
}
payload = {
"url": "https://www.google.com/search?q=Scraping web tools&gl=us&hl=en&brd_json=1",
"country": "us"
}
response = requests.post(url, params=params, headers=headers, json=payload, timeout=30)
response.raise_for_status()
response_id = response.headers.get("x-response-id")
print(f"En attente. ID de réponse : {response_id}")
# Interrogation des résultats (pour la production, configurez plutôt une URL webhook dans les paramètres de votre zone)
# Fenêtre d'interrogation totale : 30 tentatives × 10 s = 300 s. Augmentez range() pour les lots volumineux.
for attempt in range(30):
time.sleep(10) # attendez avant de vérifier - les résultats ne sont jamais prêts immédiatement
result = requests.get(
"https://api.brightdata.com/unblocker/get_result",
params={"customer": "<CUSTOMER_ID>", "zone": "<ZONE_NAME>", "response_id": response_id},
headers={"Authorization": "Bearer <API_TOKEN>"},
timeout=30
)
if result.status_code == 200:
data = result.json()
if "organic" in data and len(data["organic"]) > 0:
print(json.dumps(data, indent=2))
else:
print("Avertissement : réponse renvoyée mais ne contenant aucun résultat organique")
break
elif result.status_code == 202:
continue # résultats non encore prêts
else:
print(f"Délai d'attente expiré après 300 secondes pour response_id={response_id}")Au lieu d’effectuer un sondage, vous pouvez configurer une URL webhook (soit par défaut dans les paramètres de votre zone, soit pour chaque requête à l’aide du paramètre webhook_url ). Bright Data envoie une notification à votre point de terminaison lorsque les résultats sont prêts (avec le response_id et le statut), vous n’avez donc pas besoin de sonder manuellement le point de terminaison /get_result. Les réponses sont conservées pendant 48 heures maximum.
Même avec une API gérée, respectez les limites de débit de votre zone. La configuration par défaut gère un débit élevé, mais l’envoi simultané de milliers de requêtes de synchronisation sans régulation peut déclencher des réponses HTTP 429. Le mode asynchrone évite cela, car l’API met en file d’attente et régule les requêtes en interne.
Méthode 4 : intégration LangChain pour les workflows d’IA
Si vous développez des agents IA qui ont besoin de données de recherche en temps réel, il existe une intégration LangChain officielle (langchain-brightdata) qui vous permet d’utiliser la recherche en temps réel comme outil dans les workflows des agents :
pip install langchain-brightdatafrom langchain_brightdata import BrightDataSERP
serp_tool = BrightDataSERP(
bright_data_api_key="<API_TOKEN>",
zone="<ZONE_NAME>", # doit correspondre au nom de la zone dans votre tableau de bord Bright Data
search_engine="google",
country="us",
language="en",
results_count=10,
parse_results=True)
# Remplacer les valeurs par défaut du constructeur pour cette requête spécifique :
results = serp_tool.invoke({
"query": "best web scraping tools 2026",
« country » : « de »,
« language » : « de »,
« search_type » : « shop »,
« device_type » : « mobile »,
})Quelques points à surveiller dans cette intégration :
results_countcorrespond en interne ànumde Google. Étant donné quenumne fonctionne plus (voir la section num), les valeurs supérieures à 10 n’ont aucun effet.countryetlanguagecorrespondent àglethl(résultats du pays et langue). Contrairement à l’API Direct, où« country »contrôle le nœud de sortie du Proxy, LangChain gère automatiquement le routage du Proxy.Zoneest défini par défaut sur« serp ».Si le nom de votre zone est différent (par exemple,« serp_api1 »), définissez-le explicitement, sinon vous obtiendrez une erreur « zone introuvable ».
Au-delà de LangChain, consultez les guides d’intégration pour CrewAI, AWS Bedrock et Google Vertex AI. Pour la collecte de données non liées à la recherche, consultez les outils d’accès Web IA de Bright Data.
