

Dans ce tutoriel, vous apprendrez :
- Comment une approche basée sur l’éventail des requêtes et la comparaison des aperçus de Google AI peut être utilisée pour améliorer la géolocalisation et le référencement.
- Comment construire ce flux de travail à un niveau élevé en utilisant six agents d’intelligence artificielle.
- Comment mettre en œuvre ce workflow d’optimisation de contenu par l’IA avec CrewAI, intégré à Gemini et Bright Data.
- Quelques idées et conseils pour améliorer encore le flux de travail.
Plongeons dans l’aventure !
TL;DR
Vous souhaitez passer directement aux fichiers de projet prêts à l’emploi ? Consultez le projet sur GitHub.
Expliquer le Fan-Out des requêtes et la comparaison des aperçus d’IA pour améliorer le GEO et le SEO
Nous savons tous que le SEO(Search Engine Optimization) est l’art d’améliorer la visibilité d’un site web dans les résultats de recherche organiques. Mais le monde évolue désormais vers le GEO(Generative Engine Optimization).
Si vous ne connaissez pas GEO, il s’agit d’une stratégie de marketing numérique visant à rendre le contenu plus visible dans les moteurs de recherche alimentés par l’IA, tels que Google AI Overviews, ChatGPT et d’autres.
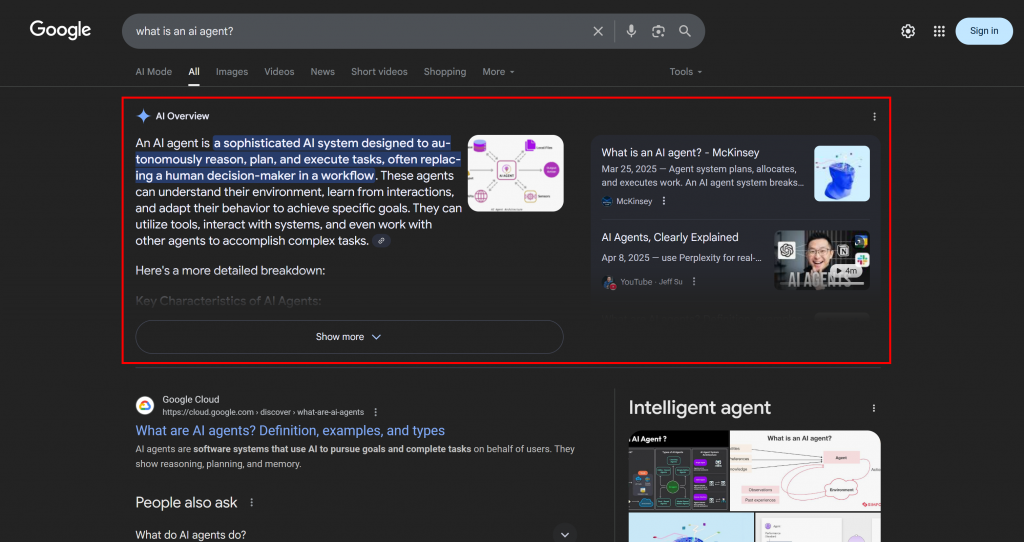
Les LLM étant essentiellement des boîtes noires, il n’existe pas de moyen direct d'”optimiser” une page web pour la GEO (tout comme l’était le référencement avant que les outils de recherche par volume de mots clés ne soient disponibles).
Ce que vous pouvez faire, c’est suivre une approche empirique : examiner les résumés générés par l’IA dans le monde réel et interroger les fans pour vos mots clés cibles. Pour un terme de recherche spécifique, si certains sujets apparaissent régulièrement dans les résultats de l’IA, vous devriez optimiser le contenu de votre page en fonction de ces sujets.
Dans le contexte de la recherche assistée par ordinateur de Google, une requête en éventail est une technique qui transforme une requête unique de l’utilisateur en un réseau de sous-requêtes connexes. Au lieu de simplement faire correspondre la requête originale à la meilleure réponse, le mode Google AI va plus loin en générant et en recherchant plusieurs questions connexes à la fois.
Comme vous pouvez le voir dans l’exemple ci-dessous, le mode Google AI renvoie généralement une dizaine de liens connexes accompagnés de brefs résumés pour vous aider à approfondir le sujet :
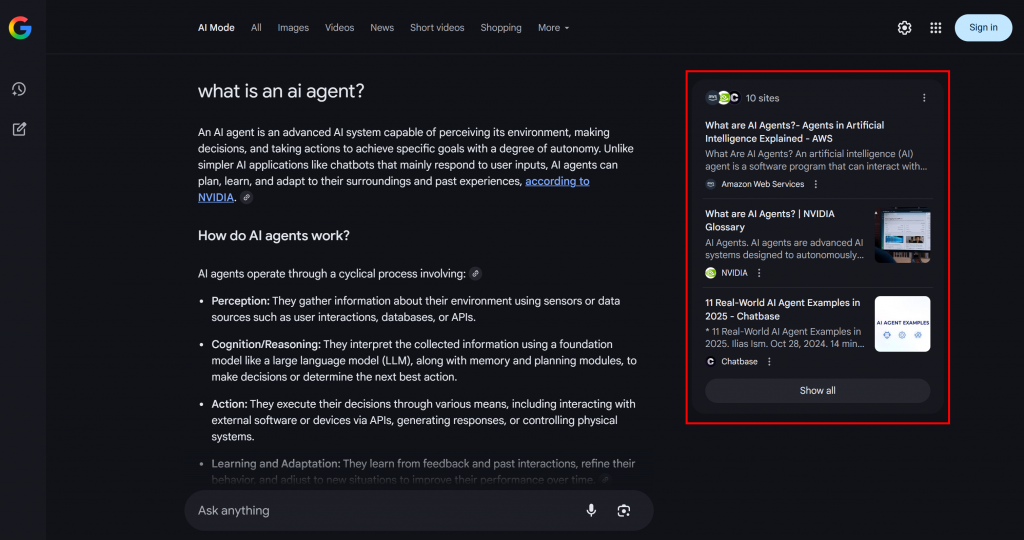
C’est ce que l’on appelle un “fan-out” de requête Google, que l’on peut définir en termes plus simples comme un ensemble de sous-requêtes connexes générées à partir d’une seule recherche d’IA.
