

Dans cet article, vous apprendrez :
- Si les données synthétiques sont vraiment l’avenir de l’entraînement IA et ML.
- Ce que sont les données web réelles, leurs principaux types et comment les collecter à grande échelle.
- Ce que sont les données synthétiques, comment elles peuvent être catégorisées et comment elles sont générées avec succès.
- L’impact des données synthétiques vs réelles en termes de coût, confidentialité, robustesse et qualité de distribution.
- Comment le choix des données affecte le pipeline d’entraînement IA et les performances du modèle.
- Pourquoi une approche hybride combinant les deux types de données est souvent la stratégie la plus efficace.
- Les avantages et inconvénients de chaque approche.
Commençons.
Les Données Synthétiques sont-elles l’Avenir de l’IA/ML, ou les Données Web ont-elles encore leur Place ?
Les lois de mise à l’échelle de l’IA montrent que les performances tendent à s’améliorer lorsque les modèles sont entraînés sur davantage de paramètres, de calcul et, surtout, de données. En d’autres termes, les modèles plus grands nécessitent des jeux de données exponentiellement plus importants pour maintenir les gains de performance.
Historiquement, les données web réelles ont servi de fondation à l’entraînement moderne de l’IA, mais les données web de haute qualité sont limitées. Elon Musk a déclaré que les entreprises d’IA ont épuisé leurs données d’entraînement et ont « épuisé » la somme des connaissances humaines disponibles pour l’entraînement des modèles.
De plus, les données web sont de plus en plus dupliquées et coûteuses à collecter, nettoyer et vérifier légalement. Cela souligne aussi l’importance de sélectionner des fournisseurs de jeux de données web qui livrent des jeux de données optimisés pour l’IA, régulièrement mis à jour et conformes à la confidentialité.
