

Le mode Google AI représente un changement fondamental dans la façon dont les résultats de recherche sont présentés, offrant des réponses conversationnelles alimentées par l’IA qui synthétisent des informations provenant de sources multiples. Pour les entreprises qui suivent leur présence numérique, les équipes de veille concurrentielle et les professionnels du référencement, ce nouveau format de recherche crée à la fois des opportunités et des défis pour l’extraction de données.
Ce guide complet explique ce qu’est le mode Google AI, pourquoi l’extraction de ces données apporte une valeur stratégique à l’entreprise, les défis techniques auxquels vous serez confronté et les approches manuelles et automatisées permettant d’extraire ces informations de manière efficace et à grande échelle.
Qu’est-ce que le mode Google AI ?
Le mode Google AI est une nouvelle expérience de recherche de Google qui propose des réponses synthétisées et conversationnelles en haut des résultats, permettant ainsi aux utilisateurs de poser des questions complémentaires de manière naturelle. Chaque réponse comporte des liens source bien visibles, ce qui permet d’accéder facilement au contenu sous-jacent.
Sous le capot, AI Mode exploite Gemini en même temps que les systèmes de recherche de Google, en utilisant une approche de type “query fan-out”. Cette technique permet de diviser les questions en sous-thèmes et d’effectuer plusieurs recherches connexes en parallèle, ce qui permet d’obtenir des informations plus pertinentes que celles fournies par les requêtes uniques traditionnelles.
Voici un exemple de Google AI Mode répondant à une requête avec des sources citées (à droite) sur lesquelles les utilisateurs peuvent cliquer pour obtenir des détails supplémentaires :
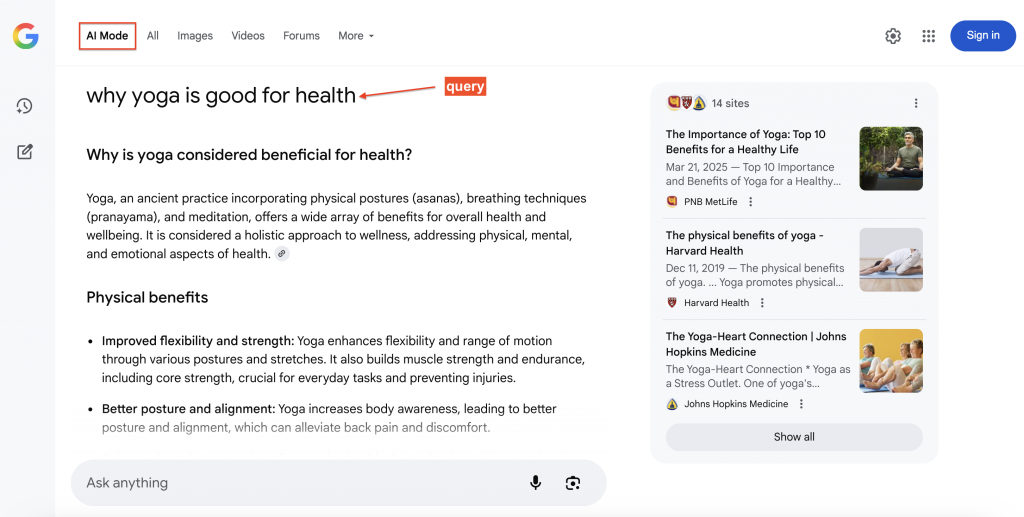
Pourquoi exploiter les données de Google AI Mode ?
Les données de Google AI Mode fournissent des informations mesurables qui ont un impact significatif sur le référencement, le développement de produits et la recherche concurrentielle.
- Suivi du partage des citations. Surveillez les domaines référencés par Google AI pour vos requêtes cibles, y compris l’ordre de classement et la fréquence au fil du temps. Cela indique l’autorité thématique et aide à mesurer si les améliorations de contenu conduisent à une meilleure inclusion des réponses de l’IA.
- Veille concurrentielle. Identifiez les marques, les produits ou les lieux qui apparaissent dans les requêtes de recommandation et de comparaison. Cela révèle le positionnement sur le marché, la dynamique concurrentielle et les attributs sur lesquels les réponses de l’IA mettent l’accent.
- Analyse des écarts de contenu. Comparez les faits clés des réponses du mode IA avec votre contenu existant afin d’identifier les possibilités de créer un contenu structuré comme des FAQ, des guides ou des tableaux de données qui permettent d’obtenir des citations.
- Surveillance de la marque. Examinez les réponses générées par l’IA au sujet de votre marque ou de votre secteur d’activité afin d’identifier les informations obsolètes et de mettre à jour votre contenu en conséquence.
