

Dans ce guide, vous découvrirez :
- Ce qu’est AG2 et comment il prend en charge le développement de systèmes à agent unique et à agents multiples, ainsi que les avantages de son extension avec Bright Data.
- Les conditions préalables pour commencer à utiliser cette intégration.
- Comment alimenter une architecture multi-agents AG2 avec Bright Data via des outils personnalisés.
- Comment connecter AG2 au Web MCP de Bright Data.
C’est parti !
Présentation d’AG2 (anciennement AutoGen)
AG2 est un framework AgentOS open source permettant de créer des agents IA et des systèmes multi-agents capables de collaborer de manière autonome pour résoudre des tâches complexes. Il vous permet de créer des workflows à agent unique, d’orchestrer plusieurs agents spécialisés et d’intégrer des outils externes dans des pipelines modulaires prêts à l’emploi.
AG2, anciennement AutoGen, est une évolution de la bibliothèque Microfost AutoGen. Il conserve l’architecture d’origine et la rétrocompatibilité tout en permettant des flux de travail multi-agents, l’intégration d’outils et l’IA avec intervention humaine. Écrit en Python, il compte plus de 4 000 étoiles GitHub.
(Si vous cherchez des conseils sur l’intégration de Bright Data avec AutoGen, consultez l’article de blog dédié.)
AG2 offre la flexibilité et les modèles d’orchestration avancés nécessaires pour faire passer les projets d’IA agentielle de l’expérimentation à la production.
Parmi ses principales fonctionnalités, on trouve des modèles de conversation multi-agents, la prise en charge de l’intervention humaine, l’intégration d’outils et la gestion structurée des flux de travail. Son objectif final est de vous aider à créer des systèmes d’IA sophistiqués avec un minimum de frais généraux.
Malgré ces formidables capacités, les agents AG2 sont toujours confrontés aux limitations fondamentales des LLM : des connaissances statiques issues des données d’entraînement et aucun accès natif aux informations web en temps réel !
L’intégration d’AG2 à un fournisseur de données web tel que Bright Data permet de résoudre tous ces problèmes. La connexion des agents AG2 aux API de Bright Data pour le Scraping web, la recherche et l’automatisation des navigateurs permet d’obtenir des données web structurées en temps réel, ce qui renforce leur intelligence, leur autonomie et leur utilité pratique.
Prérequis
Pour suivre ce guide, vous devez disposer des éléments suivants :
- Python 3.10 ou supérieur installé sur votre ordinateur local.
- Un compte Bright Data avec l’API Web Unlocker, l’API SERP et une clé API configurée. (Ce tutoriel vous guidera à travers toutes les configurations requises.)
- Une clé API OpenAI (ou une clé API de tout autre LLM pris en charge par AG2).
Il est également utile de se familiariser avec les produits et services de Bright Data, ainsi que d’avoir une compréhension de base du fonctionnement du système d’outils AG2.
Comment intégrer Bright Data dans un flux de travail multi-agents AG2
Dans cette section étape par étape, vous allez créer un workflow AG2 multi-agents basé sur les services Bright Data. Plus précisément, un agent dédié à la récupération de données web accédera à Web Unlocker et à l’API SERP de Bright Data via des fonctions personnalisées de l’outil AG2.
Ce système multi-agents identifiera les principaux influenceurs sur des plateformes telles que Twitch dans le secteur alimentaire afin de soutenir la promotion d’un nouveau type de hamburger. Cet exemple montre comment AG2 peut automatiser la collecte de données, produire des rapports commerciaux structurés et permettre une prise de décision éclairée, le tout sans effort manuel.
Découvrez comment le mettre en œuvre !
Étape n° 1 : créer un projet AG2
Ouvrez un terminal et créez un nouveau dossier pour votre projet AG2. Par exemple, nommez-le ag2-bright-data-agent:
mkdir ag2-bright-data-agentag2-bright-data-agent/ contiendra le code Python permettant de mettre en œuvre et d’orchestrer les agents AG2 qui s’intègrent aux fonctions Bright Data.
Ensuite, accédez au répertoire du projet et créez un environnement virtuel à l’intérieur :
cd ag2-bright-data-agent
python -m venv .venvAjoutez un nouveau fichier appelé agent.py à la racine du projet. La structure de votre projet devrait maintenant ressembler à ceci :
ag2-bright-data-agent/
├── .venv/
└── agent.py # <----Le fichier agent.py contiendra la définition de l’agent AG2 et la logique d’orchestration.
Ouvrez le dossier du projet dans votre IDE Python préféré, tel que Visual Studio Code avec l’extension Python ou PyCharm Community Edition.
Activez maintenant l’environnement virtuel que vous venez de créer. Sous Linux ou macOS, exécutez :
source .venv/bin/activateDe manière équivalente, sous Windows, exécutez :
.venv/Scripts/activateUne fois l’environnement virtuel activé, installez les dépendances PyPI requises :
pip install ag2[openai] requests python-dotenvCette application s’appuie sur les bibliothèques suivantes :
ag2[openai]: pour créer et orchestrer des workflows IA multi-agents alimentés par les modèles OpenAI.requests: pour effectuer des requêtes HTTP vers les services Bright Data via des outils personnalisés.python-dotenv: pour charger les secrets requis à partir des variables d’environnement définies dans un fichier.env
Bravo ! Vous disposez désormais d’un environnement Python prêt à l’emploi pour le développement d’IA multi-agents avec AG2.
Étape n° 2 : configurer l’intégration LLM
Les agents AG2 que vous allez créer dans les étapes suivantes ont besoin d’un cerveau, qui est fourni par un LLM. Chaque agent peut utiliser sa propre configuration LLM, mais pour simplifier, nous allons connecter tous les agents au même modèle OpenAI.
AG2 inclut un mécanisme intégré pour charger les paramètres LLM à partir d’un fichier de configuration dédié. Pour ce faire, ajoutez le code suivant à agent.py:
from autogen import LLMConfig
# Charger la configuration LLM à partir du fichier de liste de configuration OpenAI
llm_config = LLMConfig.from_json(path="OAI_CONFIG_LIST")Ce code charge la configuration LLM à partir d’un fichier nommé OAI_CONFIG_LIST.json. Créez ce fichier dans le répertoire racine de votre projet :
ag2-bright-data-agent/
├── .venv/
├── OAI_CONFIG_LIST.json # <----
└── agent.pyMaintenant, remplissez OAI_CONFIG_LIST.json avec le contenu suivant :
[
{
"model": "gpt-5-mini",
"api_key": "<YOUR_OPENAI_API_KEY>"
}
]Remplacez l’espace réservé <VOTRE_CLÉ_API_OPENAI> par votre clé API OpenAI réelle. Cette configuration alimente vos agents AG2 à l’aide du modèle GPT-5 Mini, mais vous pouvez remplacer celui-ci par n’importe quel autre modèle OpenAI pris en charge si nécessaire.
La variable llm_config sera transmise à vos agents et à l’orchestrateur de chat de groupe. Cela leur permet de raisonner, de communiquer et d’exécuter des tâches à l’aide du LLM configuré. Génial !
Étape n° 3 : gérer la lecture des variables d’environnement
Vos agents AG2 peuvent désormais se connecter à OpenAI, mais ils ont également besoin d’accéder à un autre service tiers : Bright Data. Tout comme OpenAI, Bright Data authentifie les requêtes à l’aide d’une clé API externe.
Pour éviter les risques de sécurité, vous ne devez jamais coder en dur les clés API directement dans votre code. La meilleure pratique consiste plutôt à les charger à partir de variables d’environnement. C’est exactement pour cette raison que vous avez installé python-dotenv précédemment.
Commencez par importer python-dotenv dans agent.py. Utilisez-le pour charger les variables d’environnement à partir d’un fichier .env à l’aide de la fonction load_dotenv():
from dotenv import load_dotenv
import os
# Charger les variables d'environnement à partir du fichier .env
load_dotenv()Ensuite, ajoutez un fichier .env au répertoire racine de votre projet, qui doit contenir :
ag2-bright-data-agent/
├── .venv/
├── OAI_CONFIG_LIST.json
├── .env # <----
└── agent.pyAprès avoir ajouté vos valeurs secrètes au fichier .env, vous pourrez y accéder dans le code à l’aide de os.getenv():
ENV_VALUE = os.getenv("ENV_NAME")Super ! Votre script peut désormais charger en toute sécurité les secrets d’intégration tiers à partir des variables d’environnement.
Étape n° 4 : configurer les services Bright Data
Comme prévu dans l’introduction, l’agent de données web se connectera à l’API SERP et à l’API Web Unlocker de Bright Data pour gérer les recherches web et la récupération de contenu à partir de pages web. Ensemble, ces services permettent à l’agent de récupérer des données web en direct dans une couche de récupération de données de type RAG.
Pour interagir avec ces deux services, vous devrez définir deux outils AG2 personnalisés ultérieurement. Avant cela, vous devez tout configurer dans votre compte Bright Data.
