Ce guide explique de A à Z comment extraire des données de sites web avec Go, et pourquoi Go est l’un des meilleures langages pour le web scraping.
20 min de lecture
Dans ce tutoriel, vous comprendrez pourquoi Go est l’un des meilleures langages pour faire du web scraping de manière efficace et vous apprendrez à construire un web scraper en Go à partir de zéro.
Dans cet article, nous parlerons des points suivants :
Peut-on faire du web scraping avec Go ?
Les meilleures librairies de web scraping avec Go
Construction d’un web scraper en Go
Peut-on faire du web scraping avec Go ?
Go, également connu sous le nom de Golang, est un langage de programmation de type statique créé par Google. Il est conçu pour être efficace, concurrent, facile à écrire et à modifier. Ces derniers temps, ces caractéristiques ont fait de Go un choix privilégié pour diverses applications, notamment le web scraping.
Plus précisément, Go fournit des fonctionnalités puissantes qui sont très pratiques pour les tâches de web scraping. Il dispose notamment d’un modèle de concurrence intégré, qui autorise le traitement concurrent de plusieurs requêtes web. Cela fait de Go le langage idéal pour extraire efficacement de gros volumes de données de plusieurs sites web. De plus, la bibliothèque standard de Go inclut un package HTTP client et un package d’analyse HTML, qui peuvent être utilisés pour extraire des pages web, analyser du HTML et extraire des données de sites web.
Si ces capacités et ces packages par défaut s’avèrent insuffisants ou trop difficiles à utiliser, il existe également plusieurs bibliothèques Go dédiées au web scraping. Jetons maintenant un coup d’œil aux plus populaires d’entre elles.
Les meilleures bibliothèques Go pour le web scraping
Voici une liste de quelques-unes des meilleures bibliothèques de web scraping pour Go :
Colly: une structure puissante de web scraping et de web crawling pour Go. Colly fournit une API fonctionnelle pour la création de requêtes HTTP, la gestion des en-têtes et l’analyse du DOM. Colly prend également en charge le web scraping en parallèle, la limitation du débit et la gestion automatique des cookies.
Goquery: une bibliothèque Go populaire pour l’analyse HTML, basée sur une syntaxe de type jQuery. Goquery vous permet de sélectionner des éléments HTML à l’aide de sélecteurs CSS, de manipuler le DOM et d’extraire des données.
Selenium : un client Go de la structure de tests web la plus populaire. Il vous permet d’automatiser les navigateurs web pour diverses tâches, y compris le web scraping. Plus précisément, Selenium peut contrôler un navigateur web et lui demander d’interagir avec des pages comme le ferait un utilisateur humain. Il est également capable de faire du web scraping sur des pages qui utilisent JavaScript pour la récupération ou le rendu des données.
Prérequis
Avant de commencer, vous devez installer Go sur votre machine. Il est à noter que la procédure d’installation dépend du système d’exploitation.
Ouvrez le fichier téléchargé et suivez les instructions d’installation. Le package va installer Go dans /usr/local/go et ajouter /usr/local/go/bin à votre variable d’environnement PATH.
Redémarrez toutes les sessions de terminal ouvertes.
Lancez le fichier MSI que vous avez téléchargé et suivez les instructions de l’assistant d’installation. Le programme d’installation installe Go dans C:/Program Files ou dans C:/Program ( x86) et ajoute le dossier bin à la variable d’environnement PATH.
Assurez-vous que votre système n’a pas de dossier /usr/local/go. S’il existe, supprimez-le avec :
rm -rf /usr/local/go
Extrayez l’archive téléchargée dans /usr/local :
tar -C /usr/local -xzf goX.Y.Z.linux-amd64.tar.gz
Veillez à remplacer X.Y.Z par la version du package Go que vous avez téléchargé.
Ajoutez /usr/local/go/bin à la variable d’environnement PATH :
export PATH=$PATH:/usr/local/go/bin
Rebootez votre PC.
