

À la fin de cet article, vous saurez comment :
- Utiliser le service API Bright Data Google IA Scraper
- Tirer parti de Skyvern pour l’automatisation des tâches
- Utiliser le service API Bright Data avec Skyvern pour automatiser les tâches web.
- Combiner l’automatisation et les flux de données pour créer un assistant e-commerce.
- Récupérer automatiquement les détails des produits du panier
C’est parti !
Tirer parti du service API de Bright Data
La base de l’automatisation du navigateur est la capacité à contourner les obstacles tels que les CAPTCHA, les interdictions d’IP et le chargement dynamique des pages web. C’est là que Bright Data devient indispensable.
Grâce au Web Scraper de Bright Data, qui prend en charge plus de 120 domaines web, l’automatisation du navigateur est plus efficace et plus fiable. Il gère les défis courants liés au scraping web, tels que les interdictions d’IP, les CAPTCHA, les cookies et autres formes de détection de bots.
Pour commencer, inscrivez-vous à un essai gratuit et obtenez votre clé API et votre dataset_id pour le domaine que vous souhaitez scraper. Une fois que vous les avez, vous êtes prêt à commencer.
Voici les étapes à suivre pour récupérer des données récentes à partir de n’importe quel domaine, comme BBC News :
- Créez un compte Bright Data si vous ne l’avez pas déjà fait. Un essai gratuit est disponible.
- Accédez à la page Web Scrapers. Sous Web Scrapers Library, explorez les modèles de Scrapers disponibles.
- Recherchez le domaine cible, tel que BBC News, et sélectionnez-le.
- Dans la liste des Scrapers BBC News, sélectionnez BBC News — collect by URL. Ce Scraper vous permet de récupérer des données sans vous connecter au domaine.
- Choisissez l’option Scraper API. Le No-Code Scraper permet de récupérer des Jeux de données sans code.
- Cliquez sur API Request Builder, puis copiez votre
clé API,l'URL de l'ensemble de données BBCetle dataset_id. - La
clé APIetle dataset_idsont nécessaires pour activer les capacités d’automatisation dans votre flux de travail. Ils vous permettent d’accéder directement aux capacités de Bright Data pendant la programmation.
Qu’est-ce que Skyvern
Skyvern est un outil d’automatisation de navigateur IA qui utilise l’IA pour automatiser les tâches dans les navigateurs web. Il combine l’apprentissage automatique, le traitement du langage naturel et la vision par ordinateur pour gérer des actions complexes dans le navigateur.
Skyvern se distingue des outils d’automatisation traditionnels tels que Selenium et Playwright par les caractéristiques suivantes :
- Adaptabilité aux changements d’interface utilisateur : ses capacités d’auto-réparation permettent à Skyvern de s’adapter dynamiquement aux changements d’interface utilisateur sans interrompre les scripts.
- Complexité du flux de travail : capable de gérer des flux de travail en plusieurs étapes grâce au raisonnement de l’IA à partir d’une seule invite.
- Reconnaissance visuelle : utilise la vision par ordinateur pour comprendre et interagir visuellement avec les éléments de l’interface utilisateur.
Grâce à ces capacités, vous pouvez utiliser Skyvern pour vous connecter à des sites de réservation, remplir des formulaires ou ajouter des articles à des paniers d’achat. Lorsqu’il est intégré aux capacités de Scraping web de Bright Data, Skyvern peut fournir un cadre puissant pour répondre à divers besoins d’automatisation web.
Flux de travail d’automatisation
Par exemple, si vous souhaitez acheter une pièce automobile dans une boutique en ligne, vous pouvez comparer les options disponibles et en ajouter automatiquement une à votre panier. Le flux de travail ressemblerait à ceci :
- L’API Bright Data IA Scraper récupère la description et les détails du produit, tels que la référence, auprès du fabricant que vous avez spécifié.
- Vous examinez le résultat et faites votre sélection. Bright Data fournit une récupération rapide et fiable des données web.
- Skyvern utilise les détails récupérés par Bright Data pour accéder à finditparts.com. Il navigue ensuite sur le site, ajoute le ou les produits sélectionnés au panier et affiche les détails du panier et l’URL du panier.
- Passez directement à la caisse et au paiement.
