
Dans ce guide, nous allons aborder :
- Démarrer avec le web scraping dans R
- Comprendre les outils
- Configurer l’environnement de développement
- Comprendre la page web
- Comprendre DevTools
- Comprendre les outils
- Approfondir le web scraping dans R : Tutoriel
- Prérequis
- Exploration interactive de la page web
- Sélecteur CSS vs. XPath pour le web scraping
- Extraction d’informations de la page web par programmation
- Mise à l’échelle vers plusieurs URL
- Prochaine étape : prédéfini ou Défini par l’utilisateur ?
Démarrer avec le web scraping dans R
La première étape serait de comprendre les outils que nous allons utiliser dans ce tutoriel R.
Comprendre les outils : R et rvest
R est une bibliothèque riche et facile à utiliser pour l’analyse statistique et la visualisation de données qui fournit des outils utiles à la gestion des données et à la saisie dynamique.
rvest(de « harvest ») est l’un des packages R les plus populaires offrant des fonctionnalités de web scraping, notamment grâce à son interface extrêmement conviviale. Vanilla rvest vous permet d’extraire des données d’une seule page web, ce qui est parfait pour une première exploration. Vous pouvez ensuite l’étendre avec la bibliothèque polite pour scraper plusieurs pages.
Configurer l’environnement de développement.
Si vous n’utilisez pas encore R dans RStudio, suivez les instructions d’installation ici.
À la fin, ouvrez la console et installez rvest :
install.packages("rvest")
Dans le cadre de la collection tidyverse, l’extension de fonctionnalités intégrées rvest avec d’autres packages de la collection est officiellement recommandée : magrittr pour la lisibilité du code ou xml2 pour le fonctionnement avec HTML et XML. Vous pouvez le faire en installant directement tidyverse :
install.packages("tidyverse")Comprendre la page web
Le web scraping est une technique qui permet de récupérer des données de sites web selon des processus automatisés et conformes.
Trois considérations importantes découlent de cette définition :
- Les données sont disponibles dans différents formats.
- Les sites web affichent les informations de manières très différentes.
- Les données scrapées doivent être légalement accessibles.
Pour comprendre comment scraper une URL, vous devez d’abord appréhender le mode d’affichage du contenu de la page web via le langage de balisage HTML et le langage de style de feuille CSS.
Le HTML fournit le contenu et la structure de la page web chargée dans le navigateur web pour créer un modèle d’objet de document (DOM) sous la forme d’arbres en organisant le contenu avec des balises “. Les balises “
ont une structure hiérarchique, chacune ayant une fonctionnalité spécifique appliquée à tout le contenu présent dans ses instructions () d’ouverture et () de fermeture :
<!DOCTYPE html>
<html lang="en-gb" class="a-ws a-js a-audio a-video a-canvas a-svg a-drag-drop a-geolocation a-history a-webworker a-autofocus a-input-placeholder a-textarea-placeholder a-local-storage a-gradients a-transform3d -scrolling a-text-shadow a-text-stroke a-box-shadow a-border-radius a-border-image a-opacity a-transform a-transition a-ember" data-19ax5a9jf="dingo" data-aui-build-date="3.22.2-2022-12-01">
▶<head>..</head>
▶<body class="a-aui_72554-c a-aui_accordion_a11y_role_354025-c a-aui_killswitch_csa_logger_372963-c a-aui_launch_2021_ally_fixes_392482-t1 a-aui_pci_risk_banner_210084-c a-aui_preload_261698-c a-aui_rel_noreferrer_noopener_309527-c a-aui_template_weblab_cache_333406-c a-aui_tnr_v2_180836-c a-meter-animate" style="padding-bottom: 0px;">..</body>
</html>La balise <html> est le composant minimal de toute page web, avec les balises <html> et <html> imbriquées à l’intérieur. Les balises <html> et <html> sont les « parents » des autres balises qu’elles contiennent, la balise <div> (pour la section du document) et la balise <p> (pour le paragraphe) étant parmi leurs « enfants » les plus courants.
Dans l’extrait ci-dessus, vous pouvez voir les « attributs » associés à chaque « élément » HTML : lang, classet style sont prédéfinis. Les attributs commençant par data- sont personnalisés pour Amazon.
L’élément class présente un intérêt particulier pour le web scraping, tout comme l’attribut identifiant, car ils nous permettent de cibler respectivement un groupe d’éléments et un élément spécifique. À l’origine, c’était pour le style en CSS.
