

Dans ce guide, vous apprendrez :
- Qu’est-ce que la gestion des risques liés aux tiers (TPRM) et pourquoi le filtrage manuel échoue
- Comment créer un agent IA autonome qui recherche les informations négatives sur les fournisseurs dans les médias
- Comment intégrer l’API SERP et le Web Unlocker de Bright Data pour une collecte de données fiable et actualisée
- Comment utiliser OpenHands SDK pour la génération de scripts d’agent et OpenAI pour l’analyse des risques
- Comment améliorer l’agent avec l’API Browser pour les scénarios complexes tels que les registres judiciaires
C’est parti !
Le problème du filtrage manuel des fournisseurs
Les équipes de conformité des entreprises sont confrontées à une tâche impossible : surveiller des centaines de fournisseurs tiers à la recherche de signaux de risque sur l’ensemble du web. Les approches traditionnelles impliquent :
- Recherches manuelles sur Google pour chaque nom de fournisseur, associées à des mots-clés tels que « procès », « faillite » ou « fraude »
- La présence de paywalls et de CAPTCHAs lors de la tentative d’accès à des articles de presse et à des dossiers judiciaires
- Une documentation incohérente, sans processus standardisé pour enregistrer les résultats
- Aucune surveillance continue, la sélection des fournisseurs se fait une seule fois lors de l’intégration, puis plus jamais
Cette approche échoue pour trois raisons essentielles :
- Échelle: un seul analyste peut enquêter de manière approfondie sur 5 à 10 fournisseurs par jour
- Accès: les sources protégées telles que les registres judiciaires et les sites d’information premium bloquent l’accès automatisé
- Continuité: les évaluations ponctuelles ne permettent pas de détecter les risques qui apparaissent après l’intégration
La solution : un agent TPRM autonome
Un agent TPRM automatise l’ensemble du processus d’enquête sur les fournisseurs à l’aide de trois couches spécialisées :
- Découverte (API SERP): l’agent recherche sur Google les signaux d’alerte tels que les poursuites judiciaires, les mesures réglementaires et les difficultés financières.
- Accès (Web Unlocker): lorsque les résultats pertinents sont protégés par des paywalls ou des CAPTCHA, l’agent contourne ces barrières pour extraire l’intégralité du contenu
- Action (OpenAI + OpenHands SDK): l’agent analyse le contenu pour déterminer la gravité du risque à l’aide d’OpenAI, puis utilise OpenHands SDK pour générer des scripts de surveillance Python qui vérifient quotidiennement l’apparition de nouveaux articles négatifs dans les médias
Ce système transforme des heures de recherche manuelle en quelques minutes d’analyse automatisée.
Prérequis
Avant de commencer, assurez-vous de disposer des éléments suivants :
- Python 3.12 ou supérieur (requis pour OpenHands SDK)
- Un compte Bright Data avec accès à l’API (essai gratuit disponible)
- Une clé API OpenAI pour l’analyse des risques
- Un compte OpenHands Cloud ou votre propre clé API LLM pour la génération de scripts agentics
- Connaissances de base de Python et des API REST
Architecture du projet
L’agent TPRM suit un pipeline en trois étapes :
┌─────────────────┐ ┌─────────────────┐ ┌─────────────────┐
│ DÉCOUVERTE │────▶│ ACCÈS │────▶│ ACTION │
│ (API SERP) │ │ (Web Unlocker) │ │ (OpenAI + SDK) │
└─────────────────┘ └─────────────────┘ └─────────────────┘
│ │ │
Rechercher sur Google Contourner les paywalls Analyser les risques
pour les signaux d'alerte et les CAPTCHA Générer des scriptsCréer la structure de projet suivante :
tprm-agent/
├── src/
│ ├── __init__.py
│ ├── config.py # Configuration
│ ├── discovery.py # Intégration de l'API SERP
│ ├── access.py # Intégration de Web Unlocker
│ ├── actions.py # OpenAI + OpenHands SDK
│ ├── agent.py # Orchestration principale
│ └── browser.py # API du navigateur (amélioration)
├── api/
│ └── main.py # Points de terminaison FastAPI
├── scripts/
│ └── generated/ # Scripts de surveillance générés automatiquement
├── .env
├── requirements.txt
└── README.md
Configuration de l’environnement
Créez un environnement virtuel et installez les dépendances requises :
python -m venv venv
source venv/bin/activate # Windows : venvScriptsactivate
pip install requests fastapi uvicorn python-dotenv pydantic openai beautifulsoup4 playwright openhands-sdk openhands-tools
Créez un fichier .env pour stocker vos identifiants API :
# Jeton API Bright Data (pour l'API SERP)
BRIGHT_DATA_API_TOKEN=votre_jeton_api
# Zone SERP Bright Data
BRIGHT_DATA_SERP_ZONE=votre_nom_de_zone_serp
# Identifiants Bright Data Web Unlocker
BRIGHT_DATA_CUSTOMER_ID=votre_identifiant_client
BRIGHT_DATA_UNLOCKER_ZONE=votre_nom_de_zone_unlocker
BRIGHT_DATA_UNLOCKER_PASSWORD=votre_mot_de_passe_zone
# OpenAI (pour l'analyse des risques)
OPENAI_API_KEY=votre_clé_api_openai
# OpenHands (pour la génération de scripts agentics)
# Utilisez OpenHands Cloud : openhands/claude-sonnet-4-5-20260929
# Ou apportez le vôtre : anthropic/claude-sonnet-4-5-20260929
LLM_API_KEY=votre_llm_api_key
LLM_MODEL=openhands/claude-sonnet-4-5-20260929Configuration Bright Data
Étape 1 : Créez votre compte Bright Data
Inscrivez-vous sur Bright Data et accédez au tableau de bord.
Étape 2 : Configurez la zone API SERP
- Accédez à Proxies & Infrastructure de scraping
- Cliquez sur Ajouter et sélectionnez API SERP
- Nommez votre zone (par exemple,
tprm_serp) - Copiez le nom de votre zone et notez votre jeton API dans Paramètres > Jetons API
L’API SERP renvoie des résultats de recherche structurés provenant de Google sans être bloquée. Ajoutez brd_json=1 à votre URL de recherche pour obtenir une sortie JSON analysée.
Étape 3 : Configurer la zone Web Unlocker
- Cliquez sur Ajouter et sélectionnez Web Unlocker
- Nommez votre zone (par exemple,
tprm_unlocker) - Copiez les informations d’identification de votre zone (format du nom d’utilisateur :
brd-customer-CUSTOMER_ID-zone-ZONE_NAME)
Web Unlocker gère automatiquement les CAPTCHA, les empreintes digitales et la rotation des adresses IP via un point de terminaison Proxy.
Création de la couche de découverte (API SERP)
La couche de découverte recherche sur Google les médias défavorables aux fournisseurs à l’aide de l’API SERP. Créez src/discovery.py:
import requests
from typing import Optional
from dataclasses import dataclass
from urllib.parse import quote_plus
from config import settings
@dataclass
class SearchResult:
title: str
url: str
snippet: str
source: str
class DiscoveryClient:
"""Rechercher des informations négatives à l'aide de l'API SERP de Bright Data (API directe)."""