Ces pressions accélèrent l’intérêt pour des sources de données alternatives, notamment les données synthétiques. Selon Gartner, d’ici 2030, les données synthétiques devraient éclipser les données réelles dans l’entraînement des modèles IA. La firme attribue ce changement à des exigences de confidentialité plus strictes, à la rareté des données réelles et aux organisations cherchant des alternatives moins coûteuses réduisant les risques juridiques et de conformité.
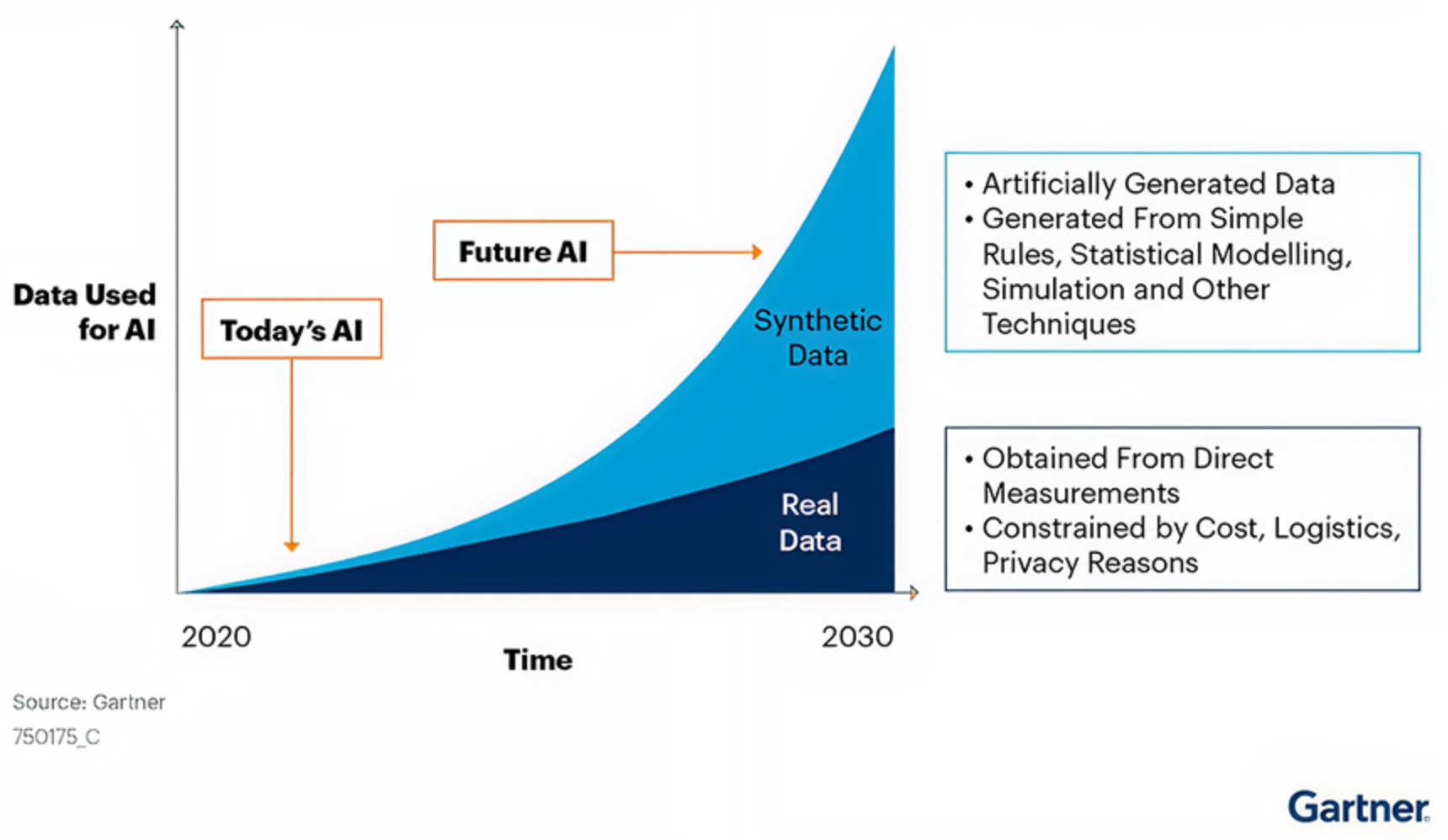
En même temps, cette prédiction doit être considérée comme une estimation plutôt qu’une inévitabilité. Internet continue de générer d’énormes volumes de contenu, avec environ 402 millions de téraoctets de données web créées chaque jour !
Pour mettre cela en perspective, GPT-3 a été entraîné sur environ 45 téraoctets de texte brut avant filtrage. Cette comparaison suggère que les données humaines à l’échelle du web restent vastes et très pertinentes pour l’entraînement de l’IA.
Par conséquent, l’avenir de l’entraînement IA ne dépendra probablement pas exclusivement des données synthétiques. À la place, de nombreux experts en apprentissage automatique anticipent une approche hybride, un sujet que nous examinerons plus loin dans cet article.
Données Synthétiques vs Données Web Réelles : Comparaison des Deux Paradigmes
Dans les chapitres suivants, vous découvrirez ce que sont les données synthétiques et les données web réelles, ce qu’elles offrent et comment elles se comparent sur plusieurs aspects de l’entraînement des modèles IA. Nous commencerons par les données web réelles, plus naturelles à appréhender, puis passerons aux données synthétiques.
