

Exa est un moteur de recherche sémantique. Bright Data est une infrastructure de données Web. Il s’agit de produits fondamentalement différents, et le choix de l’un ou de l’autre dépend entièrement de ce que votre agent IA doit réellement accomplir.
Cette comparaison passe au crible les deux produits sous tous les angles qui comptent pour les équipes d’IA en production : coût, limites de débit, couverture, accès et données historiques. Pas d’évaluations vagues, juste des chiffres et des faits.
TL;DR – Bright Data vs Exa en bref
- Exa est un moteur de recherche sémantique ; Bright Data est une infrastructure de données Web.
- L’API SERP de Bright Data coûte 1,50 $ pour 1 000 requêtes ; Exa facture 7 $ pour 1 000 requêtes.
- La limite
de requêtespar seconde (QPS) par défaut d’Exa est de 10. Bright Data n’impose aucune limite de requêtes simultanées. - Bright Data Web Unlocker peut explorer les pages protégées contre les bots. Exa ne le peut pas.
- Bright Data détient plus de 50 pétaoctets de données Web historiques. Exa fonctionne uniquement en temps réel.
- La fonctionnalité « Find Similar » d’Exa est unique et n’a pas d’équivalent direct chez Bright Data.
- Utilisez Exa pour la découverte sémantique. Utilisez Bright Data pour l’extraction de données de référence à grande échelle.
Bright Data vs Exa : comparaison directe
| Dimension | Bright Data | Exa |
|---|---|---|
| Catégorie de produit | Infrastructure de données Web (réseau de proxys + scraping + jeux de données) | API de moteur de recherche sémantique |
| Approche de recherche | Scraping réel des moteurs de recherche (Google, Bing, Yandex, etc.) via l’API SERP + découverte en temps réel via l’API Discover | Index neuronal basé sur des embeddings personnalisés (index propre) |
| Résultats par requête | Jusqu’à 1 000 (API Discover) | Jusqu’à 100 (standard) ; jusqu’à 1 000 en version Entreprise |
| Contenu de la page complète | Oui, extraction en direct via Web Unlocker, renvoyée au format Markdown | Oui, via le point de terminaison /contents (1 $ par 1 000 pages supplémentaires) |
| Anti-bot et contournement du CAPTCHA | Oui, intégré à Web Unlocker ; plus de 150 millions d’adresses IP Proxy | Non, impossible d’explorer les pages protégées par un identifiant ou une protection anti-bot |
| Données historiques | Oui, plus de 50 Po d’archives Web ; Jeux de données prédéfinis | Non, index en temps réel uniquement |
| Limites de débit | Aucune limite sur les requêtes simultanées (API SERP) | 10 QPS par défaut sur /search; personnalisable sur Enterprise |
| Tarification (PAYG) | À partir de 1,50 $ pour 1 000 requêtes (API SERP) | 7 $ pour 1 000 requêtes (recherche standard, 1 à 10 résultats) |
| Moteurs de recherche pris en charge | Google, Bing, DuckDuckGo, Yandex, Baidu, Naver, Yahoo | Index neuronal propriétaire d’Exa |
| Conformité | RGPD, CCPA, SOC 2, SOC 3, ISO 27701 | SOC 2 Type II, option ZDR |
| Intégration MCP | Oui, serveur MCP Bright Data (gratuit, 5 000 requêtes gratuites/mois) | Oui, serveur Exa MCP |
| Intégrations de frameworks | LangChain, LlamaIndex, CrewAI, Agno, Dify, n8n, Zapier, plus de 70 | LangChain, LlamaIndex, CrewAI, Vercel IA SDK, plus de 20 |
| Offre gratuite | Oui, essai gratuit | Oui, 1 000 requêtes/mois |
| SLA Entreprise | Oui, SLA à 99,9 %, gestionnaire de compte dédié | Oui, SLA personnalisé, accompagnement individuel |
Qu’est-ce qu’Exa ?
