

TL:DR: Apprenons à construire un web scraper Yahoo Finance pour extraire des données boursières afin d’effectuer des analyses financières pour vos besoins de trading et d’investissement.
Dans ce tutoriel, nous parlerons des points suivants :
- Pourquoi collecter des données financières sur le web ?
- Bibliothèques et des outils de web scraping pour la finance
- Extraction de données boursières sur Yahoo Finance avec Selenium
Pourquoi collecter des données financières sur le web ?
La collecte de données financières sur le web vous permet d’obtenir des informations utiles dans divers scénarios, notamment :
- Trading automatisé : en collectant des données historiques ou en temps réel sur le marché, telles que le prix et le volume des actions, les développeurs peuvent élaborer des stratégies de trading automatisées.
- Analyses techniques : les données et indicateurs historiques du marché sont extrêmement importants pour les analystes techniques. Ils permettent d’identifier des modèles et les tendances, ce qui aide les entreprises à prendre des décisions en matière d’investissements.
- Modélisation financière : les chercheurs et les analystes peuvent collecter des données pertinentes, comme des bilans financiers et des indicateurs économiques, afin de créer des modèles complexes permettant d’évaluer les performances des entreprises, prévoir leurs bénéfices et évaluer des opportunités d’investissement.
- Études de marché : les données financières fournissent beaucoup d’informations sur les actions, les indices du marché et les matières premières. L’analyse de ces données aide les chercheurs à comprendre les tendances du marché, les sentiments des différents acteurs et l’état de santé du secteur afin de prendre des décisions d’investissement éclairées.
Yahoo Finance est l’un des sites web de finance les plus populaires chez ceux qui désirent surveiller leur marché. Il offre un ensemble très fourni d’informations et d’outils aux investisseurs et aux traders : données historiques et en temps réel sur les actions, les obligations, les fonds communs de placement, les matières premières, les devises, et les indices de marché. De plus, il propose des articles d’actualités, des bilans financiers, des estimations d’analystes, des graphiques et autres ressources précieuses.
En collectant des données sur Yahoo Finance, vous pouvez accéder à une mine d’informations pour soutenir vos processus d’analyse financière, de recherche et de prise de décision.
Bibliothèques et des outils de web scraping pour la finance
Python est considéré comme l’un des meilleurs langages pour le web scraping grâce à sa syntaxe, sa simplicité d’utilisation et son riche écosystème de bibliothèques. Consultez notre guide sur le web scraping avec Python.
Pour choisir les bonnes bibliothèques de scraping parmi les nombreuses options disponibles, explorez Yahoo Finance dans votre navigateur. Vous remarquerez que la plupart des données du site sont mises à jour en temps réel ou modifiées après une interaction. Cela signifie que le site repose fortement sur AJAX pour charger et mettre à jour ses données de manière dynamique, sans nécessiter de rechargements de page. En d’autres termes, vous avez besoin d’un outil capable d’exécuter du JavaScript.
Selenium permet de faire du web scraping en Python sur des sites web dynamiques. Selenium permet également d’assurer le rendu des sites dans les navigateurs web, en effectuant des opérations sur eux même s’ils utilisent JavaScript pour le rendu ou la récupération des données.
Grâce à Selenium, vous pourrez extraire des données de votre site cible avec Python. Voyons comment.
Extraction de données boursières sur Yahoo Finance avec Selenium
Suivez ce tutoriel étape par étape et apprenez à créer en Python un script de web scraping pour Yahoo Finance.
Étape 1 : configuration
Avant de vous lancer dans le web scraping financier, assurez-vous de respecter les prérequis suivants :
- Python 3.0 ou supérieur installé sur votre machine : Téléchargez le programme d’installation, double-cliquez dessus et suivez les instructions de l’assistant d’installation.
- Un environnement de développement intégré Python de votre choix : PyCharm Community Edition ou Visual Studio Code avec l’extension Python conviendront.
