
Dans ce guide détaillé, nous parlerons des points suivants :
- Les meilleures bibliothèques C# pour le web scraping
- Prérequis
- Web scraping de sites web à contenu statique en C#
- Web scraping de sites web à contenu dynamique en C#
- Que faire des données extraites ?
- La confidentialité des données grâce aux proxys
- Conclusion
Les meilleures bibliothèques C# pour le web scraping
Le web scraping devient plus facile lorsque vous adoptez les bons outils. Examinons les meilleures bibliothèques de web scraping NuGet pour C# :
- HtmlAgilyPack : la bibliothèque de web scraping C# la plus populaire. HtmlAgilityPack vous permet de télécharger des pages web, d’analyser leur contenu HTML, de sélectionner des éléments HTML et d’en extraire des données
HttpClient: le client HTTP C# le plus populaire. HttpClient est particulièrement utile pour le web crawling car il vous permet d’exécuter des requêtes HTTP facilement et de manière asynchrone.Selenium WebDriverest une bibliothèque qui prend en charge différents langages de programmation et vous permet d’écrire des tests automatisés pour les applications web. Vous pouvez également l’utiliser pour vos besoins de web scraping.Puppeteer Sharpest le port C# de Puppeteer. Puppeteer Sharp fournit des fonctionnalités de navigateur sans tête et permet d’extraire des données sur des pages à contenu dynamique.
Dans ce tutoriel, vous allez découvrir comment faire du web scraping en utilisant C# avec HtmlAgilyPack et Selenium.
Prérequis pour le web scraping avec C#
Avant d’écrire la première ligne de code de votre web scraper C#, vous devez respecter certains prérequis :
- Visual Studio: tl’édition gratuite communautaire de Visual Studio 2022 conviendra parfaitement.
- .NET 6+: toute version LTS supérieure ou égale à 6 conviendra.
Si vous ne remplissez pas l’une de ces conditions, cliquez sur le lien ci-dessus pour télécharger les outils nécessaires et suivez l’assistant d’installation pour les configurer
Vous êtes maintenant prêt à créer un projet de web scraping C# dans Visual Studio.
Configuration d’un projet dans Visual Studio
Ouvrez Visual Studio et cliquez sur l’option « Créer un nouveau projet ».
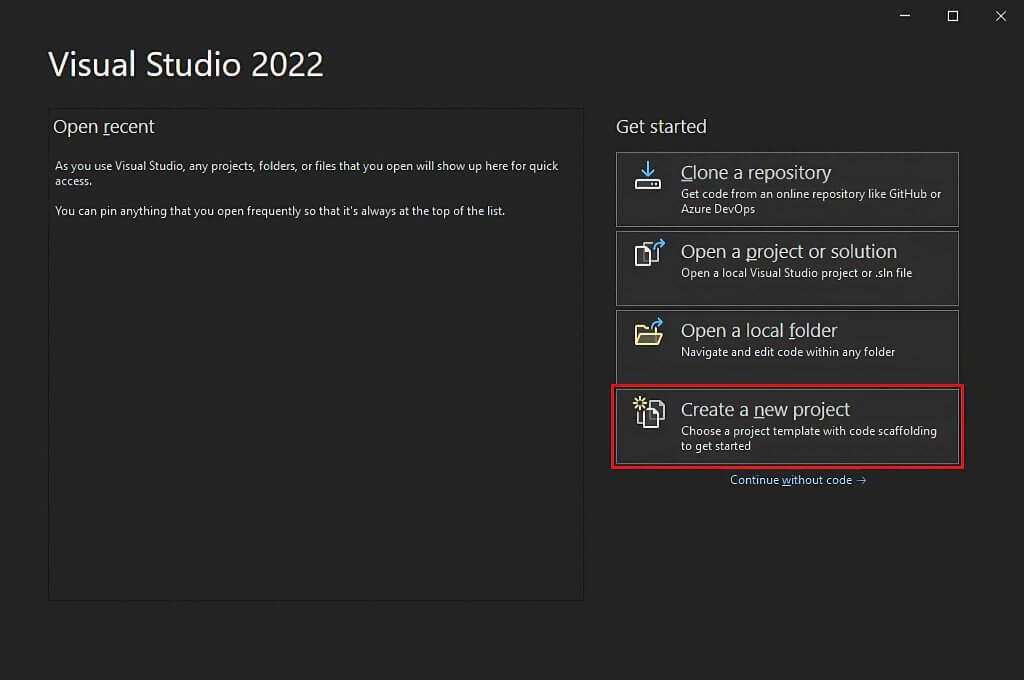
Dans la fenêtre « Créer un nouveau projet », sélectionnez l’option « C# » dans la liste déroulante. Après avoir spécifié le langage de programmation, sélectionnez le modèle « Application console », puis cliquez sur « Suivant ».
