

Dans ce guide, vous apprendrez :
- Qu’est-ce que SeleniumBase et pourquoi est-il utile pour le Scraping web ?
- Comment il se compare à Selenium vanilla
- Les fonctionnalités et les avantages offerts par SeleniumBase
- Comment l’utiliser pour créer un Scraper simple
- Comment l’utiliser pour des cas d’utilisation plus complexes
C’est parti !
Qu’est-ce que SeleniumBase ?
SeleniumBase est un framework Python pour l’automatisation des navigateurs. Basé sur les API Selenium/WebDriver, il fournit une boîte à outils professionnelle pour l’automatisation web. Il prend en charge un large éventail de tâches, du test au scraping.
SeleniumBase est une bibliothèque tout-en-un pour tester des pages web, automatiser des workflows et faire évoluer des opérations basées sur le web. Elle est dotée de fonctionnalités avancées telles que le contournement des CAPTCHA, la détection des bots et des outils d’amélioration de la productivité.
SeleniumBase vs Selenium : comparaison des fonctionnalités et des API
Pour mieux comprendre les raisons qui ont motivé la création de SeleniumBase, il est judicieux de le comparer directement à la version vanilla de Selenium, l’outil sur lequel il est basé.
Pour une comparaison rapide entre Selenium et SeleniumBase, consultez le tableau récapitulatif ci-dessous :
| Fonctionnalité | SeleniumBase | Selenium |
|---|---|---|
| Exécuteurs de tests intégrés | S’intègre à pytest, pynose et behave |
Nécessite une configuration manuelle pour l’intégration des tests |
| Gestion des pilotes | Télécharge automatiquement le pilote de navigateur correspondant à la version du navigateur | Nécessite le téléchargement et la configuration manuels du pilote |
| Logique d’automatisation Web | Combine plusieurs étapes en un seul appel de méthode | Nécessite plusieurs lignes de code pour une fonctionnalité similaire |
| Gestion des sélecteurs | Détecte automatiquement les sélecteurs CSS ou XPath | Nécessite la définition explicite des types de sélecteurs dans les appels de méthode |
| Gestion des délais d’expiration | Applique des délais d’attente par défaut pour éviter les échecs | Les méthodes échouent immédiatement si les délais d’expiration ne sont pas explicitement définis |
| Sorties d’erreur | Fournit des messages d’erreur clairs et lisibles pour faciliter le débogage | Génère des journaux d’erreurs détaillés et moins interprétables |
| Tableaux de bord et rapports | Comprend des tableaux de bord, des rapports et des captures d’écran des échecs intégrés | Pas de tableaux de bord ni de fonctionnalités de rapport intégrés |
| Applications GUI de bureau | Offre des outils visuels pour l’exécution des tests | Ne dispose pas d’outils GUI de bureau pour l’exécution des tests |
| Enregistreur de tests | Enregistreur de tests intégré pour créer des scripts à partir d’actions manuelles dans le navigateur | Nécessite la rédaction manuelle de scripts |
| Gestion des cas de test | Fournit CasePlans pour organiser les tests et documenter les étapes directement dans le cadre | Pas d’outils intégrés de gestion des cas de test |
| Prise en charge des applications de données | Comprend ChartMaker pour générer du JavaScript à partir de Python afin de créer des applications de données | Pas d’outils supplémentaires pour créer des applications de données |
Il est temps d’examiner les différences !
Exécuteurs de tests intégrés
SeleniumBase s’intègre à des exécuteurs de tests populaires tels que pytest, pynose et behave. Ces outils offrent une structure organisée, une découverte et une exécution transparentes des tests, un suivi de l’état des tests (par exemple, réussis, échoués ou ignorés) et des options de ligne de commande pour personnaliser les paramètres tels que la sélection du navigateur.
Avec Selenium vanilla, vous devriez implémenter manuellement un analyseur d’options ou vous fier à des outils tiers pour configurer les tests à partir de la ligne de commande.
Gestion améliorée des pilotes
Par défaut, SeleniumBase télécharge une version de pilote compatible qui correspond à la version principale de votre navigateur. Vous pouvez remplacer cette option en utilisant l’option --driver-version=VER dans votre commande pytest. Par exemple :
pytest my_script.py --driver-version=114
Selenium vous oblige à télécharger et à configurer manuellement le pilote approprié. Dans ce cas, vous êtes responsable de la compatibilité avec la version du navigateur.
Méthodes multi-actions
SeleniumBase combine plusieurs étapes en une seule méthode pour simplifier l’automatisation Web. Par exemple, la méthode driver.type(selector, text) effectue les opérations suivantes :
- Attend que l’élément soit visible
- Attend que l’élément soit interactif
- Efface tout texte existant
- Saisit le texte fourni
- Soumet si le texte se termine par
« n »
Avec Selenium brut, reproduire la même logique nécessiterait quelques lignes de code.
Gestion simplifiée des sélecteurs
SeleniumBase peut automatiquement faire la différence entre les sélecteurs CSS et les expressions XPath. Il n’est donc plus nécessaire de spécifier explicitement les types de sélecteurs avec By.CSS_SELECTOR ou By.XPATH. Cependant, vous pouvez toujours fournir le type explicitement si vous le souhaitez.
Exemple avec SeleniumBase :
driver.click("button.submit") # Détecte automatiquement comme sélecteur CSS
driver.click("//button[@class='submit']") # Détecte automatiquement comme XPath
Le code équivalent en Selenium vanilla est :
driver.find_element(By.CSS_SELECTOR, "button.submit").click()
driver.find_element(By.XPATH, "//button[@class='submit']").click()
Valeurs de délai d’attente par défaut et personnalisées
SeleniumBase applique automatiquement un délai d’attente par défaut de 10 secondes aux méthodes, garantissant ainsi que les éléments ont le temps de se charger. Cela évite les échecs immédiats, qui sont fréquents dans Selenium brut.
Vous pouvez également définir des valeurs de délai d’attente personnalisées directement dans les appels de méthode, comme dans l’exemple ci-dessous :
driver.click("button", timeout=20)
Le code Selenium équivalent serait beaucoup plus verbeux et complexe :
WebDriverWait(driver, 20).until(EC.element_to_be_clickable((By.CSS_SELECTOR, "button"))).click()
Sorties d’erreurs claires
SeleniumBase fournit des messages d’erreur clairs et faciles à lire lorsque les scripts échouent. En revanche, Selenium brut génère souvent des journaux d’erreurs verbeux et moins interprétables, ce qui nécessite des efforts supplémentaires pour le débogage.
