
Dans cet article, vous apprendrez :
- Comment créer un système RAG prêt à l’emploi à l’aide de Google ADK et du moteur RAG Vertex IA
- Comment mettre en œuvre une recherche hybride avec récupération sémantique et par mot-clé
- Comment éviter les hallucinations grâce à un ancrage et une citation appropriés
- Comment traiter du contenu multimodal, notamment du texte, des images et des tableaux
- Comment améliorer votre RAG avec des données web en temps réel à l’aide de l’intégration Bright Data (facultatif)
C’est parti !
Le défi de la gestion moderne des connaissances
La documentation technique est stockée dans des wikis, les spécifications des produits se trouvent dans des fichiers PDF, les données clients sont dans des bases de données et les connaissances institutionnelles résident dans des e-mails. Les employés passent des heures à rechercher des informations et tombent souvent sur des réponses obsolètes ou incomplètes. Les grands modèles linguistiques formés à partir de données générales ne peuvent pas accéder à vos connaissances propriétaires. Ils font souvent des erreurs lorsqu’on leur demande des informations spécifiques à l’entreprise.
Les agents RAG résolvent ce problème en récupérant le contexte pertinent dans votre base de connaissances avant de générer des réponses. Cela permet d’ancrer l’IA dans des informations factuelles, de réduire les hallucinations et de fournir des citations transparentes à des fins de vérification.
Ce que nous construisons : un système d’agent RAG intelligent
Nous allons créer un agent RAG prêt à être mis en production qui prend des documents provenant de diverses sources, les traite en éléments consultables, les transforme en représentations vectorielles, récupère le contexte pertinent à l’aide d’une recherche hybride, génère des réponses correctes avec des citations appropriées et évite les inexactitudes.
Le système gérera :
- La réception de documents provenant du stockage cloud, de Drive et de fichiers locaux
- Le découpage intelligent avec chevauchement et conservation des métadonnées
- La recherche hybride combinant la similarité sémantique et la correspondance de mots-clés
- Le contenu multimodal comprenant des images et des tableaux
- La génération de citations pour vérifier les réponses
- Détection et prévention des erreurs
Prérequis
Configurez votre environnement de développement avec :
- Python 3.10 ou supérieur – Requis pour la compatibilité avec Google ADK.
- Projet Google Cloud – Créez un projet dans la console Google Cloud avec la facturation activée.
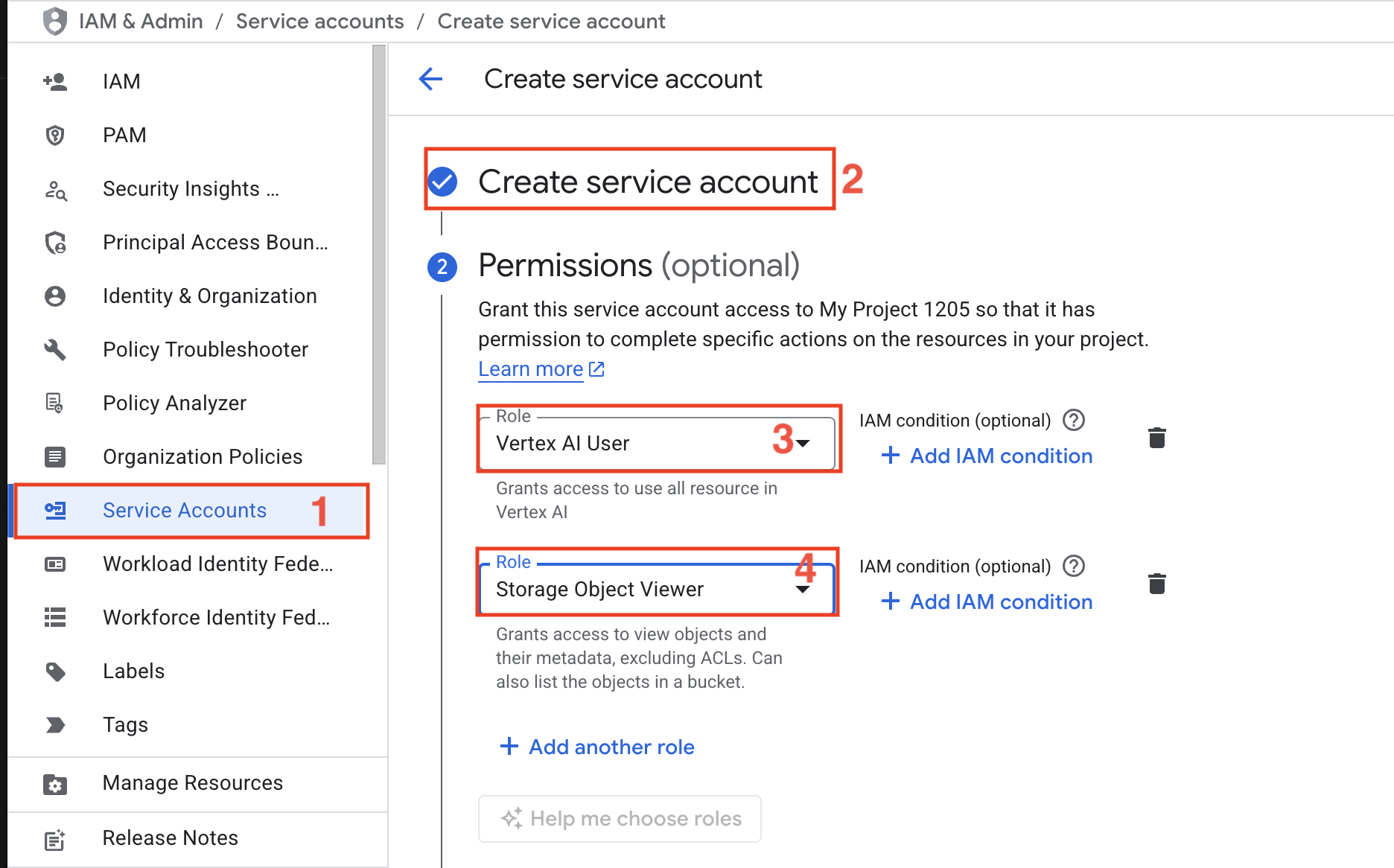
- Compte de service – Créez un compte de service avec les rôles IA User et Storage Object Viewer.
- Google ADK – Kit de développement d’agents pour la création d’agents IA ; consultez la documentation.
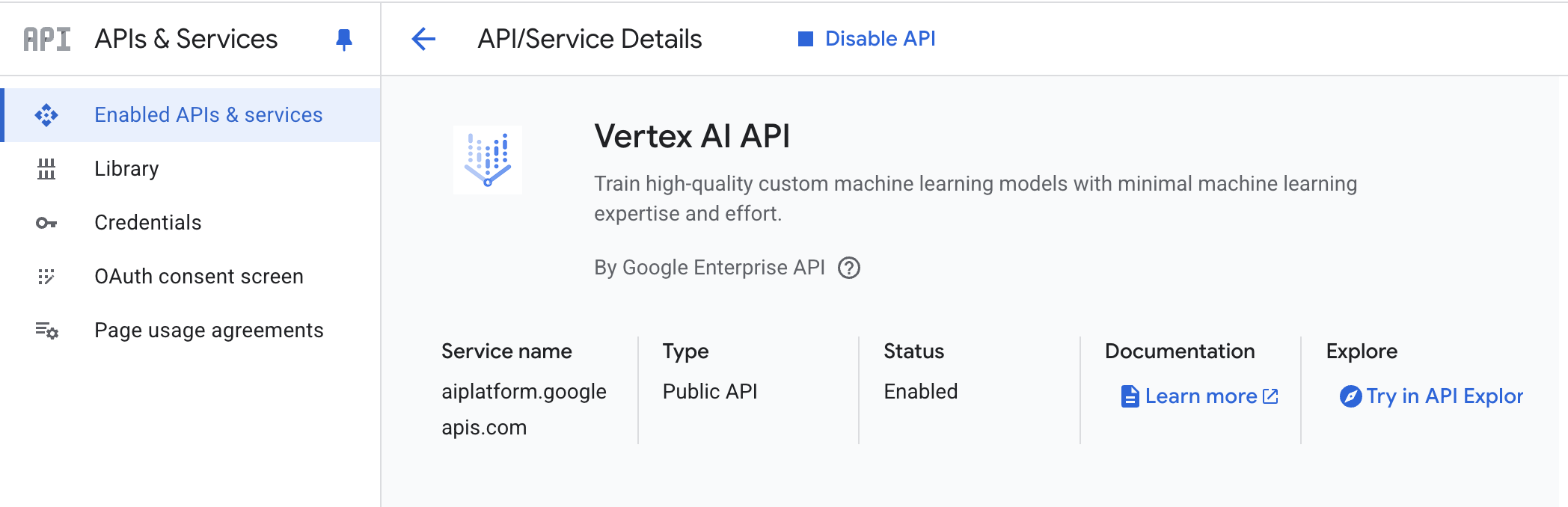
- API Vertex AI – Activez l’API Vertex AI dans votre projet Google Cloud
- Environnement virtuel Python – Permet d’isoler les dépendances ; consultez la documentation
venv.
