

Dans ce guide, vous apprendrez :
- Ce qu’est Agno et pourquoi c’est un excellent choix pour construire des flux de travail agentiques.
- Pourquoi le web scraping joue un rôle si important dans les agents d’intelligence artificielle.
- Comment intégrer Agno avec ses outils Bright Data intégrés pour créer un agent de scraping web.
Plongeons dans l’aventure !
Qu’est-ce qu’Agno ?
Agno est un framework Python complet pour construire des systèmes multi-agents qui exploitent la mémoire, la connaissance et le raisonnement avancé. Il permet de créer des agents d’intelligence artificielle sophistiqués pour un large éventail de cas d’utilisation. Ceux-ci vont de simples agents utilisant des outils à des équipes d’agents collaboratifs avec état et déterminisme.
Agno est agnostique, très performant et place le raisonnement au centre de sa conception. Il prend en charge les entrées et sorties multimodales, l’orchestration multi-agents complexe, la recherche agentive intégrée avec des bases de données vectorielles et la gestion complète de la mémoire et des sessions.
À ce jour, Agno est l’une des bibliothèques open-source les plus populaires pour la construction d’agents d’intelligence artificielle, avec plus de 29 000 étoiles sur GitHub :
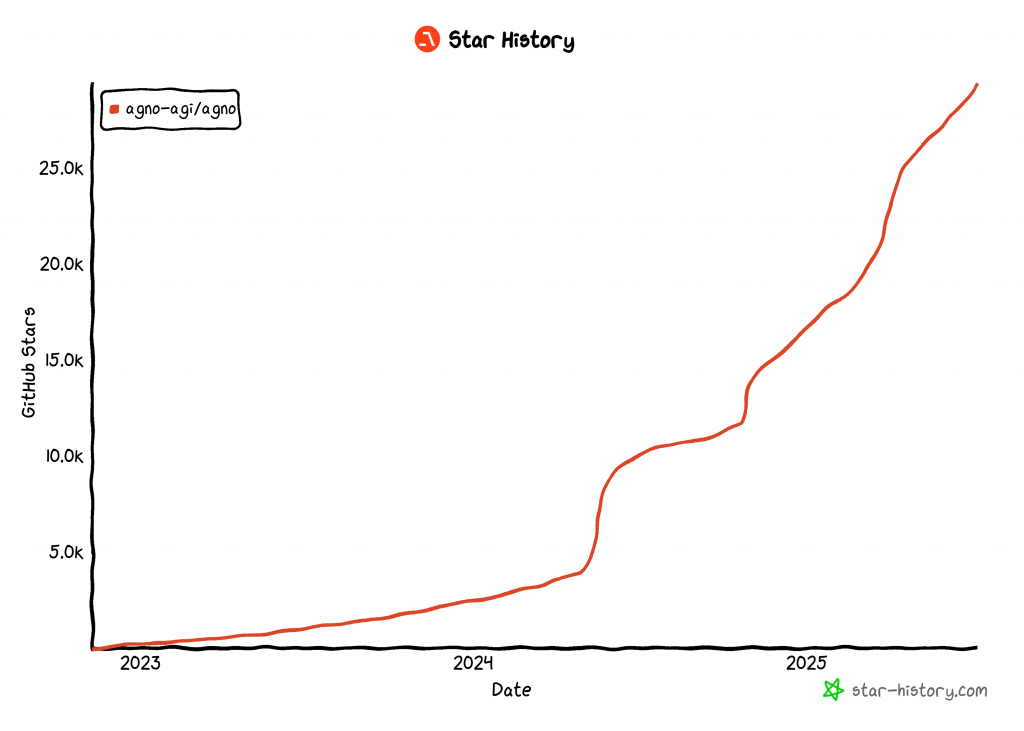
Son ascension rapide montre à quel point Agno gagne rapidement du terrain dans la communauté des développeurs et de l’IA.
Pourquoi le Web Scraping Agentic est si utile
Le web scraping traditionnel repose sur l’écriture de règles d’analyse de données rigides pour extraire des données de pages web spécifiques. Le problème ? Les sites changent fréquemment de structure, ce qui signifie que vous devez constamment mettre à jour votre logique de scraping. Cela entraîne des coûts de maintenance élevés et des pipelines fragiles.
C’est la raison pour laquelle l ‘IA web scraping gagne en popularité. Au lieu d’élaborer des scripts d’analyse personnalisés, vous pouvez utiliser un modèle d’IA pour extraire des données directement à partir du code HTML d’une page web à l’aide d’une simple invite. Cette approche est si populaire que de nombreux outils de scraping d’IA ont récemment vu le jour.
Cependant, l’IA pour le web scraping devient encore plus puissante lorsqu’elle est intégrée dans une architecture d’IA agentique. En particulier, vous pouvez créer un agent dédié au web scraping auquel d’autres agents d’IA peuvent se connecter. Cela est possible dans des flux de travail multi-agents ou via des protocoles d’IA tels que A2A de Google.
Agno rend tout cela possible. Il vous permet de construire des agents autonomes de grattage d’IA ou des écosystèmes multi-agents complexes. Cependant, les LLM ordinaires ne sont pas conçus pour un scraping web efficace. Ils ne parviennent souvent pas à se connecter à des sites dotés de solides défenses contre les robots – ou pire, ils peuvent “halluciner” et renvoyer de fausses données.
