

Dans ce guide, vous apprendrez :
- Ce qu’est Ferret et ce qu’il offre en tant que bibliothèque déclarative de scraping web
- Comment le configurer pour une utilisation locale dans un environnement Go ?
- Comment l’utiliser pour collecter des données à partir d’un site web statique ?
- Comment l’utiliser pour récupérer un site dynamique
- Les principales limites du furet et comment les contourner
Plongeons dans l’aventure !
Introduction à Ferret pour le Web Scraping
Avant de le voir à l’œuvre, découvrez ce qu’est Ferret, comment il fonctionne, ce qu’il offre et quand l’utiliser.
Qu’est-ce qu’un furet ?
Ferret est une bibliothèque de scraping web open-source écrite en Go. Son objectif est de simplifier l’extraction de données à partir de pages web en utilisant une approche déclarative. Plus précisément, elle fait abstraction des complexités techniques de l’analyse et de l’extraction en utilisant son propre langage déclaratif : le langage de requête Ferret (FQL).
Avec près de 6k étoiles sur GitHub, Ferret est l’une des bibliothèques de web scraping les plus populaires pour Go. Elle est intégrable et supporte à la fois le web scraping statique et dynamique.
FQL : Le langage de requête Ferret pour le Web Scraping déclaratif
Le Ferret Query Language (FQL) est un langage d’interrogation polyvalent, fortement inspiré de l’AQL d’ArangoDB. Bien qu’il soit capable d’aller plus loin, FQL est principalement utilisé pour extraire des données de pages web.
FQL suit une approche déclarative, ce qui signifie qu’il se concentre sur les données à extraire plutôt que sur la manière de les extraire. Comme AQL, il présente des similitudes avec SQL. Mais, contrairement à l’AQL, le FQL est strictement en lecture seule. Notez que toute forme de manipulation de données doit être effectuée à l’aide de fonctions intégrées spécifiques.
Pour plus d’informations sur la syntaxe FQL, les mots-clés, les constructions et les types de données pris en charge, consultez la page de documentation FQL.
Cas d’utilisation
Comme le souligne la page officielle GitHub, les principaux cas d’utilisation de Ferret sont les suivants :
- Tests de l’interface utilisateur: Automatiser les tests des applications web en simulant les interactions avec le navigateur et en validant que les éléments de la page se comportent et s’affichent correctement dans différents scénarios.
- Apprentissage automatique: Extraire des données structurées des pages web et les utiliser pour créer des ensembles de données de haute qualité. Ceux-ci peuvent ensuite être utilisés pour former ou valider des modèles d’apprentissage automatique de manière plus efficace. Voir comment utiliser le web scraping pour l’apprentissage automatique.
- Analyse: Récupérer et agréger des données web, telles que les prix, les avis ou l’activité des utilisateurs, afin de générer des informations, de suivre les tendances ou d’alimenter des tableaux de bord.
En même temps, il faut garder à l’esprit que les cas d’utilisation potentiels du web scraping vont bien au-delà de ces exemples.
Débuter avec un furet
Maintenant que vous savez ce qu’est Ferret, vous êtes prêt à le voir à l’œuvre sur des pages web statiques et dynamiques. Si vous n’êtes pas familier avec la différence entre les deux, lisez notre guide sur le contenu statique et dynamique dans le web scraping.
Mettons en place un environnement permettant d’utiliser Ferret pour le web scraping !
Conditions préalables
Assurez-vous que les éléments suivants sont installés sur votre machine locale :
- Aller
- Docker
Pour vérifier que Golang est installé et prêt, lancez la commande suivante dans le terminal :
go versionVous devriez obtenir un résultat similaire à celui-ci :
go version go1.24.3 windows/amd64Si vous obtenez une erreur, installez Golang et configurez-le pour votre système d’exploitation.
De même, vérifiez que Docker est installé et correctement configuré pour votre système.
