

curl, abréviation de « client URL », est un outil en ligne de commande utilisé pour transférer des données vers un serveur spécifique via son URL. curl est très accessible : il ne nécessite qu’une interface en ligne de commande (CLI) et une connexion Internet, ce qui le rend très répandu dans les routeurs, les imprimantes, les voitures et les appareils médicaux. Il est même utilisé sur Mars.
Pour la plupart des développeurs, curl est un excellent outil pour tester rapidement un service backend directement à partir de n’importe quel système d’exploitation.
Dans cet article, vous en apprendrez davantage sur curl et son utilisation.
Histoire de curl
Créé et distribué à l’origine par le développeur brésilien Rafael Sagula en 1996, Daniel Stenberg a repris le projet peu après sa première version, en y apportant quelques modifications qui lui ont permis de récupérer automatiquement les taux de change sur le web.
Compte tenu de sa fonction, curl a d’abord été nommé httpget. Lorsque le nombre de protocoles pris en charge a augmenté, le nom a été changé en urlget. En 1998, lorsque le projet s’est suffisamment développé pour prendre en charge les fonctionnalités de téléchargement, il a finalement été nommé curl.
Sa croissance ne s’est pas arrêtée là. Au fil des ans, curl prend en charge plus de vingt-cinq protocoles et plusieurs fonctionnalités, et traite des centaines de millions de requêtes chaque mois. Aujourd’hui, curl est un projet open source maintenu par une communauté de membres bénévoles à l’échelle mondiale.
Ce que fait curl
L’outil en ligne de commande curl est connu des développeurs pour sa capacité à effectuer des requêtes HTTP rapides afin de faciliter vos tâches de test et de débogage. En exécutant des commandes simples à partir du terminal de votre ordinateur, curl peut effectuer des requêtes GET, POST ou d’autres requêtes HTTP prises en charge par l’API spécifiée.
Si les utilisateurs interagissent principalement avec l’outil en ligne de commande de curl, la partie la plus difficile du travail est prise en charge par sa bibliothèque de développement appelée libcurl, une immense bibliothèque qui prend en charge la majorité des bases de code. Cette partie centrale du projet curl fonctionne en arrière-plan, traitant les requêtes et les réponses.
Comment utiliser curl
Pour utiliser les lignes de commande curl, vous avez besoin d’une interface CLI pour les exécuter (Mac Terminal pour macOS, Command Prompt pour Windows ou Bash pour Linux) et d’une connexion Internet afin que votre machine puisse les exécuter, afficher le résultat et lire la réponse, le cas échéant.
Chaque commande curl suit une syntaxe simple :
curl [OPTIONS] [URL]
Dans ce schéma, [URL] est le point de terminaison auquel vous envoyez la requête, tandis que [OPTIONS] est la commande qui détermine le type de requête HTTP que vous souhaitez effectuer. Le format par défaut est un tiret suivi d’une lettre (par exemple -d) ou, dans une forme plus détaillée, un double tiret suivi d’un mot (par exemple --data). De plus, vous pouvez spécifier des méthodes HTTP à l’aide de la syntaxe -X [MÉTHODE] (par exemple -X POST).
Voici quelques commandes curl que tout développeur devrait connaître.
Envoi de requêtes GET
La forme la plus courante de requête HTTP est la requête GET. Elle est le plus souvent utilisée pour récupérer des données (sous forme de texte, d’image ou de fichier) à partir de l’adresse spécifiée. La syntaxe par défaut d’une commande de requête GET curl est curl [URL]. Aucune option n’est spécifiée ici, car GET est le comportement par défaut implicite défini pour une commande curl.