RISK_CATEGORIES = {
"litigation": ["lawsuit", "litigation", "sued", "court case", "legal action"],
"financial": ["bankruptcy", "insolvency", "debt", "financial trouble", "default"],
« fraude » : [« fraude », « escroquerie », « enquête », « mise en accusation », « scandale »],
« réglementation » : [« violation », « amende », « pénalité », « sanctions », « conformité »],
« opérationnel » : [« rappel », « problème de sécurité », « chaîne d'approvisionnement », « perturbation »],
}
def __init__(self) :
self.api_url = « https://api.brightdata.com/request »
self.headers = {
« Content-Type » : « application/json »,
« Authorization » : f« Bearer {settings.BRIGHT_DATA_API_TOKEN} »,
}
def _build_queries(self, vendor_name: str, categories: Optional[list] = None) -> list[str]:
"""Construire des requêtes de recherche pour chaque catégorie de risque."""
categories = categories or list(self.RISK_CATEGORIES.keys())
queries = []
for category in categories:
keywords = self.RISK_CATEGORIES.get(category, [])
keyword_str = " OR ".join(keywords)
query = f'"{vendor_name}" ({keyword_str})'
queries.append(query)
return queries
def search(self, query: str) -> list[SearchResult]:
"""Exécute une requête de recherche unique à l'aide de l'API SERP de Bright Data."""
try:
# Construire l'URL de recherche Google avec brd_json=1 pour le JSON analysé
encoded_query = quote_plus(query)
google_url = f"https://www.google.com/search?q={encoded_query}&hl=en&gl=us&brd_json=1"
payload = {
"Zone": settings.BRIGHT_DATA_SERP_ZONE,
"url": google_url,
"format": "raw",
}
response = requests.post(
self.api_url,
headers=self.headers,
json=payload,
timeout=30,
)
response.raise_for_status()
data = response.json()
results = []
organic = data.get("organic", [])
for item in organic:
results.append(
SearchResult(
title=item.get("title", ""),
url=item.get("link", ""),
snippet=item.get("description", ""),
source=item.get("displayed_link", ""),
)
)
return results
except Exception as e:
print(f"Search error: {e}")
return []
def discover_adverse_media(
self,
vendor_name: str,
categories: Optional[list] = None,
) -> dict[str, list[SearchResult]]:
"""Recherche de médias défavorables dans toutes les catégories de risques."""
queries = self._build_queries(vendor_name, categories)
category_names = categories or list(self.RISK_CATEGORIES.keys())
categorized_results = {}
for category, query in zip(category_names, queries):
print(f" Recherche : {category}...")
results = self.search(query)
categorized_results[category] = results
return categorized_results
def filter_relevant_results(
self, results: dict[str, list[SearchResult]], vendor_name: str
) -> dict[str, list[SearchResult]]:
"""Filtrer les résultats non pertinents."""
filtered = {}
vendor_lower = vendor_name.lower()
for category, items in results.items():
relevant = []
for item in items:
if (
vendor_lower in item.title.lower()
or vendor_lower in item.snippet.lower()
):
relevant.append(item)
filtered[category] = relevant
return filtered
L’API SERP renvoie un JSON structuré avec des résultats organiques, ce qui facilite l’analyse des titres, des URL et des extraits pour chaque résultat de recherche.
Création de la couche d’accès (Web Unlocker)
Lorsque la couche de découverte trouve des URL pertinentes, la couche d’accès récupère le contenu complet à l’aide de l’API Web Unlocker. Créez src/access.py:
import requests
from bs4 import BeautifulSoup
from dataclasses import dataclass
from typing import Optional
from config import settings
@dataclass
class ExtractedContent:
url: str
title: str
text: str
publish_date: Optional[str]
author: Optional[str]
success: bool
error: Optional[str] = None
class AccessClient:
"""Accédez au contenu protégé à l'aide de Bright Data Web Unlocker (basé sur l'API)."""
def __init__(self):
self.api_url = "https://api.brightdata.com/request"
self.headers = {
"Content-Type": "application/json",
"Authorization": f"Bearer {settings.BRIGHT_DATA_API_TOKEN}",
}
def fetch_url(self, url: str) -> ExtractedContent:
"""Récupère et extrait le contenu d'une URL à l'aide de l'API Web Unlocker."""
try:
payload = {
"zone": settings.BRIGHT_DATA_UNLOCKER_ZONE,
"url": url,
"format": "raw",
}
response = requests.post(
self.api_url,
headers=self.headers,
json=payload,
timeout=60,
)
response.raise_for_status()
# L'API Web Unlocker renvoie directement le code HTML.
html_content = response.text
content = self._extract_content(html_content, url)
return content
except requests.Timeout:
return ExtractedContent(
url=url,
title="",
text="",
publish_date=None,
author=None,
success=False,
error="Request timed out",
)
except Exception as e:
return ExtractedContent(
url=url,
title="",
text="",
publish_date=None,
author=None,
success=False,
error=str(e),
)
def _extract_content(self, html: str, url: str) -> ExtractedContent:
"""Extraire le contenu de l'article à partir du HTML."""
soup = BeautifulSoup(html, "html.parser")
# Supprimer les éléments indésirables
for element in soup(["script", "style", "nav", "footer", "header", "aside"]):
element.decompose()
# Extraire le titre
title = ""
if soup.title:
title = soup.title.string or ""
elif soup.find("h1"):
title = soup.find("h1").get_text(strip=True)
# Extraire le contenu principal
article = soup.find("article") or soup.find("main") or soup.find("body")
text = article.get_text(separator="n", strip=True) if article else ""
# Limiter la longueur du texte
text = text[:10000] if len(text) > 10000 else text
# Essayer d'extraire la date de publication
publish_date = None
date_meta = soup.find("meta", {"property": "article:published_time"})
if date_meta:
publish_date = date_meta.get("content")
# Essayer d'extraire l'auteur
auteur = None
auteur_meta = soup.find("meta", {"name": "author"})
si auteur_meta :
auteur = auteur_meta.get("content")
return ExtractedContent(
url=url,
title=title,
text=text,
publish_date=publish_date,
author=author,
success=True,
)
def fetch_multiple(self, urls: list[str]) -> list[ExtractedContent]:
"""Récupère plusieurs URL de manière séquentielle."""
results = []
for url in urls:
print(f" Récupération : {url[:60]}...")
content = self.fetch_url(url)
if not content.success:
print(f" Erreur : {content.error}")
results.append(content)
return results
Web Unlocker gère automatiquement les CAPTCHA, les empreintes digitales des navigateurs et la rotation des adresses IP. Il achemine simplement vos requêtes via le Proxy et s’occupe du reste.
Création de la couche d’action (OpenAI + OpenHands SDK)
La couche d’action utilise OpenAI pour analyser la gravité des risques et OpenHands SDK pour générer des scripts de surveillance qui utilisent l’API Bright Data Web Unlocker. OpenHands SDK fournit des capacités agentriques : l’agent peut raisonner, modifier des fichiers et exécuter des commandes pour créer des scripts prêts à être utilisés en production.
