

Dans ce guide, vous verrez :
- Les raisons pour lesquelles l’analyse du code HTML en PHP est utile
- Les conditions préalables à l’atteinte de l’objectif de l’article
- Comment analyser le HTML en PHP en utilisant :
DomHTMLDocument- Parseur HTML DOM simple
DomCrawlerde Symfony
- Un tableau comparatif des trois approches
Plongeons dans l’aventure !
Pourquoi analyser le HTML en PHP ?
L’analyse HTML en PHP consiste à convertir le contenu HTML dans sa structure DOM (Document Object Model). Une fois au format DOM, vous pouvez facilement naviguer et manipuler le contenu HTML.
En particulier, les principales raisons d’analyser le code HTML en PHP sont les suivantes :
- Extraction de données: Collecte d’un contenu spécifique à partir de pages web, tel que du texte ou des attributs d’éléments HTML.
- Automatisation: Automatisez les tâches telles que l’extraction de contenu, l’établissement de rapports et l’agrégation de données à partir de contenu HTML.
- Traitement du contenu HTML côté serveur: Analyse du code HTML pour manipuler, nettoyer ou formater le contenu web sur le serveur avant de l’afficher dans votre application.
Découvrez les meilleures bibliothèques d’analyse HTML!
Conditions préalables
Avant de commencer à coder, assurez-vous que PHP 8.4+ est installé sur votre machine. Vous pouvez le vérifier en exécutant la commande suivante :
php -v
Le résultat devrait ressembler à ceci :
PHP 8.4.3 (cli) (built: Jan 19 2026 14:20:58) (NTS)
Copyright (c) The PHP Group
Zend Engine v4.4.3, Copyright (c) Zend Technologies
with Zend OPcache v8.4.3, Copyright (c), by Zend Technologies
Ensuite, vous souhaitez initialiser un projet Composer pour faciliter la gestion des dépendances. Si Composer n’est pas installé sur votre système, téléchargez-le et suivez les instructions d’installation.
Tout d’abord, créez un nouveau dossier pour votre projet PHP HTML :
mkdir php-html-parser
Naviguez vers le dossier dans votre terminal et initialisez un projet Composer à l’intérieur en utilisant la commande composer init:
composer init
Au cours de ce processus, quelques questions vous seront posées. Les réponses par défaut fonctionneront, mais n’hésitez pas à ajouter des détails plus spécifiques à votre projet d’analyse PHP HTML si vous le souhaitez.
Ensuite, ouvrez le dossier du projet dans votre IDE préféré. Visual Studio Code avec l’extension PHP ou IntelliJ WebStorm sont de bons choix pour le développement PHP.
Ajoutez maintenant un fichier index.php vide dans le dossier du projet. La structure de votre projet devrait maintenant ressembler à ceci :
php-html-parser/
├── vendor/
├── composer.json
└── index.php
Ouvrez le fichier index.php et ajoutez le code suivant pour initialiser votre projet :
<?php
require_once __DIR__ . "/vendor/autoload.php";
// scraping logic...
Ce fichier contiendra bientôt la logique d’analyse du HTML en PHP.
Vous pouvez maintenant exécuter votre script à l’aide de cette commande :
php index.php
C’est très bien ! Vous êtes prêt à analyser du HTML en PHP. A partir de là, vous pouvez commencer à ajouter la logique de récupération et d’analyse HTML nécessaire à votre script.
Récupération de HTML en PHP
Avant d’analyser du HTML en PHP, vous avez besoin de HTML à analyser. Dans cette section, nous verrons deux approches différentes pour accéder au contenu HTML en PHP.
Avec CURL
PHP supporte nativement cURL, un client HTTP populaire utilisé pour effectuer des requêtes HTTP. Activez l’extension cURL ou installez-la sur Linux avec :
sudo apt-get install php8.4-curl
Vous pouvez utiliser cURL pour envoyer une requête HTTP GET à un serveur en ligne et récupérer le document HTML renvoyé par le serveur.