Si certains sujets reviennent régulièrement dans les résultats des requêtes et les aperçus de l’IA, il est logique de structurer une page de contenu autour d’eux. Cette approche peut également avoir un effet secondaire positif sur le référencement traditionnel, puisque des moteurs tels que Google sont susceptibles d’améliorer les pages des SERP qui ont déjà de bons résultats dans leurs résultats de recherche alimentés par l’IA.
Maintenant que vous avez compris les principes de base, entrez dans les détails techniques de cette approche de la géolocalisation !
Comment construire un système d’optimisation GEO multi-agents ?
Comme vous pouvez l’imaginer, la mise en œuvre d’un agent d’IA pour soutenir votre flux de travail d’optimisation de contenu GEO n’est pas simple. Une approche efficace consiste à s’appuyer sur un système multi-agents basé sur six agents spécialisés :
- Title Scraper: Extrait le titre principal d’une page web, à partir de son URL.
- Chercheur d’éventail de requêtes Google: Utilise le titre extrait pour appeler l’outil de recherche Google disponible dans Gemini et générer une requête en éventail.
- Extracteur de la requête principale de Google: Analyse l’éventail des requêtes afin d’identifier et d’extraire la requête principale de type Google.
- Récupérateur de l’aperçu de l’IA de Google: Utilise la requête principale pour effectuer une recherche dans les SERP de Google et en extrait la section AI Overview.
- Résumé de l’éventail de la requête: Condense le contenu du fan-out de la requête (qui est généralement assez long) en un résumé Markdown optimisé, mettant en évidence les sujets clés.
- Optimiseur de contenu AI: Compare le résumé de la requête en éventail avec la vue d’ensemble de Google AI pour identifier les modèles et les sujets récurrents. Il génère un document Markdown contenant des informations exploitables pour l’optimisation du contenu GEO.
Certains des agents décrits ci-dessus sont assez génériques et peuvent être mis en œuvre avec la plupart des LLM (par exemple, Google Main Query Extractor, Query Fan-Out Summarizer, et AI Content Optimizer). Cependant, d’autres agents nécessitent des capacités plus spécialisées et l’accès à des modèles ou à des outils spécifiques.
Par exemple, l’agent Google Main Query Extractor doit avoir accès à l’outil google_search, qui n’est disponible que dans les modèles Gemini. De même, l’agent Title Scraper doit accéder au contenu de la page web pour en extraire le titre. Cette tâche peut s’avérer difficile, car de nombreux sites web ont mis en place des mesures anti-AI. Pour éviter ces problèmes, vous pouvez intégrer Title Scraper à Web Unlocker. Cette API de scraping de Bright Data récupère le contenu au format HTML brut ou au format Markdown optimisé pour l’IA, en contournant tous les blocages.
De la même manière, l’outil Google AI Overview Retriever nécessite un outil tel que Bright Data SERP API pour effectuer la requête de recherche et récupérer l’aperçu de l’IA en temps réel.
En d’autres termes, grâce à Gemini et à l’infrastructure d’IA de Bright Data, vous pouvez mettre en œuvre ce cas d’utilisation GEO/SEO. Ce qu’il vous faut maintenant, c’est un système de construction d’agents d’IA pour orchestrer ces agents, comme le montre ce graphique récapitulatif :
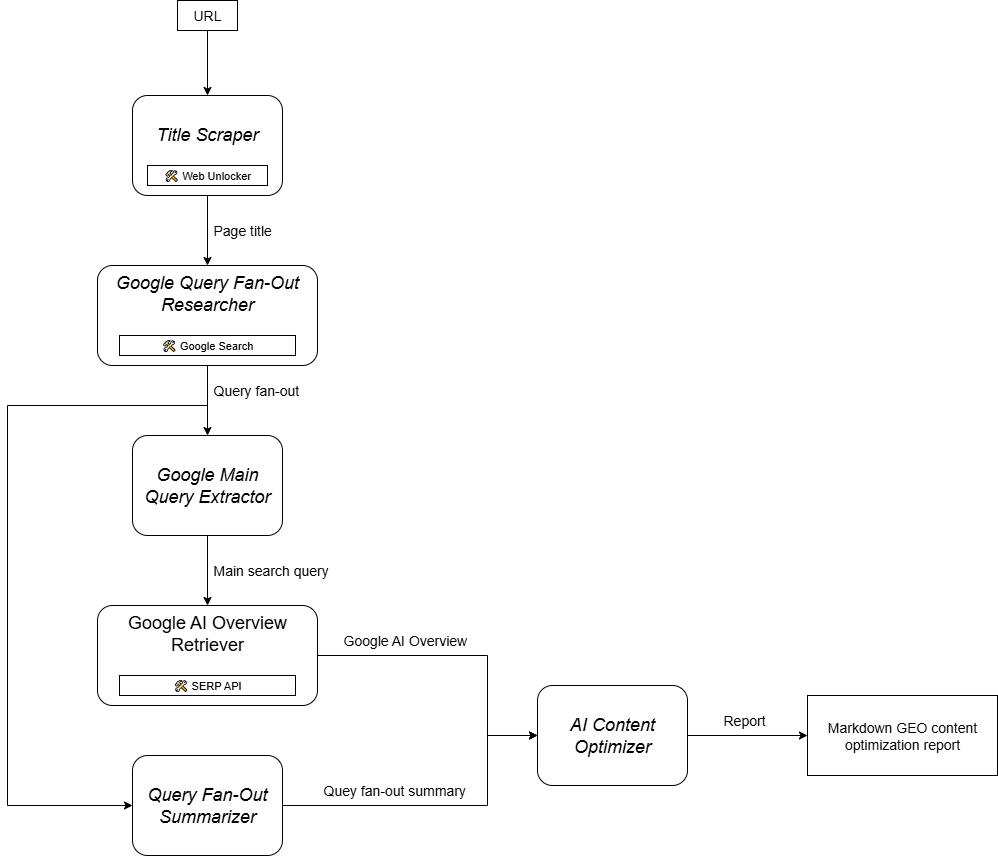
CrewAI étant spécifiquement conçu pour orchestrer des systèmes multi-agents, il constitue le cadre idéal pour construire et gérer ce flux de travail.