Créer le projet Ferret
Maintenant, créez un dossier pour votre projet de web scraping Ferret et naviguez-y :
mkdir ferret-web-scraping
cd ferret-web-scrapingTéléchargez le CLI Ferret pour votre système d’exploitation et décompressez-le directement dans le dossier ferret-web-scraping/. Vérifiez qu’il fonctionne en exécutant :
./ferret helpLe résultat devrait être :
Usage:
ferret [flags]
ferret [command]
Available Commands:
browser Manage Ferret browsers
config Manage Ferret configs
exec Execute a FQL script or launch REPL
help Help about any command
update
version Show the CLI version information
Flags:
-h, --help help for ferret
-l, --log-level string Set the logging level ("debug"|"info"|"warn"|"error"|"fatal") (default "info")
Use "ferret [command] --help" for more information about a command.Ensuite, ouvrez le dossier du projet dans votre IDE préféré, tel que Visual Studio Code. Dans le dossier du projet, créez un fichier nommé scraper.fql:
ferret-web-scraping/
├── ferret
├── CHANGELOG.md
├── LICENSE
├── README.md
└── scraper.fql # <-- The FQL file for web scraping in Ferretscraper.fql contiendra votre logique déclarative FQL pour le web scraping.
Configurer l’installation Docker Ferret
Pour utiliser toutes les fonctionnalités de Ferret, vous devez avoir Chrome ou Chromium installé localement ou exécuté dans Docker. La documentation officielle recommande d’exécuter Chrome/Chromium dans un conteneur Docker.
Vous pouvez utiliser n’importe quelle image headless basée sur Chromium, mais celle de montferret/chromium est recommandée. Récupérez-la avec :
docker pull montferret/chromiumEnsuite, lancez cette image Docker avec cette commande :
docker run -d -p 9222:9222 montferret/chromiumRemarque: si vous souhaitez voir ce qui se passe dans le navigateur pendant l’exécution de vos scripts FQL, lancez Chrome sur votre machine hôte en activant le débogage à distance avec :
chrome.exe --remote-debugging-port=9222Scraper un site statique avec Ferret
Suivez les étapes ci-dessous pour apprendre à utiliser Ferret pour récupérer un site web statique. Dans cet exemple, la page cible sera le site bac à sable “Books to Scrape” :
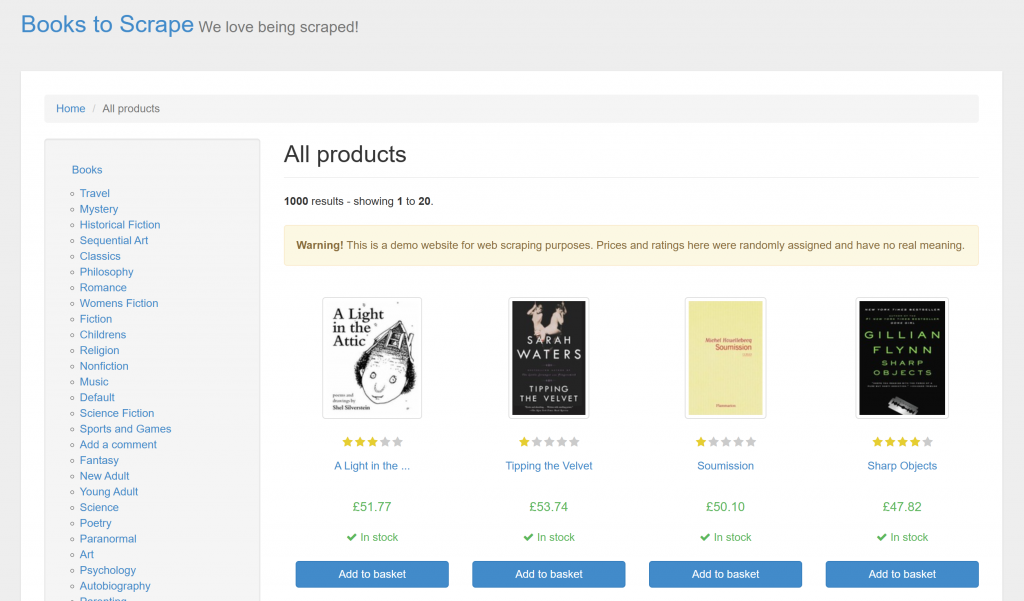
L’objectif est d’extraire les informations clés de chaque livre sur la page en utilisant l’approche déclarative de Ferret via FQL.
