

Wikipédia est une source d’informations vaste et complète, contenant des millions d’articles couvrant presque tous les sujets. Pour les chercheurs, les scientifiques des données et les développeurs, ces données ouvrent d’innombrables possibilités, de la création de Jeux de données d’apprentissage automatique à la conduite de recherches universitaires. Dans cet article, nous vous guiderons pas à pas à travers le processus de scraping de Wikipédia.
Utilisation de l’API Bright Data Wikipedia Scraper
Si vous cherchez à extraire efficacement des données de Wikipédia, l’API Bright Data Wikipedia Scraper est une excellente alternative au Scraping web manuel. Cette API puissante automatise le processus, facilitant ainsi la collecte de grands volumes d’informations.
Principaux cas d’utilisation :
- Recueillir des explications sur un large éventail de sujets
- Comparer les informations de Wikipédia avec d’autres sources de données
- Effectuer des recherches à l’aide de grands jeux de données
- Extraire des images de Wikipédia Commons
Vous pouvez obtenir vos données dans des formats tels que JSON, CSV et .gz, et plusieurs options de livraison sont prises en charge, notamment Amazon S3, Google Cloud Storage et Microsoft Azure.
Un simple appel API vous permet d’accéder rapidement et facilement à une multitude de données !
Comment extraire des données de Wikipédia à l’aide de Python
Suivez ce tutoriel étape par étape pour extraire des données de Wikipédia à l’aide de Python.
1. Configuration et prérequis
Avant de commencer, assurez-vous que votre environnement de développement est correctement configuré :
- Installez Python: téléchargez et installez la dernière version de Python depuis le site officiel de Python.
- Choisissez un IDE: utilisez un IDE tel que PyCharm, Visual Studio Code ou Jupyter Notebook pour votre travail de développement.
- Connaissances de base: assurez-vous de bien connaître les sélecteurs CSS et d’être à l’aise avec l’utilisation des outils de développement du navigateur pour inspecter les éléments de la page.
Si vous débutez avec Python, consultez ce guide sur le scraping avec Python pour obtenir des instructions détaillées.
Ensuite, créez un nouveau projet à l’aide de Poetry, un outil de gestion des dépendances qui simplifie la gestion des paquets et des environnements virtuels dans Python.
poetry new wikipedia-Scraper
Cette commande générera la structure de projet suivante :
wikipedia-Scraper/
├── pyproject.toml
├── README.md
├── wikipedia_Scraper/
│ └── __init__.py
└── tests/
└── __init__.py
Accédez au répertoire du projet et installez les dépendances nécessaires :
cd wikipedia-Scraper
poetry add requests beautifulsoup4 pandas lxml
Tout d’abord, BeautifulSoup est utilisé pour l’analyse des documents HTML et XML, ce qui facilite la navigation et l’extraction d’éléments spécifiques à partir de pages web. La bibliothèque requests gère l’envoi de requêtes HTTP et la récupération du contenu des pages web. Pandas est un outil puissant pour manipuler et analyser les données extraites, particulièrement utile lorsque vous travaillez avec des tableaux. Enfin, lxml est utilisé pour accélérer le processus d’analyse, améliorant ainsi les performances de BeautifulSoup.
Ensuite, activez l’environnement virtuel et ouvrez le dossier du projet dans votre éditeur de code préféré (VS Code dans ce cas) :
poetry shell
code .
Ouvrez le fichier pyproject.toml pour vérifier les dépendances de votre projet. Il devrait ressembler à ceci :
[tool.poetry.dependencies]
python = "^3.12"
requests = "^2.32.3"
beautifulsoup4 = "^4.12.3"
pandas = "^2.2.3"
lxml = "^5.3.0"
Enfin, créez un fichier main.py dans le dossier wikipedia_scraper où vous écrirez votre logique de scraping. La structure mise à jour de votre projet devrait maintenant ressembler à ceci :
wikipedia-Scraper/
├── pyproject.toml
├── README.md
├── wikipedia_Scraper/
│ ├── __init__.py
│ └── main.py
└── tests/
└── __init__.py
Votre environnement est maintenant configuré et vous êtes prêt à commencer à écrire le code Python pour scraper Wikipédia.
2. Connexion à la page Wikipédia cible
Pour commencer, connectez-vous à la page Wikipédia souhaitée. Dans cet exemple, nous allons extraire la page Wikipédia suivante.
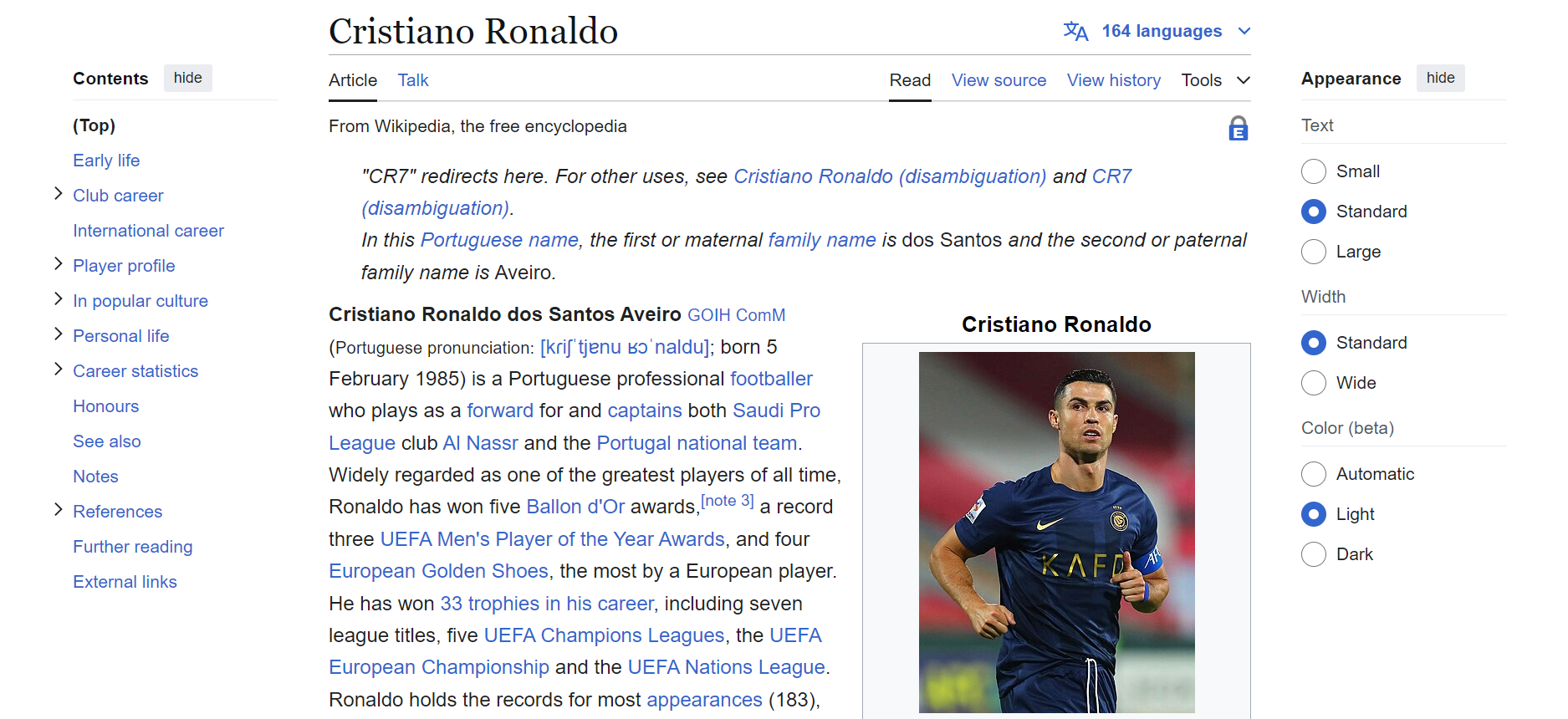
Voici un simple extrait de code pour se connecter à une page Wikipédia à l’aide de Python :
import requests # Pour effectuer des requêtes HTTP
from bs4 import BeautifulSoup # Pour analyser le contenu HTML
def connect_to_wikipedia(url):
response = requests.get(url) # Envoyer une requête GET à l'URL
# Vérifier si la requête a abouti
if response.status_code == 200:
return BeautifulSoup(response.text, "html.parser") # Analyser et renvoyer le HTML
else:
print(f"Échec de récupération de la page. Code d'état : {response.status_code}")
return None # Renvoie None si la requête échoue
wikipedia_url = "<https://en.wikipedia.org/wiki/Cristiano_Ronaldo>"
soup = connect_to_wikipedia(wikipedia_url) # Obtient l'objet soup pour l'URL spécifiée
Dans le code, la bibliothèque Python requests vous permet d’envoyer une requête HTTP à l’URL, et avec BeautifulSoup, vous pouvez analyser le contenu HTML de la page.