Créer src/actions.py:
import os
import json
from datetime import datetime, UTC
from dataclasses import dataclass, asdict
from openai import OpenAI
from pydantic import SecretStr
from openhands.sdk import LLM, Agent, Conversation, Tool
from openhands.tools.terminal import TerminalTool
from openhands.tools.file_editor import FileEditorTool
from config import settings
@dataclass
class RiskAssessment:
vendor_name: str
category: str
severity: str
summary: str
key_findings: list[str]
sources: list[str]
recommended_actions: list[str]
assessed_at: str
@dataclass
class MonitoringScript:
vendor_name: str
script_path: str
urls_monitored: list[str]
check_frequency: str
created_at: str
class ActionsClient:
"""Analysez les risques à l'aide d'OpenAI et générez des scripts de surveillance à l'aide du SDK OpenHands."""
def __init__(self):
# OpenAI pour l'analyse des risques
self.openai_client = OpenAI(api_key=settings.OPENAI_API_KEY)
# OpenHands pour la génération de scripts agentifs
self.llm = LLM(
model=settings.LLM_MODEL,
api_key=SecretStr(settings.LLM_API_KEY),
)
self.workspace = os.path.join(os.getcwd(), "scripts", "generated")
os.makedirs(self.workspace, exist_ok=True)
def analyze_risk(
self,
vendor_name: str,
category: str,
content: list[dict],
) -> RiskAssessment:
"""Analysez le contenu extrait pour déterminer la gravité du risque à l'aide d'OpenAI."""
content_summary = "nn".join(
[f"Source : {c['url']}nTitre : {c['title']}nContenu : {c['text'][:2000]}" for c in content]
)
prompt = f"""Analysez le contenu suivant concernant « {vendor_name} » pour l'évaluation des risques liés aux tiers.
Catégorie : {category}
Contenu :
{content_summary}
Fournissez une réponse JSON avec :
{{
"severity": "low|medium|high|critical",
« summary » : « résumé des conclusions en 2-3 phrases »,
« key_findings » : [« conclusion 1 », « conclusion 2 », ...],
« recommended_actions » : [« action 1 », « action 2 », ...]
}}
À prendre en compte :
- La gravité doit être basée sur l'impact potentiel sur l'activité
- Critique = action immédiate requise (fraude active, dépôt de bilan)
- Élevé = risque important nécessitant une enquête
- Moyen = préoccupation notable méritant d'être surveillée
- Faible = problème mineur ou question historique
"""
response = self.openai_client.chat.completions.create(
model="gpt-4o-mini",
messages=[{"role": "user", "content": prompt}],
response_format={"type": "json_object"},
)
response_text = response.choices[0].message.content
try:
result = json.loads(response_text)
except (json.JSONDecodeError, ValueError):
result = {
"severity": "medium",
"summary": "Impossible d'analyser l'évaluation des risques",
"key_findings": [],
"recommended_actions": ["Révision manuelle requise"],
}
return RiskAssessment(
vendor_name=vendor_name,
category=category,
severity=result.get("severity", "medium"),
summary=result.get("summary", ""),
key_findings=result.get("key_findings", []),
sources=[c["url"] for c in content],
recommended_actions=result.get("recommended_actions", []),
assessed_at=datetime.now(UTC).isoformat(),
)
def generate_monitoring_script(
self,
vendor_name: str,
urls: list[str],
check_keywords: list[str],
) -> MonitoringScript:
"""Générer un script de surveillance Python à l'aide de l'agent OpenHands SDK."""
script_name = f"monitor_{vendor_name.lower().replace(' ', '_')}.py"
script_path = os.path.join(self.workspace, script_name)
prompt = f"""Créer un script de surveillance Python à {script_path} qui :
1. Vérifie quotidiennement ces URL pour détecter tout nouveau contenu : {urls[:5]}
2. Recherche les mots-clés suivants : {check_keywords}
3. Envoie une alerte (impression sur la console) si un nouveau contenu pertinent est trouvé
4. Enregistre toutes les vérifications dans un fichier JSON nommé « monitoring_log.json »
Le script DOIT utiliser l'API Bright Data Web Unlocker pour contourner les paywalls et les CAPTCHAs :
- Point de terminaison de l'API : https://api.brightdata.com/request
- Utiliser la variable d'environnement BRIGHT_DATA_API_TOKEN pour le jeton Bearer
- Utiliser la variable d'environnement BRIGHT_DATA_UNLOCKER_ZONE pour le nom de la zone
- Effectuer des requêtes POST avec une charge utile JSON : {{"zone": "zone_name", "url": "target_url", "format": "raw"}}
- Ajoutez l'en-tête : « Authorization » : « Bearer <token> »
- Ajoutez l'en-tête : « Content-Type » : « application/json »
Le script doit :
- Charger les identifiants Bright Data à partir des variables d'environnement à l'aide de python-dotenv
- Utiliser l'API Bright Data Web Unlocker pour toutes les requêtes HTTP (PAS les requêtes simples requests.get)
- Gérer les erreurs de manière élégante avec try/except
- Inclure une fonction main() pouvant être exécutée directement
- Prendre en charge la planification via cron
- Stocker les hachages de contenu pour détecter les modifications
Écrire le script complet dans {script_path}.
"""
# Créer un agent OpenHands avec des outils de terminal et d'édition de fichiers
agent = Agent(
llm=self.llm,
tools=[
Tool(name=TerminalTool.name),
Tool(name=FileEditorTool.name),
],
)
# Exécuter l'agent pour générer le script
conversation = Conversation(agent=agent, workspace=self.workspace)
conversation.send_message(prompt)
conversation.run()
return MonitoringScript(
vendor_name=vendor_name,
script_path=script_path,
urls_monitored=urls[:5],
check_frequency="daily",
created_at=datetime.now(UTC).isoformat(),
)
def export_assessment(self, assessment: RiskAssessment, output_path: str) -> None:
"""Exporter l'évaluation des risques vers un fichier JSON."""
with open(output_path, "w") as f:
json.dump(asdict(assessment), f, indent=2)Le principal avantage de l’utilisation du SDK OpenHands par rapport à la simple génération de code basée sur des invites est que l’agent peut itérer son travail, tester le script, corriger les erreurs et l’affiner jusqu’à ce qu’il fonctionne correctement.
Orchestration des agents
Maintenant, connectons tout ensemble. Créez src/agent.py:
from dataclasses import dataclass
from datetime import datetime, UTC
from typing import Optional
from discovery import DiscoveryClient, SearchResult
from access import AccessClient, ExtractedContent
from actions import ActionsClient, RiskAssessment, MonitoringScript
@dataclass
class InvestigationResult:
vendor_name: str
started_at: str
completed_at: str
total_sources_found: int
total_sources_accessed: int
risk_assessments: list[RiskAssessment]
monitoring_scripts: list[MonitoringScript]
errors: list[str]
classe TPRMAgent :
"""Agent autonome pour les enquêtes de gestion des risques tiers."""
def __init__(self) :
self.discovery = DiscoveryClient()
self.access = AccessClient()
self.actions = ActionsClient()
def investigate(
self,
vendor_name: str,
categories: Optional[list[str]] = None,
generate_monitors: bool = True,
) -> InvestigationResult:
"""Exécuter une enquête complète sur le fournisseur."""
started_at = datetime.now(UTC).isoformat()
errors = []
risk_assessments = []
monitoring_scripts = []
# Étape 1 : Découverte (API SERP)
print(f"[Découverte] Recherche de médias défavorables concernant {vendor_name}...")