Pour une comparaison immédiate de haut niveau, consultez le tableau ci-dessous comparant données synthétiques et données web réelles :
| Données Web Réelles | Données Synthétiques | |
|---|---|---|
| Définition | Données collectées depuis des sources web réelles | Données générées artificiellement imitant les distributions réelles via des modèles ou des règles |
| Exemples | Pages web, forums, articles d’actualité, pages produits, PDFs, etc. | Texte généré par LLM, images GAN, environnements robotiques simulés, jeux de données basés sur des règles, etc. |
| Objectif principal | Capturer la complexité réelle et le comportement naturel | Augmenter l’échelle, la couverture et la contrôlabilité |
| Types de données | Non structurées (texte, images), semi-structurées (JSON, XML) | Structurées, semi-structurées, non structurées (texte, image, audio, vidéo) |
| Mode d’obtention | Principalement le Scraping web | Génération LLM, GANs, VAEs, systèmes à base de règles, moteurs de simulation |
| Risque de confidentialité | Élevé (PII, conformité requise) | Faible (pas de données utilisateurs réelles si correctement générées) |
| Qualité des données | Bruitées, inconsistantes, mais authentiques | Propres, structurées, mais peuvent contenir des artefacts ou hallucinations |
| Distribution | Distribution naturelle du monde réel | Contrôlée mais peut introduire un biais ou un décalage synthétique |
| Robustesse | Bonne généralisation aux entrées réelles | Forte pour les scénarios ciblés, généralisation plus faible |
| Couverture des cas rares | Naturellement présente mais clairsemée | Peut être explicitement générée et suréchantillonnée |
| Risque de biais | Reflète les biais du monde réel | Peut amplifier ou introduire de nouveaux biais |
| Rôle typique dans le pipeline | Pré-entraînement, ajustement fin, évaluation | Pré-entraînement, augmentation, génération de cas limites |
| Risques | Rareté des données, contraintes de conformité, bruit | Écart synthétique-réel, effondrement du modèle, patterns hallucinés |
Il est maintenant temps de plonger dans les deux paradigmes de données qui façonnent l’entraînement moderne de l’IA !
Explorer le Monde des Données Web Réelles
Ici, nous couvrirons tout ce que vous devez savoir sur les données web réelles pour l’entraînement des modèles IA et ML.
Qu’est-ce que les Données Web ?
Les données web sont des informations collectées depuis des pages web et d’autres sources web publiques, principalement via le Scraping web. Elles incluent du contenu non structuré tel que du texte, des images, du code, des métadonnées et des documents (ex. : PDFs), ainsi que des données semi-structurées comme JSON et XML.
Types de Données Web
Il existe de nombreuses catégories possibles de données web. Néanmoins, à un niveau élevé, surtout dans le contexte de l’IA, il est utile de distinguer deux types principaux :
- Données web historiques : Généralement collectées via des pipelines de Scraping web, puis nettoyées, enrichies, dédupliquées et agrégées en jeux de données structurés aux formats CSV, JSON et Parquet. Ces jeux de données sont utilisés pour le pré-entraînement et l’ajustement fin des modèles.
- Données web en direct : Récupérées en temps réel depuis des pages web via scraping ou APIs. Elles reflètent les informations les plus récentes disponibles sur internet. Cela les rend particulièrement utiles pour ancrer les réponses IA et pour les systèmes RAG, où la fraîcheur et l’exactitude factuelle sont essentielles.
Ensemble, ces deux formes de données web jouent des rôles complémentaires dans les systèmes IA modernes.
Comment Obtenir des Données Web
Pour obtenir des données web pour l’entraînement IA/ML, vous avez besoin d’un pipeline de Scraping web évolutif. Le construire en interne nécessite une expertise technique significative.
Cela implique de gérer un large éventail de défis anti-scraping comme le blocage d’IP, la Résolution de CAPTCHA et les limiteurs de débit. De plus, cela exige de solides capacités d’ingénierie des données pour le nettoyage, la déduplication et la normalisation. C’est pourquoi les entreprises préfèrent s’appuyer sur des plateformes dédiées aux données web, comme Bright Data.
Bright Data fournit un écosystème de bout en bout pour la collecte et la livraison de données web. Ce qui le distingue est son réseau de Proxys résidentiels de 400M+ dans 195 pays, qui prend en charge une collecte de données web hautement évolutive et simultanée. Cette infrastructure de niveau entreprise est également conforme au RGPD et au CCPA, ainsi qu’à d’autres normes de confidentialité et de sécurité.