Quel que soit votre système d’exploitation, vérifiez que Go a été installé avec succès à l’aide de la commande ci-dessous :
go version
Cela devrait renvoyer quelque chose comme :
go version go1.20.3
Bravo ! Vous êtes maintenant prêt à vous lancer dans le web scraping avec Go.
Construction d’un web scraper en Go
Vous allez apprendre ici comment construire un web scraper en Go. Ce script automatisé pourra extraire automatiquement des données de la page d’accueil de Bright Data. Le but du processus de web scraping en Go sera de sélectionner certains éléments HTML sur la page, d’en extraire les données et de convertir les données collectées à un format plus facile à consulter.
À l’heure où nous écrivons ces lignes, voici à quoi ressemble notre site cible :
Suivez ce tutoriel étape par étape pour apprendre à faire du web scraping en Go.
Étape 1 : Configurer un projet Go
Initialisons maintenant votre projet de web scraper Go. Ouvrez le terminal et créez un dossier go-web-scraper :
Cela initialisera un module web-scraper dans la racine du projet.
Le répertoire go-web-scraper contient maintenant le fichier go.mod suivant :
module web-scraper
go 1.20
Notez que la dernière ligne dépend de votre version de Go.
Vous êtes maintenant prêt à commencer à écrire de la logique Go dans votre EDI. Dans ce tutoriel, nous allons utiliser Visual Studio Code. Comme celui-ci ne prend pas en charge Go nativement, vous devez d’abord installer l’extension Go.
Lancez VS Code, cliquez sur l’icône « Extensions » dans la barre de gauche et tapez « Go ».
Cliquez sur le bouton « Installer » de la première carte pour ajouter l’extension Go pour Visual Studio Code.
Cliquez sur « Fichier », sélectionnez « Ouvrir le dossier… », puis ouvrez le répertoire go-web-scraper.
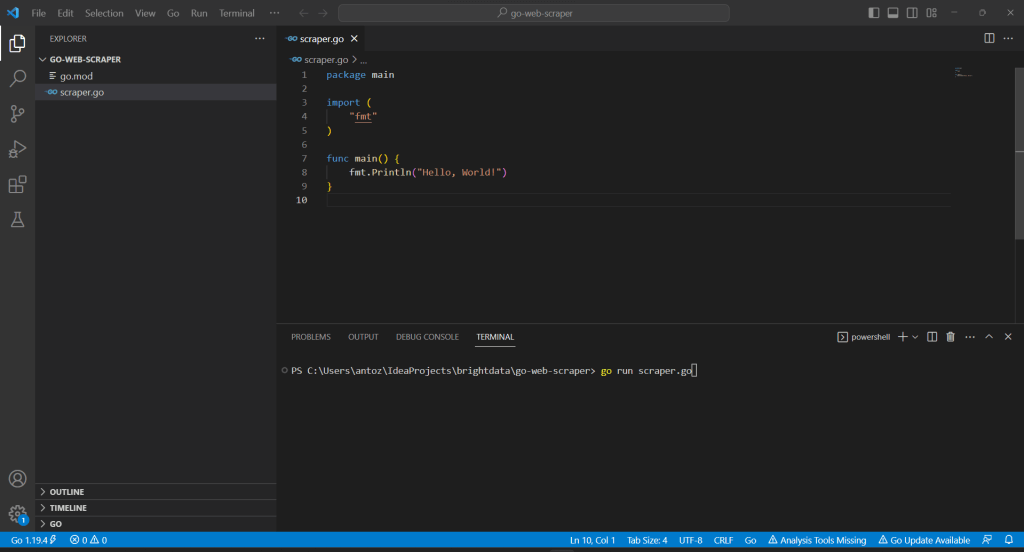
Cliquez avec le bouton droit de la souris sur la section “Explorateur”, sélectionnez “Nouveau fichier…” et créez un fichier scraper.go comme suit :
Gardez à l’esprit que la fonction main() représente le point d’entrée de toutes les applications Go. C’est là que vous devrez placer votre logique de web scraping Golang.