Exa est un moteur de recherche spécialement conçu pour les applications d’IA. Plutôt que d’utiliser l’indexation traditionnelle par mots-clés, Exa a développé son propre index neuronal, un modèle d’embeddings à grande échelle entraîné sur le Web. Lorsque vous interrogez Exa, il effectue une recherche vectorielle sémantique dans cet index et renvoie des résultats classés par pertinence conceptuelle, et non par chevauchement de mots-clés.
Ce choix architectural est le principal facteur de différenciation d’Exa. Il permet de répondre à des questions telles que « trouver des articles similaires à cette URL arXiv » ou « des entreprises qui font ce que fait Nvidia dans le domaine des semi-conducteurs » d’une manière qu’un Scraper de SERP basé sur des mots-clés ne peut pas faire. En mars 2026, l’index d’Exa comprenait plus d’un milliard de profils de personnes et 70 millions d’entrées d’entreprises, et proposait des modes de recherche dédiés aux actualités, au code et aux rapports financiers. Si vous évaluez des alternatives à Exa, le guide des meilleures alternatives à Exa pour la recherche IA présente une comparaison détaillée des outils concurrents, notamment Bright Data, Tavily et Firecrawl.
Les points forts d’Exa
Recherche sémantique « Trouver des pages similaires ». Aucune autre API de recherche ne propose de « trouver des pages conceptuellement similaires à cette URL ». Il s’agit d’un véritable écart de fonctionnalités que Bright Data ne comble pas.
Récupération à faible latence. Exa Instant fournit des réponses en moins de 200 ms. Une recherche standard prend entre 100 et 1 200 ms. Pour les interfaces de chat interactives et les agents en temps réel, cette vitesse constitue un véritable avantage.
Expérience développeur. SDK en Python et TypeScript, intégrations natives avec LangChain, LlamaIndex et CrewAI, prise en charge de MCP Server et 1 000 requêtes gratuites par mois. Passer de zéro à une intégration d’agent fonctionnelle ne prend que quelques minutes.
Index de domaines spécialisés. L’index des personnes d’Exa (plus d’un milliard de profils, plus de 50 millions de mises à jour hebdomadaires) et l’index des entreprises (plus de 70 millions d’entreprises) sont spécialement conçus pour les agents de recrutement, les pipelines de veille commerciale et les workflows d’enrichissement des données sur les entreprises.
Précision de référence élevée. Lors d’un test de récupération multi-sauts sur WebWalker, Exa a obtenu un score de 81 % contre 71 % pour Tavily lors d’une évaluation menée par une entreprise du Fortune 100 (janvier 2025). Dans le benchmark de 100 requêtes d’AIMultiple sur 8 API, Exa s’est classé 3e avec un Agent Score de 14,39.
Limites fondamentales d’Exa à grande échelle
Les limites de débit d’Exa restreignent les charges de travail en production. La limite par défaut pour /search est de 10 QPS (600 requêtes par minute). Cela a été confirmé directement dans la documentation officielle d’Exa sur les limites de débit. Pour les pipelines multi-agents exécutant des milliers de tâches de recherche en parallèle, ce plafond oblige les équipes à mettre en place une logique de réessai et une file d’attente des requêtes dès le premier jour. Les clients professionnels peuvent négocier des limites plus élevées, mais cela nécessite une discussion commerciale distincte.
Exa ne peut pas contourner les protections anti-bot. Exa explore le Web ouvert selon son propre calendrier. Il ne peut pas récupérer les pages protégées par Cloudflare, des pages nécessitant une connexion, des systèmes CAPTCHA ou des détections de bots utilisant beaucoup de JavaScript. Pour l’Intelligence compétitive, la Surveillance des prix ou tout autre cas d’utilisation où les pages les plus précieuses sont aussi les plus protégées, il s’agit d’une limite infranchissable.
Pas de couche de données historiques. Exa fonctionne uniquement en temps réel. Il n’y a pas de produit d’archivage, pas d’ensemble de données historiques, aucun moyen de comparer les résultats d’aujourd’hui à ceux du trimestre dernier. Pour la détection d’anomalies, l’analyse des tendances ou les résultats d’agents basés sur des références, il s’agit d’une lacune structurelle.