- Recherche et développement. Stockez les réponses du mode IA avec des métadonnées (horodatage, lieux, entités) pour alimenter les systèmes d’IA internes, soutenir les équipes de recherche et améliorer les applications RAG.
Méthode 1 – scraping manuel avec automatisation du navigateur
Le scraping du mode IA de Google nécessite une automatisation sophistiquée du navigateur en raison de la nature dynamique et riche en JavaScript du contenu généré par l’IA. Les frameworks d’automatisation de navigateur tels que Playwright, Selenium ou Puppeteer utilisent de véritables moteurs de navigateur pour exécuter du JavaScript, attendre le chargement du contenu et reproduire l’expérience de navigation humaine – ce qui est important pour capturer les réponses de l’IA générées de manière dynamique.
Voici comment le mode AI de Google apparaît dans les résultats de recherche :
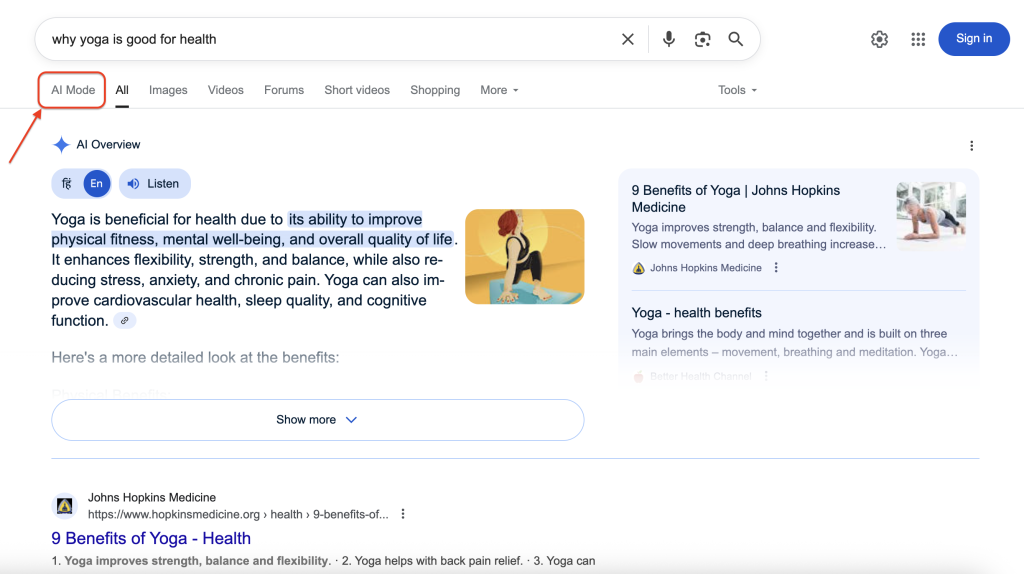
En cliquant sur AI Mode, on accède à l’interface conversationnelle complète avec des réponses détaillées et des citations de sources. Notre objectif est d’accéder par programme à ces informations riches et structurées et de les extraire.
Étape 1 – Configuration de l’environnement et conditions préalables
Installez la dernière version de Python, puis les dépendances nécessaires. Pour ce tutoriel, installez Playwright en lançant ces commandes dans votre terminal :
pip install playwright
playwright installCette commande installe Playwright et télécharge les binaires de navigateur requis (exécutables de navigateur nécessaires à l’automatisation).
Étape 2 – importation des dépendances et configuration
Importez les bibliothèques essentielles pour la tâche de scraping :
import asyncio
import urllib.parse
from playwright.async_api import async_playwrightRépartition des bibliothèques :
- asyncio – permet la programmation asynchrone pour améliorer les performances et les opérations simultanées.
- urllib.parse – gère l’encodage des URL pour s’assurer que les requêtes sont correctement formatées pour les demandes web.
- playwright – fournit des capacités d’automatisation du navigateur pour interagir avec Google comme un utilisateur humain.
Étape 3 – Architecture et paramètres de la fonction
Définissez la fonction de scraping principale avec des paramètres et des valeurs de retour clairs :
async def scrape_google_ai_mode(query : str, output_path : str = "ai_response.txt") -> bool :Paramètres de la fonction :
- query – terme de recherche à soumettre à Google AI Mode.
- output_path – destination du fichier pour l’enregistrement de la réponse (par défaut “ai_response.txt”).
- Renvoie une valeur booléenne indiquant le succès(True) ou l’échec(False) de l’extraction du contenu.
Étape 4 – Construction de l’URL et activation du mode AI
Construisez l’URL de recherche qui déclenche l’interface AI Mode de Google :
url = f "https://www.google.com/search?q={urllib.parse.quote_plus(query)}&udm=50"Composants clés :
- urllib.parse.quote_plus(query) – code en toute sécurité la requête de recherche, en convertissant les espaces en ‘+’ et en échappant les caractères spéciaux.