Mise en œuvre d’un système multi-agents d’optimisation du contenu GEO dans CrewAI à l’aide de Gemini et de Bright Data
Suivez les étapes ci-dessous pour apprendre à construire un système multi-agents qui fournit un flux de travail reproductible pour optimiser les pages web pour les moteurs de recherche alimentés par l’IA. En analysant systématiquement les résultats des requêtes et les aperçus de l’IA, cette approche vous aide à découvrir les sujets prioritaires et à structurer le contenu afin d’obtenir un meilleur classement grâce à l’IA.
Le code ci-dessous est écrit en Python à l’aide de CrewAI, avec l’intégration de Bright Data et de Gemini pour fournir aux agents les outils et les capacités nécessaires.
Conditions préalables
Pour suivre ce tutoriel, assurez-vous d’avoir :
- Python 3.10+ installé localement.
- Une clé API Gemini (aucun crédit n’est requis).
- Un compte Bright Data.
Ne vous inquiétez pas si vous n’avez pas de compte Bright Data. Vous serez guidé tout au long du processus de création d’un compte.
Il est également très important de comprendre le fonctionnement de CrewAI. Avant de commencer, nous vous recommandons de consulter la documentation officielle.
Étape 1 : Configurer votre application CrewAI
CrewAI nécessite l’installation d’uv. Vous pouvez l’installer globalement avec la commande suivante :
pip install uvVous pouvez également suivre le guide d’installation officiel de votre système d’exploitation.
Ensuite, installez CrewAI globalement sur votre système :
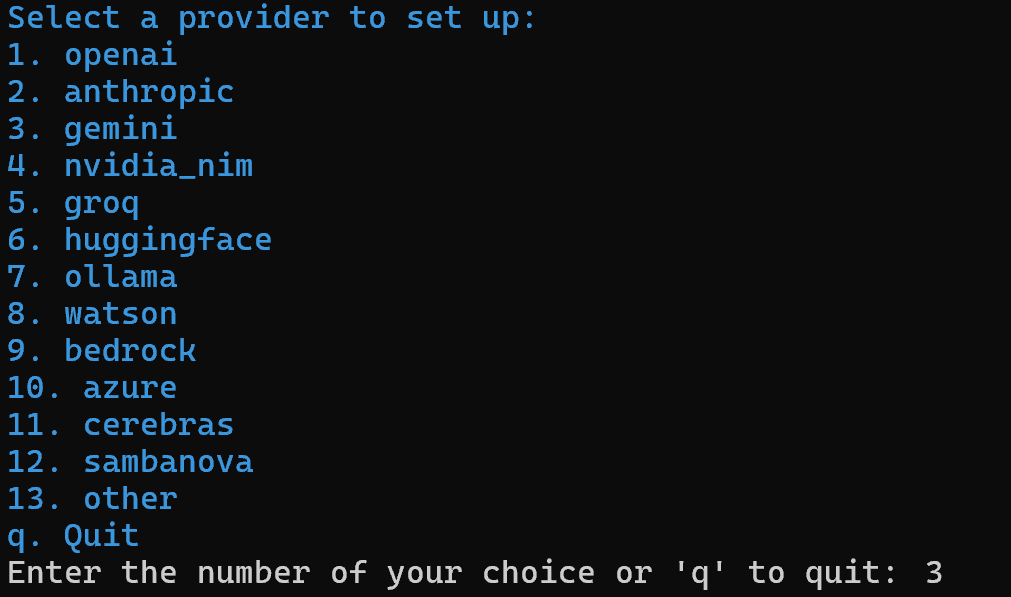
uv tool install crewai Maintenant, créez un nouveau projet CrewAI appelé ai_content_optimization_agent:
crewai create crew ai_content_optimization_agentIl vous sera demandé de sélectionner un fournisseur d’IA. Étant donné que le flux de travail actuel fonctionne sur Gemini, choisissez l’option 3 :
Sélectionnez ensuite un modèle Gemini :
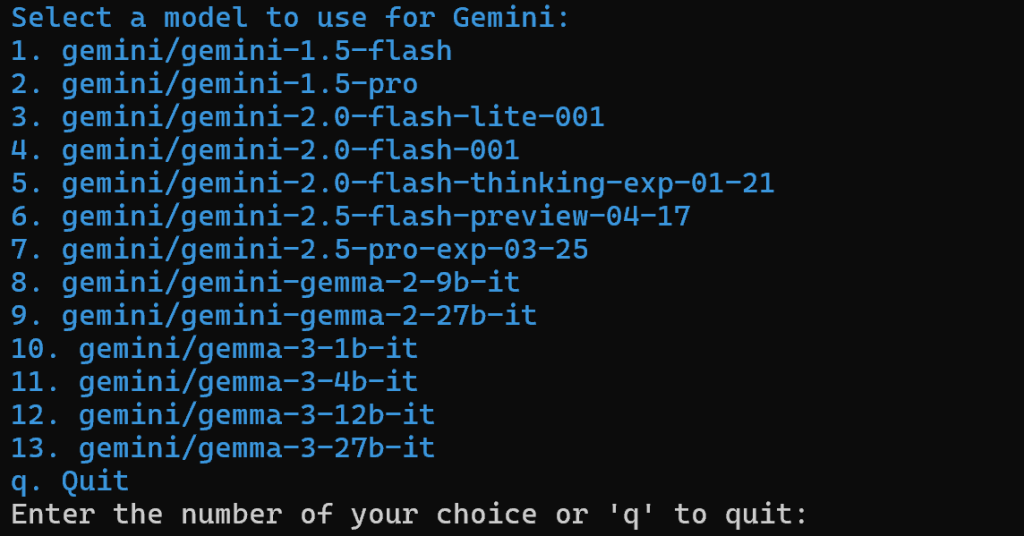
Vous pouvez choisir n’importe lequel des modèles disponibles, car vous le remplacerez plus loin dans l’article. Ce n’est donc pas important.