Commencez par créer un compte Bright Data, si vous n’en avez pas déjà un. Sinon, connectez-vous et accédez à votre tableau de bord. À partir de là, naviguez vers la page « Proxies & Scraping » et consultez le tableau « My Zones » qui répertorie les services configurés dans votre profil :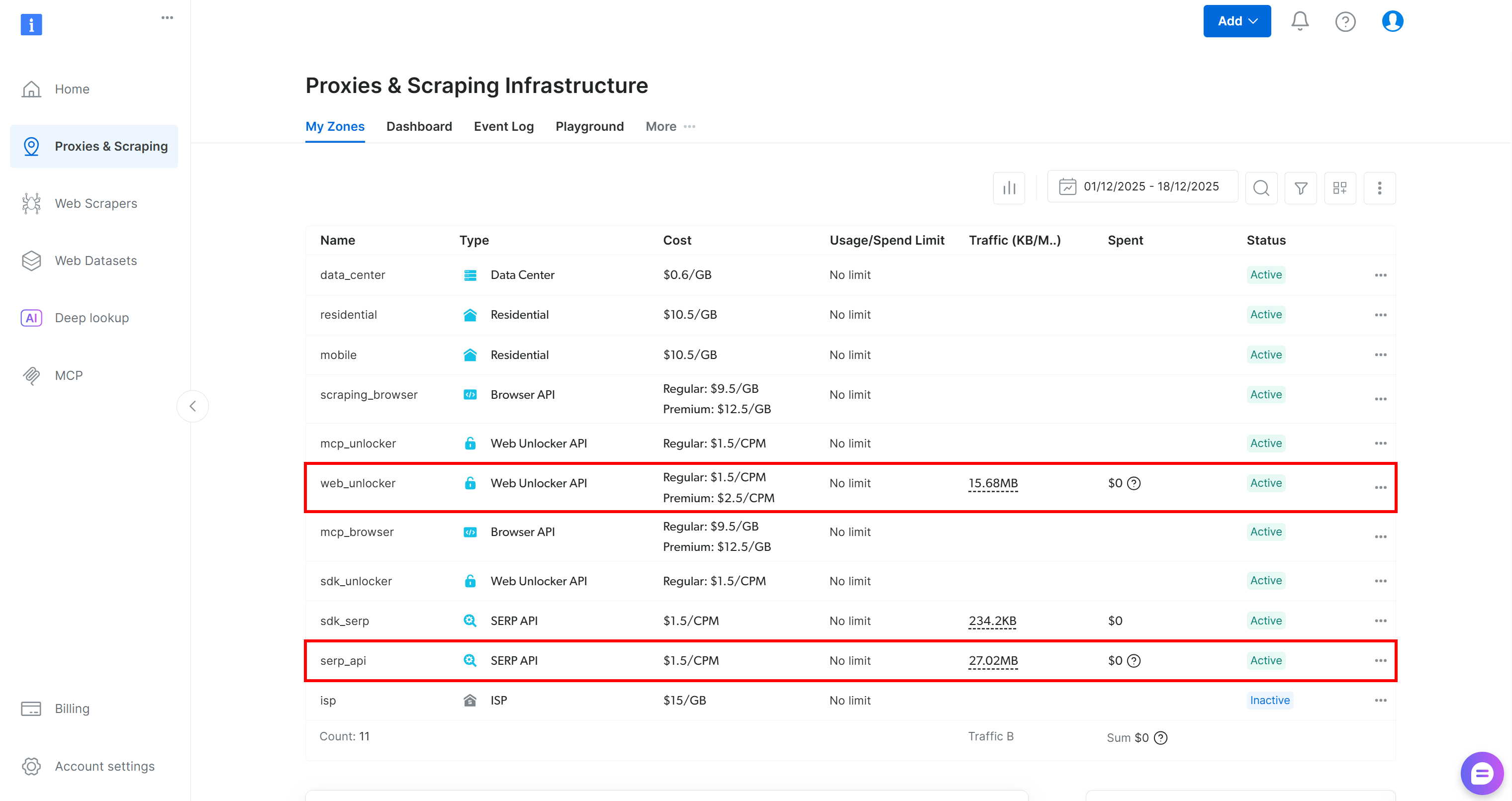
Si, comme ci-dessus, le tableau comprend déjà une zone Web Unlocker API (dans ce cas, appelée web_unlocker) et une zone API SERP (dans ce cas, appelée serp_api), alors tout est prêt. Ces deux zones seront utilisées par vos outils AG2 personnalisés pour appeler les services Bright Data requis.
Si l’une des zones ou les deux manquent, faites défiler vers le bas jusqu’aux cartes « Unblocker API » et « API SERP » et cliquez sur « Create zone » (Créer une zone) pour chacune d’elles. Suivez l’assistant de configuration pour créer les deux zones :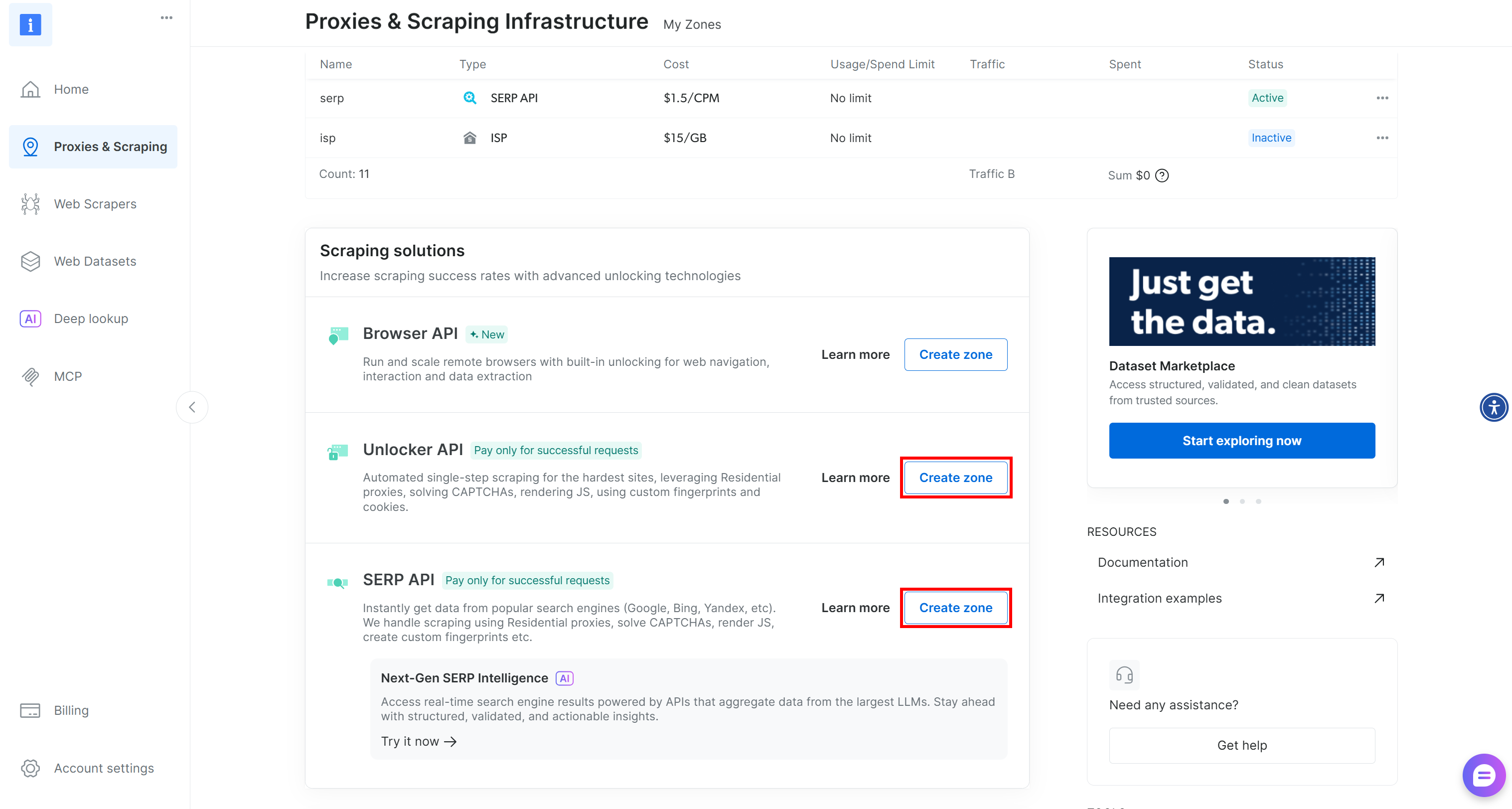
Pour obtenir des instructions détaillées étape par étape, consultez la documentation officielle :
Important: à partir de maintenant, nous supposerons que vos zones s’appellent respectivement serp_api et web_unlocker.
Une fois vos zones prêtes, générez votre clé API Bright Data. Enregistrez-la en tant que variable d’environnement dans .env:
BRIGHT_DATA_API_KEY="<VOTRE_CLÉ_API_BRIGHT_DATA>"Ensuite, chargez-la dans agent.py comme indiqué ci-dessous :
BRIGHT_DATA_API_KEY = os.getenv("BRIGHT_DATA_API_KEY")Parfait ! Vous disposez désormais de tous les éléments nécessaires pour connecter vos agents AG2 aux services API SERP et Web Unlocker de Bright Data via des outils personnalisés.
Étape n° 5 : définir les outils Bright Data pour vos agents AG2
Dans AG2, les outils fournissent des capacités spécialisées que les agents peuvent invoquer pour effectuer des actions et prendre des décisions. En réalité, les outils sont simplement des fonctions Python personnalisées qu’AG2 expose aux agents de manière structurée.
Dans cette étape, vous allez implémenter deux fonctions d’outil dans agent.py:
serp_api_tool(): se connecte à l’API SERP de Bright Data pour effectuer des recherches Google.web_unlocker_api_tool(): se connecte à l’API Bright Data Web Unlocker pour récupérer le contenu des pages web, en contournant tous les systèmes anti-bot.
Les deux outils utilisent le client HTTP Python Requests pour effectuer des requêtes POST authentifiées vers Bright Data, conformément à la documentation :
- Envoyez votre première requête avec l’API SERP de Bright Data
- Envoyez votre première requête avec l’API Web Unlocker de Bright Data
Pour définir les deux fonctions de l’outil, ajoutez le code suivant à agent.py:
from typing import Annotated
import requests
import urllib.parse
def serp_api_tool(
query: Annotated[str, "La requête de recherche Google"],)
-> str:
payload = {
"zone": "serp_api", # Remplacez-le par le nom de votre zone API SERP Bright Data
"url": f"https://www.google.com/search?q={urllib.parse.quote_plus(query)}&brd_json=1",
"format": "raw",
}
headers = {
"Authorization": f"Bearer {BRIGHT_DATA_API_KEY}",
"Content-Type": "application/json",
}
response = requests.post(
"https://api.brightdata.com/request",
json=payload,
headers=headers,
)
response.raise_for_status()
return response.text
def web_unlocker_api_tool(
url_to_fetch: Annotated[str, "URL de la page cible à récupérer"],
data_format: Annotated[
str | None,
"Format de la page de sortie (par exemple, 'markdown', ou omettre pour du HTML brut)"
] = "markdown",)
-> str:
payload = {
"zone": "web_unlocker", # Remplacez-le par le nom de votre zone Bright Data Web Unlocker
"url": url_to_fetch,
"format": "raw",
"data_format": data_format,
}
headers = {
« Authorization » : f« Bearer {BRIGHT_DATA_API_KEY} »,
« Content-Type » : « application/json »,
}
response = requests.post(
"https://api.brightdata.com/request",
json=payload,
headers=headers
)
response.raise_for_status()
return response.textLes deux outils authentifient les requêtes à l’aide de votre clé API Bright Data et envoient des requêtes POST au point de terminaison de l’API Bright Data :
serp_api_tool()interroge Google et récupère les résultats de recherche au format JSON structuré en activant le paramètrebrd_json=1.web_unlocker_api_tool()récupère n’importe quelle page web et renvoie son contenu au format Markdown (ou HTML brut si vous le souhaitez).
Important: JSON et Markdown sont deux formats excellents pour l’ingestion LLM dans les agents IA.