3. Inspection de la page
Pour extraire efficacement les données, vous devez comprendre la structure du DOM (Document Object Model) de la page web. Par exemple, pour extraire tous les liens de la page, vous pouvez cibler les balises <a>, comme indiqué ci-dessous :
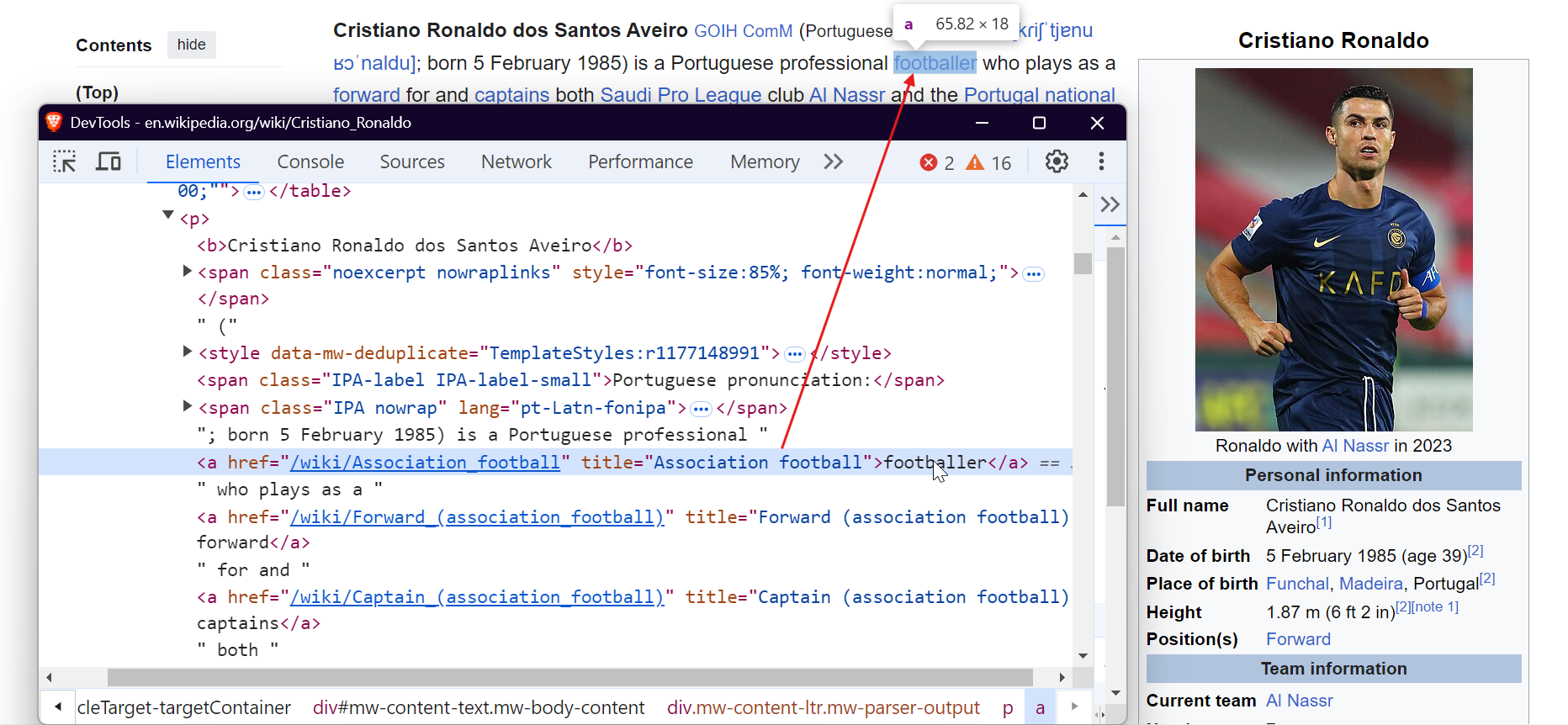
Pour extraire des images, ciblez les balises <img> et extrayez l’attribut src pour obtenir les URL des images.
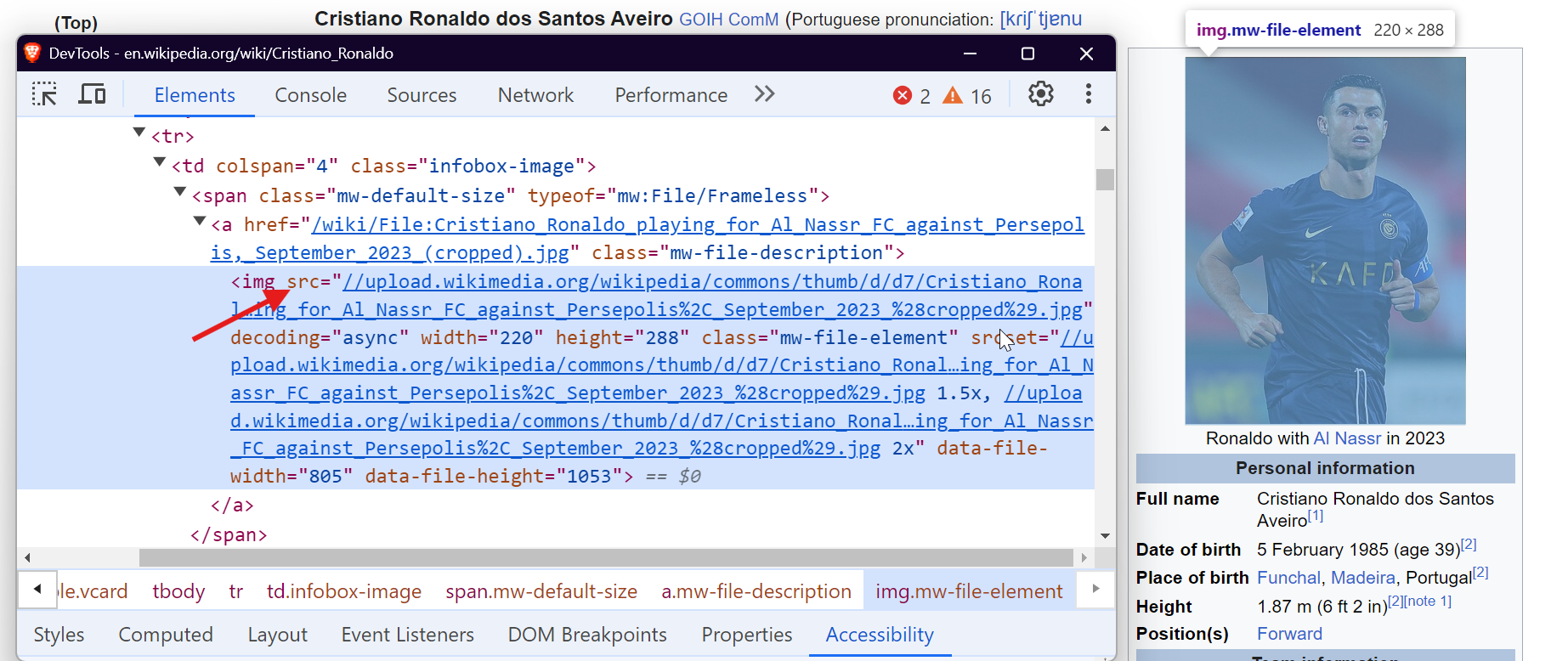
Pour extraire des données à partir de tableaux, vous pouvez cibler la balise <table> avec la classe wikitable. Cela vous permet de rassembler toutes les lignes et colonnes du tableau et d’extraire les données requises.