Étape 1 : Connexion au site cible
Dans scraper.fql, utilisez la fonction DOCUMENT pour vous connecter à la page cible :
LET doc = DOCUMENT("https://books.toscrape.com/")LET permet de définir une variable en FQL. Après cette instruction, doc contiendra le HTML de la page cible.
Étape 2 : Sélectionner tous les éléments du livre
Tout d’abord, familiarisez-vous avec la structure de la page web cible en la visitant dans votre navigateur et en l’inspectant. En détail, cliquez avec le bouton droit de la souris sur un élément du livre et sélectionnez l’option “Inspecter” pour ouvrir les DevTools :
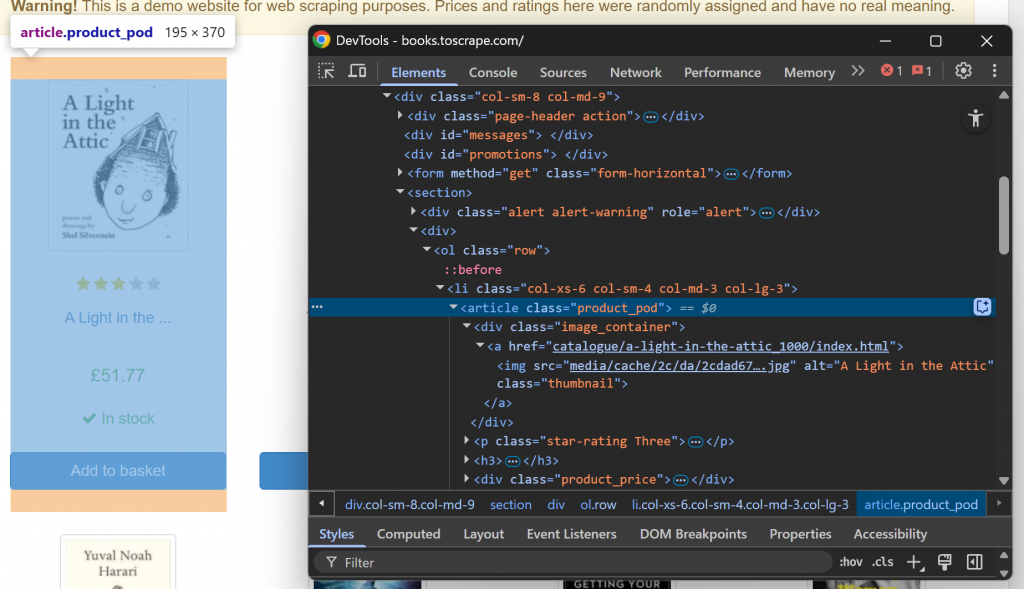
Notez que chaque élément de livre est un nœud
. Sélectionnez tous les éléments livres avec la fonction ELEMENTS():
LET book_elements = ELEMENTS(doc, "section article")ELEMENTS() applique au document le sélecteur CSS transmis en tant que deuxième argument. En d’autres termes, elle sélectionne les éléments HTML souhaités sur la page.
Interroger la liste des éléments sélectionnés et se préparer à leur appliquer la logique d’extraction :
FOR book_element IN book_elements
// book scraping logic...Incroyable ! Il est temps d’itérer sur chaque élément du livre et d’extraire les données de chacun d’entre eux.