Le CSS fournit le style de la page web. Vous pouvez sélectionner n’importe quel élément HTML et attribuer de nouvelles valeurs à ses propriétés de style à partir de la coloration au positionnement et au dimensionnement. Vous pouvez également appliquer un style CSS en ligne dans l’élément HTML avec l’attribut style, comme vous l’avez vu dans l’extrait ci-dessus :
<body .. style="padding-bottom: 0px;">En CSS pur, cela s’écrirait ainsi :
body {padding-bottom: 0px;}
Ici, l’élément body est le « sélecteur », padding-bottom est la « propriété » et 0px est la « valeur ».
N’importe quelle balise, classeou n’importe quel identifiant peut être utilisé comme sélecteur CSS.
Les utilisateurs peuvent interagir de manière dynamique avec le contenu affiché sur la page web via les fonctionnalités fournies par le langage de programmation JavaScript via la balise script. Après une interaction utilisateur, le contenu affiché peut changer et de nouveaux contenus peuvent apparaître. Les web scrapers avancés peuvent imiter les interactions des utilisateurs, comme nous le verrons plus loin.
Comprendre DevTools
Les principaux navigateurs web fournissent des outils de développement intégrés qui permettent de collecter et de mettre à jour en direct des informations techniques sur une page web à des fins de journalisation, de débogage, de test et d’analyse des performances. Pour ce tutoriel, nous utiliserons DevTools de Chrome.