Ensuite, utilisez les commandes ci-dessous pour configurer un projet Python avec un environnement virtuel :
mkdir yahoo-finance-scraper
cd yahoo-finance-scraper
python -m venv envCela permettra d’initialiser le dossier de projet yahoo-finance-scraper. À l’intérieur, ajoutez un fichier scraper.py comme suit :
print('Hello, World!')Vous allez ajouter ici la logique permettant d’extraire des données de Yahoo Finance. Pour l’instant, il s’agit d’un script qui se contente d’afficher « Hello, World! ».
Lancez-le pour vérifier qu’il fonctionne :
python scraper.pySur le terminal, vous devriez voir :
Hello, World!Parfait ! Vous avez maintenant un projet Python pour votre web scraper de données financières. Il nous reste seulement à installer les dépendances du projet. Installez Selenium et Webdriver Manager à l’aide de la commande suivante :
pip install selenium webdriver-managerCela peut prendre un certain temps ; soyez donc patient.
webdriver-manager n’est pas strictement indispensable. Cependant, il est fortement recommandé car il facilite grandement la gestion des pilotes web dans Selenium. Avec lui, vous n’avez pas besoin de télécharger, configurer et importer manuellement le pilote web.
Mettez à jour scraper.py
from selenium import webdriver
from selenium.webdriver.chrome.service import Service as ChromeService
from webdriver_manager.chrome import ChromeDriverManager
# initialize a web driver instance to control a Chrome window
driver = webdriver.Chrome(service=ChromeService(ChromeDriverManager().install()))
# scraping logic...
# close the browser and free up the resources
driver.quit()Ce script implémente simplement une instance de ChromeWebDriver. Vous allez bientôt l’utiliser pour implémenter votre logique d’extraction de données.
Étape 2 : connectez-vous à la page web cible
Voici à quoi ressemble l’URL d’une page de données boursières sur Yahoo Finance :
https://finance.yahoo.com/quote/AMZNComme vous pouvez le voir, il s’agit d’une URL dynamique qui change en fonction du code ticker. Si vous n’êtes pas familier avec le concept, il s’agit d’une courte chaîne de caractères permettant de désigner une action négociée sur le marché boursier. Par exemple, « AMZN » est le code ticker de l’action Amazon.
Modifions le script pour qu’il permette de lire le code ticker avec un argument de ligne de commande.
import sys
# if there are no CLI parameters
if len(sys.argv) <= 1:
print('Ticker symbol CLI argument missing!')
sys.exit(2)
# read the ticker from the CLI argument
ticker_symbol = sys.argv[1]
# build the URL of the target page
url = f'https://finance.yahoo.com/quote/{ticker_symbol}'Sys est une bibliothèque Python standard qui donne accès aux arguments de ligne de commande. N’oubliez pas que l’argument avec l’index 0 est le nom de votre script. Vous devez donc cibler l’argument avec l’index 1.
Après avoir été lu à partir de l’interface en ligne de commande, le code ticker est utilisé dans une f-string pour produire l’URL cible.
Par exemple, supposons que nous lancions le web scraper avec le code ticker de Tesla, « TSLA » :
python scraper.py TSLA
l’url contiendra :
https://finance.yahoo.com/quote/TSLASi vous oubliez le code ticker dans l’interface en ligne de commande, le programme échouera et l’erreur ci-dessous sera émise :
Ticker symbol CLI argument missing!Avant d’ouvrir une page dans Selenium, il est recommandé de définir la taille de la fenêtre pour garantir la bonne visibilité de chaque élément :
driver.set_window_size(1920, 1080)Utilisez Selenium pour vous connecter à la page cible avec :
driver.get(url)La fonction get() indique au navigateur de visiter la page souhaitée.