Continuez en collant votre clé API Gemini :

Après cette étape, votre projet dans la structure du dossier ai_content_optimization_agent/ ressemblera à ceci :
ai_content_optimization_agent/
├── .gitignore
├── knowledge/
├── pyproject.toml
├── README.md
├── .env
└── src/
└── ai_content_optimization_agent/
├── __init__.py
├── main.py
├── crew.py
├── tools/
│ ├── custom_tool.py
│ └── __init__.py
└── config/
├── agents.yaml
└── tasks.yamlChargez le projet dans votre IDE Python préféré et familiarisez-vous avec lui. Explorez les fichiers actuels et notez que .env contient déjà le modèle Gemini sélectionné et votre clé API Gemini :
MODEL=<SELECTED_GEMINI_MODEL>
GEMINI_API_KEY=<YOUR_GEMINI_API_KEY>Si vous n’êtes pas familier avec les fichiers de CrewAI ou si vous rencontrez des problèmes, reportez-vous au guide d’installation officiel.
Naviguez dans le dossier de votre projet dans votre terminal :
cd ai_content_optimization_agentEnsuite, initialiser un environnement virtuel Python à l’intérieur de celui-ci :
python -m venv .venv Note: L’environnement virtuel doit être nommé .venv. Sinon, la commande crewai run pour démarrer le workflow CrewAI échouera.
Sous Linux et macOS, activez l’environnement virtuel avec :
source .venv/bin/activateAlternativement, sous Windows, exécutez :
.venvScriptsactivateC’est fait ! Vous avez maintenant un projet CrewAI vierge en place.
Étape 2 : Intégrer Gemini
Comme mentionné précédemment, CrewAI ajoute par défaut le modèle Gemini sélectionné au fichier .env. Pour configurer le dernier modèle, écrasez la variable d’environnement MODEL dans le fichier .env comme suit :
MODEL=gemini/gemini-2.5-flashAinsi, vos agents d’IA orchestrés avec CrewAI pourront se connecter à gemini-2.5-flash. À l’heure où nous écrivons ces lignes, il s’agit du dernier modèle Gemini Flash. De plus, il offre des limites de débit très généreuses lorsqu’il est interrogé via l’API (comme dans cette intégration CrewAI).
Dans crew.py, chargez le nom du MODÈLE à partir de l’environnement en utilisant :
MODEL = os.getenv("MODEL")Cette variable sera utilisée ultérieurement pour définir le LLM dans les agents.
N’oubliez pas d’importer os de la bibliothèque standard de Python :
import osCool ! L’installation des Gémeaux est terminée.
Étape 3 : Installer et configurer les outils de données CrewAI Bright
L’extraction du titre d’une page web par l’IA n’est pas simple. La plupart des LLM ne peuvent pas accéder directement au contenu des pages web. Et même lorsqu’ils disposent d’outils intégrés pour le faire, ceux-ci échouent souvent en raison de mesures anti-scraping avancées telles que l’empreinte digitale du navigateur et les CAPTCHA. Les mêmes difficultés s’appliquent au scraping en direct des SERP, Google empêchant activement le scraping automatisé.
C’est là que les données lumineuses deviennent fondamentales. Heureusement, elles sont officiellement prises en charge par les outils Bright Data de CrewAI.
Pour commencer, créez un compte Bright Data (ou connectez-vous si vous en avez déjà un). Accédez ensuite au tableau de bord de votre profil et suivez les instructions officielles pour configurer une zone Web Unlocker:

Assurez-vous que la zone est réglée sur “Active” :
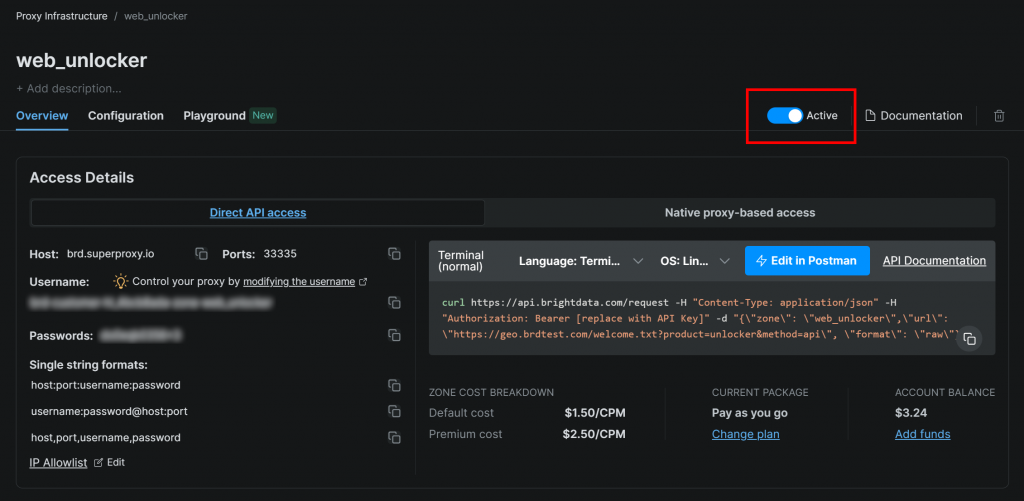
Dans ce cas, le nom de la zone Web Unlocker est "web_unlocker", mais vous pouvez lui donner le nom que vous souhaitez. Gardez ce nom à l’esprit, car vous en aurez bientôt besoin.
Une fois la configuration terminée, suivez le guide officiel pour générer votre clé API Bright Data. Conservez-la en lieu sûr, car vous en aurez besoin prochainement.
