

Ce tutoriel vous apprendra à créer un script de Scraping web en Kotlin. Plus précisément, vous apprendrez :
- Pourquoi Kotlin est un excellent langage pour le scraping d’un site
- Quelles sont les meilleures bibliothèques de scraping Kotlin.
- Comment créer un Scraper Kotlin à partir de zéro.
C’est parti !
Kotlin est-il une option viable pour le Scraping web ?
TL;DR: Oui, tout à fait ! Et il peut même être meilleur que Java !
Kotlin est un langage de programmation polyvalent, statique et multiplateforme, dont la bibliothèque standard dépend de la bibliothèque de classes Java. Ce qui rend Kotlin spécial, c’est son approche concise et ludique du codage. Il est approuvé par Google, qui l’a choisi comme langage préféré pour le développement Android.
Grâce à son interopérabilité avec la JVM, il prend en charge toutes les bibliothèques de scraping Java. Vous pouvez ainsi profiter du vaste écosystème des bibliothèques Java, mais avec une syntaxe plus concise et intuitive. C’est une situation gagnant-gagnant !
De plus, Kotlin est livré avec certaines bibliothèques natives, notamment des analyseurs HTML et des bibliothèques d’automatisation de navigateur, qui simplifient l’extraction de données. Découvrez certaines des plus populaires !
Meilleures bibliothèques de Scraping web Kotlin
Voici une liste de certaines des meilleures bibliothèques de Scraping web pour Kotlin :
- skrape{it}: une bibliothèque de test HTML/XML et de Scraping web basée sur Kotlin pour analyser et interpréter le HTML. Elle comprend plusieurs récupérateurs de données qui permettent à skrape{it} d’agir à la fois comme un analyseur HTML traditionnel et comme un navigateur de scraping sans interface graphique pour le rendu DOM côté client.
- chrome-reactive-kotlin: un client DevTools Protocol de bas niveau écrit en Kotlin pour contrôler par programmation les navigateurs basés sur Chromium.
- ksoup: une bibliothèque Kotlin légère inspirée de Jsoup. Ksoup fournit des méthodes pour analyser le HTML, extraire les balises, les attributs et le texte HTML, et encoder et décoder les entités HTML.
N’oubliez pas que Kotlin est interopérable avec Java. Cela signifie que vous pouvez utiliser n’importe quelle autre bibliothèque de Scraping web en Java. L’une d’entre elles est Jsoup, l’un des analyseurs HTML les plus populaires disponibles. Pour en savoir plus, consultez notre guide sur le Scraping web avec Jsoup.
Prérequis
Suivez les instructions ci-dessous pour configurer votre environnement Kotlin de Scraping web.
Configurer l’environnement
Pour écrire et exécuter une application Kotlin sur votre machine, vous devez disposer d’un JDK (Java Development Kit) installé localement. Téléchargez la dernière version LTS du JDK sur le site Oracle, exécutez le programme d’installation et suivez l’assistant d’installation. À l’heure où nous écrivons ces lignes, il s’agit de Java 21.
Vous aurez ensuite besoin d’un outil pour gérer les dépendances et créer votre application Kotlin. Gradle et Maven sont deux excellentes options, vous pouvez donc choisir librement votre outil de création Java préféré. Étant donné que Gradle prend en charge Kotlin en tant que langage DSL (Domain-Specific Language), nous opterons pour Gradle. N’oubliez pas que vous pouvez facilement suivre le tutoriel même si vous êtes un utilisateur de Maven.
Téléchargez Maven ou Gradle et installez-le. Gradle est particulièrement sensible à la version de Java, veillez donc à télécharger le bon package. La version de Gradle compatible avec Java 21 est supérieure ou égale à la version 8.5.
Enfin, vous aurez besoin d’un IDE Kotlin. Visual Studio Code avec l’extension Kotlin Language et IntelliJ IDEA Community Edition sont deux excellents choix gratuits.
C’est fait ! Vous disposez désormais d’un environnement prêt pour Kotlin !
Créer un projet Kotlin
Créez un dossier pour votre projet de Scraping web Kotlin et entrez-le dans le terminal :
mkdir KotlinWebScraper
cd KotlinWebScraperIci, nous avons appelé le répertoire KotlinWebScraper, mais vous pouvez lui donner le nom que vous souhaitez.
Ensuite, lancez la commande ci-dessous dans le dossier du projet pour créer une application Gradle :
gradle init --type kotlin-applicationAu cours de la procédure, quelques questions vous seront posées. Vous devez choisir « Kotlin » comme script DSL de compilation et donner à votre application un nom de package approprié, tel que com.kotlin.scraper. Pour les autres questions, les réponses par défaut devraient convenir.
Voici ce que vous verrez à la fin du processus d’initialisation :
Sélectionnez le script de compilation DSL :
1 : Kotlin
2 : Groovy
Entrez votre sélection (par défaut : Kotlin) [1..2] 1
Nom du projet (par défaut : KotlinWebScraper) :
Paquet source (par défaut : kotlinwebscraper) : com.kotlin.scraper
Entrez la version cible de Java (min. 8) (par défaut : 21) :
Générer la compilation à l'aide des nouvelles API et du nouveau comportement (certaines fonctionnalités peuvent changer dans la prochaine version mineure) ? (par défaut : non) [oui, non]
> Tâche :init
Pour en savoir plus sur Gradle, explorez nos exemples sur https://docs.gradle.org/8.5/samples/sample_building_kotlin_applications.html
COMPILATION RÉUSSIE en 2 min 10 s
2 tâches exécutables : 2 exécutéesFantastique ! Le dossier KotlinWebScraper contient désormais un projet Gradle.
Ouvrez le dossier dans votre IDE Kotlin, attendez que les tâches d’arrière-plan requises soient terminées, puis consultez le fichier App.kt principal dans le package com.kotlin.scraper. Voici ce qu’il devrait contenir :
/*
* Ce fichier source Kotlin a été généré par la tâche « init » de Gradle.
*/
package com.kotlin.scraping.demo
class App {
val greeting: String
get() {
return "Hello World!"
}
}
fun main() {
println(App().greeting)
}Il s’agit d’un script Kotlin simple qui affiche « Hello World ! » dans le terminal.