Tableaux de bord, rapports et captures d’écran
SeleniumBase comprend des fonctionnalités permettant de générer des tableaux de bord et des rapports pour les exécutions de tests. Il enregistre également des captures d’écran des échecs dans le dossier ./latest_logs/ pour faciliter le débogage. Raw Selenium ne dispose pas de ces fonctionnalités prêtes à l’emploi.
Fonctionnalités supplémentaires
Par rapport à Selenium, SeleniumBase comprend :
- Des applications GUI de bureau pour exécuter des tests visuellement, telles que SeleniumBase Commander pour
pytestet SeleniumBase Behave GUI pourbehave. - Un enregistreur/générateur de tests intégré pour créer des scripts de test basés sur des actions manuelles du navigateur. Cela réduit considérablement l’effort nécessaire pour écrire des tests pour des workflows complexes.
- Un logiciel de gestion des cas de test appelé CasePlans pour organiser les tests et documenter les descriptions des étapes directement dans le cadre.
- Des outils tels que ChartMaker pour créer des applications de données en générant du code JavaScript à partir de Python. Cela en fait une solution polyvalente qui va au-delà de l’automatisation standard des tests.
SeleniumBase : fonctionnalités, méthodes et options CLI
Découvrez ce qui rend SeleniumBase si spécial en explorant ses capacités et son API.
Fonctionnalités
Voici une liste de certaines des fonctionnalités les plus pertinentes de SleniumBase :
- Comprend un mode enregistreur pour générer instantanément des tests de navigateur en Python.
- Prend en charge plusieurs navigateurs, onglets, iframes et Proxys dans le même test.
- Comprend un logiciel de gestion des cas de test avec la technologie Markdown.
- Mécanisme d’attente intelligent qui améliore automatiquement la fiabilité et réduit les tests instables.
- Compatible avec
pytest,unittest,noseetbehavepour la découverte et l’exécution des tests. - Comprend des outils de journalisation avancés pour les tableaux de bord, les rapports et les captures d’écran.
- Peut exécuter des tests en mode Headless pour masquer l’interface du navigateur.
- Prend en charge l’exécution de tests multithreads sur des navigateurs parallèles.
- Permet d’exécuter des tests à l’aide de l’émulateur d’appareil mobile de Chromium.
- Prend en charge l’exécution de tests via un Proxy, même authentifié.
- Personnalise la chaîne user-agent du navigateur pour les tests.
- Empêche la détection par les sites web qui bloquent l’automatisation Selenium.
- S’intègre à selenium-wire pour inspecter les requêtes réseau du navigateur.
- Interface de ligne de commande flexible pour des options d’exécution de tests personnalisées.
- Fichier de configuration global pour la gestion des paramètres de test.
- Prend en charge les intégrations avec GitHub Actions, Google Cloud, Azure, S3 et Docker.
- Prend en charge l’exécution de JavaScript à partir de Python.
- Peut interagir avec les éléments Shadow DOM en utilisant
::shadowdans les sélecteurs CSS.
Pourconsulter la liste complète,consultez la documentation. N’oubliez pas de lire notre blog sur l’utilisation de SeleniumBase avec des Proxies.
Méthodes
Vous trouverez ci-dessous une liste des méthodes SeleniumBase les plus utiles :
driver.open(url): navigue dans la fenêtre du navigateur vers l’URL spécifiée.driver.go_back(): revient à l’URL précédente.driver.type(selector, text): met à jour le champ identifié par le sélecteur avec le texte spécifié.driver.click(selector): cliquer sur l’élément identifié par le sélecteur.driver.click_link(link_text): clique sur le lien contenant le texte spécifié.driver.select_option_by_text(dropdown_selector, option): sélectionne une option dans un menu déroulant à partir du texte visible.driver.hover_and_click(hover_selector, click_selector): survole un élément et clique sur un autre.driver.drag_and_drop(drag_selector, drop_selector): faire glisser un élément et le déposer sur un autre élément.driver.get_text(selector): Obtenir le texte de l’élément spécifié.driver.get_attribute(selector, attribute): Obtenir l’attribut spécifié d’un élément.driver.get_current_url(): Obtenir l’URL de la page actuelle.driver.get_page_source(): récupère le code source HTML de la page actuelle.driver.get_title(): Obtenir le titre de la page actuelle.driver.switch_to_frame(frame): Basculer vers le conteneur iframe spécifié.driver.switch_to_default_content(): Quitter le conteneur iframe et revenir au document principal.driver.open_new_window(): ouvre une nouvelle fenêtre de navigateur dans la même session.driver.switch_to_window(window): bascule vers la fenêtre de navigateur spécifiée.driver.switch_to_default_window(): revenir à la fenêtre de navigateur d’origine.driver.get_new_driver(OPTIONS): ouvre une nouvelle session de pilote avec les options spécifiées.driver.switch_to_driver(driver): bascule vers le pilote de navigateur spécifié.driver.switch_to_default_driver(): revenir au pilote de navigateur d’origine.driver.wait_for_element(selector): Attendre que l’élément spécifié soit visible.driver.is_element_visible(selector): Vérifie si l’élément spécifié est visible.driver.is_text_visible(text, selector): Vérifie si le texte spécifié est visible dans un élément.driver.sleep(seconds): Met l’exécution en pause pendant la durée spécifiée.driver.save_screenshot(name): Enregistrer une capture d’écran au format.pngavec le nom donné.driver.assert_element(selector): Vérifie que l’élément spécifié est visible.driver.assert_text(text, selector): vérifie que le texte spécifié est présent dans l’élément.driver.assert_exact_text(text, selector): vérifie que le texte spécifié correspond exactement à celui de l’élément.driver.assert_title(title): vérifie que le titre de la page actuelle correspond au titre spécifié.driver.assert_downloaded_file(file): vérifie que le fichier spécifié a été téléchargé.driver.assert_no_404_errors(): vérifie qu’il n’y a pas de liens rompus sur la page.driver.assert_no_js_errors(): vérifie qu’il n’y a pas d’erreurs JavaScript sur la page.
Pour obtenir la liste complète, consultez la documentation.