Voici ce à quoi ressemble pour l’instant votre script de web scraping Yahoo Finance :
from selenium import webdriver
from selenium.webdriver.chrome.service import Service as ChromeService
from webdriver_manager.chrome import ChromeDriverManager
import sys
# if there are no CLI parameters
if len(sys.argv) <= 1:
print('Ticker symbol CLI argument missing!')
sys.exit(2)
# read the ticker from the CLI argument
ticker_symbol = sys.argv[1]
# build the URL of the target page
url = f'https://finance.yahoo.com/quote/{ticker_symbol}'
# initialize a web driver instance to control a Chrome window
driver = webdriver.Chrome(service=ChromeService(ChromeDriverManager().install()))
# set up the window size of the controlled browser
driver.set_window_size(1920, 1080)
# visit the target page
driver.get(url)
# scraping logic...
# close the browser and free up the resources
driver.quit()Si vous le lancez, il ouvrira la fenêtre suivante pendant une fraction de seconde avant de fermer :
Pour le débogage, il peut s’avérer utile de lancer le navigateur avec l’interface utilisateur afin de surveiller ce que fait le web scraper sur la page web. Cela étant, cette tâche va consommer énormément de ressources. Pour éviter cela, configurez Chrome pour qu’il fonctionne en mode sans tête :
from selenium.webdriver.chrome.options import Options
# ...
options = Options()
options.add_argument('--headless=new')
driver = webdriver.Chrome(
service=ChromeService(ChromeDriverManager().install()),
options=options
)Le navigateur contrôlé va maintenant être lancé en arrière-plan, sans interface utilisateur.
Étape 3 : inspectez la page cible
Si vous voulez structurer une stratégie efficace d’extraction de données, vous devez d’abord analyser la structure de votre page web cible. Ouvrez votre navigateur et accédez à la page de l’action désirée sur Yahoo.
Si vous êtes basé en Europe, vous verrez d’abord une fenêtre modale vous demandant d’accepter les cookies :

Pour la fermer et continuer à visiter la page souhaitée, vous devez cliquer sur « Accepter tout » ou « Rejeter tout ». Cliquez avec le bouton droit de la souris sur le premier bouton et sélectionnez l’option « Inspecter » pour ouvrir les outils DevTools de votre navigateur :

Ici, vous remarquerez que vous pouvez sélectionner ce bouton avec le sélecteur CSS suivant :
.consent-overlay .accept-allUtilisez ces lignes pour gérer la fenêtre modale de consentement dans Selenium :
try:
# wait up to 3 seconds for the consent modal to show up
consent_overlay = WebDriverWait(driver, 3).until(
EC.presence_of_element_located((By.CSS_SELECTOR, '.consent-overlay')))
# click the "Accept all" button
accept_all_button = consent_overlay.find_element(By.CSS_SELECTOR, '.accept-all')
accept_all_button.click()
except TimeoutException:
print('Cookie consent overlay missing')WebDriverWait vous permet d’attendre qu’une condition attendue se produise sur la page. Si rien ne se passe dans le délai spécifié, une exception TimeoutException est générée. Comme la fenêtre d’acceptation des cookies ne s’affiche que lorsque votre adresse IP de sortie est européenne, vous pouvez gérer une telle exception avec une instruction try-catch. De cette façon, le script continuera à s’exécuter si la fenêtre modale de consentement n’est pas présente.
Pour que le script fonctionne, vous devez ajouter les importations suivantes :
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
from selenium.webdriver.common.by import By
from selenium.common import TimeoutExceptionMaintenant, continuez à inspecter le site cible dans DevTools et familiarisez-vous avec sa structure DOM.
