

Dans cet article de blog, vous comprendrez :
- Ce que sont les jeux de données, les avantages qu’ils offrent, comment ils fonctionnent, quand il est judicieux de les utiliser, et où trouver des jeux de données fiables et de haute qualité.
- Ce que sont les APIs de Scraping web, les avantages qu’elles impliquent, comment elles fonctionnent, quand s’appuyer sur elles, et où trouver des solutions évolutives.
- Comment utiliser les deux dans des scénarios similaires à travers des exemples guidés.
- Comment les jeux de données et les APIs de Scraping web se comparent, et lequel est le mieux adapté selon vos besoins.
- S’il est judicieux de les utiliser ensemble.
Plongeons dans le vif du sujet !
Plonger dans l’Univers des Jeux de Données
Nous commencerons ce guide sur les jeux de données vs APIs de Scraping web par une introduction aux jeux de données.
Qu’est-ce qu’un Jeu de Données ?
Un jeu de données est une collection structurée d’informations organisées pour faciliter l’analyse, le traitement et la réutilisation. Ils sont généralement stockés dans des formats tels que CSV, JSON ou SQL, et peuvent inclure du texte, des chiffres, des images, des vidéos et d’autres types de données.
La plupart des jeux de données se concentrent sur un sujet, une industrie, un marché ou un domaine d’intérêt spécifique, comme la B2B, la vente au détail et d’autres. Cette focalisation plus étroite aide les entreprises et les chercheurs à extraire des informations, identifier des tendances et soutenir la prise de décision basée sur les données.
Les jeux de données sont généralement considérés comme des instantanés statiques de données collectées à un moment précis. Cependant, la plupart des meilleurs fournisseurs de jeux de données proposent des services pour recevoir des enregistrements périodiquement actualisés en récupérant des informations mises à jour depuis les sources de données sous-jacentes.
Plus précisément, les trois principaux avantages offerts par les jeux de données sont :
- Prêts à l’emploi : Données pré-collectées et structurées, immédiatement utilisables pour l’analyse, l’IA ou les applications métier. Aucune connaissance technique requise.
- Rentabilité : Réduit le besoin de ressources internes pour la collecte de données et l’ingénierie.
- Évolutivité : Fournit l’accès à de grands jeux de données couvrant des millions ou des milliards d’enregistrements dans tous les secteurs.
Comment Fonctionnent les Jeux de Données
La plupart des jeux de données modernes proviennent du web, qui est la source d’informations publiques la plus grande et la plus à jour sur Terre. En effet, de nouvelles données sont continuellement générées sur les sites web, les marchés et les plateformes de médias sociaux.
Le processus de création de jeux de données implique les étapes suivantes :
- Collecte de données : Les informations sont rassemblées à partir d’une ou plusieurs sources, le plus souvent des sites web via le Scraping web, des APIs ou des flux publics. Selon le cas d’usage, cela peut inclure des listes de produits, des prix, des avis, des offres d’emploi, du contenu de médias sociaux ou des données d’entreprises.
- Nettoyage et validation des données : Les données brutes sont souvent désordonnées, incomplètes ou dupliquées. Dans cette étape, les erreurs sont supprimées, les formats sont standardisés et les valeurs manquantes sont traitées. Les données sont validées pour garantir leur exactitude et leur cohérence.
- Structuration des données : Les données nettoyées sont organisées dans un format cohérent comme CSV, JSON ou Parquet. Cela facilite leur stockage dans des bases de données ou des entrepôts de données pour les requêtes et leur utilisation dans des workflows d’analyse de données ou d’IA.
Bien que ces étapes puissent techniquement être réalisées en interne, elles sont généralement déléguées à un fournisseur de jeux de données. En effet, la collecte et le traitement de données à grande échelle nécessitent des outils et une expertise spécialisés. Rappelons que certains jeux de données peuvent inclure plusieurs milliards d’enregistrements.
Une fois traités, les fournisseurs de jeux de données distribuent les données via différentes méthodes de livraison. Celles-ci incluent les téléchargements directs pour les petits jeux de données, les intégrations S3 et l’accès via API.
Remarque : Tous les jeux de données ne proviennent pas du web. Certains sont créés via des enquêtes, des études de recherche, des capteurs, des systèmes internes d’entreprise, ou en combinant plusieurs sources. Par exemple, ils peuvent combiner des données ouvertes publiques avec des informations propriétaires ou collectées en privé.
Cas d’Usage
Voici quelques-uns des scénarios les plus pertinents pour les jeux de données dans les grandes entreprises, les petites entreprises, les particuliers et le secteur public :
- Entraînement de modèles IA : Les jeux de données sont au cœur des processus d’apprentissage automatique et d’entraînement de l’IA. En alimentant les modèles avec de grands volumes de données de haute qualité, ils apprennent des schémas et développent des capacités telles que la compréhension du langage, la reconnaissance d’images, les recommandations et les prévisions.
- Analyse des tendances du marché : Analysez les données historiques du marché pour étudier les tendances sectorielles et comprendre le comportement des clients. Validez les idées de produits et soutenez les décisions stratégiques basées sur des données externes réelles plutôt que sur des hypothèses.
- Analytique des médias sociaux : Extrayez des informations sur le comportement des utilisateurs, l’engagement et le sentiment. Surveillez les marques, analysez les audiences, identifiez les influenceurs et évaluez les performances du contenu sur des plateformes telles que Reddit, Facebook et d’autres.
- Intelligence d’affaires et prise de décision : Étudiez les prix, les concurrents et les signaux du marché pour découvrir des opportunités, optimiser l’allocation des ressources et améliorer la prise de décision stratégique.
- Recrutement et intelligence des talents : Analysez les données du marché du travail pour trouver des candidats, comprendre les tendances d’embauche, évaluer la demande de compétences et cartographier les structures de main-d’œuvre des concurrents pour améliorer les stratégies de recrutement.
- Développement de produits et optimisation de l’expérience utilisateur : Analysez les avis des utilisateurs, les retours et les données comportementales pour améliorer les produits. Affinez les fonctionnalités, personnalisez les expériences et optimisez les parcours utilisateurs pour augmenter la satisfaction et la rétention.
Où Obtenir des Jeux de Données Mis à Jour, Structurés et Prêts pour l’IA
Parmi les principaux marchés de jeux de données, Bright Data se classe en première position car il combine une infrastructure web
de données à grande échelle avec des jeux de données prêts à l’emploi de qualité professionnelle.
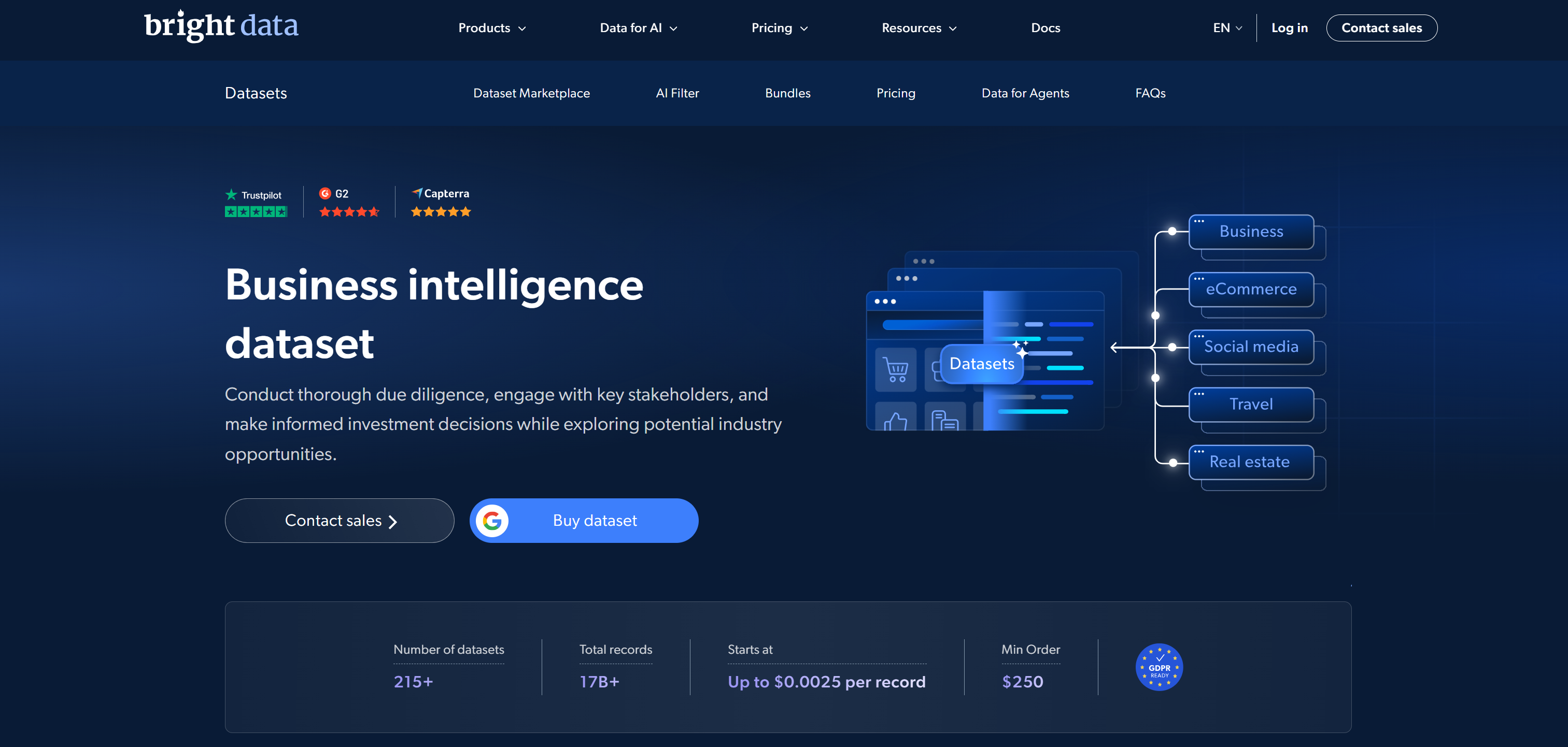
Son marché de jeux de données propose des jeux de données pré-collectés provenant de plus de 350 domaines web, totalisant plus de 17 milliards d’enregistrements. Ceux-ci couvrent le commerce électronique, les médias sociaux, l’immobilier, la finance, les réseaux professionnels et de nombreux autres secteurs. Les jeux de données sont nettoyés, structurés, standardisés et optimisés pour l’IA et le ML. Ils sont livrés dans des formats tels que JSON, CSV, Parquet et NDJSON.
Les jeux de données de Bright Data peuvent également être personnalisés pour répondre à des objectifs très ciblés en les filtrant selon plusieurs dimensions, y compris des critères appliqués aux champs de données. Une couche de filtrage supplémentaire alimentée par l’IA permet aux utilisateurs d’affiner les grands jeux de données à l’aide de requêtes en langage naturel, rendant la sélection des données plus accessible.
Les données sont livrées via plusieurs canaux, notamment l’accès API, Amazon S3, Snowflake, les webhooks, les intégrations de stockage cloud et les téléchargements directs. Cette flexibilité le rend adapté aussi bien aux cas d’usage légers qu’aux pipelines à l’échelle de l’entreprise.
Les jeux de données Bright Data respectent les normes de conformité RGPD et CCPA. Ils sont également soutenus par des processus de validation, de sécurité et de contrôle qualité qui garantissent la fiabilité et l’approvisionnement éthique des données publiquement disponibles.