L’index d’Exa n’est pas celui de Google. Exa renvoie des résultats provenant de son propre index neuronal propriétaire, et non de Google, Bing ou Yandex. Pour tout cas d’utilisation nécessitant de savoir exactement ce qu’un utilisateur réel voit sur Google à l’instant présent (surveillance SEO, veille publicitaire, suivi de classement, Protection de la marque), l’index d’Exa n’est pas la bonne source de données.
La tarification est peu évolutive à fort volume. À 1 million de requêtes par mois, la recherche standard d’Exa coûte plus de 7 000 $. Avec le contenu de la page complète, ce chiffre grimpe à plus de 8 000 $. Exa a mis à jour sa tarification en mars 2026, faisant passer la recherche standard de 5 $/1 000 à 7 $/1 000 et introduisant un niveau « Agentic » à 12 $/1 000.
Qu’est-ce que Bright Data ?
Bright Data est une infrastructure de données web. Elle ne dispose pas de son propre index de recherche, mais accède au web réel en direct à grande échelle, grâce à une suite de produits conçus pour différents modèles d’acquisition de données.
L’API SERP récupère en temps réel les résultats réels de Google, Bing, Yandex, Baidu, DuckDuckGo, Yahoo et Naver, depuis n’importe lequel des 195 pays, avec un ciblage géographique au niveau de la ville. Elle renvoie ce qu’un utilisateur réel situé à cet endroit verrait à l’instant même, et non ce qu’un index estime qu’il devrait voir.
L’API Discover est spécialement conçue pour les charges de travail des agents qui ont besoin de données plus larges et plus approfondies provenant du Web en temps réel plutôt que d’une liste superficielle de liens classés par référencement. Elle trouve des URL en temps réel avec jusqu’à 1 000 résultats par requête, classés en fonction de l’intention spécifique de l’agent plutôt que de la position SEO, avec un contenu Markdown nettoyé en option pour l’ancrage et la vérification RAG. Contrairement aux moteurs de recherche ou aux index mis en cache, chaque requête Discover est exécutée au moment de la requête sur le Web en temps réel, ce qui la rend particulièrement adaptée aux workflows d’intelligence compétitive, de surveillance des risques et de diligence raisonnable.
Web Unlocker récupère n’importe quelle page web, y compris celles protégées par Cloudflare, des CAPTCHA, des pages de connexion ou le rendu JavaScript, et renvoie un contenu Markdown nettoyé. Il achemine les requêtes via un réseau de plus de 150 millions d’IPs résidentielles dans 195 pays, gérant automatiquement le contournement de la détection.
La couche de Jeux de données fournit des données structurées prêtes à l’emploi couvrant plus de 100 domaines. L’API Web Archive fournit plus de 50 pétaoctets de données Web historiques remontant à plusieurs années, ce qui en fait la solution idéale pour l’ancrage historique.
Comment Bright Data aborde les données Web pour l’IA
L’architecture de Bright Data repose sur un principe fondamental : la réalité de terrain est le Web en direct tel qu’il existe réellement, et non une approximation fournie par un index. Pour les équipes d’IA en entreprise qui développent des systèmes de production, cela est important lorsque :
- Votre agent doit récupérer la page de tarification d’un concurrent, et cette page bloque les Scrapers
- Votre agent doit savoir ce que Google affiche réellement pour un mot-clé, et non ce qu’estime un index neuronal
- Votre agent doit exécuter 10 000 requêtes en parallèle sans atteindre le plafond de la limite de débit
- Votre agent doit déterminer si les résultats d’aujourd’hui sont anormaux par rapport à ceux d’il y a six mois
Bright Data bénéficie de la confiance de plus de 20 000 clients, dont des entreprises du classement Fortune 500, et est citée dans le rapport « Competitive Landscape for Web Data Collection Solutions » de Gartner. Elle détient les certifications RGPD, CCPA, SOC 2, SOC 3 et ISO 27701.