Visual Studio Code vous demandera d’installer certains packages pour terminer l’intégration avec Go. Installez-les tous. Exécutez ensuite le script Go en lançant la commande ci-dessous dans le terminal de VS :
go run scraper.go
Cela produira le résultat suivant :
Hello, World!
Étape 2 : Commencer à travailler avec Colly
Pour construire un web scraper Go plus facilement, vous devez utiliser l’un des packages présentés ci-avant. Mais tout d’abord, vous devez déterminer quelle bibliothèque Golang de web scraping est la plus adaptée à vos objectifs. Pour ce faire, visitez le site web cible, cliquez avec le bouton droit de la souris sur l’arrière-plan et sélectionnez l’option « Inspecter ». Cela permet d’ouvrir les outils DevTools de votre navigateur. Dans l’onglet Network, consultez la section Fetch/XHR.
Notez que le site cible n’effectue pas d’appels AJAX significatifs
Comme vous pouvez le voir ci-dessus, la page web cible n’exécute que quelques requêtes AJAX. Si vous explorez les différentes requêtes XHR, vous constaterez qu’elle ne renvoient aucune donnée significative. En d’autres termes, le document HTML renvoyé par le serveur contient déjà toutes les données. C’est ce qui se passe généralement avec les sites à contenu statique.
Cela montre que le site cible n’utilise pas JavaScript pour récupérer des données de manière dynamique ou pour des besoins de rendu. Vous n’avez donc pas besoin d’une bibliothèque ayant des capacités de navigateur sans tête pour récupérer les données de votre page web cible. Vous pouvez quand même utiliser Selenium, mais cela n’introduirait qu’une surcharge au niveau des performances. Pour cette raison, il est préférable d’opter pour un analyseur HTML simple comme Colly.
Ajoutez Colly aux dépendances de votre projet avec :
go get github.com/gocolly/colly
Cette commande crée un fichier go.sum et met à jour le fichier go.mod en conséquence.
Avant de commencer à l’utiliser, vous devez vous familiariser avec certains concepts clés de Colly.
L’entité principale de Colly est le Collector. Cet objet vous permet d’exécuter des requêtes HTTP et de faire du web scraping via les rappels suivants :
OnRequest() : appelé avant d’effectuer une requête HTTP avec Visit().
OnError() : appelé si une erreur se produit dans une requête HTTP.
OnResponse() : Appelé après l’obtention d’une réponse de la part du serveur.
OnHTML() : Appelé après OnResponse(), si le serveur a renvoyé un document HTML valide.
OnScraped() : appelé après la fin de tous les appels d’OnHTML().
Chacune de ces fonctions prend un rappel comme paramètre. Lorsque l’événement associé à la fonction se produit, Colly exécute le rappel d’entrée. Ainsi, pour créer un web scraper de données dans Colly, vous devez suivre une approche fonctionnelle basée sur les rappels.
Vous pouvez initialiser un objet Collector avec la fonction NewCollector() :
c := colly.NewCollector()
Importez Colly et créez un Collector en mettant à jour scraper.go comme ceci :
Utilisez Colly pour vous connecter à la page cible avec :
c.Visit("https://brightdata.com/")
En arrière-plan, la fonction Visit() exécute une requête HTTP GET et ré
cupère le document HTML cible du serveur. Plus précisément, elle déclenche l’événement onRequest et démarre le cycle de vie fonctionnel de Colly. Gardez à l’esprit que Visit() doit être appelé après l’enregistrement des autres rappels de Colly.