- udm=50 – paramètre critique qui active l’interface AI Mode de Google.
Étape 5 – Configuration du navigateur et anti-détection
Lancez une instance de navigateur configurée pour éviter la détection tout en conservant un comportement réaliste :
async avec async_playwright() as pw :
browser = await pw.chromium.launch(
headless=False, args=["--disable-blink-features=AutomationControlled"]
)
page = await browser.new_page(
user_agent="Mozilla/5.0 (Macintosh ; Intel Mac OS X 10_15_7) "
"AppleWebKit/537.36 (KHTML, comme Gecko) "
"Chrome/120.0.0.0 Safari/537.36"
)Détails de la configuration :
- headless=False – affiche la fenêtre du navigateur pour le débogage (défini à True pour les environnements de production).
- -disable-blink-features=AutomationControlled – supprime les indicateurs de détection de l’automatisation.
- User agent – imite un navigateur Chrome légitime sur macOS afin de réduire la probabilité de détection des robots.
Ces mesures anti-détection permettent au scraper d’apparaître comme un utilisateur normal naviguant sur Google plutôt que comme un script automatisé.
Étape 6 – navigation et chargement de contenu dynamique
Naviguez jusqu’à l’URL construite et attendez le chargement complet du contenu dynamique :
await page.goto(url, wait_until="networkidle")
await page.wait_for_timeout(2000)Explication de la stratégie de chargement :
- wait_until=”networkidle ” – attend que l’activité du réseau s’arrête, ce qui indique que la page est entièrement chargée.
- wait_for_timeout – tampon supplémentaire pour la génération de contenu AI.
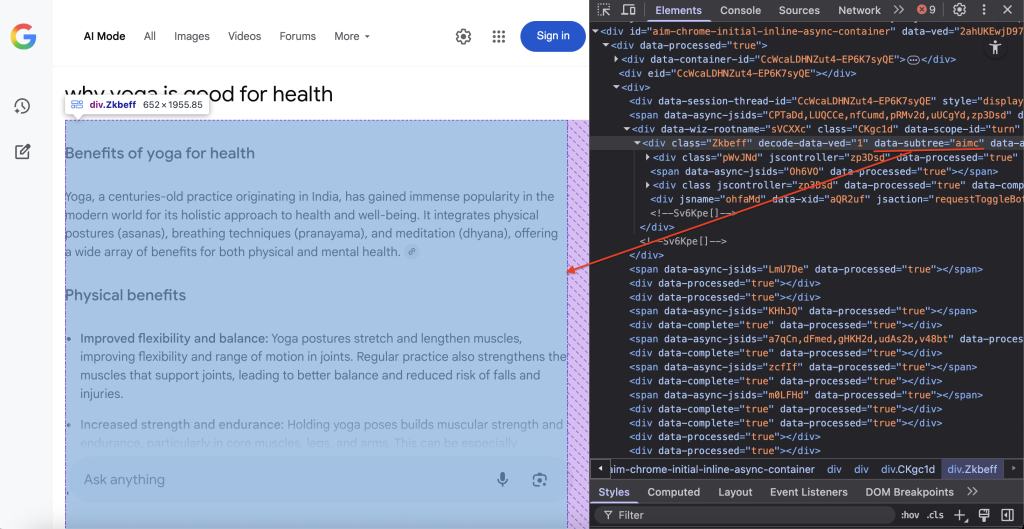
Étape 7 – localisation du contenu et extraction du DOM
Localisez le conteneur DOM spécifique qui contient le contenu du mode IA de Google :
container = await page.query_selector('div[data-subtree="aimc"]')Le sélecteur CSS div[data-subtree=”aimc”] cible l’AIMC (AI Mode Container) de Google.
Étape 8 – Extraction et stockage des données
Extrayez le contenu du texte et enregistrez-le dans le fichier spécifié :
si container :
text = (await container.inner_text()).strip()
si texte :
avec open(output_path, "w", encoding="utf-8") as f :
f.write(text)
print(f "Réponse AI enregistrée à '{chemin_de_sortie}' ({len(texte) :,} caractères)")
await browser.close()
return True
else :
print("Le conteneur du mode AI a été trouvé mais ne contient aucun contenu.")
else :
print("Aucun contenu en mode AI n'a été détecté sur la page.")
await browser.close()
return FalseDéroulement du processus :
- Vérifier que le conteneur AI existe sur la page à l’aide de l’interrogation du DOM.
- Extraire le contenu en texte brut sans balises HTML à l’aide de la fonction inner_text().
- Enregistrer le contenu dans le fichier spécifié avec le codage UTF-8.
