

Dans ce guide, vous apprendrez :
- La définition d’un jeu de données
- Les meilleures façons de créer des jeux de données
- Comment créer un jeu de données dans Python
- Comment créer un jeu de données dans R
C’est parti !
Qu’est-ce qu’un jeu de données ?
Un jeu de données est une collection de données associées à un thème, un sujet ou un secteur spécifique. Les jeux de données peuvent englober différents types d’informations, notamment des chiffres, du texte, des images, des vidéos et des fichiers audio, et peuvent être stockés dans des formats tels que CSV, JSON, XLS, XLSX ou SQL.
Essentiellement, un jeu de données comprend des données structurées destinées à un usage particulier.
Les 5 meilleures stratégies pour créer un jeu de données
Découvrez les 5 meilleures stratégies pour créer des Jeux de données, en analysant leur fonctionnement et leurs avantages et inconvénients.
Stratégie n° 1 : externaliser la tâche
La création et la gestion d’une unité commerciale dédiée à la création de Jeux de données peuvent s’avérer irréalisables ou peu pratiques. Cela est particulièrement vrai si vous manquez de ressources internes ou de temps. Dans un tel scénario, une stratégie efficace pour la création de Jeux de données consiste à externaliser la tâche.
L’externalisation consiste à déléguer le processus de création de Jeux de données à des experts externes ou à des agences spécialisées, plutôt que de le gérer en interne. Cette approche vous permet de tirer parti des compétences de professionnels ou d’organisations expérimentés dans la collecte, le nettoyage et le formatage des données.
À qui devriez-vous externaliser la création de Jeux de données ? De nombreuses entreprises proposent des Jeux de données prêts à l’emploi ou des services de collecte de données personnalisés. Pour plus de détails, consultez notre guide sur les meilleurs sites web de Jeux de données.
Ces fournisseurs utilisent des techniques avancées pour garantir que les données récupérées sont exactes et formatées selon vos spécifications. Si l’externalisation vous permet de vous concentrer sur d’autres aspects importants de votre activité, il est essentiel de choisir un partenaire fiable qui répond à vos attentes en matière de qualité.
Avantages:
- Vous n’avez à vous soucier de rien
- Jeux de données provenant de n’importe quel site et dans n’importe quel format
- Données historiques ou récentes
Inconvénients
- Vous n’avez pas le contrôle total sur le processus de récupération des données
- Problèmes potentiels de conformité des données avec le RGPD et le CCPA
- Ce n’est peut-être pas la solution la plus rentable
Stratégie n° 2 : récupérer les données à partir d’API publiques
De nombreuses plateformes, des réseaux sociaux aux sites de commerce électronique, proposent des API publiques qui exposent une multitude de données. Par exemple, l’API de X donne accès à des informations sur les comptes publics, les publications et les réponses.
La récupération de données à partir d’API publiques est une technique efficace pour créer des Jeux de données. En effet, ces points de terminaison renvoient des données dans un format structuré, ce qui facilite la génération d’un jeu de données à partir de leurs réponses. Sans surprise, les API constituent l’une des meilleures stratégies pour l’approvisionnement en données.
En tirant parti de ces API, vous pouvez rapidement collecter de grands volumes de données fiables directement à partir de plateformes établies. Le principal inconvénient est que vous devez respecter les limites d’utilisation et les conditions d’utilisation des API.
Avantages:
- Accès aux données officielles
- Intégration simple dans n’importe quel langage de programmation
- Obtention de données structurées directement à la source
Inconvénients
- Toutes les plateformes ne disposent pas d’API publiques
- Vous devez vous conformer aux restrictions imposées par le fournisseur de l’API
- Les données renvoyées par ces API peuvent changer au fil du temps
Stratégie n° 3 : recherchez des données ouvertes
Les données ouvertes désignent les jeux de données qui sont partagés ouvertement et gratuitement avec le public. Ces données sont principalement utilisées dans la recherche et les articles scientifiques, mais elles peuvent également répondre à des besoins commerciaux, tels que l’analyse de marché.