Maintenant, dans votre environnement virtuel activé, installez les exigences de l’outil CrewAI Bright Data :
pip install crewai[tools] aiohttp requestsPour que l’intégration fonctionne, ajoutez vos identifiants Bright Data au fichier .env via les deux env suivants :
BRIGHT_DATA_API_KEY="<BRIGHT_DATA_API_KEY>"
BRIGHT_DATA_ZONE="<YOUR_BRIGHT_DATA_ZONE>"Remplacer les et par votre clé d’API Bright Data et votre nom de zone Web Unlocker, respectivement.
Ensuite, dans crew.py, importez les outils Bright Data :
from crewai_tools import BrightDataWebUnlockerTool, BrightDataSearchToolInitialisez-les comme suit :
web_unlocker_tool = BrightDataWebUnlockerTool()
serp_search_tool = BrightDataSearchTool()Vous pouvez désormais fournir à vos agents des capacités de déverrouillage de sites web et de récupération de SERP en leur transmettant simplement ces outils. C’est fantastique !
Étape 4 : Création de l’agent racleur de titres
Vous avez maintenant tout ce qu’il faut pour construire votre premier agent. Commencez par l’agent Title Scraper, qui est chargé d’extraire le titre d’une page web.
Pour obtenir le titre de la page, il existe deux méthodes principales :
- Récupère le contenu textuel de l’élément HTML
<h1>. - Si le
<h1>est absent, demandez à l’IA de déduire le titre de la page à partir du reste du contenu de la page.
N’oubliez pas que cela nécessite l’intégration de l’outil Web Unlocker. Dans crew.py, définissez l’agent et la tâche CrewAI comme suit :
@agent
def title_scraper_agent(self) -> Agent:
return Agent(
config=self.agents_config["title_scraper_agent"],
tools=[web_unlocker_tool], # <--- Web Unlocker tool integration
verbose=True,
llm=MODEL,
)
@task
def scrape_title_task(self) -> Task:
return Task(
config=self.tasks_config["scrape_title_task"],
agent=self.title_scraper_agent(),
max_retries=3,
)Étant donné que cette tâche implique l’appel à un outil tiers, il est logique d’activer la logique de réessai (jusqu’à 3 fois) via l’option max_retries. Cela permet d’éviter que l’ensemble du flux de travail n’échoue en raison de problèmes de réseau temporaires ou d’erreurs de l’outil. La même logique doit être appliquée à toutes les autres tâches qui s’appuient sur des services tiers (via des outils) ou qui impliquent des opérations d’IA complexes susceptibles d’échouer en raison d’erreurs de traitement LLM.
Ensuite, dans votre fichier de configuration agents.yaml, définissez l’agent Title Scraper comme suit :
title_scraper_agent:
role: "Title Scraper"
goal: "Extract the main H1 heading or title from a given web page URL."
backstory: "You are an expert scraper with a specialization in identifying and extracting the main heading (H1) or title of a webpage."Ensuite, dans tasks.yaml, décrivez sa tâche principale comme suit :
scrape_title_task:
description: |
1. Visit the URL: '{url}'.
2. Scrape the page's full content using the Bright Data Web Unlocker tool (using the Markdown data format).
3. Locate and extract only the text within the `<h1>` tag. If no `<h1>` tag is present, infer a title from the page content.
4. Output the extracted text as a plain string.
expected_output: "The plain string containing the extracted text from the specified URL."Notez que cette tâche lit l’URL à partir d’une entrée CrewAI grâce à la syntaxe {url}. Vous verrez comment remplir cet argument d’entrée dans l’une des prochaines étapes.
C’est très bien ! L’agent Title Scraper est terminé. Vous allez maintenant appliquer une logique similaire pour définir tous les autres agents.
Étape 5 : Mettre en œuvre l’agent de recherche Google Query Fan-Out
CrewAI ne fournit pas de moyen intégré pour accéder à l’outil de recherche Google disponible dans les modèles Gemini. Au lieu de cela, vous devez définir une intégration Gemini LLM personnalisée , comme indiqué dans le référentiel officiel d’intégration Gemini CrewAI.
Essentiellement, vous devez créer une classe qui étend la classe CrewAI LLM. Celle-ci se connectera à Gemini et activera l’outil google_search. Vous pouvez placer cette classe dans un fichier appelé gemini_google_search_llm.py dans un sous-dossier personnalisé llms/ (ou vous pouvez mettre la classe directement en haut de crew.py).
Définissez votre classe d’intégration Gemini LLM personnalisée comme suit :
# src/ai_content_optimization_agent/llms/gemini_google_search_llm.py
from crewai import LLM
import os
from typing import Any, Optional
# Define a custom Gemini LLM integration with Google Search grounding
class GeminiWithGoogleSearch(LLM):
"""
A Gemini-specific LLM that has the "google_search" tool enabled.
"""
def __init__(self, model: str | None = None, **kwargs):
if not model:
# Use a default Gemini model.
model = os.getenv("MODEL")
super().__init__(model, **kwargs)
def call(
self,
messages: str | list[dict[str, str]],
tools: list[dict] | None = None,
callbacks: list[Any] | None = None,
available_functions: dict[str, Any] | None = None,
from_task: Optional[Any] = None,
from_agent: Optional[Any] = None,
) -> str | Any:
if not tools:
tools = []
# LiteLLM will throw a warning if it sees `google_search`,
# so you must use camel case here
tools.insert(0, {"googleSearch": {}})
return super().call(
messages=messages,
tools=tools,
callbacks=callbacks,
available_functions=available_functions,
from_task=from_task,
from_agent=from_agent,
)Cela vous permet d’accéder à l’outil de recherche Google dans votre modèle Gemini configuré.
Remarque: l’outil Google Search inclut un certain quota dans le volet gratuit de l’API, de sorte que vous pouvez l’utiliser dans votre application sans avoir besoin d’un plan premium.
