
Dans cet article de blog, vous apprendrez :
- Ce qu’est Stagehand et ce qu’il offre pour l’automatisation des navigateurs.
- Les avantages d’utiliser Stagehand avec des sessions de navigateur furtif dans le cloud fournies par l’API Browser de Bright Data.
- Un guide étape par étape pour configurer l’API Browser dans Stagehand.
Plongeons dans le vif du sujet !
Qu’est-ce que Stagehand ?
Stagehand est un framework d’automatisation de navigateur open source développé par Browserbase. Il combine l’IA en langage naturel avec du code déterministe. Il résout le compromis entre les outils fragiles basés sur des sélecteurs (comme Playwright) et les agents IA imprévisibles en vous laissant choisir quand utiliser chaque approche.
Il fonctionne en traduisant des instructions en actions de navigateur et en sorties structurées, en utilisant un LLM sous-jacent ainsi qu’une couche d’exécution contrôlée. Stagehand prend également en charge le développement d’agents IA basés sur le navigateur.
Il est également doté de capacités qui lui permettent de fonctionner comme un outil de Scraping web par IA. Stagehand est soutenu par une grande communauté de développeurs, avec plus de 22 900 étoiles sur GitHub et plus d’un million de téléchargements hebdomadaires sur npm.
Fonctionnalités de Stagehand
Les principales fonctionnalités offertes par Stagehand sont :
- Exécution
act(): Effectuez des actions dans le navigateur comme cliquer, faire défiler et remplir des formulaires à l’aide d’instructions en langage naturel. - Données structurées
extract(): Extrayez le contenu d’une page dans des schémas strictement validés par Zod pour une utilisation fiable en aval. - Conscience de page
observe(): Détectez les éléments actionnables sur une page avant d’exécuter des opérations, améliorant la sécurité et la précision. - Flux de travail autonomes
agent(): Exécutez des tâches de navigation en plusieurs étapes de bout en bout avec une supervision minimale. - Automatisation auto-réparatrice : S’adapte aux changements d’interface, réduisant les échecs fragiles basés sur des sélecteurs.
- Mise en cache des actions : Évitez les appels LLM redondants en mettant en cache les actions, garantissant une exécution hautement prévisible et économique sur plusieurs exécutions.
- Flexibilité LLM : Fonctionne avec plusieurs fournisseurs tout en maintenant une exécution déterministe et déboguable.
- Primitives composables : Combinez act, extract, observe et agent pour construire des pipelines d’automatisation personnalisés.
- Outillage orienté développeur : Conçu pour la maintenabilité, la reproductibilité et l’intégration dans des systèmes IA modernes.
Pour en savoir plus, consultez la documentation officielle.
Pourquoi combiner Stagehand avec l’API Browser de Bright Data
Les outils d’automatisation de navigateur comme Stagehand rencontrent les mêmes problèmes fondamentaux :
- Les sites web bloquent activement le trafic automatisé à l’aide de systèmes de détection de bots, de CAPTCHA, de prise d’empreintes digitales et de vérifications de réputation IP. Cela rend les automatisations fragiles, car un script peut fonctionner lors des tests mais échouer de manière imprévisible en production.
- L’exécution de nombreuses instances de navigateur localement ou sur une infrastructure autogérée est gourmande en ressources. Les navigateurs nécessitent un CPU et une mémoire importants, ce qui rend l’exécution simultanée de nombreuses instances coûteuse et difficile à faire évoluer de manière fiable.
- La gestion des proxies et de la géo-distribution ajoute une charge opérationnelle. Au fil du temps, cette complexité devient difficile à maintenir pour les charges de travail de scraping ou d’agents IA en production.
L’API Browser de Bright Data résout ces problèmes en déplaçant l’exécution locale du navigateur vers une infrastructure cloud entièrement gérée, conçue pour l’évolutivité et la discrétion.
Au lieu de gérer les navigateurs localement, vous pouvez vous connecter via un seul point de terminaison CDP. Vous accédez à des navigateurs distants préconfigurés avec rotation de Proxy intégrée, résolution de CAPTCHA et évasion avancée des empreintes digitales.
Ce qui distingue Bright Data, c’est son architecture de niveau entreprise, soutenue par un réseau de Proxy de plus de 400 millions d’IPs résidentielles. Cela permet un anonymat élevé, un géo-ciblage mondial et une simultanéité infinie tout en atteignant un taux de succès de 99,95 % et une disponibilité garantie par SLA de 99,99 %.
Comment intégrer Stagehand avec l’API Browser
Dans ce chapitre, vous verrez comment utiliser Stagehand pour automatiser des instances de navigateur distantes. En détail, vous vous connecterez à des sessions de navigateur cloud furtives, anti-détection et infiniment évolutives via l’API Browser de Bright Data.
Suivez les instructions ci-dessous.
Prérequis
Pour suivre cette section du tutoriel, assurez-vous d’avoir :
- Node.js 20+ installé localement (Node.js 22+ recommandé).
- Une clé API d’un fournisseur IA Stagehand pris en charge (ici, nous utiliserons une clé API OpenAI).
- Un compte Bright Data.
- Des connaissances de base de l’API Stagehand et de ses capacités d’automatisation de navigateur pilotées par IA.
Étape 1 : Initialiser le projet Stagehand
Configurez un nouveau projet Stagehand en suivant le guide de démarrage rapide. Vous pouvez également exécuter la commande ci-dessous :
npx create-browser-app bright-data-stagehand-exampleLa commande npx create-browser-app crée un nouveau projet Stagehand dans le répertoire bright-data-stagehand-example.