Notez que les deux fonctions utilisent le typage Python ainsi que Annotated pour décrire leurs arguments. Les types sont nécessaires pour transformer ces fonctions en outils AG2 appropriés, tandis que les descriptions des annotations aident le LLM à comprendre comment remplir chaque argument lors de l’invocation des outils à partir d’un agent.
Parfait ! Votre application AG2 comprend désormais deux outils Bright Data, prêts à être configurés et utilisés par vos agents IA.
Étape n° 6 : implémenter les agents AG2
Maintenant que vos outils sont en place, il est temps de construire la structure de l’agent IA décrite dans l’introduction. Cette configuration se compose de trois agents complémentaires :
user_proxy: agit comme couche d’exécution, exécutant en toute sécurité les appels d’outils et orchestrant le flux de travail sans intervention humaine. Il s’agit d’une instance deUserProxyAgent, un agent AG2 spécial qui fonctionne comme un Proxy pour l’utilisateur, exécutant du code et fournissant des commentaires aux autres agents si nécessaire.web_data_agent: responsable de la découverte et de la récupération des données web. Cet agent effectue des recherches sur le web à l’aide de l’API SERP de Bright Data et récupère le contenu des pages via l’API Web Unlocker. En tant qu’agentConversableAgent, il peut communiquer avec d’autres agents et des humains, traiter des informations, suivre les instructions définies dans son message système, etc.reporting_agent: analyse les données collectées et les transforme en un rapport Markdown structuré et prêt à l’emploi pour les décideurs.
Ensemble, ces agents forment un pipeline multi-agents entièrement autonome conçu pour l’identification des streamers Twitch et la promotion d’un produit ciblé.
Dans agent.py, spécifiez les trois agents avec le code suivant :
from autogen import (
UserProxyAgent,
ConversableAgent,)
# Exécute les appels d'outils et orchestre le flux de travail sans intervention humaine.
user_proxy = UserProxyAgent(
name="user_proxy",
code_execution_config=False,
human_input_mode="NEVER",
llm_config=llm_config,
)
# Responsable de la recherche et de la récupération des données web
web_data_agent = ConversableAgent(
name="web_data_agent",
code_execution_config=False,
llm_config=llm_config,
system_message=(
"""
Vous êtes un agent de récupération de données web.
Vous effectuez des recherches sur le Web à l'aide de l'outil API SERP de Bright Data
et récupérez le contenu des pages à l'aide de l'outil API Web Unlocker.
"""
),
)
# Analyse les données collectées et produit un rapport structuré
reporting_agent = ConversableAgent(
name="reporting_agent",
code_execution_config=False,
system_message=(
"""
Vous êtes analyste marketing.
Vous produisez des rapports Markdown structurés et prêts à l'emploi
destinés aux décideurs.
"""
),
llm_config=llm_config,
# Met automatiquement fin à la conversation dès que le mot « rapport » apparaît.
is_termination_msg=lambda msg: "report" in (msg.get("content", "") or "").lower()
)Dans le code ci-dessus, notez que :
- Les agents AG2 peuvent exécuter le code contenu dans les messages (par exemple, les blocs de code) et transmettre les résultats à l’agent suivant. Dans cette configuration, l’exécution du code est désactivée via
code_execution_config=Falsepour des raisons de sécurité. - Tous les agents sont alimentés par le
llm_configchargé à l’étape n° 2. - Le
reporting_agentinclut une fonctionis_termination_msgqui met automatiquement fin au flux de travail dès que le message contient le mot « report », signalant que le résultat final a été produit.
Ensuite, vous allez enregistrer les outils Bright Data avec le web_data_agent pour activer la récupération Web !
Étape n° 7 : Enregistrer les outils AG2 Bright Data
Enregistrez les fonctions Bright Data en tant qu’outils et attribuez-les au web_data_agent via register_function(). L’agent user_proxy agira en tant qu’exécuteur pour ces outils, comme l’exige l’architecture AG2 :
from autogen import register_function
# Enregistrer l'outil de recherche SERP pour l'agent de données web
register_function(
serp_api_tool,
caller=web_data_agent,
executor=user_proxy,
description="Utiliser l'API SERP de Bright Data pour effectuer une recherche Google et renvoyer les résultats bruts."
)
# Enregistrer l'outil Web Unlocker pour récupérer les pages protégées
register_function(
web_unlocker_api_tool,
caller=web_data_agent,
executor=user_proxy,
description="Récupérer une page web à l'aide de l'API Web Unlocker de Bright Data, en contournant les protections anti-bot courantes.",
)Notez que chaque fonction comprend une description concise pour aider le LLM à comprendre son objectif et à savoir quand l’appeler.
Une fois ces outils enregistrés, le web_data_agent peut désormais planifier les recherches sur le Web et l’accès aux pages Web, tandis que le user_proxy se charge de l’exécution.
Votre pipeline multi-agents AG2 est désormais pleinement capable de découvrir et d’extraire des données de manière autonome à l’aide des API de Bright Data. Mission accomplie !
Étape n° 8 : Introduire la logique d’orchestration multi-agents AG2
AG2 prend en charge plusieurs façons d’orchestrer et de gérer plusieurs agents. Dans cet exemple, vous verrez le modèle GroupChat.
Le principe fondamental d’un chat de groupe AG2 est que tous les agents contribuent à un seul fil de conversation, partageant le même contexte. Cette approche est idéale pour les tâches qui nécessitent une collaboration entre plusieurs agents, comme dans notre pipeline.
Ensuite, un GroupChatManager gère la coordination des agents au sein du chat de groupe. Il prend en charge différentes stratégies pour sélectionner le prochain agent à agir. Ici, vous allez configurer la stratégie automatique par défaut, qui utilise le LLM du gestionnaire pour décider quel agent doit parler ensuite.
Combinez tous les éléments pour l’orchestration multi-agents comme ci-dessous :
from autogen import (
GroupChat,
GroupChatManager,)
# Définir le chat de groupe multi-agents
groupchat = GroupChat(
agents=[user_proxy, web_data_agent, reporting_agent],
speaker_selection_method="auto",
messages=[],
max_round=20
)
# Gestionnaire responsable de la coordination des interactions entre les agents
manager = GroupChatManager(
name="group_manager",
groupchat=groupchat,
llm_config=llm_config
)Remarque: le flux de travail prendra fin lorsque l'agent reporting_agent produira un message qui déclenchera sa logique is_termination_msg ou après 20 cycles d’interactions entre les agents (en raison de l’argument max_round ), selon la première éventualité.
C’est parti ! Les définitions des agents et la logique d’orchestration sont terminées. La dernière étape consiste à lancer le workflow et à exporter les résultats.
Étape n° 9 : lancer le workflow Agentic et exporter le résultat
Décrivez en détail la tâche de recherche d’influenceurs streamers sur Twitch et transmettez-la sous forme de message à l’agent user_proxy pour exécution :
prompt_message = """
Scénario :
---------
Une marque de produits alimentaires et de boissons souhaite promouvoir un nouveau type de hamburger.
Objectif :
- Rechercher la page de la catégorie Alimentation et boissons sur TwitchMetrics
- Récupérer le contenu de la page de catégorie TwitchMetrics extraite du SERP et sélectionner les 5 meilleurs streamers
- Visiter la page de profil TwitchMetrics de chaque streamer et récupérer les informations pertinentes
- Produire un rapport Markdown structuré comprenant :
- Le nom de la chaîne
- La portée estimée
- Le thème principal du contenu
- L'adéquation avec l'audience
- La faisabilité de la promotion de la marque
"""
# Démarrer le workflow multi-agents
user_proxy.initiate_chat(recipient=manager, message=prompt_message)Une fois le workflow terminé, enregistrez le résultat (c’est-à-dire le rapport Markdown) sur le disque avec :
with open("report.md", "w", encoding="utf-8") as f:
f.write(user_proxy.last_message()["content"])Incroyable ! Votre workflow multi-agents AG2 + Bright Data est désormais pleinement opérationnel et prêt à collecter, analyser et rapporter les données des influenceurs Twitch.
Étape n° 10 : assembler le tout
Le code final dans votre fichier agent.py sera :
from autogen import (
LLMConfig,
UserProxyAgent,
ConversableAgent,
register_function,
GroupChat,
GroupChatManager,)
from dotenv import load_dotenv
import os
from typing import Annotated
import requests
import urllib.parse
# Charger la configuration LLM à partir du fichier de liste de configuration OpenAI
llm_config = LLMConfig.from_json(path="OAI_CONFIG_LIST")
# Charger les variables d'environnement à partir du fichier .env
load_dotenv()
# Récupérer la clé API Bright Data à partir des variables d'environnement
BRIGHT_DATA_API_KEY = os.getenv("BRIGHT_DATA_API_KEY")
# Définir les fonctions pour implémenter les outils Bright Data
def serp_api_tool(
query: Annotated[str, "La requête de recherche Google"],)
-> str:
payload = {
"zone": "serp_api", # Remplacez-la par le nom de votre zone API SERP Bright Data
"url": f"https://www.google.com/search?q={urllib.parse.quote_plus(query)}&brd_json=1",
"format": "raw",
}
headers = {
"Authorization": f"Bearer {BRIGHT_DATA_API_KEY}",
"Content-Type": "application/json",
}
response = requests.post(
"https://api.brightdata.com/request",
json=payload,
headers=headers,
)
response.raise_for_status()
return response.text
def web_unlocker_api_tool(
url_to_fetch: Annotated[str, "URL de la page cible à récupérer"],
data_format: Annotated[
str | None,
"Format de la page de sortie (par exemple, 'markdown', ou omettre pour du HTML brut)"
] = "markdown",)
-> str:
payload = {
"zone": "web_unlocker", # Remplacez-le par le nom de votre zone Bright Data Web Unlocker
"url": url_to_fetch,
"format": "raw",
"data_format": data_format,
}
headers = {
« Authorization » : f« Bearer {BRIGHT_DATA_API_KEY} »,
« Content-Type » : « application/json »,
}
response = requests.post(
« https://api.brightdata.com/request »,
json=payload,
headers=headers
)
response.raise_for_status()
return response.text
# Exécute les appels d'outils et orchestre le flux de travail sans intervention humaine.
user_proxy = UserProxyAgent(
name="user_proxy",
code_execution_config=False,
human_input_mode="NEVER",
llm_config=llm_config,
)
# Responsable de la recherche et de la récupération des données web
web_data_agent = ConversableAgent(
name="web_data_agent",
code_execution_config=False,
llm_config=llm_config,
system_message=(
"""
Vous êtes un agent de récupération de données web.