Les données ouvertes sont fiables, car elles sont fournies par des sources réputées telles que les gouvernements, les organisations à but non lucratif et les institutions universitaires. Ces organisations proposent des référentiels de données ouvertes couvrant un large éventail de sujets, notamment les tendances sociales, les statistiques sur la santé, les indicateurs économiques, les données environnementales, etc.
Voici quelques sites populaires où vous pouvez trouver des données ouvertes :
- Data.gov: un référentiel complet de données fédérales américaines.
- Portail des données ouvertes de l’Union européenne: propose des Jeux de données provenant de toute l’Europe.
- World Bank Open Data: fournit des données économiques et de développement mondiales.
- UN Data: propose divers jeux de données sur les indicateurs sociaux et économiques mondiaux.
- Registre des données ouvertes sur AWS: une plateforme permettant de découvrir et de partager des Jeux de données disponibles via les ressources AWS.
Les données ouvertes sont un moyen populaire de créer des Jeux de données, car elles éliminent le besoin de collecter des données en fournissant des données librement accessibles. Néanmoins, vous devez vérifier la qualité, l’exhaustivité et les conditions de licence des données afin de vous assurer qu’elles répondent aux exigences de votre projet.
Avantages:
- Données gratuites
- Jeux de données prêts à l’emploi, volumineux et complets
- Jeux de données provenant de sources fiables telles que des agences gouvernementales
Inconvénients
- Donne généralement accès uniquement à des données historiques
- Nécessite un certain travail pour obtenir des informations utiles pour votre entreprise
- Vous risquez de ne pas trouver les données qui vous intéressent
Stratégie n° 4 : télécharger des Jeux de données depuis GitHub
GitHub héberge de nombreux référentiels contenant des jeux de données à des fins diverses, allant de l’apprentissage automatique et de la science des données au développement de logiciels et à la recherche. Ces jeux de données sont partagés par des particuliers et des organisations afin de recevoir des commentaires et de contribuer à la communauté.
Dans certains cas, ces référentiels GitHub comprennent également du code permettant de traiter, d’analyser et d’explorer les données.
Voici quelques référentiels notables à partir desquels vous pouvez obtenir des données :
- Awesome Public Datasets: une collection sélectionnée de Jeux de données de haute qualité dans divers domaines, notamment la finance, le climat et le sport. Elle sert de plateforme pour trouver des Jeux de données liés à des sujets ou à des secteurs spécifiques.
- Jeux de données Kaggle: Kaggle, une plateforme de premier plan pour les concours de science des données, héberge certains de ses jeux de données sur GitHub. Les utilisateurs peuvent créer des jeux de données Kaggle à partir des référentiels GitHub en quelques clics seulement.
- Autres référentiels de données ouvertes : plusieurs organisations et groupes de recherche utilisent GitHub pour héberger des jeux de données ouvertes.
Ces référentiels proposent des jeux de données préexistants qui peuvent être facilement utilisés ou adaptés à vos besoins. Pour y accéder, il suffit d’une seule commande git clone ou d’un clic sur le bouton « Télécharger ».
Avantages:
- Jeux de données prêts à l’emploi
- Code pour analyser et interagir avec les données
- De nombreuses catégories de données différentes parmi lesquelles choisir
Inconvénients
- Problèmes potentiels liés aux licences
- La plupart de ces référentiels ne sont pas à jour
- Données génériques, non adaptées à vos besoins
Stratégie n° 5 : créez votre propre ensemble de données grâce au Scraping web
Le scraping web consiste à extraire des données de pages web et à les convertir dans un format utilisable.
La création de jeux de données par Scraping web est une approche populaire pour plusieurs raisons :
- Accès à des tonnes de données: le Web est la plus grande source de données au monde. Le scraping web vous permet d’exploiter cette vaste ressource et de recueillir des informations qui ne seraient peut-être pas disponibles par d’autres moyens.