Voici un exemple de script qui effectue une simple requête GET et récupère un contenu HTML :
// initialize cURL session
$ch = curl_init();
// set the URL you want to make a GET request to
curl_setopt($ch, CURLOPT_URL, "https://www.scrapethissite.com/pages/forms/?per_page=100");
// return the response instead of outputting it
curl_setopt($ch, CURLOPT_RETURNTRANSFER, true);
// execute the cURL request and store the result in $response
$html = curl_exec($ch);
// close the cURL session
curl_close($ch);
// output the HTML response
echo $html;
Ajoutez l’extrait ci-dessus à index.php et lancez-le. Il produira le code HTML suivant :
<!doctype html>
<html lang="en">
<head>
<meta charset="utf-8">
<title>Hockey Teams: Forms, Searching and Pagination | Scrape This Site | A public sandbox for learning web scraping</title>
<link rel="icon" type="image/png" href="/static/images/scraper-icon.png" />
<!-- Omitted for brevity... -->
</html>
Pour en savoir plus, consultez notre guide sur les requêtes GET cURL en PHP.
À partir d’un fichier
Une autre façon d’obtenir le contenu HTML est de le stocker dans un fichier dédié. Pour ce faire, il faut
- Visitez une page de votre choix dans le navigateur
- Cliquer avec le bouton droit de la souris sur la page
- Sélectionnez l’option “Voir la source de la page”.
- Copier et coller le code HTML dans un fichier
Vous pouvez également écrire votre propre logique HTML dans un fichier.
Pour cet exemple, nous supposerons que le fichier s’appelle index.html. Il contient le code HTML de la page “Hockey Teams” de Scrape This Site, qui a été précédemment récupérée à l’aide de cURL :
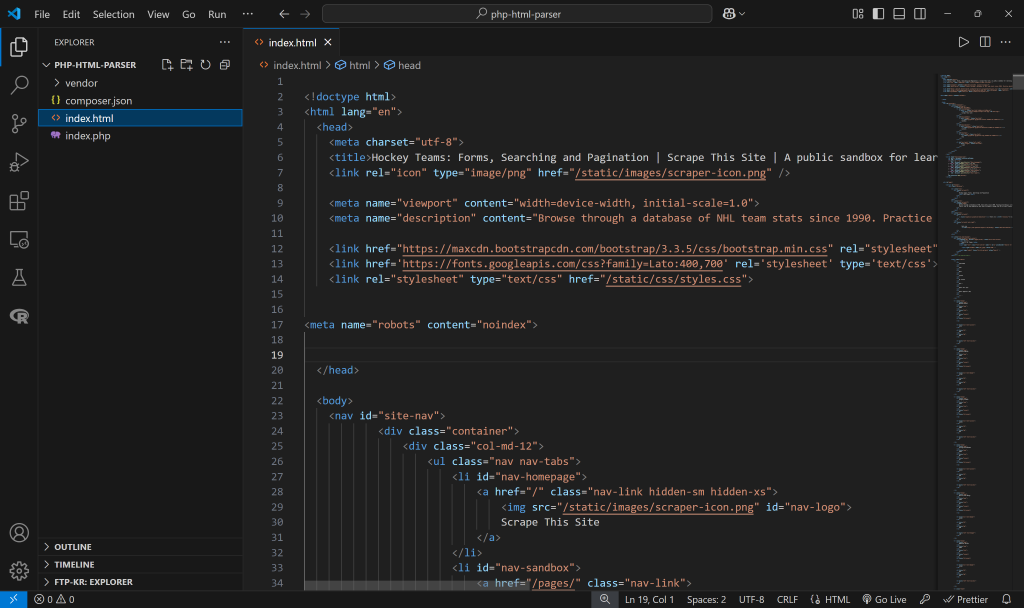
Analyse HTML en PHP : 3 approches
Dans cette section, vous apprendrez à utiliser trois bibliothèques différentes pour analyser le code HTML en PHP :
- Utilisation de
DomHTMLDocumentpour PHP vanille - Utilisation de la bibliothèque Simple HTML DOM Parser
- Utilisation du composant
DomCrawlerde Symfony
Dans les trois cas, vous verrez comment analyser la chaîne HTML récupérée via cURL ou le contenu HTML lu à partir du fichier local index.html.