Vous effectuez des recherches sur le Web à l'aide de l'outil API SERP de Bright Data
et récupérez le contenu des pages à l'aide de l'outil API Web Unlocker.
"""
),
)
# Analyse les données collectées et produit un rapport structuré
reporting_agent = ConversableAgent(
name="reporting_agent",
code_execution_config=False,
system_message=(
"""
Vous êtes analyste marketing.
Vous produisez des rapports Markdown structurés et prêts à l'emploi
destinés aux décideurs.
"""
),
llm_config=llm_config,
# Met automatiquement fin à la conversation dès que le mot « rapport » apparaît.
is_termination_msg=lambda msg: "rapport" in (msg.get("content", "") or "").lower()
)
# Enregistrer l'outil de recherche SERP pour l'agent de données Web.
register_function(
serp_api_tool,
caller=web_data_agent,
executor=user_proxy,
description="Utiliser l'API SERP de Bright Data pour effectuer une recherche Google et renvoyer les résultats bruts."
)
# Enregistrer l'outil Web Unlocker pour récupérer les pages protégées
register_function(
web_unlocker_api_tool,
caller=web_data_agent,
executor=user_proxy,
description="Récupérer une page web à l'aide de l'API Web Unlocker de Bright Data, en contournant les protections anti-bot courantes.",
)
# Définir le chat de groupe multi-agents
groupchat = GroupChat(
agents=[user_proxy, web_data_agent, reporting_agent],
speaker_selection_method="auto",
messages=[],
max_round=20
)
# Gestionnaire chargé de coordonner les interactions entre les agents
manager = GroupChatManager(
name="group_manager",
groupchat=groupchat,
llm_config=llm_config)
prompt_message = """
Scénario :
---------
Une marque de produits alimentaires et de boissons souhaite promouvoir un nouveau type de hamburger.
Objectif :
- Rechercher la page de la catégorie Alimentation et boissons sur TwitchMetrics
- Récupérer le contenu de la page de catégorie TwitchMetrics extraite du SERP et sélectionner les 5 meilleurs streamers
- Visiter la page de profil TwitchMetrics de chaque streamer et récupérer les informations pertinentes
- Produire un rapport Markdown structuré comprenant :
- Nom de la chaîne
- Portée estimée
- Thème principal du contenu
- Adéquation avec l'audience
- Faisabilité de la promotion de la marque
"""
# Démarrer le workflow multi-agents
user_proxy.initiate_chat(recipient=manager, message=prompt_message)
# Enregistrer le rapport final dans un fichier Markdown
with open("report.md", "w", encoding="utf-8") as f:
f.write(user_proxy.last_message()["content"])Grâce à la puissante API AG2, vous avez créé, en seulement 170 lignes de code, un workflow multi-agents complexe, prêt à l’emploi et optimisé par Bright Data !
Étape n° 11 : tester le système multi-agents
Dans votre terminal, vérifiez que votre application agentique AG2 fonctionne avec :
python agent.pyLe résultat attendu ressemblera à ceci :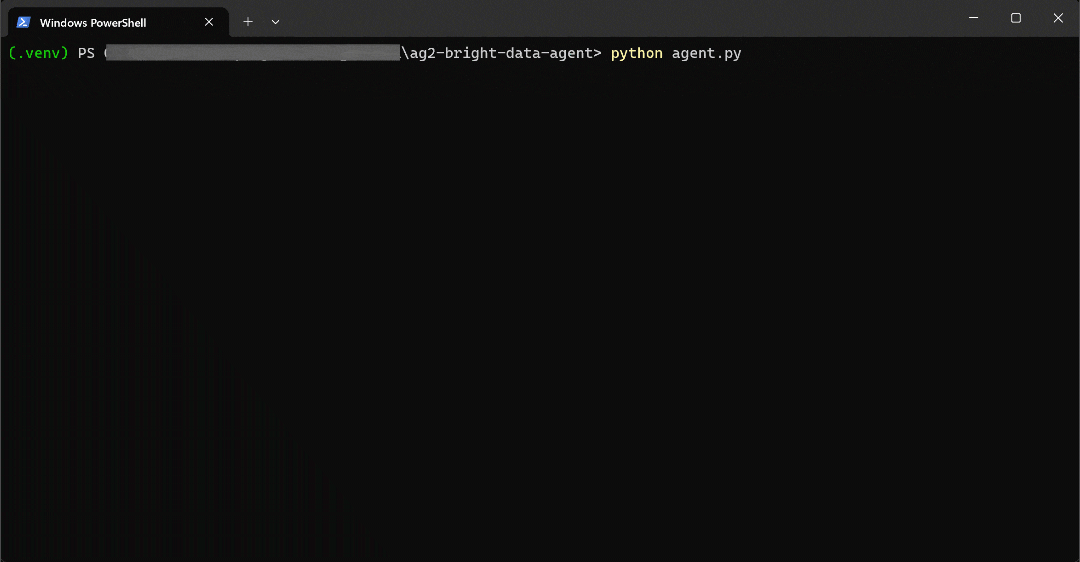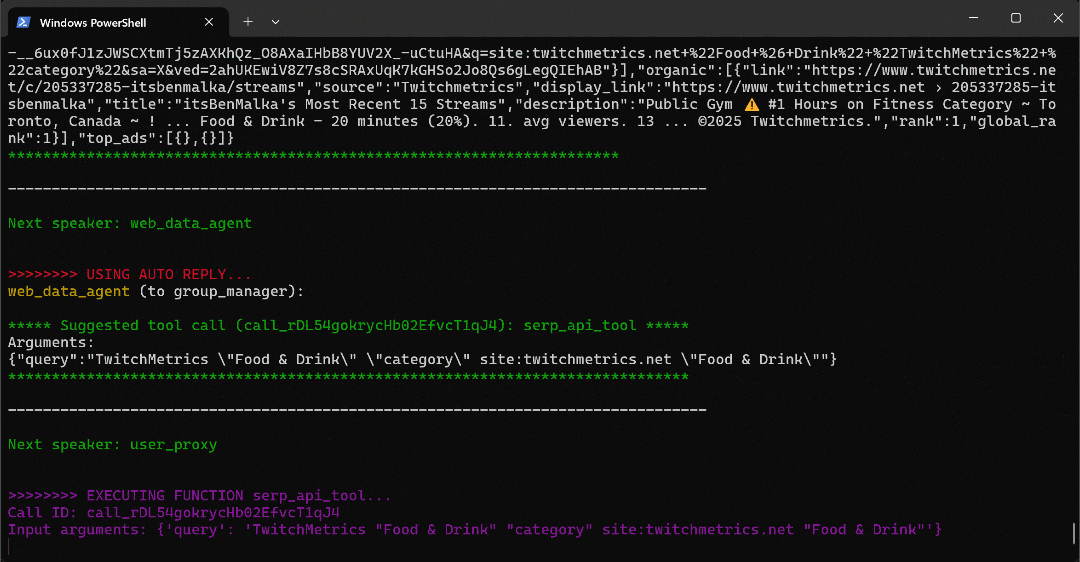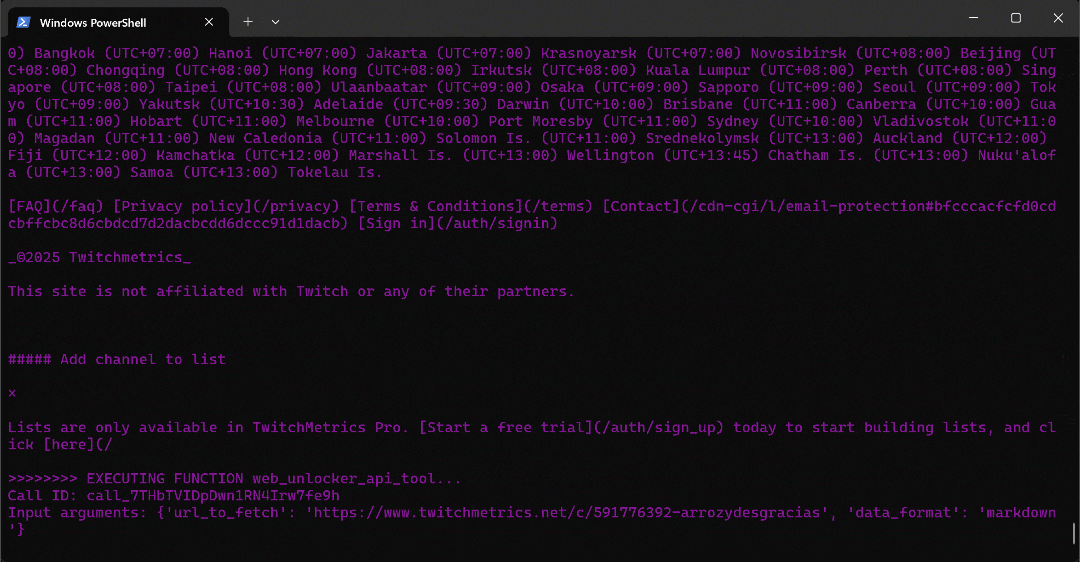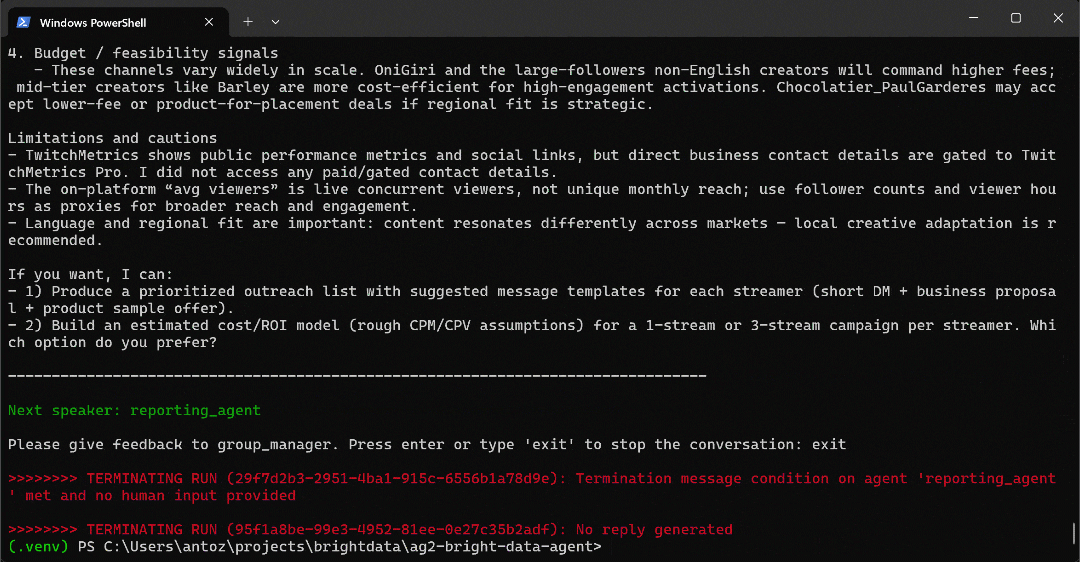
Plus précisément, notez comment le flux de travail multi-agents se déroule étape par étape :
- Le
web_data_agentdétermine qu’il doit appeler leserp_api_toolpour localiser la page de catégorie « Food & Drink » requise de TwitchMetrics. - Grâce à l’agent
user_proxy, l’outil exécute plusieurs requêtes de recherche. - Une fois la bonne page de catégorie TwitchMetrics identifiée, il appelle l’outil
web_unlocker_api_toolpour extraire le contenu au format Markdown. - À partir de la sortie Markdown, il extrait les URL des 5 profils TwitchMetrics les plus influents dans la catégorie « Food & Drink ».