Pour vérifier qu’il fonctionne, lancez le script à l’aide de la commande Gradle suivante :
./gradlew runAttendez que le projet soit compilé et exécuté, puis vous verrez s’afficher :
> Task :app:run
Hello World!
BUILD SUCCESSFUL in 3s
3 actionable tasks: 2 executed, 1 up-to-dateVous pouvez ignorer les messages du journal Gradle. Concentrez-vous plutôt sur le message « Hello World! », qui correspond exactement au résultat attendu du script. En d’autres termes, votre configuration Kotlin fonctionne comme prévu.
Il est temps de procéder au Scraping web avec Kotlin !
Créer un script Kotlin de Scraping web
Dans cette section étape par étape, vous verrez comment créer un Scraper web dans Kotlin. Vous apprendrez notamment à définir un script automatisé qui extrait des données du site de scraping Quotes.
À un niveau élevé, le script de Scraping web Kotlin que vous êtes sur le point de coder va :
- Se connecter à la page cible.
- Sélectionner les éléments HTML des citations sur la page.
- Extraire les données souhaitées à partir de ceux-ci.
- Répéter cette opération pour toutes les citations du site, en visitant chaque page de pagination.
- Exporter les données collectées au format CSV.
Voici à quoi ressemble le site cible :
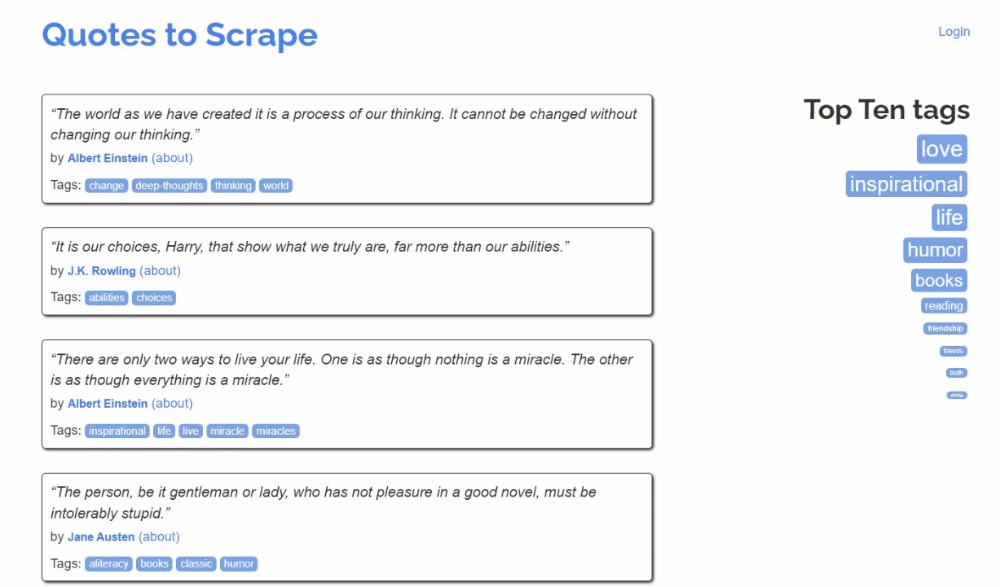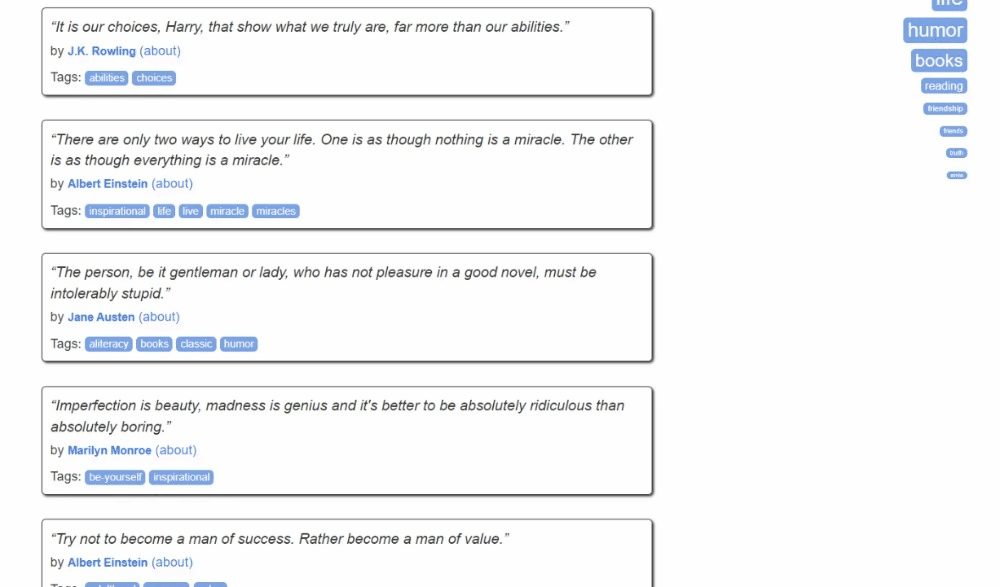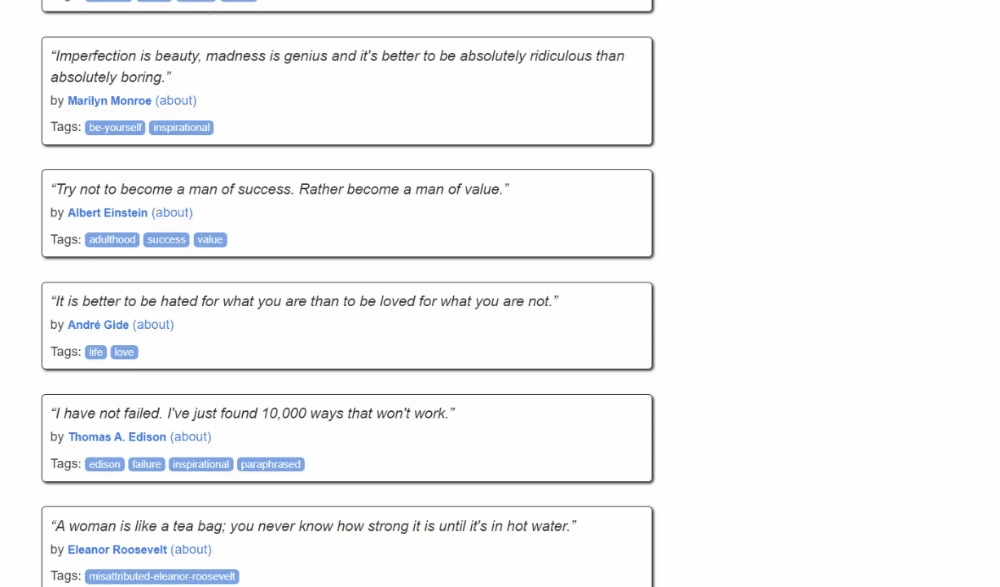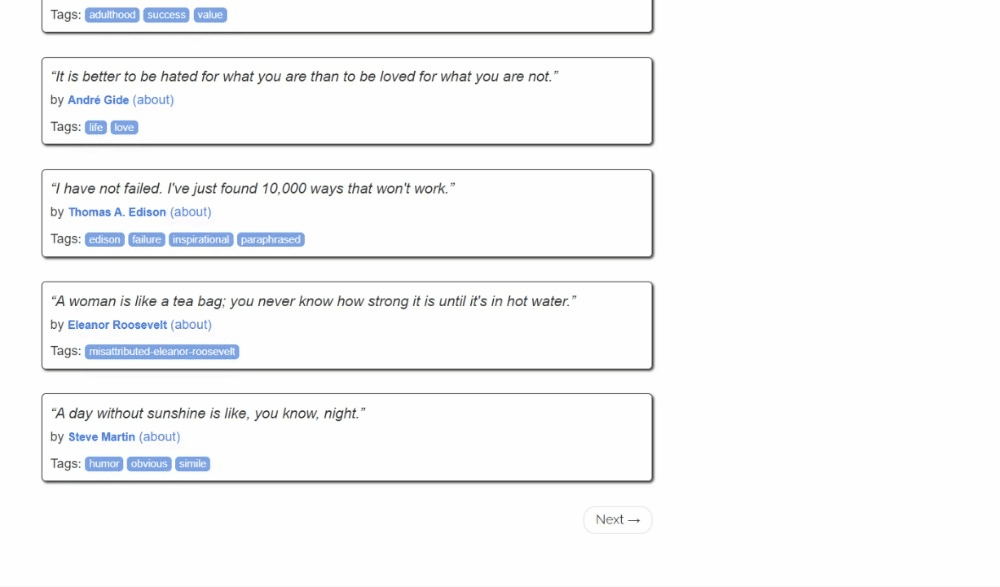
Suivez les étapes ci-dessous et découvrez comment effectuer du Scraping web dans Kotlin !
Étape 1 : Installez la bibliothèque de scraping
La première chose à faire est de déterminer quelles bibliothèques de Scraping web Kotlin sont les mieux adaptées à vos objectifs. Pour cela, vous devez inspecter le site cible.