Configuration de l’environnement
Créez votre répertoire de projet et installez les dépendances :
python -m venv venv
# macOS/Linux : source venv/bin/activate
# Windows : venvScriptsactivate
pip install google-genai google-cloud-aiplatform google-cloud-storage langchain-google-vertexai pypdf python-dotenv pandas pillowCréez un nouveau fichier appelé rag_agent.py et ajoutez les importations suivantes :
import os
import json
import PyPDF2
import fitz
import time
import vertexai
from google import genai
from vertexai.preview import rag
from pathlib import Path
from vertexai.preview.generative_models import GenerativeModel, Tool
from google.cloud import storage
from typing import List, Dict, Any, Optional
from datetime import datetime
from dotenv import load_dotenv
from google.api_core.exceptions import ResourceExhausted
from google.genai import types
load_dotenv()Créez un fichier .env avec vos identifiants :
GOOGLE_CLOUD_PROJECT="votre-identifiant-de-projet"
GOOGLE_CLOUD_LOCATION="us-central1"
GOOGLE_APPLICATION_CREDENTIALS="chemin/vers/service-account-key.json"
GENAI_API_KEY="votre-clé-API-genai"
GCS_BUCKET_NAME="votre-nom-de-compartiment"Vous avez besoin :
- ID de projet: votre identifiant de projet Google Cloud depuis la console
- Emplacement: région pour les ressources IA (us-east1 recommandé)
- Clé de compte de service: fichier de clé JSON téléchargé depuis IAM & Admin
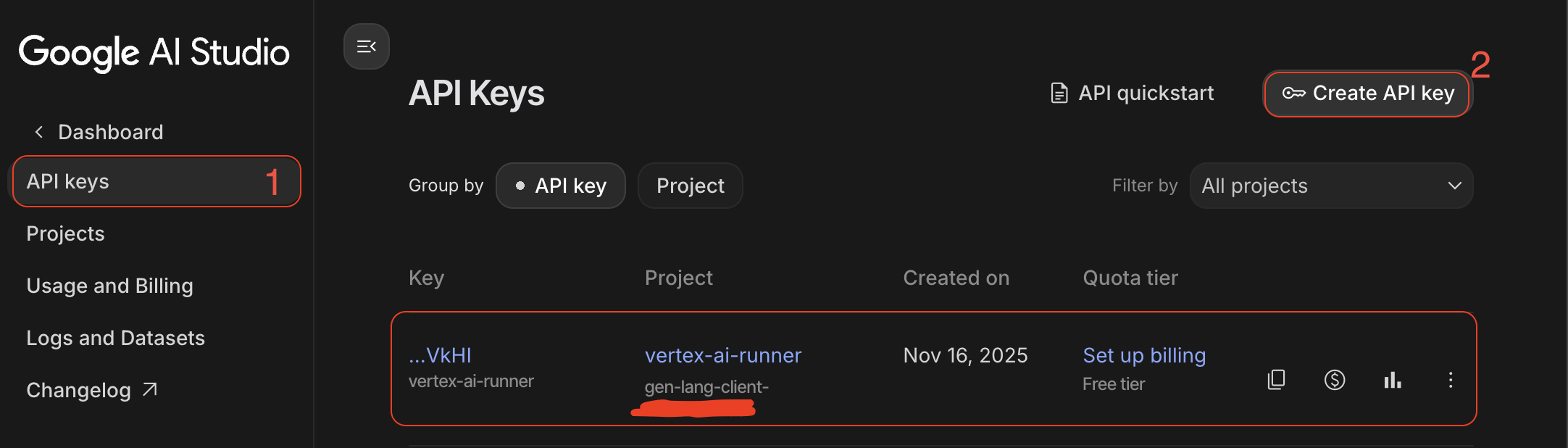
- Clé API IA: à créer à partir de Google AI Studio
- Bucket GCS: bucket Cloud Storage pour le stockage de documents
Création du système d’agent RAG
Étape 1 : configuration de Google ADK
Configurez le client Google ADK et initialisez Vertex AI avec une authentification appropriée. Le client gère toutes les interactions avec les services d’IA générative de Google.
def initialize_adk():
"""Initialisez Vertex IA avec une authentification appropriée."""
os.environ["GOOGLE_APPLICATION_CREDENTIALS"] = os.getenv("GOOGLE_APPLICATION_CREDENTIALS")
vertexai.init(
project=os.getenv("GOOGLE_CLOUD_PROJECT"),
location=os.getenv("GOOGLE_CLOUD_LOCATION")
)
print(f"✓ Initialisation de Vertex IA")
# Initialiser le système
initialize_adk()L’initialisation établit des connexions à la fois au client GenAI pour les opérations de l’agent et à Vertex AI pour les capacités RAG. Elle valide les informations d’identification et confirme la configuration du projet avant de poursuivre.
Étape 2 : Configuration du moteur RAG Vertex IA
Créez un corpus RAG qui servira de base à votre base de connaissances. Le corpus stocke les documents indexés, gère les intégrations et traite les requêtes de recherche.
def create_rag_corpus(corpus_name: str, description: str) -> str:
"""Créer un nouveau corpus RAG pour le stockage et la récupération de documents."""
try:
corpus = rag.create_corpus(
display_name=corpus_name,
description=description,
embedding_model_config=rag.EmbeddingModelConfig(
publisher_model="publishers/google/models/text-embedding-004"
)
)
corpus_id = corpus.name.split('/')[-1]
print(f"✓ Création du corpus RAG : {corpus_name}")
print(f"✓ ID du corpus : {corpus_id}")
print(f"✓ Modèle d'intégration : text-embedding-004")
return corpus_id
except Exception as e:
print(f"Erreur lors de la création du corpus : {str(e)}")
raise
def configure_retrieval_parameters(corpus_id: str) -> Dict[str, Any]:
"""Configure les paramètres de recherche pour une performance optimale."""
retrieval_config = {
"corpus_id": corpus_id,
"similarity_top_k": 10,
"vector_distance_threshold": 0.5,
"filter": {},
"ranking_config" : {
"rank_service" : "default",
"alpha" : 0.5
}
}
print(f"✓ Paramètres de recherche configurés")
print(f" - Top K résultats : {retrieval_config['similarity_top_k']}")
print(f" - Seuil de distance : {retrieval_config['vector_distance_threshold']}")
print(f" - Alpha de recherche hybride : {retrieval_config['ranking_config']['alpha']}")
return retrieval_configLa création du corpus utilise le modèle text-embedding-004 de Google pour des intégrations sémantiques de haute qualité. La configuration de la recherche équilibre la similarité sémantique et la correspondance des mots-clés grâce au paramètre alpha, où 0,5 fournit une pondération égale.