Étape 4 : extrayez les données relatives à l’action
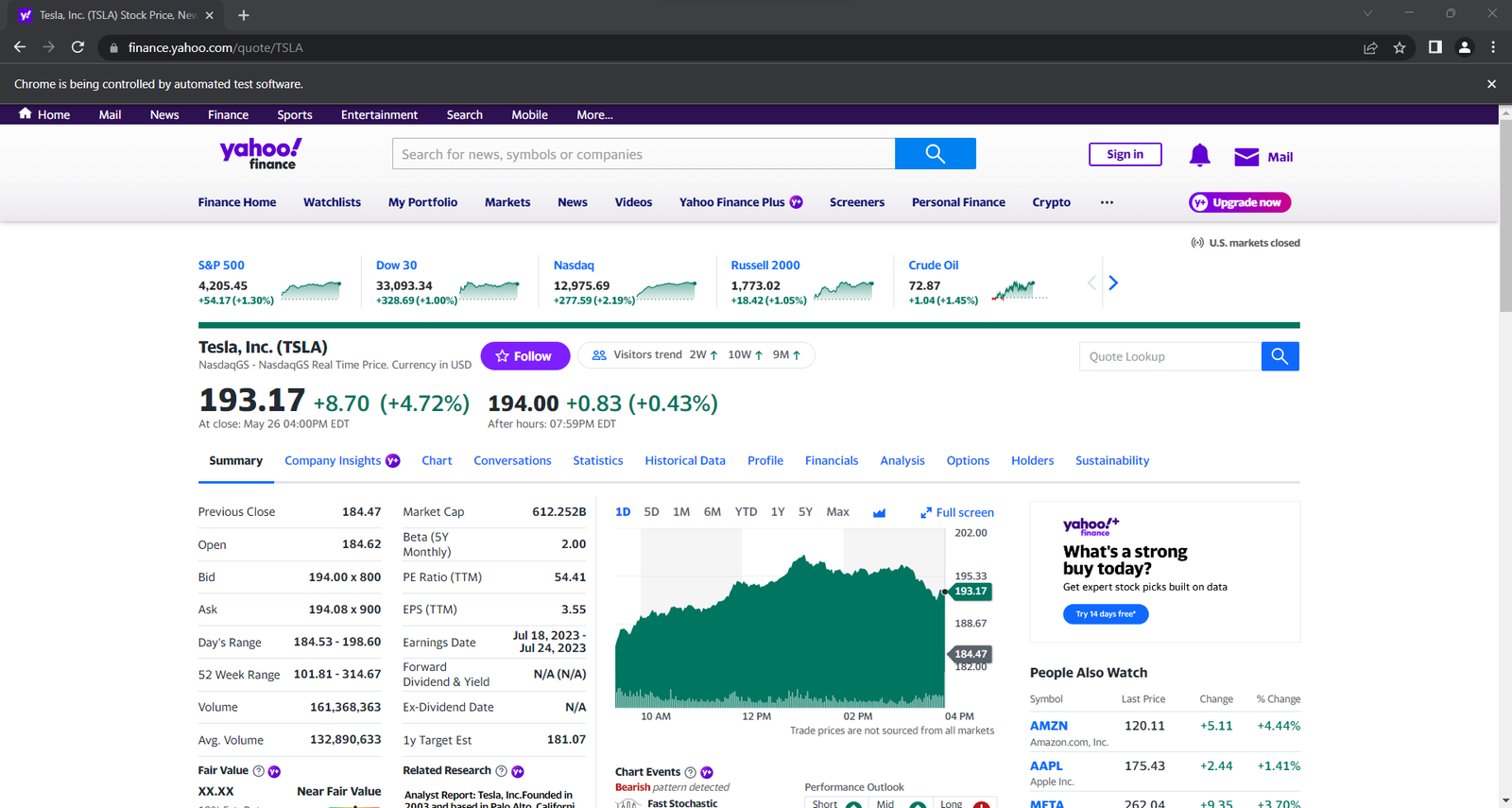
Comme vous l’avez remarqué à l’étape précédente, certaines des informations les plus intéressantes se trouvent dans cette section :

Inspectez l’élément HTML d’indicateur de prix :

Notez que les classes CSS ne sont pas utiles pour définir des sélecteurs appropriés dans Yahoo Finance. Elles semblent suivre une syntaxe inhabituelle. Concentrez-vous plutôt sur les autres attributs HTML. Par exemple, vous pouvez obtenir le prix de l’action avec le sélecteur CSS ci-dessous :
[data-symbol="TSLA"][data-field="regularMarketPrice"]En suivant une approche similaire, extrayez toutes les données relatives à l’action à partir des indicateurs de prix :
regular_market_price = driver\
.find_element(By.CSS_SELECTOR, f'[data-symbol="{ticker_symbol}"][data-field="regularMarketPrice"]')\
.text
regular_market_change = driver\
.find_element(By.CSS_SELECTOR, f'[data-symbol="{ticker_symbol}"][data-field="regularMarketChange"]')\
.text
regular_market_change_percent = driver\
.find_element(By.CSS_SELECTOR, f'[data-symbol="{ticker_symbol}"][data-field="regularMarketChangePercent"]')\
.text\
.replace('(', '').replace(')', '')
post_market_price = driver\
.find_element(By.CSS_SELECTOR, f'[data-symbol="{ticker_symbol}"][data-field="postMarketPrice"]')\
.text
post_market_change = driver\
.find_element(By.CSS_SELECTOR, f'[data-symbol="{ticker_symbol}"][data-field="postMarketChange"]')\
.text
post_market_change_percent = driver\
.find_element(By.CSS_SELECTOR, f'[data-symbol="{ticker_symbol}"][data-field="postMarketChangePercent"]')\
.text\
.replace('(', '').replace(')', '')
Après avoir sélectionné un élément HTML avec le sélecteur CSS considéré, vous pouvez extraire son contenu avec le champ text. Comme les champs de pourcentage font intervenir des parenthèses rondes, il faut supprimer ces dernières avec replace().
Ajoutez-les à un dictionnaire stock (action), que vous pourrez afficher pour vous assurer que votre processus de collecte de données financières fonctionne comme prévu :
# initialize the dictionary
stock = {}
# stock price scraping logic omitted for brevity...
# add the scraped data to the dictionary
stock['regular_market_price'] = regular_market_price
stock['regular_market_change'] = regular_market_change
stock['regular_market_change_percent'] = regular_market_change_percent
stock['post_market_price'] = post_market_price
stock['post_market_change'] = post_market_change
stock['post_market_change_percent'] = post_market_change_percent
print(stock)Exécutez le script sur le titre sur lequel vous souhaitez obtenir des données ; vous devriez voir quelque chose qui ressemble à ceci :