Après l’avoir exécutée, vous devriez obtenir :
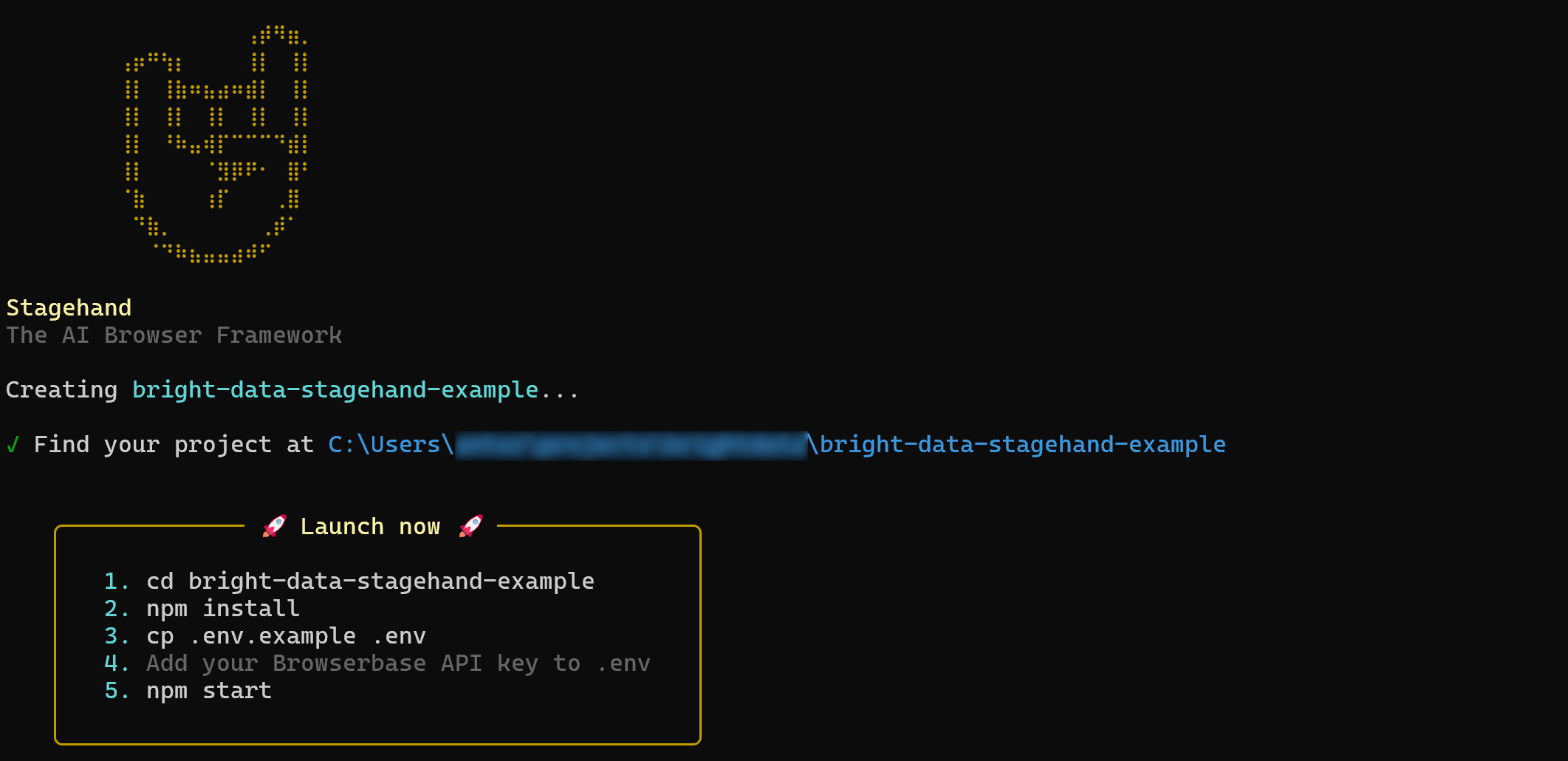
Ensuite, entrez dans le répertoire du projet :
cd bright-data-stagehand-exampleLa structure de votre projet devrait ressembler à ceci :
bright-data-stagehand-example/
├── .cursorrules
├── .env.example
├── claude.md
├── index.ts
├── package.json
├── README.md
└── tsconfig.jsonPrenez quelques minutes pour explorer les fichiers générés et vous familiariser avec la structure du projet. Concentrez-vous sur index.ts, qui représente le fichier principal de Stagehand.
Maintenant, nettoyez le fichier index.ts en ne laissant que :
import { Stagehand } from "@browserbasehq/stagehand";Vous verrez bientôt comment connecter Stagehand à l’API Browser de Bright Data. Excellent !
Étape 2 : Configurer la lecture des variables d’environnement
Votre projet d’automatisation cloud Stagehand reposera sur quelques secrets (par exemple, clé API du fournisseur IA, identifiants de l’API Browser Bright Data, etc.). Plutôt que de les coder en dur, la bonne pratique est de les charger depuis des variables d’environnement.
Par défaut, Stagehand ne charge pas automatiquement les fichiers .env. Pour activer cela, commencez par installer le package `dotenv :
npm install dotenvEnsuite, dans index.ts, ajoutez ce qui suit :
import dotenv from "dotenv";
dotenv.config({
path: ".env",
});Maintenant, vous devez définir un fichier .env. Vous pouvez le créer en copiant le fichier .env.example généré lors de l’exécution de npx create-browser-app. Sinon, ajoutez manuellement un fichier .env à votre projet Stagehand :
bright-data-stagehand-example/
├── .cursorrules
├── .env # <---------
├── .env.example
├── claude.md
├── index.ts
├── package.json
├── README.md
└── tsconfig.jsonRemplissez le fichier .env avec votre clé API du fournisseur IA (dans ce cas, OpenAI) :
OPENAI_API_KEY="<YOUR_OPENAI_API_KEY>"Remplacez le placeholder <YOUR_OPENAI_API_KEY> par votre clé API OpenAI réelle.
