

Dans ce tutoriel, nous allons apprendre à extraire les offres d’emploi de JOBKOREA, un portail d’emploi moderne.
Nous aborderons les thèmes suivants :
- Le scraping manuel avec Python en extrayant les données Next.js intégrées
- Scraping web avec Bright Data Web MCP pour une solution plus stable et évolutive
- Extraction sans code à l’aide de l’AI Scraper Studio de Bright Data
Chaque technique est mise en œuvre à l’aide du code de projet fourni dans ce référentiel, passant d’un scraping de bas niveau à une extraction entièrement automatisée et alimentée par l’IA.
Prérequis
Avant de commencer ce tutoriel, assurez-vous de disposer des éléments suivants :
- Python 3.9+
- Connaissances de base de Python et JSON
- Un compte Bright Data avec accès à MCP
- Claude Desktop installé (utilisé comme agent IA pour l’approche sans code)
Configuration du projet
Clonez le référentiel du projet et installez les dépendances :
python -m venv venv
source venv/bin/activate # macOS / Linux
venvScriptsactivate # Windows
pip install -r requirements.txtStructure du projet
Le référentiel est organisé de manière à ce que chaque technique de scraping soit facile à suivre :
jobkorea_scraper/
│
├── manual_scraper.py # Extraction manuelle Python
├── mcp_scraper.py # Extraction Bright Data Web MCP
├── parsers/
│ └── jobkorea.py # Logique d'analyse partagée
├── schemas.py # Schéma des données d'emploi
├── requirements.txt
├── README.mdChaque script peut être exécuté indépendamment, en fonction de la méthode que vous souhaitez explorer.
Technique 1 : scraping manuel Python
Nous commencerons par l’approche la plus basique : le scraping de JOBKOREA à l’aide de Python simple, sans navigateur, MCP ou agent IA.
Cette technique est utile pour comprendre comment JOBKOREA fournit ses données et pour prototyper rapidement un scraper avant de passer à des solutions plus robustes.
Récupération de la page
Ouvrez manual_scraper.py.
Le Scraper commence par envoyer une requête HTTP standard à l’aide de requests. Pour éviter d’être immédiatement bloqué, nous incluons des en-têtes de type navigateur.
headers = {
"User-Agent": "Mozilla/5.0 (...)",
"Accept": "text/html,application/xhtml+xml,*/*",
"Accept-Language": "en-US,en;q=0.9,ko;q=0.8",
"Referer": "https://www.jobkorea.co.kr/"
}L’objectif est simplement de faire en sorte que la requête ressemble à un trafic web normal. Nous récupérons ensuite la page et forçons l’encodage UTF-8 pour éviter les problèmes avec le texte coréen :
response = requests.get(url, headers=headers, timeout=20)
response.raise_for_status()
response.encoding = "utf-8"
html = response.textÀ des fins de débogage, le code HTML brut est enregistré localement :
with open("debug.html", "w", encoding="utf-8") as f:
f.write(html)Ce fichier est extrêmement utile lorsque le site change et que l’analyse cesse soudainement de fonctionner.
Analyse de la réponse
Une fois le code HTML téléchargé, il est transmis à une fonction d’analyse partagée :
jobs = parse_job_list(html)Cette fonction se trouve dans parsers/jobkorea.py et contient toute la logique spécifique à JOBKOREA.
Tentative d’analyse HTML traditionnelle
Dans parse_job_list, nous essayons d’abord d’extraire les offres d’emploi à l’aide de BeautifulSoup, comme si JOBKOREA était un site traditionnel rendu par le serveur.
soup = BeautifulSoup(html, "html.parser")
job_lists = soup.find_all("div", class_="list-default")Si aucune offre n’est trouvée, un sélecteur secondaire est essayé :
job_lists = soup.find_all("ul", class_="clear")Lorsque cela fonctionne, le scraper extrait des champs tels que :
- Intitulé du poste
- Nom de l’entreprise
- Lieu
- Date de publication
- Lien vers l’offre
Cependant, cette approche ne fonctionne que lorsque JOBKOREA expose des éléments HTML significatifs, ce qui n’est pas toujours le cas.