L’offre de Bright Data pour les données web comprend :
- Marketplace de données web : Une collection de 350+ jeux de données prêts à l’emploi couvrant plus de 250 domaines (dont Reddit, Amazon, LinkedIn, Yahoo Finance et bien d’autres). Ces jeux de données couvrent plus de 17 pétaoctets de données web et sont optimisés pour les applications ML et IA. Ils sont livrés dans plusieurs formats, tels que JSON, CSV et Parquet, via livraison cloud et d’autres méthodes de distribution.
- Produits de Scraping web : Une suite de solutions basées sur API pour l’extraction de données web en direct :
– API Web Unlocker : Contourne les blocages et CAPTCHAs pour garantir l’accès aux données sur n’importe quelle page web.
– API SERP : Fournit des résultats de moteurs de recherche structurés en temps réel depuis Google, Bing, Yandex et d’autres.
– API Discover : Retourne un ensemble classé et en direct d’URLs du web public, prêt pour un traitement en aval.
– API Crawl : Effectue une exploration évolutive de sites web et une extraction de données structurées.
– APIs Scraper : Couvrent 120+ sites web pour l’extraction directe de données structurées depuis des domaines populaires.
Bright Data propose également des services gérés pour l’acquisition de données clé en main. Ceux-ci permettent aux organisations de se concentrer sur le développement des modèles plutôt que sur l’ingénierie des données.
Entrer dans le Domaine des Données Synthétiques
Dans ce chapitre, vous explorerez l’utilisation des données synthétiques pour l’entraînement des modèles IA/ML.
Qu’est-ce que les Données Synthétiques ?
Les données synthétiques sont des informations générées artificiellement qui reproduisent les patterns statistiques et les caractéristiques des données réelles. Au lieu d’être collectées à partir d’événements réels, elles sont produites artificiellement.
Types de Données Synthétiques
Les données synthétiques peuvent être catégorisées :
- Par composition et niveau de confidentialité :
– Entièrement synthétiques : Générées entièrement de zéro à l’aide de modèles d’apprentissage automatique entraînés sur des données réelles. Comme elles ne contiennent aucun point de données original, elles offrent le niveau de protection de la confidentialité le plus élevé.
– Partiellement synthétiques : Prennent un jeu de données réel existant et remplacent uniquement les attributs sensibles (comme les noms, adresses ou numéros de sécurité sociale) par des valeurs artificielles. Cela préserve certaines tendances des données tout en anonymisant les PII.
– Hybrides : Mélangent des enregistrements réels anonymisés avec des enregistrements générés artificiellement. Cela est couramment utilisé pour « suréchantillonner » ou enrichir des jeux de données en créant artificiellement des événements rares (ex. : ajout d’enregistrements de fraude synthétiques à un jeu de données bancaires).
- Par structure de données :
– Données structurées : Données quantitatives très organisées présentées dans des formats tabulaires.
– Données non structurées : Formats de données qualitatifs ou riches en médias. Elles incluent du texte synthétique, des images, vidéos et audios générés artificiellement.
Comment Produire des Données Synthétiques
À un niveau élevé, les données synthétiques peuvent être générées selon trois approches prédominantes :
- Entièrement générées par IA : Créées à l’aide de modèles tels que les GANs (Réseaux Antagonistes Génératifs), les VAEs (Auto-encodeurs Variationnels) ou les LLMs. Ces systèmes apprennent la distribution sous-jacente des jeux de données réels, puis génèrent de nouveaux échantillons ressemblant aux données originales sans les copier directement.
- Génération basée sur des règles : Les données sont produites à l’aide de règles prédéfinies écrites par des humains, de contraintes ou de logique métier. Cela garantit une cohérence stricte, une exactitude structurelle et un comportement contrôlé, ce qui est utile pour les systèmes nécessitant des sorties prévisibles.
- Données simulées ou fictives : Générées via des simulations physiques ou comportementales. Cela est couramment utilisé dans des environnements comme la conduite autonome ou la robotique, où des jumeaux numériques et des moteurs physiques créent des scénarios réalistes de type « et si ».