- Fermer correctement les ressources du navigateur pour éviter les fuites de mémoire.
Étape 9 – Exécuter la fonction de scraping
Exécutez l’opération de scraping complète en appelant la fonction avec la requête souhaitée :
if __name__ == "__main__" :
asyncio.run(scrape_google_ai_mode("why yoga is good for health"))Code complet
Voici le code complet combinant toutes les étapes :
import asyncio
import urllib.parse
from playwright.async_api import async_playwright
async def scrape_google_ai_mode(
query : str, output_path : str = "ai_response.txt"
) -> bool :
url = f "https://www.google.com/search?q={urllib.parse.quote_plus(query)}&udm=50"
async avec async_playwright() as pw :
browser = await pw.chromium.launch(
headless=False, args=["--disable-blink-features=AutomationControlled"]
)
page = await browser.new_page(
user_agent="Mozilla/5.0 (Macintosh ; Intel Mac OS X 10_15_7) "
"AppleWebKit/537.36 (KHTML, comme Gecko) "
"Chrome/139.0.0.0 Safari/537.36"
)
await page.goto(url, wait_until="networkidle")
await page.wait_for_timeout(1000)
container = await page.query_selector('div[data-subtree="aimc"]')
if container :
text = (await container.inner_text()).strip()
if text :
with open(output_path, "w", encoding="utf-8") as f :
f.write(text)
print(
f "Réponse AI enregistrée à '{chemin_de_sortie}' ({len(texte) :,} caractères)"
)
await browser.close()
return True
else :
print("Conteneur Mode AI trouvé mais vide.")
else :
print("Aucun contenu en mode AI n'a été trouvé.")
await browser.close()
return False
if __name__ == "__main__" :
asyncio.run(scrape_google_ai_mode("why yoga is good for health"))Lorsqu’il est exécuté avec succès, ce script crée un fichier texte contenant la réponse AI extraite :

Bon travail ! Vous avez réussi à extraire le contenu de Google AI Mode.
Défis et limites du scraping manuel
Le scraping manuel s’accompagne de difficultés opérationnelles importantes qui s’accentuent à grande échelle.
- Détection des robots et vérification CAPTCHA. Google met en œuvre des mécanismes de détection sophistiqués qui identifient les modèles de trafic automatisés. Après un nombre limité de requêtes, le système déclenche la vérification CAPTCHA, ce qui bloque efficacement la collecte de données supplémentaires.
- Complexité de l’infrastructure et de la maintenance. Les opérations à grande échelle qui réussissent nécessitent diverses techniques pour éviter d’être bloquées, comme des réseaux proxy résidentiels de haute qualité, la rotation des agents utilisateurs, l’évasion des empreintes digitales des navigateurs et des stratégies sophistiquées de distribution des requêtes. Cela entraîne des frais généraux techniques importants et des coûts de maintenance permanents.
- Contenu dynamique et modifications de la présentation. Google met fréquemment à jour la structure de son interface, ce qui peut casser les analyseurs existants du jour au lendemain, nécessitant une attention immédiate et des mises à jour du code pour maintenir la fonctionnalité.
- Complexité de l’analyse. Les réponses du mode IA contiennent des structures imbriquées, des citations dynamiques et un formatage variable qui nécessitent une logique d’analyse sophistiquée. Le maintien de l’exactitude des différents types de réponses exige des tests approfondis et une gestion des erreurs.
- Limites de l’extensibilité. Les approches manuelles se heurtent à la difficulté du traitement en masse, de la gestion des requêtes simultanées et de la cohérence des performances entre les régions géographiques et les secteurs de recherche verticaux.
Ces limites expliquent pourquoi de nombreuses organisations préfèrent des solutions spécialisées qui gèrent la complexité de manière professionnelle. Cela nous amène à explorer l’API Google AI Mode Scraper spécialement conçue par Bright Data.
Méthode 2 – API Google AI Mode Scraper
L’API Google AI Mode Scraper de Bright Data fournit une solution prête à la production qui élimine la complexité de la maintenance de l’infrastructure de scraping tout en offrant une fiabilité et des performances de niveau professionnel. L’API extrait des points de données complets, notamment le code HTML de la réponse, le texte de la réponse, les liens joints, les citations et 12 champs supplémentaires.
Caractéristiques principales
- Gestion automatisée de l’antibot et du proxy. L’API exploite le vaste réseau de proxy résidentiel de Bright Data, qui compte plus de 150 millions d’adresses IP, associé à des techniques avancées d’évasion des robots. Cette infrastructure élimine les problèmes de CAPTCHA et de blocage d’IP.
- Sortie de données structurées. L’API fournit des données formatées de manière cohérente dans plusieurs formats d’exportation, notamment JSON, NDJSON et CSV, pour des options d’intégration flexibles.