Étape 3 : Pipeline d’ingestion de documents
Construisez un pipeline d’ingestion de documents robuste qui gère plusieurs formats de fichiers, extrait du texte propre et conserve les métadonnées importantes pour une recherche améliorée.
def extract_text_from_pdf(file_path: str) -> Dict[str, Any]:
"""Extraire le texte et les métadonnées des documents PDF."""
with open(file_path, 'rb') as file:
pdf_reader = PyPDF2.PdfReader(file)
metadata = {
'source': file_path,
'num_pages': len(pdf_reader.pages),
'title': pdf_reader.metadata.get('/Title', ''),
'author': pdf_reader.metadata.get('/Author', ''),
'created_date': str(datetime.now())
}
text_content = []
for page_num, page in enumerate(pdf_reader.pages):
page_text = page.extract_text()
text_content.append({
'page': page_num + 1,
'text': page_text,
'char_count': len(page_text)
})
return {
'metadata': metadata,
'content': text_content,
'full_text': ' '.join([p['text'] for p in text_content])
}
def preprocess_document(text: str) -> str:
"""Nettoyer et normaliser le texte du document pour une indexation optimale."""
text = ' '.join(text.split())
text = text.replace('x00', '')
text = text.replace('rn', 'n')
lines = text.split('n')
cleaned_lines = [
line for line in lines
if len(line.strip()) > 3
and not line.strip().isdigit()
]
return 'n'.join(cleaned_lines)La stratégie de segmentation utilise les limites des phrases pour éviter de couper au milieu d’une pensée, met en œuvre un chevauchement pour préserver le contexte entre les segments et conserve les métadonnées sur la position des segments pour une citation précise. La taille des segments de 1 000 caractères permet d’équilibrer la précision de la recherche et l’exhaustivité du contexte.
Étape 4 : Intégration et indexation
Téléchargez les documents dans le corpus RAG et générez des intégrations vectorielles pour la recherche sémantique. Le système gère automatiquement la génération des intégrations et l’optimisation de l’index.
def chunk_document(text: str, chunk_size: int = 1000, overlap: int = 200) -> List[Dict[str, Any]]:
"""Divisez le document en morceaux qui se chevauchent pour une recherche optimale."""
chunks = []
start = 0
text_length = len(text)
chunk_id = 0
while start < text_length:
end = start + chunk_size
if end < text_length:
last_period = text.rfind('.', start, end)
if last_period != -1 and last_period > start:
end = last_period + 1
chunk_text = text[start:end].strip()
if chunk_text:
chunks.append({
'chunk_id': chunk_id,
'text': chunk_text,
'start_char': start,
'end_char': end,
'char_count': len(chunk_text)
})
chunk_id += 1
start = end - overlap
print(f"✓ Création de {len(chunks)} morceaux avec {overlap} caractères en chevauchement")
return chunks
def upload_file_to_gcs(local_path: str, gcs_bucket: str) -> str:
"""Téléchargement du document vers Google Cloud Storage pour l'ingestion RAG."""
storage_client = storage.Client()
bucket = storage_client.bucket(gcs_bucket)
blob_name = f"rag-docs/{Path(local_path).name}"
blob = bucket.blob(blob_name)
blob.upload_from_filename(local_path)
gcs_uri = f"gs://{gcs_bucket}/{blob_name}"
print(f"✓ Téléchargé vers GCS : {gcs_uri}")
return gcs_uri
def import_documents_to_corpus(corpus_id: str, file_uris: List[str]) -> str:
"""Importez les documents dans le corpus RAG et générez des intégrations."""
print(f"⚡ Démarrage de l'importation de {len(file_uris)} documents...")
response = rag.import_files(
corpus_name=f"projects/{os.getenv('GOOGLE_CLOUD_PROJECT')}/locations/{os.getenv('GOOGLE_CLOUD_LOCATION')}/ragCorpora/{corpus_id}",
paths=file_uris,
chunk_size=1000,
chunk_overlap=200
)
try:
if hasattr(response, 'result'):
print("⏳ En attente de la fin de l'opération d'importation (cela peut prendre une minute)...")
response.result()
else:
print("✓ Demande d'importation envoyée.")
except Exception as e:
print(f"⚠️ Remarque sur l'attente : {e}")
print(f"✓ Documents importés et indexation déclenchée.")
return getattr(response, 'name', 'unknown_operation')
def create_vector_index(corpus_id: str, index_config: Dict[str, Any]) -> str:
"""Créer un index vectoriel optimisé pour une recherche rapide par similarité."""
index_settings = {
'corpus_id': corpus_id,
'distance_measure': 'COSINE',
'algorithm': 'TREE_AH',
'leaf_node_embedding_count': 1000,
'leaf_nodes_to_search_percent': 10
}
print(f"✓ Création d'un index vectoriel avec l'algorithme TREE_AH")
print(f"✓ Mesure de distance : similarité COSINE")
print(f"✓ Optimisé pour une couverture de recherche de {index_settings['leaf_nodes_to_search_percent']}%")
return corpus_idLe processus d’importation gère automatiquement l’analyse syntaxique des documents, le découpage en morceaux et la génération d’intégration. L’algorithme TREE_AH permet une recherche rapide des voisins les plus proches tout en conservant un rappel élevé. La similarité cosinus mesure la distance angulaire entre les vecteurs d’intégration pour la correspondance sémantique.
Étape 5 : Développement d’agents avec ADK
Créez l’architecture de l’agent principal qui gère le contexte, traite les requêtes des utilisateurs et coordonne la récupération avec la génération de réponses.
class RAGAgent:
"""Agent RAG intelligent avec gestion du contexte et ancrage."""
def __init__(self, corpus_id: str, model_name: str = "gemini-2.5-flash"):
self.corpus_id = corpus_id
self.model_name = model_name
self.conversation_history = []
self.rag_tool = Tool.from_retrieval(
retrieval=rag.Retrieval(
source=rag.VertexRagStore(
rag_corpora=[f"projects/{os.getenv('GOOGLE_CLOUD_PROJECT')}/locations/{os.getenv('GOOGLE_CLOUD_LOCATION')}/ragCorpora/{corpus_id}"],
similarity_top_k=5,
vector_distance_threshold=0.3
)
)
)
self.model = GenerativeModel(
model_name=model_name,
tools=[self.rag_tool]
)
print(f"✓ Agent RAG initialisé avec {model_name}")
print(f"✓ Connecté au corpus : {corpus_id}")
def manage_context(self, query: str, max_history: int = 5) -> List[Dict[str, str]]:
"""Gérer le contexte de la conversation avec troncature de l'historique."""
self.conversation_history.append({
'role': 'user',
'content': query,
'timestamp': datetime.now().isoformat()
})
if len(self.conversation_history) > max_history * 2:
self.conversation_history = self.conversation_history[-max_history * 2:]
formatted_history = []
for msg in self.conversation_history:
formatted_history.append({
'role': msg['role'],
'parts': [msg['content']]
})
return formatted_history
def build_grounded_prompt(self, query: str, retrieved_context: List[Dict[str, Any]]) -> str:
"""Construire une invite avec des instructions explicites d'ancrage."""
context_text = "nn".join([
f"[Source {i+1}]: {ctx['text']}"
for i, ctx in enumerate(retrieved_context)
])
prompt = f"""Vous êtes un assistant IA utile qui a accès à une base de connaissances.
Répondez à la question suivante en utilisant UNIQUEMENT les informations fournies dans le contexte ci-dessous.
INSTRUCTIONS IMPORTANTES :
1. Basez votre réponse strictement sur le contexte fourni.
2. Si le contexte ne contient pas suffisamment d'informations, indiquez-le explicitement.
3. Citez les sources spécifiques en utilisant la notation [Source X].
4. N'ajoutez pas d'informations issues de vos connaissances générales.
5. Si vous n'êtes pas sûr, reconnaissez-le.
CONTEXTE :
{context_text}
QUESTION :
{query}
RÉPONSE :"""
return promptL’agent conserve l’historique des conversations pour les interactions à plusieurs tours, gère la taille de la fenêtre contextuelle afin d’éviter les limites de jetons et crée des invites avec des instructions explicites afin de réduire les hallucinations. L’intégration de l’outil RAG permet une récupération automatique pendant la génération.