Ensuite, vous apprendrez à utiliser les méthodes fournies par chaque bibliothèque d’analyse HTML PHP pour sélectionner toutes les entrées des équipes de hockey sur la page et en extraire les données :
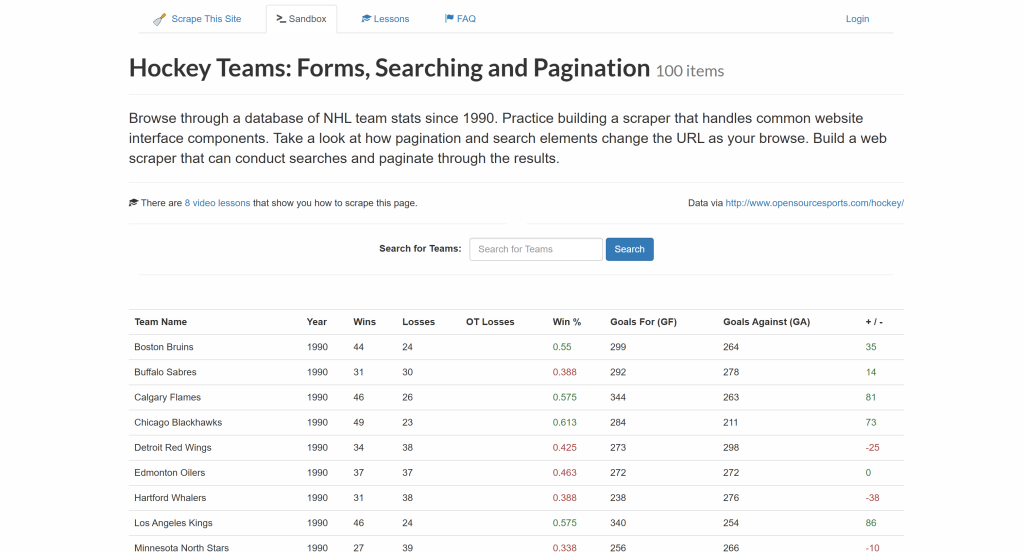
Le résultat final sera une liste d’entrées d’équipes de hockey récupérées contenant les détails suivants :
- Nom de l’équipe
- Année
- Victoires
- Pertes
- % de gain
- Buts pour (GF)
- Buts contre (GA)
- Différence de buts
Vous pouvez les extraire du tableau HTML à l’aide de cette structure :
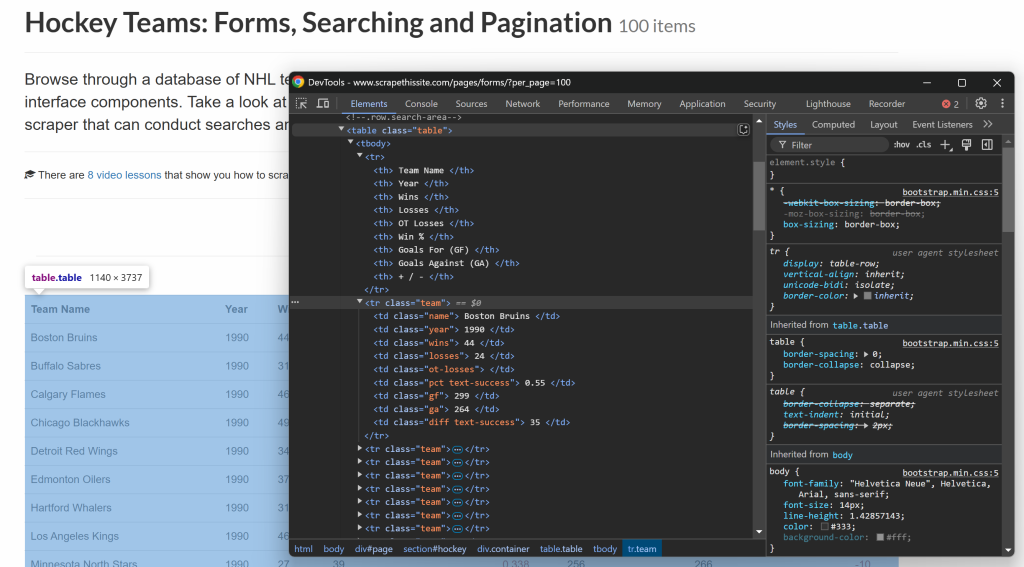
Comme vous pouvez le constater, chaque colonne d’un tableau possède une classe spécifique. Vous pouvez en extraire des données en sélectionnant des éléments à l’aide de leur classe en tant que sélecteur CSS, puis en récupérant leur contenu en accédant à leur texte.