Ensuite, dans crew.py, importez la classe GeminiWithGoogleSearch:
from .llms.gemini_google_search_llm import GeminiWithGoogleSearchUtilisez-le pour spécifier l’agent Query Fan-Out Researcher comme suit :
@agent
def query_fanout_researcher_agent(self) -> Agent:
return Agent(
config=self.agents_config["query_fanout_researcher_agent"],
verbose=True,
llm=GeminiWithGoogleSearch(MODEL), # <--- Gemini integration with the Google Search tool
)
@task
def google_search_task(self) -> Task:
return Task(
config=self.tasks_config["google_search_task"],
context=[self.scrape_title_task()],
agent=self.query_fanout_researcher_agent(),
max_retries=3,
markdown=True,
output_file="output/query_fanout.md",
)Notez que le LLM utilisé dans la classe Agent est une instance de la classe personnalisée GeminiWithGoogleSearch. Puisque la tâche de génération de l’éventail de requêtes produit un résultat précieux pour le débogage et l’analyse ultérieure, vous devez l’exporter vers un fichier de sortie personnalisé. Dans ce cas, la sortie produite sera stockée dans le fichier output/query_fanout.md.
Remarquez également que le contexte de la tâche principale de l’agent est exactement le résultat de la tâche principale de l’agent précédent dans le flux de travail. Ainsi, l’agent actuel aura accès à la sortie produite par l’agent Title Scraper. En particulier, il l’utilisera comme entrée lorsqu’il effectuera la recherche en éventail via l’outil de recherche Google.
Ensuite, dans agents.yaml, ajoutez :
query_fanout_researcher_agent:
role: "Google Query Fan-Out Researcher"
goal: "Given a title, perform a comprehensive web search to get the query fan-out."
backstory: "You are an AI research assistant, powered by the Google Search tool from Gemini."Et dans tasks.yaml:
google_search_task:
description: |
1. Use the title from the previous task as your search query.
2. Perform a web search using the Google Search tool.
3. Return the results from the Google Search tool.
expected_output: "The output from the Google Search tool in Markdown format."Si vous vous demandez à quoi ressemble une requête en éventail, vous trouverez ci-dessous un court extrait d’une sortie réelle de l’outil google_search:
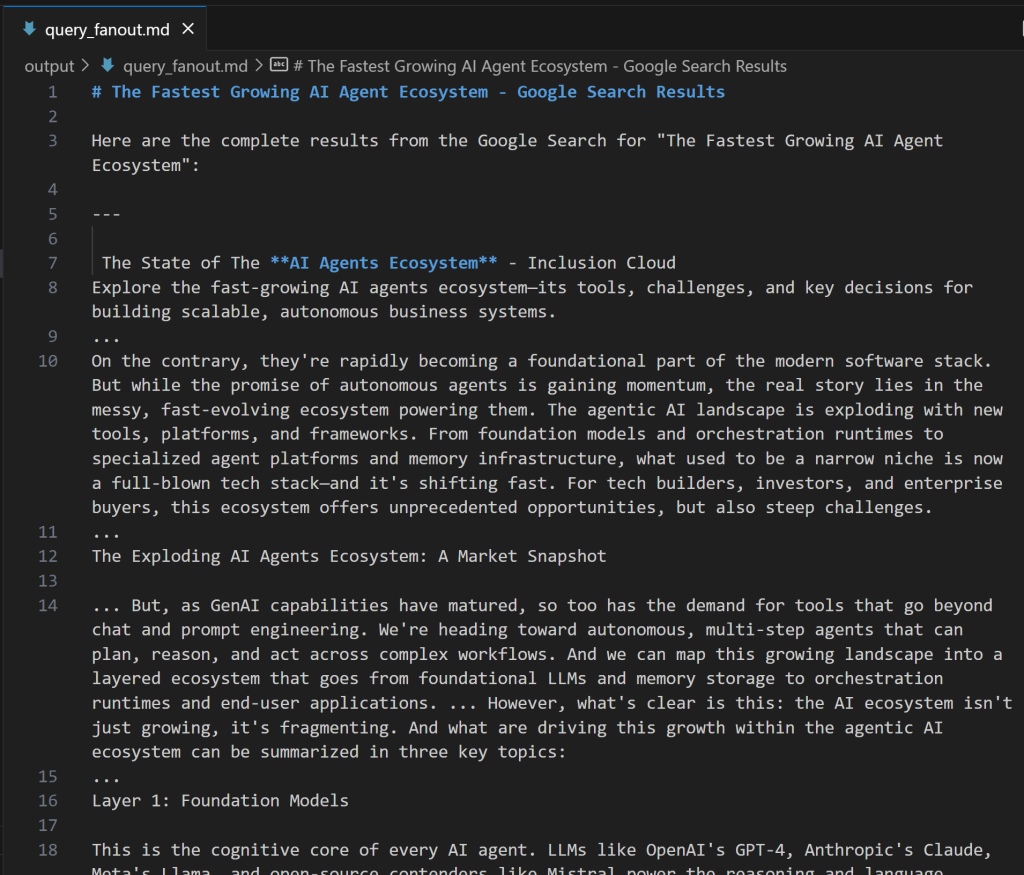
C’est parfait ! L’agent Google Query Fan-Out Researcher est prêt.