Solution de repli : extraction des données d’hydratation Next.js
Si aucune offre d’emploi n’est trouvée via l’analyse HTML, le scraper passe à une stratégie de secours qui cible les données d’hydratation Next.js intégrées.
nextjs_jobs = parse_nextjs_data(html)Cette fonction analyse la page à la recherche de chaînes JSON injectées lors du rendu côté client. Une version simplifiée de la logique de correspondance ressemble à ceci :
pattern = r'\"id\":\"(?P<id>d+)\",\"title\":\"(?P<title>.*?)\",\"postingCompanyName\":\"(?P<company>.*?)\"'À partir de ces données, nous reconstruisons les URL des offres d’emploi :
link = f"https://www.jobkorea.co.kr/Recruit/GI_Read/{job_id}"Cette solution de secours permet au scraper de fonctionner sans exécuter de navigateur.
Enregistrement des résultats
Chaque offre d’emploi est validée à l’aide d’un schéma partagé et enregistrée sur le disque :
with open("jobs.json", "w", encoding="utf-8") as f:
json.dump(
[job.model_dump() for job in jobs],
f,
ensure_ascii=False,
indent=2
)Exécutez le scraper comme suit :
python manual_scraper.py "https://www.jobkorea.co.kr/Search/?stext=python"Vous devriez maintenant avoir un fichier jobs.json contenant les listes extraites.
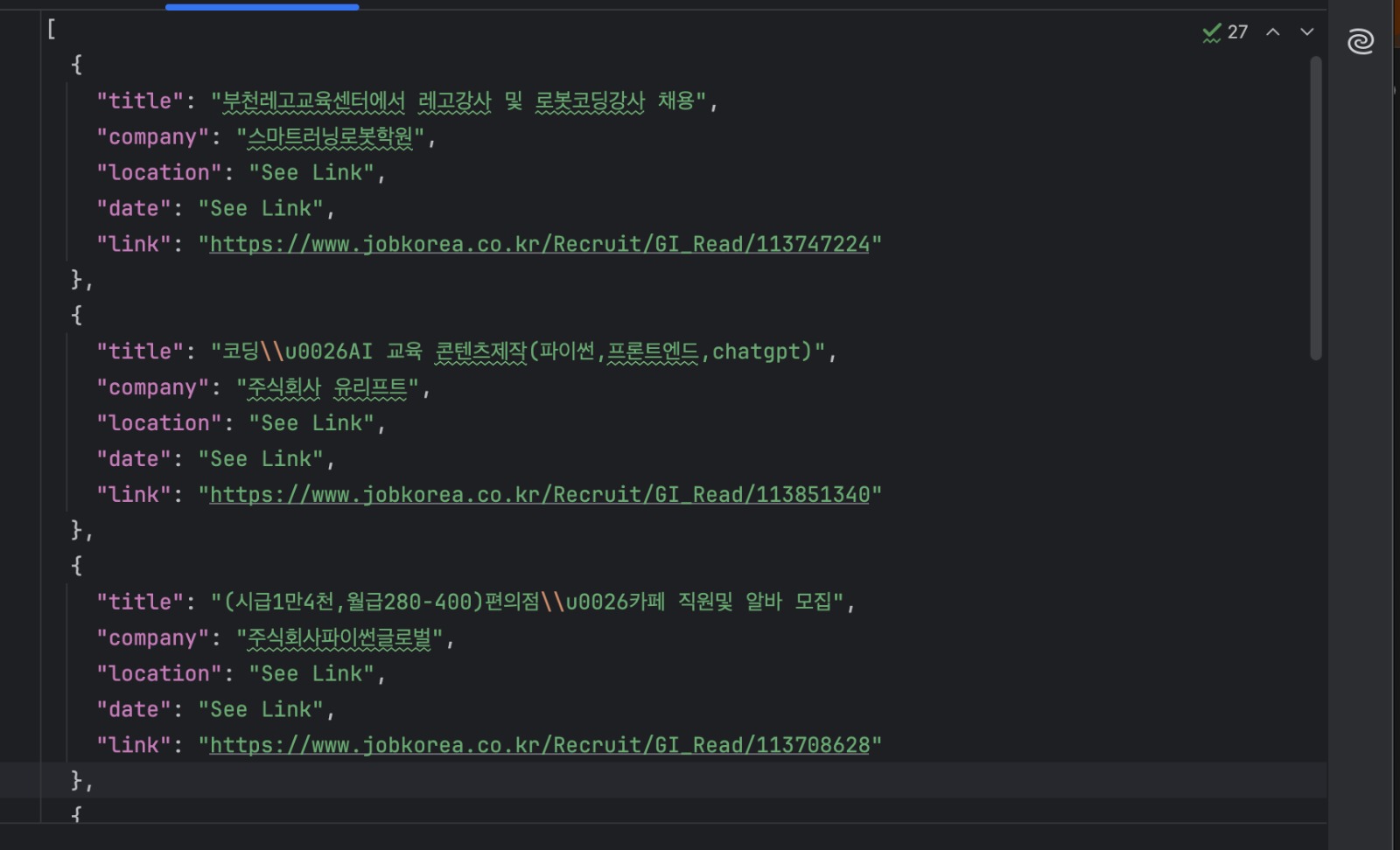
Quand cette approche est-elle idéale ?