Notez que la requête HTTP lancée par Visit() peut échouer. Lorsque cela se produit, Colly génère l’événement OnError. Les raisons de l’échec peuvent être très diverses, d’un serveur temporairement indisponible à une URL non valide. Cela étant, les web scrapers échouent généralement lorsque le site cible adopte des mesures anti-bot. Par exemple, ces technologies bloquent généralement les requêtes qui n’ont pas d’en-tête HTTP d’agent utilisateur valide. Consultez notre guide pour en savoir plus sur les agents utilisateurs pour le web scraping.
Par défaut, Colly définit un paramètre substituable User-Agent qui ne correspond pas aux agents utilisés par les navigateurs courants. Cela rend les requêtes Colly facilement identifiables par les technologies anti-scraping. Pour éviter de vous faire bloquer à cause de cela, spécifiez un en-tête User-Agent valide dans Colly :
c.UserAgent = "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/111.0.0.0 Safari/537.36
Tout appel de Visit() va maintenant exécuter une requête avec cet en-tête HTTP.
Votre fichier scraper.go devrait maintenant ressembler à ceci :
// scraper.go
package main
import (
// import Colly
"github.com/gocolly/colly"
)
func main() {
// initialize the Collector
c := colly.NewCollector()
// set a valid User-Agent header
c.UserAgent = "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/111.0.0.0 Safari/537.36"
// connect to the target site
c.Visit("https://brightdata.com/")
// scraping logic...
}
Étape 4 : Inspectez la page HTML
Analysons le DOM de la page web cible pour définir une stratégie efficace de récupération des données.
Ouvrez la page d’accueil de Bright Data dans votre navigateur. Si vous y jetez un coup d’œil, vous remarquerez une liste de cartes avec les secteurs d’activité où les services de Bright Data peuvent fournir un avantage concurrentiel. Il s’agit d’informations intéressantes à extraire.
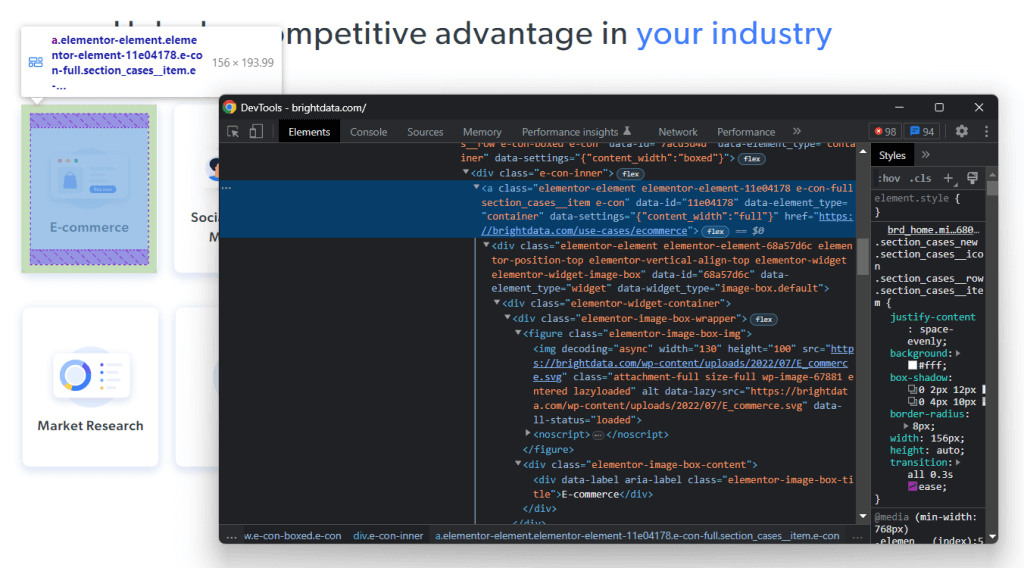
Cliquez avec le bouton droit de la souris sur l’une de ces cartes HTML et sélectionnez « Inspecter» :
Une , dans laquelle est stockée l’image figurant dans la carte de secteur d’activité.
Un
présentant le nom du domaine de l’industrie.