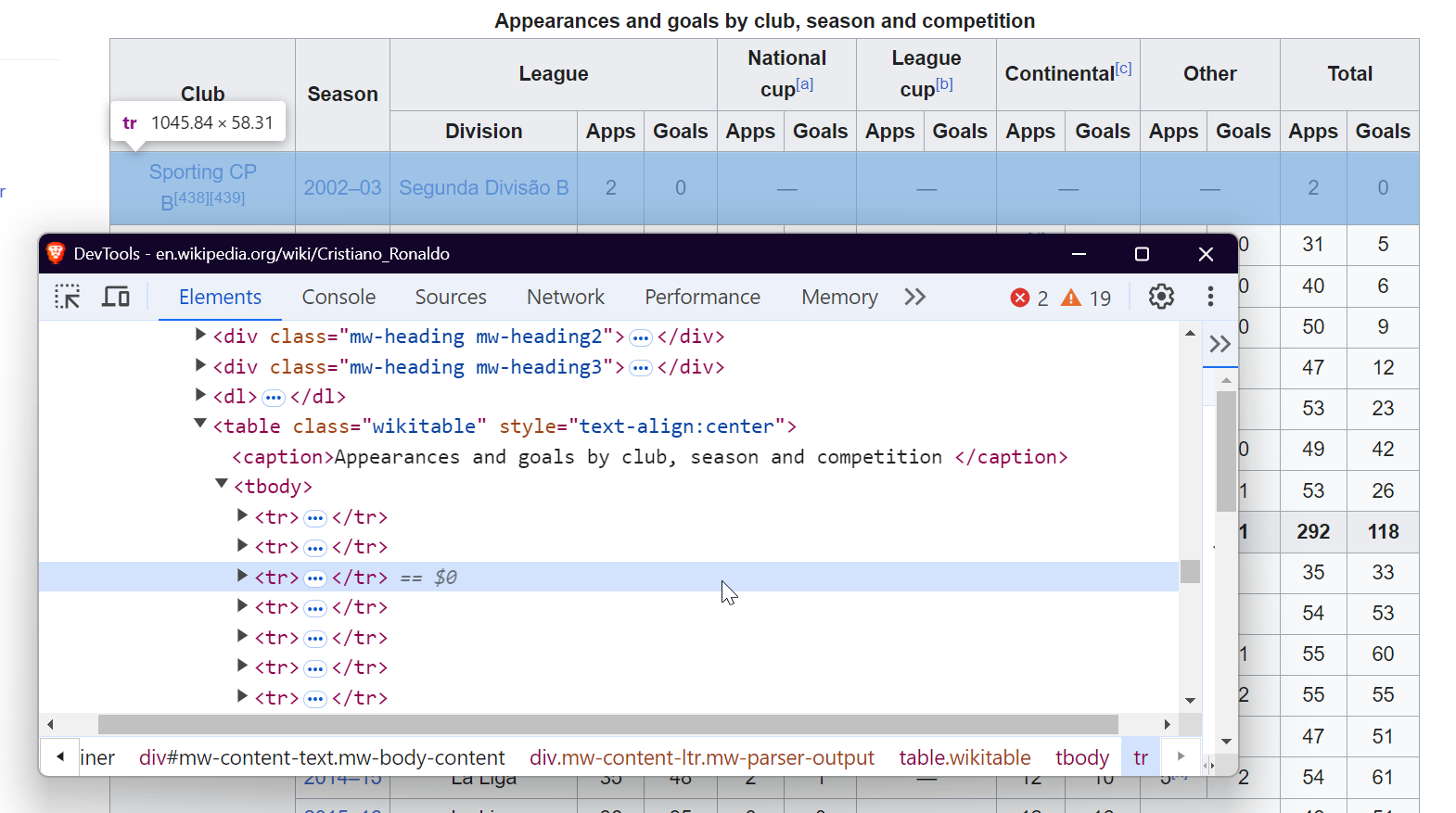
Pour extraire des paragraphes, ciblez simplement les balises <p> qui contiennent le contenu textuel principal de la page.
C’est tout ! En ciblant ces éléments spécifiques, vous pouvez extraire les données souhaitées de n’importe quelle page Wikipédia.
4. Extraction de liens
Les articles Wikipédia contiennent des liens internes et externes qui dirigent les utilisateurs vers des sujets connexes, des références ou des ressources externes. Pour extraire tous les liens d’une page Wikipédia, vous pouvez utiliser le code suivant :
def extract_links(soup):
links = []
for link in soup.find_all("a", href=True): # Trouver toutes les balises d'ancrage avec l'attribut href
url = link["href"]
if not url.startswith("http"): # Vérifier si l'URL est relative
url = "<https://en.wikipedia.org>" + url # Convertir les liens relatifs en URL absolues
links.append(url)
return links # Renvoyer la liste des liens extraits
La fonction soup.find_all('a', href=True) récupère toutes les balises <a> de la page qui contiennent un attribut href, ce qui inclut à la fois les liens internes et externes. Le code garantit également que les URL relatives sont correctement formatées.
Le résultat peut ressembler à ceci :
<https://en.wikipedia.org#Early_life>
<https://en.wikipedia.org#Club_career>
<https://en.wikipedia.org/wiki/Real_Madrid>
<https://en.wikipedia.org/wiki/Portugal_national_football_team>
5. Extraction de paragraphes
Pour extraire le contenu textuel d’un article Wikipédia, vous pouvez cibler les balises <p>, qui contiennent le corps principal du texte. Voici comment extraire des paragraphes à l’aide de BeautifulSoup:
def extract_paragraphs(soup):
paragraphs = [p.get_text(strip=True) for p in soup.find_all("p")] # Extraire le texte des balises de paragraphe
return [p for p in paragraphs if p and len(p) > 10] # Renvoyer les paragraphes de plus de 10 caractères
Cette fonction capture tous les paragraphes de la page, en filtrant ceux qui sont vides ou trop courts afin d’éviter les contenus non pertinents tels que les citations ou les mots isolés.
Exemple de résultat :
Cristiano Ronaldo dos Santos AveiroGOIHComM(prononciation portugaise : [kɾiʃˈtjɐnuʁɔˈnaldu] ; né le 5 février 1985) est un footballeur professionnel portugais qui joue au poste d'attaquant et est capitaine du club Al Nassr de la Ligue professionnelle saoudienne et de l'équipe nationale du Portugal. Largement considéré comme l'un des plus grands joueurs de tous les temps, Ronaldo a remporté cinq Ballons d'Or, [note 3] un record de trois titres de Joueur de l'année de l'UEFA et quatre Soulier d'or européen, le plus grand nombre pour un joueur européen. Il a remporté 33 trophées au cours de sa carrière, dont sept titres de champion, cinq Ligues des champions de l'UEFA, le Championnat d'Europe de l'UEFA et la Ligue des nations de l'UEFA. Ronaldo détient les records du plus grand nombre d'apparitions (183), de buts (140) et de passes décisives (42) en Ligue des champions, du plus grand nombre d'apparitions (30), de passes décisives (8) et de buts en Championnat d'Europe (14), de buts internationaux (133) et d'apparitions internationales (215). Il est l'un des rares joueurs à avoir disputé plus de 1 200 matchs professionnels, le plus grand nombre pour un joueur de champ, et a marqué plus de 900 buts officiels en carrière senior pour son club et son pays, ce qui fait de lui le meilleur buteur de tous les temps.
