

Dans ce guide, vous découvrirez :
- Qu’est-ce qu’un Scraper Crunchbase et comment fonctionne-t-il ?
- Quelles données vous pouvez collecter automatiquement à partir de Crunchbase
- Comment créer un script de scraping Crunchbase avec Python
- Pourquoi vous pourriez avoir besoin d’une solution plus avancée pour scraper le site
C’est parti !
Qu’est-ce qu’un Scraper Crunchbase ?
Un scraper Crunchbase est un outil automatisé conçu pour extraire des données des pages web Crunchbase. Il navigue sur le site, identifie les informations souhaitées et les collecte par Scraping web.
Crunchbase utilise des mesures anti-bot et anti-scraping avancées pour protéger ses données. Par conséquent, un Scraper Crunchbase efficace doit inclure des fonctionnalités telles que le rendu JavaScript, la Résolution de CAPTCHA et l’usurpation d’empreinte digitale du navigateur.
Quelles données extraire de Crunchbase
Vous trouverez ci-dessous une liste des données que vous pouvez récupérer automatiquement à partir de Crunchbase via le Scraping web :
- Informations sur l’entreprise: nom, description, secteur d’activité, emplacement du siège social, date de création, statut (par exemple, active, acquise), etc.
- Données de financement: montant total du financement, cycles de financement, investisseurs, etc.
- Personnes clés: fondateurs, dirigeants, membres, rôles et titres, etc.
- Produits et services: descriptions des produits, catégories de produits ou services proposés, etc.
- Acquisitions et fusions: détails sur les entreprises acquises, dates et conditions des acquisitions, etc.
- Données financières et relatives au marché: estimations du chiffre d’affaires, nombre d’employés, etc.
- Actualités et événements: communiqués de presse, étapes ou événements importants, etc.