Prérequis
- Connaissances de base en programmation Python. Téléchargez Python ici
- Un compte Bright Data actif. Inscrivez-vous ici et récupérez votre clé API dans l’e-mail de bienvenue
- Connaissances de base en JSON et API REST
Configuration du projet
Étape 1 : Configurer Bright Data
Récupérez votre clé API Bright Data, votre ID de jeu de données et votre URL Google AI Mode en suivant les mêmes étapes que celles décrites dans la section « Tirer parti du service API robuste de Bright Data pour votre cas d’utilisation ».
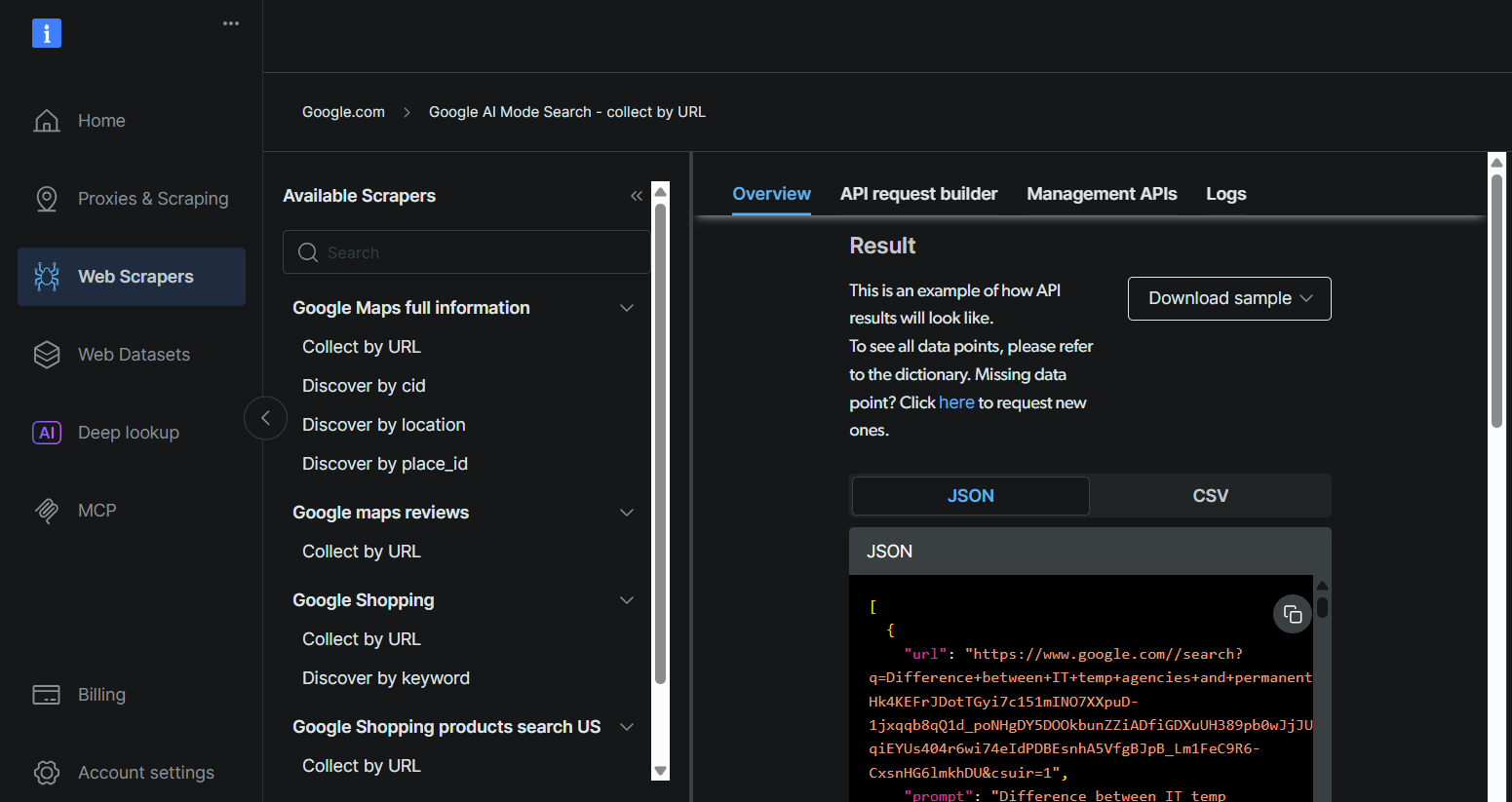
Étape 2 : Inscrivez-vous sur Skyvern Cloud
- Rendez-vous sur https://app.skyvern.com/ et inscrivez-vous pour recevoir 5 USD de crédits gratuits.