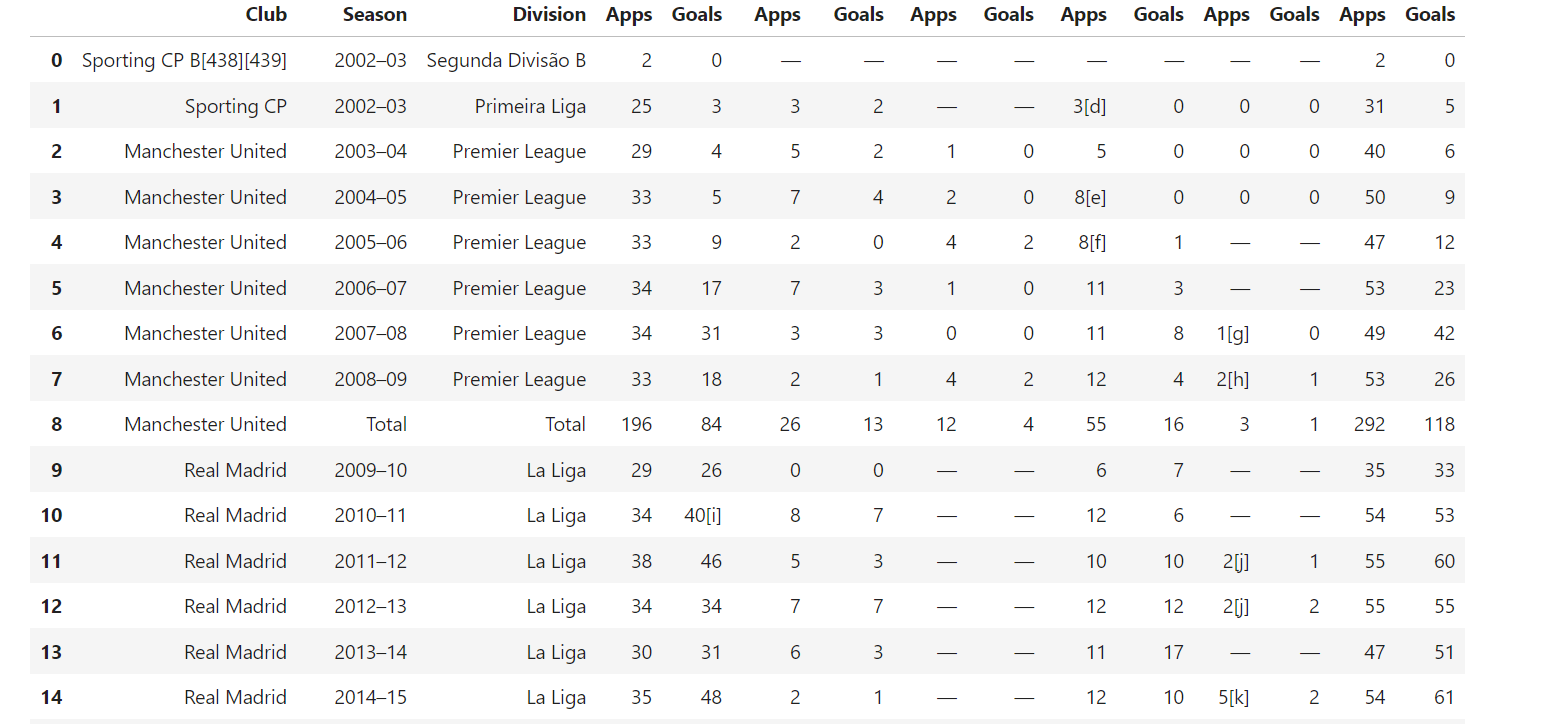
6. Extraction de tableaux
Wikipédia comprend souvent des tableaux contenant des données structurées. Pour extraire ces tableaux, utilisez ce code :
def extract_tables(soup):
tables = []
for table in soup.find_all("table", {"class": "wikitable"}): # Rechercher les tableaux avec la classe « wikitable »
table_html = StringIO(str(table)) # Convertir le HTML du tableau en chaîne
df = pd.read_html(table_html)[0] # Lire le tableau HTML dans un DataFrame
tables.append(df)
return tables # Renvoyer la liste des DataFrames
Cette fonction recherche tous les tableaux de la classe wikitable et utilise pandas.read_html() pour les convertir en DataFrames afin de pouvoir les manipuler ultérieurement.
Exemple de résultat :
7. Extraction d’images
Les images sont une autre ressource précieuse que vous pouvez extraire de Wikipédia. La fonction suivante capture les URL des images de la page :
def extract_images(soup):
images = []
for img in soup.find_all("img", src=True): # Trouve toutes les balises d'image avec l'attribut src
img_url = img["src"]
if not img_url.startswith("http"): # Ajoute « https: » pour les URL relatives
img_url = "https:" + img_url
if "static/images" not in img_url: # Exclut les images statiques ou non pertinentes
images.append(img_url)
return images # Renvoie la liste des URL d'images
Cette fonction recherche toutes les images (balises<img> ) sur la page, ajoute https: aux URL relatives et filtre les images sans rapport avec le contenu, afin de garantir que seules les images pertinentes sont extraites.
Exemple de résultat :
<https://upload.wikimedia.org/wikipedia/commons/d/d7/Cristiano_Ronaldo_2018.jpg>
<https://upload.wikimedia.org/wikipedia/commons/7/76/Cristiano_Ronaldo_Signature.svgb>
8. Enregistrement des données extraites
Une fois les données extraites, l’étape suivante consiste à les enregistrer pour une utilisation ultérieure. Enregistrons les données dans des fichiers séparés pour les liens, les images, les paragraphes et les tableaux.
def store_data(links, images, tables, paragraphs):
# Enregistrer les liens dans un fichier texte
with open("wikipedia_links.txt", "w", encoding="utf-8") as f:
for link in links:
f.write(f"{link}n")
# Enregistrer les images dans un fichier JSON
with open("wikipedia_images.json", "w", encoding="utf-8") as f:
json.dump(images, f, indent=4)
# Enregistrer les paragraphes dans un fichier texte
with open("wikipedia_paragraphs.txt", "w", encoding="utf-8") as f:
for para in paragraphs:
f.write(f"{para}nn")
# Enregistrer chaque tableau dans un fichier CSV distinct
for i, table in enumerate(tables):
table.to_csv(f"wikipedia_table_{i+1}.csv", index=False, encoding="utf-8-sig")
La fonction store_data organise les données récupérées :
- Les liens sont enregistrés dans un fichier texte.
- Les URL des images sont enregistrées dans un fichier JSON.
- Les paragraphes sont stockés dans un autre fichier texte.
- Les tableaux sont enregistrés dans des fichiers CSV.
Cette organisation facilite l’accès et l’utilisation ultérieure des données.
Consultez notre guide pour en savoir plus sur la manière d’analyser et de sérialiser des données au format JSON dans Python.