{'regular_market_price': '193.17', 'regular_market_change': '+8.70', 'regular_market_change_percent': '+4.72%', 'post_market_price': '194.00', 'post_market_change': '+0.83', 'post_market_change_percent': '+0.43%'}Vous trouverez d’autres informations utiles dans le tableau #quote-summary :

Ici, vous pouvez extraire chaque champ de données grâce à l’attribut data-test, comme dans le sélecteur CSS ci-dessous :
#quote-summary [data-test="PREV_CLOSE-value"]Vous pouvez extraire tous ces éléments comme ceci :
previous_close = driver.find_element(By.CSS_SELECTOR, '#quote-summary [data-test="PREV_CLOSE-value"]').text
open_value = driver.find_element(By.CSS_SELECTOR, '#quote-summary [data-test="OPEN-value"]').text
bid = driver.find_element(By.CSS_SELECTOR, '#quote-summary [data-test="BID-value"]').text
ask = driver.find_element(By.CSS_SELECTOR, '#quote-summary [data-test="ASK-value"]').text
days_range = driver.find_element(By.CSS_SELECTOR, '#quote-summary [data-test="DAYS_RANGE-value"]').text
week_range = driver.find_element(By.CSS_SELECTOR, '#quote-summary [data-test="FIFTY_TWO_WK_RANGE-value"]').text
volume = driver.find_element(By.CSS_SELECTOR, '#quote-summary [data-test="TD_VOLUME-value"]').text
avg_volume = driver.find_element(By.CSS_SELECTOR, '#quote-summary [data-test="AVERAGE_VOLUME_3MONTH-value"]').text
market_cap = driver.find_element(By.CSS_SELECTOR, '#quote-summary [data-test="MARKET_CAP-value"]').text
beta = driver.find_element(By.CSS_SELECTOR, '#quote-summary [data-test="BETA_5Y-value"]').text
pe_ratio = driver.find_element(By.CSS_SELECTOR, '#quote-summary [data-test="PE_RATIO-value"]').text
eps = driver.find_element(By.CSS_SELECTOR, '#quote-summary [data-test="EPS_RATIO-value"]').text
earnings_date = driver.find_element(By.CSS_SELECTOR, '#quote-summary [data-test="EARNINGS_DATE-value"]').text
dividend_yield = driver.find_element(By.CSS_SELECTOR, '#quote-summary [data-test="DIVIDEND_AND_YIELD-value"]').text
ex_dividend_date = driver.find_element(By.CSS_SELECTOR, '#quote-summary [data-test="EX_DIVIDEND_DATE-value"]').text
year_target_est = driver.find_element(By.CSS_SELECTOR, '#quote-summary [data-test="ONE_YEAR_TARGET_PRICE-value"]').textEnsuite, ajoutez-les à stock :
stock['previous_close'] = previous_close
stock['open_value'] = open_value
stock['bid'] = bid
stock['ask'] = ask
stock['days_range'] = days_range
stock['week_range'] = week_range
stock['volume'] = volume
stock['avg_volume'] = avg_volume
stock['market_cap'] = market_cap
stock['beta'] = beta
stock['pe_ratio'] = pe_ratio
stock['eps'] = eps
stock['earnings_date'] = earnings_date
stock['dividend_yield'] = dividend_yield