Étape 6 : Traitement et récupération des requêtes
Mettre en œuvre une recherche hybride qui combine la compréhension sémantique et la correspondance de mots-clés pour une précision de recherche optimale.
def hybrid_search(
self,
corpus_id: str,
query: str,
semantic_weight: float = 0.7,
top_k: int = 10
) -> List[Dict[str, Any]]:
"""Effectuer une recherche hybride avec réessai automatique en cas de limites de quota."""
rag_resource = rag.RagResource(
rag_corpus=f"projects/{os.getenv('GOOGLE_CLOUD_PROJECT')}/locations/{os.getenv('GOOGLE_CLOUD_LOCATION')}/ragCorpora/{corpus_id}"
)
max_retries = 3
base_delay = 90
for attempt in range(max_retries):
try:
print(f"🔍 Recherche dans le corpus (Tentative {attempt + 1})...")
results = rag.retrieval_query(
rag_resources=[rag_resource],
text=query,
similarity_top_k=top_k,
vector_distance_threshold=0.5
)
# En cas de succès, traiter et renvoyer les résultats
retrieved_chunks = []
for i, context in enumerate(results.contexts.contexts):
retrieved_chunks.append({
'rank': i + 1,
'text': context.text,
'source': context.source_uri if hasattr(context, 'source_uri') else 'unknown',
'distance': context.distance if hasattr(context, 'distance') else 0.0
})
print(f"✓ {len(retrieved_chunks)} fragments pertinents récupérés")
return retrieved_chunks
except ResourceExhausted:
wait_time = base_delay * (2 ** attempt)
print(f"⚠️ Quota atteint (Limite : 5/min). Refroidissement pendant {wait_time}s...")
time.sleep(wait_time)
except Exception as e:
print(f"❌ Erreur de récupération : {str(e)}")
raise
print("❌ Nombre maximal de tentatives atteint. Échec de la récupération.")
return []
def rerank_results(
self,
results: List[Dict[str, Any]],
query: str,
model_name: str = "gemini-2.5-flash"
) -> List[Dict[str, Any]]:
"""Reclassement des résultats récupérés en fonction de la pertinence de la requête."""
if not results:
return []
rerank_prompt = f"""Évaluez la pertinence de chaque passage par rapport à la requête sur une échelle de 0 à 10.
Requête : {query}
Passages :
{chr(10).join([f"{i+1}. {r['text'][:200]}..." pour i, r dans enumerate(results)])}
Renvoyer uniquement une liste de scores séparés par des virgules (par exemple, 8,6,9,3,7)."""
model = GenerativeModel(model_name)
response = model.generate_content(rerank_prompt)
if response.text:
try:
scores = [float(s.strip()) for s in response.text.strip().split(',')]
for i, score in enumerate(scores[:len(results)]):
results[i]['rerank_score'] = score
results.sort(key=lambda x: x.get('rerank_score', 0), reverse=True)
print(f"✓ Résultats reclassés à l'aide du score LLM")
except Exception as e:
print(f"Avertissement : reclassement échoué, utilisation de l'ordre d'origine : {str(e)}")
return resultsLa recherche hybride récupère les candidats à l’aide de la similarité vectorielle, puis le reclassement utilise le LLM pour noter la pertinence en fonction du contexte spécifique à la requête. Cette approche en deux étapes permet d’équilibrer efficacité et précision.
Étape 7 : Génération de réponses et ancrage
Générer des réponses avec des citations appropriées et mettre en œuvre la prévention des hallucinations grâce à une vérification stricte de l’ancrage.
def generate_grounded_response(
self,
agent: 'RAGAgent',
query: str,
retrieved_context: List[Dict[str, Any]],
temperature: float = 0.2
) -> Dict[str, Any]:
"""Générer une réponse avec des citations et une prévention des hallucinations."""
grounded_prompt = agent.build_grounded_prompt(query, retrieved_context)
chat = agent.model.start_chat()
response = chat.send_message(
grounded_prompt,
generation_config={
'temperature': temperature,
'top_p': 0.8,
'top_k': 40,
'max_output_tokens': 1024
}
)
return {
'answer': response.text,
'sources': retrieved_context,
'query': query,
'timestamp': datetime.now().isoformat()
}
def verify_grounding(
self,
response: str,
sources: List[Dict[str, Any]],
model_name: str = "gemini-2.5-flash"
) -> Dict[str, Any]:
"""Vérifier que les affirmations de la réponse sont fondées sur les sources."""
verification_prompt = f"""Analysez si la réponse suivante est entièrement étayée par les sources fournies.
SOURCES :
{chr(10).join([f"Source {i+1}: {s['text']}" for i, s in enumerate(sources)])}
RÉPONSE :
{response}
Vérifiez chaque affirmation dans la réponse. Répondez avec JSON :
{{
"is_grounded": true/false,
"unsupported_claims": ["claim1", "claim2"],
"confidence_score": 0.0-1.0
}}"""
model = GenerativeModel(model_name)
verification_response = model.generate_content(verification_prompt)
try:
json_text = verification_response.text.strip()
if '```json' in json_text:
json_text = json_text.split('```json')[1].split('```')[0].strip()
verification_result = json.loads(json_text)
print(f"✓ Vérification de l'ancrage terminée")
print(f" - Ancré : {verification_result.get('is_grounded', False)}")
print(f" - Confiance : {verification_result.get('confidence_score', 0.0):.2f}")
return verification_result
except Exception as e:
print(f"Avertissement : échec de la vérification de la justification : {str(e)}")
return {'is_grounded': True, 'confidence_score': 0.5}La vérification de la mise à la terre permet de s’assurer que chaque affirmation contenue dans la réponse peut être retracée jusqu’aux documents sources. Une génération à basse température (0,2) réduit les embellissements créatifs et améliore l’exactitude factuelle.
Étape 8 : mise en œuvre multimodale du RAG
Étendez le système RAG pour traiter les images, les tableaux et autres contenus non textuels afin d’obtenir une recherche complète des connaissances.
def extract_images_from_pdf(self, pdf_path: str, output_dir: str) -> List[Dict[str, Any]]:
"""Extraire les images des documents PDF pour l'indexation multimodale."""
doc = fitz.open(pdf_path)
images = []
os.makedirs(output_dir, exist_ok=True)
for page_num in range(len(doc)):
page = doc[page_num]
image_list = page.get_images()
for img_index, img in enumerate(image_list):
xref = img[0]
base_image = doc.extract_image(xref)
image_bytes = base_image["image"]
# Enregistrer l'image
image_filename = f"page{page_num + 1}_img{img_index + 1}.png"
image_path = os.path.join(output_dir, image_filename)
with open(image_path, "wb") as img_file:
img_file.write(image_bytes)
images.append({
'page': page_num + 1,
'image_path': image_path,
'format': base_image['ext'],
'size': len(image_bytes)
})
print(f"✓ Extraction de {len(images)} images à partir du PDF")
return images
def process_table_content(self, table_text: str) -> Dict[str, Any]:
"""Traitement et structuration des données du tableau pour une recherche améliorée."""
lines = table_text.strip().split('n')
if not lines:
return {}
headers = [h.strip() for h in lines[0].split('|') if h.strip()]
rows = []
for line in lines[1:]:
cells = [c.strip() for c in line.split('|') if c.strip()]
if len(cells) == len(headers):
row_dict = dict(zip(headers, cells))
rows.append(row_dict)
return {
'headers': headers,
'rows': rows,
'row_count': len(rows),
'column_count': len(headers)
}
def create_multimodal_embedding(
self,
text: str,
image_path: Optional[str] = None,
table_data: Optional[Dict[str, Any]] = None
) -> Dict[str, Any]:
"""Créer un encodage unifié pour le contenu multimodal."""
combined_text = text
if table_data and table_data.get('rows'):
table_desc = f"nTable avec {table_data['row_count']} lignes et colonnes : {', '.join(table_data['headers'])}n"
combined_text += table_desc
if image_path:
combined_text += f"n[Image: {Path(image_path).name}]"
return {
'text': combined_text,
'has_image': image_path is not None,
'has_table': table_data is not None,
'modalities': sum([bool(text), bool(image_path), bool(table_data)])
}Le traitement multimodal extrait et indexe les images et les tableaux en même temps que le texte. L’approche d’intégration unifiée combine les métadonnées descriptives de toutes les modalités dans un texte consultable. Cela permet à des requêtes telles que « affichez-moi le tableau des prix du rapport du troisième trimestre » de récupérer à la fois les données du tableau et le contexte environnant.