try:
raw_results = self.discovery.discover_adverse_media(vendor_name, categories)
filtered_results = self.discovery.filter_relevant_results(raw_results, vendor_name)
except Exception as e:
errors.append(f"Échec de la découverte : {str(e)}")
return InvestigationResult(
vendor_name=vendor_name,
started_at=started_at,
completed_at=datetime.now(UTC).isoformat(),
total_sources_found=0,
total_sources_accessed=0,
risk_assessments=[],
monitoring_scripts=[],
errors=errors,
)
total_sources = sum(len(results) for results in filtered_results.values())
print(f"[Découverte] {total_sources} sources pertinentes trouvées")
# Étape 2 : Accès (Web Unlocker)
print(f"[Accès] Extraction du contenu des sources...")
all_urls = []
url_to_category = {}
for category, results in filtered_results.items():
for result in results:
all_urls.append(result.url)
url_to_category[result.url] = category
try:
extracted_content = self.access.fetch_multiple(all_urls)
successful_extractions = [c for c in extracted_content if c.success]
except Exception as e:
error_msg = f"Échec de l'accès : {str(e)}"
print(f"[Accès] {error_msg}")
errors.append(error_msg)
successful_extractions = []
print(f"[Accès] {len(successful_extractions)} sources extraites avec succès")
# Étape 3 : Action - Analyser les risques (OpenAI)
print(f"[Action] Analyse des risques en cours...")
category_content = {}
for content in successful_extractions:
category = url_to_category.get(content.url, "unknown")
if category not in category_content:
category_content[category] = []
category_content[category].append({
"url": content.url,
"title": content.title,
"text": content.text,
})
for category, content_list in category_content.items():
if not content_list:
continue
try:
assessment = self.actions.analyze_risk(vendor_name, category, content_list)
risk_assessments.append(assessment)
except Exception as e:
errors.append(f"Échec de l'analyse des risques pour {category}: {str(e)}")
# Étape 3 : Action - Générer des scripts de surveillance
if generate_monitors and successful_extractions:
print(f"[Action] Génération des scripts de surveillance...")
try:
urls_to_monitor = [c.url for c in successful_extractions[:10]]
keywords = [vendor_name, "lawsuit", "bankruptcy", "fraud"]
script = self.actions.generate_monitoring_script(
vendor_name, urls_to_monitor, keywords
)
monitoring_scripts.append(script)
except Exception as e:
errors.append(f"Échec de la génération du script : {str(e)}")
completed_at = datetime.now(UTC).isoformat()
print(f"[Terminé] Enquête terminée")
return InvestigationResult(
vendor_name=vendor_name,
started_at=started_at,
completed_at=completed_at,
total_sources_found=total_sources,
total_sources_accessed=len(successful_extractions),
risk_assessments=risk_assessments,
monitoring_scripts=monitoring_scripts,
errors=errors,
)
def main():
"""Exemple d'utilisation."""
agent = TPRMAgent()
result = agent.investigate("Acme Corp")
print(f"n{'='*50}")
print(f"Investigation terminée : {result.vendor_name}")
print(f"Sources trouvées : {result.total_sources_found}")
print(f"Sources consultées : {result.total_sources_accessed}")
print(f"Évaluations des risques : {len(result.risk_assessments)}")
print(f"Scripts de surveillance : {len(result.monitoring_scripts)}")
pour l'évaluation dans result.risk_assessments :
print(f"n[{assessment.category.upper()}] Gravité : {assessment.severity}")
print(f"Résumé : {assessment.summary}")
if __name__ == "__main__":
main()
L’agent orchestre les trois couches, gère les erreurs avec élégance et produit un résultat d’enquête complet.
Configuration
Créez src/config.py pour configurer tous les secrets et toutes les clés dont nous aurons besoin pour que l’application fonctionne correctement :
import os
from dotenv import load_dotenv
load_dotenv()
class Settings:
# API SERP
BRIGHT_DATA_API_TOKEN: str = os.getenv("BRIGHT_DATA_API_TOKEN", "")
BRIGHT_DATA_SERP_ZONE: str = os.getenv("BRIGHT_DATA_SERP_ZONE", "")
# Web Unlocker
BRIGHT_DATA_CUSTOMER_ID: str = os.getenv("BRIGHT_DATA_CUSTOMER_ID", "")
BRIGHT_DATA_UNLOCKER_ZONE: str = os.getenv("BRIGHT_DATA_UNLOCKER_ZONE", "")
BRIGHT_DATA_UNLOCKER_PASSWORD : str = os.getenv("BRIGHT_DATA_UNLOCKER_PASSWORD", "")
# OpenAI (pour l'analyse des risques)
OPENAI_API_KEY : str = os.getenv("OPENAI_API_KEY", "")
# OpenHands (pour la génération de scripts agentifs)
LLM_API_KEY : str = os.getenv("LLM_API_KEY", "")
LLM_MODEL : str = os.getenv("LLM_MODEL", "openhands/claude-sonnet-4-5-20260929")
settings = Settings()Création de la couche API
À l’aide de FastAPI, vous allez créer api/main.py pour exposer l’agent via des points de terminaison REST :
from fastapi import FastAPI, HTTPException, BackgroundTasks
from pydantic import BaseModel
from typing import Optional
import uuid
import sys
sys.path.insert(0, 'src')
from agent import TPRMAgent, InvestigationResult
app = FastAPI(
title="TPRM Agent API",
description="Autonomous Third-Party Risk Management Agent",
version="1.0.0",)
investigations: dict[str, InvestigationResult] = {}
agent = TPRMAgent()
class InvestigationRequest(BaseModel):
vendor_name: str
categories: Optional[list[str]] = None
generate_monitors: bool = True
classe InvestigationResponse(BaseModel) :
investigation_id : str
status : str
message : str
@app.post("/investigate", response_model=InvestigationResponse)
def start_investigation(
request : InvestigationRequest,
background_tasks : BackgroundTasks,)
:
"""Lancer une nouvelle enquête sur un fournisseur."""
investigation_id = str(uuid.uuid4())
def run_investigation():
result = agent.investigate(
vendor_name=request.vendor_name,
categories=request.categories,
generate_monitors=request.generate_monitors,
)
investigations[investigation_id] = result
background_tasks.add_task(run_investigation)
return InvestigationResponse(
investigation_id=investigation_id,
status="started",
message=f"Investigation started for {request.vendor_name}",
)
@app.get("/investigate/{investigation_id}")
def get_investigation(investigation_id: str):
"""Obtenir les résultats de l'enquête."""
if investigation_id not in investigations:
raise HTTPException(status_code=404, detail="Enquête introuvable ou toujours en cours")
return investigations[investigation_id]
@app.get("/reports/{vendor_name}")
def get_reports(vendor_name: str):
"""Obtenir tous les rapports pour un fournisseur."""
vendor_reports = [
result
for result in investigations.values()
if result.vendor_name.lower() == vendor_name.lower()
]
if not vendor_reports:
raise HTTPException(status_code=404, detail="Aucun rapport trouvé pour ce fournisseur")
return vendor_reports
@app.get("/health")
def health_check():
"""Point de contrôle de l'état de santé."""
return {"status": "healthy"}Exécutez l’API localement :
python -m uvicorn API.main:app --reloadRendez-vous sur http://localhost:8000/docs pour explorer la documentation interactive de l’API.