- Concurrents: liste des entreprises concurrentes, etc.
Comment créer un Scraper Crunchbase en Python
Dans cette section du tutoriel, vous apprendrez à créer un Scraper Crunchbase à l’aide de Python. L’objectif est de développer un script capable de collecter automatiquement des données à partir de la page Bright Data Crunchbase:
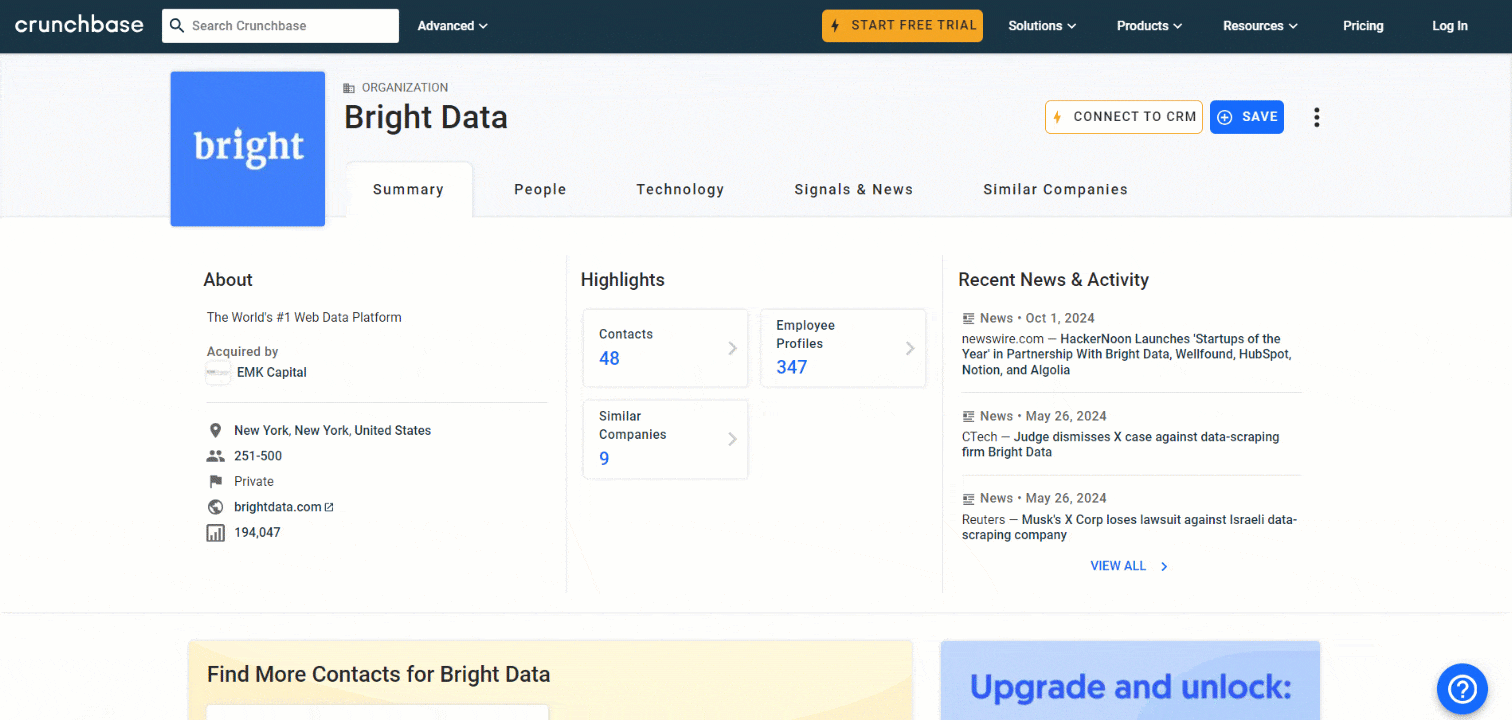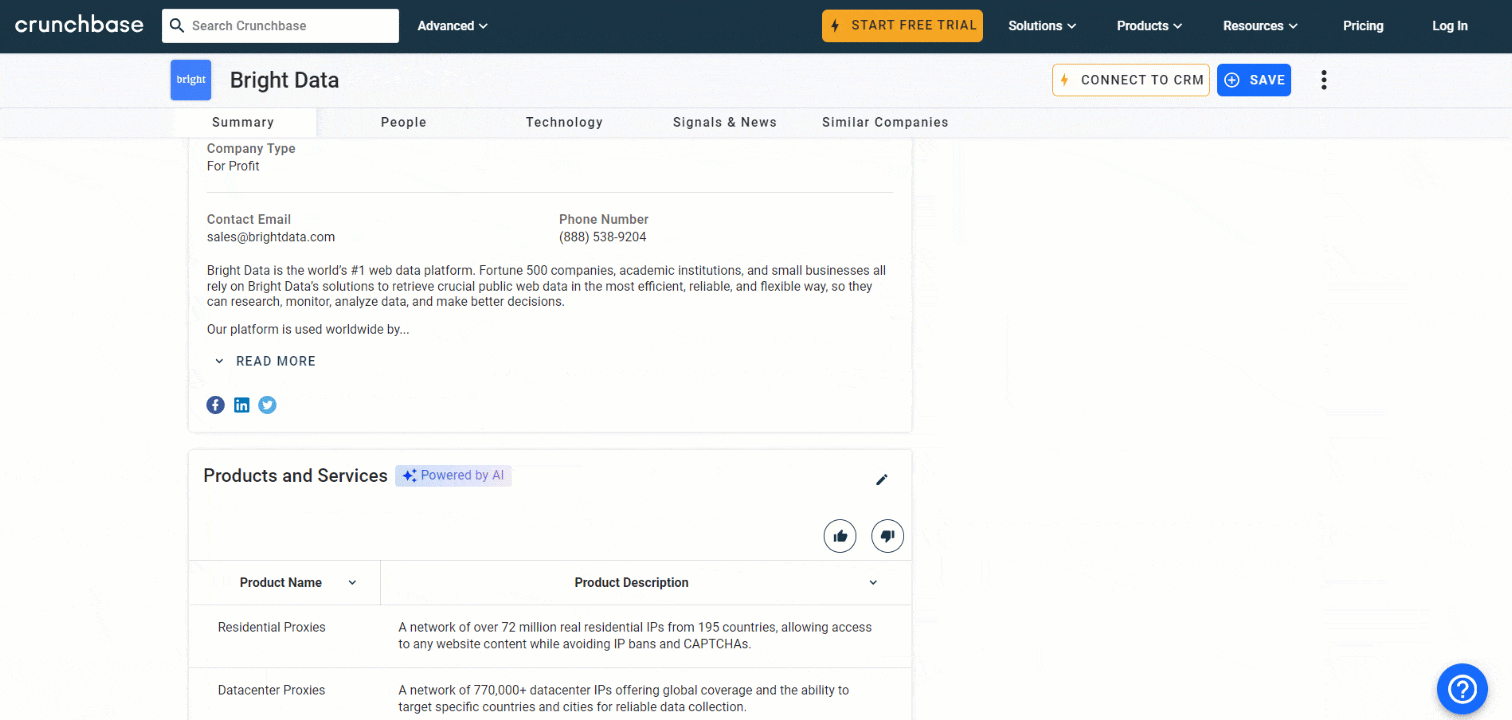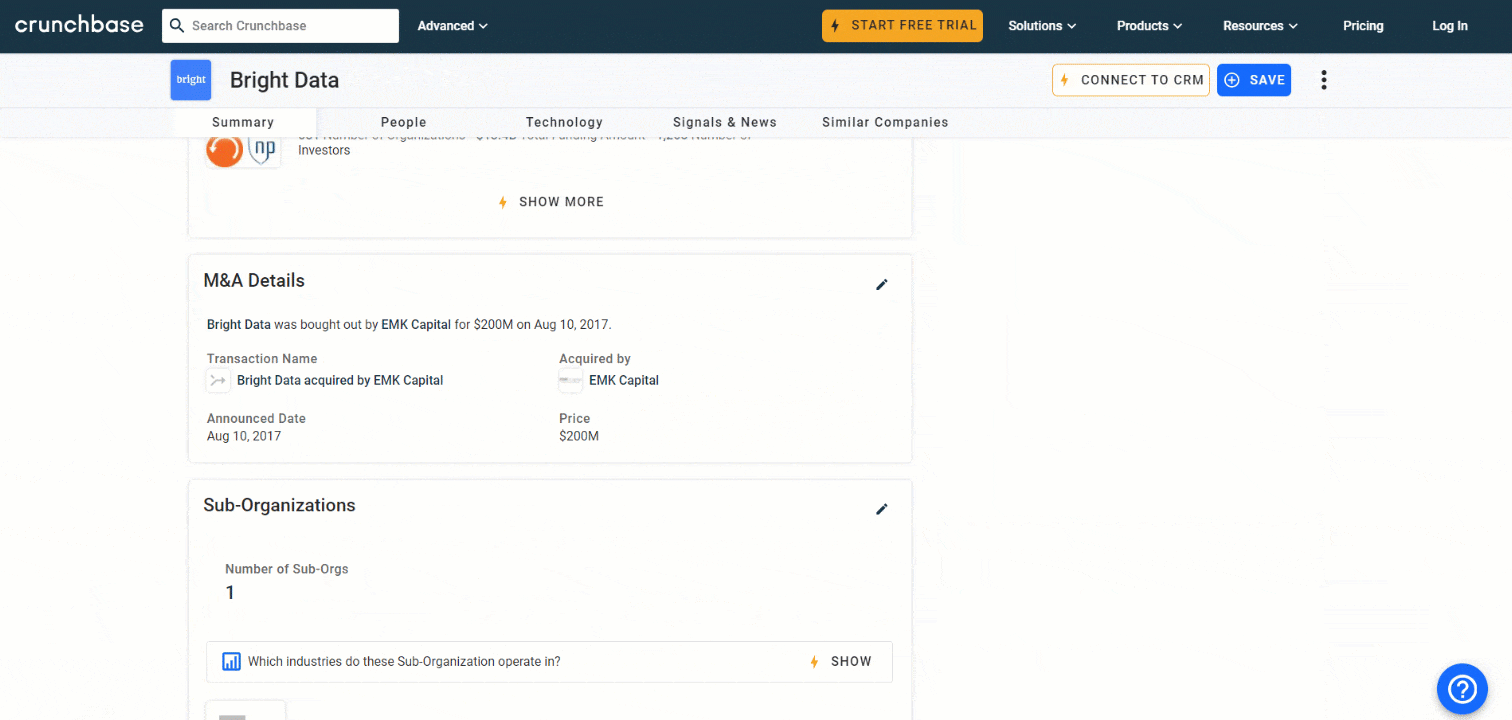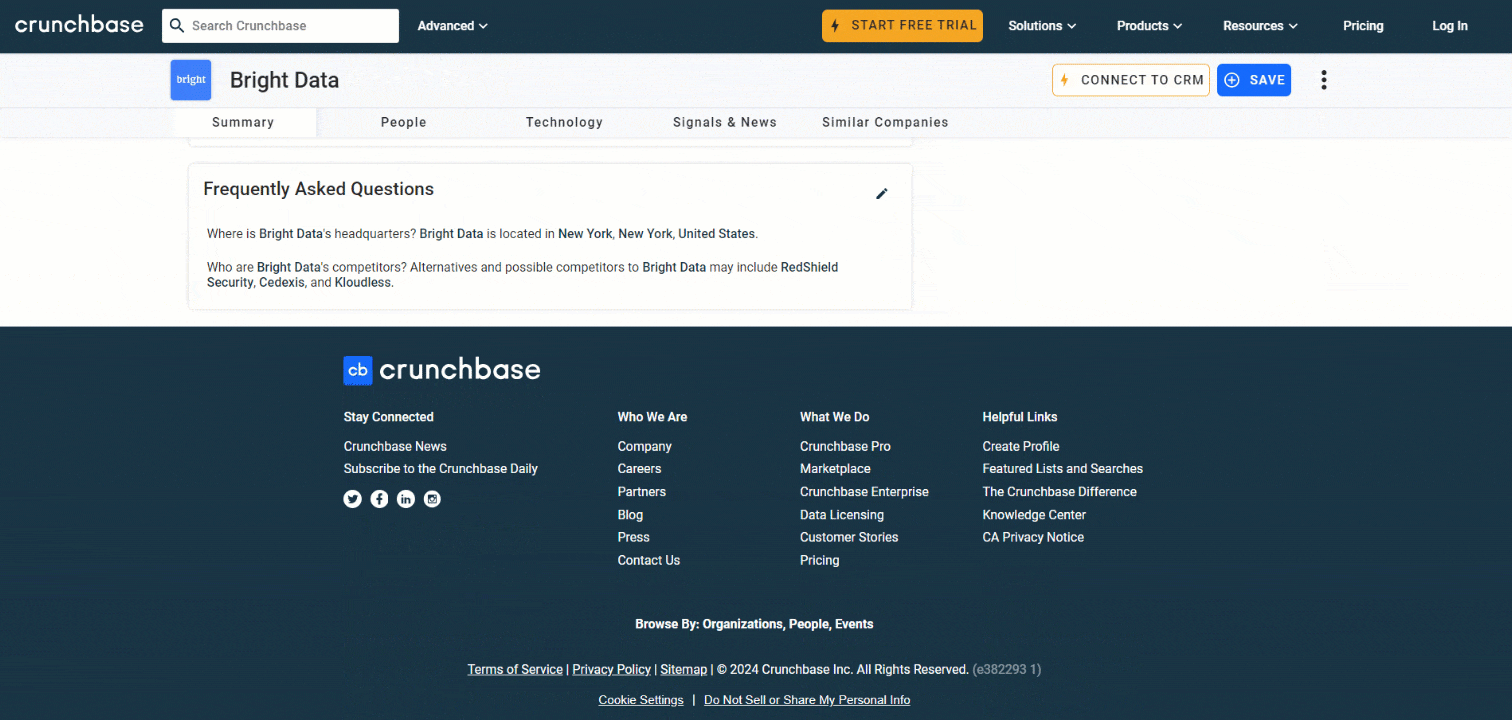
Suivez les étapes ci-dessous pour découvrir comment scraper Crunchbase avec Python !
Étape n° 1 : créer un projet Python
Tout d’abord, assurez-vous que Python 3+ est installé sur votre ordinateur. Si ce n’est pas le cas, téléchargez-le depuis le site officiel et suivez les instructions.
Créez un répertoire pour votre Scraper Python Crunchbase :
mkdir crunchbase-scraperLe dossier crunchbase-scraper contiendra votre bot de scraping.
Ouvrez le dossier du projet dans votre IDE Python préféré, tel que PyCharm Community Edition ou Visual Studio Code avec l’extension Python.
Ensuite, créez un fichier scraper.py dans le dossier du projet. Ce fichier contiendra la logique de scraping Crunchbase.
Maintenant, initialisez un environnement virtuel Python. Si vous êtes un utilisateur macOS ou Linux, exécutez :
python3 -m venv envDe manière équivalente, sous Windows, exécutez :
python -m venv envCela ajoutera un répertoire env à votre projet.
À présent, votre projet devrait avoir la structure suivante :

Activez l’environnement virtuel à l’aide de cette commande :
source env/bin/activateOu, sous Windows :
envScriptsactivateParfait ! Vous disposez désormais d’un projet Python dans lequel vous pouvez installer des dépendances locales.