- Évolutivité à l’échelle de l’entreprise. Conçue pour les opérations à fort volume, l’API traite efficacement des milliers de requêtes avec une évolution prévisible des coûts grâce à notre modèle de tarification par résultat réussi.
- Personnalisation géographique. La spécification de pays cibles pour les résultats spécifiques à un lieu vous permet de comprendre comment les réponses de l’IA varient en fonction des différents marchés et de la démographie des utilisateurs.
- Fonctionnement sans maintenance. Notre équipe surveille et adapte en permanence le scraper aux changements apportés par Google. Lorsque Google modifie les interfaces du mode IA ou met en œuvre de nouvelles mesures anti-bots, les mises à jour se déploient automatiquement sans nécessiter d’intervention de la part de votre équipe de développement.
Résultat : une extraction complète des données de Google AI Mode avec la fiabilité d’une entreprise et sans frais d’infrastructure.
Démarrer avec l’API Google AI Mode Scraper
Le processus de mise en œuvre implique la création d’un compte et la génération d’une clé API pour les nouveaux utilisateurs de Bright Data, puis le choix de votre méthode d’intégration préférée. Créez votre compte Bright Data gratuit et générez votre clé d’authentification API en 4 étapes simples.
Ensuite, accédez à la bibliothèque de scrapeurs Web de Bright Data et recherchez “google” pour localiser les options de scraper disponibles. Cliquez sur “google.com”.
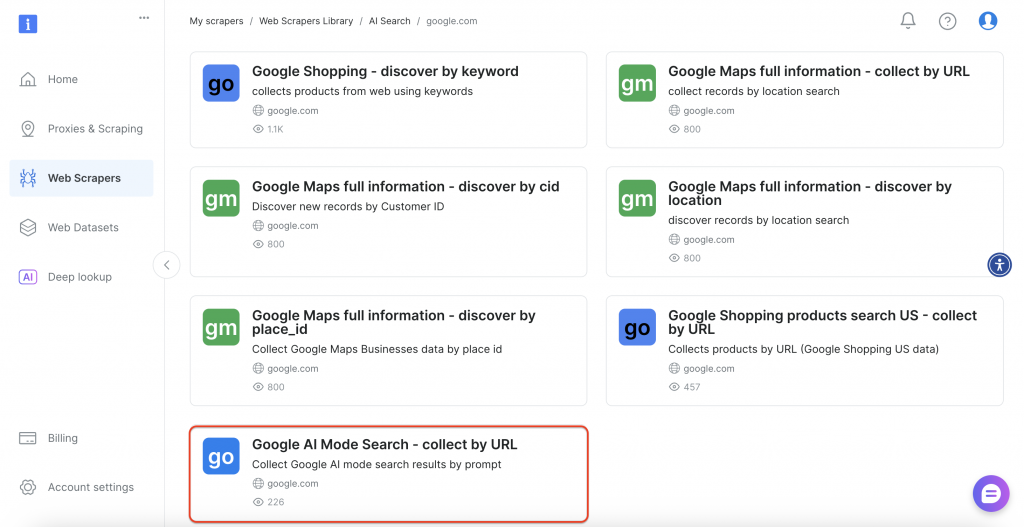
Sélectionnez ensuite l’option “Google AI Mode Search” dans l’interface.
Le scraper propose des méthodes de mise en œuvre sans code et basées sur l’API afin de répondre aux différentes exigences techniques et capacités de l’équipe.
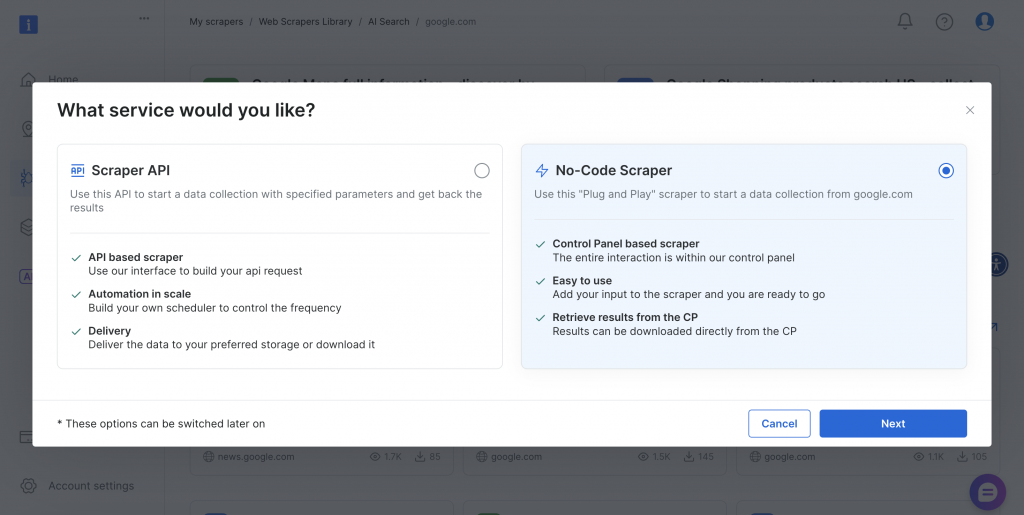
Examinons ces deux approches.