En utilisant l’URL d’exemple https://dummyjson.com/products, une requête GET effectuée vers ce point de terminaison avec curl ressemble à ceci :
curl https://dummyjson.com/products
Le résultat de cette commande ressemble à ceci :
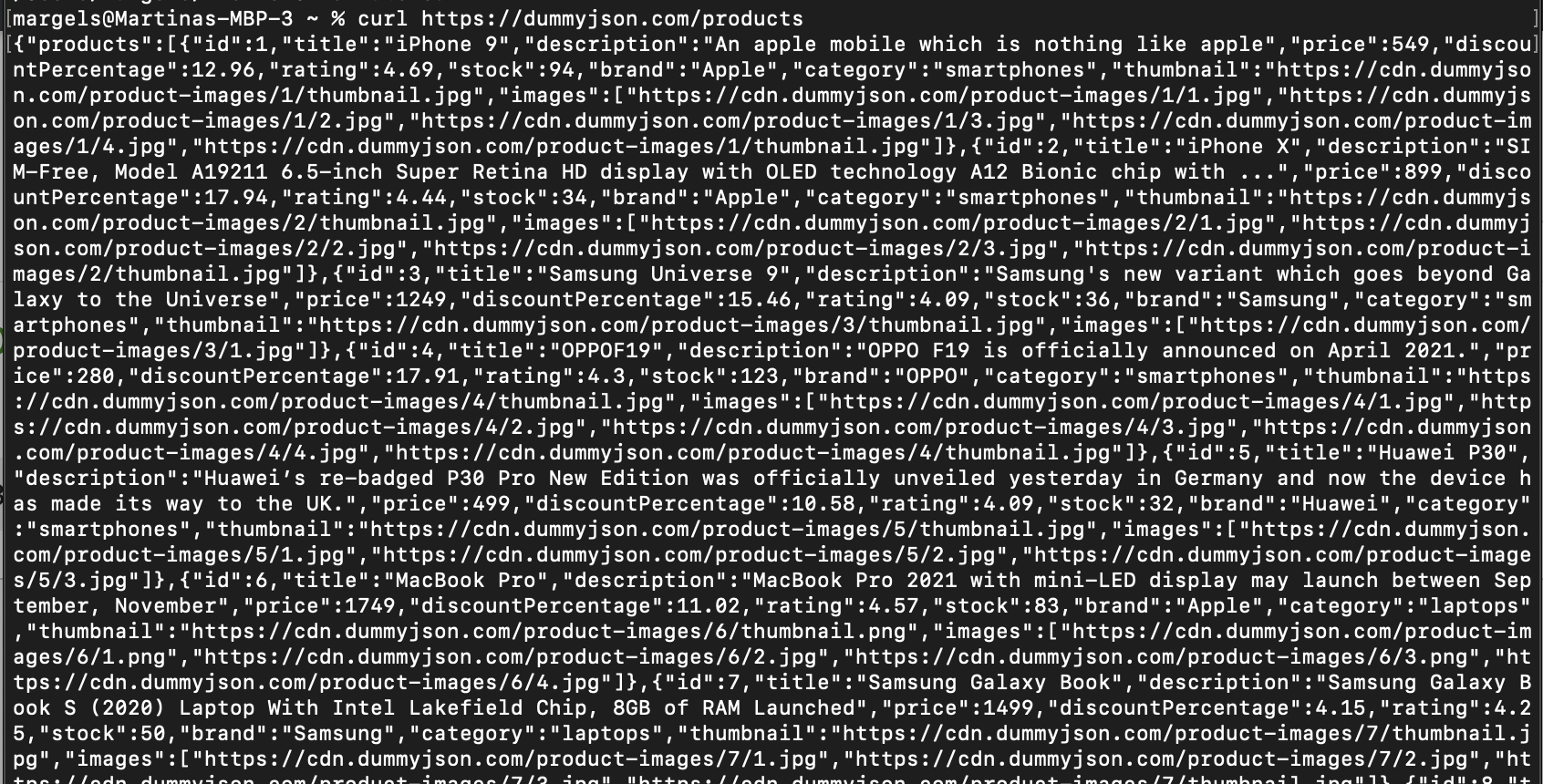
Cependant, toutes les requêtes GET ne sont pas aussi faciles à exécuter. Certaines nécessitent des paramètres, et bien qu’ils puissent être spécifiés dans l’URL, il est plus facile d’utiliser la syntaxe appropriée de curl. Ajoutez -G pour spécifier une requête GET, suivi de -d « paramètre1=valeur1 » pour autant de paramètres que nécessaire. La syntaxe doit ressembler à ceci : curl -G -d « paramètre1=valeur1 » -d « paramètre2=valeur2 » https://yoururl.com/yourendpoint.