Étape 9 : Intégration de l’agent Google ADK
Intégrez le kit de développement d’agent (ADK) de Google pour créer une meilleure interface d’agent qui se connecte à votre backend Vertex AI RAG Engine. L’ADK offre des fonctionnalités d’agent améliorées, notamment l’appel d’outils, les conversations à plusieurs tours et les réponses structurées.
class ADKRAGAgent:
"""Wrapper Google ADK Agent qui utilise le moteur Vertex AI RAG comme backend."""
def __init__(self, corpus_id: str, project_id: str, location: str):
"""Initialise l'agent ADK avec les capacités RAG."""
self.corpus_id = corpus_id
self.project_id = project_id
self.location = location
self.rag_agent = RAGAgent(corpus_id)
self.client = genai.Client(
vertexai=True,
project=project_id,
location=location
)
self.model_name = "gemini-2.0-flash-001"
print(f"✓ Agent Google ADK initialisé")
print(f" - Framework : Google ADK (genai.Client)")
print(f" - Backend : Vertex IA RAG Engine")
print(f" - Projet : {project_id}")
print(f" - Emplacement : {location}")
print(f" - Corpus RAG : {corpus_id}")
def create_rag_search_tool(self) -> types.Tool:
"""Créer un outil de recherche RAG pour l'agent ADK."""
def rag_search(query: str) -> str:
"""
Rechercher dans le corpus RAG et renvoyer des réponses fondées.
Arguments :
query : question de l'utilisateur à rechercher.
Résultats :
Une réponse fondée avec des citations provenant de la base de connaissances.
"""
try:
results = self.rag_agent.hybrid_search(
self.corpus_id,
query,
semantic_weight=0.7,
top_k=10)
if not results:
return "Aucune information pertinente trouvée dans la base de connaissances."
reranked = self.rag_agent.rerank_results(results, query)
response = self.rag_agent.generate_grounded_response(
self.rag_agent,
query,
reranked[:5]
)
verification = self.rag_agent.verify_grounding(
response['answer'],
response['sources']
)
answer = response['answer']
if not verification.get('is_grounded', True):
answer += f"nn[Confidence: {verification.get('confidence_score', 0):.0%}]"
return answer
except Exception as e:
return f"Error searching knowledge base: {str(e)}"
rag_tool = types.Tool(
function_declarations=[
types.FunctionDeclaration(
name="rag_search",
description="Rechercher dans la base de connaissances de l'entreprise à l'aide de RAG (Retrieval-Augmented Generation) pour trouver des réponses précises et fondées aux questions concernant la documentation technique, les spécifications des produits et les guides d'utilisation.",
parameters={
"type": "object",
"properties": {
"query": {
"type": "string",
"description": "Question ou requête de recherche de l'utilisateur"
}
},
"required": ["query"]
}
)
]
)
self.rag_search_function = rag_search
return rag_tool
def create_agent(self) -> Dict[str, Any]:
"""Créer une configuration Google ADK Agent avec l'outil RAG."""
rag_tool = self.create_rag_search_tool()
agent_instructions = """Vous êtes un agent RAG (Retrieval-Augmented Generation) intelligent ayant accès à une base de connaissances d'entreprise.
Vos capacités :
- Rechercher de la documentation technique, des spécifications de produits et des guides d'utilisation.
- Fournir des réponses précises et fondées, accompagnées de citations.
- Gérer des conversations à plusieurs tours avec une conscience du contexte.
- Vérifier l'exactitude des informations avant de répondre.
Directives :
1. Toujours utiliser l'outil rag_search pour trouver des informations avant de répondre.
2. Fournir des réponses spécifiques et détaillées basées sur les documents récupérés.
3. Inclure des citations et des sources pertinentes.
4. Si aucune information n'est trouvée, l'indiquer clairement.
5. Maintenir le contexte de la conversation sur plusieurs requêtes.
Être utile, précis et professionnel dans toutes les réponses. » » »
agent_config = {
'model': self.model_name,
'instructions': agent_instructions,
'tools': [rag_tool],
'display_name': 'RAG Agent with Vertex IA (Google ADK + Vertex IA RAG Engine)'
}
print(f"✓ Configuration de l'agent Google ADK créée")
print(f" - Modèle : {self.model_name}")
print(f" - Outils : Recherche RAG (moteur RAG Vertex IA)")
return agent_config
def chat(self, agent_config: Dict[str, Any], query: str, session_id: str = "default") -> str:
"""Envoie un message à l'agent ADK et obtient une réponse à l'aide de Google GenAI."""
self.rag_agent.manage_context(query)
try:
response = self.client.models.generate_content(
model=agent_config['model'],
contents=query,
config=types.GenerateContentConfig(
system_instruction=agent_config['instructions'],
tools=agent_config['tools'],
temperature=0.2
)
)
if response.candidates and len(response.candidates) > 0:
candidate = response.candidates[0]
if candidate.content and candidate.content.parts:
for part in candidate.content.parts:
if hasattr(part, 'function_call') and part.function_call:
function_name = part.function_call.name
function_args = part.function_call.args
print(f" → ADK Agent calling tool: {function_name}")
if function_name == "rag_search":
query_arg = function_args.get("query", query)
tool_result = self.rag_search_function(query_arg)
response = self.client.models.generate_content(
model=agent_config['model'],
contents=[
types.Content(role="user", parts=[types.Part(text=query)]),
types.Content(role="model", parts=[part]),
types.Content(
role="function",
parts=[types.Part(
function_response=types.FunctionResponse(
name=function_name,
response={"result": tool_result}
)
)]
)
],
config=types.GenerateContentConfig(
system_instruction=agent_config['instructions'],
tools=agent_config['tools'],
temperature=0.2
)
)
elif hasattr(part, 'text') and part.text:
answer = part.text
self.rag_agent.conversation_history.append({
'role': 'assistant',
'content': answer,
'timestamp': datetime.now().isoformat()
})
return answer
if response.candidates and response.candidates[0].content.parts:
for part in response.candidates[0].content.parts:
if hasattr(part, 'text') and part.text:
answer = part.text
self.rag_agent.conversation_history.append({
'role': 'assistant',
'content': answer,
'timestamp': datetime.now().isoformat()
})
return answer
return "No response generated."
except Exception as e:
error_msg = f"Erreur dans le chat de l'agent ADK : {str(e)}"
print(f"❌ {error_msg}")
return error_msgL’intégration ADK ajoute le framework d’agent de Google à votre agent RAG existant. La classe ADKRAGAgent configure un genai.Client pour les opérations de l’agent et utilise votre RAGAgent pour la récupération. La méthode create_rag_search_tool définit une fonction que l’agent peut appeler, lui permettant de rechercher dans votre base de connaissances à l’aide du moteur Vertex IA RAG.
Le mécanisme d’appel de l’outil permet à l’agent de déterminer automatiquement quand effectuer une recherche dans la base de connaissances en fonction des requêtes des utilisateurs. Lorsqu’une recherche est nécessaire, il exécute le pipeline de recherche hybride, réorganise les résultats, génère des réponses fondées et vérifie leur exactitude avant de fournir des réponses. La méthode chat gère l’ensemble du flux de conversation, y compris l’exécution de l’outil et la gestion du contexte multi-tours.
Étape 10 : Boostez votre RAG avec les données web en temps réel de Bright Data
Si votre système RAG excelle dans la récupération d’informations à partir de votre base de connaissances interne, les applications d’IA d’entreprise ont souvent besoin de données récentes et en temps réel provenant de sources externes. C’est là que la plateforme de données web de Bright Data devient inestimable, car elle permet à votre agent RAG d’accéder à des informations en direct provenant de l’ensemble du web, ce qui garantit l’actualité et l’exhaustivité de votre base de connaissances.
Pourquoi intégrer Bright Data à votre système RAG ?
1. Maintenez votre base de connaissances à jour
- Mettez automatiquement à jour votre corpus RAG avec les dernières informations sur les produits, les données sur les prix, les renseignements sur la concurrence et les tendances du marché.