Les produits phares : API SERP, Discover API, Web Unlocker, Jeux de données
| Produit | Fonctionnalités | Tarifs |
|---|---|---|
| API SERP | Extraction en temps réel de 7 moteurs de recherche, 195 pays, sortie structurée au format JSON/Markdown | À partir de 1,50 $ pour 1 000 résultats (paiement à l’utilisation) ; jusqu’à 1,00 $ pour 1 000 résultats à partir de 2 millions par mois |
| API Discover | Découverte d’URL en direct jusqu’à 1 000 résultats/requête, classés par intention, contenu Markdown en option | Gratuit (bêta) |
| Web Unlocker | Récupère n’importe quelle page protégée par un système anti-bot, renvoie du Markdown propre | À partir de 1 $ pour 1 000 requêtes |
| Jeux de données | Données structurées prêtes à l’emploi provenant de plus de 100 domaines | À partir de 250 $ pour 100 000 enregistrements |
| API d’archives Web | Plus de 50 Po de données Web historiques | À partir de 0,20 $ pour 1 000 pages HTML |
| Serveur MCP | Connectez directement vos agents IA à la suite complète de produits Bright Data | Gratuit, 5 000 requêtes/mois |
Comparaison des tarifs : Bright Data vs Exa
Tarifs Exa (mars 2026)
| Produit | Prix |
|---|---|
| Recherche standard (1 à 10 résultats) | 7 $ / 1 000 requêtes |
| Résultats supplémentaires au-delà de 10 | +1 $ / 1 000 résultats |
| Recherche avancée / approfondie | 12 $ / 1 000 requêtes |
| Recherche approfondie avec raisonnement | 15 $ / 1 000 requêtes |
| Contenu (texte complet de la page) | 1 $ / 1 000 pages |
| API de réponse | 5 $ / 1 000 réponses |
| Forfait gratuit | 1 000 requêtes/mois |
| Entreprise | Personnalisé |
Nuance importante : la tarification d’Exa est cumulative. Si votre agent a besoin de 10 résultats ainsi que du contenu complet de la page, vous payez la recherche (7 $) plus le contenu (1 $) par 1 000 requêtes. Le coût effectif minimum pour les agents qui ont besoin du texte intégral en ligne est de 8 $/1 000.
Tarification de Bright Data
| Produit | Prix |
|---|---|
| API SERP (PAYG) | 1,50 $ / 1 000 résultats |
| API SERP (380 000 résultats/mois) | 1,30 $ / 1 000 résultats |
| API SERP (900 000 résultats/mois) | 1,10 $ / 1 000 résultats |
| API SERP (2 millions de résultats/mois) | 1,00 $ / 1 000 résultats |
| Web Unlocker | À partir de 1 $ / 1 000 requêtes |
| Jeux de données | À partir de 250 $ / 100 000 enregistrements |
| Archive Web | À partir de 0,20 $ / 1 000 pages HTML |
| API Discover | Gratuit (bêta) |
| Serveur MCP | Gratuit (5 000 requêtes/mois) |
Coût à grande échelle : les chiffres sont éloquents
| Volume | Exa (recherche standard uniquement) | Exa (recherche + contenu) | API SERP de Bright Data |
|---|---|---|---|
| 10 000 requêtes | 70 $ | 80 $ | 15 $ |
| 100 000 requêtes | 700 | 800 | 130-150 $ |
| 1 000 000 de requêtes | 7 000 $ et plus | 8 000 $ et plus | 1 000-1 500 |
Avec 1 million de requêtes par mois, Bright Data est 5 à 7 fois moins cher qu’Exa pour la recherche seule. Pour une comparaison complète des fournisseurs d’API SERP et de recherche Web à grande échelle, consultez les meilleures API SERP et de recherche Web de 2026. Pour les agents qui ont besoin du contenu complet des pages, l’écart se creuse encore davantage : Exa ajoute 1 $ par 1 000 requêtes ; Bright Data Web Unlocker propose un tarif tout compris à partir de 1 $ par 1 000 requêtes.
Bright Data n’impose aucune limite de requêtes simultanées
Il ne s’agit pas d’une différence subtile. La limite de débit par défaut d’Exa pour la recherche est de 10 QPS, soit 10 requêtes par seconde, 600 par minute. Ceci est confirmé dans la documentation officielle d’Exa sur les limites de débit.