Options CLI
SeleniumBase étend pytest avec les options de ligne de commande suivantes :
--browser=BROWSER: définit le navigateur Web (par défaut : « chrome »).--chrome: raccourci pour--browser=chrome.--edge: raccourci pour--browser=edge.--firefox: raccourci pour--browser=firefox.--safari: raccourci pour--browser=safari.--settings-file=FILE: Remplace les paramètres SeleniumBase par défaut.--env=ENV: définit l’environnement de test, accessible viadriver.env.--account=STR: définit le compte, accessible viadriver.account.--data=STRING: données de test supplémentaires, accessibles viadriver.data.--var1=STRING: données de test supplémentaires, accessibles viadriver.var1.--var2=STRING: données de test supplémentaires, accessibles viadriver.var2.--var3=STRING: données de test supplémentaires, accessibles viadriver.var3.--variables=DICT: données de test supplémentaires, accessibles viadriver.variables.--proxy=SERVER:PORT: se connecter à un serveur Proxy.--proxy=USERNAME:PASSWORD@SERVER:PORT: Utilisation d’un Proxy authentifié.--proxy-bypass-list=STRING: hôtes à contourner (par exemple, « *.foo.com »).--proxy-pac-url=URL: connexion via l’URL PAC.--proxy-pac-url=USERNAME:PASSWORD@URL: Proxy authentifié avec URL PAC.--proxy-driver: Utiliser un Proxy pour le téléchargement du pilote.--multi-proxy: autoriser plusieurs Proxys authentifiés en multithreading.--agent=STRING: Modifier la chaîne User-Agent du navigateur.--mobile: active l’émulateur d’appareil mobile.--metrics=STRING: définit les métriques mobiles (par exemple, « CSSWidth,CSSHeight,PixelRatio »).--chromium-arg="ARG=N,ARG2": définit les arguments Chromium.--firefox-arg="ARG=N,ARG2": définit les arguments Firefox.--firefox-pref=SET: définit les préférences Firefox.--extension-zip=ZIP: charge les fichiers.zip/.crxde l’extension Chrome.--extension-dir=DIR: charge les répertoires d’extension Chrome.--disable-features="F1,F2": désactiver les fonctionnalités.--binary-location=PATH: Définit le chemin d’accès au fichier binaire Chromium.--driver-version=VER: Définit la version du pilote.--headless: mode sans affichage par défaut.--headless1: Utilise l’ancien mode sans affichage de Chrome.--headless2: Utiliser le nouveau mode sans affichage de Chrome.--headed: active le mode GUI sous Linux.--xvfb: exécute les tests avec Xvfb sous Linux.--locale=LOCALE_CODE: définit la langue du navigateur.--reuse-session: réutilise la session du navigateur pour tous les tests.--reuse-class-session: réutilise la session pour les tests de classe.--crumbs: Supprimer les cookies entre les sessions réutilisées.--disable-cookies: désactive les cookies.--disable-js: désactive JavaScript.--disable-csp: désactiver la politique de sécurité du contenu.--disable-ws: désactiver la sécurité Web.--enable-ws: Activer la sécurité Web.--log-cdp: enregistrer les événements du protocole Chrome DevTools (CDP).--remote-debug: synchroniser avec Chrome Remote Debugger.--visual-baseline: définit la base visuelle pour les tests de mise en page.--timeout-multiplier=MULTIPLIER: multiplier les valeurs de délai d’expiration par défaut.
Consultez la liste complète des définitions des options de ligne de commande dans la documentation.
Utilisation de SeleniumBase pour le Scraping web : guide étape par étape
Suivez ce tutoriel étape par étape pour apprendre à créer un Scraper SeleniumBase afin de récupérer des données à partir du bac à sable Quotes to Scrape:
Pour un tutoriel similaire utilisant Selenium vanilla, consultez notre guide sur le Scraping web avec Selenium.
Étape n° 1 : Initialisation du projet
Avant de commencer, assurez-vous que Python 3 est installé sur votre ordinateur. Sinon, téléchargez-le et installez-le.
Ouvrez le terminal et lancez la commande ci-dessous pour créer un répertoire pour votre projet :
mkdir seleniumbase-Scraper
seleniumbase-scraper contiendra votre Scraper SeleniumBase.
Naviguez à l’intérieur et initialisez un environnement virtuel:
cd seleniumbase-Scraper
python -m venv env
Ensuite, chargez le dossier du projet dans votre IDE Python préféré. Visual Studio Code avec l’extension Python ou PyCharm Community Edition feront l’affaire.
Créez un fichier scraper.py dans le répertoire du projet, qui devrait maintenant contenir cette structure de fichiers :

scraper.py contiendra bientôt votre logique de scraping.
Activez l’environnement virtuel dans le terminal de l’IDE. Sous Linux ou macOS, utilisez la commande ci-dessous :
./env/bin/activate
De manière équivalente, sous Windows, exécutez :
env/Scripts/activate
Dans l’environnement activé, lancez cette commande pour installer SeleniumBase:
pip install seleniumbase
Parfait ! Vous disposez désormais d’un environnement Python pour le Scraping web avec SeleniumBase.
Étape n° 2 : configuration du test SeleniumBase
Bien que SeleniumBase prenne en charge la syntaxe pytest pour la création de tests, un bot de Scraping web n’est pas un script de test. Vous pouvez toujours profiter de toutes les options d’extension de ligne de commande pytest de SeleniumBase en utilisant la syntaxeSB:
from seleniumbase import SB
with SB() as sb:
pass
# Logique de scraping...
Vous pouvez désormais exécuter votre test avec :
python3 Scraper.py
Remarque: sous Windows, remplacez python3 par python.
Pour l’exécuter en mode headless, lancez :
python3 Scraper.py --headless
N’oubliez pas que vous pouvez combiner plusieurs options de ligne de commande.
Étape n° 3 : se connecter à la page cible
Utilisez la méthode open() pour demander au navigateur contrôlé de visiter votre page cible :
sb.open("https://quotes.toscrape.com/")
Si vous exécutez le script de test de scraping en mode headed, voici ce que vous verrez pendant une fraction de seconde :
Notez que, contrairement à Selenium vanilla, vous n’avez pas besoin de fermer manuellement le pilote. SeleniumBase s’en chargera pour vous.