Maintenant, concentrez-vous sur les classes CSS utilisées par les éléments HTML d’intérêt et leurs parents. Grâce à eux, vous serez en mesure de définir la stratégie de sélecteur CSS requise pour obtenir les éléments DOM souhaités.
Plus précisément, chaque carte est caractérisée par la classe section_cases__item et se trouve dans .élémentor-element-6b05593c <div> Ainsi, vous pouvez obtenir toutes les cartes de secteur d’activité avec le sélecteur CSS suivant :
.elementor-element-6b05593c .section_cases__item
Étant donné une carte, vous pouvez ensuite sélectionner ses enfants <figure> et <div> avec :
Le but du web scraper Go est d’extraire l’URL, l’image et le nom du secteur d’activité correspondant à chaque carte.
Étape 5 : Sélectionner des éléments HTML avec Colly
You can apply a CSS or XPath selector in Colly as follows:
c.OnHTML(".your-css-selector", func(e *colly.HTMLElement) {
// data extraction logic...
})
Colly appellera la fonction transmise par paramètre pour chaque élément HTML correspondant au sélecteur CSS. En d’autres termes, il effectue automatiquement une itération sur tous les éléments sélectionnés.
N’oubliez pas qu’un Collector peut avoir plusieurs rappels OnHTML(). Ceux-ci seront exécutées dans l’ordre où les instructions onHTML() apparaîtront dans le code.
Étape 6 : Extraire les données d’une page web avec Colly
Apprenez à utiliser Colly pour extraire les données souhaitées de la page web HTML.
Avant d’écrire la logique de web scraping, vous avez besoin de structures de données dans lesquelles stocker les données extraites. Par exemple, vous pouvez utiliser une Struct pour définir un type de données Industrie de la façon suivante :
type Industry struct {
Url, Image, Name string
}
Dans Go, une Struct spécifie un ensemble de champs typés qui peuvent être instanciés en tant qu’objet. Si vous connaissez bien la programmation orientée objet, vous pouvez considérer qu’une Struct est une sorte de classe.
Ensuite, vous aurez besoin d’un slice de type Industry :
var industries []Industry
Les tranches Go ne sont rien de plus que des listes.
Maintenant, vous pouvez utiliser la fonction OnHTML() pour implémenter la logique de scraping comme ceci :
// iterating over the list of industry card
// HTML elements
c.OnHTML(".elementor-element-6b05593c .section_cases__item", func(e *colly.HTMLElement) {
url := e.Attr("href")
image := e.ChildAttr(".elementor-image-box-img img", "data-lazy-src")
name := e.ChildText(".elementor-image-box-content .elementor-image-box-title")
// filter out unwanted data
if url!= "" || image != "" || name != "" {
// initialize a new Industry instance
industry := Industry{
Url: url,
Image: image,
Name: name,
}
// add the industry instance to the list
// of scraped industries
industries = append(industries, industry)
}
})
Le snippet de web scraping Go ci-dessus sélectionne toutes les cartes de secteur d’activité figurant sur la page d’accueil de Bright Data et effectue une itération sur elles. Ensuite, il se remplit en collectant l’URL, l’image et le nom de secteur associés à chaque carte. Enfin, il instancie un nouvel objet Industry et l’ajoute à la tranche Industries.
Comme vous pouvez le voir, faire du web scraping dans Colly est simple. Grâce à la méthodeAttr() , vous pouvez extraire un attribut HTML de l’élément courant. Par ailleurs, ChildAttr() et ChildText() vous donnent le texte et la valeur et de l’attribut d’un enfant HTML sélectionné via un sélecteur CSS.
Gardez à l’esprit que vous pouvez également collecter des données sur les pages consacrées aux différents secteurs d’activité. Tout ce que vous avez à faire est de suivre les liens découverts sur la page actuelle et de mettre en œuvre une nouvelle logique de scraping en conséquence. C’est là tout l’intérêt du web crawling et du web scraping.