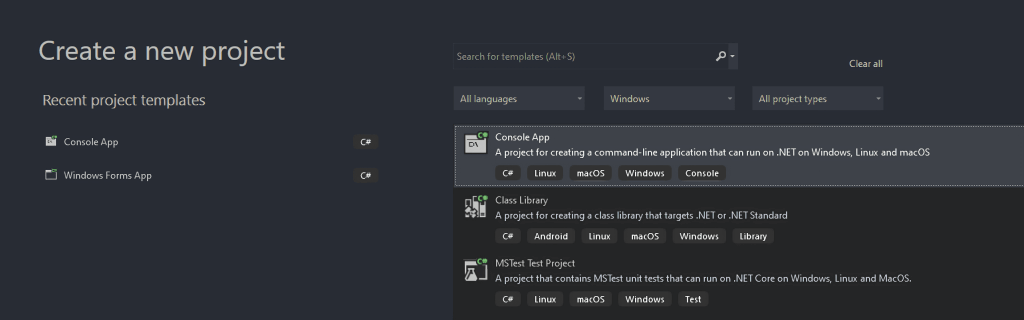
Appelez ensuite votre projet StaticWebScraping, cliquez sur « Sélectionner » et choisissez la version de .NET. Si vous avez installé .NET 6.0, Visual Studio devrait déjà le sélectionner pour vous.
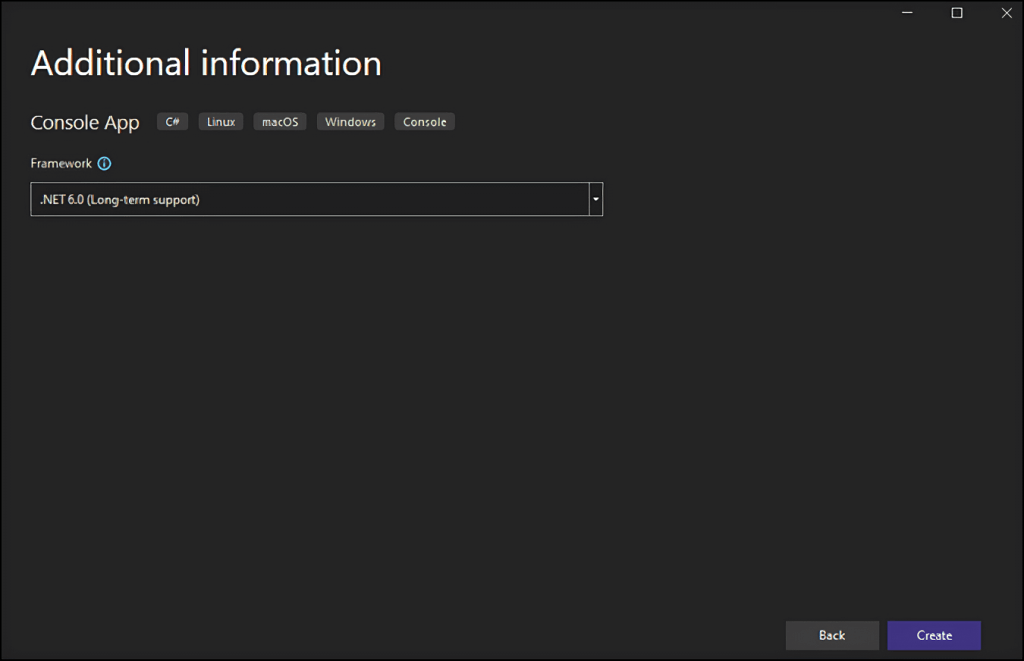
Cliquez sur le bouton « Créer » pour initialiser votre projet de web scraping C#. Visual Studio initialise pour vous un dossier StaticWebScraping contenant un fichier App.cs. Ce fichier enregistre votre logique de web scraping en C# :
namespace WebScraping {
public class Program {
public static void Main() {
// scraping logic...