Rendez-vous donc sur le site sandbox Quotes To Scrape dans votre navigateur. Cliquez avec le bouton droit de la souris sur une section vide et sélectionnez l’option « Inspecter » pour ouvrir les DevTools. Accédez à l’onglet « Réseau », rechargez la page et explorez la section « Fetch/XHR ».
Voici ce que vous devriez voir :
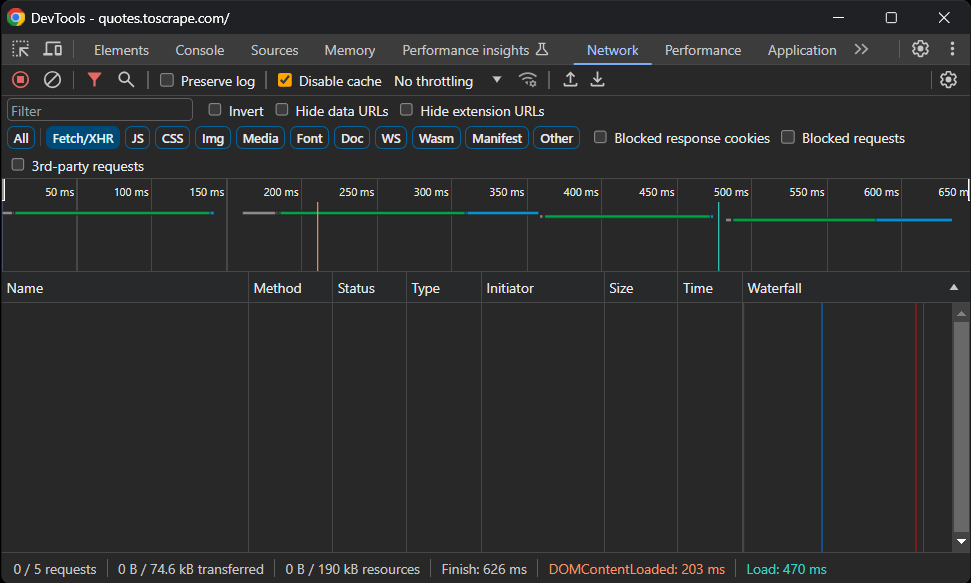
Aucune requête AJAX! En d’autres termes, la page cible ne récupère pas les données de manière dynamique via JavaScript. Cela signifie que le serveur renvoie les pages aux clients avec toutes les données d’intérêt intégrées dans le code HTML.
Par conséquent, une bibliothèque d’analyse HTML fera très bien l’affaire. Vous pouvez toujours utiliser un outil d’automatisation du navigateur, mais le chargement et le rendu de la page dans un navigateur n’apporteraient qu’une surcharge de performance sans réel avantage.
Ainsi, skrape{it} sera un excellent choix pour atteindre l’objectif de Scraping web. Ajoutez-le aux dépendances de votre projet avec cette ligne dans l’objet dependencies de votre fichier build.gradle.kts :
implementation("it.skrape:skrapeit:1.2.2")Sinon, si vous êtes un utilisateur de Maven, ajoutez ces lignes à la balise <dependencies> dans votre pom.xml :
<dependency>
<groupId>it.skrape</groupId>
<artifactId>skrapeit</artifactId>
<version>1.2.2</version>
</dependency>Si vous utilisez IntelliJ IDEA, l’IDE affichera un bouton permettant de recharger les dépendances du projet et d’installer la nouvelle bibliothèque. Cliquez dessus pour installer skrape{it}.