Les outils de développement sont accessibles depuis le coin supérieur droit du navigateur, dans Plus d’outils :
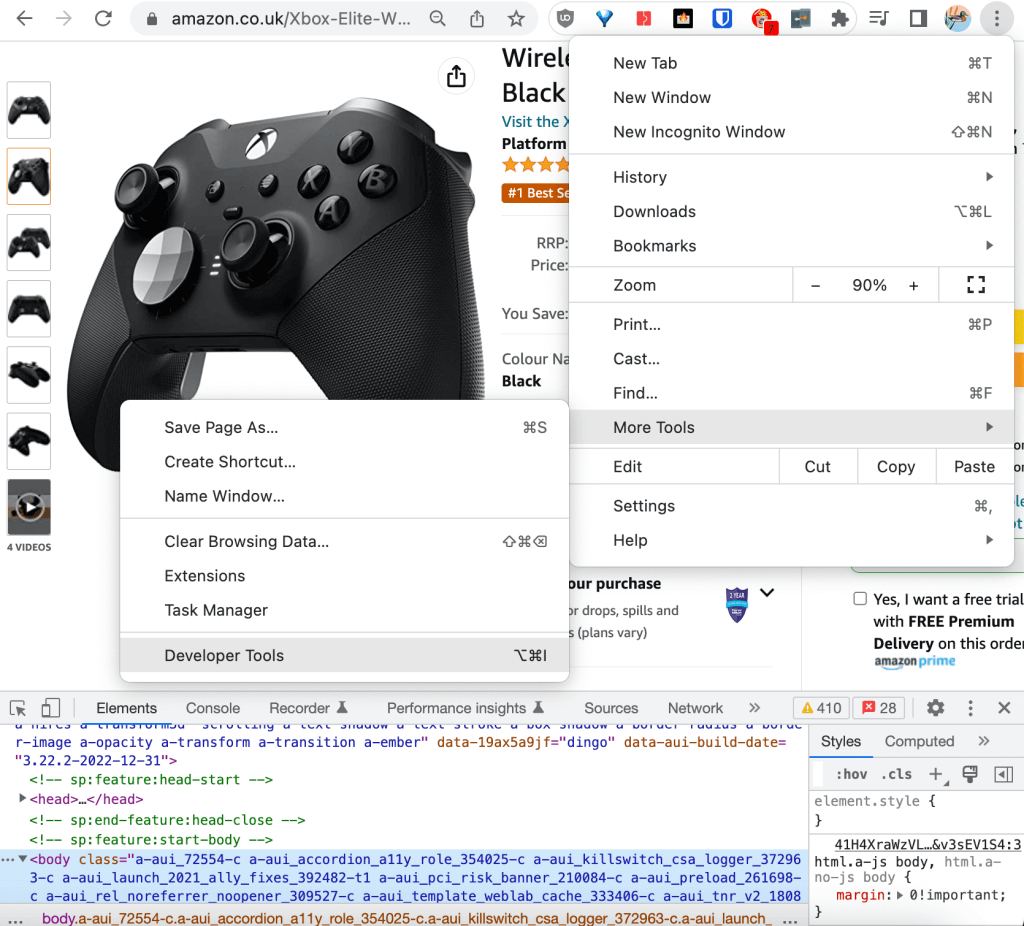
Dans DevTools, vous pouvez faire défiler le code HTML brut dans l’onglet Éléments. Lorsque vous faites défiler l’une des lignes HTML, l’élément correspondant s’affiche dans la page web surligné en bleu :
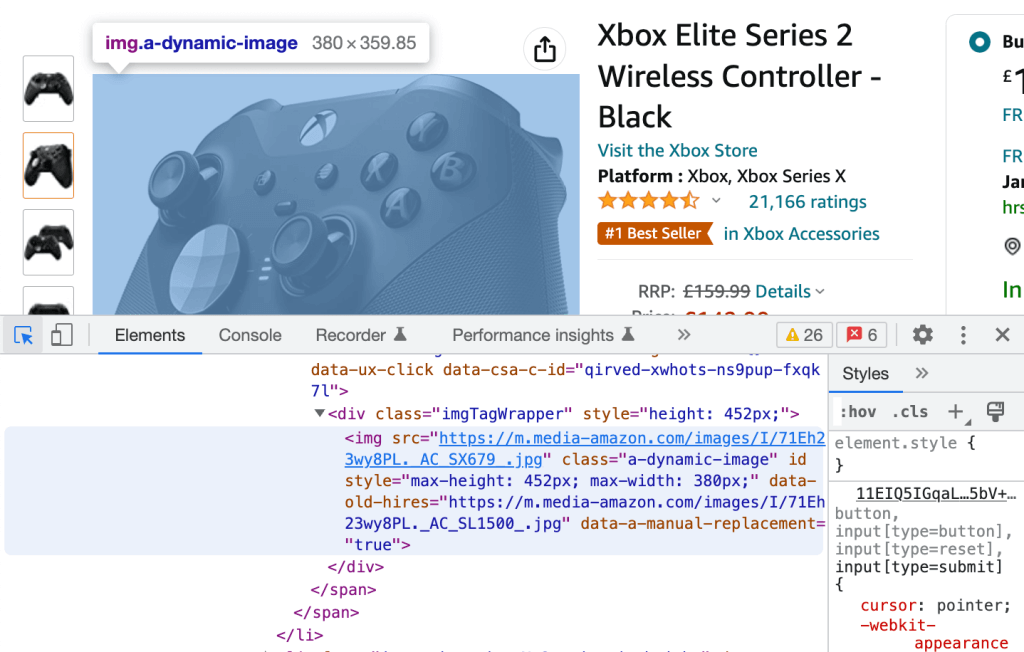
À l’inverse, vous pouvez cliquer sur l’icône dans le coin supérieur gauche et sélectionner n’importe quel élément rendu de la page web à rediriger vers son équivalent HTML brut, à nouveau surligné en bleu.
Ces deux processus sont tout ce dont vous avez besoin pour extraire les descripteurs CSS pour notre tutoriel pratique.
Approfondir le web scraping dans R : le tutoriel
Dans cette section, nous allons découvrir comment scraper en ligne les URL Amazon pour extraire les avis sur les produits.
Prérequis
Vérifiez que les éléments suivants sont installés dans votre environnement Rstudio :
- R = 4.2.2
- rvest = 1.0.3
- tidyverse = 1.3.2
Exploration interactive de la page web
Vous pouvez utiliser DevTools de Chrome pour explorer le code HTML de votre URL et créer une liste de toutes les classes et de tous les identifiants des éléments HTML contenant les informations que nous souhaitons scraper, à savoir les avis sur les produits :

Chaque avis client appartient à un div avec un id dans le format :
customer_review_$INTERNAL_ID.