}
}
}
Il vous faut maintenant comprendre comment construire un web scraper en C#.
Web scraping de sites web à contenu statique en C#
Dans les sites web à contenu statique, le contenu des pages web est déjà stocké dans les documents HTML renvoyés par le serveur. Cela signifie qu’une page web à contenu statique n’exécute pas de requêtes XHR pour récupérer des données et ne nécessite pas de rendu de JavaScript.
Extraire des données de sites web statiques est assez simple. Il vous suffit de :
- Installer une bibliothèque C# de web scraping
- Télécharger votre page web cible et analyser son document HTML
- Utiliser une bibliothèque de web scraping pour sélectionner les éléments HTML qui vous intéressent
- Extrayez-en les données
Appliquons toutes ces étapes à la page Wikipédia (en anglais) « List of SpongeBob SquarePants episodes (Liste des épisodes de Bob l’éponge) » :

L’objectif du web scraper C# que vous êtes sur le point de construire est de récupérer automatiquement toutes les données des épisodes sur cette page Wikipédia à contenu statique.
Commençons !
Étape 1 : Installez HtmlAgilityPack
HtmlAgilityPack est une bibliothèque C# open source qui vous permet d’analyser des documents HTML, de sélectionner des éléments du DOM et d’en extraire des données. Fondamentalement, HtmlAgilityPack vous fournit tout ce dont vous avez besoin pour extraire des données d’un site web à contenu statique.
Pour l’installer, cliquez avec le bouton droit de la souris sur l’option « Dépendances » sous le nom de votre projet dans « Explorateur de solutions ». Sélectionnez ensuite « Gérer les paquets NuGet ». Dans la fenêtre du gestionnaire de paquets NuGet, recherchez « HtmlAgilityPack », puis cliquez sur le bouton « Installer » dans la partie droite de votre écran.
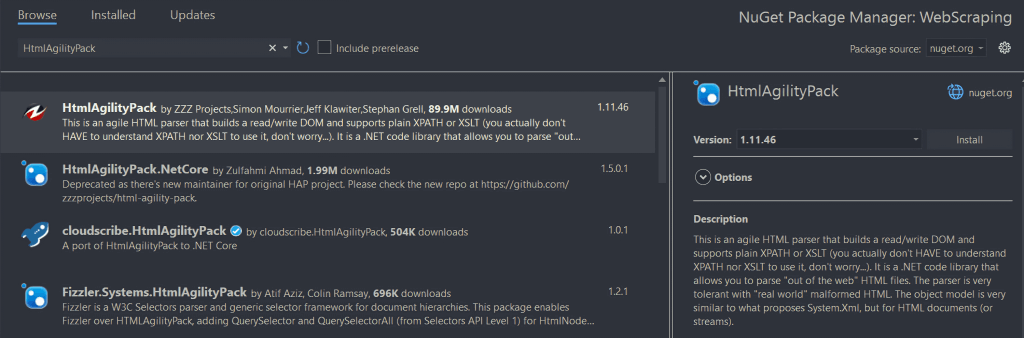
Une fenêtre contextuelle vous demande si vous acceptez d’apporter des modifications à votre projet. Cliquez sur OK pour installer HtmlAgilityPack. Vous êtes maintenant prêt à utiliser HtmlAgilityPack pour faire du web scraping en C# sur un site web statique.