Stagehand lira automatiquement la variable d’environnement OPENAI_API_KEY au moment de l’exécution, aucune configuration supplémentaire n’est donc nécessaire. Excellent !
Étape 3 : Démarrer avec l’API Browser de Bright Data
Il est temps de récupérer l’URL de connexion distante basée sur CDP pour l’API Browser de Bright Data.
Si vous ne l’avez pas encore fait, créez un compte Bright Data. Sinon, connectez-vous et accédez au panneau de contrôle :
Ensuite, naviguez vers l’option « Web Access > Web Access API » dans le menu de gauche :
Si vous voyez déjà une entrée API Browser dans le tableau « My APIs » (comme ci-dessous, via l’API browser_api), vous êtes prêt :
Sinon, cliquez sur le menu déroulant du bouton « Create API » et sélectionnez « Browser API » :
Cela lancera l’assistant de configuration de l’API Browser. Donnez un nom à votre API Browser (par exemple, browser_api) et configurez l’API selon vos besoins :
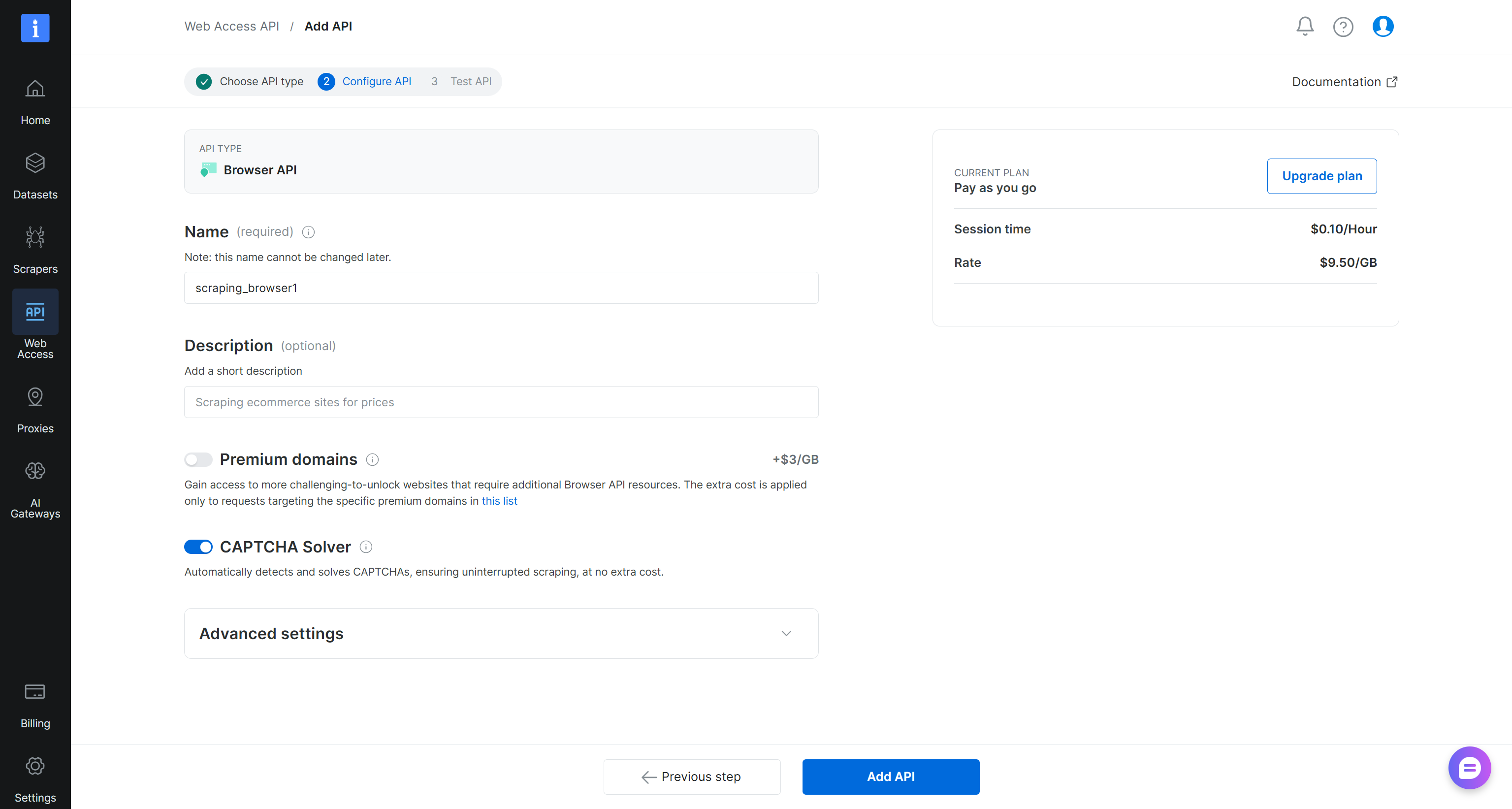
Lorsque vous avez terminé, cliquez sur le bouton « Add API ». Accédez à la page de détails de l’API Browser :
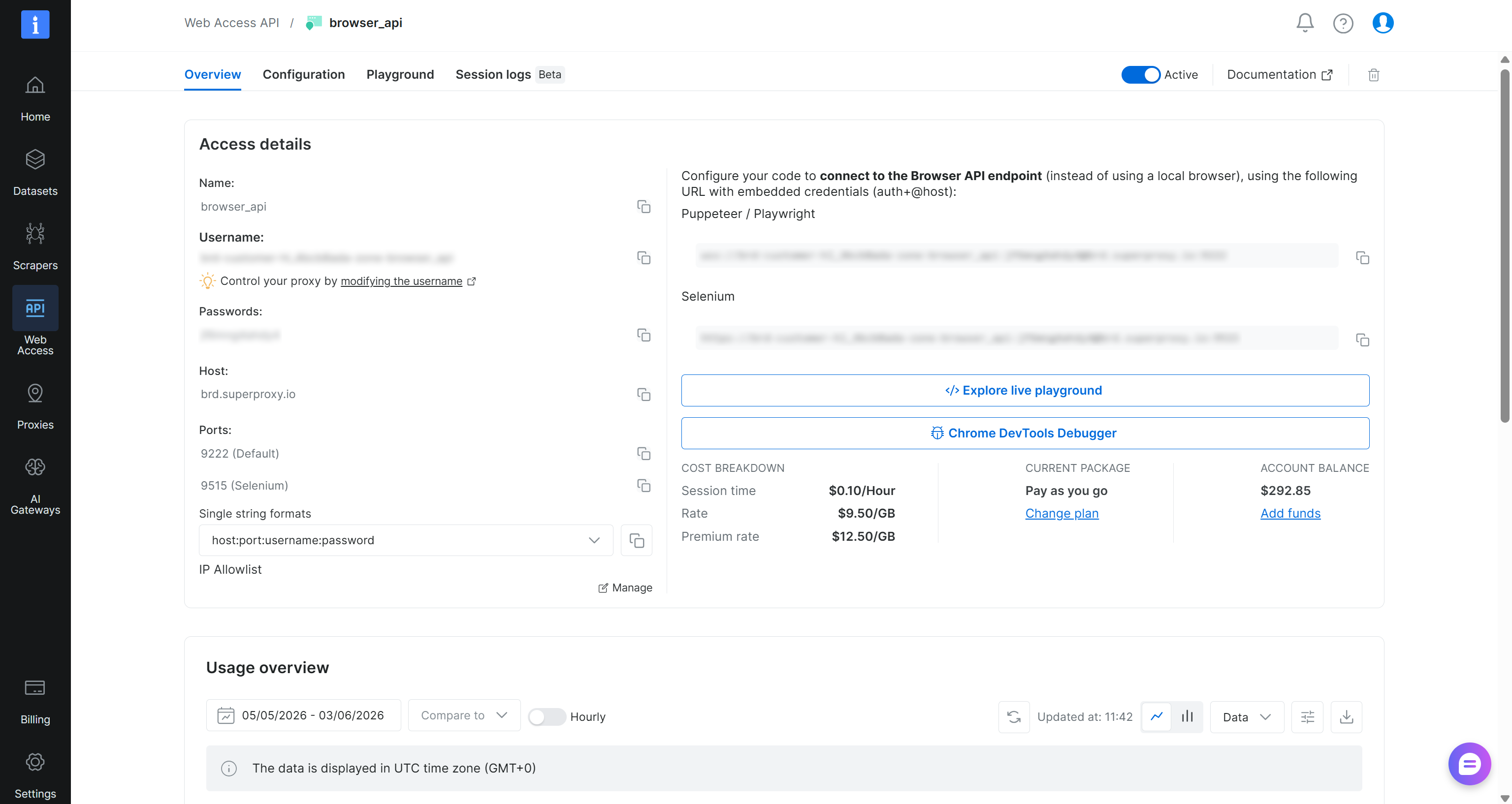
Vous y trouverez les détails de connexion pour les intégrations basées sur CDP (l’URL sous « Puppeteer / Playwright »). L’URL WebSocket de l’API Browser suit ce format :
wss://<BROWSER_API_USERNAME>:<BROWSER_API_USERNAME>@brd.superproxy.io:9222Copiez le nom d’utilisateur et le mot de passe de l’API Browser depuis la page de l’API Browser et ajoutez-les à votre fichier .env :
BRIGHT_DATA_BROWSER_API_USERNAME="<BROWSER_API_USERNAME>"
BRIGHT_DATA_BROWSER_API_PASSWORD="<BROWSER_API_PASSWORD>"Vous utiliserez ces variables ultérieurement dans index.ts pour construire l’URL de connexion CDP distante.
Vous disposez maintenant de tous les éléments nécessaires pour l’automatisation du navigateur cloud avec Stagehand via l’API Browser de Bright Data. Excellent !