Étape 6 : Définir les agents restants
Comme précédemment, définissez les agents restants dans crew.py :
@agent
def main_query_extractor_agent(self) -> Agent:
return Agent(
config=self.agents_config["main_query_extractor_agent"],
verbose=True,
llm=MODEL,
)
@task
def main_query_extraction_task(self) -> Task:
return Task(
config=self.tasks_config["main_query_extraction_task"],
context=[self.google_search_task()],
agent=self.main_query_extractor_agent(),
)
@agent
def ai_overview_retriever_agent(self) -> Agent:
return Agent(
config=self.agents_config["ai_overview_retriever_agent"],
tools=[serp_search_tool], # <--- SERP API tool integration
verbose=True,
llm=MODEL,
)
@task
def ai_overview_extraction_task(self) -> Task:
return Task(
config=self.tasks_config["ai_overview_extraction_task"],
context=[self.main_query_extraction_task()],
agent=self.ai_overview_retriever_agent(),
max_retries=3,
markdown=True,
output_file="output/ai_overview.md",
)
@agent
def query_fanout_summarizer_agent(self) -> Agent:
return Agent(
config=self.agents_config["query_fanout_summarizer_agent"],
verbose=True,
llm=MODEL,
)
@task
def query_fanout_summarization_task(self) -> Task:
return Task(
config=self.tasks_config["query_fanout_summarization_task"],
context=[self.google_search_task()],
agent=self.query_fanout_summarizer_agent(),
markdown=True,
output_file="output/query_fanout_summary.md",
)
@agent
def ai_content_optimizer_agent(self) -> Agent:
return Agent(
config=self.agents_config["ai_content_optimizer_agent"],
verbose=True,
llm=MODEL,
)
@task
def compare_ai_overview_task(self) -> Task:
return Task(
config=self.tasks_config["compare_ai_overview_task"],
context=[self.query_fanout_summarization_task(), self.ai_overview_extraction_task()],
agent=self.ai_content_optimizer_agent(),
max_retries=3,
markdown=True,
output_file="output/report.md",
)Respectivement, le code ci-dessus spécifie :
- L’agent Google Main Query Extractor et sa tâche principale.
- L’agent Google AI Overview Retriever et sa tâche principale.
- L’agent Query Fan-Out Summarizer et sa tâche principale.
- L’agent AI Content Optimizer et sa tâche principale.
Complétez les définitions des agents en ajoutant ces lignes au fichier agents.yaml:
main_query_extractor_agent:
role: "Google Main Query Extractor"
goal: "Extract the main Google-like search query from a provided query fan-out."
backstory: "You are an AI assistant specialized in parsing query fan-outs and identifying the main, concise search query suitable for Google searches."
ai_overview_retriever_agent:
role: "Google AI Overview Retriever"
goal: "Given a query fan-out, extract the main search query and use it to perform a SERP search on Google to retrieve the AI Overview section."
backstory: "You are an AI SERP search assistant with the ability to retrieve SERPs from Google."
query_fanout_summarizer_agent:
role: "Query Fan-Out Summarizer"
goal: "Generate a concise and structured summary from the provided query fan-out."
backstory: "You are an AI summarization expert focused on condensing query fan-outs into clear, actionable summaries in Markdown format."
ai_content_optimizer_agent:
role: "AI Content Optimizer"
goal: "Compare a summary generated from a query fan-out with the Google AI Overview, identify patterns and similarities, and generate a list of action items based on common topics."
backstory: "You are an AI assistant that analyzes content summaries and AI overviews to find recurring themes, patterns, and actionable insights to optimize content strategies."Et ces lignes dans tasks.yaml :
main_query_extraction_task:
description: |
1. From the provided query fan-out, extract the main search query.
2. Transform the search query into a concise, Google-like keyphrase that users would type into Google.
expected_output: "A short, clear, Google-style search query."
ai_overview_extraction_task:
description: |
1. Use the search query from the previous task to perform a SERP search on Google via the Bright Data SERP Search tool by setting the `brd_ai_overview` argument to 2.
2. Retrieve and return an aggregated Markdown version of the AI Overview section from the search results.
3. After all attempts, if none of the responses contain a Google AI Overview, generate one based on the results from the SERP API, and include a note indicating it was generated.
expected_output: "The AI Overview section Markdown format (either retrieved from the SERP API or generated if unavailable)."
query_fanout_summarization_task:
description: |
1. Generate a summary from the query fan-out received as input.
expected_output: "A Markdown summary containing the main information from the query fan-out."
compare_ai_overview_task:
description: |
1. Compare the previously generated summary with the Google AI Overview provided as input.
2. Identify patterns and similarities (such as sub-topics or recurring themes), as well as differences between the two sources.
3. Generate a list of action items based on the comparison, focusing on topics that appear in both the Google AI Overview and the initial summary.
4. Produce a summary table to compare the patterns, similarities, and differences, containing these columns: Aspect, Query Fan-Out Summary, Google AI Overview, Similarities/Patterns, Differences.
expected_output: |
A comparison report in Markdown that highlights patterns, similarities, and a list of action items derived from the query fan-out.
The document must with a summary table presenting the main similarities and differences, and then all remaining content.Découvrez comment la tâche ai_overview_extraction_task inclut les spécifications techniques pour récupérer la vue d’ensemble de l’IA dans la réponse de l’API SERP. Pour en savoir plus, consultez la documentation officielle.
C’est formidable ! Tous les agents AI du flux de travail d’optimisation du contenu GEO ont maintenant été créés. Il est maintenant temps d’ajouter un Crew pour les orchestrer.
Étape 7 : Regrouper tous les agents d’une équipe
Dans crew.py, définissez une nouvelle fonction Crew pour exécuter les agents de manière séquentielle :
@crew
def crew(self) -> Crew:
return Crew(
agents=self.agents,
tasks=self.tasks,
process=Process.sequential,
verbose=True,
)C’est incroyable ! La classe AiContentOptimizationAgent du fichier crew.py est complète. Il suffit d’exécuter sa méthode crew() dans le fichier main.py pour lancer le flux de travail.
Étape n° 8 : Définir le flux d’exécution
Remplacer le fichier main.py par :
- Lire l’URL d’entrée à partir du terminal à l’aide de la fonction Python
input(). - Utilisez l’URL fournie pour construire l’entrée d’agent requise.
- Initialiser une instance d’
AiContentOptimizationAgentet appeler sa méthodecrew(), en lui passant un objet input avec le champ{url}renseigné. - Exécuter le flux de travail de l’IA.
Implémentez toute la logique ci-dessus dans main.py comme suit :
#!/usr/bin/env python
import warnings
from ai_content_optimization_agent.crew import AiContentOptimizationAgent
warnings.filterwarnings("ignore", category=SyntaxWarning, module="pysbd")
def run():
# Read URL from the terminal
url = input("Please enter the URL to process: ").strip()
if not url:
raise ValueError("No URL provided. Exiting.")
# Build the required agent input
inputs = {
"url": url,
}
try:
print(f"Analyzing '${url}' for AI content optimization...")