- Éliminez les données obsolètes qui conduisent à des réponses IA dépassées.
- Planifiez des actualisations périodiques des données pour garantir leur exactitude.
2. Allez au-delà des documents internes
- Accédez à des données en temps réel provenant de plus de 120 sites web populaires, notamment des plateformes de commerce électronique, des sites d’information, des réseaux sociaux et des sources spécifiques à votre secteur d’activité.
- Enrichissez votre documentation technique avec de la documentation API en direct, des discussions communautaires et des spécifications mises à jour
- Intégrez les avis, les commentaires et les données sur les sentiments des clients pour améliorer votre base de connaissances sur les produits
3. Activez l’amélioration dynamique des requêtes
- Lorsque votre agent RAG détecte une requête nécessitant des informations actuelles (prix, disponibilité, actualités récentes), récupérez automatiquement les données les plus récentes.
- Combinez les connaissances internes avec les données web externes pour obtenir des réponses complètes.
- Fournissez aux utilisateurs à la fois le contexte historique et les informations actualisées
4. Adaptez facilement la collecte de données
- Plus besoin de gérer des Proxy, de traiter des CAPTCHA ou de faire face à des systèmes anti-bot
- Bright Data gère toute l’infrastructure, le déblocage et la qualité des données.
- Concentrez-vous sur le développement de l’IA pendant que Bright Data se charge de l’acquisition des données
Mise en œuvre : ajouter Bright Data à votre pipeline RAG
Étendons votre système RAG avec les capacités de Bright Data. Nous ajouterons trois modèles d’intégration : l’intégration de Jeux de données pour les données pré-collectées, l’API Web Scraper pour le scraping web en temps réel et les AI Scrapers pour des informations enrichies générées par l’IA.
Modèle 1 : intégration de jeux de données pour les données historiques
Utilisez le Dataset Marketplace de Bright Data pour alimenter rapidement votre corpus RAG avec des données structurées de haute qualité.
import requests
from typing import List, Dict
import json
class BrightDataRAGEnhancer:
"""Améliorez le système RAG grâce aux capacités de données web de Bright Data."""
def __init__(self, api_key: str, rag_agent: RAGAgent):
self.api_key = api_key
self.rag_agent = rag_agent
self.base_url = "https://api.brightdata.com"
def fetch_dataset_data(
self,
dataset_id: str,
filters: Dict[str, Any] = None,
limit: int = 1000
) -> List[Dict[str, Any]]:
"""Récupérer les données depuis Bright Data Dataset Marketplace."""
headers = {
"Authorization": f"Bearer {self.api_key}",
"Content-Type": "application/json"
}
endpoint = f"{self.base_url}/Jeux de données/v3/snapshot/{dataset_id}"
params = {
"format": "json",
"limit": limit
}
if filters:
params["filter"] = json.dumps(filters)
response = requests.get(endpoint, headers=headers, params=params)
response.raise_for_status()
print(f"✓ Récupération de {len(response.json())} enregistrements à partir de l'ensemble de données {dataset_id}")
return response.json()
def ingest_dataset_to_rag(
self,
corpus_id: str,
dataset_records: List[Dict[str, Any]],
text_fields: List[str]
) -> None:
"""Traiter les enregistrements de l'ensemble de données et les ajouter au corpus RAG."""
processed_chunks = []
for record in dataset_records:
# Combiner les champs de texte spécifiés en contenu consultable
combined_text = " ".join([
str(record.get(field, ""))
for field in text_fields
if record.get(field)
])
if combined_text.strip():
# Ajouter des métadonnées pour une meilleure récupération
metadata = {
"source": "bright_data_dataset",
"record_id": record.get("id", "unknown"),
"ingestion_date": datetime.now().isoformat(),
"data_type": "external_web_data"
}
# Diviser le contenu en morceaux
morceaux = chunk_document(texte_combiné, taille_morceau=1000, chevauchement=200)
pour chaque morceau dans morceaux :
morceau['métadonnées'] = métadonnées
morceaux_traités.append(morceau)
print(f"✓ {len(morceaux_traités)} morceaux traités à partir de l'ensemble de données")
# Créer un fichier temporaire pour le téléchargement
temp_file = "temp_dataset_content.txt"
with open(temp_file, 'w') as f:
for chunk in processed_chunks:
f.write(chunk['text'] + "nn")
# Télécharger vers GCS et importer vers le corpus
gcs_uri = upload_file_to_gcs(temp_file, os.getenv('GCS_BUCKET_NAME'))
import_documents_to_corpus(corpus_id, [gcs_uri])
os.remove(temp_file)
print(f"✓ Contenu de l'ensemble de données ajouté au corpus RAG")Exemple d’utilisation : alimenter votre RAG e-commerce avec des données produit
# Créer d'abord un corpus RAG
corpus_id = create_rag_corpus(
corpus_name="bright_data_corpus",
description="Corpus pour RAG amélioré par Bright Data")
# Initialiser l'agent RAG avec le corpus
rag_agent = RAGAgent(corpus_id=corpus_id)
# Initialiser l'optimiseur
enhancer = BrightDataRAGEnhancer(
api_key=os.getenv("BRIGHT_DATA_API_KEY"),
rag_agent=rag_agent)
print("✓ BrightDataRAGEnhancer initialisé avec succès !")
# Récupérer les données sur les produits Amazon
amazon_data = enhancer.fetch_dataset_data(
dataset_id="gd_l7q7dkf244hwxr90h", # Ensemble de données sur les produits Amazon
filters={"category": "Electronics"},
limit=5000
)
# Intégrer dans le corpus RAG
enhancer.ingest_dataset_to_rag(
corpus_id=corpus_id,
dataset_records=amazon_data,
text_fields=["title", "description", "features", "reviews"]
)Modèle 2 : intégration de l’API Web Scraper en temps réel
Pour obtenir des informations dynamiques et actualisées, intégrez l’API Web Scraper de Bright Data directement dans le pipeline de requêtes de votre agent RAG.
def scrape_real_time_data(
self,
scraper_id: str,
inputs: List[Dict[str, Any]],
wait_for_completion: bool = True)
-> List[Dict[str, Any]]:
"""Exécutez le Scraping web en temps réel à l'aide des Scrapers Bright Data."""
headers = {
"Authorization": f"Bearer {self.api_key}",
"Content-Type": "application/json"
}
# Déclencher le Scraper
trigger_url = f"{self.base_url}/dca/trigger"
params = {
"Scraper": Scraper_id,
"queue_next": 1
}
response = requests.post(
trigger_url,
headers=headers,
params=params,
json=inputs
)
response.raise_for_status()
snapshot_id = response.json().get("snapshot_id")
print(f"✓ Scraper déclenché. ID de l'instantané : {snapshot_id}")
if not wait_for_completion:
return {"snapshot_id": snapshot_id, "status": "processing"}
# Polling des résultats
results_url = f"{self.base_url}/dca/dataset"
params = {"id": snapshot_id}
max_retries = 30
for i in range(max_retries):
time.sleep(10) # Attendre 10 secondes entre chaque polling
results_response = requests.get(results_url, headers=headers, params=params)
if results_response.status_code == 200:
data = results_response.json()
print(f"✓ Récupération terminée. {len(data)} enregistrements récupérés")
return data
elif results_response.status_code == 202:
print(f"⏳ Toujours en cours de traitement... ({i+1}/{max_retries})")
continue
else:
print(f"❌ Erreur lors de la récupération des résultats : {results_response.status_code}")
break
return []
def create_dynamic_rag_tool(self) -> types.Tool:
"""Créer un outil RAG avec augmentation des données web en temps réel."""
def augmented_rag_search(query: str, include_live_data: bool = False) -> str:
"""
Rechercher dans la base de connaissances avec enrichissement optionnel des données web en temps réel.
Arguments :
query : question de l'utilisateur
include_live_data : s'il faut récupérer les données web récentes
Retourne :
Réponse fondée combinant des données internes et externes
"""
# Tout d'abord, recherchez dans la base de connaissances interne
internal_results = self.rag_agent.hybrid_search(
corpus_id=self.rag_agent.corpus_id,
query=query,
top_k=5
)
combined_results = internal_results
# Si la requête nécessite des informations actuelles, récupérer les données en temps réel
if include_live_data or self._requires_fresh_data(query):
print("🌐 Récupération des données web en temps réel...")