Impact des Données Synthétiques vs Données Web Réelles sur l’Entraînement des Modèles IA/ML
Comparons maintenant plusieurs aspects pour comprendre les conséquences de l’utilisation de données synthétiques vs réelles pour l’entraînement IA.
Distribution des Données et Réalisme
Les données web approchent étroitement une distribution naturelle des données. Elles capturent la complexité inhérente du langage et du comportement humains tels qu’ils apparaissent dans le monde réel. Cela apporte des avantages importants, notamment des corrélations naturelles entre les caractéristiques, des cas limites authentiques, des styles linguistiques diversifiés et un bruit réaliste comme les erreurs humaines, l’ambiguïté et les incohérences.
Cependant, les données web réelles sont aussi intrinsèquement désordonnées. Elles sont souvent déséquilibrées, dupliquées, difficiles à organiser à grande échelle et peuvent contenir du contenu de faible qualité ou spam nécessitant un filtrage extensif.
En revanche, les données synthétiques représentent une distribution contrôlée. Elles sont intentionnellement conçues et générées, permettant aux praticiens de façonner les propriétés du jeu de données de manière précise. Cela permet des distributions de classes équilibrées, une couverture ciblée de scénarios spécifiques, la génération d’événements rares et un apprentissage curriculaire structuré.
En même temps, les données synthétiques introduisent des risques importants, notamment le décalage de distribution, les artefacts irréalistes, l’effondrement de mode et la sur-régularisation lorsque le générateur est trop contraint.
Important : Un concept central d’apprentissage automatique à cet égard est l’écart synthétique-réel, similaire au problème sim-to-real en robotique. Les modèles entraînés massivement sur des données synthétiques peuvent sous-performer sur des entrées réalistes car la distribution générée ne correspond pas entièrement à la réalité.
Couverture des Cas Rares
Les données web réelles incluent naturellement un large éventail de connaissances. Cela comprend des faits obscurs, des événements rares et des cas limites inattendus qui émergent organiquement de l’activité humaine. Pourtant, ces exemples de longue traîne sont intrinsèquement clairsemés. Par définition, les événements rares apparaissent peu fréquemment, ce qui rend difficile pour les modèles d’apprendre des patterns robustes à partir d’eux lors de l’entraînement.
D’autre part, vous pouvez utiliser des données synthétiques pour générer explicitement des scénarios rares ou sous-représentés. Ainsi, vous pouvez cibler des lacunes spécifiques dans un jeu de données et améliorer la couverture là où les données réelles sont insuffisantes. Les exemples incluent les bugs de code rares et les langues à faibles ressources.
Un avantage majeur de l’utilisation des données synthétiques pour la couverture des cas rares est la capacité de suréchantillonner les événements rares. Cela peut aider à réduire le déséquilibre des classes et améliorer les performances du modèle sur des cas peu fréquents mais importants. Néanmoins, si des scénarios rares sont artificiellement surreprésentés, les priors appris par le modèle peuvent devenir distordus.
Par exemple, si les cas d’exploitation en cybersécurité sont fortement suréchantillonnés dans les données synthétiques, le modèle peut commencer à surestimer leur probabilité dans des contextes réels. Par conséquent, une calibration soigneuse est fondamentale pour s’assurer que la génération synthétique de cas rares améliore la couverture sans introduire de distributions irréalistes.
Considérations de Coût et de Confidentialité
Comme mentionné précédemment, les entreprises construisent rarement leur propre infrastructure de Scraping web et de jeux de données. À la place, elles s’appuient sur des fournisseurs de données tiers comme Bright Data, qui abstraient l’exploration, le déblocage, le nettoyage et la livraison. Cela modifie fondamentalement à la fois la structure des coûts et les compromis de confidentialité de l’acquisition de données.