Étape n° 4 : sélectionnez les éléments de citation
Ouvrez la page cible en mode incognito dans votre navigateur et inspectez un élément de citation :
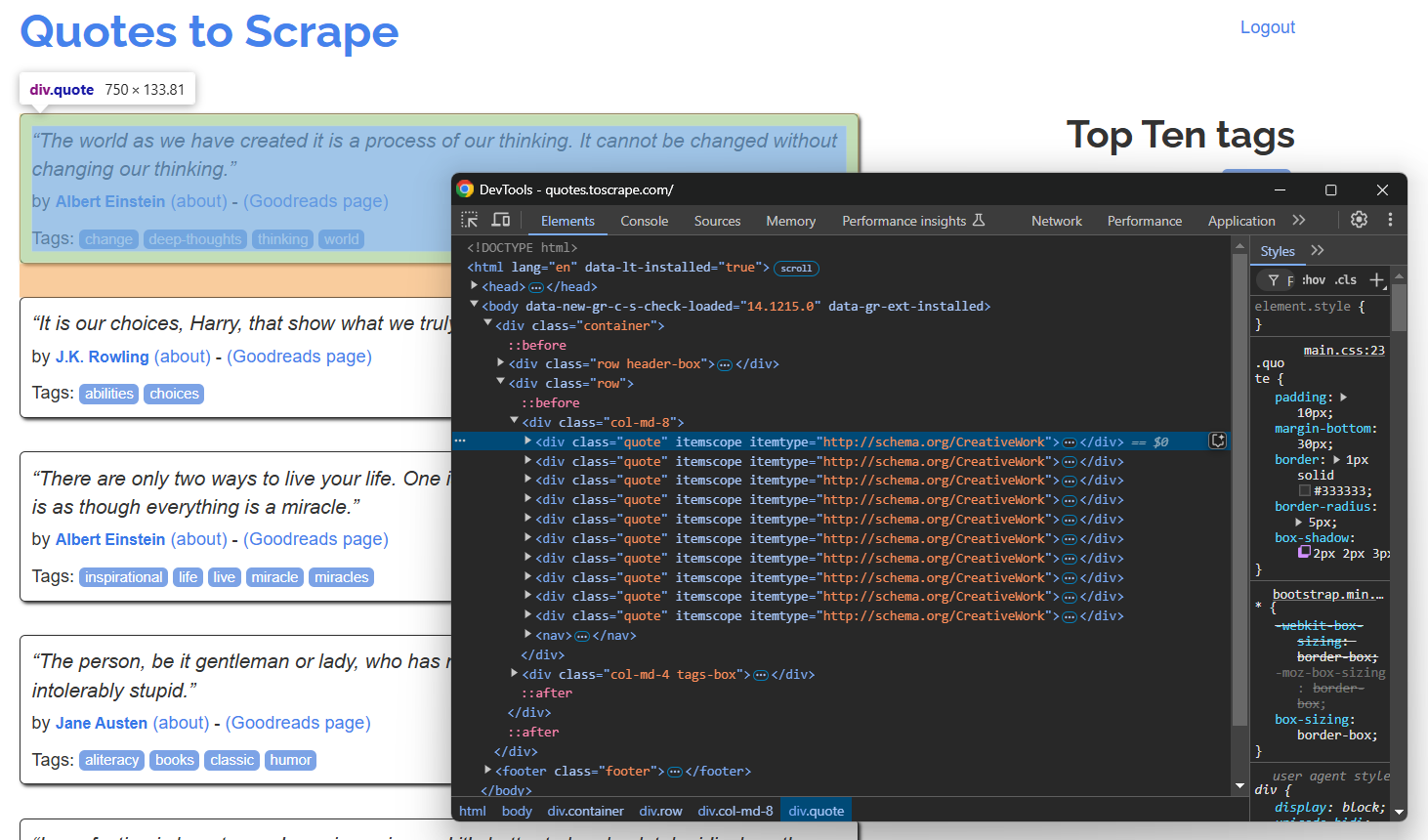
Comme la page contient plusieurs citations, créez un tableau de citations pour stocker les données extraites :
quotes = []
Dans la section DevTools ci-dessus, vous pouvez voir que toutes les citations peuvent être sélectionnées à l’aide du sélecteur CSS .quote. Utilisez find_elements() pour les sélectionner toutes :
quote_elements = sb.find_elements(".quote")
Ensuite, préparez-vous à itérer sur les éléments et à extraire les données de chaque élément de citation. Ajoutez les données extraites à un tableau :
for quote_element in quote_elements:
# Logique de scraping...
Parfait ! La logique de récupération de haut niveau est maintenant prête.
Étape n° 5 : extraire les données des citations
Inspectez un seul élément de citation :
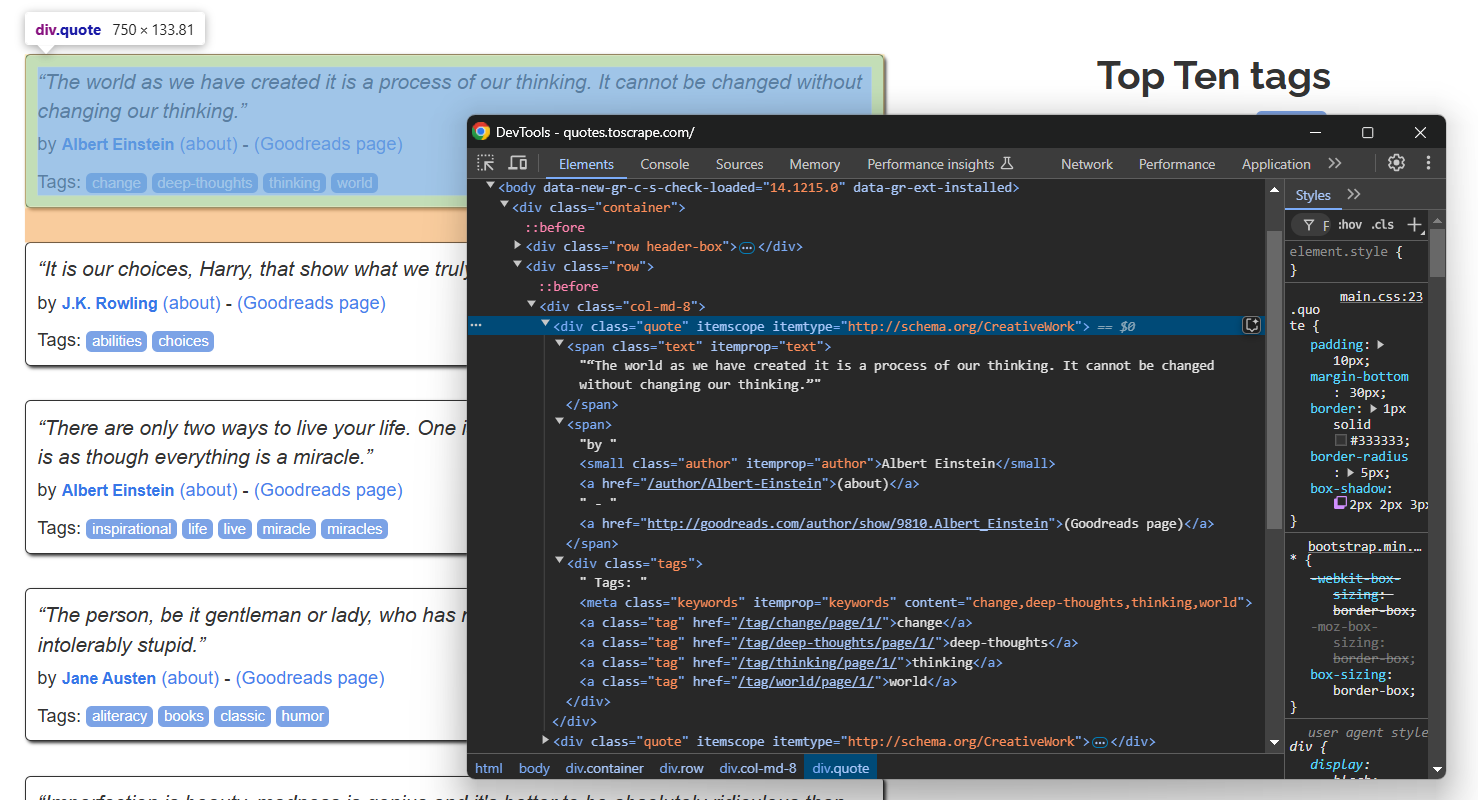
Notez que vous pouvez extraire :
- Le texte de la citation à partir de
.text - L’auteur de la citation à partir de
.author - Les balises de citation à partir de
.tag
Sélectionnez chaque nœud et extrayez les données à partir de ceux-ci avec l’attribut text:
text_element = quote_element.find_element(By.CSS_SELECTOR, ".text")
text = text_element.text.replace("“", "").replace("”", "")
author_element = quote_element.find_element(By.CSS_SELECTOR, ".author")
author = author_element.text
tags = []
tag_elements = quote_element.find_elements(By.CSS_SELECTOR, ".tag")
for tag_element in tag_elements:
tag = tag_element.text
tags.append(tag)