Tout rassembler
Maintenant, combinons toutes les fonctions pour créer un Scraper complet qui extrait et enregistre les données d’une page Wikipédia :
import requests
from bs4 import BeautifulSoup
import pandas as pd
from io import StringIO
import json
# Extraire tous les liens de la page
def extract_links(soup):
links = []
for link in soup.find_all("a", href=True):
url = link["href"]
if not url.startswith("http"):
url = "<https://en.wikipedia.org>" + url
links.append(url)
return links
# Extraire les URL des images de la page
def extract_images(soup):
images = []
for img in soup.find_all("img", src=True):
img_url = img["src"]
if not img_url.startswith("http"):
img_url = "https:" + img_url
if "static/images" not in img_url: # Exclure les images statiques indésirables
images.append(img_url)
return images
# Extraire tous les tableaux de la page
def extract_tables(soup):
tables = []
for table in soup.find_all("table", {"class": "wikitable"}):
table_html = StringIO(str(table))
df = pd.read_html(table_html)[0] # Convertir le tableau HTML en DataFrame
tables.append(df)
return tables
# Extraire les paragraphes de la page
def extract_paragraphs(soup):
paragraphs = [p.get_text(strip=True) for p in soup.find_all("p")]
return [p for p in paragraphs if p and len(p) > 10] # Filtrer les paragraphes vides ou courts
# Stocker les données extraites dans des fichiers séparés
def store_data(links, images, tables, paragraphs):
# Enregistrer les liens dans un fichier texte
with open("wikipedia_links.txt", "w", encoding="utf-8") as f:
for link in links:
f.write(f"{link}n")
# Enregistrer les images dans un fichier JSON
with open("wikipedia_images.json", "w", encoding="utf-8") as f:
json.dump(images, f, indent=4)
# Enregistrer les paragraphes dans un fichier texte
with open("wikipedia_paragraphs.txt", "w", encoding="utf-8") as f:
for para in paragraphs:
f.write(f"{para}nn")
# Enregistrer chaque tableau dans un fichier CSV
for i, table in enumerate(tables):
table.to_csv(f"wikipedia_table_{i+1}.csv", index=False, encoding="utf-8-sig")
# Fonction principale pour extraire une page Wikipédia et enregistrer les données extraites
def scrape_wikipedia(url):
response = requests.get(url) # Récupérer le contenu de la page
soup = BeautifulSoup(response.text, "html.parser") # Analyser le contenu avec BeautifulSoup
links = extract_links(soup)
images = extract_images(soup)
tables = extract_tables(soup)
paragraphs = extract_paragraphs(soup)
# Enregistrer toutes les données extraites dans des fichiers
store_data(links, images, tables, paragraphs)
# Exemple d'utilisation : extraire la page Wikipédia de Cristiano Ronaldo
if __name__ == "__main__":
scrape_wikipedia("<https://en.wikipedia.org/wiki/Cristiano_Ronaldo>")
Lorsque vous exécutez le script, plusieurs fichiers sont créés dans votre répertoire :
wikipedia_images.jsoncontenant toutes les URL des images.wikipedia_links.txtavec tous les liens de la page.wikipedia_paragraphs.txtcontenant les paragraphes extraits.- Des fichiers CSV pour chaque tableau trouvé sur la page (par exemple,
wikipedia_table_1.csv,wikipedia_table_2.csv).
Le résultat peut ressembler à ceci :

Et voilà ! Vous avez réussi à extraire et à stocker les données de Wikipédia dans des fichiers séparés.
Configuration de l’API Bright Data Wikipedia Scraper
La configuration et l’utilisation de l’API Bright Data Wikipedia Scraper sont simples et ne prennent que quelques minutes. Suivez ces étapes pour vous lancer rapidement et commencer à collecter facilement des données depuis Wikipédia.
Étape 1 : Créer un compte Bright Data
Rendez-vous sur le site web de Bright Data et connectez-vous à votre compte. Si vous n’avez pas encore de compte, créez-en un : l’inscription est gratuite. Suivez ces étapes :
- Rendez-vous sur le site web de Bright Data.
- Cliquez sur « Essai gratuit » et suivez les instructions pour créer votre compte.
- Une fois dans votre tableau de bord, repérez l’icône de carte de crédit dans la barre latérale gauche pour accéder à la page « Facturation ».
- Ajoutez un moyen de paiement valide pour activer votre compte.
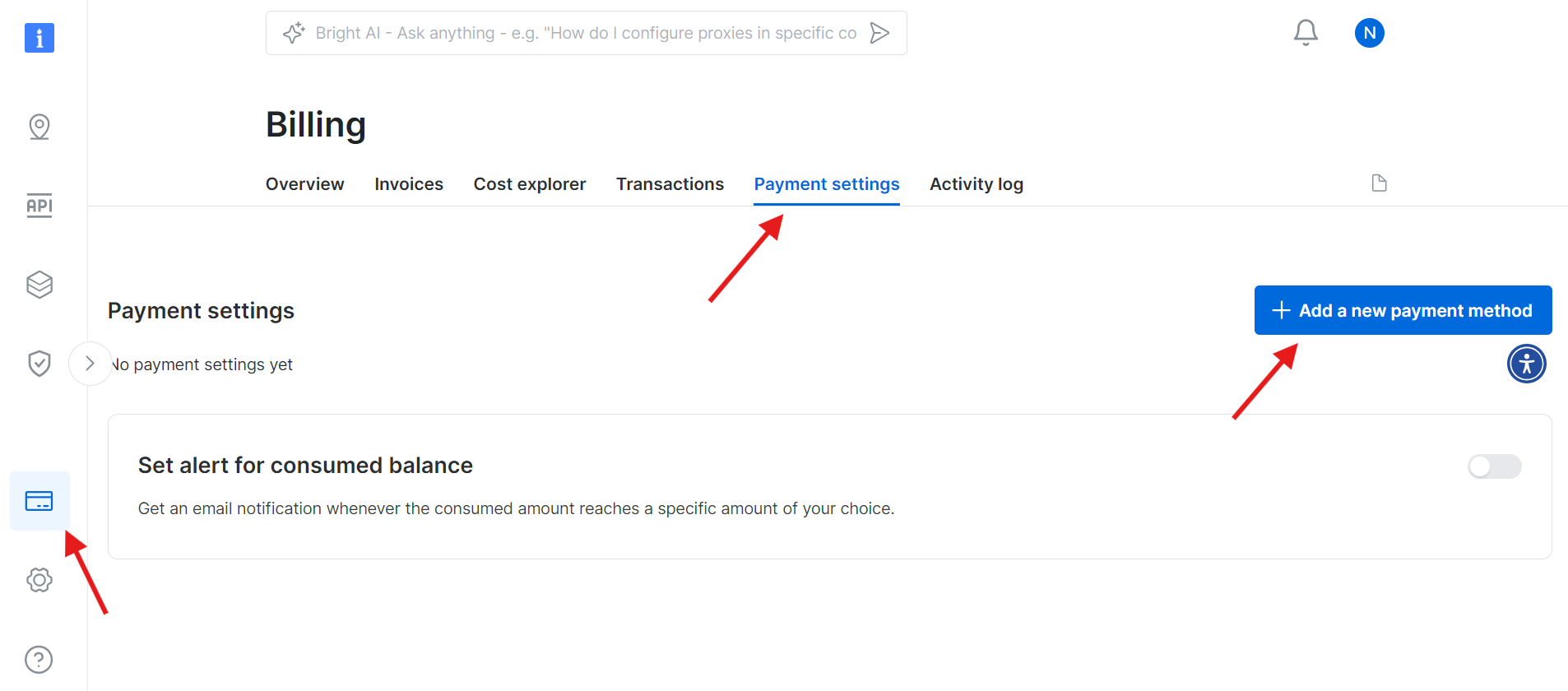
Une fois votre compte activé, accédez à la section « Web Scraper API » (API de scraping Web) dans le tableau de bord. Vous pouvez y rechercher n’importe quelle API de scraping Web que vous souhaitez utiliser. Pour nos besoins, recherchez Wikipédia.