N’oubliez pas que vous pouvez lancer votre script avec :
python3 Scraper.pyOu, sous Windows :
python Scraper.pyÉtape n° 2 : déterminer et installer les bibliothèques de scraping
Vous devez maintenant déterminer quelles bibliothèques de scraping sont les mieux adaptées pour extraire des données de Crunchbase. Commencez par envoyer une requête HTTP GET à la page web cible à l’aide d’un client HTTP de bureau. Voici le résultat que vous obtiendrez :
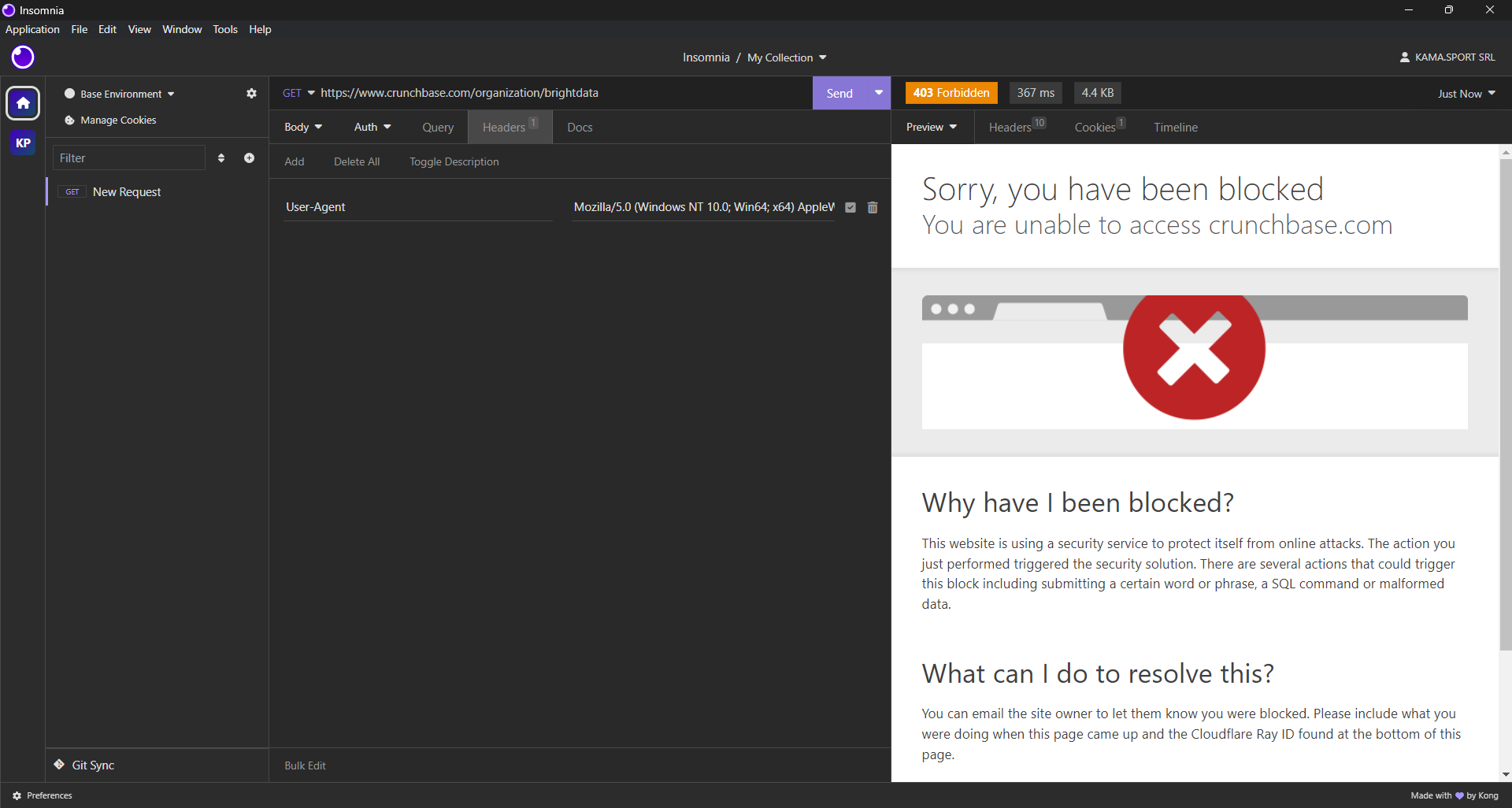
Comme vous pouvez le constater, Crunchbase bloque votre requête, même si vous utilisez des en-têtes de navigateur réalistes. En d’autres termes, vous aurez besoin d’un outil d’automatisation de navigateur pour scraper efficacement Crunchbase. Pour en savoir plus, consultez notre article sur les meilleurs navigateurs headless.
Pour Python, Selenium est l’un des outils d’automatisation de navigateur sans interface utilisateur les plus populaires. Plus précisément, il vous permet de demander à un navigateur d’effectuer des interactions spécifiques et de scraper des données à partir de pages dynamiques.
Pour installer Selenium, utilisez le paquet pip selenium. Dans un environnement virtuel Python activé, exécutez la commande suivante :
pip install -U seleniumEnsuite, importez Selenium dans votre fichier scraper.py avec la ligne suivante :
from selenium import webdriverParfait ! Vous disposez désormais de tout ce dont vous avez besoin pour effectuer du Scraping web sur Crunchbase.
Étape n° 3 : visitez la page cible
Initialisez une instance Chrome WebDriver et utilisez la méthode get() pour demander au navigateur contrôlé de visiter la page souhaitée :
driver = webdriver.Chrome()
url = "https://www.crunchbase.com/organization/brightdata"
driver.get(url)N’oubliez pas ensuite de fermer le WebDriver et de libérer les ressources du navigateur à l’aide de :
driver.quit()À présent, votre script de scraping Crunchbase contient :
from selenium import webdriver
# initialise le pilote pour contrôler une instance Chrome
# en mode headed
driver = webdriver.Chrome()
# navigue vers la page Crunchbase souhaitée
url = "https://www.crunchbase.com/organization/brightdata"
driver.get(url)
# logique de scraping...
# fermer le pilote et libérer les ressources du navigateur
driver.quit()Si vous l’exécutez, vous verrez la page suivante s’afficher pendant une fraction de seconde avant que le script ne se termine :
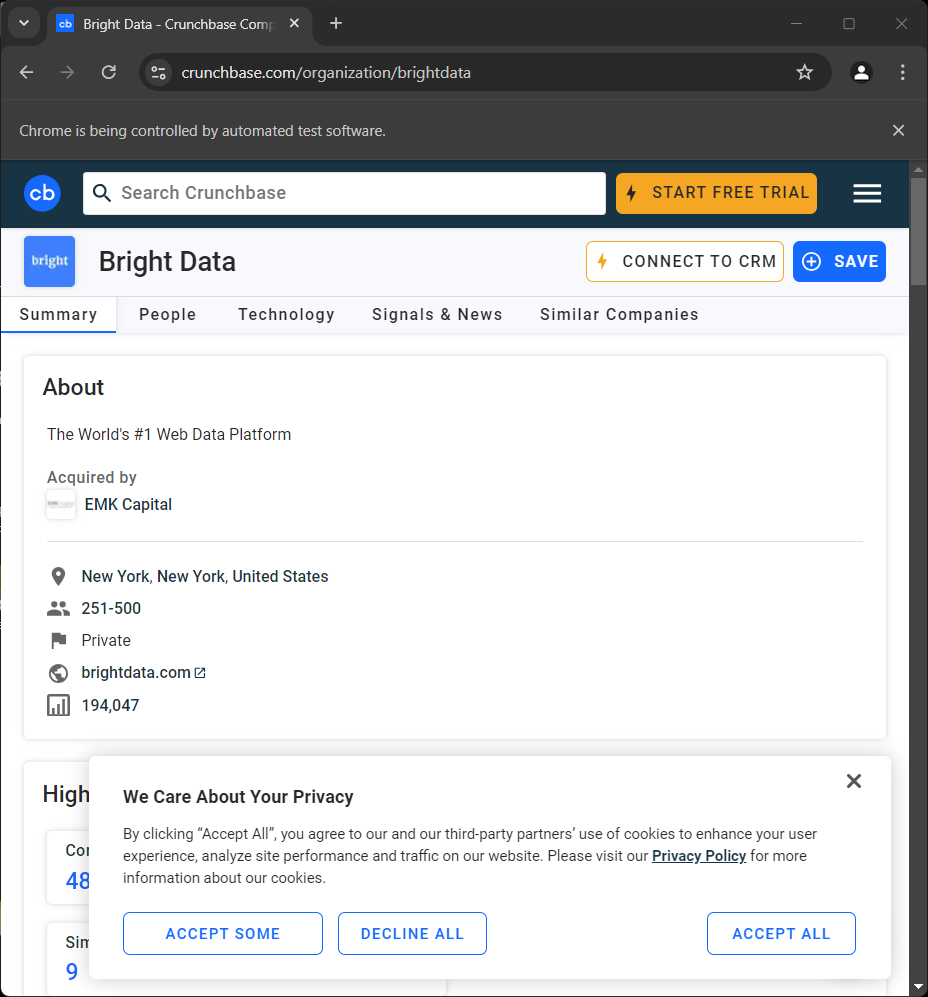
Le message « Chrome est contrôlé par un logiciel de test » indique que Selenium fonctionne comme prévu sur Chrome.
En général, les navigateurs dans les scripts de scraping Selenium sont lancés en mode headless afin d’économiser des ressources. Malheureusement, Crunchbase dispose d’un système avancé de détection anti-bot qui bloque les navigateurs headless. Vous devez donc garder le navigateur en mode headed. Vous pouvez également essayer d’utiliser Playwright Stealth pour contourner ces mécanismes de détection.
Étape n° 4 : gérer la fenêtre contextuelle des cookies
Si vous êtes un utilisateur européen, la page affichera la fenêtre contextuelle suivante concernant les cookies après quelques secondes :
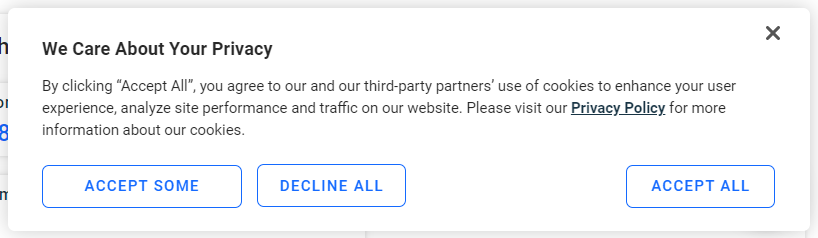
Si vous ne cliquez pas sur le bouton « Accepter tout », il ne sera pas possible d’interagir avec la page. Inspectez le bouton :
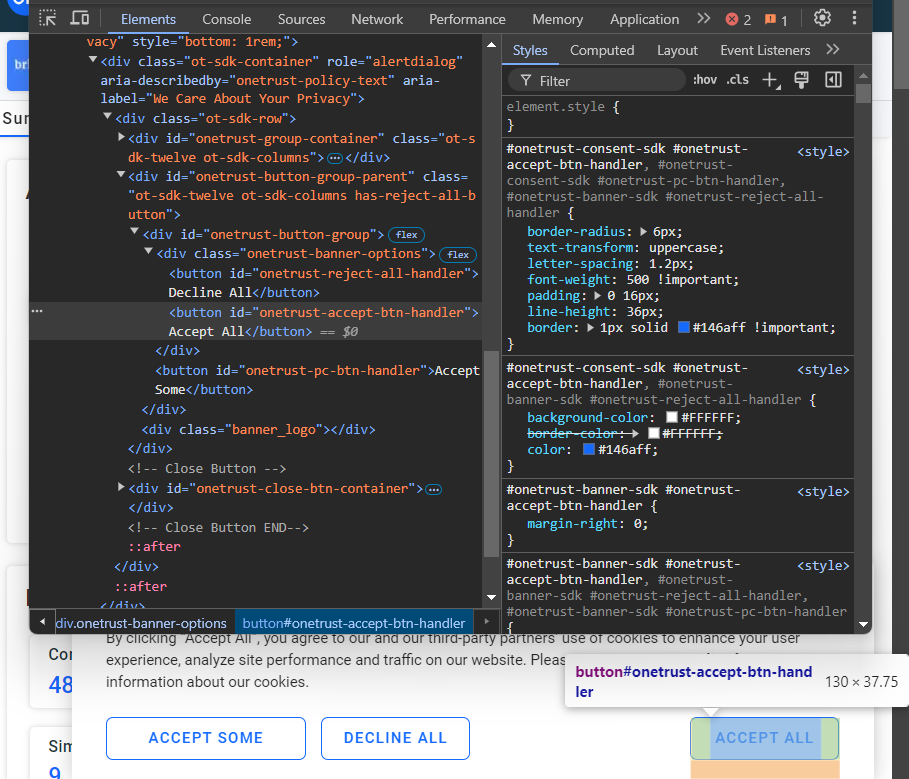
Vous pouvez le sélectionner à l’aide du sélecteur CSS #onetrust-accept-btn-handler.