- L’outil
web_unlocker_api_toolest à nouveau appelé pour récupérer le contenu de la page de chaque profil au format Markdown. - Toutes les données collectées sont transmises à
l'agent de rapport, qui les analyse et produit le rapport final.
Ce rapport final est enregistré sur le disque sous le nom report.md, comme spécifié dans le code :
Consultez-le dans VS Code à l’aide de l’aperçu Markdown pour voir à quel point le rapport est détaillé et riche en informations :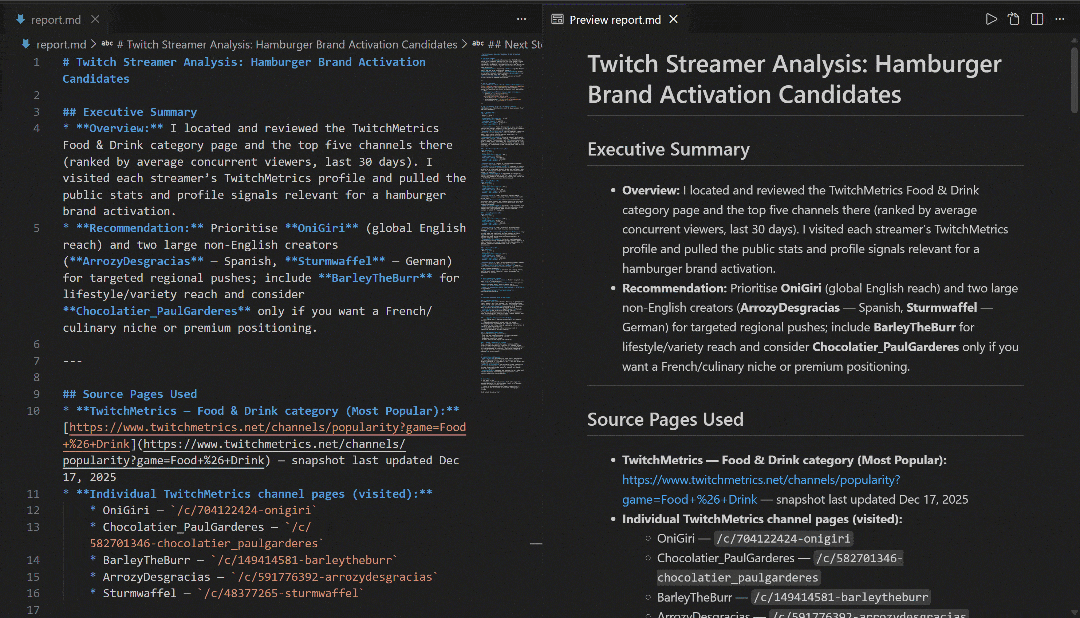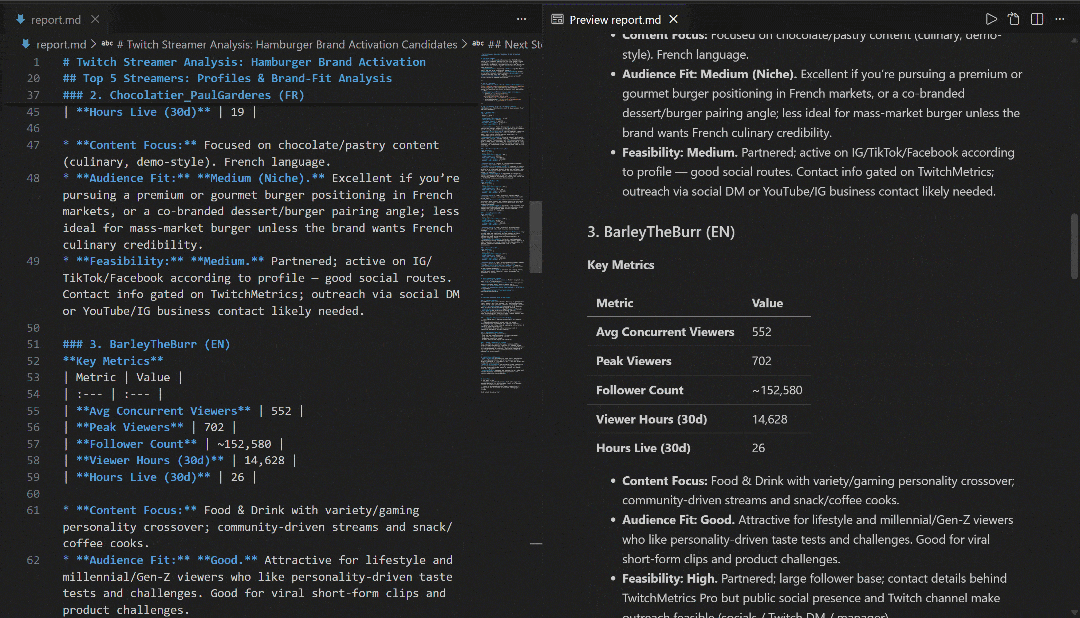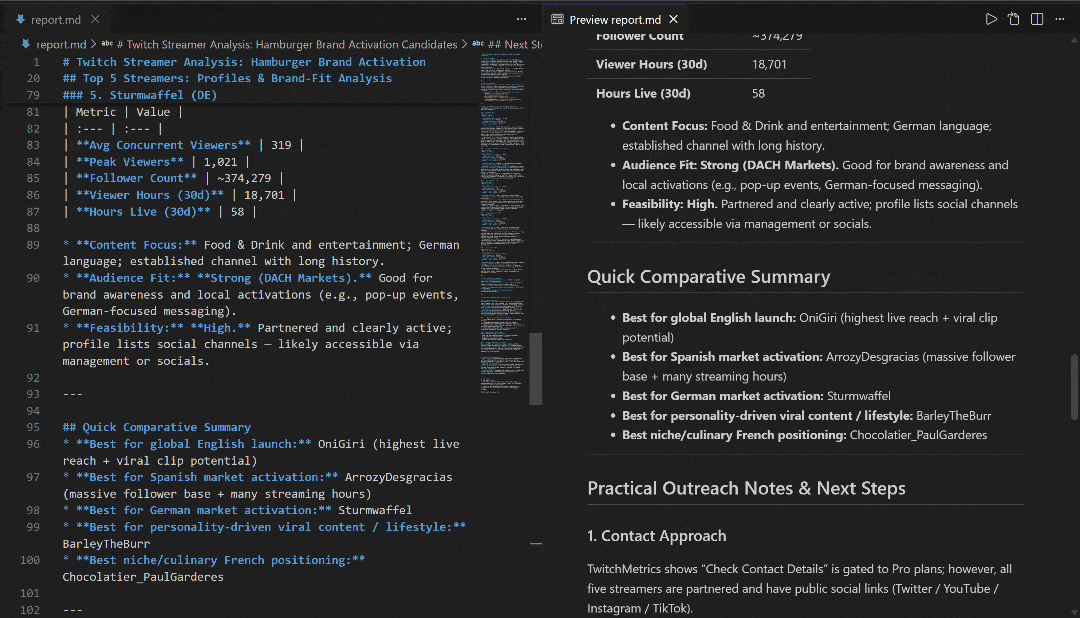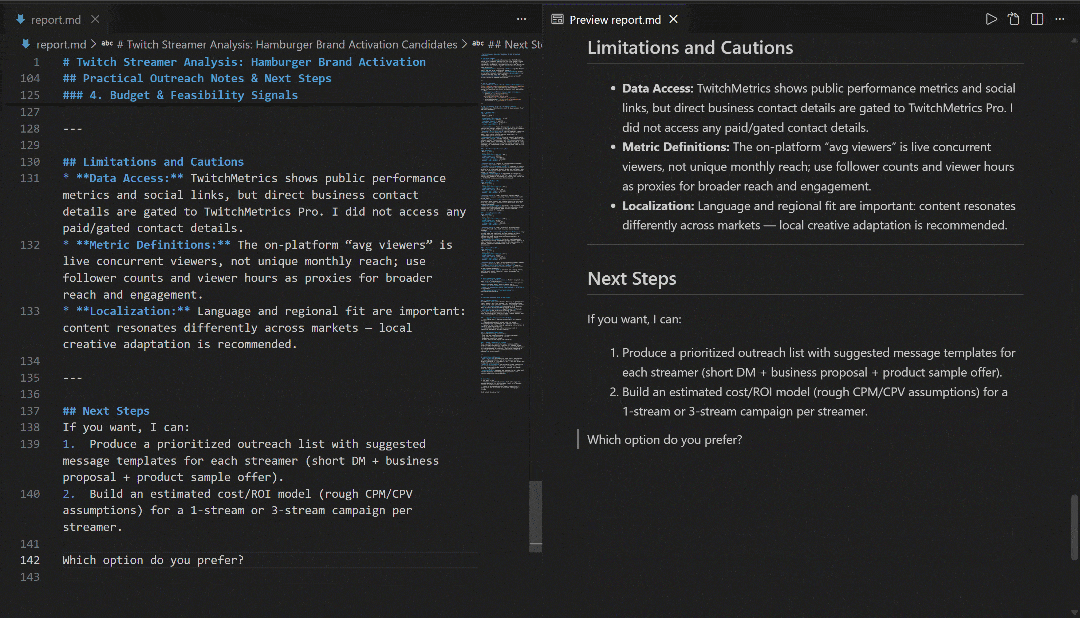
Si vous vous demandez d’où proviennent les données sources, consultez la page de la catégorie Food & Drink Twitch stream sur TwitchMetrics: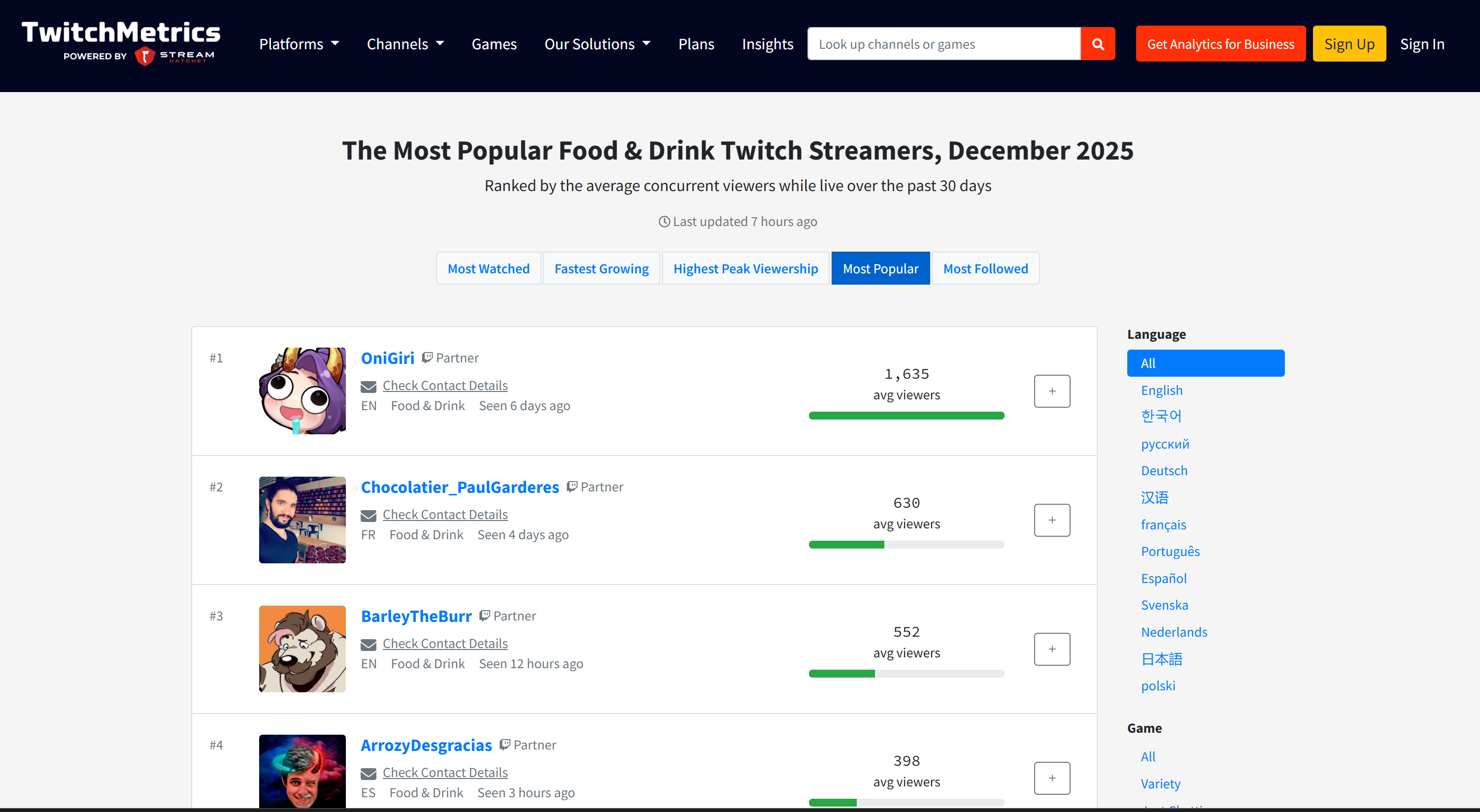
Notez que les informations sur les streamers Twitch figurant dans le rapport correspondent aux pages de profil TwitchMetrics dédiées à chacun des 5 profils les plus populaires :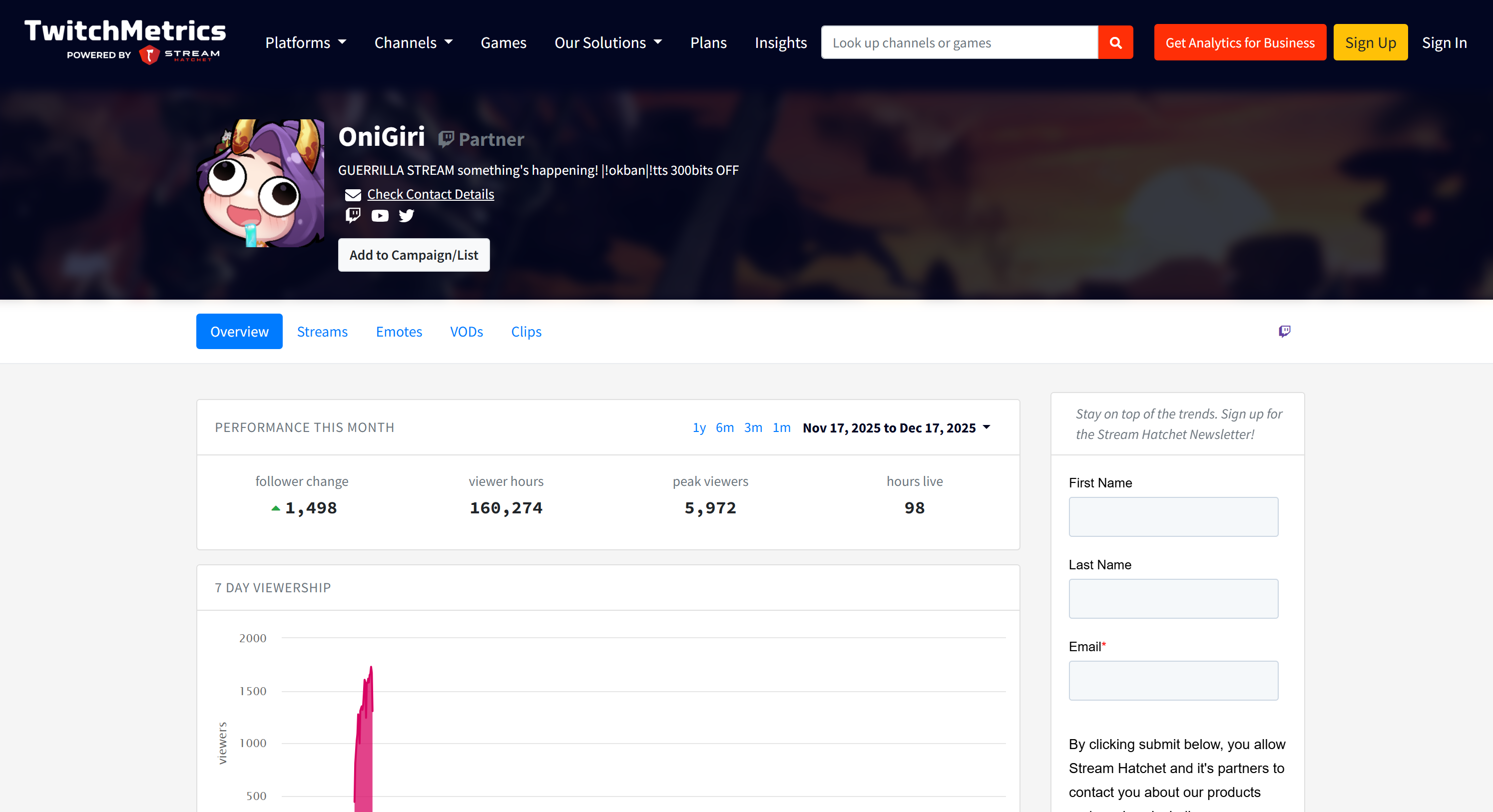
Toutes ces informations ont été récupérées automatiquement par le système multi-agents, démontrant la puissance d’AG2 et son intégration avec Bright Data.
N’hésitez pas à tester différentes invites de saisie. Grâce à Bright Data, votre workflow multi-agents AG2 peut gérer une grande variété de tâches concrètes.
Et voilà ! Vous venez de découvrir les capacités d’un flux de travail AG2 amélioré avec Bright Data
Connexion d’AG2 à Bright Data Web MCP : guide étape par étape
Une autre façon d’intégrer Bright Data à AG2 consiste à utiliser le serveur Bright Data Web MCP.
Web MCP vous donne accès à plus de 60 outils basés sur la plateforme d’automatisation web et de collecte de données de Bright Data. Même dans sa version gratuite, il offre deux outils puissants :
| Outil | Description |
|---|---|
search_engine |