Étape 4 : Connecter Stagehand à l’API Browser de Bright Data
Dans index.ts, commencez par lire les identifiants de l’API Browser depuis vos variables d’environnement :
const BRIGHT_DATA_BROWSER_API_USERNAME = process.env.BRIGHT_DATA_BROWSER_API_USERNAME || "";
const BRIGHT_DATA_BROWSER_API_PASSWORD = process.env.BRIGHT_DATA_BROWSER_API_PASSWORD || "";Ensuite, initialisez Stagehand dans une fonction main() pour la connexion à l’API Browser de Bright Data via l’URL WebSocket CDP :
async function main() {
// configure Stagehand to connect remotely to Bright Data's Browser API
// and use an OpenAI model
const stagehand = new Stagehand({
env: "LOCAL",
localBrowserLaunchOptions: {
cdpUrl: `wss://${BRIGHT_DATA_BROWSER_API_USERNAME}:${BRIGHT_DATA_BROWSER_API_PASSWORD}@brd.superproxy.io:9222`,
},
model: "openai/gpt-5.4-mini",
});
// launch Stagehand and get the browser page
await stagehand.init();
const page = stagehand.context.pages()[0];
// browser automation logic...
// close the Stagehand instance and release the browser resources
await stagehand.close();
}
main().catch(console.error); L’extrait ci-dessus configure Stagehand avec l’URL WSS authentifiée de l’API Browser construite à partir des identifiants lus dans les variables d’environnement. Il lance ensuite une session de navigateur distant et expose un objet page pour l’automatisation. Après l’exécution de votre logique d’automatisation, il ferme la session et libère toutes les ressources du navigateur distant.
Dans l’exemple ci-dessus, nous avons configuré OpenAI GPT-5.4 Mini. Notez que tout autre modèle OpenAI (ou une configuration de fournisseur IA prise en charge) fonctionnera également.
L’élément clé se trouve dans le constructeur Stagehand. La configuration peut sembler légèrement déroutante au premier abord car, pour se connecter à un navigateur distant, vous devez toujours définir env sur "LOCAL". Ensuite, dans localBrowserLaunchOptions, vous devez fournir l’URL WSS de l’API Browser Bright Data via le champ cdpUrl.
Ainsi, même si env est défini sur "LOCAL", Stagehand se connecte en réalité aux instances de navigateur cloud anti-détection distantes de Bright Data.
Vous pouvez maintenant tester l’intégration avec un exemple simple pour confirmer que tout fonctionne correctement.
Étape 5 : Vérifier l’intégration de l’API Browser de Bright Data
Pour vérifier que l’intégration avec l’API Browser fonctionne, essayez la logique d’automatisation suivante :
// connect to the example.com page
await page.goto("https://example.com");
// take the screenshot of the page
await page.screenshot({
path: "screenshot.png",
type: "png",
fullPage: false,
});Cela demande au navigateur distant (exposé via l’API Browser de Bright Data) d’ouvrir example.com et de capturer une capture d’écran.
Assemblez le tout :
// index.ts
import { Stagehand } from "@browserbasehq/stagehand";
import dotenv from "dotenv";
// load the environment variables from the .env file
dotenv.config({
path: ".env",
});
// read the Bright Data Browser API credentials
const BRIGHT_DATA_BROWSER_API_USERNAME = process.env.BRIGHT_DATA_BROWSER_API_USERNAME || "";
const BRIGHT_DATA_BROWSER_API_PASSWORD = process.env.BRIGHT_DATA_BROWSER_API_PASSWORD || "";
async function main() {
// configure Stagehand to connect remotely to Bright Data's Browser API
// and use an OpenAI model
const stagehand = new Stagehand({
env: "LOCAL",
localBrowserLaunchOptions: {
cdpUrl: `wss://${BRIGHT_DATA_BROWSER_API_USERNAME}:${BRIGHT_DATA_BROWSER_API_PASSWORD}@brd.superproxy.io:9222`,
},
model: "openai/gpt-5.4-mini",
});
// launch Stagehand and get the browser page
await stagehand.init();
const page = stagehand.context.pages()[0];
// connect to the example.com page
await page.goto("https://example.com");
// take the screenshot of the page
await page.screenshot({
path: "screenshot.png",
type: "png",
fullPage: false,
});
// close the Stagehand instance and release the browser resources
await stagehand.close();
}
main().catch(console.error);Exécutez le script avec :
npm run startDans le terminal, vous devriez voir des journaux similaires à :

Important : Les journaux peuvent mentionner « connecting to local browser ». Cela est dû à la configuration env: "LOCAL" requise. Cependant, la connexion réelle est établie avec l’API Browser distante de Bright Data.
Une fois l’exécution terminée, un fichier screenshot.png apparaîtra dans votre répertoire de projet :
bright-data-stagehand-example/
├── .cursorrules
├── .env
├── .env.example
├── claude.md
├── index.ts
├── package.json
├── README.md
├── screenshot.png # <---------
└── tsconfig.jsonOuvrez screenshot.png, et vous devriez voir la page example.com rendue :
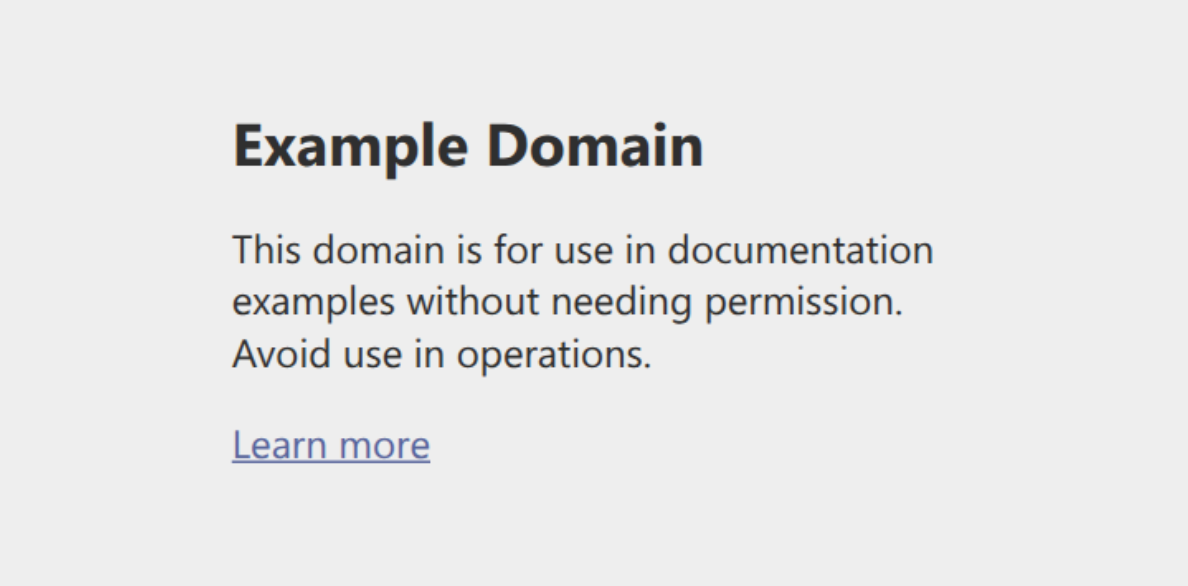
Cela confirme que Stagehand s’est connecté avec succès au site cible et a exécuté l’automatisation du navigateur comme prévu.