Scraper interactif (scraper sans code)
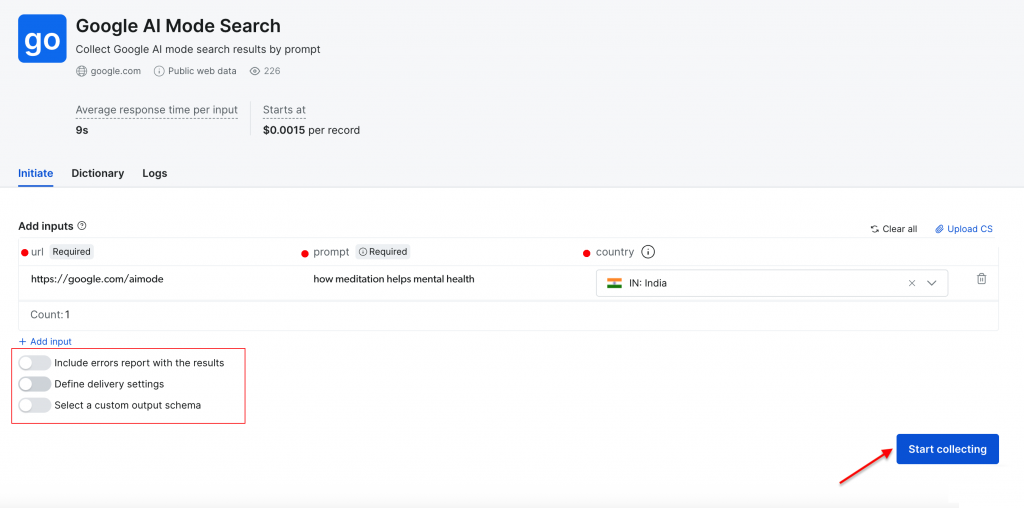
L’interface web offre une approche conviviale pour ceux qui préfèrent ne pas travailler avec du code. Vous pouvez saisir des requêtes de recherche directement dans le tableau de bord ou télécharger des fichiers CSV contenant plusieurs requêtes pour un traitement par lots. La plateforme se charge de tout automatiquement et fournit les résultats sous forme de fichiers téléchargeables.
Paramètres requis :
- URL – définie par défaut à https://google.com/aimode (elle reste constante).
- Invitation – votre requête ou question pour l’analyse de l’IA de Google.
- Pays – emplacement géographique pour les résultats spécifiques à une région (facultatif).
Configuration supplémentaire :
- Paramètres de livraison – sélectionnez le format de sortie et la méthode de livraison que vous préférez.
- Schéma personnalisé – choisissez les champs de données à inclure dans votre exportation.
- Traitement par lots – traiter plusieurs requêtes simultanément via le téléchargement de fichiers CSV.
Effectuons une recherche simple en utilisant l’invite “comment la méditation aide la santé mentale” avec “l’Inde” comme pays cible. Cliquez sur le bouton “Commencer la collecte” pour lancer le processus.
Le tableau de bord permet de suivre la progression en temps réel(Ready, Running) et, une fois la collecte terminée, vous pouvez télécharger vos résultats dans le format de votre choix.
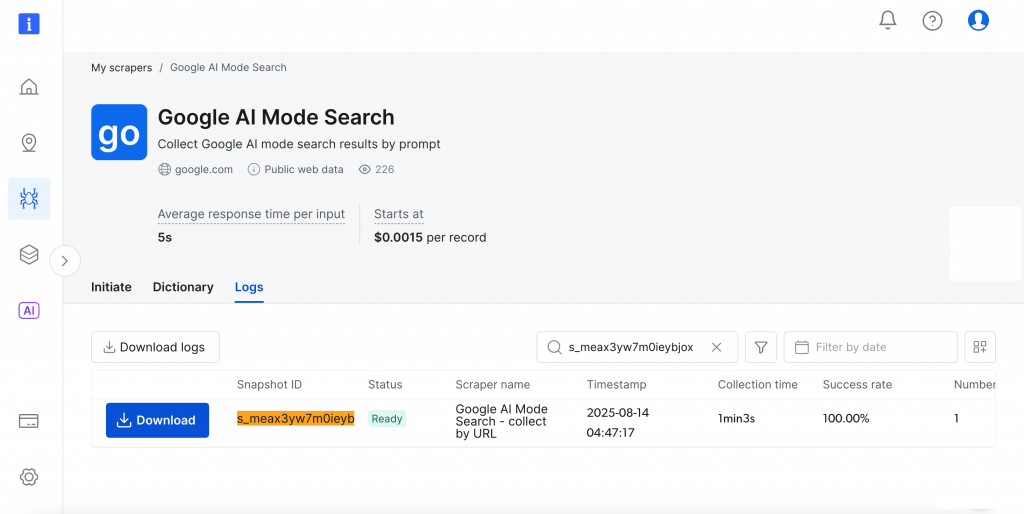
Plutôt génial, non ?