- Demandez à l’agent Skyvern d’exécuter une tâche pour la voir en action. Par exemple : accédez à la page d’accueil de Hacker News et récupérez les trois premiers articles.
- Consultez l’historique pour suivre la progression de la tâche. Le statut « Terminé » indique que la tâche s’est déroulée avec succès.
- Une fois la tâche terminée, cliquez dessus dans l’historique pour afficher le résultat, les paramètres et des informations supplémentaires à son sujet.
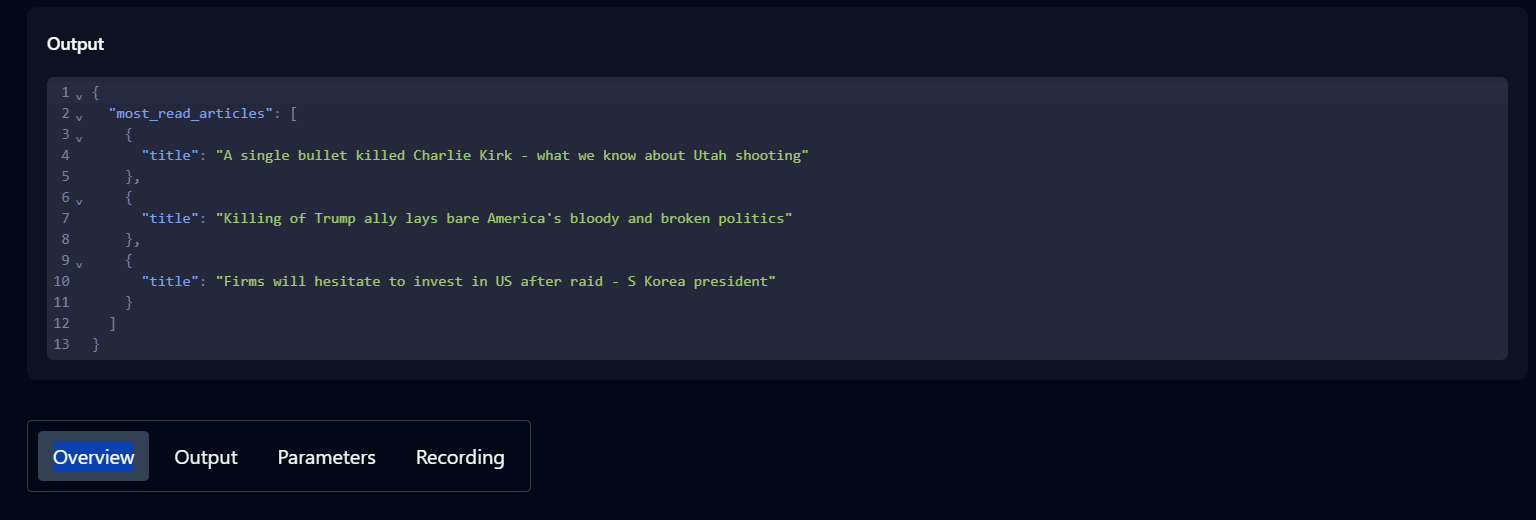
Maintenant que Skyvern est configuré, vous pouvez commencer à écrire votre script de code.
Étape 3 : Installez Skyvern sur votre machine
3.1 Créer un environnement virtuel
Dans le dossier de projet souhaité, créez un environnement virtuel avec Python :
python -m venv .venv
Activez l’environnement.
.venvScriptsactivate
3.2 Installez Skyvern sur n’importe quel appareil avec
pip install skyvern
Si vous rencontrez des problèmes d’installation, vous pouvez utiliser le terminal Ubuntu sous Windows. Consultez cet article pour savoir comment configurer le terminal Ubuntu.
Une fois le terminal lancé, accédez au répertoire souhaité et exécutez :
pip install uvCréez un environnement virtuel avec :
uv venv venvInstallez ensuite Skyvern à l’aide de la commande suivante :
uv pip install skyvern3.3 Démarrage rapide de Skyvern
Une fois l’installation terminée, exécutez :
skyvern quickstart- Lorsque le message « Souhaitez-vous exécuter Skyvern localement ou dans le cloud ? » s’affiche, tapez « cloud ».