Pour remédier à ces limitations, Agno s’intègre nativement à Bright Data via des outils de scraping dédiés. Grâce à ces outils, votre agent d’IA peut extraire des données fraîches et structurées de n’importe quel site Web.
Pour éviter les blocages et les perturbations, Bright Data surmonte pour vous des défis tels que l’empreinte TLS, l’empreinte du navigateur et de l’appareil, les CAPTCHA, les protections Cloudflare, et bien d’autres encore. Une fois les données récupérées, elles sont introduites dans le LLM pour être interprétées et analysées, en suivant les instructions de votre tâche initiale.
Découvrez comment intégrer les outils Bright Data dans un agent Agno pour un scraping web de haut niveau !
Comment intégrer les outils Bright Data pour le Web Scraping dans Agno
Dans cette section étape par étape, vous verrez comment utiliser Agno pour construire un agent d’intelligence artificielle pour l’exploration du Web. En intégrant les outils Bright Data, vous donnerez à votre agent Agno la possibilité d’extraire des données de n’importe quelle page web.
Suivez les instructions ci-dessous pour créer votre agent de scraping alimenté par Bright Data dans Agno !
Conditions préalables
Pour suivre ce tutoriel, assurez-vous d’avoir les éléments suivants :
- Python 3.7 ou supérieur installé localement (nous recommandons d’utiliser la dernière version).
- Une clé d’API de Bright Data.
- Une clé API pour un fournisseur LLM supporté (ici, nous utiliserons Gemini parce qu’il est gratuit à utiliser via l’API, mais n’importe quel fournisseur LLM supporté fera l’affaire).
Ne vous inquiétez pas si vous n’avez pas encore de clé API Bright Data ou Gemini. Nous vous expliquerons comment les créer dans les prochaines étapes.
Étape 1 : Configuration du projet
Ouvrez un terminal et créez un nouveau répertoire pour votre projet d’agent Agno AI, qui utilisera Bright Data pour le web scraping :
mkdir agno-web-scraperLe dossier agno-web-scraper contiendra tout le code Python pour votre agent Agno scraping.
Ensuite, naviguez dans le répertoire du projet et mettez en place un environnement virtuel à l’intérieur de celui-ci :
cd agno-web-scraper
python -m venv venvMaintenant, chargez le projet dans votre IDE Python préféré. Nous recommandons Visual Studio Code avec l’extension Python ou PyCharm Community Edition.
Dans le dossier du projet, créez un nouveau fichier nommé scraper.py. La structure de votre répertoire devrait ressembler à ceci :
agno-web-scraper/
├── venv/
└── scraper.pyActivez l’environnement virtuel dans votre terminal. Sous Linux ou macOS, exécutez :
source venv/bin/activateDe manière équivalente, sous Windows, lancez cette commande :
venv/Scripts/activateDans les étapes suivantes, vous serez guidé dans l’installation des paquets Python requis. Si vous préférez tout installer maintenant, dans l’environnement virtuel activé, exécutez :
pip install agno python-dotenv google-genai requestsNote: Nous installons google-genai parce que ce tutoriel utilise Gemini comme fournisseur LLM. Si vous prévoyez d’utiliser un autre LLM, assurez-vous d’installer la bibliothèque appropriée pour ce fournisseur.
Vous êtes prêt ! Vous disposez maintenant d’un environnement de développement Python prêt à construire un flux de travail agentique de scraping à l’aide d’Agno et de Bright Data.
Étape 2 : Configuration des variables d’environnement Lecture
Votre agent de scraping Agno se connectera à des services tiers tels que Bright Data et Gemini par le biais d’intégrations API. Pour garantir la sécurité, évitez de coder en dur vos clés d’API directement dans votre code Python. Stockez-les plutôt sous forme de variables d’environnement.
Pour faciliter le chargement des variables d’environnement, adoptez la bibliothèque python-dotenv. Avec votre environnement virtuel activé, installez-la en exécutant :
pip install python-dotenvEnsuite, dans votre fichier scraper.py, importez la bibliothèque et appelez load_dotenv() pour charger vos variables d’environnement :
from dotenv import load_dotenv
load_dotenv()Cette fonction permet à votre script de lire les variables d’un fichier .env local. Créez un fichier .env à la racine du répertoire de votre projet :
agno-web-scraper/
├── venv/
├── .env # <-----------
└── scraper.pyC’est formidable ! Vous êtes maintenant prêt à gérer en toute sécurité vos secrets d’intégration à l’aide de variables d’environnement.
Étape 3 : Configurer Bright Data
Les outils Bright Data intégrés dans Agno vous donnent accès à plusieurs solutions de collecte de données. Dans ce tutoriel, nous nous concentrerons sur l’intégration de ces deux produits spécifiques au scraping :
- API Web Unlocker: Une API de scraping avancée qui surmonte les protections des robots et permet d’accéder à n’importe quelle page web au format Markdown.
- Web Scraper APIs: Points de terminaison spécialisés pour l’extraction éthique de données fraîches et structurées à partir de sites web populaires, tels que LinkedIn, Amazon et bien d’autres.