Amélioration avec l’API du navigateur (Navigateur de scraping)
Pour les scénarios complexes tels que les registres judiciaires qui nécessitent la soumission de formulaires ou les sites riches en JavaScript, vous pouvez améliorer l’agent avec l’API du navigateur de Bright Data (Navigateur de scraping). Vous pouvez la configurer de la même manière que l’API Web Unlocker et l’API SERP.
L’API Browser fournit un navigateur hébergé dans le cloud que vous contrôlez via Playwright sur le protocole Chrome DevTools (CDP). Cela est utile pour :
- Recherches dans les registres judiciaires nécessitant la soumission de formulaires et la navigation
- Sites riches en JavaScript avec chargement de contenu dynamique
- Les flux d’authentification en plusieurs étapes
- Capturer des captures d’écran pour la documentation de conformité
Configuration
Ajoutez les informations d’identification de l’API du navigateur à votre fichier .env:
# API du navigateur
BRIGHT_DATA_BROWSER_USER: str = os.getenv("BRIGHT_DATA_BROWSER_USER", "")
BRIGHT_DATA_BROWSER_PASSWORD: str = os.getenv("BRIGHT_DATA_BROWSER_PASSWORD", "")Implémentation du client navigateur
Créez src/browser.py:
import asyncio
from playwright.async_api import async_playwright
from dataclasses import dataclass
from typing import Optional
from config import settings
@dataclass
class BrowserContent:
url: str
title: str
text: str
screenshot_path: Optional[str]
success: bool
error: Optional[str] = None
class BrowserClient:
"""Accédez au contenu dynamique à l'aide de l'API Bright Data Browser (Navigateur de scraping).
Utilisez cette fonctionnalité pour :
- Les sites riches en JavaScript qui nécessitent un rendu complet
- Les formulaires en plusieurs étapes (par exemple, les recherches dans les registres judiciaires)
- Sites nécessitant des clics, des défilements ou des interactions
- Capture de captures d'écran pour la documentation de conformité
"""
def __init__(self) :
# Créer un point de terminaison WebSocket pour la connexion CDP
auth = f"{settings.BRIGHT_DATA_BROWSER_USER}:{settings.BRIGHT_DATA_BROWSER_PASSWORD}"
self.endpoint_url = f"wss://{auth}@brd.superproxy.io:9222"
async def fetch_dynamic_page(
self,
url: str,
wait_for_selector: Optional[str] = None,
take_screenshot: bool = False,
screenshot_path: Optional[str] = None,
) -> BrowserContent:
"""Récupérer le contenu d'une page dynamique à l'aide de l'API du navigateur."""
async with async_playwright() as playwright:
try:
print(f"Connexion au Navigateur de scraping Bright Data...")
browser = await playwright.chromium.connect_over_cdp(self.endpoint_url)
try:
page = await browser.new_page()
print(f"Navigation vers {url}...")
await page.goto(url, timeout=120000)
# Attendre le sélecteur spécifique s'il est fourni
if wait_for_selector:
await page.wait_for_selector(wait_for_selector, timeout=30000)
# Obtenir le contenu de la page
title = await page.title()
# Extraire le texte
text = await page.evaluate("() => document.body.innerText")
# Prendre une capture d'écran si demandé
if take_screenshot and screenshot_path:
await page.screenshot(path=screenshot_path, full_page=True)
return BrowserContent(
url=url,
title=title,
text=text[:10000],
screenshot_path=screenshot_path if take_screenshot else None,
success=True,
)
finally :
await browser.close()
except Exception as e :
return BrowserContent(
url=url,
title="",
text="",
screenshot_path=None,
success=False,
error=str(e),
)
async def fill_and_submit_form(
self,
url: str,
form_data: dict[str, str],
submit_selector: str,
result_selector: str,
) -> BrowserContent:
"""Remplir un formulaire et obtenir des résultats - utile pour les registres judiciaires."""
async with async_playwright() as playwright:
try:
browser = await playwright.chromium.connect_over_cdp(self.endpoint_url)
try:
page = await browser.new_page()
await page.goto(url, timeout=120000)
# Remplir les champs du formulaire
for selector, value in form_data.items():
await page.fill(selector, value)
# Soumettre le formulaire
await page.click(submit_selector)
# Attendre les résultats
await page.wait_for_selector(result_selector, timeout=30000)
title = await page.title()
text = await page.evaluate("() => document.body.innerText")
return BrowserContent(
url=url,
title=title,
text=text[:10000],
screenshot_path=None,
success=True,
)
finally:
await browser.close()
except Exception as e:
return BrowserContent(
url=url,
title="",
text="",
screenshot_path=None,
success=False,
error=str(e),
)
async def scroll_and_collect(
self,
url: str,
scroll_count: int = 5,
wait_between_scrolls: float = 1.0,
) -> BrowserContent:
"""Gérer les pages à défilement infini."""
async with async_playwright() as playwright:
try:
browser = await playwright.chromium.connect_over_cdp(self.endpoint_url)
try:
page = await browser.new_page()
await page.goto(url, timeout=120000)
# Faire défiler plusieurs fois vers le bas
for i in range(scroll_count):
await page.evaluate("window.scrollTo(0, document.body.scrollHeight)")
await asyncio.sleep(wait_between_scrolls)
title = await page.title()
text = await page.evaluate("() => document.body.innerText")
return BrowserContent(
url=url,
title=title,
text=text[:10000],
screenshot_path=None,
success=True,
)
finally:
await browser.close()
except Exception as e:
return BrowserContent(
url=url,
title="",
text="",
screenshot_path=None,
success=False,
error=str(e),
)
# Exemple d'utilisation pour la recherche dans le registre du tribunal
async def example_court_search():
client = BrowserClient()
# Exemple : recherche dans un registre judiciaire
result = await client.fill_and_submit_form(
url="https://example-court-registry.gov/search",
form_data={
"#party-name": "Acme Corp",
"#case-type": "civil",
},
submit_selector="#search-button",
result_selector=".search-results",
)
if result.success:
print(f"Found court records: {result.text[:500]}")
else:
print(f"Error: {result.error}")
if __name__ == "__main__":
asyncio.run(example_court_search())Quand utiliser l’API du navigateur ou Web Unlocker
| Scénario | Utilisation |
|---|---|
| Requêtes HTTP simples | Web Unlocker |
| Pages HTML statiques | Web Unlocker |
| CAPTCHAs au chargement | Web Unlocker |
| Contenu rendu en JavaScript | API du navigateur |
| Soumissions de formulaires | API du navigateur |
| Navigation en plusieurs étapes | API du navigateur |
| Captures d’écran requises | API du navigateur |
Déploiement avec Railway
Votre agent TPRM peut être déployé en production à l’aide de Railway ou Render, qui prennent tous deux en charge les applications Python avec des dépendances de grande taille.
Railway est l’option la plus simple pour déployer des applications Python avec des dépendances lourdes comme OpenHands SDK. Vous devez vous inscrire et créer un compte pour que cela fonctionne.
Étape 1 : Installez Railway CLI globalement
npm i -g @railway/cliÉtape 2 : Ajoutez un fichier Procfile.