Maintenant, ajoutez la ligne suivante au-dessus de votre fichier App.cs pour importer HtmlAgilityPack :
using HtmlAgilityPack;Étape 2 : Chargez une page web HTML
Vous pouvez vous connecter à la page web cible avec HtmlAgilityPack comme ceci :
// the URL of the target Wikipedia page
string url = "https://en.wikipedia.org/wiki/List_of_SpongeBob_SquarePants_episodes";
var web = new HtmlWeb();
// downloading to the target page
// and parsing its HTML content
var document = web.Load(url);
L’instance de la classe HtmWeb vous permet de charger une page web grâce à sa méthode Load(). En arrière-plan, cette méthode exécute une requête HTTP GET pour extraire le document HTML associé à l’URL passée par paramètre. Ensuite, Load() renvoie une instance HtmlAgilyPack HtmlDocument que vous pouvez utiliser pour sélectionner des éléments HTML sur la page.
Étape 3 : Sélectionnez des éléments HTML
Vous pouvez sélectionner des éléments HTML sur une page web à l’aide de sélecteurs XPath. Plus précisément, XPath vous permet de sélectionner un ou plusieurs éléments DOM spécifiques. Pour que le sélecteur XPath soit lié à un élément HTML, cliquez dessus avec le bouton droit de la souris, ouvrez les outils d’inspection dans votre navigateur, assurez-vous qu’il sélectionne l’élément DOM qui vous intéresse, cliquez avec le bouton droit de la souris sur l’élément DOM et sélectionnez « Copier XPath ».
L’objectif du web scraper C# est d’extraire les données associées à chaque épisode. Extrayez donc le sélecteur XPath en appliquant la procédure décrite ci-dessus à un élément d’épisode
Cela renvoie :
//*[@id="mw-content-text"]/div[1]/table[2]/tbody/tr[2]
N’oubliez pas que vous souhaitez sélectionner tous les éléments <tr>. Vous devez donc modifier l’index associé à l’élément de sélection de ligne. Plus précisément, vous ne voulez pas extraire des données de la première ligne de la table, car celle-ci ne contient que des en-têtes de table. Dans XPath, les index commencent à partir de 1 ; vous pouvez donc sélectionner tous les éléments de la première table d’épisode de la page en ajoutant la syntaxe XPath position()>1.
Vous voulez également extraire des données de toutes les tables de saison. Sur la page Wikipédia, les tables contenant des données sur les épisodes vont de la deuxième à la quinzième table HTML contenue dans le document HTML. Voici donc ce à quoi ressemblera la dernière chaîne Xpath :
//*[@id='mw-content-text']/div[1]/table[position()>1 and position()<15]/tbody/tr[position()>1]
Maintenant, vous pouvez utiliser la fonction SelectNodes() fournie par HtmlAgilityPack pour sélectionner les éléments HTML qui vous intéressent :
var nodes = document.DocumentNode.SelectNodes("//*[@id='mw-content-text']/div[1]/table[position()>1 and position()<15]/tbody/tr[position()>1]");Attention, vous ne pouvez appeler la méthode SelectNodes() que sur une instance HtmlNode. Vous devez donc obtenir le nœud HTML racine du document HTML avec la propriété DocumentNode .
De plus, n’oubliez pas que les sélecteurs XPath ne sont qu’une des nombreuses méthodes dont vous disposez pour sélectionner des éléments HTML sur une page web. Les sélecteurs CSS sont une autre option couramment utilisée.
Étape 4 : Extrayez des données des éléments HTML
Tout d’abord, vous avez besoin d’une classe personnalisée où stocker les données collectées. Créez un fichier Episode.cs dans le dossier WebScraping et initialisez-le comme suit :
namespace StaticWebScraping {
public class Episode {
public string OverallNumber { get; set; }
public string Title { get; set; }
public string Directors { get; set; }
public string WrittenBy { get; set; }
public string Released { get; set; }
}
}
Comme vous pouvez le voir, cette classe possède quatre attributs pour stocker toutes les informations les plus importantes à mettre en mémoire au sujet d’un épisode. Notez que OverallNumber est une chaîne car le numéro d’épisode de Bob l’éponge contient toujours un caractère.