Pour utiliser ces outils, vous devez
- Configurez la solution Web Unlocker dans votre compte Bright Data.
- Obtenez votre clé API Bright Data pour authentifier les demandes d’API Web Unlocker et Web Scraper.
Suivez les instructions ci-dessous pour le faire !
Tout d’abord, si vous n’avez pas encore de compte Bright Data, inscrivez-vous gratuitement. Si vous en avez déjà un, connectez-vous et ouvrez votre tableau de bord. Cliquez sur le bouton “Obtenir des produits proxy” :
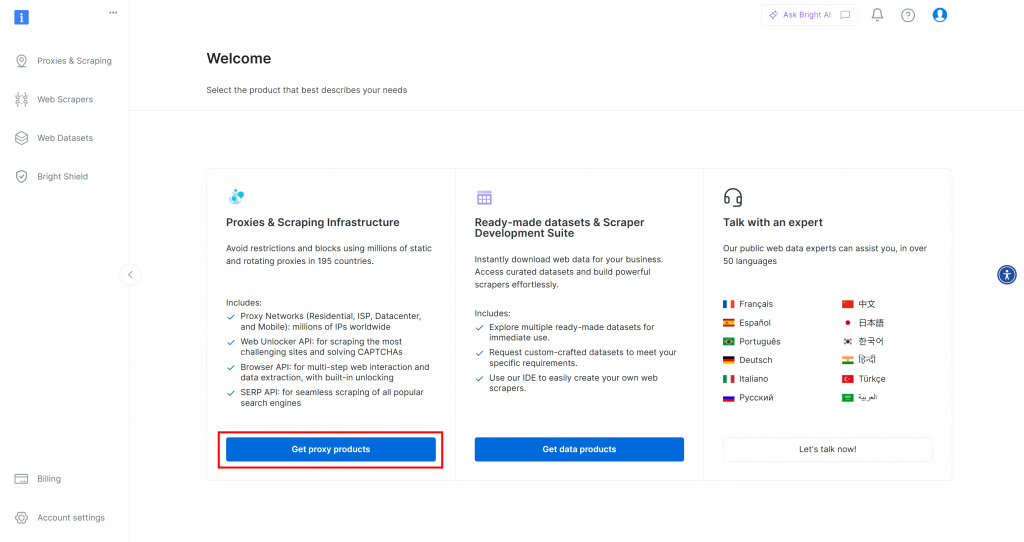
Vous serez redirigé vers la page “Proxies & Scraping Infrastructure” :
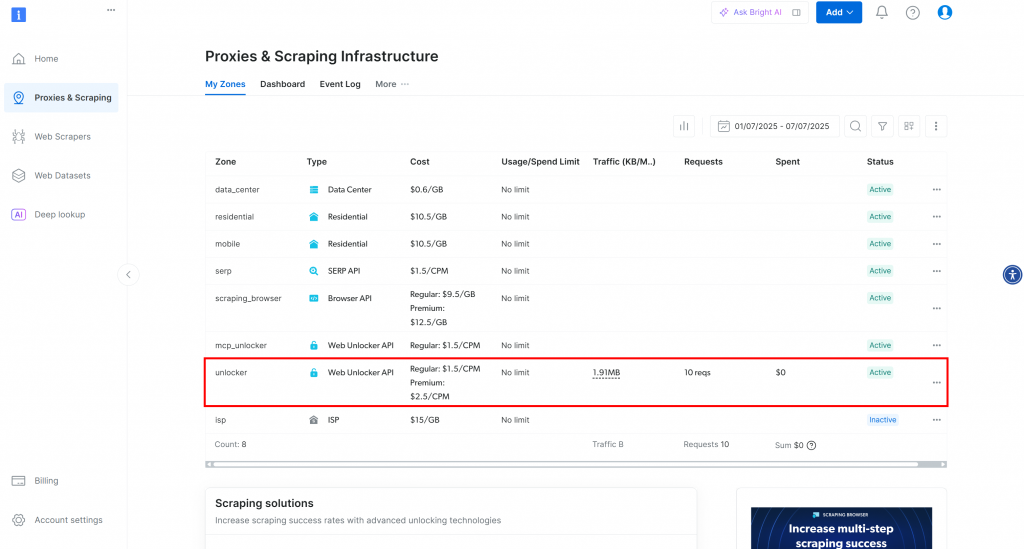
Sur cette page, vous verrez des solutions Bright Data déjà configurées. Dans cet exemple, une zone Web Unloker est activée. Le nom de cette zone est “unblocker” (vous en aurez besoin plus tard lorsque vous l’intégrerez dans votre script).