Le scraping manuel est utile lorsque vous explorez le fonctionnement d’un site ou que vous créez un prototype rapide. Il est rapide, simple et ne dépend pas de services externes.
Cependant, cette approche est étroitement liée à la structure actuelle des pages de JOBKOREA. Comme elle dépend de mises en page HTML spécifiques et de modèles d’hydratation intégrés, elle peut ne plus fonctionner si le site change.
Pour un scraping plus stable et à long terme, il est préférable de s’appuyer sur des outils qui gèrent le rendu et les modifications du site à votre place, ce que nous allons faire ensuite à l’aide de Bright Data Web MCP.
Technique 2 : scraping web avec Bright Data Web MCP
Dans la section précédente, nous avons scrapé JOBKOREA en téléchargeant manuellement le code HTML et en extrayant les données intégrées. Bien que cette approche fonctionne, elle est étroitement liée à la structure actuelle du site.
Dans cette technique, nous utilisons Bright Data Web MCP pour gérer la récupération et le rendu des pages. Nous nous concentrons ensuite uniquement sur la transformation du contenu renvoyé en données structurées sur les offres d’emploi.
Cette approche est mise en œuvre dans mcp_scraper.py.
Obtenir votre clé/jeton API Bright Data
- Connectez-vous au tableau de bord Bright Data
- Ouvrez les paramètres dans la barre latérale gauche
- Accédez à Utilisateurs et clés API
- Copiez votre clé API
Plus loin dans ce tutoriel, des captures d’écran vous montreront exactement où se trouve cette page et où apparaît le jeton.
Créez un fichier .env à la racine du projet et ajoutez :
BRIGHT_DATA_API_TOKEN=votre_jeton_iciLe script charge le jeton au moment de l’exécution et s’arrête prématurément s’il est manquant.
Exigences pour MCP
Bright Data Web MCP est lancé localement à l’aide de npx, donc assurez-vous d’avoir :
- Node.js installé
- npx disponible dans votre PATH
Le serveur MCP est démarré à partir de Python à l’aide de :
server_params = StdioServerParameters( command="npx", args=["-y", "@brightdata/mcp"], env={"API_TOKEN": BRIGHT_DATA_API_TOKEN, **os.environ} )Exécution du scraper MCP
Exécutez le script avec une URL de recherche JOBKOREA :
python mcp_scraper.py "https://www.jobkorea.co.kr/Search/?stext=python"Le script ouvre une session MCP et initialise la connexion :
async with stdio_client(server_params) as (read, write):
async with ClientSession(read, write) as session:
await session.initialize()Une fois connecté, le scraper est prêt à récupérer le contenu.
Récupération de la page avec MCP
Dans ce projet, le scraper utilise l’outil MCP scrape_as_markdown:
result = await session.call_tool(
"scrape_as_markdown",
arguments={"url": url}
)Le contenu renvoyé est collecté et enregistré localement :
with open("scraped_data.md", "w", encoding="utf-8") as f:
f.write(content_text)Cela vous donne un aperçu lisible de ce que MCP a renvoyé, ce qui est utile pour le débogage et l’analyse.
Analyse des tâches à partir de Markdown
Le markdown renvoyé par MCP est ensuite converti en données de tâches structurées.
La logique d’analyse recherche les liens Markdown :
link_pattern = re.compile(r"[(.*?)]((.*?))")Les offres d’emploi sont identifiées par des URL contenant :
if "Recruit/GI_Read" in url:Une fois qu’un lien vers une offre d’emploi est trouvé, les lignes environnantes sont utilisées pour extraire le nom de l’entreprise, le lieu et la date de publication.