L’API SERP de Bright Data n’impose aucune limite sur les requêtes simultanées. D’après leur propre FAQ : « Il n’y a pas de limite au nombre de requêtes simultanées. L’API SERP est conçue pour l’évolutivité. »
Pour les charges de travail à agent unique, avec une requête à la fois, cela n’a pas d’importance. Pour les pipelines d’IA en production exécutant des dizaines ou des centaines de tâches de recherche en parallèle, les systèmes d’Intelligence compétitive, les frameworks de recherche multi-agents et les piles de surveillance en temps réel, la différence est fondamentale. Avec Exa, vous concevez votre architecture en fonction d’un plafond dès le premier jour.
Bright Data peut accéder à des pages auxquelles Exa ne peut pas accéder
Exa explore le Web ouvert. Il ne peut pas accéder aux :
- aux pages protégées par Cloudflare
- Les sites avec des barrières de connexion ou des exigences d’authentification
- Les pages avec CAPTCHA
- Les sites riches en JavaScript qui ne renvoient aucun contenu aux requêtes HTTP brutes
- du contenu soumis à des restrictions géographiques nécessitant des adresses IP locales
Ce n’est pas une critique, cela ne relève tout simplement pas du champ d’application du produit Exa.
Le Web Unlocker de Bright Data a été spécialement conçu pour résoudre ce problème. Il achemine les requêtes via plus de 150 millions d’adresses IP résidentielles, gère l’empreinte digitale du navigateur, effectue la Résolution de CAPTCHA et renvoie le contenu complet de la page sous forme de Markdown épuré. Pour les équipes qui ont besoin de comprendre toute la portée de ce qu’implique le contournement des mesures anti-bot, le guide sur le contournement de Cloudflare pour le Scraping web couvre en détail les techniques pertinentes. Pour l’analyse compétitive des prix, où les données les plus précieuses se trouvent souvent sur les pages les mieux protégées, il s’agit d’une fonctionnalité essentielle.
Voici un exemple minimal illustrant comment un agent de production utiliserait l’API SERP de Bright Data par rapport à Exa pour la même tâche :