- Lorsque le message « Entrez l’URL de base de Skyvern » s’affiche, appuyez sur Entrée.
- Tapez « n » pour chaque invite d’installation, sauf pour l’invite MCP, où vous devez taper « y ».
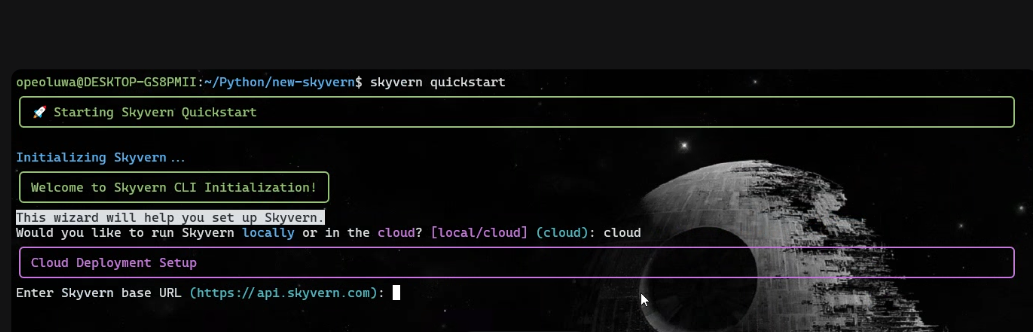
Après la configuration, exécutez :
skyvern initCréez un script Python appelé app.py.
Étape 4 : récupérer les détails du produit avec Bright Data
4.1 Récupérez le numéro de pièce avec Bright Data à l’aide de ce code dans app.py :
import asyncio
import requests
import time
import json
def trigger_scraping_job(api_key, data):
"""
Déclenche une tâche de jeu de données Bright Data avec une liste de dictionnaires contenant l'URL, l'invite et le pays.
Renvoie l'identifiant snapshot_id en cas de succès.
"""
endpoint = "https://api.brightdata.com/datasets/v3/trigger"
params = {
"dataset_id": "gd_mcswdt6z2elth3zqr2", # Votre ID de jeu de données
"include_errors": "true",
}
headers = {
"Authorization": f"Bearer {api_key}",
"Content-Type": "application/json",
}
response = requests.post(endpoint, headers=headers, params=params, json=data)
if response.status_code == 200:
snapshot_id = response.json().get("snapshot_id")
print(f"Demande réussie ! ID de l'instantané : {snapshot_id}")
return snapshot_id
else:
print(f"Demande échouée ! Statut : {response.status_code}")
print(response.text)
return None
def poll_and_retrieve_snapshot(api_key, snapshot_id, output_file, polling_timeout=20):
"""
Interroger le point de terminaison Bright Data snapshot jusqu'à ce que les données soient prêtes.
Enregistrer la réponse JSON dans un fichier de sortie.
"""
snapshot_url = f"https://api.brightdata.com/datasets/v3/snapshot/{snapshot_id}?format=json"
headers = {
"Authorization": f"Bearer {api_key}"
}
print(f"Interrogation de l'instantané pour l'ID : {snapshot_id}...")
while True:
response = requests.get(snapshot_url, headers=headers)
if response.status_code == 200:
print("L'instantané est prêt. Téléchargement en cours...")
snapshot_data = response.json()
with open(output_file, "w", encoding="utf-8") as file:
json.dump(snapshot_data, file, indent=4)
print(f"Instantané enregistré dans {output_file}")
return
elif response.status_code == 202:
print(f"L'instantané n'est pas encore prêt. Réessai dans {polling_timeout} secondes...")
time.sleep(polling_timeout)
else:
print(f"Échec de la requête ! Statut : {response.status_code}")
print(response.text)
break
if __name__ == "__main__":
BRIGHT_DATA_API_KEY = "YOUR_BRIGHT_DATA_API_KEY" # Votre clé API
# Correspond exactement à la structure de données JSON curl
data = [
{
"url": "https://google.com/aimode",
"prompt": "trouver le numéro de pièce d'un joint de roue sur finditparts.com dont le fabricant est SKF",
"country": ""
}
]
snapshot_id = trigger_scraping_job(BRIGHT_DATA_API_KEY, data)
if snapshot_id:
poll_and_retrieve_snapshot(BRIGHT_DATA_API_KEY, snapshot_id, "product.json")L’invite est la suivante : « Trouvez le numéro de pièce d’un joint de roue sur finditparts.com dont le fabricant est SKF. »
Cela créera un fichier product.json contenant les descriptions des produits et les numéros de pièce du fabricant SKF.