Maintenant, vous pouvez implémenter la logique C# de web scraping dans votre fichier App.cs :
using HtmlAgilityPack;
using System;
using System.Collections.Generic;
namespace StaticWebScraping {
public class Program {
public static void Main() {
// the URL of the target Wikipedia page
string url = "https://en.wikipedia.org/wiki/List_of_SpongeBob_SquarePants_episodes";
var web = new HtmlWeb();
// downloading to the target page
// and parsing its HTML content
var document = web.Load(url);
// selecting the HTML nodes of interest
var nodes = document.DocumentNode.SelectNodes("//*[@id='mw-content-text']/div[1]/table[position()>1 and position()<15]/tbody/tr[position()>1]");
// initializing the list of objects that will
// store the scraped data
List<Episode> episodes = new List<Episode>();
// looping over the nodes
// and extract data from them
foreach (var node in nodes) {
// add a new Episode instance to
// to the list of scraped data
episodes.Add(new Episode() {
OverallNumber = HtmlEntity.DeEntitize(node.SelectSingleNode("th[1]").InnerText),
Title = HtmlEntity.DeEntitize(node.SelectSingleNode("td[2]").InnerText),
Directors = HtmlEntity.DeEntitize(node.SelectSingleNode("td[3]").InnerText),
WrittenBy = HtmlEntity.DeEntitize(node.SelectSingleNode("td[4]").InnerText),
Released = HtmlEntity.DeEntitize(node.SelectSingleNode("td[5]").InnerText)
});
}
// converting the scraped data to CSV...
// storing this data in a db...
// calling an API with this data...
}
}
}
Ce web scraper C# effectue une boucle sur les nœuds HTML sélectionnés, crée une instance de la classe Episode pour chacun d’eux et la stocke dans la liste episodes. N’oubliez pas que les nœuds HTML qui vous intéressent sont des lignes d’une table. Vous devez donc sélectionner certains éléments avec la méthode SelectSingleNode(). Ensuite, utilisez l’attribut InnerText pour en extraire les données souhaitées. Remarquez l’utilisation de la fonction statique HtmlEntity.DeEntize() pour remplacer les caractères spéciaux HTML par leurs représentations naturelles.
Étape 5 : Exportez les données extraites au format CSV
Maintenant que vous avez appris à faire du web scraping en C#, vous pouvez faire tout ce que vous voulez avec les données obtenues. L’un des scénarios les plus courants consiste à convertir les données extraites à un format lisible par l’homme, tel que CSV. De la sorte, n’importe qui dans votre équipe sera en mesure d’explorer les données collectées directement dans Excel.
Voyons maintenant comment exporter les données extraites au format CSV avec C#.
Pour faciliter les choses, utilisons une bibliothèque. CSVHelper est une bibliothèque .NET rapide, facile à utiliser et puissante pour la lecture et l’écriture de fichiers CSV. Pour ajouter la dépendance CSVHelper, ouvrez la section« Gérer les paquets NuGet » dans Visual Studio, recherchez « CSVHelper » et installez-le.
Vous pouvez utiliser CSVHelper de la manière suivante pour convertir nos données en fichiers CSV :
using CsvHelper;
using System.IO;
using System.Text;
using System.Globalization;
// scraping logic…
// initializing the CSV file
using (var writer = new StreamWriter("output.csv"))
using (var csv = new CsvWriter(writer, CultureInfo.InvariantCulture))
{
// populating the CSV file
csv.WriteRecords(episodes);
}
Si vous ne connaissez pas le mot clé using, sachez qu’il définit une portée au terme de laquelle les objets contenus seront éliminés. En d’autres termes, using convient parfaitement pour traiter les ressources de fichiers. Ensuite, la fonction CSVHelper WriteRecords() prend en charge la conversion automatique des données extraites en CSV et leur écriture dans le fichier output.csv.