Pour la liste complète des paramètres : Documentation API SERP
Pourquoi utiliser une API SERP gérée ?
L’API SERP gère le rendu JavaScript, la rotation des proxys, la Résolution de CAPTCHA et le ciblage géographique :
Vous pourriez le créer vous-même avec Playwright, Selenium ou l’API Browser de Bright Data. Mais la maintenance d’un Scraper Google implique la gestion des CAPTCHA, des blocages IP, des Proxys résidentiels, du rendu JavaScript et de l’analyse HTML qui ne fonctionne plus dès que Google met à jour son balisage. Consultez la section scraping géré vs scraping basé sur API pour une comparaison des deux approches.
Avec l’API SERP, vous envoyez une URL de recherche et obtenez en retour un JSON structuré. Elle fonctionne sur Google, Bing, DuckDuckGo, Yandex et d’autres moteurs de recherche. Consultez la page des tarifs pour connaître les prix actuels.
Le Playground de l’API SERP vous permet d’effectuer des recherches de base sans code, et l’espace de travail Postman contient des requêtes prédéfinies. Voici le Playground :
Interface utilisateur du Playground : choisissez un moteur de recherche, un pays et une langue, entrez une requête et consultez la réponse JSON analysée à droite.
Créez un compte pour exécuter les exemples ci-dessus (les nouveaux comptes bénéficient d’un crédit gratuit pour les tests).
Cas d’utilisation réels
Ces combinaisons de paramètres reviennent régulièrement dans les workflows de scraping en production.
Suivi du classement SEO
Suivez le classement des mots-clés dans différents endroits en combinant q, gl, hl, pws=0, udm=14 et start:
# Vérifiez le classement des « outils de Scraping web » aux États-Unis, au Royaume-Uni et en Allemagne.
curl --proxy brd.superproxy.io:33335
--proxy-user brd-customer-<CUSTOMER_ID>-zone-<ZONE_NAME>:<PASSWORD> -k
« https://www.google.com/search?q=Scraping web tools&gl=us&hl=en&pws=0&udm=14&brd_json=1 »
# Répétez ensuite avec gl=gb et gl=de
# Utilisez start=10, start=20 pour vérifier les positions au-delà de la page 1Consultez la procédure complète pour créer un outil de suivi du classement SEO avec v0 et l’API SERP.
Surveillance des publicités des concurrents
Les emplacements publicitaires de vos concurrents changent quotidiennement. Combinez les termes de marque avec tbs=qdr:d pour trouver les changements récents :
https://www.google.com/search?q=competitor+brand+name&gl=us&hl=en&tbs=qdr:d&brd_json=1La réponse JSON sépare les top_ads, bottom_ads et popular_products (annonces pour une liste de produits) des résultats organiques.
Comparaison des prix et informations sur le commerce électronique
Pour comparer les prix sur différents marchés, modifiez la valeur gl tout en conservant tbm=shop:
https://www.google.com/search?q=sony+wh-1000xm5&tbm=shop&gl=us&brd_json=1
https://www.google.com/search?q=sony+wh-1000xm5&tbm=shop&gl=gb&brd_json=1
https://www.google.com/search?q=sony+wh-1000xm5&tbm=shop&gl=de&brd_json=1Suivi de l’actualité et analyse des sentiments
https://www.google.com/search?q=openai&tbm=nws&tbs=qdr:h&filter=0&brd_json=1. Utilisez tbm=nws pour les actualités, tbs=qdr:h pour l’heure écoulée, filter=0 pour empêcher Google de regrouper les articles similaires. Exécutez cette commande dans une tâche cron pour surveiller la couverture horaire.
Recherche alimentée par l’IA et applications RAG
Ancrez les applications LLM dans les données de recherche en direct en utilisant l’API SERP comme couche de récupération. L’intégration LangChain (méthode 4 ci-dessus), le serveur MCP et les appels API directs fonctionnent tous. Découvrez comment créer un chatbot RAG avec l’API SERP pour un exemple fonctionnel.