Étape 3 : Extraire les données de chaque devis
Inspectez maintenant un seul élément HTML book :
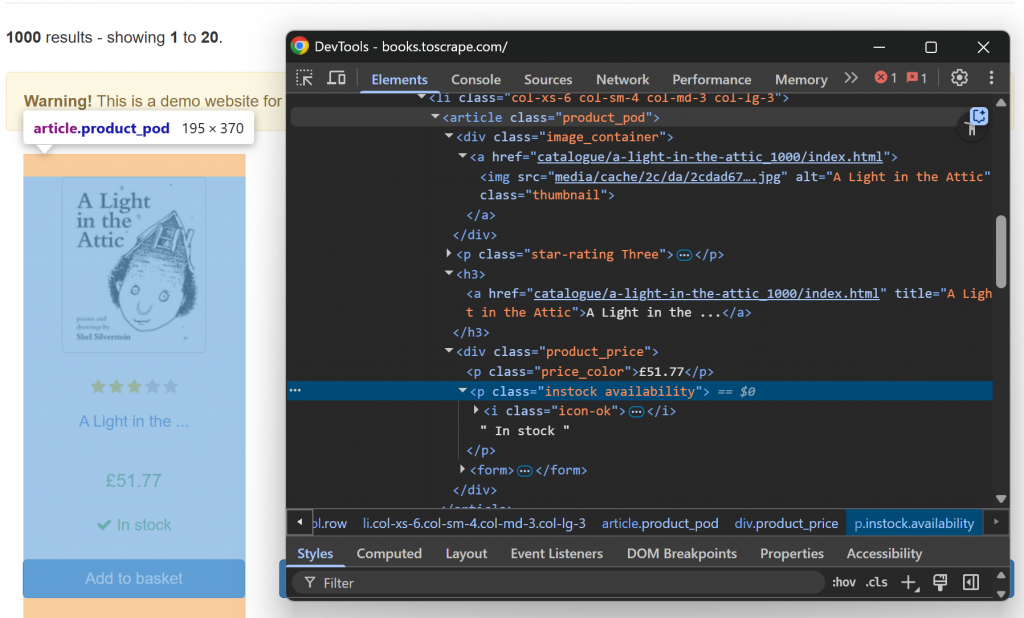
Notez que vous pouvez gratter :
- L’URL de l’image provenant de l’attribut
srcde l’élément.image_container img. - Le titre du livre provenant de l’attribut
titlede l’élémenth3 a. - L’URL de la page du livre à partir de l’attribut
hrefdu nœudh3 a. - Le prix du livre indiqué dans le texte de
.price_color. - L’information sur la disponibilité provient du texte du
fichier .instock.
Mettre en œuvre cette logique d’analyse des données avec :
LET image_element = ELEMENT(book_element, ".image_container img")
LET title_element = ELEMENT(book_element, "h3 a")
LET price_element = ELEMENT(book_element, ".price_color")
LET availability_element = ELEMENT(book_element, ".instock")
RETURN {
image_url: base_url + image_element.attributes.src,
title: base_url+ title_element.attributes.title,
book_url: title_element.attributes.href,
price: TRIM(INNER_TEXT(price_element)),
availability: TRIM(INNER_TEXT(availability_element))
}Où base_url est une variable définie en dehors de la boucle for :
LET base_url = "https://books.toscrape.com/"Dans le code ci-dessus :
ELEMENT()permet de sélectionner un seul élément de la page à l’aide d’un sélecteur CSS.attributesest un attribut spécial que possèdent tous les objets renvoyés parELEMENT(). Il contient les valeurs des attributs HTML de l’élément actuel.INNER_TEXT()renvoie le texte contenu dans l’élément courant.TRIM()supprime les espaces blancs de début et de fin.
Fantastique ! La logique de raclage statique est terminée.
Étape 4 : Assembler le tout
Votre fichier scraper.fql devrait ressembler à ceci :
// connect to the target site
LET doc = DOCUMENT("https://books.toscrape.com/")
// select the book HTML elements
LET book_elements = ELEMENTS(doc, "section article")
// the base URL of the target site
LET base_url = "https://books.toscrape.com/"
// iterate over each book element and apply the scraping logic
FOR book_element IN book_elements
// select all info elements
LET image_element = ELEMENT(book_element, ".image_container img")
LET title_element = ELEMENT(book_element, "h3 a")
LET price_element = ELEMENT(book_element, ".price_color")
LET availability_element = ELEMENT(book_element, ".instock")
// scrape the data of interest
RETURN {
image_url: base_url + image_element.attributes.src,
title: base_url+ title_element.attributes.title,
book_url: title_element.attributes.href,
price: TRIM(INNER_TEXT(price_element)),
availability: TRIM(INNER_TEXT(availability_element))
}Comme vous pouvez le constater, la logique de scraping se concentre davantage sur les données à extraire que sur la manière de les extraire. C’est la puissance du scraping web déclaratif avec Ferret !