Vous pouvez également installer manuellement la nouvelle dépendance à l’aide de cette commande Gradle :
./gradlew build --refresh-dependenciesLe processus d’installation peut prendre un certain temps, soyez donc patient.
Ensuite, préparez-vous à utiliser skrape{it} dans votre script App.kt en y ajoutant les importations suivantes :
import it.skrape.core.*
import it.skrape.fetcher.*N’oubliez pas que kkrape{it} est fourni avec de nombreux récupérateurs de données. Ici, nous les avons tous importés par souci de simplicité. En réalité, vous n’aurez besoin que de HttpFetcher, un client HTTP classique qui envoie une requête HTTP à l’URL donnée et renvoie une réponse analysée.
Super ! Vous disposez désormais de tout ce dont vous avez besoin pour effectuer du Scraping web avec Kotlin !
Étape 2 : Téléchargez la page cible et effectuez l’analyse de son code HTML
Dans App.kt, supprimez la classe App et ajoutez les lignes suivantes dans la fonction main() pour vous connecter à la page cible à l’aide de skrape{it} :
skrape(HttpFetcher) {
// envoyer une requête HTTP GET à l'URL spécifiée
request {
url = "https://quotes.toscrape.com/"
}
}En arrière-plan, skrape{it} utilisera la classe HttpFetcher mentionnée précédemment pour effectuer une requête HTTP GET synchrone vers l’URL donnée.
Si vous voulez vous assurer que le script fonctionne comme prévu, ajoutez la section suivante dans la définition skrape(HttpFetcher) :
response {
// récupérer le code source HTML et l'imprimer
htmlDocument {
print(html)
}
}Cela indique à skrape{it} ce qu’il doit faire avec la réponse du serveur. Plus précisément, il accède à la réponse analysée, puis imprime le code HTML de la page.
Votre script de scraping App.kt Kotlin devrait désormais contenir :
package com.kotlin.scraper
import it.skrape.core.*
import it.skrape.fetcher.*
fun main() {
skrape(HttpFetcher) {
// effectue une requête HTTP GET vers l'URL spécifiée
request {
url = "https://quotes.toscrape.com/"
}
response {
// récupérer le code source HTML et l'imprimer
htmlDocument {
print(html)
}
}
}
}Exécutez le script et il affichera :
<!doctype html>
<html lang="en">
<head>
<meta charset="UTF-8">
<title>Citations à extraire</title>
<link rel="stylesheet" href="/static/bootstrap.min.css">
<link rel="stylesheet" href="/static/main.css">
</head>
<body>
<!-- omis pour plus de concision... -->C’est exactement le code HTML de la page cible. Bravo !
Étape 3 : inspecter le contenu de la page
L’étape suivante consiste à définir la logique de scraping. Mais comment faire sans savoir comment sélectionner les éléments de la page ? C’est pourquoi il est important de prendre le temps d’inspecter la structure de la page cible.
Ouvrez à nouveau Quotes To Scrape dans votre navigateur. Cliquez avec le bouton droit sur un élément de citation et sélectionnez « Inspecter » pour ouvrir les DevTools comme ci-dessous :
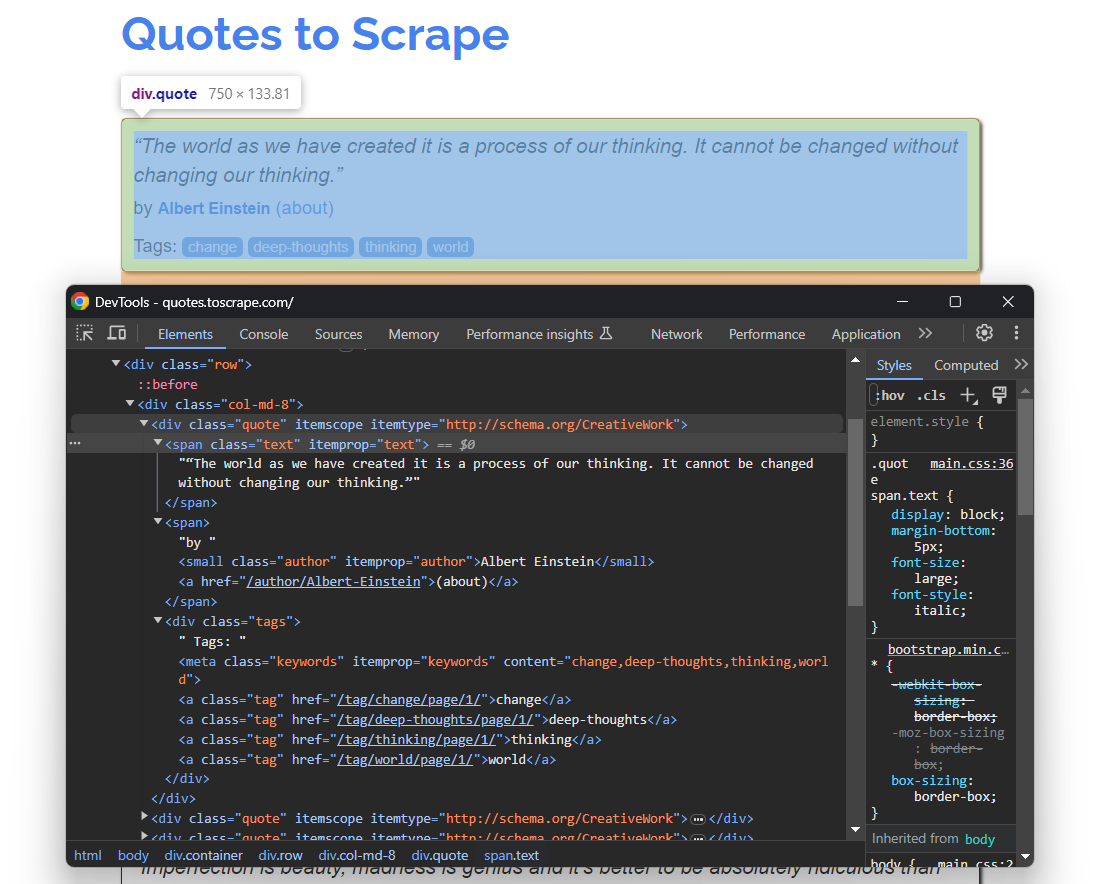
Ici, vous pouvez remarquer que chaque carte de citation est un élément HTML .quote qui encapsule :
- Un élément .text avec le texte de la citation.