Récupérez les résultats de Google, Bing ou Yandex au format JSON ou Markdown. |
scrape_as_markdown |
Récupérez n’importe quelle page web au format Markdown propre tout en contournant les mesures anti-bot. |
Le mode Pro de Web MCP va encore plus loin. Cette option premium permet l’extraction de données structurées pour les principales plateformes telles qu’Amazon, LinkedIn, Instagram, Reddit, YouTube, TikTok, Google Maps, etc. Elle ajoute également des outils pour l’automatisation avancée du navigateur.
Remarque: pour la configuration du projet, reportez-vous à l’étape n° 1 du chapitre précédent.
Voyons maintenant comment utiliser Web MCP de Bright Data dans AG2 !
Prérequis
Pour suivre cette section du tutoriel, vous devez avoir installé Node.js localement, car il est nécessaire pour exécuter Web MCP sur votre machine.
Vous devez également installer le package MCP pour AG2 avec:
pip install ag2[mcp]Cela permet à AG2 d’agir comme un client MCP.
Étape n° 1 : commencer à utiliser le Web MCP de Bright Data
Avant de connecter AG2 au Web MCP de Bright Data, assurez-vous que votre ordinateur local peut exécuter le serveur MCP. Ceci est important, car nous allons vous montrer comment vous connecter au serveur Web MCP localement.
Remarque: le Web MCP est également disponible en tant que serveur distant via Streamable HTTP, qui est plus adapté aux cas d’utilisation de niveau entreprise grâce à son évolutivité illimitée.
Tout d’abord, assurez-vous que vous disposez d’un compte Bright Data. Si c’est déjà le cas, connectez-vous simplement. Pour une configuration rapide, suivez les instructions de la section «MCP »de votre tableau de bord :
Pour plus d’informations, reportez-vous aux étapes ci-dessous.
Commencez par générer votre clé API Bright Data. Conservez-la en lieu sûr, car vous l’utiliserez bientôt pour authentifier votre instance Web MCP locale.