Maintenant, écrivez une fonction qui attend jusqu’à 60 secondes que le bouton « Tout accepter » apparaisse sur la page et soit cliquable, puis cliquez dessus :
def handle_cookie_banner(driver, seconds=60):
try:
# attendre le nombre de secondes donné pour que le bouton « Tout accepter »
# de la bannière de cookies apparaisse sur la page
accept_button = WebDriverWait(driver, seconds).until(
EC.element_to_be_clickable((By.CSS_SELECTOR, "#onetrust-accept-btn-handler"))
)
# cliquer sur la bannière via JavaScript pour éviter
# les erreurs ElementClickInterceptedException
driver.execute_script("arguments[0].click();", accept_button)
print("Bouton « Accepter tout » cliqué")
except:
print("Bouton « Accepter tout » introuvable dans les {seconds} secondes")Remarque :
- Le bloc
try ... exceptest nécessaire car la fenêtre contextuelle des cookies peut ne pas être présente sur la page. Dans ce cas,WebDriverWait déclencherauneexception NoSuchElementException, qui sera interceptée parexcept. - « Accepter tout » est cliqué via JavaScript et non via la méthode
click(). La raison en est que le bouton HTML apparaît lentement avec une animation en fondu. Ainsi, si vous essayez de cliquer dessus avecclick(), vous risquez d’obtenir uneElementClickInterceptedException.
Pour fonctionner, la fonction ci-dessus nécessite les importations suivantes :
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
from selenium.webdriver.common.by import ByVous pouvez désormais gérer la fenêtre contextuelle des cookies en appelant :
handle_cookie_banner(driver)Fantastique ! Préparez-vous à commencer à extraire les données de la page.
Étape n° 5 : extraire les informations « À propos
La première information à extraire dans la carte « Résumé » est la description « À propos » de l’entreprise :
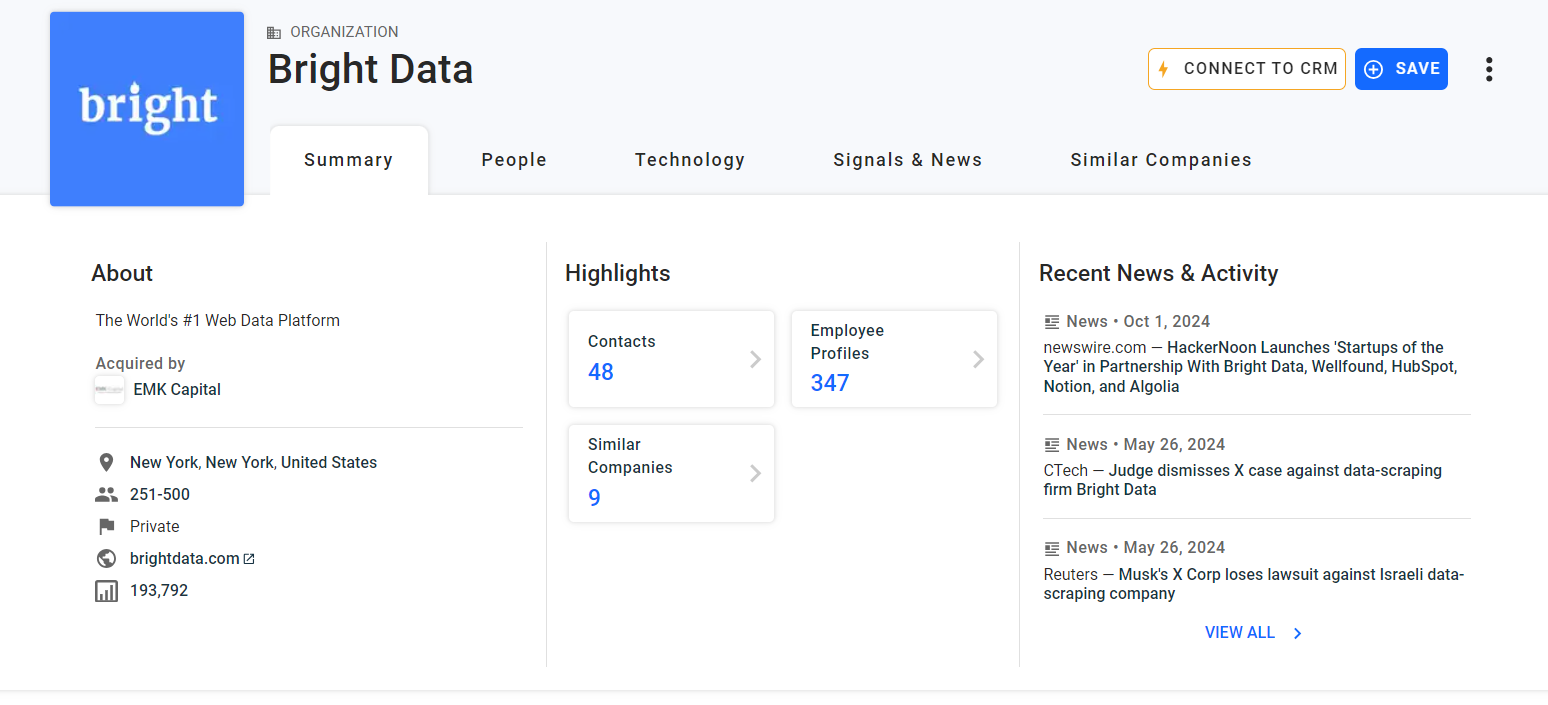
Inspectez l’élément HTML « À propos » :
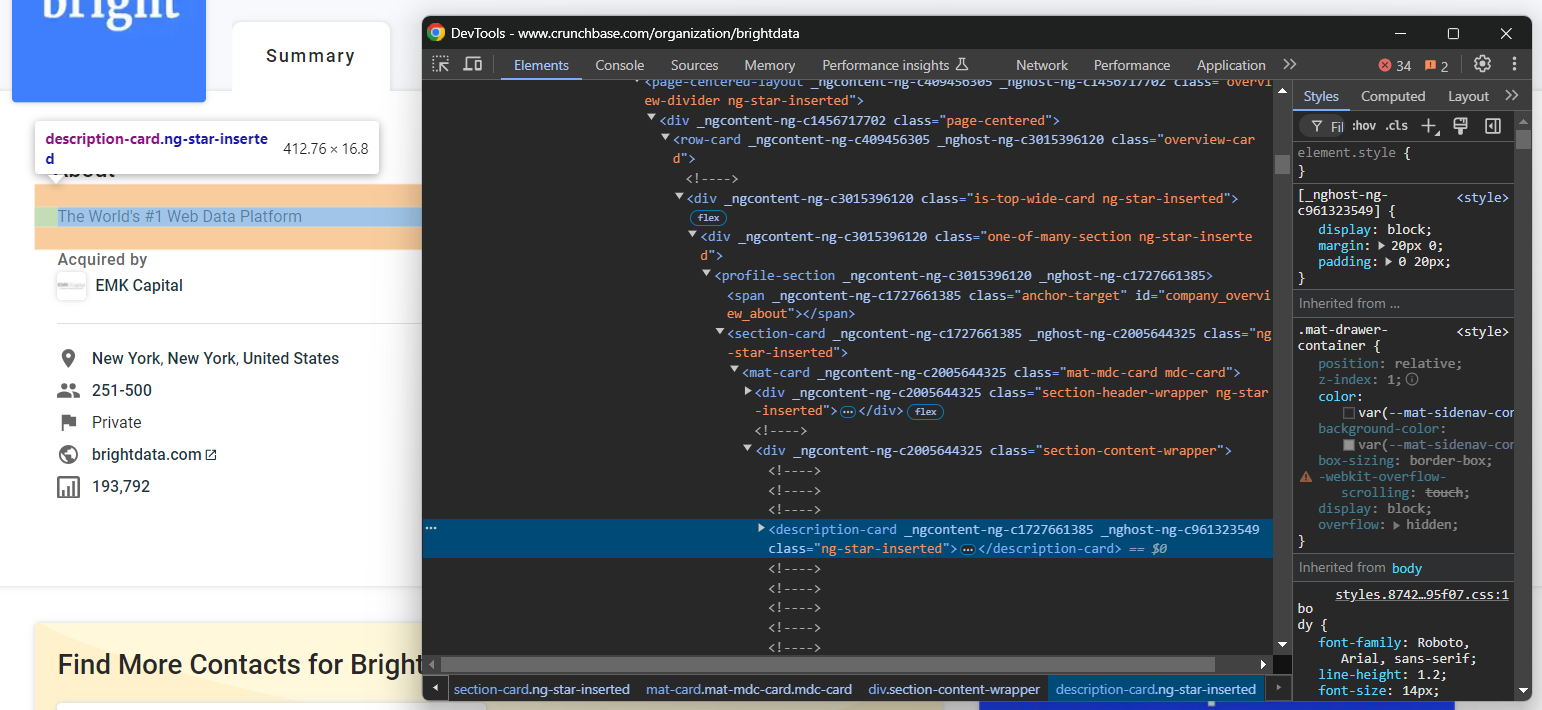
Notez que vous pouvez le sélectionner à l’aide du sélecteur CSS ci-dessous :
profile-section description-cardUtilisez la méthode find_element() pour appliquer le sélecteur CSS à la page. Ensuite, extrayez le texte à l’intérieur du nœud avec l’attribut text:
about_node = driver.find_element(By.CSS_SELECTOR, "profile-section description-card")
about = about_node.textLa variable about contiendra désormais :
« La plateforme de données Web n° 1 au monde »Et voilà !