# API SERP de Bright Data - résultats Google réels, sans limite de requêtes
import requests
response = requests.get(
"https://api.brightdata.com/serp/req",
headers={"Authorization": "Bearer VOTRE_CLÉ_API"},
params={
"q": "competitor pricing enterprise 2026",
"gl": "us",
"num": 10,
"data_format": "markdown" # Sortie compatible LLM
}
)
results = response.json()
# Exa - recherche sémantique, limite de 10 QPS
from exa_py import Exa
exa = Exa(api_key="VOTRE_CLÉ_EXA")
results = exa.search_and_contents(
"prix des concurrents entreprise 2026",
num_results=10,
text=True
)
# 7 $/1 000 (recherche) + 1 $/1 000 (contenu) = 8 $/1 000 de coût effectifLe résultat fonctionnel est similaire pour les requêtes de base. Les différences apparaissent lorsque vous devez exécuter cette opération en parallèle pour 1 000 concurrents, ou lorsque la page cible bloque les robots d’indexation d’Exa. Voir cet exemple :
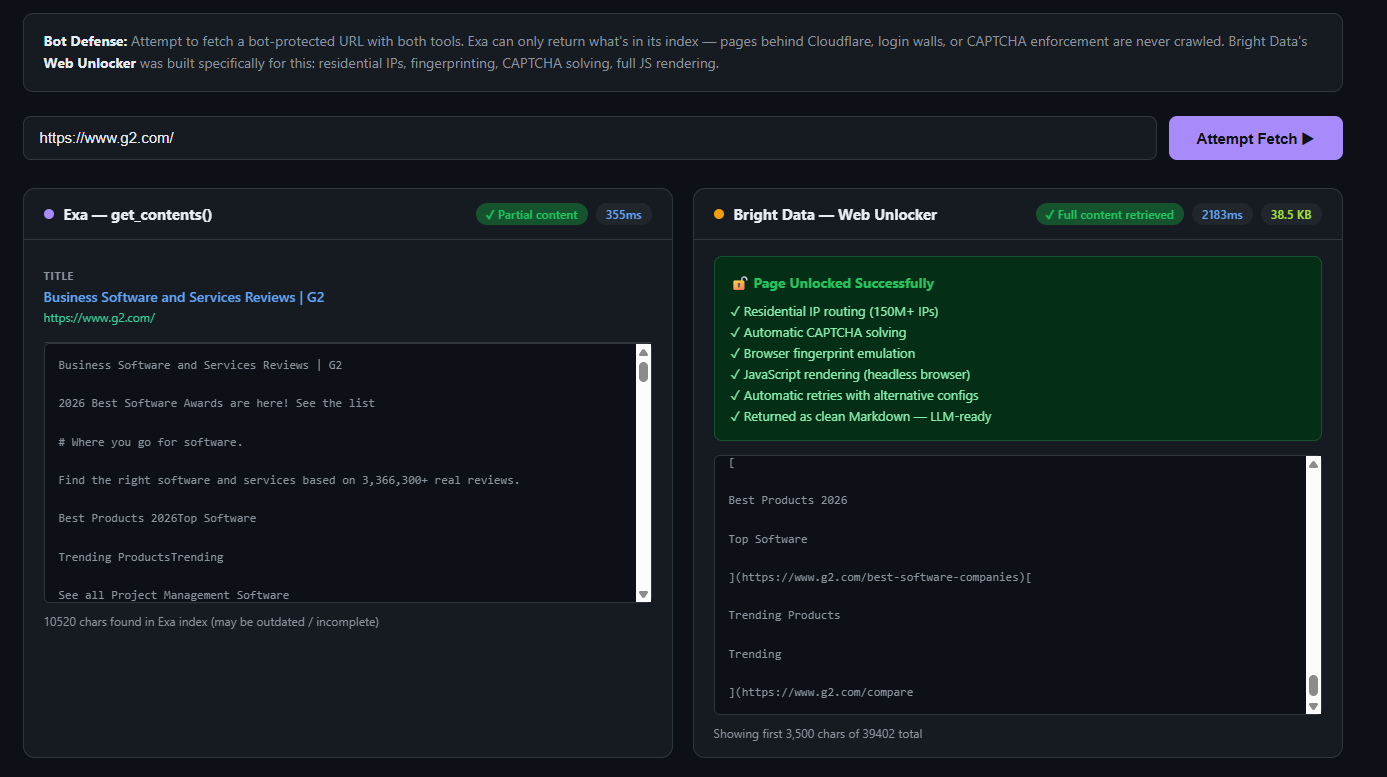
Si vous souhaitez l’essayer vous-même, consultez cette démo sur GitHub.
Exa ne dispose pas de couche de données historiques
Les agents IA qui détectent les changements de prix, les changements de politique ou les mouvements du marché ont besoin d’une base de référence pour fonctionner. On ne peut pas qualifier quelque chose d’anomalie sans savoir à quoi ressemble la normale.
Exa fonctionne uniquement en temps réel. Il n’y a pas de produit d’archivage, pas d’ensemble de Jeux de données historiques, pas de fonctionnalité de séries chronologiques.
L’API Web Archive de Bright Data contient plus de 50 Po de données Web historiques, et ce volume augmente chaque jour. Des Jeux de données structurés prêts à l’emploi couvrent plus de 100 domaines et fournissent des références historiques pour le commerce électronique, les réseaux sociaux, l’immobilier et bien plus encore. Pour les travaux d’analyse longitudinale, comme surveiller l’évolution de la page de tarification d’un concurrent sur 12 mois, suivre les dépôts réglementaires au fil du temps ou détecter les changements dans l’opinion publique, Bright Data dispose de l’infrastructure nécessaire, contrairement à Exa.