Les tarifs débutent à 250 $ par jeu de données (100 000 enregistrements), selon le volume et la fréquence de mise à jour (mensuelle, trimestrielle ou semestrielle).
Aperçu des APIs de Scraping Web
Maintenant que vous savez ce que sont les jeux de données et quand les utiliser, vous êtes prêt à explorer les mêmes aspects des APIs de Scraping web.
Qu’est-ce qu’une API de Scraping Web ?
Une API de Scraping web est un service qui vous permet d’extraire des données de sites web sans gérer votre propre infrastructure de scraping. Elle gère des tâches telles que la récupération des pages web cibles, le contournement des protections anti-scraping et anti-bot, et l’analyse des résultats dans des formats structurés.
Les APIs de Scraping web ont tendance à cibler des sites web ou des sources de données spécifiques, comme les plateformes de commerce électronique, les moteurs de recherche ou les sites de médias sociaux. Certaines sont plus génériques ou peuvent être étendues via l’IA pour retourner des données structurées depuis n’importe quel site web. Cela permet aux entreprises et aux développeurs de récupérer des données en direct ou à la demande depuis des sources en ligne pertinentes.
En particulier, les trois avantages fondamentaux des APIs de Scraping web sont :
- Accès aux données en temps réel : Récupérez des informations à jour directement depuis les sites web quand vous en avez besoin.
- Aucune gestion d’infrastructure : Pas besoin de construire et de maintenir des scrapers, des proxies et des systèmes anti-bot.
- Évolutivité : Collectez des données sur des centaines ou des milliers de pages de manière fiable et efficace.
Comment Fonctionnent les APIs de Scraping Web
En coulisses, une API de Scraping web fonctionne ainsi :
- Traitement des requêtes : Un utilisateur envoie une requête à l’API en spécifiant l’URL de la page web cible, avec des arguments potentiels pour personnaliser le comportement de scraping sous-jacent (par exemple, le rendu JavaScript, la localisation IP, etc.).
- Récupération de page et gestion des accès : L’API récupère les pages web cibles en prenant en charge les défis techniques tels que le rendu JavaScript, les proxies, les limites de débit, les CAPTCHAs et autres protections anti-bot.
- Extraction et analyse des données : Le contenu HTML brut ou de réponse est traité et transformé en formats structurés (par exemple, JSON, CSV et autres). Certaines APIs utilisent des modèles prédéfinis, tandis que d’autres s’appuient sur l’IA pour extraire dynamiquement des champs structurés depuis n’importe quelle page web.
- Livraison des données : Les données structurées finales sont retournées à l’utilisateur via la réponse API. Optionnellement, elles peuvent également être envoyées vers des systèmes de stockage tels que S3, des webhooks ou des bases de données pour un traitement ultérieur.
Cas d’Usage
Voici les scénarios les plus importants où les APIs de Scraping web font la différence :
- Etude de marché et suivi concurrentiel : Surveillez les sites web des concurrents, les changements de prix et la disponibilité des produits. Repérez les tendances à mesure qu’elles émergent et adaptez les stratégies commerciales en fonction des signaux du marché en constante évolution.
- Prise de décision financière : Extrayez des données de marché en direct telles que les cours des actions, les mouvements crypto et les mises à jour d’entreprises. Soutenez les stratégies de trading, l’analyse d’investissement et la gestion des risques en vous appuyant sur des mises à jour en continu.
- Surveillance du commerce électronique et optimisation des prix : Suivez les listes de produits, les niveaux de stock et les fluctuations de prix sur plusieurs plateformes. Activez la tarification dynamique, la découverte de bonnes affaires et l’optimisation du catalogue grâce à des données web fréquemment actualisées.
- Surveillance des actualités et des événements : Collectez des actualités de dernière minute, des mises à jour réglementaires et des annonces sectorielles de plusieurs sources. Améliorez la conscience situationnelle et soutenez une réponse plus rapide aux changements de marché ou de politique.
- Génération de leads et intelligence commerciale : Extrayez des données commerciales et de contact à jour depuis des annuaires, des sites web d’entreprises et des plateformes professionnelles. Identifiez de nouveaux prospects et enrichissez les pipelines de vente avec des informations constamment actualisées.
- Surveillance de la marque et suivi de la réputation : Observez les mentions dans les chatbots IA et les moteurs de recherche. Suivez le sentiment des avis et des discussions sur les forums, les médias sociaux et les sites d’actualités. Détectez rapidement les changements de sentiment et répondez promptement aux risques ou opportunités réputationnels.
- Ancrage des agents IA et accès au web : Équipez les agents IA d’un accès direct aux APIs de Scraping web pour récupérer des données contextuelles, fraîches et externes à la demande. Cela permet un raisonnement ancré, réduit les hallucinations et permet aux agents d’agir sur les dernières informations disponibles en ligne.
APIs de Scraping Web : Quel est le Meilleur Fournisseur ?
Bright Data s’impose comme le meilleur fournisseur d’APIs de Scraping web. Il combine de grands réseaux de proxies avec un écosystème complet d’API Web Scraper conçu pour une extraction de données fiable, conforme et évolutive.
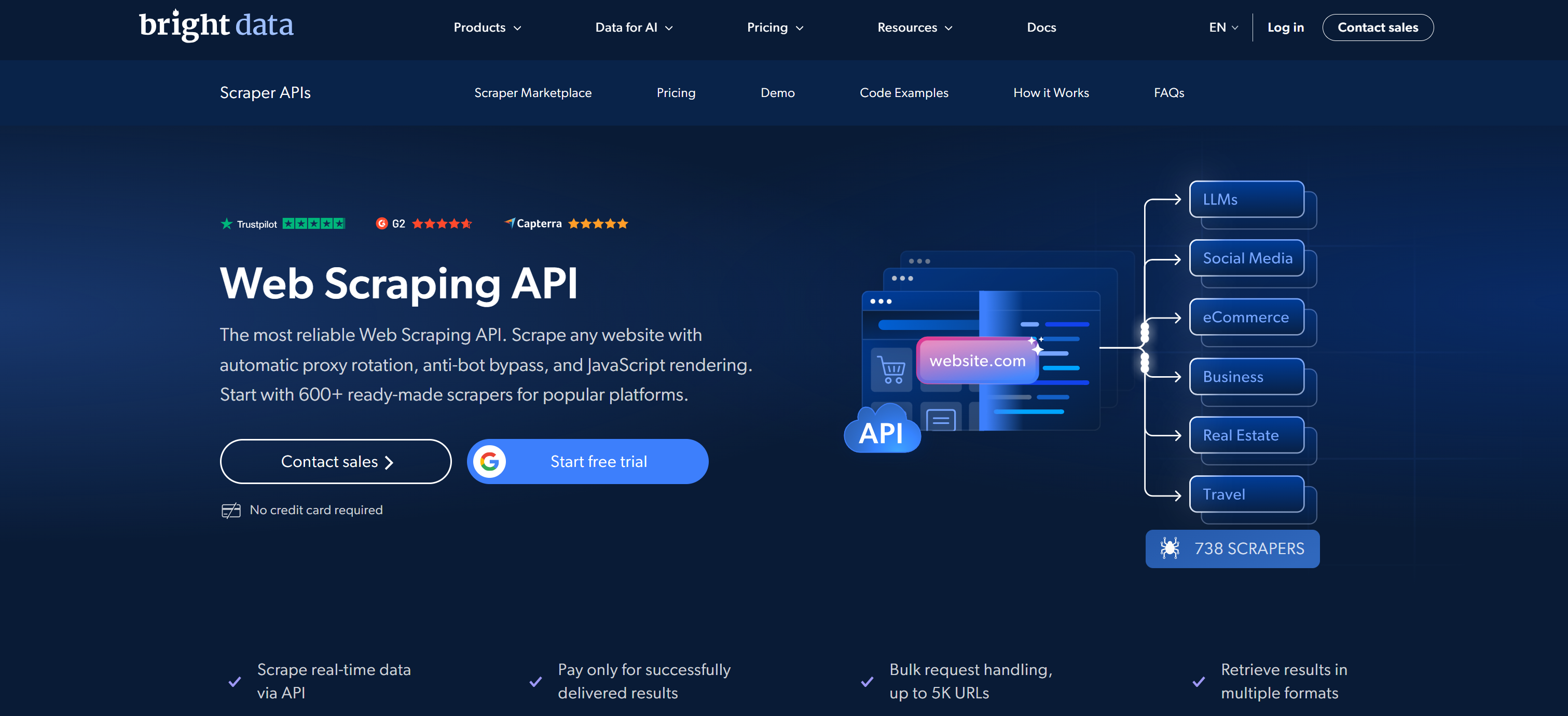
Sa bibliothèque Web Scraper API prend en charge plus de 600 scrapers prêts à l’emploi couvrant les principales sources de données. Celles-ci incluent Amazon, LinkedIn, X/Twitter, Instagram, TikTok, YouTube, Walmart, Zillow, Indeed, Glassdoor, Booking, Airbnb, Yelp, Yahoo Finance, Facebook et bien d’autres. Ces APIs de scraping permettent l’extraction directe de données structurées et spécifiques à un domaine en JSON, NDJSON ou CSV.
Ce qui distingue Bright Data, c’est son réseau mondial sous-jacent de plus de 400 millions d’IPs résidentielles dans 195 pays. Cela permet une architecture à grande échelle, prête pour l’entreprise, avec un temps de disponibilité de 99,99 % garanti par SLA et un taux de succès des requêtes de 99,95 %.
L’API Web Scraper de Bright Data gère automatiquement l’ensemble du cycle de vie du scraping, notamment la rotation des proxies, la résolution de CAPTCHA, le rendu JavaScript, la limitation du débit et le contournement des anti-bots. Elles prennent également en charge les requêtes en masse (jusqu’à 5 000 URLs par tâche), le scraping planifié et des pipelines de livraison flexibles.
La tarification est basée sur l’utilisation, et vous ne payez que pour les requêtes réussies. Le modèle de paiement à l’utilisation commence à 1,5 $ pour 1 000 enregistrements, avec plusieurs plans d’abonnement disponibles pour les entreprises et les grandes organisations.
Jeux de Données et APIs de Scraping Web dans un Scénario Réel
Pour comprendre comment récupérer des données en utilisant soit des jeux de données, soit des APIs de Scraping web, considérez le même cas d’usage de haut niveau. Vous souhaitez extraire des données d’entreprises depuis Crunchbase, dans un cas pour la prospection de clients et dans l’autre pour une analyse d’entreprises en direct alimentée par l’IA.
Le premier cas d’usage nécessite un jeu de données Crunchbase, tandis que le second nécessite une API de Scraping web Crunchbase. Dans les deux prochains chapitres, vous verrez comment accéder aux deux types de données en utilisant les solutions de Bright Data.
Remarque : Le prérequis pour les sections guidées ci-dessous est que vous disposez déjà d’un compte Bright Data. Sinon, créez-en un nouveau.
Démarrer avec les Jeux de Données de Bright Data
Dans cette section étape par étape, vous verrez comment récupérer un jeu de données Crunchbase clé en main depuis Bright Data.
Étape #1 : Accéder au Jeu de Données Crunchbase
Commencez par vous connecter à votre compte Bright Data. Dans le panneau de contrôle, sélectionnez l’option « Dataset Marketplace » sous le menu « Datasets ».