Notez que find_elements() renvoie des objets Selenium WebElement vanilla. Ainsi, pour sélectionner des éléments à l’intérieur, vous devez utiliser les méthodes natives de Selenium. C’est pourquoi vous devez spécifier By.CSS_SELECTOR comme localisateur.
Veillez à importer By au début de votre script :
from selenium.webdriver.common.by import By
Notez que le scraping des balises nécessite une boucle, car une seule citation peut comporter une ou plusieurs balises. Observez également l’utilisation de la méthode replace() pour supprimer les guillemets doubles spéciaux qui entourent le texte.
Étape n° 6 : remplir le tableau Quotes
Remplissez un nouvel objet quotes avec les données récupérées et ajoutez-le à quotes:
quote = {
"text": text,
"author": author,
"tags": tags
}
quotes.append(quote)
Incroyable ! La logique de scraping SelenumBase est terminée.
Étape n° 7 : implémenter la logique de crawling
N’oubliez pas que le site cible contient plusieurs pages. Pour passer à la page suivante, cliquez sur le bouton « Suivant → » en bas :
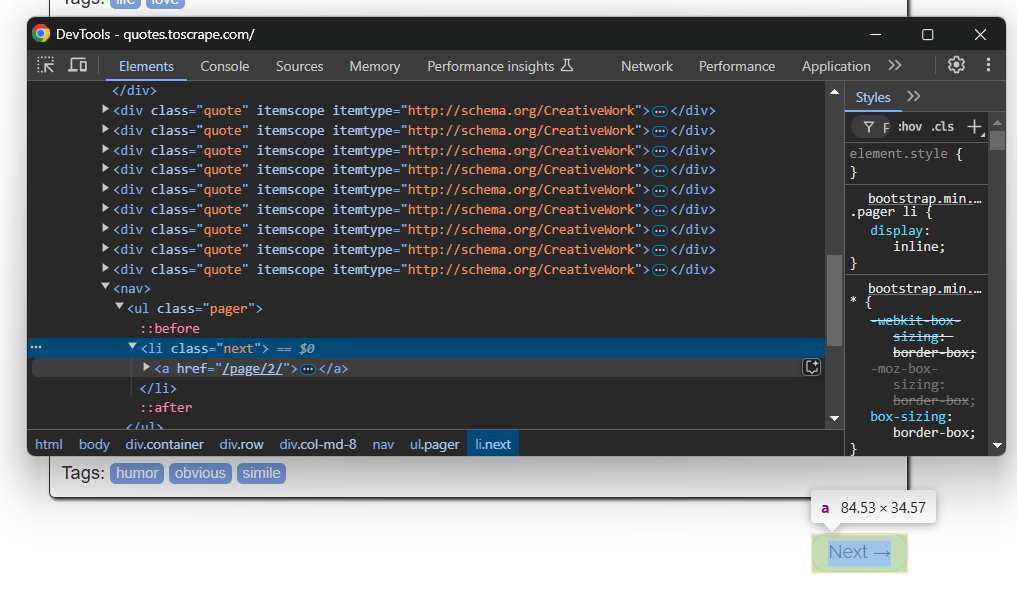
Sur la dernière page, ce bouton n’apparaîtra pas.
Pour implémenter le crawling web et scraper toutes les pages, placez votre logique de scraping dans une boucle qui clique sur le bouton « Suivant → » et s’arrête lorsque le bouton n’est plus disponible :
while sb.is_element_present(".next"):
# Logique de scraping...
# Visiter la page suivante
sb.click(".next a")
Notez l’utilisation de la méthode spéciale SleniumBae is_element_present() pour vérifier si le bouton est présent ou non.
Parfait ! Votre Scraper SeleniumBase va maintenant parcourir l’ensemble du site.