Pour vérifier que l’API Browser de Bright Data a bien été utilisée, consultez votre tableau de bord Bright Data :
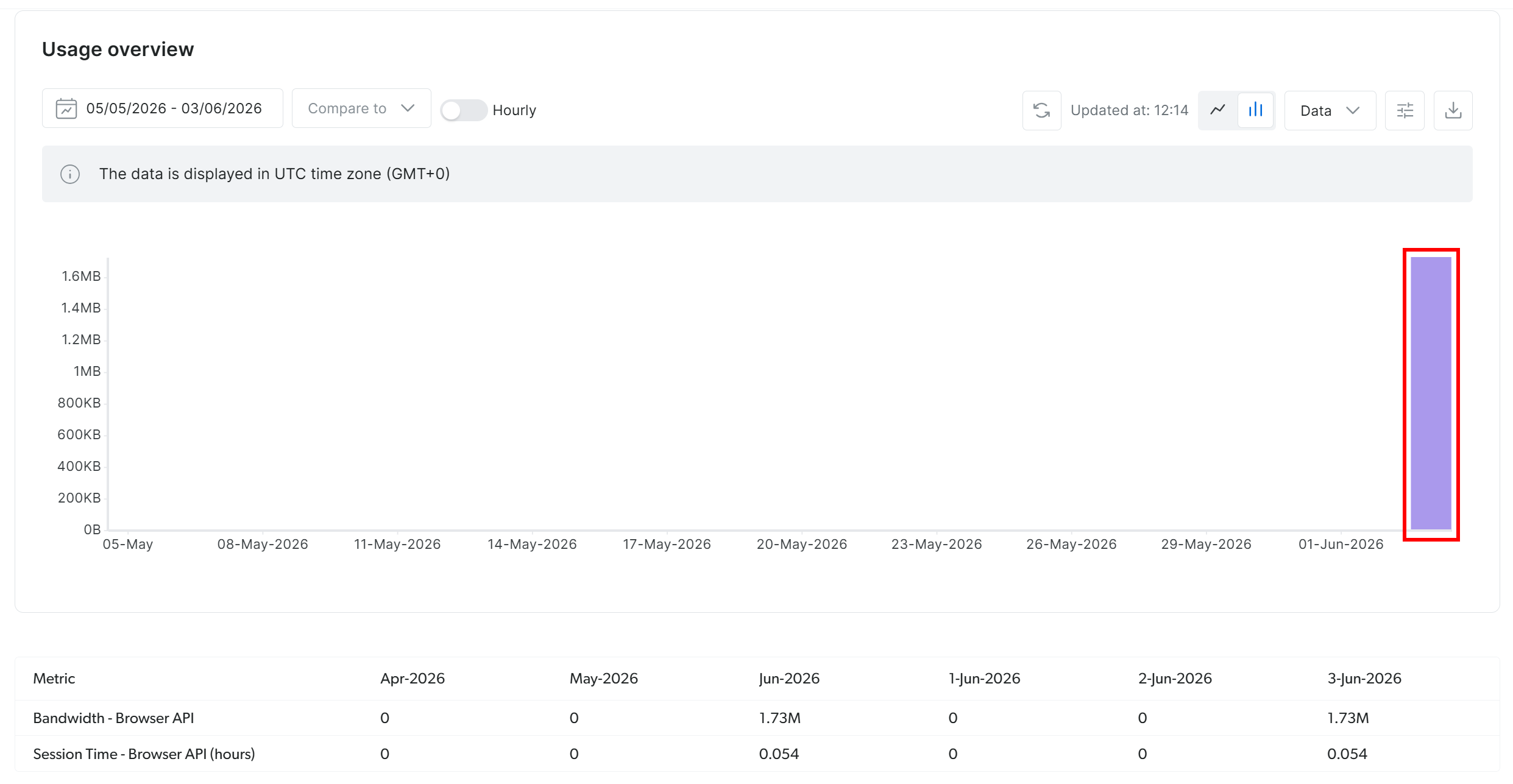
Vous devriez voir un pic de Trafic indiquant une utilisation active depuis la session de l’API Browser configurée via la connexion CDP distante. Cela confirme que toute l’automatisation Stagehand est correctement acheminée via l’API Browser de Bright Data. Parfait !
Étape 6 : Implémenter une automatisation de navigateur distant réelle pilotée par IA
Supposons maintenant que vous souhaitiez automatiser une logique de navigation pour collecter des données d’articles de presse sur Yahoo Finance.