# Exemple : récupération des informations sur les prix
if "price" in query.lower() or "cost" in query.lower():
live_data = self.scrape_real_time_data(
scraper_id="your_product_scraper_id",
inputs=[{"url": "https://example.com/products"}],
wait_for_completion=True
)
# Convertir les données en temps réel en blocs consultables
for record in live_data[:3]: # 3 premiers résultats
combined_results.append({
'rank': len(combined_results) + 1,
'text': f"{record.get('title', '')}: {record.get('price', '')} - {record.get('description', '')}",
'source': f"Données web en direct : {record.get('url', 'unknown')}",
'distance': 0.3 # Pertinence élevée pour les données récentes
})
# Générer une réponse avec tout le contexte disponible
response = self.rag_agent.generate_grounded_response(
self.rag_agent,
query,
combined_results
)
return response['answer']
return types.Tool(
function_declarations=[
types.FunctionDeclaration(
name="augmented_rag_search",
description="Rechercher dans la base de connaissances interne et, éventuellement, récupérer des données web en temps réel pour obtenir des informations actuelles",
parameters={
« type » : « object »,
« properties » : {
« query » : {« type » : « string », « description » : « Question de l'utilisateur »},
« include_live_data » : {« type » : « boolean », « description » : « Récupérer les données Web récentes »}
},
"required": ["query"]
}
)
]
)
def _requires_fresh_data(self, query: str) -> bool:
"""Détermine si la requête nécessite des données en temps réel."""
fresh_data_keywords = [
« latest », « current », « today », « now », « recent »,
« price », « cost », « available », « in stock »
]
return any(keyword in query.lower() for keyword in fresh_data_keywords)Modèle 3 : intégration d’un Scraper IA pour une intelligence enrichie
Tirez parti des Scrapers IA de Bright Data (ChatGPT, Perplexity, Gemini) pour enrichir votre RAG avec des informations générées par l’IA et un contexte web complet.
def query_ai_scraper(
self,
scraper_type: str,
prompt: str,
country_code: str = "us"
) -> Dict[str, Any]:
"""Interroger les scrapers IA (ChatGPT, Perplexity, etc.) pour un contexte enrichi."""
scraper_ids = {
"chatgpt": "chatgpt_scraper_id",
"perplexity": "perplexity_scraper_id",
"gemini": "gemini_scraper_id"
}
inputs = [{
"prompt": prompt,
"country": country_code
}]
results = self.scrape_real_time_data(
scraper_id=scraper_ids.get(scraper_type),
inputs=inputs,
wait_for_completion=True
)
if results:
return {
"answer": results[0].get("answer", ""),
"sources": results[0].get("sources", []),
"citations": results[0].get("citations", [])
}
return {}
def create_hybrid_intelligence_agent(self) -> Dict[str, Any]:
"""Créer un agent qui combine RAG avec l'intelligence IA scraper."""
def hybrid_search(query: str) -> str:
"""
Combiner RAG interne avec l'intelligence IA scraper externe.
Cela fournit :
1. Le contexte de la base de connaissances interne
2. Des informations générées en temps réel par l'IA à partir du Web
3. Des réponses complètes et bien sourcées
"""
# Obtenir les connaissances internes
internal_answer = self.rag_agent.hybrid_search(
corpus_id=self.rag_agent.corpus_id,
query=query,
top_k=3
)
internal_context = "n".join([r['text'][:200] for r in internal_answer])
# Obtenir l'enrichissement du Scraper IA
print("🤖 Récupération des informations web enrichies par l'IA...")
ai_insight = self.query_ai_scraper(
scraper_type="perplexity", # Connu pour ses réponses bien documentées
prompt=query
)
# Synthétiser les deux sources
synthesis_prompt = f"""Synthétiser une réponse complète en utilisant à la fois les connaissances internes et les informations externes issues de l'IA.
BASE DE CONNAISSANCES INTERNE :
{internal_context}
INFORMATIONS EXTERNES DE L'IA :
{ai_insight.get('answer', 'Aucune information externe disponible')}
SOURCES :
{json.dumps(ai_insight.get('citations', []), indent=2)}
QUESTION : {query}
Fournissez une réponse complète qui :
1. Donne la priorité aux connaissances internes pour les informations spécifiques à l'entreprise.
2. Utilise les informations externes pour un contexte plus large et les développements récents.
3. Cite clairement toutes les sources.
4. Indique quand les informations proviennent de sources externes ou internes.
model = GenerativeModel("gemini-2.0-flash-001")
response = model.generate_content(synthesis_prompt)
return response.text
return {
'search_function': hybrid_search,
'description': 'Système hybride RAG + IA Scraper Intelligence'
}Exécution de votre système d’agent RAG
Rassemblez tous les composants dans un flux de travail complet qui traite les documents, gère les requêtes et génère des réponses fondées. Téléchargez également les documents PDF que vous souhaitez traiter et placez-les dans le dossier docs/ afin de permettre à l’IA de créer un contexte autour de votre produit.
def main():
"""Flux d'exécution principal pour le système d'agent RAG."""
print("=" * 60)
print("Système d'agent RAG - Initialisation")
print("=" * 60)
initialize_adk()
corpus_id = create_rag_corpus(
corpus_name="enterprise-knowledge-base-3",
description="Documentation d'entreprise multimodale et référentiel de connaissances"
)
retrieval_config = configure_retrieval_parameters(corpus_id)
print(f"n✓ Utilisation de la configuration de recherche avec top_k={retrieval_config['similarity_top_k']}")
print("n" + "=" * 60)
print("Pipeline d'ingestion de documents")
print("=" * 60)
document_paths = [
"docs/technical_manual.pdf",
"docs/product_specs.pdf",
"docs/user_guide.pdf"
]
gcs_uris = []
all_chunks = []
extracted_images = []