Bravo ! Vous venez d’apprendre à réaliser vos tâches de web scraping avec Go !
Étape 7 : Exportation des données extraites
Après l’instruction OnHTML(), les objets Industry contiendront les données extraites dans les objets Go. Pour rendre plus accessibles les données extraites du web, vous devez les convertir à un format différent. Découvrez comment exporter les données extraites au format CSV et JSON.
Notez que la bibliothèque standard Go est fournie avec des fonctionnalités avancées d’exportation de données. Vous n’avez pas besoin de package externe pour convertir les données au format CSV et JSON. Il vous suffit de vous assurer que votre script Go contient les importations suivantes :
Pour l’exportation en CSV :
import (
"encoding/csv"
"log"
"os"
)
Pour l’exportation en JSON :
import (
"encoding/json"
"log"
"os"
)
Vous pouvez exporter les données des objets Industry vers un fichier industries.csv dans Go comme suit :
// open the output CSV file
file, err := os.Create("industries.csv")
// if the file creation fails
if err != nil {
log.Fatalln("Failed to create the output CSV file", err)
}
// release the resource allocated to handle
// the file before ending the execution
defer file.Close()
// create a CSV file writer
writer := csv.NewWriter(file)
// release the resources associated with the
// file writer before ending the execution
defer writer.Flush()
// add the header row to the CSV
headers := []string{
"url",
"image",
"name",
}
writer.Write(headers)
// store each Industry product in the
// output CSV file
for _, industry := range industries {
// convert the Industry instance to
// a slice of strings
record := []string{
industry.Url,
industry.Image,
industry.Name,
}
// add a new CSV record
writer.Write(record)
}
Le snippet ci-dessus crée un fichier CSV et l’initialise avec la ligne d’en-tête. Ensuite, il effectue une itération sur l’ensemble des objets Industry, convertit chaque élément en un ensemble de chaînes et l’ajoute au fichier de sortie. Le CSV Writer de Go convertit automatiquement la liste de chaînes en un nouvel enregistrement au format CSV.
Exécutez le script avec :
go run scraper.go
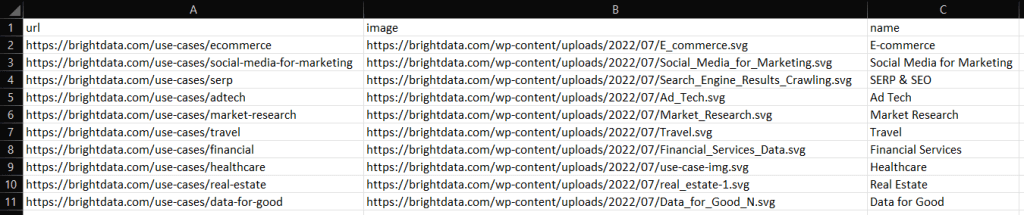
Après son exécution, vous remarquerez qu’un fichier industries.csv se trouve dans le dossier racine de votre projet Go. Ouvrez-le ; il devrait contenir les données suivantes :
De même, vous pouvez exporter les données vers industry.json de la manière suivante :
file, err:= os.Create("industries.json")
if err != nil {
log.Fatalln("Failed to create the output JSON file", err)
}
defer file.Close()
// convert industries to an indented JSON string
jsonString, _ := json.MarshalIndent(industries, " ", " ")
// write the JSON string to file
file.Write(jsonString)
This will produce the JSON file below:
[
{
"Url": "https://brightdata.com/use-cases/ecommerce",
"Image": "https://brightdata.com/wp-content/uploads/2022/07/E_commerce.svg",
"Name": "E-commerce"
},
// ...