Dès que votre web scraper C# a terminé son exécution, un fichier output.csv apparaît dans le dossier racine du projet. Ouvrez-le dans Excel et vous verrez les données suivantes :
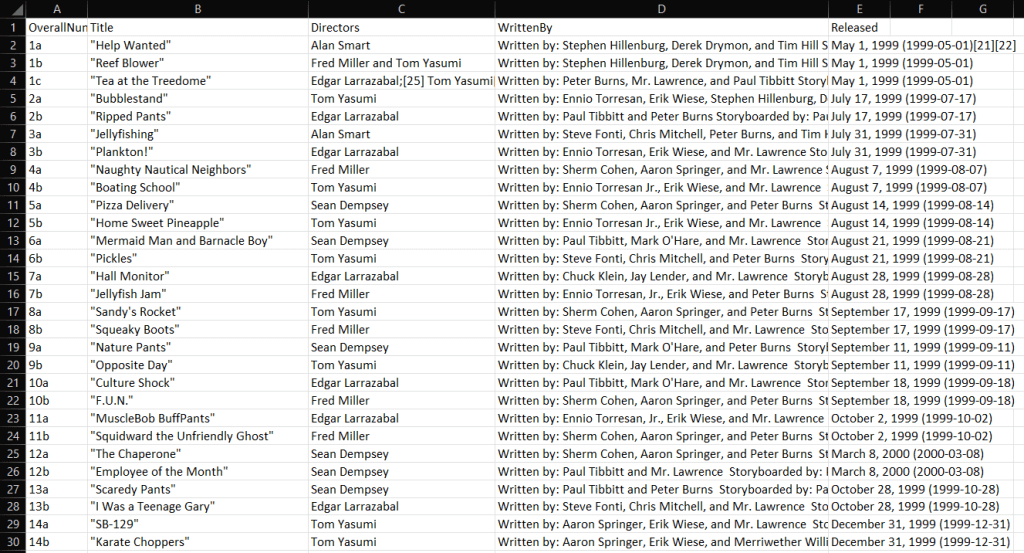
Et voilà ! Vous venez d’apprendre à faire du web scraping avec C# sur des sites à contenu statique !
Web scraping de sites web à contenu dynamique en C#
Les sites web à contenu dynamique utilisent JavaScript pour extraire dynamiquement des données grâce à la technologie AJAX. Les documents HTML associés aux pages à contenu dynamique peuvent être pratiquement vides. En même temps, ils contiennent des scripts JavaScript qui sont en charge de la récupération et du rendu dynamique des données, au moment du rendu. Cela signifie que si vous voulez en extraire des données, vous avez besoin d’un navigateur pour assurer le rendu de leurs pages. La raison en est que seul un navigateur peut exécuter JavaScript.
Extraire des données de sites web dynamiques peut être difficile et est certainement plus difficile qu’extraire des données de sites statiques. Plus précisément, vous avez besoin d’un navigateur sans tête pour extraire des données de sites web de ce type. Si vous n’êtes pas familier avec cette technologie, sachez qu’un navigateur sans tête est un navigateur sans interface graphique. En d’autres termes, si vous voulez extraire les données de sites web à contenu dynamique en C#, vous avez besoin d’une bibliothèque offrant des capacités de navigateur sans tête, par exemple Selenium.
Suivez le paragraphe présenté au début de l’article pour configurer un nouveau projet C#. Cette fois, appelez-le DynamicWebScraping.
Étape 1 : Installez Selenium
Selenium est un cadre open-source pour les tests automatisés, qui prend en charge plusieurs langages de programmation. Selenium offre des fonctionnalités de navigateur sans tête et vous permet de demander à un navigateur d’effectuer des actions spécifiques.
Pour ajouter Selenium aux dépendances de votre projet, allez de nouveau à la section « gérer les paquets NuGet », recherchez « Selenium.WebDriver » et installez-le.