Si vous envoyez une requête GET à la même URL que précédemment, mais que vous définissez le nombre limite à 1, cela devrait ressembler à ceci :
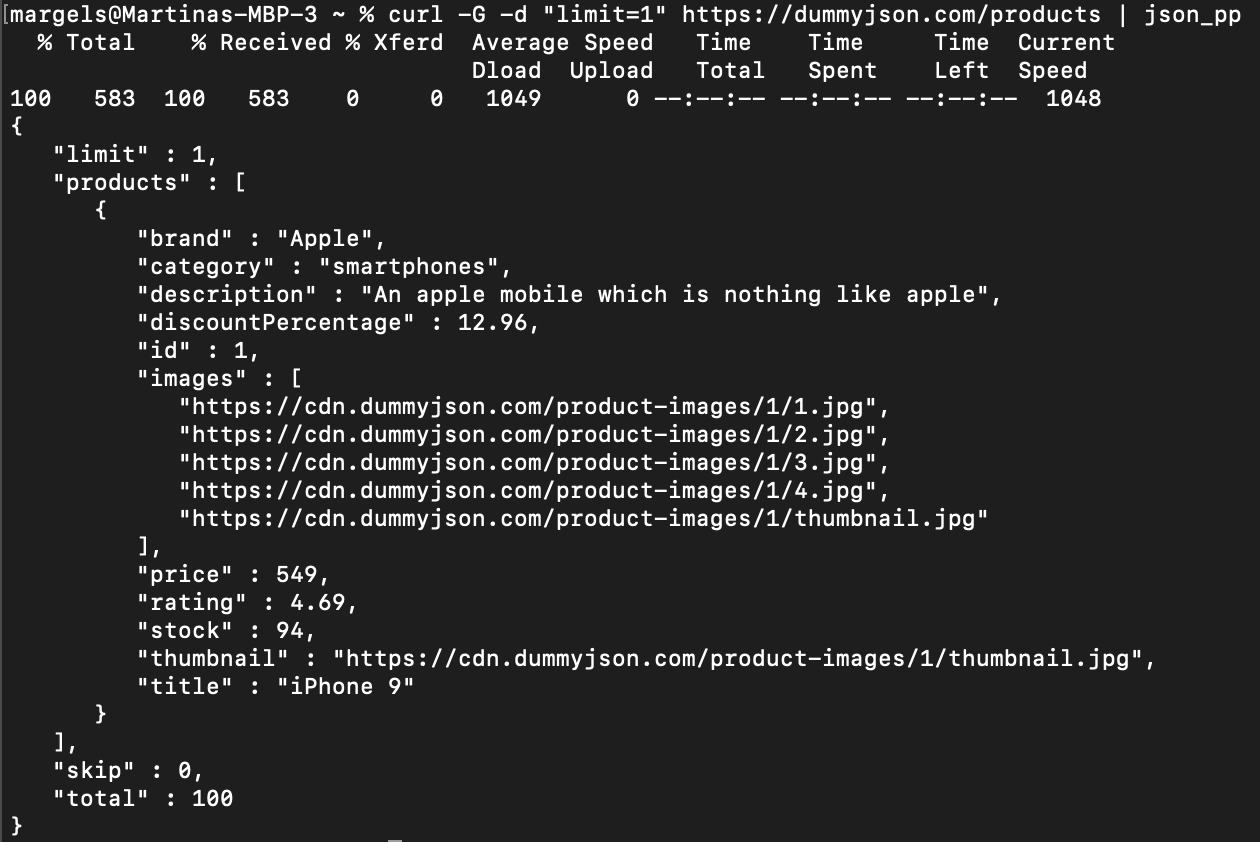
curl -G -d "limit=1" https://dummyjson.com/products
curl utilise cette commande pour former l’URL complète https://dummyjson.com/products?limit=1 en utilisant l’URL de base et le paramètre que vous avez défini pour envoyer une requête GET.
Voici le résultat obtenu :

Bien que curl soit puissant, il ne formate pas le résultat qu’il reçoit de la requête. Sur Mac, vous pouvez embellir la réponse en ajoutant | json_pp à votre ligne de commande :
Windows n’est pas équipé d’un tel outil préinstallé, vous devez donc installer un outil tel que jq et utiliser son raccourci | jq pour obtenir des JSON joliment formatés.
Notez également que vous pouvez traiter les requêtes curl à l’aide de votre langage de programmation intégré. Par exemple, vous pouvez en savoir plus sur la gestion des requêtes GET à l’aide de PHP sur ce blog.
Envoi de requêtes POST
Une autre requête HTTP fréquemment utilisée est POST, qui envoie et met à jour des données vers un serveur.