- Flexibilité: vous pouvez choisir les données à récupérer, le format dans lequel produire les Jeux de données et contrôler la fréquence de mise à jour des données.
- Personnalisation: adaptez votre extraction de données à vos besoins spécifiques, par exemple en extrayant des données provenant de marchés de niche ou de sujets spécialisés qui ne sont pas couverts par les Jeux de données publics.
Voici comment fonctionne généralement le Scraping web :
- Identifiez le site cible
- Inspectez ses pages web afin d’élaborer une stratégie d’extraction des données
- Créez un script pour vous connecter aux pages cibles.
- Analysez le contenu HTML des pages
- Sélectionner les éléments DOM contenant les données qui vous intéressent
- Extraire les données de ces éléments
- Exportez les données collectées au format souhaité, tel que JSON, CSV ou XLSX
Notez que le script permettant d’effectuer le Scraping web peut être écrit dans pratiquement n’importe quel langage de programmation, tel que Python, JavaScript ou Ruby. Pour en savoir plus, consultez notre article sur les meilleurs langages pour le Scraping web. Jetez également un œil aux meilleurs outils pour le Scraping web.
Comme la plupart des entreprises connaissent la valeur de leurs données, même si celles-ci sont accessibles au public sur leur site, elles les protègent à l’aide de technologies anti-bot. Ces solutions peuvent bloquer les requêtes automatisées effectuées par vos scripts. Découvrez comment contourner ces mesures dans notre tutoriel sur la manière d’effectuer du Scraping web sans être bloqué.
De plus, si vous souhaitez savoir en quoi le Scraping web diffère de l’obtention de données à partir d’API publiques, consultez notre article sur le Scraping web et les API.
Avantages:
- Données publiques provenant de n’importe quel site
- Vous contrôlez le processus d’extraction des données
- Solution rentable qui fonctionne avec la plupart des langages de programmation
Inconvénients
- Les solutions anti-bot et anti-scraping peuvent vous bloquer
- Nécessite une certaine maintenance
- Peut nécessiter une logique d’agrégation de données personnalisée
Comment créer des jeux de données en Python
Python est l’un des principaux langages utilisés en science des données et est donc un choix populaire pour la création de Jeux de données. Comme vous allez le voir, la création d’un jeu de données en Python ne nécessite que quelques lignes de code.
Ici, nous nous concentrerons sur le scraping d’informations sur tous les Jeux de données disponibles sur le Bright Data Dataset Marketplace:
Suivez le tutoriel guidé pour atteindre votre objectif !
Pour obtenir des instructions plus détaillées, consultez notre guide sur le Scraping web avec Python.
Étape 1 : Installation et configuration
Nous partons du principe que Python 3+ est installé sur votre ordinateur et que vous avez configuré un projet Python.
Vous devez d’abord installer les bibliothèques requises pour ce projet :
- requests: pour envoyer des requêtes HTTP et récupérer les documents HTML associés aux pages web.
- Beautiful Soup: pour l’analyse des documents HTML et XML et l’extraction des données des pages web.
- pandas: pour manipuler les données et les exporter vers des Jeux de données CSV.
Ouvrez le terminal dans l’environnement virtuel activé dans le dossier de votre projet et exécutez :
pip install requests beautifulsoup4 pandasUne fois installées, vous pouvez importer ces bibliothèques dans votre script Python :
import requests
from bs4 import BeautifulSoup
import pandas as pdÉtape 2 : se connecter au site cible
Récupérez le code HTML de la page à partir de laquelle vous souhaitez extraire des données. Utilisez la bibliothèque requests pour envoyer une requête HTTP au site cible et récupérer son contenu HTML :
url = 'https://brightdata.com/products/Jeux de données'
headers = { 'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/128.0.0.0 Safari/537.36' }
response = requests.get(url=url, headers=headers)Pour plus de détails, consultez notre guide sur la configuration d’un agent utilisateur dans les requêtes Python.