Enfin, les résultats sont enregistrés sur le disque :
with open("jobs_mcp.json", "w", encoding="utf-8") as f:
json.dump(
[job.model_dump() for job in jobs],
f,
ensure_ascii=False,
indent=2
)Fichiers de sortie
Une fois le script terminé, vous devriez obtenir :
scraped_data.md
Le markdown brut renvoyé par Bright Data Web MCP
jobs_mcp.json
Les listes d’emplois analysées au format JSON structuré
Quand cette approche est-elle idéale ?
L’utilisation directe de Bright Data Web MCP depuis Python est idéale lorsque vous recherchez un scraper à la fois fiable et reproductible.
Comme MCP gère le rendu, la mise en réseau et les défenses de base du site, cette approche est beaucoup moins sensible aux changements de mise en page que le scraping manuel. En même temps, le fait de conserver la logique dans Python facilite l’automatisation, la planification et l’intégration dans des pipelines de données plus importants.
Cette technique fonctionne bien lorsque vous avez besoin de résultats cohérents dans le temps ou lorsque vous scrapez plusieurs pages de recherche ou mots-clés. Elle offre également une voie de mise à niveau claire depuis le scraping manuel sans nécessiter de passer complètement à un workflow basé sur l’IA.
Nous allons maintenant passer à la troisième technique, dans laquelle nous utilisons Claude Desktop comme agent IA connecté à Bright Data Web MCP pour scraper JOBKOREA sans écrire de code de scraping.
Technique 3 : code de scraping généré par l’IA à l’aide de Bright Data IDE
Dans cette dernière technique, nous générons un code de scraping à l’aide du scraper assisté par IA de Bright Data dans l’IDE Scraping web.
Vous n’avez pas à écrire manuellement la logique de scraping à partir de zéro. Il vous suffit de décrire ce que vous voulez, et l’IDE vous aide à générer et à affiner le scraper.
Ouverture de l’IDE Scraper
Depuis le tableau de bord Bright Data :
Ouvrez Data dans la barre latérale gauche
- Cliquez sur Mes scrapers

- Sélectionnez « Nouveau » dans le coin supérieur droit
- Sélectionnez Développez votre propre scraper web

Cela ouvre l’environnement de développement intégré (IDE) JavaScript
Entrez votre URL cible « https://www.jobkorea.co.kr/Search/ » et cliquez sur « Générer le code »
L’IDE traitera votre demande et générera un modèle de code prêt à l’emploi. Vous recevrez une notification par e-mail une fois qu’il sera prêt. Vous pourrez alors modifier ou exécuter le code selon vos besoins.
Comparaison des trois techniques de scraping
Chaque technique de ce projet résout le même problème, mais convient à un flux de travail différent. Le tableau ci-dessous met en évidence les différences pratiques.
| Technique | Effort de configuration | Fiabilité | Automatisation | Où elle fonctionne | Meilleur cas d’utilisation |
|---|---|---|---|---|---|
| Grattage manuel Python | Faible | Faible à moyen | Limité | Machine locale | Apprentissage, expériences rapides |
| Bright Data MCP (Python) | Moyen | Élevé | Élevé | Local + Bright Data | Production de scraping, tâches planifiées |
| Récupérateur généré par IA (Bright Data IDE) | Faible | Élevé | Élevé | Plateforme Bright Data | Configuration rapide, scrapers gérés réutilisables |
Conclusion
Dans ce tutoriel, nous avons abordé trois méthodes différentes pour scraper JOBKOREA : le scraping manuel avec Python, un workflow plus stable basé sur Bright Data Web MCP, et l’utilisation de Bright Data AI Scraper Studio pour une approche sans code.
Chaque technique s’appuie sur la précédente. Le scraping manuel aide à comprendre le fonctionnement du site, le scraping basé sur MCP offre fiabilité et automatisation, et l’approche par agent IA offre le chemin le plus rapide vers des données structurées avec une configuration minimale.
Si vous scrapez des sites web modernes rendus par le client comme JOBKOREA et que vous avez besoin d’une alternative plus fiable aux sélecteurs fragiles et à l’automatisation des navigateurs, Bright Data Web MCP fournit une base solide qui fonctionne à la fois avec les scripts traditionnels et les workflows basés sur l’IA.