Gardez à l’esprit que l’analyse du code HTML n’est qu’une étape dans un script de web scraping. Pour aller plus loin, lisez notre tutoriel sur le web scraping avec PHP.
Explorons maintenant trois approches différentes de l’analyse HTML en PHP.
Approche #1 : Avec DomHTMLDocument
PHP 8.4+ est livré avec une classe intégrée DomHTMLDocument. Elle représente un document HTML et vous permet d’analyser le contenu HTML et de naviguer dans l’arbre DOM. Voyez comment l’utiliser pour l’analyse HTML en PHP !
Étape 1 : Installation et configuration
DomHTMLDocument fait partie de la bibliothèque standard de PHP. Cependant, vous devez activer l’extension DOM ou l’installer avec cette commande Linux pour l’utiliser :
sudo apt-get install php-dom
Aucune autre action n’est nécessaire. Vous êtes maintenant prêt à utiliser DomHTMLDocument pour l’analyse HTML en PHP.
Étape 2 : Analyse HTML
Vous pouvez analyser la chaîne HTML comme suit :
$dom = DOMHTMLDocument::createFromString($html);
De manière équivalente, vous pouvez analyser le fichier index.html avec :
$dom = DOMHTMLDocument::createFromFile("./index.html");
$dom est un objet DomHTMLDocument qui expose les méthodes dont vous avez besoin pour l’analyse des données.
Étape 3 : Analyse des données
Vous pouvez sélectionner toutes les entrées de l’équipe de hockey en utilisant DOMHTMLDocument avec l’approche suivante :
// select each row on the page
$table = $dom->getElementsByTagName("table")->item(0);
$rows = $table->getElementsByTagName("tr");
// iterate through each row and extract data
foreach ($rows as $row) {
$cells = $row->getElementsByTagName("td");
// extracting the data from each column
$team = trim($cells->item(0)->textContent);
$year = trim($cells->item(1)->textContent);
$wins = trim($cells->item(2)->textContent);
$losses = trim($cells->item(3)->textContent);
$win_pct = trim($cells->item(5)->textContent);
$goals_for = trim($cells->item(6)->textContent);
$goals_against = trim($cells->item(7)->textContent);
$goal_diff = trim($cells->item(8)->textContent);
// create an array for the scraped team data
$team_data = [
"team" => $team,
"year" => $year,
"wins" => $wins,
"losses" => $losses,
"win_pct" => $win_pct,
"goals_for" => $goals_for,
"goals_against" => $goals_against,
"goal_diff" => $goal_diff
];
// print the scraped team data
print_r($team_data);
print ("n");
}
DOMNHTMLDocument n’offre pas de méthodes d’interrogation avancées. Vous devez donc vous appuyer sur des méthodes telles que getElementsByTagName() et l’itération manuelle.
Voici un aperçu des méthodes utilisées :
getElementsByTagName(): Récupère tous les éléments d’une balise donnée (comme<table>,<tr>ou<td>) dans le document.item(): renvoie un élément individuel à partir d’une liste d’éléments renvoyés pargetElementsByTagName().textContent: Cette propriété donne le contenu textuel brut d’un élément, ce qui permet d’extraire les données visibles (comme le nom de l’équipe, l’année, etc.).