{
"url": "https://www.finditparts.com/products/16775486/skf-45093xt?srcid=CHL01SCL010-Npla-Dmdt-Gusa-Svbr-Mmuu-K16775486-L22",
"title": "www.finditparts.com",
"description": "SKF 45093XT Wheel Seal | FinditParts",
"icon": "https://encrypted-tbn0.gstatic.com/faviconV2?url=https://www.finditparts.com&client=AIM&size=128&type=FAVICON&fallback_opts=TYPE,SIZE,URL",
"domain": "https://www.finditparts.com",
"cited": true
},
{
"url": "https://www.finditparts.com/products/193780/cr-slash-skf-14115?srcid=CHL01SCL010-Npla-Dmdt-Gusa-Svbr-Mmuu-K193780-L1464",
« title » : « www.finditparts.com »,
« description » : « Joint de roue SKF 14115 | FinditParts »,
« icon » : « https://encrypted-tbn0.gstatic.com/faviconV2?url=https://www.finditparts.com&client=AIM&size=128&type=FAVICON&fallback_opts=TYPE,SIZE,URL",
"domain": "https://www.finditparts.com",
"cited": true
},
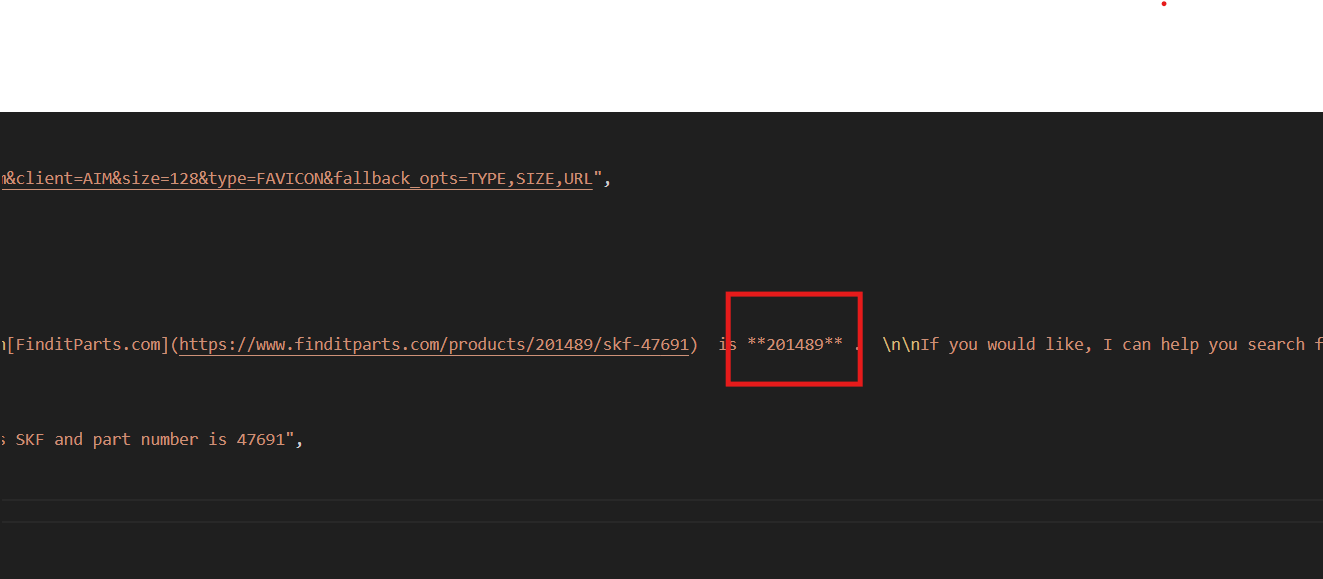
{Ensuite, choisissez votre référence préférée (située dans la description) et relancez le code Bright Data avec cette invite : « Trouvez l’ID produit du joint de roue SKF avec la référence 47691 ».
# Faites correspondre exactement la structure des données JSON curl.
data = [
{
"url": "https://google.com/aimode",
"prompt": "Trouvez l'ID produit du joint de roue SKF avec le numéro de pièce 47691",
"country": ""
}
]Skyvern a besoin de l’ID produit pour ajouter des détails au panier sur finditparts.com (un site web de commerce électronique de pièces automobiles).