- Un élément .author avec le nom de l’auteur.
- Plusieurs éléments .tag, chacun affichant une seule balise.
Notez que toutes les citations ne comportent pas la section tag :

Les sélecteurs CSS ci-dessus vous aideront à sélectionner les éléments DOM souhaités sur la page afin d’en extraire les données. Vous aurez également besoin d’une classe dans laquelle stocker ces données. Ajoutez donc la définition de classe Quote suivante en haut de votre script Kotlin de Scraping web :
class Quote(var text: String, var author: String, tags: List<String>?) {
var tags: MutableList<String> = ArrayList()
init {
if (tags != null) {
this.tags.addAll(tags)
}
}
}Comme la page contient plusieurs citations, instanciez une liste d’objets Quote dans main() :
val quotes: MutableList<Quote> = ArrayList()À la fin du script, quotes contiendra toutes les citations collectées sur le site.
Utilisez ce que vous avez compris et défini ici pour implémenter la logique de scraping à l’étape suivante !
Étape 4 : implémentez la logique de scraping
skrape{it} a une façon particulière de sélectionner les nœuds HTML sur une page. Pour appliquer un sélecteur CSS sur la page, vous devez définir une section dans htmlDocument avec le même nom que le sélecteur CSS :
skrape(HttpFetcher) {
// section de requête...
response {
htmlDocument {
// sélectionner tous les éléments HTML « .quote » de la page
«.quote» {
// logique de scraping...
}
}
}
}À l’intérieur de la section « .quote », vous pouvez ensuite définir une section findAll. Celle-ci contiendra la logique qui sera appliquée à chaque nœud HTML quote sélectionné avec le sélecteur CSS spécifié. À la place, findFirst vous permettra d’obtenir uniquement le premier élément sélectionné.
En coulisses, toutes ces sections ne sont rien d’autre que des fonctions lambda Kotlin. De ce fait, vous pouvez accéder à l’élément DOM unique avec celui-ci dans une section forEach à l’intérieur de findAll. Si vous n’êtes pas familier avec cela, il s’agit du nom implicite d’un paramètre unique dans un lambda.
Il suit une logique similaire, mais basée sur des méthodes et des attributs. Vous pouvez ensuite implémenter une logique de scraping pour extraire les données souhaitées de chaque citation, instancier un objet Quote et l’ajouter à la liste des citations comme suit :
".quote" {
findAll {
forEach {
// logique de scraping sur un élément de citation unique
val text = it.findFirst(".text").text
val author = it.findFirst(".author").text
val tags = try {
it.findAll(".tag").map { tag -> tag.text }
} catch(e: ElementNotFoundException) {
null
}
// créer un objet Quote et l'ajouter à la liste
val quote = Quote(
text = text,
author = author,
tags = tags
)
quotes.add(quote)
}
}
}Grâce à l’attribut text, vous pouvez récupérer le texte interne d’un élément HTML. Étant donné que tous les éléments HTML quote ne contiennent pas de balises, vous devez gérer l’exception ElementNotFoundException. Celle-ci est levée par findAll lorsque le sélecteur CSS donné ne correspond à aucun nœud de la page.
Importez ElementNotFoundException avec :
import it.skrape.selects.ElementNotFoundException
Assemblez tous les extraits et enregistrez les données contenues dans le tableau quotes :
package com.kotlin.scraper
import it.skrape.core.*
import it.skrape.fetcher.*
import it.skrape.selects.ElementNotFoundException
// définir une classe pour représenter les données extraites dans Kotlin
class Quote(var text: String, var author: String, tags: List<String>?) {
var tags: MutableList<String> = ArrayList()
init {
if (tags != null) {
this.tags.addAll(tags)
}
}
}
fun main() {
// où stocker les données récupérées
val quotes: MutableList<Quote> = ArrayList()
skrape(HttpFetcher) {
// envoyer une requête HTTP GET à l'URL spécifiée
request {
url = "https://quotes.toscrape.com/"
}
response {
htmlDocument {
// sélectionner tous les éléments HTML « .quote » de la page
.quote {
findAll {
forEach {
// logique de scraping sur un seul élément quote
val text = it.findFirst(".text").text
val author = it.findFirst(".author").text
val tags = try {
it.findAll(".tag").map { tag -> tag.text }
} catch(e: ElementNotFoundException) {
null
}
// création d'un objet Quote et ajout à la liste
val quote = Quote(
text = text,
author = author,
tags = tags
)
quotes.add(quote)
}
}
}
}
}
}
// enregistrer les données récupérées
for (quote in quotes) {
println("Texte : ${quote.text}")
println("Auteur : ${quote.author}")
println("Balises : ${quote.tags.joinToString("; ")}")
println()
}
}Notez l’utilisation de joingToString() pour fusionner la liste des balises en une chaîne séparée par des virgules.
Si vous exécutez le script, vous obtiendrez :
Texte : « Le monde tel que nous l'avons créé est le résultat de notre pensée. Il ne peut être changé sans changer notre façon de penser. »
Auteur : Albert Einstein
Balises : changement ; réflexions profondes ; pensée ; monde
# omis pour plus de concision...
Texte : « Une journée sans soleil, c'est comme, vous savez, la nuit. »
Auteur : Steve Martin
Balises : humour ; évident ; comparaisonWaouh ! Vous venez d’apprendre à effectuer du Scraping web avec Kotlin !