Référencement local et surveillance multi-sites
Les classements locaux peuvent varier considérablement d’une ville à l’autre. Utilisez uule avec gl et pws=0 pour comparer :
# Vérifiez les classements pour « plombier près de chez moi » dans 3 villes
curl --proxy brd.superproxy.io:33335
--proxy-user brd-customer-<CUSTOMER_ID>-zone-<ZONE_NAME>:<PASSWORD> -k
« https://www.google.com/search?q=plumber+near+me&uule=Chicago,Illinois,United+States&gl=us&pws=0&brd_json=1 »
# Répétez l'opération avec uule=Miami,Florida,United+States et uule=Seattle,Washington,United+StatesComparez les résultats snack_pack (pack local de 3) et organiques entre les différents emplacements afin d’identifier les points à améliorer dans vos annonces.
Recherche universitaire et étude de marché
https://www.google.com/search?q=site:arxiv.org+large+language+models&lr=lang_en&tbs=cdr:1,cd_min:01/01/2025,cd_max:12/31/2025&brd_json=1Combinez les filtres site: avec lr et date-range tbs pour créer des Jeux de données de recherche ciblés. Remplacez arxiv.org par scholar.google.com, pubmed.ncbi.nlm.nih.gov ou tout autre domaine.
Conclusion
Ce qui importe réellement dans tout ce qui précède :
- Utilisez
gl+hl+pws=0+udm=14pour un suivi cohérent et non personnalisé du classement sur tous les marchés numest obsolète. Utilisezstartpour la pagination ou le point de terminaison Top 100 de Bright Data pour les résultats en masseudm=14supprime les aperçus IA et renvoie des résultats organiques classiques.udmétendtbmavec des modes supplémentairestbsgère le filtrage temporel, le tri par date (sbd:1) et la recherche littérale (li:1)- Les caractères spéciaux doivent être encodés dans l’URL. Le point-virgule dans
ibp=htl%3Bjobsest l’erreur d’encodage la plus courante, avec les requêtes non latines
Google modifie constamment ces paramètres. Ils ont supprimé num sans avertissement, et ils pourraient faire de même avec start ou déprécier tbm au profit de udm. Si vous effectuez un scraping à un volume significatif, l’API SERP de Bright Data gère le rendu, la rotation et l’analyse. Essayez-la avec les exemples ci-dessus.
Prochaines étapes
Lectures recommandées, en fonction de votre cas d’utilisation :
Si vous souhaitez commencer à scraper Google dès maintenant :
- Comment scraper les résultats de recherche Google avec Python: tutoriel Python complet avec code fonctionnel
- Comment scraper Google AI Overview: extraire des résumés générés par l’IA
- Comment extraire des données du mode IA de Google: extraire des données de la recherche conversationnelle IA de Google
Si vous développez des applications IA :
- Construisez un chatbot RAG avec l’API SERP: basez les réponses LLM sur des données de recherche en temps réel
- Construisez un outil de suivi du classement SEO avec v0 et l’API SERP: guide étape par étape
- Agent GEO & SEO IA: optimisez le contenu pour les moteurs de recherche alimentés par l’IA
- CrewAI avec API SERP: workflows IA multi-agents
Si vous évaluez des fournisseurs d’API SERP :
- Les meilleures API SERP et de recherche Web de 2026: comparaison côte à côte des principaux fournisseurs
- Scraping géré ou basé sur une API: comparaison des services gérés et des approches basées sur une API
Autres sources de données Google :
- Comment scraper les données Google Trends
- Meilleurs fournisseurs de données hôtelières: comparaison des services de collecte de données hôtelières
- Meilleurs fournisseurs de données sur les vols: comparaison des services de collecte de données sur les vols
Références externes :
- Affiner les recherches Google: guide officiel de Google pour affiner les requêtes de recherche
Références
- API de recherche Google Bright Data (GitHub)
- API SERP Bright Data (GitHub)
- Documentation API SERP Bright Data
Foire aux questions
Que sont les paramètres de recherche Google ?