Étape 3 : implémenter la logique de scraping
Une fois le contenu HTML en votre possession, analysez-le à l’aide de BeautifulSoup et extrayez-en les données dont vous avez besoin. Sélectionnez les éléments HTML qui contiennent les données qui vous intéressent et récupérez les données qu’ils contiennent :
# analyser le HTML récupéré
soup = BeautifulSoup(response.text, 'html.parser')
# où stocker les données extraites
data = []
# logique d'extraction
dataset_elements = soup.select('.datasets__loop .datasets__item--wrapper')
for dataset_element in dataset_elements:
dataset_item = dataset_element.select_one('.datasets__item')
title = dataset_item.select_one('.datasets__item--title').text.strip()
url_item = dataset_item.select_one('.datasets__item--title a')
if (url_item is not None):
url = url_item['href']
else:
url = None
type = dataset_item.get('aria-label', 'regular').lower()
data.append({
'title': title,
'url': url,
'type': type
})Étape 4 : Exporter au format CSV
Utilisez pandas pour convertir les données extraites en un DataFrame et exportez-les vers un fichier CSV.
df = pd.DataFrame(data, columns=data[0].keys())
df.to_csv('dataset.csv', index=False)Étape 5 : Exécuter le script
Votre script Python final contiendra les lignes de code suivantes :
import requests
from bs4 import BeautifulSoup
import pandas as pd
# envoyer une requête GET au site cible avec un agent utilisateur personnalisé
url = 'https://brightdata.com/products/Jeux de données'
headers = { 'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/128.0.0.0 Safari/537.36' }
response = requests.get(url=url, headers=headers)
# analyser le code HTML récupéré
soup = BeautifulSoup(response.text, 'html.parser')
# où stocker les données extraites
data = []
# logique de scraping
dataset_elements = soup.select('.datasets__loop .datasets__item--wrapper')
for dataset_element in dataset_elements:
dataset_item = dataset_element.select_one('.datasets__item')
title = dataset_item.select_one('.datasets__item--title').text.strip()
url_item = dataset_item.select_one('.datasets__item--title a')
if (url_item is not None):
url = url_item['href']
else:
url = None
type = dataset_item.get('aria-label', 'regular').lower()
data.append({
'title': title,
'url': url,
'type': type
})
# export to CSV
df = pd.DataFrame(data, columns=data[0].keys())
df.to_csv('dataset.csv', index=False)Lancez-le, et le fichier dataset.csv suivant apparaîtra dans le dossier de votre projet :
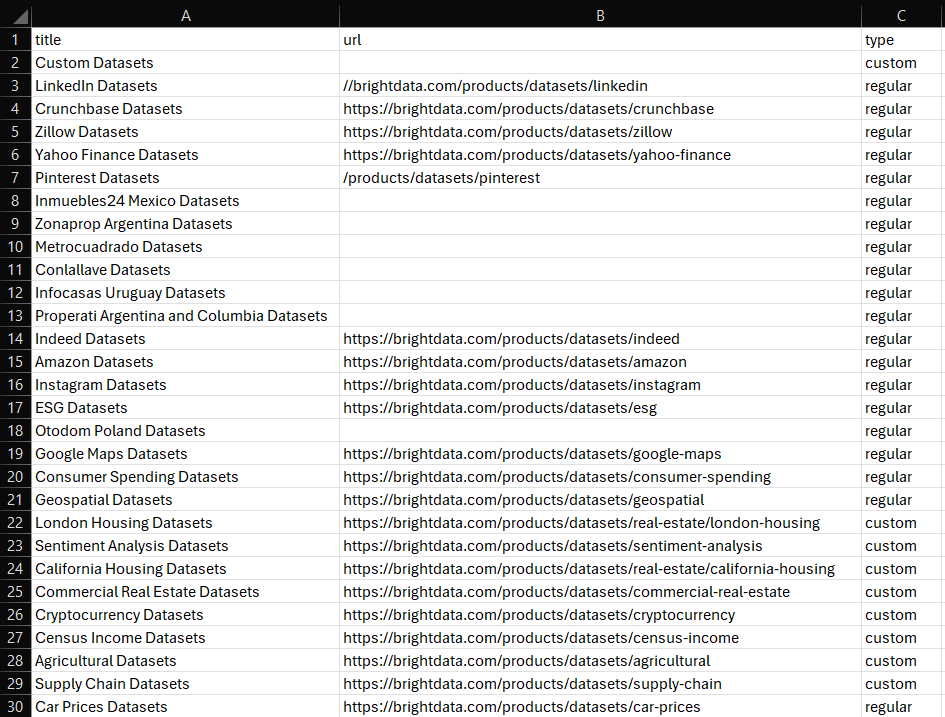
Et voilà ! Vous savez désormais comment créer des Jeux de données dans Python.