Étape 5 : Exécuter le script FQL
Exécutez votre script Ferret avec :
./ferret exec scraper.fqlDans le terminal, la sortie sera :
[{"availability":"In stock","book_url":"catalogue/a-light-in-the-attic_1000/index.html","image_url":"https://books.toscrape.com/media/cache/2c/da/2cdad67c44b002e7ead0cc35693c0e8b.jpg","price":"£51.77","title":"https://books.toscrape.com/A Light in the Attic"},{"availability":"In stock","book_url":"catalogue/tipping-the-velvet_999/index.html","image_url":"https://books.toscrape.com/media/cache/26/0c/260c6ae16bce31c8f8c95daddd9f4a1c.jpg","price":"£53.74","title":"https://books.toscrape.com/Tipping the Velvet"},
// omitted for brevity...
,{"availability":"In stock","book_url":"catalogue/its-only-the-himalayas_981/index.html","image_url":"https://books.toscrape.com/media/cache/27/a5/27a53d0bb95bdd88288eaf66c9230d7e.jpg","price":"£45.17","title":"https://books.toscrape.com/It's Only the Himalayas"}]Il s’agit d’une chaîne JSON contenant toutes les données relatives aux livres collectées à partir de la page web comme prévu. Pour une approche non déclarative de l’analyse des données, consultez notre guide sur le web scraping avec Go.
Mission accomplie !
Scraper un site dynamique avec Ferret
Ferret prend également en charge le scraping de sites web dynamiques qui nécessitent l’exécution de JavaScript. Dans cette section du guide, le site cible sera la version retardée par JavaScript du site “Citations à gratter” :

La page utilise JavaScript pour injecter dynamiquement des éléments de citation dans le DOM après un court délai. Ce scénario nécessite l’exécution de JavaScript, d’où la nécessité de rendre la page dans un navigateur. (C’est également la raison pour laquelle nous avons précédemment mis en place un conteneur Chromium Docker).
Suivez les étapes ci-dessous pour apprendre à gérer des pages web dynamiques avec Ferret !
Étape 1 : Connexion à la page cible dans le navigateur
Utilisez les lignes suivantes pour vous connecter à la page cible via un navigateur sans tête :
LET doc = DOCUMENT("https://quotes.toscrape.com/js-delayed/?delay=2000", {
driver: "cdp"
})Notez l’utilisation du champ driver dans la fonction DOCUMENT(). C’est ce qui indique à Ferret de rendre la page dans l’instance headless de Chroumium configurée via Docker.
Étape 2 : Attendre que les éléments ciblés soient sur la page
Visitez la page cible dans votre navigateur, attendez que les éléments de citation se chargent et inspectez l’un d’entre eux :
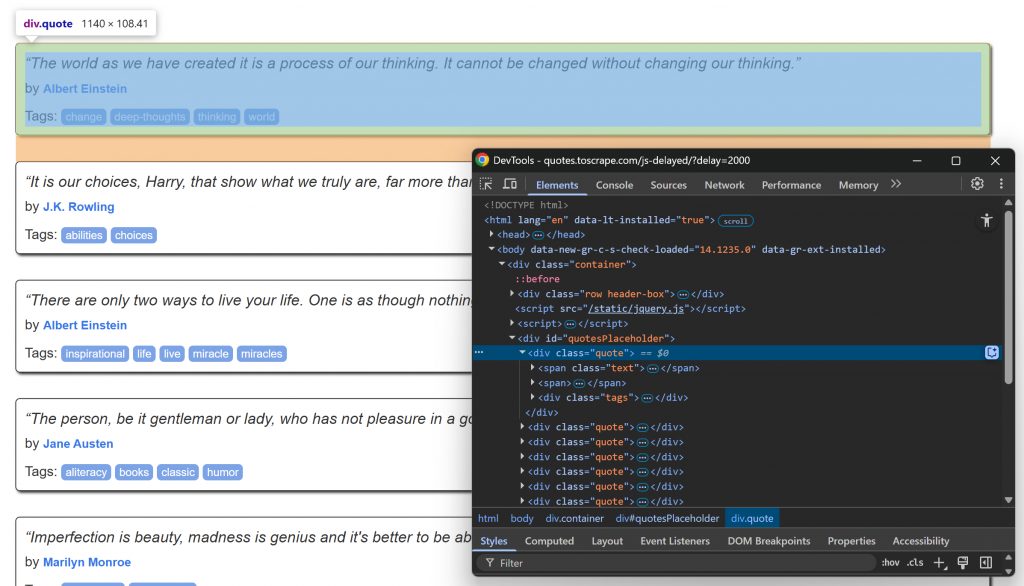
Remarquez que les éléments de citation peuvent être sélectionnés à l’aide du sélecteur CSS .quote. Ces éléments de citation seront rendus par JavaScript après un court délai, vous devez donc les attendre.