Si vous n’avez pas encore de zone Web Unlocker, descendez jusqu’à la carte “Web Unlocker API” et cliquez sur “Créer une zone” :
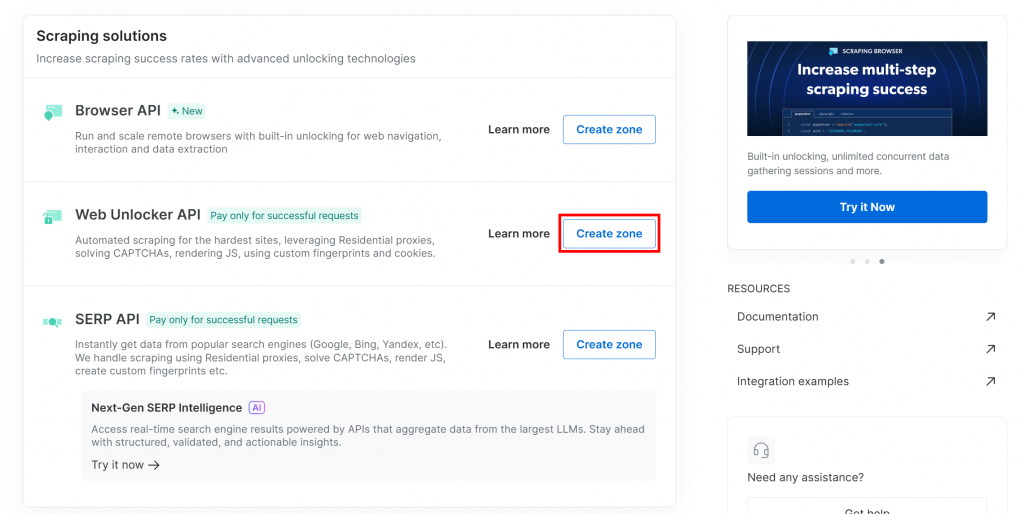
Donnez un nom à votre zone (comme “débloqueur”), activez les fonctions avancées pour de meilleures performances et cliquez sur le bouton “Ajouter” :
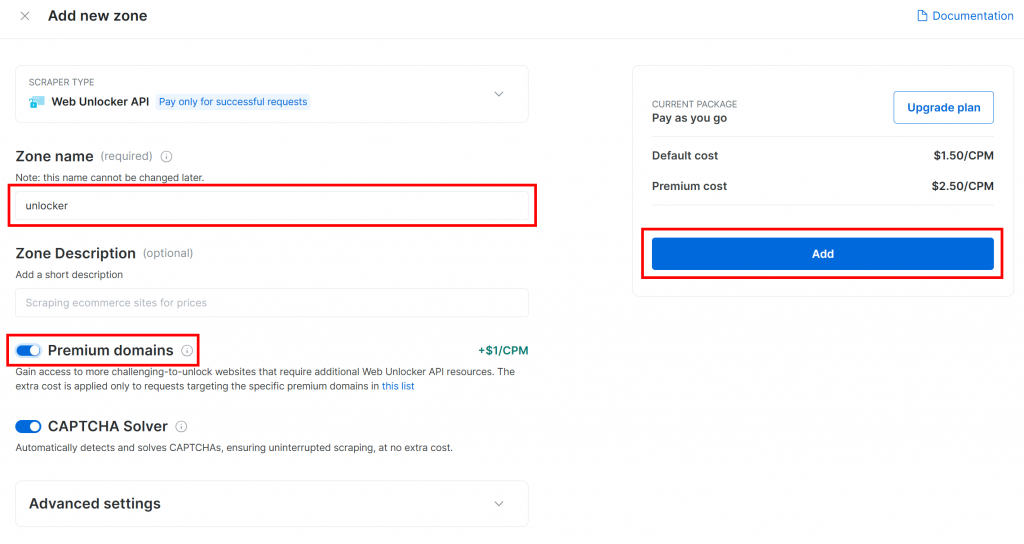
Vous accéderez à la page de votre nouvelle zone. Assurez-vous que la bascule est réglée sur le statut “Actif”, ce qui confirme que le produit est prêt à être utilisé :
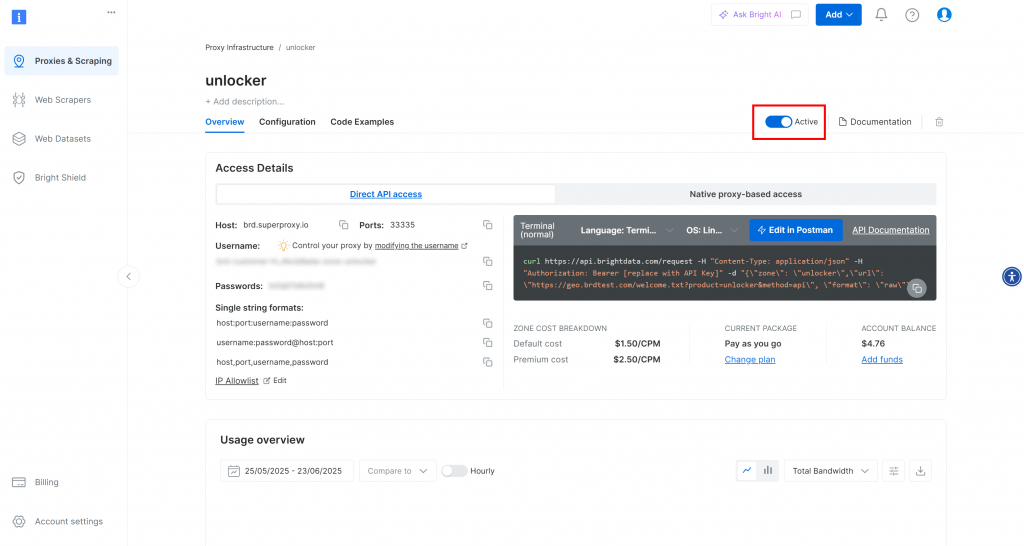
Maintenant, suivez la documentation officielle de Bright Data pour générer votre clé API. Une fois que vous l’avez obtenue, ajoutez-la à votre fichier .env comme suit :
BRIGHT_DATA_API_KEY="<YOUR_BRIGHT_DATA_API_KEY>"Remplacez le par la valeur réelle de votre clé API.