Sur la page « Mes jeux de données », naviguez vers l’onglet « Dataset Marketplace » et vous atteindrez cette page :
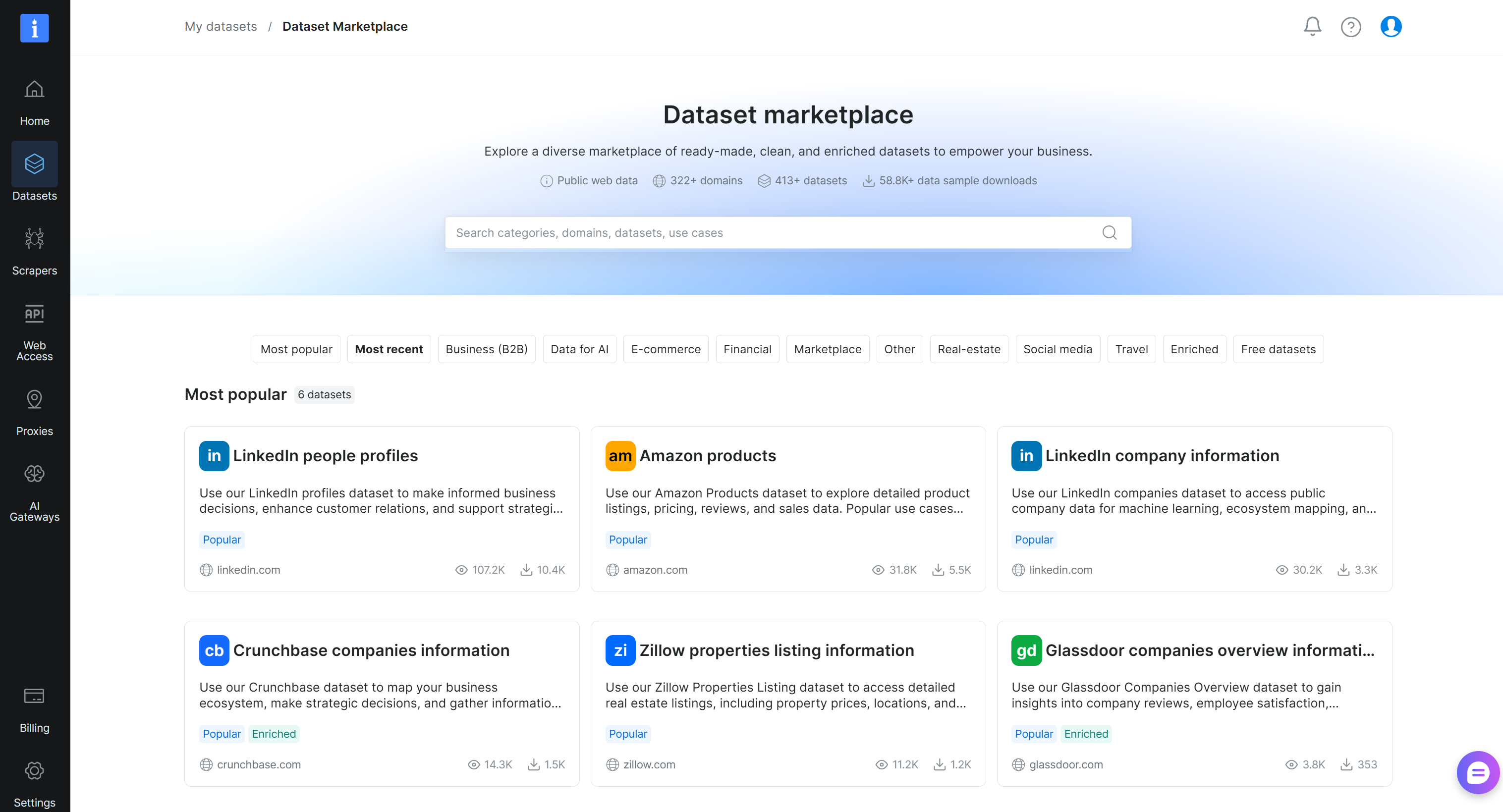
Recherchez « crunchbase » et sélectionnez le jeu de données « Crunchbase companies information » :
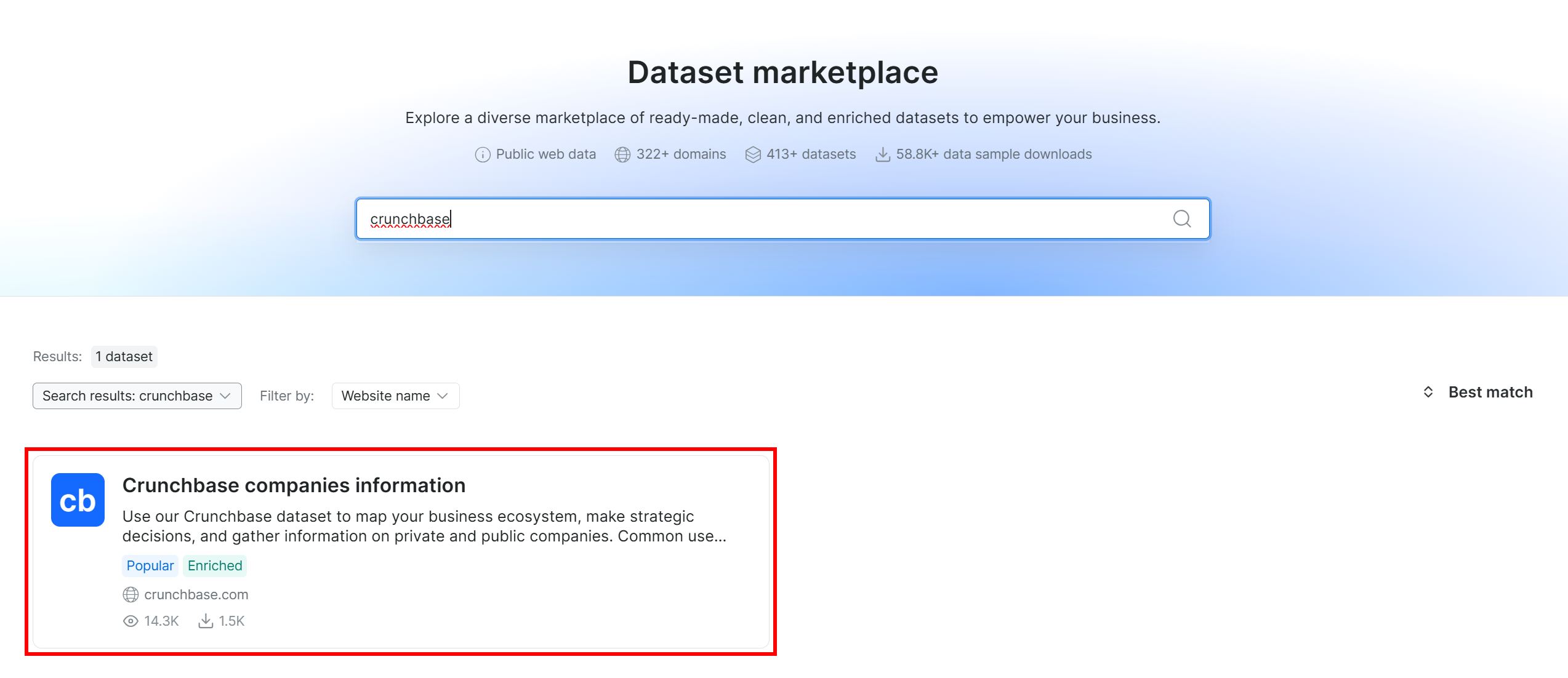
Vous serez ensuite redirigé vers la page du jeu de données « Crunchbase companies information ». Parfait !
Étape #2 : Se Familiariser avec le Jeu de Données
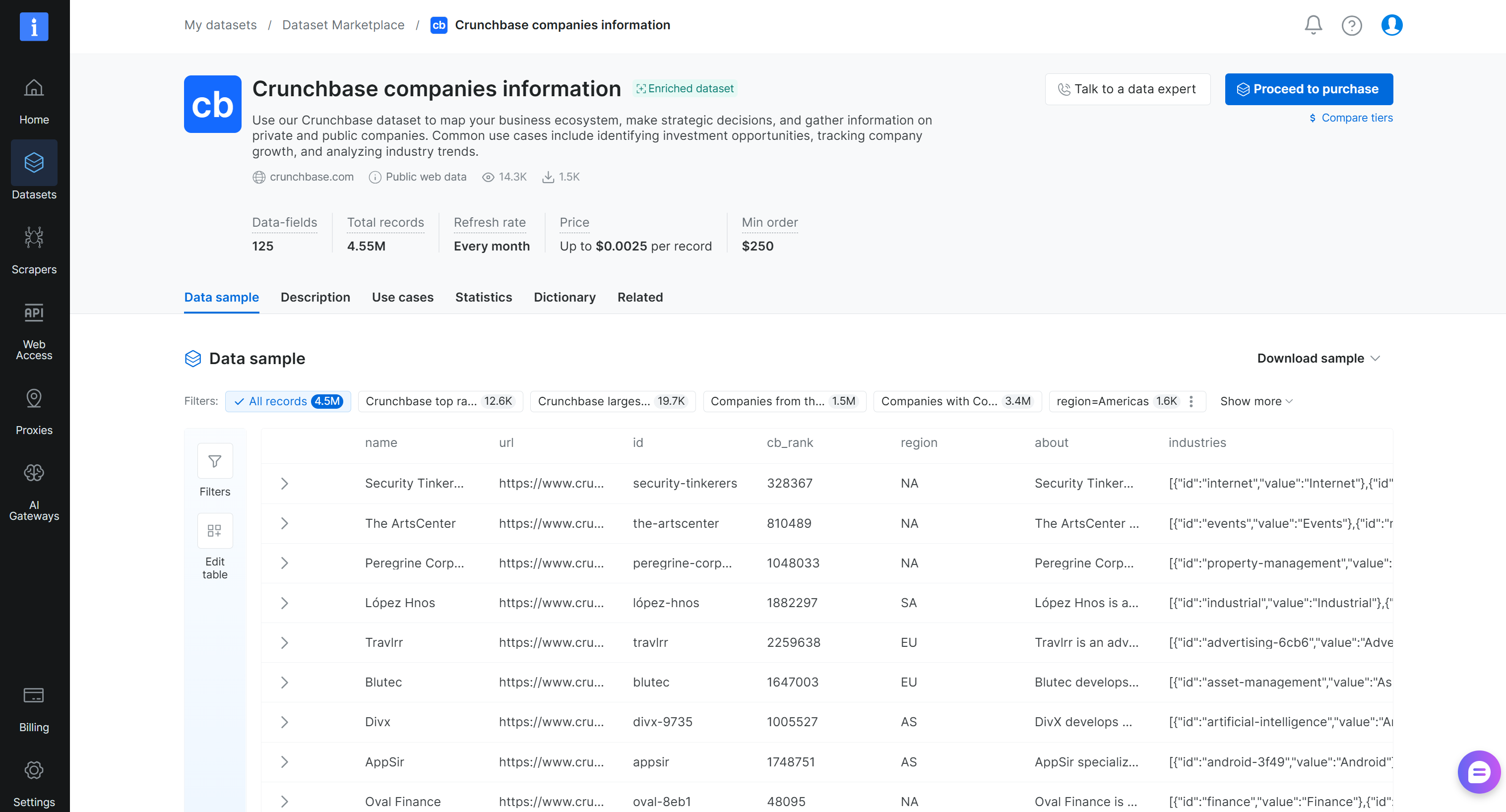
Sur la page du jeu de données « Crunchbase companies information », vous pouvez explorer le jeu de données. En détail, vous pouvez accéder à des exemples d’enregistrements, parcourir des sous-ensembles prêts à l’emploi (par exemple, les entreprises Crunchbase les mieux classées) et consulter des statistiques clés telles que les taux de remplissage des champs. Vous pouvez également afficher le dictionnaire de données complet, incluant les noms de champs, les types et les descriptions, et appliquer des filtres pour affiner le jeu de données.