Étape 5 : Ajouter la logique de crawling
Vous venez de scraper les données d’une seule page, mais la liste des citations s’étend sur plusieurs pages. Si vous faites défiler la page jusqu’à la fin, vous remarquerez un bouton « Suivant → » avec un lien vers la page suivante :
C’est le cas pour toutes les pages sauf la dernière :
Pour effectuer un crawling web dans Kotlin et extraire chaque citation du site, vous devez ensuite :
- Extraire toutes les citations de la page actuelle.
- Sélectionner l’élément « Suivant → », s’il est présent, et en extraire l’URL de la page suivante.
- Répéter la première étape sur la nouvelle page.
Implémentez l’algorithme ci-dessus comme suit :
Au lieu de récupérer une seule page puis de s’arrêter, le script s’appuie désormais sur une boucle while. Celle-ci continue à s’itérer jusqu’à ce qu’il n’y ait plus de pages à récupérer. Cela se produit lorsque le sélecteur CSS .next a déclenche une exception ElementNotFoundException, ce qui signifie que le bouton « Suivant → » ne se trouve pas sur la page et que vous êtes donc sur la dernière page de pagination du site.
Notez que la section htmlDocument peut contenir plusieurs sections de sélecteurs CSS. Chacune sera exécutée dans l’ordre spécifié. Si vous relancez le script Kotlin de Scraping web, quotes stockera désormais les 100 citations du site.
Parfait ! La logique de Scraping web et de crawling Kotlin est prête. Il ne reste plus qu’à supprimer le code de journalisation avec la logique d’exportation des données.
Étape 7 : Exporter les données extraites au format CSV
Les données collectées sont actuellement stockées dans une liste d’objets Quote. L’impression sur le terminal est utile, mais l’exportation au format CSV est le meilleur moyen d’en tirer le meilleur parti. Cela permettra aux autres membres de votre équipe de filtrer, lire et analyser ces données.
Kotlin vous fournit tout ce dont vous avez besoin pour créer un fichier CSV et le remplir, mais l’utilisation d’une bibliothèque facilite grandement les choses. Une bibliothèque native Kotlin populaire pour lire et écrire des fichiers CSV est kotlin-csv.
Ajoutez-la aux dépendances de votre projet dans build.gradle.kts :
implementation("com.github.doyaaaaaken:kotlin-csv-jvm:1.9.3")Ou si vous utilisez Maven :
<dependency>
<groupId>com.github.doyaaaaaken</groupId>
<artifactId>kotlin-csv-jvm</artifactId>
<version>1.9.3</version>
</dependency>Installez la bibliothèque et importez-la dans votre fichier App.kt :
import com.github.doyaaaaaken.kotlincsv.dsl.*Vous pouvez désormais exporter des citations vers un fichier CSV en quelques lignes de code seulement :
val header = listOf("quote", "author", "tags")
val csvContent: List<List<String>> = quotes.map { quote ->
listOf(
quote.text,
quote.author,
quote.tags.joinToString("; ")
)
}
csvWriter().open("quotes.csv") {
writeRow(header)
writeRows(csvContent)
}Notez que List<String> est la façon dont un enregistrement CSV est représenté dans kotlin-csv. Commencez par définir un enregistrement pour la ligne d’en-tête. Convertissez ensuite les citations en données souhaitées. Initialisez ensuite un éditeur CSV, créez un fichier quotes.csv et remplissez-le avec writeRow() et writeRows().
Et voilà ! Il ne reste plus qu’à jeter un œil au code final de votre script de Scraping web Kotlin.
Étape 8 : Assemblez le tout
Voici le code final de votre Scraper Kotlin :
package com.kotlin.scraper
import it.skrape.core.*
import it.skrape.fetcher.*
import it.skrape.selects.ElementNotFoundException
import com.github.doyaaaaaken.kotlincsv.dsl.*
// définir une classe pour représenter les données scrapées dans Kotlin
class Quote(var text: String, var author: String, tags: List<String>?) {
var tags: MutableList<String> = ArrayList()
init {
if (tags != null) {
this.tags.addAll(tags)
}
}
}
fun main() {
// où stocker les données récupérées
val quotes: MutableList<Quote> = ArrayList()
// l'URL de la page suivante à visiter
var nextUrl: String? = "https://quotes.toscrape.com/"
// jusqu'à ce qu'il y ait une page à visiter
while (nextUrl != null) {
skrape(HttpFetcher) {
// envoyer une requête HTTP GET à l'URL spécifiée
request {
url = nextUrl!!
}
response {
htmlDocument {
// sélectionner tous les éléments HTML « .quote » de la page
«.quote» {
findAll {
forEach {
// logique de scraping sur un seul élément de citation
val text = it.findFirst(«.text»).text
val author = it.findFirst(".author").text
val tags = try {
it.findAll(".tag").map { tag -> tag.text }
} catch (e: ElementNotFoundException) {
null
}
// créer un objet Quote et l'ajouter à la liste
val citation = Citation(
texte = texte,
auteur = auteur,
balises = balises
)
citations.ajouter(citation)
}
}
}
// logique d'exploration
essayer {
".next a" {
findFirst {
nextUrl = "https://quotes.toscrape.com" + attribute("href")
}
}
} catch (e: ElementNotFoundException) {
nextUrl = null
}
}
}
}
}
// créer un fichier « quotes.csv » et le remplir
// avec les données récupérées
val header = listOf("quote", "author", "tags")
val csvContent: List<List<String>> = quotes.map { quote ->
listOf(
quote.text,
quote.author,
quote.tags.joinToString("; ")
)
}
csvWriter().open("quotes.csv") {
writeRow(header)
writeRows(csvContent)
}
}Incroyable, non ? Grâce à skrape{it}, vous pouvez récupérer les données d’un site entier en moins de 100 lignes de code !