Guide de décision sur les cas d’utilisation
| Cas d’utilisation | Meilleur choix | Raison |
|---|---|---|
| Prototypage RAG / hackathon | Exa | Rapide, offre gratuite, LangChain natif, configuration minimale |
| Recherche de similarité sémantique (« trouver des pages similaires à cette URL ») | Exa | L’endpoint « Find Similar » n’a pas d’équivalent chez Bright Data |
| Enrichissement des données sur les personnes/entreprises (agents de recrutement, informations commerciales) | Exa | Plus d’un milliard de profils indexés, index d’entreprises structuré |
| Intelligence compétitive sur les prix (contenu de pages en temps réel) | Bright Data | Web Unlocker contourne les mesures anti-bot ; Exa ne peut pas accéder aux pages protégées |
| Agent de production avec plus de 1 000 requêtes simultanées | Bright Data | Pas de limite de débit ; API SERP conçue pour les charges de travail parallèles |
| Données SERP Google réelles (SEO, surveillance des annonces, suivi des classements) | Bright Data | L’API SERP extrait les données réelles de Google, Exa utilise son propre index |
| Référence historique / détection des anomalies | Bright Data | Archives Web de plus de 50 Po, Jeux de données, capacité de séries chronologiques |
| Pages derrière Cloudflare / murs de connexion | Bright Data | Web Unlocker ; Exa ne peut pas accéder au contenu protégé |
| Recherche multi-moteurs (Google + Bing + Yandex) | Bright Data | L’API SERP couvre 7 moteurs de recherche majeurs dans 195 pays |
| Expérience utilisateur de chat interactif à faible latence | Exa | Exa Instant offre un temps de réponse inférieur à 200 ms |
| Économique pour les volumes élevés (plus de 100 000 requêtes/mois) | Bright Data | 1 à 1,50 $/1 000 contre 7 à 15 $/1 000 chez Exa |
Quand choisir Exa
Exa est l’outil qu’il vous faut si :
- Vous développez un prototype ou menez des recherches préliminaires. Les 1 000 requêtes mensuelles gratuites, la prise en charge native de LangChain/LlamaIndex et l’intégration simple du SDK font d’Exa la solution la plus simple pour ajouter une fonctionnalité de recherche Web à un agent IA.
- Votre cas d’utilisation principal est la similarité sémantique. La fonction « Trouvez-moi des pages similaires à cette URL » est une exclusivité d’Exa. Si c’est votre principal modèle de recherche, choisissez Exa.
- Vous avez besoin de données structurées sur les personnes ou les entreprises. L’index de plus d’un milliard de profils et l’index de plus de 70 millions d’entreprises d’Exa sont véritablement conçus pour les agents d’intelligence commerciale et de recrutement.
- La latence est la principale contrainte. Avec un temps de réponse inférieur à 200 ms via Exa Instant, Exa surpasse toute solution de scraping en direct pour les applications interactives en temps réel.
- Votre volume de requêtes est inférieur à 50 000-100 000 requêtes/mois et vous n’avez pas besoin de données Google réelles ni d’accès à des pages protégées.
Quand choisir Bright Data
Bright Data est l’outil qu’il vous faut si :
- Vous opérez à l’échelle de la production. Un nombre illimité de requêtes simultanées et un SLA garantissant une disponibilité de 99,9 % vous évitent toute solution de contournement technique pour les limites de débit.
- Vous avez besoin de résultats Google réels. L’API SERP effectue le scraping de Google (ainsi que de Bing, Yandex, Baidu, Yahoo, Naver et DuckDuckGo) en temps réel, dans n’importe quel pays, en affichant ce que voient les utilisateurs réels, et non ce qu’estime un index neuronal.
- Votre agent doit accéder à des pages protégées. Web Unlocker gère Cloudflare, les barrières CAPTCHA, les pages de connexion et le rendu JavaScript. Exa ne le peut pas.
- Vous avez besoin de données historiques. L’API Web Archive fournit plus de 50 Po de données historiques pour établir des bases de référence et effectuer des analyses longitudinales.
- Le coût à grande échelle est un facteur important. Avec plus de 100 000 requêtes par mois, Bright Data est 5 à 7 fois moins cher qu’Exa.
- Vous développez des systèmes de niveau entreprise. Avec plus de 20 000 clients, une adoption par les entreprises du Fortune 500, la reconnaissance de Gartner et plus de 70 intégrations de frameworks d’IA, Bright Data s’intègre parfaitement aux piles de données d’entreprise existantes.
Conclusion : deux outils différents pour deux tâches différentes
Exa et Bright Data ne sont pas en concurrence pour la même tâche.