Si vous cliquez sur le bouton « Filtres » à gauche, la fenêtre modale suivante s’ouvrira :
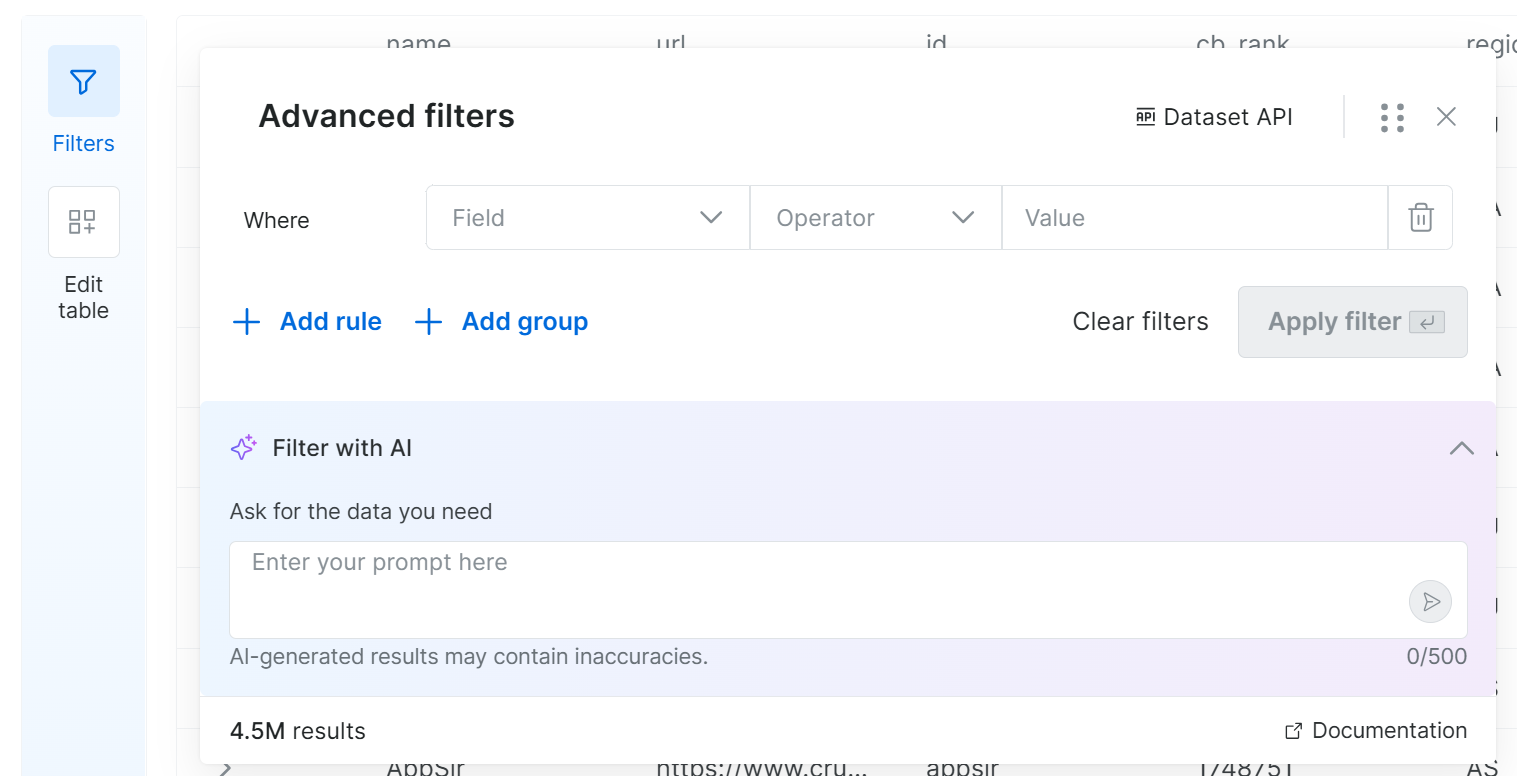
Grâce à cette fonctionnalité, vous pouvez définir des filtres en définissant un ou plusieurs critères sur des champs sélectionnés. Sinon, rédigez simplement une invite en langage naturel et laissez le système générer les filtres pour vous. Fantastique !
Étape #3 : Acheter le Jeu de Données
Après avoir filtré les données pour votre cas d’usage spécifique (ou en les laissant telles quelles), appuyez sur le bouton « Procéder à l’achat » :

Ensuite, définissez la taille de l’instantané du jeu de données et sélectionnez la fréquence de mise à jour :
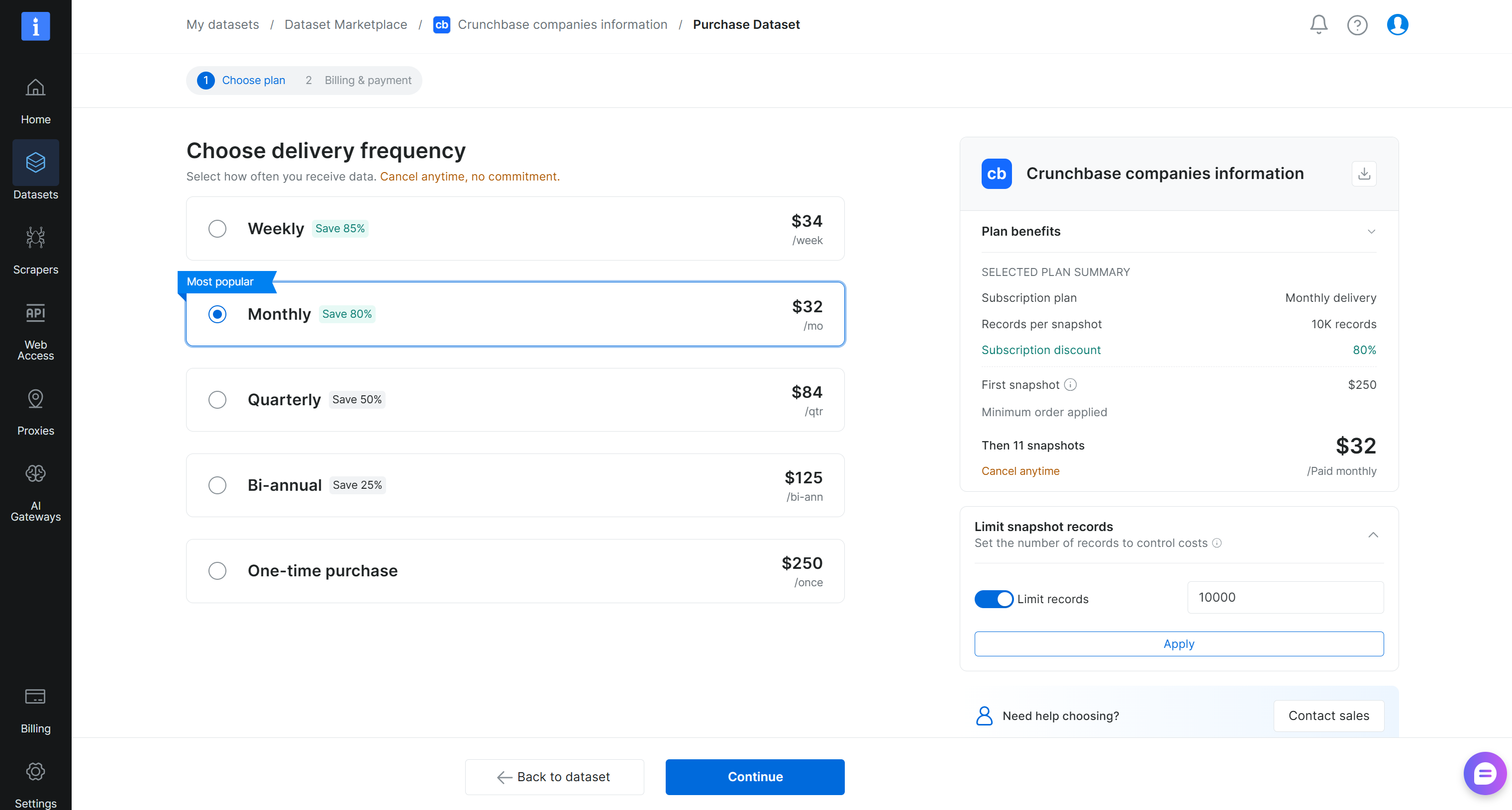
Dans cet exemple, nous avons configuré la livraison pour inclure 10 000 enregistrements immédiatement, suivis de 11 mises à jour mensuelles continues. Cliquez sur « Continuer » et finalisez le processus de paiement en ajoutant vos informations de paiement. Super !
Étape #4 : Explorer le Jeu de Données Reçu
Lorsque le jeu de données est prêt, vous recevrez une notification par e-mail et pourrez le télécharger depuis le panneau de contrôle Bright Data. De là, vous pouvez définir dans quel format télécharger le jeu de données et configurer votre méthode de livraison préférée (téléchargement de fichier, S3, etc.).
Dans le cas d’une livraison en fichier plat au format CSV, vous recevrez un fichier comme celui-ci :
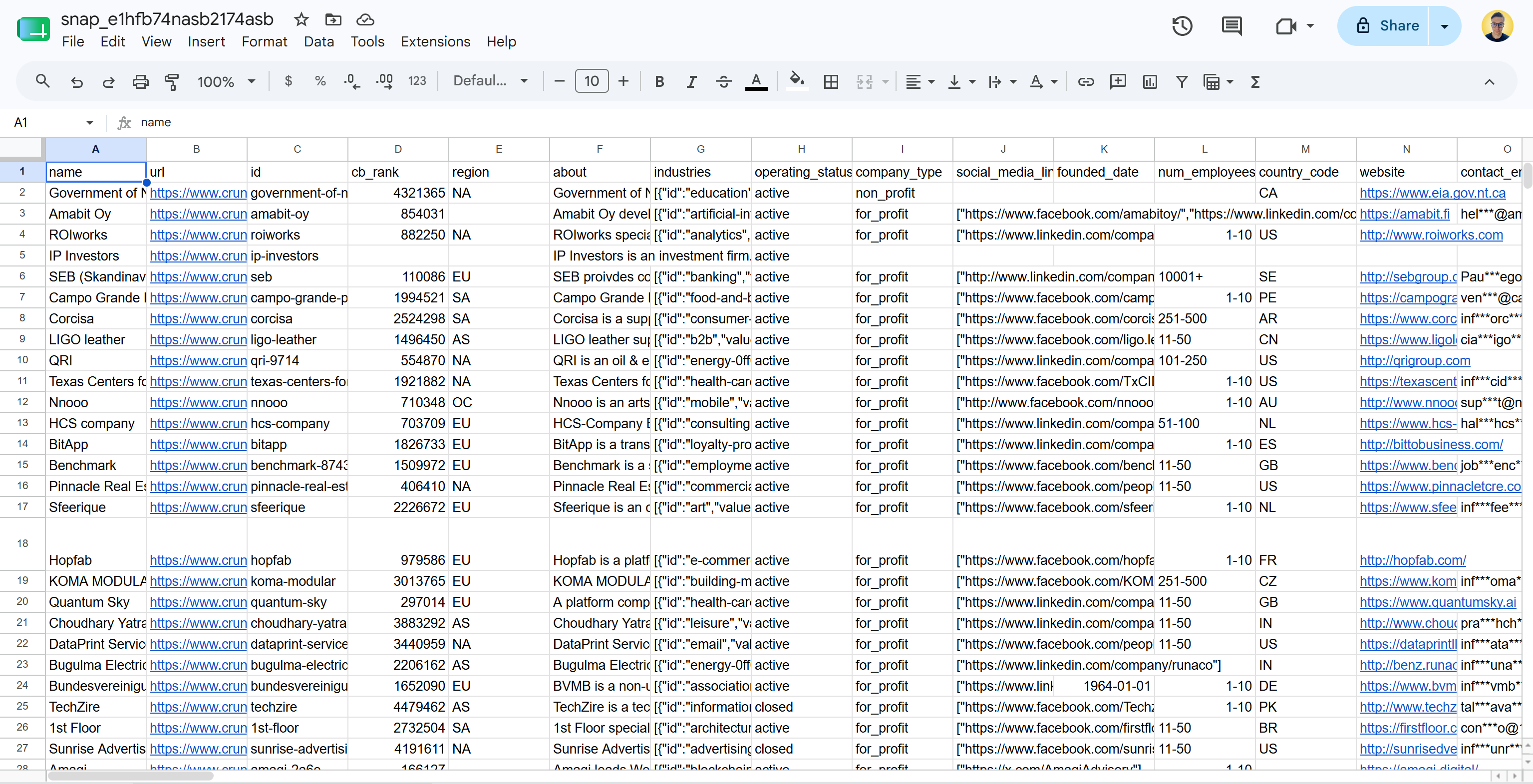
Notez que cela inclut des données Crunchbase réelles et prêtes à analyser dans un format structuré. Mission accomplie !