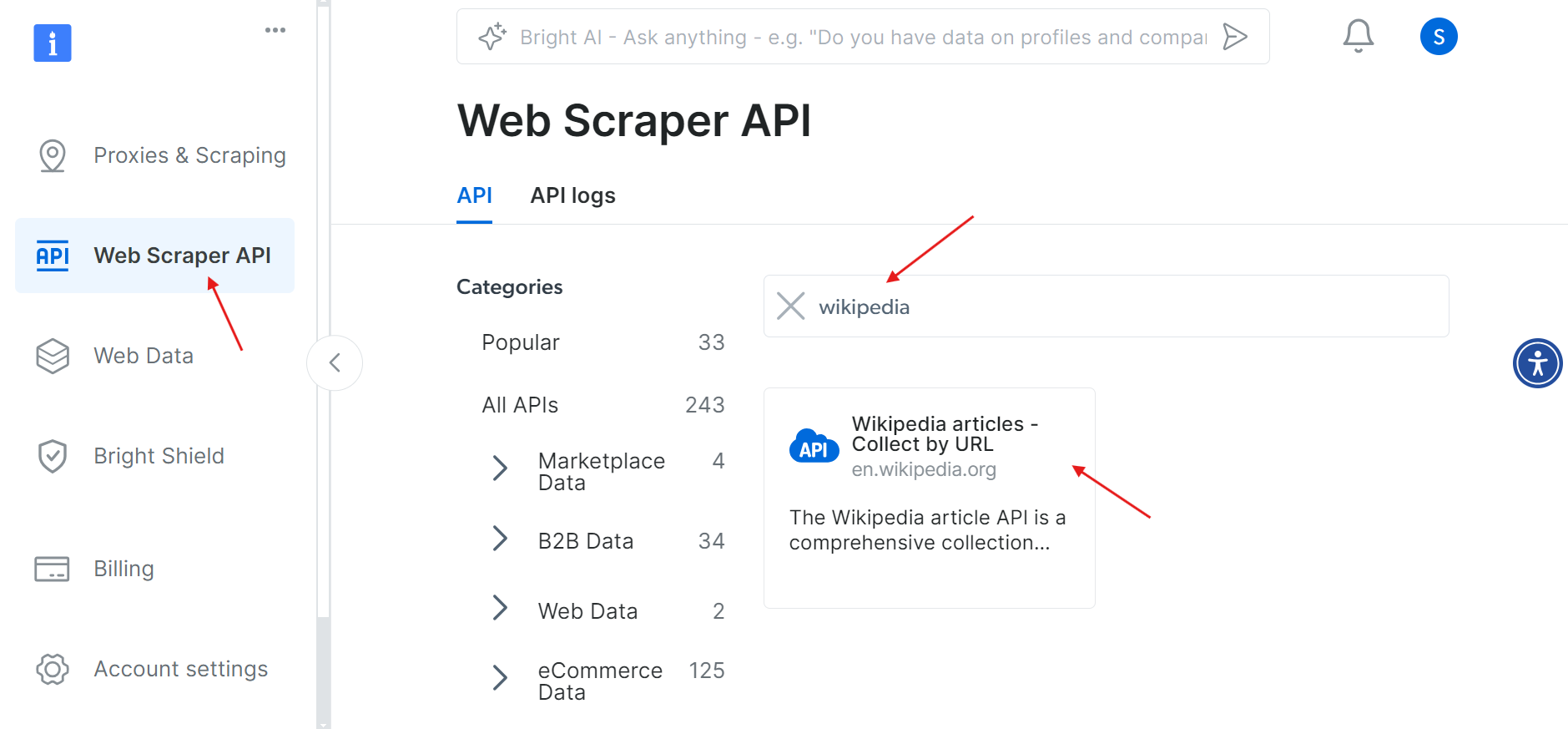
Cliquez sur l’option « Articles Wikipédia – Collecter par URL ». Cela vous permettra de collecter des articles Wikipédia en fournissant simplement les URL.
Étape 2 : Commencez à configurer un appel API
Une fois que vous avez cliqué, vous serez redirigé vers une page où vous pourrez configurer votre appel API.
Avant de continuer, vous devez créer un jeton API pour authentifier vos appels API. Cliquez sur le bouton « Create Token » (Créer un jeton) et copiez le jeton généré. Conservez ce jeton en lieu sûr, car vous en aurez besoin plus tard.
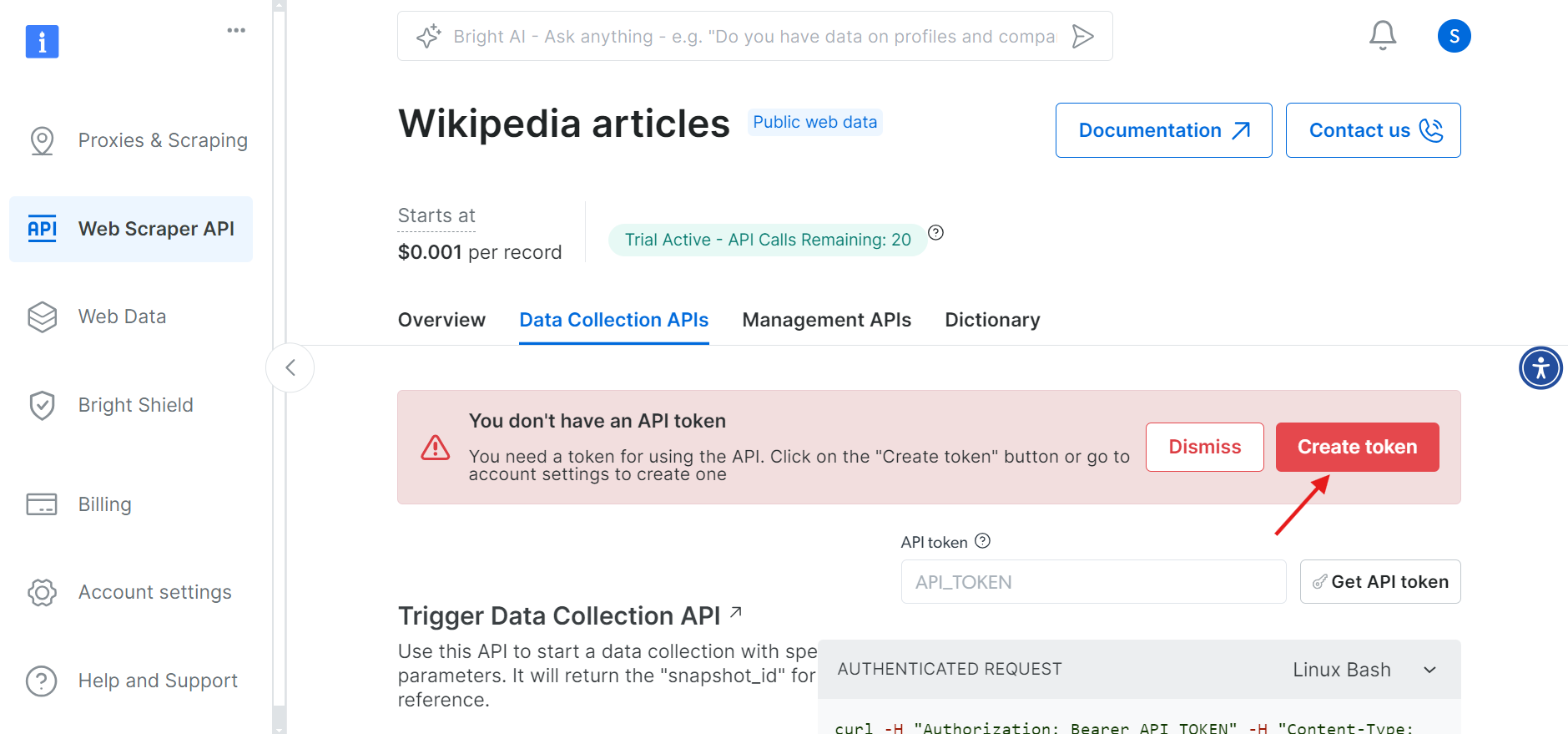
Étape 3 : Définissez les paramètres et générez l’appel API
Maintenant que vous disposez de votre jeton, vous êtes prêt à configurer votre appel API. Indiquez les URL des pages Wikipédia que vous souhaitez extraire, et une commande cURL sera générée à droite en fonction de vos informations.