Le scraping basé sur une API (Scraper API)
L’approche programmatique offre une plus grande flexibilité et des capacités d’automatisation grâce à des points d’extrémité d’API RESTful. L’interface complète de création et de gestion des requêtes API permet de contrôler entièrement vos opérations de scraping :
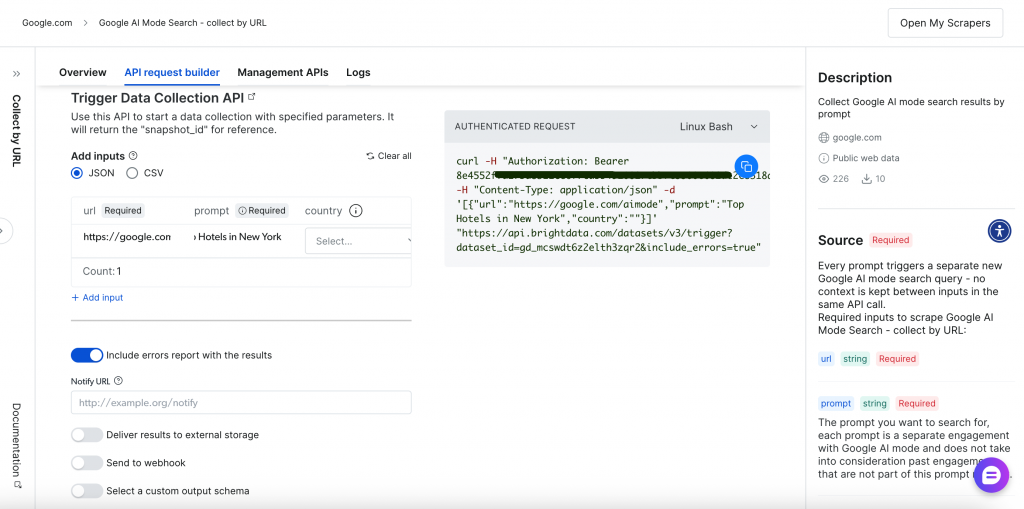
Découvrons le processus de scraping basé sur l’API.
Étape 1 – déclencher la collecte de données
Commencez par déclencher la collecte de données à l’aide de l’une des méthodes suivantes :
Exécution d’une seule requête :
curl -H "Authorization : Bearer <YOUR_API_TOKEN>" N -H "Content-Type : application, application, etc.
-H "Content-Type : application/json" N- -d '[[[[]]]].
-d '[
{
"url" : "https://google.com/aimode",
"prompt" : "conseils de santé pour les utilisateurs d'ordinateurs",
"country" : "US"
}
]'
"https://api.brightdata.com/datasets/v3/trigger?dataset_id=gd_mcswdt6z2elth3zqr2&include_errors=trueTraitement par lots avec téléchargement CSV :
curl -H "Authorization : Bearer <YOUR_API_TOKEN>" N -F '' N
-F 'data=@/path/to/your/queries.csv' N- "data=@/path/to/your/queries.csv" ]
"https://api.brightdata.com/datasets/v3/trigger?dataset_id=gd_mcswdt6z2elth3zqr2&include_errors=true"Composants de la requête :
- Authentification – jeton de porteur dans l’en-tête pour un accès sécurisé.
- Dataset ID – identifiant spécifique pour Google AI Mode scraper.
- Format d’entrée – tableau JSON ou fichier CSV contenant les paramètres de la requête.
- Gestion des erreurs – inclure le paramètre “erreurs” pour un retour d’information complet.
Vous pouvez également sélectionner votre méthode de livraison via un webhook pour un traitement automatisé des résultats.
Étape 2 – Suivre la progression du travail
Utilisez l’ID de l’instantané renvoyé pour suivre la progression de la collecte:
curl -H "Authorization : Bearer <YOUR_API_TOKEN>" N- "<snapshot ID".
"https://api.brightdata.com/datasets/v3/progress/<snapshot_id>"La réponse indique “en cours” pendant la collecte des données et “prêt” lorsque les résultats sont disponibles pour le téléchargement.