Nous avons également utilisé trim() pour supprimer les espaces blancs supplémentaires avant et après le contenu du texte afin d’obtenir des données plus propres.
Ajouté à index.php, l’extrait ci-dessus produira le résultat suivant :
Array
(
[team] => Boston Bruins
[year] => 1990
[wins] => 44
[losses] => 24
[win_pct] => 0.55
[goals_for] => 299
[goals_against] => 264
[goal_diff] => 35
)
// omitted for brevity...
Array
(
[team] => Detroit Red Wings
[year] => 1994
[wins] => 33
[losses] => 11
[win_pct] => 0.688
[goals_for] => 180
[goals_against] => 117
[goal_diff] => 63
)
Approche n°2 : Utilisation d’un simple analyseur HTML DOM
Simple HTML DOM Parser est une bibliothèque PHP légère qui facilite l’analyse et la manipulation du contenu HTML. La bibliothèque est activement maintenue et possède plus de 880 étoiles sur GitHub.
Étape 1 : Installation et configuration
Vous pouvez installer Simple HTML Dom Parser via Composer avec cette commande :
composer require voku/simple_html_dom
Vous pouvez également télécharger manuellement le fichier simple_html_dom.php et l’inclure dans votre projet.
Ensuite, importez-le dans index.php avec cette ligne de code :
use vokuhelperHtmlDomParser;
Étape 2 : Analyse HTML
Pour analyser une chaîne HTML, utilisez la méthode file_get_html() :
$dom = HtmlDomParser::str_get_html($html);
Pour analyser index.html, écrivez file_get_html() à la place :
$dom = HtmlDomParser::file_get_html($str);
Cela chargera le contenu HTML dans un objet $dom, ce qui vous permettra de naviguer facilement dans le DOM.
Étape 3 : Analyse des données
Extraire les données relatives à l’équipe de hockey du code HTML à l’aide de l’analyseur DOM HTML simple :
// find all rows in the table
$rows = $dom->findMulti("table tr.team");
// loop through each row to extract the data
foreach ($rows as $row) {
// extract data using CSS selectors
$team_element = $row->findOne(".name");
$team = trim($team_element->plaintext);
$year_element = $row->findOne(".year");
$year = trim($year_element->plaintext);
$wins_element = $row->findOne(".wins");
$wins = trim($wins_element->plaintext);
$losses_element = $row->findOne(".losses");
$losses = trim($losses_element->plaintext);
$win_pct_element = $row->findOne(".pct");
$win_pct = trim($win_pct_element->plaintext);
$goals_for_element = $row->findOne(".gf");
$goals_for = trim($goals_for_element->plaintext);
$goals_against_element = $row->findOne(".ga");
$goals_against = trim(string: $goals_against_element->plaintext);
$goal_diff_element = $row->findOne(".diff");
$goal_diff = trim(string: $goal_diff_element->plaintext);
// create an array with the extracted team data
$team_data = [
"team" => $team,
"year" => $year,
"wins" => $wins,
"losses" => $losses,
"win_pct" => $win_pct,
"goals_for" => $goals_for,
"goals_against" => $goals_against,
"goal_diff" => $goal_diff
];
// print the scraped team data
print_r($team_data);
print("n");
}
Les fonctionnalités du Simple HTML DOM Parser utilisées ci-dessus sont les suivantes :
findMulti(): Sélectionne tous les éléments identifiés par le sélecteur CSS donné.findOne(): Localise le premier élément correspondant au sélecteur CSS donné.texte brut: Attribut permettant d’obtenir le contenu textuel brut d’un élément HTML.
Cette fois, nous avons utilisé des sélecteurs CSS avec une logique plus complète et plus robuste. Cependant, le résultat sera le même que dans l’approche initiale de l’analyse HTML en PHP.
Approche #3 : Utiliser le composant DomCrawler de Symfony
Le composant DomCrawler de Symfony permet d’analyser facilement les documents HTML et d’en extraire des données.
Note: Le composant fait partie du framework Symfony mais peut également être utilisé de manière autonome, comme nous le ferons dans cette section.