Parfait ! Il est temps d’intégrer les outils de Bright Data dans votre script d’agent Agno pour le web scraping agentique.
Étape 4 : Intégrer les outils Agno Bright Data Tools pour le Web Scraping
Dans votre dossier de projet, avec l’environnement virtuel activé, installez Agno en exécutant :
pip install agnoGardez à l’esprit que le paquet agno comprend déjà une prise en charge intégrée des outils Bright Data. Vous n’avez donc pas besoin de paquets supplémentaires spécifiques à l’intégration.
Le seul paquetage supplémentaire requis est la bibliothèque Python Requests, que les outils Bright Data utilisent pour appeler les produits que vous avez configurés précédemment via l’API. Installez Requests avec :
pip install requestsDans votre fichier scraper.py, importez les outils de scraping Bright Data d’agno:
from agno.tools.brightdata import BrightDataToolsEnsuite, initialisez les outils comme suit :
bright_data_tools = BrightDataTools(
web_unlocker_zone="unlocker", # Replace with your Web Unlocker API zone name
search_engine=False,
)Remplacez "unlocker" par le nom réel de votre zone Bright Data Web Unlocker.
Notez également que search_engine est défini sur False puisque nous n’utilisons pas l’outil SERP API dans cet exemple, qui se concentre uniquement sur le web scraping.
Astuce: Au lieu de coder en dur les noms de zones, vous pouvez les charger à partir de votre fichier .env. Pour ce faire, ajoutez cette ligne à votre fichier .env:
BRIGHT_DATA_WEB_UNLOCKER_ZONE="<YOUR_BRIGHT_DATA_WEB_UNLOCKER_ZONE>"Remplacez l’espace réservé par le nom de votre zone de déverrouillage Web. Vous pouvez ensuite supprimer l’argument web_unlocker_zone de BrightDataTools. La classe récupérera automatiquement le nom de la zone dans votre environnement.
Remarque: pour se connecter à Bright Data, BrightDataTools recherche votre clé d’API dans la variable d’environnement BRIGHT_DATA_API_KEY. C’est pourquoi nous l’avons ajoutée à votre fichier .env à l’étape précédente.
Génial ! Intégrez Gemini pour alimenter votre flux de travail agentique de web scraping Agno.
Étape 5 : Configurer le modèle LLM à partir de Gemini
Il est temps de se connecter à Gemini, le fournisseur LLM choisi dans ce tutoriel. Commencez par installer le paquetage google-genai:
pip install google-genaiEnsuite, importez la classe d’intégration Gemini d’Agno :
from agno.models.google import GeminiInitialisez maintenant votre modèle LLM comme suit :
llm_model = Gemini(id="gemini-2.5-flash")Dans l’extrait ci-dessus, gemini-2.5-flash est le nom du modèle Gemini que vous voulez que votre agent utilise. N’hésitez pas à le remplacer par n’importe quel autre modèle Gemini pris en charge (n’oubliez pas que certains d’entre eux ne sont pas libres d’utilisation via l’API).
Sous le capot, la bibliothèque google-genai s’attend à ce que votre clé d’API Gemini soit stockée dans une variable d’environnement nommée GOOGLE_API_KEY. Pour la mettre en place, ajoutez la ligne suivante à votre fichier .env :
GOOGLE_API_KEY="<YOUR_GOOGLE_API_KEY>"Remplacez le par votre clé API réelle. Si vous n’en avez pas encore, suivez le guide officiel pour générer une clé API Gemini.
Remarque: si vous souhaitez vous connecter à un autre fournisseur de LLM, consultez la documentation officielle pour obtenir des instructions de configuration.
Fantastique ! Vous disposez maintenant de tous les composants de base dont vous avez besoin pour créer votre agent de raclage Agno.
Étape 6 : Définir l’agent de raclage
Dans votre fichier scraper.py, configurez votre agent de scraping Agno comme suit :
agent = Agent(
tools=[bright_data_tools],
model=llm_model,
)Cela crée un objet Agno Agent qui utilise votre LLM configuré pour traiter les invites et qui tire parti des outils Bright Data pour l’exploration du Web.
N’oubliez pas d’ajouter cette importation en tête de votre fichier :
from agno.agent import AgentFormidable ! Il ne vous reste plus qu’à envoyer une requête à votre agent et à exporter les données recueillies.
Étape 7 : Interroger l’agent de scraping d’Agno
Lisez l’invite de la CLI et transmettez-la à votre agent de scraping Agno pour qu’il l’exécute :
# Read the agent request from the CLI
request = input("Request -> ")
# Run a task in the AI agent
response = agent.run(request)La première ligne utilise la fonction input() intégrée à Python pour lire une invite tapée par l’utilisateur. L’invite doit décrire la tâche de scraping ou la question que vous voulez que votre agent traite. La deuxième ligne [appelle run()] sur l’agent pour traiter l’invite et exécuter la tâche] (https://docs.agno.com/agents/run#running-your-agent).