Exa excelle dans ce pour quoi il a été conçu : la recherche neuronale sémantique, l’intégration rapide des développeurs et les index spécialisés pour les personnes et les entreprises. Si vous avez besoin de trouver des pages conceptuellement similaires, d’explorer un voisinage sémantique ou de rechercher parmi 1 milliard de profils LinkedIn, l’architecture d’Exa est parfaitement adaptée à ces tâches.
Bright Data est conçu pour répondre à un ensemble de problèmes différents : accéder à la réalité du Web en temps réel à l’échelle de la production, y compris aux parties du Web qui bloquent les robots d’indexation. L’API SERP fournit de véritables résultats Google à 1,50 $/1 000, sans limite de requêtes simultanées. Le Web Unlocker atteint des pages auxquelles les robots d’Exa ne peuvent pas accéder. L’archive Web fournit la base historique que les API en temps réel ne peuvent pas offrir.
Voici le cadre de décision :
- Si votre agent doit trouver des pages sémantiquement similaires, effectuer des recherches parmi plus d’un milliard de profils ou renvoyer des réponses en moins de 200 ms, Exa est conçu pour cela.
- Si votre agent a besoin d’une échelle de production, de données Google réelles, d’un accès anti-bot, de références historiques ou d’une rentabilité supérieure à 100 000 requêtes par mois, Bright Data est l’infrastructure qu’il vous faut.
De nombreuses équipes d’IA en production utilisent les deux : Exa pour la découverte sémantique aux premières étapes d’un pipeline, et Bright Data pour la vérification en temps réel, l’extraction de pages complètes et l’intelligence SERP à grande échelle. Elles ne s’excluent pas mutuellement. Elles ont simplement des plafonds différents, et à l’échelle de l’entreprise, le plafond d’Exa est rapidement atteint. Pour les équipes qui évaluent l’ensemble des meilleurs serveurs MCP pour les workflows d’IA, le serveur MCP de Bright Data se classe systématiquement comme la meilleure option pour ancrer les agents dans les données Web en temps réel.
Foire aux questions
Quelle est la différence entre Bright Data et Exa ?
Exa est une API de moteur de recherche sémantique qui renvoie des résultats à partir de son propre index neuronal. Bright Data est une infrastructure de données Web qui explore les moteurs de recherche réels, extrait les pages protégées par des mesures anti-bot et fournit des Jeux de données historiques. Ils résolvent des problèmes différents à des échelles différentes.
Bright Data est-il moins cher qu’Exa ?
Oui. L’API SERP de Bright Data est proposée à partir de 1,50 $ pour 1 000 requêtes, selon un modèle de paiement à l’utilisation. La recherche standard d’Exa coûte 7 $ pour 1 000 requêtes. À raison d’un million de requêtes par mois, Bright Data est environ 5 à 7 fois moins cher.
Exa peut-il explorer les sites web protégés par Cloudflare ?
Non. Exa ne peut pas explorer les pages protégées par Cloudflare, les pages nécessitant une connexion ou les systèmes CAPTCHA. Le Web Unlocker de Bright Data est spécialement conçu pour contourner les protections anti-bot, grâce à un réseau de plus de 150 millions d’IPs résidentielles.
Exa impose-t-il une limite de débit ?
Oui. La limite de débit par défaut pour la recherche /search d’Exa est de 10 QPS (600 requêtes par minute). Les clients Enterprise peuvent négocier des limites plus élevées. L’API SERP de Bright Data n’impose aucune limite de requêtes simultanées.
Quelle est la meilleure alternative à Exa pour les agents IA d’entreprise ?
Bright Data est la principale alternative à Exa pour les entreprises. Elle offre un nombre illimité de requêtes simultanées, le scraping en temps réel de Google/Bing/Yandex, le contournement des protections anti-bot via Web Unlocker, des archives de données historiques et la prise en charge des workflows d’agents IA basés sur MCP, le tout avec une tarification au résultat.
Exa dispose-t-il de données historiques ?
Non. Exa fonctionne uniquement en temps réel et ne propose ni archives ni Jeux de données. L’API Web Archive de Bright Data contient plus de 50 Po de données Web historiques, et ce volume augmente chaque jour.