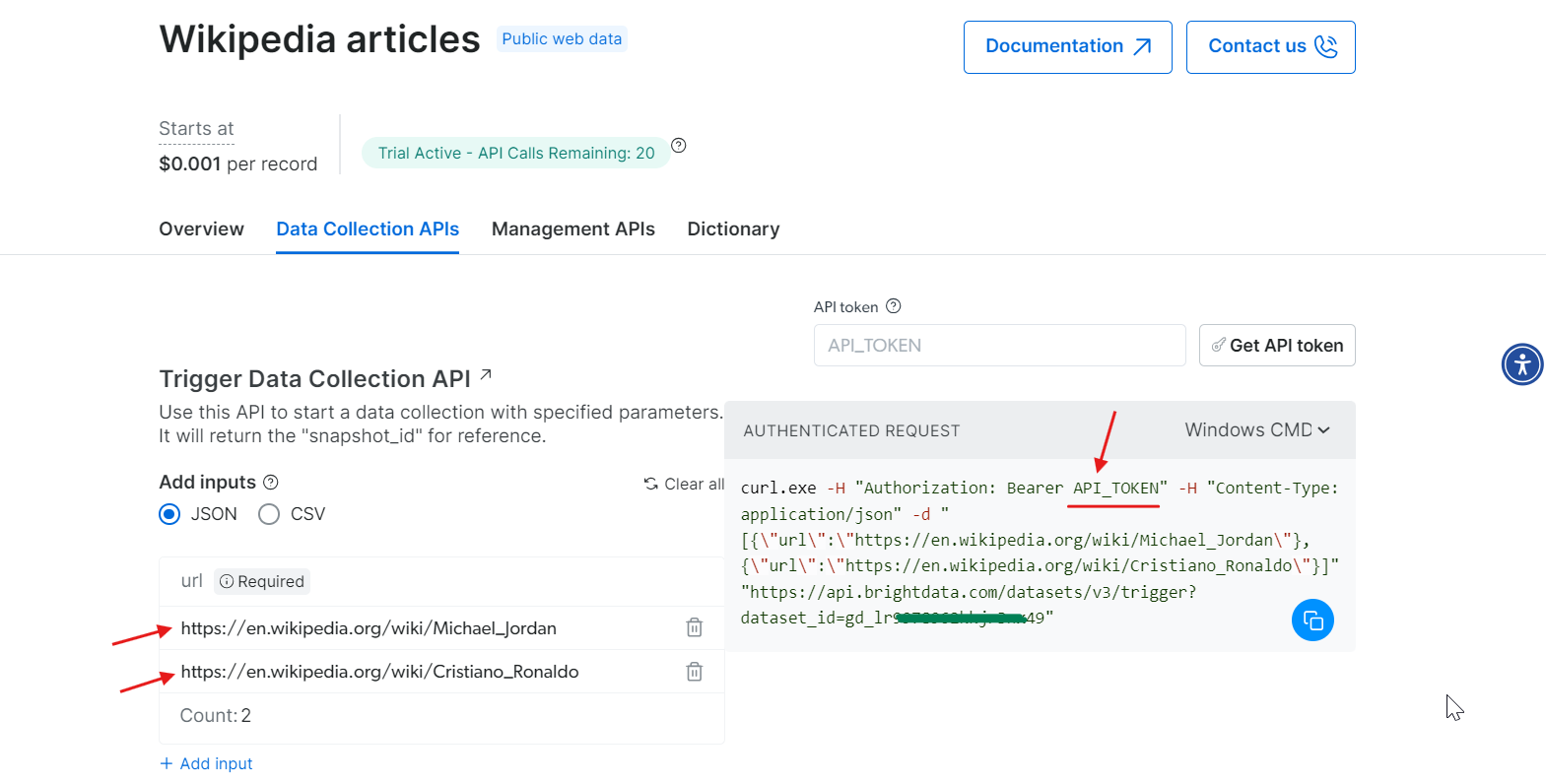
Copiez la commande cURL, remplacez API_Token par votre jeton réel et exécutez-la dans votre terminal. Cela générera un snapshot_id, que vous utiliserez pour récupérer les données extraites.
Étape 4 : récupérer les données
À l’aide du snapshot_id que vous avez généré, vous pouvez désormais récupérer les données. Il vous suffit de coller cet ID dans le champ Snapshot ID, et l’API générera automatiquement une nouvelle commande cURL sur le côté droit. Vous pouvez utiliser cette commande pour extraire les données. De plus, vous pouvez choisir le format de fichier pour les données, tel que JSON, CSV ou d’autres options disponibles.
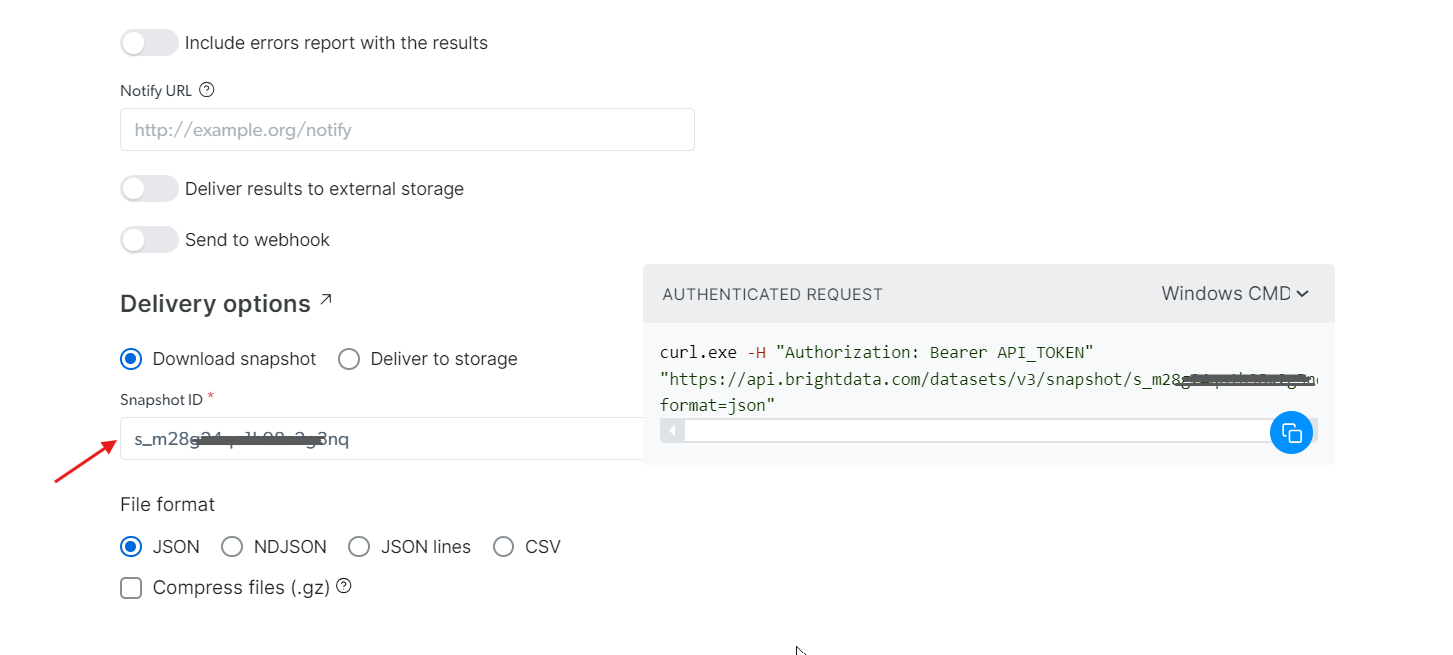
Vous avez également la possibilité de transférer les données vers différents services de stockage tels qu’Amazon S3, Google Cloud Storage ou Microsoft Azure Storage.