Voici un aperçu simplifié du modèle de tarification de Bright Data pour la collecte de données web :
| Prix | Plans personnalisés pour entreprises | Conforme RGPD | Conforme CCPA | Conforme aux réglementations SEC | |
|---|---|---|---|---|---|
| Jeux de données | De 0,001 $ à 0,0025 $ par enregistrement | ✔️ | ✔️ | ✔️ | ✔️ |
| APIs de Scraping web | 1 $-1,5 $/1K résultats | ✔️ | ✔️ | ✔️ | ✔️ |
Bright Data propose également des services d’annotation de données, aidant les organisations à réduire davantage leur dépendance à l’ingénierie des données en interne. Surtout, ses données sont alignées sur les cadres de confidentialité, ce qui contribue à réduire les risques juridiques et réglementaires.
Sans de tels fournisseurs de données web, vous devriez gérer le développement de l’infrastructure, la maintenance continue et la gouvernance complexe des PII, du matériel protégé par droits d’auteur et des données comportementales sensibles en interne.
Avec les données synthétiques, les coûts principaux proviennent du calcul d’inférence et de l’accès aux modèles enseignants ou aux APIs. Du point de vue de la confidentialité, les données générées artificiellement offrent un avantage inhérent. Étant générées plutôt que collectées auprès de personnes réelles, les données synthétiques éliminent naturellement l’exposition aux informations personnellement identifiables.
Maintenant, le bon choix entre données synthétiques et données web réelles dépend des exigences de qualité, de l’échelle, des contraintes de confidentialité et du cas d’utilisation cible. Selon ces facteurs, l’une ou l’autre approche peut être plus rentable ou plus coûteuse.
Facteurs de Qualité des Données
Les données web fournissent généralement une supervision faible. Les modèles apprennent à partir de signaux naturellement présents tels que la prédiction du prochain token, les métadonnées et le contenu généré par l’humain. Le problème est que les données réelles sont bruitées et peuvent contenir de la désinformation, des contradictions, du spam, des opinions biaisées et une mise en forme inconsistante.
Au contraire, les données synthétiques offrent un meilleur contrôle sur la qualité et la supervision. Elles peuvent fournir des étiquettes parfaitement formatées, des sorties structurées, un raisonnement étape par étape et des exemples vérifiés automatiquement. Par exemple, les jeux de données synthétiques peuvent inclure des réponses mathématiquement vérifiées ou des extraits de code validés par des tests unitaires. Cela améliore la cohérence et facilite l’entraînement ciblé.
Le risque majeur avec les données synthétiques est que leur qualité est fondamentalement limitée par la qualité du modèle générateur, de l’algorithme ou de l’approche sous-jacente. Les hallucinations générées ou les erreurs factuelles peuvent se propager dans le jeu de données final, amenant les modèles à apprendre des patterns incorrects avec confiance. De même, les biais cachés présents dans les systèmes de génération peuvent aussi être hérités par les modèles en aval. Du côté positif, les données synthétiques soutiennent un meilleur alignement et un ajustement de sécurité.
Généralisation et Robustesse
L’une des questions les plus importantes en apprentissage automatique est la capacité d’un modèle à généraliser sur des entrées inédites. En d’autres termes, quelle source de données conduit à une meilleure robustesse sous un décalage de distribution : les données web réelles ou les données synthétiques ?
Les données web tendent à atteindre une forte robustesse, car elles reflètent le comportement humain, le langage et le bruit naturellement présents. Cela améliore les performances sur les entrées hors distribution et améliore le transfert de domaine, particulièrement lorsque les modèles sont déployés dans des environnements imprévisibles.
En revanche, les données synthétiques sont mieux adaptées à l’optimisation ciblée. Elles vous permettent de concevoir précisément des exemples d’entraînement pour des compétences spécifiques, des cas limites ou des scénarios rares.
Considérations Clés lors de l’Entraînement IA avec des Données Synthétiques ou Web Réelles
Maintenant que vous connaissez les différences entre données synthétiques et données web, vous êtes prêt à voir les implications pratiques de l’utilisation de chaque approche dans l’entraînement des modèles IA.
Pipelines d’Entraînement des Données
Lorsqu’on s’appuie sur des données web, le pipeline suit généralement ces étapes :
- Exploration : Collecter des données brutes depuis des sites web à l’aide de systèmes de scraping à grande échelle ou de bots de Scraping web personnalisés sur plusieurs domaines.