{
"Url": "https://brightdata.com/use-cases/real-estate",
"Image": "https://brightdata.com/wp-content/uploads/2022/07/real_estate-1.svg",
"Name": "Real Estate"
},
{
"Url": "https://brightdata.com/use-cases/data-for-good",
"Image": "https://brightdata.com/wp-content/uploads/2022/07/Data_for_Good_N.svg",
"Name": "Data for Good"
}
]
Et voilà ! Vous savez maintenant comment convertir les données extraites à un format plus exploitable.
Étape 8 : Au final
Voici à quoi ressemble le code complet du web scraper Golang :
// scraper.go
package main
import (
"encoding/csv"
"encoding/json"
"log"
"os"
// import Colly
"github.com/gocolly/colly"
)
// definr some data structures
// to store the scraped data
type Industry struct {
Url, Image, Name string
}
func main() {
// initialize the struct slices
var industries []Industry
// initialize the Collector
c := colly.NewCollector()
// set a valid User-Agent header
c.UserAgent = "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/111.0.0.0 Safari/537.36"
// iterating over the list of industry card
// HTML elements
c.OnHTML(".elementor-element-6b05593c .section_cases__item", func(e *colly.HTMLElement) {
url := e.Attr("href")
image := e.ChildAttr(".elementor-image-box-img img", "data-lazy-src")
name := e.ChildText(".elementor-image-box-content .elementor-image-box-title")
// filter out unwanted data
if url != "" && image != "" && name != "" {
// initialize a new Industry instance
industry := Industry{
Url: url,
Image: image,
Name: name,
}
// add the industry instance to the list
// of scraped industries
industries = append(industries, industry)
}
})
// connect to the target site
c.Visit("https://brightdata.com/")
// --- export to CSV ---
// open the output CSV file
csvFile, csvErr := os.Create("industries.csv")
// if the file creation fails
if csvErr != nil {
log.Fatalln("Failed to create the output CSV file", csvErr)
}
// release the resource allocated to handle
// the file before ending the execution
defer csvFile.Close()
// create a CSV file writer
writer := csv.NewWriter(csvFile)
// release the resources associated with the
// file writer before ending the execution
defer writer.Flush()
// add the header row to the CSV
headers := []string{
"url",
"image",
"name",
}
writer.Write(headers)
// store each Industry product in the
// output CSV file
for _, industry := range industries {
// convert the Industry instance to
// a slice of strings
record := []string{
industry.Url,
industry.Image,
industry.Name,
}
// add a new CSV record
writer.Write(record)
}
// --- export to JSON ---
// open the output JSON file
jsonFile, jsonErr := os.Create("industries.json")
if jsonErr != nil {
log.Fatalln("Failed to create the output JSON file", jsonErr)
}
defer jsonFile.Close()
// convert industries to an indented JSON string
jsonString, _ := json.MarshalIndent(industries, " ", " ")
// write the JSON string to file
jsonFile.Write(jsonString)
}
Vous pouvez construire un web scraper en Go en moins de 100 lignes de code.
Conclusion
Dans ce tutoriel, vous avez vu pourquoi Go est un bon langage pour le web scraping. En outre, vous avez découvert les meilleures bibliothèques de web scraping pour Go et ce qu’elles proposent. Ensuite, vous avez appris à utiliser Colly et la bibliothèque standard de Go pour créer une application de web scraping. Le web scraper Go construit ici permet d’extraire des données d’une cible réelle. Comme vous l’avez vu, le web scraping sous Go ne nécessite que quelques lignes de code.
Cela étant, gardez à l’esprit qu’il y a de nombreux défis à prendre en compte lors de l’extraction de données d’Internet. C’est pourquoi de nombreux sites web adoptent des solutions anti-scraping et anti-bot capables de détecter et de bloquer votre script de web scraping Go. Heureusement, vous pouvez construire un web scraper capable de contourner et d’éviter les blocages avec le Web Scraper IDE, qui est l’outil de nouvelle génération de Bright Data.
Vous ne voulez pas du tout vous occuper de web scraping, mais vous êtes intéressés par les données web ? Découvrez nos jeux de données prêts à l’emploi.