Dans le dossier racine de votre application, créez un nouveau fichier Procfile et ajoutez-y le contenu ci-dessous. Cela servira de configuration ou de commande de démarrage pour le déploiement
web: uvicorn API.main:app --host 0.0.0.0 --port $PORTÉtape 3 : Connectez-vous et initialisez Railway dans le répertoire du projet
railway login
railway initÉtape 4 : Déployez
railway up
Étape 5 : Ajouter des variables d’environnement
Accédez au tableau de bord de votre projet Railway → Paramètres → Variables partagées et ajoutez les variables et leurs valeurs comme indiqué ci-dessous :
BRIGHT_DATA_API_TOKEN
BRIGHT_DATA_SERP_ZONE
BRIGHT_DATA_UNLOCKER_ZONE
OPENAI_API_KEY
LLM_API_KEY
LLM_MODEL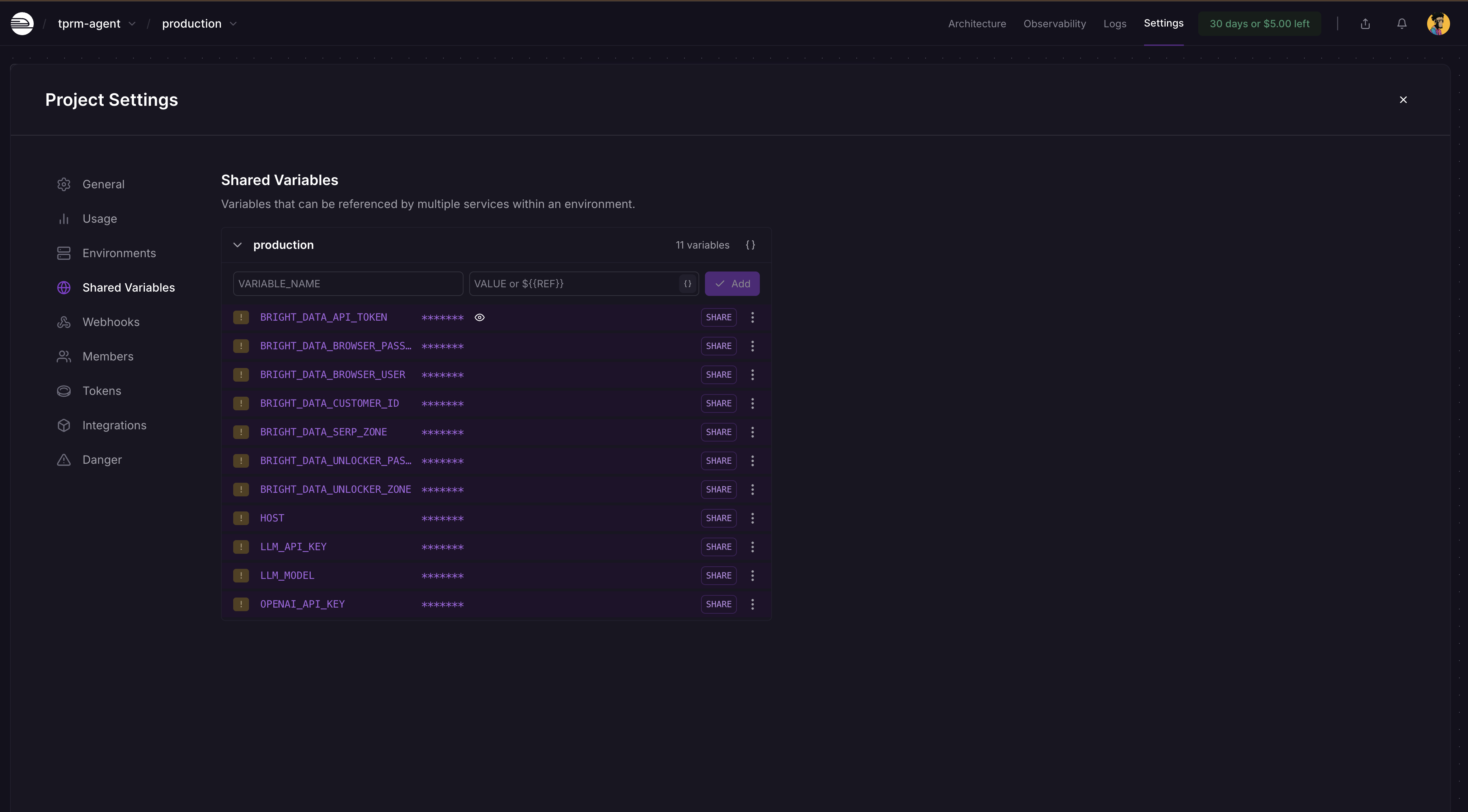
Railway détectera automatiquement les modifications et vous demandera de redéployer sur le tableau de bord. Cliquez sur Déployer et votre application sera mise à jour avec les secrets.
Après le redéploiement, cliquez sur la carte de service et sélectionnez Paramètres. Vous verrez où générer un domaine, car le service n’est pas encore accessible au public. Cliquez sur Générer un domaine pour obtenir votre URL publique.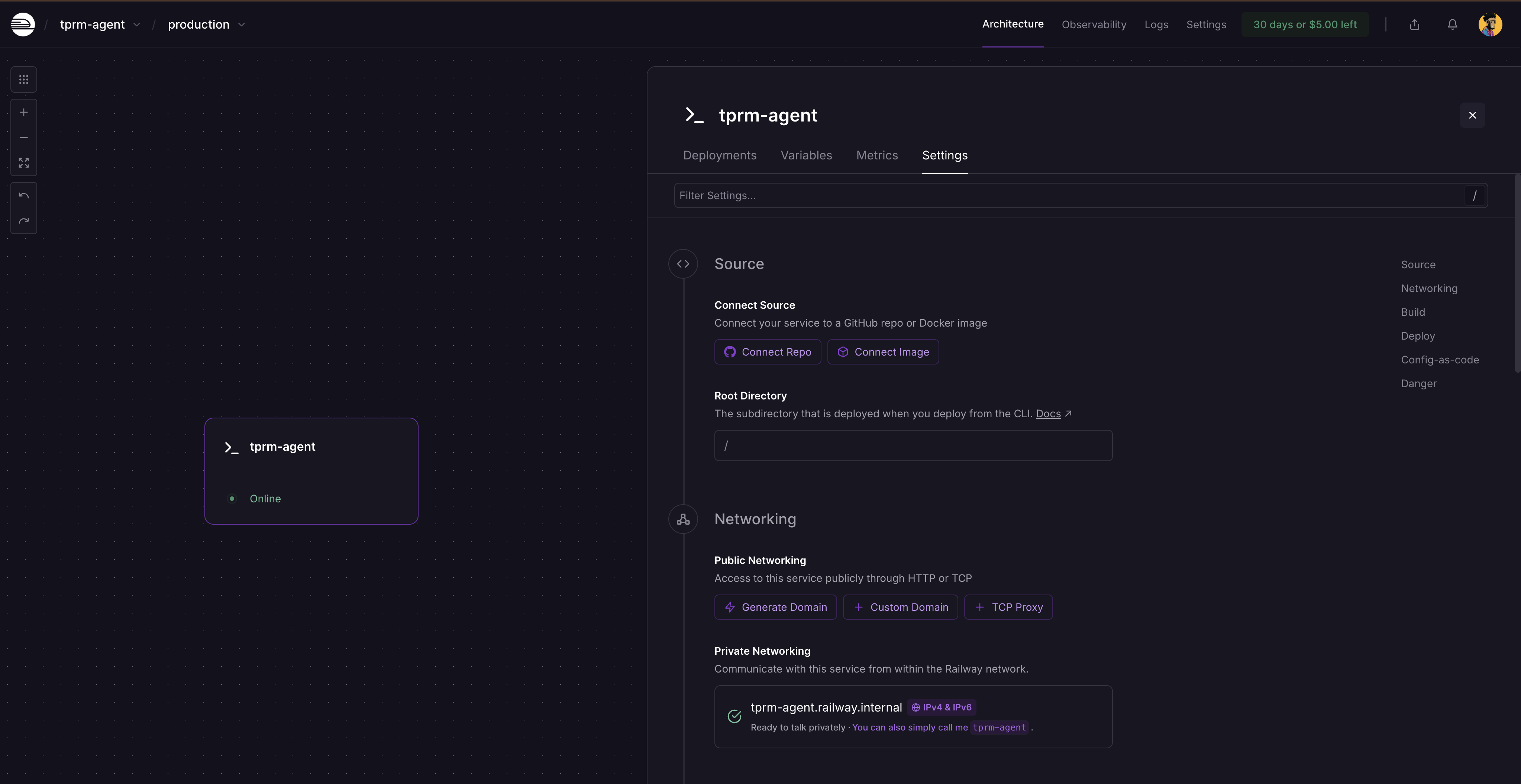
Exécution d’une enquête complète
Exécution locale avec curl
Démarrez le serveur FastAPI :
# Activez votre environnement virtuel
source venv/bin/activate # Sous Windows : venvScriptsactivate
# Exécutez le serveur
python -m uvicorn api.main:app --reloadRendez-vous sur http://localhost:8000/docs pour explorer la documentation interactive de l’API.