Étape n° 6 : inspecter la structure de la page
Concentrez-vous maintenant sur les informations contenues dans la carte « Détails » de la page :
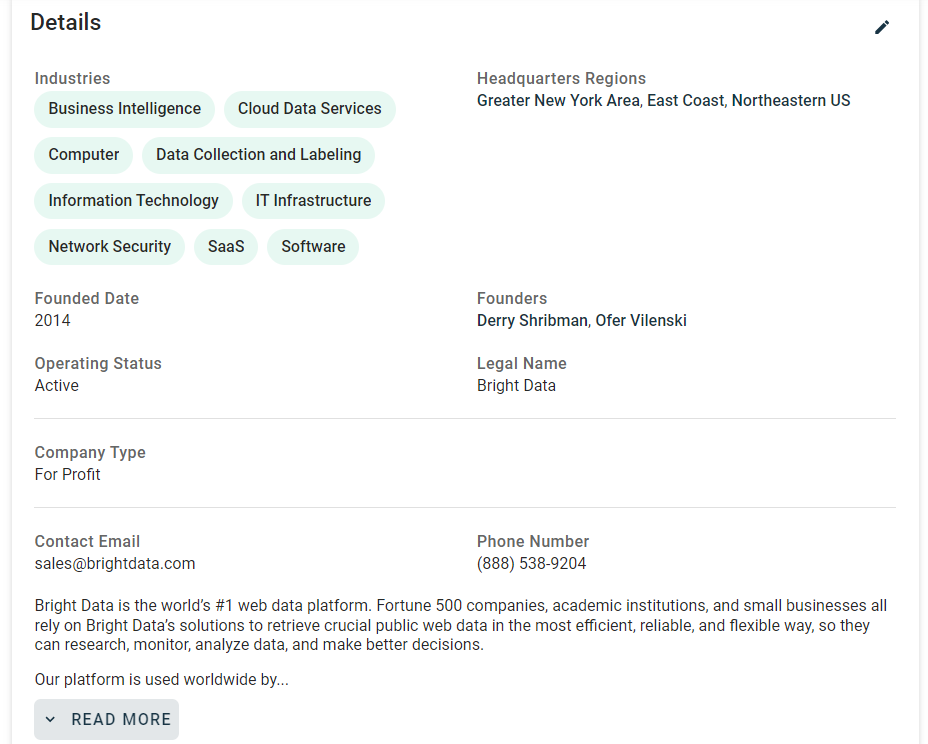
Si vous inspectez cette section, vous remarquerez qu’il n’existe pas de moyen simple de sélectionner les éléments HTML à partir desquels extraire les données :
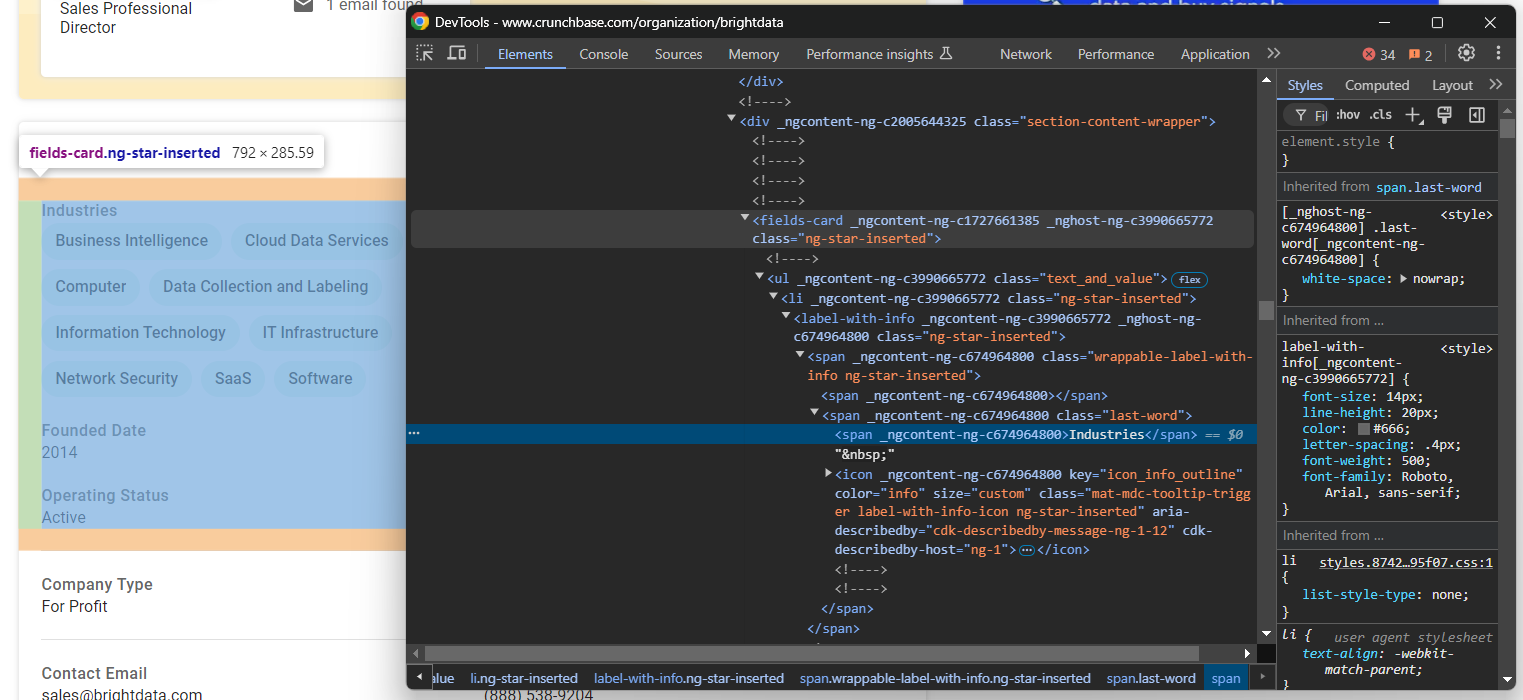
La plupart de ces nœuds ont des attributs HTML aléatoires qui sont probablement générés au moment de la compilation. Ces attributs changent après chaque déploiement, vous ne pouvez donc pas vous y fier pour sélectionner les nœuds. De plus, bon nombre de ces éléments ne sont pas marqués avec des classes ou des identifiants uniques.
Une approche efficace pour sélectionner les éléments qui vous intéressent consiste à vous concentrer sur leurs étiquettes. Par exemple, vous pouvez sélectionner le nœud fields-card contenant les informations sur les secteurs d’activité en identifiant quel fields-card possède un nœud label-with-info contenant la chaîne « Industries ».
Cette technique sera utilisée pour extraire les données de cette section. Il est donc logique de centraliser la logique dans une fonction :
def find_parent_node_based_on_child_node_text(parent_nodes_selector, child_node_selector, text):
# sélectionner tous les nœuds parents
parent_nodes = driver.find_elements(By.CSS_SELECTOR, parent_nodes_selector)
# parcourir les nœuds parents pour trouver celui
# dont le nœud enfant spécifique contient le texte souhaité
for parent_node in parent_nodes:
try:
# obtenir le nœud enfant spécifique dans le nœud parent actuel
child_node = parent_node.find_element(By.CSS_SELECTOR, child_node_selector)
# vérifier s'il contient le texte souhaité
if text.upper() in child_node.text.upper():
return parent_node
except:
continue
return NoneUtilisez la fonction ci-dessus pour sélectionner le nœud « Industries » de la carte de champs avec :
industries_parent_node = find_parent_node_based_on_child_node_text("fields-card li", "label-with-info", "Industries")Super ! Le scraping de Crunchbase sera désormais beaucoup plus facile.