Pour afficher la réponse joliment formatée dans votre terminal, utilisez :
pprint_run_response(response)Importez cette fonction d’aide d’Agno de la manière suivante :
from agno.utils.pprint import pprint_run_responsepprint_run_response imprime la réponse de l’agent IA. Mais vous voudrez probablement aussi extraire et sauvegarder les données brutes extraites par l’outil Bright Data. C’est ce que nous allons faire à l’étape suivante !
Étape 8 : Exporter les données extraites
Lors de l’exécution d’une tâche de scraping, votre agent de scraping Web Agno appelle les outils Bright Data configurés en arrière-plan. Le fait de s’assurer que votre script exporte également les données brutes renvoyées par ces outils ajoute beaucoup de valeur à votre flux de travail. En effet, vous pouvez réutiliser ces données pour d’autres scénarios (par exemple, l’analyse de données) ou d’autres cas d’utilisation agentique.
Actuellement, votre agent de scraping a accès à ces deux méthodes d’outils de BrightDataTools:
scrape_as_markdown(): Scrape n’importe quelle page web et renvoie le contenu au format Markdown.web_data_feed(): Récupère des données JSON structurées à partir de sites populaires comme LinkedIn, Amazon, Instagram, et plus encore.
Ainsi, en fonction de la tâche, les données extraites peuvent être soit au format Markdown, soit au format JSON. Pour traiter les deux cas, vous pouvez lire la sortie brute du résultat de l’outil dans response.tools[0].result. Essayez ensuite de l’analyser au format JSON. En cas d’échec, vous traiterez les données extraites au format Markdown.
Mettez en œuvre la logique ci-dessus à l’aide des lignes de code suivantes :
if (len(response.tools) > 0):
# Access the scraped data from the Bright Data tool
scraping_data = response.tools[0].result
try:
# Check if the scraped data is in JSON format
parsed_json = json.loads(scraping_data)
output_extension = "json"
except json.JSONDecodeError:
output_extension = "md"
# Write the scraped data to an output file
with open(f"output.{output_extension}", "w", encoding="utf-8") as file:
file.write(scraping_data) N’oubliez pas d’importer json de la bibliothèque standard de Python :
import jsonC’est très bien ! Votre flux de travail de l’agent de raclage Web Agno est maintenant terminé.
Étape n° 9 : Assembler le tout
C’est le code final de votre fichier scraper.py :
from dotenv import load_dotenv
from agno.tools.brightdata import BrightDataTools
from agno.models.google import Gemini
from agno.agent import Agent
from agno.utils.pprint import pprint_run_response
import json
# Load the environment variables from the .env file
load_dotenv()
# Configure the Bright Data tools for Agno integration
bright_data_tools = BrightDataTools(
web_unlocker_zone="web_unlocker", # Replace with your Web Unlocker API zone name
search_engine=False, # As the SERP API tool is not required in this use case
)
# The LLM that will be used by the AI scraping agent
llm_model = Gemini(id="gemini-2.5-flash")
# Define your Agno agent with Bright Data tools
agent = Agent(
tools=[bright_data_tools],
model=llm_model,
)
# Read the agent request from the CLI
request = input("Request -> ")
# Run a task in the AI agent
response = agent.run(request)
# Print the agent response in the terminal
pprint_run_response(response)
# Export the scraped data
if (len(response.tools) > 0):
# Access the scraped data from the Bright Data tool
scraping_data = response.tools[0].result
try:
# Check if the scraped data is in JSON format
parsed_json = json.loads(scraping_data)
output_extension = "json"
except json.JSONDecodeError:
output_extension = "md"
# Write the scraped data to an output file
with open(f"output.{output_extension}", "w", encoding="utf-8") as file:
file.write(scraping_data)En moins de 50 lignes de code, vous avez construit un workflow de scraping piloté par l’IA qui peut extraire des données de n’importe quelle page Web. C’est la puissance de la combinaison de Bright Data et d’Agno pour le développement d’agents !
Étape n° 10 : Exécuter l’agent d’Agno Scraping
Dans votre terminal, lancez votre agent de scraping web Agno en exécutant :
python scraper.pyVous serez invité à saisir une demande. Essayez quelque chose comme :
Give me a short summary from "https://www.reuters.com/sports/formula1/hulkenberg-rids-himself-unwanted-record-239th-attempt-2025-07-06/"Vous devriez obtenir un résultat similaire à celui-ci :
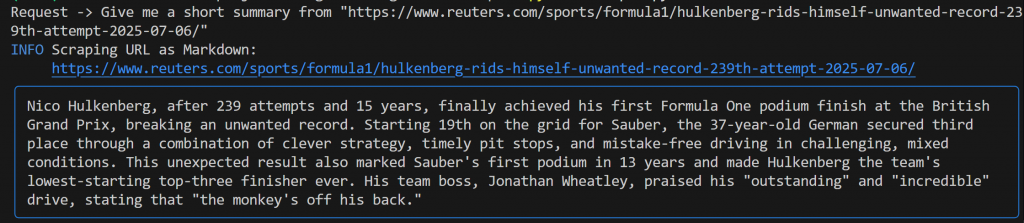
Cette sortie comprend
- L’invite originale que vous avez soumise.