# Run the multi-agent workflow
AiContentOptimizationAgent().crew().kickoff(inputs=inputs)
except Exception as e:
raise Exception(f"An error occurred while running the crew: {e}")Étape n° 9 : Testez votre agent
Dans votre environnement virtuel activé, avant de démarrer votre agent, installez les dépendances requises avec :
crewai installLancez ensuite votre système d’optimisation GEO multi-agents :
crewai runVous serez invité à saisir l’URL d’entrée :

Dans cet exemple, nous utiliserons une page du site CrewAI lui-même comme entrée :
https://www.crewai.com/ecosystem
Cette page présente les principaux acteurs de l’écosystème des agents d’IA.
Exécutez l’agent sur cette page, et vous obtiendrez un résultat comme celui-ci :
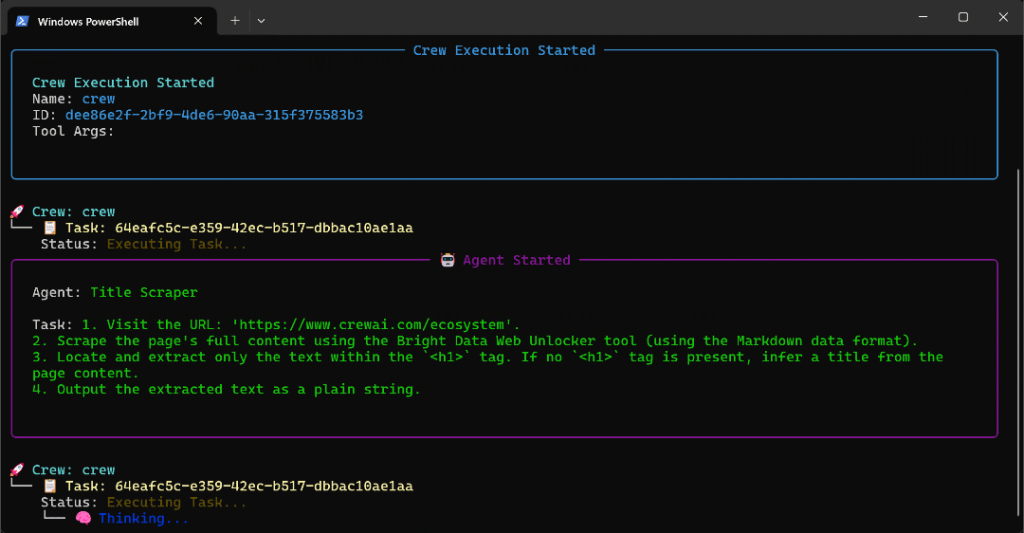
Le GIF ci-dessus a été accéléré, mais voici ce qui se passe étape par étape :
- L’agent Title Scraper collecte le titre de la page via l’outil Bright Data Web Unlocker. Le résultat est
"The Fastest Growing AI Agent Ecosystem"(exactement comme indiqué dans la capture d’écran de la page). - Google Query Fan-Out Researcher génère la sortie de l’éventail de requêtes à partir de l’outil
google_search. Cela produit le fichierquery_fanout.mddans le dossieroutput/. - Google Main Query Extractor identifie la principale requête de recherche de type Google à partir de l’éventail de requêtes. Le résultat est
"AI agent ecosystem growth" (croissance de l'écosystème des agents d'IA). - Google AI Overview Retriever obtient l’aperçu de l’IA pour la requête de recherche via l’API SERP de Bright Data. La sortie est stockée dans
ai_overview.md. - L’agent Query Fan-Out Summarizer condense le contenu de l’éventail de la requête en un résumé Markdown détaillé dans le fichier
query_fanout_summary.md. - AI Content Optimizer compare le résumé de la requête en éventail avec l’aperçu de Google AI pour générer le fichier
.md du rapportfinal.
À la fin de l’exécution, le dossier output/ doit contenir les quatre fichiers suivants :
Ouvrez le fichier report.md en mode prévisualisation dans Visual Studio Code et parcourez-le :

Comme vous pouvez le voir, il contient un rapport Markdown détaillé pour vous aider à optimiser le contenu de la page d’entrée donnée pour le GEO (et le SEO) !
Maintenant, utilisez cet agent sur les URL des pages web que vous voulez améliorer pour le classement AI, et vous améliorerez votre positionnement GEO et SEO.
Et voilà ! Mission accomplie.
Prochaines étapes
L’agent d’optimisation de contenu IA construit ci-dessus est déjà assez puissant, mais il peut toujours être amélioré. Une idée est d’ajouter un autre agent au début du flux de travail qui prend un plan du site en entrée (en utilisant éventuellement une expression rationnelle pour filtrer les URL, par exemple, pour ne sélectionner que les articles de blog). Cet agent pourrait ensuite transmettre les URL au flux de travail existant, potentiellement en parallèle, ce qui vous permettrait d’analyser plusieurs pages en même temps pour l’optimisation du contenu par l’IA.
En général, gardez à l’esprit que vous pouvez expérimenter les instructions dans agents.yaml et tasks.yaml pour adapter le comportement de chacun des six agents à votre cas d’utilisation spécifique. Aucune compétence technique avancée n’est requise pour effectuer ces ajustements !
Conclusion
Dans cet article, vous avez appris à tirer parti des capacités d’intégration de l’IA de Bright Data pour construire un flux de travail multi-agents complexe pour l’optimisation GEO/SEO dans CrewAI.
Le flux de travail d’IA présenté ici est idéal pour tous ceux qui recherchent un moyen programmatique d’améliorer le contenu des pages web pour les moteurs de recherche traditionnels et les recherches alimentées par l’IA.
Pour créer des flux de travail avancés similaires, explorez la gamme complète de solutions de récupération, de validation et de transformation des données Web en direct dans l’infrastructure Bright Data AI.
Créez un compte Bright Data gratuit dès aujourd’hui et commencez à expérimenter avec nos outils web prêts pour l’IA !