for doc_path in document_paths:
if os.path.exists(doc_path):
extracted = extract_text_from_pdf(doc_path)
print(f"n✓ Extraction de {extracted['metadata']['num_pages']} pages à partir de {Path(doc_path).name}")
cleaned_text = preprocess_document(extracted['full_text'])
print(f"✓ Texte prétraité : {len(cleaned_text)} caractères")
chunks = chunk_document(cleaned_text, chunk_size=1000, overlap=200)
all_chunks.extend(chunks)
print(f"✓ Document découpé en {len(chunks)} segments")
gcs_uri = upload_file_to_gcs(doc_path, os.getenv('GCS_BUCKET_NAME'))
gcs_uris.append(gcs_uri)
print(f"n✓ Nombre total de segments créés : {len(all_chunks)}")
print(f"✓ Total d'images extraites : {len(extracted_images)}")
if gcs_uris:
import_documents_to_corpus(corpus_id, gcs_uris)
index_config = {"distance_measure": "COSINE", "algorithm": "TREE_AH"}
create_vector_index(corpus_id, index_config)
time.sleep(180)
# ========================================================================
# Initialisation de Google ADK Agent avec Vertex AI RAG Engine
# ========================================================================
print("n" + "=" * 60)
print("Initialisation de Google ADK Agent")
print("=" * 60)
adk_agent = ADKRAGAgent(
corpus_id=corpus_id,
project_id=os.getenv("GOOGLE_CLOUD_PROJECT"),
location=os.getenv("GOOGLE_CLOUD_LOCATION")
)
agent = adk_agent.create_agent()
for doc_path in document_paths:
if os.path.exists(doc_path):
try:
images = adk_agent.rag_agent.extract_images_from_pdf(doc_path, "extracted_images")
extracted_images.extend(images)
if images:
print(f"✓ Extraction de {len(images)} images pour le traitement multimodal")
except Exception as e:
print(f"⚠️ Extraction d'image ignorée : {str(e)}")
queries = [
"Quelle est la configuration système requise pour l'installation ?",
"Comment configurer les paramètres d'authentification ?",
« Quels sont les niveaux de prix et leurs fonctionnalités ? »
]
print("n" + "=" * 60)
print("Google ADK Agent - Traitement des requêtes")
print("=" * 60)
print("Utilisation : Google ADK + Vertex IA RAG Engine")
print("=" * 60)
session_id = f"session_{datetime.now().strftime('%Y%m%d_%H%M%S')}"
for idx, query in enumerate(queries):
print(f"n📝 Requête {idx + 1}: {query}")
print("-" * 60)
try:
answer = adk_agent.chat(agent, query, session_id)
print(f"n💬 Réponse de l'agent ADK :n{answer}n")
print(f"✓ Historique de la conversation : {len(adk_agent.rag_agent.conversation_history)} messages")
except Exception as e:
print(f"❌ Erreur : {str(e)}")
import traceback
traceback.print_exc()
print("-" * 60)
if idx < len(queries) - 1:
time.sleep(90)
if extracted_images:
print("n" + "=" * 60)
print("Démonstration du traitement multimodal")
print("=" * 60)
sample_table = """Fonctionnalité | Basique | Pro | Entreprise
Stockage | 10 Go | 100 Go | Illimité
Utilisateurs | 1 | 10 | Illimité
Prix | 10 $ | 50 $ | Personnalisé"""
table_data = adk_agent.rag_agent.process_table_content(sample_table)
print(f"n✓ Tableau traité avec {table_data.get('row_count', 0)} lignes")
if all_chunks and extracted_images:
multimodal_embed = adk_agent.rag_agent.create_multimodal_embedding(
text=all_chunks[0]['text'][:500],
image_path=extracted_images[0]['image_path'] if extracted_images else None,
table_data=table_data
)
print(f"✓ Création d'un intégrement multimodal avec {multimodal_embed['modalities']} modalités")
print(f" - Contient une image : {multimodal_embed['has_image']}")
print(f" - Contient un tableau : {multimodal_embed['has_table']}")
print("n" + "=" * 60)
print(f"Système Google ADK RAG Agent - Terminé")
print(f"✓ Architecture : Google ADK + Vertex IA RAG Engine")
print(f"✓ Nombre total de tours de conversation : {len(adk_agent.rag_agent.conversation_history)}")
print("=" * 60)
if __name__ == "__main__":
try:
main()
except Exception as e:
print(f"n❌ Erreur : {str(e)}")
import traceback
traceback.print_exc()Exécutez le système d’agent RAG :
python3 rag_agent.pyVous verrez le pipeline de traitement de l’agent dans la console alors qu’il :
- Initialise le client Google ADK et la connexion Vertex IA.
- Il crée le corpus RAG avec la configuration du modèle d’intégration.
- Traite les documents en les extrayant, en les nettoyant et en les découpant.
- Il télécharge les fichiers vers Cloud Storage et les importe dans le corpus.
- Génère des intégrations vectorielles et construit l’index de recherche.
- Exécute des requêtes avec expansion, récupération et reclassement.
- Produit des réponses fondées avec des citations et des vérifications.
- Évalue la qualité des réponses en fonction de leur pertinence, de leur exhaustivité, de leur exactitude et de leur clarté.
La console affiche la progression détaillée de chaque étape.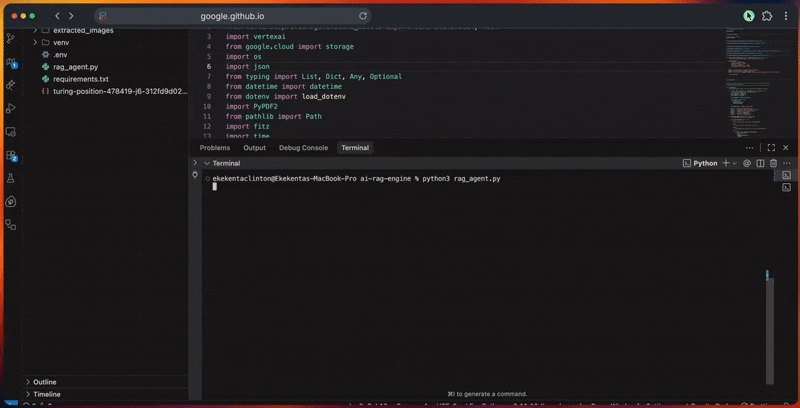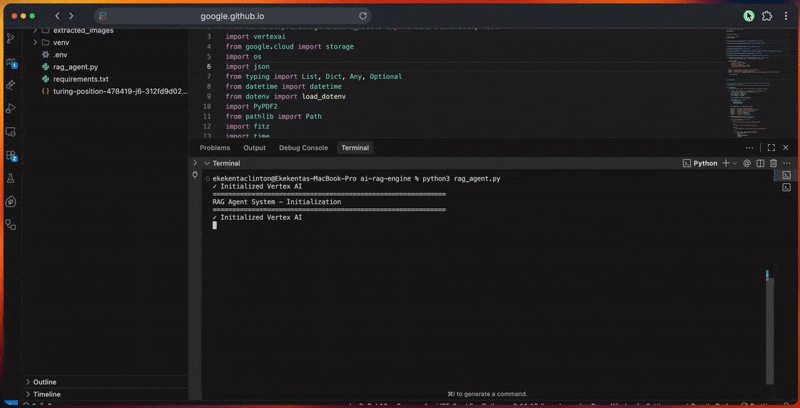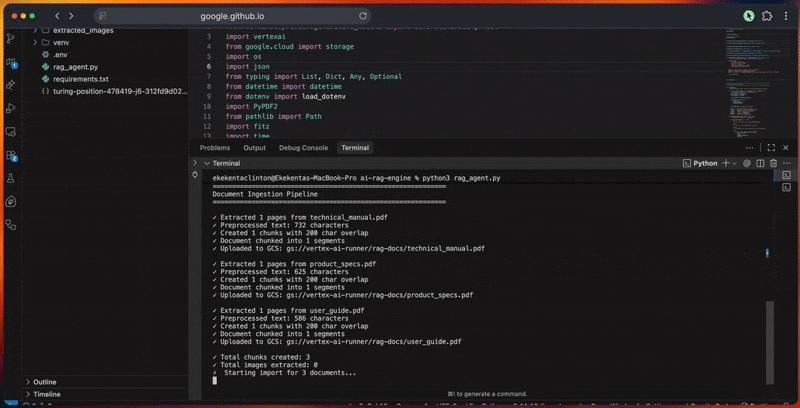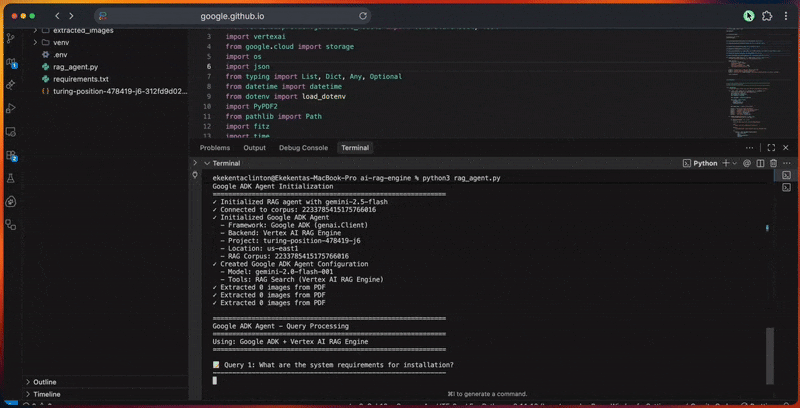
Conclusion
Vous disposez désormais d’un système d’agent RAG prêt à l’emploi combinant le kit de développement d’agent de Google et Vertex IA. Le système ingère des documents, récupère le contexte pertinent via une recherche hybride et génère des réponses précises avec des citations.
Améliorez-le en optimisant les stratégies de segmentation, en ajoutant des boucles de rétroaction, en intégrant des sources de données supplémentaires ou en activant la surveillance en temps réel. Sa conception modulaire permet une personnalisation aisée.
Découvrez les workflows IA avancés et l’infrastructure IA de Bright Data pour bénéficier de fonctionnalités supplémentaires.
Créez un compte gratuit pour commencer à développer.