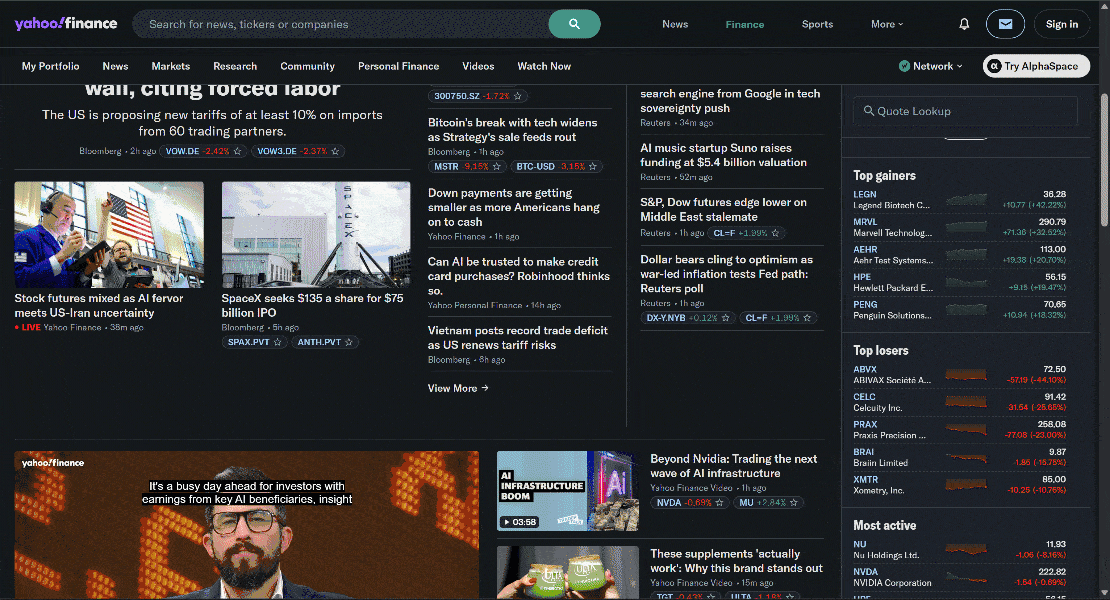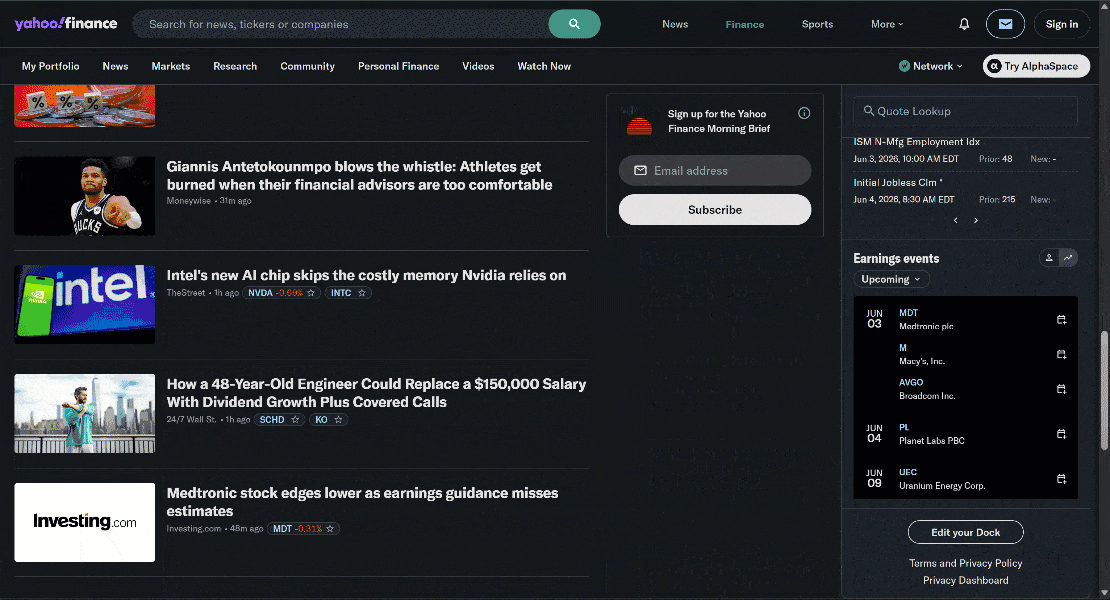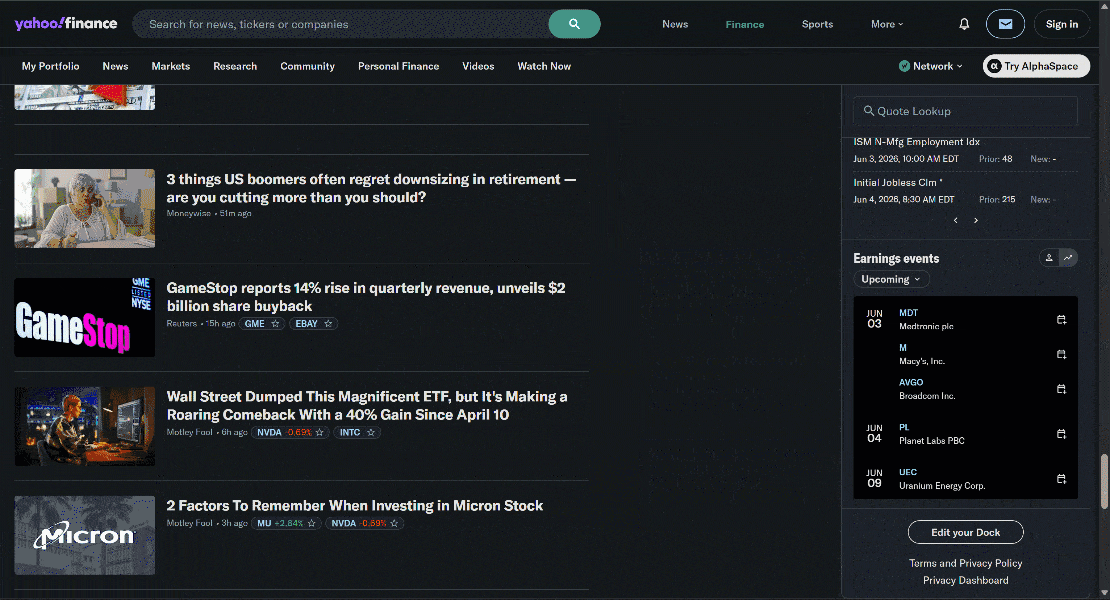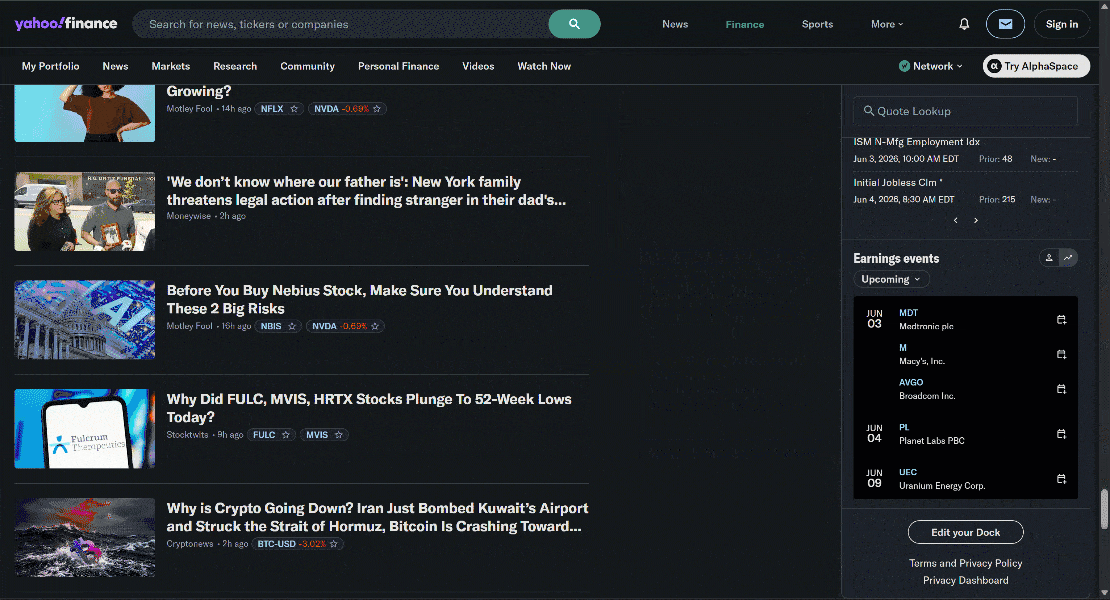
C’est un bon exemple car la page d’accueil de Yahoo Finance utilise le défilement infini pour charger de nouveaux articles de manière dynamique. C’est également un site connu pour ses protections strictes anti-bot et anti-scraping.
Grâce aux capacités de discrétion et de contournement anti-bot fournies par l’API Browser, vous pouvez accéder à Yahoo Finance via Stagehand sans être bloqué.
Puisque vous souhaitez que les données extraites suivent une structure spécifique, commencez par définir un type de données de sortie avec Zod :
import { z } from "zod";
// ...