Ce processus générera un fichier product.json contenant l’ID produit souhaité.
Étape 5 : Demander à Skyvern d’effectuer ses tâches
Commencez par vous rendre sur https://app.skyvern.com/tasks/create/finditparts. Cette URL est un raccourci permettant de créer des tâches sur Skyvern.
Cliquez sur « Advanced Settings » (Paramètres avancés) dans la section « Base Content » (Contenu de base), puis mettez à jour l’ID du produit et demandez votre cas d’utilisation.
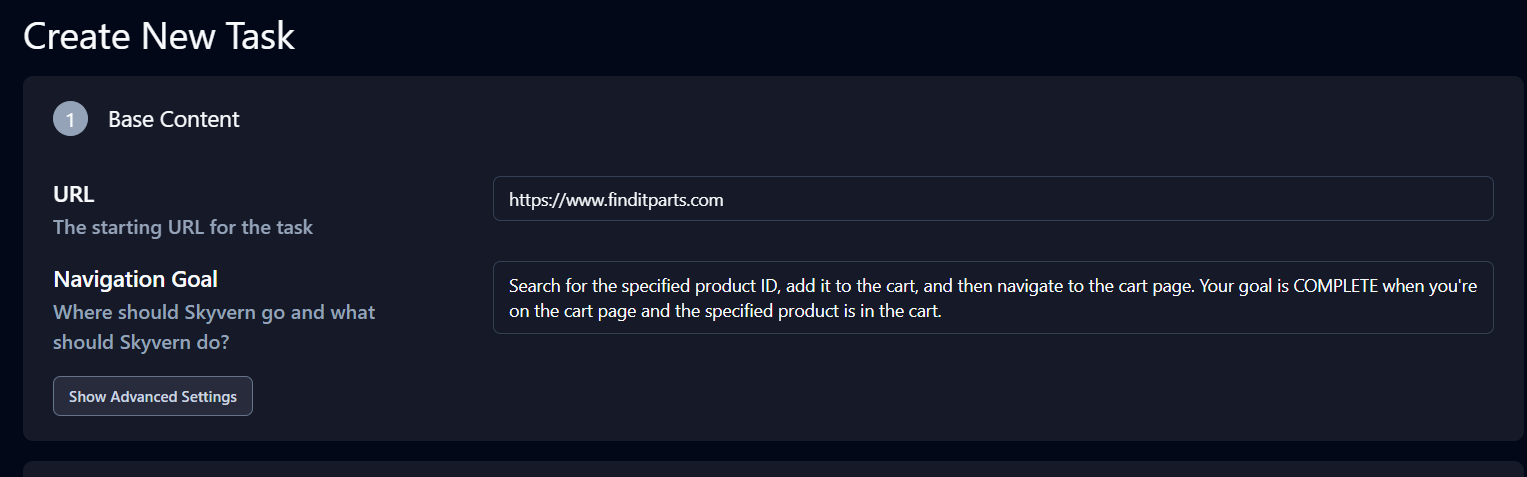
La demande est la suivante : « Recherchez l’ID de produit spécifié, ajoutez-le au panier, puis accédez à la page du panier. Votre objectif est ATTEINT lorsque vous êtes sur la page du panier et que le produit spécifié se trouve dans le panier. »
La section Extraction située sous Paramètres avancés est également importante. Modifiez l’objectif d’extraction de données comme suit : « Extraire l’URL de la page du panier et toutes les informations relatives à la quantité des produits de la page du panier. »
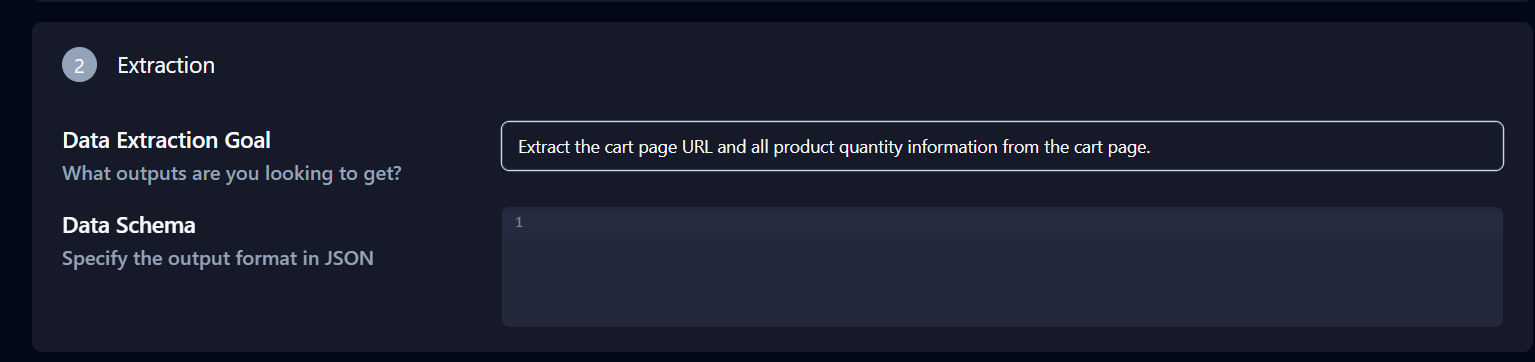
Cliquez sur Copier la commande API en bas de la page, collez-la dans votre terminal et appuyez sur Entrée.