- Déduplication : Supprimer le contenu dupliqué ou quasi-dupliqué pour réduire la redondance et améliorer la diversité et l’efficacité du jeu de données.
- Détection de la langue : Identifier la langue de chaque échantillon et filtrer ou segmenter le jeu de données en fonction des exigences linguistiques cibles.
- Évaluation de la qualité : Évaluer et classer le contenu à l’aide d’heuristiques ou de modèles pour filtrer les informations de faible qualité ou non pertinentes.
- Filtrage de la toxicité : Détecter et supprimer le contenu nuisible, dangereux ou inapproprié pour assurer la sécurité de l’entraînement et la conformité.
- Suppression des PII et décontamination : Supprimer les informations personnellement identifiables et éliminer la contamination provenant de sources sensibles ou indésirables.
En ce qui concerne les pipelines de données synthétiques, les étapes sont davantage axées sur la génération :
- Génération de prompts : Concevoir des prompts ou des modèles qui définissent la structure, la tâche ou le scénario pour la création de données synthétiques.
- Échantillonnage de modèles : Générer des sorties candidates à l’aide de modèles génératifs tels que des LLMs, GANs ou d’autres systèmes.
- Vérification : Valider les sorties à l’aide de vérifications automatisées, de règles ou d’outils externes pour garantir l’exactitude et la cohérence.
- Filtrage : Supprimer les échantillons de faible qualité, incohérents ou hallucinés qui ne répondent pas aux normes prédéfinies.
- Évaluation par récompense : Attribuer des scores de qualité ou de préférence pour classer et sélectionner les meilleurs exemples synthétiques.
- Raffinement itératif : Améliorer la qualité des données à travers des cycles répétés de génération, de filtrage et de ré-échantillonnage pour renforcer la robustesse.
Comme vous pouvez le constater, les pipelines de données web réelles se concentrent sur le nettoyage des entrées bruitées du monde réel. En revanche, les pipelines synthétiques visent davantage à contrôler et valider les sorties générées. Enfin, une fois le jeu de données d’entraînement produit, vous pouvez procéder à l’entraînement du modèle IA.
Comparaison des Performances
La question finale est de savoir si les données synthétiques peuvent surpasser les données web réelles.
Un article récent sur l’IA pour l’ingénierie des exigences (AI4RE) suggère que les jeux de données générés par LLM peuvent être une alternative solide lorsque les données réelles sont rares ou difficiles d’accès. Les résultats empiriques montrent que les modèles entraînés exclusivement sur des données synthétiques peuvent surpasser ceux entraînés uniquement sur des jeux de données écrits par des humains. En détail, des améliorations allant jusqu’à +37 % en précision et +30 % en rappel ont été observées par rapport aux bases de référence utilisant uniquement des données réelles.
Cela dit, ce n’est pas une conclusion binaire ou absolue. Les preuves ne suggèrent pas que les données synthétiques devraient entièrement remplacer les données réelles, mais plutôt que les meilleures performances sont souvent atteintes grâce à une approche hybride. Apprenez-en plus !
Données Synthétiques + Données Web Réelles : Pourquoi une Approche Hybride Fonctionne le Mieux
Le débat entre données synthétiques et données web réelles ne porte plus sur le choix de l’une ou de l’autre, mais sur la manière de les combiner.
Des preuves récentes montrent que les configurations hybrides combinant données synthétiques et réelles atteignent des gains allant jusqu’à +85 % en précision et un doublement du rappel par rapport à l’utilisation uniquement des données web réelles.
En même temps, de nombreuses études et rapports sectoriels soulignent que mélanger naïvement des échantillons synthétiques et réels peut en réalité dégrader les performances en raison d’un décalage de distribution, de redondance ou d’une amplification des biais. Il est donc clair que les gains de performance dépendent d’une conception soigneuse du jeu de données plutôt que d’une simple accumulation de données.