Étape 3 – Téléchargement des résultats
Téléchargez le contenu de l’instantané ou livrez-le à l’emplacement de stockage spécifié. Récupérez les résultats dans le format de votre choix :
curl -H "Authorization : Bearer <YOUR_API_TOKEN>" N- "<snapshotshot.com".
"https://api.brightdata.com/datasets/v3/snapshot/<snapshot_id>?format=json"L’API renvoie des données structurées complètes pour chaque requête :
{
"url" : "https://www.google.co.in/search?q=health+tips+for+computer+users&hl=en&udm=50&aep=11&...",
"prompt" : "conseils de santé pour les utilisateurs d'ordinateurs",
"answer_html" : "<html>...réponse HTML complète...</html>",
"answer_text" : "Conseils de santé pour les utilisateurs d'ordinateurs Passer de longues périodes devant un ordinateur peut entraîner divers problèmes de santé, notamment une fatigue oculaire, des douleurs musculo-squelettiques et une réduction de l'activité physique...",
"links_attached" : [
{
"url" : "https://www.aao.org/eye-health/tips-prevention/computer-usage",
"text" : null,
"position" : 1
},
{
"url" : "https://uhs.princeton.edu/health-resources/ergonomics-computer-use",
"text" : null,
"position" : 2
}
],
"citations" : [
{
"url" : "https://www.ramsayhealth.co.uk/blog/lifestyle/five-healthy-tips-for-working-at-a-computer",
"title" : null,
"description" : "Soins de santé Ramsay",
"icône" : "https://...icon-url...",
"domaine" : "https://www.ramsayhealth.co.uk",
"cité" : faux
},
{
"url" : "https://my.clevelandclinic.org/health/diseases/24802-computer-vision-syndrome",
"title" : null,
"description" : "Clinique de Cleveland",
"icône" : "https://...icon-url...",
"domaine" : "https://my.clevelandclinic.org",
"cited" : faux
}
],
"country" : "IN",
"answer_text_markdown" : "Conseils de santé pour les utilisateurs d'ordinateurs...",
"timestamp" : "2026-08-07T05:02:56.887Z",
"input" : {
"url" : "https://google.com/aimode",
"prompt" : "conseils de santé pour les utilisateurs d'ordinateurs",
"country" : "IN"
}
}Si simple et si efficace !
Ce flux de travail API simple s’intègre de manière transparente dans toute application ou projet. Le générateur de requêtes API de Bright Data fournit également des exemples de code dans plusieurs langages de programmation pour faciliter la mise en œuvre.
Conclusion
Nous avons exploré deux approches : une solution à faire soi-même en utilisant Python et Playwright, et l’API clé en main Google AI Mode Scraper de Bright Data.
Dans un paysage de recherche en évolution rapide, où les algorithmes et les interfaces changent fréquemment, disposer d’une infrastructure de scraping robuste et bien entretenue est inestimable. L’API vous évite de devoir constamment mettre à jour la logique d’analyse ou de gérer les restrictions d’IP, ce qui vous permet de vous concentrer entièrement sur l’analyse des riches informations générées par l’IA à partir des résultats de recherche de Google et d’extraire le maximum de valeur des données.
Prochaine étape
- Élargissez votre collecte de données Google. Puisque vous travaillez déjà avec le mode Google AI, envisagez d’explorer d’autres sources de données Google. Nous disposons également d’un guide complet sur la récupération des aperçus de Google AI pour une couverture plus large. Vous pouvez accéder à des fonctionnalités spécialisées pour Google News, Maps, Search, Trends, Reviews, Hotels, Videos et Flights.
- Testez sans risque. Tous les produits principaux sont assortis d’options d’essai gratuit, et nous remboursons les premiers dépôts jusqu’à 500 €. Vous avez ainsi la possibilité d’expérimenter les fonctionnalités étendues avant de vous engager.
- Évoluez avec des solutions intégrées. Au fur et à mesure que vos besoins augmentent, envisagez le serveur Web MCP, qui connecte les applications d’intelligence artificielle directement aux données Web sans développement personnalisé pour chaque site. Commencez dès maintenant avec un plan gratuit de 5 000 requêtes mensuelles !
- Une infrastructure d’entreprise dès que vous êtes prêt. De nombreuses équipes commencent par des projets individuels comme le vôtre et ont ensuite besoin d’une infrastructure robuste pour des opérations plus importantes. La plateforme complète fournit l’infrastructure sous-jacente lorsque vous êtes prêt à vous développer.
Vous n’êtes pas sûr de l’étape suivante ? Parlez-en à notre équipe – nous la tracerons pour vous.