Étape n° 8 : exporter les données récupérées
Exportez les données récupérées entre guillemets dans un fichier CSV comme suit :
with open("quotes.csv", mode="w", newline="", encoding="utf-8") as file:
writer = csv.DictWriter(file, fieldnames=["text", "author", "tags"])
writer.writeheader()
# Aplatir les objets citations pour l'écriture CSV
for quote in quotes:
writer.writerow({
"text": quote["text"],
"author": quote["author"],
"tags": ";".join(quote["tags"])
})
N’oubliez pas d’importer csv depuis la bibliothèque standard Python :
import csv
Étape n° 9 : assembler le tout
Votre fichier script.py devrait maintenant contenir le code suivant :
from seleniumbase import SB
from selenium.webdriver.common.by import By
import csv
with SB() as sb:
# Se connecter à la page cible
sb.open("https://quotes.toscrape.com/")
# Où stocker les données récupérées
quotes = []
# Parcourir toutes les pages de citations
while sb.is_element_present(".next"):
# Sélectionner tous les éléments de citation sur la page
quote_elements = sb.find_elements(".quote")
# Parcourir ces éléments et extraire les données pour chaque élément de citation
for quote_element in quote_elements:
# Logique d'extraction des données
text_element = quote_element.find_element(By.CSS_SELECTOR, ".text")
text = text_element.text.replace("“", "").replace("”", "")
author_element = quote_element.find_element(By.CSS_SELECTOR, ".author")
author = author_element.text
tags = []
tag_elements = quote_element.find_elements(By.CSS_SELECTOR, ".tag")
for tag_element in tag_elements:
tag = tag_element.text
tags.append(tag)
# Remplir un nouvel objet citation avec les données extraites
quote = {
"text": text,
"author": author,
"tags": tags
}
# L'ajouter à la liste des citations extraites
quotes.append(quote)
# Aller à la page suivante
sb.click(".next a")
# Exporter les données récupérées au format CSV
with open("quotes.csv", mode="w", newline="", encoding="utf-8") as file:
writer = csv.DictWriter(file, fieldnames=["text", "author", "tags"])
writer.writeheader()
# Aplatir les objets citation pour l'écriture CSV
for quote in quotes:
writer.writerow({
"text": quote["text"],
"author": quote["author"],
"tags": ";".join(quote["tags"])
})
Exécutez le Scraper SeleniumBase en mode headless avec :
python3 script.py --headless
Après quelques secondes, un fichier quotes.csv apparaîtra dans le dossier du projet.
Ouvrez-le et vous verrez :
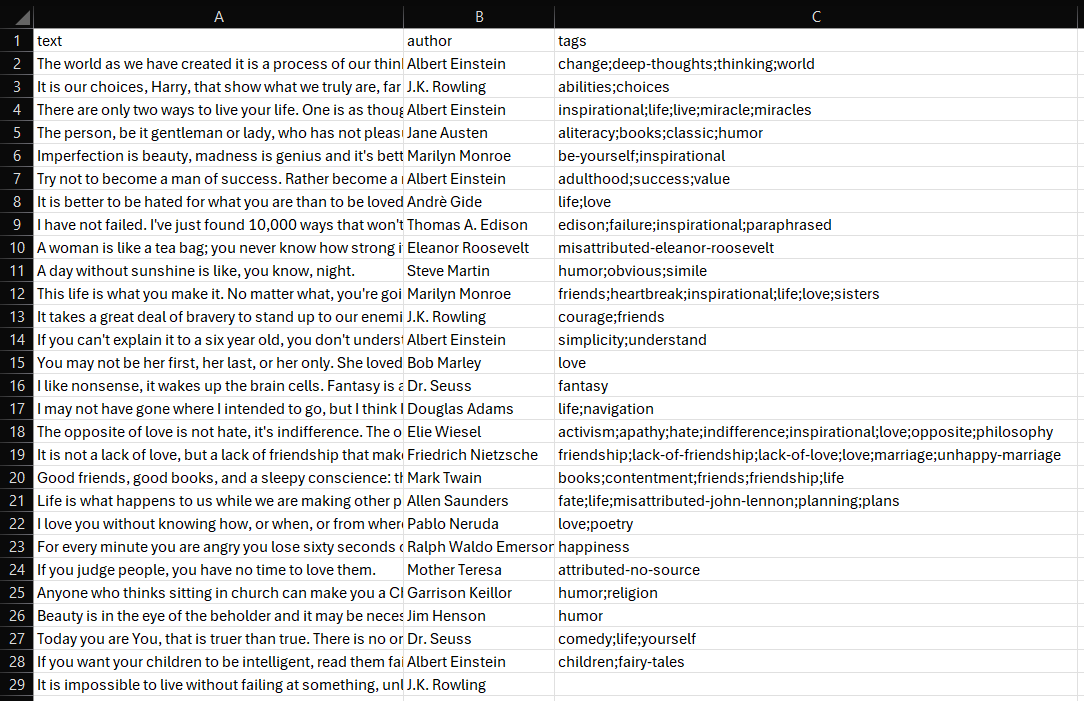
Et voilà ! Votre script de Scraping web SeleniumBase fonctionne à merveille.
Cas d’utilisation avancés du scraping avec SeleniumBase
Maintenant que vous connaissez les bases de SeleniumBase, vous êtes prêt à explorer des scénarios plus complexes.
Automatisation du remplissage et de la soumission de formulaires
Remarque : Bright Data n’effectue pas de scraping derrière une connexion.
SeleniumBase vous permet également d’interagir avec les éléments d’une page comme le ferait un utilisateur humain. Par exemple, supposons que vous deviez interagir avec un formulaire de connexion comme celui ci-dessous :
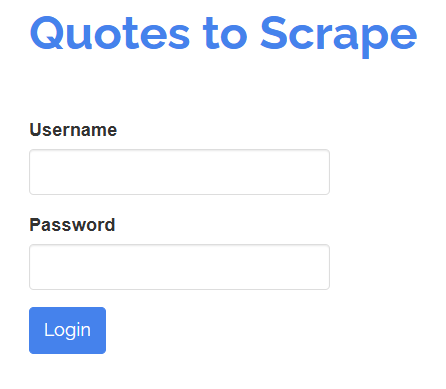
Votre objectif est de remplir les champs « Nom d’utilisateur » et « Mot de passe », puis de soumettre le formulaire en cliquant sur le bouton « Connexion ». Vous pouvez y parvenir avec un test SeleniumBase comme suit :
# login.py
from seleniumbase import BaseCase
BaseCase.main(__name__, __file__)
class LoginTest(BaseCase):
def test_submit_login_form(self):
# Visitez la page cible
self.open("https://quotes.toscrape.com/login")
# Remplir le formulaire
self.type("#username", "test")
self.type("#password", "test")
# Soumettre le formulaire
self.click("input[type="submit"]")
# Vérifier que vous êtes sur la bonne page
self.assert_text("Top Ten tags")
Cet exemple est idéal pour créer un test, alors notez l’utilisation de la classe BaseCase. Cela vous permet de créer des tests pytest.
Exécutez le test à l’aide de cette commande :
pytest login.py
Vous verrez le navigateur s’ouvrir, charger la page de connexion, remplir le formulaire, le soumettre, puis vérifier que le texte donné apparaît sur la page.