Étape 1 : Installation et configuration
Installez le composant DomCrawler de Symfony avec cette commande Composer :
composer require symfony/dom-crawler
Ensuite, importez-le dans le fichier index.php :
use SymfonyComponentDomCrawlerCrawler;
Étape 2 : Analyse HTML
Pour analyser une chaîne HTML, créez une instance de Crawler avec la méthode html() :
$crawler = new Crawler($html);
Pour analyser un fichier, utilisez file_get_contents() et créez l’instance de Crawler:
$crawler = new Crawler(file_get_contents("./index.html"));
Les lignes ci-dessus chargeront le contenu HTML dans l’objet $crawler, qui fournit des méthodes simples pour parcourir et extraire les données.
Étape 3 : Analyse des données
Extraire les données sur les équipes de hockey à l’aide du composant DomCrawler:
// select all rows within the table
$rows = $crawler->filter("table tr.team");
// loop through each row to extract the data
$rows->each(function ($row, $i) {
// extract data using CSS selectors
$team_element = $row->filter(".name");
$team = trim($team_element->text());
$year_element = $row->filter(".year");
$year = trim($year_element->text());
$wins_element = $row->filter(".wins");
$wins = trim($wins_element->text());
$losses_element = $row->filter(".losses");
$losses = trim($losses_element->text());
$win_pct_element = $row->filter(".pct");
$win_pct = trim($win_pct_element->text());
$goals_for_element = $row->filter(".gf");
$goals_for = trim($goals_for_element->text());
$goals_against_element = $row->filter(".ga");
$goals_against = trim($goals_against_element->text());
$goal_diff_element = $row->filter(".diff");
$goal_diff = trim($goal_diff_element->text());
// create an array with the extracted team data
$team_data = [
"team" => $team,
"year" => $year,
"wins" => $wins,
"losses" => $losses,
"win_pct" => $win_pct,
"goals_for" => $goals_for,
"goals_against" => $goals_against,
"goal_diff" => $goal_diff
];
// print the scraped team data
print_r($team_data);
print ("n");
});
Les méthodes DomCrawler utilisées sont les suivantes :
each(): Pour parcourir une liste d’éléments sélectionnés.filter(): Sélectionner des éléments sur la base de sélecteurs CSS.text(): Extrait le contenu textuel des éléments sélectionnés.
C’est formidable ! Vous êtes maintenant un maître de l’analyse HTML en PHP.
Analyse du HTML en PHP : Tableau de comparaison
Vous pouvez comparer les trois approches de l’analyse HTML en PHP explorées ici dans le tableau récapitulatif ci-dessous :
| DOMHTMLDocument | Parseur HTML DOM simple | DomCrawler de Symfony | |
|---|---|---|---|
| Type | Composant PHP natif | Bibliothèque externe | Composant Symfony |
| Étoiles GitHub | – | 880+ | 4,000+ |
| Support XPath | ❌ | ✔️ | ✔️ |
| Support des sélecteurs CSS | ❌ | ✔️ | ✔️ |
| Courbe d’apprentissage | Faible | Faible à moyen | Moyen |
| Simplicité d’utilisation | Moyen | Haut | Haut |
| API | De base | Riche | Riche |
Conclusion
Dans cet article, vous avez découvert trois approches de l’analyse HTML en PHP, allant de l’utilisation d’extensions intégrées à vanille à celle de bibliothèques tierces.
Bien que toutes ces solutions fonctionnent, il faut garder à l’esprit que la page web cible peut utiliser JavaScript pour le rendu. Dans ce cas, les approches d’analyse HTML simples comme celles présentées ci-dessus ne fonctionneront pas. Vous avez plutôt besoin d’un navigateur de scraping complet avec des capacités d’analyse HTML avancées comme Scraping Browser.
Vous voulez éviter l’analyse HTML et obtenir les données immédiatement ? Consultez nos ensembles de données prêts à l’emploi couvrant des centaines de sites web !
Créez un compte Bright Data gratuit dès aujourd’hui pour tester nos solutions de données et de scraping avec un essai gratuit !