Étape n° 7 : extraire les informations sur les entreprises
Inspectez le nœud « Industries » :
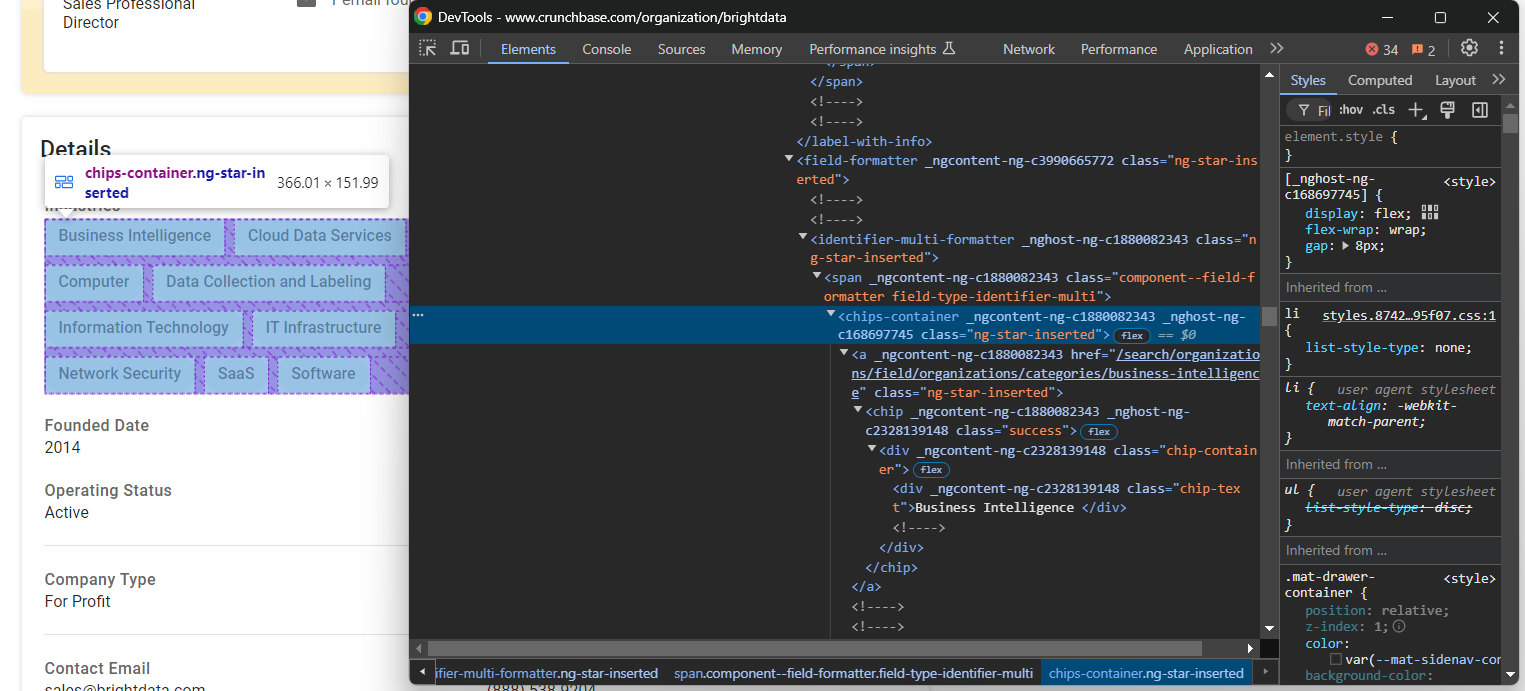
Il stocke les secteurs dans lesquels l’entreprise opère dans des nœuds chips-container a. Sélectionnez-les tous, parcourez-les et extrayez-en les données :
industries_parent_node = find_parent_node_based_on_child_node_text("fields-card li", "label-with-info", "Industries")
industries_nodes = industries_parent_node.find_elements(By.CSS_SELECTOR, "chips-container a")
industries = []
for industry_node in industries_nodes:
industries.append(industry_node.text)Concentrons-nous maintenant sur l’élément « Date de création » :
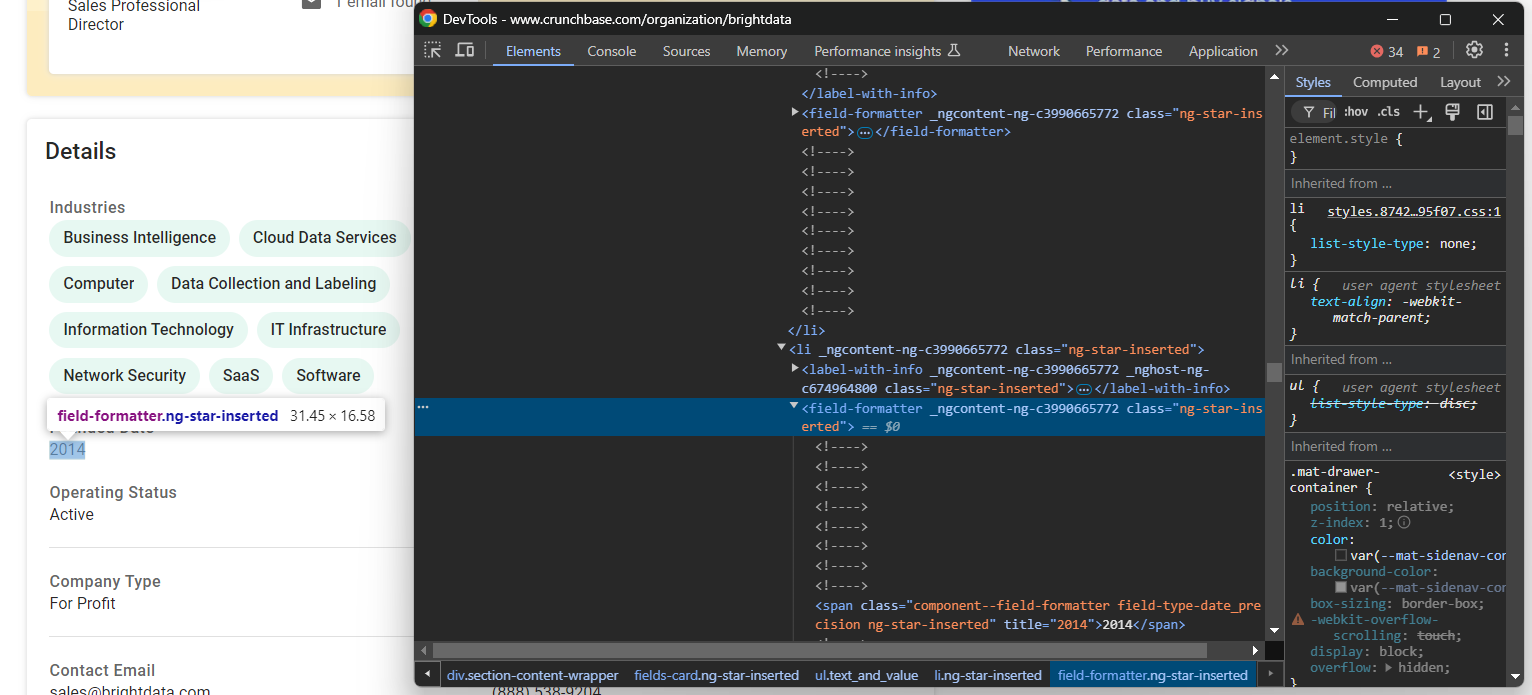
Dans ce cas, la logique de scraping est plus simple, car vous n’avez qu’à extraire le texte de l’élément field-formatter à l’intérieur du nœud parent fields-card li:
founded_date_parent_node = find_parent_node_based_on_child_node_text("fields-card li", "label-with-info", "Founded Date")
founded_date_node = founded_date_parent_node.find_element(By.CSS_SELECTOR, "field-formatter")
founded_date = founded_date_node.textLa même logique peut être appliquée à la plupart des autres éléments relatifs aux détails de l’entreprise :
company_type_parent_node = find_parent_node_based_on_child_node_text("fields-card li", "label-with-info", "Company Type")
company_type_node = company_type_parent_node.find_element(By.CSS_SELECTOR, "field-formatter")
company_type = company_type_node.text
operating_status_parent_node = find_parent_node_based_on_child_node_text("fields-card li", "label-with-info", "Operating Status")
operating_status_node = operating_status_parent_node.find_element(By.CSS_SELECTOR, "field-formatter")
operating_status = operating_status_node.text
headquarters_parent_node = find_parent_node_based_on_child_node_text("fields-card li", "label-with-info", "Régions du siège social")
headquarters_node = headquarters_parent_node.find_element(By.CSS_SELECTOR, "field-formatter")
headquarters = headquarters_node.text
legal_name_parent_node = find_parent_node_based_on_child_node_text("fields-card li", "label-with-info", "Nom légal")
legal_name_node = legal_name_parent_node.find_element(By.CSS_SELECTOR, "field-formatter")
legal_name = legal_name_node.text
contact_email_parent_node = find_parent_node_based_on_child_node_text("fields-card li", "label-with-info", "Contact Email")
contact_email_node = contact_email_parent_node.find_element(By.CSS_SELECTOR, "field-formatter")
contact_email = contact_email_node.text
phone_number_parent_node = find_parent_node_based_on_child_node_text("fields-card li", "label-with-info", "Numéro de téléphone")