- Un journal indiquant quel outil Bright Data a été utilisé pour le scraping. Dans ce cas, il confirme que
scrape_as_markdown()a été invoqué. - Un résumé au format Markdown généré par Gemini, mis en évidence par un rectangle bleu.
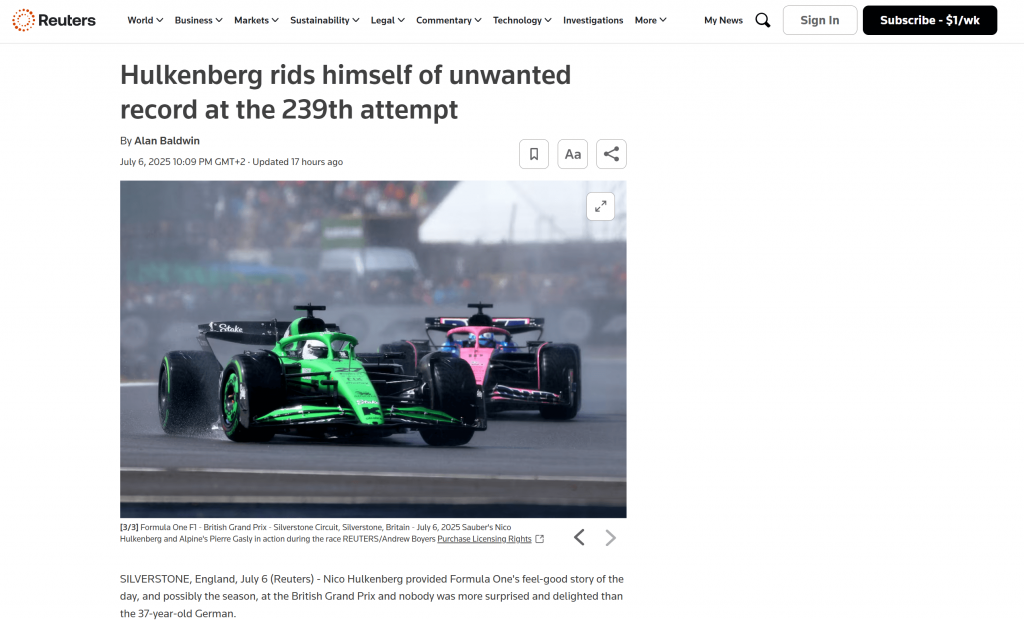
Si vous regardez dans le dossier racine de votre projet, vous verrez un nouveau fichier nommé output.md. Ouvrez-le dans n’importe quelle visionneuse Markdown, et vous obtiendrez une version Markdown du contenu de la page scrappée :

Comme vous pouvez le constater, la sortie Markdown de Bright Data reproduit fidèlement le contenu de la page Web d’origine :
Maintenant, essayez de relancer votre agent de scraping avec une demande différente et plus spécifique :
Summarize the main features of the product on this Amazon page: "https://www.amazon.com/PlayStation%C2%AE5-console-slim-PlayStation-5/dp/B0CL61F39H/" Cette fois, votre résultat pourrait ressembler à ceci :
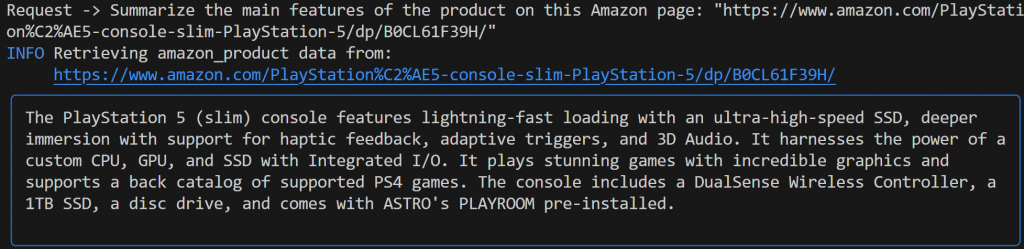
Remarquez que l’agent Agno alimenté par Gemini a automatiquement choisi l’outil web_data_feed, qui est correctement configuré pour le scraping structuré des pages de produits Amazon.