Cela créera un task_id dans votre terminal et une instance de la tâche sur votre Skyvern Cloud. Vous pouvez vérifier son statut dans l’historique pour voir s’il est en attente, en cours d’exécution ou terminé.
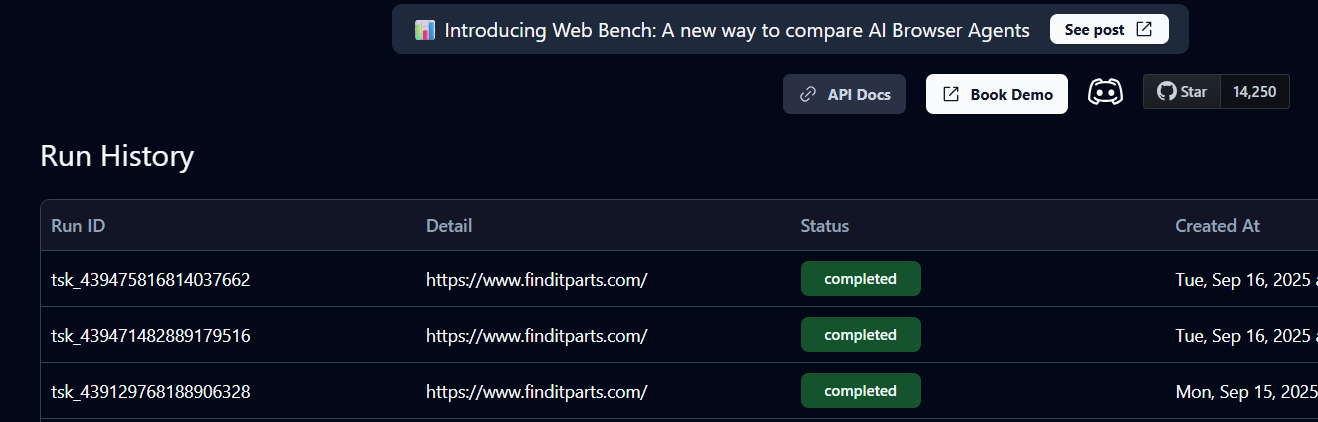
Un statut « Terminé » signifie que la tâche est terminée. Vous pouvez désormais afficher les détails du panier et l’URL du produit renvoyés par Skyvern.