La syntaxe de base d’une requête POST avec curl est curl -X POST [URL]. Ce type de requête envoie une requête POST sans le corps des données, ce qui peut être utile lorsque la requête est effectuée uniquement pour mettre à jour le statut d’un élément dans la base de données. Par exemple, en utilisant l’URL d’exemple https://httpbin.org/anything, vous pouvez effectuer une simple requête POST avec la commande suivante :
curl -X POST https://httpbin.org/anything
Dans la plupart des cas, vous devez télécharger des données. Pour ce faire, commencez par indiquer à curl comment lire le corps des données que vous envoyez en spécifiant leur format. Ajoutez un en-tête avec la commande -H 'HEADER: VALUE', puis insérez le corps de votre requête à l’aide de la commande de données -d 'VALUE'. La syntaxe complète est curl -X POST -H 'HEADER: VALUE' -d 'VALUE' [URL].
Si vous souhaitez envoyer un corps JSON contenant un prénom et un nom, vous pouvez utiliser Content-Type pour définir votre type de contenu au format JSON et définir un JSON simple comme données :
curl -X POST -H "Content-Type: application/json" -d "{
"FirstName": "Joe",
"LastName": "Soap"
}" https://httpbin.org/anything
Voici le résultat de la commande précédente :
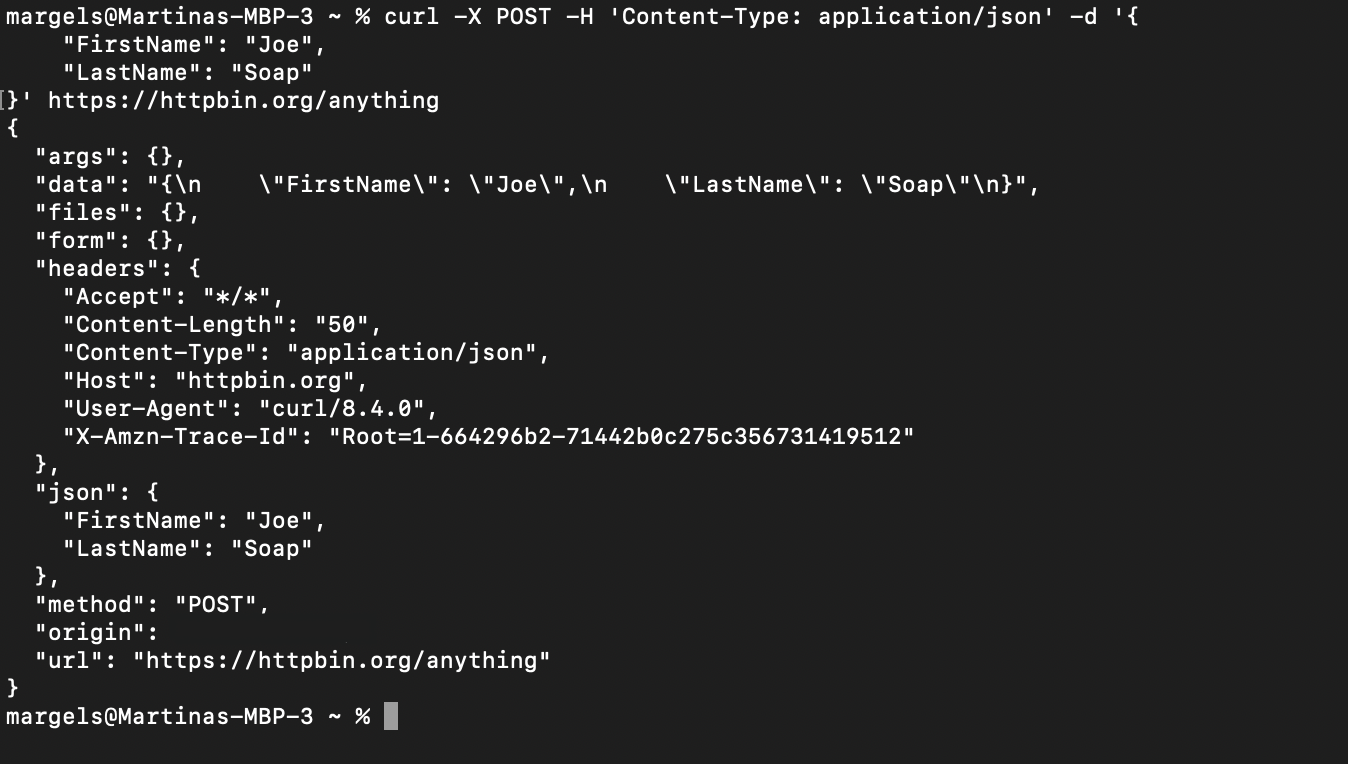
Comme vous pouvez le voir, le champ data contient le corps des données que vous avez envoyées dans votre requête.