Le contenu HTML du div correspondant à l’avis client dans la capture d’écran ci-dessus est le suivant :
<div id="customer_review-R2U9LWUSIPY0GS" class="a-section celwidget" data-csa-c-id="kj23dv-axnw47-69iej3-apdvzi" data-cel-widget="customer_review-R2U9LWUSIPY0GS">
<div data-hook="genome-widget" class="a-row a-spacing-mini">..</div>
<div class="a-row">
<a class="a-link-normal" title="4.0 out of 5 stars" href="https://www.amazon.co.uk/gp/customer-reviews/R2U9LWUSIPY0GS/ref=cm_cr_dp_d_rvw_ttl?ie=UTF8&ASIN=B07SR4R8K1">
<i data-hook="review-star-rating" class="a-icon a-icon-star a-star-4 review-rating">
<span class="a-icon-alt">4.0 out of 5 stars</span>
</i>
</a>
<span class="a-letter-space"></span>
<a data-hook="review-title" class="a-size-base a-link-normal review-title a-color-base review-title-content a-text-bold" href="https://www.amazon.co.uk/gp/customer-reviews/R2U9LWUSIPY0GS/ref=cm_cr_dp_d_rvw_ttl?ie=UTF8&ASIN=B07SR4R8K1">
<span>Very good controller if a little overpriced</span>
</a>
</div>
<span data-hook="review-date" class="a-size-base a-color-secondary review-date">..</span>
<div class="a-row a-spacing-mini review-data review-format-strip">..</div>
<div class="a-row a-spacing-small review-data">
<span data-hook="review-body" class="a-size-base review-text">
<div data-a-expander-name="review_text_read_more" data-a-expander-collapsed-height="300" class="a-expander-collapsed-height a-row a-expander-container a-expander-partial-collapse-container" style="max-height:300px">
<div data-hook="review-collapsed" aria-expanded="false" class="a-expander-content reviewText review-text-content a-expander-partial-collapse-content">
<span>In all honesty I'm not sure why the price is quite as high ….</span>
</div>
…</div>
…</span>
…</div>
…</div>
Chaque contenu qui vous intéresse pour les avis clients a sa propre classe : review-title-content pour le titre, review-text-content pour le corps et review-rating pour la note.
Vous pouvez vérifier que la classe est unique dans le document et utiliser directement le « sélecteur simple ». Une approche plus infaillible consiste à utiliser le descripteur CSS à la place, qui restera unique même si la classe est affectée ultérieurement à de nouveaux éléments.
Récupérez simplement le descripteur CSS en cliquant avec le bouton droit sur l’élément dans les DevTools et en sélectionnant Copier le sélecteur :
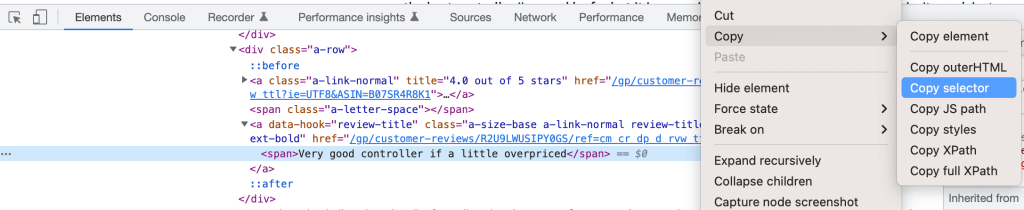
Vous pouvez définir vos trois sélecteurs ainsi :
customer_review-R2U9LWUSIPY0GS > div:nth-child(2) > a.a-size-base.a-link-normal.review-title.a-color-base.review-title-content.a-text-bold > spanpour le titrecustomer_review-R2U9LWUSIPY0GS > div.a-row.a-spacing-small.review-data > span > div > div.a-expander-content.reviewText.review-text-content.a-expander-partial-collapse-content > spanpour le corpscustomer_review-R2U9LWUSIPY0GS > div:nth-child(2) > a:nth-child(1) > i.review-rating > spanpour la note*
.review-ratinga été ajouté manuellement pour une meilleure cohérence.
Sélecteur CSS vs. XPath pour le web scraping
Pour ce tutoriel, nous avons décidé d’utiliser un sélecteur CSS pour identifier les éléments à utiliser pour le web scraping. L’autre approche courante consiste à utiliser XPath, c’est-à-dire le chemin XML, qui identifie un élément via son chemin complet dans le DOM.