Les paramètres de recherche Google sont des paires clé-valeur ajoutées à l’URL https://www.google.com/search? qui contrôlent la manière dont les résultats de recherche sont générés et affichés. Par exemple, q=pizza définit la requête de recherche, gl=us cible les États-Unis et hl=en définit la langue de l’interface en anglais. Ils sont séparés par & et suivent le ? dans l’URL.
Quelle est la différence entre gl et hl dans la recherche Google ?
Le paramètre gl contrôle la géolocalisation (le pays d’où semble provenir la recherche), ce qui influe sur les résultats affichés. Le paramètre hl contrôle la langue hôte (la langue de l’interface Google). Par exemple, gl=de&hl=en vous donne des résultats pertinents pour l’Allemagne, mais avec l’interface affichée en anglais.
Le paramètre num de Google est-il obsolète ?
Il n’est pas seulement obsolète. Il ne fonctionne plus du tout. Google l’a discrètement désactivé entre le 12 et le 14 septembre 2025. Passer num=100 ne fait rien, et Google renvoie 10 résultats quoi qu’il arrive. Utilisez start pour la pagination ou le point de terminaison Top 100 de l’API Web Scraper de Bright Data pour obtenir les positions 1 à 100 en une seule requête.
Qu’est-ce que le paramètre udm de Google ?
udm signifie probablement User Display Mode (mode d’affichage utilisateur) (d’après le reverse engineering de la communauté ; Google n’a pas confirmé l’acronyme). Vous utiliserez principalement udm=14, qui supprime les aperçus IA et renvoie des résultats organiques classiques. Les autres valeurs incluent udm=2 (images), udm=39 (vidéos courtes) et udm=50 (mode IA). udm étend tbm avec des modes supplémentaires, et les deux fonctionnent toujours. Toutes les valeurs sont répertoriées dans la section udm.
Quelle est la différence entre tbm et udm?
tbm est l’ancien paramètre, udm est la nouvelle extension. Ils se recoupent pour les images, les actualités et les achats (tbm=isch ≈ udm=2), mais udm inclut également des fonctionnalités que tbm ne prend pas en charge : mode IA (udm=50), forums (udm=18), vidéos courtes (udm=39). Les deux fonctionnent aujourd’hui. Créez un nouveau code basé sur udm, conservez tbm comme solution de secours.
Comment paginer les résultats Google maintenant que num n’existe plus ?
Utilisez le paramètre start. start=0 (ou omis) vous donne les résultats 1 à 10, start=10 donne les résultats 11 à 20, et ainsi de suite. Chaque page renvoie 10 résultats. Pour les positions 1 à 100 dans une seule requête, utilisez le point de terminaison Top 100 de Bright Data avec les paramètres start_page et end_page.
Comment filtrer les résultats Google par date ?
Utilisez le paramètre tbs. tbs=qdr:h = dernière heure, tbs=qdr:d = dernière journée, tbs=qdr:w = dernière semaine, tbs=qdr:m = dernier mois, tbs=qdr:y = dernière année. Pour une plage de dates personnalisée : tbs=cdr:1,cd_min:MM/JJ/AAAA,cd_max:MM/JJ/AAAA. Ajoutez tbs=sbd:1 pour trier par date plutôt que par pertinence.
Comment extraire les résultats de recherche Google sans être bloqué ?
Pour maintenir un Scraper Google à grande échelle, il faut mettre à jour les analyseurs HTML chaque fois que Google modifie son balisage, réaliser la résolution de CAPTCHA, faire tourner les adresses IP et rendre le JavaScript pour chaque requête depuis janvier 2025. Une API SERP gérée prend en charge cette infrastructure. Vous envoyez une URL, vous recevez un JSON structuré en retour et vous n’avez pas à maintenir l’analyseur.





