

Dans cet article de blog consacré au scraping web géré par rapport au scraping web basé sur une API, vous découvrirez :
- Un aperçu des services de scraping web gérés et des solutions de scraping web basées sur des API.
- Ce qu’est le Scraping web géré, comment il fonctionne, ses principaux cas d’utilisation et quand il constitue le meilleur choix.
- Ce que sont les API de Scraping web, comment elles fonctionnent, leurs principaux cas d’utilisation et quand elles sont les plus efficaces.
- Une comparaison finale pour vous aider à décider quelle approche correspond le mieux à vos besoins en matière de collecte de données web.
C’est parti !
Introduction aux services de Scraping web gérés et aux API de Scraping web
Le scraping web géré et le scraping web basé sur des API sont deux des approches les plus courantes pour collecter des données web. Dans les deux cas, les principaux défis du scraping web (par exemple, l’empreinte digitale du navigateur, le rendu JavaScript, les empreintes digitales TLS, les limites de débit, les CAPTCHA et autres obstacles similaires) sont externalisés à un fournisseur tiers.
Avec les services gérés, l’ensemble du processus de scraping est entièrement externalisé. Le fournisseur travaille avec vous pour comprendre vos besoins et vous fournit les données requises, souvent enrichies d’informations et d’analyses personnalisées. Il s’agit essentiellement d’une solution clé en main de bout en bout.
D’autre part, le scraping web basé sur des API implique la création de scripts personnalisés, d’agents IA ou de pipelines qui se connectent aux API de scraping. Ces points de terminaison collectent des données web structurées à partir de domaines connus tout en prenant en charge le contournement des mesures anti-scraping, l’évolutivité et l’infrastructure. Cependant, vous restez responsable de l’intégration, du stockage des données et d’autres aspects techniques.
Dans les deux approches, il est essentiel de choisir un fournisseur fiable. Bright Data est l’un des principaux fournisseurs de solutions de Scraping web, couvrant les deux approches :
- Acquisition de données gérée: accédez aux données et aux informations sans effort de développement ou de maintenance grâce à un service entièrement géré et de niveau entreprise.
- API de scraping web: un ensemble complet de points de terminaison de scraping pour plus de 120 plateformes populaires. Elles prennent en charge la rotation automatique des proxys, le contournement anti-bot, le rendu JavaScript, etc.
Ce qui distingue Bright Data, c’est son infrastructure prête à l’emploi, qui prend en charge plus de 20 000 entreprises dans le monde entier avec un temps de disponibilité et un taux de réussite de 99,99 %, une assistance experte 24 heures sur 24, 7 jours sur 7, des données conformes et éthiques, et l’accès à plus de 150 millions d’adresses IP d’utilisateurs réels dans 195 pays, l’un des plus grands réseaux de Proxy au monde.
Scraping web géré : une analyse approfondie
Commençons cet article sur le scraping géré par opposition au scraping basé sur une API en nous concentrant sur les services gérés d’acquisition de données web et en comprenant à quoi ils sont le mieux adaptés.
Qu’est-ce que c’est ?
Le scraping web géré est un service de collecte de données de bout en bout où un fournisseur s’occupe de tout pour vous.
Cela comprend la recherche de pages web, le contournement des systèmes anti-bots, l’analyse des données des pages identifiées, la validation et le nettoyage des résultats, la mise à l’échelle de l’infrastructure et la fourniture de données structurées, fiables et conformes qui répondent à vos besoins.
Au lieu de créer et de maintenir des robots de scraping et de gérer l’ensemble de l’infrastructure, il vous suffit de décrire vos besoins au fournisseur. En retour, celui-ci vous fournit des jeux de données, des tableaux de bord ou des informations prêts à l’emploi qui répondent à vos besoins.
L’objectif du Scraping web géré est de gagner du temps, de réduire les efforts d’ingénierie et de diminuer les coûts opérationnels tout en vous donnant accès aux données que vous souhaitez.