Vous pouvez extraire le XPath complet en suivant la même procédure que pour le sélecteur CSS. Par exemple, le titre de l’avis est :
/html/body/div[2]/div[3]/div[6]/div[32]/div/div/div[2]/div/div[2]/span[2]/div/div/div[3]/div[3]/div/div[1]/div/div/div[2]/a[2]/span
Un sélecteur CSS est légèrement plus rapide, tandis que la rétrocompatibilité avec XPath est légèrement meilleure. À part ces petites différences, le choix de l’un par rapport à l’autre dépend davantage de préférences personnelles que d’implications techniques.
Extraction d’informations de la page web par programmation
Bien que nous puissions utiliser la console directement pour commencer à explorer comment scraper l’URL sur le web, nous allons plutôt créer un script pour la traçabilité et la reproductibilité et l’exécuter via la console à l’aide de la commande source() .
Après la création du script, la première étape consiste à charger les bibliothèques installées :
library(”rvest”)
library(”tidyverse”)Ensuite, vous pouvez extraire par programmation le contenu qui vous intéresse comme suit. D’abord, créez une variable dans laquelle vous allez stocker l’URL à rechercher :
HtmlLink <- "https://www.amazon.co.uk/Xbox-Elite-Wireless-Controller-2/dp/B07SR4R8K1/ref=sr_1_1_sspa?crid=3F4M36E0LDQF3"
Ensuite, extrayez le numéro d’identification standard Amazon (ASIN) de l’URL pour l’utiliser comme identifiant de produit unique :
ASIN <- str_match(HtmlLink, "/dp/([A-Za-z0-9]+)/")[,2]
L’utilisation de RegEx pour nettoyer le texte extrait via le web scraping est courante et recommandée pour garantir la qualité des données.
Maintenant, téléchargez le contenu HTML de la page web :
HTMLContent <- read_html(HtmlLink)
La fonction read_html() fait partie du package xml2.
Si vous utilisez print() pour imprimer le contenu, nous verrons qu’il correspond à la structure HTML brute analysée précédemment :
{html_document}
<html lang="en-gb" class="a-no-js" data-19ax5a9jf="dingo">
[1] <head>n<meta http-equiv="Content-Type" content="text/ht ...
[2] <body class="a-aui_72554-c a-aui_accordion_a11y_role_354 ...
Vous pouvez désormais extraire les trois nœuds qui vous intéressent pour toutes les avis de produits de la page. Utilisez les descripteurs CSS fournis par les DevTools de Chrome, modifiés pour supprimer l’identifiant spécifique des avis clients #customer_review -R2U9LWUSIPY0GS et le connecteur « > » de la chaîne. Vous pouvez également utiliser des fonctionnalités html_nodes () et html_text () de rvest pour enregistrer le contenu HTML dans des objets distincts.
Les commandes suivantes permettent d’extraire les titres des avis :
review_title <- HTMLContent %>%
html_nodes("div:nth-child(2) a.a-size-base.a-link-normal.review-title.a-color-base.review-title-content.a-text-bold span") %>%
html_text()
Un exemple d’entrée dans review_title est « Très bonne manette si elle est un peu trop chère ».
Le code ci-dessous permet d’extraire le corps de l’avis :
review_body <- HTMLContent %>%
html_nodes("div.a-row.a-spacing-small.review-data span div div.a-expander-content.reviewText.review-text-content.a-expander-partial-collapse-content span") %>%
html_text()
Un exemple d’entrée dans review_body commence par « En toute honnêteté, je ne sais pas pourquoi ce prix… ».
Et vous pouvez utiliser les commandes suivantes pour extraire la note de l’avis :
review_rating <- HTMLContent %>%
html_nodes("div:nth-child(2) a:nth-child(1) i.review-rating span") %>%
html_text()
Un exemple d’entrée dans review_rating est « 4 étoiles sur 5 ».
Pour améliorer la qualité de cette variable, extrayez uniquement la note « 4.0 » et convertissez-la en int :
review_rating <- substr(review_rating, 1, 3) %>% as.integer()
La fonctionnalité de canal %>% est fournie par la boîte à outils Magrittr.
Il est maintenant temps d’exporter le contenu scrapé dans un tibble à des fins d’analyse des données.
tibble est un package R qui appartient également à la collection tidyverse et est utilisé pour manipuler et imprimer des trames de données.
df <- tibble(review_title, review_body, review_rating)
La trame de données en sortie est la suivante :

Enfin, il est judicieux de refactoriser le code dans la fonction scrape_amazon <- function(HTMLlink) afin de respecter les pratiques conseillées et de préparer au mieux le code pour l’adapter à plusieurs URL.