Utilisez la fonction WAIT_ELEMENT() de Ferret pour attendre que les éléments de citation apparaissent sur la page :
// wait up to 5 seconds for the quote elements to be on the page
WAIT_ELEMENT(doc, ".quote", 5000)Il s’agit d’une construction essentielle à utiliser lors du scraping de pages web dynamiques qui s’appuient sur JavaScript pour rendre le contenu.
Étape 3 : Appliquer la logique du scraping
Concentrons-nous à présent sur la structure HTML des éléments d’information à l’intérieur d’un nœud .quote :
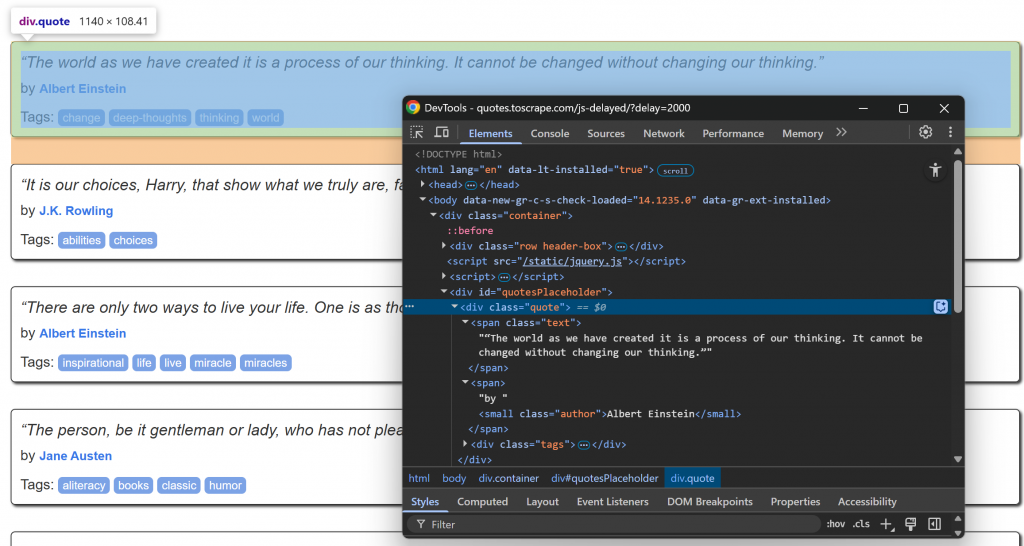
Notez que vous pouvez gratter :
- Le texte de la citation de
.quote - L’auteur de
.author
Implémenter la logique de scraping web de Ferret avec :
// select the quote HTML elements
LET quote_elements = ELEMENTS(doc, ".quote")
// iterate over each quote element and apply the scraping logic
FOR quote_element IN quote_elements
// select all info elements
LET text_element = ELEMENT(quote_element, ".text")
LET author_element = ELEMENT(quote_element, ".author")
// scrape the data of interest
RETURN {
quote: TRIM(INNER_TEXT(text_element)),
author: TRIM(INNER_TEXT(author_element))
} Génial ! La logique d’analyse est terminée.
Étape 4 : Assembler le tout
Le fichier scraper.fql doit contenir :
// connect to the target site via the Chromium headless instance
LET doc = DOCUMENT("https://quotes.toscrape.com/js-delayed/?delay=2000", {
driver: "cdp"
})
// wait up to 5 seconds for the quote elements to be on the page
WAIT_ELEMENT(doc, ".quote", 5000)
// select the quote HTML elements
LET quote_elements = ELEMENTS(doc, ".quote")
// iterate over each quote element and apply the scraping logic
FOR quote_element IN quote_elements
// select all info elements
LET text_element = ELEMENT(quote_element, ".text")
LET author_element = ELEMENT(quote_element, ".author")
// scrape the data of interest
RETURN {
quote: TRIM(INNER_TEXT(text_element)),
author: TRIM(INNER_TEXT(author_element))
}Comme vous pouvez le constater, ce script n’est pas très différent de celui d’un site statique. Là encore, la raison en est que Ferret utilise une approche déclarative du web scraping.