À partir de la version 7.82, curl a également introduit le raccourci --json, qui simplifie vos requêtes POST avec un corps JSON à curl --json '[CORPS JSON]' [URL]. La commande permettant d’effectuer la même tâche qu’auparavant à l’aide du raccourci --json serait la suivante :
curl --json '{"FirstName": "Joe", "LastName": "Soap"}' https://httpbin.org/anything
Si vous avez un corps JSON long que vous préférez enregistrer dans un fichier local, vous pouvez choisir de le télécharger à la place en utilisant la syntaxe curl --json @[FILENAME].txt [URL]:
curl --json @file-name.txt https://httpbin.org/anything
Vous disposez de plusieurs options pour télécharger des données sur votre serveur. Par exemple, vous pouvez avoir besoin d’un format différent ou souhaiter télécharger des fichiers sur le Web. Pour en savoir plus sur les requêtes POST avec curl, cliquez ici.
Connexion via des Proxys
De nombreux développeurs utilisent des serveurs Proxy pour améliorer la sécurité. Tout comme un pare-feu, un serveur Proxy fiable protège ses utilisateurs et leur réseau contre les menaces potentielles sur Internet. Il offre également une confidentialité renforcée.
Pour utiliser correctement un Proxy, vous devez disposer des informations suivantes sur votre Proxy :
- Le protocole, tel que
http:// - L’hôte, généralement quatre chiffres séparés par des points, tel que
71.00.00.00 - Le port, généralement un nombre à quatre chiffres, tel que
0000 - Les identifiants (facultatifs) sous la forme d’un nom d’utilisateur et d’un mot de passe
La syntaxe de l’URL du Proxy suit le schéma [PROTOCOLE]://[[NOM D'UTILISATEUR]:[MOT DE PASSE]][HÔTE]:[PORT] ou, si le Proxy n’est pas protégé par des identifiants, [PROTOCOLE]://[HÔTE]:[PORT].
Une fois que vous disposez de l’URL du Proxy, vous pouvez la configurer sur curl à l’aide de la commande -x. Notez que celle-ci est différente de -X, qui fait référence à une méthode de requête HTTP personnalisée. (N’oubliez pas que curl est sensible à la casse.) Vous pouvez également utiliser l’option plus explicite --proxy si vous la trouvez plus facile à mémoriser. L’une ou l’autre de ces commandes doit être suivie de l’URL du Proxy et de l’URL finale.
Compte tenu des points mentionnés, votre commande curl pour configurer une URL Proxy devrait ressembler à ceci :
curl --Proxy "http://71.00.00.00:0000" https://httpbin.org/ip
Votre réponse doit contenir un objet d'origine, dont la valeur doit correspondre à l’adresse IP hôte du Proxy :
{
"origin": "71.00.00.00"
}
Cela signifie que le site web considère que la requête provient de l’adresse IP de votre Proxy plutôt que de celle de votre ordinateur.
Pour en savoir plus sur l’utilisation de curl avec des Proxies, consultez cet article de blog.
Utilisation des en-têtes
Comme vous l’avez peut-être remarqué, certaines requêtes HTTP nécessitent des informations supplémentaires pour s’exécuter correctement. Par exemple, vous avez utilisé l’en-tête Content-Type dans votre requête POST précédemment pour indiquer à curl comment lire le corps des données que vous avez téléchargées.
Les en-têtes, qui sont toujours précédés de la commande -H, peuvent également être utilisés dans plusieurs autres cas.
Un type d’en-tête courant est Authorization: Bearer [TOKEN], qui spécifie un jeton porteur pour authentifier et accéder à une URL protégée. Un autre en-tête couramment utilisé est Accept: application/json, qui spécifie une préférence de réponse JSON.
Si vous souhaitez recevoir une liste des en-têtes de réponse pour une URL, vous pouvez utiliser la commande -I curl dans votre terminal, comme suit :
curl -I https://dummyjson.com/products
Vous pouvez également utiliser -i pour afficher la réponse à la requête avec les en-têtes.