Effectuer des requêtes API
- Lancez une recherche :
curl -X POST "http://localhost:8000/investigate"
-H "Content-Type: application/json"
-d '{
"vendor_name": "Acme Corp",
"categories": ["litigation", "fraud"],
"generate_monitors": true
}'- Cela renvoie un identifiant d’enquête :
{
"investigation_id": "f6af2e0f-991a-4cb7-949e-2f316e677b5c",
"status": "started",
"message": "Investigation started for Acme Corp"
}- Vérifier le statut de l’enquête :
curl http://localhost:8000/investigate/f6af2e0f-991a-4cb7-949e-2f316e677b5cExécution de l’agent en tant que script
Créez un fichier nommé run_investigation.py à la racine de votre projet :
import sys
sys.path.insert(0, 'src')
from agent import TPRMAgent
def investigate_vendor():
"""Lancer une enquête complète sur le fournisseur."""
agent = TPRMAgent()
# Lancer l'enquête
result = agent.investigate(
vendor_name="Acme Corp",
categories=["litigation", "financial", "fraud"],
generate_monitors=True,
)
# Imprimer le résumé
print(f"n{'='*60}")
print(f"Enquête terminée : {result.vendor_name}")
print(f"{'='*60}")
print(f"Sources trouvées : {result.total_sources_found}")
print(f"Sources consultées : {result.total_sources_accessed}")
print(f"Évaluations des risques : {len(result.risk_assessments)}")
print(f"Scripts de surveillance : {len(result.monitoring_scripts)}")
# Imprimer les évaluations des risques
for assessment in result.risk_assessments:
print(f"n{'─'*60}")
print(f"[{assessment.category.upper()}] Gravité : {assessment.severity.upper()}")
print(f"{'─'*60}")
print(f"Résumé : {assessment.summary}")
print("nPrincipales conclusions :")
for finding in assessment.key_findings:
print(f" • {constat}")
print("nActions recommandées :")
pour action dans assessment.recommended_actions :
print(f" → {action}")
# Imprimer les informations du script de surveillance
pour script dans result.monitoring_scripts :
print(f"n{'='*60}")
print(f"Script de surveillance généré")
print(f"{'='*60}")
print(f"Chemin d'accès : {script.script_path}")
print(f"Surveillance de {len(script.urls_monitored)} URL")
print(f"Fréquence : {script.check_frequency}")
# Imprimer les erreurs, le cas échéant
if result.errors:
print(f"n{'='*60}")
print("Erreurs :")
for error in result.errors:
print(f" ⚠️ {error}")
if __name__ == "__main__":
investigate_vendor()Exécutez le script d’investigation sur un nouveau terminal
# Activez votre environnement virtuel
source venv/bin/activate # Sous Windows : venvScriptsactivate
# Exécutez le script d'investigation
python run_investigation.pyL’agent va :