Le résultat dans le terminal ressemblera à ceci :
login.py . [100 %]
======================================== 1 réussi en 11,20 s =========================================
Contourner les technologies anti-bot simples
De nombreux sites mettent en œuvre des mesures anti-scraping avancées pour empêcher les bots d’accéder à leurs données. Ces techniques comprennent les défis CAPTCHA, les limites de débit, l’empreinte digitale du navigateur, etc. Pour scraper efficacement des sites web sans être bloqué, vous devez contourner ces protections.
SeleniumBase offre une fonctionnalité spéciale appelée « mode UC » (Undetected-Chromedriver Mode), qui aide les robots de scraping à ressembler davantage à des utilisateurs humains. Cela leur permet d’échapper à la détection par les services anti-bots, qui pourraient autrement bloquer directement le robot de scraping ou déclencher des CAPTCHA.
Le mode UC est basé sur undetected-chromedriver et comprend plusieurs mises à jour, corrections et améliorations, telles que :
- Rotation automatique des agents utilisateurs pour éviter la détection.
- Configuration automatique des arguments Chromium selon les besoins.
- Méthodes spéciales
uc_*()pour contourner les CAPTCHA.
Voyons maintenant comment utiliser le mode UC dans SeleniumBase pour contourner les défis anti-bot.
Pour cette démonstration, vous verrez comment accéder à la page anti-bot du site Scraping Course:
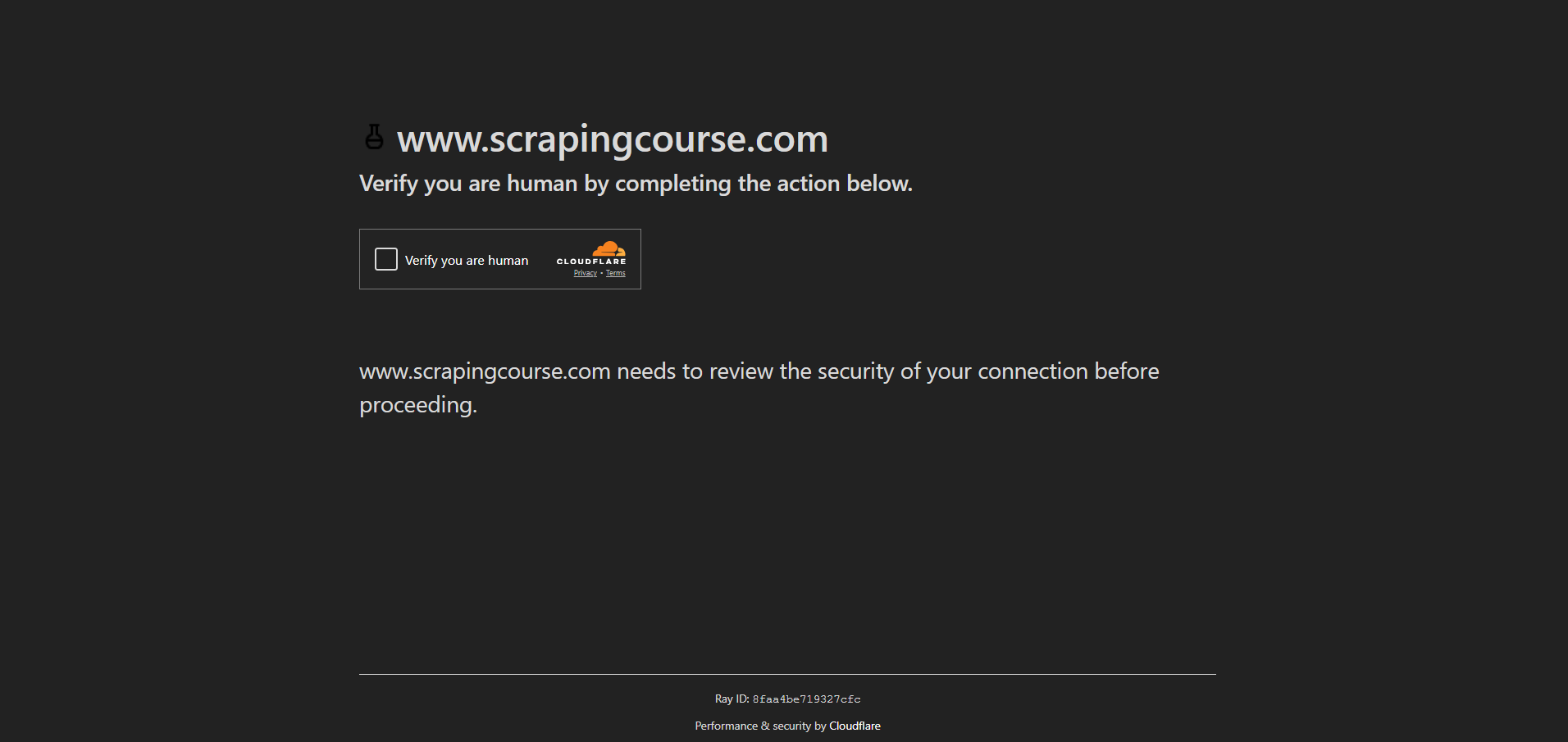
Pour contourner les mesures anti-bot et gérer le CAPTCHA, activez le mode UC et utilisez les méthodes uc_open_with_reconnect() et uc_gui_click_captcha():
from seleniumbase import SB
with SB(uc=True) as sb:
# Page cible avec mesures anti-bot
url = "https://www.scrapingcourse.com/antibot-challenge"
# Ouvrez l'URL en utilisant le mode UC avec un temps de reconnexion de 4 secondes pour éviter la détection initiale.
sb.uc_open_with_reconnect(url, reconnect_time=4)
# Tenter de contourner le CAPTCHA
sb.uc_gui_click_captcha()
# Prendre une capture d'écran de la page
sb.save_screenshot("screenshot.png")
Lancez maintenant le script et vérifiez qu’il fonctionne comme prévu. Étant donné que uc_gui_click_captcha() nécessite PyAutoGUI pour fonctionner, SeleniumBase l’installera pour vous lors de la première exécution :
PyAutoGUI requis ! Installation en cours...