Comment ça marche
Lorsque vous optez pour une solution gérée d’acquisition de données web, l’ensemble du parcours des données est pris en charge pour vous. De la configuration initiale à la livraison finale, le fournisseur s’occupe de toutes les étapes nécessaires pour vous fournir les données que vous souhaitez dans le format ou la présentation souhaités.
Le processus comprend généralement les étapes suivantes :
- Lancement du projet: vous commencez par sélectionner un service de collecte de données géré. Vous travaillez ensuite en étroite collaboration avec les experts du fournisseur pour définir les sources de données, les champs obligatoires, les informations et les indicateurs clés de performance (KPI) qui correspondent à vos objectifs commerciaux.
- Collecte des données: le fournisseur de scraping géré dirige l’ensemble du processus de collecte des données. Son équipe élabore, automatise et adapte la solution d’extraction en fonction de vos besoins et la fait fonctionner en continu, tandis que votre chef de projet supervise l’exécution.
Vous avez désormais accès aux données que vous avez demandées. Cependant, avec les meilleurs fournisseurs, le processus ne s’arrête pas là et comprend deux étapes supplémentaires :
- Validation et enrichissement des données: le fournisseur affine les données à l’aide d’une déduplication automatisée, de recoupements et d’un contrôle qualité continu. L’objectif est de fournir des données précises, cohérentes, enrichies et de haute qualité.
- Rapports et informations: une fois les données collectées et affinées, le fournisseur peut également fournir des informations via des tableaux de bord, un suivi en temps réel et des conseils d’experts afin de faciliter la prise de meilleures décisions commerciales.
Comme vous pouvez le constater, cette approche est véritablement complète. Elle garantit que l’ensemble du processus de récupération, de traitement et de finalisation des données est entièrement géré pour vous, des données brutes aux connaissances exploitables.
Exigences
Les services de Scraping web gérés ne nécessitent pratiquement aucune compétence technique de votre part. La raison en est que l’ensemble du processus de scraping des données est externalisé. Vous n’avez donc pas besoin d’expertise technique pour créer des scrapers, gérer des Proxy ou gérer l’infrastructure sous-jacente.
La principale exigence est d’avoir une compréhension claire de vos besoins en matière de données, y compris des aspects tels que les sources cibles, les champs de données, le nombre d’enregistrements et la fréquence de mise à jour. Évidemment, vous devez également être capable de comprendre et d’exploiter les résultats fournis.
Cas d’utilisation
Le Scraping web géré peut prendre en charge pratiquement tous les secteurs d’activité. Les fournisseurs peuvent même agréger des données provenant de plusieurs sources à la fois, par exemple en combinant des informations provenant de plusieurs plateformes de commerce électronique avec des données issues des réseaux sociaux pour effectuer une analyse des sentiments.
Idéal pour
Le Scraping web géré est idéal lorsque vous ne disposez pas des compétences, de l’infrastructure ou de la capacité nécessaires pour gérer un projet de collecte de données.
En effet, il est loin d’être facile de mettre en place un pipeline de données fiable alimenté par le scraping web. Vous devez choisir les bons outils de scraping, intégrer des Proxy et mettre en œuvre des solutions anti-scraping pour que vos scripts soient efficaces dans des scénarios réels.
En outre, vous devez surveiller les changements structurels des sites web, vérifier que votre logiciel personnalisé fonctionne de manière cohérente et gérer l’évolutivité de votre infrastructure. Et ce ne sont là que quelques-uns des aspects liés à la création et à la gestion d’un processus de Scraping web prêt à être mis en production…
Tout cela entraîne un investissement important en temps et en argent dans le personnel, les serveurs et les solutions tierces. En adoptant un service géré plutôt qu’en développant une solution en interne, vous éliminez ces besoins. Cela se traduit par un flux de travail plus rationalisé qui peut vous faire économiser beaucoup d’argent, surtout si votre équipe n’a que peu ou pas d’expérience en matière de Scraping web.