Exécutez votre script Kotlin de Scraping web avec :
./gradlew runPatientez pendant que le Scraper parcourt chaque page du site cible. Une fois terminé, un fichier quotes.csv apparaîtra dans le répertoire racine de votre projet. Ouvrez-le et vous devriez voir les données suivantes :
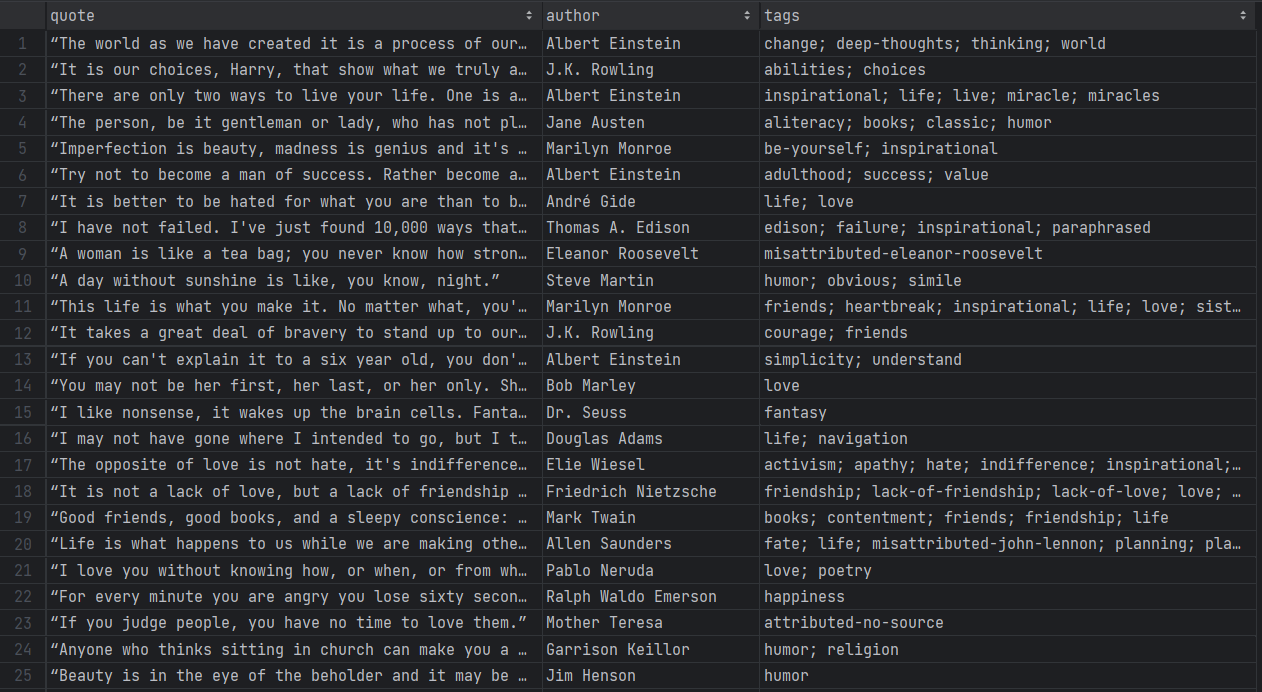
Et voilà ! Vous avez commencé avec des données non structurées dans des pages en ligne et vous les avez maintenant dans un fichier CSV facile à explorer !
Évitez les interdictions d’IP dans Kotlin avec un Proxy
Lorsque vous effectuez du Scraping web avec Kotlin, l’un des plus grands défis consiste à éviter d’être bloqué par les technologies anti-bot. Ces systèmes peuvent détecter la nature automatisée de votre script et bloquer votre IP. De cette façon, ils mettent fin à votre opération de scraping.
Comment éviter cela ? Avec un Proxy web !
Suivez les étapes ci-dessous et découvrez comment intégrer un Proxy Bright Data dans Kotlin.
Configurer un Proxy dans Bright Data
Bright Data est le meilleur serveur proxy du marché, surveillant des milliers de serveurs proxy à travers le monde. En matière de rotation d’IP, le meilleur type de proxy à utiliser est un Proxy résidentiel.
Pour commencer, si vous avez déjà un compte, connectez-vous à Bright Data. Sinon, créez un compte gratuitement. Vous aurez alors accès au tableau de bord utilisateur suivant :
Cliquez sur le bouton « Voir les produits Proxy » comme indiqué ci-dessous :
Vous serez redirigé vers la page « Proxies & Infrastructure de scraping » (Proxys et Infrastructure de scraping) suivante :
Faites défiler vers le bas, trouvez la carte « Proxys résidentiels » et cliquez sur le bouton « Commencer » :
Vous accéderez au tableau de bord de configuration du Proxy résidentiel. Suivez l’assistant guidé et configurez le service Proxy en fonction de vos besoins. Si vous avez des doutes sur la configuration du Proxy, n’hésitez pas à contacter l’assistance disponible 24 heures sur 24, 7 jours sur 7.
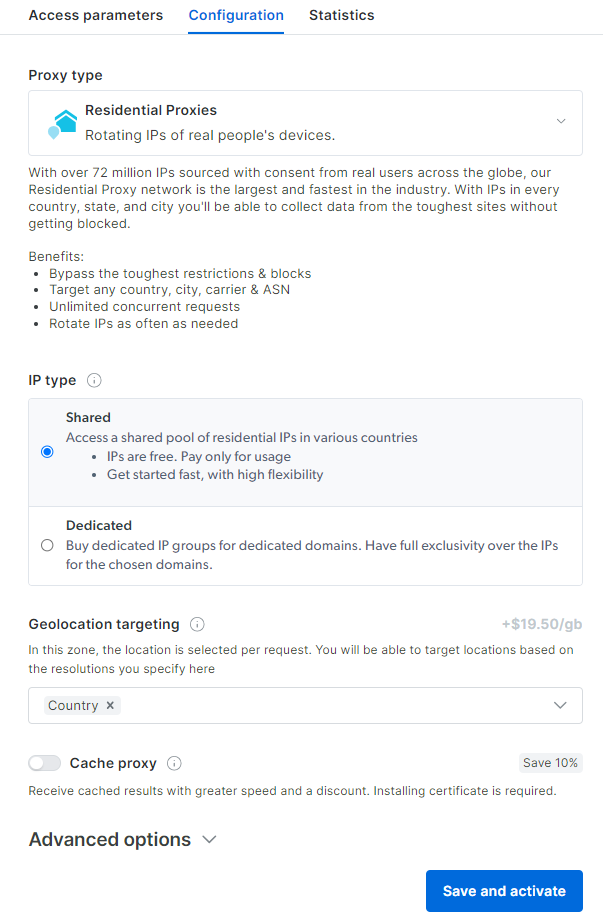
Accédez à l’onglet « Paramètres d’accès » et récupérez l’hôte, le port, le nom d’utilisateur et le mot de passe de votre Proxy comme suit :
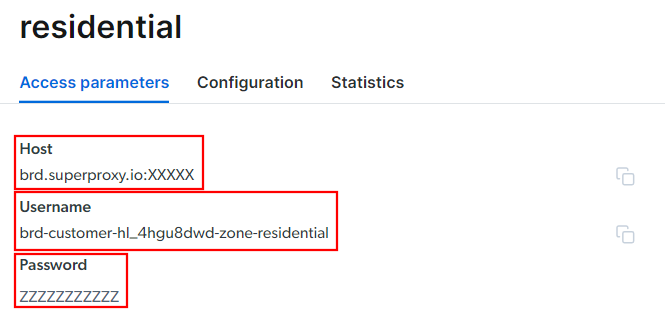
Notez que le champ « Hôte » inclut déjà le port.