En conséquence, vous trouverez maintenant un fichier output.json dans le dossier de votre projet. Ouvrez-le et collez son contenu dans n’importe quelle visionneuse JSON :
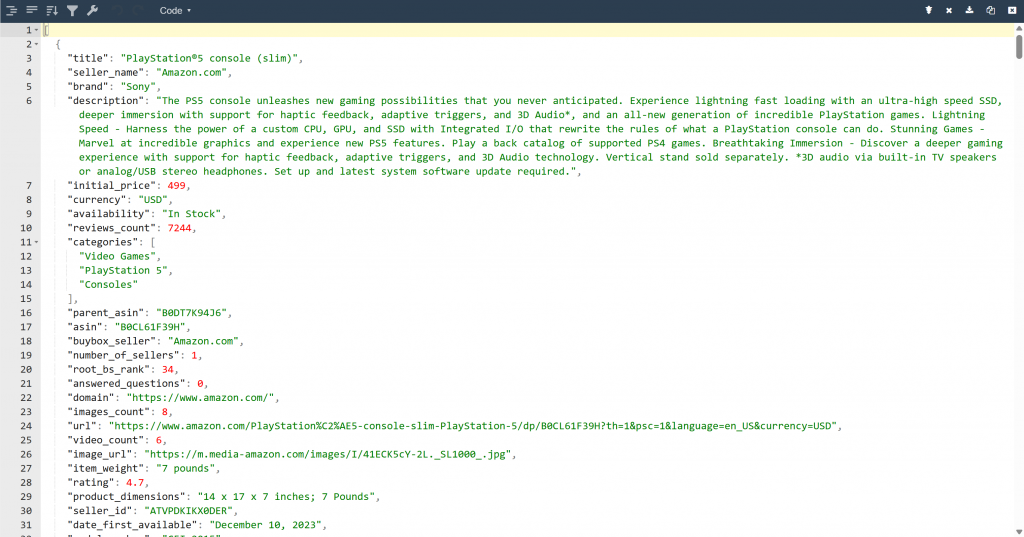
Regardez comment l’outil Bright Data a extrait des données JSON structurées de cette page Amazon :
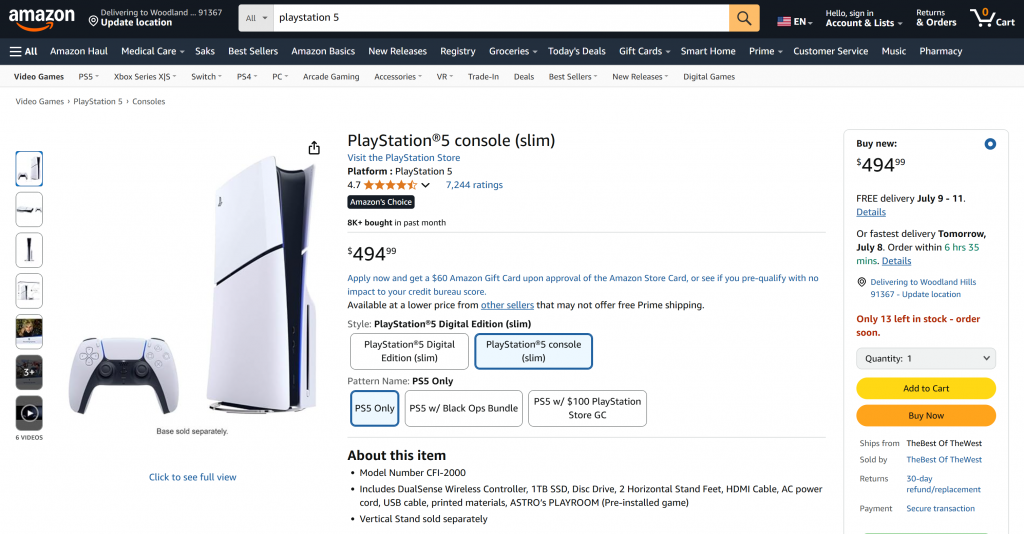
Ces deux exemples montrent comment votre agent peut désormais extraire des données de pratiquement n’importe quelle page web. Cela est vrai même pour des sites complexes tels qu’Amazon qui sont réputés pour leurs défenses anti-scraping (comme le fameux CAPTCHA d’Amazon).
Et voilà ! Vous venez de faire l’expérience d’un scraping web transparent dans votre agent d’IA, alimenté par les outils Bright Data et Agno.
Prochaines étapes
L’agent de scraping web que vous venez de construire avec Agno n’est qu’un début. À partir de là, vous pouvez explorer plusieurs façons d’étendre et d’améliorer votre projet :
- Incorporez une couche de mémoire: Utilisez la base de données vectorielle native d’Agno pour stocker les données que votre agent collecte par le biais de Bright Data. Votre agent dispose ainsi d’une mémoire à long terme, ce qui ouvre la voie à des cas d’utilisation avancés tels que le RAG agentique.
- Créer une interface conviviale: Créez une interface web ou de bureau simple pour que les utilisateurs puissent discuter avec votre agent de manière naturelle et conversationnelle (comme avec ChatGPT ou Gemini). Cela rendra votre outil de scraping beaucoup plus accessible.
- Explorez des intégrations plus riches: Agno offre une variété d’outils et de capacités qui peuvent étendre les compétences de votre agent bien au-delà du scraping. Plongez dans la documentation d’Agno pour trouver de l’inspiration sur la manière de connecter davantage de sources de données, d’utiliser différents LLM ou d’orchestrer des flux de travail d’agent à plusieurs étapes.
Conclusion
Dans cet article, vous avez appris à utiliser Agno pour construire un agent d’IA pour le web scraping. Cela a été rendu possible grâce à l’intégration d’Agno avec les outils Bright Data. Ceux-ci permettent au LLM choisi d’extraire des données de n’importe quel site web.
N’oubliez pas qu’il ne s’agit que d’un exemple simple. Si vous souhaitez développer des agents plus avancés, vous aurez besoin de solutions pour récupérer, valider et transformer les données Web en direct. C’est précisément ce que vous trouverez dans l’infrastructure Bright Data AI.
Créez un compte Bright Data gratuit et commencez à expérimenter nos outils de scraping prêts pour l’IA !