stock['ex_dividend_date'] = ex_dividend_date
stock['year_target_est'] = year_target_estParfait ! Vous venez de collecter des données financières sur le web avec Python.
Étape 5 : Extraire les données relatives à plusieurs actions
Un portefeuille de placements diversifié est constitué de plusieurs titres. Pour récupérer des données sur ces derniers, vous devez compléter votre script pour qu’il permette d’extraire les données associées à plusieurs codes ticker.
Tout d’abord, encapsulez votre logique de web scraping dans une fonction :
def scrape_stock(driver, ticker_symbol):
url = f'https://finance.yahoo.com/quote/{ticker_symbol}'
driver.get(url)
# deal with the consent modal...
# initialize the stock dictionary with the
# ticker symbol
stock = { 'ticker': ticker_symbol }
# scraping the desired data and populate
# the stock dictionary...
return stockEnsuite, effectuez une itération sur les arguments du ticker en ligne de commande, puis appliquez la fonction de scraping :
if len(sys.argv) <= 1:
print('Ticker symbol CLI arguments missing!')
sys.exit(2)
# initialize a Chrome instance with the right
# configs
options = Options()
options.add_argument('--headless=new')
driver = webdriver.Chrome(
service=ChromeService(ChromeDriverManager().install()),
options=options
)
driver.set_window_size(1150, 1000)
# the array containing all scraped data
stocks = []
# scraping all market securities
for ticker_symbol in sys.argv[1:]:
stocks.append(scrape_stock(driver, ticker_symbol))À la fin de la boucle for, la liste stocks de dictionnaires Python contiendra toutes les données recherchées.
Étape 6 : exportez les données extraites au format CSV
Vous pouvez exporter les données collectées au format CSV avec seulement quelques lignes de code :
import csv
# ...
# extract the name of the dictionary fields
# to use it as the header of the output CSV file
csv_header = stocks[0].keys()
# export the scraped data to CSV
with open('stocks.csv', 'w', newline='') as output_file:
dict_writer = csv.DictWriter(output_file, csv_header)
dict_writer.writeheader()
dict_writer.writerows(stocks)Ce code crée un fichier stocks.csv avec open(), l’initialise avec une ligne d’en-tête et le remplit. Plus précisément, DictWriter.writerows() convertit chaque dictionnaire en un enregistrement CSV et l’ajoute au fichier de sortie.
csv vient de la bibliothèque standard de Python ; vous n’avez donc même pas besoin d’installer une dépendance supplémentaire pour atteindre l’objectif souhaité.
Vous êtes passé de données brutes contenues dans une page web à des données semi-structurées stockées dans un fichier CSV. Il est temps de jeter un coup d’œil à l’ensemble de notre web scraper Yahoo Finance.