// structured output schema
const YahooFinanceNewsSchema = z.object({
news: z.array(
z.object({
title: z
.string()
.describe("The visible headline text of the news article"),
articleUrl: z
.string()
.describe("The full article URL"),
imageUrl: z
.string()
.describe("The full image URL"),
source: z
.string()
.optional()
.describe("The publisher name, such as Reuters or Yahoo Finance"),
timestamp: z
.string()
.optional()
.describe("The visible publication time, such as '4h ago'"),
marketMoves: z
.array(
z.object({
ticker: z
.string()
.describe("The stock ticker symbol, such as NVDA or ^GSPC"),
changePercent: z
.string()
.optional()
.describe(
"The visible market percentage change, such as '+2.4%' or '-0.69%'"
),
})
)
.optional()
.describe(
"List of stock tickers mentioned in the article footer with their change percentages"
),
})
),
});Cela définit la structure de sortie attendue pour les données extraites. En particulier, elle correspond aux informations disponibles dans les cartes d’actualités de Yahoo Finance :
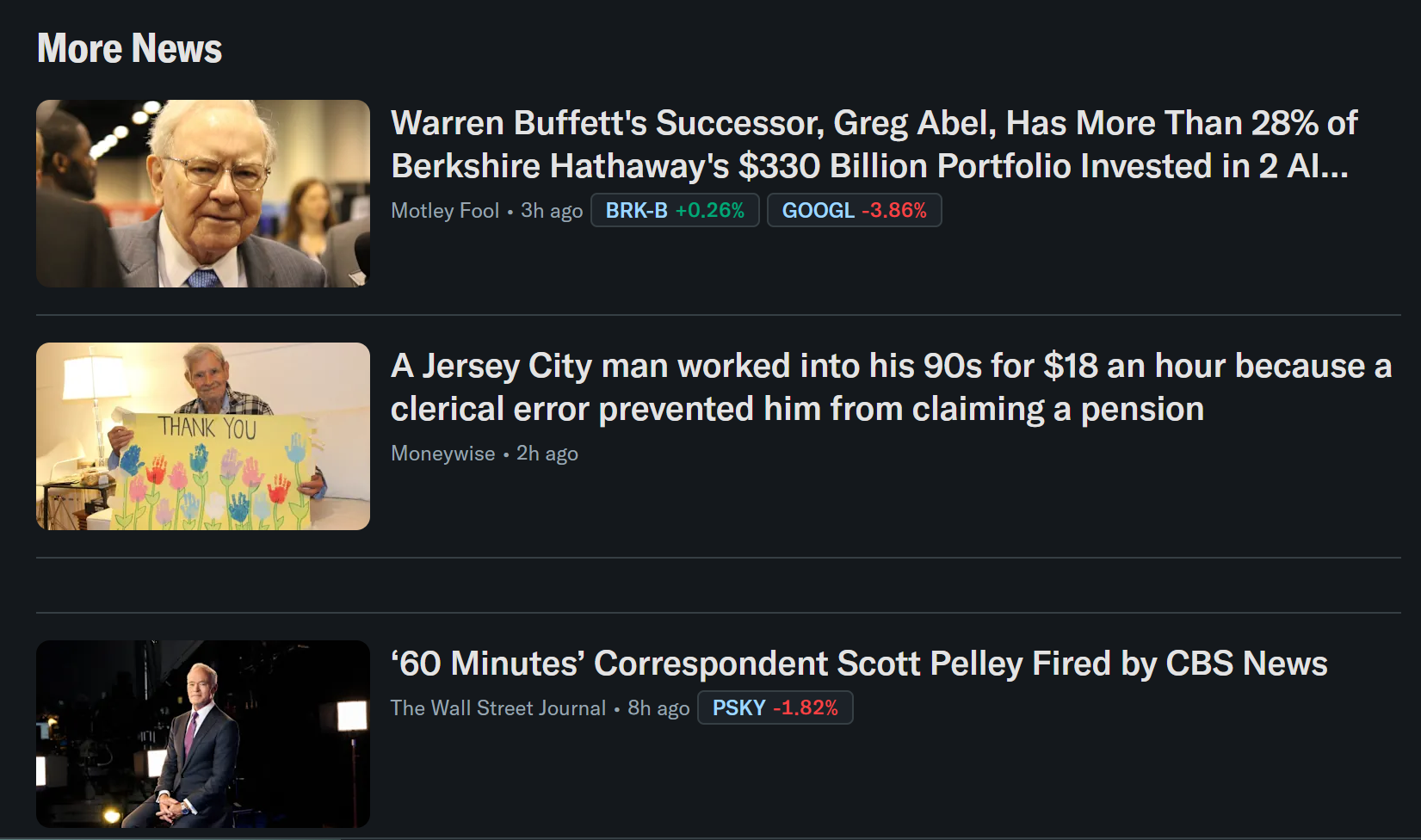
Si vous initialisez votre application Stagehand via npx create-browser-app, vous n’avez pas besoin d’installer zod manuellement. Il est déjà inclus dans les dépendances du projet. Sinon, installez-le avec :
npm install zod Maintenant, vous pouvez automatiser le flux de navigation et d’extraction avec :
// automate the news article loading
await stagehand.act(
`Scroll down multiple times and wait for articles to load in the "More News" section. Repeat until at least 20 news articles are loaded.`,
{
timeout: 90000, // 90-second timeout
}
);
// scrape the news information
const data = await stagehand.extract(
`Scrape all visible news articles`,
YahooFinanceNewsSchema,
{
"timeout": 120000, // 120-second timeout
}
);Cela reproduit le comportement d’un vrai utilisateur faisant défiler la page pour charger plus d’articles, mais piloté par des instructions IA. Il utilise ensuite l’extraction structurée par IA pour convertir le contenu de la page dans le schéma défini.
Notez comment le script d’automatisation s’appuie sur deux API Stagehand pilotées par IA :
.act(): Effectue des actions dans la session du navigateur (par exemple, défilement, clics, navigation).extract(): Extrait des données structurées de la page à l’aide d’un schéma
Fantastique ! L’étape suivante consiste à exporter les données extraites.
Étape 7 : Extraire les données collectées
À ce stade, les données extraites sont déjà stockées dans l’objet data retourné par stagehand.extract(). La dernière étape consiste à les exporter dans un fichier news.json afin qu’elles puissent être réutilisées ou traitées ultérieurement.
Réalisez cela en utilisant l’API native fs/promises de Node.js :
import fs from "fs/promises";
// ...
// save extracted news to a JSON file
await fs.writeFile(
"news.json",
JSON.stringify(data.news, null, 2),
"utf-8"
);Cela écrit un fichier news.json contenant les données d’actualités structurées dans un format propre et lisible.
Mission accomplie ! Le flux de travail de scraping Stagehand utilisant l’API Browser comme agent IA de navigateur est maintenant entièrement implémenté.
Étape 8 : Assembler le tout
Votre script final index.ts pour automatiser le scraping de Yahoo Finance avec Stagehand ressemblera à ceci :
import { Stagehand } from "@browserbasehq/stagehand";
import dotenv from "dotenv";
import { z } from "zod";
import fs from "fs/promises";
// load the environment variables from the .env file
dotenv.config({
path: ".env",
});
// read the Bright Data Browser API credentials
const BRIGHT_DATA_BROWSER_API_USERNAME = process.env.BRIGHT_DATA_BROWSER_API_USERNAME || "";
const BRIGHT_DATA_BROWSER_API_PASSWORD = process.env.BRIGHT_DATA_BROWSER_API_PASSWORD || "";
// structured output schema
const YahooFinanceNewsSchema = z.object({
news: z.array(
z.object({
title: z
.string()
.describe("The visible headline text of the news article"),
articleUrl: z
.string()
.describe(
"The full article URL."
),
imageUrl: z
.string()
.describe(
"The full image URL."