Ensuite, installez Web MCP globalement sur votre machine à l’aide du package @brightdata/mcp:
npm install -g @brightdata/mcpDémarrez le serveur MCP en exécutant :
API_TOKEN="<VOTRE_API_BRIGHT_DATA>" npx -y @brightdata/mcpOu, de manière équivalente, dans PowerShell :
$Env:API_TOKEN="<VOTRE_API_BRIGHT_DATA>"; npx -y @brightdata/mcpRemplacez <VOTRE_API_BRIGHT_DATA> par votre jeton API Bright Data. Ces commandes définissent la variable d’environnement API_TOKEN requise et lancent le serveur Web MCP localement.
Si l’opération réussit, vous devriez voir un résultat similaire à celui-ci :
Par défaut, Web MCP crée deux zones dans votre compte Bright Data lors du premier lancement :
mcp_unlocker: une zone pour Web Unlocker.mcp_browser: une zone pour Browser API.
Ces zones alimentent les plus de 60 outils disponibles dans Web MCP.
Vous pouvez vérifier que les zones ont bien été créées en vous rendant dans « Proxies & Infrastructure de scraping » (Proxys et Infrastructure de scraping) dans votre tableau de bord Bright Data :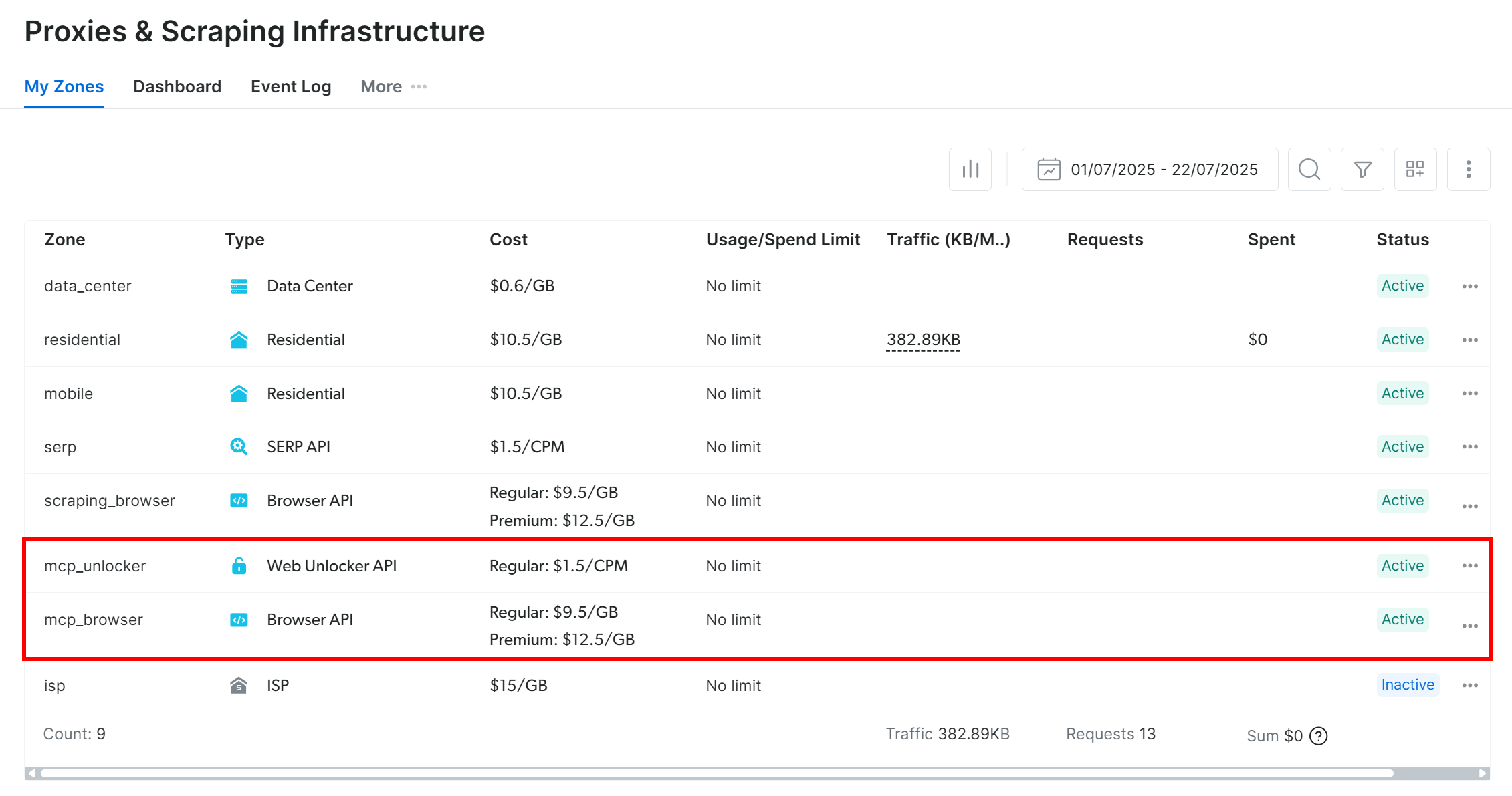
Dans la version gratuite de Web MCP, seuls les outils search_engine et scrape_as_markdown (et leurs versions batch) sont disponibles.
Pour débloquer tous les outils, activez le mode Pro en définissant la variable d’environnement PRO_MODE="true":
API_TOKEN="<YOUR_BRIGHT_DATA_API>" PRO_MODE="true" npx -y @brightdata/mcpOu, sous Windows :
$Env:API_TOKEN="<VOTRE_API_BRIGHT_DATA>"; $Env:PRO_MODE="true"; npx -y @brightdata/mcpLe mode Pro débloque plus de 60 outils, mais il n’est pas inclus dans l’offre gratuite et peut entraîner des frais supplémentaires.
C’est fait ! Vous avez maintenant vérifié que le serveur Web MCP fonctionne localement. Arrêtez le processus MCP pour l’instant, car l’étape suivante consiste à configurer AG2 pour démarrer le serveur localement et s’y connecter.
Étape n° 2 : intégration de Web MCP dans AG2
Utilisez le client AG2 MCP pour vous connecter à une instance Web MCP locale via STDIO et récupérer les outils disponibles :
from mcp import ClientSession, StdioServerParameters
from mcp.client.stdio import stdio_client
from autogen.mcp import create_toolkit
# Instructions pour se connecter à une instance Web MCP locale
server_params = StdioServerParameters(
command="npx",
args=["-y", "@brightdata/mcp"],
env={
"API_TOKEN": BRIGHT_DATA_API_KEY,
"PRO_MODE": "true" # Facultatif
},)
async with stdio_client(server_params) as (read, write), ClientSession(read, write) as session:
# Créer une session de connexion MCP et récupérer les outils
await session.initialize()
web_mcp_toolkit = await create_toolkit(session, use_mcp_resources=False)L’objet StdioServerParameters reflète la commande npx que vous avez exécutée précédemment, y compris les variables d’environnement pour les informations d’identification et les paramètres :
API_TOKEN: obligatoire. Définissez votre clé API Bright Data.PRO_MODE: facultatif. Supprimez-le si vous souhaitez rester sur le niveau gratuit (search_engineetscrape_as_markdownet leurs versions batch uniquement).
La session est utilisée pour se connecter à Web MCP et créer une boîte à outils AG2 MCP à l’aide de create_toolkit.
Remarque: comme souligné dans un ticket GitHub dédié, l’option use_mcp_resources=False est requise pour éviter l’erreur mcp.shared.exceptions.McpError: Method not found.
Une fois créé, l’objet web_mcp_toolkit contient tous les outils Web MCP. Vérifiez cela avec :
for tool in web_mcp_toolkit.tools:
print(tool.name)
print(tool.description)
print("---n")Le résultat sera :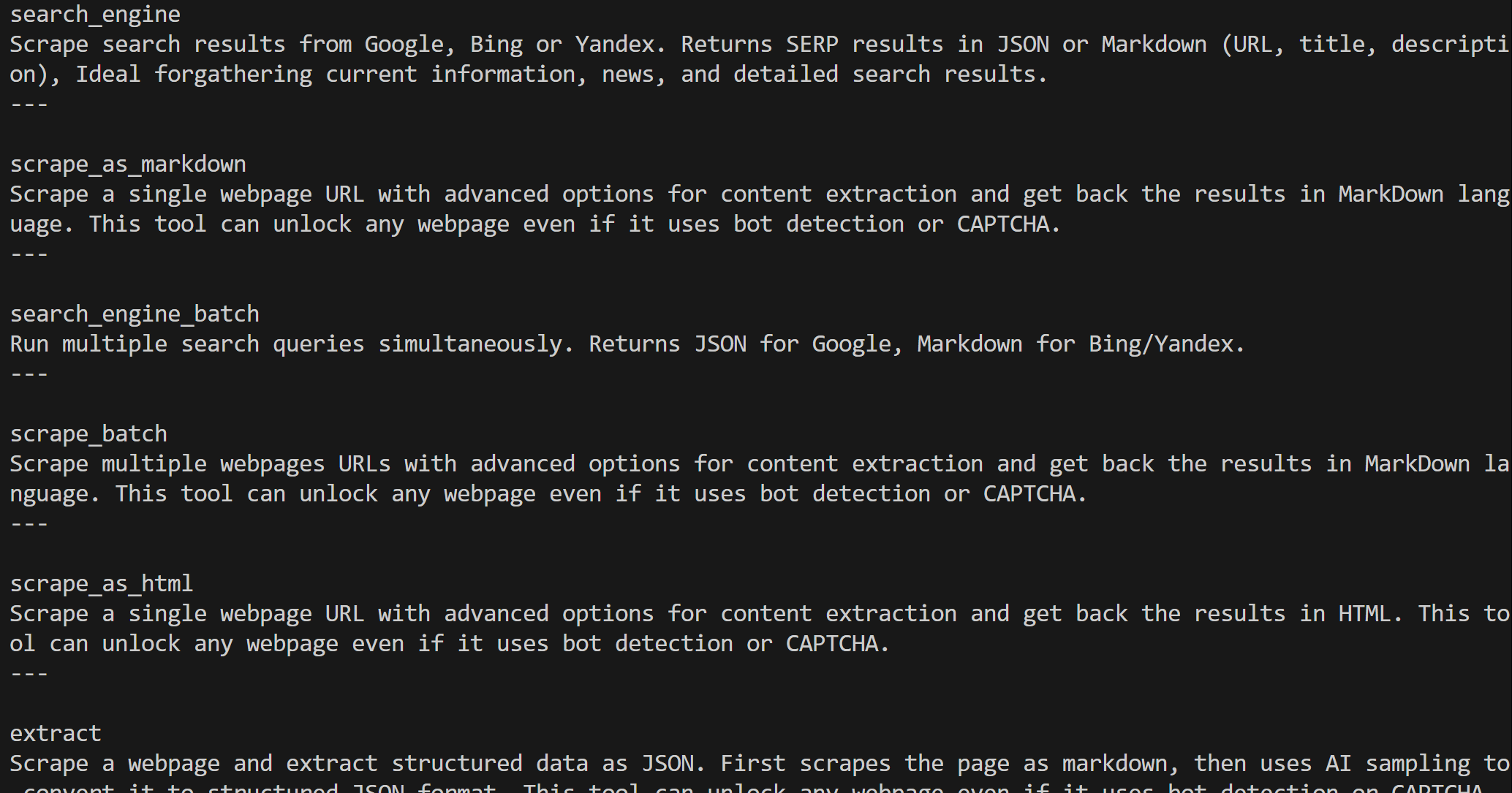
En fonction du niveau configuré, vous disposerez soit de l’ensemble des 60+ outils Web MCP (mode Pro), soit uniquement des outils du niveau gratuit.