Prenons par exemple le retour sur investissement estimé du choix des services de Scraping web gérés de Bright Data plutôt que la mise en œuvre et la gestion du processus par vous-même :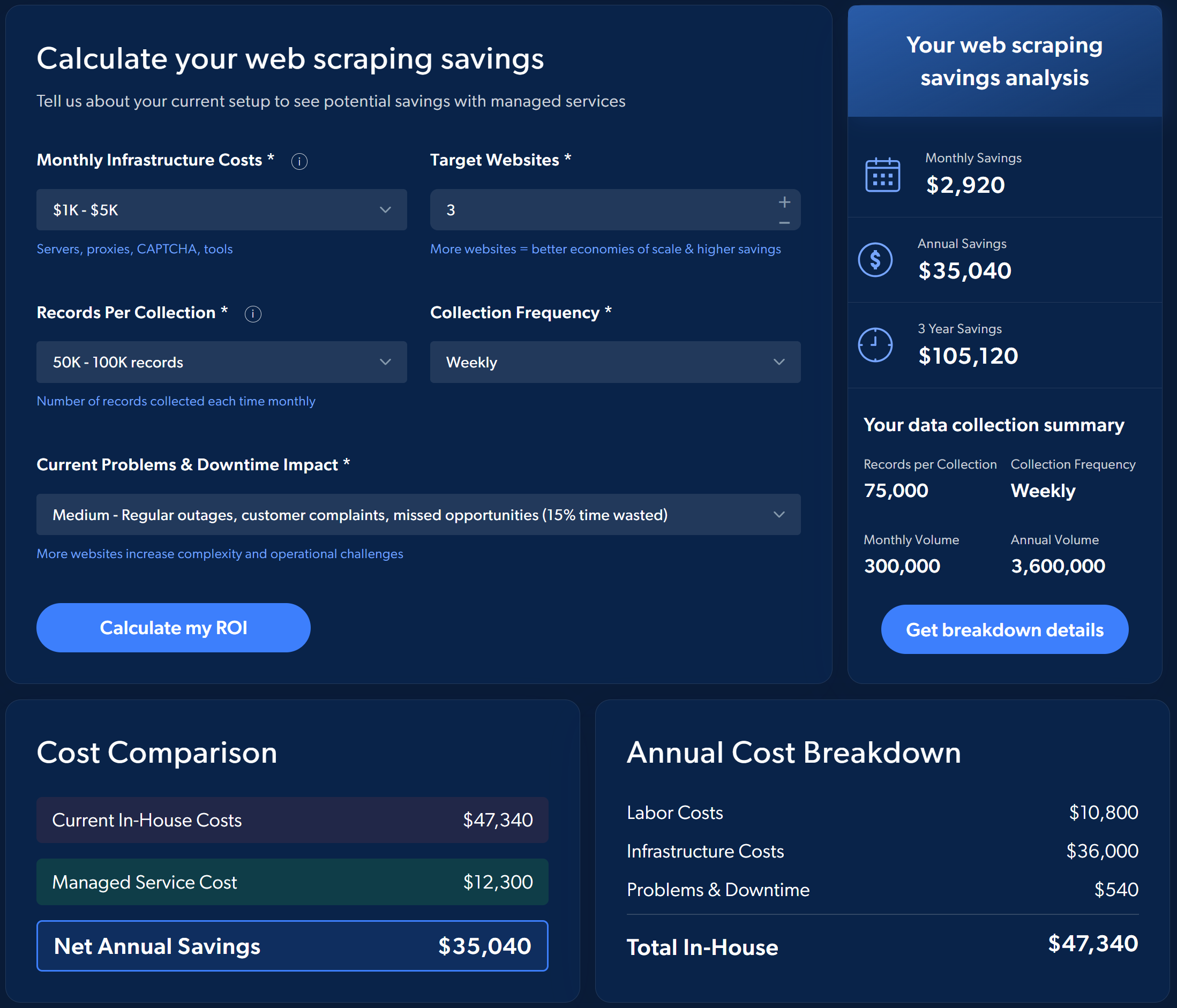
Pour avoir une idée des économies potentielles, effectuez une simulation simple directement sur la page du service de collecte de données géré de Bright Data.