Vous pouvez en savoir plus sur les en-têtes dans curl sur ce blog.
Enregistrement des sorties
Parfois, la lecture des données ne suffit pas et vous devez enregistrer ces sorties quelque part sur votre ordinateur. Comme mentionné précédemment, curl est capable de traiter des données qui ne sont pas au format texte. Par exemple, il peut télécharger ou charger des fichiers entiers.
À l’aide de la commande -o, vous pouvez spécifier le nom et l’emplacement du fichier que vous souhaitez enregistrer. Par exemple, si vous souhaitez enregistrer le contenu de cette page au format TXT sur votre bureau, vous pouvez utiliser la commande suivante :
curl -o /Users/User/Desktop/file.txt https://brightdata.com/blog
Exécutez cette commande et ouvrez votre bureau pour voir votre fichier nouvellement enregistré.
Téléchargement de fichiers
Tout comme curl est capable de télécharger des fichiers depuis le web, il vous permet également de les télécharger. Pour indiquer à curl que vous ne téléchargez pas des données sous forme textuelle, mais plutôt sous forme de fichier, vous devez placer le symbole @ avant le nom du fichier.
De nombreux développeurs commettent l’erreur d’utiliser uniquement le drapeau -X POST, pensant qu’il s’agit de la commande appropriée pour télécharger des fichiers sur un serveur à l’aide de curl. Cependant, les téléchargements de fichiers nécessitent généralement le type de contenu multipart/form-data, car les fichiers sont joints dans le cadre d’un formulaire. Vous devez donc définir le type d’en-tête correct avec le drapeau -X POST. Le drapeau -F définit l’en-tête de type de contenu correct, et le drapeau -X POST automatiquement, ce qui vous permet d’utiliser une commande plus courte et plus simple.
Avec l’indicateur -F, vous pouvez soumettre un formulaire en spécifiant les valeurs des champs du formulaire. Pour joindre un fichier en tant que champ de formulaire, utilisez le symbole @ avant le nom du fichier.
La syntaxe correcte est curl -F "file=@[CHEMIN D'ACCÈS AU FICHIER]/[NOM DU FICHIER].txt" [URL], où file est le nom du champ de fichier dans le formulaire. Par exemple, en supposant que vous souhaitiez télécharger le fichier que vous avez téléchargé précédemment vers une URL fictive telle que https://example.com/upload, votre commande devrait ressembler à ceci :
curl -F "file=@/Users/User/Desktop/file.txt" https://example.com/upload
Si vous souhaitez télécharger plusieurs fichiers, vous pouvez répéter la syntaxe de la commande -F autant de fois que vous le souhaitez avant la définition de l’URL.
Cas d’utilisation de curl
En raison de sa grande compatibilité et de sa polyvalence, curl peut être utilisé dans un large éventail de scénarios différents.
L’utilisation la plus courante de curl est en tant que client HTTP pour effectuer des tests d’API, interagir avec des services web et effectuer différentes opérations HTTP telles que GET ou POST. De nombreux langages de programmation utilisent également libcurl pour effectuer des requêtes HTTP en interne.
Bien que curl soit principalement axé sur l’exécution de requêtes HTTP et la récupération de leurs réponses, il peut également être combiné avec d’autres outils ou scripts pour analyser et traiter le contenu reçu. Par exemple, il peut récupérer le contenu HTML d’une page web dans le cadre du Scraping web.
Avantages de curl
curl offre de nombreux avantages. Les plus notables sont son taux de compatibilité élevé, qui le rend utilisable par presque tous les appareils, et sa syntaxe, qui est simple à apprendre et à maîtriser.
curl est également riche en fonctionnalités, polyvalent, rapide et particulièrement léger, ce qui lui permet d’effectuer des tâches sans surcharger votre CPU.
Conclusion
Dans cet article, vous en avez appris davantage sur l’histoire de curl, son fonctionnement, ses cas d’utilisation et ses avantages. Vous avez également vu comment exécuter certaines des commandes les plus basiques avec curl.
Et si vous êtes intéressé par des méthodes plus rapides pour le Scraping web, n’hésitez pas à consulter l’API Bright Data Web Scraper. Inscrivez-vous dès maintenant pour un essai gratuit !