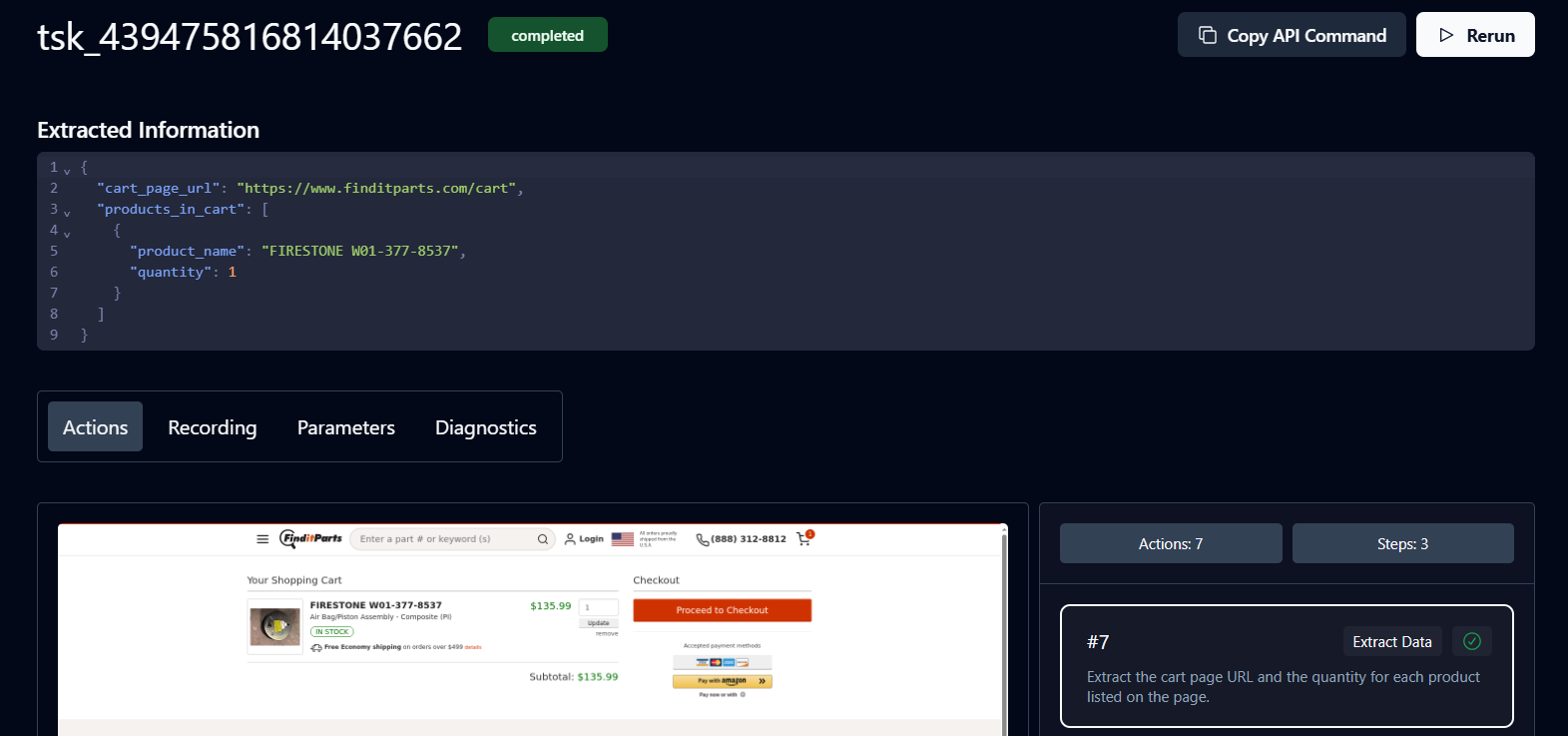
Félicitations. Votre flux de travail est terminé. Cliquez sur l’URL pour procéder au paiement.
Bright Data vous évite d’avoir à rechercher manuellement des produits en ligne en vous proposant directement des options sur votre machine. Cela vous permet de sélectionner le meilleur produit et d’automatiser le processus d’achat avec Skyvern.
Étapes suivantes
Vous pouvez étendre le flux de travail pour inclure l’ajout de plusieurs produits au panier pour le paiement et générer un résumé en langage naturel (NLP) du total des produits. Vous pouvez également déployer le flux de travail dans le cloud pour une surveillance continue. Enfin, vous pouvez l’intégrer à Google Agenda pour suivre les remises.
Conclusion
Dans ce tutoriel, vous avez appris à combiner l’API Scraper de Bright Data avec Skyvern pour automatiser le processus de recherche et d’achat de produits en ligne. Au-delà de l’API Scraper, Bright Data propose d’autres outils qui peuvent alimenter vos agents IA, tels que des jeux de données prêts à l’emploi adaptés au commerce électronique, aux réseaux sociaux et plus encore, ainsi que le serveur Web MCP pour une automatisation avancée en plusieurs étapes et l’accès à plus de 40 outils spécialisés. Ensemble, ces produits facilitent la création de workflows basés sur l’IA qui peuvent collecter, analyser et exploiter efficacement les données web.
Commencez dès aujourd’hui à explorer la suite complète de Bright Data pour améliorer vos projets d’automatisation IA.