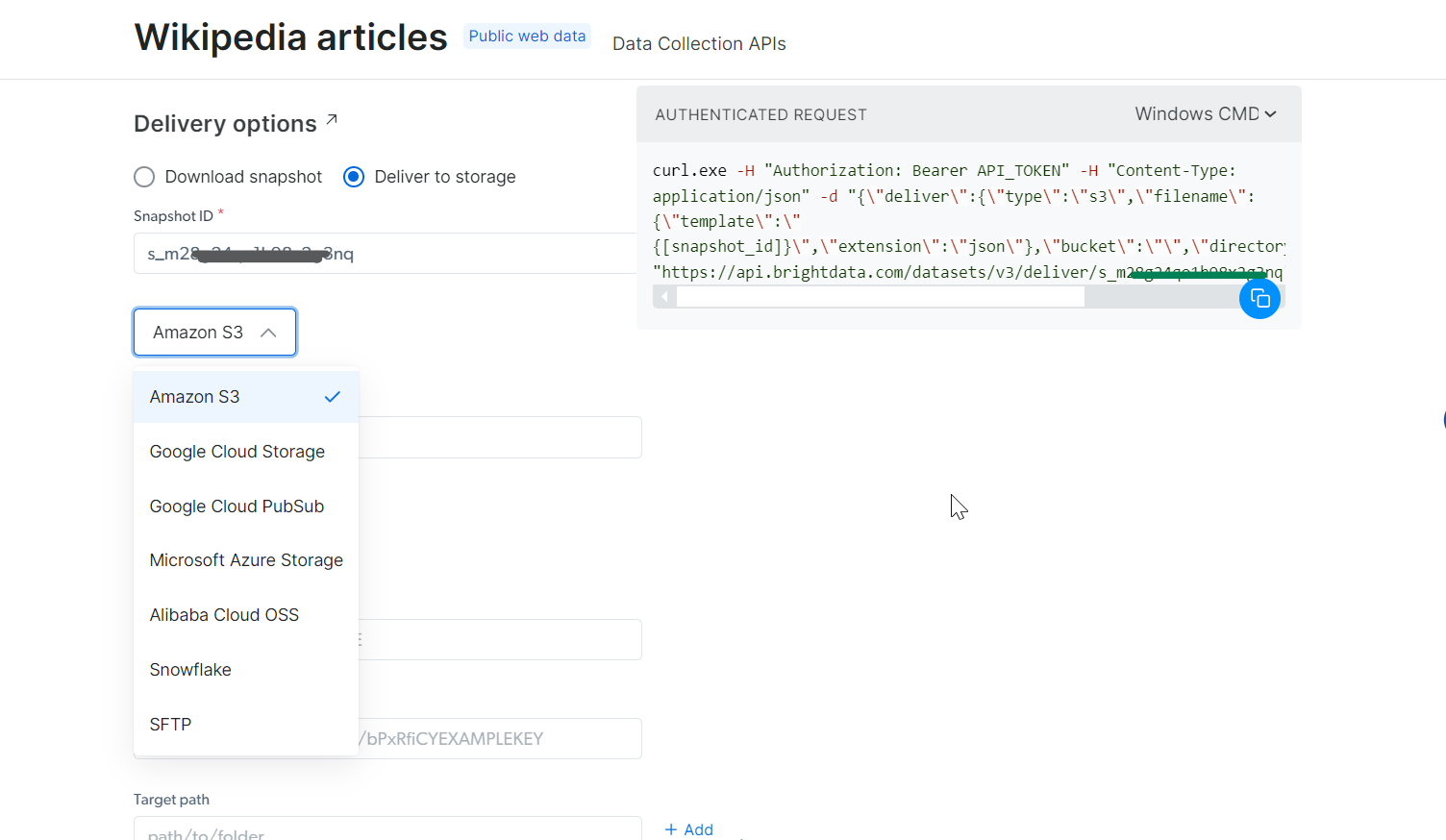
Étape 5 : Exécutez la commande
Pour cet exemple, supposons que vous souhaitiez obtenir les données dans un fichier JSON. Choisissez JSON comme format de fichier et copiez la commande cURL générée. Si vous souhaitez enregistrer les données directement dans un fichier, ajoutez simplement -o my_data.json à la fin de la commande cURL. Si vous préférez stocker ces données sur votre machine locale, l’ajout de -o stockera automatiquement les données dans le fichier spécifié.
Exécutez-la dans votre terminal et vous obtiendrez toutes les données extraites en quelques secondes seulement !
curl.exe -H "Authorization: Bearer 50xxx52c-xxxx-xxxx-xxxx-2748xxxxx487" "<HTTPS://api.brightdata.com/Jeux de données/v3/snapshot/s_mxxg2xxxxx2g3nq?format=json>" -o my_data.json
Vous ne souhaitez pas vous occuper vous-même du Scraping web de Wikipédia, mais vous avez tout de même besoin des données ? Envisagez plutôt d’acheter un ensemble de données Wikipédia.
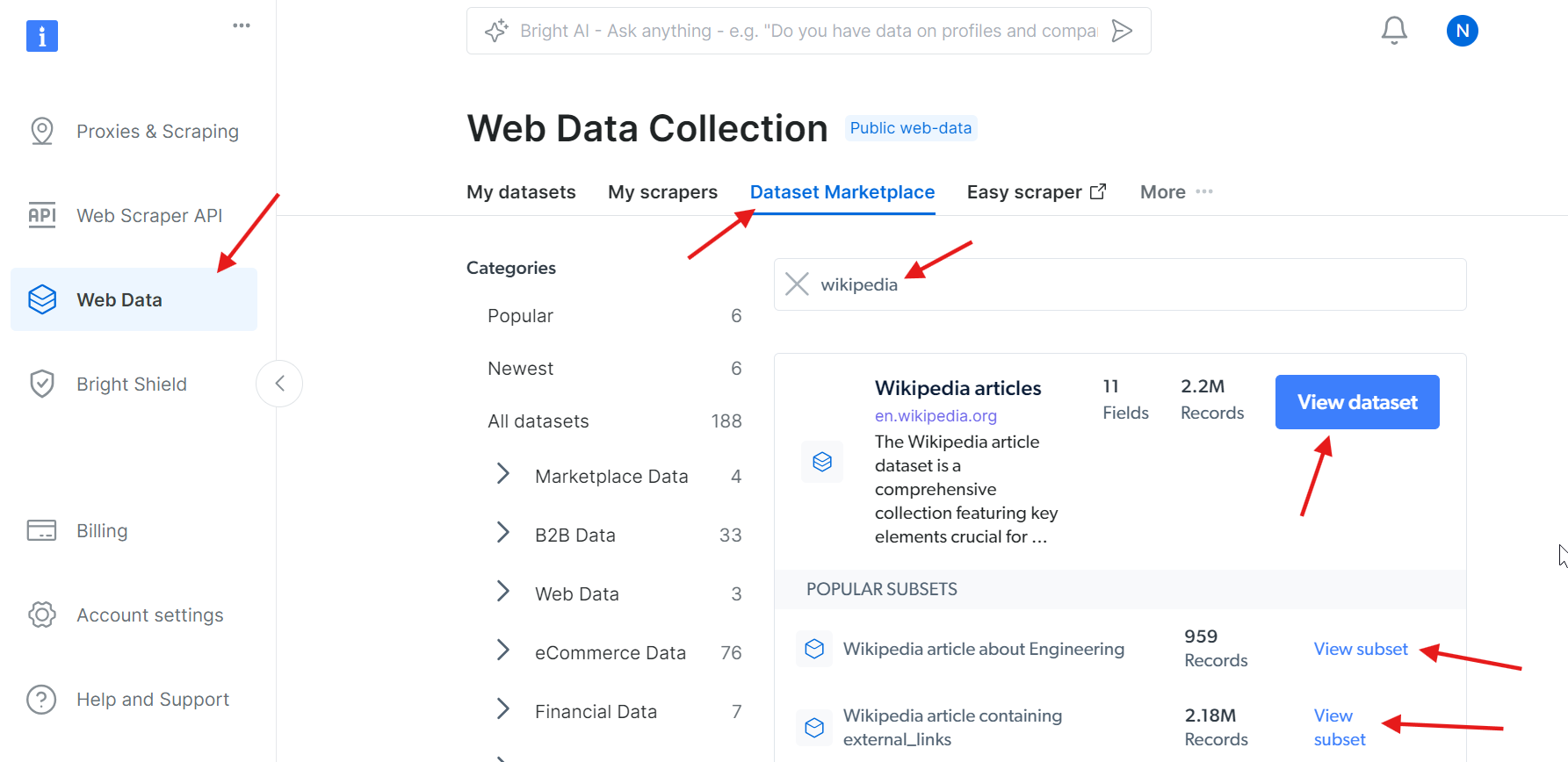
Oui, c’est aussi simple que cela !
Conclusion
Cet article couvre tout ce dont vous avez besoin pour commencer à extraire des données de Wikipédia à l’aide de Python. Nous avons réussi à extraire diverses données, notamment des URL d’images, du contenu textuel, des tableaux et des liens internes et externes. Cependant, pour une extraction de données plus rapide et plus efficace, l’utilisation de l’API Wikipedia Scraper de Bright Data est une solution simple.
Vous souhaitez extraire des données d’autres sites web ? Inscrivez-vous dès maintenant et essayez notre API Web Scraper. Commencez votre essai gratuit dès aujourd’hui !