phone_number_node = phone_number_parent_node.find_element(By.CSS_SELECTOR, "field-formatter")
phone_number = phone_number_node.textUn autre nœud qui nécessite une attention particulière est l’élément « Fondateurs » :
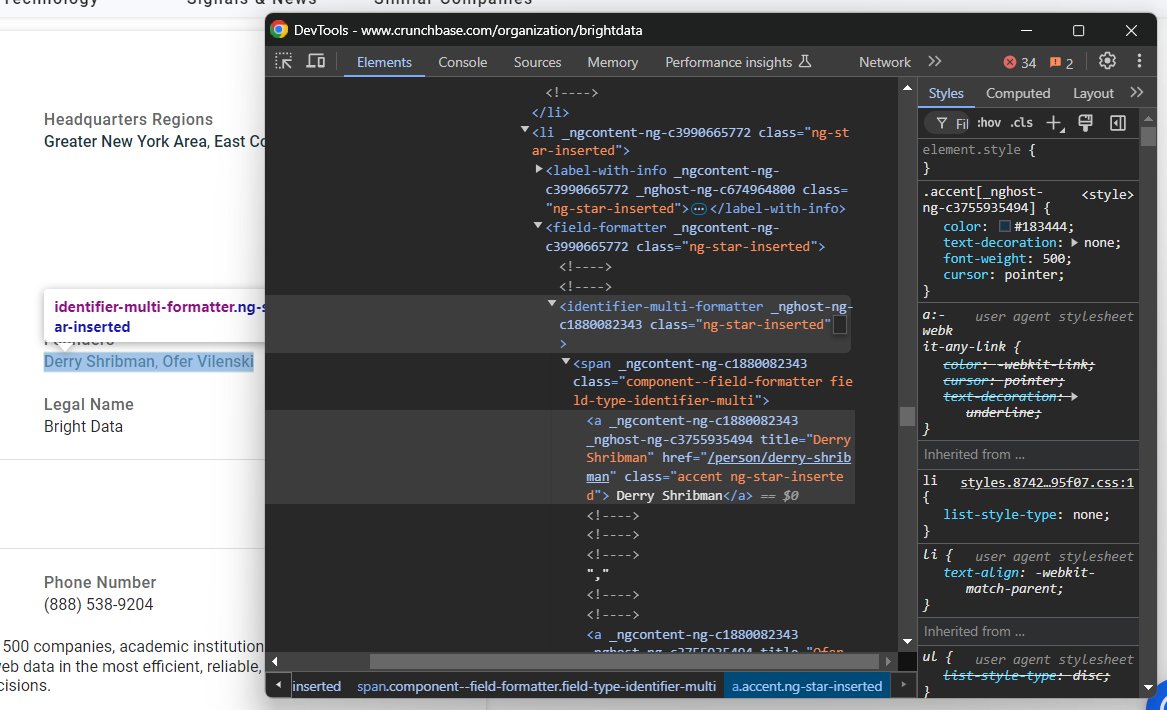
Dans ce cas, vous devez itérer sur les nœuds identifier-multi-formatter a et en extraire les données :
founders_parent_node = find_parent_node_based_on_child_node_text("fields-card li", "label-with-info", "Fondateurs")
founders_nodes = founders_parent_node.find_elements(By.CSS_SELECTOR, "identifier-multi-formatter a")
founders = []
for founders_node in founders_nodes:
founders.append(founders_node.text)Enfin, examinez le nœud de description à la fin de la section « Détails » :
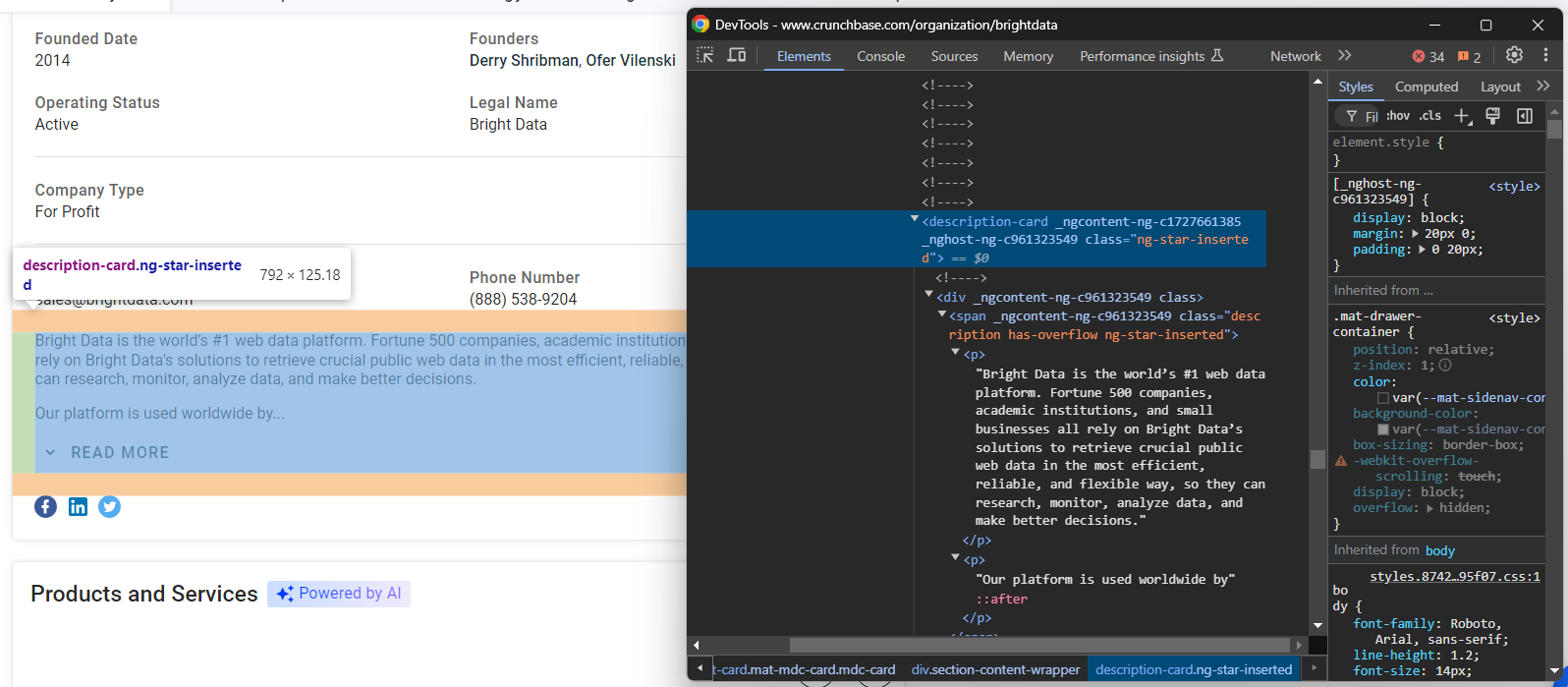
Récupérez ces données avec :
description_node = driver.find_element(By.CSS_SELECTOR, « section-card description-card »)
description = description_node.textIncroyable ! Votre Scraper Crunchbase est presque terminé.
Étape n° 8 : récupérez le tableau des produits et services
Une autre information qui mérite d’être collectée est la liste des produits et services proposés par l’entreprise :
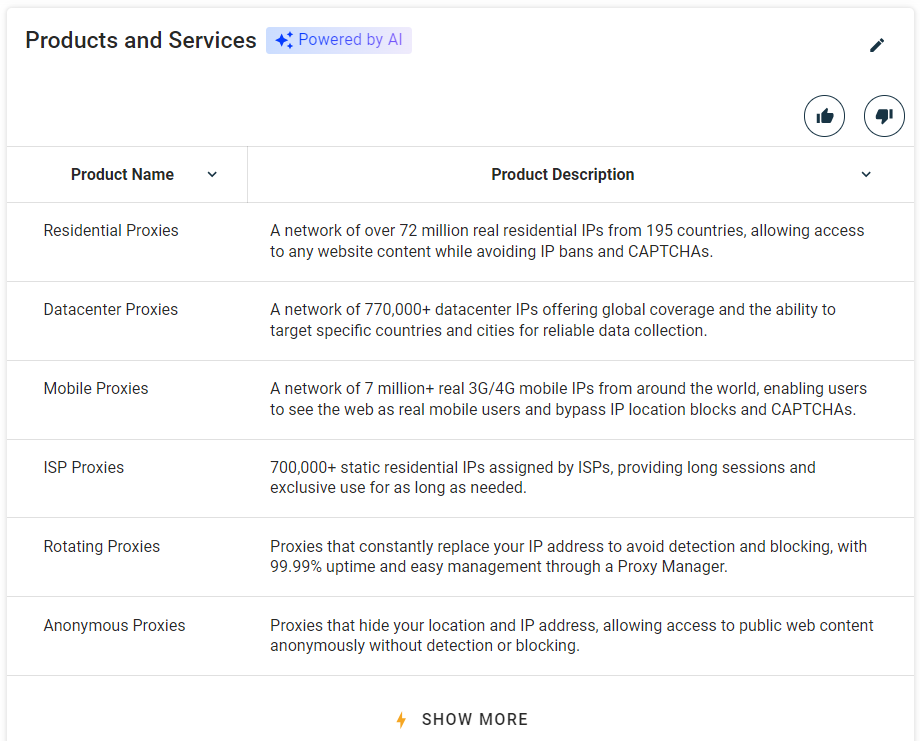
Sélectionnez la section « Produits et services » à l’aide de la fonction définie précédemment :
products_parent_node = find_parent_node_based_on_child_node_text("profile-section", ".section-title", "Produits et services")Ensuite, scrapez les données du tableau avec :
products = []
for row in products_table_rows:
# extraire le nom et la description des colonnes de chaque ligne
name = row.find_element(By.CSS_SELECTOR, "td:nth-child(1)").text
description = row.find_element(By.CSS_SELECTOR, "td:nth-child(2)").text
product = {
"name": name,
"description": description
}
products.append(product)Impressionnant ! La logique de scraping de Crunchbase est terminée.
Étape n° 9 : exporter les données extraites
Remplissez un dictionnaire d’entreprise avec les données extraites :
company = {
"about": about,
"industries": industries,
"founded_date": founded_date,
"company_type": company_type,
« operating_status » : operating_status,
« headquarters » : headquarters,
« founders » : founders,
« email » : contact_email,
« phone » : phone_number,
« description » : description,
« products » : products
}Ensuite, exportez-le dans un fichier company.json:
with open("company.json", "w") as json_file:
json.dump(company, json_file, indent=4)Tout d’abord, open() crée un fichier de sortie company.json. Ensuite, json.dump() transforme company en sa représentation JSON et l’écrit dans le fichier de sortie.