Étape 7 : au final
Voici le fichier scraper.py complet :
from selenium import webdriver
from selenium.webdriver.chrome.service import Service as ChromeService
from webdriver_manager.chrome import ChromeDriverManager
from selenium.webdriver.chrome.options import Options
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
from selenium.webdriver.common.by import By
from selenium.common import TimeoutException
import sys
import csv
def scrape_stock(driver, ticker_symbol):
# build the URL of the target page
url = f'https://finance.yahoo.com/quote/{ticker_symbol}'
# visit the target page
driver.get(url)
try:
# wait up to 3 seconds for the consent modal to show up
consent_overlay = WebDriverWait(driver, 3).until(
EC.presence_of_element_located((By.CSS_SELECTOR, '.consent-overlay')))
# click the 'Accept all' button
accept_all_button = consent_overlay.find_element(By.CSS_SELECTOR, '.accept-all')
accept_all_button.click()
except TimeoutException:
print('Cookie consent overlay missing')
# initialize the dictionary that will contain
# the data collected from the target page
stock = { 'ticker': ticker_symbol }
# scraping the stock data from the price indicators
regular_market_price = driver \
.find_element(By.CSS_SELECTOR, f'[data-symbol="{ticker_symbol}"][data-field="regularMarketPrice"]') \
.text
regular_market_change = driver \
.find_element(By.CSS_SELECTOR, f'[data-symbol="{ticker_symbol}"][data-field="regularMarketChange"]') \
.text
regular_market_change_percent = driver \
.find_element(By.CSS_SELECTOR, f'[data-symbol="{ticker_symbol}"][data-field="regularMarketChangePercent"]') \
.text \
.replace('(', '').replace(')', '')
post_market_price = driver \
.find_element(By.CSS_SELECTOR, f'[data-symbol="{ticker_symbol}"][data-field="postMarketPrice"]') \
.text
post_market_change = driver \
.find_element(By.CSS_SELECTOR, f'[data-symbol="{ticker_symbol}"][data-field="postMarketChange"]') \
.text
post_market_change_percent = driver \
.find_element(By.CSS_SELECTOR, f'[data-symbol="{ticker_symbol}"][data-field="postMarketChangePercent"]') \
.text \
.replace('(', '').replace(')', '')
stock['regular_market_price'] = regular_market_price
stock['regular_market_change'] = regular_market_change
stock['regular_market_change_percent'] = regular_market_change_percent
stock['post_market_price'] = post_market_price
stock['post_market_change'] = post_market_change
stock['post_market_change_percent'] = post_market_change_percent
# scraping the stock data from the "Summary" table
previous_close = driver.find_element(By.CSS_SELECTOR, '#quote-summary [data-test="PREV_CLOSE-value"]').text
open_value = driver.find_element(By.CSS_SELECTOR, '#quote-summary [data-test="OPEN-value"]').text
bid = driver.find_element(By.CSS_SELECTOR, '#quote-summary [data-test="BID-value"]').text
ask = driver.find_element(By.CSS_SELECTOR, '#quote-summary [data-test="ASK-value"]').text
days_range = driver.find_element(By.CSS_SELECTOR, '#quote-summary [data-test="DAYS_RANGE-value"]').text
week_range = driver.find_element(By.CSS_SELECTOR, '#quote-summary [data-test="FIFTY_TWO_WK_RANGE-value"]').text
volume = driver.find_element(By.CSS_SELECTOR, '#quote-summary [data-test="TD_VOLUME-value"]').text
avg_volume = driver.find_element(By.CSS_SELECTOR, '#quote-summary [data-test="AVERAGE_VOLUME_3MONTH-value"]').text
market_cap = driver.find_element(By.CSS_SELECTOR, '#quote-summary [data-test="MARKET_CAP-value"]').text
beta = driver.find_element(By.CSS_SELECTOR, '#quote-summary [data-test="BETA_5Y-value"]').text
pe_ratio = driver.find_element(By.CSS_SELECTOR, '#quote-summary [data-test="PE_RATIO-value"]').text