Excellent ! Votre connexion Web MCP est désormais pleinement fonctionnelle dans AG2.
Étape n° 3 : connecter les outils Web MCP à un agent
La façon la plus simple de tester l’intégration Web MCP dans AG2 est d’utiliser AssistantAgent, une sous-classe de ConversableAgent conçue pour résoudre rapidement des tâches à l’aide du LLM. Commencez par définir l’agent et enregistrez-y la boîte à outils Web MCP :
from autogen import AssistantAgent
# Définir un agent capable de rechercher et de récupérer des données Web
assistant_agent = AssistantAgent(
name="assistant",
code_execution_config=False,
llm_config=llm_config,
system_message="""
Vous avez accès à tous les outils exposés par le Web MCP, notamment :
- Recherche Web
- Scraping web et récupération de pages
- Flux de données Web
- Simulation d'utilisateur basée sur un navigateur
Utilisez ces outils lorsque cela est nécessaire.
""")
# Enregistrer les outils Web MCP auprès de l'agent
web_mcp_toolkit.register_for_llm(assistant_agent)Une fois enregistré, vous pouvez lancer l’agent à l’aide de la fonction a_run() et spécifier directement les outils à utiliser. Voici, par exemple, comment tester l’agent sur une tâche de Scraping web Amazon :
prompt = """
Récupérez les données du produit Amazon suivant et produisez un résumé rapide avec les informations principales :
"""
# Exécutez l'agent Web MCP étendu de manière asynchrone.
result = await assistant_agent.a_run(
message=prompt,
tools=web_mcp_toolkit.tools,
user_input=False,)
await result.process()Important: gardez à l’esprit qu’il s’agit uniquement d’une démonstration visant à présenter l’intégration. Grâce à tous les outils Web MCP, l’agent peut gérer des tâches beaucoup plus complexes, en plusieurs étapes, sur différentes plateformes Web et sources de données.
Étape n° 4 : code final + exécution
Vous trouverez ci-dessous le code final pour votre intégration AG2 + Bright Data Web MCP :
import asyncio
from autogen import (
LLMConfig,
AssistantAgent,)
from dotenv import load_dotenv
import os
from mcp import ClientSession, StdioServerParameters
from mcp.client.stdio import stdio_client
from autogen.mcp import create_toolkit
# Charger les variables d'environnement à partir du fichier .env
load_dotenv()
# Récupérer la clé API Bright Data à partir des variables d'environnement
BRIGHT_DATA_API_KEY = os.getenv("BRIGHT_DATA_API_KEY")
# Définir la boîte à outils MCP contenant tous les outils Web MCP
async def launch_mcp_agent():
# Charger la configuration LLM à partir du fichier de liste de configuration OpenAI
llm_config = LLMConfig.from_json(path="OAI_CONFIG_LIST")
# Instructions pour se connecter à une instance Web MCP locale
server_params = StdioServerParameters(
command="npx",
args=["-y", "@brightdata/mcp"],
env={
"API_TOKEN": BRIGHT_DATA_API_KEY,
"PRO_MODE": "true" # Facultatif
},
)
async with stdio_client(server_params) as (read, write), ClientSession(read, write) as session:
# Créer une session de connexion MCP et récupérer les outils
await session.initialize()
web_mcp_toolkit = await create_toolkit(session, use_mcp_resources=False)
# Définir un agent capable de rechercher et de récupérer des données Web
assistant_agent = AssistantAgent(
name="assistant",
code_execution_config=False,
llm_config=llm_config,
system_message="""
Vous avez accès à tous les outils exposés par le Web MCP, notamment :
- Recherche Web
- Scraping web et récupération de pages
- Flux de données Web
- Simulation utilisateur basée sur un navigateur
Utilisez ces outils lorsque cela est nécessaire.
"""
)
# Enregistrer les outils Web MCP auprès de l'agent
web_mcp_toolkit.register_for_llm(assistant_agent)
# Invite à transmettre à l'agent
prompt = """
Récupérez les données du produit Amazon suivant et produisez un résumé rapide contenant les informations principales :
"""
# Exécutez l'agent Web MCP étendu de manière asynchrone
result = await assistant_agent.a_run(
message=prompt,
tools=web_mcp_toolkit.tools,
user_input=False,
)
await result.process()
asyncio.run(launch_mcp_agent())Exécutez-le, et le résultat sera :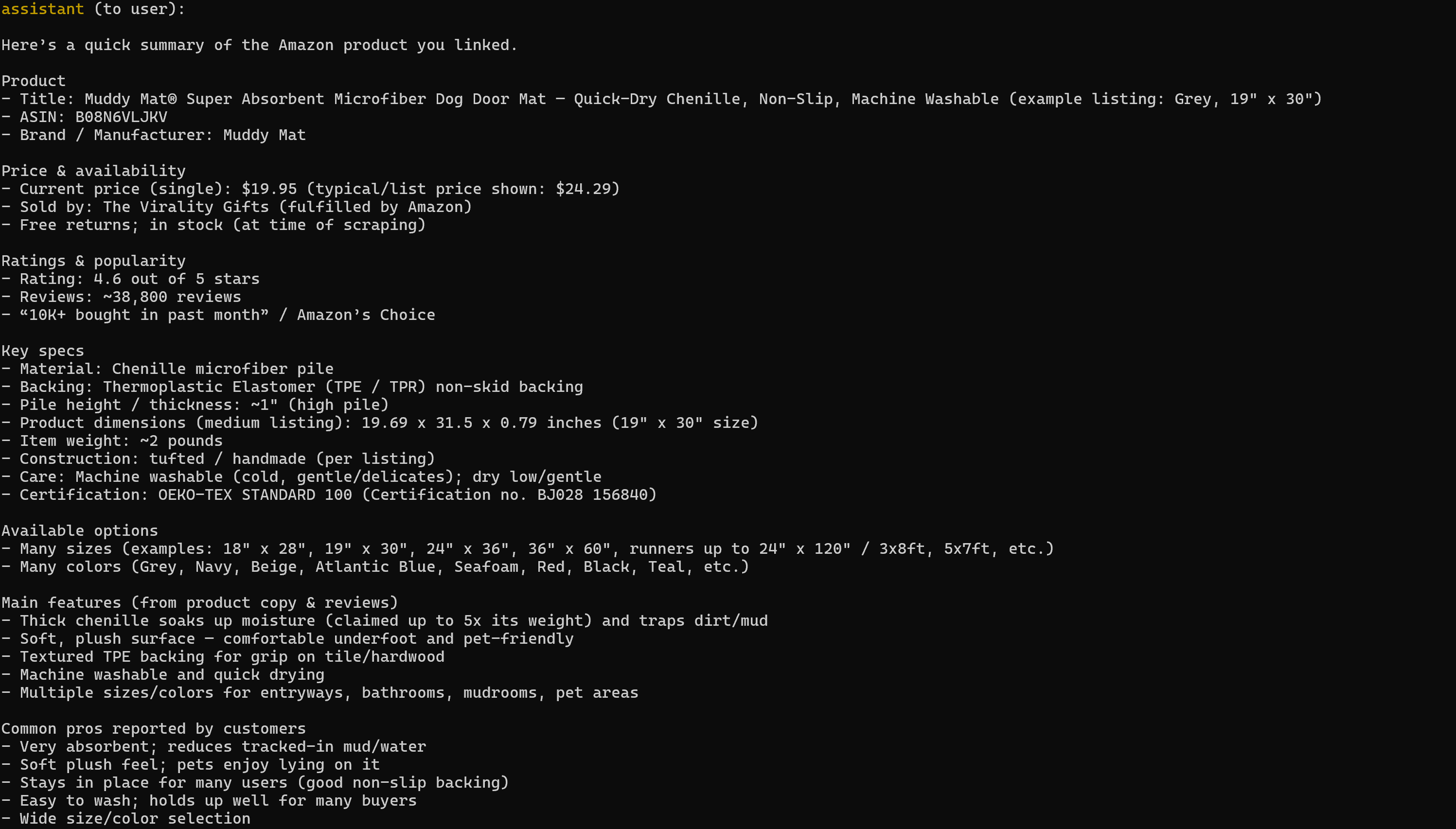
Notez que le rapport généré comprend toutes les données pertinentes de la page produit Amazon cible :
Si vous avez déjà essayé d’extraire des données de produits Amazon en Python, vous savez que ce n’est pas une mince affaire. Amazon utilise le CAPTCHA Amazon, réputé pour sa difficulté, ainsi que d’autres mesures anti-bot. De plus, les pages de produits changent constamment et ont des structures variables.
Web MCP de Bright Data s’occupe de tout cela pour vous. Dans la version gratuite, il appelle l’outil scrape_as_markdown en arrière-plan pour récupérer la structure de la page dans un format Markdown propre via Web Unlocker. En mode Pro, il utilise le produit web_data_amazon_product, qui appelle Amazon Scraper de Bright Data pour recueillir des données de produits entièrement structurées.
Et voilà ! Vous savez maintenant comment étendre AG2 avec Bright Data Web MCP.
Conclusion
Dans ce tutoriel, vous avez appris à intégrer Bright Data à AG2, soit via des fonctions personnalisées, soit via Web MCP.
Cette intégration permet aux agents AG2 d’effectuer des recherches sur le web, d’extraire des données structurées, d’accéder à des flux web en direct et d’automatiser les interactions web. Tout cela est rendu possible grâce à la suite de services pour l’IA de Bright Data.
Créez gratuitement un compte Bright Data et commencez dès aujourd’hui à explorer nos outils de données web compatibles avec l’IA !