Prochaines Étapes
Une fois le jeu de données prêt, intégrez-le dans votre entrepôt de données ou votre base de données pour faciliter les requêtes. Vous pouvez également l’intégrer dans vos pipelines d’analyse et de traitement de données.
Par exemple, vous pourriez :
- L’utiliser pour affiner un modèle IA.
- L’intégrer dans un système IA pour l’analyse, la détection de tendances ou les prédictions.
- L’intégrer dans des tableaux de bord BI pour le reporting et la surveillance.
- Le combiner avec d’autres jeux de données pour enrichir vos données internes.
Ce ne sont que quelques idées pour transformer des données brutes en informations exploitables pour votre cas d’usage spécifique.
Collectez des Données Fraîches et Structurées via les APIs de Scraping Web de Bright Data
Ici, vous apprendrez comment démarrer avec les APIs de Scraping Web. Vous verrez comment récupérer des données structurées et à jour depuis Crunchbase en utilisant l’API Scraper Crunchbase de Bright Data.
Remarque : Le prérequis pour cette section est que vous disposez déjà d’une clé API Bright Data. Si ce n’est pas le cas, suivez le guide officiel pour générer votre clé API Bright Data.
Étape #1 : Accéder à l’API Web Scraper Crunchbase
Commencez par vous connecter à votre compte Bright Data. Ensuite, sélectionnez la page « Scrapers Library » dans le menu :
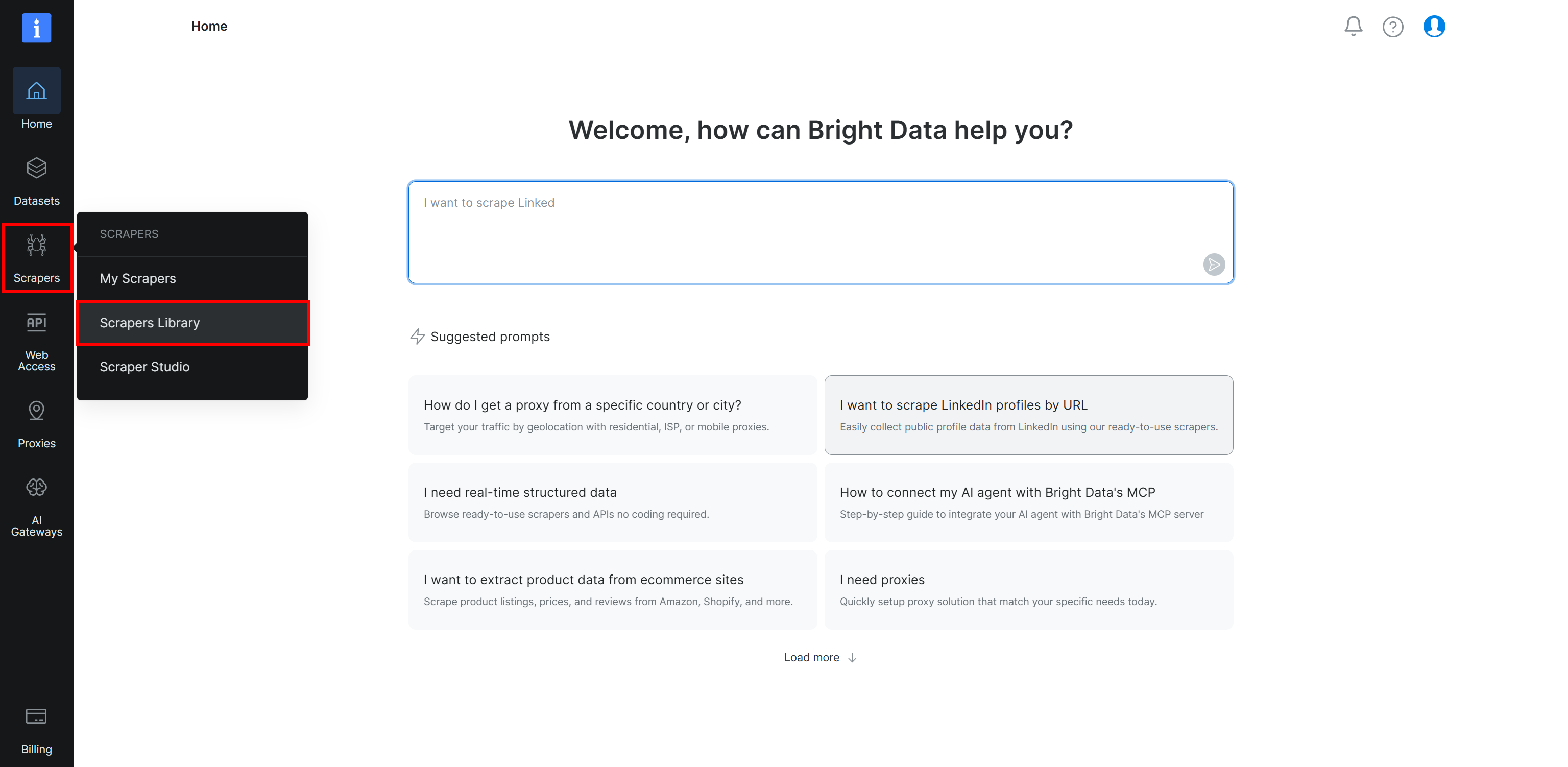
Vous arriverez sur la page « Scrapers Library », où vous pouvez explorer toutes les APIs Web Scraper de Bright Data disponibles :
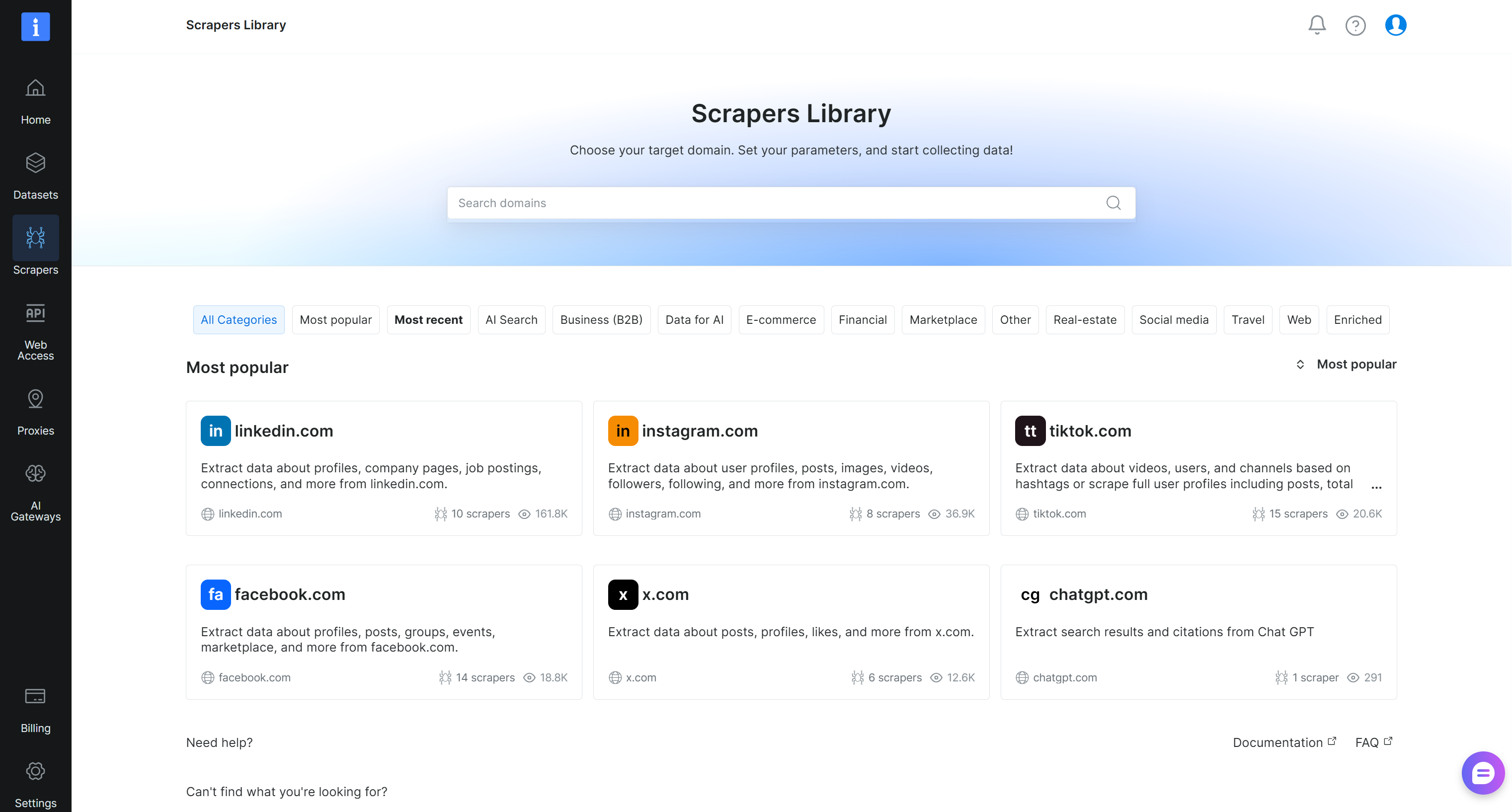
Recherchez « crunchbase.com » et sélectionnez le scraper « crunchbase.com » :
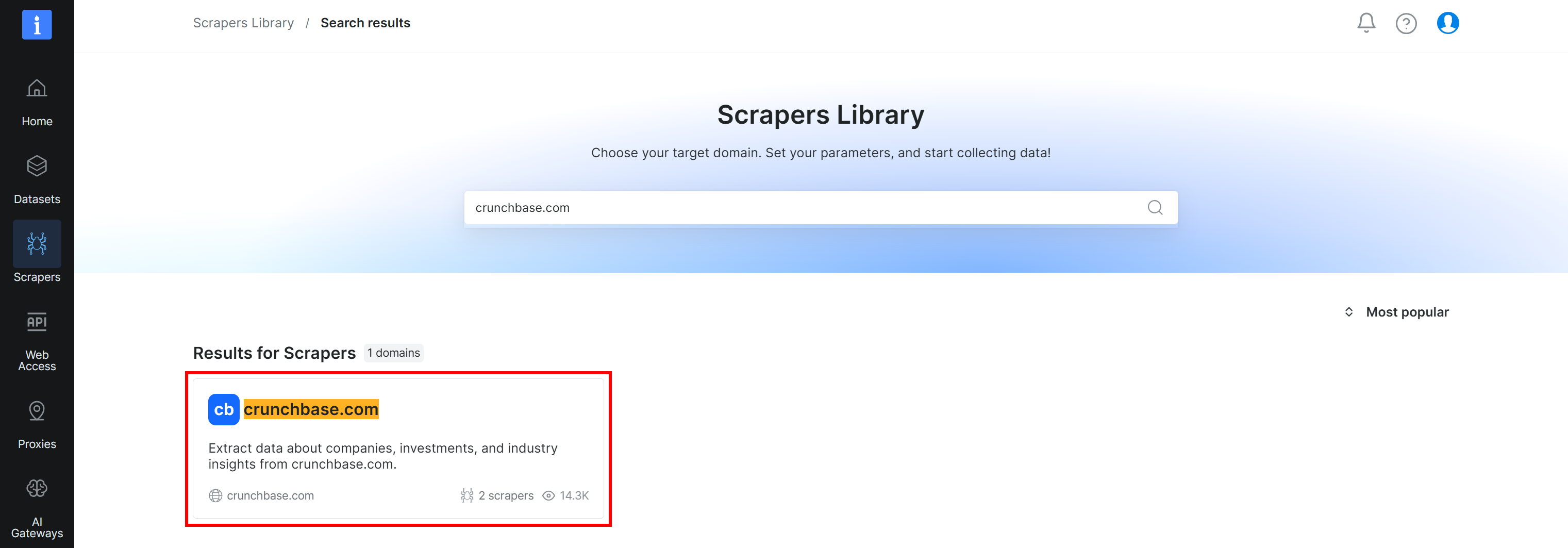
Vous atteindrez ensuite la page « crunchbase.com Scraper API » dans le panneau de contrôle. Excellent !