),
source: z
.string()
.optional()
.describe("The publisher name, such as Reuters or Yahoo Finance"),
timestamp: z
.string()
.optional()
.describe("The visible publication time, such as '4h ago'"),
marketMoves: z
.array(
z.object({
ticker: z
.string()
.describe("The stock ticker symbol, such as NVDA or ^GSPC"),
changePercent: z
.string()
.optional()
.describe(
"The visible market percentage change, such as '+2.4%' or '-0.69%'"
),
})
)
.optional()
.describe(
"List of stock tickers mentioned in the article footer with their market change percentages"
),
})
),
});
async function main() {
// configure Stagehand to connect remotely to Bright Data's Browser API
// and use an OpenAI model
const stagehand = new Stagehand({
env: "LOCAL",
localBrowserLaunchOptions: {
cdpUrl: `wss://${BRIGHT_DATA_BROWSER_API_USERNAME}:${BRIGHT_DATA_BROWSER_API_PASSWORD}@brd.superproxy.io:9222`,
},
model: "openai/gpt-5.4-mini",
keepAlive: true,
verbose: 1,
});
// launch Stagehand and get the browser page
await stagehand.init();
const page = stagehand.context.pages()[0];
// go to Yahoo Finance
await page.goto("https://finance.yahoo.com/");
// automate the news article loading
await stagehand.act(
`Scroll down multiple times and wait for articles to load in the "More News" section. Repeat until at least 20 news articles are loaded.`,
{
timeout: 90000, // 90-second timeout
}
);
// scrape the news information
const data = await stagehand.extract(
`Scrape all visible news articles`,
YahooFinanceNewsSchema,
{
"timeout": 120000, // 120-second timeout
}
);
// save extracted news to a JSON file
await fs.writeFile(
"news.json",
JSON.stringify(data.news, null, 2),
"utf-8"
);
console.log("News exported to news.json");
// close the Stagehand instance and release the browser resources
await stagehand.close();
}
main().catch(console.error);Ensuite, le fichier .env contiendra :
OPENAI_API_KEY="<YOUR_OPENAI_API_KEY>"
BRIGHT_DATA_BROWSER_API_USERNAME="<BROWSER_API_USERNAME>"
BRIGHT_DATA_BROWSER_API_PASSWORD="<BROWSER_API_PASSWORD>"Lancez le script avec :
npm run startUne fois le script terminé, un fichier news.json apparaîtra dans votre dossier de projet. Si vous l’ouvrez, vous devriez voir des données structurées comme ceci :
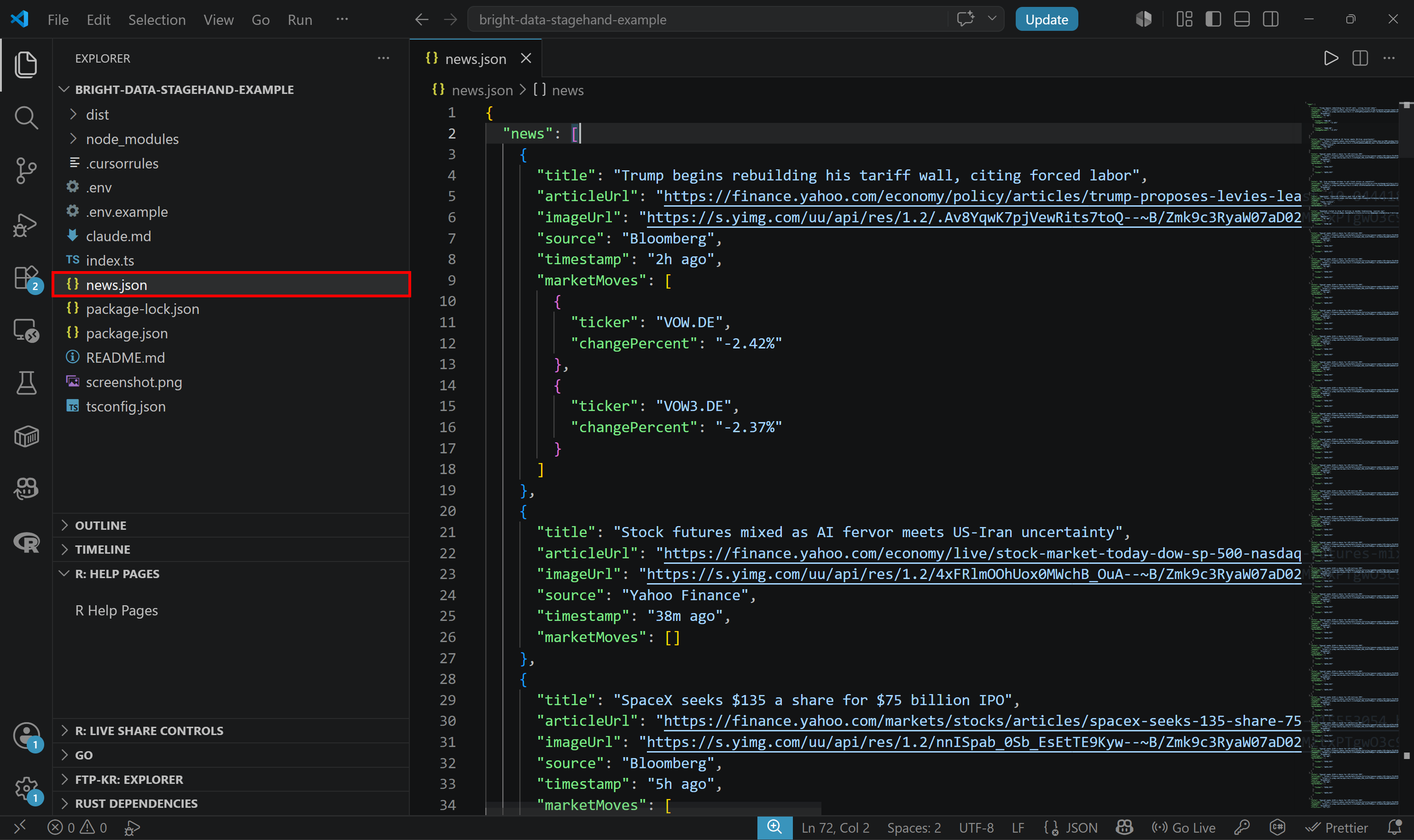
Remarquez comment le fichier contient les mêmes articles qui apparaissent sur la page d’accueil de Yahoo Finance après plusieurs défilements, mais maintenant dans un format propre et structuré.
Cela prouve comment l’API Browser peut accéder au contenu dynamique et extraire des données à grande échelle, même depuis un site avec des protections anti-bot.
Et voilà ! Ce n’était qu’un exemple, mais vous pouvez utiliser Stagehand pour automatiser les flux de travail de l’API Browser de Bright Data dans de nombreux autres scénarios et cas d’usage.
Conclusion
Dans cet article, vous avez appris ce qu’est Stagehand et comment il prend en charge l’automatisation des navigateurs. Plus précisément, vous avez vu comment l’utiliser avec l’API Browser de Bright Data pour exécuter des sessions de navigateur cloud hautement évolutives et indétectables.
Le résultat est une configuration d’automatisation de navigateur qui peut s’adapter aux charges de travail de niveau entreprise. Avec la même intégration, vous pouvez également implémenter des opérations d’agents IA de navigateur soutenues par une infrastructure cloud à grande échelle.
Créez un nouveau compte Bright Data et explorez nos solutions de scraping de données web et d’automatisation de navigateur prêtes pour l’IA !