C’est tout ce dont vous avez besoin pour créer l’URL du Proxy et l’utiliser dans skrape{it}. Rassemblez toutes les informations et créez une URL avec la syntaxe suivante :
<Nom d'utilisateur>:<Mot de passe>@<Hôte>Par exemple, dans ce cas, cela donnerait :
brd-customer-hl_4hgu8dwd-Zone-residential:[email protected]:XXXXXActivez « Proxy actif », suivez les dernières instructions, et vous êtes prêt à commencer !

Intégrer le Proxy dans Kotlin
L’extrait de code pour l’intégration de Bright Data dans skrape{it} ressemblera à ceci :
skrape(HttpFetcher) {
request {
url = "https://quotes.toscrape.com/"
proxy = proxyBuilder {
type = Proxy.Type.HTTP
host = "brd.superproxy.io"
port = XXXXX
}
authentication = basic {
username = "brd-customer-hl_4hgu8dwd-zone-residential"
password = "ZZZZZZZZZZ"
}
}
// ...
}Comme vous pouvez le constater, tout repose sur l’utilisation des options de Proxy et d’authentification. À partir de maintenant, skrape{it} enverra la requête à l’URL spécifiée via le Proxy Bright Data. Adieu les interdictions d’IP !
Veillez à ce que vos opérations de Scraping web Kotlin restent éthiques et respectueuses
Le scraping web est un moyen efficace de collecter des données utiles pour divers cas d’utilisation. Gardez à l’esprit que l’objectif final est de récupérer ces données, et non d’endommager le site cible. Vous devez donc aborder cette tâche avec les précautions qui s’imposent.
Suivez les conseils ci-dessous pour effectuer un Scraping web Kotlin responsable :
- Ciblez uniquement les informations accessibles au public : concentrez-vous sur la récupération des données accessibles au public sur le site. Évitez les pages protégées par des identifiants de connexion ou d’autres formes d’autorisation. Le scraping de données privées ou sensibles sans autorisation appropriée est contraire à l’éthique et peut entraîner des conséquences juridiques.
- Respectez le fichier robots.txt : chaque site dispose d’un fichier robots.txt qui définit les règles d’accès de ses pages par les robots d’indexation automatisés. Pour respecter les pratiques éthiques en matière de scraping, vous devez vous conformer à ces directives. Pour en savoir plus, consultez notre guide robots.txt pour le Scraping web.
- Limitez la fréquence de vos requêtes : effectuer trop de requêtes en peu de temps entraînera une surcharge du serveur, ce qui affectera les performances du site pour tous les utilisateurs. Cela pourrait également déclencher des mesures de limitation du débit et vous faire bloquer. Pour cette raison, évitez de saturer le serveur de destination en ajoutant des délais aléatoires à vos requêtes.
- Vérifiez et respectez les conditions d’utilisation du site: avant de scraper un site, consultez ses conditions d’utilisation. Celles-ci peuvent contenir des informations sur les droits d’auteur, les droits de propriété intellectuelle et des directives sur la manière et le moment d’utiliser leurs données.
- Faites confiance à des outils de scraping fiables et à jour : sélectionnez des fournisseurs réputés et optez pour des outils et des bibliothèques bien entretenus et régulièrement mis à jour. C’est la seule façon de vous assurer qu’ils sont conformes aux derniers principes éthiques en matière de Scraping web Kotlin. Si vous avez des doutes, consultez notre article sur la manière de choisir le meilleur service de Scraping web.
Conclusion
Dans ce guide, vous avez vu pourquoi Kotlin est un excellent langage pour le Scraping web, en particulier par rapport à Java. Vous avez également découvert une liste des meilleures bibliothèques de Scraping Kotlin. Ensuite, vous avez appris à utiliser skrape{it} pour créer un Scraper qui extrait des données de plusieurs pages d’un site réel. Comme vous l’avez constaté ici, le Scraping web avec Kotlin est simple et ne nécessite que quelques lignes de code.
Le principal défi de votre opération de scraping réside dans les solutions anti-bot. Les sites web adoptent ces systèmes pour protéger leurs données contre les scripts automatisés, en les bloquant avant qu’ils ne puissent accéder à leurs pages. Les contourner n’est pas facile et nécessite des outils avancés. Heureusement, Bright Data est là pour vous aider !
Voici quelques-uns des produits de scraping proposés par Bright Data :
- API Web Scraper: API faciles à utiliser pour un accès programmatique à des données web structurées provenant de dizaines de domaines populaires.
- Navigateur de scraping: un navigateur contrôlable basé sur le cloud qui offre des capacités de rendu JavaScript tout en gérant pour vous les empreintes digitales du navigateur, les CAPTCHA, les réessais automatisés, etc. Il s’intègre aux bibliothèques de navigateurs d’automatisation les plus populaires, telles que Playwright et Puppeteer.
- Web Unlocker: une API de déverrouillage qui peut renvoyer de manière transparente le code HTML brut de n’importe quelle page, contournant ainsi toutes les mesures anti-scraping.
Vous ne voulez pas vous occuper du Scraping web, mais vous êtes toujours intéressé par les données en ligne ? Découvrez les jeux de données prêts à l’emploi de Bright Data !