En bref, les services gérés sont idéaux pour les entreprises qui souhaitent disposer de données fiables, à jour, évolutives et validées sans investir dans une équipe dédiée.
Scraping web basé sur une API : une analyse approfondie
Poursuivez la lecture de cet article de blog sur le scraping web géré par rapport au scraping web basé sur une API en explorant la collecte de données web via des API de scraping, qui couvre toutes les informations essentielles que vous devez connaître.
Qu’est-ce que c’est ?
Le scraping web basé sur une API consiste à se connecter directement à une solution d’API de scraping pour collecter des données web. Ces API peuvent être classées en trois types :
- API de sites officiels: elles donnent accès à un ensemble prédéfini de données directement à partir du site web.
- API générales de déblocage Web: points de terminaison qui contournent les protections anti-bot sur n’importe quelle page Web.
- API de scraping web spécifiques: elles permettent de scraper des domaines particuliers et de renvoyer des données structurées selon un schéma donné.
Ici, nous nous concentrerons sur les deux derniers types d’API de Scraping web. La raison en est que les API de sites officiels sont souvent coûteuses, ont des limites de débit strictes et vous offrent peu de contrôle, car le site peut cesser d’exposer les données à tout moment. Pour plus de détails, consultez notre guide sur le Scraping web vs API.
Comment ça marche
Le scraping web basé sur des API est un bon compromis entre les approches entièrement internes et entièrement externalisées.
L’idée est de créer des scripts simples qui se connectent à ces API, qui se chargent de toutes les tâches lourdes, notamment la récupération des pages, le rendu JavaScript, le contournement des protections anti-scraping et même, éventuellement, le renvoi de données déjà structurées.
Vous commencez par trouver le fournisseur d’API de Scraping web qui correspond à vos besoins. Si des API de scraping fournissant les données que vous souhaitez sont disponibles, vous devez les utiliser directement. Sinon, vous pouvez opter pour une API de déblocage web qui fournit le code HTML débloqué des pages web qui vous intéressent.
Lorsque vous utilisez des API de scraping, il vous suffit de créer des scripts simples qui appellent l’API, gèrent les erreurs avec une logique de réessai en cas de défaillances occasionnelles et stockent les données récupérées dans une base de données, dans des fichiers locaux, dans le cloud ou en utilisant votre méthode de stockage préférée.
Si vous choisissez une API de déblocage Web, vous devez implémenter une logique d’analyse des données personnalisée, soit à l’aide de sélecteurs CSS/expressions XPath, soit à l’aide de l’intelligence artificielle. Une fois les données extraites du code HTML déverrouillé, elles doivent être stockées comme indiqué précédemment.
Enfin, les données doivent être validées, nettoyées, traitées et analysées afin d’en extraire des informations utiles.
Exigences
Bien que le scraping web basé sur une API soit beaucoup plus léger que la création d’un scraper web à partir de zéro, il nécessite tout de même une certaine configuration technique.
Vous devez disposer de compétences de base en codage pour écrire des scripts qui appellent les API de manière programmatique dans votre langage de programmation préféré. Vous devez également savoir comment aborder l’authentification, gérer les requêtes HTTP parallèles et traiter les erreurs courantes.
Remarque: les principaux fournisseurs proposent souvent des solutions sans code, qui vous permettent d’utiliser des API de Scraping web sans écrire de code ni avoir besoin de compétences techniques.
Pour enregistrer les données collectées, vous devez également vous familiariser avec les options de stockage des données. De plus, vous devez posséder des compétences en gestion des données afin d’éviter les doublons et d’assurer des mises à jour régulières avec un versionnage approprié.