eps = driver.find_element(By.CSS_SELECTOR, '#quote-summary [data-test="EPS_RATIO-value"]').text
earnings_date = driver.find_element(By.CSS_SELECTOR, '#quote-summary [data-test="EARNINGS_DATE-value"]').text
dividend_yield = driver.find_element(By.CSS_SELECTOR, '#quote-summary [data-test="DIVIDEND_AND_YIELD-value"]').text
ex_dividend_date = driver.find_element(By.CSS_SELECTOR, '#quote-summary [data-test="EX_DIVIDEND_DATE-value"]').text
year_target_est = driver.find_element(By.CSS_SELECTOR,
'#quote-summary [data-test="ONE_YEAR_TARGET_PRICE-value"]').text
stock['previous_close'] = previous_close
stock['open_value'] = open_value
stock['bid'] = bid
stock['ask'] = ask
stock['days_range'] = days_range
stock['week_range'] = week_range
stock['volume'] = volume
stock['avg_volume'] = avg_volume
stock['market_cap'] = market_cap
stock['beta'] = beta
stock['pe_ratio'] = pe_ratio
stock['eps'] = eps
stock['earnings_date'] = earnings_date
stock['dividend_yield'] = dividend_yield
stock['ex_dividend_date'] = ex_dividend_date
stock['year_target_est'] = year_target_est
return stock
# if there are no CLI parameters
if len(sys.argv) <= 1:
print('Ticker symbol CLI argument missing!')
sys.exit(2)
options = Options()
options.add_argument('--headless=new')
# initialize a web driver instance to control a Chrome window
driver = webdriver.Chrome(
service=ChromeService(ChromeDriverManager().install()),
options=options
)
# set up the window size of the controlled browser
driver.set_window_size(1150, 1000)
# the array containing all scraped data
stocks = []
# scraping all market securities
for ticker_symbol in sys.argv[1:]:
stocks.append(scrape_stock(driver, ticker_symbol))
# close the browser and free up the resources
driver.quit()
# extract the name of the dictionary fields
# to use it as the header of the output CSV file
csv_header = stocks[0].keys()
# export the scraped data to CSV
with open('stocks.csv', 'w', newline='') as output_file:
dict_writer = csv.DictWriter(output_file, csv_header)
dict_writer.writeheader()
dict_writer.writerows(stocks)En moins de 150 lignes de code, vous avez créé un web scraper complet pour extraire des données de Yahoo Finance.
Lancez-le pour collecter des données sur vos actions préférées, comme dans l’exemple ci-dessous :
python scraper.py TSLA AMZN AAPL META NFLX GOOGÀ la fin du processus de scraping, ce fichier stocks.csv apparaît dans le dossier racine de votre projet :

Conclusion
Dans ce tutoriel, vous avez compris pourquoi Yahoo Finance est l’un des meilleurs portails financiers qui existent sur le web et vous avez appris à en extraire des données. Plus précisément, vous avez vu comment construire un web scraper en Python pour y collecter des données relatives à des actions. Comme vous l’avez vu, ce n’est pas difficile et cela ne nécessite que quelques lignes de code.
Cela étant, Yahoo Finance est un site dynamique qui repose fortement sur JavaScript. Lorsque vous avez affaire à de tels sites, une approche traditionnelle basée sur une bibliothèque HTTP et un analyseur HTML ne suffira pas. De plus, ces sites populaires ont tendance à mettre en œuvre des technologies avancées de protection des données. Pour en extraire des données, vous avez besoin d’un navigateur contrôlable capable de gérer automatiquement les CAPTCHA, les empreintes de navigateur, l’itération de nouvelles tentatives, etc. C’est exactement à cela que sert notre nouveau Scraping Browser !
Aucune carte de crédit requise
Vous ne voulez pas du tout vous occuper de web scraping, mais vous êtes intéressés par les données financières ? Explorez notre offre de jeux de données.