Mise à l’échelle vers plusieurs URL
Après la création du modèle de web scraping créé, vous pouvez établir une liste d’URL pour les produits de tous les principaux concurrents sur Amazon via l’exploration et le scraping du web.
Lorsque vous mettez à l’échelle vers plusieurs URL pour mettre la solution en production, vous devez définir les exigences techniques de l’application.
Le fait de disposer d’exigences techniques bien définies vous permettra de répondre correctement à celles de l’entreprise et d’intégrer parfaitement vos systèmes existants.
Suivant les exigences techniques spécifiques, la fonction de scraping doit être mise à jour pour prendre en charge une combinaison des éléments suivants :
- Traitement en temps réel ou en lots
- Format(s) de sortie, comme JSON, NDJSON, CSV ou XLSX
- Cible(s) de sortie, comme l’e-mail, l’API, le webhook ou le stockage cloud
Nous avons déjà mentionné que vous pouvez étendre rvest avec polite pour scraper plusieurs pages web. polite crée et gère une session de collecte web à l’aide de trois fonctionnalités principales, en totale conformité avec le fichier robots.txt de l’hébergeur et avec une limitation de débit et une mise en cache des réponses intégrées :
bow()crée la session de scraping pour une URL spécifique, c’est-à-dire qu’il vous présente l’hébergeur du site et vous demande l’autorisation de scraper.scrape()accède au code HTML de l’URL. Vous pouvez rediriger la fonction vershtml_nodes ()ethtml_text ()depuis rvest pour récupérer un contenu spécifique.nod()met à jour l’URL de la session jusqu’à la page suivante, sans nécessairement recréer de session.
Citons directement leur site web : « Les trois piliers d’une session polite sont la demande d’autorisation, l’action lente sans demande répétée deux fois. »
Prochaine étape : prédéfini ou défini par l’utilisateur ?
Pour développer un web scraper de pointe permettant d’extraire des données pertinentes pour une entreprise, quelques fonctionnalités doivent être disponibles :
- Une équipe de spécialistes des données spécialisés dans l’extraction de données web
- Une équipe d’ingénieurs DevOps spécialisés dans la gestion de proxys et le contournement des robots afin de passer les CAPTCHA et de débloquer des sites web moins accessibles au public
- Une équipe d’ingénieurs de données spécialisés dans la création d’infrastructures pour l’extraction de données en temps réel et par lots
- Une équipe d’experts juridiques chargée de comprendre les exigences légales concernant la protection des données en matière de confidentialité (RGPD et CCPA)
Le contenu pour le web se présente sous différents formats. Il est difficile de trouver deux sites web ayant exactement la même structure. Plus un site web est complexe et plus il contient de fonctionnalités et de données à scraper, plus les connaissances en programmation requises seront avancées, sans oublier le temps et les ressources supplémentaires nécessaires pour trouver la solution.
En règle générale, vous devez au moins implémenter les fonctionnalités avancées suivantes :
- Minimisez les risques liés aux CAPTCHA et à la détection de robots : une approche simple consiste à ajouter un sleep() aléatoire pour éviter de surcharger les serveurs web et les modèles de requêtes habituels. Une approche plus efficace consiste à utiliser un user_agent ou un serveur proxy pour répartir les requêtes entre différentes adresses IP.
- Sites web utilisant JavaScript : dans notre exemple Amazon, l’URL ne change pas lors de la sélection d’une variante de produit spécifique. Cela est acceptable pour le scraping des avis, car ils sont partagés, mais pas pour le scraping des spécifications de produits. Pour imiter les interactions des utilisateurs dans les pages web dynamiques, vous pouvez utiliser un outil comme RSelenium qui automatise la navigation du navigateur web.
Lorsque vous souhaitez accéder à des données web avec des ressources limitées, garantir la qualité des données ou débloquer des cas d’utilisation plus avancés, un web scraper prédéfini peut être la solution.
Le web scraper de Bright Data fournit des modèles pour de nombreux sites web dotés de fonctionnalités de pointe, notamment une implémentation beaucoup plus avancée de la démo Amazon Scraper !
Vous ne voulez pas vous occuper de la collecte des données ? Consultez nos ensembles de données : des échantillons gratuits sont disponibles.