Si vous utilisez une API de déblocage Web au lieu d’une API de scraping web dédiée, vous aurez besoin de compétences supplémentaires pour analyser le code HTML et structurer les données en fonction de vos besoins. Enfin, des compétences en matière de données sont nécessaires pour préparer les données en vue de leur traitement, de leur visualisation et de leur analyse.
Cas d’utilisation
Les API de Scraping web prennent en charge une longue liste de cas d’utilisation, tels que :
- Commerce électronique: récupérez des informations sur les produits, les prix, les avis et les données des vendeurs sur des sites tels qu’Amazon, eBay et Walmart.
- Finance: accéder aux données boursières, aux rapports financiers et aux tendances du marché à partir de plateformes telles que Yahoo Finance ou Nasdaq.
- Marché de l’emploi: collecter des offres d’emploi et des données sur les entreprises à partir de LinkedIn, Indeed et d’autres sites.
- Voyages: suivre les vols, la disponibilité des hôtels et les tarifs sur Expedia, Booking.com et d’autres sites similaires.
- B2B: obtenir des données sur les entreprises à partir de sources telles que Crunchbase ou ZoomInfo.
- Réseaux sociaux: surveillez les publications, les tendances et l’engagement sur X, Instagram et TikTok.
- Moteurs de recherche: effectuez des recherches programmatiques sur des moteurs de recherche tels que Google, Bing, Yandex et autres à l’aide d’API SERP et d’API de recherche Web.
Grâce à une API de déblocage Web, vous pouvez alors accéder à des données structurées provenant de pratiquement n’importe quel site Web, même ceux qui ne disposent pas d’une API de scraping dédiée.
Idéal pour
Le scraping basé sur une API est particulièrement adapté aux situations où vous avez besoin de données web cohérentes et structurées sans externaliser totalement le processus. Il offre un compromis entre le développement en interne et les services gérés, vous permettant de garder le contrôle sur la collecte de données tandis que l’API se charge des principaux défis.
Scraping web géré ou basé sur une API : comparaison directe
Maintenant que vous comprenez les deux méthodologies permettant d’obtenir des données web, il est temps de les comparer dans une section consacrée au scraping géré et au scraping basé sur une API.
Comment choisir la bonne approche de scraping
Comparez le scraping web géré et le scraping web basé sur une API dans le tableau récapitulatif ci-dessous :
| Scraping web géré | Scraping web basé sur une API | |
|---|---|---|
| Description | Vous décrivez vos besoins au fournisseur, qui extrait et fournit les données à partir des sources sélectionnées. | Vous vous connectez aux API pour récupérer les données web. L’API gère la récupération des pages, le contournement des anti-bots, l’intégration des proxys, etc. |
| À qui s’adresse | Aux entreprises qui ont besoin d’une solution clé en main sans compétences ni infrastructure internes. | Aux équipes disposant d’ingénieurs ou de ressources techniques en interne qui souhaitent contrôler la collecte de données tout en externalisant les tâches fastidieuses. |
| Configuration et maintenance | Entièrement géré de bout en bout par le fournisseur. Aucune configuration technique n’est requise de votre part. | Nécessite des compétences de base en programmation et la configuration de scripts, la gestion des erreurs et le stockage. |
| Gestion anti-bot | Entièrement gérée par le fournisseur. | Entièrement gérée par le fournisseur. |
| Infrastructure | Entièrement gérée par le fournisseur. | Gérée par le fournisseur d’API, mais le déploiement et l’intégration de vos scripts sont sous votre responsabilité. |
| Livraison | Les données sont livrées dans le format et selon les modalités de votre choix. | Les données sont renvoyées par l’API de scraping au format HTML, JSON ou Markdown. |
| Nettoyage des données et assurance qualité | Validation automatisée, déduplication, enrichissement et contrôles qualité continus gérés par le fournisseur. | Vous êtes responsable de la validation, du nettoyage et du traitement ultérieurs. |
| Informations et tableaux de bord | Le fournisseur peut fournir des tableaux de bord, des rapports, des analyses et des informations exploitables personnalisés. | Non inclus. |
| Conseil et stratégie | Recommandations et conseils d’experts inclus pour optimiser la collecte et l’utilisation des données. | Non inclus. |
| Assistance | Équipe d’assistance dédiée, comprenant un concierge de données pour le dépannage et la gestion de projet. | Limité à la documentation API et à l’assistance technique de base. |
Scraping web géré
👍 Avantages:
- Accès à des données structurées, des tableaux de bord ou des informations prêtes à l’emploi.