Étape #2 : Comprendre les Options de l’API Scraper
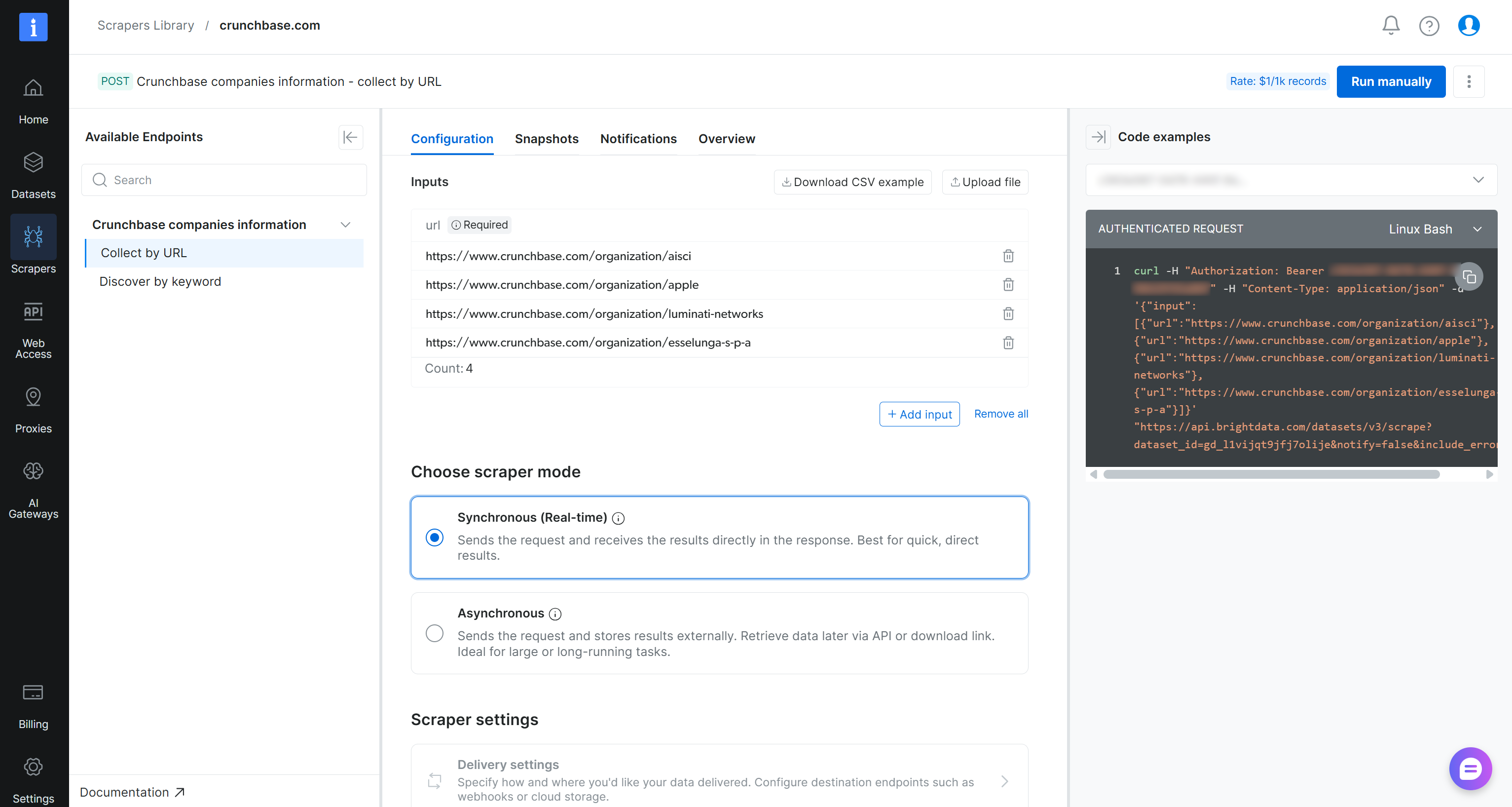
Sur la page de l’API Scraper « crunchbase.com », vous pouvez accéder à tous les points de terminaison de scraping disponibles dans le panneau de gauche. Pour chaque point de terminaison, vous pouvez configurer un appel API en ajoutant les URLs cibles. Vous pouvez également choisir le mode de scraping (synchrone ou asynchrone) et configurer les options de livraison des données.
Important : Exécutez l’API directement en cliquant sur le bouton « Exécuter manuellement ». Une fois prêt, vous pourrez accéder aux données extraites depuis l’onglet « Snapshots ». Ce workflow rend l’API accessible aux utilisateurs non techniques.
Excellent ! Il est temps de configurer un appel API spécifique pour obtenir des données Crunchbase fraîches.
Étape #3 : Configurer l’Appel API
Sur le côté droit de la page, vous pouvez accéder à des extraits de code prédéfinis pour appeler l’API de Scraping Web. Ceux-ci sont automatiquement configurés avec votre clé API Bright Data.
Par exemple, si vous souhaitez récupérer les données d’entreprise Crunchbase pour Anthropic en utilisant Python, collez l’URL cible dans la section Inputs (c’est-à-dire https://www.crunchbase.com/organization/anthropic). Choisissez le mode « Synchrone (Temps réel) », puis sélectionnez l’extrait « Python (requests) » parmi les options disponibles :
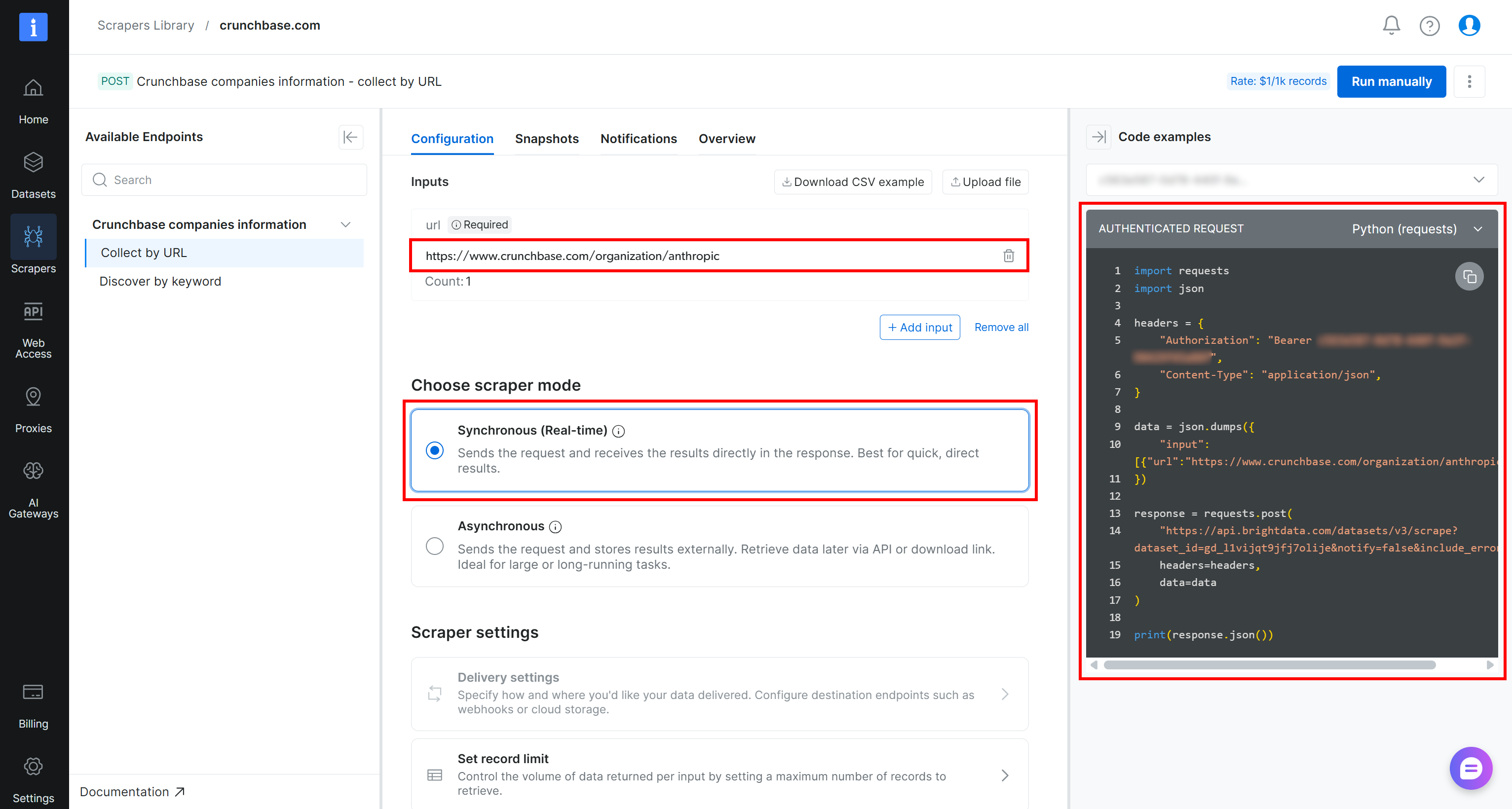
Voici le script que vous recevrez :
import requests
import json
headers = {
"Authorization": "Bearer <YOUR_BRIGHT_DATA_API_KEY>",
"Content-Type": "application/json",
}
data = json.dumps({
"input": [{"url":"https://www.crunchbase.com/organization/anthropic"}],
})
response = requests.post(
"https://api.brightdata.com/datasets/v3/scrape?dataset_id=gd_l1vijqt9jfj7olije¬ify=false&include_errors=true",
headers=headers,
data=data
)
print(response.json())Il est temps de l’exécuter pour obtenir les résultats !