Comment créer un jeu de données dans R
R est un autre langage largement utilisé par les chercheurs et les scientifiques des données. Vous trouverez ci-dessous le script équivalent (selon ce que nous avons vu précédemment en Python) pour créer un jeu de données dans R :
library(httr)
library(rvest)
library(dplyr)
library(readr)
# envoyer une requête GET au site cible avec un agent utilisateur personnalisé
url <- "https://brightdata.com/products/Jeux de données"
headers <- add_headers(`User-Agent` = "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/128.0.0.0 Safari/537.36")
response <- GET(url, headers)
# analyser le HTML récupéré
page <- read_html(response)
# où stocker les données extraites
data <- tibble()
# logique d'extraction
dataset_elements <- page %>%
html_nodes(".datasets__loop .datasets__item--wrapper")
for (dataset_element in dataset_elements) {
title <- dataset_element %>%
html_node(".datasets__item .datasets__item--title") %>%
html_text(trim = TRUE)
url_item <- dataset_element %>%
html_node(".datasets__item .datasets__item--title a")
url <- if (!is.null(url_item)) {
html_attr(url_item, "href")
} else {
""
}
type <- dataset_element %>%
html_attr("aria-label", "regular") %>%
tolower()
data <- bind_rows(data, tibble(
title = title,
url = url,
type = type
))
}
# export to CSV
write_csv(data, "dataset.csv")Pour plus d’informations, suivez notre tutoriel sur le Scraping web avec R.
Conclusion
Dans cet article, vous avez appris à créer des jeux de données. Vous avez compris ce qu’est un jeu de données et exploré différentes stratégies pour en créer un. Vous avez également vu comment appliquer la stratégie de Scraping web dans Python et R.
Bright Data exploite un réseau de Proxys vaste, rapide et fiable, utilisé par de nombreuses entreprises du classement Fortune 500 et plus de 20 000 clients. Ce réseau sert à récupérer de manière éthique des données sur le Web et à les proposer sur un vaste marché de Jeux de données, qui comprend :
- Jeux de données commerciales: données provenant de sources clés telles que LinkedIn, CrunchBase, Owler et Indeed.
- Jeux de données sur le commerce électronique: données provenant d’Amazon, Walmart, Target, Zara, Zalando, Asos et bien d’autres.
- Jeux de données immobilières: données provenant de sites Web tels que Zillow, MLS, etc.
- Jeux de données issus des réseaux sociaux: données provenant de Facebook, Instagram, YouTube et Reddit.
- Jeux de données financières: données provenant de Yahoo Finance, Market Watch, Investopedia, etc.
Si ces options prédéfinies ne répondent pas à vos besoins, envisagez nos services de collecte de données personnalisés.
En outre, Bright Data propose une large gamme d’outils de scraping puissants, notamment des API Web Scraper et Navigateur de scraping.
Inscrivez-vous dès maintenant et découvrez quels produits et services de Bright Data répondent le mieux à vos besoins.