Étape 5 : Exécuter le code FQL
Exécutez votre script de scraping Ferret avec :
./ferret exec scraper.fqlCette fois-ci, le résultat sera le suivant :
[{"author":"Albert Einstein","quote":"“The world as we have created it is a process of our thinking. It cannot be changed without changing our thinking.”"},{"author":"J.K. Rowling","quote":"“It is our choices, Harry, that show what we truly are, far more than our abilities.”"},{"author":"Albert Einstein","quote":"“There are only two ways to live your life. One is as though nothing is a miracle. The other is as though everything is a miracle.”"},{"author":"Jane Austen","quote":"“The person, be it gentleman or lady, who has not pleasure in a good novel, must be intolerably stupid.”"},{"author":"Marilyn Monroe","quote":"“Imperfection is beauty, madness is genius and it's better to be absolutely ridiculous than absolutely boring.”"},{"author":"Albert Einstein","quote":"“Try not to become a man of success. Rather become a man of value.”"},{"author":"André Gide","quote":"“It is better to be hated for what you are than to be loved for what you are not.”"},{"author":"Thomas A. Edison","quote":"“I have not failed. I've just found 10,000 ways that won't work.”"},{"author":"Eleanor Roosevelt","quote":"“A woman is like a tea bag; you never know how strong it is until it's in hot water.”"},{"author":"Steve Martin","quote":"“A day without sunshine is like, you know, night.”"}]Et voilà ! C’est exactement le contenu structuré extrait de la page rendue par JavaScript.
Limites de l’approche déclarative Ferret pour la capture du Web
Ferret est sans aucun doute un outil puissant et l’un des rares à adopter une approche déclarative du scraping web. Cependant, il présente au moins trois inconvénients majeurs :
- Documentation médiocre et mises à jour peu fréquentes: Bien que la documentation officielle contienne des textes utiles, elle ne contient pas de références complètes aux API. Il est donc difficile d’élaborer des scripts complexes. En outre, le projet ne reçoit pas de mises à jour régulières, ce qui signifie qu’il peut être en retard par rapport aux techniques modernes de scraping.
- Pas de prise en charge du contournement des mesures anti-scraping: Ferret n’offre pas de mécanismes intégrés pour gérer les CAPTCHA, les limites de taux ou d’autres défenses anti-scraping avancées. Il n’est donc pas adapté au scraping de sites plus protégés.
- Expression limitée: FQ, le langage de requête Ferret, est encore en cours de développement et n’offre pas le même niveau de flexibilité ou de contrôle que des outils de scraping plus modernes tels que Playwright ou Puppeteer.
Ces limitations ne peuvent pas être facilement résolues par de simples intégrations. N’oubliez pas non plus que l’objectif principal de Ferret est de récupérer des données web. La solution consiste donc à envisager une alternative plus robuste.
L‘infrastructure d’IA de Bright Data comprend une suite de services avancés conçus pour une extraction fiable et intelligente des données web. Ces services vous permettent d’extraire des données à partir de n’importe quel site web et à grande échelle.
Conclusion
Dans ce tutoriel, vous avez appris à utiliser Ferret pour le web scraping déclaratif en Go. Comme nous l’avons démontré, cette bibliothèque vous permet d’extraire des données de pages statiques et dynamiques en vous concentrant sur ce qu’il faut récupérer, plutôt que sur la manière de le faire.
Le problème, c’est que Ferret présente plusieurs limites et n’est donc peut-être pas la meilleure solution qui soit. Si vous recherchez un moyen plus rationnel et plus évolutif de récupérer des données web, envisagez d’adopter les API Web Scraper – despoints de terminaison dédiés àl’extraction de données web fraîches, structurées et entièrement conformes à partir de plus de 120 sites web populaires.
Créez un compte Bright Data gratuit dès aujourd’hui et testez notre puissante infrastructure de scraping web !