- Service complet couvrant la collecte, la validation, l’enrichissement et la livraison des données, sans nécessiter de compétences techniques.
- Réduit les coûts opérationnels et les efforts d’ingénierie.
- Applicable à pratiquement tous les cas d’utilisation, secteurs d’activité ou scénarios.
- Assistance et recommandations d’une équipe d’experts multisectorielle.
👎 Inconvénients:
- Moins de contrôle sur le processus de scraping.
- Dépendance totale vis-à-vis d’un fournisseur tiers spécifique.
Scraping web basé sur une API
👍 Avantages:
- Intégration facile dans les systèmes existants.
- Vitesse et concurrence élevées, prenant en charge de nombreuses requêtes simultanées.
- Pas besoin de se soucier des blocages ou des restrictions anti-bot.
- Aucune gestion ou maintenance de l’infrastructure requise.
- Bien adapté à la création d’outils de scraping personnalisés pour les agents IA ou les workflows automatisés.
👎 Inconvénients:
- Nécessite des compétences techniques.
- Vous êtes responsable de la validation, du nettoyage et de la structuration des données.
Commentaire final
Les services web gérés et les API de scraping web ont tous deux pour objectif de fournir des données web, mais ils abordent le problème différemment.
Les API de scraping web sont des points de terminaison permettant une récupération simplifiée des données, que les développeurs peuvent intégrer directement dans des scripts, des pipelines ou même des agents IA et des workflows. Elles sont idéales lorsque vous avez besoin de points de données spécifiques, tels que les prix des produits, les avis ou les résultats de recherche, sans avoir à gérer l’infrastructure sous-jacente. Cependant, elles nécessitent tout de même une certaine configuration et des compétences techniques.
À l’inverse, les services gérés d’acquisition par Scraping web gèrent l’ensemble du cycle de vie des données, de l’extraction à la validation, en passant par l’enrichissement et la livraison, sans nécessiter d’ingénierie ou de maintenance en interne.
La solution d’acquisition de données gérée de Bright Data illustre particulièrement bien cette approche. Elle fournit des pipelines de niveau entreprise, des contrôles de qualité automatisés, la conformité aux lois sur la confidentialité et des tableaux de bord pour des informations en temps réel. Il vous suffit de définir vos cibles et vos indicateurs clés de performance, et Bright Data se charge de la mise à l’échelle, de la surveillance et de la livraison de données structurées prêtes à l’emploi pour vous aider à maximiser votre retour sur investissement.
En conclusion, voyez les choses ainsi : les API vous fournissent les outils, les services gérés vous livrent le produit fini !
Conclusion
Dans ce guide, vous avez examiné les nuances des deux approches les plus populaires en matière de Scraping web : les services gérés et les solutions basées sur des API.
Vous avez appris que le Scraping web géré est idéal lorsque vous souhaitez une expérience entièrement automatisée. Il vous fournit non seulement les données, mais aussi des jeux de données validés et des informations intéressantes. Tout cela sans avoir à gérer la complexité technique. En revanche, les API de Scraping web offrent une plus grande flexibilité et un meilleur contrôle, mais peuvent nécessiter une expérience en codage.
Quelle que soit l’approche que vous choisissez, Bright Data est là pour vous. Il propose des API de Scraping web de pointe, telles que l’API Unlocker et les API Scraper spécifiques à un domaine, ainsi que des services de collecte de données gérés de niveau entreprise.
Inscrivez-vous gratuitement à Bright Data et découvrez dès aujourd’hui nos solutions de Scraping web !