Vous verrez le navigateur cliquer automatiquement sur la case « Vérifiez que vous êtes humain » en déplaçant votre souris. Le fichier screenshot.png dans votre dossier de projet affichera :
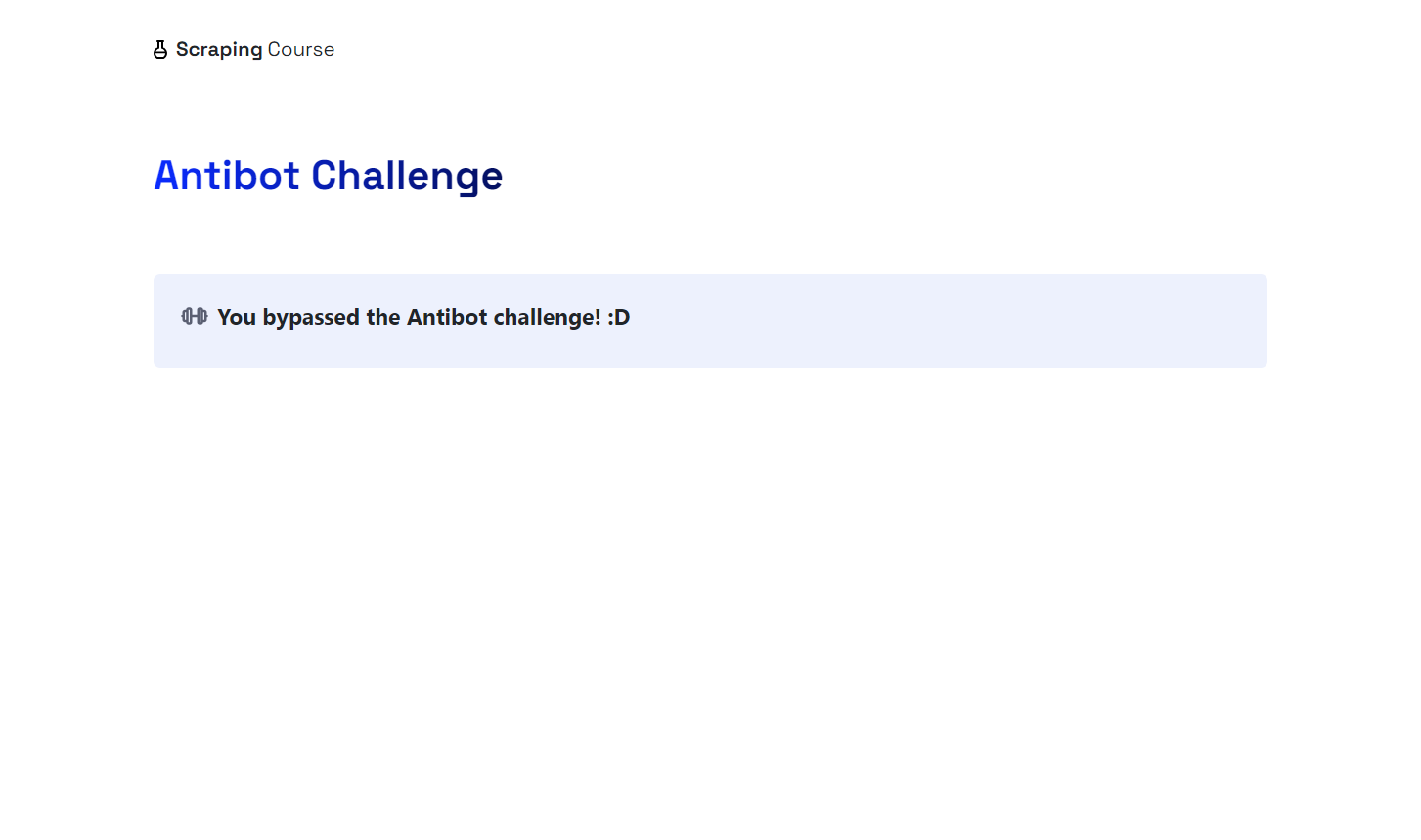
Waouh ! Cloudflare a été contourné.
Contourner les technologies anti-bot complexes
Les solutions anti-bot sont de plus en plus sophistiquées, et le mode UC n’est pas toujours efficace. C’est pourquoi SeleniumBase propose également un mode CDP spécial (Chrome DevTools Protocol Mode).
Le mode CDP fonctionne dans le mode UC et permet aux bots d’apparaître plus humains en contrôlant le navigateur via le pilote CDP. Alors que le mode UC standard ne peut pas effectuer d’actions WebDriver lorsque le pilote est déconnecté du navigateur, le pilote CDP peut toujours interagir avec le navigateur, surmontant ainsi cette limitation.
Le mode CDP est basé sur python-cdp, trio-cdp et nodriver. Il est conçu pour contourner les solutions anti-bots avancées des sites réels, comme dans l’exemple ci-dessous :
from seleniumbase import SB
with SB(uc=True, test=True) as sb:
# Page cible avec mesures anti-bot avancées
url = "https://gitlab.com/users/sign_in"
# Visiter la page en mode CDP
sb.activate_cdp_mode(url)
# Gérer le CAPTCHA
sb.uc_gui_click_captcha()
# Attendre 2 secondes que la page se recharge et que le pilote reprenne le contrôle
sb.sleep(2)
# Prendre une capture d'écran de la page
sb.save_screenshot("screenshot.png")
Le résultat sera le suivant :
Et voilà ! Vous êtes désormais un expert en scraping avec SeleniumBase.
Conclusion
Dans cet article, vous avez découvert SeleniumBase, ses fonctionnalités et ses méthodes, ainsi que son utilisation pour le Scraping web. Vous avez commencé par des scénarios basiques, puis vous avez exploré des cas d’utilisation plus complexes.
Si les modes UC et CDP sont efficaces pour contourner certaines mesures anti-bot, ils ne sont pas infaillibles.
Les sites web peuvent toujours bloquer votre IP si vous effectuez trop de requêtes ou vous mettre au défi avec des CAPTCHA plus complexes qui nécessitent plusieurs actions. Une solution plus efficace consiste à utiliser un outil d’automatisation de navigateur web comme Selenium en combinaison avec un navigateur dédié au scraping, basé sur le cloud et hautement évolutif comme Navigateur de scraping de Bright Data.
Le Navigateur de scraping est un navigateur qui fonctionne avec Playwright, Puppeteer, Selenium et d’autres. Il fait automatiquement tourner les adresses IP de sortie à chaque requête et peut gérer les empreintes digitales du navigateur, les nouvelles tentatives, la résolution des CAPTCHA et bien plus encore. Oubliez les blocages et rationalisez vos opérations de scraping.
Inscrivez-vous dès maintenant et commencez votre essai gratuit !