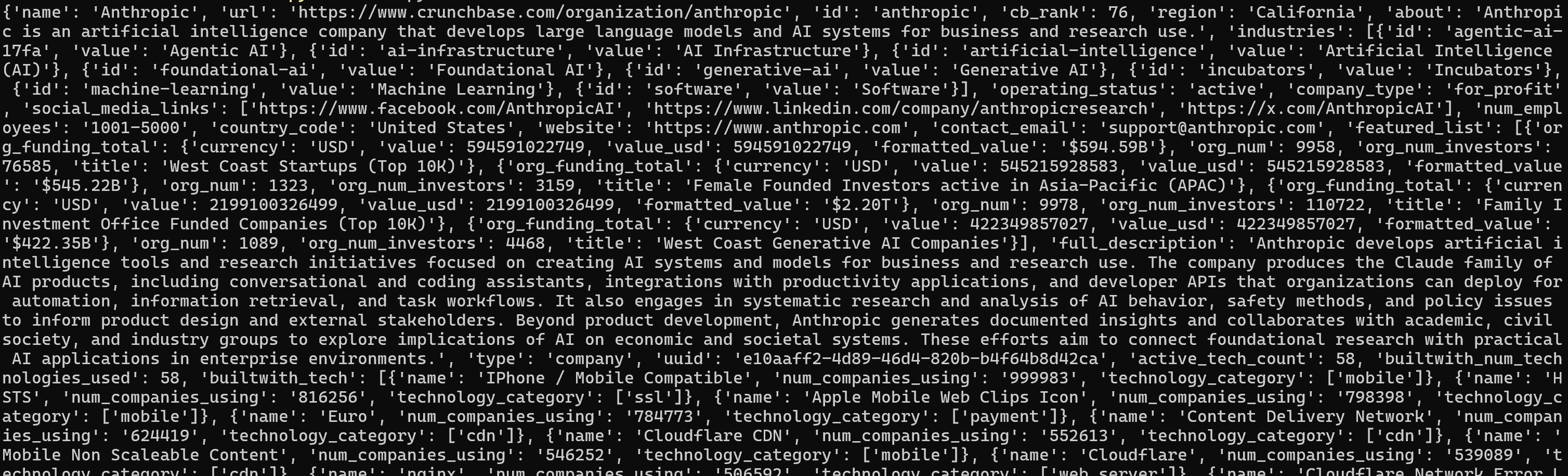
Étape #4 : Explorer les Résultats
Enregistrez l’extrait du panneau de contrôle Bright Data localement dans un fichier tel que script.py.
En supposant que vous avez Python installé localement, installez la dépendance requise :
pip install requestsEnsuite, exécutez le script avec :
python script.pyLe résultat ressemblera à ceci :
Pour une meilleure vue, collez la sortie dans un visualiseur JSON :
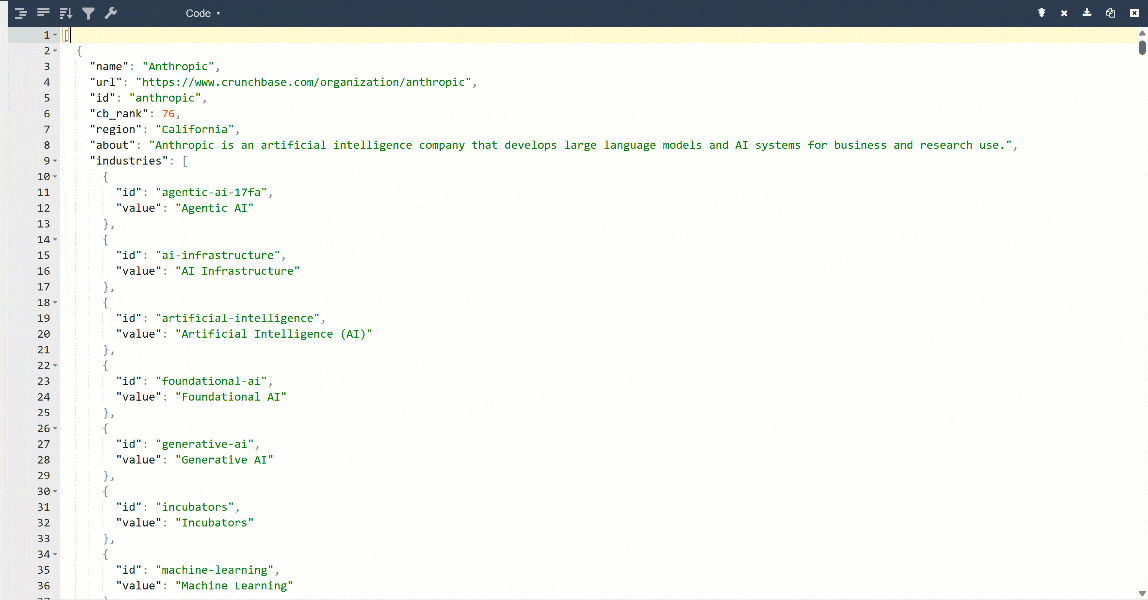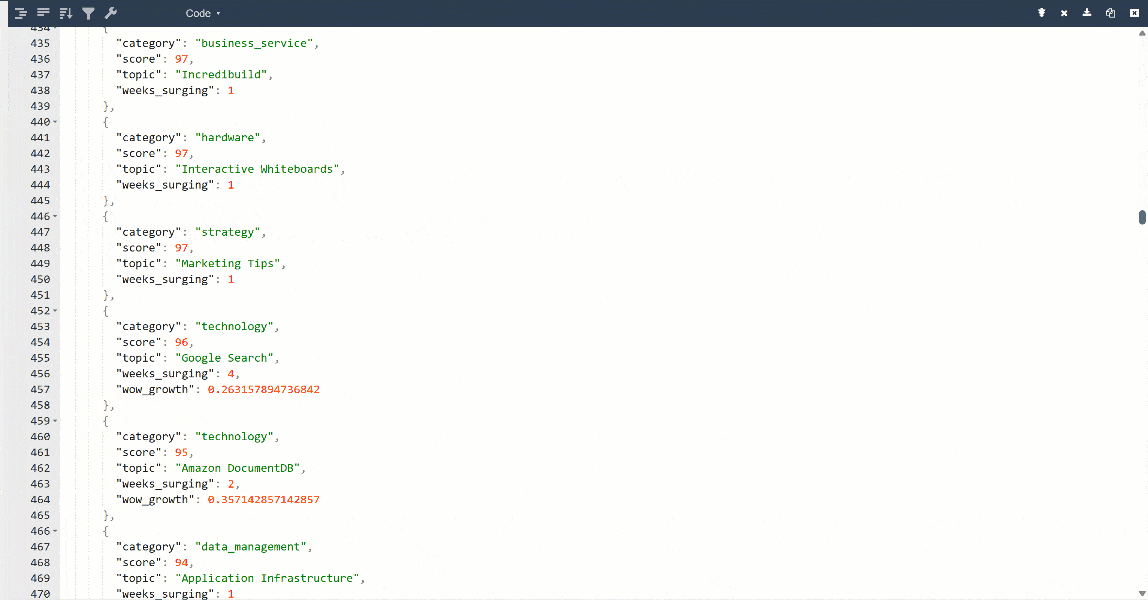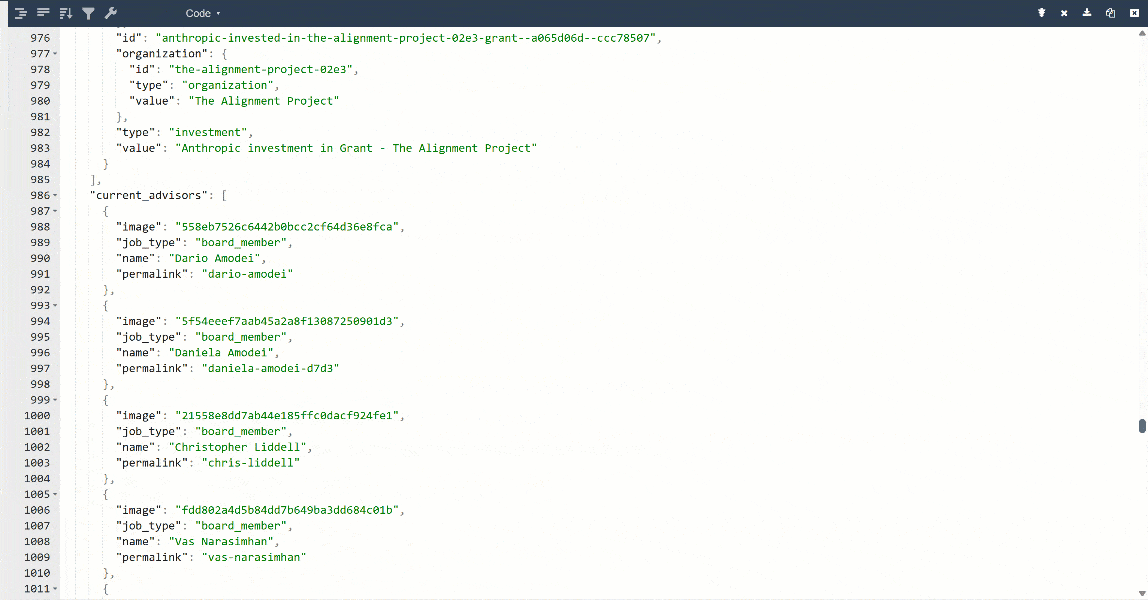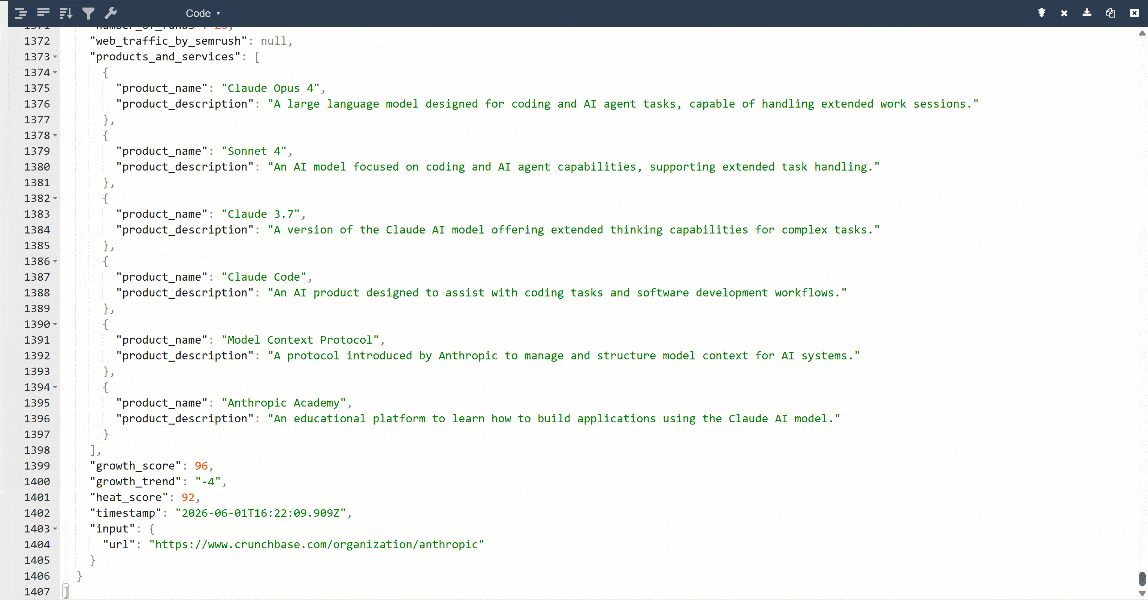
Voici les mêmes données extraites de la page cible, mais dans un format structuré :
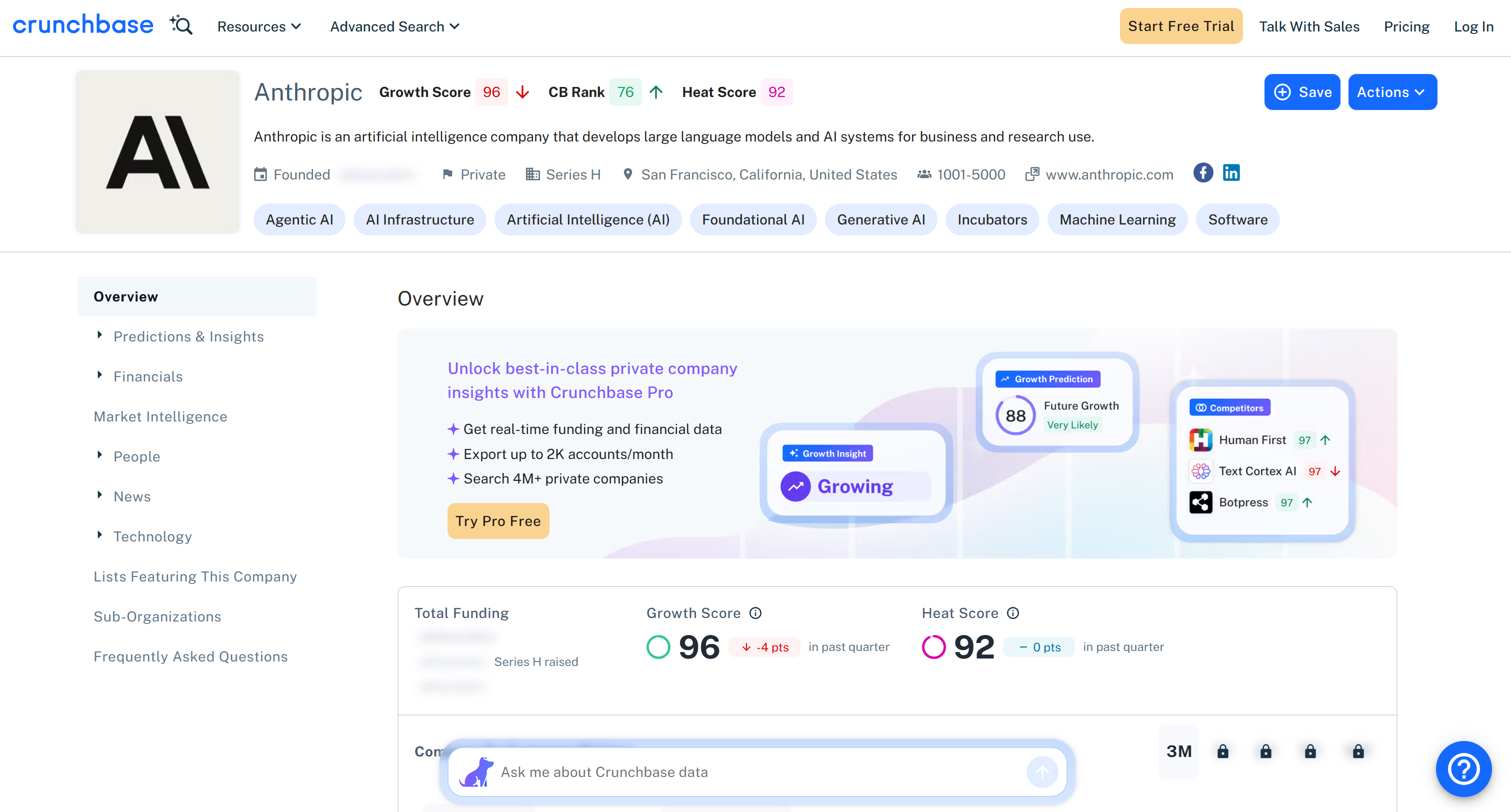
Notez que toutes les informations retournées par l’API Scraper Crunchbase de Bright Data correspondent au contenu de la page cible. En effet, les données sont récupérées à la volée via le Scraping web, elles sont donc toujours à jour.
Et voilà ! Vous avez récupéré avec succès des données en utilisant l’API de Scraping Web de Bright Data.
Prochaines Étapes
Le chapitre ci-dessus a montré un exemple simple de comment appeler une API de Scraping Web Bright Data en Python. Cependant, les APIs de Scraping Web peuvent faire bien plus que cela. Grâce à elles, vous pouvez diffuser des données structurées et à jour directement dans vos applications, systèmes ou workflows IA.
Pour les cas d’usage d’agents IA en particulier, ces APIs agissent comme une couche d’ancrage en direct, alimentant continuellement votre système avec un contexte externe frais. Par exemple, vous pouvez :
- Alimenter les agents IA avec des données web réelles et à jour pour la récupération et le raisonnement (par exemple, via le Web MCP de Bright Data).
- Ancrer les sorties LLM avec des informations en direct provenant de sources comme Crunchbase, des plateformes de commerce électronique ou des médias sociaux.
- Construire des pipelines RAG en temps réel où les données web scrapées sont injectées dans des prompts ou des bases de données vectorielles.
- Soutenir les agents financiers ou commerciaux qui s’appuient sur les prix actuels, les mises à jour d’entreprises, les signaux du marché, etc.
En général, les APIs de Scraping Web de Bright Data constituent une couche d’infrastructure essentielle pour construire des systèmes dynamiques et conscients des données qui s’appuient sur une intelligence web fraîche.
Jeux de Données ou APIs de Scraping Web : Tableau de Comparaison Final
Comparez les deux approches de récupération de données en un coup d’œil dans le tableau de comparaison jeux de données vs APIs de Scraping web ci-dessous :
| Jeux de données | APIs de Scraping Web | |
|---|---|---|
| Description | Collections de données pré-collectées et structurées | APIs qui extraient et retournent des données web en direct depuis des sites web cibles à la demande |
| Formats de données | CSV, JSON, Excel, Parquet, NDJSON, etc. | JSON, CSV |
| Fraîcheur des données | Instantanés statiques ou périodiquement actualisés | Temps réel |
| Modèle de mise à jour | Cycles de mise à jour quotidiens, mensuels, trimestriels | Temps réel |
| Évolutivité | Des milliards d’enregistrements | Élevée, selon les limites de débit et l’infrastructure du fournisseur d’API |
| Infrastructure requise | Aucune (gérée par le fournisseur) | Aucune (gérée par le fournisseur) |
| Couverture | Large mais limitée par la portée du jeu de données | Potentiellement n’importe quel site web ou domaine |
| Complexité pour l’utilisateur | Très faible | Faible à moyenne (intégration API requise) |
| Usage IA | Principalement pour l’entraînement | Ancrage en temps réel et plus (pris en charge via Web MCP) |
Choisissez les Jeux de Données Quand…