Importez Selenium en ajoutant ces deux lignes en haut de votre fichier App.cs :
using OpenQA.Selenium;
using OpenQA.Selenium.Chrome;
Étape 2 : Connectez-vous au site web cible
Puisque Selenium ouvre le site web cible dans un navigateur, vous n’avez pas besoin d’effectuer manuellement une requête HTTP GET. Il vous suffit d’utiliser le pilote web Selenium comme ceci :
// the URL of the target Wikipedia page
string url = "https://en.wikipedia.org/wiki/List_of_SpongeBob_SquarePants_episodes";
// to initialize the Chrome Web Driver in headless mode
var chromeOptions = new ChromeOptions();
chromeOptions.AddArguments("headless");
var driver = new ChromeDriver();
// connecting to the target web page
driver.Navigate().GoToUrl(url);
Vous venez de créer une instance de pilote web Chrome. Si vous utilisez un autre navigateur, adaptez le code en conséquence en utilisant le pilote du navigateur approprié. Ensuite, grâce à la méthode Navigate() de la variable de pilote, vous pouvez appeler la méthode GoToUrl() pour vous connecter à la page web cible. Plus précisément, cette fonction accepte un paramètre d’URL et l’utilise pour visiter la page web associée à l’URL dans le navigateur sans tête.
Étape 3 : Extrayez les données des éléments HTML
Comme précédemment, vous pouvez utiliser le sélecteur XPath suivant pour sélectionner les éléments HTML qui vous intéressent :
//*[@id='mw-content-text']/div[1]/table[position()>1 and position()<15]/tbody/tr[position()>1]
Utilisez un sélecteur XPath dans Selenium avec :
var nodes = driver.FindElements(By.XPath("//*[@id='mw-content-text']/div[1]/table[position()>1 and position()<15]/tbody/tr[position()>1]"));
Plus précisément, la méthode Selenium by.XPath() vous permet d’appliquer une chaîne XPath pour sélectionner des éléments HTML dans le DOM de la page.
Supposons maintenant que vous ayez déjà défini une classe Episode.cs comme précédemment dans l’espace de noms DynamicWebScraping. Vous pouvez maintenant construire un web scraper C# avec Selenium de la manière suivante :
using System;
using System.Collections.Generic;
using OpenQA.Selenium;
using OpenQA.Selenium.Chrome;
namespace DynamicWebScraping {
public class Program {
public static void Main() {
// the URL of the target Wikipedia page
string url = "https://en.wikipedia.org/wiki/List_of_SpongeBob_SquarePants_episodes";
// to initialize the Chrome Web Driver in headless mode
var chromeOptions = new ChromeOptions();
chromeOptions.AddArguments("headless");
var driver = new ChromeDriver();
// connecting to the target web page
driver.Navigate().GoToUrl(url);
// selecting the HTML nodes of interest
var nodes = driver.FindElements(By.XPath("//*[@id='mw-content-text']/div[1]/table[position()>1 and position()<15]/tbody/tr[position()>1]"));
// initializing the list of objects that will
// store the scraped data
List<Episode> episodes = new();
// looping over the nodes
// and extract data from them
foreach (var node in nodes) {
// add a new Episode instance to
// to the list of scraped data
episodes.Add(new Episode() {
OverallNumber = node.FindElement(By.XPath("th[1]")).Text,
Title = node.FindElement(By.XPath("td[2]")).Text,
Directors = node.FindElement(By.XPath("td[3]")).Text,
WrittenBy = node.FindElement(By.XPath("td[4]")).Text,
Released = node.FindElement(By.XPath("td[5]")).Text
});
}
// converting the scraped data to CSV...
// storing this data in a db...
// calling an API with this data...
}
}
}
Comme vous pouvez le voir, la logique de web scraping n’est pas très différente de celle que vous utiliseriez avec HtmlAgilyPack. Plus précisément, grâce aux méthodes Selenium FindElements() et FindElement(), vous pouvez atteindre le même objectif de scraping qu’auparavant. Ce qui change vraiment, c’est que Selenium effectue toutes ces opérations dans un navigateur.