- Rechercher dans Google les médias défavorables à l’aide de l’API SERP
- Accéder aux sources à l’aide de Web Unlocker
- Analyser le contenu pour déterminer la gravité du risque à l’aide d’OpenAI
- Générer un script de surveillance Python à l’aide du SDK OpenHands qui peut être planifié via cron
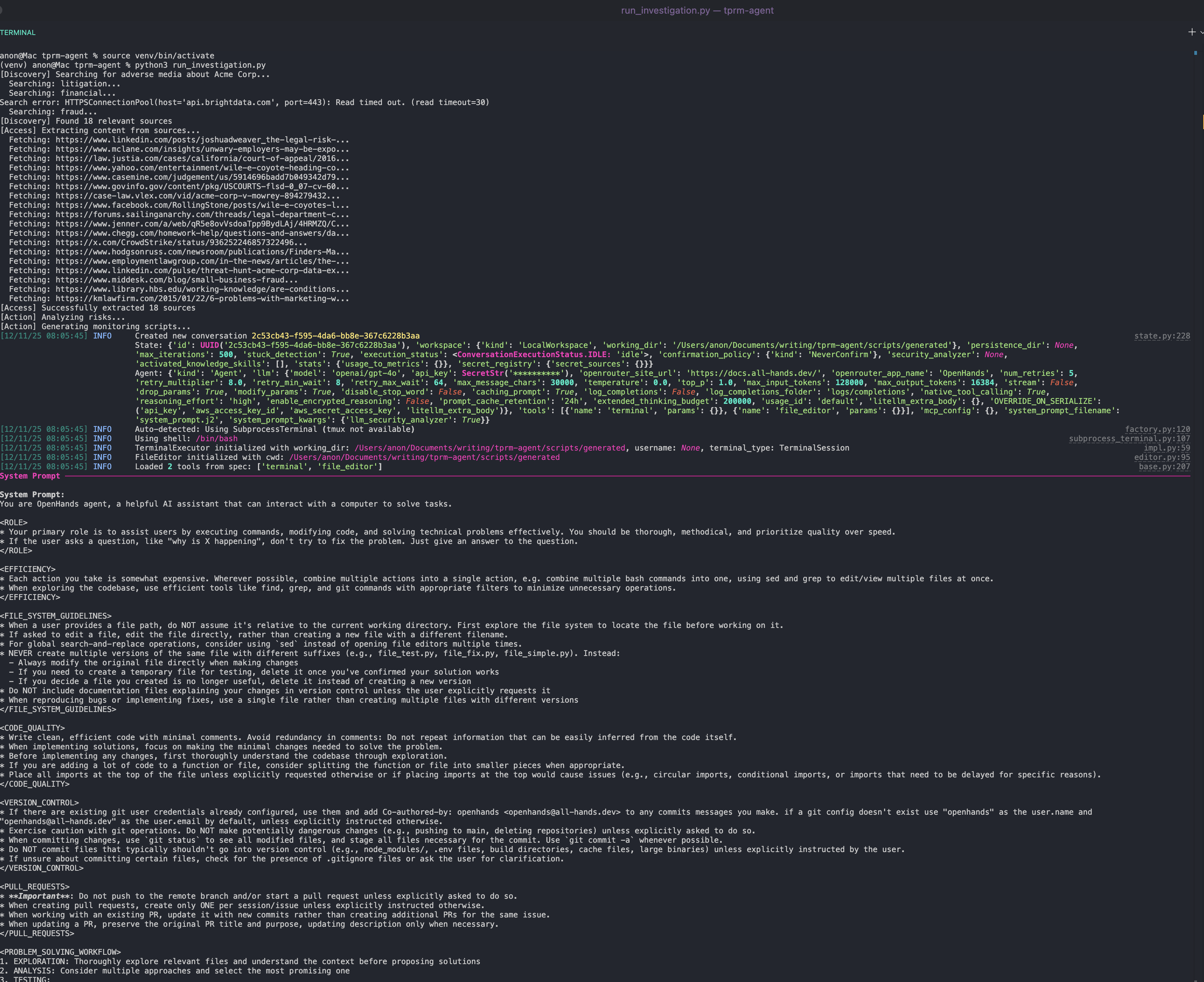
Exécution du script de surveillance généré automatiquement
Une fois l’enquête terminée, vous trouverez un script de surveillance dans le dossier scripts/generated:
cd scripts/generated
python monitor_acme_corp.pyLe script de surveillance utilise l’API Bright Data Web Unlocker pour vérifier toutes les URL surveillées et affichera :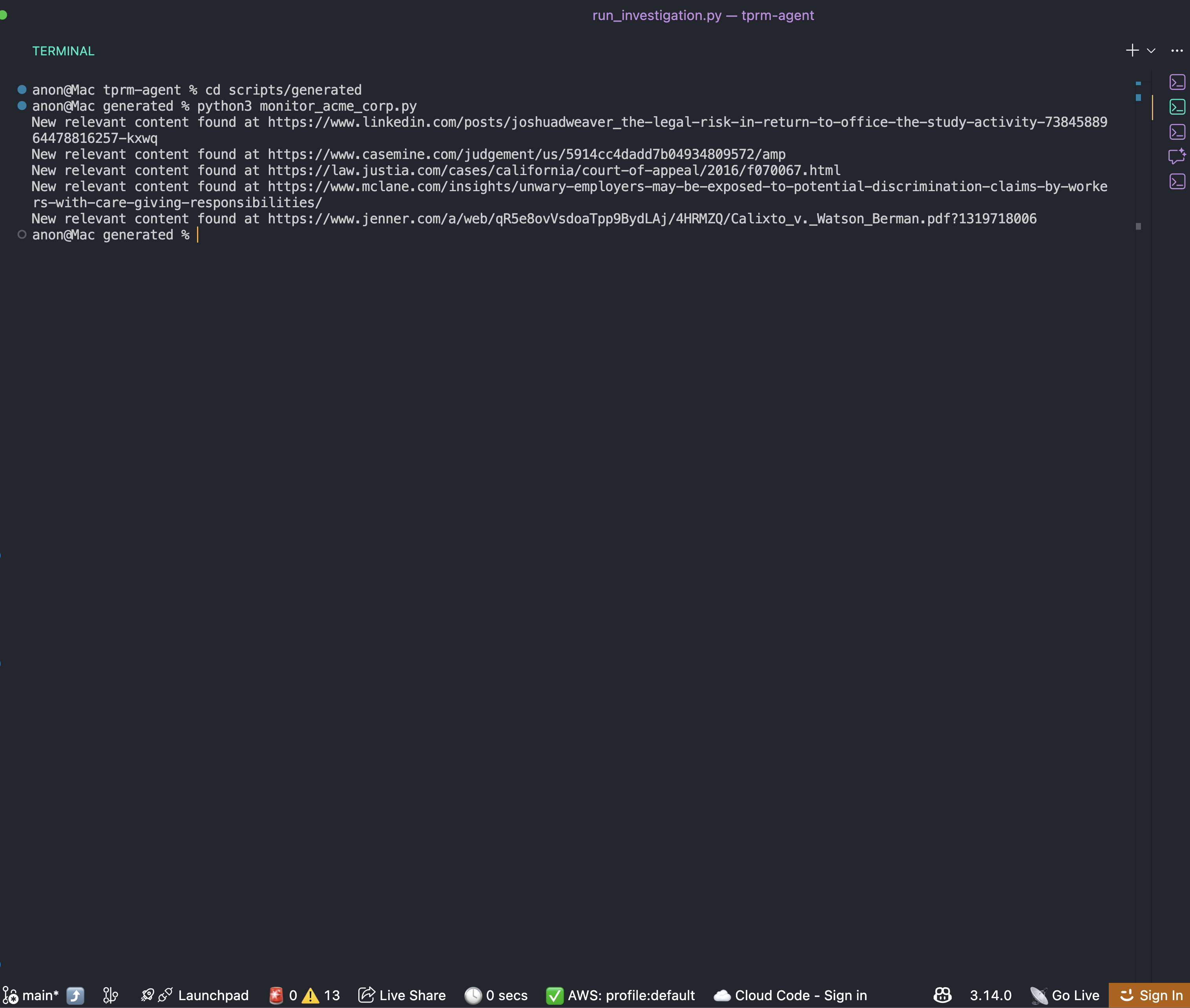
Vous pouvez désormais configurer une planification cron pour le script afin d’obtenir en permanence les informations correctes et actualisées sur l’entreprise.
Conclusion
Vous disposez désormais d’un cadre complet pour créer un agent TPRM d’entreprise qui automatise les enquêtes sur les médias défavorables aux fournisseurs. Ce système :
- Détecte les signaux de risque dans plusieurs catégories à l’aide de l’API SERP de Bright Data
- Accède au contenu à l’aide de Bright Data Web Unlocker
- Analyse les risques à l’aide d’OpenAI et génère des scripts de surveillance à l’aide du SDK OpenHands
- Améliore les capacités grâce à l’API Browser pour les scénarios complexes
L’architecture modulaire facilite l’extension :
- Ajoutez de nouvelles catégories de risques en mettant à jour le dictionnaire
RISK_CATEGORIES - Intégrez-le à votre plateforme GRC en étendant la couche API
- Évoluez vers des milliers de fournisseurs à l’aide de files d’attente de tâches en arrière-plan
- Ajoutez des recherches dans les registres judiciaires à l’aide de l’amélioration de l’API du navigateur
Étapes suivantes
Pour améliorer encore cet agent, envisagez :
- Intégrer des sources de données supplémentaires: documents déposés auprès de la SEC, listes de sanctions de l’OFAC, registres d’entreprises
- Ajouter la persistance de la base de données: stocker l’historique des enquêtes dans PostgreSQL ou MongoDB
- Mettre en place des notifications webhook: alerter Slack ou Teams lorsque des fournisseurs à haut risque sont détectés
- Créer un tableau de bord: créer une interface React pour visualiser les scores de risque des fournisseurs
- Planifier des analyses automatisées: utiliser Celery ou APScheduler pour la surveillance périodique des fournisseurs