- Vous avez besoin de données propres et structurées immédiatement prêtes pour l’analyse ou l’entraînement ML.
- Votre cas d’usage repose sur des informations historiques ou agrégées, sans besoin de mises à jour en temps réel.
- Vous préférez éviter toute complexité d’ingénierie des données ou de scraping.
- Vous souhaitez un accès rentable à des données curées à grande échelle.
- Vous préférez un workflow orienté par lots (téléchargement → stockage → requête).
Préférez les APIs de Scraping Web Quand…
- Vous avez besoin de données fraîches et en temps réel depuis le web.
- Votre système doit réagir aux changements ou événements en direct (prix, actualités, mises à jour d’entreprises, etc.).
- Vous construisez des agents IA qui nécessitent un ancrage externe.
- Vous souhaitez des données web sans maintenir une infrastructure de scraping en interne.
- Vous avez besoin d’une extraction continue ou répétée de données en constante évolution.
Jeux de Données + APIs de Scraping Web : Est-ce Possible ?
Utiliser des jeux de données conjointement avec des APIs de Scraping web n’est pas seulement possible, c’est souvent la configuration la plus pratique pour les systèmes modernes de données et d’IA.
Les jeux de données vous fournissent des instantanés historiques propres, structurés et prêts à l’emploi. Ils sont parfaits lorsque vous avez besoin de cohérence, de reproductibilité et d’une analyse à grande échelle sans vous soucier de l’infrastructure.
D’un autre côté, les APIs de Scraping web fournissent des données fraîches et à la demande directement depuis le web. Elles sont mieux adaptées aux applications en temps réel et aux sources à évolution rapide.
En pratique, les deux approches sont très complémentaires. Un schéma courant consiste à commencer avec un jeu de données pour définir l’état de référence d’un domaine. Puis utiliser des APIs de Scraping web pour enrichir ou actualiser des parties spécifiques de celui-ci. Cette combinaison est particulièrement utile dans les scénarios où des connaissances de fond stables et un contexte en direct sont tous deux nécessaires.
Pour un exemple concret sur Crunchbase, consultez notre article « Filtrer un Jeu de Données Crunchbase et le Traiter avec l’IA pour Prospecter de Nouveaux Clients ». Il explique comment construire un workflow de prospection client alimenté par l’IA en filtrant d’abord un jeu de données Crunchbase, puis en utilisant des APIs de Scraping web pour récupérer des sites web d’entreprises en direct et évaluer les clients potentiels avec l’IA.
Conclusion
Dans cet article de blog, vous avez compris ce que les jeux de données et les APIs de Scraping web apportent. Vous avez appris que les jeux de données sont idéaux pour les scénarios où vous avez besoin de grands volumes de données statiques et structurées. En revanche, les APIs de Scraping web sont préférables lorsque vous avez besoin de données fraîches récupérées directement depuis le web.
Dans les deux cas, quelle que soit l’approche choisie, vous avez besoin d’un fournisseur de données web fiable. Bright Data vous soutient avec :
- Marché de jeux de données : Données web publiques pré-construites et filtrées sur plus de 350 domaines en JSON, CSV, Parquet et autres formats. Il vous donne accès à une collection de plus de 17 milliards d’enregistrements de données.
- APIs de Scraping Web : Une collection de plus de 600 points de terminaison de scraping qui automatisent l’extraction de données web en temps réel sur plus de 250 domaines. Elles gèrent la rotation des IPs, les CAPTCHAs et les systèmes anti-bot, et retournent des données structurées sans surcharge d’infrastructure.
Créez un compte Bright Data aujourd’hui et essayez nos solutions de données web gratuitement !