N’oubliez pas d’importer json depuis la bibliothèque standard Python :
import jsonÉtape n° 10 : assembler le tout
Voici le fichier scraper.py final :
from selenium import webdriver
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
from selenium.webdriver.common.by import By
import json
def find_parent_node_based_on_child_node_text(parent_nodes_selector, child_node_selector, text):
# sélectionner tous les nœuds parents
parent_nodes = driver.find_elements(By.CSS_SELECTOR, parent_nodes_selector)
# parcourir les nœuds parents pour trouver celui
# dont le nœud enfant spécifique contient le texte souhaité
for parent_node in parent_nodes:
try:
# obtenir le nœud enfant spécifique dans le nœud parent actuel
child_node = parent_node.find_element(By.CSS_SELECTOR, child_node_selector)
# vérifier s'il contient le texte souhaité
if text.upper() in child_node.text.upper():
return parent_node
except:
continue
return None
def handle_cookie_popup(driver, seconds=60):
try:
# attendre le nombre de secondes indiqué pour que le bouton « Accepter tout »
# de la fenêtre contextuelle des cookies apparaisse sur la page
accept_button = WebDriverWait(driver, seconds).until(
EC.element_to_be_clickable((By.CSS_SELECTOR, "#onetrust-accept-btn-handler"))
)
# cliquer sur la fenêtre contextuelle via JavaScript pour éviter
# les erreurs ElementClickInterceptedException
driver.execute_script("arguments[0].click();", accept_button)
print("Bouton « Accepter tout » cliqué")
except:
print("Bouton « Accepter tout » introuvable dans les {seconds} secondes")
# initialiser le pilote pour contrôler une instance Chrome
# en mode headed
driver = webdriver.Chrome()
# naviguer vers la page Crunchbase souhaitée
url = "https://www.crunchbase.com/organization/brightdata"
driver.get(url)
# gérer la fenêtre contextuelle des cookies, si présente
handle_cookie_popup(driver)
# logique de scraping
about_node = driver.find_element(By.CSS_SELECTOR, "profile-section description-card")
about = about_node.text
industries_parent_node = find_parent_node_based_on_child_node_text("fields-card li", "label-with-info", "Industries")
industries_nodes = industries_parent_node.find_elements(By.CSS_SELECTOR, "chips-container a")
industries = []
for industry_node in industries_nodes:
industries.append(industry_node.text)
fondée_date_parent_node = trouver_parent_node_basé_sur_enfant_node_texte("fields-card li", "label-with-info", "Date de fondation")
fondée_date_node = fondée_date_parent_node.trouver_élément(By.CSS_SELECTOR, "field-formatter")
fondée_date = fondée_date_node.texte
company_type_parent_node = find_parent_node_based_on_child_node_text("fields-card li", "label-with-info", "Company Type")
company_type_node = company_type_parent_node.find_element(By.CSS_SELECTOR, "field-formatter")
company_type = company_type_node.text
operating_status_parent_node = find_parent_node_based_on_child_node_text("fields-card li", "label-with-info", "Statut opérationnel")
operating_status_node = operating_status_parent_node.find_element(By.CSS_SELECTOR, "field-formatter")
operating_status = operating_status_node.text
headquarters_parent_node = find_parent_node_based_on_child_node_text("fields-card li", "label-with-info", "Régions du siège social")
headquarters_node = headquarters_parent_node.find_element(By.CSS_SELECTOR, "field-formatter")
headquarters = headquarters_node.text
founders_parent_node = find_parent_node_based_on_child_node_text("fields-card li", "label-with-info", "Fondateurs")
founders_nodes = founders_parent_node.find_elements(By.CSS_SELECTOR, "identifier-multi-formatter a")
founders = []
for founders_node in founders_nodes:
founders.append(founders_node.text)
legal_name_parent_node = find_parent_node_based_on_child_node_text("fields-card li", "label-with-info", "Legal Name")
legal_name_node = legal_name_parent_node.find_element(By.CSS_SELECTOR, "field-formatter")
legal_name = legal_name_node.text
contact_email_parent_node = find_parent_node_based_on_child_node_text("fields-card li", "label-with-info", "Contact Email")
contact_email_node = contact_email_parent_node.find_element(By.CSS_SELECTOR, « field-formatter »)
contact_email = contact_email_node.text
phone_number_parent_node = find_parent_node_based_on_child_node_text(« fields-card li », « label-with-info », « Phone Number »)
phone_number_node = phone_number_parent_node.find_element(By.CSS_SELECTOR, « field-formatter »)
phone_number = phone_number_node.text
description_node = driver.find_element(By.CSS_SELECTOR, « section-card description-card »)
description = description_node.text
products_parent_node = find_parent_node_based_on_child_node_text("profile-section", ".section-title", "Produits et services")
products_table_rows = products_parent_node.find_elements(By.CSS_SELECTOR, "table tbody tr")
# extraire le tableau des produits
products = []
for row in products_table_rows:
# extraire le nom et la description des colonnes de chaque ligne
name = row.find_element(By.CSS_SELECTOR, "td:nth-child(1)").text
description = row.find_element(By.CSS_SELECTOR, "td:nth-child(2)").text
product = {
"name": name,
"description": description
}
products.append(product)
# remplir un dictionnaire avec les données récupérées
company = {
"about": about,
"industries": industries,
"founded_date": founded_date,
« type_entreprise » : type_entreprise,
« statut_opérationnel » : statut_opérationnel,
« siège » : siège,
« fondateurs » : fondateurs,
« e-mail » : e-mail_contact,
« téléphone » : numéro_de_téléphone,
« description » : description,
« produits » : produits
}
# exporter les données extraites vers un fichier JSON
with open("company.json", "w") as json_file:
json.dump(company, json_file, indent=4)
# fermer le pilote et libérer les ressources du navigateur
driver.quit()En un peu plus de 100 lignes de code, vous venez de créer un Scraper Crunchbase en Python !
Lancez le script à l’aide de la commande suivante :
python3 script.pyOu, sous Windows :
python script.pyUn fichier company.json apparaîtra dans le dossier de votre projet. Ouvrez-le et vous verrez :
{
"about": "La plateforme de données Web n° 1 au monde",
"industries": [
"Business Intelligence",
"Services de données dans le cloud",
"Informatique",
"Collecte et étiquetage de données",
"Technologies de l'information",
« Infrastructure informatique »,
« Sécurité réseau »,
« SaaS »,
« Logiciels »
],
« founded_date » : « 2014 »,
« type_d'entreprise » : « À but lucratif »,
« statut_opérationnel » : « Actif »,
« siège_social » : « Région métropolitaine de New York, côte Est, nord-est des États-Unis »,
« fondateurs » : [
« Derry Shribman »,
« Ofer Vilenski »
],
« email » : « [email protected] »,
« phone » : « (888) 538-9204 »,
« description » : « Proxys qui masquent votre emplacement et votre adresse IP, vous permettant d'accéder anonymement à du contenu web public sans être détecté ou bloqué. »,
« produits » : [
{
« nom » : « Proxys résidentiels »,
« description » : « Un réseau de plus de 400 millions par mois IPs résidentielles réelles provenant de 195 pays, permettant d'accéder à n'importe quel contenu web tout en évitant les interdictions d'IP et les CAPTCHA. »
},
{
"name": "Proxys de centres de données",
"description": "Un réseau de plus de 770 000 adresses IP de centres de données offrant une couverture mondiale et la possibilité de cibler des pays et des villes spécifiques pour une collecte de données fiable."
},
{
"name": "Proxys mobiles",
"description": "Un réseau de plus de 7 millions d'adresses IP mobiles 3G/4G réelles provenant du monde entier, permettant aux utilisateurs de voir le Web comme de véritables utilisateurs mobiles et de contourner les blocages de localisation IP et les CAPTCHA."
},
{
"name": "Proxy ISP",
"description": "Plus de 700 000 adresses IP résidentielles statiques attribuées par les FAI, offrant des sessions longues et une utilisation exclusive aussi longtemps que nécessaire."
},
{
"name": "Proxys rotatifs",
"description": "Proxys qui remplacent constamment votre adresse IP pour éviter la détection et le blocage, avec une disponibilité de 99,99 % et une gestion facile grâce à un gestionnaire de proxys."
},
{
"name": "Proxys anonymes",
"description": "Proxys qui masquent votre emplacement et votre adresse IP, vous permettant d'accéder anonymement à du contenu web public sans être détecté ni bloqué."
}
]
}Ce sont les données disponibles sur la page Crunchbase de la société Bright Data.
Et voilà ! Vous venez d’apprendre à effectuer du Scraping web sur Crunchbase à l’aide de Python.
Débloquer facilement les données Crunchbase
Crunchbase fournit une multitude de données précieuses, mais prend également des mesures importantes pour les protéger contre les Scrapers et les bots automatisés. Lorsque vous interagissez avec le site à l’aide d’un navigateur sans interface graphique ou que vous effectuez certaines actions, vous pouvez rencontrer des pages 403 Forbidden ou des CAPTCHA.
Dans un premier temps, vous pouvez vous référer à notre guide sur la manière de contourner les CAPTCHA dans Python. Cependant, Crunchbase utilise des solutions anti-scraping avancées supplémentaires qui peuvent encore entraîner des blocages.
Sans les bons outils, le scraping de Crunchbase peut rapidement devenir une expérience lente et frustrante. La meilleure solution est l’API Crunchbase Scraper dédiée de Bright Data. Récupérez les données de Crunchbase sans être bloqué !
Conclusion
Dans ce tutoriel étape par étape, vous avez appris ce qu’est un Scraper Crunchbase et les types de données qu’il peut récupérer. Vous avez également vu comment créer un script Python pour scraper Crunchbase afin d’obtenir des données générales sur les entreprises, ce qui n’a nécessité qu’environ 150 lignes de code.
Le problème est que Crunchbase adopte des mesures strictes contre les bots et les scripts automatisés. Les CAPTCHA, les empreintes digitales des navigateurs et les interdictions d’IP ne sont que quelques-unes des défenses utilisées pour empêcher le scraping. Oubliez tous ces défis grâce à notre API Crunchbase Scraper.
Si le Scraping web ne vous convient pas, mais que vous êtes toujours intéressé par les données Crunchbase, explorez nos Jeux de données Crunchbase!
Discutez avec l’un de nos experts pour découvrir laquelle des solutions Bright Data correspond le mieux à vos besoins.