Une question ouverte clé est le ratio optimal entre données synthétiques et réelles. Il n’y a pas de réponse universelle. Certains praticiens adoptent un partage 80/20 de style Pareto (principalement des données réelles avec augmentation synthétique), tandis que d’autres préfèrent des mélanges plus équilibrés comme 60/40, selon la complexité de la tâche, le risque de domaine et la disponibilité des données.
De même, la place des données synthétiques dans le pipeline est importante. La pratique industrielle guide une stratégie par étapes : pré-entraînement à forte composante synthétique pour la couverture, suivi d’un ajustement fin sur données réelles pour l’ancrage et l’évaluation.
En définitive, les pipelines hybrides fonctionnent le mieux car ils combinent des forces complémentaires. Les données synthétiques fournissent l’échelle et la couverture des cas limites, tandis que les données web réelles garantissent la fidélité, le réalisme et une évaluation fiable dans les environnements de production.
Données Web Réelles vs Données Synthétiques : Avantages et Inconvénients
En guise de section récapitulative, voici les avantages et inconvénients des deux paradigmes de données.
Données Web Réelles
👍 Avantages :
- Capture les patterns et le bruit authentiques du monde réel
- Solide référence pour l’évaluation et la validation
- Réduit le risque de biais ou d’artefacts synthétiques
👎 Inconvénients :
- Coûteuse et chronophage à collecter et étiqueter
- Peut être limitée par des contraintes de confidentialité et réglementaires
- Peut être déséquilibrée ou incomplète
Données Synthétiques
👍 Avantages :
- Hautement évolutives et rapides à générer
- Peuvent simuler des événements rares et des cas limites
- Soutiennent des pipelines d’entraînement respectueux de la confidentialité
👎 Inconvénients :
- Risque d’écart de domaine par rapport aux données réelles
- Nécessite une validation et un contrôle qualité rigoureux
- Peut manquer de diversité par rapport aux données réelles, entraînant un surapprentissage sur des artefacts synthétiques
Données Web Réelles + Données Synthétiques
👍 Avantages :
- Combine l’échelle (synthétique) avec le réalisme (données réelles)
- Atteint souvent les meilleures performances en pratique
- Robustesse accrue sur les cas limites et les cas normaux
👎 Inconvénients :
- Nécessite un équilibrage et un ajustement soigneux des ratios
- Risque de dégradation des performances si mal mélangées
- Conception et maintenance du pipeline plus complexes
Conclusion
Dans cet article sur les données synthétiques vs les données web réelles, vous avez appris l’impact de l’utilisation de données réelles ou générées artificiellement pour l’entraînement des modèles IA/ML. Comme toujours dans ces situations, il n’y a pas de gagnant unique. La bonne approche dépend de votre budget spécifique, de vos compétences techniques et de vos objectifs de performance.
Quelle que soit la configuration, les données web jouent toujours un rôle central dans l’entraînement des modèles IA, que ce soit pour le pré-entraînement ou l’ajustement fin. Sa large couverture et son ancrage dans le monde réel en font un élément essentiel. Cependant, certaines entreprises préfèrent opter pour des approches plus axées sur le synthétique. La principale raison est la complexité de construire et maintenir des pipelines de récupération de données web en interne.
C’est là que Bright Data peut aider. Avec une infrastructure de niveau entreprise, hautement évolutive et conforme, elle fournit :
- Jeux de données web : 350+ jeux de données prêts à l’emploi avec des milliards d’enregistrements, déjà collectés, organisés et optimisés pour les cas d’utilisation d’entraînement IA.
- Produits de Scraping web : Solutions basées sur API pour accéder à des données web fraîches depuis de nombreux sites à grande échelle.
De plus, Bright Data propose des services d’annotation de données. Elle fournit des solutions d’étiquetage évolutives, précises et personnalisables pour les cas d’utilisation NLP, vision par ordinateur et reconnaissance vocale.
Découvrez toutes les solutions Bright Data pour l’IA !
Créez un compte Bright Data gratuitement et explorez nos solutions de données web !