Notez que sur les sites web à contenu dynamique, vous devrez peut-être attendre que les données soient récupérées et rendues. Vous pouvez y parvenir avec WebDriverWait.
Félicitations ! Vous venez d’apprendre à faire du web scraping en C# sur des sites à contenu dynamique. Il ne vous reste plus qu’à apprendre ce que vous devez faire avec les données collectées.
Que faire des données collectées ?
- Stockez-les dans une base de données que vous pourrez interroger à tout moment.
- Convertissez-les en JSON et utilisez-les pour appeler des API.
- Transformez-les en des formats lisibles par l’homme, tels que CSV, que vous pouvez ouvrir avec Excel.
Ce ne sont que quelques exemples. Ce qui compte vraiment, c’est qu’une fois que vous avez vos données extraites dans le code, vous pouvez les utiliser comme bon vous semble. En général, les données collectées sont converties en un format plus utile pour votre équipe marketing, d’analyse des données ou de ventes.
Mais gardez à l’esprit que le web scraping comporte un certain nombre de défis !
Confidentialité des données et proxys
Si vous voulez éviter d’exposer votre adresse IP, de vous faire bloquer et de protéger votre identité, envisagez d’adopter des proxys de web scraping. Un serveur proxy sert de passerelle entre votre application et le serveur du site web cible, ce qui permet de masquer votre adresse IP.
Par conséquent, un service de proxys vous permet de surmonter les blocages d’adresses IP, de collecter des données de manière anonyme et de débloquer des contenus dans n’importe quel pays. Il existe différents types de proxys ; chacun d’eux correspond à des cas d’utilisation et à des objectifs différents. Assurez-vous de choisir le bon fournisseur de proxy.
Examinons maintenant les avantages que les proxys web peuvent apporter à votre processus de web scraping.
Évitez les interdictions d’adresse IP
Lorsque votre application de web scraping tente d’accéder à un site web sur Internet, l’adresse IP à partir de laquelle la requête est envoyée est publique. Cela signifie que les sites web peuvent savoir cela et bloquer les utilisateurs qui font trop de requêtes. C’est précisément en cela que consiste la détection de bot. Si vous utilisez un proxy web, le serveur cible verra l’adresse IP du proxy rotatif, pas la vôtre. Ainsi, avec les proxys, nous pouvons facilement contourner les interdictions d’adresse IP.
Adresses IP en rotation
Les proxys Premium offrent généralement des fonctionnalités de rotation des adresses IP. Cela signifie que chaque fois que vous contactez le serveur proxy, vous recevez une nouvelle adresse IP provenant d’un grand pool d’adresses IP. Il s’agit de la solution idéale pour éviter de vous faire suivre par les systèmes anti-scraping.
Web scraping dans une région spécifique
De nombreux sites web modifient leurs informations en fonction de l’origine de la requête. En outre, certains d’entre eux ne sont accessibles que dans certaines régions. Extraire les données de ces sites web pour effectuer des études de marché au niveau international peut s’avérer problématique. Heureusement, vous pouvez utiliser des proxys anonymes pour sélectionner l’emplacement de l’adresse IP de sortie. Il s’agit d’un excellent moyen de recueillir des informations précieuses sur les produits figurant sur des sites web internationaux.
Conclusion
Vous venez d’apprendre à construire un web scraper en C#. Comme vous l’avez vu, il n’y a pas besoin de beaucoup de lignes de code. Cela étant, lorsque vos pages web cibles changent, vous devez mettre à jour votre web scraper en conséquence. Certains sites web modifient quotidiennement leur structure. C’est pourquoi vous avez intérêt à opter pour un environnement de développement intégré avancé pour le web scraping. Les web scrapers de Bright Data sont toujours à jour ; vous pouvez donc vous concentrer sur les données au lieu de passer votre temps à reconfigurer votre web scraper.





